Oggi si sente spesso parlare di tecnologie come i sistemi DLP. Cos'è un tale sistema? come si puó usare? I sistemi DLP significano Software, progettato per prevenire la perdita di dati rilevando possibili violazioni nel filtraggio e nell'invio. Questi servizi monitorano, rilevano e bloccano informazioni confidenziali durante il suo utilizzo, spostamento e conservazione. La perdita di informazioni riservate, di norma, si verifica a causa del lavoro con la tecnologia utenti inesperti o attività dannose.
Tali informazioni sotto forma di informazioni aziendali o private, proprietà intellettuale, mediche e informazioni finanziarie, informazioni su carte di credito ah, ha bisogno di misure di protezione speciali che moderne Tecnologie dell'informazione. I casi di perdita di informazioni si trasformano in una fuga di notizie quando una fonte contenente informazioni riservate scompare e finisce con una parte non autorizzata. La fuga di informazioni è possibile senza perdite.
Convenzionalmente, i mezzi tecnologici utilizzati per combattere la fuga di informazioni possono essere suddivisi nelle seguenti categorie:
— misure di sicurezza standard;
— misure intelligenti (avanzate);
— controllo degli accessi e crittografia;
— sistemi specializzati DLP.
Misure standard
Le misure di sicurezza standard includono firewall, sistemi di rilevamento delle intrusioni (IDS), software antivirus. Proteggono il computer da attacchi esterni e interni. Così. Ad esempio, una connessione firewall impedisce agli estranei di accedere alla rete interna. Un sistema di rilevamento delle intrusioni può rilevare i tentativi di intrusione. Per prevenire attacchi interni, puoi usare programmi antivirus, rilevamento cavalli di Troia installato sul PC. È inoltre possibile utilizzare servizi specializzati che funzionano in un'architettura client-server senza alcuna informazione riservata o personale memorizzata sul computer.
Ulteriori misure di sicurezza
IN misure aggiuntive la sicurezza utilizza servizi altamente specializzati e algoritmi di temporizzazione progettati per rilevare l'accesso anomalo ai dati e, più specificamente, ai database e ai sistemi di recupero delle informazioni. Inoltre, tali protezioni possono rilevare scambi di posta elettronica anomali. Tali moderne tecnologie dell'informazione rilevano richieste e programmi che arrivano con intenzioni dannose ed eseguono controlli approfonditi. sistemi informaticiÈ come riconoscere i suoni degli altoparlanti o le sequenze di tasti. Alcuni di questi servizi sono anche in grado di monitorare l'attività dell'utente per rilevare accessi insoliti ai dati.
Cosa sono i sistemi DLP appositamente progettati?
Le soluzioni DLP progettate per proteggere le informazioni servono a rilevare e prevenire la copia e la trasmissione non autorizzate di informazioni riservate senza autorizzazione o accesso da parte di utenti che hanno il diritto di accedere alle informazioni riservate. Per classificare le informazioni certo tipo e regolano l'accesso ad esso, questi sistemi utilizzano meccanismi come l'esatta corrispondenza dei dati, metodi statistici, fingerprinting strutturato, accettazione di espressioni regolari e regole, pubblicazione frasi in codice, parole chiave, definizioni concettuali. Considera i principali tipi e caratteristiche dei sistemi DLP.
DLP di rete
Questo sistema è di solito soluzione hardware o software installato nei punti della rete originati vicino al perimetro. Questo sistema analizza traffico di rete al fine di rilevare informazioni riservate inviate in violazione della politica di sicurezza delle informazioni.
Endpoint DLP
I sistemi di questo tipo funzionano su workstation utenti finali o server nelle organizzazioni. Un endpoint, come in altri sistemi di rete, può indirizzare collegamenti interni ed esterni e può quindi essere utilizzato per controllare il flusso di informazioni tra tipi di utenti e gruppi. Sono anche in grado di controllare lo scambio messaggistica istantanea ed e-mail. Ciò accade come segue, prima che questi messaggi vengano scaricati sul dispositivo, vengono controllati dal servizio. I messaggi che contengono una richiesta sfavorevole verranno bloccati. Pertanto, non vengono inviati e non sono soggetti alle regole per la memorizzazione delle informazioni sul dispositivo.
Il vantaggio di un sistema DLP è che può controllare e gestire l'accesso ai dispositivi fisici e alle informazioni di accesso prima che vengano crittografate. Alcuni sistemi che si basano sulle perdite finali possono anche fornire controlli dell'applicazione per bloccare i tentativi di trasmissione di informazioni riservate e fornire un feedback immediato all'utente. Lo svantaggio di tali sistemi è che devono essere installati su ciascuno postazione di lavoro online e non può essere utilizzato su dispositivi mobili come palmari o telefoni cellulari. Questa circostanza deve essere presa in considerazione quando si scelgono i sistemi DLP per eseguire determinate attività.
Identificazione dei dati
I sistemi DLP contengono diversi metodi volti a rivelare informazioni riservate e segrete. Questo processo spesso confuso con la procedura di decrittografia delle informazioni. Tuttavia, l'identificazione delle informazioni è il processo mediante il quale le organizzazioni utilizzano la tecnologia DLP per determinare cosa cercare. I dati sono classificati come strutturati o non strutturati. I dati del primo tipo sono memorizzati in campi fissi all'interno del file, ad esempio nel modulo fogli di calcolo. I dati non strutturati si riferiscono al testo in formato libero. Secondo le stime degli esperti, l'80% di tutte le informazioni elaborate può essere attribuito a dati non strutturati. Di conseguenza, solo il 20% della quantità totale di informazioni è strutturato. Per classificare le informazioni, viene utilizzata l'analisi del contenuto, che si concentra su informazioni strutturate e analisi contestuali. Viene eseguito nel luogo di creazione dell'applicazione o del sistema in cui sono apparse le informazioni. Pertanto, la risposta alla domanda "cosa sono i sistemi DLP" può essere la definizione di un algoritmo di analisi delle informazioni.
Metodi
I metodi utilizzati nei sistemi DLP per descrivere i contenuti riservati sono oggi molto numerosi. Convenzionalmente, possono essere divisi in due categorie: accurati e imprecisi. Preciso: si tratta di metodi associati all'analisi del contenuto e praticamente riducono a zero tutte le risposte false positive alle richieste. Il resto dei metodi sono imprecisi. Questi includono analisi statistica, analisi bayesiana, meta tag, avanzato espressioni regolari, parole chiave, dizionari, ecc. L'efficacia dell'analisi dei dati dipenderà direttamente dalla sua accuratezza. Sistema DLP con valutazione alta ha un punteggio alto dato parametro. Importanza da evitare falsi positivi e altre conseguenze negative ha l'accuratezza dell'identificazione DLP. La precisione dipende da molti fattori, che possono essere tecnologici o situazionali. I test di precisione aiutano a garantire l'affidabilità del sistema DLP.
Rilevamento e prevenzione delle perdite di informazioni
In alcuni casi, la fonte di distribuzione dei dati mette a disposizione di terzi informazioni riservate. È probabile che alcuni di questi dati vengano trovati in un luogo non autorizzato dopo un po' di tempo, ad esempio sul laptop di un altro utente o su Internet. I sistemi DLP, il cui costo è fornito dagli sviluppatori su richiesta, possono variare da diverse decine a diverse migliaia di rubli. I sistemi DLP devono indagare su come i dati sono stati trapelati da una o più terze parti, se è stato fatto in modo indipendente o se le informazioni sono trapelate con altri mezzi.
Dati a riposo
La descrizione "dati inattivi" si riferisce a vecchie informazioni archiviate che sono memorizzate su uno qualsiasi dei dischi fissi cliente personal computer, su un file server remoto, su un'unità di archiviazione di rete. Questa definizione si applica anche ai dati memorizzati nel sistema Riserva copia su CD o unità flash. Tali informazioni sono di grande interesse per le agenzie governative o le imprese, poiché una grande quantità di dati non viene utilizzata nei dispositivi di memoria. In questo caso, esiste un'elevata probabilità che l'accesso alle informazioni venga ottenuto da persone non autorizzate al di fuori della rete.
Al giorno d'oggi, puoi spesso sentire parlare di tecnologie come i sistemi DLP. Che cos'è e dove si usa? Questo è un software progettato per prevenire la perdita di dati rilevando possibili violazioni durante l'invio e il filtraggio dei dati. Inoltre, tali servizi monitorano, rilevano e bloccano quando viene utilizzato, quando si sposta (traffico di rete) e quando viene archiviato.
Di norma, la fuga di dati riservati si verifica a causa di utenti inesperti che lavorano con apparecchiature o è il risultato di azioni dannose. Tali informazioni sotto forma di informazioni private o aziendali, proprietà intellettuale (IP), finanziarie o informazioni mediche, informazioni sulla carta di credito e simili necessitano di misure di sicurezza potenziate che la moderna tecnologia dell'informazione può offrire.
I termini "perdita di dati" e "fuga di dati" sono correlati e sono spesso usati in modo intercambiabile, sebbene siano leggermente diversi. I casi di perdita di informazioni si trasformano in perdita di informazioni quando la fonte contenente informazioni riservate scompare e successivamente finisce con una parte non autorizzata. Tuttavia, la perdita di dati è possibile senza perdita.
Categorie DLP
Gli strumenti tecnologici utilizzati per combattere la fuga di dati possono essere suddivisi nelle seguenti categorie: misure di sicurezza standard, misure intelligenti (avanzate), controllo degli accessi e crittografia, nonché sistemi DLP specializzati (descritti in dettaglio di seguito).

Misure standard
Le misure di sicurezza standard come i sistemi di rilevamento delle intrusioni (IDS) e il software antivirus sono meccanismi comuni disponibili che proteggono i computer dagli estranei e dagli attacchi interni. La connessione firewall, ad esempio, esclude l'accesso alla rete interna estranei e il sistema di rilevamento delle intrusioni rileva i tentativi di intrusione. Gli attacchi interni possono essere prevenuti da scansioni antivirus che rilevano installati sul PC che inviano informazioni riservate, nonché tramite l'uso di servizi che funzionano in un'architettura client-server senza alcun dato personale o riservato memorizzato sul computer.
Ulteriori misure di sicurezza
Ulteriori misure di sicurezza utilizzano servizi altamente specializzati e algoritmi di temporizzazione per rilevare accessi anomali ai dati (ad esempio database o sistemi di recupero delle informazioni) o scambi di e-mail anormali. Inoltre, tali moderne tecnologie dell'informazione rilevano programmi e richieste che arrivano con intenti dannosi ed eseguono controlli approfonditi sui sistemi informatici (ad esempio, riconoscimento di sequenze di tasti o suoni degli altoparlanti). Alcuni di questi servizi sono anche in grado di monitorare l'attività dell'utente per rilevare accessi insoliti ai dati.

Sistemi DLP progettati su misura: che cos'è?
Progettate per la sicurezza delle informazioni, le soluzioni DLP sono progettate per rilevare e prevenire tentativi non autorizzati di copiare o trasferire dati riservati (intenzionalmente o meno) senza autorizzazione o accesso, di solito da parte di utenti che hanno il diritto di accedere ai dati riservati.
Per classificare determinate informazioni e regolano l'accesso ad esso, questi sistemi utilizzano meccanismi come la corrispondenza esatta dei dati, il fingerprinting strutturato, l'accettazione di regole ed espressioni regolari, la pubblicazione di frasi in codice, definizioni concettuali e parole chiave. I tipi e il confronto dei sistemi DLP possono essere rappresentati come segue.
Network DLP (noto anche come data-in-motion o DiM)
Di norma, si tratta di una soluzione hardware o software che viene installata in punti della rete che hanno origine vicino al perimetro. Analizza il traffico di rete per rilevare i dati sensibili inviati in violazione di

Endpoint DLP (dati durante l'utilizzo )
Tali sistemi operano su workstation o server di utenti finali in varie organizzazioni.
Come con altri sistemi di rete, un endpoint può indirizzare comunicazioni sia interne che esterne e può quindi essere utilizzato per controllare il flusso di informazioni tra tipi o gruppi di utenti (ad es. "firewall"). Sono anche in grado di monitorare la posta elettronica e la messaggistica istantanea. Ciò accade come segue: prima che i messaggi vengano scaricati sul dispositivo, vengono controllati dal servizio e, se contengono una richiesta sfavorevole, vengono bloccati. Di conseguenza, non vengono inviati e non sono soggetti alle regole di conservazione dei dati sul dispositivo.
Un sistema DLP (tecnologia) ha il vantaggio di poter controllare e gestire l'accesso a dispositivi di tipo fisico (ad es. dispositivi mobili con capacità di archiviazione) e talvolta accedere alle informazioni prima che vengano crittografate.

Alcuni sistemi basati su endpoint possono anche fornire il controllo dell'applicazione per bloccare i tentativi di trasmissione di informazioni riservate, oltre a fornire un feedback immediato all'utente. Presentano però lo svantaggio di dover essere installati su ogni postazione della rete, e non possono essere utilizzati su dispositivi mobili (es. telefono cellulare e PDA) o dove non possono essere praticamente installati (ad esempio, su una workstation in un Internet cafè). Questa circostanza deve essere presa in considerazione quando si sceglie un sistema DLP per qualsiasi scopo.
Identificazione dei dati
I sistemi DLP includono diversi metodi volti a identificare informazioni segrete o riservate. A volte questo processo viene confuso con la decrittazione. Tuttavia, l'identificazione dei dati è il processo mediante il quale le organizzazioni utilizzano la tecnologia DLP per determinare cosa cercare (in movimento, a riposo o in uso).
I dati sono classificati come strutturati o non strutturati. Il primo tipo è memorizzato in campi fissi all'interno del file (come fogli di calcolo), mentre non strutturato si riferisce al testo in formato libero (sotto forma di documenti di testo o PDF).
Gli esperti stimano che l'80% di tutti i dati non sia strutturato. Di conseguenza, il 20% è strutturato. basato sull'analisi dei contenuti incentrata su informazioni strutturate e analisi contestuali. Viene eseguito nel luogo di creazione dell'applicazione o del sistema in cui sono originati i dati. Quindi, la risposta alla domanda "Sistemi DLP - che cos'è?" servirà come definizione dell'algoritmo di analisi delle informazioni.
Metodi utilizzati
I metodi per descrivere i contenuti sensibili oggi sono numerosi. Possono essere divisi in due categorie: accurati e imprecisi.
I metodi accurati sono quelli relativi all'analisi dei contenuti e praticamente annullano le risposte false positive alle richieste.
Tutti gli altri sono imprecisi e possono includere: dizionari, parole chiave, espressioni regolari, espressioni regolari estese, meta tag di dati, analisi bayesiana, analisi statistica, ecc.

L'efficacia dell'analisi dipende direttamente dalla sua accuratezza. Un sistema DLP con un punteggio elevato ha un punteggio elevato su questo parametro. L'accuratezza dell'identificazione DLP è essenziale per evitare falsi positivi e conseguenze negative. La precisione può dipendere da molti fattori, alcuni dei quali possono essere situazionali o tecnologici. I test di precisione possono garantire l'affidabilità del sistema DLP: quasi zero falsi positivi.
Rilevamento e prevenzione delle fughe di informazioni
A volte la fonte di distribuzione dei dati mette a disposizione di terzi informazioni riservate. Dopo qualche tempo, molto probabilmente una parte di esso verrà trovata in un luogo non autorizzato (ad esempio su Internet o sul laptop di un altro utente). I sistemi DLP, il cui prezzo è fornito dagli sviluppatori su richiesta e può variare da diverse decine a diverse migliaia di rubli, devono quindi indagare su come sono stati trapelati i dati - da una o più terze parti, sia indipendentemente l'uno dall'altro, se il la perdita è stata fornita da qualsiasi, quindi con altri mezzi, ecc.
Dati a riposo
"Dati a riposo" si riferisce a vecchie informazioni archiviate memorizzate su uno qualsiasi dei dischi rigidi del PC client, su un file server remoto, su un disco. Anche questa definizione si riferisce a dati archiviati in un sistema di backup (su unità flash o CD) . Queste informazioni sono di grande interesse per aziende e governi semplicemente perché una grande quantità di dati viene archiviata inutilizzata nei dispositivi di archiviazione ed è più probabile che persone non autorizzate accedano all'esterno della rete.
Per essere abbastanza coerenti nelle definizioni, possiamo dire che la sicurezza delle informazioni è iniziata proprio con l'avvento dei sistemi DLP. Prima di questo, tutti i prodotti che erano impegnati nella "sicurezza delle informazioni" in realtà proteggevano non le informazioni, ma l'infrastruttura - luoghi per l'archiviazione, la trasmissione e l'elaborazione dei dati. Il computer, l'applicazione o il canale che ospita, elabora o trasmette informazioni riservate è protetto da questi prodotti allo stesso modo in cui l'infrastruttura che fa circolare informazioni completamente innocue è protetta da questi prodotti. Cioè, è stato con l'avvento dei prodotti DLP che i sistemi informatici hanno finalmente imparato a distinguere le informazioni riservate da quelle non riservate. Forse, con l'integrazione delle tecnologie DLP nell'infrastruttura informatica, le aziende saranno in grado di risparmiare molto sulla protezione delle informazioni, ad esempio utilizzare la crittografia solo quando vengono archiviate o trasmesse informazioni riservate e non crittografare le informazioni negli altri casi.
Tuttavia, questa è una questione di futuro e, nel presente, queste tecnologie vengono utilizzate principalmente per proteggere le informazioni dalle perdite. Le tecnologie di categorizzazione delle informazioni costituiscono il nucleo dei sistemi DLP. Ogni produttore considera unici i suoi metodi di rilevamento delle informazioni riservate, li protegge con brevetti e crea marchi speciali per loro. Dopotutto, il resto degli elementi dell'architettura diversi da queste tecnologie (intercettori di protocollo, parser di formato, gestione degli incidenti e archiviazione dei dati) sono identici per la maggior parte dei produttori e per grandi aziende anche integrato con altri prodotti di sicurezza infrastruttura dell'informazione. Principalmente per la categorizzazione dei dati nei prodotti di sicurezza informazioni aziendali dalle fughe di notizie vengono utilizzati due gruppi principali di tecnologie: analisi linguistica (morfologica, semantica) e metodi statistici (impronte digitali, DNA di documenti, antiplagio). Ogni tecnologia ha i suoi punti di forza e di debolezza che determinano l'ambito della loro applicazione.
Analisi linguistica
L'uso di stop word ("segreto", "riservato" e simili) per bloccare l'uscita messaggi elettronici in server di posta può essere considerato il capostipite dei moderni sistemi DLP. Naturalmente, questo non protegge dagli intrusi: non è difficile rimuovere una parola d'arresto, il più delle volte inserita in un timbro separato di un documento, mentre il significato del testo non cambierà affatto.
L'impulso per lo sviluppo delle tecnologie linguistiche è stato dato all'inizio di questo secolo dai creatori di filtri di posta elettronica. Prima di tutto, per proteggere la posta elettronica dallo spam. Ora sono i metodi reputazionali a prevalere nelle tecnologie anti-spam e all'inizio del secolo ci fu una vera guerra linguistica tra il proiettile e l'armatura: spammer e anti-spammer. Ricordi i metodi più semplici per ingannare i filtri basati su stopword? Sostituzione di lettere con lettere simili da altre codifiche o numeri, traslitterazione, a caso spazi distanziati, trattini bassi o interruzioni di riga nel testo. Gli anti-spamer hanno imparato rapidamente a gestire tali trucchi, ma poi sono comparsi spam grafico e altre astute varietà di corrispondenza indesiderata.
Tuttavia, è impossibile utilizzare le tecnologie anti-spam nei prodotti DLP senza seri miglioramenti. Per combattere lo spam, infatti, è sufficiente dividere il flusso di informazioni in due categorie: spam e non spam. Il metodo di Bayes, utilizzato nel rilevamento dello spam, fornisce solo un risultato binario: "sì" o "no". Questo non è sufficiente per proteggere i dati aziendali dalle fughe di notizie: non puoi semplicemente dividere le informazioni in riservate e non riservate. Devi essere in grado di classificare le informazioni per affiliazione funzionale (finanziaria, industriale, tecnologica, commerciale, marketing) e all'interno delle classi - classificarle in base al livello di accesso (per la distribuzione gratuita, per accesso limitato, per uso ufficiale, segreto, top secret e così via).
La maggior parte dei moderni sistemi di analisi linguistica utilizza non solo l'analisi contestuale (cioè in quale contesto, in combinazione con quali altre parole viene utilizzato un termine particolare), ma anche l'analisi semantica del testo. Queste tecnologie funzionano in modo più efficiente, più grande è il frammento analizzato. Su un ampio frammento di testo, l'analisi viene svolta in modo più accurato, con più probabilmente la categoria e la classe del documento sono determinate. Quando si analizza brevi messaggi(SMS, cercapersone Internet) non è stato ancora inventato niente di meglio delle parole d'arresto. L'autore ha affrontato un tale compito nell'autunno del 2008, quando dai luoghi di lavoro di molte banche, tramite messaggistica istantanea, migliaia di messaggi sono andati sul Web come "siamo tagliati", "ti toglieranno la licenza", "il deflusso di depositanti", che hanno dovuto essere immediatamente bloccati dai loro clienti.
Vantaggi della tecnologia
I vantaggi delle tecnologie linguistiche sono che lavorano direttamente con il contenuto dei documenti, ovvero non si preoccupano di dove e come è stato creato il documento, quale firma c'è su di esso e come si chiama il file: i documenti sono protetti immediatamente. Questo è importante, ad esempio, durante l'elaborazione delle bozze documenti riservati o per proteggere la documentazione in entrata. Se i documenti creati e utilizzati all'interno dell'azienda possono ancora essere denominati, timbrati o etichettati in un modo specifico, i documenti in arrivo potrebbero avere timbri e marchi non accettati nell'organizzazione. Le bozze (a meno che, ovviamente, non vengano create in un sistema di flusso di lavoro sicuro) possono anche contenere già informazioni riservate, ma non contengono ancora i timbri e i contrassegni necessari.
Un altro vantaggio delle tecnologie linguistiche è la loro capacità di addestramento. Se almeno una volta nella vita hai premuto client di posta il pulsante "Non spam", lo immagini già dalla parte del cliente sistemi di apprendimento dei motori linguistici. Prendo atto che non è assolutamente necessario essere un linguista certificato e sapere cosa cambierà esattamente nel database delle categorie: è sufficiente indicare un falso positivo al sistema e farà il resto da solo.
Il terzo vantaggio delle tecnologie linguistiche è la loro scalabilità. La velocità di elaborazione delle informazioni è proporzionale alla sua quantità e non dipende assolutamente dal numero di categorie. Fino a poco tempo, la costruzione di un database di categorie gerarchiche (storicamente si chiama BKF - content filtering base, ma questo nome non riflette più il vero significato) sembrava una sorta di sciamanesimo dei linguisti professionisti, quindi l'impostazione del BKF poteva essere tranquillamente attribuita a carenze. Ma con l'uscita nel 2010 di diversi prodotti "autolinguisti" contemporaneamente, costruire il database primario delle categorie è diventato estremamente semplice: il sistema indica i luoghi in cui sono archiviati i documenti di una determinata categoria e determina esso stesso le caratteristiche linguistiche di questa categoria, e in caso di falsi positivi, impara da solo. Così ora la facilità di personalizzazione si è aggiunta ai vantaggi delle tecnologie linguistiche.
E un altro vantaggio delle tecnologie linguistiche, che vorrei sottolineare nell'articolo, è la capacità di rilevare categorie nei flussi informativi che non sono correlati a documenti situati all'interno dell'azienda. Uno strumento di monitoraggio del contenuto dei flussi informativi può definire categorie quali le attività illecite (pirateria, distribuzione di beni vietati), l'utilizzo per propri fini di un'infrastruttura aziendale, il danneggiamento dell'immagine aziendale (ad esempio diffusione di voci diffamatorie) e presto.
Carenze tecnologiche
Il principale svantaggio delle tecnologie linguistiche è la loro dipendenza dalla lingua. Non è possibile utilizzare un motore linguistico progettato per una lingua per analizzarne un'altra. Ciò è stato particolarmente evidente quando i produttori americani sono entrati nel mercato russo: non erano pronti ad affrontare la formazione di parole russe e la presenza di sei codifiche. Non è stato sufficiente tradurre categorie e parole chiave in russo - in lingua inglese la formazione delle parole è abbastanza semplice e i casi vengono presi come preposizioni, cioè quando cambia il caso cambia la preposizione e non la parola stessa. La maggior parte dei nomi in inglese diventano verbi senza modifiche alle parole. Eccetera. In russo, tutto è diverso: una radice può dare origine a dozzine di parole parti differenti discorso.
In Germania, i produttori americani di tecnologie linguistiche hanno incontrato un altro problema: i cosiddetti "composti", parole composte. In tedesco, è consuetudine allegare definizioni alla parola principale, risultando in parole, a volte composte da una dozzina di radici. Non esiste una cosa del genere in inglese, una parola è una sequenza di lettere tra due spazi, quindi il motore linguistico inglese non è stato in grado di elaborare parole lunghe sconosciute.
In tutta onestà, va detto che ora questi problemi sono in gran parte risolti dai produttori americani. Il motore linguistico ha dovuto essere rielaborato (e talvolta riscritto) parecchio, ma i grandi mercati in Russia e Germania ne valgono sicuramente la pena. È anche difficile elaborare testi multilingue con tecnologie linguistiche. Tuttavia, la maggior parte dei motori gestisce ancora due lingue, di solito è la lingua nazionale + inglese: questo è abbastanza per la maggior parte delle attività aziendali. Sebbene l'autore si sia imbattuto in testi riservati contenenti, ad esempio, kazako, russo e inglese allo stesso tempo, questa è più un'eccezione che una regola.
Un altro svantaggio delle tecnologie linguistiche per il controllo dell'intera gamma di informazioni riservate aziendali è che non tutte le informazioni riservate sono sotto forma di testi coerenti. Sebbene i database memorizzino le informazioni in forma di testo e non ci sono problemi nell'estrazione del testo dal DBMS, le informazioni ricevute contengono più spesso nomi propri - nomi completi, indirizzi, nomi di società, nonché informazioni digitali - numeri di conto, carte di credito, il loro saldo e così via. L'elaborazione di tali dati con l'aiuto della linguistica non porterà molti benefici. Lo stesso si può dire dei formati CAD/CAM, ovvero i disegni, che spesso contengono proprietà intellettuale, codici di programma e formati multimediali (video/audio): alcuni testi possono essere estratti da essi, ma anche la loro elaborazione è inefficiente. Tre anni fa, questo valeva anche per i testi scansionati, ma i principali produttori di sistemi DLP hanno prontamente aggiunto riconoscimento ottico e affrontato questo problema.
Ma la carenza più grande e più spesso criticata delle tecnologie linguistiche è ancora l'approccio probabilistico alla categorizzazione. Se hai mai letto un'e-mail con la categoria "Probabilmente SPAM", capirai cosa intendo. Se questo accade con lo spam, dove ci sono solo due categorie (spam/non spam), puoi immaginare cosa accadrà quando diverse dozzine di categorie e classi di privacy verranno caricate nel sistema. Sebbene sia possibile ottenere un'accuratezza del 92-95% addestrando il sistema, per la maggior parte degli utenti ciò significa che ogni decimo o ventesimo movimento di informazioni verrà assegnato erroneamente alla classe sbagliata con tutte le conseguenze aziendali che ne conseguono (perdita o interruzione di un processo legittimo) .
Di solito non è consuetudine attribuire agli svantaggi la complessità dello sviluppo tecnologico, ma è impossibile non menzionarlo. Lo sviluppo di un motore linguistico serio con la categorizzazione dei testi in più di due categorie è un processo tecnologico ad alta intensità di scienza e piuttosto complesso. La linguistica applicata è una scienza in rapido sviluppo che ha ricevuto un forte impulso nello sviluppo con la diffusione della ricerca su Internet, ma oggi esistono sul mercato unità di motori di categorizzazione praticabili: ce ne sono solo due per la lingua russa e per alcune lingue semplicemente non sono stati ancora sviluppati. Pertanto, ci sono solo un paio di aziende nel mercato DLP in grado di classificare completamente le informazioni al volo. Si può presumere che quando il mercato DLP aumenterà a dimensioni multimiliardarie, Google lo entrerà facilmente. Con un proprio motore linguistico, testato su trilioni di query di ricerca in migliaia di categorie, non sarà difficile per lui accaparrarsi subito un pezzo serio di questo mercato.
Metodi statistici
Il compito della ricerca informatica di citazioni significative (perché esattamente "significative" - un po 'più tardi) ha interessato i linguisti negli anni '70 del secolo scorso, se non prima. Il testo è stato suddiviso in pezzi di una certa dimensione, ciascuno dei quali è stato sottoposto a hash. Se una certa sequenza di hash si verificava contemporaneamente in due testi, allora con un'alta probabilità i testi in queste aree coincidevano.
Un sottoprodotto della ricerca in questo settore è, ad esempio, la "cronologia alternativa" di Anatoly Fomenko, uno studioso rispettato che ha lavorato sulle "correlazioni testuali" e una volta ha confrontato le cronache russe di diversi periodi storici. Sorpreso di quanto gli annali di secoli diversi coincidano (di oltre il 60%), alla fine degli anni '70 avanzò la teoria secondo cui la nostra cronologia è di diversi secoli più breve. Pertanto, quando alcune società DLP che entrano nel mercato offrono una "tecnologia rivoluzionaria di ricerca di citazioni", è molto probabile che nient'altro che una nuova marchio, la società non ha creato.
Le tecnologie statistiche trattano i testi non come una sequenza coerente di parole, ma come una sequenza arbitraria di caratteri, quindi funzionano ugualmente bene con i testi in qualsiasi lingua. Poiché qualsiasi oggetto digitale - anche un'immagine, anche un programma - è anche una sequenza di caratteri, gli stessi metodi possono essere utilizzati per analizzare non solo informazioni di testo, ma anche qualsiasi oggetto digitale. E se gli hash in due file audio corrispondono, uno di essi probabilmente contiene una citazione dell'altro, quindi i metodi statistici sono mezzi efficaci per proteggere dalla perdita di audio e video, che vengono utilizzati attivamente negli studi musicali e nelle case cinematografiche.
È tempo di tornare al concetto di "citazione significativa". Caratteristica fondamentale hash complesso rimosso dall'oggetto protetto (che in diversi prodotti è chiamato Digital Fingerprint o Document DNA), è il passaggio con cui l'hash viene rimosso. Come si evince dalla descrizione, tale “impronta digitale” è una caratteristica unica dell'oggetto e, allo stesso tempo, ha una propria dimensione. Questo è importante perché se stampi milioni di documenti (che è la capacità di archiviazione di una banca media), hai bisogno di abbastanza per archiviare tutte le stampe. spazio sul disco. La dimensione di una tale stampa dipende dal passaggio di hash: più piccolo è il passaggio, maggiore è la stampa. Se prendi un hash con incrementi di un carattere, la dimensione della stampa supererà la dimensione del campione stesso. Se, per ridurre il "peso" della stampa, si aumenta il passaggio (ad esempio 10.000 caratteri), contestualmente la probabilità che un documento contenente una citazione da un campione di 9.900 caratteri sia riservato, ma scivoli inosservato, aumenta.
D'altra parte, se viene fatto un passo molto piccolo, alcuni simboli, per aumentare la precisione del rilevamento, il numero di falsi positivi può essere aumentato fino a un valore inaccettabile. In termini di testo, ciò significa che non dovresti rimuovere l'hash da ogni lettera: tutte le parole sono composte da lettere e il sistema considererà la presenza di lettere nel testo come contenuto di una citazione dal testo di esempio. Di solito, i produttori stessi consigliano alcuni passaggi di hashing ottimali in modo che la dimensione del preventivo sia sufficiente e allo stesso tempo il peso della stampa stessa sia ridotto, dal 3% (testo) al 15% (video compresso). In alcuni prodotti, i produttori consentono di modificare la dimensione del significato della citazione, ovvero aumentare o diminuire l'hash step.
Vantaggi della tecnologia
Come si evince dalla descrizione, per rilevare un preventivo è necessario un oggetto campione. E i metodi statistici possono dire con buona accuratezza (fino al 100%) se c'è una citazione significativa dal campione nel file da controllare o meno. Cioè, il sistema non si assume la responsabilità della categorizzazione dei documenti: tale lavoro ricade interamente sulla coscienza di chi ha classificato i file prima del rilevamento delle impronte digitali. Ciò facilita notevolmente la protezione delle informazioni nel caso in cui file modificati di rado e già classificati siano archiviati in un'azienda in qualche luogo. Quindi è sufficiente rimuovere l'impronta da ciascuno di questi file e il sistema, in base alle impostazioni, bloccherà il trasferimento o la copia di file contenenti citazioni significative dai campioni.
Anche l'indipendenza dei metodi statistici dal linguaggio del testo e dalle informazioni non testuali è un indiscutibile vantaggio. Sono bravi a proteggere oggetti digitali statici di qualsiasi tipo: immagini, audio/video, database. Parlerò della protezione degli oggetti dinamici nella sezione "svantaggi".
Svantaggi tecnologici
Come nel caso della linguistica, gli svantaggi della tecnologia - lato posteriore meriti. La facilità di addestrare il sistema (indicato il file al sistema, ed è già protetto) sposta la responsabilità di addestrare il sistema all'utente. Se improvvisamente un file riservato si trova nel posto sbagliato o non è stato indicizzato a causa di negligenza o intento dannoso, il sistema non lo proteggerà. Di conseguenza, le aziende che si preoccupano di proteggere le informazioni riservate dalla fuga dovrebbero fornire una procedura per controllare il modo in cui i file riservati vengono indicizzati dal sistema DLP.
Un altro svantaggio è dimensione fisica impronta. L'autore ha visto più volte progetti pilota impressionanti sulle stampe, quando il sistema DLP con il 100% di probabilità blocca il trasferimento di documenti contenenti citazioni significative da trecento documenti campione. Tuttavia, dopo un anno di funzionamento del sistema in modalità combattimento, l'impronta di ciascuno posta in uscita viene confrontato non con trecento, ma con milioni di stampe di esempio, il che rallenta notevolmente il lavoro sistema postale, provocando ritardi di decine di minuti.
Come ho promesso sopra, descriverò la mia esperienza nella protezione di oggetti dinamici utilizzando metodi statistici. Il tempo necessario per stampare una stampa dipende dalle dimensioni e dal formato del file. Per documento di testo come questo articolo, ci vuole una frazione di secondo, per un'ora e mezza di film MP4 - decine di secondi. Per i file che cambiano raramente, questo non è critico, ma se un oggetto cambia ogni minuto o anche un secondo, allora sorge un problema: dopo ogni modifica nell'oggetto, è necessario rimuovere una nuova impronta da esso ... Il codice che il il programmatore su cui sta lavorando non è la più grande complessità, è molto peggio con i database utilizzati nella fatturazione, ABS o call center. Se il tempo di rilevamento delle impronte digitali è maggiore del tempo di persistenza dell'oggetto, il problema non ha soluzione. Questo non è un caso così esotico, ad esempio l'impronta digitale di un database che memorizza i numeri di telefono dei clienti federali. operatore di telefonia mobile, viene rimosso per diversi giorni e cambia ogni secondo. Quindi, quando un fornitore di DLP afferma che il suo prodotto può proteggere il tuo database, aggiungi mentalmente la parola "quasi statico".
Unità e lotta degli opposti
Come puoi vedere dalla sezione precedente dell'articolo, la forza di una tecnologia si manifesta dove l'altra è debole. La linguistica non ha bisogno di schemi, classifica i dati al volo e può proteggere le informazioni che non sono state impresse per caso o per progettazione. L'impronta dà migliore precisione ed è quindi preferito per l'uso in Modalità automatica. La linguistica funziona alla grande con testi, stampe - con altri formati per la memorizzazione delle informazioni.
Pertanto, la maggior parte delle aziende leader utilizza entrambe le tecnologie nei propri sviluppi, mentre una di esse è la principale e l'altra è aggiuntiva. Ciò è dovuto al fatto che inizialmente i prodotti dell'azienda utilizzavano una sola tecnologia, in cui l'azienda avanzava ulteriormente, e poi, su richiesta del mercato, ne veniva collegata una seconda. Ad esempio, in precedenza InfoWatch utilizzava solo la tecnologia linguistica Morph-OLogic con licenza e Websense utilizzava la tecnologia PreciseID, che appartiene alla categoria Digital Fingerprint, ma ora le aziende utilizzano entrambi i metodi. Idealmente, queste due tecnologie non dovrebbero essere utilizzate in parallelo, ma in serie. Ad esempio, le stampe faranno un lavoro migliore nell'identificare il tipo di documento, ad esempio un contratto o un bilancio. Quindi puoi collegare un database linguistico creato appositamente per questa categoria. Ciò consente di risparmiare notevolmente le risorse di elaborazione.
Ci sono alcuni altri tipi di tecnologie utilizzate nei prodotti DLP al di fuori dell'articolo. Questi includono, ad esempio, un analizzatore di struttura che consente di trovare strutture formali in oggetti (numeri di carte di credito, passaporti, TIN e così via) che non possono essere rilevati né con la linguistica né con le impronte digitali. Inoltre non coperto tipo diverso etichette - dalle voci nei campi degli attributi di un file o solo un nome di file speciale a speciali criptocontainer. Quest'ultima tecnologia sta diventando obsoleta poiché la maggior parte dei fornitori preferisce non reinventare la ruota da soli, ma integrarsi con fornitori di DRM come Oracle IRM o Microsoft RMS.
I prodotti DLP sono un settore della sicurezza delle informazioni in rapida crescita, con alcuni fornitori che rilasciano nuove versioni molto frequentemente, più di una volta all'anno. Attendiamo con impazienza l'emergere di nuove tecnologie per l'analisi aziendale campo informazioni per aumentare l'efficienza della protezione delle informazioni riservate.
Sempre più popolare nel mercato dei video consumer alta risoluzione proiettori e televisori stanno utilizzando la tecnologia di proiezione digitale - DLP (Digital Light Processing). Quali sono i principali vantaggi e svantaggi di una tale tecnica, come funziona questa tecnologia può essere trovato in questo articolo.
Nuovo tipo di videoproiezione
La base di qualsiasi sistema di proiezione tipo DLP- un chip a semiconduttore ottico, noto anche come chip DLP, inventato nel 1987 da un dipendente della famosa compagnia americana Texas Instruments di Larry Hornbeck.
Se proviamo a descrivere brevemente il funzionamento di un chip DLP, allora può essere definito lo switch più complesso al mondo. Il microcircuito è costituito da due milioni di specchi microscopici disposti a forma di rettangolo e che cambiano posizione rispetto alla sorgente luminosa. Ciascuno di questi microspecchi non supera un quinto dello spessore di un capello umano.
Se si utilizza una sorgente di luce esterna e un obiettivo di proiezione e si applica un segnale video digitalizzato all'ingresso del chip DLP, è possibile proiettare filmati video su uno schermo o un'altra superficie e immagini grafiche. L'uso della tecnologia DLP in video moderno l'attrezzatura consente di raggiungere un livello di qualità completamente nuovo nella riproduzione di film e video.
Immagine in scala di grigi
I microspecchi nel microcircuito possono occupare due posizioni, girando verso la sorgente luminosa (On) e nella direzione opposta rispetto alla sorgente luminosa (Off). Pertanto, i pixel chiari e scuri vengono proiettati sulla superficie dello schermo.
 Il segnale codificato che arriva al microcircuito fa sì che ogni specchio cambi la sua posizione fino a diverse migliaia di volte al secondo. Quando lo specchio assume lo stato "On" più spesso di "Off", sullo schermo viene visualizzato un pixel più chiaro, se viceversa, uno più scuro.
Il segnale codificato che arriva al microcircuito fa sì che ogni specchio cambi la sua posizione fino a diverse migliaia di volte al secondo. Quando lo specchio assume lo stato "On" più spesso di "Off", sullo schermo viene visualizzato un pixel più chiaro, se viceversa, uno più scuro.
Pertanto, gli specchi in un sistema di proiezione DLP possono visualizzare fino a 1024 sfumature di grigio per ogni pixel, convertendo un segnale video o un'immagine digitalizzata che arriva al chip DLP in un'immagine in scala di grigi altamente dettagliata.
Aggiunta di colore
Nei sistemi di proiezione che utilizzano la tecnologia DLP, la luce bianca della lampada passa attraverso un filtro colorato rotante prima di raggiungere la superficie del chip. Dalla luce bianca, i filtri separano i colori primari (rosso, verde e blu), il che consente di creare almeno 16,7 milioni di colori utilizzando un solo chip DLP.
La tecnologia BrilliantColor consente inoltre di proiettare colori aggiuntivi, inclusi ciano chiaro, magenta e giallo, in espansione palette dei colori e rendendo la riproduzione dei colori ancora più vivida. In un moderno più avanzato Proiettore DLP ah, al posto delle lampade tradizionali, vengono utilizzate sorgenti luminose a LED, che emettono separatamente i colori di base, il che consente di eliminare il filtro della luce e il meccanismo per la sua rotazione. Esistono sistemi di proiezione che utilizzano tre chip DLP. Questi proiettori sono diversi. maggiore luminosità e in grado di visualizzare almeno 35 trilioni di colori, sono utilizzati nei cinema e nei sistemi teatrali e da concerto con grande taglia immagine proiettata.
Lo stato di ogni microspecchio viene regolato in base all'immagine proiettata. questo momento elemento base colori. Ad esempio, uno specchio che proietta un pixel magenta su uno schermo riflette solo il rosso e di colore blu, che, una volta miscelati, creano la tonalità necessaria sullo schermo.
Casi d'uso
Molti proiettori standard e televisori di proiezione HD basati sulla tecnologia DLP utilizzano un solo chip DLP.
La luce bianca della lampada di proiezione passa attraverso una lente di focalizzazione e un filtro colorato rotante. Pertanto, la superficie di un chip DLP viene illuminata in sequenza con la luce di uno dei colori primari (rosso, verde o blu) o aggiuntivi (giallo, azzurro, magenta). Il cambiamento degli stati degli specchi e il tempo trascorso in ciascuna posizione sono regolati in base al colore che li illumina. I colori proiettati in sequenza vengono mescolati e creano l'immagine a colori che vediamo sullo schermo.
La tecnologia DLP rende i proiettori molto alta luminosità, incluso il tipo cinematografico widescreen. Questi proiettori utilizzano una configurazione DLP a tre chip.
In una configurazione a tre chip, il flusso di luce bianca è diviso da un prisma in tre flussi monocromatici: rosso, verde e blu. Ogni flusso è diretto alla superficie del suo chip; I raggi colorati riflessi dai microspecchi sono focalizzati sullo schermo da una lente di proiezione.
I sistemi di proiezione DLP, indipendentemente dal design e dalla portata, migliorano costantemente e alzano il livello della qualità e delle caratteristiche dell'immagine proiettata sullo schermo. Tutto inizia con un'immagine in miniatura riflessa da milioni di microspecchi, che poi si trasforma in un'incredibile immagine widescreen!
Vantaggi della tecnologia DLP
Immagine super nitida
I video e la grafica ottenuti utilizzando la tecnologia DLP sono caratterizzati da una maggiore nitidezza riducendo al minimo lo spazio tra i pixel dell'immagine adiacenti. La distanza tra loro è inferiore a un micron, quindi la qualità di tale proiezione digitale è molto vicina alla qualità della proiezione di film analogici.
 Eccezionale qualità dell'immagine "Hollywood".
Eccezionale qualità dell'immagine "Hollywood".
Incredibile alta qualità completamente immagine digitale, ottenuto utilizzando la tecnologia DLP Cinema, cambia l'idea abituale di visitare un cinema. I proiettori e i televisori a proiezione basati sulla tecnologia DLP hanno gli stessi vantaggi, mostrando immagini fisse straordinariamente nitide, video straordinari con luminosità e riproduzione dei colori incredibili. L'affidabilità dell'immagine è tale da farti dimenticare che tutta l'azione si svolge solo sullo schermo.
Formato ad alta definizione 1080p
La tecnologia DLP consente di visualizzare più di due milioni di pixel sullo schermo risoluzione massima 1920x1080, che corrisponde al formato Full HD 1080p. Un proiettore o una TV DLP da 1080p ti consente di goderti appieno i programmi TV, i film o i giochi ad alta definizione dai dischi Blu-ray.
L'eccezionale qualità dell'immagine e il tempo di risposta senza precedenti rendono DLP 1080p opzione ideale per videogiochi, visualizzazione programmi di sport e film. Allo stesso tempo, i televisori e i proiettori DLP di proiezione sono altamente affidabili e durevoli.
Immagine reale
La tecnologia DLP offre una qualità dell'immagine senza precedenti con nitidezza cristallina, nitidezza e dinamismo reale. La tecnologia raggiunge rapporti di contrasto estremamente elevati (fino a 20.000:1) per i bianchi più luminosi e gli scuri più intensi, l'immagine sembra fuori dallo schermo!
La proiezione digitale garantisce una precisione assoluta
Il chip DLP riflettente ha un full controllo digitale. Milioni di persone gestite modalità digitale i microspecchi trasmettono un'immagine assolutamente precisa e vivida con una ricca tavolozza di colori.
Perfetta trasmissione di scene dinamiche
Il chip DLP ultraveloce ha un tempo di risposta senza pari di 16 millisecondi. I proiettori e i televisori basati sulla tecnologia DLP hanno l'immagine precisa e nitida necessaria per guardare le trasmissioni sportive e le scene dinamiche, nonché per i videogiochi.
Straordinaria qualità dell'immagine e durata
Usando la tecnologia DLP, puoi dimenticare l'intrinseco pannelli al plasma e TV CRT effetto burn-in dei pixel dello schermo. Poiché questa tecnologia non utilizza né CRT né fosforo, non c'è nulla da bruciare qui. Ciò significa che non devi preoccuparti che il logo del canale TV "penso" sullo schermo per molto tempo o che un elemento statico nella schermata iniziale del gioco rimanga sullo schermo come un contorno bruciato.
Basato su materiali DLP.
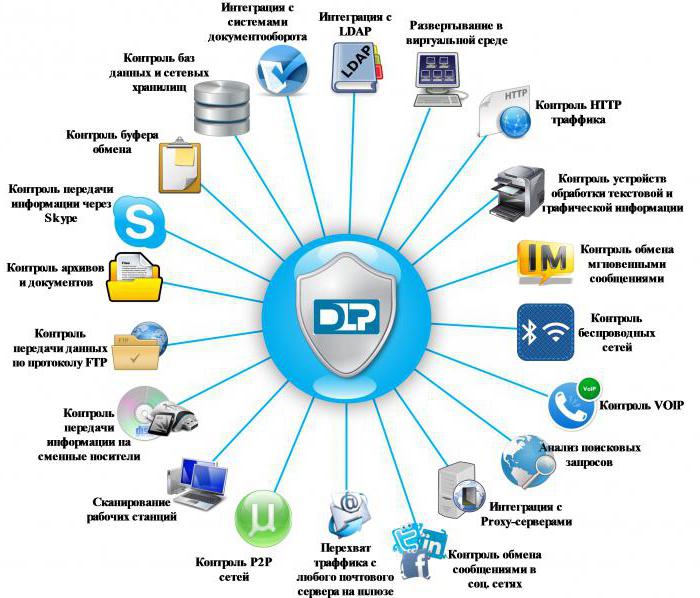
Sul problema Oggi, la tecnologia dell'informazione è una componente importante di qualsiasi organizzazione moderna. In senso figurato, la tecnologia dell'informazione è il cuore dell'impresa, che mantiene l'attività in funzione e ne aumenta l'efficienza e la competitività nell'agguerrita concorrenza di oggi. Sistemi di automazione dei processi aziendali, come la gestione dei documenti, i sistemi CRM, i sistemi ERP, i sistemi analisi multivariata e la pianificazione consentono di raccogliere rapidamente informazioni, sistematizzarle e raggrupparle, velocizzando i processi decisionali del management e garantendo trasparenza del business e dei processi aziendali per il management e gli azionisti. un gran numero di i dati strategici, riservati e personali sono un importante patrimonio informativo dell'azienda e le conseguenze della fuga di queste informazioni influenzeranno l'efficienza dell'organizzazione.L'uso delle misure di sicurezza tradizionali oggi, come antivirus e firewall, protegge le risorse informative da minacce esterne, ma non protegge in alcun modo le risorse informative da perdite, distorsioni o distruzioni da parte di un utente malintenzionato interno. Le minacce interne alla sicurezza delle informazioni possono rimanere ignorate o in alcuni casi ignorate dal management a causa della mancanza di comprensione della criticità di queste minacce per le aziende. è per questo motivo Protezione della privacy così importante oggi. Sulla soluzione Protezione delle informazioni riservate dalla perdita è una componente importante del complesso di sicurezza delle informazioni dell'organizzazione. Per risolvere il problema delle fughe accidentali e intenzionali di dati riservati, si ricorre ai sistemi DLP (data leak protection system).
Sistema integrato protezione dalla fuga di dati (sistema DLP) sono un complesso software o hardware-software che impedisce la fuga di dati riservati.
Viene svolto dal sistema DLP utilizzando le seguenti funzioni principali:
- Filtraggio del traffico su tutti i canali di trasmissione dati;
- Analisi approfondita del traffico a livello di contenuto e contesto.
Dati in movimento– dati trasmessi sui canali di rete:
- Web (protocolli HTTP/HTTPS);
- Messaggeri Internet (ICQ, QIP, Skype, MSN, ecc.);
- Posta aziendale e personale (POP, SMTP, IMAP, ecc.);
- Sistemi wireless (WiFi, Bluetooth, 3G, ecc.);
- Connessioni FTP.
- Server;
- postazioni di lavoro;
- I Quaderni;
- Sistemi di archiviazione dati (SHD).
Misure volte a prevenire fughe di informazioni si compone di due parti principali: organizzativa e tecnica.
Protezione delle informazioni riservate include disposizioni organizzative ricercare e classificare i dati disponibili in azienda. Il processo di classificazione divide i dati in 4 categorie:
- Informazioni segrete;
- Informazioni confidenziali;
- Informazioni per uso ufficiale;
- Informazione pubblica.
Nei sistemi DLP, le informazioni riservate possono essere determinate da una serie di caratteristiche diverse, oltre a diversi modi, Per esempio:
- Analisi linguistica delle informazioni;
- Analisi statistica delle informazioni;
- Espressioni regolari (modelli);
- Metodo dell'impronta digitale, ecc.
Misure tecniche:
Protezione delle informazioni riservate con misure tecniche si basa sull'uso delle funzionalità e delle tecnologie del sistema di protezione dalla fuga di dati. Il sistema DLP è costituito da due moduli: un modulo host e modulo di rete.
Moduli ospiti sono installati sulle postazioni degli utenti e forniscono il controllo delle azioni compiute dall'utente in relazione ai dati classificati (informazioni riservate). Inoltre, il modulo host consente di monitorare l'attività dell'utente in base a vari parametri, come il tempo trascorso su Internet, le applicazioni avviate, i processi e i percorsi di spostamento dei dati, ecc.
modulo di rete analizza le informazioni trasmesse sulla rete e controlla il traffico che va oltre il protetto sistema informativo. Se vengono rilevate informazioni riservate nel traffico trasmesso, il modulo di rete interrompe la trasmissione dei dati.
Cosa darà l'introduzione di un sistema DLP?
Dopo aver implementato un sistema di protezione dalla fuga di dati, l'azienda riceverà:
- Protezione del patrimonio informativo e delle informazioni strategiche importanti dell'azienda;
- Dati strutturati e sistematizzati nell'organizzazione;
- Trasparenza dei processi aziendali e aziendali per servizi di gestione e sicurezza;
- Controllo dei processi di trasferimento dei dati riservati in azienda;
- Ridurre i rischi associati alla perdita, al furto e alla distruzione di informazioni importanti;
- Protezione contro il malware che entra nell'organizzazione dall'interno;
- Salvataggio e archiviazione di tutte le azioni relative alla movimentazione dei dati all'interno del sistema informativo;
- Monitoraggio della presenza del personale sul posto di lavoro;
- Salvataggio del traffico Internet;
- Ottimizzazione della rete aziendale;
- Controllo delle applicazioni utilizzate dall'utente;
- Migliorare l'efficienza del personale.