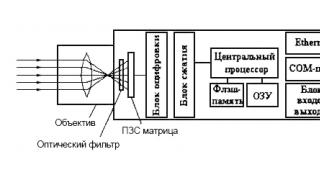
Lako je izračunati da će nekomprimirana slika u punoj boji od 2000*1000 piksela biti veličine oko 6 megabajta. Ako govorimo o slikama dobivenim profesionalnim kamerama ili skenerima visoke rezolucije, tada njihova veličina može biti i veća. Unatoč brzom rastu kapaciteta uređaja za pohranu podataka, različiti algoritmi za kompresiju slike i dalje su vrlo relevantni.
Svi postojeći algoritmi mogu se podijeliti u dvije velike klase:
- Algoritmi kompresije bez gubitaka;
- Algoritmi kompresije s gubitkom.
Algoritmi kompresije bez gubitaka
RLE algoritam
Svi algoritmi serije RLE temelje se na vrlo jednostavnoj ideji: grupe elemenata koje se ponavljaju zamjenjuju se parom (broj ponavljanja, element koji se ponavlja). Razmotrimo ovaj algoritam na primjeru niza bitova. U ovom nizu izmjenjivat će se skupine nula i jedinica. Štoviše, u grupama će često biti više od jednog elementa. Tada će niz 11111 000000 11111111 00 odgovarati sljedećem skupu brojeva 5 6 8 2. Ovi brojevi označavaju broj ponavljanja (brojenje počinje od jedinica), ali te brojeve također treba kodirati. Pretpostavit ćemo da se broj ponavljanja nalazi u rasponu od 0 do 7 (tj. 3 bita će nam biti dovoljna za kodiranje broja ponavljanja). Tada je gore razmatrani niz kodiran sljedećim nizom brojeva 5 6 7 0 1 2. Lako je izračunati da je 21 bit potreban za kodiranje izvornog niza, au komprimiranom RLE metoda obliku, ovaj niz zauzima 18 bita.Iako je ovaj algoritam vrlo jednostavan, njegova učinkovitost je relativno niska. Štoviše, u nekim slučajevima primjena ovog algoritma ne dovodi do smanjenja, već do povećanja duljine niza. Na primjer, razmotrite sljedeći niz 111 0000 11111111 00. Odgovarajući RL niz izgleda ovako: 3 4 7 0 1 2. Dužina originalnog niza je 17 bita, duljina komprimiranog niza je 18 bita.
Ovaj algoritam je najučinkovitiji za crno-bijele slike. Također se često koristi kao jedan od međufaza kompresije složenijih algoritama.
Algoritmi rječnika
Ideja koja leži u osnovi algoritama rječnika je da postoji kodiranje lanaca elemenata izvornog niza. Ovo kodiranje koristi poseban rječnik koji se dobiva na temelju izvornog niza.Postoji cijela obitelj rječničkih algoritama, ali mi ćemo razmotriti najčešći LZW algoritam, nazvan po njegovim kreatorima Lepel, Ziv i Welch.
Rječnik u ovom algoritmu je tablica koja se puni lancima kodiranja dok algoritam radi. Prilikom dekodiranja komprimiranog koda, rječnik se automatski obnavlja, tako da nema potrebe za prijenosom rječnika zajedno sa komprimiranim kodom.
Rječnik se inicijalizira sa svim pojedinačnim nizovima, tj. prvi redovi rječnika predstavljaju abecedu kojom kodiramo. Kompresija traži najdulji lanac koji je već zabilježen u rječniku. Svaki put kada se naiđe na niz koji još nije upisan u rječnik, on se tamo dodaje, a prikazuje se komprimirani kod koji odgovara nizu koji je već upisan u rječnik. U teoriji nema ograničenja na veličinu rječnika, ali u praksi ima smisla ograničiti ovu veličinu, jer se s vremenom počinju javljati lanci koji se više ne nalaze u tekstu. Osim toga, kada se veličina tablice udvostruči, moramo dodijeliti dodatni bit za pohranu komprimiranih kodova. Kako bi se spriječile takve situacije, uvodi se poseban kod koji simbolizira inicijalizaciju tablice sa svim lancima od jednog elementa.
Razmotrimo primjer kompresije pomoću algoritma. Komprimirati ćemo niz cuckoocuckooboughthood. Pretpostavimo da će rječnik sadržavati 32 pozicije, što znači da će svaki njegov kod imati 5 bita. U početku se rječnik popunjava sljedećim:
Ova tablica je, kako na strani onoga tko komprimira informaciju, tako i na strani onoga koji dekompresira. Sada ćemo pogledati proces kompresije. 
U tablici je prikazan proces popunjavanja rječnika. Lako je izračunati da rezultirajući komprimirani kod zauzima 105 bita, a izvorni tekst (pod pretpostavkom da potrošimo 4 bita na kodiranje jednog znaka) zauzima 116 bita.
Zapravo se proces dekodiranja svodi na direktno dekodiranje kodova, pri čemu je važno da se tablica inicijalizira na isti način kao i kod kodiranja. Sada razmotrite algoritam dekodiranja. 
Niz dodan u rječnik u i-tom koraku može se u potpunosti odrediti tek na i+1. Očito, i-ti red mora završiti prvim znakom i+1 retka. Da. upravo smo smislili kako vratiti rječnik. Zanimljiva je situacija kada je kodirana sekvenca oblika cScSc, gdje je c jedan znak, a S niz, a riječ cS je već u rječniku. Na prvi pogled može se činiti da dekoder neće moći riješiti ovu situaciju, ali zapravo svi nizovi ovog tipa moraju uvijek završavati istim znakom kojim počinju.
Algoritmi entropijskog kodiranja
Algoritmi u ovoj seriji dodjeljuju najkraći komprimirani kod najčešćim elementima sekvenci. Oni. nizovi iste duljine kodirani su komprimiranim kodovima različitih duljina. Štoviše, što je niz uobičajeniji, to je odgovarajući komprimirani kod kraći.Huffmanov algoritam
Huffmanov algoritam omogućuje vam izgradnju prefiksni kodovi. Prefiks kodove možete zamisliti kao putove do binarno stablo: prijelaz od čvora do njegovog lijevog djeteta odgovara 0 u kodu, a desnom djetetu - 1. Označimo li listove stabla kodiranim znakovima, dobivamo binarnu reprezentaciju stabla prefiks koda.Opišimo algoritam za konstruiranje Huffmanovog stabla i dobivanje Huffmanovih kodova.
- Znakovi ulazne abecede tvore listu slobodnih čvorova. Svaki list ima težinu koja jednaka frekvenciji izgled lika
- Odabrana su dva slobodna čvora stabla s najmanjim težinama
- Njihov je roditelj stvoren s težinom jednakom njihovoj ukupnoj težini
- Roditelj se dodaje na popis slobodnih čvorova, a njegova dva djeteta se uklanjaju s ovog popisa.
- Jednom luku koji izlazi iz roditelja dodijeljen je bit 1, drugom je dodijeljen bit 0
- Koraci počevši od drugog ponavljaju se sve dok na popisu slobodnih čvorova ne ostane samo jedan slobodni čvor. Smatrat će se korijenom stabla.
Aritmetičko kodiranje
Algoritmi aritmetičkog kodiranja kodiraju nizove elemenata u razlomke. Ovo uzima u obzir frekvencijsku distribuciju elemenata. Trenutno su algoritmi aritmetičkog kodiranja zaštićeni patentima, pa ćemo razmotriti samo glavnu ideju.Neka se naša abeceda sastoji od N znakova a1,…,aN i učestalosti njihovog pojavljivanja p1,…,pN. Podijelimo interval ID tablice: 0
Preostala 64 bajta trebaju ispuniti tablicu 8x8.
Pažljivije pogledajte redoslijed popunjavanja vrijednosti tablice. Ovaj poredak se naziva cik-cak redoslijed: 
Oznaka: SOF0 - Osnovna DCT
Ovaj marker se zove SOF0, što znači da je slika kodirana osnovnom metodom. Vrlo je čest. Ali na internetu nije manje popularna progresivna metoda koju znate, kada se prvo učitava slika niske rezolucije, a zatim normalna slika. To vam omogućuje da razumijete što je tamo prikazano, bez čekanja puno opterećenje. Specifikacija definira još nekoliko, čini mi se, ne baš uobičajenih metoda.FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01
Duljina: 17 bajtova.
Preciznost: 8 bita U osnovnoj metodi uvijek je 8. Koliko sam shvatio, ovo je dubina bita vrijednosti kanala.
Visina slike: 0x10 = 16
Širina uzorka: 0x10 = 16
Broj komponenti: 3. Najčešće je to Y, Cb, Cr.
1. komponenta:
ID: 1
Horizontalno stanjivanje (H 1): 2
[_2]
Vertikalno stanjivanje (V 1): 2
ID kvantizacijske tablice: 0
2. komponenta:
ID: 2
Horizontalno stanjivanje (H 2): 1
[_1]
Vertikalno stanjivanje (V 2): 1
3. komponenta:
ID: 3
Horizontalno stanjivanje (H 3): 1
[_1]
Vertikalno stanjivanje (V 3): 1
Identifikator kvantizacijske tablice: 1
Sada pogledajte kako odrediti koliko je slika istanjena. Nalazimo H max \u003d 2 i V max \u003d 2. Kanal i bit će desetkovan za H max /H i puta vodoravno i V max /V i puta okomito.
Marker: DHT (Huffmanova karta)
Ovaj odjeljak pohranjuje kodove i vrijednosti dobivene Huffmanovim kodiranjem.FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 03 02
duljina: 21 bajt.
klasa: 0 (0 - tablica koeficijenata istosmjerne struje, 1 - tablica koeficijenata izmjenične struje).
[_0]
ID tablice: 0
Duljina Huffmanovog koda: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Broj kodova:
Pod brojem kodova podrazumijeva se broj kodova te duljine. Imajte na umu da odjeljak pohranjuje samo duljine kodova, a ne same kodove. Moramo sami pronaći kodove. Dakle, imamo jedan kod duljine 1 i jedan duljine 2. Ukupno postoje 2 koda, u ovoj tablici nema više kodova.
Svaki kôd ima pridruženu vrijednost i oni su navedeni sljedeći u datoteci. Vrijednosti su jednobajtne, tako da čitamo 2 bajta.
- vrijednost 1. šifre.
- vrijednost 2. šifre.
Izgradnja stabla Huffmanovih kodova
Moramo izgraditi binarno stablo iz tablice koju smo dobili u odjeljku DHT. I već po ovom stablu ćemo prepoznati svaki kod. Vrijednosti se dodaju redoslijedom kojim su navedene u tablici. Algoritam je jednostavan: bez obzira gdje se nalazimo, uvijek pokušavamo dodati vrijednost lijevoj grani. A ako je zauzeta, onda desno. A ako tamo nema mjesta, onda se vraćamo na razinu iznad i pokušavamo od tamo. Morate se zaustaviti na razini koja je jednaka duljini koda. Lijeve grane odgovaraju vrijednosti 0, desne - 1.Komentar:
Ne morate svaki put krenuti od vrha. Dodana vrijednost - povratak na razinu iznad. Postoji li prava grana? Ako da, idite ponovno gore. Ako ne, stvorite desnu granu i idite tamo. Zatim, od tamo, počnite tražiti kako biste dodali sljedeću vrijednost.
Stabla za sve tablice u ovom primjeru: 
UPD (hvala): Čvorovi prvog stabla (DC, id =0) moraju imati vrijednosti 0x03 i 0x02
U krugovima - vrijednosti kodova, ispod krugova - sami kodovi (objasnit ću da smo ih dobili idući od vrha do svakog čvora). Upravo je takvim kodovima (ove i drugih tablica) kodiran sam sadržaj slike.
Oznaka: SOS (početak skeniranja)
Bajt u tokenu znači "DA! Konačno, prešli smo izravno na analizu dijela kodirane slike! No rubrika je simbolično nazvana SOS. FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00
Dužina zaglavlja (ne cijele sekcije): 12 bajtova.
Broj komponenti skeniranja. Imamo 3, po jedan za Y, Cb, Cr.
1. komponenta:
Broj komponente slike: 1 (Y)
ID Huffmanove tablice za DC koeficijente: 0
[_0]
ID Huffmanove tablice za AC koeficijente: 0
2. komponenta:
Broj komponente slike: 2 (Cb)
[_1]
3. komponenta:
Broj komponente slike: 3 (Cr)
ID Huffmanove tablice za DC koeficijente: 1
[_1]
ID Huffmanove tablice za AC koeficijente: 1
Ove komponente se ciklički izmjenjuju.
Ovdje završava dio zaglavlja, odavde do kraja (marker) kodiranih podataka.
0
Određivanje DC koeficijenta.
1.
Čitanje niza bitova (ako sretnemo 2 bajta, onda ovo nije marker, već samo bajt). Nakon svakog bita, krećemo se po Huffmanovom stablu (s pripadajućim identifikatorom) duž grane 0 ili 1, ovisno o pročitanom bitu. Zaustavljamo se ako smo na završnom čvoru.
10
1011101110011101100001111100100
2.
Uzimamo vrijednost čvora. Ako je jednak 0, onda je koeficijent 0, upišite ga u tablicu i prijeđite na očitavanje ostalih koeficijenata. U našem slučaju - 02. Ova vrijednost je duljina koeficijenta u bitovima. Odnosno, čitamo sljedeća 2 bita, to će biti koeficijent.
10
10
11101110011101100001111100100
3. Ako je prva znamenka vrijednosti u binarnom prikazu 1, ostavite kako jest: DC_coef = vrijednost. Inače, pretvorite: DC_coef = value-2 value length +1 . Koeficijent upisujemo u tablicu na početku cik-cak - gornji lijevi kut.
Određivanje AC-koeficijenata.
1.
Slično točki 1, pronalaženje DC koeficijenta. Nastavljamo čitati niz:
10
10
1110
1110011101100001111100100
2.
Uzimamo vrijednost čvora. Ako je jednak 0, to znači da preostale vrijednosti matrice moraju biti popunjene nulama. Zatim se kodira sljedeća matrica. Prvih nekoliko koji su pročitali do ove točke i pisali mi o tome u osobnom, dobit će plus u karmi. U našem slučaju, vrijednost čvora je 0x31.
Prvi grickanje: 0x3 - toliko nula trebamo dodati matrici. To su 3 nula koeficijenta.
Drugi nibble: 0x1 - duljina koeficijenta u bitovima. Pročitajte sljedeći dio.
10
10
1110
1
110011101100001111100100
3. Slično točki 3 određivanja DC-koeficijenta.
Kao što ste već shvatili, morate čitati AC koeficijente dok ne naletite na nultu vrijednost koda ili dok se matrica ne ispuni.
U našem slučaju dobit ćemo:
10
10
1110
1
1100
11
101
10
0
0
0
1
11110
0
100
i matrica:
Jeste li primijetili da su vrijednosti popunjene istim cik-cak uzorkom?
Razlog za korištenje ovog reda je jednostavan - budući da su veće vrijednosti v i u, manje je značajan koeficijent S vu u diskretnoj kosinusnoj transformaciji. Stoga se pri visokim omjerima kompresije beznačajni koeficijenti postavljaju na nulu, čime se smanjuje veličina datoteke.
[-4 1 1 1 0 0 0 0] [ 5 -1 1 0 0 0 0 0]
[ 0 0 1 0 0 0 0 0] [-1 -2 -1 0 0 0 0 0]
[ 0 -1 0 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-1 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-4 2 2 1 0 0 0 0]
[-1 0 -1 0 0 0 0 0]
[-1 -1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Oh, zaboravio sam reći da kodirani DC koeficijenti nisu sami DC koeficijenti, već njihove razlike između koeficijenata prethodne tablice (istog kanala)! Morate popraviti matrice:
DC za 2.: 2 + (-4) = -2
DC za 3.: -2 + 5 = 3
DC za 4.: 3 + (-4) = -1
[-2 1 1 1 0 0 0 0] [ 3 -1 1 0 0 0 0 0] [-1 2 2 1 0 0 0 0]
………
Sada naručite. Ovo pravilo vrijedi do kraja datoteke.
... i matricom za Cb i Cr:
[-1 0 0 0 0 0 0 0]
[ 1 1 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Budući da postoji samo jedna matrica, koeficijenti istosmjerne struje mogu se ostaviti netaknuti.
Računalstvo
Kvantizacija
Sjećate li se da matrica prolazi kroz fazu kvantizacije? Elementi matrice moraju se pomnožiti član po član s elementima kvantizacijske matrice. Ostaje odabrati onaj pravi. Prvo smo skenirali prvu komponentu, njezinu komponentu slike = 1. Komponenta slike s ovim ID-om koristi matricu kvantizacije 0 (imamo prvu od dvije). Dakle, nakon množenja:
[ 0 120 280 0 0 0 0 0]
[ 0 -130 -160 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
Slično tome, dobivamo još 3 matrice Y-kanala ...
[-320 110 100 160 0 0 0 0] [ 480 -110 100 0 0 0 0 0]
[ 0 0 140 0 0 0 0 0] [-120 -240 -140 0 0 0 0 0]
[ 0 -130 0 0 0 0 0 0] [ 0 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [-140 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[-160 220 200 160 0 0 0 0]
[-120 0 -140 0 0 0 0 0]
[-140 -130 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
… i matricom za Cb i Cr.
[-170 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 180 210 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
Inverzna diskretna kosinusna transformacija
Formula ne bi trebala biti teška*. S vu je naša rezultirajuća matrica koeficijenata. u - stupac, v - red. s yx - izravne vrijednosti kanala.
* Općenito govoreći, to nije posve točno. Kada sam uspio dekodirati i prikazati crtež veličine 16x16 na ekranu, napravio sam sliku veličine 600x600 (usput, ovo je bila naslovnica mog omiljenog albuma Mind.In.A.Box - Lost Alone). Nije odmah uspjelo - pojavile su se razne greške. Uskoro sam se mogao diviti ispravno učitanoj slici. Jedino razočaranje bila je brzina preuzimanja. Još se sjećam da je trajalo 7 sekundi. Ali to nije iznenađujuće, ako nepromišljeno koristite gornju formulu, tada za izračunavanje jednog kanala od jednog piksela morate pronaći 128 kosinusa, 768 množenja i neke dodatke tamo. Razmislite samo o tome - gotovo tisuću teških operacija za samo jedan kanal od jednog piksela! Srećom, ima prostora za optimizaciju (nakon mnogo eksperimentiranja, smanjio sam vrijeme učitavanja na granicu točnosti timera od 15 ms, a nakon toga sam promijenio sliku u fotografiju 25 puta veću. Možda ću o tome pisati u posebnom članku) .
Napisat ću rezultat izračuna samo prve matrice Y kanala (vrijednosti su zaokružene):
[ 87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87 -50 6 56 79 72 48 29]
I druga 2:
Cb Cr
[ 60 52 38 20 0 -18 -32 -40] [ 19 27 41 60 80 99 113 120]
[ 48 41 29 13 -3 -19 -31 -37] [ 0 6 18 34 51 66 78 85]
[ 25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[ -4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[ -37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[ -67 -63 -55 -44 -33 -22 -14 -10] [ -5 -9 -17 -28 -39 -50 -58 -62]
[ -90 -84 -71 -56 -39 -23 -11 -4] [ 32 26 14 -1 -18 -34 -46 -53]
[-102 -95 -81 -62 -42 -23 -9 -1] [ 58 50 36 18 -2 -20 -34 -42]
- Oh, idemo jesti!
- Da, uopće ne ulazim, o čemu pričate.
- Kada se dobiju vrijednosti YCbCr boja, preostaje izvršiti konverziju u RGB, ovako: YCbCrToRGB(Y ij , Cb ij , Cr ij) , Y ij , Cb ij , Cr ij - naše primljene matrice.
- 4 Y matrice, te po jedna Cb i Cr, pošto smo prorijedili kanale i 4 Y piksela odgovaraju po jednom Cb i Cr. Stoga izračunajte ovako: YCbCrToRGB(Y ij , Cb , Cr )
YCbCr u RGB
R = Y + 1,402 * CrG = Y - 0,34414 * Cb - 0,71414 * Cr
B = Y + 1,772 * Cb
Nemojte zaboraviti dodati 128. Ako vrijednosti prelaze interval, dodijelite granične vrijednosti. Formula je jednostavna, ali također oduzima djelić vremena procesora.
Ovdje su dobivene tablice za R, G, B kanale za gornji lijevi kvadrat 8x8 našeg primjera:
255 248 194 148 169 215 255 255
255 238 172 115 130 178 255 255
255 208 127 59 64 112 208 255
255 223 143 74 77 120 211 255
237 192 133 83 85 118 184 222
177 161 146 132 145 162 201 217
56 73 101 126 144 147 147 141
0 17 76 126 153 146 127 108
231 185 117 72 67 113 171 217
229 175 95 39 28 76 139 189
254 192 100 31 15 63 131 185
255 207 115 46 28 71 134 185
255 241 175 125 112 145 193 230
226 210 187 173 172 189 209 225
149 166 191 216 229 232 225 220
72 110 166 216 238 231 206 186
255 255 249 203 178 224 255 255
255 255 226 170 140 187 224 255
255 255 192 123 91 138 184 238
255 255 208 139 103 146 188 239
255 255 202 152 128 161 194 232
255 244 215 200 188 205 210 227
108 125 148 172 182 184 172 167
31 69 122 172 191 183 153 134
Kraj
Općenito, nisam stručnjak za JPEG, pa teško mogu odgovoriti na sva pitanja. Baš kad sam pisao svoj dekoder, često sam se morao baviti raznim nerazumljivim problemima. A kad je slika bila netočno prikazana, nisam znao gdje sam pogriješio. Možda je pogrešno protumačio bitove ili je krivo upotrijebio DCT. Stvarno mi je nedostajao primjer korak po korak, pa se nadam da će ovaj članak pomoći pri pisanju dekodera. Mislim da pokriva opis osnovne metode, ali ipak ne možete proći samo s njom. Evo nekoliko linkova koji su mi pomogli:Fotografije i slike se međusobno razlikuju ne samo po sadržaju, već i po drugim "računalnim" karakteristikama. Na primjer, veličina.
Događa se da, čini se, dva identična crteža, ali jedan ima veličinu tri puta veću od druge.
Također, slike se razlikuju u kvaliteti. Mislim da ste jako dobro vidjeli fotografije Loša kvaliteta. To je vidljivo golim okom. Na primjer, dvije identične fotografije, ali je jedna kvalitetnija, a druga lošije kvalitete.
A događa se da slici nedostaje boja. Evo primjera.

A za sve to odgovoran je format ili vrsta datoteke.
Zapravo, slike dolaze u raznim formatima. A ima ih mnogo, mnogo. Nećemo ih sve razmatrati, ali ćemo govoriti o najčešćim. To su formati kao što su bmp, gif, jpg, png, tiff.
Međusobno se razlikuju, prije svega, kvalitetom. A kvaliteta se razlikuje po broju (zasićenosti) boja.
Na primjer, slikam sliku različitim bojama. A onda su odjednom neki od njih završili i morate završiti slikanje s onim što imate. Naravno, pokušat ću učiniti sve što je moguće kako to ne bi uvelike utjecalo na rezultat, ali ipak slika neće ispasti onako kako bismo željeli - izblijedjela, mutna.
Tako je i sa slikovnim formatima. Jedan ostavlja sve boje, drugi odreže dio. I, ponekad, zbog toga, slika se pogoršava.
Ovo je prilično grub primjer. Zapravo, tu je sve nešto kompliciranije, ali mislim da ste uhvatili bit.
Uobičajeni formati slika
BMP je format za crteže izrađene u programu Paint. Može se koristiti za spremanje nacrtanih slika na računalu. Ali na Internetu se ova vrsta datoteke ne koristi zbog velikog volumena. Dakle, ako želite objaviti sliku nacrtanu u Paintu na blogu ili društvenoj mreži, ona mora biti druge vrste - gif, jpg ili png.
GIF je popularan format slike na internetu. Možete ih spremiti u njega bez gubitka kvalitete, ali s ograničenim brojem boja - 256. GIF je stekao posebnu popularnost zbog činjenice da u njemu možete stvarati male animirane (pokretne) slike.
JPG je format za fotografije i slike s puno boja. U njemu možete spremiti sliku i bez gubitka kvalitete i s gubitkom.
PNG je moderan format slike. Dobiva se slika ove vrste mala veličina i bez gubitka kvalitete. Vrlo prikladno: datoteka je mala, a kvaliteta je dobra. Također podržava transparentnost.
TIFF - slike vrlo dobre kvalitete, bez kompresije, stoga je veličina takvih datoteka ogromna. TIFF se koristi kada je kvaliteta bitna. Na primjer, prilikom izrade posjetnica, brošura, naslovnica časopisa.
Koji format odabrati
- BMP - ako je ovo crtež napravljen u programu Paint, a vi ćete ga čuvati samo u računalu.
- GIF - ako je animacija ili crtež s malom količinom boje za objavljivanje na webu.
- PNG - ako se radi o crtežu u kojem ima puno boja ili nekih prozirnih dijelova.
- JPG (jpeg) - ako je fotografija.
- TIFF - slika za ispis (vizitke, brošure, plakati i sl.).
Pozdrav dragi prijatelji. Danas ćemo razgovarati o tome koji je format slike bolje koristiti na web mjestu, koji su formati grafičkih datoteka danas dostupni za web mjesto i je li potrebno tragati za novim grafičkim formatima.
Dobivam dosta ovakvih pitanja, mnogi moji studenti pitaju mogu li koristiti nove formate SVG i WebP i gdje je najbolje primijeniti te slike. Naravno, možete koristiti nove formate, samo trebate razumjeti koji je format za što najprikladniji.
Do danas su slike na stranici sastavni dio. Počevši od Grafički dizajn i učitavanje slika u članke, grafika prati većinu stranica na webu. Ali ljepota ima svoju cijenu
Neoptimizirane slike jedan su od čimbenika koji usporavaju stranicu, na što ukazuju servisi za provjeru.
Stoga ćete uvijek biti suočeni s izborom koji format odabrati za sliku. To će ovisiti o njegovoj veličini i kvaliteti. I koristiti slike manji i bez gubitka kvalitete, trebali biste znati neke stvari.
Koje slike web stranica danas koristim?
Sve slike za web stranice dijele se na:
- raster (primjer - JPG, JPEG, GIF, PNG),
- vektor (primjer - SVG).
Raster slike se sastoje od piksela koji pohranjuju boju i vrijednost prozirnosti. Ti formati uključuju slike u člancima, gumbe, ikone i elemente dizajna. Ove su slike popularne među programerima i vlasnicima web stranica. Glavni nedostatak rasterskih slika je što se ne skaliraju dobro.
To jest, kada se veličina slike poveća, dolazi do gubitka kvalitete.

Vektor slike se sastoje od linija i putnih točaka. Informacije o slici pohranjuju se u matematičkim uputama za crtanje, što vam omogućuje skaliranje takvih slika koliko želite bez gubitka kvalitete.
Sve ove slike mogu se i koriste na modernim web stranicama. Samo trebate shvatiti da prije postavljanja na stranicu, !
Opis popularnih formata slika za web mjesto
Iz opisa ovih formata shvatit ćete gdje i koji format je najbolje koristiti na web mjestu.
JPEG
JPEG ili JPG jedan je od najpopularnijih formata slika za web stranice. Format podržava milijune boja, što mu daje vodeću poziciju u prezentaciji fotografija i slika na web mjestu.
Slike u ovom formatu su prilično dobro optimizirane gotovo bez gubitka kvalitete, što vam omogućuje da dobijete manju datoteku bez gubitka vizualne kvalitete. Treba imati na umu da svaka sljedeća optimizacija smanjuje kvalitetu.
Datoteke ovog formata podržavaju svi uređaji i preglednici, što još jednom potvrđuje njegovu popularnost i omogućuje vam da ne brinete o problemima s prikazom na web-mjestima.
Veliki nedostatak ovog formata je nedostatak transparentnosti. Odnosno, kombiniranje slika u ovom formatu neće raditi. Za takve zadatke bolje je koristiti sljedeći format.
PNG
Ovaj format koristi algoritam kompresije bez gubitaka. Po broju boja i stupnju prozirnosti dostupan je u dvije vrste: 8 i 24-bitni. Oba podržavaju transparentnost.
8-bitni nije jako popularan, ali 24-bitni se široko koristi za razne slike Na liniji. Zbog transparentnosti, omogućuje vam stvaranje kombiniranih slika. Često se koristi za stvaranje animiranih gumba, ikona, gdje je potreban efekt prozirnosti.
PNG slike mogu se optimizirati, uređivati mnogo puta - zadržat će svoju izvornu kvalitetu.
Format također podržavaju svi preglednici i uređaji, što jamči njegov prikaz na bilo kojem zaslonu.
Kvaliteta slika izgleda bolja od JPG-a, ali će veličina datoteke biti veća. To se mora uzeti u obzir prilikom postavljanja datoteka na web mjesto.
gif
To je 8-bitni format koji podržava 256 boja, transparentnost i animaciju. Zbog podrške malog broja boja, veličina datoteke je također minimalna.
Format nije prikladan za fotografije i slike s širok raspon boje.
Ali naširoko se koristi pri izradi bannera, gumba, ikona i tako dalje.
Na modernim stranicama ovaj se format sve rjeđe koristi.
Zatim, razgovarajmo o relativno novijim formatima SVG i WebP, koji nisu toliko popularni, ali dobivaju popularnost i podršku, te najbolje odgovaraju zahtjevima brzine učitavanja i prilagodljivosti web-mjesta.
SVG
Ovo je format vektorske datoteke na Temeljen na XML-u. Format je počeo dobivati popularnost nedavno, jer je prethodno bio slabo podržan u preglednicima. A zbog problema s prikazom, nitko ga nije žurio koristiti.
Danas SVG podržavaju svi moderni preglednici. No, problemi s prikazom i dalje se javljaju.
Ovaj format se najčešće koristi za jednostavne slike kao što su logotipi, elementi dizajna i tako dalje. Nije primjenjivo za fotografije.
SVG format je lagan, dobro skalira za oštre slike na bilo kojoj razlučivosti zaslona, podržava animaciju, može se njime upravljati putem CSS-a i postaviti u HTML, smanjujući broj zahtjeva.
WebP
Format otvorenog koda koji je razvio Google posebno za web. YouTube danas koristi pretvaranje video minijatura u WebP format.

Format pruža izvrsnu kompresiju i podržava prozirnost. Kombinira prednosti JPG i PNG formata bez povećanja veličine datoteke.
No, unatoč prednostima formata, ne podržavaju ga svi preglednici, kao što su IE, Edge, Firefox i Safari.
Postoje načini zaobilaženja ovih ograničenja, ali one sprječavaju univerzalnu upotrebu formata.
Zaključak
Prijatelji, nadam se da sam sve jasno objasnio i sada znate koji je format slike bolje koristiti na web mjestu i zašto ne inzistiram na korištenju jednog određenog formata, već preporučujem integrirani pristup.
Možda kada WebP dobije široku podršku, svi ćemo se prebaciti na njega i zamijeniti jpg i png na našim stranicama.
Raspravimo u komentarima koje formate koristite na svojim stranicama, što vam se sviđa, a što ne.
To je sve za danas, veselim se vašim komentarima.
S poštovanjem, Maxim Zaitsev.
- 1-bitna boja (21 = 2 boje) binarna boja, najčešće predstavljena crnom i bijelom (ili crnom i zelenom)
- 2-bitna boja (22 = 4 boje) CGA, NeXTstation u sivim tonovima
- 3-bitna boja (23 = 8 boja) mnoga naslijeđena osobna računala s TV izlazom
- 4-bitna boja (24 = 16 boja) poznata je kao EGA i u manjoj mjeri kao VGA standard visoke rezolucije
- 5-bitna boja (25 = 32 boje) Originalni Amiga čipset
- 6-bitna boja (26 = 64 boje) Originalni Amiga čipset
- 8-bitna boja (28 = 256 boja) Legacy Unix radne stanice, VGA niske rezolucije, Super VGA, AGA
- 12-bitna boja (212 = 4096 boja) na nekim Silicon Graphics sustavima, NeXTstation sustavima boja i Amiga HAM sustavima načina rada.
- Algoritmi kompresije bez gubitaka;
- Algoritmi kompresije s gubitkom.
S Tri najpopularnija formata datoteka su JPEG, RAW i TIFF. Ponekad možete čuti nesuglasice među fotografima - koji je najbolji format datoteke za fotografiju, u kojem formatu je bolje slikati, jer moderni fotoaparati omogućuju snimanje fotografija.ispisuje u bilo kojem od ovih formata, a ponekad iu nekoliko odjednom!
Format datoteke u kojoj je slika pohranjena zapravo je određeni kompromis između kvalitete slike i veličine datoteke.
Vjerojatno već znate da se bitmapa sastoji od piksela. Način na koji je bitmap datoteka organizirana i kako pohranjuje informacije o pikselima određuje format datoteke. Kvalitetu slike za bitmap datoteku određuju dva glavna parametra: veličina piksela (to jest, ukupni broj piksela) i točnost reprodukcije stvarne boje bojom piksela.S veličinom piksela je jasno - što više piksela (ili - "manji" piksel), to bolje.A točnost boja ovisi o broju boja po pikselu ili dubini boje.
Dubina boje (kvaliteta boje, dubina bita slike) - količina memorije u broju bitova koji se koriste za pohranjivanje i predstavljanje boje prilikom kodiranja jednog piksela rasterske grafike ili video slike. Broj bitova označava broj gradacija (tonalnih koraka) u svakoj komponenti boje ili, jednostavno, broj boja. Dodavanje 1 bita je dodavanje još jednog bita binarni kod kromatičnost.



Na primjer, radimo u RGB prostoru boja. To znači da postoje tri kanala iz kojih se formira konačna boja piksela: crveni kanal (Rad), zeleni kanal (Green), plavi kanal (Blue). Pretpostavimo da su kanali četverobitni. To znači da svaki kanal ima mogućnost prikaza 16 boja. Kao rezultat toga, sav RGB bit će 12-bitni i moći će se prikazivati
C=16x16x16=4096 boja
Dubina boje u ovom slučaju je 12 bita.
Kada govore o 24-bitnom RGB-u, misle na 8-bitne kanale (svaki po 256 boja) s ukupnim brojem opcija boja po pikselu
C=256x256x256=16777216 boja.
Brojka je impresivna. Ovaj broj boja za svaki piksel zadovoljava zahtjeve i najzahtjevnijeg fotografskog umjetnika.
Malo o samim formatima.
TIFF format
TIFF je kratica za "Tagged Image File Format" i standard je za tisak i tiskarsku industriju.
Kao rezultat toga događa se sljedeće:
1. Ako je vaš fotoaparat tako jednostavan da snima samo JPEG-ove i želite ih dobiti maksimalna kvaliteta, postavite maksimalnu veličinu i minimalnu kompresiju i ne brinite da nemate druge formate. U većini slučajeva, mukotrpno ručno izrađena RAW slika odgovara JPEG-u koji automatski snima fotoaparat.
2. Možda ne biste trebali slikati u TIFF-u. Snimanje ovog formata je teže i nema primjetne razlike u odnosu na visokokvalitetni JPEG.
3. Ako imate priliku slikati se, radite s tim. Sami ćete osjetiti da li vam odgovara. U nekim slučajevima samo RAW omogućuje snimanje jedinstvene fotografije za veliko povećanje ispisa.
Ostaje još jedno rješenje, reklo bi se univerzalni. Postoji način koji vam omogućuje snimanje okvira u dva formata istovremeno: RAW + JPEG. Snimite važne scene u ovom načinu. Moderna pohrana digitalnih informacija - i memorijske kartice i tvrdi diskovi - to vam omogućuje. U tom slučaju dobivate JPEG za korištenje fotografije odmah, bez trošenja vremena na reviziju. I, ako vam treba ovaj, povjerite RAW datoteku stručnjaku na obradu.
Fotografija. Formati datoteka.
Lako je izračunati da će nekomprimirana slika u punoj boji od 2000*1000 piksela biti veličine oko 6 megabajta. Ako govorimo o slikama dobivenim profesionalnim kamerama ili skenerima visoke rezolucije, tada njihova veličina može biti i veća. Unatoč brzom rastu kapaciteta uređaja za pohranu podataka, različiti algoritmi za kompresiju slike i dalje su vrlo relevantni.
Svi postojeći algoritmi mogu se podijeliti u dvije velike klase:
Algoritmi kompresije bez gubitaka
RLE algoritam
Svi algoritmi serije RLE temelje se na vrlo jednostavnoj ideji: grupe elemenata koje se ponavljaju zamjenjuju se parom (broj ponavljanja, element koji se ponavlja). Razmotrimo ovaj algoritam na primjeru niza bitova. U ovom nizu izmjenjivat će se skupine nula i jedinica. Štoviše, u grupama će često biti više od jednog elementa. Tada će niz 11111 000000 11111111 00 odgovarati sljedećem skupu brojeva 5 6 8 2. Ovi brojevi označavaju broj ponavljanja (brojenje počinje od jedinica), ali te brojeve također treba kodirati. Pretpostavit ćemo da se broj ponavljanja nalazi u rasponu od 0 do 7 (tj. 3 bita će nam biti dovoljna za kodiranje broja ponavljanja). Tada je gore razmatrani niz kodiran sljedećim nizom brojeva 5 6 7 0 1 2. Lako je izračunati da je za kodiranje originalnog niza potreban 21 bit, au obliku komprimiranom RLE metodom ovaj niz zauzima 18 bita .Iako je ovaj algoritam vrlo jednostavan, njegova učinkovitost je relativno niska. Štoviše, u nekim slučajevima primjena ovog algoritma ne dovodi do smanjenja, već do povećanja duljine niza. Na primjer, razmotrite sljedeći niz 111 0000 11111111 00. Odgovarajući RL niz izgleda ovako: 3 4 7 0 1 2. Dužina originalnog niza je 17 bita, duljina komprimiranog niza je 18 bita.
Ovaj algoritam je najučinkovitiji za crno-bijele slike. Također se često koristi kao jedan od međufaza kompresije složenijih algoritama.
Algoritmi rječnika
Ideja koja leži u osnovi algoritama rječnika je da postoji kodiranje lanaca elemenata izvornog niza. Ovo kodiranje koristi poseban rječnik koji se dobiva na temelju izvornog niza.Postoji cijela obitelj rječničkih algoritama, ali mi ćemo razmotriti najčešći LZW algoritam, nazvan po njegovim kreatorima Lepel, Ziv i Welch.
Rječnik u ovom algoritmu je tablica koja se puni lancima kodiranja dok algoritam radi. Prilikom dekodiranja komprimiranog koda, rječnik se automatski obnavlja, tako da nema potrebe za prijenosom rječnika zajedno sa komprimiranim kodom.
Rječnik se inicijalizira sa svim pojedinačnim nizovima, tj. prvi redovi rječnika predstavljaju abecedu kojom kodiramo. Kompresija traži najdulji lanac koji je već zabilježen u rječniku. Svaki put kada se naiđe na niz koji još nije upisan u rječnik, on se tamo dodaje, a prikazuje se komprimirani kod koji odgovara nizu koji je već upisan u rječnik. U teoriji nema ograničenja na veličinu rječnika, ali u praksi ima smisla ograničiti ovu veličinu, jer se s vremenom počinju javljati lanci koji se više ne nalaze u tekstu. Osim toga, kada se veličina tablice udvostruči, moramo dodijeliti dodatni bit za pohranu komprimiranih kodova. Kako bi se spriječile takve situacije, uvodi se poseban kod koji simbolizira inicijalizaciju tablice sa svim lancima od jednog elementa.
Razmotrimo primjer kompresije pomoću algoritma. Komprimirati ćemo niz cuckoocuckooboughthood. Pretpostavimo da će rječnik sadržavati 32 pozicije, što znači da će svaki njegov kod imati 5 bita. U početku se rječnik popunjava sljedećim:
Ova tablica je, kako na strani onoga tko komprimira informaciju, tako i na strani onoga koji dekompresira. Sada ćemo pogledati proces kompresije.

U tablici je prikazan proces popunjavanja rječnika. Lako je izračunati da rezultirajući komprimirani kod zauzima 105 bita, a izvorni tekst (pod pretpostavkom da potrošimo 4 bita na kodiranje jednog znaka) zauzima 116 bita.
Zapravo se proces dekodiranja svodi na direktno dekodiranje kodova, pri čemu je važno da se tablica inicijalizira na isti način kao i kod kodiranja. Sada razmotrite algoritam dekodiranja.

Niz dodan u rječnik u i-tom koraku može se u potpunosti odrediti tek na i+1. Očito, i-ti red mora završiti prvim znakom i+1 retka. Da. upravo smo smislili kako vratiti rječnik. Zanimljiva je situacija kada je kodirana sekvenca oblika cScSc, gdje je c jedan znak, a S niz, a riječ cS je već u rječniku. Na prvi pogled može se činiti da dekoder neće moći riješiti ovu situaciju, ali zapravo svi nizovi ovog tipa moraju uvijek završavati istim znakom kojim počinju.
Algoritmi entropijskog kodiranja
Algoritmi u ovoj seriji dodjeljuju najkraći komprimirani kod najčešćim elementima sekvenci. Oni. nizovi iste duljine kodirani su komprimiranim kodovima različitih duljina. Štoviše, što je niz uobičajeniji, to je odgovarajući komprimirani kod kraći.Huffmanov algoritam
Huffmanov algoritam omogućuje izradu prefiks kodova. Možemo zamisliti prefiks kodove kao staze na binarnom stablu: prijelaz od čvora do njegovog lijevog djeteta odgovara 0 u kodu, a njegovom desnom potomku odgovara 1. Ako označimo listove stabla kodiranim znakovima, dobivamo prikaz binarnog stabla prefiks koda.Opišimo algoritam za konstruiranje Huffmanovog stabla i dobivanje Huffmanovih kodova.
- Znakovi ulazne abecede tvore listu slobodnih čvorova. Svaki list ima težinu koja je jednaka učestalosti pojavljivanja simbola
- Odabrana su dva slobodna čvora stabla s najmanjim težinama
- Njihov je roditelj stvoren s težinom jednakom njihovoj ukupnoj težini
- Roditelj se dodaje na popis slobodnih čvorova, a njegova dva djeteta se uklanjaju s ovog popisa.
- Jednom luku koji izlazi iz roditelja dodijeljen je bit 1, drugom je dodijeljen bit 0
- Koraci počevši od drugog ponavljaju se sve dok na popisu slobodnih čvorova ne ostane samo jedan slobodni čvor. Smatrat će se korijenom stabla.
Aritmetičko kodiranje
Algoritmi aritmetičkog kodiranja kodiraju nizove elemenata u razlomke. Ovo uzima u obzir frekvencijsku distribuciju elemenata. Trenutno su algoritmi aritmetičkog kodiranja zaštićeni patentima, pa ćemo razmotriti samo glavnu ideju.- tutorial

Iz naslova ste točno shvatili da ovo nije sasvim uobičajeni opis JPEG algoritma (format datoteke sam detaljno opisao u članku "JPEG dekodiranje za glupane"). Prije svega, odabrani način prezentiranja materijala pretpostavlja da ne znamo ništa ne samo o JPEG-u, već io Fourierovoj transformaciji i Huffmanovu kodiranju. Općenito, malo toga pamtimo s predavanja. Samo su slikali i počeli razmišljati kako se to može komprimirati. Stoga sam pokušao izraziti samo bit na pristupačan način, ali u kojem će čitatelj razviti dovoljno duboko i, što je najvažnije, intuitivno razumijevanje algoritma. Formule i matematički izračuni - u najmanju ruku samo oni koji su važni za razumijevanje onoga što se događa.
Poznavanje JPEG algoritma vrlo je korisno za više od puke kompresije slike. Koristi se teorijom digitalna obrada signali, matematička analiza, linearna algebra, teorija informacija, posebice Fourierova transformacija, kodiranje bez gubitaka, itd. Stoga stečeno znanje može biti korisno bilo gdje.
Ako postoji želja, predlažem da sami prođete kroz iste korake paralelno s člankom. Provjerite u kojoj je mjeri gornje obrazloženje prikladno različite slike, pokušajte sami modificirati algoritam. Jako je zanimljivo. Kao alat, mogu preporučiti prekrasan paket Python + NumPy + Matplotlib + PIL(Pillow). Gotovo sav moj rad (uključujući grafiku i animaciju) napravljen je s njima.
Pozor promet! Puno ilustracija, grafikona i animacija (~ 10Mb). Ironično, u članku o JPEG postoje samo 2 slike u ovom formatu od pedeset.
Kakav god bio algoritam za sažimanje informacija, njegov će princip uvijek biti isti - pronalaženje i opisivanje obrazaca. Što više uzoraka, više redundancije, manje informacija. Arhivari i koderi obično su "naoštreni" za određenu vrstu informacija i znaju gdje ih pronaći. U nekim slučajevima, uzorak je odmah vidljiv, na primjer, slika plavog neba. Svaki red njegovog digitalnog prikaza može se prilično precizno opisati ravnom linijom.
Trenirati ćemo na rakunskim mačkama. Siva slika iznad uzeta je kao primjer. Dobro kombinira i homogena područja i kontrastna područja. A ako naučimo komprimirati sivo, onda neće biti problema s bojom.
Vektorski prikaz
Prvo, provjerimo koliko su dva susjedna piksela ovisna. Logično je pretpostaviti da će najvjerojatnije biti vrlo slični. Provjerimo ovo za sve parove slike. Označavamo ih na koordinatnoj ravnini točkama tako da je vrijednost točke duž X osi vrijednost prvog piksela, duž Y osi - drugog. Za našu sliku od 256 x 256 dobivamo 256*256/2 piksela:
Očekivano, većina točaka nalazi se na ili blizu linije y=x (a ima ih čak i više nego što možete vidjeti na slici, budući da se mnogo puta preklapaju, a štoviše, prozirne su). A ako je tako, bilo bi lakše raditi ako ih okrenete za 45 °. Da biste to učinili, morate ih izraziti u drugom koordinatnom sustavu.

Osnovni vektori novog sustava očito su sljedeći: . Prisiljeno dijeliti s korijenom iz dva da bi se dobio ortonormirani sustav (duljine baznih vektora jednake su jedan). Ovdje je pokazano da će neka točka p = (x, y) u novom sustavu biti predstavljena kao točka (a 0 , a 1). Poznavajući nove koeficijente, lako možemo dobiti stare obrnutom rotacijom. Očito, prva (nova) koordinata je srednja vrijednost, a druga je razlika između x i y (ali podijeljena s korijenom iz 2). Zamislite da se od vas traži da ostavite samo jednu vrijednost: ili 0 ili 1 (to jest, drugu postavite na nulu). Bolje je odabrati 0 jer je vrijednost 1 vjerojatno oko nule. Evo što se događa ako vratimo sliku samo s 0:

4 puta povećanje:

Takva vrsta kompresije nije baš impresivna, da budemo iskreni. Bolje je na sličan način podijeliti sliku u trostruke piksele i prikazati ih u trodimenzionalnom prostoru.


To je isti grafikon, ali s različitih gledišta. Crvene linije su osi koje su se same sugerirale. Oni odgovaraju vektorima: . Podsjećam vas da morate podijeliti s nekim konstantama tako da duljine vektora postanu jednake jedan. Dakle, proširenjem na takvoj osnovi, dobivamo 3 vrijednosti a 0, a 1, a 2, a 0 je važnija od 1, a 1 je važnija od 2. Ako izbacimo a 2 , tada će se graf "spljoštiti" u smjeru vektora e 2 . Ova već prilično tanka trodimenzionalna ploča postat će ravna. Neće puno izgubiti, ali ćemo se riješiti trećine vrijednosti. Usporedimo slike restaurirane trojkama: (a 0 , 0, 0), (a 1 , a 2 , 0) i (a 0 , a 1 , a 2). U zadnja verzija nismo ništa bacili, pa dobijemo original.

4 puta povećanje:

Drugi crtež je već dobar. Oštra područja su malo izglađena, ali općenito je slika vrlo dobro očuvana. A sada, podijelimo na četiri na isti način i vizualno odredimo osnovu u četverodimenzionalnom prostoru ... Ah, pa, da. Ali možete pogoditi koji će biti jedan od baznih vektora, ovo je: (1,1,1,1)/2. Stoga se može promatrati projekcija četverodimenzionalnog prostora na prostor okomit na vektor (1,1,1,1) kako bi se identificirali drugi. Ali ovo nije najbolji način.
Naš cilj je naučiti kako transformirati (x 0 , x 1 , ..., x n-1) u (a 0 , a 1 , ..., a n-1) tako da je svaka vrijednost a i manja i manje važni od prethodnih . Ako to možemo učiniti, onda se možda posljednje vrijednosti niza mogu u potpunosti odbaciti. Gornji eksperimenti nagovještavaju da je to moguće. Ali ne može se bez matematičkog aparata.
Dakle, trebate pretvoriti bodove u novu osnovu. Ali prvo morate pronaći odgovarajuću osnovu. Vratimo se prvom eksperimentu sparivanja. Razmotrimo to općenito. Definirali smo bazne vektore:

Izraženo kroz njih vektor str:
ili u koordinatama:

Da biste pronašli 0 i 1 morate projicirati str na e 0 i e 1 odnosno. A za ovo morate pronaći skalarni produkt
slično:
U koordinatama:

Često je prikladnije provesti transformaciju u obliku matrice.

Tada je A = EX i X = E T A. Ovo je lijep i zgodan oblik. Matrica E naziva se transformacijska matrica i ortogonalna je, s njom ćemo se susresti kasnije.
Prijelaz s vektora na funkcije.
Pogodno je raditi s vektorima malih dimenzija. Međutim, želimo pronaći uzorke u većim blokovima, pa je umjesto N-dimenzionalnih vektora prikladnije raditi sa sekvencama koje predstavljaju sliku. Takve ću nizove nazvati diskretnim funkcijama, budući da se sljedeće razmišljanje odnosi i na kontinuirane funkcije.Vraćajući se našem primjeru, zamislite funkciju f(i) koja je definirana u samo dvije točke: f(0)=x i f(1)=y. Slično, definiramo bazne funkcije e 0 (i) i e 1 (i) na temelju baza e 0 i e 1 . Dobivamo:

Ovo je vrlo važan zaključak. Sada u frazi "proširenje vektora u smislu ortonormiranih vektora" možemo zamijeniti riječ "vektor" sa "funkcija" i dobiti potpuno ispravan izraz "proširenje funkcije u smislu ortonormiranih funkcija". Nije važno što smo dobili tako kratku funkciju, budući da isto razmišljanje vrijedi za N-dimenzionalni vektor, koji se može prikazati kao diskretna funkcija s N vrijednostima. I rad s funkcijama je jasniji nego s N-dimenzionalnim vektorima. Možete, i obrnuto, prikazati takvu funkciju kao vektor. Štoviše, uobičajeno kontinuirana funkcija može se prikazati kao beskonačnodimenzionalni vektor, ali ne u euklidskom, već u Hilbertovom prostoru. Ali nećemo ići tamo, zanimat će nas samo diskretne funkcije.
I naš problem pronalaženja baze pretvara se u problem pronalaženja odgovarajućeg sustava ortonormiranih funkcija. U sljedećem obrazloženju, pretpostavlja se da smo već nekako definirali skup osnovnih funkcija, u smislu kojih ćemo se proširiti.
Recimo da imamo neku funkciju (predstavljenu, na primjer, vrijednostima) koju želimo prikazati kao zbroj drugih. Ovaj proces možete prikazati u vektorskom obliku. Da biste proširili funkciju, trebate je "projicirati" na osnovne funkcije jednu po jednu. U vektorskom smislu, izračun projekcije daje minimalnu konvergenciju izvornog vektora prema drugom po udaljenosti. Imajući na umu da se udaljenost izračunava pomoću Pitagorinog poučka, tada sličan prikaz u obliku funkcija daje najbolju aproksimaciju srednje kvadrata jedne funkcije drugoj. Dakle, svaki koeficijent (k) određuje "bliskost" funkcije. Formalnije, k*e(x) je najbolja efektivna aproksimacija f(x) među l*e(x).
Sljedeći primjer prikazuje postupak aproksimacije funkcije sa samo dvije točke. S desne strane je vektorski prikaz.

U odnosu na naš eksperiment uparivanja, možemo reći da su ove dvije točke (0 i 1 na apscisi) par susjednih piksela (x, y).
Isto ali s animacijom:

Ako uzmemo 3 boda, onda moramo razmisliti 3d vektori, ali će aproksimacija biti točnija. A za diskretnu funkciju s N vrijednostima, trebate uzeti u obzir N-dimenzionalne vektore.
Imajući skup dobivenih koeficijenata, lako se može dobiti izvorna funkcija zbrajanjem baznih funkcija uzetih s odgovarajućim koeficijentima. Analiza ovih koeficijenata može puno dati korisna informacija(ovisno o osnovi). Poseban slučaj ovih razmatranja je princip širenja u Fourierov red. Na kraju krajeva, naše razmišljanje je primjenjivo na bilo koju bazu, a kada se proširi u Fourierov niz, uzima se sasvim specifična.
Diskretne Fourierove transformacije (DFT)
U prethodnom dijelu smo došli do zaključka da bi bilo lijepo funkciju rastaviti na komponente. O tome je početkom 19. stoljeća razmišljao i Fourier. Istina, nije imao sliku s rakunom, pa je morao istraživati raspodjelu topline preko metalnog prstena. Zatim je otkrio da je vrlo zgodno izraziti temperaturu (i njezinu promjenu) u svakoj točki prstena kao zbroj sinusoida s različitim periodima. “Fourier je ustanovio (preporučam čitanje, zanimljivo) da drugi harmonik opada 4 puta brže od prvog, a harmonici višeg reda opadaju čak i bržom brzinom.”Općenito, ubrzo se pokazalo da se periodične funkcije mogu izvanredno rastaviti na zbroj sinusoida. A budući da u prirodi postoji mnogo objekata i procesa opisanih periodičkim funkcijama, pojavio se moćan alat za njihovu analizu.
Možda je jedan od najočitijih periodičnih procesa zvuk.

- 1. grafikon - čisti ton frekvencije 2500 herca.
- 2. - bijeli šum. To jest, šum s ravnomjerno raspoređenim frekvencijama u cijelom rasponu.
- 3. - zbroj prva dva.
Zašto ne pokušati uzeti sinusoide kao osnovu? Zapravo, mi smo to već učinili. Prisjetite se naše dekompozicije u 3 bazna vektora i predstavite ih na grafu:

Da, da, znam da izgleda kao fit, ali s tri vektora teško je očekivati više. Ali sada je jasno kako dobiti, na primjer, 8 baznih vektora:

Nije dobro teška provjera pokazuje da su ti vektori u paru okomiti, tj. ortogonalni. To znači da se mogu koristiti kao osnova. Transformacija preko takve baze dobro je poznata i naziva se diskretna kosinusna transformacija (DCT). Mislim da je iz gornjih grafikona jasno kako se dobiva formula DCT-transformacije:
I dalje je ista formula: A = EX sa zamijenjenom bazom. Bazisni vektori navedenog DCT (oni su vektori reda matrice E) su ortogonalni, ali ne i ortonormirani. Ovo treba zapamtiti tijekom inverzne transformacije (neću se zadržavati na ovome, ali, za one koje zanima, inverzni DCT ima član 0,5*a 0 , budući da je nulti vektor baze veći od ostalih).
Sljedeći primjer prikazuje postupak približavanja međuzbrojeva izvornim vrijednostima. U svakoj iteraciji, sljedeća baza se množi sa sljedećim koeficijentom i dodaje međuzbroju (to jest, na isti način kao u ranim eksperimentima na rakunu - jedna trećina vrijednosti, dvije trećine).

No, unatoč nekim argumentima o svrsishodnosti odabira takve osnove, pravih argumenata još nema. Doista, za razliku od zvuka, svrhovitost rastavljanja slike na periodične funkcije mnogo je manje očita. Međutim, slika doista može biti previše nepredvidljiva čak i na malom području. Stoga je slika podijeljena na dovoljno male dijelove, ali ne baš sitne, da bi razlaganje imalo smisla. U JPEG-u, slika je "isječena" na kvadrate 8x8. Unutar takvog djela fotografije su obično vrlo ujednačene: pozadina plus male fluktuacije. Takvim se područjima elegantno približava sinusoida.
Pa, recimo da je ova činjenica više-manje intuitivna. Ali postoji loš osjećaj u vezi oštrih prijelaza boja, jer nas polagano mijenjanje funkcija neće spasiti. Moramo dodati razne visokofrekventne funkcije koje rade svoj posao, ali se pojavljuju postrance na homogenoj pozadini. Uzmimo sliku 256x256 s dva područja kontrasta:

Svaki red dekomponiramo pomoću DCT-a, čime dobivamo 256 koeficijenata po retku.
Tada ostavljamo samo prvih n koeficijenata, a ostale postavljamo na nulu, pa će slika biti predstavljena kao zbroj samo prvih harmonika:

Broj na slici je broj preostalih kvota. Na prvoj slici ostaje samo prosječna vrijednost. Jedna niskofrekventna sinusoida već je dodana drugoj, i tako dalje. Usput, obratite pozornost na granicu - unatoč svim najboljim aproksimacijama, 2 pruge su jasno vidljive u blizini dijagonale, jedna je svjetlija, druga je tamniji. Dio zadnje slike uvećan 4 puta:
I općenito, ako daleko od granice vidimo početnu uniformnu pozadinu, tada kada joj se približimo, amplituda počinje rasti, konačno doseže minimalnu vrijednost, a zatim naglo postaje maksimalna. Ovaj fenomen je poznat kao Gibbsov efekt.

Visina ovih izbočina, koja se pojavljuje u blizini diskontinuiteta funkcije, neće se smanjivati s povećanjem broja članova funkcije. U diskretnoj transformaciji nestaje tek kada su gotovo svi koeficijenti sačuvani. Točnije, postaje nevidljiv.
Sljedeći primjer potpuno je sličan gornjoj dekompoziciji trokuta, ali na pravom rakunu:

Pri proučavanju DCT-a može se steći pogrešan dojam da je samo prvih nekoliko (niskofrekventnih) koeficijenata uvijek dovoljno. To vrijedi za mnoge fotografije, one čije se vrijednosti drastično ne mijenjaju. Međutim, na granici kontrastnih područja, vrijednosti će naglo "skočiti", a čak će i posljednji koeficijenti biti veliki. Dakle, kada čujete o svojstvu DCT-a za očuvanje energije, uzmite u obzir činjenicu da se ono odnosi na mnoge vrste signala s kojima se susrećete, ali ne na sve. Kao primjer, razmotrite kako bi izgledala diskretna funkcija ako su njezini koeficijenti proširenja jednaki nuli, osim posljednjeg. Savjet: predstavite dekompoziciju u vektorskom obliku.
Unatoč nedostacima, odabrana podloga jedna je od najboljih na stvarnim fotografijama. Nešto kasnije vidjet ćemo malu usporedbu s drugima.
DCT protiv svega ostalog
Kada sam proučavao pitanje ortogonalnih transformacija, onda, iskreno, nisam bio baš uvjeren argumentima da je sve oko zbroj harmonijske vibracije, pa slike treba rastaviti na sinusoide. Ili bi možda neke funkcije koraka bolje odgovarale? Stoga sam tražio rezultate istraživanja o optimalnosti DCT-a na stvarnim slikama. Činjenica da se “DCT najčešće nalazi u praktičnim primjenama zbog svojstva “gustoće energije”” je posvuda napisana. Ovo svojstvo znači da je najveća količina informacija sadržana u prvim koeficijentima. I zašto? Nije teško provesti studiju: naoružamo se hrpom različitih slika, raznim poznatim bazama i počnemo izračunavati standardno odstupanje od stvarne slike za različiti broj koeficijenata. Pronašao sam malu studiju u članku (korištene slike) o ovoj tehnici. Sadrži grafove ovisnosti pohranjene energije o broju prvih koeficijenata širenja u različitim bazama. Ako ste pogledali ljestvice, vidjet ćete da DCT dosljedno drži časno... hm... 3. mjesto. Kako to? Što je još KLT transformacija? Hvalio sam DCT, a onda...KLT
Sve transformacije osim KLT su transformacije konstantne baze. A u KLT-u (Karhunen-Loeve transformacija) izračunava se najoptimalnija baza za nekoliko vektora. Izračunava se na način da će prvi koeficijenti dati najmanju srednju kvadratnu pogrešku ukupno za sve vektore. Ranije smo slične radove obavljali ručno, vizualno određujući osnovu. Isprva se ovo čini kao dobra ideja. Mogli bismo, na primjer, podijeliti sliku u male dijelove i za svaki izračunati drugu osnovu. Ali ne samo da se pojavljuje briga o pohranjivanju ove osnove, već je i operacija njenog izračuna prilično naporna. I DCT gubi samo malo, a osim toga, DCT ima brze algoritme konverzije.DFT
DFT (diskretna Fourierova transformacija) - diskretna transformacija Fourier. Ovaj naziv ponekad se odnosi ne samo na određenu transformaciju, već i na cijelu klasu diskretnih transformacija (DCT, DST...). Pogledajmo DFT formulu:
Kao što možete pogoditi, ovo je ortogonalna transformacija s nekom vrstom složene baze. Budući da se takav složeni oblik javlja malo češće nego inače, ima smisla proučiti njegovo podrijetlo.
Moglo bi se steći dojam da će svaki čisti harmonijski signal (s cijelobrojnom frekvencijom) u DCT dekompoziciji dati samo jedan koeficijent različit od nule koji odgovara ovom harmoniku. To nije tako, jer osim frekvencije bitna je i faza ovog signala. Na primjer, širenje sinusa u kosinuse (slično u diskretnom širenju) bit će kako slijedi:
Evo ti čista harmonika. Iznjedrila je hrpu drugih. Animacija prikazuje DCT koeficijente sinusoide u različite faze.

Ako vam se činilo da se stupci okreću oko osi, onda vam se nije činilo.
Dakle, sada ćemo rastaviti funkciju na zbroj sinusoida ne samo različite frekvencije, ali i pomaknut u nekoj fazi. Bit će prikladnije razmotriti fazni pomak na primjeru kosinusa:
Jednostavan trigonometrijski identitet daje važan rezultat: fazni pomak zamijenjen je zbrojem sinusa i kosinusa, uzetog s koeficijentima cos(b) i sin(b). To znači da se funkcije mogu rastaviti na zbroj sinusa i kosinusa (bez ikakvih faza). Ovo je uobičajeni trigonometrijski oblik. Međutim, kompleks se koristi mnogo češće. Da biste ga dobili, morate koristiti Eulerovu formulu. Samo zamijenimo formule za izvode za sinus i kosinus, dobivamo:

Sada mala promjena. Podvlaka je konjugirani broj.
Dobivamo konačnu jednakost:
c je kompleksni koeficijent čiji je realni dio jednak kosinusnom koeficijentu, a imaginarni dio jednak sinusnom koeficijentu. A skup točaka (cos(b), sin(b)) je kružnica. U takvom zapisu svaki harmonik ulazi u proširenje i s pozitivnom i s negativnom frekvencijom. Stoga se u raznim formulama Fourierove analize obično javlja zbrajanje ili integracija od minus do plus beskonačno. Često je prikladnije izvoditi izračune u tako složenom obliku.
Transformacija rastavlja signal na harmonike s frekvencijama od jedan do N oscilacija u području signala. Ali stopa uzorkovanja je N po području signala. A prema Kotelnikovom teoremu (aka Nyquist-Shannonov teorem), frekvencija uzorkovanja trebala bi biti barem dvostruku frekvenciju signala. Ako to nije slučaj, tada se dobiva učinak pojave signala s lažnom frekvencijom:

Isprekidana linija prikazuje pogrešno rekonstruirani signal. Često ste se u životu susreli s ovom pojavom. Na primjer, smiješno kretanje kotača automobila u videu ili moiré efekt.
To dovodi do činjenice da se čini da se druga polovica N kompleksnih amplituda sastoji od drugih frekvencija. Ovi lažni harmonici druge polovine su zrcalna slika prvi i ne nose dodatne informacije. Dakle, ostaje nam N/2 kosinusa i N/2 sinusa (tvoreći ortogonalnu bazu).
Dobro, postoji osnova. Njegove komponente su harmonici s cijelim brojem oscilacija u području signala, što znači da su ekstremne vrijednosti harmonika jednake. Točnije, gotovo su jednake, budući da je posljednja vrijednost uzeta ne sasvim s ruba. Štoviše, svaki harmonik je gotovo zrcalno simetričan u odnosu na svoje središte. Sve ove pojave su posebno jake u niske frekvencije, koji su nam važni kod kodiranja. To je također loše jer će granice blokova biti vidljive na komprimiranoj slici. Ilustrirat ću DFT osnovu s N=8. Prva 2 reda su kosinusne komponente, posljednji su sinusne komponente:

Obratite pozornost na pojavu dupliciranih komponenti kako se učestalost povećava.
Možete mentalno razmišljati o tome kako bi se signal mogao rastaviti, čije se vrijednosti glatko smanjuju od maksimalne vrijednosti na početku do minimalne vrijednosti na kraju. Koliko-toliko adekvatnu aproksimaciju mogli bi dati tek harmonici pred kraj, što nam nije baš cool. Slika s lijeve strane je aproksimacija jednostranog signala. Desno - simetrično: 
Prvi je izuzetno loš.
Dakle, može se učiniti kao u DCT-u - smanjiti frekvencije za 2 ili neki drugi broj puta, tako da je broj nekih oscilacija razlomak i da su granice u različitim fazama? Tada će komponente biti neortogonalne. I nema se što učiniti.
DST
Što ako koristimo sinuse umjesto kosinusa u DCT-u? Dobit ćemo diskretnu sinusnu transformaciju (DST). Ali za naš zadatak, svi oni su nezanimljivi, budući da su i cijeli broj i poluperiode sinusa blizu nule na granicama. To jest, dobit ćemo približno istu neprikladnu dekompoziciju kao kod DFT-a.Povratak na DCT
Kako mu je na granicama? Fino. Postoje protufaze i nema nula.Sve ostalo
Ne-Fourierove transformacije. neću opisivati.WHT - matrica se sastoji samo od komponenti koraka s vrijednostima -1 i 1.
Haar - part-time ortogonalna valićna transformacija.
Oni su inferiorni u odnosu na DCT, ali ih je lakše izračunati.
Dakle, sinula vam je ideja da osmislite vlastitu transformaciju. Zapamtite ovo:
- Baza mora biti ortogonalna.
- S fiksnom osnovom ne možete pobijediti KLT u smislu kvalitete kompresije. U međuvremenu, na stvarnim fotografijama, DCT je gotovo jednako dobar.
- Na primjeru DFT i DST, morate zapamtiti o granicama.
- I zapamtite da DCT ima još jednu dobru prednost - u blizini granica njihovih komponenti, derivacije su jednake nuli, što znači da će prijelaz između susjednih blokova biti prilično gladak.
- Fourierove transformacije imaju brze algoritme složenosti O(N*logN), za razliku od izračuna u čelo: O(N 2).
2D transformacije
Pokušajmo sada provesti takav eksperiment. Uzmimo, na primjer, dio slike.
Njegov 3D grafikon:

Prođimo kroz DCT (N=32) za svaki redak:

Sada želim da prijeđete očima preko svakog stupca dobivenih koeficijenata, tj. od vrha do dna. Podsjetimo da je naš cilj zadržati što manje vrijednosti, izostavljajući one koje nisu bitne. Vjerojatno ste pogodili da se vrijednosti svakog stupca dobivenih koeficijenata mogu rastaviti na potpuno isti način kao i vrijednosti izvorne slike. Nitko nas ne ograničava u odabiru matrice ortogonalne transformacije, ali ćemo to ponovno učiniti pomoću DCT(N=8):

Koeficijent (0,0) se pokazao prevelikim pa je na grafu smanjen za 4 puta.
Dakle, što se dogodilo?
U gornjem lijevom kutu su najznačajniji koeficijenti dekompozicije najznačajnijih koeficijenata.
Donji lijevi kut je najbeznačajniji koeficijent širenja najvažnijih koeficijenata.
Gornji desni kut je najznačajniji koeficijent širenja najbeznačajnijih koeficijenata.
Donji desni kut je najbeznačajniji koeficijent širenja najbeznačajnijih koeficijenata.
Jasno je da se značaj koeficijenata smanjuje ako se pomaknemo dijagonalno iz gornjeg lijevog kuta u donji desni. I što je važnije: (0, 7) ili (7, 0)? Što oni uopće znače?
Prvo po redovima: A 0 = (EX T) T = XE T (transponirano, budući da je formula A=EX za stupce), zatim po stupcima: A=EA 0 = EXE T . Ako pažljivo izračunate, dobit ćete formulu:
Dakle, ako se vektor rastavi na sinusoide, onda matrica na funkcije oblika cos(ax)*cos(by). Svaki blok 8x8 u JPEG-u predstavljen je kao zbroj 64 funkcije oblika:

U Wikipediji i drugim izvorima takve su funkcije predstavljene u prikladnijem obliku:

Stoga su koeficijenti (0, 7) ili (7, 0) jednako korisni.
Međutim, zapravo, ovo je uobičajeno jednodimenzionalno širenje u 64 64-dimenzionalne baze. Sve navedeno ne vrijedi samo za DCT, već i za svaku ortogonalnu dekompoziciju. Djelujući analogno, u općem slučaju dobivamo N-dimenzionalnu ortogonalnu transformaciju.
A evo i 2D transformacije rakuna (DCT 256x256). Opet s nultim vrijednostima. Brojevi - broj koeficijenata koji nisu nula od svih (ostavljene su najznačajnije vrijednosti, smještene u trokutastom području u gornjem lijevom kutu).

Zapamtite da se koeficijent (0, 0) naziva DC, a ostalih 63 su AC.
Odabir veličine bloka
Drug pita: zašto se u JPEG koristi cijepanje 8x8. Iz pozitivno glasanog odgovora:DCT tretira blok kao da je periodičan i mora rekonstruirati rezultirajući skok na granicama. Ako uzmete blokove 64x64, najvjerojatnije ćete imati ogroman skok na granicama i trebat će vam mnogo visokofrekventnih komponenti da to rekonstruirate do zadovoljavajuće preciznostiKao, DCT radi dobro samo na periodičkim funkcijama, a ako uzmete veliku veličinu, najvjerojatnije ćete dobiti ogroman skok na granicama bloka i trebat će vam puno visokofrekventnih komponenti da to pokrijete. Ovo nije istina! Takvo objašnjenje je vrlo slično DFT-u, ali ne i DCT-u, budući da savršeno pokriva takve skokove već kod prvih komponenti.
Na istoj stranici nalazi se odgovor iz MPEG FAQ-a, s glavnim argumentima protiv velikih blokova:
- Mali profit pri razbijanju velikih blokova.
- Sve veća računalna složenost.
- Velika vjerojatnost veliki broj oštre rubove u jednom bloku, što će izazvati Gibbsov efekt.

Na vodoravnoj osi - udio prvih koeficijenata koji nisu nula. Okomito - standardno odstupanje piksela od originala. Maksimalno moguće odstupanje uzima se kao jedan. Naravno, jedna slika očito nije dovoljna za presudu. Osim toga, ne radim to kako treba, samo nuliram. U stvarnom JPEG-u, ovisno o kvantizacijskoj matrici, samo su male vrijednosti visokofrekventnih komponenti nulirane. Stoga su sljedeći pokusi i zaključci namijenjeni površno otkrivanju načela i obrazaca.
Možete usporediti podjelu u različite blokove s preostalih 25 posto koeficijenata (slijeva nadesno, zatim zdesna nalijevo):

Veliki blokovi nisu prikazani jer se vizualno gotovo ne razlikuju od 32x32. Sada pogledajmo apsolutnu razliku u odnosu na izvornu sliku (poboljšanu 2 puta, inače ništa nije stvarno vidljivo): 
8x8 daje najbolji rezultat nego 4x4. Daljnje povećanje veličine više ne daje jasno vidljivu prednost. Iako bih ozbiljno razmotrio 16x16 umjesto 8x8: povećanje težine od 33% (više o težini u sljedećem odlomku) daje mali, ali ipak vidljiv napredak s istim brojem koeficijenata. Međutim, čini se da je izbor 8x8 sasvim razuman i možda je zlatna sredina. JPEG je objavljen 1991. Mislim da je takva kompresija bila vrlo teška za procesore tog vremena.
Drugi argument. Mora se imati na umu da će, kako se veličina bloka povećava, biti potrebno više izračuna. Procijenimo kako. Složenost pretvorbe u čelo, kao što već znamo kako se radi: O (N 2), budući da se svaki koeficijent sastoji od N članova. Ali u praksi se koristi učinkoviti algoritam brze Fourierove transformacije (FFT). Njegov opis je izvan opsega članka. Njegova složenost: O(N*logN). Za dvodimenzionalno širenje morate ga upotrijebiti dvaput N puta. Dakle, složenost 2D DCT je O(N 2 logN). Sada usporedimo složenost izračunavanja slike s jednim blokom i nekoliko malih:
- U jednom bloku (kN)x(kN): O((kN) 2 log(kN)) = O(k 2 N 2 log(kN))
- k*k N*N blokova: O(k 2 N 2 logN)
Treći argument. Ako imamo oštru granicu boja na slici, to će utjecati na cijeli blok. Možda je bolje da taj blok bude dovoljno mali, jer u mnogim susjednim blokovima takva granica vjerojatno više neće postojati. Međutim, daleko od granica, slabljenje se događa vrlo brzo. Osim toga, sama granica će izgledati bolje. Provjerimo na primjeru s velikim brojem kontrastnih prijelaza, opet sa samo četvrtinom koeficijenata: 
Iako se distorzija blokova 16x16 proteže dalje od 8x8, slova su glatkija. Dakle, samo su me prva dva argumenta uvjerila. Ali više mi se sviđa podjela 16x16.
Kvantizacija
U ovoj fazi imamo hrpu 8x8 matrica s koeficijentima kosinusne transformacije. Vrijeme je da se riješite beznačajnih koeficijenata. Postoji elegantnije rješenje nego samo poništiti zadnje koeficijente na nulu, kao što smo učinili gore. Nismo zadovoljni ovom metodom, jer se vrijednosti različite od nule pohranjuju s pretjeranom preciznošću, a među onima koji nemaju sreće moglo bi biti vrlo važnih. Izlaz je korištenje kvantizacijske matrice. U ovoj fazi nastaju gubici. Svaki Fourierov koeficijent se dijeli s odgovarajućim brojem u matrici kvantizacije. Pogledajmo primjer. Uzmimo prvi blok od našeg rakuna i kvantizirajmo ga. JPEG specifikacija daje standardnu matricu:
Standardna matrica odgovara 50% kvalitete u FastStone i IrfanView. Takva je tablica odabrana u smislu ravnoteže kvalitete i omjera kompresije. Mislim da je vrijednost za DC koeficijent veća od susjednih zbog činjenice da DCT nije normaliziran i prva vrijednost je veća nego što bi trebala biti. Visokofrekventni koeficijenti su više grubi zbog svoje manje važnosti. Mislim da se sada takve matrice rijetko koriste, jer je pogoršanje kvalitete jasno vidljivo. Nitko ne zabranjuje korištenje njihove tablice (s vrijednostima od 1 do 255)
Prilikom dekodiranja dolazi do obrnutog procesa - kvantizirani koeficijenti se množe po članu s vrijednostima matrice kvantizacije. Ali budući da smo zaokružili vrijednosti, nećemo moći točno vratiti izvorne Fourierove koeficijente. Što je veći kvantizacijski broj, to je veća greška. Dakle, dobiveni koeficijent je samo najbliži višekratnik.
Još jedan primjer:

I za desert, razmislite o 5% kvalitete (prilikom kodiranja u Fast Stone). 
Kada vratimo ovaj blok, dobit ćemo samo prosječnu vrijednost plus vertikalni gradijent (zbog očuvane vrijednosti -1). Ali za njega su pohranjene samo dvije vrijednosti: 7 i -1. S ostalim blokovima situacija nije bolja, evo obnovljene slike:

Usput, oko 100% kvaliteta. Kao što možete pogoditi, u ovom slučaju kvantizacijska matrica sastoji se isključivo od jedinica, to jest, nema kvantizacije. Međutim, zbog zaokruživanja koeficijenata na najbliži cijeli broj, ne možemo točno vratiti izvornu sliku. Na primjer, rakun je točno zadržao 96% piksela, a 4% se razlikovalo za 1/256. Naravno, takve se "izobličenja" ne mogu vizualno vidjeti.
I možete pogledati kvantizacijske matrice raznih kamera.
Kodiranje
Prije nego krenemo dalje, moramo razumjeti, koristeći jednostavnije primjere, kako možemo komprimirati primljene vrijednosti.Primjer 0(za zagrijavanje)
Zamislite situaciju da je vaš prijatelj kod vas zaboravio papirić s popisom i sada traži da mu ga izdiktirate preko telefona (nema drugih načina komunikacije).
Popis:
- d9rg3
- wfr43gt
- wfr43gt
- d9rg3
- d9rg3
- d9rg3
- wfr43gt
- d9rg3
Riječi ćemo označiti kao A, B, C... i nazvati ih simbolima. Štoviše, pod simbolom se može sakriti bilo što: slovo abecede, riječ ili nilski konj u zoološkom vrtu. Glavna stvar je da isti simboli odgovaraju istim konceptima, a različiti - različitim. Budući da je naš zadatak učinkovito kodiranje (kompresija), radit ćemo s bitovima, jer su to najmanje jedinice reprezentacije informacija. Stoga popis pišemo kao ABBAAABA. Umjesto "prve riječi" i "druge riječi" mogu se koristiti bitovi 0 i 1. Tada se ABBAAABA kodira kao 01100010 (8 bitova = 1 bajt). 
Primjer 1
Kodiraj ABC.
3 različita znaka (A, B, C) ne mogu se mapirati u 2 moguće bitne vrijednosti (0 i 1). I ako je tako, onda možete koristiti 2 bita po znaku. Na primjer:
- O:00
- b:01
- C:10

Primjer 2
Kodiraj AAAAAABC.
Korištenje 2 bita po znaku A čini se pomalo rasipnim. Što ako pokušate ovako:
- C:00

Kodirani niz: 000000100.
Očito, ova opcija nije prikladna, jer nije jasno kako dekodirati prva dva bita ovog niza: kao AA ili kao C? Korištenje neke vrste separatora između kodova je vrlo rasipno, razmislit ćemo o tome kako zaobići ovu prepreku na drugačiji način. Dakle, neuspjeh je zato što kod C počinje kodom A. Ali mi smo odlučni kodirati A s jednim bitom, čak i ako su B i C dva. Na temelju te želje A dajemo kod 0. Tada kodovi B i C ne mogu početi s 0. Ali mogu početi s 1:
- B:10
- C:11

Niz će biti kodiran ovako: 0000001011. Pokušajte ga mentalno dekodirati. To možete učiniti samo na jedan način.
Razvili smo dva zahtjeva za kodiranje:
- Što je veća težina znaka, to bi njegov kod trebao biti kraći. I obrnuto.
- Za nedvosmisleno dekodiranje, kod znaka ne može započeti bilo kojim drugim kodom znaka.
Primjer 3
Razmotrimo opći slučaj za 4 znaka s bilo kojim težinama.
- O: pa
- B: pb
- C: kom
- D:pd

Koji je poželjniji? Da biste to učinili, morate izračunati primljene duljine kodiranih poruka:
W1 = 2*pa + 2*pb + 2*pc + 2*pd
W2 = pa + 2*pb + 3*pc + 3*pd
Ako je W1 manji od W2 (W1-W2<0), то лучше использовать первый вариант:
W1-W2 = pa - (pc+pd)< 0 =>godišnje< pc+pd.
Ako se C i D pojavljuju zajedno češće od ostalih, tada njihov zajednički vrh prima najkraći jednobitni kod. Inače, jedan bit ide znaku A. To znači da se unija znakova ponaša kao neovisni znak i ima težinu jednaku zbroju dolazećih znakova.
Općenito, ako je p težina znaka predstavljena dijelom njegovog pojavljivanja (između 0 i 1), tada je najbolja duljina koda s=-log 2 p.
Uzmite u obzir jednostavan slučaj(lako se može prikazati kao stablo). Dakle, moramo kodirati 2 s znakova s jednakim težinama (1/2 s). Zbog jednakosti težina, duljine kodova će biti iste. Svaki znak će trebati s bitova. Dakle, ako je težina znaka 1/2 s, tada je njegova duljina s. Ako težinu zamijenimo s p, tada dobivamo duljinu koda s=-log 2 p . To znači da ako se jedan znak pojavljuje dvostruko rjeđe od drugoga, tada će duljina njegovog koda biti jedan bit duža. Međutim, lako je izvući takav zaključak ako se sjetite da dodavanje jednog bita omogućuje udvostručenje broja mogućih opcija.
I još jedno zapažanje - dva lika s najmanjim težinama uvijek imaju najveću, ali jednake duljinešifre. Štoviše, njihovi su dijelovi, osim posljednjeg, isti. Da to nije točno, onda bi se barem jedan kod mogao skratiti za 1 bit bez narušavanja prefiksa. To znači da dva znaka s najmanjim težinama u stablu koda imaju zajedničkog roditelja jednu razinu više. Ovo možete vidjeti u C i D gore.
Primjer 4
Pokušajmo riješiti sljedeći primjer, prema zaključcima dobivenim u prethodnom primjeru.
- Svi znakovi poredani su silaznim redoslijedom težine.
- Zadnja dva znaka su spojena u grupu. Ovoj grupi se dodjeljuje težina jednaka zbroju težina ovih elemenata. Ova grupa sudjeluje u algoritmu zajedno sa simbolima i drugim grupama.
Ovaj algoritam se naziva Huffmanovo kodiranje.
Ilustracija prikazuje primjer s 5 znakova (A: 8, B: 6, C: 5, D: 4, E: 3). S desne strane je težina simbola (ili grupe).

Kodiranje koeficijenata
Vraćamo se. Sada imamo mnogo blokova sa po 64 koeficijenta, koje treba nekako spremiti. Najjednostavnije rješenje je korištenje fiksnog broja bitova po faktoru - očito nesretno. Izgradimo histogram svih dobivenih vrijednosti (tj. Ovisnost broja koeficijenata o njihovoj vrijednosti):
Napomena - skala je logaritamska! Možete li objasniti razlog akumulacije vrijednosti većih od 200? Ovo su DC koeficijenti. Budući da su vrlo različiti od ostalih, ne čudi što su zasebno kodirani. Evo samo DC:

Imajte na umu da oblik grafikona nalikuje obliku grafikona iz vrlo ranih eksperimenata sparivanja i trijade piksela.
Općenito, vrijednosti DC koeficijenata mogu varirati od 0 do 2047 (točnije -1024 do 1023, jer JPEG oduzima 128 od svih izvornih vrijednosti, što odgovara oduzimanju 1024 od DC) i distribuira se prilično ravnomjerno s malim vrhovima . Dakle, Huffmanovo kodiranje ovdje neće puno pomoći. Također zamislite koliko će stablo kodiranja biti veliko! A tijekom dekodiranja morat ćete tražiti vrijednosti u njemu. Ovo je vrlo skupo. Razmišljamo dalje.
DC-koeficijent - prosječna vrijednost bloka 8x8. Zamislimo gradijentni prijelaz (iako ne idealan), koji se često nalazi na fotografijama. Same DC vrijednosti bit će različite, ali će predstavljati aritmetičku progresiju. Stoga će njihova razlika biti više-manje konstantna. Izgradimo histogram razlika:

Sada je ovo bolje, jer su vrijednosti općenito koncentrirane oko nule (ali opet, Huffmanov algoritam će dati preveliko stablo). Male vrijednosti (prema apsolutna vrijednost) su česti, veliki su rijetki. A budući da male vrijednosti zauzimaju nekoliko bitova (ako se uklone vodeće nule), jedno od pravila kompresije je dobro ispunjeno: dodijelite simbole s velikim težinama kratke kodove(i obrnuto). Još uvijek smo ograničeni neispunjavanjem još jednog pravila: nemogućnosti jednoznačnog dekodiranja. Općenito, ovaj se problem rješava na sljedeće načine: zbunite se s kodom za razdvajanje, označite duljinu koda, koristite prefiks kodove (već ih znate - to je slučaj kada nijedan kod ne počinje drugim). Idemo s jednostavnom drugom opcijom, tj. svaki koeficijent (točnije, razlika između susjednih) bit će napisan na sljedeći način: (duljina) (vrijednost), prema takvoj pločici:

To jest, pozitivne vrijednosti su izravno kodirane njihovim binarnim prikazom, a negativne vrijednosti su kodirane na isti način, ali s vodećim 1 zamijenjenim 0. Ostaje odlučiti kako kodirati duljine. Budući da postoji 12 mogućih vrijednosti, 4 bita se mogu koristiti za pohranu duljine. Ali ovdje je jednostavno bolje koristiti Huffmanovo kodiranje.

Najviše je vrijednosti s duljinama 4 i 6, pa su dobili najkraće kodove (00 i 01).
Može se postaviti pitanje zašto u primjeru vrijednost 9 ima šifru 1111110, a ne 1111111? Uostalom, možete sigurno podići "9" na višu razinu, pored "0"? Činjenica je da u JPEG-u ne možete koristiti kod koji se sastoji samo od jedinica - takav kod je rezerviran.
Postoji još jedna značajka. Kodovi dobiveni opisanim Huffmanovim algoritmom možda neće odgovarati bitovima kodovima u JPEG-u, iako će njihove duljine biti iste. Pomoću Huffmanovog algoritma dobivaju se duljine kodova i generiraju se sami kodovi (algoritam je jednostavan - započinju s kratkim kodovima i dodaju ih jedan po jedan u stablo što je više moguće ulijevo, čuvajući prefiks vlasništvo). Na primjer, za stablo iznad, popis je pohranjen: 0,2,3,1,1,1,1,1. I, naravno, pohranjuje se popis vrijednosti: 4,6,3,5,7,2,8,1,0,9. Prilikom dekodiranja, kodovi se generiraju na isti način.
Sada naručite. Shvatili smo kako se DC-ovi pohranjuju:
[Huffmanov kod za duljinu DC razlike (u bitovima)]
gdje je DC diff = DC struja - DC prethodni
Gledajte AC:

Budući da je dijagram vrlo sličan dijagramu za DC razlike, princip je isti: [Huffmanov kod za AC duljinu (u bitovima)]. Ali ne baš! Budući da je ljestvica na grafikonu logaritamska, nije odmah vidljivo da postoji oko 10 puta više nultih vrijednosti od vrijednosti 2 - sljedeće po učestalosti. To je razumljivo - nisu svi preživjeli kvantizaciju. Vratimo se na matricu vrijednosti dobivenih u koraku kvantizacije (koristeći FastStone matricu kvantizacije, 90%).

Budući da postoji mnogo skupina uzastopnih nula, nameće se ideja - zapisati samo broj nula u skupini. Ovaj algoritam kompresije naziva se RLE (Run-length encoding, repetition encoding). Ostaje doznati smjer zaobilaznice "koji idu u nizu" - tko iza koga stoji? Pisanje s lijeva na desno i odozgo prema dolje nije vrlo učinkovito, budući da su koeficijenti različiti od nule koncentrirani blizu gornjeg lijevog kuta, a što su bliže donjem desnom kutu, to je više nula.

Stoga JPEG koristi redoslijed koji se zove "Zig-zag" kao što je prikazano na lijevoj slici. Ova metoda dobro odabire grupe nula. Na desnoj slici - alternativni način zaobilaženja, koji nije povezan s JPEG-om, ali sa znatiželjnim imenom (dokaz). Može se koristiti u MPEG-u pri komprimiranju isprepletenog videa. Odabir algoritma premosnice ne utječe na kvalitetu slike, ali može povećati broj kodiranih nultih grupa, što u konačnici može utjecati na veličinu datoteke.
Promijenimo naš unos. Za svaki koeficijent AC koji nije nula:
[Broj nula prije AC][Huffmanov kod za duljinu AC (u bitovima)]
Mislim da ćete odmah reći - broj nula također je savršeno kodiran kod Huffmana! Ovo je vrlo blizu i nije loš odgovor. Ali možete malo optimizirati. Zamislimo da imamo neki koeficijent AC, ispred kojeg je bilo 7 nula (naravno, ako je napisano cik-cak). Te nule su duh vrijednosti koje nisu preživjele kvantizaciju. Najvjerojatnije je i naš koeficijent jako potučen i postao je mali, što znači da mu je duljina kratka. Dakle, broj nula ispred AC i duljina AC su ovisne veličine. Stoga je napisano ovako:
[Huffmanov kod za (broj nula prije AC, duljina AC (u bitovima)]
Algoritam kodiranja ostaje isti: oni parovi (broj nula ispred AC, duljina AC) koji se često pojavljuju primit će kratke kodove i obrnuto.
Gradimo histogram ovisnosti količine o tim parovima i Huffmanovo stablo. 
Dug "planinski lanac" potvrđuje našu pretpostavku.
Značajke implementacije u JPEG:
Takav par zauzima 1 bajt: 4 bita za broj nula i 4 bita za duljinu AC. 4 bita su vrijednosti od 0 do 15. AC je više nego dovoljan za duljinu, ali može biti više od 15 nula, zar ne? Zatim se koristi više parova. Na primjer, za 20 nula: (15, 0)(5, AC). To jest, 16. nula je kodirana kao koeficijent koji nije nula. Budući da je kraj bloka uvijek pun nula, par (0,0) se koristi nakon posljednjeg koeficijenta koji nije nula. Ako se dogodi tijekom dekodiranja, tada su preostale vrijednosti jednake 0.
Saznao sam da je svaki kodirani blok pohranjen u datoteci ovako:
[Huffmanov kod za duljinu istosmjerne razlike]
[huffmanov kod za (broj nula prije AC 1 , duljina AC 1 ]
…
[huffmanov kod za (broj nula prije AC n, duljina AC n]
Gdje su AC i AC koeficijenti različiti od nule.
slika u boji
Način prikaza slike u boji ovisi o odabranom modelu boja. Jednostavno rješenje je koristiti RGB i kodirati svaki kanal boja slike zasebno. Tada se kodiranje neće razlikovati od kodiranja sive slike, samo 3 puta više posla. Ali kompresija slike može se povećati ako se prisjetimo da je oko osjetljivije na promjene svjetline nego boje. To znači da se boja može pohraniti s većim gubitkom nego svjetlinom. RGB nema zaseban kanal osvjetljenja. Ovisi o zbroju vrijednosti svakog kanala. Stoga se RGB kocka (ovo je prikaz svih mogućih vrijednosti) jednostavno "stavlja" na dijagonalu - što je viša, to je svjetlija. Ali nisu ograničeni na ovo - kocka je lagano pritisnuta sa strane i ispada više poput paralelopipeda, ali to je samo da se uzmu u obzir značajke oka. Primjerice, on više prihvaća zelenu nego plavu. Tako je rođen model YCbCr.
(Slika s Intel.com)
Y je komponenta osvjetljenja, Cb i Cr su komponente razlike plave i crvene boje. Stoga, ako žele jače komprimirati sliku, onda se RGB pretvara u YCbCr, a kanali Cb i Cr se stanji. Odnosno, podijeljeni su u male blokove, na primjer 2x2, 4x2, 1x2, a sve vrijednosti jednog bloka su prosječne. Ili, drugim riječima, smanjite veličinu slike za ovaj kanal 2 ili 4 puta okomito i/ili vodoravno.

Svaki 8x8 blok je kodiran (DCT + Huffman) i kodirane sekvence su zapisane ovim redoslijedom:
Zanimljivo je da JPEG specifikacija ne ograničava izbor modela, odnosno implementacija enkodera može proizvoljno podijeliti sliku na komponente boja (kanale) i svaka će biti spremljena zasebno. Svjestan sam korištenja Grayscale (1 kanal), YCbCr (3), RGB (3), YCbCrK (4), CMYK (4). Prva tri podržavaju gotovo svi, ali ima problema sa zadnjim 4-kanalnim. FastStone, GIMP ih ispravno i redovito podržavaju Windows programi, paint.net ispravno izvuče sve informacije, ali onda izbaci 4. crni kanal, pa (Antelle je rekao da ga ne izbacuju, čitaj njegove komentare) prikaži svjetliju sliku. Lijevo - klasični YCbCr JPEG, desno CMYK JPEG:


Ako se boje razlikuju ili je vidljiva samo jedna slika, najvjerojatnije imate IE (bilo koju verziju) (UPD. u komentarima kažu "ili Safari"). Možete pokušati otvoriti članak u različitim preglednicima.
I još jedna stvar
Ukratko o dodatnim značajkama.progresivni način rada
Rastavimo dobivene tablice DCT koeficijenata na zbroj tablica (ovako (DC, -19, -22, 2, 1) = (DC, 0, 0, 0, 0) + (0, -20, -20 , 0, 0) + (0, 1, -2, 2, 1)). Prvo kodiramo sve prve članove (kao što smo već naučili: Huffman i cik-cak premosnica), zatim druge, itd. Ovaj trik je koristan za spor Internet, jer se prvo učitavaju samo DC koeficijenti koji se koriste za izgradnju gruba slika s 8x8 "piksela". Zatim zaokružite AC koeficijente za pročišćavanje uzorka. Zatim grubi ispravci na njima, pa točniji. Pa, i tako dalje. Koeficijenti su zaokruženi, jer točnost nije toliko važna u ranim fazama učitavanja, ali zaokruživanje ima pozitivan učinak na duljinu kodova, jer svaka faza koristi svoju Huffmanovu tablicu.Način rada bez gubitaka
Kompresija bez gubitaka. DCT nije. Koristi se predviđanje 4. točke od strane tri susjeda. Pogreške u predviđanju kodirao je Huffman. Po mom mišljenju, koristi se malo češće nego nikad.Hijerarhijski način rada
Iz slike se stvara više slojeva. različite dozvole. Prvi grubi sloj je kodiran kao i obično, a zatim samo razlika (pročišćavanje slike) između slojeva (pretvara se da je Haarov valić). Za kodiranje se koristi DCT ili Lossless. Po mom mišljenju, koristi se malo manje nego nikad.Aritmetičko kodiranje
Huffmanov algoritam stvara optimalne kodove prema težini znakova, ali to vrijedi samo za fiksnu podudarnost znakova s kodovima. Aritmetika nema tako kruto vezanje, što omogućuje korištenje kodova, kao što je bilo, s frakcijskim brojem bitova. Tvrdi se da smanjuje veličinu datoteke u prosjeku za 10% u usporedbi s Huffmanom. Nije uobičajeno zbog problema s patentima, ne podržavaju svi.Nadam se da sada intuitivno razumijete JPEG algoritam. Hvala na čitanju!
UPD
vanwin je ponudio naznaku korištenog softvera. Zadovoljstvo mi je objaviti da su svi dostupni i besplatni:
- Python + NumPy + Matplotlib + PIL (Jastuk). Glavni alat. Pronađeno u izdanju "Matlab besplatne alternative". Preporučam! Čak i ako niste upoznati s Pythonom, za nekoliko sati naučit ćete kako napraviti izračune i izgraditi prekrasne grafikone.
- jpeg njuškanje. Prikazuje detaljne informacije o jpeg datoteci.
- yEd. Uređivač grafikona.
- inkscape. U njemu sam radio ilustracije, kao što je primjer Huffmanovog algoritma. Pročitao sam nekoliko tutorijala i bilo je super.
- Urednik Daumovih jednadžbi. Tražio sam uređivač vizualnih formula, budući da nisam baš prijatelj s Latexom. Daum Equation je dodatak za Chrome, smatram ga vrlo zgodnim. Osim bockanja mišem, možete urediti Latex.
- brzi kamen. Mislim da to ne treba uvoditi.
- PicPick. Besplatna alternativa za SnagIt. Sjedi u ladici, snima zaslone što govore gdje govore. Plus sve vrste stvari, kao što su ravnalo, pipeta, goniometar itd.
Oznake: Dodajte oznake
„Implementacija algoritamaJPEG i JPEG2000"
Završeno:
studentska grupa 819
Ugarov Dmitrij
Kako rade algoritmi JPEG i JPEG2000
1. JPEG algoritam
JPEG (engleski Joint Photographic Experts Group - zajednička skupina stručnjaka u području fotografije) - široko je korištena metoda za kompresiju fotografskih slika. Format datoteke koji sadrži komprimirane podatke obično se naziva i JPEG naziv; najčešći nastavci za takve datoteke su .jpeg, .jfif, .jpg, .JPG ili .JPE. Međutim, od ovih, .jpg je najpopularnije proširenje na svim platformama.
JPEG algoritam je algoritam kompresije uz gubitak kvalitete.
Područje primjene
Format je format kompresije s gubitkom, pa je netočno pretpostaviti da JPEG pohranjuje podatke kao 8 bita po kanalu (24 bita po pikselu). S druge strane, budući da su podaci komprimirani JPEG format a dekomprimirani podaci obično su predstavljeni u 8 bita po kanalu, ova se terminologija ponekad koristi. Podržana je i kompresija crno-bijelih slika u sivim tonovima.
Prilikom spremanja JPEG datoteke možete odrediti stupanj kvalitete, a time i stupanj kompresije, koji se obično postavlja u proizvoljnim jedinicama, na primjer, od 1 do 100 ili od 1 do 10. Veći broj odgovara boljoj kvaliteti , ali se veličina datoteke povećava. Obično se razlika u kvaliteti između 90 i 100 praktički ne percipira okom. Treba imati na umu da se obnovljena slika malo po bit uvijek razlikuje od izvornika. Uobičajena zabluda je da jpeg kvaliteta identičan udjelu pohranjenih informacija.
Faze kodiranja
Proces JPEG kompresije uključuje nekoliko koraka:
1. Pretvaranje slike u optimalni prostor boja;
U slučaju primjene prostor boja luminance/chrominance (YCbCr) postiže najbolji omjer kompresije. U ovoj fazi kodiranja, korištenjem odgovarajućih omjera, RGB model boja se pretvara u YCbCr:
Y = 0,299*R + 0,587*G + 0,114*B
Cb = - 0,1687*R – 0,3313*G + 0,5*B
Cr = 0,5*R – 0,4187*G – 0,0813*B.
Tijekom dekodiranja može se koristiti odgovarajuća inverzna transformacija:
R = Y + 1,402*Cr
G = Y – 0,34414*Cb – 0,71414*Cr
B = Y + 1,772*Cb.
Napomena koja se odnosi na Y,Cb,Cr u ljudskom vizualnom sustavu:
Oko, posebno mrežnica, ima dvije vrste stanica kao vizualnih analizatora: stanice za noćni vid koje percipiraju samo nijanse sive (od svijetle bijele do tamnocrne) i stanice za dnevni vid koje percipiraju nijanse boja. Prve ćelije koje daju RGB boju otkrivaju razinu svjetline sličnu vrijednosti Y. Ostale ćelije odgovorne za percepciju nijanse boje određuju vrijednost povezanu s razlikom u boji.
2. Poduzorkovanje komponenti boje usrednjavanjem skupina piksela;
Velik dio vizualnih informacija na koje je ljudsko oko najosjetljivije sastoji se od visokofrekventnih komponenata svjetline u sivim tonovima (Y) YCbCr prostora boja. Druge dvije komponente kromatičnosti (Cb i Cr) sadrže visokofrekventne informacije o boji na koje je ljudsko oko manje osjetljivo. Dakle, određeni dio se može odbaciti i time je moguće smanjiti broj razmatranih piksela za kanale boja.
1) tip 4:2:0 (kada je slika podijeljena na kvadrate od 2x2 piksela i u svakom od njih svi pikseli primaju iste vrijednosti Cb i Cr kanala, a svjetlina Y y ostaje različita za svaki)
2) tip 4:2:2 (unija po komponentama kromatičnosti događa se samo horizontalno u grupama od dva piksela).
3) Tip 4:4:4 podrazumijeva da svaki piksel u svakom retku ima svoju jedinstvenu vrijednost komponenti Y, Cb i Cr. (Sl. 1 a)
4) tip 4:2:2. Poduzorkovanjem signala boje za faktor 2 vodoravno, dobivamo 4:2:2 YCbCr tok iz 4:4:4 YCbCr toka. Unos "4: 2: 2" znači da u jednom retku postoje 4 vrijednosti svjetline po 2 vrijednosti boje (vidi sliku 1 b). 4:2:2 YCbCr signal gubi vrlo malo u kvaliteti slike u odnosu na 4:4:4 YCbCr signal, ali je potrebna propusnost smanjena za 33% od izvorne.
3. Primjena diskretnih kosinusnih transformacija za smanjenje redundantnosti slikovnih podataka;
Glavna faza algoritma je diskretna kosinusna transformacija (DCT ili DCT), koja je vrsta Fourierove transformacije. Koristi se pri radu sa slikama u razne svrhe, a ne samo u svrhu kompresije. Prijelaz na frekvencijski prikaz vrijednosti piksela omogućuje nam drugačiji pogled na sliku, obradu i, što nam je zanimljivo, kompresiju. Štoviše, znajući koeficijente pretvorbe, uvijek možemo izvršiti suprotnu radnju - vratiti izvornu sliku.
DCT izravno primijenjen na blok (u našem slučaju 8x8 piksela) slike izgledao bi ovako:
gdje su x, y - prostorne koordinate piksela (0..7) ,
f(x,y) - vrijednosti piksela originalnog makrobloka (recimo svjetlina)
u,v - koordinate piksela u frekvencijskom prikazu (0..7)
w(u) =1/SQRT(2) za u=0, inače w(u)=1 (SQRT je kvadratni korijen)
w(v) =1/SQRT(2) za v=0, inače w(v)=1
Ili u obliku matrice:
4. Kvantizacija svakog bloka DCT koeficijenata korištenjem težinskih funkcija optimiziranih za ljudsku vizualnu percepciju;
Diskretna kosinusna transformacija priprema informacije za kompresiju i zaokruživanje s gubitkom. Za svaki element matrice koji se transformira postoji odgovarajući element matrice kvantizacija. Rezultirajuća matrica se dobiva dijeljenjem svakog elementa transformirane matrice s odgovarajućim elementom matrice kvantizacije i zatim zaokruživanjem rezultata na najbliži cijeli broj. Kod sastavljanja kvantizacijske matrice, njeni veliki elementi su u donjem lijevom kutu, tako da kada se podijeli s njima, podaci u ovom kutu nakon diskretne kosinusne transformacije (samo oni koji zaokružuju bit će manje bolni) su grublje zaokruženi. Odnosno izgubljene informacije nama manje važni od ostalih.
5. Faza sekundarne kompresije
Završna faza JPEG kodera je kodiranje rezultirajuće matrice.
5.1 Cik-cak permutacija 64 DCT koeficijenta
Dakle, nakon što smo izvršili DCT transformaciju na 8x8 bloku vrijednosti, imamo novi blok 8x8. Zatim se ovaj blok 8x8 skenira u cik-cak ovako:
(Brojevi u bloku 8x8 označavaju redoslijed kojim gledamo 2-dimenzionalnu matricu 8x8)
0, 1, 5, 6,14,15,27,28,
2, 4, 7,13,16,26,29,42,
3, 8,12,17,25,30,41,43,
9,11,18,24,31,40,44,53,
10,19,23,32,39,45,52,54,
20,22,33,38,46,51,55,60,
21,34,37,47,50,56,59,61,
35,36,48,49,57,58,62,63
Kao što vidite, prvi gornji lijevi kut je (0,0), zatim vrijednost na (0,1), zatim (1,0), zatim (2,0), (1,1), (0, 2), (0,3), (1,2), (2,1), (3,0) itd.
Nakon što smo napravili cik-cak matricu 8x8, sada imamo vektor sa 64 koeficijenta (0..63). Poanta ovog cik-cak vektora je da gledamo 8x8 DCT koeficijente uzlaznim redoslijedom prostornih frekvencija. Dakle, dobivamo vektor razvrstan po kriteriju prostorne frekvencije: prva vrijednost na vektoru (indeks 0) odgovara najnižoj frekvenciji na slici - označava se izrazom DC. Kako se indeks na vektoru povećava, dobivamo vrijednosti koje odgovaraju višim frekvencijama (vrijednost s indeksom 63 odgovara amplitudi najviše frekvencije u bloku 8x8). Ostali DCT koeficijenti označeni su AC.
5.2 RunLength kodiranje nula (RLE)
Sada imamo vektor s dugim nizom nula. To možemo koristiti kodiranjem uzastopnih nula. VAŽNO: Kasnije ćete vidjeti zašto, ali ovdje preskačemo kodiranje prvog koeficijenta vektora (DC koeficijent), koji je drugačije kodiran. Razmotrite izvorni vektor 64 kao vektor 63 (ovo je vektor 64 bez prvog koeficijenta)
Recimo da imamo 57,45,0,0,0,0,23,0,-30,-16,0,0,1,0,0,0,0,0,0, samo 0,... .0
Evo kako se RLC JPEG kompresija radi za ovaj primjer:
(0,57); (0,45); (4,23); (1,-30); (0,-16); (2.1); EOB
Kao što vidite, za svaku vrijednost koja nije 0, kodiramo broj uzastopnih PRIJODNIH 0 prije vrijednosti, a zatim dodajemo vrijednost. Još jedna napomena: EOB je skraćenica za End of Block i posebna je kodirana vrijednost (marker). Ako smo dosegli poziciju na vektoru od koje imamo samo nule do kraja vektora, dodijelit ćemo tu poziciju s EOB-om i prekinuti RLC kompresiju kvantiziranog vektora.
[Imajte na umu da ako kvantizirani vektor nije završen nulom (ima posljednji element koji nije 0), nećemo imati EOB marker.]
(0,57); (0,45); (4,23); (1,-30); (0,-16); (2,1); (0,0)
Još jedna OSNOVNA stvar: recimo da negdje na kvantiziranom vektoru imamo:
57, osamnaest nula, 3, 0.0,0.0 2, trideset tri nule, 895, EOB
JPG Huffmanovo kodiranje postavlja ograničenje da broj vodećih nula mora biti kodiran kao 4-bitna vrijednost - ne smije premašiti 15.
Dakle, prethodni primjer bi trebao biti kodiran kao:
(0,57); (15,0) (2,3); (4,2); (15,0) (15,0) (1,895), (0,0)
(15,0) je posebna kodirana vrijednost koja označava ono što slijedi nakon 16 uzastopnih nula.
5.3 Završni korak - Huffmanovo kodiranje
Prvo VAŽNA napomena: Umjesto pohranjivanja stvarne vrijednosti, JPEG standard navodi da pohranjujemo minimalnu veličinu u bitovima u kojima možemo zadržati tu vrijednost (ovo se naziva kategorija te vrijednosti), a zatim bit-kodirani prikaz te vrijednosti vrijednost poput ove:
7,..,-4,4,..,7 3 000,001,010,011,100,101,110,111
15,..,-8,8,..,15 4 0000,..,0111,1000,..,1111
31,..,-16,16,..,31 5 00000,..,01111,10000,..,11111
63,..,-32,32,..,63 6 .
127,..,-64,64,..,127 7 .
255,..,-128,128,..,255 8 .
511,..,-256,256,..,511 9 .
1023,..,-512,512,..,1023 10 .
2047,..,-1024,1024,..,2047 11 .
4095,..,-2048,2048,..,4095 12 .
8191,..,-4096,4096,..,8191 13 .
16383,..,-8192,8192,..,16383 14 .
32767,..,-16384,16384,..,32767 15 .
Nakon toga, za prethodni primjer:
(0,57); (0,45); (4,23); (1,-30); (0,-8); (2,1); (0,0)
kodirajmo samo ispravnu vrijednost ovih parova, osim parova koji su posebni markeri poput (0,0) ili (ako moramo) (15,0)
45 bi na sličan način bio kodiran kao (6.101101)
30 -> (5,00001)
A sada ćemo ponovo napisati niz parova:
(0,6), 111001; (0,6), 101101; (4,5), 10111; (1,5), 00001; (0,4), 0111; (2,1), 1; (0,0)
Parovi od 2 vrijednosti u zagradama mogu se predstaviti u bajtu, budući da zapravo svaka od 2 vrijednosti može biti predstavljena u 4-bitnom komadu (broj vodećih nula uvijek je manji od 15, a isto je i s kategorija [brojevi kodirani u JPG datoteci - u području -32767..32767]). U ovom bajtu, visoki bit predstavlja broj vodećih nula, a niži bit predstavlja kategoriju nove vrijednosti koja nije 0.
Posljednji korak kodiranja je da Huffman kodira taj bajt, a zatim upisuje u JPG datoteku, kao bitstream, Huffmanov kod tog bajta, nakon čega slijedi bitna reprezentacija tog broja.
Na primjer, za bajt 6 (ekvivalent (0.6)) imamo Huffmanov kod = 111000;
21 = (1,5) - 11111110110
4 = (0,4) - 1011
33 = (2,1) - 11011
0 = EOB= (0,0) - 1010
Konačni bitstream zapisan u JPG datoteci na disk za prethodni primjer je 63 koeficijenta (sjetite se da smo izostavili prvi koeficijent) -
111000 111001 111000 101101 1111111110011001 10111 11111110110 00001
1011 0111 11011 1 1010
Prednosti i nedostatci
Nedostaci formata uključuju činjenicu da se, s jakim omjerima kompresije, blokovska struktura podataka osjeća, slika je "podijeljena na kvadrate" (svaki je veličine 8x8 piksela). Ovaj je učinak posebno vidljiv u područjima s niskom prostornom frekvencijom (glatki prijelazi slike, poput vedrog neba). U područjima s visokom prostornom frekvencijom (primjerice, kontrastni rubovi slike) pojavljuju se karakteristični "artefakti" - nepravilna struktura piksela iskrivljene boje i/ili svjetline. Osim toga, sitni detalji u boji nestaju sa slike. Također ne treba zaboraviti da danom formatu ne podržava transparentnost.
Međutim, unatoč svojim nedostacima, JPEG je postao vrlo raširen zbog visokog omjera kompresije, u odnosu na alternative koje su postojale u vrijeme njegovog uvođenja.
2. JPEG2000 algoritam
Algoritam JPEG-2000 razvila je ista skupina stručnjaka za fotografiju kao i JPEG. Formiranje JPEG-a kao međunarodnog standarda završeno je 1992. godine. Godine 1997. postalo je jasno da je potreban novi, fleksibilniji i snažniji standard, koji je finaliziran do zime 2000. godine.
Glavne razlike između algoritma u JPEG 2000 i algoritma u JPEG su sljedeće:
1) Bolja kvaliteta slike s jakim omjerom kompresije. Ili, što je isto, veliki omjer kompresije uz istu kvalitetu za visoke omjere kompresije. Zapravo, to znači značajno smanjenje veličine grafike "web-kvalitete" koju koristi većina stranica.
2) Podržava individualno kodiranje područja najbolja kvaliteta. Poznato je da su određena područja slike kritična za ljudsku percepciju (primjerice oči na fotografiji), dok kvaliteta drugih može biti žrtvovana (primjerice pozadina). Kod "ručne" optimizacije povećava se omjer kompresije sve dok se ne izgubi kvaliteta u nekom važnom dijelu slike. Sada je moguće postaviti kvalitetu u kritičnim područjima, jače sabijajući ostala područja, tj. dobivamo još veći konačni omjer kompresije uz subjektivno jednaku kvalitetu slike.
3) Glavni algoritam kompresije zamijenjen je valićkom. Uz gore navedeno povećanje omjera kompresije, ovo je eliminiralo blokiranje 8 piksela koje se javlja kada se omjer kompresije poveća. Osim toga, glatko razvijanje slike sada je inherentno standardno (progresivni JPEG, koji se aktivno koristi na Internetu, pojavio se mnogo kasnije od JPEG-a).
4) Za povećanje omjera kompresije, algoritam koristi aritmetičku kompresiju. JPEG standard izvorno je uključivao i aritmetičku kompresiju, ali je kasnije zamijenjena manje učinkovitom Huffman kompresijom jer je aritmetička kompresija bila zaštićena patentima. Sada je glavni patent istekao i postoji prilika za poboljšanje algoritma.
5) Podržava kompresiju bez gubitaka. Uz uobičajenu kompresiju bez gubitaka, novi JPEG sada podržava i kompresiju bez gubitaka. Tako postaje moguće koristiti JPEG za komprimiranje medicinskih slika, u ispisu, dok se tekst sprema za prepoznavanje od strane OCR sustava, itd.
6) Podržava kompresiju jednobitnih (2 boje) slika. Za spremanje jednobitnih slika (crteži tintom, skenirani tekst, itd.), GIF format je ranije bio naširoko preporučen, jer je kompresija pomoću DCT-a vrlo neučinkovita za slike s oštrim prijelazima boja. U JPEG-u, kada je kompresirana, 1-bitna slika je smanjena na 8-bitnu, tj. povećan za 8 puta, nakon čega se pokušalo sažimati, često manje od 8 puta. Sada možemo preporučiti JPEG 2000 kao univerzalni algoritam.
7)Transparentnost je podržana na razini formata. Sada će biti moguće glatko prekriti pozadinu pri izradi WWW stranica ne samo u GIF-u, već iu JPEG 2000. Osim toga, nije podržan samo 1 bit prozirnosti (piksel je proziran/neproziran), već i zasebni kanal, što će vam omogućiti da postavite glatki prijelaz s neprozirne slike na prozirnu pozadinu.
Osim toga, uključenje informacija o autorskim pravima u sliku podržano je na razini formata, podrška za otpornost na pogreške bitova tijekom prijenosa i emitiranja, može se zatražiti za dekompresiju ili obradu. vanjska sredstva(plug-ins), možete uključiti njegov opis, informacije o pretraživanju itd. u sliku.
Faze kodiranja
Proces kompresije prema shemi JPEG2000 uključuje nekoliko koraka:
1. Pretvaranje slike u optimalni prostor boja.
U ovoj fazi kodiranja, korištenjem odgovarajućih omjera, RGB model boja se pretvara u YUV:

Prilikom dekompresije primjenjuje se odgovarajuća inverzna transformacija:

2. Diskretna valna transformacija.
Diskretna valićna transformacija(DWT) također može biti dvije vrste - za slučaj kompresije s gubicima i za kompresiju bez gubitaka.
Ova transformacija u jednodimenzionalnom slučaju je skalarni umnožak odgovarajućih koeficijenata i niza vrijednosti. Ali budući da mnogi koeficijenti su nula, tada se izravna i inverzna valna transformacija mogu napisati sljedećim formulama (za transformaciju krajnjih elemenata linije koristi se njezino proširenje za 2 piksela u svakom smjeru, čije su vrijednosti simetrične s vrijednosti elemenata linije u odnosu na krajnje piksele):
y(2*n + 1) = x(2*n + 1) - (int)(x(2*n) + x(2*n + 2)) / 2
y(2*n) = x(2*n) + (int)(y(2*n - 1) + y(2*n + 1) + 2) / 4
i obrnuto
x(2*n) = y(2*n) - (int)(y(2*n - 1) + y(2*n + 1) + 2) / 4
x(2*n + 1) = y(2*n + 1) + (int)(x(2*n) + x(2*n + 2)) / 2.
3. Kvantizacija koeficijenata.
Kao iu JPEG algoritmu, kvantizacija se koristi kod kodiranja slike u JPEG2000 formatu. Diskretna valićna transformacija, poput svog analoga, razvrstava koeficijente po frekvenciji. Ali, za razliku od JPEG-a, u novom formatu matrica kvantizacije je ista za cijelu sliku.
4. Faza sekundarne kompresije
. Kao i kod JPEG-a, u novom formatu posljednji korak u algoritmu kompresije je kodiranje bez gubitaka. No, za razliku od prethodnog formata, JPEG2000 koristi algoritam aritmetičke kompresije.
Implementacija softvera
U ovom radu implementirani su algoritmi JPEG i JPEG2000. Oba algoritma implementiraju izravno i obrnuto kodiranje (ne postoji zadnji stupanj sekundarne kompresije). Izračun JPEG-a traje prilično dugo (oko 30 sekundi) zbog "izravnog" izračuna DCT-a. Ako trebate povećati brzinu rada, prvo morate izračunati DCT matricu (napraviti promjene u DCT klasi).
Pogledajmo program:
Nakon pokretanja pojavljuje se prozor gdje
 a možete ga spremiti pritiskom na tipku (2) i unosom željenog naziva u dijaloški okvir.
a možete ga spremiti pritiskom na tipku (2) i unosom željenog naziva u dijaloški okvir. S dovoljno velikim faktorom kvalitete, slika će se dramatično promijeniti. Ako se radi o JPEG algoritmu, tada će se izgovarati blokovi 8x8 (u slučaju algoritma JPEG2000, neće biti podjele blokova)

Nakon: