GRUP SIPAS ofertës(Deklarata SELECT) ju lejon të gruponi të dhënat (rreshtat) sipas vlerës së një kolone ose kolonave ose shprehjeve të shumta. Rezultati do të jetë një grup rreshtash përmbledhës.
Çdo kolonë në listën e përzgjedhur duhet të jetë e pranishme në klauzolën GROUP BY, me përjashtim të konstanteve dhe kolonave që janë operandë të funksioneve agregate.
Një tabelë mund të grupohet sipas çdo kombinimi të kolonave të saj.
Funksionet agregate përdoren për të marrë një vlerë të vetme përmbledhëse nga një grup rreshtash. Të gjithë funksionet agregate kryejnë llogaritjet në një argument të vetëm, i cili mund të jetë ose një kolonë ose një shprehje. Rezultati i çdo funksioni agregat është një vlerë konstante e shfaqur në një kolonë të veçantë rezultati.
Funksionet e përmbledhura janë të specifikuara në listën e kolonave të deklaratës SELECT, e cila mund të përmbajë gjithashtu një klauzolë GROUP BY. Nëse nuk ka asnjë klauzolë GROUP BY në deklaratën SELECT, dhe lista e kolonave zgjidhni përmban të paktën një funksion agregat, atëherë ajo nuk duhet të përmbajë kolona të thjeshta. Nga ana tjetër, një listë e përzgjedhjes së kolonave mund të përmbajë emra kolonash që nuk janë argumente për një funksion agregat, nëse ato kolona janë argumente të klauzolës GROUP BY.
Nëse pyetja përmban një klauzolë WHERE, atëherë funksionet agregate llogaritin një vlerë për rezultatet e përzgjedhjes.
Funksionet agregate MIN dhe MAX llogaritni respektivisht vlerën më të vogël dhe më të madhe të kolonës. Argumentet mund të jenë numra, vargje dhe data. Gjithçka vlera NULL hiqen para llogaritjes (d.m.th., ato nuk merren parasysh).
Funksioni agregat SUM llogarit shumën totale të vlerave të kolonës. Argumentet mund të jenë vetëm numra. Përdorimi i opsionit DISTINCT eliminon të gjitha vlerat e kopjuara në kolonë përpara se të aplikoni funksionin SUM. Në mënyrë të ngjashme, të gjitha vlerat NULL hiqen përpara se të aplikoni këtë funksion agregat.
Funksioni i Agregatit AVG kthen mesataren e të gjitha vlerave në një kolonë. Argumentet gjithashtu mund të jenë vetëm numra, dhe të gjitha vlerat NULL hiqen para vlerësimit.
Funksioni i përmbledhur COUNT ka dy forma të ndryshme:
- COUNT( col_name) - numëron numrin e vlerave në kolonën col_name, vlerat NULL janë injoruar
- COUNT(*) - numëron numrin e rreshtave në tabelë, gjithashtu merren parasysh vlerat NULL
Nëse fjala kyçe DISTINCT përdoret në një pyetje, çdo vlerë e dyfishtë e kolonës hiqet përpara se të zbatohet funksioni COUNT.
COUNT_BIG funksion ngjashëm me funksionin COUNT. I vetmi ndryshim midis tyre është lloji i rezultatit që ata kthejnë: funksioni COUNT_BIG kthen gjithmonë vlera BIGINT, ndërsa funksioni COUNT kthen vlera të dhënash INTEGER.
NË Duke pasur ofertë përcakton një kusht që zbatohet për një grup rreshtash. Ka të njëjtin kuptim për grupet e rreshtave si klauzola WHERE për përmbajtjen e tabelës përkatëse (WHERE zbatohet para grupimit, HAVING pas).
Nënseksionet e mëposhtme përshkruajnë oferta të tjera SELECT deklaratë, të cilat mund të përdoren në pyetje, si dhe në funksione agreguese dhe grupe operatorësh. Më lejoni t'ju kujtoj momenti aktual ne shikuam përdorimin e klauzolës WHERE dhe në këtë artikull do të shikojmë klauzolat GROUP BY, ORDER BY dhe HAVING dhe do të japim disa shembuj të përdorimit të këtyre klauzolave në lidhje me funksionet e përgjithshme që mbështeten në Transact- SQL.
GRUP SIPAS ofertës
Fjali GRUP NGA grupon grupin e rreshtave të zgjedhur për të prodhuar një grup rreshtash përmbledhës bazuar në vlerat e një ose më shumë kolonave ose shprehjeve. Një përdorim i thjeshtë i klauzolës GROUP BY tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; ZGJIDH PUNËN NGA Punimet_Në GRUPI SIPAS Punës;
Në këtë shembull, pozicionet e punonjësve zgjidhen dhe grupohen.
Në shembullin e mësipërm, klauzola GROUP BY krijon një grup të veçantë për të gjitha vlerat e mundshme (përfshirë NULL) të kolonës Job.
Përdorimi i kolonave në klauzolën GROUP BY duhet të plotësojë disa kushte. Në veçanti, çdo kolonë në listën e përzgjedhjes së pyetjes duhet të shfaqet gjithashtu në klauzolën GROUP BY. Kjo kërkesë nuk zbatohet për konstantat dhe kolonat që janë pjesë e një funksioni agregat. (Funksionet agregate diskutohen në nënseksionin tjetër.) Kjo ka kuptim sepse vetëm kolonave në klauzolën GROUP BY u garantohet një vlerë për grup.
Një tabelë mund të grupohet sipas çdo kombinimi të kolonave të saj. Shembulli më poshtë tregon grupimin e rreshtave të tabelës Works_on në dy kolona:
PËRDORIMI SampleDb; SELECT Numri i Projektit, Puna NGA Punimet_Në GRUPI SIPAS Numri i projektit, Punë;
Rezultati i kësaj pyetje është:

Bazuar në rezultatet e pyetjes, mund të shihni se ka nëntë grupe me kombinime të ndryshme të numrit dhe pozicionit të projektit. Sekuenca e emrave të kolonave në klauzolën GROUP BY nuk duhet të jetë e njëjtë si në listën e kolonave SELECT.
Funksionet agregate
Funksionet agregate përdoren për të marrë vlerat totale. Të gjitha funksionet e përgjithshme mund të ndahen në kategoritë e mëposhtme:
funksionet e zakonshme të agregatit;
funksionet e agregatit statistikor;
funksionet agregate të përcaktuara nga përdoruesi;
funksionet e agregatit analitik.
Këtu do të shikojmë tre llojet e para të funksioneve agregate.
Funksionet e zakonshme të agregatit
Gjuha Transact-SQL mbështet gjashtë funksionet e mëposhtme agregate: MIN, MAX, SHUMË, AVG, COUNT, COUNT_BIG.
Të gjithë funksionet agregate kryejnë llogaritjet në një argument të vetëm, i cili mund të jetë ose një kolonë ose një shprehje. (Përjashtimi i vetëm është forma e dytë e dy funksioneve COUNT dhe COUNT_BIG, përkatësisht COUNT(*) dhe COUNT_BIG(*) përkatësisht.) Rezultati i çdo funksioni agregat është një vlerë konstante e shfaqur në një kolonë të veçantë rezultati.
Funksionet e përmbledhura janë të specifikuara në listën e kolonave të deklaratës SELECT, e cila mund të përmbajë gjithashtu një klauzolë GROUP BY. Nëse nuk ka asnjë klauzolë GROUP BY në deklaratën SELECT, dhe lista e kolonave zgjidhni përmban të paktën një funksion agregat, atëherë ajo nuk duhet të përmbajë kolona të thjeshta (përveç kolonave që shërbejnë si argumente për funksionin agregat). Prandaj, kodi në shembullin e mëposhtëm është i pasaktë:
PËRDORIMI SampleDb; SELECT Mbiemri, MIN(Id) FROM Employee;
Këtu, kolona LastName e tabelës Employee nuk duhet të jetë në listën e përzgjedhjes së kolonës sepse nuk është një argument i funksionit agregat. Nga ana tjetër, një listë e përzgjedhjes së kolonave mund të përmbajë emra kolonash që nuk janë argumente për një funksion agregat, nëse ato kolona janë argumente të klauzolës GROUP BY.
Një argument i funksionit agregat mund të paraprihet nga një nga dy fjalë kyçe të mundshme:
TE GJITHAPërcakton që llogaritjet kryhen në të gjitha vlerat në kolonë. Kjo është vlera e paracaktuar.
TË DAKTUARPërcakton që vetëm vlerat unike të kolonës përdoren për llogaritjet.
Funksionet agregate MIN dhe MAX
Funksionet e agregatit MIN dhe MAX llogaritin respektivisht vlerën më të vogël dhe më të madhe të një kolone. Nëse pyetja përmban një klauzolë WHERE, funksionet MIN dhe MAX kthejnë vlerën më të vogël dhe më të madhe të rreshtave që plotësojnë kushtet e specifikuara. Shembulli i mëposhtëm tregon përdorimin e funksionit të agregatit MIN:
PËRDORIMI SampleDb; -- Kthen 2581 SELECT MIN(Id) AS "Min Id" FROM Employee;
Rezultati i dhënë në shembullin e mësipërm nuk është shumë informues. Për shembull, emri i punonjësit që zotëron këtë numër nuk dihet. Megjithatë, nuk është e mundur të merret ky mbiemër në mënyrën e zakonshme, sepse, siç u përmend më herët, nuk lejohet specifikimi i qartë i kolonës LastName. Për të marrë mbiemrin e këtij punonjësi së bashku me numrin më të ulët të personelit të një punonjësi, përdoret një nënpyetje. Shembulli i mëposhtëm tregon përdorimin e një nënpyetjeje të tillë, ku nënpyetja përmban deklaratën SELECT nga shembulli i mëparshëm:
Rezultati i ekzekutimit të pyetjes:

Përdorimi i funksionit të agregatit MAX tregohet në shembullin e mëposhtëm:
Funksionet MIN dhe MAX gjithashtu mund të marrin vargje dhe data si argumente. Në rastin e një argumenti të vargut, vlerat krahasohen duke përdorur rendin aktual të renditjes. Për të gjitha argumentet e datës së përkohshme, vlera më e vogël e kolonës është data më e hershme dhe vlera më e madhe e kolonës është data më e fundit.
Mund të përdorni fjalën kyçe DISTINCT me funksionet MIN dhe MAX. Përpara se të përdoren funksionet e agregatit MIN dhe MAX, të gjitha vlerat NULL përjashtohen nga kolonat e tyre të argumentit.
Funksioni agregat SUM
Agregat Funksioni SUM llogarit shumën totale të vlerave të kolonës. Argumenti për këtë funksion agregat duhet të jetë gjithmonë i një lloji të të dhënave numerike. Përdorimi i funksionit agregat SUM tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; SELECT SUM (Buxhet) "Buxheti përmbledhës" NGA Projekti;
Ky shembull llogarit shumën totale të buxheteve të të gjitha projekteve. Rezultati i ekzekutimit të pyetjes:

Në këtë shembull, funksioni i përgjithshëm grupon të gjitha vlerat e buxhetit të projektit dhe përcakton shumën totale të tyre. Për këtë arsye, pyetja përmban një funksion grupimi të nënkuptuar (si të gjitha pyetjet e ngjashme). Funksioni i grupimit të nënkuptuar nga shembulli i mësipërm mund të specifikohet në mënyrë eksplicite, siç tregohet në shembullin më poshtë:
PËRDORIMI SampleDb; SELECT SUM (Buxhet) "Buxheti Total" FROM Project GROUP BY();
Përdorimi i opsionit DISTINCT eliminon të gjitha vlerat e kopjuara në kolonë përpara se të aplikoni funksionin SUM. Në mënyrë të ngjashme, të gjitha vlerat NULL hiqen përpara se të aplikoni këtë funksion agregat.
Funksioni i Agregatit AVG
Agregat Funksioni AVG kthen mesataren aritmetike të të gjitha vlerave në një kolonë. Argumenti për këtë funksion agregat duhet të jetë gjithmonë i një lloji të të dhënave numerike. Përpara se të përdoret funksioni AVG, të gjitha vlerat NULL hiqen nga argumenti i tij.
Përdorimi i funksionit të agregatit AVG tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; -- Kthen 133833 SELECT AVG (Budget) "Buxheti mesatar për projekt" FROM Project;
Këtu llogaritet mesatarja aritmetike e buxhetit për të gjitha buxhetet.
Përmbledhja e funksioneve COUNT dhe COUNT_BIG
Agregat COUNT funksion ka dy forma të ndryshme:
COUNT( emri_color) COUNT(*)
Forma e parë e funksionit numëron numrin e vlerave në kolonën col_name. Nëse fjala kyçe DISTINCT përdoret në një pyetje, çdo vlerë e dyfishtë e kolonës hiqet përpara se të zbatohet funksioni COUNT. Kjo formë e funksionit COUNT nuk merr parasysh vlerat NULL kur numëron numrin e vlerave në një kolonë.
Përdorimi i formës së parë të funksionit agregat COUNT tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; ZGJIDH numrin e projektit, COUNT (Punë e dallueshme) "Punon në projekt" NGA Works_on GROUP BY Project Number;
Këtu llogaritet numri i pozicioneve të ndryshme për çdo projekt. Rezultati i kësaj pyetje është:

Siç mund ta shihni nga pyetja e shembullit, vlerat NULL nuk u morën parasysh nga funksioni COUNT. (Shuma e të gjitha vlerave në kolonën e punës doli të jetë 7, jo 11, siç duhet të jetë.)
Forma e dytë e funksionit COUNT, d.m.th. funksioni COUNT(*) numëron numrin e rreshtave në një tabelë. Po sikur udhëzimi ZGJIDH pyetjen me funksionin COUNT(*) përmban një klauzolë WHERE me një kusht, funksioni kthen numrin e rreshtave që plotësojnë kusht të specifikuar. Ndryshe nga forma e parë e funksionit COUNT, forma e dytë nuk i injoron vlerat NULL sepse ky funksion funksionon në rreshta, jo në kolona. Shembulli i mëposhtëm tregon përdorimin e funksionit COUNT(*):
PËRDORIMI SampleDb; SELECT Job AS "Lloji i punës", COUNT(*) "Ka nevojë për punëtorë" FROM Works_on GROUP BY Job;
Këtu llogaritet numri i pozitave në të gjitha projektet. Rezultati i ekzekutimit të pyetjes:

COUNT_BIG funksion ngjashëm me funksionin COUNT. I vetmi ndryshim midis tyre është lloji i rezultatit që ata kthejnë: funksioni COUNT_BIG kthen gjithmonë vlera BIGINT, ndërsa funksioni COUNT kthen vlera të dhënash INTEGER.
Funksionet e agregatit statistikor
Funksionet e mëposhtme përbëjnë një grup funksionesh agregate statistikore:
VARLlogarit variancën statistikore të të gjitha vlerave të përfaqësuara në një kolonë ose shprehje.
VARPLlogarit variancën statistikore të popullatës së të gjitha vlerave të përfaqësuara në një kolonë ose shprehje.
STDEVLlogarit devijimin standard (i cili llogaritet si Rrenja katrore nga varianca përkatëse) e të gjitha vlerave të kolonës ose shprehjes.
STDEVPLlogarit devijimin standard të tërësisë së të gjitha vlerave në një kolonë ose shprehje.
Funksionet e përgjithshme të përcaktuara nga përdoruesi
Motori i bazës së të dhënave gjithashtu mbështet zbatimin e funksioneve të përcaktuara nga përdoruesi. Kjo aftësi i lejon përdoruesit të shtojnë funksionet agreguese të sistemit me funksione që ata mund t'i zbatojnë dhe instalojnë vetë. Këto funksione përfaqësojnë një klasë të veçantë funksionesh të përcaktuara nga përdoruesi dhe do të diskutohen më në detaje më vonë.
Duke pasur ofertë
Në një fjali DUKE përcakton një kusht që zbatohet për një grup rreshtash. Kështu, kjo klauzolë ka të njëjtin kuptim për grupet e rreshtave siç ka fjalia WHERE për përmbajtjen e tabelës përkatëse. Sintaksë DUKE oferta tjetër:
DUKE kusht
Këtu, parametri i kushtit përfaqëson një kusht dhe përmban funksione ose konstante agregate.
Përdorimi i klauzolës HAVING me funksionin agregat COUNT(*) tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; -- Ktheni "p3" ZGJIDHni Numrin e Projektit NGA Works_on GRUPI SIPAS NUMRI i projektit duke pasur COUNT(*)
Në këtë shembull, duke përdorur klauzolën GROUP BY, sistemi grupon të gjitha rreshtat bazuar në vlerat në kolonën Numri i projektit. Pas kësaj, numërohet numri i rreshtave në secilin grup dhe zgjidhen grupet që përmbajnë më pak se katër rreshta (tre ose më pak).
Klauzola HAVING mund të përdoret gjithashtu pa funksione agregate, siç tregohet në shembullin më poshtë:
PËRDORIMI SampleDb; -- Kthen "Konsulent" ZGJIDH PUNËN NGA Works_on GRUPI SIPAS PUNËS QË KA PUNË LIKE "K%";
Ky shembull grupon rreshtat në tabelën Works_on sipas pozicionit dhe eliminon ato pozicione që nuk fillojnë me shkronjën "K".
Klauzola HAVING mund të përdoret gjithashtu pa klauzolën GROUP BY, megjithëse kjo nuk është një praktikë e zakonshme. Në këtë rast, të gjitha rreshtat e tabelës kthehen në të njëjtin grup.
Porositni sipas ofertës
Fjali URDHËR NGA përcakton rendin e renditjes së rreshtave në grupin e rezultateve të kthyera nga pyetja. Kjo fjali ka sintaksën e mëposhtme:
Rendi i renditjes është specifikuar në parametrin col_name. Parametri col_number është një specifikues alternativ i renditjes së renditjes që specifikon kolonat në rendin në të cilin ato shfaqen në listën e përzgjedhjes së deklaratës SELECT (1 është kolona e parë, 2 është kolona e dytë, e kështu me radhë). Parametri ASC përcakton renditjen në rend rritës, dhe Parametri DESC- duke zbritur. Parazgjedhja është ASC.
Emrat e kolonave në klauzolën ORDER BY nuk duhet të jenë në listën e kolonave të zgjedhura. Por kjo nuk vlen për pyetjet SELECT DISTINCT, sepse në pyetje të tilla, emrat e kolonave të specifikuara në klauzolën ORDER BY duhet gjithashtu të specifikohen në listën e kolonave të zgjedhura. Përveç kësaj, kjo klauzolë nuk mund të përmbajë emra kolonash nga tabelat që nuk janë të listuara në klauzolën FROM.
Siç mund ta shihni nga sintaksa e klauzolës ORDER BY, grupi i rezultateve mund të renditet në kolona të shumta. Ky renditje tregohet në shembullin e mëposhtëm:
Ky shembull zgjedh numrat e departamenteve dhe mbiemrat dhe mbiemrat e punonjësve për punonjësit, numri i personelit të të cilëve është më pak se 20,000, dhe rendit sipas mbiemrit dhe emrit. Rezultati i kësaj pyetje është:

Kolonat në klauzolën ORDER BY mund të specifikohen jo me emrat e tyre, por me renditje në listën e përzgjedhur. Prandaj, fjalia në shembullin e mësipërm mund të rishkruhet si më poshtë:
Të tillë mënyrë alternative përcaktimi i kolonave sipas pozicionit të tyre në vend të emrave përdoret nëse kriteri i renditjes përmban një funksion agregat. (Një mënyrë tjetër është përdorimi i emrave të kolonave, të cilët më pas shfaqen në klauzolën ORDER BY.) Megjithatë, në klauzolën ORDER BY, rekomandohet që kolonat të specifikohen me emrat e tyre dhe jo me numra, për ta bërë më të lehtë përditësimin e pyetni nëse kolonat duhet të shtohen ose hiqen nga lista e përzgjedhur. Specifikimi i kolonave në klauzolën ORDER BY me numrat e tyre tregohet në shembullin më poshtë:
PËRDORIMI SampleDb; SELECT Numri i projektit, COUNT(*) "Numri i punonjësve" NGA Works_on GROUP BY ProjectNumber RENDOSJE NGA 2 DESC;
Këtu, për secilin projekt, zgjidhet numri i projektit dhe numri i punonjësve që marrin pjesë në të, duke renditur rezultatin në rend zbritës sipas numrit të punonjësve.
Transact-SQL vendos vlerat NULL në fillim të listës kur renditet në rend rritës dhe në fund të listës kur renditet në rend zbritës.
Përdorimi i klauzolës ORDER BY për të faqezuar rezultatet
Shfaqja e rezultateve të pyetjeve në faqen aktuale mund të zbatohet ose në aplikacioni i përdoruesit, ose udhëzoni serverin e bazës së të dhënave ta bëjë këtë. Në rastin e parë, të gjitha rreshtat e bazës së të dhënave dërgohen në aplikacion, detyra e të cilit është të zgjedhë rreshtat e kërkuar dhe t'i shfaqë ato. Në rastin e dytë, në anën e serverit, vetëm rreshtat e kërkuara për Faqja aktuale. Siç mund të prisni, paging nga ana e serverit zakonisht ofron performancë më të mirë, sepse klientit i dërgohen vetëm rreshtat e nevojshëm për shfaqje.
Për të mbështetur krijimin e faqeve nga ana e serverit në SQL Server 2012 prezanton dy klauzola të reja të deklaratës SELECT: OFFSET dhe FETCH. Zbatimi i këtyre dy fjalive tregohet në shembullin e mëposhtëm. Këtu, nga baza e të dhënave AdventureWorks2012 (që mund ta gjeni në burime), merret ID e biznesit, titulli i punës dhe ditëlindja e të gjitha punonjëseve femra, duke renditur rezultatin sipas titullit të punës në rend rritës. Grupi i rreshtave që rezulton ndahet në faqe me 10 rreshta dhe shfaqet faqja e tretë:
Në një fjali OFFSET specifikon numrin e rreshtave të rezultateve që duhen kapërcyer në rezultatin e shfaqur. Ky numër llogaritet pasi rreshtat të renditen sipas klauzolës ORDER BY. Në një fjali MERR TJETËR specifikon numrin e rreshtave WHERE që përputhen dhe të renditura për t'u kthyer. Parametri i kësaj klauzole mund të jetë një konstante, një shprehje ose rezultat i një pyetjeje tjetër. Klauzola FETCH NEXT është e ngjashme me klauzolën MERRNI SË PARË.
Qëllimi kryesor kur krijohen faqe në anën e serverit është që të jemi në gjendje të implementojmë forma të zakonshme të faqeve duke përdorur variabla. Ju mund ta kryeni këtë detyrë përmes paketës SQL Server.
SELECT deklaratën dhe pronësinë IDENTITY
prona IDENTITET ju lejon të përcaktoni vlerat për një kolonë specifike të tabelës si një numërues automatik në rritje. Kolonat numerike të tipit të të dhënave si TINYINT, SMALLINT, INT dhe BIGINT mund ta kenë këtë veti. Për një kolonë të tillë tabele, motori i bazës së të dhënave gjeneron automatikisht vlera sekuenciale duke filluar nga vlera fillestare e specifikuar. Kështu, vetia IDENTITY mund të përdoret për të krijuar unike vlerat numerike për kolonën e zgjedhur.
Një tabelë mund të përmbajë vetëm një kolonë me vetinë IDENTITY. Pronari i tabelës ka aftësinë të specifikojë vlerën fillestare dhe rritjen, siç tregohet në shembullin më poshtë:
PËRDORIMI SampleDb; KRIJO TABELA Produkti (ID INT IDENTITY(10000, 1) JO NULL, Emri NVARCHAR(30) JO NULL, PARA Çmimi) INSERT NË PRODHIM (Emri, Çmimi) VLERAT ("Artikulli 1", 10), ("Artikulli 2", 15) , ("Artikulli 3", 8), ("Artikulli 4", 15), ("Artikulli 5", 40); -- Kthen 10004 SELECT IDENTITYCOL FROM Produkt WHERE Emri = "Product5"; -- Ngjashëm me deklaratën e mëparshme SELECT $identity FROM Product WHERE Emri = "Product5";
Ky shembull fillimisht krijon një tabelë Produkti që përmban një kolonë ID me një veçori IDENTITY. Vlerat në kolonën Id gjenerohen automatikisht nga sistemi, duke filluar nga 10,000 dhe duke u rritur me një për çdo vlerë pasuese: 10,000, 10,001, 10,002, e kështu me radhë.
Disa funksione dhe variabla të sistemit shoqërohen me veçorinë IDENTITY. Për shembull, përdoret shembulli i kodit ndryshorja e sistemit $identity. Siç mund ta shihni nga dalja e këtij kodi, kjo variabël i referohet automatikisht vetisë IDENTITY. Në vend të kësaj, mund të përdorni gjithashtu funksionin e sistemit IDENTITETI.
Vlera fillestare dhe rritja e një kolone me vetinë IDENTITY mund të gjenden duke përdorur funksionet IDENT_SEED Dhe IDENT_INCR përkatësisht. Këto funksione zbatohen si më poshtë:
PËRDORIMI SampleDb; SELECT IDENT_SEED ("Produkt"), IDENT_INCR ("Produkt")
Siç është përmendur tashmë, vlerat IDENTITY vendosen automatikisht nga sistemi. Por përdoruesi mund të specifikojë në mënyrë eksplicite vlerat e veta për rreshta të caktuar duke vendosur parametrin IDENTITY_INSERT AKTIV para se të futni një vlerë të qartë:
SET IDENTITY INSERT emrin e tabelës ON
Për shkak se opsioni IDENTITY_INSERT mund të vendoset në çdo vlerë për një kolonë të veçorisë IDENTITY, duke përfshirë një vlerë të dyfishtë, vetia IDENTITY zakonisht nuk zbaton uniken e vlerave të kolonës. Prandaj, kufizimet UNIQUE ose KRYESORE KRYESORE duhet të përdoren për të zbatuar uniken e vlerave të kolonës.
Kur futni vlera në një tabelë pasi IDENTITY_INSERT është aktivizuar, sistemi krijon vlerën tjetër të kolonës IDENTITY, duke rritur vlerën më të madhe aktuale të asaj kolone.
Deklarata CREATE SEQUENCE
Përdorimi i pronës IDENTITY ka disa disavantazhe të rëndësishme, më të rëndësishmet prej të cilave janë këto:
aplikimi i pronës është i kufizuar në tabelën e specifikuar;
vlera e re e kolonës nuk mund të merret në asnjë mënyrë tjetër veçse duke e aplikuar atë;
vetia IDENTITY mund të specifikohet vetëm kur krijohet një kolonë.
Për këto arsye, SQL Server 2012 prezanton sekuenca që kanë të njëjtën semantikë si vetia IDENTITY, por pa të metat e listuara më parë. Në këtë kontekst, një sekuencë është një funksionalitet i bazës së të dhënave që ju lejon të specifikoni vlerat e kundërta për objekte të ndryshme të bazës së të dhënave, të tilla si kolonat dhe variablat.
Sekuencat krijohen duke përdorur udhëzimet KRIJO SEKUENCE. Deklarata CREATE SEQUENCE përcaktohet në standardin SQL dhe mbështetet nga sisteme të tjera të bazës së të dhënave relacionale si IBM DB2 dhe Oracle.
Shembulli më poshtë tregon se si të krijoni një sekuencë në SQL Server:
PËRDORIMI SampleDb; KRIJO SEKUENCE dbo.Sekuenca1 SI NË FILLIM ME 1 RRITJE ME 5 MINVLERË 1 MAXVLERË 256 CIKLE;
Në shembullin e mësipërm, vlerat për Sekuencën 1 gjenerohen automatikisht nga sistemi, duke filluar nga vlera 1 dhe duke u rritur me 5 për çdo vlerë pasuese. Kështu, në oferta FILLOështë specifikuar vlera fillestare dhe Oferta RRITJE- hap. (Hapi mund të jetë pozitiv ose negativ.)
Në dy fjalitë e ardhshme fakultative MINVALUES Dhe MAXVLERA minimale dhe vlera maksimale objekt sekuence. (Vini re se vlera MINVALUE duhet të jetë më e vogël ose e barabartë me vlerën fillestare dhe vlera MAXVALUE nuk mund të jetë më e madhe se kufiri i sipërm i llojit të të dhënave të specifikuar për sekuencën.) Në klauzolën CIKLI tregon se sekuenca përsëritet nga fillimi kur tejkalohet vlera maksimale (ose minimale për një sekuencë me hap negativ). Si parazgjedhje, kjo klauzolë është NO CIKLE, që do të thotë se tejkalimi i vlerës së sekuencës maksimale ose minimale shkakton një përjashtim.
Tipari kryesor i sekuencave është pavarësia e tyre nga tabelat, d.m.th. ato mund të përdoren me çdo objekt të bazës së të dhënave siç janë kolonat e tabelës ose variablat. (Kjo veti ka një efekt pozitiv në ruajtjen dhe, për rrjedhojë, në performancën. Një sekuencë specifike nuk ka nevojë të ruhet; ruhet vetëm vlera e fundit e saj.)
Vlerat e reja të sekuencës krijohen me VLERA E TJETËR PËR shprehjet, përdorimi i të cilave tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; -- Kthen 1 ZGJIDH VLERËN TJETËR PËR dbo.sequence1; -- Kthen 6 (hapi tjetër) ZGJIDH VLERËN TJETËR PËR dbo.sequence1;
Ju mund të përdorni shprehjen NEXT VALUE FOR për të caktuar rezultatin e një sekuence në një variabël ose qelizë kolone. Shembulli më poshtë tregon përdorimin e kësaj shprehjeje për të caktuar rezultatet në një kolonë:
PËRDORIMI SampleDb; KRIJO TABELA Produkti (Id INT NOT NULL, Emri NVARCHAR(30) JO NULL, PARA Çmimi) INSERT NË VLERAT E PRODUKTIT (VLERA TJETËR PËR dbo.sequence1, "Product1", 10); INSERT NË VLERAT E PRODUKTIT (VLERA E TJETËR PËR dbo.sequence1, "Product2", 15); --...
Shembulli i mësipërm fillimisht krijon një tabelë të produktit me katër kolona. Më pas, dy deklarata INSERT futin dy rreshta në këtë tabelë. Dy qelizat e para në kolonën e parë do të kenë vlerat 11 dhe 16.
Shembulli i mëposhtëm tregon përdorimin e pamjes së katalogut sys.sekuenca për të parë vlerën aktuale të një sekuence pa e përdorur atë:
Në mënyrë tipike, shprehja NEXT VALUE FOR përdoret në një deklaratë INSERT për të detyruar sistemin të futë vlerat e krijuara. Kjo shprehje mund të përdoret gjithashtu si pjesë e një pyetjeje me shumë rreshta duke përdorur klauzolën OVER.
Për të ndryshuar një veti të një sekuence ekzistuese, përdorni Deklarata ALTER SEQUENCE. Një nga përdorimet më të rëndësishme të kësaj deklarate është me opsionin RISTART WITH, i cili rivendos sekuencën e specifikuar. Shembulli i mëposhtëm tregon përdorimin e deklaratës ALTER SEQUENCE për të rivendosur pothuajse të gjitha vetitë e Sequence1:
PËRDORIMI SampleDb; SEKUENCA NDRYSHIME dbo.sekuenca1 RIFIKONI ME 100 RRITJE ME 50 MINVLERË 50 MAXVLERË 200 PA CIKLI;
Fshini një sekuencë duke përdorur udhëzimin SEKUENCA E RËZIMIT.
Set Operatorët
Përveç operatorëve të diskutuar më parë, Transact-SQL mbështet tre operatorë të tjerë të grupeve: UNION, INTERSECT dhe EXCEPT.
Operatori UNION
Operatori UNION kombinon rezultatet e dy ose më shumë pyetjeve në një grup të vetëm rezultatesh që përfshin të gjitha rreshtat që u përkasin të gjitha pyetjeve në bashkim. Prandaj, rezultati i bashkimit të dy tabelave është një tabelë e re që përmban të gjitha rreshtat e përfshirë në njërën nga tabelat origjinale ose në të dyja këto tabela.
Forma e përgjithshme e operatorit UNION duket si kjo:
zgjidhni_1 UNION zgjidhni_2(zgjidh_3])...
Opsionet select_1, select_2, ... janë deklarata SELECT që krijojnë një bashkim. Nëse përdoret opsioni ALL, shfaqen të gjitha rreshtat, duke përfshirë dublikatat. Në operatorin UNION, parametri ALL ka të njëjtin kuptim si në listën e përzgjedhjes SELECT, me një ndryshim: për listën e përzgjedhjes SELECT, ky parametër aplikohet si parazgjedhje, por për operatorin UNION duhet të specifikohet në mënyrë eksplicite.
Në formën e saj origjinale, baza e të dhënave SampleDb nuk është e përshtatshme për të demonstruar përdorimin e operatorit UNION. Prandaj, ky seksion krijon një tabelë të re EmployeeEnh që është identike me tabelën ekzistuese Employee, por ka një kolonë shtesë City. Kjo kolonë tregon se ku jetojnë punonjësit.
Krijimi i tabelës EmployeeEnh na ofron një mundësi për të demonstruar përdorimin e klauzolës NË në deklaratën SELECT. Deklarata SELECT INTO kryen dy operacione. Së pari, krijohet një tabelë e re me kolonat e listuara në listën e përzgjedhjes SELECT. Pastaj rreshtat e tabelës origjinale futen në tabelën e re. Emri i tabelës së re është specifikuar në klauzolën INTO, dhe emri i tabelës burimore është specifikuar në klauzolën FROM.
Shembulli më poshtë tregon krijimin e tabelës EmployeeEnh nga tabela Employee:
PËRDORIMI SampleDb; SELECT * INTO EmployeeEnh FROM Employee; ALTER TABLE PunonjësEnh SHTO Qyteti NCHAR(40) NULL;
Në këtë shembull, deklarata SELECT INTO krijon tabelën EmployeeEnh, fut të gjitha rreshtat nga tabela burimore Employee në të dhe më pas deklarata ALTER TABLE shton kolonën City në tabelën e re. Por kolona e shtuar Qyteti nuk përmban asnjë vlerë. Vlerat në këtë kolonë mund të futen duke përdorur Menaxhimi i Mjedisit Studio ose me kodin e mëposhtëm:
PËRDORIMI SampleDb; PËRDITËSOJE EmployeeEnh SET Qyteti="Kazan" WHERE Id=2581; PËRDITËSOJE EmployeeEnh SET City = "Moscow" WHERE Id = 9031; PËRDITËSOJE EmployeeEnh SET Qyteti = "Yekaterinburg" WHERE Id = 10102; UPDATE EmployeeEnh SET City = "Saint Petersburg" WHERE Id = 18316; UPDATE EmployeeEnh SET City = "Krasnodar" WHERE Id = 25348; UPDATE EmployeeEnh SET City="Kazan" WHERE Id=28559; UPDATE EmployeeEnh SET City="Perm" WHERE Id=29346;
Tani jemi gati të demonstrojmë përdorimin e deklaratës UNION. Shembulli më poshtë tregon një pyetje për të krijuar një bashkim midis tabelave EmployeeEnh dhe Department duke përdorur këtë deklaratë:
PËRDORIMI SampleDb; ZGJIDH Qyteti AS "Qytet" NGA PunonjësitEnh UNION ZGJEDH vendndodhjen NGA Departamenti;
Rezultati i kësaj pyetje është:
Vetëm tabelat e përputhshme mund të bashkohen duke përdorur deklaratën UNION. Me tabela të pajtueshme, nënkuptojmë që të dyja listat e kolonave në përzgjedhje duhet të përmbajnë të njëjtin numër kolonash dhe se kolonat përkatëse duhet të kenë lloje të dhënash të përputhshme. (Për sa i përket përputhshmërisë, llojet e të dhënave INT dhe SMALLINT nuk janë të pajtueshme.)
Rezultati i një bashkimi mund të porositet vetëm duke përdorur klauzolën ORDER BY në deklaratën e fundit SELECT, siç tregohet në shembullin më poshtë. Klauzolat GROUP BY dhe HAVING mund të përdoren me udhëzime të veçanta SELECT, por jo në vetë bashkimin.
Pyetja në këtë shembull merr punonjësit që ose punojnë në departamentin d1 ose kanë filluar të punojnë në projekt përpara 1 janarit 2008.
Operatori UNION mbështet opsionin ALL. Kur përdoret ky opsion, dublikatat nuk hiqen nga grupi i rezultateve. Një operator OR mund të përdoret në vend të një operatori UNION nëse të gjitha deklaratat SELECT të bashkuara nga një ose më shumë operatorë UNION i referohen të njëjtës tabelë. Në këtë rast, grupi i deklaratave SELECT zëvendësohet nga një deklaratë e vetme SELECT me një grup deklaratash OR.
Deklaratat KRYQËZOJNË dhe PËRVEÇ
Dy operatorë të tjerë për të punuar me grupe, KRYQËZOHET Dhe PËRVEÇ, përcaktoni përkatësisht kryqëzimin dhe ndryshimin. Nën kryqëzimin në këtë kontekst është një grup rreshtash që u përkasin të dy tabelave. Dhe ndryshimi i dy tabelave përcaktohet si të gjitha vlerat që i përkasin tabelës së parë dhe nuk janë të pranishme në të dytën. Shembulli i mëposhtëm tregon përdorimin e deklaratës INTERSECT:
Transact-SQL nuk e mbështet përdorimin e opsionit ALL as me deklaratën INTERSECT ose me deklaratën EXCEPT. Përdorimi i deklaratës EXCEPT tregohet në shembullin e mëposhtëm:
Mbani në mend se këta tre operatorë grupesh kanë përparësi të ndryshme ekzekutimi: Deklarata KRYQËZOHET ka precedencën më të lartë, i ndjekur nga operatori EXCEPT, dhe operatori UNION ka përparësinë më të ulët. Mosvëmendja ndaj prioritetit të ekzekutimit kur përdoret shumëfish operatorë të ndryshëm për të punuar me grupe mund të çojë në rezultate të papritura.
Shprehjet RAST
Në fushën e programimit të aplikacionit të bazës së të dhënave, ndonjëherë është e nevojshme të modifikohet prezantimi i të dhënave. Për shembull, njerëzit mund të ndahen duke i koduar sipas përkatësisë së tyre sociale, duke përdorur vlerat 1, 2 dhe 3, që tregojnë përkatësisht meshkuj, femra dhe fëmijë. Kjo teknikë programimi mund të zvogëlojë kohën e nevojshme për zbatimin e programit. Shprehje RASTE Gjuha Transact-SQL e bën të lehtë zbatimin e këtij lloji të kodimit.
Ndryshe nga shumica e gjuhëve programuese, CASE nuk është një deklaratë, por një shprehje. Prandaj, një shprehje CASE mund të përdoret pothuajse kudo ku gjuha Transact-SQL lejon përdorimin e shprehjeve. Shprehja CASE ka dy forma:
një shprehje e thjeshtë RAST;
shprehja e kërkimit RAST.
Sintaksa për një shprehje të thjeshtë CASE është si më poshtë:
Një deklaratë me një shprehje të thjeshtë CASE fillimisht kërkon listën e të gjitha shprehjeve në klauzola KUR shprehja e parë që përputhet me shprehjen_1 dhe më pas ekzekuton atë përkatëse PASTAJ klauzolë. Nëse nuk ka asnjë shprehje që përputhet në listën WHEN, atëherë klauzolë TJETËR.
Sintaksa për një shprehje kërkimi CASE është:
NË këtë rast kërkohet kushti i parë i përputhjes dhe më pas ekzekutohet klauzola përkatëse THEN. Nëse asnjë nga kushtet nuk përputhet me kërkesat, klauzola ELSE ekzekutohet. Përdorimi i shprehjes së kërkimit CASE tregohet në shembullin e mëposhtëm:
PËRDORIMI SampleDb; ZGJIDH emrin e projektit, RASTIN KUR Buxheti > 0 DHE Buxheti 100000 DHE Buxheti 150000 DHE Buxheti
Rezultati i kësaj pyetje është:

Ky shembull peshon buxhetet e të gjitha projekteve dhe shfaq peshat e tyre të llogaritura së bashku me emrat e tyre përkatës të projekteve.
Shembulli më poshtë tregon një mënyrë tjetër për të përdorur një shprehje CASE, ku klauzola WHEN përmban nënpyetje që janë pjesë e shprehjes:
PËRDORIMI SampleDb; SELECT Emri i Projektit, RASTI WHEN p1.Budget (SELECT AVG(p2.Budget) FROM Project p2) PAS "Mbi mesataren" FUND "Kategoria e buxhetit" NGA Projekti p1;
Rezultati i kësaj pyetjeje është si më poshtë:

Mësimi do të mbulojë temën sql duke riemërtuar një kolonë (fusha) duke përdorur fjalën e shërbimit AS; merret parasysh edhe tema e funksioneve agregate në sql. Shembujt e kërkesave specifike do të analizohen
Emrat e kolonave në pyetje mund të riemërohen. Kjo i bën rezultatet më të lexueshme.
NË Gjuha SQL riemërtimi i fushave lidhet me përdorimin fjalë kyçe AS, i cili përdoret për të riemërtuar emrat e fushave në grupet e rezultateve
Sintaksë:
ZGJIDH<имя поля>AS<псевдоним>NGA…
Konsideroni një shembull të riemërtimit në SQL:
Një shembull i bazës së të dhënave "Instituti": Shfaqni emrat e mësuesve dhe pagat e tyre, për ata mësues që paga e tyre është nën 15000, riemërtoni fushën zarplata në "paga e ulët"
✍ Zgjidhja:
Riemërtimi i kolonave në SQL është shpesh i nevojshëm kur llogaritni vlerat e lidhura me fusha të shumta tabelat. Konsideroni një shembull:
Një shembull i bazës së të dhënave "Instituti": Nga tabela e mësuesve, shfaqni fushën e emrit dhe llogaritni shumën e pagës dhe bonusit, duke emërtuar fushën "bonus_paga"
✍ Zgjidhja:
| 1 2 | SELECT emrin, (zarplata+ premia) AS zarplata_premia FROM mësues; |
SELECT emrin, (zarplata+premia) AS zarplata_premia FROM mësues;
Rezultati:
Funksionet agregate në SQL
Funksionet agregate në sql përdoren për të marrë vlerat totale dhe për të vlerësuar shprehjet:
Të gjitha funksionet agregate kthejnë një vlerë të vetme.
Funksionet COUNT, MIN dhe MAX zbatohen për çdo lloj të dhënash.
Funksionet SUM dhe AVG përdoren vetëm për fushat numerike.
Ekziston një ndryshim midis funksioneve COUNT(*) dhe COUNT(): ky i fundit nuk merr parasysh vlerat NULL gjatë llogaritjes.
E rëndësishme: kur punoni me funksione agregate në SQL, përdoret një fjalë funksioni AS
Një shembull i bazës së të dhënave "Instituti": Merrni vlerën e pagës më të lartë midis mësuesve, shfaqni totalin si "max_zp"
✍ Zgjidhja:
| SELECT MAX (zarplata) AS max_zp NGA mësuesit; |
SELECT MAX(zarplata) AS max_sal NGA mësuesit;
Rezultatet:
Konsideroni më shumë shembull kompleks duke përdorur funksionet agregate në sql.
✍ Zgjidhja:
Klauzola GROUP BY në SQL
Grupi sipas deklaratës në sql zakonisht përdoret në lidhje me funksionet agregate.
Funksionet e përmbledhura ekzekutohen në të gjitha vargjet e pyetjeve që rezultojnë. Nëse pyetja përmban një klauzolë GROUP BY, çdo grup rreshtash i specifikuar në klauzolën GROUP BY përbën një grup dhe funksionet e përgjithshme ekzekutohen. për secilin grup veç e veç.
Shqyrtoni një shembull me tabelën e mësimeve: 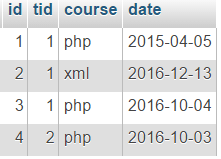
Shembull:
E rëndësishme: Kështu, si rezultat i përdorimit të GROUP BY, të gjitha rreshtat dalëse të pyetjes ndahen në grupe të karakterizuara nga i njëjti kombinim vlerash në këto kolona (d.m.th., funksionet agregate kryhen për secilin grup veç e veç).
Në të njëjtën kohë, duhet të merret parasysh se kur grupohet sipas një fushe që përmban vlera NULL, të gjitha regjistrimet e tilla do të bien në një grup.
Për lloje të ndryshme printerësh, identifikoni ato kosto mesatare dhe sasinë (d.m.th. veçmas për laserin, bojën dhe matricën). Përdorni funksionet agregate. Rezultati duhet të duket si ky:

Duke pasur deklaratë SQL
Klauzola HAVING në SQL nevojitet për të kontrolluar vlerat, të cilat fitohen duke përdorur funksionin agregat pas grupimit(pas përdorimit GROUP BY). Një kontroll i tillë nuk mund të përfshihet në një klauzolë WHERE.
Shembull: Dyqani i kompjuterëve DB. Llogaritni çmimin mesatar të kompjuterëve me të njëjtën shpejtësi procesori. Kryeni llogaritjen vetëm për ato grupe, çmimi mesatar i të cilëve është më pak se 30,000.
nga vlera e rubrikës Disiplina . Do të marrim 4 grupe, për të cilat mund të llogarisim disa vlera grupi, si numri i tupave në grup, vlera maksimale ose minimale e kolonës Score.| Funksioni | Rezultati |
|---|---|
| COUNT | Numri i rreshtave ose vlerave të fushës jo të zbrazët që pyeti ka zgjedhur |
| SHUMË | Shuma e të gjitha vlerave të zgjedhura të një fushe të caktuar |
| AVG | Mesatarja aritmetike e të gjitha vlerave të zgjedhura në një fushë të caktuar |
| MIN | Më e vogla nga të gjitha vlerat e zgjedhura për këtë fushë |
| MAX | Më e madhja nga të gjitha vlerat e zgjedhura për këtë fushë |
| R1 | |||
|---|---|---|---|
| Emri i plotë | Disipline | Gradë | |
| Grupi 1 | Petrov F.I. | Baza e të dhënave | 5 |
| Sidorov K. A. | Baza e të dhënave | 4 | |
| Mironov A.V. | Baza e të dhënave | 2 | |
| Stepanova K. E. | Baza e të dhënave | 2 | |
| Krylova T. S. | Baza e të dhënave | 5 | |
| Vladimirov V. A. | Baza e të dhënave | 5 | |
| Grupi 2 | Sidorov K. A. | Teoria e informacionit | 4 |
| Stepanova K. E. | Teoria e informacionit | 2 | |
| Krylova T. S. | Teoria e informacionit | 5 | |
| Mironov A.V. | Teoria e informacionit | I pavlefshëm | |
| Grupi 3 | Trofimov P. A. | Rrjetet dhe telekomunikacioni | 4 |
| Ivanova E. A. | Rrjetet dhe telekomunikacioni | 5 | |
| Utkina N.V. | Rrjetet dhe telekomunikacioni | 5 | |
| Grupi 4 | Vladimirov V. A. | gjuhe angleze | 4 |
| Trofimov P. A. | gjuhe angleze | 5 | |
| Ivanova E. A. | gjuhe angleze | 3 | |
| Petrov F.I. | gjuhe angleze | 5 | |
Funksionet agregate përdoren si emrat e fushave në një deklaratë SELECT, me një përjashtim: ata marrin emrin e fushës si argument. Vetëm me funksionet SUM dhe AVG fusha numerike. Të dyja fushat numerike dhe të karaktereve mund të përdoren me funksionet COUNT , MAX dhe MIN. Kur përdoren me fushat e karaktereve, MAX dhe MIN do t'i përkthejnë ato në ekuivalentin e tyre ASCII dhe do t'i përpunojnë si sipas rendit alfabetik. Disa DBMS lejojnë agregate të mbivendosur, por kjo është një largim nga standardi ANSI, me të gjitha implikimet e tij.
Për shembull, mund të llogarisni numrin e studentëve që kanë marrë provime në secilën disiplinë. Për ta bërë këtë, duhet të ekzekutoni një pyetje të grupuar sipas fushës "Subject" dhe të shfaqni emrin e disiplinës dhe numrin e rreshtave në grup për këtë disiplinë si rezultat. Përdorimi i karakterit * si argument për funksionin COUNT do të thotë të numërosh të gjitha rreshtat në grup.
SELECT R1.Disiplina, COUNT(*) FROM R1 GROUP BY R1.Disiplina
Rezultati:
Nëse duam të numërojmë numrin e studentëve që kanë kaluar provimin në çdo disiplinë, atëherë duhet të përjashtojmë vlerat zero nga raporti origjinal përpara se të grupojmë. Në këtë rast, kërkesa do të duket si kjo:
Ne marrim rezultatin:
Në këtë rast, linja me studentin
| Mironov A.V. | Teoria e informacionit | I pavlefshëm |
|---|
nuk do të bjerë në grupin e tuples përpara grupimit, kështu që numri i tupleve në grup për disiplinë " Teoria e informacionit“do të jetë 1 më pak.
Mund të aplikohet funksionet agregate edhe pa operacionin e para-grupimit, me ç'rast e gjithë relacioni konsiderohet si një grup dhe për këtë grup mund të llogaritet një vlerë për grup.
Duke iu referuar sërish bazës së të dhënave "Session" (tabelat R1, R2, R3), gjejmë numrin e provimeve të mbartura me sukses:
Kjo sigurisht është e ndryshme nga zgjedhja e një fushe, pasi gjithmonë kthehet një vlerë e vetme, pavarësisht se sa rreshta ka në tabelë. Argumenti funksionet agregate mund të ketë kolona të veçanta tabelash. Por për të llogaritur, për shembull, numrin e vlerave të ndryshme të një kolone të caktuar në një grup, duhet të përdorni fjalën kyçe DISTINCT së bashku me emrin e kolonës. Le të llogarisim numrin e notave të ndryshme të marra në secilën disiplinë:
Rezultati:
Rezultati mund të përfshijë një vlerë të fushës së grupimit dhe disa funksionet agregate, dhe fusha të shumta mund të përdoren në kushtet e grupimit. Në këtë rast, grupet formohen sipas një grupi fushash grupimi të specifikuara. Operacionet agregate mund të aplikohen për të bashkuar tabela të shumta burimore. Për shembull, le të parashtrojmë pyetjen: përcaktoni për çdo grup dhe çdo disiplinë numrin e atyre që e kaluan me sukses provimin dhe rezultatin mesatar për disiplinën.
Rezultati:
Nuk mund të përdorim funksionet agregate në fjalinë WHERE, sepse kallëzuesit vlerësohen në terma të një rreshti të vetëm, dhe funksionet agregate- përsa i përket grupeve të rreshtave.
Klauzola GROUP BY ju lejon të përcaktoni një nëngrup vlerash në një fushë të caktuar në terma të një fushe tjetër dhe të aplikoni një funksion agregat në nëngrup. Kjo bën të mundur kombinimin e fushave dhe funksionet agregate në një klauzolë të vetme SELECT. Funksionet agregate mund të përdoret si në shprehjen dalëse të rezultateve të rreshtit SELECT, ashtu edhe në shprehjen e kushtit të përpunimit për grupet e formuara HAVING . Në këtë rast, çdo funksion agregat llogaritet për çdo grup të përzgjedhur. Vlerat që rezultojnë nga llogaritja funksionet agregate, mund të përdoret për të shfaqur rezultatet përkatëse ose për të kushtëzuar zgjedhjen e grupeve.
Le të ndërtojmë një pyetje që shfaq grupet në të cilat janë marrë më shumë se një deuce në një disiplinë në provime:
Në të ardhmen, si shembull, nuk do të punojmë me bazën e të dhënave "Session", por me bazën e të dhënave "Banka", e përbërë nga një tabelë F , e cila ruan relacionin F që përmban informacione për llogaritë në degët e një banke të caktuar:
F = (N, Emri i plotë, Dega, Data e Hapjes, Data e Mbylljes, Bilanci); Q = (Dega, Qyteti);
sepse mbi këtë bazë mund të ilustrohet më qartë puna me funksione agregate dhe grupim.
Për shembull, supozoni se duam të gjejmë gjendjen totale të llogarive në degë. Ju mund të bëni një pyetje të veçantë për secilën prej tyre duke zgjedhur SUM(Balance) nga tabela për secilën degë. GROUP BY, megjithatë, do t'i vendosë të gjitha në një komandë:
ZGJIDH Degën, SHUMË(Balance) FROM F GROUP BY Degë;
Zbatohet GROUP BY funksionet agregate në mënyrë të pavarur për çdo grup të përcaktuar nga vlera e fushës Degë. Grupi përbëhet nga linja me të njëjtën vlerë fusha Dega, dhe
Standardi ISO përcakton pesë të mëposhtmet funksionet e grumbullimit:
COUNT- kthen numrin e vlerave në kolonën e specifikuar;
SHUMË- kthen shumën e vlerave në kolonën e specifikuar;
AVG– kthen vlerën mesatare në kolonën e specifikuar;
MIN– kthen vlerën minimale në kolonën e specifikuar;
MAX- kthen vlerën maksimale në kolonën e specifikuar.
Të gjitha këto funksione funksionojnë në vlerat në një kolonë të vetme tabele dhe kthejnë një vlerë të vetme. Funksionet COUNT, MIN dhe MAX zbatohen si për fushat numerike ashtu edhe për ato jonumerike, ndërsa funksionet SUM dhe AVG mund të përdoren vetëm për fushat numerike. Me përjashtim të COUNT(*), gjatë llogaritjes së rezultateve të çdo funksioni, së pari përjashtohen të gjitha vlerat null, pas së cilës operacioni i kërkuar zbatohet vetëm për vlerat e mbetura jo null të kolonës. Varianti COUNT (*) është një përdorim i veçantë i funksionit COUNT - qëllimi i tij është të numërojë të gjitha rreshtat në një tabelë, pavarësisht nëse ato përmbajnë null, dublikatë ose ndonjë vlerë tjetër. Nëse dëshironi të eliminoni vlerat e dyfishta përpara se të përdorni një funksion agregat, duhet t'i paraprini emrit të kolonës në përkufizimin e funksionit me fjalën kyçe DISTINCT. Standardi ISO lejon përdorimin e fjalës kyçe ALL për të treguar në mënyrë eksplicite se eliminimi i vlerave të dyfishta nuk kërkohet, megjithëse kjo fjalë kyçe supozohet si parazgjedhje nëse nuk specifikohen kualifikues të tjerë. Fjala kyçe DISTINCT nuk ka asnjë kuptim për funksionet MIN dhe MAX. Sidoqoftë, përdorimi i tij mund të ndikojë në rezultatet e funksioneve SUM dhe AVG, kështu që duhet të mendoni paraprakisht nëse ai duhet të jetë i pranishëm në secilin rast specifik. Gjithashtu, fjala kyçe DISTINCT mund të specifikohet maksimumi një herë në çdo pyetje.
Vini re se funksionet e përmbledhura mund të përdoren vetëm në një listë të përzgjedhur SELECT dhe në një klauzolë HAVING (shih seksionin 5.3.4). Në të gjitha rastet e tjera, përdorimi i këtyre funksioneve nuk lejohet. Nëse lista SELECT përmban një funksion grumbullimi dhe trupi i pyetjes nuk përmban një klauzolë GROUP BY që ofron grupimin e të dhënave, atëherë asnjë nga elementët e listës SELECT nuk mund të përfshijë ndonjë referencë kolone, përveç nëse kjo kolonë përdoret si funksion agregat. parametri. Për shembull, pyetja e mëposhtme është e pavlefshme:
ZGJIDHstafi Jo,COUNT (paga)
NGAstafi;
Gabimi është se në kërkesë e dhënë mungon dizajni GRUP NGA, dhe kolona staffNo në listën SELECT aksesohet pa përdorur një funksion grumbullimi.
Shembulli 13: Përdorimi i funksionit COUNT(*).Përcaktoni se sa prona me qira kanë një normë qiraje prej më shumë se 350 £ në muaj,
ZGJIDH NUMRIN(*) numërimi AS
NGAprone perrent
KUqiraja > 350;
Kufizimi për të numëruar vetëm ato objekte me qira, qiraja e të cilave është më shumë se 350 £ në muaj zbatohet nëpërmjet përdorimit të klauzolës WHERE. Numri total i objekteve të marra me qira që plotësojnë kushtin e specifikuar mund të përcaktohet duke përdorur funksionin grumbullues COUNT. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 23.
Tabela 23
| numëroj |
Shembulli 14. Duke përdorur funksionin COUNT(DISTINCT).Përcaktoni sa prona të ndryshme me qira janë inspektuar nga klientët në maj 2001.
ZGJIDH NUMËRIN (DALLIMNr i pasurisë) AS numërimi
NGADuke parë
Përsëri, kufizimi i rezultateve të pyetjes në analizimin e vetëm atyre qirave që u inspektuan në maj 2001 arrihet duke përdorur klauzolën WHERE. Numri total i objekteve të inspektuara që plotësojnë kushtin e specifikuar mund të përcaktohet duke përdorur funksionin grumbullues COUNT. Megjithatë, duke qenë se i njëjti objekt mund të shihet disa herë nga klientë të ndryshëm, fjala kyçe DISTINCT duhet të specifikohet në përkufizimin e funksionit për të përjashtuar vlerat e dyfishta nga llogaritja. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 24.
Tabela 24
Shembulli 16. Përdorimi i funksioneve MIN, MAXnAVG.Llogaritni vlerën e pagës minimale, maksimale dhe mesatare.
ZGJIDH MIN(paga) AS min, MAX(paga) AS maksimumi, AVG(paga) AS mesatare
NGAstafi;
Në këtë shembull, ju duhet të përpunoni informacione për të gjithë personelin në kompani, kështu që nuk keni nevojë të përdorni klauzolën WHERE. Vlerat e kërkuara mund të llogariten duke përdorur funksionet MIN, MAX dhe AVG të aplikuara në kolonën e pagave të tabelës së Stafit. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 26.
Tabela 26
Rezultati i pyetjes
| min | maksimumi | mesatare |
| 9000.00 | 30000.00 | 17000.00 |
Rezultatet e grupimit (ndërtimi GROUP BY). Shembujt e të dhënave përmbledhëse të mësipërme janë të ngjashëm me rreshtat përmbledhës që gjenden zakonisht në fund të raporteve. Si rezultat, të gjitha të dhënat e detajuara të raportit kompresohen në një linjë përmbledhëse. Megjithatë, shumë shpesh në raporte kërkohet të formohen edhe nëntotalet. Për këtë qëllim, klauzola GROUP BY mund të specifikohet në deklaratën SELECT. Një pyetje që përmban një klauzolë GROUP BY quhet pyetje në grup, sepse grupon të dhënat që rezultojnë nga operacioni SELECT, pas së cilës krijohet një rresht i vetëm përmbledhës për çdo grup individual. Kolonat e renditura në klauzolën GROUP BY thirren kolona të grupuara. Standardi ISO kërkon që klauzolat SELECT dhe GROUP BY të jenë të lidhura ngushtë. Kur përdorni klauzolën GROUP BY në një deklaratë SELECT, çdo artikull i listës në listën e përzgjedhjes SELECT duhet të ketë vlera e vetme për të gjithë grupin. Për më tepër, një konstrukt SELECT mund të përfshijë vetëm llojet e mëposhtme të elementeve:
emrat e kolonave;
funksionet e grumbullimit;
konstante;
Shprehje që përfshijnë kombinime të elementeve të mësipërm.
Të gjithë emrat e kolonave në listën SELECT duhet të shfaqen gjithashtu në klauzolën GROUP BY, përveç nëse emri i kolonës përdoret vetëm në një funksion agregat. Deklarata e kundërt nuk është gjithmonë e vërtetë - klauzola GROUP BY mund të përmbajë emra kolonash që nuk janë në listën SELECT. Nëse klauzola WHERE përdoret së bashku me klauzolën GROUP BY, atëherë ajo përpunohet së pari dhe grupohen vetëm ato rreshta që plotësojnë kushtin e kërkimit. Standardi ISO specifikon që kur kryhet grupimi, të gjitha vlerat që mungojnë trajtohen si të barabarta. Nëse dy rreshtat e tabelës në të njëjtën kolonë grupimi përmbajnë vlera NULL dhe vlera identike në të gjitha kolonat e tjera të grupimit jo bosh, ato vendosen në të njëjtin grup.
Shembulli 17: Përdorimi i klauzolës GROUP BY.Përcaktoni numrin e punonjësve që punojnë në secilin prej departamenteve të kompanisë, si dhe pagat e tyre totale.
ZGJIDHdegët Jo, COUNT(nr personeli) AS numëro, SHUMË(paga) AS shuma
NGAStafi
GRUP NGAdega Nr
URDHËR NGAdega nr;
Nuk është e nevojshme të përfshihen emrat e kolonave stafiNr dhe paga në listën GROUP BY, sepse ato shfaqen vetëm në listën SELECT me funksione të përmbledhura. Në të njëjtën kohë, kolona e degës Jo në listën e klauzolës SELECT nuk shoqërohet me asnjë funksion grumbullimi dhe, për këtë arsye, duhet të specifikohet në klauzolën GROUP BY. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 27.
Tabela 27
Rezultati i pyetjes
| dega Nr | Numëroni | shuma |
| B003 | 54000.00 | |
| B005 | 39000.00 | |
| B007 | 9000.00 |
Konceptualisht gjatë përpunimit të kësaj kërkese kryhen veprimet e mëposhtme.
1. Rreshtat e tabelës Stafi shpërndahen në grupe sipas vlerave në kolonën e numrit të degës së shoqërisë. Brenda secilit prej grupeve janë të dhëna për të gjithë personelin e një prej departamenteve të kompanisë. Në shembullin tonë, do të krijohen tre grupe, siç tregohet në fig. një.
2. Për secilin nga grupet, llogaritet numri total i rreshtave, i cili është i barabartë me numrin e punonjësve të departamentit, si dhe shuma e vlerave në kolonën e pagave, që është shuma e pagave të të gjithë departamentit. punonjës me interes për ne. Pastaj krijohet një rresht i vetëm përmbledhës për të gjithë grupin e rreshtave burimor.
3. Rreshtat e marra të tabelës që rezulton renditen në rend rritës të numrit të degës të specifikuar në kolonën degaNo.
| dega Nr | stafi nr | Paga |
| B00Z | SG37 | 12000.00 |
| B00Z | SG14 | 18000.00 |
| B00Z | SG5 | 24000.00 |
| B005 | SL21 | 30000.00 |
| B005 | SL41 | 9000.00 |
| B007 | SA9 | 9000.00 |
| COUNT (nr personel) | SUM (paga) |
| 54000.00 | |
| 39000.00 | |
| 9000.00 |
Oriz. 1. Tre grupe regjistrimesh të krijuara gjatë ekzekutimit të një pyetësori
Standardi SQL lejon që pyetjet e nënshtruara të vendosen në listën e përzgjedhjes SELECT. Prandaj, pyetja e mësipërme mund të përfaqësohet si më poshtë:
ZGJIDHJo dega, (ZGJIDH COUNT (Nr. stafi)AS numëroj
NGAstafi s
KUs.branchNo = b.branchNo),
(ZGJIDH SHUMËN(rrogën) AS shumë
NGAstafi s
KUs.branchNo = b.branchNo)
NGAdega b
URDHËR NGAdega nr;
Por në këtë version të pyetjes, për secilën nga degët e kompanisë të përshkruara në tabelën e Degës, gjenerohen dy rezultate të llogaritjes së funksioneve të grumbullimit, kështu që në disa raste mund të shfaqen rreshta që përmbajnë vlera zero.
Kufizimet e grupimit (HAVING construct). Klauzola HAVING synohet të përdoret në lidhje me klauzolën GROUP BY për të specifikuar kufizimet për të zgjedhur ato grupe, i cili do të vendoset në tabelën e pyetësorit që rezulton. Megjithëse klauzolat HAVING dhe WHERE kanë sintaksë të ngjashme, qëllimi i tyre është i ndryshëm. Klauzola WHERE është krijuar për të zgjedhur rreshta individualë që synojnë të plotësojnë tabelën e pyetjeve që rezulton dhe konstrukti HAVING përdoret për të zgjedhur grupe, vendosur në tabelën e pyetjeve që rezulton. Standardi ISO kërkon që emrat e kolonave të përdorura në klauzolën HAVING duhet të jenë të pranishëm në listën e elementeve GROUP BY ose të përdoren në funksionet agregate. Në praktikë, kushtet e kërkimit në një klauzolë HAVING përfshijnë gjithmonë të paktën një funksion grumbullimi; përndryshe, këto terma kërkimi duhet të vendosen në një klauzolë WHERE dhe të aplikohen për të zgjedhur rreshta individualë. (Mos harroni se funksionet e përgjithshme nuk mund të përdoren në një klauzolë WHERE.) Klauzola HAVING nuk është një pjesë e nevojshme e gjuhës SQL - çdo pyetje e shkruar duke përdorur klauzolën HAVING mund të përfaqësohet ndryshe pa e përdorur atë.
Shembulli 18: Përdorimi i konstruksionit HAVING.Për çdo degë të shoqërisë me më shumë se një punonjës, përcaktoni numrin e punonjësve dhe masën e pagave të tyre.
ZGJIDHdegët Jo, KONTI T (nr personeli) AS numëro, SHUMË(paga) AS shuma
NGAStafi
GRUP NGAdega Nr
DUKE NUMËRIM(Nr stafi) > 1
URDHËR NGAdega nr;
Ky shembull është i ngjashëm me atë të mëparshëm, por përdor kufizime shtesë për të treguar se ne jemi të interesuar vetëm për informacione për ato departamente të kompanisë që punësojnë më shumë se një person. Një kërkesë e ngjashme vlen për grupet, kështu që pyetja duhet të përdorë konstruktin HAVING. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 28.
Tabela 28
| dega Nuk ka shumë shumë |
| В00З 3 54000,00 |
| B005 2 39000,00 |
Nënpyetje. Në këtë seksion, ne do të diskutojmë përdorimin e deklaratave të plota SELECT të ngulitura në trupin e një deklarate tjetër SELECT. E jashtme Deklarata (e dyta) SELECT përdor rezultatin e ekzekutimit e brendshme(së pari) deklaratë për të përcaktuar përmbajtjen e rezultatit përfundimtar të të gjithë operacionit. Pyetjet e brendshme mund të jenë në klauzolat WHERE dhe HAVING të deklaratës së jashtme SELECT, me ç'rast ato quhen nënpyetje ose pyetjet e mbivendosura. Gjithashtu, deklaratat e brendshme SELECT mund të përdoren në deklaratat INSERT, UPDATE dhe DELETE . Ekzistojnë tre lloje të nënpyetjeve.
Nënpyetje skalar kthen një vlerë të zgjedhur nga kryqëzimi i një kolone me një rresht, d.m.th. vlerë e vetme. Në parim, një nënpyetje skalare mund të përdoret kudo ku kërkohet një vlerë e vetme. Variantet e nënpyetjeve skalare janë paraqitur në shembujt 13 dhe 14.
Nënpyetje e vargut kthen vlerat e kolonave të shumta të një tabele, por si një rresht i vetëm. Një nënpyetje e vargut mund të përdoret kudo ku përdoret një konstruktor i vlerës së vargut - zakonisht kallëzues. Një variant i nënpyetjes së vargut është paraqitur në shembullin 15.
Nënpyetje e tabelës kthen vlerat e një ose më shumë kolonave të një tabele që përfshin më shumë se një rresht. Një nënpyetje e tabelës mund të përdoret kudo ku lejohet një tabelë, si p.sh. si një operand i një kallëzuesi IN.
Shembulli 19: Përdorimi i një nënpyetjeje me një test barazie. Make up një listë e personelit që punon në degën e kompanisë, që ndodhet në 463 Main St1.
ZGJIDH
NGAStafi
KUNumri i degës = (ZGJIDHni degën nr
NGAdegë
KUrruga = "163 Main S t ");
Deklarata e brendshme SELECT (SELECT dega No FROM Branch ...) është krijuar për të përcaktuar numrin e degës së kompanisë që ndodhet në "Rr. Main 163". (Ekziston vetëm një degë e tillë, kështu që ky shembull është një shembull i një nënpyetjeje skalare.) Pas marrjes së numrit të degës së dëshiruar, nënpyetja e jashtme ekzekutohet për të zgjedhur detajet për punonjësit e këtij departamenti. Me fjale te tjera, operator i brendshëm SELECT kthen një tabelë të përbërë nga vlera e vetme "BOOV". Ky është numri i degës së kompanisë që ndodhet në "163 Main St1. Si rezultat, deklarata e jashtme SELECT bëhet:
ZGJIDHstafiNr, fEmri, INEmri, pozicioni
NGAStafi
KUdega No = "B0031;
Rezultatet e këtij pyetësori janë paraqitur në tabelë. 29.
Tabela 29
Rezultati i pyetjes
| stafi nr | fEmri | INEmri | pozicion |
| SG37 | Ann | Ahu | Asistent |
| SG14 | Davidi | Ford | Mbikëqyrësi |
| SG5 | Susan | markë | menaxher |
Një subquery është një mjet për krijimin e një tabele të përkohshme, përmbajtja e së cilës merret dhe përpunohet nga një deklaratë e jashtme. Nënpyetja, mund të specifikohet direkt pas operatorëve të krahasimit (d.m.th. operatorët =,<, >, <=, >=, <>) në një klauzolë WHERE ose HAVING. Teksti i nënpyetjes duhet të vendoset në kllapa.
Shembulli 20. Përdorimi i nënpyetjeve me funksione agregate. Bëni një listë të të gjithë punonjësve që paguhen mbi mesataren, duke treguar se sa paga e tyre tejkalon pagën mesatare në ndërmarrje.
ZGJIDHstafiNr, fEmri, IName, pozicioni, paga - ( ZGJIDHNI AVG(paga) NGA stafi) AS salDiff
NGAStafi
KUpaga > ( ZGJIDHNI AVG(paga) NGA S t a f f) ;
Duhet të theksohet se nuk mundet drejtpërdrejt përfshijnë në shprehje pyetëse"WHERE paga > AVG(paga)", që nga përdorimi i agregimit funksionet në klauzolën WHERE nuk lejohen. Për të arritur rezultatin e dëshiruar, duhet të krijoni një nën-pyetës që llogarit pagën mesatare vjetore dhe më pas ta përdorni në një deklaratë të jashtme SELECT për të zgjedhur informacionin për ata punonjës në kompani, paga e të cilëve e kalon këtë mesatare. Me fjalë të tjera, nënpyetja kthen pagën mesatare të kompanisë në vit, e cila është 17,000 £.
Rezultati i ekzekutimit të këtij nënpyetje skalar përdoret në deklaratën e jashtme SELECT si për të llogaritur devijimin e pagave nga mesatarja ashtu edhe për të zgjedhur informacionin e punonjësve. Pra, deklarata e jashtme SELECT bëhet:
ZGJIDHpersoneli nr, emri, emri, pozicioni, paga - 17000 Si salDiff
NGAStafi
KUpaga > 17000;
Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. tridhjetë.
Tabela 30
Rezultati i pyetjes
| stafi nr | fEmri | INEmri | pozicion | salDiff |
| SL21 | Gjoni | E bardha | menaxher | 13000.00 |
| SG14 | Davidi | Ford | Mbikëqyrësi | 1000.00 |
| SG5 | Susan | markë | menaxher | 7000.00 |
Zbatohen pyetjet e nënshtruara duke ndjekur rregullat dhe kufizimet.
1. Nënpyetjet nuk duhet të përdorin klauzolën ORDER BY, megjithëse mund të jetë e pranishme në deklaratën e jashtme SELECT.
2. Lista SELECT e nënpyetës duhet të përbëhet nga emra individualë të kolonave ose shprehje të përbëra prej tyre, përveç rasteve kur pyetësori përdor fjalën kyçe EXISTS.
3. Si parazgjedhje, emrat e kolonave në nënpyetës i referohen tabelës emri i së cilës është specifikuar në klauzolën FROM të nënpyetjes. Sidoqoftë, lejohet gjithashtu t'i referohet kolonave të tabelës të specifikuara në klauzolën FROM të pyetjes së jashtme duke përdorur emrat e kolonave të kualifikuara (siç përshkruhet më poshtë).
4. Nëse nënpyetja është një nga dy operandët e përfshirë në operacionin e krahasimit, atëherë nënpyetja duhet të specifikohet në anën e djathtë të këtij operacioni. Për shembull, shënimi i pyetjes nga shembulli i mëparshëm më poshtë është i pasaktë sepse nënpyetja vendoset në anën e majtë të operacionit të krahasimit kundrejt vlerës së kolonës së pagës.
ZGJIDH
NGAStafi
KU(ZGJIDH AVG (paga) NGA Stafi)< salary;
Shembulli 21. Nënpyetjet e mbivendosura dhe përdorimi i kallëzuesit IN. Bëni një listë të pronave me qira për të cilat punonjësit e degës së kompanisë që ndodhet në “163 Main r1.
ZGJIDHproneNr, rruge, qytet, kod postar, tip, dhoma, qera
NGAprone perrent
Kapitulli 5. Gjuha SQL: Manipulimi i të dhënave 189
KUstafi Jo IN (ZGJIDHni personelin nr
NGAStafi
KUbrancliNo = (ZGJIDH degën nr
NGAdegë
KUrrugë = "Rr. 163 Main")) ;
Pyetja e parë, më e brendshme, është krijuar për të përcaktuar numrin e degës së kompanisë që ndodhet në Rrugën kryesore 463. Pyetja e dytë, e ndërmjetme, zgjedh informacione për personelin që punon në këtë degë. Në këtë rast, më shumë se një rresht të dhënat zgjidhen dhe për këtë arsye nuk mund të përdorni operatorin e krahasimit =. Në vend të kësaj, duhet të përdorni fjalën kyçe IN. Pyetja e jashtme zgjedh informacionin për objektet e dhëna me qira, për të cilat janë përgjegjës punonjësit e kompanisë, të dhënat për të cilat janë marrë si një rezultati i pyetjes së ndërmjetme. Rezultatet e pyetjes janë paraqitur në tabelën 31.
Tabela 31
Rezultati i pyetjes
| pasuria nr | rrugë | qytet | kod postar | lloji | dhomat | qira |
| PG16 | 5 Novar Dr | Glasgow | G129AX | E sheshtë | ||
| PG36 | 2 Manor Road | Glasgow | G324QX | E sheshtë | ||
| PG21 | 18 Rruga Dale | Glasgow | G12 | shtëpi |
Fjalë kyçe ANY dhe ALL. Fjalë kyçe ANY dhe ALL mund të përdoren me nënpyetje që kthejnë një kolonë të vetme numrash. Nëse nënpyetja paraprihet nga fjala kyçe ALL, kushti i krahasimit konsiderohet i vërtetë vetëm nëse është i vërtetë për të gjitha vlerat në kolonën e rezultateve të nënpyetjes. Nëse teksti i nënpyetjes paraprihet nga Fjala kyçe ANY, atëherë kushti i krahasimit do të konsiderohet i përmbushur nëse plotësohet për të paktën një (një ose më shumë) vlera në kolonën e nënpyetjes që rezulton. Nëse nënkërkesa rezulton në vlerë boshe, më pas për fjalën kyçe ALL kushti i krahasimit do të konsiderohet i përmbushur dhe për fjalën kyçe ANY do të konsiderohet i dështuar. Sipas standardit ISO, mund të përdorni edhe fjalën kyçe SOME, e cila është sinonim për fjalën kyçe ANY.
Shembulli 22. Përdorimi i fjalëve kyçe ANY dhe SOME. Gjeni të gjithë punonjësit, paga e të cilëve e tejkalon të paktën pagën një një punonjës i një dege të shoqërisë me numrin "booz".
ZGJIDHstafiNr, fEmri, INEmri, pozicioni, paga
NGAStafi
KUpaga > SOME(ZGJIDH rrogën
NGAStafi
KUbranchNo = "B003");
Megjithëse kjo pyetje mund të shkruhet duke përdorur një nënpyetje që specifikon pagën minimale për stafin e departamentit me numër "WHO", pas së cilës pyetësori i jashtëm mund të zgjedhë informacione për të gjithë stafin e kompanisë, paga e të cilëve e kalon këtë vlerë (shih shembullin 20). është e mundur një qasje tjetër, e cila konsiston në përdorimin e fjalëve kyçe SOME/ANY. Në këtë rast, nënpyetja e brendshme gjeneron një grup vlerash (12000, 18000, 24000) dhe pyetja e jashtme zgjedh detajet e atyre punëtorëve, paga e të cilëve është më e madhe se çdo vlerë në këtë.
vendosur (në fakt, më shumë se vlera minimale - 12000). si metodë alternative mund të konsiderohet më e natyrshme sesa përcaktimi i pagës minimale në nënpyetje. Por në të dyja rastet, ato prodhojnë të njëjtat rezultate ekzekutimi i kërkesës, të cilat janë paraqitur në tabelë. 32 .
Tabela 32
Rezultati i pyetjes
| stafi nr | fEmri | INEmri | pozicion | paga |
| SL21 | Gjoni | E bardha | menaxher | 30000.00 |
| SG14 | Davidi | Ford | Mbikëqyrësi | 18000.00 |
| SG5 | Susan | markë | menaxher | 24000.00 |
Shembulli 23. Duke përdorur fjalën kyçe ALL. Gjeni të gjithë punonjësit pagat e të cilëve janë më të mëdha se pagat e çdo punonjësi në degën e kompanisë me numrin "booz".
ZGJIDHstafiNr, fEmri, INarae, pozicioni, paga
NGAStafi
KUpaga > TE GJITHA(ZGJIDH rrogën
NGAStafi
KUdega No = "BOG3");
Në përgjithësi, kjo pyetje është e ngjashme me atë të mëparshme. Dhe në këtë rast, do të ishte e mundur të përdoret një nënpyetje që përcakton vlerën maksimale të pagës së stafit të departamentit nën numrin "BOOS", dhe më pas të përdoret një pyetje e jashtme për të zgjedhur informacione për të gjithë punonjësit e kompanisë, të cilëve paga e kalon këtë vlerë. Megjithatë, në ky shembull zgjidhet qasja që përdor fjalën kyçe ALL. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 33 .
Tabela 33
Rezultati i pyetjes
| stafi nr | INEmri | fEmri | pozicion | paga |
| SL21 | E bardha | Gjoni | menaxher | 30000,00 |
Pyetje me shumë tabela. Të gjithë shembujt e diskutuar më sipër kanë të njëjtin kufizim të rëndësishëm: kolonat e vendosura në tabelën që rezulton zgjidhen gjithmonë nga një tabelë e vetme. Megjithatë, në shumë raste kjo nuk mjafton. Për të bashkuar kolonat nga disa tabela burimore në tabelën që rezulton, duhet të kryeni operacionin lidhjet. Në SQL, operacioni bashkim përdoret për të kombinuar informacionin nga dy tabela duke formuar çifte rreshtash të lidhur të zgjedhur nga secila tabelë. Çiftet e rreshtave të vendosura në tabelën e kombinuar përbëhen nga barazia e vlerave të kolonave të specifikuara të përfshira në to.
Nëse keni nevojë të merrni informacion nga tabela të shumta, mund të përdorni ose një nënpyetje ose të bashkoni tabelat. Nëse tabela e pyetjeve që rezulton duhet të përmbajë kolona nga tabela të ndryshme burimore, atëherë këshillohet të përdorni mekanizmin e bashkimit të tabelës. Për të kryer një bashkim, mjafton të specifikoni emrat e dy ose më shumë tabelave në klauzolën FROM, duke i ndarë ato me presje, dhe më pas të përfshini klauzolën WHERE në pyetës me përkufizimin e kolonave të përdorura për bashkimin e tabelave të specifikuara. Përveç kësaj, në vend të emrave të tabelave, mund të përdorni pseudonimet, i caktuar atyre në konstruktin FROM. Në këtë rast, emrat e tabelave dhe pseudonimet që u janë caktuar duhet të ndahen me hapësira. Pseudonimet mund të përdoren për të kualifikuar emrat e kolonave sa herë që ka paqartësi se cilës tabelë i përket një kolonë. Përveç kësaj, pseudonimet mund të përdoren për të shkurtuar emrat e tabelave. Nëse një pseudonim përcaktohet për një tabelë, ai mund të përdoret kudo që kërkohet emri i asaj tabele.
Shembulli 24. Lidhje e thjeshtë. Bëni një listë me emrat e të gjithë klientëve që kanë parë tashmë të paktën një pronë me qira dhe kanë dhënë mendimin e tyre për këtë çështje.
ZGJIDHc.ClientNo, fEmri, IName, pronaNo, koment
NGAKlienti c, Shikimi v
KUc.No Client = v.KlientNo;
Ky raport duhet të paraqesë informacion si nga tabela e Klientit ashtu edhe nga tabela e Shikimit, kështu që kur ndërtojmë një pyetje, ne do të përdorim mekanizmin e bashkimit të tabelës. Konstrukti SELECT liston të gjitha kolonat që duhet të vendosen në tabelën e rezultateve të pyetjes. Vini re se kolona e numrit të klientit (klientNo) duhet të kualifikohet, pasi një kolonë e tillë mund të jetë e pranishme edhe në një tabelë tjetër që merr pjesë në bashkim. Prandaj, është e nevojshme të tregojmë në mënyrë eksplicite se cilat vlera të tabelës na interesojnë. (Në këtë shembull, ju gjithashtu mund të keni zgjedhur vlerat e kolonës së klientit Jo nga tabela e shikimit). Kualifikimi i emrit kryhet duke prefiksuar emrin e kolonës me emrin e tabelës përkatëse (ose pseudonimin e saj). Në shembullin tonë, vlera "c" është specifikuar si një pseudonim për tabelën Klient. Për të formuar rreshtat që rezultojnë, përdoren ato rreshta të tabelave burimore që kanë një vlerë identike në kolonën klientNo. Ky kusht përcaktohet duke specifikuar kushtin e kërkimit c.clientNo=v.clientNo. Quhen kolona të ngjashme të tabelave burimore kolona që përputhen. Operacioni i përshkruar është i barabartë me operacionin bashkohet me barazi algjebër relacionale. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 34.
Tabela 34
Rezultati i pyetjes
| klienti nr | fEmri | INEmri | pasuria nr | koment |
| CR56 | Aline | Stewart | PG36 | |
| CR56 | Aline | Stewart | PA14 | shumë e vogël |
| CR56 | Aline | Stewart | PG4 | |
| CR62 | Maria | Tregear | PA14 | nuk ka dhomë ngrënie |
| CR76 | Gjoni | Kay | PG4 | shumë i largët |
Më shpesh, pyetjet me shumë tabela kryhen në dy tabela të lidhura nga një marrëdhënie një me shumë (1:*) ose një marrëdhënie prind-fëmijë. Në shembullin e mësipërm, i cili përfshin aksesin në tabelat Klienti dhe Shikimi, këto të fundit janë të lidhura pikërisht nga një marrëdhënie e tillë. Çdo rresht i tabelës së shikimit (fëmijë) shoqërohet vetëm me një rresht të tabelës Klient (prind), ndërsa i njëjti rresht i tabelës së Klientit (prindi) mund të shoqërohet.
me shumë rreshta të tabelës Shikim (fëmijë). Çiftet e rreshtave që krijohen kur ekzekutohet një pyetje janë rezultat i të gjitha kombinimeve të vlefshme të rreshtave në tabelat fëmijë dhe prind. Seksioni 3.2.5 detajon se si baza e të dhënave relacionale të dhënat, çelësat primar dhe të huaj të tabelave krijojnë një marrëdhënie "prind-fëmijë". Një tabelë që përmban një çelës të huaj është zakonisht një fëmijë, ndërsa një tabelë që përmban një çelës kryesor do të jetë gjithmonë një prind. Për të përdorur një marrëdhënie prind-fëmijë në një pyetje SQL, duhet të specifikoni një kusht kërkimi që krahason çelësat e huaj dhe kryesorë. Shembulli 24 krahason çelësin primar të tabelës Klienti (v. KlientNo) me çelësin e huaj të tabelës Shikim (v. Klienti No).
Standardi SQL ofron gjithashtu mënyrat e mëposhtme për të përcaktuar kjo lidhje:
NGAKlient me BASHKOHU Shikimi v AKTIV c.Nr i klientit = v.Nr i klientit
NGAKlienti J OIN Duke parë PËRDORIMI klienti nr
NGAklient BASHKIMI NATYROR Duke parë
Në secilin rast, klauzola FROM zëvendëson klauzolat origjinale FROM dhe WHERE. Megjithatë, në rastin e parë, krijohet një tabelë me dy kolona identike klientNo, ndërsa në dy rastet e tjera, tabela që rezulton do të përmbajë vetëm një kolonë klientNo.
Shembulli 25. Rendit rezultatet e bashkimit të tabelës. Për çdo degë të kompanisë, listoni numrat e personelit dhe emrat e punonjësve që janë përgjegjës për çdo objekt të dhënë me qira dhe listoni objektet për
të cilave ata përgjigjen.
ZGJIDHs.degaNo, s.staffNo, fEmri, IName, pasuriaNr
NGAStafi s, PronëPër Qira f
KUs.staffNo = p.staffNo
URDHËR NGAs.DegaNr, s.staffNr, pasuria nr;
Për t'i bërë rezultatet më të lehta për t'u lexuar, rezultati renditet duke përdorur numrin e departamentit si çelës kryesor të renditjes dhe numrin e personelit dhe numrin e pronës si çelësa të vegjël. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 35.
Tabela 35
Rezultati i pyetjes
| dega Nr | Stafi Nr | fEmri | INEmri | pasuria nr |
| OBSH | SG14 | Davidi | Ford | PG16 |
| OBSH | SG37 | Ann | Ahu | PG21 |
| OBSH | SG37 | Ann | Ahu | PG36 |
| BOO5 | SL41 | Maria | Lee | PL94 |
| SBI7 | SA9 | Julie | si | PA14 |
Shembulli 26. Bashkimi i tre tavolinave. Për çdo degë të shoqërisë, listoni numrat e personelit dhe emrat e punonjësve përgjegjës për çdo objekt të dhënë me qira, duke përfshirë qytetin në të cilin ndodhet dega, dhe numrat e objekteve për të cilat çdo punonjës është përgjegjës.
ZGJIDH b.degaNr, b.qytet, s.staffNr, fEmri, IName, nr. pasurie
NGA Dega b, Stafi s, PronaMe Qira fq
KU b.branchNo = s.branchNo DHE s.staffNo = p.staffNo
URDHËR NGA b.Nr. i degës, s.Nr. i personelit, nr.
Tabela që rezulton duhet të përmbajë kolona nga tre tabelat burimore - Branch, Staff dhe PropertyForRent - kështu që pyetja duhet t'i bashkojë këto tabela. Tabelat e Degës dhe Stafit mund të bashkohen duke përdorur kushtin b.branchNo=*s .branchNo, i cili do të lidhë degët e kompanisë me stafin që punon në to. Tabelat Staff dhe PropertyForRent mund të bashkohen duke përdorur kushtin s.staffNo=p.staffNo. Si rezultat, çdo punëtor do të shoqërohet me ato objekte të dhëna me qira për të cilat ai është përgjegjës. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 36.
Tabela 36
Rezultatet e pyetjes
| dega Nr | qytet | stafiMo | fEmri | INEmri | pasuria nr |
| B003 | Glasgow | SG14 | Davidi | Ford | PG16 |
| B003 | Glasgow | SG37 | Ann | Ahu | PG21 |
| B003 | Glasgow | SG37 | Ann | Ahu | PG36 |
| B005 | Londra | SL41 | Julie | Lee | PL94 |
| B007 | Aberdeen | SA9 | Maria | si | PA14 |
Vini re se standardi SQL lejon një formulim alternativ të klauzolave FROM dhe WHERE:
NGA(Dega b BASHKOHU STAFI SHFRYTËZIM Nr dega) AS bs
BASHKOHUPronëPër Qira f PËRDORIMI stafi nr
Shembulli 27. Grupimi sipas kolonave të shumta. Përcaktoni numrin e objekteve të dhëna me qira për të cilat është përgjegjës secili punonjës i shoqërisë.
ZGJIDHs.dega nr, S.staffNo, COUNT(*) AS numëroj
NGA Stafi s, PronaPër Qira f
KU S.staffNo = p.staffNo
GRUP NGAs.degaJo, s.stafNr
URDHËR NGAs.degaNo, s.staffNo;
Për të hartuar raportin e kërkuar, para së gjithash, është e nevojshme të zbulohet se cili nga punonjësit e kompanisë është përgjegjës për objektet e dhëna me qira. Ky problem mund të zgjidhet duke bashkuar tabelat Staff dhe PropertyForRent në kolonën staffNo në klauzolat FROM/WHERE. Më pas është e nevojshme të formohen grupe të përbëra nga numri i degës dhe numri i personelit të punonjësve të saj, për të cilët duhet të përdoret ndërtimi GROUP BY. Së fundi, tabela që rezulton duhet të renditet duke përdorur klauzolën ORDER BY. Rezultatet e ekzekutimit të pyetjes janë paraqitur në tabelë. 37.
Tabela 37
Rezultati i pyetjes
| dega Nr | stafi nr | numëroj |
| B00Z | SG14 | |
| B00Z | SG37 | |
| B005 | SL41 | |
| B007 | SA9 |
Krijimi i lidhjeve. Një bashkim është një nëngrup i një kombinimi më të përgjithshëm të të dhënave nga dy tabela të quajtura karteziane. Prodhimi kartezian i dy tabelave është një tabelë tjetër e përbërë nga të gjitha çiftet e mundshme të rreshtave që janë pjesë e të dy tabelave. Grupi i kolonave të tabelës që rezulton është të gjitha kolonat e tabelës së parë të ndjekura nga të gjitha kolonat e tabelës së dytë. Nëse futni një pyetje në dy tabela pa specifikuar një klauzolë WHERE, rezultati i pyetjes në mjedisin SQL do të jetë produkti kartezian i këtyre tabelave. Për më tepër, standardi ISO ofron një format të veçantë për deklaratën SELECT që ju lejon të llogaritni produktin kartezian të dy tabelave:
SELECT(* j lista e kolonave]
NGA tabelaEmri KRYQ JOINCayeUlte2
Konsideroni përsëri një shembull në të cilin lidhja e klientit dhe tabelave të shikimit kryhet duke përdorur kolonën e përbashkët klient nr. Kur punoni me tabela, përmbajtja e të cilave është dhënë në tabelë. 3.6 dhe 3.8, prodhimi kartezian i këtyre tabelave do të ketë 20 rreshta (4 rreshta të tabelës Klienti x 5 rreshta të tabelës së shikimit = 20 rreshta). Kjo është e barabartë me lëshimin e pyetjes së përdorur në Shembullin 5-24, por pa klauzolën WHERE. Procedura për gjenerimin e një tabele që përmban rezultatet e bashkimit të dy tabelave duke përdorur deklaratën SELECT është si më poshtë.
1. Formohet prodhimi kartezian i tabelave të specifikuara në konstruktin FROM.
2. Nëse pyetja përmban një klauzolë WHERE, zbatoni kushtet e kërkimit për çdo rresht të tabelës së produkteve karteziane dhe ruani vetëm ato rreshta në tabelë që plotësojnë kushtet e dhëna. Në aspektin e algjebrës relacionale, ky operacion quhet kufizim produkt kartezian.
3. Për çdo rresht të mbetur, përcaktohet vlera e secilit element të specifikuar në listën SELECT, duke rezultuar në një rresht të veçantë të tabelës që rezulton.
4. Nëse konstrukti SELECT DISTINCT është i pranishëm në pyetjen origjinale, të gjitha rreshtat dublikatë hiqen nga tabela që rezulton.
5. Nëse pyetja që po ekzekutohet përmban një klauzolë ORDER BY,
©2015-2019 faqe
Të gjitha të drejtat u përkasin autorëve të tyre. Kjo faqe nuk pretendon autorësinë, por ofron përdorim falas.
Data e krijimit të faqes: 2016-08-07