Programimi funksional në Haskell
Pjesa 1. Hyrje
Seria e përmbajtjes:
Programim imperativ
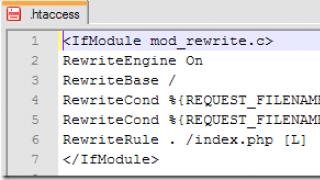
Më e zakonshme gjuhët urdhërore, në të cilën llogaritja reduktohet në zbatimi konsistent udhëzimet. Zgjidhja e një problemi në një gjuhë imperative zbret në përshkrimin e asaj që duhet bërë për të marrë rezultatin. Shembuj klasikë janë FORTRAN (1957), ALGOL (1958) dhe C (1972).
Gjuhët imperative janë afër arkitekturës së von Neumann. Në to, një pjesë e konsiderueshme e kodit është e zënë nga caktimi i vlerave në variabla.
Variablat konsiderohen si qeliza të kujtesës që ndryshojnë në kohë. Vlerat aktuale të variablave në program formojnë një gjendje në ndryshim.
Një shembull i kodit imperativ është një procedurë për llogaritjen e faktorialit në C:
int fac (int n) (int x = 1; ndërsa (n> 0) (x = x * n; n = n-1;) kthen x;)Këtu, përsëritja e operacionit të shumëzimit shprehet përmes një cikli. Gjatë llogaritjes ndryshojnë vlerat e variablave x dhe n.
Inicializimi: n: = 3; x: = 1; Përsëritja e parë e ciklit: x: = 1 * 3 = 3; n: = 3-1 = 2; Përsëritja e dytë e ciklit: x: = 3 * 2 = 6; n: = 2 - 1 = 1; Cikli i tretë i ciklit: x: = 6 * 1 = 6; n: = 1 - 1 = 0; Rezultati - 6Gjuhët funksionale i referohet deklarative- në to, programi formulon me saktësi rezultatin e kërkuar të llogaritjes për sa i përket varësive të funksioneve nga njëri-tjetri, dhe detajet e llogaritjes (për shembull, si saktësisht duhet të vendosen vlerat në memorie dhe të dërgohen) bien në supet e zbatimit të gjuhës.
Karakteristikat dhe funksionaliteti
Në kuptimin matematikor funksionin f: X → Y është një rregull që cakton një element x nga bashkësia X ( zonave) një element y = f x nga bashkësia Y ( bashkërajonet).

Është e rëndësishme që funksioni të përcaktohet saktë, domethënë të mos ketë paqartësi për vlerën e tij për secilin argument.
Nëse vlerat janë të përcaktuara për të gjithë elementët e rajonit, atëherë funksioni quhet i përcaktuar në mënyrë universale; përndryshe quhet i pjesshëm.
Ashtu si në matematikë, në gjuhët funksionale me interes për ne, nuk ka qeliza që ruhen kuptime të ndryshme... Variablat janë vetëm emrat e vlerave.
Zakonisht për të përcaktuar një funksion në gjuha funksionale përdoren ekuacione. Për shembull,
fac 0 = 1 fac n = n * fac (n-1)n - argument formal funksionet fa. Në të djathtë pas shenjës =, përshkruhet, çfarë funksioni bën me argumentin e tij. Funksionet bazë për shumëzim dhe zbritje shkruhen duke përdorur operatorët infiks (të specifikuar midis argumenteve) * dhe -.
Këtu ka dy ekuacione. Gjatë llogaritjes së një funksioni, ekuacionet shikohen sipas renditjes. Nëse n = 0, atëherë do të përdoret ekuacioni i parë. Nëse n ≠ 0, atëherë nuk do të funksionojë, dhe përdoret e dyta.
Ju lutemi vini re: argumentet e funksionit janë renditur pranë emrit të tij, të ndara me një hapësirë. Kjo është e përshtatshme sepse përdorimi i një funksioni është shumë i zakonshëm në programet funksionale (Tabela 1).
| Të shkruarit në matematikë | Duke shkruar në Haskell |
|---|---|
| f (x) | f x |
| f (x, y) | f x y |
| f (g (x)) | f (g x) |
| f (g (x), h (y)) | f (g x) (h y) |
| f (x) + g (x) | f x + g x |
| f (x + y) | f (x + y) |
| f (-x) | f (-x) |
Tabela 1. Regjistrimi i zbatimit të një funksioni në matematikë dhe në Haskell
Ekuacionet për fac përbëjnë një përkufizim të saktë të një funksioni, jo një sekuencë hapash llogaritës, siç ishte rasti në kodin imperativ.
Përdoret rekursioni, d.m.th., fac përcaktohet përmes vetvetes. Ky përkufizim funksionon sepse fac shprehet në termat e rastit më të thjeshtë dhe, në fund (nëse n ≥ 0), arrin rastin bazë n = 0. Llogaritja e fac 3 sipas këtij përkufizimi mund të bëhet si më poshtë (shprehjet e thjeshtuara janë të nënvizuara në çdo hap):
fac 3 → 3 * fac 2 → 3 * (2 * fac 1) → 3 * (2 * (1 * fac 0)) → 3 * (2 * (1 * 1)) → 3 * (2 * 1) → 3 * 2 → 6Këtu kemi aplikuar f në vlerën 3. Për më tepër, 3 quhet argumenti aktual.
Qasja funksionale fokusohet në vlerësimin e shprehjeve dhe jo në ekzekutimin e komandave. Në fakt, një program funksional është një shprehje dhe ekzekutimi i tij korrespondon me vlerësimin e një shprehjeje.
Gjatë vlerësimit, ne rishkruajmë shprehjet duke zëvendësuar vlerat për variablat dhe duke aplikuar funksione derisa të merret rezultati përfundimtar.
Vini re se për n< 0 наше определение будет вычисляться бесконечно, поэтому наша функция является частичной (если ее областью считать все целые числа).
Tani shkruajmë një funksion që llogarit koeficientin binomial për numrin e plotë k dhe r real

Për k ≥ 0, kemi një shprehje ku emëruesi përmban faktorialin e sapopërcaktuar të numrit k, dhe numëruesi përmban fuqinë faktoriale në rënie
Le të shkruajmë një përkufizim rekurziv për të:
ffp r 0 = 1 ffp r k = (r-k + 1) * ffp r (k-1)Ekuacioni i parë nuk përdor r, kështu që mund të përdorni vendmbajtësin _ dhe të shkruani ffp _ 0 = 1.
Dikush mund të sigurohet që
(kontrolloje). Prandaj, ekuacionet faktoriale mund të zëvendësohen me
fac n = ffp n nPasi të kemi shkruar ekuacionet për funksionin ffp, mund të mendohet si një kuti e zezë abstrakte me dy hyrje dhe një dalje pa u shqetësuar se çfarë saktësisht po ndodh brenda. Gjithçka që është e rëndësishme për ne tani është shfaqja e saktë hyrjet në dalje.
Figura 2. Kutia e zezë që llogarit shkallën faktoriale në rënie

Le të marrim një kuti tjetër të zezë (/) me dy hyrje x dhe y dhe një dalje të barabartë me herësin x / y:
do të llogarisë skemën e mëposhtme:
Figura 3. Diagrami i kutitë e zeza duke llogaritur koeficientin binomial

Përputhet me shprehjen
ffp r k / fac kLe të përcaktojmë funksionin e kërkuar:
binc r k | k> = 0 = ffp r k / fac k | ndryshe = 0Një shënim i tillë quhet ekuacion me kushte (krahaso me shënimin matematikor të përkufizimit). Pas | dhe ka kushte përpara shenjës =. "Përndryshe" do të thotë "ndryshe". Kjo do të diskutohet në detaje në artikujt vijues.
Një shembull i llogaritjes së binc 6 2:
binc 6 2 → ffp 6 2 / fac 2 → (5 * ffp 6 1) / fac 2 → (5 * (6 * ffp r 0)) / fac 2 → (5 * (6 * 1)) / fac 2 → (5 * 6) / fac 2 → 30 / fac 2 → 30 / ffp 2 2 → 30 / (1 * ffp 2 1) → 30 / (1 * (2 * ffp r 0)) → 30 / (1 * ( 2 * 1)) → 30 / (1 * 2) → 30/2 → 15Kur lidhëm kutitë e zeza, supozuam se, së pari, ato gjithmonë japin të njëjtin rezultat për të njëjtat hyrje dhe, së dyti, nuk ndikojnë në funksionimin e kutive të tjera.
Ajo çon në koncept i rëndësishëm pastërti.
Pastërti
Kur telefononi procedurat në një gjuhë imperative, ne shpesh jo vetëm i kalojmë argumente dhe marrim rezultatin, por presim efekte anesore- diçka që nuk lidhet me përkthimin e argumenteve në një vlerë të kthimit (shfaqja e të dhënave në një skedar, ndryshimi i një ndryshoreje globale, etj.). Fatkeqësisht, efektet anësore shfaqen shpesh edhe kur nuk parashikohen.
Nëse një funksion ka efekte anësore, atëherë vlerësimi i tij me të njëjtat argumente në kontekste të ndryshme mund të prodhojë rezultate të ndryshme.
Nëse ka shumë efekte anësore, atëherë programimi bëhet më i ndërlikuar, shfaqen më shumë gabime në kod dhe korrektësia e tij bëhet e vështirë për t'u verifikuar si me mjete formale ashtu edhe joformale.
Këtu nuk e quajtëm procedurën funksion, sepse në prani të efekteve anësore, procedura nuk duket si një funksion në kuptimin matematikor (nganjëherë funksione të tilla quhen pastër).
Nëse nuk ka efekte anësore, atëherë shprehja gjithmonë mund të zëvendësohet me vlerën e saj, dhe programi do të funksionojë si më parë - kjo quhet transparencë në lidhje... E njëjta shprehje duhet të prodhojë të njëjtin rezultat kur vlerësohet në çdo kohë.
Çdo shprehje në një gjuhë funksionale korrespondon me kuptimin e saj; vlerësimi modifikon vetëm shprehjen, por nuk ndikon në vlerë.
Programimi pa efekte anësore mund të shihet tërësisht nga këndvështrimi i aplikimit të funksioneve në argumente.
Një gjuhë pa efekte anësore quhet thjesht funksionale.
Gjuhët si ML dhe Scheme janë përgjithësisht funksionale në stil, por lejojnë si detyra ashtu edhe efekte anësore.
Shembuj të gjuhëve thjesht funksionale janë Miranda, Haskell dhe Clean.
Në fillim mund të duket se një gjuhë thjesht funksionale është jopraktike, por kjo është larg nga rasti - për një programim të suksesshëm, thjesht duhet të njiheni me disa ide të thjeshta dhe elegante (dhe gjithashtu të harroni zakonet e vjetra).
Përtacia dhe përtacia
Kur një funksion thirret me vlerë, fillimisht llogariten argumentet e tij dhe më pas vlerat që rezultojnë kalohen në trupin e funksionit. Kur thirren sipas nevojës, argumentet kalohen të pallogaritura dhe vlerësohen në trupin e funksionit vetëm nëse nevojitet.
Kjo përafërsisht korrespondon me atë që gjuhët funksionale e quajnë vlerësim të etur dhe dembel. Në rastin energjik llogaritet gjithçka që është e mundur, dhe në rastin dembel gjithçka që nevojitet. (Ne do të shtyjmë një qasje formale për këtë çështje derisa të jetë e qartë se cili model llogaritjeje qëndron në themel të gjuhëve funksionale.)
Një funksion quhet strikt në një nga argumentet e tij nëse kërkon gjithmonë vlerën e tij për të marrë një rezultat. Nëse vlera nuk kërkohet gjithmonë, atëherë funksioni quhet lax për këtë argument.
Për shembull, funksioni ynë binc do të kërkojë gjithmonë k, por r kërkohet vetëm nëse k ≥ 0.
Në përputhje me këtë, flitet për gjuhë me semantikë të fortë dhe gjuhë me semantikë të dobët. ("Dembelia" dhe "dembelizmi" nuk janë të njëjta, por koncepte të afërta.)
Gjuha strikte vlerëson argumentet përpara se të thërrasë një funksion. Kështu, nëse vlerësimi i shprehjes e nuk përfundon (ajo qarkullon ose ndalon me gabim), atëherë nuk do të vlerësohet as përdorimi i funksionit f e.
Në një gjuhë të dobët, llogaritja bëhet sipas nevojës. Nëse f nuk është strikte, atëherë llogaritja e f e mund të përfundojë edhe nëse llogaritja e e jo.
Për shembull,
tregon një listë me tre elementë. Llogaritja e fac (-1) është e mbyllur. Kjo do të thotë që llogaritja e listës gjithashtu do të qarkullojë.
Tani lëreni gjatësinë e funksionit të kthejë gjatësinë e listës. Shprehje
gjatësianuk do të vlerësohet në një gjuhë strikte, por në një gjuhë jo strikte rezultati do të jetë 3, sepse vlerat e tyre nuk nevojiten për të numëruar elementët.
Shembuj të gjuhëve të dobëta janë Miranda dhe Haskell. Gjuhët strikte janë ML dhe Scheme.
Çështja e ashpërsisë është mjaft delikate dhe nuk mund të reduktohet në pyetjen e thjeshtë "Çfarë është më e përshtatshme dhe më efektive?" > Kalimi i llogaritjeve dembele në vend të vlerave gjatë një thirrjeje funksioni është i kushtueshëm. Në të njëjtën kohë, në shumë situata, dembelizmi ju lejon të kurseni në llogaritjet ose të shkruani shprehje që nuk do të vlerësoheshin ose do të vlerësoheshin pafundësisht në një gjuhë energjike.
Laksësia është një karakteristikë e pavarur e pastërtisë, megjithëse e ndihmon gjuhën në shumë mënyra të përmbahet nga efektet anësore.
Histori e shkurtër
Programimi funksional nxjerr ide nga logjika kombinuese dhe llogaritja lambda.
Disa nga gjuhët e para me një stil funksional ishin LISP (1958), APL (1964), ISWIM (1966) dhe (1977).
Nga fundi i viteve 1980, tashmë kishte shumë gjuhë funksionale. Ndër ato që kanë pasur një ndikim të rëndësishëm në Haskell:
- (1973) - gjuha e parë me shtypjen Hindley-Milner.
- SASL, KRC, Miranda (1972-1985) - disa nga gjuhët e para dembel.
- Hope (1980) është një nga gjuhët e para me lloje të të dhënave algjebrike. Haskell është zhvilluar nga një grup i madh studiuesish që nga viti 1987. Ai është emëruar pas Haskell Curry.

Detyra kryesore në të cilën u përqendrua dizajni - Haskell duhej të mblidhte zhvillimet e disponueshme në fushën e gjuhëve të dobëta thjesht funksionale.
Të reja në Haskell janë monadat dhe klasat e tipit. Pikat e tjera të forta të huazuara nga gjuhë të tjera janë currying, llojet e të dhënave algjebrike, përputhja e modeleve. (Ne thjesht po rendisim një grup fjalësh kyçe këtu; të gjitha këto koncepte do të shpjegohen së shpejti.)
Përshkrimi i fundit i dokumentuar është Haskell 98, por gjuha po zhvillohet vazhdimisht dhe po bëhet më komplekse; Haskell aktualisht është duke u planifikuar.
Haskell është bërë gjuha më e përhapur e dobët, thjesht funksionale. Shumë projekte komplekse janë zbatuar në Haskell:
- Përpiluesit dhe mjetet e tjera të zhvillimit.
- Sistemi i kontrollit të versionit të shpërndarë Darcs.
- Menaxheri i dritares xmonad.
- Serveri i aplikacionit në ueb HAppS.
- Përkthyesi / përpiluesi i Pugs për Perl 6.
- Sistemi operativ i shtëpisë.
- Përshkrimi i harduerit Gjuha Lava.
- Sistemi i përpunimit të gjuhës natyrore LOLITA.
- Sistemet e vërtetimit të teoremës Ekuinoks / Paradoks dhe Agda.
Burimet kryesore të informacionit mbi Haskell
Haskell ka një komunitet të gjerë dhe miqësor.
Burimi kryesor i informacionit është serveri haskell.org.
- [email i mbrojtur]- diskutim i lirë.
- [email i mbrojtur]- më shumë tema të thjeshta për fillestarët.
Ekziston një kanal shumë i gjallë #haskell IRC në irc.freenode.net. Ai ofron një përgjigje të shpejtë dhe të dobishme për pothuajse çdo pyetje.
Shumë blogje tematike janë mbledhur në http://planet.haskell.org/
- Një hyrje e butë në Haskell 98 është një hyrje e mirë për Haskell.
- Për dokumentacion të gjerë të bibliotekës, shihni http://haskell.org/ghc/docs/latest/html/libraries/
- Raporti zyrtar është Raporti Haskell 98.
Redaktimi dhe ekzekutimi i kodit
Implementimet Haskell
Formalisht, Haskell nuk ka një zbatim të vetëm "standard".
Për punë interaktive, përkthyesi i lehtë Hugs është i përshtatshëm.
Ka edhe projekt interesant Yhc përpilimi tekstet burimore në bytecode, dhe Helium është një version tutorial miqësor për fillestarët i Haskell (për shembull, ai prodhon mesazhe gabimi më të qarta). Megjithatë, ato janë ende në zhvillim e sipër.
Përpiluesi / interpretuesi GHC është bërë standardi de facto. Është më i avancuari, përputhet me standardin në gjithçka dhe ofron një sërë zgjerimesh eksperimentale. Ne do të përqendrohemi në të.
GHC mund të shkarkohet nga http://haskell.org/ghc/. Nëse jeni duke përdorur GNU / Linux, atëherë shikoni ndërtimet e parandërtuara në shpërndarjen tuaj. Binarët mund të gjenden gjithashtu për MacOS X dhe Windows. (Vini re se ndërtimi i GHC direkt nga burimi mund të jetë mjaft i lodhshëm.)
Ne do të jemi të interesuar kryesisht për programin interaktiv ghci, në të cilin është i përshtatshëm për të testuar shembuj trajnimi.
Pra, pas instalimit të GHC, mund të ekzekutoni ghci në terminal:
Këtu Prelude është emri i modulit të ngarkuar. Preludi përmban përkufizime bazë dhe është gjithmonë i aktivizuar si parazgjedhje. Duke studiuar ose rishkruar vetë kodin Prelude, fillestarët mund të mësojnë shumë. (Ti dhe unë pjesërisht do ta bëjmë këtë gjithashtu.)
Simboli> do të thotë që ghci pret hyrjen e përdoruesit. Këto mund të jenë shprehje Haskell, si dhe komanda për interpretuesin.
Tastet ← dhe → lëvizin kursorin rreth vijës së komandës ghci. dhe ↓ lëvizni historinë e komandës përpara dhe mbrapa.
Në vend të Prelude> ose emrave të tjerë të moduleve, ne do të vazhdojmë të shkruajmë ghci> (nëse dëshironi të bëni të njëjtën gjë, ekzekutoni komandën në ghci: vendosni prompt "ghci>").
Si fillim, ghci mund të përdoret si një kalkulator i avancuar:
ghci> 1 * 2 + 2 * 3 + 3 * 5 23 ghci> 23 ^ 23 ghci> gcd 3020199 1161615 232323Operatorët janë të njëjtë si në gjuhët e tjera (tabela 2).
Tabela 2. Operatorët aritmetikë nga Preludi
Ata përdorin shënimin infix dhe prioritetin përkatës. Për shembull, 2 * 3 + 4 përputhen (2 * 3) +4, dhe 2 ^ 3 ^ 4 - 2 ^ (3 ^ 4). Ju mund të vendosni kllapa për të ndryshuar përparësinë e pranuar.
Ghci ka një variabël të veçantë atë, e cila është e barabartë me vlerën e shprehjes së fundit të vlerësuar me sukses.
ghci> 15 - 2 13 ghci> it + 10 23Redaktimi i kodit burimor
Kodi burimor mund të modifikohet në të preferuarën tuaj redaktori i tekstit... Thënë kështu, është mirë të kesh nënvizim të sintaksës Haskell, si dhe mbështetje për shtrirjen e kodit (siç do ta shohim, ai luan një rol të veçantë në Haskell).
- Shtesa për Emacs: http://www.iro.umontreal.ca/~monnier/elisp/
- Shtesa për Vim: http://projects.haskell.org/haskellmode-vim/
Mjete të tjera zhvillimi përshkruhen në http://haskell.org/haskellwiki/Libraries_and_tools/Program_development
Zgjatja e skedarit Hs përdoret për kodin Haskell.
Nëse shkruani kodin Haskell në skedarin foo.hs, atëherë përkufizimet ngarkohen në ghci me komandën: load foo. Paralelisht, skedari mund të modifikohet dhe, nëse është e nevojshme, të rifreskohet përkufizimet duke përdorur: rifreskoni.
Drejtoria aktuale ndryshohet me komandën: cd (për shembull: cd / home / bob).
Ju mund të shkarkoni kodin burimor bashkangjitur artikullit dhe të vlerësoni shprehjet:
$ ghci ghci, versioni 6.10.3: http://www.haskell.org/ghc/:? për ndihmë Po ngarkohet paketa ghc-prim ... lidhja ... u krye. Po ngarkohet numri i plotë i paketës ... lidhja ... u krye. Duke ngarkuar bazën e paketës ... lidhja ... u krye. Preludi>: ngarkoni fph01.lhs Përpilimi kryesor (fph01.lhs, i interpretuar) Ok, modulet e ngarkuara: Kryesore. * Main> ffp 6 6 720 * Main> fac 6 720 * Main> binc 6 2 15.0 * Main> binc 6.5 4 23.4609375Këto dhe komanda të tjera mund të shkurtohen - në vend të: load use: l, në vend të: reload -: r, e kështu me radhë.
Lista e komandave të guaskës printon: ndihmë. Për të dalë nga ghci, shkruani: quit.
Gjatë prezantimit tonë, shpesh do të hasim shembuj të thjeshtë që përbëhen nga një ose dy ekuacione. Ato mund të injektohen direkt në ghci duke përdorur let:
ghci> le të dyfishohet x = 2 * x ghci> dyfish 23 46Nëse ka disa ekuacione, atëherë ato duhet të mbyllen në mbajtëse kaçurrelë dhe të ndahen me një pikëpresje (në një nga artikujt vijues do të shqyrtojmë në detaje një regjistrim të tillë).
ghci> let (fac 0 = 1; fac n = n * fac (n-1)) ghci> fac 23 25852016738884976640000konkluzioni
Ne ekzaminuam në skicë e përgjithshme veçoritë e qasjes funksionale, historia e Haskell, burimet kryesore të informacionit për gjuhën dhe softuerin që na nevojitet në të ardhmen. Në artikujt e mëposhtëm, ne do të shqyrtojmë llojet dhe sintaksën bazë të Haskell.
Programim funksional
në Haskell
Shënime leksioni
Rybinsk 2010
Prezantimi ................................................. ................................................ ................. 3
1 Historia e programimit funksional ................................................ ...... 4
2 Veçoritë e gjuhëve funksionale.......................................... .................... 5
2.1 Karakteristikat kryesore ..................................................... ...................................... 5
2.2 Përfitimet ................................................ ................................................ 9
2.3 Disavantazhet ................................................ ................................................ njëmbëdhjetë
3 Vështrim i përgjithshëm i gjuhëve ekzistuese...................................... ... ................................. trembëdhjetë
4 Parimet themelore të gjuhës Haskell .......................................... .. ............................ gjashtëmbëdhjetë
4.1 Mjedisi ndërveprues ..................................................... ................................... gjashtëmbëdhjetë
4.2 Struktura e programit ..................................................... ................................ tetëmbëdhjetë
4.3 Llojet e funksioneve ................................................ ................................................ 22
4.4 Llogaritja e kushtëzuar (degëzimi) ............................................ ................. 24
4.5 Përputhja e modelit ................................................. .......................... 27
4.6 Listat ................................................ ................................................ ...... 29
4.7 Përkufizimet lokale............................................................................. 33
4.8 Veçoritë shtesë të mjedisit ndërveprues ................................ 35
4.9 Funksionet e rendit më të lartë ...................................... ................................ 36
4.10 Strukturat e të dhënave të pafundme ................................................ ................ 37
5 Llojet dhe modulet e të dhënave .............................................. ................................................ 40
5.1 Llojet e personalizuara dhe strukturat e të dhënave .......................................... 40
5.2 Modulet ................................................ ................................................ ...... 44
6 Klasat dhe Monadat ................................................ ................................................ ... 47
6.1 Klasat ................................................ ................................................ ....... 47
6.2 I / O ................................................ ................................................ .. 49
7 Shembuj ................................................ ................................................ .............. 53
konkluzioni................................................ ................................................ ........... 54
Lista e burimeve të përdorura ................................................ ...................... 55
Prezantimi
Përpara se të përshkruajmë drejtpërdrejt programimin funksional, le t'i drejtohemi historisë së programimit në përgjithësi. Në vitet 1940, u shfaqën kompjuterët e parë dixhitalë, të cilët programoheshin duke ndërruar lloje të ndryshme të çelësave, telave dhe butonave. Numri i ndërrimeve të tilla arriti në disa qindra dhe u rrit me kompleksitetin e programeve. Prandaj, hapi tjetër në zhvillimin e programimit ishte krijimi i të gjitha llojeve të gjuhëve të asamblesë me mnemonikë të thjeshtë.
Por edhe montuesit nuk mund të bëheshin mjeti që mund të përdornin shumë njerëz, pasi kodet mnemonike ishin ende shumë komplekse dhe çdo asembler ishte i lidhur ngushtë me arkitekturën në të cilën u ekzekutua. Hapi tjetër pas montimit ishin të ashtuquajturat gjuhë imperative të nivelit të lartë: BASIC, Pascal, C, Ada dhe të tjera, duke përfshirë ato të orientuara nga objekti. Gjuhë të tilla quhen imperative ("përshkrimore") sepse ato janë të përqendruara në ekzekutimin vijues të udhëzimeve që punojnë me kujtesën (d.m.th., detyrat) dhe unazat përsëritëse. Thirrjet e funksioneve dhe procedurave, madje edhe ato rekursive, nuk i çliruan gjuhë të tilla nga imperativiteti i qartë.
Në paradigmën e programimit funksional, funksioni është gurthemeli. Funksionet matematikore shprehin marrëdhënien midis të dhënave hyrëse dhe produktit përfundimtar të një procesi. Procesi i llogaritjes ka gjithashtu një hyrje dhe një dalje, kështu që një funksion është një mjet krejtësisht i përshtatshëm dhe adekuat për të përshkruar llogaritjet. Është ky parim i thjeshtë që qëndron në themel të paradigmës funksionale dhe stilit të programimit funksional. Program funksionalështë një koleksion i përkufizimeve të funksionit. Funksionet përcaktohen përmes funksioneve të tjera ose në mënyrë rekursive përmes tyre. Në gjuhën funksionale, programuesi duhet vetëm të përshkruajë rezultatin e dëshiruar si një sistem funksionesh.
2 Historia e programimit funksional
Siç e dini, bazat teorike të programimit imperativ u hodhën në vitet 1930 nga Alan Turing dhe John von Neumann. Teoria që qëndron në themel të qasjes funksionale lindi gjithashtu në vitet 1920 dhe 1930. Ndër zhvilluesit e themeleve matematikore të programimit funksional janë Moses Scheinfinkel dhe Haskell Curry, të cilët zhvilluan logjikën kombinuese dhe Alonzo Church, krijuesi i llogaritjes λ (llogaritja lambda).
Teoria mbeti një teori derisa, në fillim të viteve 1950, John McCarthy zhvilloi gjuhën Lisp, e cila u bë gjuha e parë pothuajse funksionale e programimit dhe mbeti e vetmja për shumë vite. Lisp është ende në përdorim, pas shumë vitesh evolucioni i plotëson nevojat moderne.
Në lidhje me kompleksitetin në rritje të softuerit, shtypja po fillon të luajë një rol gjithnjë e më të rëndësishëm. Në fund të viteve 70 dhe në fillim të viteve 80 të shekullit XX, u zhvilluan intensivisht modelet e shtypjes të përshtatshme për gjuhët funksionale. Shumica e këtyre modeleve përfshinin mbështetje për mekanizma të fuqishëm si abstraksioni i të dhënave dhe polimorfizmi. Shumë gjuhë funksionale të shtypura po shfaqen: ML, Scheme, Hope, Miranda, Clean dhe shumë të tjera. Përveç kësaj, numri i dialekteve është vazhdimisht në rritje. Pothuajse çdo grup funksional programimi ka gjuhën e vet. Kjo pengoi përhapjen e mëtejshme të këtyre gjuhëve dhe shkaktoi shumë probleme më të vogla. Për të korrigjuar situatën, një grup i përbashkët studiuesish kryesorë të programimit funksional u nisën për të rikrijuar virtytet e gjuhë të ndryshme në një gjuhë të re funksionale universale. Zbatimi i parë i kësaj gjuhe, i quajtur Haskell pas Haskell Curry, u krijua në fillim të viteve '90.
3 Veçoritë e gjuhëve funksionale
Si çdo grup gjuhësh programimi, gjuhët funksionale kanë disa veçori që i dallojnë nga gjuhët e tjera dhe i bëjnë ato gjuhë programimi saktësisht funksionale.
3.1 Vetitë themelore
Ndër vetitë e gjuhëve funksionale, zakonisht dallohen këto:
- shkurtësia dhe thjeshtësia;
- shtypje e fortë;
- funksionet janë vlera;
- pastërti (pa efekte anësore);
- llogaritjet e shtyra (dembele);
- modulariteti.
Le të shqyrtojmë secilën nga këto prona në më shumë detaje.
Shkurtësi dhe thjeshtësi
Programet gjuhësore funksionale janë përgjithësisht më të shkurtra dhe më të thjeshta se ato në gjuhët imperative. Një nga shembujt më të zakonshëm është Hoare Quicksort.
Në imperativin C, renditja e shpejtë zakonisht zbatohet si kjo:
qsort e pavlefshme (int a, int l, int r)
int i = l, j = r, x = a [(l + r) / 2];
ndërsa (a [i]< x) i++;
ndërsa (x< a[j]) j--;
int temp = a [i];
nderkohe une<= j);
nëse (l< j) qsort (a, l, j);
nese une< r) qsort (a, i, r);
Në gjuhën funksionale të Haskell, e njëjta renditje shkruhet shumë më shkurt dhe më qartë:
qsort (x: xs) = qsort
++ [x] ++ qsort
Ky shembull duhet lexuar si më poshtë: nëse lista që do të renditet është bosh, atëherë rezultati i renditjes do të jetë gjithashtu një listë boshe, përndryshe zgjidhen koka dhe fundi i listës (elementi i parë i listës dhe një listë e elementët e mbetur, ndoshta bosh), dhe rezultati do të jetë lidhja (bashkimi) i listës së renditur të të gjithë elementëve të bishtit që janë më pak se koka, një listë nga vetë koka dhe një listë e të gjithë elementëve të bishtit që janë më të mëdhenj. se ose e barabartë me kokën.
Kodi funksional i gjuhës fiton në madhësinë dhe qartësinë e kodit. Përveç kësaj, zbatimi i mësipërm C rendit një grup, elementët e të cilit janë të një lloji të plotë (int), ndërsa zbatimi Haskell mund të rendit listat e elementeve të çdo lloji në të cilin është përcaktuar operacioni i krahasimit.
Shkrimi i fortë
Shumica e gjuhëve funksionale të programimit janë të shtypura fort. Shtypja e fortë nënkupton plotësimin e kushteve të mëposhtme:
- çdo vlerë, variabël, argument dhe vlerë kthyese e një funksioni në fazën e projektimit të programit është i lidhur pa kushte me një lloj specifik të dhënash që nuk mund të ndryshohet gjatë ekzekutimit të programit;
- funksionet mund të pranojnë dhe kthejnë vlera që kanë rreptësisht të njëjtin lloj të dhënash siç specifikohet në përshkrimin e funksionit;
- çdo operacion kërkon argumente të llojeve të përcaktuara rreptësisht;
- Nuk lejohet konvertimi i nënkuptuar i tipit (d.m.th., përkthyesi trajton si gabim çdo përpjekje për të përdorur një vlerë të një lloji të ndryshëm nga ajo e përshkruar për një variabël, argument, funksion ose operacion).
Në teorinë e programimit, shtypja e fortë është një element i domosdoshëm për të siguruar besueshmërinë e softuerit të zhvilluar. Kur përdoret në mënyrë korrekte (që do të thotë se programi deklaron dhe përdor lloje të veçanta të dhënash për vlera logjikisht të papajtueshme), ai mbron programuesin nga gabimet e thjeshta, por të vështira për t'u gjetur, që lidhen me ndarjen e vlerave logjikisht të papajtueshme, që ndonjëherë vijnë thjesht nga një gabim rudimentar. Gabime të tilla zbulohen edhe në fazën e përpilimit të programit, ndërsa kur është e mundur që në mënyrë implicite të transmetohet pothuajse çdo lloj me njëri-tjetrin (si, për shembull, në gjuhën klasike C), këto gabime zbulohen vetëm gjatë testimit, dhe jo të gjitha dhe jo të gjitha përnjëherë.
Funksionon si vlera
Në gjuhët funksionale të programimit, funksionet mund të përdoren si çdo objekt tjetër, ato mund të kalohen në funksione të tjera si argumente, të kthehen si rezultat i funksioneve të tjera, të ruajtura në lista dhe struktura të tjera të dhënash. Funksionet që marrin ose kthejnë funksione të tjera si argumente quhen funksione të rendit më të lartë.
Përdorimi i funksioneve të rendit më të lartë ju lejon të krijoni funksione më fleksibël, duke rritur kështu ripërdorimin e kodit tuaj. Një shembull është zakonisht kalimi i një funksioni krahasimi të elementeve në një funksion të renditjes.
Pastërti
Pastërtia qëndron në mungesën e efekteve anësore gjatë llogaritjes së vlerave të funksionit. Një efekt anësor i një funksioni është aftësia për të lexuar dhe ndryshuar vlerat e variablave globale, për të kryer operacione hyrëse / dalëse, për t'iu përgjigjur situatave të jashtëzakonshme dhe për të ndryshuar vlerat e variablave të hyrjes në procesin e llogaritjes së llogaritjeve të tij. Prandaj, nëse e thërrisni një funksion të tillë dy herë me të njëjtin grup vlerash të argumenteve hyrëse, atëherë rezultatet e llogaritjes mund të ndryshojnë dhe gjendja e disa objekteve globale (për shembull, vlerat e variablave) mund të gjithashtu ndryshojnë. Këto funksione quhen funksione jo-përcaktuese me efekt anësor.
Në programimin e pastër funksional, i njëjti funksion me të njëjtat argumente kthen gjithmonë të njëjtin rezultat. Objektet e krijuara nuk mund të ndryshohen ose shkatërrohen, ju mund të krijoni vetëm të reja bazuar në ato ekzistuese. Për shkak të pastërtisë, programet jo vetëm që bëhen më të qarta, por edhe thjeshtojnë organizimin e paralelizmit në to, pasi funksionet mund të llogariten në mënyrë të pavarur nga njëri-tjetri. Nëse rezultati i një funksioni të pastër nuk përdoret, atëherë vlerësimi i tij mund të hiqet pa dëmtuar shprehjet e tjera. Dhe nëse nuk ka varësi të të dhënave midis dy funksioneve të pastra, atëherë mund të ndryshoni rendin e llogaritjes së tyre ose t'i llogaritni ato paralelisht. Në një rast të tillë, përpiluesi mund të përdorë çdo politikë llogaritëse. Kjo i jep kompajlerit lirinë për të kombinuar dhe riorganizuar vlerësimin e shprehjeve në një program.
Llogaritje dembele
Në gjuhët tradicionale, para se të thërrisni një funksion, llogariten vlerat e të gjitha argumenteve të tij. Kjo metodë e thirrjes së funksioneve quhet thirrje sipas vlerës. Nëse disa nga argumentet nuk përdoren, atëherë llogaritjet janë humbur. Shumë gjuhë funksionale përdorin një metodë të ndryshme të thirrjes së funksioneve - "thirrni kur nevojitet". Për më tepër, çdo argument funksioni llogaritet vetëm nëse vlera e tij është e nevojshme për të llogaritur rezultatin e funksionit. Për shembull, operacioni i lidhjes C ++ (&&) nuk kërkon vlerësimin e vlerës së argumentit të dytë nëse i pari është false.
Vlerësimi dembel në disa raste ju lejon të shpejtoni ekzekutimin e programit, dhe gjithashtu ju lejon të përdorni struktura të ndryshme të pafundme të të dhënave.
Modulariteti
Mekanizmi i modularitetit lejon që programet të ndahen në disa pjesë (ose module) relativisht të pavarura me marrëdhënie të mirëpërcaktuara ndërmjet tyre. Kjo lehtëson projektimin dhe mirëmbajtjen pasuese të sistemeve të mëdha softuerike. Mbështetja për modularitetin nuk është veçori e gjuhëve funksionale të programimit, por mbështetet nga shumica e këtyre gjuhëve.
3.2 Përfitimet
Gjuhët e programimit funksional kanë disa përparësi ndaj gjuhëve imperative. Përdorimi i paradigmës së programimit funksional rrit besueshmërinë e programeve, shpejtësinë e shkrimit të tyre, komoditetin e testimit të njësive, mundësinë e optimizimit gjatë kompilimit dhe mundësinë e organizimit automatik të paralelizmit.
Besueshmëria e programimit
Mungesa e efekteve anësore i bën të pamundura shumë gabime të vështira për t'u gjetur, si p.sh. caktimi aksidental i një vlere të pavlefshme për një ndryshore globale. Shtypja strikte statike lejon në fazën e përpilimit të kapni një numër të madh gabimesh që lidhen me përdorimin e gabuar të disa të dhënave.
Një tipar interesant i gjuhëve funksionale është se ato i kushtohen analizave matematikore. Meqenëse një gjuhë funksionale është thjesht një zbatim i një sistemi formal, të gjitha veprimet matematikore që mund të kryheshin në letër zbatohen edhe për programet e shkruara në një gjuhë të tillë. Për shembull, përpiluesi mund të konvertojë pjesë të kodit në pjesë ekuivalente por më efikase duke vërtetuar matematikisht se pjesët janë ekuivalente. Për më tepër, ju mund t'i përdorni këto teknologji për të vërtetuar se disa pjesë të programit tuaj janë të sakta.
Komoditeti i testimit të njësisë
Meqenëse një funksion në programimin funksional nuk mund të gjenerojë efekte anësore, objektet nuk mund të ndryshohen si brenda fushëveprimit ashtu edhe jashtë (ndryshe nga programet imperative, ku një funksion mund të ndryshojë disa ndryshore të jashtme të lexuara nga funksioni i dytë). Efekti i vetëm i vlerësimit të një funksioni është rezultati që ai kthen dhe i vetmi faktor që ndikon në rezultat janë vlerat e argumenteve.
Kështu, është e mundur të testohet çdo funksion në program thjesht duke e vlerësuar atë nga grupe të ndryshme vlerash argumentesh. Në këtë rast, nuk duhet të shqetësoheni për thirrjen e funksioneve në rendin e duhur, ose për formimin e saktë të gjendjes së jashtme. Nëse ndonjë funksion në një program kalon testet e njësisë, atëherë mund të jeni të sigurt në cilësinë e të gjithë programit. Në programet imperative, kontrollimi i vlerës së kthyer të një funksioni nuk është i mjaftueshëm: funksioni mund të modifikojë gjendjen e jashtme, e cila gjithashtu duhet të kontrollohet, gjë që nuk ka nevojë të bëhet në programet funksionale.
Mundësitë e optimizimit
Përshkrimi i programit në formën e një grupi funksionesh pa treguar qartë rendin e llogaritjes së tyre dhe pastërtinë e funksioneve bën të mundur aplikimin e metodave mjaft komplekse dhe efektive të optimizimit automatik në programet funksionale.
Një avantazh tjetër i programeve funksionale është se ato ofrojnë mundësi më të gjera për paralelizimin automatik të llogaritjeve. Meqenëse mungesa e efekteve anësore është e garantuar, në çdo thirrje funksioni është gjithmonë e mundur të vlerësohen paralelisht dy argumente të ndryshëm - radha në të cilën ato vlerësohen nuk mund të ndikojë në rezultatin e thirrjes.
Vërtetimi i vetive të funksioneve
Meqenëse llogaritja e funksioneve në programimin funksional nuk shkakton efekte anësore, metodat matematikore (për shembull, metoda e induksionit matematik) janë të zbatueshme për analizën e funksioneve të tilla. Kjo ju lejon të provoni funksionimin e saktë të funksioneve, ose disa prej vetive të tyre, pa prova.
3.3 Disavantazhet
Disavantazhet e programimit funksional burojnë nga të njëjtat veçori. Mungesa e detyrave dhe zëvendësimi i tyre me gjenerimin e të dhënave të reja çon në nevojën për shpërndarje të vazhdueshme dhe çlirim automatik të memories, kështu që një grumbullues shumë efikas i mbeturinave bëhet një komponent i detyrueshëm në sistemin e ekzekutimit të një programi funksional. Që mbledhja e mbeturinave të jetë efikase, duhet të mbani shënim referencat e të dhënave, gjë që kërkon gjithashtu kohë dhe memorie intensive. Mungesa e sytheve për programet industriale është një kufizim mjaft serioz, pasi shumë algoritme kërkojnë unaza shumë të gjata ose edhe formalisht të pafundme, të cilat janë joefikase apo edhe të pamundura për t'u paraqitur në një formë rekursive, sepse thellësia e kërkuar e rekursionit është shumë e madhe. Në një farë mase, pengesa e fundit mund të anashkalohet duke e kthyer automatikisht rekursionin në një lak, të kryer nga disa përkthyes të gjuhëve funksionale për rastin specifik të rekursionit të bishtit, por jo të gjitha format e rekursionit e lejojnë një konvertim të tillë (megjithatë, ato që nuk mund të konvertohet në një konvertim të tillë nuk mund të jenë të dizajnuara si një cikël i thjeshtë dhe në gjuhë urdhërore).
Për të kapërcyer këto mangësi, shumë gjuhë funksionale përfshijnë mjete programimi imperative që ju lejojnë të specifikoni në mënyrë eksplicite rendin e veprimeve, përdorimin e sytheve dhe efektet anësore (për shembull, operacionet hyrëse dhe dalëse).
4 Pasqyrë e gjuhëve ekzistuese
Aktualisht, një numër i madh i gjuhëve funksionale të programimit janë zhvilluar. Të gjithë ata kanë karakteristika unike, cilësi pozitive dhe negative. Më të zakonshmet dhe më efektivet sot janë gjuhët ose familjet gjuhësore të mëposhtme:
Le të shqyrtojmë veçoritë e secilës prej këtyre gjuhëve:
– Lisp... Emrin e ka marrë nga gjuha angleze LISt Processing - list processing. Lisp është një nga gjuhët më të hershme të programimit funksional. Programet dhe të dhënat Lisp përfaqësohen nga sistemet lineare të listave të karaktereve. Lisp, së bashku me Ada, kaluan një proces standardizimi themelor për përdorim ushtarak dhe industrial, duke rezultuar në standardin Common Lisp. Implementimet e tij ekzistojnë për shumicën e platformave. Përdorimet e para të Lisp u shoqëruan me përpunimin simbolik të të dhënave dhe proceset e vendimmarrjes. Dialekti më i njohur i Common Lisp sot është një gjuhë programimi universal. Përdoret gjerësisht në një shumëllojshmëri të gjerë projektesh: serverë dhe shërbime interneti, serverë aplikacionesh dhe klientë që ndërveprojnë me bazat e të dhënave, kompjuterë shkencorë dhe programe lojrash.
– Haskell... Është një nga gjuhët më të zakonshme të programimit dembel. Ka një sistem shumë të zhvilluar të shtypjes. Kohët e fundit, grupi i bibliotekave të aplikuara është zgjeruar, gjuha po integrohet në sistemet e zakonshme softuerike, gjë që e bën gjuhën gjithnjë e më tërheqëse për programuesit profesionistë. Karakteristikat kryesore të gjuhës: aftësia për të përdorur abstraksionin lambda; funksionet e rendit më të lartë; aplikim i pjesshëm; papranueshmëria e efekteve anësore (pastërtia e gjuhës); vlerësim dembel; përputhje modelesh, modele funksionale; polimorfizmi parametrik dhe polimorfizmi i klasave të tipit; shtypje statike; përfundimi automatik i tipit (bazuar në modelin e shtypjes Hindley-Milner); llojet algjebrike të të dhënave; llojet e të dhënave me parametra; llojet e të dhënave rekursive; llojet abstrakte të të dhënave (encapsulimi); lista e të kuptuarit; shprehje roje (roje); aftësia për të shkruar programe me efekte anësore pa thyer paradigmën e programimit funksional duke përdorur monadat; aftësia për t'u integruar me programet e zbatuara në gjuhë programimi imperative përmes ndërfaqeve të hapura (një zgjerim standard i gjuhës së ndërfaqes së funksionit të huaj).
– ML(Meta Language) është një familje e gjuhëve programuese funksionale strikte me një sistem të zhvilluar të tipit polimorfik dhe module të parametrizueshme. ML mësohet në shumë universitete perëndimore. Një gjuhë e shtypur fort me shtypje statike dhe ekzekutim aplikativ të programit. Përparësitë kryesore të ML janë verifikueshmëria e lartë e programit, lehtësia e korrigjimit, potenciali për optimizim të lartë, shkurtësia unike e shkrimit. Disavantazhet kryesore janë kompleksiteti i sintaksës, mosnjohja e marrëveshjeve dhe kufizimeve të pranuara, pamundësia praktike e makrotransformimeve.
– Erlang- një gjuhë programimi funksionale që ju lejon të shkruani programe për lloje të ndryshme të sistemeve të shpërndara. Zhvilluar dhe mirëmbajtur nga Ericsson. Gjuha përfshin mjetet e gjenerimit të proceseve paralele dhe komunikimin e tyre duke dërguar mesazhe asinkrone. Programi përkthehet në bytecode, i cili ekzekutohet nga makina virtuale për transportueshmëri. Çelësi i Erlang është modeli i tij i lehtë i procesit. Për të parafrazuar sloganin Erlang "Gjithçka është një objekt", mund të themi "Gjithçka është një proces". Proceset janë të lira, krijimi i një procesi nuk kërkon më shumë burime sesa thirrja e një funksioni. Mënyra e vetme që proceset komunikojnë është mesazhet asinkrone.
Nga këto gjuhë, Haskell është përfaqësuesi më i spikatur i gjuhëve të programimit funksional. Ka një sintaksë të thjeshtë dhe të gjitha vetitë e listuara më sipër për gjuhët funksionale.
5 Parimet themelore të gjuhës Haskell
Siç u tha, gjuha e programimit Haskell është një gjuhë funksionale dhe ka të gjitha vetitë e mësipërme.
Së pari, le të shohim mjetet e nevojshme për punë. Kompiluesi më i përhapur dhe më efikas sot është GHC(Përpiluesi i Glasgow Haskell). Ai shpërndahet nën një licencë të hapur dhe kushdo mund të shkarkojë kodin burimor ose versionin e përpiluar për sistemet operative të njohura nga faqja zyrtare http: // haskell. org / ghc / (përveç kësaj, ka shumë informacione shtesë për gjuhën në http: // haskell.org /).
Përveç vetë përpiluesit, GHC përfshin mjedisin ndërveprues GHCi (GHC interactive), një përkthyes Haskell që ju lejon të vlerësoni çdo shprehje dhe të interpretoni programet e shkruara.
Fatkeqësisht, një mjedis zhvillimi me funksione të plota për Haskell nuk është zhvilluar ende (përveç, ndoshta, Leksah, një mjedis zhvillimi për Haskell i shkruar në Haskell dhe disa shtojca për Visual Studio dhe Eclipse), por shpesh vetëm aftësitë e mjafton një redaktues teksti i avancuar (për shembull, Notepad ++, gedit, kate) me theksimin e sintaksës dhe disa veçori të tjera.
5.1 Mjedisi interaktiv
Mjedisi interaktiv GHCi mund të vlerësojë çdo shprehje Haskell. Le të hedhim një vështrim në bazat e punës me këtë mjedis. Për ta nisur atë (pas instalimit të GHC ose Haskell-Platform), thjesht ekzekutoni programin ghci në tastierë (ose zgjidhni programin përkatës nga lista e të gjitha programeve). Pasi të lansohet, tastiera do të shfaqë një kërkesë:
Prelude nënkupton emrin e modulit aktual, si parazgjedhje është ngarkuar moduli standard Prelude, i cili përmban të gjitha funksionet kryesore dhe llojet e të dhënave.
Këtu mund të vlerësojmë çdo shprehje, për shembull, një shprehje të zakonshme aritmetike:
Siç mund ta shohim, mjedisi ndërveprues ka llogaritur rezultatin e shprehjes dhe e ka printuar atë në një rresht të ri. Le të përpiqemi të llogarisim një shprehje më të ndërlikuar:
Preludi> 1-2 * (4-3 ^ 2)
Eksponentimi (^) është një operator standard i përcaktuar në modulin standard Prelude së bashku me operacionet e mbledhjes dhe shumëzimit.
Përveç shprehjeve aritmetike në mjedisin ndërveprues, është e mundur të llogaritet çdo funksion tjetër i përcaktuar në modulin standard, ose në çdo funksion tjetër të ngarkuar nga përdoruesi.
Për të llogaritur vlerën e një funksioni, shkruani emrin e tij dhe specifikoni argumentet, të ndara me hapësira. Për shembull, moduli standard përcakton një funksion max që zgjedh vlerën maksimale nga dy argumente. Mund ta përdorni si kjo:
Preludi> maksimumi 7 100
V ky shembull llogaritet maksimumi i dy numrave - shtatë dhe njëqind. Siç mund ta shohim, rezultati i vlerësimit të funksionit është numri 100.
Çdo shprehje (por vetëm e llojit përkatës; llojet diskutohen më në detaje në seksione të tjera) mund të veprojnë si argumente për një funksion, për shembull:
Preludi> maksimumi (2 ^^ 3)
Ky shembull përcakton se dy në fuqinë e dhjetë është më e madhe se dhjetë në fuqinë e tretë. Vini re se kllapa e argumenteve kërkohet për të dalluar se cila pjesë e shprehjes është argument. Për shembull, nëse hiqni kllapat e argumentit të dytë, merrni një rezultat paksa të papritur:
Preludi> maksimumi (2 ^ 10) 10 ^ 3
Pa kllapa shprehje e dhënë interpretohet si maksimumi i dy numrave (1024 dhe 10), të ngritur në fuqinë e tretë.
Përveç kësaj, mjedisi ndërveprues GHCi mund të plotësojë automatikisht emrat e funksioneve të futura. Nëse shkruani vetëm pjesën fillestare të emrit të funksionit dhe shtypni tastin "Tab" në tastierë, atëherë GHCi do të përpiqet të plotësojë emrin e funksionit me atë të disponueshëm midis përkufizimeve të disponueshme (nga moduli standard ose i lidhur nga përdoruesi) . Për shembull, nëse shkruani "maxi" dhe shtypni "Tab", atëherë GHCi do të paraqesë emrin e funksionit në "maksimum". Në rast se është e pamundur të plotësohet pa mëdyshje (ka disa opsione të përshtatshme), atëherë shfaqen të gjitha opsionet e mundshme:
max maxBound maksimal
Tani mund të specifikoni emrin e funksionit (duke shtuar disa shkronja) dhe të shtypni përsëri tastin "Tab".
Kompletimi është shumë i dobishëm kur përdorni një numër të madh funksionesh me emra të gjatë.
5.2 Struktura e programit
Kompiluesit dhe interpretuesit Haskell punojnë me skedarë me shtesë * .hs që përmban tekstin e programit. Teksti i programit ka strukturën e mëposhtme:
1. në fillim të programit, mund të specifikohet emri i modulit aktual dhe përkufizimet e eksportuara;
3. pjesa tjetër e programit është e zënë nga përkufizime të ndryshme - përkufizime të funksioneve, llojeve të të dhënave dhe klasave.
Programi më i thjeshtë mund të përmbajë vetëm përkufizime funksionesh (në këtë rast, importohet vetëm moduli standard Prelude, i cili përmban shumicën e funksioneve standarde dhe llojeve të të dhënave; emri i modulit është vendosur si parazgjedhje si Kryesor).
Funksioni më i thjeshtë mund të mos marrë fare argumente, por të kthejë vetëm një vlerë. Në këtë rast, përkufizimi përbëhet nga emri i funksionit, shenja e barabartë "=", dhe disa shprehje me të cilat do të llogaritet vlera e këtij funksioni. Në terma të njohur, një funksion i tillë mund të quhet një ndryshore ose konstante, por kjo nuk është plotësisht e saktë. Në programimin funksional, funksionet pa argumente quhen simbole. Le të shqyrtojmë një shembull:
Ky shembull deklaron një simbol të quajtur pesë, i cili ka një vlerë të plotë prej 5. Emrat në Haskell janë të ndjeshme ndaj shkronjave të vogla, domethënë pesë dhe pesë janë emra të ndryshëm... Për më tepër, një kufizim shtesë futet në shkronjën e parë të emrit - emrat e funksioneve dhe argumentet e tyre mund të fillojnë vetëm me shkronje e vogel(pesë, max, min, x, y) dhe emrat e llojeve të të dhënave (Bool, Integer, Double), moduleve (Main, Test) dhe klasave (Eq, Ord, Num) janë vetëm me shkronja të mëdha.
Le të shohim një shembull më kompleks:
tre = një + dy
Tre simbole janë deklaruar këtu - një, dy, tre. Siç mund ta shihni nga shembulli, çdo përkufizim zë një rresht dhe ato ndahen vetëm nga fundi i rreshtit (vijat boshe do të shpërfillen). Simbolet një dhe dy përcaktohen në të njëjtën mënyrë si simboli pesë në shembullin e mëparshëm, por përkufizimi i simbolit tre përdor përkufizime para-ekzistuese. Siç mund ta merrni me mend, simboli tre do të ketë vlerën 3.
Rendi i përkufizimeve nuk është i rëndësishëm, domethënë, shembulli i mëposhtëm do të jetë plotësisht i ngjashëm me atë të mëparshëm:
tre = një + dy
Le të ngarkojmë shembullin tonë në mjedisin interaktiv GHCi. Për ta bërë këtë, kur filloni ghci, specifikoni emrin e skedarit me tekstin e programit si një parametër të linjës së komandës (për shembull, Test.hs) (në sistemet operative Windows, ju vetëm duhet të hapni skedarin, i instaluar nga GHC cakton automatikisht ghci për të hapur skedarët * .hs). Nëse programi nuk përmban gabime, atëherë do të shohim kërkesën tashmë të njohur:
Këtu Main është emri i modulit aktual (modulet diskutohen më në detaje në kapitullin përkatës). GHCi ju lejon të llogaritni çdo funksion nga moduli aktual. Për shembull, le të llogarisim simbolin tonë tre:
Shprehjet më komplekse janë gjithashtu të mundshme:
* Kryesor> (tre + dy) ^ 2
* Kryesor> maksimumi një dy
Më pas, le të shohim funksionet me argumente. Ndryshe nga gjuhët konvencionale të programimit, nuk keni nevojë të shkruani argumente në kllapa dhe të ndani me presje për të kaluar argumentet. Funksioni thirret në formën e mëposhtme: func x1 x2 x3… xN, ku func është emri i funksionit dhe xi është argumenti i-të. Rezultati i një funksioni do të jetë një objekt, si një numër, listë, funksion, shprehje lambda ose çdo strukturë tjetër të dhënash.
Përshkrimi i një funksioni me argumente është praktikisht i njëjtë me përshkrimin e simboleve në shembujt e mëparshëm. Përkufizimi i funksionit ndodhet në një rresht të veçantë dhe ka formën e mëposhtme: func x1 x2 x3… xN = shprehje, ku func është emri i funksionit të ri, xi është emri i argumentit i-të, shprehja është shprehja.
Për shembull, le të shtojmë një funksion që shton dy numra në Testin ekzistues. hs.
Tani mund të ringarkojmë modulin e modifikuar në mjedisin interaktiv. Për ta bërë këtë, thjesht rinisni ghci, ose përdorni komandën standarde ": r":
Përpilimi kryesor (Test.hs, i interpretuar)
Në rregull, modulet e ngarkuara: kryesore.
Pas kësaj, funksioni i ri bëhet i disponueshëm nga mjedisi interaktiv:
* Kryesor> plus një 8
Një shembull tjetër i një funksioni me argumente:
Secili përkufizim zë një rresht, megjithatë, nëse për qartësi është më i përshtatshëm për të ndarë përkufizimin në disa rreshta, atëherë mund të përdorni veçorinë e mëposhtme: çdo rresht që fillon me një dhëmbëzim më të madh se ai i mëparshmi konsiderohet vazhdimi i tij. Për shembull, ne mund të shkruajmë funksionin plus në dy rreshta si kjo:
Komentet e një rreshti të Haskell fillojnë me dy vija:
plus x y = x + y - funksioni i mbledhjes
Një koment blloku fillon me "" dhe përfundon me "":
ky funksion kthen një numër që është 1 më i madh
sesa ajo që merret si argument
5.3 Llojet e funksioneve
Haskell është një gjuhë e shtypur fort, çdo funksion në të ka një lloj të përcaktuar rreptësisht. Megjithatë, në shembujt e mëparshëm nuk e specifikuam llojin, pasi interpretuesit dhe përpiluesit e gjuhës Haskell kanë një mekanizëm të fuqishëm të konkluzionit të tipit. Lloji i funksioneve (dhe argumentet e tyre) në shumicën e rasteve mund të nxirret nga përkufizimet e këtyre funksioneve. Disa funksione mund të kenë lloje polimorfike (funksione të tilla mund të aplikohen për argumente të llojeve të ndryshme), për shembull, ato të dhëna më parë funksion plus mund të mbledhë numra të plotë dhe realë.
Siç u përmend më herët, emrat e tipit fillojnë me shkronja të mëdha. Këtu janë disa nga llojet standarde:
Përshkrim |
|
një numër i plotë nga - në |
|
numër i plotë i gjatë, pa kufij (aritmetika e gjatë e integruar ofrohet) |
|
numër real |
|
numër real me saktësi të dyfishtë |
|
një listë e elementeve të një lloji a, për shembull, një listë me numra të plotë shkruhet si |
|
varg (ose lista e karaktereve), ekuivalente |
|
boolean (mund të jetë e vërtetë ose e gabuar) |
|
një tufë prej dy elementësh të tipit a dhe b (p.sh. (String, Bool)) |
|
një tufë prej tre elementësh të tipit a, b dhe c (p.sh. (String, Bool, Int)) |
Nëse programuesi dëshiron të specifikojë vetë llojin e funksionit dhe argumentet e tij, ose përfundimi automatik i llojit të këtij funksioni është i pamundur, atëherë ai duhet të bëjë një përkufizim shtesë duke përdorur operatorin e treguesit të llojit "::". Për shembull, për të përshkruar një funksion që kthen një vlerë reale, mund të shkruani kodin e mëposhtëm:
Rreshti i parë do të thotë se funksioni pi është i tipit Double, pastaj vetë përkufizimi i funksionit, që do të thotë se funksioni pi kthen një vlerë të përafërt të pi. Nëse funksioni ka një argument, atëherë lloji i tij përshkruhet si më poshtë:
inc :: Integer -> Integer
Ky shënim do të thotë që funksioni inc konverton një argument Integer në një rezultat Integer.
Nëse funksioni ka dy argumente, atëherë përshkrimi i tij duket si ky:
fuqi :: Double -> Integer -> Double
Funksioni i fuqisë merr dy argumente - një bazë reale x dhe një fuqi numër të plotë n, por funksioni vlerësohet në një numër real.
Në përgjithësi, përshkrimi i llojit të funksionit duket si ky:
emri :: X1 -> X2 -> ... -> XN -> Y
Këtu emri është emri i funksionit, Xi është lloji i argumentit i-të, Y është lloji i funksionit.
Siç u përmend më herët, specifikimi i llojeve është opsional, por prania e tij mund të sigurojë kontroll shtesë mbi korrektësinë e shprehjeve të ndërtuara në një deklaratë funksioni. Përveç kësaj, në disa raste të përdorimit të llojeve polimorfike, është e pamundur të përcaktohet lloji i një funksioni pa specifikuar në mënyrë eksplicite llojin.
Këtu janë disa nga funksionet standarde.
Funksione | Përshkrim |
veprimet tradicionale aritmetike |
|
pjesëtimi i numrave realë |
|
duke ngritur një numër në një fuqi të plotë pozitiv |
|
duke ngritur një numër në një fuqi reale |
|
pjesëtimi i numrave të plotë dhe pjesa e mbetur e pjesëtimit të numrave të plotë |
|
Rrenja katrore |
|
funksionet trigonometrike |
|
asin, acos, atan | funksionet e anasjellta trigonometrike |
krahasimi për barazinë dhe pabarazinë |
|
>, <, >=, <= | krahasimi |
operacionet logjike |
|
elementi i parë i një çifti (i një dyshe) |
|
elementi i dytë i çiftit |
|
bishti (të gjithë elementët përveç të parit) të listës |
5.4 Llogaritja e kushtëzuar (degëzimi)
Në gjuhët tradicionale të programimit, mënyrat kryesore të organizimit të degëzimit janë deklarata e kushtëzuar (nëse atëherë tjetër) dhe deklarata e zgjedhjes (case ose switch). Përveç kësaj, Haskell përdor përputhjen e modeleve në përkufizimet e funksioneve dhe të ashtuquajturat shprehje mbrojtëse. Le të hedhim një vështrim më të afërt në secilën nga këto metoda.
Ndërtimi nëse-atëherë-tjetër
Struktura sintaksore "nëse-atëherë-tjetër" ju lejon të vlerësoni shprehje të ndryshme në varësi të rezultateve të një kushti të caktuar:
nëse<условие>pastaj<выражение1>tjetër<выражение2>
Këtu<условие>- disa shprehje të tipit Bool. Ndryshe nga gjuhët imperative, në Haskell, një konstrukt nëse-atëherë-tjetër është një shprehje që duhet të ketë një lloj rezultati. Në këtë drejtim, dega tjetër është e detyrueshme dhe llojet e shprehjeve<выражение1>dhe<выражение2>duhet të përputhen.
Konsideroni, si shembull, funksionin për llogaritjen e maksimumit të dy numrave:
max a b = nëse a> b atëherë një tjetër b
Siç u përmend tashmë, konstrukti "nëse-atëherë-tjetër" është një shprehje që ka një rezultat. Prandaj, mund të përdoret si pjesë e një shprehjeje tjetër:
* Kryesor> 5 + nëse False atëherë 1 tjetër 0
* Kryesor> (nëse është e vërtetë atëherë 1 tjetër 0) + 5
Vini re se kllapat kërkohen në shembullin e fundit. Pa kllapa, shprehja do të interpretohet ndryshe:
* Kryesor> nëse është e vërtetë atëherë 1 tjetër 0 + 5
Çdo gjë që shkruhet pas fjalës "tjetër" i referohet shprehjes së degës tjetër.
Ndërtimi i rastit
Merrni, si shembull, funksionin për llogaritjen e një numri të dhënë Fibonacci:
fib n = rasti n i
_ -> fib (n-1) + fib (n-2)
Ashtu si shprehje e kushtëzuar Shprehja e rastit "nëse-atëher-tjetër" ka një rezultat dhe për këtë arsye mund të jetë pjesë e shprehjeve të tjera.
Merrni parasysh shprehjen e rastit në përgjithësi:
rast<выражение0>e
<образец1> -> <выражение1>
<образец2> -> <выражение2>
<образецN> -> <выражениеN>
Këtu është rezultati i llogaritjes<выражение0>përputhet vazhdimisht me mostrat. Kur përputhet me sukses me mostra e i-të, rezultati i të gjithë rastit do të jetë rezultat i shprehjes i-të. Përputhja e modelit do të diskutohet më në detaje në seksionin përkatës, por tani për tani mund të konsiderohet si një krahasim me konstantet e dhëna.
Vini re se çdo model duhet të shkruhet në një rresht të ri me një dhëmbëzim më të madh se dhëmbëzimi i rastit të fjalës së rezervuar. Gjithashtu, vrimat përpara mostrave duhet të jenë të barabarta me njëra-tjetrën.
Për më tepër, një mënyrë alternative e shkrimit të shprehjeve të rasteve pa përdorur dhëmbëzim është e pranueshme:
fib n = rasti n i (1-> 1; 2-> 1; _-> fib (n-1) + fib (n-2))
Kjo metodë është më kompakte, por më pak përshkruese. Në përgjithësi:
rast<выражение0>nga (<образец1> -> <выражение1> ; <образец2> -> <выражение2> ; ... ; <образецN> -> <выражениеN> }
Përkufizimet e funksioneve
Në Haskell, i njëjti funksion mund të ketë disa përkufizime, të dalluara nga mënyra se si janë shkruar argumentet e tij. Shënimi i një argumenti quhet model, dhe kur funksioni vlerësohet, argumentet e kaluara përputhen me modelet në përkufizime.
Le të shqyrtojmë si shembull funksionin e llogaritjes së numrit të Fibonaçit.
fib n = fib (n-1) + fib (n-2)
Kur llogaritet vlera e një funksioni, argumenti i tij i vetëm përputhet me modelet e përkufizimeve të tij nga lart poshtë. Nëse argumenti ishte numri 2, atëherë përputhja e parë do të dështojë, dhe e dyta do të ketë sukses, dhe si rezultat funksioni do të marrë vlerën 1. Nëse argumenti nuk përputhet me modelet në dy përkufizimet e para, atëherë do të përputhet patjetër me emrin e argumentit n (në këtë rast, n do të marrë vlerën e argumentit të kaluar), dhe do të llogaritet shuma e dy numrave të mëparshëm Fibonacci.
Nëse një funksion i përshtatshëm nuk gjendet në përkufizimet e funksionit, do të ndodhë një gabim dhe ekzekutimi i programit do të ndalojë.
Shprehje mbrojtëse
Mënyra e fundit për të zgjedhur alternativat gjatë llogaritjes së rezultatit të funksioneve janë të ashtuquajturat shprehje mbrojtëse. Ato (ndryshe nga shprehjet if-ather-else dhe rastet) mund të përdoren vetëm në përkufizimet e funksioneve:
<имя функции> <список аргументов функции>
|<условие1> = <выражение1>
|<условие2> = <выражение2>
|<условиеN> = <выражениеN>
Të gjithë personazhet "|" duhet të fillojnë në vijën e tyre dhe me një dhëmbëzim. Gjatë llogaritjes së vlerës së një funksioni, të gjitha kushtet që janë shprehje të tipit Bool përsëriten nga lart poshtë. Kur gjendet kushti i-të, rezultati i të cilit është True, vlerësohet shprehja i, rezultati i së cilës do të jetë rezultati i funksionit.
Për shembull, le të shkruajmë funksionin e gjetjes së numrit Fibonacci:
| ndryshe = fib (n-1) + fib (n-2)
Këtu përndryshe është një kusht i vërtetë me vetëdije, gjithmonë i barabartë me të Vërtetën.
5.5 Përputhja e modelit
Përputhja e modelit është një mënyrë e përshtatshme për të lidhur pjesë të ndryshme të një vlere me emrat e dhënë (karakteret). Përputhja e modelit përdoret në përkufizime dhe në shprehjet e rasteve.
Gjatë përcaktimit të funksioneve, përputhja e modelit ndodh në argumente. Në rastin më të thjeshtë, kur argumentet specifikohen vetëm me emra, të gjitha argumentet janë të lidhura me ata emra. Për shembull:
f x = fst x + snd x
Ky funksion llogarit shumën e elementeve të një tupleje. Funksionet standarde fst dhe snd marrin përkatësisht elementin e parë dhe të dytë të një tupleje.
* Kryesor> f (2,4)
Duke përdorur përputhjen e modelit, ne mund të theksojmë përmbajtjen e argumentit të këtij funksioni në një mënyrë më përshkruese:
Kur llogaritet ky funksion nga (2,4), elementet e këtij tuple do të përputhen me modelin e specifikuar në përkufizimin e funksionit, domethënë, simboli "a" do të marrë vlerën 2, dhe simboli "b" do të marrë vlerën 4.
Kështu mund të përcaktojmë analoge të funksioneve fst dhe snd:
Vini re se përkufizimi i fst1 nuk përdor x, dhe përkufizimi i snd1 nuk përdor y. Në raste të tilla, kur një pjesë e modelit (ose i gjithë argumenti) nuk përdoret, nuk ka nevojë të specifikoni emrin e kësaj pjese (ose argumentit) - në vend të emrit, mjafton të specifikoni karakterin nënvizues "_" . Le të anashkalojmë këto funksione:
Duke përdorur këtë mënyrë të shkruari, nuk keni pse të gjeni emra për pjesët e panevojshme të mostrave dhe kur lexoni përkufizimin e funksionit, menjëherë bëhet e qartë se kjo pjesë e argumentit nuk përdoret.
Mostrat mund të specifikojnë çdo konstruktor (në shembullin e mëparshëm, është përdorur konstruktori i një tupleje), për shembull, konstruktorë për një listë, një tuple ose çdo lloj të dhënash të personalizuar, si dhe vlera specifike të argumentit (si në shembullin rreth numrave Fibonacci). Në disa raste, përputhja mund të dështojë, në të cilin rast tentohet përputhja tjetër (nga përkufizimi ose modeli i rastit tjetër). Le të shqyrtojmë një shembull:
f _ 0 = gabim "pjestimi me zero"
f (a, b) c = (a + b) / c
Këtu, gjatë llogaritjes së funksionit f, argumenti i dytë do të jetë i barabartë me 0, pastaj do të zgjidhet përkufizimi i parë për llogaritjen e funksionit, përndryshe i dyti, pasi krahasimi me emrin është gjithmonë i suksesshëm. Funksioni i gabimit ndalon ekzekutimin e programit me tekstin e specifikuar të gabimit. Shembuj të përdorimit të funksionit të përshkruar:
* Kryesor> f (1,2) 3
* Kryesor> f (3.2) 1
* Kryesor> f (5.5) 5
* Kryesor> f (5.5) 0
*** Përjashtim: pjesëtimi me zero
Përveç kësaj, çdo model mund të emërtohet në mënyrë që argumenti i strukturuar të mund të aksesohet si në aspektin elementar ashtu edhe në tërësinë e tij. Operatori @ përdoret për të emërtuar modelin. Paraprihet nga një emër përmes të cilit mund të aksesoni argumentin në tërësi, dhe më pas vetë modelin. Për shembull,
funksion1 [email i mbrojtur](a, b) = a + b + func2 p
func2 (a, b) = a * b
5.6 Listat
Një listë është një nga strukturat më të rëndësishme të të dhënave që përmban elementë të të njëjtit lloj. Lista nuk mund të përmbajë elementë të llojeve të ndryshme (ndryshe nga tuplet). Për të përshkruar llojin "listë", përdoren kllapa katrore. Për shembull, është një përshkrim i llojit të një liste elementesh të një lloji boolean.
Listat krijohen duke përdorur konstruktorin e listës - operacionin ":". Lista mund të jetë ose bosh, ose mund të përbëhet nga një kokë (elementi i parë i listës) dhe një bisht (një listë e elementeve të tjera). Një listë e zbrazët shënohet me kllapa katrore të zbrazëta: "", dhe një listë me kokën x dhe bishtin y shkruhet duke përdorur konstruktorin e listës: "x: y".
Ekziston gjithashtu një mënyrë më e përshtatshme për të shkruar lista: duke renditur artikujt në kllapa katrore. Për shembull, një listë e numrave të plotë nga 1 në 3 mund të shkruhet si kjo:
1: = 1:2: = 1:2:3:
Konstruktori i listës mund të përdoret me përputhjen e modelit. Kjo do ta ndajë listën e dhënë si argument në një kokë dhe një bisht, të cilat mund të aksesohen përmes karaktereve të specifikuara në model. Nëse lista është bosh, atëherë harta në këtë përkufizim do të jetë i pasuksesshëm.
Për shembull, mund të përshkruani funksionin e marrjes së kreut të një liste:
Zbatimi i mësipërm i funksionit të kokës nuk përdor bishtin e listës, mund ta zëvendësoni emrin e tij me një nënvizim:
Operacioni i marrjes së bishtit të një liste mund të përshkruhet në mënyrë të ngjashme.
Këto dy funksione (koka dhe bishti) do të shkaktojnë një gabim kur u kalohen atyre listë boshe pasi ndeshja nuk do të ketë sukses.
Le të shqyrtojmë një shembull tjetër të një funksioni për të punuar me lista: një funksion për llogaritjen e gjatësisë së një liste:
gjatësia (_: t) = 1 + gjatësia t
Nëse lista e hyrjes është bosh, atëherë përkufizimi i parë do të funksionojë si rezultat i krahasimit, përndryshe i dyti.
Vargjet në Haskell janë lista karakteresh. Karakteret shkruhen me apostrofa (për shembull, "c"), dhe vargjet janë në thonjëza (për shembull, "string"). Çdo varg mund të përfaqësohet në shënimin standard të listave, për shembull, vargu "string" është i ngjashëm me listën ["s", "t", "r", "i", "n", "g"] . Puna me vargje është e njëjtë me punën me lista.
Artikujt e listës aksesohen në mënyrë sekuenciale duke prerë kokën dhe bishtin në mënyrë graduale. Për shembull, për të marrë elementi i n-të listë (duke filluar nga 0), mund të shkruani një funksion:
merrniN (x: _) 0 = x
merrniN (_: t) n = merrniN t (n-1)
Marrja e elementit n të listës zbatohet në funksionin standard "!!". Përdoret si kjo:
Këtu lista është një listë, n është numri i elementit që kërkohet. Artikujt numërohen duke filluar nga zero. Nëse gjatësia e listës është më e vogël ose më e vogël se numri i elementit të kërkuar, llogaritja e këtij funksioni do të çojë në një gabim.
Përveç kësaj, është e mundur të specifikohen listat e elementeve të numëruar (për shembull, numra të plotë ose simbole) si më poshtë:
Këtu X1 është fillimi i progresionit aritmetik dhe X2 është fundi i tij. Për shembull, është një listë. Në këtë mënyrë, mund të specifikohen vetëm listat ngjitëse me një hap të barabartë me një. Nëse keni nevojë të vendosni një sekuencë me një hap tjetër, atëherë mund të përdorni rekordin e mëposhtëm:
Në këtë variant, X1 është elementi i parë i sekuencës, X2 është i dyti, X3 është i fundit i mundshëm. Hapi i sekuencës zgjidhet si X2-X1, dhe sekuenca përmban elementë të vendosur vetëm ndërmjet X1 dhe X3. Për shembull, është një listë.
Ekziston gjithashtu një mënyrë për të krijuar lista bazuar në ato ekzistuese. Në terma të përgjithshëm, kjo metodë mund të shkruhet si më poshtë:
[<выражение> | <образец> <- <список>, <ограничение1>, ..., <ограничениеN>]
Nga një listë e caktuar, zgjidhen elementë që përputhen me një model dhe plotësojnë të gjitha kufizimet, dhe një listë formohet nga elementët e llogaritur nga një shprehje duke përdorur këtë model. Për shembull,
[x ^ 2 | x<- ,mod x 3 == 0]
Kjo shprehje ndërton një listë katrorësh me numra tek nga një deri në 30, të pjesëtueshëm me 3. Rezultati është:
Përveç kësaj, funksioni i hartës, i përcaktuar në modulin standard, është shumë i dobishëm kur punoni me lista. Ai zbaton disa funksione në listën e dhënë dhe kthen listën që rezulton nga aplikimi i këtij funksioni në elementët e listës origjinale. Funksioni i hartës mund të zbatohet si kjo:
harta :: (a -> b) -> [a] -> [b]
harta f xs =
Kjo do të thotë, ai merr si argument të parë një funksion që konverton objektet e tipit a në objekte të tipit b dhe si argument të dytë, një listë elementësh të tipit a. Rezultati i funksionit të hartës është një listë e elementeve të tipit b.
Kur përdorni funksionin e hartës, është e përshtatshme të përdorni funksione të paemërtuara që përshkruhen si shprehje λ (diskutuar më në detaje në seksionin mbi funksionet e rendit më të lartë). Për shembull, një listë katrorësh me numra nga 1 në 10 mund të përshkruhet si më poshtë:
harta (\ x-> x * x)
Rezultati i këtij funksioni është një listë:
Meqenëse Haskell ka një operacion të integruar të fuqizimit, kjo listë mund të merret si më poshtë:
harta (^ 2)
Gjithashtu, mund të përdorni çdo funksion tjetër, për shembull:
harta inc
Le të shqyrtojmë disa funksione të përcaktuara në modulin standard për punën me listat.
Emri i funksionit | Përshkrim |
|
kreu (elementi i parë) i listës |
||
bishti (i gjithë përveç elementit të parë) të listës |
||
elementi i fundit listë |
||
të gjithë elementët e listës përveç të fundit |
||
[a] → Int → a | element me një numër të caktuar |
|
llogaritja e gjatësisë së një liste |
||
Int → [a] → [a] | merrni n elementet e parë nga lista |
|
Int → [a] → [a] | hidhni n elementët e parë nga lista |
|
duke zgjeruar listën në rend të kundërt |
||
(Numri a) => [a] → a | shuma e artikujve të listës |
|
(Numri a) => [a] → a | produkt i artikujve të listës |
|
[a] → [a] → [a] | bashkimi i listave |
5.7 Përkufizimet lokale
Haskell është një gjuhë programimi e pastër funksionale, prandaj nuk mund të ketë variabla globale, për më tepër, nuk ka fare variabla. Asnjë objekt nuk mund të ndryshohet, vetëm një i ri mund të merret duke përdorur të vjetrën. Parametrat e funksionit dhe funksionet lokale mund të shërbejnë si disa "zëvendësues" të variablave.
Ka dy mënyra për të përshkruar funksionet lokale: duke përdorur një fjalë të rezervuar ku dhe le... Përcaktimi i funksioneve lokale me ku mund të përdoret vetëm në një përkufizim funksioni. Le të përcaktojmë një funksion për llogaritjen e mesatares aritmetike të tre numrave:
mesatare3 x y z = s / 3
Në përgjithësi, përdorimi i ku mund të shkruhet kështu:
<имя функции> <аргументы> = <выражение>
<определение 1>
<определение 2>
<определение N>
Të gjitha përkufizimet duhet të jenë në të njëjtën dhëmbëzim, por më shumë se rreshti që përmban ku. Mund të përdorni në mënyrë opsionale sintaksën e mëposhtme:
<имя функции> <аргументы> = <выражение>ku (<определение 1> ; <определение 2> ; ... ; <определение N> }
Mënyra e dytë (duke përdorur let) mund të përdoret në çdo shprehje (jo vetëm kur përcaktohen funksionet). Ndryshe nga ku, përkufizimet e funksioneve lokale duhet të shkruhen përpara vetë shprehjes. Rishkruani shembullin e mëparshëm:
mesatare3 x y z =
Në përgjithësi, kjo metodë duket si kjo:
<определение 1>
<определение 2>
<определение N>
<выражение>
Të gjitha përkufizimet duhet të futen njësoj, por më shumë se rreshti që përmban letrën. Fjala në duhet të jetë e shënuar të paktën let. Mund të përdorni në mënyrë opsionale sintaksën e mëposhtme:
le (<определение 1> ; <определение 2> ; ... ; <определение N>) në<выражение>
Në këtë rast, dhëmbëzimi injorohet.
5.8 Karakteristikat shtesë të mjedisit ndërveprues
Në mjedisin interaktiv GHCi, përveç vlerësimit të funksioneve ose shprehjeve, ka edhe shumë mundësi shtesë... Shumë prej tyre janë të disponueshme përmes komandave që fillojnë me karakterin ":". Për shembull, duke shkruar komandën ":?" ju mund të shihni një listë të të gjitha komandave të tjera (përfundimi automatik funksionon gjithashtu me komanda). Le të hedhim një vështrim në komandat më të dobishme.
: t - merrni llojin e shprehjes së specifikuar. Për shembull:
* Kryesor>: t mbrapsht (bishti "mama")
anasjelltas (bishti "mama") ::
: i - marrja e informacionit për funksionin (lloji, në cilin modul ose klasë është përcaktuar). Për shembull:
* Kryesor>: i kundërt
anasjelltas :: [a] -> [a] - Përcaktuar në GHC. Listë
: l - ngarkoni modulin e specifikuar dhe bëjeni aktual.
: m - ngarkoni ose shkarkoni modulin e specifikuar.
: q - mbyll GHCi.
Një veçori tjetër e dobishme është aftësia për të përcaktuar funksionet drejtpërdrejt në GHCi. Për këtë përdoret një konstrukt i thjeshtuar letre. Për shembull:
* Kryesor> le të f x = x + 2 * x
Konstrukti i plotë i letrës është i vlefshëm vetëm brenda shprehjes së tij:
* Kryesor> le z = 10 në z + z
GHCi raporton se emri i dhënë nuk është i përcaktuar në shtrirjen aktuale.
5.9 Funksionet e rendit më të lartë
Në Haskell, funksionet mund të përdoren si çdo objekt tjetër - ato mund të ruhen në lista dhe tuples, të kalojnë në funksione të tjera dhe të kthehen si rezultat i funksioneve të tjera.
Funksionet që pranojnë ose kthejnë funksione të tjera quhen funksione të rendit më të lartë. Një funksion i tillë, për shembull, është funksioni i hartës, i cili zbatohet funksioni i dhënë për të gjithë elementët e listës.
Plotësoni këtë seksion si duhet
Merrni parasysh funksionin e mbledhjes së dy numrave:
plus x y = x + y
Funksioni plus mund të përshkruhet ndryshe:
Operacioni +, i mbyllur në kllapa, është një funksion i 2 ndryshoreve, prandaj, duke aplikuar dy parametra në të, do të marrim shumën e tyre si rezultat. Nëse aplikojmë vetëm një argument për këtë funksion, për shembull, numrin 3, marrim një funksion të një argumenti, i cili specifikon shtimin e këtij argumenti në numrin 3:
Ky proces i ndarjes graduale të funksioneve në një funksion që merr një parametër dhe një funksion që kthen një funksion tjetër që llogarit gjithçka tjetër quhet funksioni kurrizues.
Një variant tjetër i përshkrimit të funksionit plus:
Duke përdorur funksionin plus (ndonjë nga zbatimet e mësipërme), mund të shkruhet një funksion në rritje:
përfshirë x = plus 1 x
Duke përdorur currying, mund të merrni një zbatim tjetër të të njëjtit funksion:
Rezulton se funksioni inc kthen një funksion që shton 1 në një nga parametrat e tij.
Përveç kësaj mënyre të shkrimit të funksioneve në Haskell, ekziston një mënyrë për të përdorur llogaritjen λ. Për shembull, funksioni plus mund të zbatohet si më poshtë:
plus = \ x y -> x + y
Këtu "\" nënkupton fillimin e një shprehje λ, pastaj renditen parametrat (x y) dhe pas shigjetës (->) është shprehja.
L-llogaritja mund të përdoret për të përcaktuar funksione të paemërtuara. Për shembull, mund të përdorni funksionin e shtimit pa e përshkruar veçmas:
Kjo shprehje është një funksion. Prandaj, duke aplikuar parametrat në të, do të marrim rezultatin.
(\ x y -> x + y) 3 6
Rezultati do të jetë numri 9.
Funksionet e paemërtuara janë të dobishëm, për shembull, kur kaloni funksionet si parametra te funksionet e tjera kur nuk keni nevojë të stiloni funksionin në mënyrë të përshtatshme.
Nëse ndonjë parametër i funksionit nuk përdoret gjatë llogaritjes së vlerës së tij, atëherë emri i tij mund të hiqet, duke e zëvendësuar atë me simbolin "_". Për shembull, një funksion që kthen parametrin e parë të dy mund të duket kështu:
Ose, në një shënim të rregullt:
e para dy x _ = x
5.10 Strukturat e të dhënave të pafundme
Haskell është një gjuhë jo strikte, domethënë përdor të ashtuquajturin vlerësim dembel (dembel). Siç u përmend më lart, kjo do të thotë se vlerësohen vetëm ato shprehje që janë të nevojshme për të llogaritur rezultatin e funksionit. Konsideroni një funksion të përcaktuar në vetvete:
Natyrisht, vlera e tij nuk mund të llogaritet. Nëse përpiqeni ta bëni këtë, do të ndodhë një lak i pafund. Le të shqyrtojmë një funksion tjetër:
Vlera e tij nuk varet nga parametri x. Prandaj, nuk ka nevojë të llogaritet. Dhe vlerësimi i shprehjes
nuk do të shkaktojë një lak të pafund dhe do të kthejë një rezultat të barabartë me 1.
Vlerësimi dembel si ky ju lejon të organizoni struktura të pafundme të dhënash si lista të pafundme. Një nga më mënyra të thjeshta Detyrat e listës së pafundme janë progresione aritmetike. Për ta bërë këtë, nuk keni nevojë të specifikoni fundin e intervalit. Për shembull, listat e mëposhtme janë të pafundme:
Ato vendosen vetëm nga dy elementët e parë, me të cilët llogaritet hapi i progresioneve. Nëse elementi i dytë i progresionit nuk është i specifikuar (si në shembullin e parë), atëherë hapi bëhet i barabartë me 1.
Në këto lista, është e mundur të kryhen të njëjtat operacione dhe të përdoren të njëjtat funksione si për listat e zakonshme, të cilat nuk kërkojnë të gjithë elementët e listës për të llogaritur rezultatin. Këto funksione përfshijnë marrjen e kokës dhe bishtit, funksionet për marrjen e elementit të i-të të listës, e kështu me radhë.
Listat e pafundme janë të dobishme për disa detyra. Për shembull, llogaritja e faktorialit mund të zbatohet si më poshtë:
fakt n = listë faktesh !! n
faktlist = fl 1 1
ku fl x n = x: (fl (x * n) (n + 1))
Funksioni për përcaktimin e faktorialit të numrit n (fakti n) kthehet si rezultat i n-të një element i listës së fakteve, i cili është një listë e pafundme faktorësh të të gjithëve numrat natyrorë... Elementet e kësaj liste llogariten dhe zënë memorie vetëm kur është e nevojshme të merren vlerat e tyre.
Jo vetëm listat mund të jenë të pafundme, por edhe çdo strukturë tjetër e të dhënave të përcaktuar nga programuesi, si pemët.
6 Llojet dhe modulet e të dhënave
6.1 Llojet dhe strukturat e të dhënave të përcaktuara nga përdoruesi
Kur përshkruani llojet e funksioneve, mund t'ju duhen sinonime të personalizuara për llojet ekzistuese. Për shembull, me një përkufizim të rëndë të një lloji të caktuar, është e përshtatshme ta emërtoni atë me një emër. Nuk është shumë e këndshme të shkruani diçka si [(Integer,)] çdo herë, është më e përshtatshme t'i jepni këtij lloji një emër, për shembull, MyType1. Ky përkufizim ka formën:
shkruani MyType1 = [(Numër i plotë,)]
Ky përkufizim tipi nuk përshkruan një strukturë të re të dhënash, por jep vetëm emrin e një kombinimi të llojeve tashmë ekzistuese.
Për të përcaktuar llojin tuaj të të dhënave, përdoret hyrja e mëposhtme:
të dhëna<имя> = <значение1> | <значение2> | ... | <значениеN>
Kështu, një strukturë e të dhënave e quajtur<имя>, të cilat mund të jenë 1, 2, e kështu me radhë deri në N. Këto vlera të tipit të të dhënave janë konstruktorë të të dhënave. Çdo konstruktor duhet të ketë një emër unik duke filluar me shkronje e madhe... Emri i konstruktorit të të dhënave mund të jetë i njëjtë me emrin e llojit të të dhënave Për shembull, përshkrimi i llojit të të dhënave "color" mund të përfaqësohet si më poshtë:
të dhënat Ngjyra = E kuqe | E gjelbër | Blu
Përveç kësaj, konstruktori mund të pranojë disa të dhëna si funksion. Për shembull, mund të plotësoni llojin e të dhënave të ngjyrave duke shtuar një paraqitje ngjyrash në një kombinim të kuq, jeshil dhe blu:
të dhënat Ngjyra = E kuqe | E gjelbër | Blu | RGB Double Double Double
Ky shënim do të thotë që objektet e llojit Color mund të marrin vlerat e Kuqe, Jeshile, Blu ose RGB r g b, ku r g b janë numra realë. Për shembull, mund të përcaktoni një funksion që kthehet në të verdhë:
Specifikimi i llojeve të të dhënave mund të jetë polimorfik, ashtu si specifikimi i funksioneve. Kjo do të thotë, ju mund të specifikoni një lloj të dhënash që përmban një lloj tjetër, por jo një lloj specifik. Për shembull, tip standard Ndoshta mund të përshkruhet si më poshtë:
të dhëna Ndoshta a = Asgjë | Vetëm një
Kjo do të thotë se një objekt i tipit (Ndoshta a) mund të jetë ose Asgjë ose Vetëm x, ku x është një objekt i një lloji a. Përputhja e modelit përdoret për të hyrë në objekte të tilla. Për shembull, mund të zbatoni funksionin e padrejtë që do të kthejë përmbajtjen e klasës së kontejnerit Maybe nëse nuk është asgjë.
i padrejtë (Vetëm a) = a
Le të shqyrtojmë një shembull tjetër:
gjeni :: (Eq a) => a -> [a] -> Ndoshta Int
gjej _ = Asgjë
| x == a = Vetëm 0
| ndryshe = rast (gjeni një xs) të
(Vetëm i) -> Vetëm (i + 1)
Asgjë -> Asgjë
Ky funksion kthen indeksin e shfaqjes së parë të objektit të kaluar si parametër i parë në listën e kaluar si parametër i dytë, ose Asgjë nëse nuk ekziston. Përkufizimi i funksionit përdor klasën Eq, e cila kufizon llojet e parametrave të funksionit në lloje të krahasueshme. Klasat do të trajtohen në kapitullin tjetër.
Çdo strukturë e të dhënave mund të përshkruhet duke përdorur fjalën kyçe të të dhënave. Le të përshkruajmë një pemë binare si një shembull tjetër:
Pema e të dhënave a = Nil | Nyja a (pema a) (pema a)
Ky përkufizim thotë se një pemë me elementë të tipit a mund të jetë ose një pemë bosh ose të përbëhet nga një element i tipit a dhe 2 pemë të tjera, të cilat përcaktohen në mënyrë të ngjashme.
Le të përshkruajmë funksionin e shtimit të një elementi në një pemë kërkimi binar.
addtotree Nil x = Nyja x Nil Nil
addtotree (Nyja y majtas Djathtas) x
| x | x> y = Nyja y majtas (shtoni pemën djathtas x) | ndryshe = Nyja y majtas djathtas Kur shtohet në një pemë të zbrazët, rezultati është një pemë me një nyje të vetme që përmban elementin që shtohet. Dhe në rast se pema nuk është bosh, atëherë, në varësi të marrëdhënies së elementit të shtuar me elementin në rrënjën e pemës, zgjidhet strategjia tjetër e llogaritjes. Nëse elementi që shtohet është më i vogël, atëherë ai duhet të shtohet në nënpemën e majtë, prandaj, rezultati do të jetë një pemë me të njëjtin çelës dhe nënpemë të djathtë, por me një nënpemë të re të majtë të marrë kur elementi është shtuar në atë të vjetër. . Nëse elementi i shtuar është më i madh se rrënja, atëherë do të rezultojë në një pemë me një nënpemë djathtas të modifikuar. Nëse elementi i shtuar përputhet me atë rrënjë, atëherë rezultati do të përputhet me pemën e dhënë si argument. Ne do të organizojmë daljen e pemës në ekran në një formë me parvaz, duke përcaktuar funksionin e shndërrimit të saj (pemës) në një varg. pema showtree = pema showtr 0 ku showtr (Nil) n = përsërit n "\ t" ++ "- \ n" showtr (Nyja x majtas djathtas) n = showtr djathtas (n + 1) ++ repliko n "\ t" ++ shfaq x ++ "\ n" ++ showtr majtas (n + 1) Funksioni lokal showtr merr dy argumente, një pemë dhe një nivel thellësie. Funksioni i shfaqur i përdorur është një funksion standard për vargun e pothuajse çdo objekti në Haskell. Tani, si rezultat i vlerësimit të shprehjes addtotree (addtotree (addtotree (addtotree (addtotree (addtotree (addtotree Nil që do të thotë mbledhje sekuenciale në pemën e numrave të plotë 5, 3, 8, 1, 4, 6, 9, marrim një objekt të tipit Tree. Duke e kaluar në funksionin tonë showtree, marrim një paraqitje të vargut të kësaj peme. Ekziston një mënyrë tjetër për të përcaktuar të dhënat e personalizuara - fjala kyçe e tipit të ri. Përdorimi i tij është pothuajse i njëjtë me të dhënat, përveç një gjëje: llojet e të dhënave të përshkruara me newtype kanë vetëm një konstruktor të dhënash me saktësisht një fushë. Kjo metodë përdoret për të krijuar një lloj të ri të dhënash bazuar në një ekzistues: tipi i ri MyInt = MyInt Int Për më tepër, është e mundur të përcaktohen strukturat e të dhënave siç janë regjistrimet me fusha të emërtuara. Përdorimi i tupleve të zakonshëm ose strukturave të të dhënave gjatë përdorimit të objekteve me një numër të madh të vetive të ndryshme nuk është gjithmonë i përshtatshëm. Duhet të mbani mend rendin e sekuencës së tyre dhe të lundroni vetëm sipas tij, ose të filloni funksionin përkatës për secilën nga vetitë. Regjistrimi me fusha të emërtuara automatizon këtë proces dhe siguron akses në elementët e tij nëpërmjet emrave, gjë që e thjeshton shumë punën. Përshkrimi i tyre është si më poshtë: <имя записи> { <имя поля 1> :: <тип поля 1>, <имя поля 2> :: <тип поля 2>, <имя поля N> :: <тип поля N>} Për shembull: të dhënat Njerëz = Njerëz ( lartësia :: Dyshe, Për të përcaktuar një objekt të këtij lloji ti mund te shkruash: mike = Njerëz (emri = "Mike", lartësia = 173.4, pesha = 81.3) Për të ndryshuar një objekt të tillë, më saktë për të marrë një të ri, por me disa nga fushat e ndryshuara, mund të shkruani kështu: john = mike (emri = "Gjon") Haskell mbështet programimin modular, domethënë një program mund të ndahet në module dhe secili modul mund të përdoret në programe të shumta. Çdo modul duhet të duket si: Nëse pjesa opsionale hiqet, atëherë ky modul nuk mund të përdoret nga modulet e tjera. Emri i modulit, si dhe llojet e të dhënave, duhet të fillojnë me një shkronjë të madhe dhe gjithashtu të përputhen me emrin e skedarit. Për të fituar akses në përkufizimet (funksionet, llojet e të dhënave, klasat) në modulet e jashtme, duhet t'i përshkruani ato në fillim të programit si më poshtë: importit<модуль1> importit<модульN> <остальной код> Pas kësaj, të gjitha përkufizimet nga këto module bëhen të disponueshme në modulin aktual. Por nëse funksionet ose llojet e të dhënave përcaktohen në modulin aktual që përkojnë me emër me ato të importuara, ose nëse funksionet ose llojet e të dhënave me të njëjtin emër shfaqen në shtojca të ndryshme, do të ndodhë një gabim. Për të shmangur këtë, është e nevojshme të ndalohet përdorimi i përkufizimeve të tilla nga modulet përkatëse. Kjo bëhet si më poshtë: importit<модуль>duke u fshehur (<скрываемые определения>) Përveç kësaj, kur përshkruani vetë modulin e importuar, është e mundur të kontrolloni aksesin në përkufizime. Për ta bërë këtë, duhet të renditni përkufizimet e disponueshme në kllapa pas emrit të modulit: modul<Имя>(<определения>) ku<код> Nga të gjitha përshkrimet për modulet e jashtme, do të jenë të disponueshme vetëm ato të renditura në kllapa. Një shembull është një program me 3 module: --
Prog.
hs moduli Prog ku importo Mod2 fshehur (modfun) moduli Mod1 (modfun) ku modfun = pesë * 2 moduli Mod2 ku Funksioni modfun i përcaktuar në modulin Mod1 disponohet nga moduli Prog, por funksioni pesë nuk është i disponueshëm. Haskell nuk e mbështet paradigmën e orientuar nga objekti. Por ajo është paksa e ndryshme nga e zakonshme, e pranuar në gjuhë të tjera. Një shembull i një klase është një strukturë të dhënash. Çdo klasë supozon përshkrimin e disa funksioneve për të punuar me llojet e të dhënave, të cilat janë shembuj të kësaj klase. Shënimi i mëposhtëm përdoret për të përcaktuar një klasë: klasa [(<ограничения>) =>] <имя> <переменная типов>ku<функции> Një variabël tip emërton një lloj që duhet të jetë një shembull i kësaj klase. Pas fjalës ku ka përshkrime të llojeve të funksioneve, si dhe shprehje të disa prej këtyre funksioneve nëpërmjet njëri-tjetrit. Me ndihmën e këtyre shprehjeve, interpretuesi do të jetë në gjendje të përcaktojë një pjesë të funksioneve të vetë instancës së klasës, nëse specifikohet një pjesë tjetër. Kufizimet janë përkufizimi që një shembull i klasës sonë duhet të jetë gjithashtu një shembull i klasave të listuara këtu. Është një lloj trashëgimie. Le të shqyrtojmë një shembull: klasa Eq a ku (==), (/ =) :: a -> a -> Bool x == y = jo (x / = y) x / = y = jo (x == y) Klasa Eq është një klasë e tipit të krahasueshëm. Funksionet e barazisë dhe të pabarazisë duhet të përcaktohen për çdo instancë të kësaj klase. Rreshti i dytë do të thotë që funksionet (==) dhe (/ =) duhet të marrin dy argumente të tipit a dhe të kthejnë një objekt të tipit Bool, pra, True ose False. Rreshtat e mëposhtëm në përkufizimin e klasës thonë se nëse një funksion (/ =) është përcaktuar, atëherë funksioni (==) përcaktohet përmes tij në përputhje me rrethanat, dhe anasjelltas. Falë kësaj, programuesi duhet vetëm të përcaktojë funksionin e krahasimit për barazinë (ose pabarazinë), dhe interpretuesi do të përcaktojë vetë funksionin tjetër. Një shembull tjetër i përkufizimit të klasës, por me trashëgimi: klasa Eq a => MyClass a ku myFunc :: [a] -> a -> Int Kur përcaktohet një klasë, mund të deklaroni çdo lloj të dhënash si shembull të kësaj klase: shembull MyClass Double ku | x == z = 1 + myFunc xs z | ndryshe = myFunc xs z Kështu, ne deklarojmë tipin standard Double si një shembull të klasës sonë MyClass dhe përcaktojmë funksionin myFunc si një funksion që llogarit numrin e elementeve në argumentin e parë të barabartë me argumentin e dytë të funksionit. Pasi të keni përcaktuar një lloj si një shembull i një klase, mund të aplikoni funksionet e përshkruara në objekte të këtij lloji. test = myFunc x 2 ku Klasat përdoren shpesh kur përshkruajnë funksione me parametra polimorfikë. Për shembull, nëse duhet të përshkruani një funksion që përdor një operacion krahasimi për shumë lloje të dhënash, duhet të specifikoni që parametrat e tij që marrin pjesë në krahasim duhet të jenë të tipit të klasës Eq, e cila garanton zbatimin e funksionit përkatës. Kur një programues përshkruan strukturën e tij të të dhënave, ajo nuk i përket asnjërës prej klasave. Nëse është e nevojshme, programuesi duhet të zbatojë funksionet e duhura për strukturën e tij dhe të tregojë anëtarësimin në klasë. Për shembull, struktura e të dhënave të pemës së përshkruar më parë mund të shpallet një shembull i klasës Show në mënyrë që interpretuesi ta shfaqë atë në ekran pa përdorur një thirrje manuale në funksionin showtree. Për ta bërë këtë, shkruani: shembull Trego a => Trego (Pema a) ku Pas kësaj, kur interpretuesi të marrë rezultatin e tipit Tree, ai do të jetë në gjendje ta shfaqë atë në ekran, dhe gjithashtu çdo funksion tjetër mund të konvertojë objektin Tree në një formë vargu duke përdorur funksionin show. Ekziston gjithashtu një mënyrë tjetër për të deklaruar se një lloj i përket një klase. Është më e thjeshtë, por mund të mos plotësojë gjithmonë nevojat e programuesit. Ai konsiston në renditjen e klasave të kërkuara menjëherë kur deklaroni strukturën: të dhëna<имя> = <значение1> | <значение2> | ... | <значениеN>duke nxjerrë (<класс1>,<класс2>,...,<классM>) Këtu funksionet e nevojshme do të shfaqen automatikisht nëse është e mundur. Kështu, për shembull, le të përcaktojmë llojin tonë të pemës në shembuj të klasës Eq në mënyrë që pemët të krahasohen me njëra-tjetrën. Pema e të dhënave a = Nil | Pema a (Pema a) (Pema a) Tani është e mundur të krahasohen pemët me operacionin "==" dhe i lejon ato të përdoren në funksione që e kërkojnë atë. Është e mundur të shkruhet më shumë për monadat Siç u përmend më lart, Haskell është një gjuhë programimi e pastër funksionale, domethënë funksionet në të nuk mund të kenë efekte anësore, dhe rendi i vlerësimit të funksioneve nuk është i përcaktuar. Por në disa raste është e pamundur të bëhet pa të. Raste të tilla përfshijnë punën me një përdorues, me skedarë, me baza të të dhënave, etj. Gjuha Haskell parashikon përcaktimin e funksioneve të tilla duke përdorur monadat - klasa speciale të kontejnerëve. Në mësimin e Haskell-it "monadat konsiderohen si pjesa më e vështirë, prandaj le të fillojmë menjëherë me shembuj. Shpjegimet e disa gjërave do të hiqen për të mos ngatërruar lexuesin. Merrni parasysh shembullin e mëposhtëm: putStrLn "Përshëndetje botë!" putStrLn "Mirupafshim botë!" Në këtë shembull, funksioni kryesor ka efekte anësore - si rezultat i vlerësimit të tij, teksti shfaqet në ekran, dhe ai përcakton rendin e vlerësimit - së pari shfaqet rreshti i parë në ekran, pastaj i dyti. Kur përdorni shënimin do, programimi i funksioneve "të papastër" duke përdorur monadat reduktohet në programim imperativ pothuajse të njohur. Çdo rresht tjetër duhet të jetë një funksion i një lloji të veçantë - një tip monadik. Në rastin e punës me I / O, ky është lloji (IO a). Funksionet e mëposhtme përdoren për të punuar me vijën e komandës: putChar :: Char -> Prodhimi i karaktereve IO putStr :: String -> vargu i daljes IO putStrLn :: String -> IO nxjerr një linjë me një linjë të re IO a është një tip monadik I/O që fsheh efekte anësore në vetvete. Lloji IO String do të thotë që funksioni do të kthejë një rezultat që përmban një varg, dhe IO () do të thotë që funksioni kthen një rezultat që nuk përmban asgjë, kuptimi i thirrjes së tij është vetëm në efekte anësore (për shembull, dalje). Shembull: putStrLn "Si e ke emrin?" emri<- getLine Këtu hyn "detyra". Për analogji me gjuhët urdhërore mund të themi se në rresht emri<- getLine rezultati i funksionit getLine iu caktua emrit të ndryshores. Por, siç e dimë, nuk ka variabla në Haskell dhe për rrjedhojë nuk ka caktime. Në këtë rast, u krijua një objekt i quajtur emri, vlera e të cilit është e barabartë me rezultatin e funksionit getLine. Kjo do të thotë, nëse pas që ju shkruani përsëri emri<- getLine atëherë do të krijohet një objekt i ri, emri i të cilit do të mbivendoset me atë të mëparshëm. Kështu merren rezultatet e funksioneve monadike. Për të vendosur "ndryshoret" në këtë mënyrë nga vlerat e funksioneve të zakonshme, përdoret një shënim i thjeshtuar i letrës: let emri = "Gjoni" Degëzimi i procesit llogaritës kryhet duke përdorur të njëjtën nëse atëherë tjetër dhe rast: putStrLn "Si e ke emrin?" emri<- getLine "GHC" -> putStrLn "Jo! Unë jam GHC!" _ -> putStrLn ("Përshëndetje", ++ emri ++ "!") Nëse një degë duhet të përbëhet nga disa funksione, atëherë përdoret fjala kyçe do: putStrLn "Si e ke emrin?" emri<- getLine putStrLn "Jo! Unë jam GHC!" _ -> putStrLn ("Përshëndetje", ++ emri ++ "!") Sythet kryhen duke përdorur rekursionin, siç tregohet më sipër, ose duke përdorur funksione speciale (të zbatuara gjithashtu në mënyrë rekursive). Këto funksione përfshijnë funksionin mapM_. Parimi i tij i funksionimit është i ngjashëm me funksionin e hartës për listat - ai aplikon një funksion monadik për të gjithë elementët e listës dhe i ekzekuton ato në mënyrë sekuenciale. Shembull: shkruajShifra x = bëj putStr "Shifra:" hartaM_ shkruaniDigit Jepni shembuj të ndryshëm (kërkoni pemë, pemë AVL, çfarëdo) konkluzioni 1 http:// ru. wikibooks. org / wiki / Bazat e_Programimit_Funksional 2 http://www. ***** / artikull / funcprog / fp. xml 3 Programimi Dushkin në gjuhën Haskell - DMK Press, 2007 - 608 f. 4 http:// en. wikibooks. org / wiki / Haskell / Pattern_matching 5 http://www. haskell. org / tutorial / Në Haskell, thirrja e një funksioni nuk kërkon kllapa rreth argumentit. Kllapat përdoren për të grupuar argumentet: acos (cos pi) Funksioni i shumë argumenteve: maksimumi 5 42 Operacioni i aplikimit të një funksioni është shoqërues në të majtë: (maksimumi 5) 42 Funksioni maksimumi zbatohet në mënyrë sekuenciale në dy argumente. Shprehje (maksimumi 5) ky është i ashtuquajturi aplikacion i funksionit të pjesshëm. Në përgjithësi, ai mund të formulohet si më poshtë: nëse kemi një funksion të ndryshoreve N dhe e shikojmë atë si një funksion të ndryshoreve N, atëherë mund ta shikojmë nga ana tjetër dhe të themi se ky është një funksion i njërës ndryshore. që na kthen një funksion të ndryshores N - 1. 3 + mëkati 42 3 + (maksimumi 5) 42 Një funksion që përmbledh katrorët e dy argumenteve që i janë dhënë: ShumaKatrore x y = x ^ 2 + y ^ 2 rock "n" roll = 42 Një funksion me tre argumente që llogarit gjatësinë e një vektori 3D: LenVec3 x y z = sqrt (x ^ 2 + y ^ 2 + z ^ 2) Le të jetë shuma katrore x y = x ^ 2 + y ^ 2 Një funksion që nuk merr argumente është një konstante. Një funksion i tillë kthen të njëjtën vlerë gjatë gjithë kohës, pavarësisht nga çdo rrethanë. Preludi> le dyzet e dy = 39 + 3 Preludi> dyzet e dy 42 Në Haskell, nuk mund të përcaktoni një funksion që nuk merr argumente dhe kthen vlera të ndryshme për thirrje të ndryshme. Ne mund të shikojmë çdo funksion si funksion të një argumenti që kthen një funksion. Preludi> le max5 x = max 5 x Prelude> max5 4 5 Prelude> max5 42 42 Prelude> le max5 "= max 5 Prelude> max5" 4 5 Prelude> max5 "42 42 Ne kemi shkurtuar argumentin shtesë x majtas dhe djathtas. Dhe ata shkruan se funksioni max5 "është vetëm një funksion i aplikuar pjesërisht max. Kështu, ju mund të përcaktoni një funksion pa specifikuar të gjitha argumentet. Stili përkatës i programimit quhet i pakuptimtë. Shpesh, dizajni i funksioneve në Haskell akordohet në atë mënyrë që aplikimi i pjesshëm të jetë i përshtatshëm; Preludi> le të limitojë zbritjen proc sum = nëse shuma> = limit atëherë shuma * (100 - proc) / 100 tjetër shuma Preludi> le standardDiscount = zbritje 1000 5 Prelude> standardZbritje 2000 1900.0 Prelude> standardZbritje 900 900.0 Parametrat limit dhe proc ndryshohen rrallë. Megjithatë, parametri i shumës ndryshon shpesh. Në fakt, sa herë që thirret ky funksion. Supozoni se po zhvillojmë një ndërfaqe të sistemit të përkthimit për gjuhët natyrore në Haskell. Ai duhet të përmbajë një funksion përkthimi me teksti i parametrave, gjuhaNga dhe gjuhaPër. Për ta bërë të përshtatshëm zbatimin e funksioneve të mëposhtme: Prelude>: jo jo :: Bool -> Bool Prelude> (&&) False E vërtetë E rreme Preludi> ((&&) False) E vërtetë E gabuar Lloji i shprehjes së fundit mund të shkruhet si më poshtë: Preludi>: t (&&) (&&) :: Bool -> Bool -> Bool Le të kujtojmë funksionin e zbritjes, i cili ktheu shumën totale të blerjes me një zbritje të mundshme. Si parametra, u kalua shuma pa shumën e skontimit, përqindja e zbritjes proc dhe zbritja u ngarkua nëse shuma e transferuar e kalon kufirin. Të gjithë këta parametra, si dhe vlera e kthyer, mund të ruhen në llojin Double. Lloji i funksionit mund të specifikohet në skedarin burimor së bashku me përkufizimin e tij: zbritje :: Dyfish -> Dyfish -> Dyfish -> Kufiri i dyfishtë i zbritjes proc sum = nëse shuma> = limit atëherë shuma * (100 - proc) / 100 tjetër shuma Vini re se deklarata e tipit është fakultative, megjithëse shpesh rekomandohet për qëllime dokumentimi. Zakonisht vendoset përpara përkufizimit të funksionit, megjithëse kjo deklaratë niveli më i lartë mund të gjendet kudo në skedarin burimor. StandardDiscount :: Dyfish -> Double StandardDiscount = zbritje 1000 5 Merrni parasysh funksionin twoDigits2Int, i cili merr dy karaktere dhe kthen një numër të përbërë nga ato karaktere nëse të dy karakteret janë numerikë, dhe 100 përndryshe. (Karakteri i parë konsiderohet si numri i dhjetësheve, i dyti si numri i njësive.) Importoni të dhëna.Char twoDigits2Int :: Char -> Char -> Int twoDigits2Int x y = nëse është Shifra x && ështëDigit y atëherë digitToInt x * 10 + digitToInt y tjetër 100 GHCi> twoDigits2Int "4" "2" 42 Faktorial n = nëse n == 0 atëherë 1 tjetër n * faktorial (n - 1) Faktorial5 n | n> = 0 = ndihmës 1 n | përndryshe = gabim "arg duhet të jetë> = 0" ndihmës acc 0 = ndihmës acc acc n = ndihmës (acc * n) (n - 1) Një zbatim i tillë në rastin e një faktoriali nuk sjell ndonjë përfitim shtesë, por shumë shpesh implementime të tilla mund të përmirësojnë efikasitetin e funksioneve rekursive. Në shumë raste, në funksionet rekurzive, duke dhënë një përkufizim të drejtpërdrejtë të një funksioni rekurziv për sa i përket vetvetes, mund të merret asimptotika polinomiale kuadratike ose më e lartë. Dhe në rastin e përdorimit funksionet ndihmëse shumë shpesh është e mundur të korrigjohen asimptotika duke e reduktuar atë në lineare. DoubleFact :: Integer -> Integer doubleFact n = nëse n<=
0
then
1
else
n *
doubleFact (n -
2
) Në Haskell, ky përkufizim jepet nga funksioni i mëposhtëm: Fibonacci :: Integer -> Integer fibonacci n | n == 0 = 0 | n == 1 = 1 | n> 1 = fibonacci (n - 1) + fibonacci (n - 2) | n<
0
=
fibonacci (n +
2
) -
fibonacci (n +
1
)
|
otherwise =
undefined Zbatimi i një funksioni për llogaritjen e numrit Fibonacci, bazuar në një përkufizim të drejtpërdrejtë rekursiv, është jashtëzakonisht joefikas - numri i thirrjeve të funksionit rritet në mënyrë eksponenciale me një rritje të vlerës së argumentit. GHCi ju lejon të gjurmoni përdorimin e kujtesës dhe kohën e shpenzuar për vlerësimin e një shprehjeje duke ekzekutuar komandën: set + s: * Fibonacci>: set + s * Fibonacci> fibonacci 30 832040 (16,78 sekonda, 409, 318, 904 bajt) Duke përdorur mekanizmin e akumuluesit, mund të shkruani një zbatim më efikas që ka kompleksitet linear (nga numri i thirrjeve rekursive): Fibonacci ":: Integer -> Integer fibonacci" n = ndihmës n 0 1 ndihmës n a b | n == 0 = a | n> 0 = ndihmës (n - 1) b (a + b) | n<
0
=
helper (n +
1
) b (a -
b)
|
otherwise =
undefined Preludi>: t ($) ($) :: (a -> b) -> a -> b Është tip polimorfik. Operatori i dollarit është një funksion i dy argumenteve. Operandi i tij i majtë ose argumenti i parë (a -> b) është një funksion. Operandi i tij i djathtë a është një vlerë arbitrare. Operatori i dollarit thjesht zbaton argumentin e tij të parë (a -> b) në argumentin e tij të dytë a. Prandaj, këtu është e nevojshme që llojet të jenë të qëndrueshme. Lloji i argumentit të dytë për operatorin e dollarit duhet të përputhet me llojin e parametrit të funksionit që kalohet në argumentin e parë. Për më tepër, rezultati i ekzekutimit të operatorit të dollarit është rezultat i funksionit të kaluar si argumenti i parë. Meqenëse lloji i rezultatit është b, rezultati i deklaratës së dollarit është lloji b. Përdorimi i mëposhtëm është i vlefshëm vetëm kur a dhe b janë të njëjta. Preludi> le të aplikohet2 fx = f (fx) Preludi>: t zbatohet2 zbatohet2 :: (t -> t) -> t -> t Preludi> aplikohet2 (+ 5) 22 32 Preludi> aplikohet2 (++ "AB") " CD "" CDABAB" Argumenti i parë është me të vërtetë një funksion, por argumenti dhe vlera e kthimit janë të të njëjtit lloj. Dhe argumenti i dytë është vlera e këtij lloji, dhe vlera e kthimit është gjithashtu vlera e këtij lloji. Kështu, funksioni aplik2 mund të aplikohet në një grup funksionesh më të kufizuar se dollari. Nëse dollari është polimorfik në argument dhe vlerë kthyese, atëherë apply2 është polimorfik vetëm në një parametër. Funksioni flip nga biblioteka standarde përcaktohet si më poshtë: flip f y x = f x y. Prelude> rrokullisje (/) 4 2 0.5 Prelude> (/) 4 2 2.0 Prelude> rrokullisje konst 5 Prelude e vërtetë e vërtetë>: t rrokullisje :: (a -> b -> c) -> b -> a -> c Preludi>: t rrokullisje konst rrokullisje konst :: b -> c -> c (- Një funksion i dobishëm i rendit më të lartë është përcaktuar në modulin Data.Function -) më :: (b -> b -> c) -> (a -> b) -> a -> a -> c në op f x y = f x `op` f y (- Duhen katër argumente:
1) operator binar me të njëjtin lloj argumentesh (lloji b),
2) një funksion f :: a -> b që kthen një vlerë të tipit b,
3,4) dhe dy vlera të tipit a.
Funksioni on aplikon f dy herë në dy vlera të tipit a dhe ia kalon rezultatin një operatori binar.
Duke përdorur on, mund, për shembull, të shkruani funksionin e mbledhjes së katrorëve të argumenteve si kjo :-) sumSquares = (+) `on` (^ 2) (- Funksioni multSecond, i cili shumëzon elementët e dytë të çifteve, zbatohet si më poshtë -) multSecond = g `on` h g = (*) h = snd Preludi> (\ x -> 2 * x + 7) 10 27 Preludi> le f "= (\ x -> 2 * x + 7) Preludi> f" 10 27 Është një funksion anonim ose funksion lambda. Ka sheqer sintaksor për të thjeshtuar shënimin. Preludi> le lenVec xy = sqrt $ x ^ 2 + y ^ 2 Prelude> le lenVec x = \ y -> sqrt $ x ^ 2 + y ^ 2 Prelude> le lenVec = \ x -> \ y -> sqrt $ x ^ 2 + y ^ 2 Prelude> lenVec 3 4 5.0 Prelude> le lenVec = \ xy -> sqrt $ x ^ 2 + y ^ 2 Prelude> lenVec 3 4 5.0 (- Funksioni on3, ka semantikë të ngjashme me on, por merr një funksion me tre vende si argumentin e tij të parë -) on3 :: (b -> b -> b -> c) -> (a -> b) -> a -> a -> a -> c on3 op f x y z = op (f x) (f y) (f z) (- Shuma e katrorëve të tre numrave mund të shkruhet duke përdorur on3 si kështu -) shuma 3 katrore = (\ x y z -> x + y + z) `on3` (^ 2) Preludi> fst (1, 2) 1 * Demo>: t on on :: (b -> b -> c) -> (a -> b) -> a -> a -> c * Demo>: t curry fst `on` (^ 2) curry fst `on` (^ 2) :: Num b => b -> b -> b Mesatare :: (Dyfish, Dyfish) -> Mesatare e dyfishtë p = (fst p + snd p) / 2 Funksioni curry avg `on` (^ 2) është një funksion që llogarit mesataren e katrorëve të dy vlerave që i kalohen. Funksioni i kerit është: Preludi> le cur fxy = f (x, y) Preludi>: t cur cur :: ((t1, t2) -> t) -> t1 -> t2 -> t Preludi>: t curry curry :: ((a , b) -> c) -> a -> b -> c Ai merr një funksion të pandërprerë si argument të parë, d.m.th. funksion mbi një çift, por e kthen atë si një vlerë të kthimit në një funksion të caktuar në të cilin argumentet kalohen në mënyrë sekuenciale. Ekziston gjithashtu një funksion i kundërt uncurry: Prelude>: t uncurry uncurry :: (a -> Prelude>: t uncurry (rrokullisje konst) uncurry (flip const) :: (b, c) -> c Prelude>: t snd snd :: (a, b) - > b Moduli Data.Tuple i bibliotekës standarde përcakton funksionin swap :: (a, b) -> (b, a), i cili ndërron elementet e një çifti: GHCi> shkëmbim (1, "A") ("A", 1) Ky funksion mund të shprehet si: Prelude> le të shkëmbejmë = i pandërprerë (rrokullisje (,)) Prelude> shkëmbejmë (1, "A") ("A", 1) Const42 :: a -> Int const42 = const 42 Funksioni const42 injoron plotësisht vlerën e argumentit, prandaj, brenda kornizës së modelit të llogaritjes dembel, nëse kaloni ndonjë llogaritje komplekse atëherë kjo llogaritje nuk do të ndodhë kurrë. Kjo do të thotë që çdo program, duke përfshirë një program jo-përfundues, mund të kalohet si argument në const42. * Demo> const42 E vërtetë 42 * Demo> const42 123 42 * Demo> const42 (1 + 3) 42 * Demo> const42 e papërcaktuar 42 Funksionet si const42 quhen funksione të dobëta. Nëse një llogaritje divergjente i kalohet një funksioni si argument, dhe rezultati është një vlerë që nuk është divergjente, atëherë një funksion i tillë quhet jo i rreptë. Një funksion quhet strikt i tillë që nëse i kalojmë një argument divergjent, atëherë vlera e këtij funksioni është domosdoshmërisht divergjente. Një funksion me dy argumente mund të jetë i rreptë ose jo i rreptë në argumentin e dytë, në varësi të vlerës së argumentit të tij të parë. Analiza e ashpërsisë është e nevojshme për ta bërë një program Haskell shumë efikas. Përshëndetje Habr! Sot kam nxjerrë shënimet e mia të vjetra për kursin "Haskell si gjuha e parë e programimit" nga Sergei Mikhailovich Abramov dhe do të përpiqem t'u tregoj sa më qartë dhe me shembuj për këtë gjuhë të mrekullueshme atyre që nuk janë ende të njohur me të. Tregimi i drejtohet lexuesit të papërgatitur. Pra, edhe nëse keni dëgjuar për herë të parë fjalën Haskell ... Numrat Numrat me pikë lundruese: Vlerat Boolean Simbolet Listat Disa operacione standarde në shembujt: Komplete të porositura Por, zemra e Haskell dhe e gjithë programimit funksional janë, natyrisht, vetë funksionet! Rreshti i parë është deklarata e funksionit: Rreshti i dytë është përkufizimi i funksionit: Një funksion pa parametra nuk është gjë tjetër veçse një konstante: Funksioni me parametra të shumtë: Rasti… i… Por përveç nëse dhe rastit standard, Haskell ka një konstrukt degëzimi shumë të bukur dhe më të përdorur. E ashtuquajtura, shprehje roje... Shembull: Epo, kjo është e gjitha për sot. Nëse ka interes, do të shkruaj një vazhdim në të ardhmen e afërt. Edhe pse nuk përputhet me njërin tuaj kritere të mëdha(hyrje statike *) Unë do të krijoj një rast për Python. Këtu janë disa arsye që mendoj se duhet t'i hidhni një sy kësaj: Unë e kuptoj nëse jeni duke kërkuar për diçka tjetër. Programimi logjik, për shembull, mund të jetë në rrugën tuaj, si të tjerët. * Unë po supozoj se ju po nënkuptoni shtypjen statike këtu pasi dëshironi të deklaroni llojet. Teknikisht, Python -
është një gjuhë e shtypur fort sepse nuk mund të interpretosh në mënyrë arbitrare, të themi, një varg si numër. Është interesante se ka derivate të Python që lejojnë shtypjen statike, siç është Boo. 2018-12-04T00: 00Z Nëse jeni pas një prologu të fortë personal, Mërkuri është një zgjedhje interesante. E kam bërë këtë në të kaluarën dhe më pëlqeu këndvështrimi tjetër që më dha. Ai gjithashtu ka modalitet (cilat parametra duhet të jenë të lirë / fiks) dhe determinizëm (sa rezultate ka?) në sistemin e tipit. Clean është shumë i ngjashëm me Haskell, por ka një shtypje unike që përdoret si një alternativë ndaj Monads (më konkretisht, monada IO). Veçantia e hyrjes gjithashtu bën gjëra interesante për punën me vargje. 2018-12-11T00: 00Z Meqenëse nuk keni specifikuar asnjë kufizim përveç interesave tuaja subjektive dhe theksoni "shpërblimin për të mësuar" (në rregull, në rregull, unë do të injoroj kufizimin e shtypjes statike), unë do të sugjeroja të mësoni disa gjuhë të paradigmave të ndryshme dhe mundësisht ato që janë “shembullore” për secilën prej tyre. Sidomos Lisps (CL nuk është aq sa Scheme) dhe Prolog (dhe Haskell) mbulojnë rekursionin. Megjithëse nuk jam mësues feje në asnjërën nga këto gjuhë, kalova pak kohë me njëri-tjetrin përveç Erlang dhe Forth, dhe të gjithë më dhanë një përvojë mësimore hapëse dhe interesante, ndërsa secili i qaset zgjidhjes së problemeve nga një këndvështrim tjetër. Pra, megjithëse mund të duket sikur kam injoruar pjesën se nuk keni kohë të provoni shumë gjuhë, më tepër mendoj se koha me asnjërën prej tyre nuk do të jetë e humbur dhe ju duhet t'i hidhni një sy të gjitha. 2018-12-18T00: 00Z Për sa i përket asaj që i përshtatet diplomës tuaj, zgjedhje e dukshme duket si një gjuhë logjike si Prolog ose derivatet e saj. Programimi logjik mund të bëhet shumë mirë në një gjuhë funksionale (shih, për shembull, The Reasoned Schemer), por ju mund të dëshironi të punoni drejtpërdrejt me paradigmën logjike. Një sistem provë teorike interaktive si dymbëdhjetë ose coq gjithashtu mund të fryjë imagjinatën tuaj. 2018-12-25T00: 00Z Do të doja të zgjeroja njohuritë e mia për programim. (...) Mendova se do të parashtroj një pyetje këtu, si dhe disa pika për llojin e gjuhës që kërkoj. Disa prej tyre janë subjektive, disa prej tyre synojnë të lehtësojnë kalimin nga Haskell. Sistemi i tipit të fortë. (...) Gjithashtu e bën më të lehtë arsyetimin joformal për korrektësinë e programit tim. Unë jam i shqetësuar për korrektësinë, jo efikasitetin. Theksimi i rekursionit mbi përsëritjen. (...) Kam frikë se mund ta lehtësoni pak kalimin këtu. Një sistem tipi shumë i rreptë dhe një stil thjesht funksional janë të zakonshme në Haskell dhe pothuajse çdo gjë që duket si një gjuhë programimi e zakonshme do të duhet të komprometohet nga të paktën, në njërën prej tyre. Pra, duke pasur parasysh këtë, këtu janë disa propozime të gjera që synojnë ruajtjen më i madh pjesë të asaj që ju pëlqen në Haskell, por me një ndryshim të rëndësishëm. Injoroni prakticitetin dhe shkoni për "më shumë Haskell se Haskell": Sistemi i tipit Haskell është plot vrima për shkak të përfundimit dhe kompromise të tjera të çrregullta. Pastroni rrëmujën dhe shtoni më shumë karakteristika të fuqishme dhe ju merrni gjuhë si Kok dhe Agda ku lloji i funksionit përmban vërtetimin e korrektësisë së tij (madje mund të lexoni shigjetën e funksionit -> si një implikim boolean!). Këto gjuhë u përdorën për prova matematikore dhe për programe me kërkesa jashtëzakonisht të larta saktësie. Coq është ndoshta gjuha e stilit më të spikatur, por Agda ka një ndjesi më Haskell-y (dhe shkruhet gjithashtu në Haskell). Mos numëroni llojet, shtoni më shumë magji: nëse Haskell është magji, Lispështë magjia e papërpunuar, primare e krijimit. Gjuhët Lisp (përfshirë Skema dhe Clojure) kanë fleksibilitet pothuajse të pashembullt të kombinuar me minimalizëm ekstrem. Gjuhëve në thelb u mungon sintaksa, duke shkruar kodin drejtpërdrejt si një strukturë e të dhënave në pemë; Metaprogramimi në Lisp është më i lehtë se jo-meta-programimi në disa gjuhë. Bëj pak kompromis dhe afrohu me rrjedhën kryesore: Haskell bën pjesë në një familje të gjerë gjuhësh që ndikojnë shumë në ML, në cilëndo prej të cilave ndoshta mund të migroni pa shumë vështirësi. Haskell është një nga më të rreptat kur bëhet fjalë për saktësinë e tipit dhe garancitë e stilit funksional, ku të tjerët janë shpesh ose stile hibride ose / ose bëjnë kompromise pragmatike. arsye të ndryshme... Nëse dëshironi të ekspozoni OOP dhe akses në një sërë platformash kryesore teknologjike, ose Scala në JVM, ose F # në .NET ka shumë të përbashkëta me Haskell, duke siguruar përputhshmëri të lehtë me platformat Java dhe .NET. F # mbështetet drejtpërdrejt nga Microsoft, por ka disa kufizime të bezdisshme në krahasim me Haskell dhe çështjet e transportueshmërisë në platformat jo-Windows. Scala ka homologë të drejtpërdrejtë me sistemin e tipit Haskell dhe potencialin ndër-platformë të Java-s, por ka një sintaksë më të rëndë dhe i mungon mbështetja e fuqishme e palëve të treta që bën F #.6.2 Modulet
7 Klasa dhe monadat
7.1 Klasat
7.2 I / O
8 Shembuj
konkluzioni
Lista e burimeve të përdorura
Sintaksa për dy identifikues të njëpasnjëshëm nënkupton aplikimin e funksionit foo në shiritin e tij të argumenteve:
Kompiluesi e kupton konstruksionin f x y si (f x) y, dhe jo anasjelltas f (x y).Sintaksa e Deklarimit të Funksionit të Personalizuar
Emri i funksionit dhe emrat formal të parametrave duhet të fillojnë me shkronja të vogla. Dhe karakteret e mëdha përdoren për të përcaktuar llojet e të dhënave.
Për të përcaktuar një funksion në interpretuesin GHCi, duhet të përdorim fjalën kyçe let. Vetia e pastërtisë së funksionit
Një karakteristikë e rëndësishme që dallon gjuhët funksionale nga gjuhët urdhërore është vetia e pastërtisë së funksioneve. Të gjitha funksionet në Haskell janë të pastra. Kjo do të thotë që vlera e funksionit përcaktohet plotësisht nga vlerat e argumenteve që i kalohen. Asnjë burim tjetër i të dhënave nuk mund të ndikojë në rezultatin e kthyer nga funksioni. Nëse ju nevojitet një funksion për të marrë të dhëna nga diku, atëherë duhet t'ia kaloni atij këtë burim të dhënash si argument. Mekanizmi për përcaktimin e funksioneve duke përdorur aplikimin e pjesshëm
Sintaksë alternative për përcaktimin e një funksioni:
ju duhet t'i rregulloni parametrat në rendin e mëposhtëm: përktheni gjuhënNë gjuhëNga teksti. Shkruani operatorin ->
Për të shkruar llojin e një funksioni, duhet të shkruani llojin e argumentit të tij dhe llojin e rezultatit të këtij funksioni. Në Haskell, për të përshkruar llojin e një funksioni, operatori -> është një operator binar në të cilin operandi i majtë është lloji i argumentit, dhe operandi i djathtë është lloji i rezultatit. Shigjeta është midis operandit të majtë dhe të djathtë t, k, ky është një operator infix.
Bool -> (Bool -> Bool)
Operatori i tipit konsiderohet i drejtë-shoqërues. Prandaj, Bool -> (Bool -> Bool) mund të rishkruhet si Bool -> Bool -> BoolRekursioni
Në gjuhët imperative, një lak është elementi kryesor i llogaritjes së përsëritur. Në gjuhët funksionale, sythe nuk janë shumë kuptimplotë. Meqenëse gjuhëve funksionale u mungon koncepti i një ndryshoreje të ndryshueshme, nuk ka asnjë mënyrë për të dalluar një përsëritje të ciklit nga një tjetër. Për të kryer llogaritje të përsëritura në gjuhë funksionale, përdoret rekursioni. Për të parandaluar një funksion rekurziv nga looping, ai duhet të plotësojë kërkesat e mëposhtme: Faktorial
Zbatimi i llogaritjes së faktorialit duke përdorur parametrin akumulues: Faktorial i dyfishtë
Konsideroni një funksion që llogarit një faktorial të dyfishtë, domethënë produktin e numrave natyrorë që nuk e kalojnë një numër të caktuar dhe kanë të njëjtin barazi. Për shembull: 7 !! = 7⋅5⋅3⋅1, 8 !! = 8⋅6⋅4⋅2. Supozohet se argumenti i funksionit mund të marrë vetëm vlera jo negative. Sekuenca e numrave të Fibonaçit
Funksionet e rendit më të lartë
Një funksion i rendit më të lartë është një funksion që merr një funksion tjetër si argument. Funksionet e rendit më të lartë janë të rralla në gjuhët imperative. Një shembull është funksioni i renditjes nga Biblioteka standarde C. Si argument i parë, një kallëzues krahasimi binar i kalohet funksionit të renditjes me ndihmën e të cilit kalohet një varg si argument i dytë dhe renditet. Funksionet e rendit më të lartë përdoren shumë shpesh në gjuhët funksionale dhe në Haskell. Funksionet anonime
Në Haskell, si në matematikë, funksionet zakonisht emërtohen. Kur duhet të thërrasim një funksion, i referohemi me emër. Megjithatë, ekziston një qasje alternative e quajtur funksione anonime.
Funksionet anonime përdoren kur përdoren funksione të rendit më të lartë. Funksionet kurrizore dhe të pandërprera
Me sintaksën për thirrjen e funksioneve në Haskell, mund të rendisni jo të gjitha argumentet, por vetëm një pjesë të tyre. Argumentet e para të një funksioni mund të specifikohen, dhe pjesa tjetër mund të hidhet poshtë. Kjo ide e aplikimit të pjesshëm të funksioneve u shpik nga Haskell Curry dhe për nder të tij funksione të tilla me argumente të kaluara një nga një quhen të kuruara. Në Haskell, jo të gjitha funksionet kryhen. Në Haskell, ju mund të përcaktoni funksionet në tuples. Në këtë rast, sintaksa për thirrjen e funksioneve do të duket e njëjtë si në gjuhët e zakonshme:
emri_funksionit (argumenti_i parë,argumenti_i dytë)
Currying është procedura për kalimin nga funksionet jo-curried në funksione që marrin argumente një nga një. Imagjinoni që kemi një funksion të rendit më të lartë, si kombinatori on, ai pret që 2 nga 4 argumentet e tij të jenë funksion. Argumenti i parë është një funksion me dy argumente i cili është i përpunuar. Haskell ka një kombinator të veçantë kerri që kalon nga një funksion i pandërprerë në një funksion të zhveshur. V shembullin e mëposhtëm curry kthen një funksion në një çift në një funksion standard të kuruar prej dy argumentesh.
Një shembull tjetër, një funksion mesatar i pandërprerë: Funksione të rrepta dhe të dobëta
Vlerësimi dembel çon në faktin se në shumë situata është e mundur të eliminohet paplotësia e programit. Shënime leksioni "Haskell si gjuha e parë e programimit". Pjesa 1
Llojet themelore të Haskell
Llojet bazë të gjuhës Haskell janë:
Numrat
Vlerat Boolean
Simbolet
Listat
Komplete të porositura (tupa)
Funksione
Numrat e plotë:
Numër i plotë (-∞, ∞)
Int (-2 ^ 31, 2 ^ 31-1)
Ka padyshim shumë funksione të dobishme për numrat e plotë në prelud (biblioteka standarde), duke përfshirë konvertimin në pikë lundruese (ngaInt dhe fromInteger)
Float (7 vende dhjetore)
Dyshe (16 shifra dhjetore)
Bool (E vërtetë | E gabuar)
Operacionet e lidhjes, shkëputjes dhe mohimit (&&, ||, jo)
Char ('a')
Dhe funksionet Char në Int dhe Int në Char (ord, chr)
Listat mund të jenë të ndryshme:
- një listë me numra të plotë
- lista e karaktereve (string)
[] - grup
është një listë funksionesh
etj.
Krye> kokë
1
Kryesisht> bisht
Gjatësia kryesore
2
Kryesor> anasjelltas
Kryesor> 0:
Main> - linja e shpejtë në tastierën e përpiluesit ghci
":" - operacioni i bashkëngjitjes së një elementi në listë.
Shembuj:
(2.4, "mace") (Not,)
('A', E vërtetë, 1) (Char, Bool, Int)
(, sqrt) (, Float-> Float)
(1, (2, 3)) (Int, (Int, Int))Funksione
Një funksion, në matematikën moderne, është një ligj i korrespondencës që lidh çdo element x nga një grup i caktuar A me një element të vetëm (ose asnjë) y nga një bashkësi B.
Haskell, për nga qëllimi i tij, është, para së gjithash, gjuha e matematikanëve, kështu që sintaksa këtu korrespondon sa më afër që të jetë e mundur me këtë përkufizim.
Shembull:
katror :: Integer -> Integer katror x = x * x
Siç ndoshta e keni marrë me mend, ky është funksioni i katrorit të një numri. Le ta analizojmë në detaje:
Emri_funksioni :: definition_space -> value_space
katror :: Integer -> Integer
Këtu duhet thënë se në Haskell nuk është aspak e nevojshme të deklarohet gjithmonë një funksion. Në disa raste, përkthyesi tashmë do të kuptojë se cilat fusha dhe kuptime kanë një funksion të caktuar. Megjithatë, heqja e reklamave është sjellje e keqe.
Parametrat e emrit të funksionit = Rregulla_Llogaritja
katrori x = x * x
e :: Float e = exp 1.0
Faleminderit për sqarimin ().
abcFormula :: Float -> Float -> Float -> abcFormula abc = [(-b + sqrt (b * b-4.0 * a * c)) / (2.0 * a), (-b-sqrt (b * b- 4.0 * a * c)) / (2.0 * a)] - gjen rrënjët e ekuacionit ax ^ 2 + bx + c = 0Përkufizimet e funksioneve me alternativa
Si me çdo gjuhë, Haskell ka konstruksione të degëzuara.
Le t'i shohim ato duke përdorur funksionin abs (moduli) si shembull.
Nëse… atëherë… tjetër…
abs1 x = nëse x> = 0 atëherë x tjetër -x
abs2 x = rasti x> = 0 i E vërtetë -> x E gabuar -> -x
abs3 x | x> 0 = x | x<0 = -x
| otherwise = 0
Vija e drejtë duhet të lexohet si: "at".
Lexojmë: “Funksioni abs3, me një parametër hyrës x, për x> 0 merr vlerën x, për x<0 принимает значение -x, и в любом другом случае принимает значение 0».
Natyrisht, ne mund të shkruanim gjithçka duke përdorur dy shprehje roje, por unë shënova tre në mënyrë që të ishte e qartë se mund të kishte sa të duam.
Ndryshe në prelud përcaktohet shumë thjeshtë:
ndryshe :: Bool ndryshe = E vërtetë
Kjo do të thotë, ju mund të shkruani me siguri "E vërtetë" në vend të "ndryshe", por kjo, përsëri, është sjellje e keqe.Përputhja e modelit
Një nga teknikat më të zakonshme dhe më efektive në Haskell është përputhja e modeleve. Në vend të një parametri, ne mund ta rrëshqasim funksionin në një shembull se si duhet të duket parametri. Nëse kampioni doli, funksioni ekzekutohet, nëse jo, ai shkon në mostrën tjetër. Për shembull, përcaktimi i faktorialit përmes rekursionit duke përdorur modele:
fakt :: Integer -> Fakt i plotë 0 = 1 fakt n = n * fakt (n-1)
E njëjta gjë, por me ndihmën e shprehjeve roje:
fakt :: Integer -> Integer fact n | n == 0 = 1 | n> 0 = n * fakt (n-1)
Ekziston një model shumë i zakonshëm për një listë: (x: xs). X - tregon elementin e parë, XS - pjesën tjetër të listës (përveç elementit të parë). ":" - operacioni i bashkëngjitjes së një elementi në listë. Shembuj nga paraloja:
head :: [a] -> a head (x: _) = x head = gabim "Prelude.head: list bosh" tail :: [a] -> [a] tail (_: xs) = xs tail = gabim "Prelude.tail: lista bosh"
Funksioni head merr një listë të çfarëdo [a] si hyrje dhe kthen elementin e parë të asaj liste. Funksioni tail merr një listë të çfarëdo [a] si hyrje dhe heq elementin e parë nga ajo listë.
"_" - do të thotë se elementi i dhënë ne nuk jemi të interesuar.