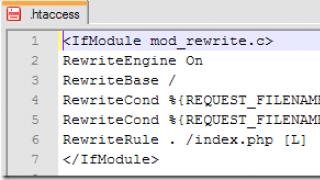
Database che lavorano sulla tecnologia FILE-SERVER;
Database che lavorano sulla tecnologia CLIENT-SERVER.
File server
- Accesso al database (query)
- Trasferimento dati con blocco dell'accesso di altri utenti
- Trattamento dei dati sul computer dell'utente
Per chiarezza, considera esempi specifici... Supponiamo che tu debba visualizzare gli ordini di pagamento inviati per il periodo dal 19 maggio al 25 maggio per un importo di 5.000 rubli. L'utente dovrà avviare un'applicazione client sul suo computer che funziona nel database con gli ordini di pagamento e inserire i criteri di selezione richiesti. Successivamente, un file contenente tutti i documenti di questo tipo per l'intero periodo per qualsiasi importo viene scaricato sul tuo computer dal server del database e caricato nella RAM. L'applicazione client in esecuzione sul computer dell'utente che lavora con il database elaborerà queste informazioni (le ordinerà), dopodiché fornirà una risposta (sullo schermo verrà visualizzato un elenco di ordini di pagamento che soddisfano i tuoi criteri). Successivamente, selezionerai l'ordine di pagamento richiesto e proverai a modificare (cambiare) un campo in esso, ad esempio la data. Durante la modifica, l'origine dati è bloccata, ovvero l'intero file contenente questo documento. Ciò significa che il file non sarà affatto disponibile per gli altri utenti o sarà disponibile solo in modalità di visualizzazione. Inoltre, questo tipo di acquisizione non avviene nemmeno a livello di record, ovvero un documento, ma viene bloccato. intero file- ovvero l'intera tabella contenente documenti simili. Solo dopo l'elaborazione completa di questo campo e l'uscita dalla modalità di modifica, questo file di ordini di pagamento verrà sbloccato dall'acquisizione da parte dell'utente. Se i dati sono archiviati in oggetti più voluminosi, ad esempio, un file contiene ordini di pagamento sia sulla ricezione di fondi che sull'invio, la maggior parte delle informazioni non sarà disponibile. Lavorerai con un campo "data" in un documento - il resto dell'azienda aspetterà fino al termine.
Gli svantaggi del sistema FILE SERVER sono evidenti:
Carico molto pesante sulla rete, maggiori requisiti di larghezza di banda. In pratica, questo lo rende quasi impossibile lavoro simultaneo un gran numero di utenti con grandi quantità di dati.
Il trattamento dei dati viene effettuato sul computer dell'utente. Ciò comporta maggiori requisiti hardware per ogni utente. Come più utenti, così più soldi dovranno spendere per dotare i loro computer.
Il blocco dei dati durante la modifica da parte di un utente rende impossibile lavorare con questi dati di altri utenti.
Sicurezza. Per poter lavorare con un sistema del genere, sarà necessario concedere a ciascun utente l'accesso completo all'intero file, in cui potrebbe essere interessato a un solo campo.
Client-server
Gestione di una richiesta di un singolo utente:
- Accesso al database (interrogazione SQL)
- Invio di una risposta - il risultato dell'elaborazione

Se è necessario elaborare le informazioni memorizzate nel database, l'applicazione client in esecuzione sul computer dell'utente che lavora con il database forma una query in SQL (il nome dalle lettere iniziali è Structured Query Language). Il server del database accetta la richiesta e la elabora da solo. Nessun array di dati (file) viene trasmesso sulla rete. Dopo aver elaborato la richiesta, solo il risultato viene trasmesso al computer dell'utente, ovvero, nell'esempio precedente, un elenco di ordini di pagamento che soddisfano i criteri richiesti. Il file stesso, che memorizzava i dati che servivano come fonte per l'elaborazione, rimane sbloccato per l'accesso da parte del server stesso su richiesta di altri utenti.
Nei DBMS client-server seri, ci sono meccanismi aggiuntivi riducendo il carico sulla rete, riducendo i requisiti per i computer degli utenti. Ad esempio, forniremo procedure memorizzate, ovvero interi programmi per l'elaborazione di dati memorizzati in un database. In questo caso, anche un'espressione SQL non viene passata dall'utente al server: viene passata una chiamata di funzione con parametri di chiamata. In questo modo, posto di lavoro l'utente viene ulteriormente semplificato, la logica del programma viene trasferita al server. Lo spazio utente diventa solo un mezzo per visualizzare le informazioni. Tutto ciò significa ulteriori riduzioni del carico sulla rete e sulle postazioni degli utenti.
Pertanto, tutti i suddetti svantaggi dello schema FILE-SERVER vengono eliminati nell'architettura CLIENT-SERVER:
Gli array di dati non vengono trasferiti in rete dal server di database al computer dell'utente. I requisiti di larghezza di banda della rete sono ridotti. Ciò consente a un numero elevato di utenti di lavorare contemporaneamente con grandi quantità di dati.
L'elaborazione dei dati viene eseguita sul server del database e non sul computer dell'utente. Ciò consente l'uso di computer più semplici e quindi più economici presso i siti dei clienti.
Il blocco (acquisizione) dei dati da parte di un utente non si verifica.
All'utente viene fornito l'accesso non all'intero file, ma solo a quei dati da esso, con i quali l'utente ha il diritto di lavorare.
Considerata la differenza tra un FILE SERVER e un CLIENT SERVER, possiamo completare la considerazione del concetto di "archiviazione delle informazioni". È importante sottolineare che il tipo di DBMS utilizzato dipende in gran parte dal lavoro sistema aziendale... È abbastanza ovvio che per le grandi imprese con grande quantità utenti con un numero enorme di record nel database, lo schema del file server è completamente inaccettabile. D'altra parte, ci sono differenze nei database in altri parametri e capacità:
tipologie di dati che possono essere archiviati nel database (numeri, date, testi, immagini, video, suoni, ecc.);
in funzione delle tecnologie di accesso ai dati nel database organizzato dal database stesso e del livello di protezione delle informazioni da accessi non autorizzati;
sugli strumenti forniti e sui metodi di sviluppo che possono essere utilizzati per progettare qualsiasi sistema informativo basato su questo database;
sugli strumenti e sui metodi forniti per l'analisi delle informazioni (dati) che possono essere applicati in un sistema informativo basato su questo database;
in termini di affidabilità e stabilità, ovvero (approssimativamente) il numero di record (campi compilati) nel database, che fornisce un'opportunità affidabile e ininterrotta per accedere, modificare, analizzare le informazioni nel database;
per velocità: il tempo impiegato per l'accesso e l'elaborazione delle informazioni;
se possibile, l'organizzazione del lavoro su computer di produttori diversi, ovvero per compatibilità con altre piattaforme e sistemi operativi;
dal livello di supporto (servizio) fornito dallo sviluppatore del database o dal suo rivenditore autorizzato;
per disponibilità buoni mezzi creazione di applicazioni utilizzando questo database, ecc.
Perché oggi non è redditizio investire in una soluzione di file server? L'ulteriore percorso di sviluppo dei database è già evidente oggi. Compaiono sistemi client-server multilivello, con client molto sottili, rimuovendo ogni restrizione dalle postazioni client, sia in termini di prestazioni che di piattaforma, sistema operativo... Se per una soluzione client-server ulteriori sviluppi Sembra abbastanza chiaro, e il passaggio da un client-server a un client-server multilivello non è problematico, ma per un file server una semplice transizione a un client-server presenta un problema enorme e costi di manodopera enormi, se improvvisamente risulta del tutto possibile.
L'architettura client-server è utilizzata in gran numero tecnologie di rete utilizzato per accedere a vari servizi di rete. Diamo una rapida occhiata ad alcuni dei tipi di tali servizi (e server).
Server web
Inizialmente, fornivano l'accesso ai documenti ipertestuali tramite il protocollo HTTP (Huper Text Protocollo di trasferimento). Ora supportano funzionalità avanzate, in particolare, funzionano con file binari (immagini, multimedia, ecc.).
Server applicazioni
Progettato per la soluzione centralizzata di problemi applicati in una determinata area tematica. Per fare ciò, gli utenti hanno il diritto eseguire programmi server per l'esecuzione. I server delle applicazioni possono ridurre i requisiti di configurazione del client e semplificare gestione generale Rete.
Server di database
I server di database vengono utilizzati per elaborare query SQL personalizzate. In questo caso il DBMS si trova sul server, al quale sono connesse le applicazioni client.
File server
File server mantiene informazioni sotto forma di file e consente agli utenti di accedervi. Di norma, il file server fornisce anche un certo livello di protezione contro l'accesso non autorizzato.
Server proxy
Innanzitutto, funge da intermediario, aiutando gli utenti a ottenere informazioni da Internet proteggendo la rete.
In secondo luogo, memorizza le informazioni richieste di frequente in una memoria cache su un disco locale, consegnandole rapidamente agli utenti senza dover accedere nuovamente a Internet.
Firewall(firewall)
Firewall analizzando e filtrando il passaggio traffico di rete, al fine di garantire la sicurezza della rete.
Fornire servizi per l'invio e la ricezione di messaggi di posta elettronica.
Server accesso remoto(RAS)
Questi sistemi forniscono la comunicazione dial-up con la rete. Un dipendente remoto può utilizzare le risorse della LAN aziendale collegandosi ad essa tramite un normale modem.
Questi sono solo alcuni tipi dell'intera varietà di tecnologie client-server utilizzate nelle reti locali e globali.
Per accedere a determinati servizi di rete vengono utilizzati client, le cui capacità sono caratterizzate dal concetto di "spessore". Definisce la configurazione hardware e software a disposizione del cliente. Considera i possibili valori limite:
Cliente sottile
Questo termine definisce un client le cui risorse di elaborazione sono sufficienti solo per eseguire l'applicazione di rete richiesta tramite un'interfaccia web. L'interfaccia utente di tale applicazione è formata da mezzi statico HTML (JavaScript non viene eseguito), tutta la logica dell'applicazione viene eseguita sul server.
Affinché un thin client funzioni, è sufficiente fornire la possibilità di avviare un browser Web, nella cui finestra vengono eseguite tutte le azioni. Per questo motivo, un browser Web viene spesso definito "client generico".
Cliente "grosso"
Si tratta di una workstation o di un personal computer che esegue il proprio sistema operativo su disco e dispone del set di software necessario. A server di rete I client “thick” si rivolgono principalmente a servizi aggiuntivi (ad esempio, accesso a un server web o database aziendale).
Inoltre, un client "spesso" indica un'applicazione di rete client in esecuzione sotto il controllo di un sistema operativo locale. Tale applicazione combina un componente di presentazione dei dati (interfaccia utente grafica del sistema operativo) e un componente dell'applicazione (potenza di calcolo di un computer client).
V Di recente un altro termine è sempre più usato: "rich" -client. "Rich" -client è una sorta di compromesso tra client "thick" e "thin". Come un thin client, anche un rich client fornisce un'interfaccia grafica già descritta tramite XML e include alcune funzionalità di un thick client (ad esempio, un'interfaccia drag-and-drop, schede, finestre multiple, menu a discesa, ecc. .)
La logica dell'applicazione rich client è implementata anche sul server. I dati vengono inviati a formato standard scambio, basato sullo stesso XML (protocolli SOAP, XML-RPC) e interpretato dal cliente.
Alcuni dei principali protocolli client "rich" basati su XML sono elencati di seguito:
- XAML (eXtensible Application Markup Language) - sviluppato da Microsoft, utilizzato nelle applicazioni su piattaforma .NET;
- XUL (XML User Interface Language) - uno standard sviluppato dal progetto Mozilla, utilizzato, ad esempio, in un client di posta elettronica Mozilla Thunderbird o Browser Mozilla Firefox;
- Flessibile - tecnologia multimediale Basato su XML sviluppato da Macromedia/Adobe.
Conclusione
Così, l'idea principale dell'architettura client-server è quella di dividere l'applicazione di rete in più componenti, ognuno dei quali implementa un insieme specifico di servizi. I componenti di tale applicazione possono essere eseguiti su diversi computer, svolgendo funzioni server e/o client. Ciò migliora l'affidabilità, la sicurezza e le prestazioni. applicazioni di rete e la rete in generale.
Inviare il tuo buon lavoro nella knowledge base è semplice. Usa il modulo sottostante
Studenti, dottorandi, giovani scienziati che utilizzano la base di conoscenza nei loro studi e nel lavoro ti saranno molto grati.
Pubblicato su http://www.allbest.ru/
[Inserire il testo]
Server. Concetti di base del server
Modello client-server
Classificazione server standard
Elenco della letteratura utilizzata
Server. Concetti di base del server
Server (dal server inglese, che serve). A seconda dello scopo, esistono diverse definizioni del concetto di server.
1. Server (rete) - un nodo di rete logico o fisico che serve richieste a un indirizzo e/o nome di dominio (nomi di dominio adiacenti), costituito da uno o da un sistema di server hardware che eseguono uno o un sistema di programmi server
2. Server (software) - software che riceve richieste dai client (in architettura client-server).
3. Server (hardware) - un computer (o attrezzatura informatica speciale) dedicato e/o specializzato per eseguire determinate funzioni di servizio.
3. Server nella tecnologia dell'informazione - componente software un sistema informatico che svolge funzioni di servizio su richiesta del cliente, fornendogli l'accesso a determinate risorse.
Interrelazione di concetti. Un'applicazione server (server) viene eseguita su un computer, chiamato anche "server", mentre considerando la topologia di rete, tale nodo è chiamato "server". V caso generale potrebbe essere che l'applicazione server sia in esecuzione regolarmente postazione di lavoro o un'applicazione server in esecuzione su computer server nell'ambito della topologia considerata, agisce come client (cioè non è un server dal punto di vista della topologia di rete).
Modello client-server
I concetti di server e client ei ruoli loro assegnati formano il concetto di programmazione di "client-server". Il modello client-server è un altro approccio alla strutturazione del sistema operativo (OS). In senso lato, il modello client-server presuppone la presenza di un componente software - un consumatore di un servizio - un client e un componente software - un fornitore di questo servizio - un server. L'interazione tra client e server è standardizzata in modo che il server possa servire client implementati in modi diversi e forse di diversi produttori... In questo caso, il requisito principale è che richiedano i servizi del server in un modo comprensibile. L'iniziatore dello scambio è solitamente un client che invia una richiesta di servizio a un server che è in attesa di una richiesta. Lo stesso componente software può essere un client per un tipo di servizio e un server per un altro tipo di servizio. Il modello client-server è piuttosto un mezzo concettuale conveniente per rappresentare chiaramente le funzioni di un particolare elemento di programma in questa o quella situazione, piuttosto che nella tecnologia. Questo modello viene applicato con successo non solo nella costruzione del sistema operativo, ma anche a tutti i livelli del software e in alcuni casi ha un significato più ristretto e specifico, pur mantenendo, ovviamente, tutte le sue caratteristiche comuni. Quando si tratta di strutturare un sistema operativo, l'idea è di suddividerlo in diversi processi - server, ognuno dei quali esegue un insieme separato di funzioni di servizio - ad esempio, gestione della memoria, creazione o pianificazione dei processi. Ogni server viene eseguito in modalità utente. Il client, che può essere un altro componente del sistema operativo o un programma applicativo, richiede un servizio inviando un messaggio al server. Il kernel (denominato qui microkernel), in esecuzione in modalità privilegiata, consegna un messaggio al server desiderato, il server esegue l'operazione e quindi il kernel restituisce i risultati al client con un altro messaggio. Per interagire con un client (o client, se è supportato il lavoro simultaneo con più client), il server alloca le risorse di comunicazione tra processi necessarie (memoria condivisa, pipe, socket, ecc.) e attende le richieste di apertura di una connessione (o, in infatti, richieste di un servizio fornito). A seconda del tipo di tale risorsa, il server può servire processi all'interno di un sistema informatico o processi su altre macchine attraverso canali di trasmissione dati (ad esempio una porta COM) o connessioni di rete.
Il formato delle richieste del client e delle risposte del server è specifico del protocollo. Specifiche protocolli aperti sono descritti da standard aperti, ad esempio i protocolli Internet sono definiti nelle RFC.
A seconda delle attività eseguite, alcuni server potrebbero rimanere inattivi quando non ci sono richieste di servizio. Altri possono eseguire qualche tipo di lavoro (ad esempio, lavorare sulla raccolta di informazioni), per tali server, lavorare con i client può essere un'attività secondaria.
Classificazione dei server standard
In genere, ogni server serve uno (o più protocolli simili) e i server possono essere classificati in base al tipo di servizio che forniscono.
I server universali sono un tipo speciale di programma server che non fornisce alcun servizio da solo. Invece, i server generici forniscono ai server di servizio un'interfaccia semplificata per le risorse di comunicazione tra processi e/o l'accesso client unificato a vari servizi. Esistono diversi tipi di tali server:
inetd dall'inglese. demone del super server internet Il demone del servizio IP è uno strumento UNIX standard - un programma per scrivere server TCP / IP (e protocolli di rete altre famiglie), lavorando con il client tramite flussi di input e output standard inetd reindirizzati (stdin e stdout).
RPC dall'inglese. Remote Procedure Call Remote Procedure Call è un sistema di integrazione del server sotto forma di procedure disponibili per la chiamata utente remoto attraverso un'interfaccia unificata. L'interfaccia inventata da Sun Microsystems per il suo sistema operativo (SunOS, Solaris; sistema Unix) è attualmente utilizzata nella maggior parte dei sistemi Unix e Windows.
Tecnologie delle applicazioni client-server di Windows:
(D-) COM (Distributed) Component Object Model, ecc. - Consente ad alcuni programmi di eseguire operazioni su oggetti dati utilizzando le procedure di altri programmi. inizialmente questa tecnologiaè inteso per il loro "incorporamento e collegamento di oggetti" (OLE English Object Linking and Embedding), ma, in generale, consente di scrivere vasta gamma vari server applicativi. COM funziona solo all'interno dello stesso computer, DCOM è disponibile in remoto tramite RPC.
Active-X - Estensione a COM e DCOM per la creazione di applicazioni multimediali.
I server generici sono spesso usati per scrivere tutti i tipi di server di informazioni, server che non necessitano di alcun lavoro specifico con la rete, server che non hanno altre attività oltre a servire i client. Ad esempio, i normali programmi e script della console possono fungere da server per inetd.
La maggior parte interna e specifica per la rete Server Windows funzionano tramite server universali (RPC, (D-) COM).
I servizi di rete garantiscono il funzionamento della rete, ad esempio i server DHCP e BOOTP forniscono l'inizializzazione di server e workstation, DNS - traduzione di nomi in indirizzi e viceversa.
I server di tunneling (come vari server VPN) e i proxy forniscono connettività a una rete non accessibile tramite routing.
I server AAA e Radius forniscono autenticazione, autorizzazione e registrazione degli accessi uniformi attraverso la rete.
Servizi di informazione. I servizi di informazione includono sia i server più semplici che riportano informazioni sull'host (ora, giorno, motd), gli utenti (finger, ident) sia i server per il monitoraggio, ad esempio SNMP. Maggioranza servizi di informazione funzionano tramite server universali.
I server di sincronizzazione dell'ora sono un tipo speciale di servizi di informazione: NTP, oltre a informare il client sull'ora esatta, il server NTP interroga periodicamente diversi altri server per correggere la propria ora. Oltre alla correzione del tempo, viene analizzata e corretta la velocità di viaggio. Orologio di sistema... La correzione dell'ora viene effettuata tramite accelerazione o decelerazione dell'orologio di sistema (a seconda della direzione di correzione) al fine di evitare problemi possibili con un semplice riordino dell'ora.
I file server sono server per fornire l'accesso ai file su un disco del server.
Prima di tutto, questi sono server di file su richiesta che utilizzano i protocolli FTP, TFTP, SFTP e HTTP. Il protocollo HTTP è orientato al trasferimento file di testo, ma i server possono fungere da file richiesti e dati arbitrari, ad esempio pagine Web, immagini, musica e così via generate dinamicamente.
Altri server consentono di montare le partizioni del disco del server in spazio sul disco client e lavorare completamente con i file su di essi. I server lo consentono Protocolli NFS e PMI. I server NFS e SMB funzionano tramite l'interfaccia RPC.
Svantaggi di un file server system:
Carico molto pesante sulla rete, maggiori requisiti di larghezza di banda. In pratica, questo rende quasi impossibile per un gran numero di utenti lavorare contemporaneamente con grandi quantità di dati.
Il trattamento dei dati viene effettuato sul computer dell'utente. Ciò comporta maggiori requisiti hardware per ogni utente. Più utenti, più soldi dovranno essere spesi per dotare i loro computer.
Il blocco dei dati durante la modifica da parte di un utente rende impossibile lavorare con questi dati di altri utenti.
Sicurezza. Per garantire la possibilità di lavorare con un tale sistema, sarà necessario concedere a ciascun utente l'accesso completo all'intero file, al quale potrebbe essere interessato solo un campo
I server di accesso ai dati mantengono il database e forniscono dati su richiesta. Uno dei più server semplici di questo tipo è LDAP (Lightweight Directory Access Protocol).
Non esiste un protocollo unico per accedere ai server di database, ma tutti i server di database sono uniti dall'uso di regole uniformi per la generazione di query: il linguaggio SQL (Structured Query Language).
I servizi di messaggistica consentono a un utente di inviare e ricevere messaggi (in genere messaggi di testo).
Prima di tutto, questi sono server E-mail lavorando su protocollo SMTP... Il server SMTP accetta il messaggio e lo consegna alla casella di posta locale dell'utente oa un altro server SMTP (destinazione o server intermedio). Sui computer multiutente, gli utenti lavorano con la posta direttamente sul terminale (o interfaccia web). Per lavorare con la posta su un personal computer, la posta viene recuperata dalla casella di posta tramite server che utilizzano i protocolli POP3 o IMAP.
Per l'organizzazione di conferenze sono presenti news server che operano su protocollo NNTP.
Per la messaggistica in tempo reale, ci sono server di chat, un server di chat standard funziona sul protocollo IRC - una chat distribuita per Internet.
Esistono molti altri protocolli di chat, come ICQ o Jabber.
Server di accesso remoto
Server di accesso remoto, tramite l'apposito programma cliente fornire all'utente l'accesso da console al sistema remoto.
I server telnet, RSH, SSH vengono utilizzati per fornire l'accesso alla riga di comando.
L'interfaccia grafica per i sistemi Unix - X Window System, ha un server di accesso remoto integrato, poiché è stata originariamente sviluppata con questa capacità. La possibilità di accedere in remoto all'interfaccia X-Window è talvolta erroneamente chiamata "X-Server" (che è il termine usato in X-Window per riferirsi al driver video).
Il server di accesso remoto della GUI di Microsoft Windows standard è chiamato Terminal Server.
Un certo tipo di gestione (più precisamente, monitoraggio e configurazione) è fornito anche dal protocollo SNMP. Il computer o il dispositivo hardware deve disporre di un server SNMP per questo.
I server di gioco vengono utilizzati per il gioco simultaneo di più utenti in un'unica situazione di gioco. Alcuni giochi hanno un server nella distribuzione principale e ti permettono di eseguirlo in modalità non dedicata (cioè ti permettono di giocare sulla macchina su cui è in esecuzione il server).
Le soluzioni server sono sistemi operativi e/o pacchetti software ottimizzati affinché un computer esegua funzioni server e/o contengano un insieme di programmi per l'implementazione di servizi tipici.
Un esempio di soluzioni server possono essere i sistemi Unix, originariamente destinati all'implementazione dell'infrastruttura server, o le modifiche al server Piattaforme Microsoft Finestre.
È inoltre necessario selezionare pacchetti di server e relativi programmi (ad esempio un insieme di server web/PHP/MySQL per la rapida implementazione dell'hosting) per l'installazione sotto Windows (Unix è caratterizzato da un'installazione modulare o "batch" di ogni componente, quindi tali soluzioni sono rare).
Nelle soluzioni server integrate, tutti i componenti vengono installati contemporaneamente, tutti i componenti sono strettamente integrati in un modo o nell'altro e sono preconfigurati l'uno con l'altro. Tuttavia, in questo caso, la sostituzione di uno dei server o delle applicazioni secondarie (se le loro capacità non soddisfano le esigenze) può essere problematica.
Le soluzioni server servono a semplificare l'organizzazione dell'infrastruttura IT di base delle aziende, ovvero a costruire rapidamente una rete completa in un'azienda, anche da zero. L'assemblaggio di singole applicazioni server in una soluzione implica che la soluzione sia progettata per eseguire la maggior parte delle attività tipiche; allo stesso tempo, la complessità dell'implementazione e il costo totale di proprietà dell'infrastruttura IT costruita su tali soluzioni sono notevolmente ridotti.
Un server proxy (dall'inglese proxy - "rappresentante, autorizzato") è un servizio nelle reti di computer che consente ai client di effettuare richieste indirette ad altri servizi di rete. Innanzitutto, il client si connette al server proxy e richiede alcune risorse (ad esempio, e-mail) che si trovano su un altro server. Quindi il server proxy si connette a il server specificato e riceve una risorsa da esso, o restituisce una risorsa dalla propria cache (nei casi in cui il proxy ha la propria cache). In alcuni casi, la richiesta del client o la risposta del server possono essere modificate dal server proxy in determinati scopi... Inoltre, un server proxy ti consente di proteggere computer cliente da alcuni attacchi di rete.
ConclusioneS
formato del serverPfinestre roxy
Pertanto, qualsiasi rete di computer è, di fatto, una rete client-server. Un utente che connette il suo computer a Internet avrà a che fare con una rete client-server e, anche se il computer non ha accesso alla rete, il suo software e lui stesso sono molto probabilmente organizzati secondo lo schema client-server.
Elenco degli usiovaleletteratura
1. Droga A.A., Zhukova P.N., Koponev D.N., Lukyanov D.B., Prokopenko A.N. Informatica e matematica. - Minsk, 2008.
2. Connolly T., Database di Begg K.. Progettazione, realizzazione e manutenzione. Teoria e pratica - 3a ed. - M.: "Williams", 2003.
3. Kuznetsov S.D. Nozioni di base sulla banca dati. - 1a ed. - M.: "Internet University of Information Technologies - INTUIT.ru", 2005.
4. Scott W. Ambler, Pramodkumar J. Sadalj. Refactoring del database: design evolutivo - M.: "Williams", 2007.
5. A.N. Morozevich, A.M. Zenevich Informatica. Minsk, 2008.
6. Titorenko G.A. Gestione delle tecnologie dell'informazione. M., Unità: 2002.
7. Melnikov V. Protezione delle informazioni in sistemi informatici... - M.: Finanza e statistica, Electroninform, 1997.
Pubblicato su Allbest.ru
...Documenti simili
I concetti di base dei server. Modello client-server. Classificazione dei server standard. Svantaggi di un file server system. Metodi crittografici di protezione delle informazioni. Server di accesso remoto. Metodi e mezzi di sicurezza delle informazioni.
test, aggiunto il 13/12/2010
Informazione Generale sul sistema operativo Linux. Analisi delle informazioni sui server. Tecnologie applicative client-server di base di Windows. Informazioni sul server SQL. Informazioni generali sul server MySQL. Installazione e specifiche di configurazione del server MYSQL su LINUX.
tesina, aggiunta il 16/12/2015
Analisi dell'architettura del sistema informativo, la cui struttura comprende sistemi file-server e client-server. Confronto tra linguaggi di query SQL e QBE. Principi di sviluppo di applicazioni client-server utilizzando linguaggio strutturato query SQL.
tesina aggiunta il 04/11/2010
Architettura client-server. Analisi del sistema database "Giornale delle dichiarazioni", il suo design infologico e fisico. Programmazione lato server SQL. Sviluppo del lato client in Borland C++ Builder 6.0 e utilizzo di tecnologie Web.
tesina aggiunta 07/07/2013
Metodologia e fasi principali dello sviluppo di un sistema di test per la valutazione del livello di conoscenza degli studenti che utilizzano la tecnologia "Client-server". Progettare le parti client e server di questo sistema di test, la procedura per la stesura dei report finali.
tesi, aggiunta 08/11/2010
Progettazione di modelli fisici e logici di un database remoto per una stazione di servizio. Sviluppo di database nel DBMS Firebird utilizzando l'utility IBExpert. Creazione applicazione client per Windows che utilizza la tecnologia client-server nell'ambiente C++ Builder.
tesina aggiunta 18/01/2017
Creazione di un prodotto software basato su tecnologia client-server che implementa il funzionamento fault-tolerant del sistema, che è in grado di connettere il client a server alternativo(usando l'esempio di un server meteo).
tesina, aggiunta il 24/08/2012
Progettazione e sviluppo di un database in Firebird RDBMS. La sequenza di creazione di un'applicazione basata su tecnologia client-server e lavoro in sala operatoria Sistema Windows... Stored procedure e trigger. Accesso alla rete e transazioni.
tesina, aggiunta il 27/07/2013
Database relazionali dati nell'ambito dei sistemi informativi aziendali, la loro costruzione secondo i principi della tecnologia client-server. Le principali caratteristiche del DBMS Firebird. Progettazione di un database per il sistema informativo "Componenti del computer".
tesina, aggiunta il 28/07/2013
Architettura client-server. Elaborazione parallela dei dati in sistemi multiprocessore. Modernizzazione dei sistemi informativi obsoleti. Tratti specifici DBMS server moderno. Il DBMS lato server più popolare. Query e transazioni distribuite.
Scopo della lezione: mostrare come i principi generali delle tecnologie client-server sono implementati nelle tecnologie web. Tenere conto elementi chiave di base protocollo HTTP.
L'argomento di questo corso sono le tecnologie della rete globale World Wide Web (abbreviata in WWW o semplicemente Web). In russo, una variante comune è il nome "Web".
In particolare, il corso tratterà temi quali: standard e protocolli di base del Web, markup e linguaggi di programmazione per le pagine Web, strumenti per lo sviluppo e la gestione di contenuti Web e applicazioni per il Web, strumenti per l'integrazione di contenuti e applicazioni Web in la rete.
Rete ragnatelaè uno spazio di informazioni globale basato sull'infrastruttura fisica di Internet e sul protocollo di trasmissione Dati HTTP... Spesso, parlando di Internet, intendono la rete. ragnatela.
Tecnologie client-server Web
Il protocollo base della rete di risorse ipertestuali Web è il protocollo HTTP. Si basa sull'interazione" client-server", cioè si assume che:
Consumatore- cliente dopo aver avviato una connessione con il provider del server, gli invia una richiesta;
Il fornitore- server Ricevuta la richiesta, esegue le azioni necessarie e restituisce al cliente una risposta con il risultato.
In questo caso, ci sono due modi possibili per organizzare il lavoro del computer client:
Cliente sottileè un computer client che trasferisce tutte le attività di elaborazione delle informazioni al server. Un esempio di thin client è un computer con un browser utilizzato per eseguire applicazioni web.
cliente grasso al contrario, elabora le informazioni indipendentemente dal server, utilizzando quest'ultimo principalmente per la memorizzazione dei dati.
Prima di passare a specifiche tecnologie web client/server, diamo un'occhiata ai fondamenti e alla struttura del protocollo HTTP sottostante.
Protocollo HTTP
HTTP(HyperText Transfer Protocol - RFC 1945, RFC 2616) è un protocollo a livello di applicazione per il trasferimento di ipertesto.
Centrale per HTTP è risorsa indicato da URI nella richiesta del cliente. In genere, queste risorse sono file archiviati sul server. Una caratteristica del protocollo HTTP è la capacità di specificare nella richiesta e nella risposta un modo per rappresentare la stessa risorsa tramite vari parametri: formato, codifica, lingua, ecc. È grazie alla possibilità di specificare il metodo di codifica del messaggio che client e server possono scambiare dati binari, sebbene inizialmente questo protocollo destinato al trasferimento di informazioni simboliche. A prima vista, questo può sembrare uno spreco di risorse. Infatti, i dati in forma simbolica occupano più memoria, i messaggi creano un carico aggiuntivo sui canali di comunicazione, ma questo formato ha molti vantaggi. I messaggi trasmessi in rete sono leggibili e, analizzando i dati ricevuti, l'amministratore di sistema può facilmente trovare l'errore e risolverlo. Se necessario, il ruolo di una delle applicazioni interagenti può essere svolto da una persona, inserendo manualmente i messaggi nel formato richiesto.
A differenza di molti altri protocolli, HTTP è un protocollo senza memoria. Ciò significa che il protocollo non memorizza informazioni sulle precedenti richieste del client e risposte del server. I componenti che utilizzano HTTP possono mantenere in modo indipendente le informazioni sullo stato associate alle richieste e risposte più recenti. Ad esempio, un'applicazione client Web che invia richieste può tenere traccia dei ritardi di risposta e un server Web può memorizzare gli indirizzi IP e le intestazioni delle richieste dei client recenti.
Tutti i software per lavorare con il protocollo HTTP rientrano in tre categorie principali:
Server- fornitori di servizi per l'archiviazione e l'elaborazione delle informazioni (richieste di elaborazione).
Clienti- consumatori finali di servizi server (invio di richieste).
Server proxy per supportare il lavoro dei servizi di trasporto.
Lo schema di sessione HTTP "classico" è simile a questo.
Stabilire una connessione TCP.
Richiesta del cliente.
Risposta del server.
Connessione TCP interrotta.
Pertanto, il client invia una richiesta al server, riceve una risposta da esso, dopodiché l'interazione viene terminata. In genere, una richiesta client è una richiesta per inviare un documento HTML o qualche altra risorsa e la risposta del server contiene il codice per quella risorsa.
La richiesta HTTP inviata da un client a un server include i seguenti componenti.
Barra di stato (a volte vengono utilizzati anche i termini barra di stato o stringa di query per denotarlo).
Campi di intestazione.
Riga vuota.
Il corpo della richiesta.
Barra di stato insieme a campi di intestazione a volte chiamato anche intestazione della richiesta.
Riso. 1.1. Struttura della richiesta del cliente.
Barra di stato ha il seguente formato:
request_method url_pecypca nttp_protocol_version
Diamo un'occhiata ai componenti della barra di stato, con un focus sui metodi di query.
Metodo, specificato nella barra di stato, determina come influenzare la risorsa, il cui URL è specificato nella stessa riga. Il metodo può assumere i valori GET, POST, HEAD, PUT, DELETE, ecc. Nonostante l'abbondanza di metodi, solo due di questi sono davvero importanti per un programmatore web: GET e POST.
OTTENERE. Secondo la definizione formale, il metodo GET ha lo scopo di ottenere una risorsa con l'URL specificato. dopo aver ricevuto OTTIENI richiesta, il server deve leggere la risorsa specificata e includere l'ID della risorsa nella risposta al client. La risorsa il cui URL viene passato come parte della richiesta non deve essere una pagina HTML, un file immagine o altri dati. L'URL della risorsa può puntare al codice eseguibile del programma, che, se vengono soddisfatte determinate condizioni, deve essere eseguito sul server. In questo caso, non è il codice del programma che viene restituito al client, ma i dati generati durante la sua esecuzione. Sebbene il metodo GET sia per definizione destinato a recuperare informazioni, può essere utilizzato anche per altri scopi. Il metodo GET è abbastanza adatto per trasferire piccoli blocchi di dati al server.
INVIARE. Secondo la stessa definizione formale, lo scopo principale del metodo POST è trasferire i dati al server. Tuttavia, come il metodo GET, il metodo POST può essere utilizzato in modi diversi ed è spesso utilizzato per recuperare informazioni da un server. Come con il metodo GET, l'URL specificato nella barra di stato punta a una risorsa specifica. Il metodo POST può essere utilizzato anche per avviare un processo.
I metodi HEAD e PUT sono modifiche dei metodi GET e POST.
Versione protocollo HTTP viene solitamente fornito nel seguente formato:
Http / version.modification
Campi di intestazione seguendo la barra di stato puoi perfezionare la tua query, ad es. inviare ulteriori informazioni al server. Il campo di intestazione ha il seguente formato:
Nome_campo: Valore
Lo scopo di un campo è determinato dal suo nome, separato dal valore da due punti.
I nomi di alcuni dei campi di intestazione più comuni in una richiesta client e il loro scopo sono indicati in scheda. 1.1.
|
Tabella 1.1. Campi di intestazione della richiesta HTTP. |
|
|
Campi dell'intestazione della richiesta HTTP |
Senso |
|
Nome di dominio o indirizzo IP dell'host a cui sta accedendo il client |
|
|
L'URL del documento che si collega alla risorsa indicata nella barra di stato |
|
|
Indirizzo email posta dell'utente lavorare con il cliente |
|
|
Tipi MIME di dati elaborati dal client. Questo campo può avere più valori, separati l'uno dall'altro da virgole. Spesso il campo di intestazione Accetta viene utilizzato per indicare al server quali tipi di file grafici supporta il client. |
|
|
Un insieme di identificatori di due caratteri, separati da virgole, che designano le lingue supportate dal client |
|
|
Elenco dei set di caratteri supportati |
|
|
Tipo MIME di dati contenuti nel corpo della richiesta (se la richiesta non è costituita da un'unica intestazione) |
|
|
Il numero di caratteri contenuti nel corpo della richiesta (se la richiesta non consiste in un'intestazione) |
|
|
Presente se il cliente non richiede l'intero documento, ma solo una parte di esso |
|
|
Utilizzato per gestire la connessione TCP. Se il campo contiene Close, significa che dopo aver elaborato la richiesta, il server dovrebbe chiudere la connessione. Il valore Keep-Alive suggerisce di non chiudere la connessione TCP in modo che possa essere utilizzata per richieste successive |
|
|
Informazioni sul cliente |
|
In molti casi, quando si lavora sul Web, manca il corpo della richiesta. Quando vengono eseguiti gli script CGI, i dati passati loro nella richiesta possono essere inseriti nel corpo della richiesta.
Di seguito è riportato un esempio di una richiesta HTML generata dal browser
OTTIENI http://oak.oakland.edu/ HTTP / 1.0
Connessione: Keep-Alive
Agente utente: Mozilla / 4.04 (Win95; I)
Ospite: oak.oakland.edu
Accetta: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */*
Accetta-Lingua: en
Accetta-Charset: iso-8859-l, *, utf-8
Dopo aver ricevuto una richiesta dal client, il server deve rispondere ad essa. La conoscenza della struttura della risposta del server è necessaria per lo sviluppatore di applicazioni web, poiché i programmi che girano sul server devono formare autonomamente la risposta al client.
Simile alla richiesta del client, anche la risposta del server ha i quattro componenti elencati di seguito.
Barra di stato.
Campi di intestazione.
Riga vuota.
Corpo di risposta.
La risposta del server al client inizia con una riga di stato, che ha il seguente formato:
Protocol_version Codice_risposta Messaggio_esplicativo
Protocol_versionè specificato nello stesso formato della richiesta del client e ha lo stesso significato.
Codice di rispostaè un numero decimale di tre cifre che ha codificato il risultato dell'elaborazione della richiesta da parte del server.
Explanatory_message duplica il codice di risposta in forma simbolica. Questa è una stringa di caratteri che non viene elaborata dal client. È progettato per amministratore di sistema o un operatore che mantiene il sistema, ed è la decrittazione del codice di risposta.
Delle tre cifre che compongono il codice di risposta, la prima (più alta) definisce la classe di risposta, le altre due rappresentano il numero di risposta all'interno della classe. Quindi, ad esempio, se la richiesta è stata elaborata con successo, il client riceve il seguente messaggio:
HTTP / 1.0 200 OK
Come puoi vedere, la versione del protocollo HTTP 1.0 è seguita da un codice 200. In questo codice, il carattere 2 indica l'elaborazione riuscita della richiesta del client e le restanti due cifre (00) sono il numero di questo messaggio.
Nelle implementazioni del protocollo HTTP attualmente in uso, la prima cifra non può essere maggiore di 5 e definisce le seguenti classi di risposta.
1 - una classe speciale di messaggi chiamati informativi. Un codice di risposta che inizia con 1 significa che il server continua a elaborare la richiesta. Quando si scambiano dati tra un client HTTP e un server HTTP, i messaggi di questa classe vengono utilizzati raramente.
2 - il buon esito della richiesta del cliente.
3 - richiesta di reindirizzamento. È necessario eseguire ulteriori passaggi per soddisfare la richiesta.
4 - errore del cliente. Di norma, viene restituito un codice di risposta che inizia con il numero 4 se la richiesta del cliente contiene Errore di sintassi.
5 - Errore del server. Per un motivo o per l'altro, il server non è in grado di soddisfare la richiesta.
Nella tabella sono riportati esempi di codici di risposta che il client può ricevere dal server e messaggi esplicativi. 1.2.
|
Tabella 1.2. Classi di codice di risposta del server. |
||
|
decrittazione |
Interpretazione |
|
|
Parte della richiesta è stata accettata e il server è in attesa che il client continui la richiesta. |
||
|
La richiesta è stata elaborata con successo e i dati specificati nella richiesta vengono trasmessi nella risposta del cliente |
||
|
Come risultato dell'elaborazione della richiesta, è stata creata una nuova risorsa |
||
|
La richiesta è stata accettata dal server, ma l'elaborazione non è stata completata. Questo codice risposta non garantisce che la richiesta verrà elaborata senza errori. |
||
|
Contenuto parziale |
Il server restituisce una parte della risorsa in risposta a una richiesta contenente un campo di intestazione Range |
|
|
Scelta multipla |
La richiesta punta a più di una risorsa. Il corpo della risposta può contenere istruzioni su come identificare correttamente la risorsa richiesta. |
|
|
trasferito |
La risorsa richiesta non si trova più sul server |
|
|
trasferito temporaneamente |
La risorsa richiesta ha temporaneamente modificato il suo indirizzo |
|
|
Errore di sintassi trovato nella richiesta del client |
||
|
La risorsa sul server non è disponibile per dato utente |
||
|
La risorsa specificata dal client è mancante sul server |
||
|
operazione non permessa |
Il server non supporta il metodo specificato nella richiesta |
|
|
Errore interno del server |
Uno dei componenti del server non funziona correttamente |
|
|
Non implementato |
La funzionalità del server è insufficiente per soddisfare la richiesta del client |
|
|
Servizio non disponibile |
Servizio temporaneamente non disponibile |
|
|
Versione HTTP non supportata |
La versione HTTP specificata nella richiesta non è supportata dal server |
|
La risposta utilizza la stessa struttura del campo di intestazione della richiesta client. I campi di intestazione hanno lo scopo di chiarire la risposta del server al client. Una descrizione di alcuni dei campi che possono essere trovati nell'intestazione della risposta del server è fornita nella tabella. 1.3.
|
Tabella 1.3. Campi di intestazione della risposta del server Web. |
|
|
Nome del campo |
Descrizione del contenuto |
|
Nome del server e numero di versione |
|
|
Tempo in secondi trascorso dalla creazione della risorsa |
|
|
Elenco dei metodi consentiti per di questa risorsa |
|
|
Contenuto-Lingua |
Lingue che il cliente deve supportare per visualizzare correttamente la risorsa trasferita |
|
MIMO-tipo di dati contenuti nel corpo della risposta del server |
|
|
Il numero di caratteri contenuti nel corpo della risposta del server |
|
|
Data e ora dell'ultima modifica della risorsa |
|
|
Data e ora che determinano quando viene generata la risposta |
|
|
Data e ora che definiscono il momento dopo il quale le informazioni trasmesse al cliente sono considerate obsolete |
|
|
Questo campo indica la posizione effettiva della risorsa. Viene utilizzato per reindirizzare la richiesta. |
|
|
Direttive di controllo della cache. Ad esempio, no-cache significa che i dati non devono essere memorizzati nella cache |
|
Il corpo della risposta contiene il codice della risorsa passata al client in risposta alla richiesta. Non deve essere il testo HTML della pagina web. Come parte della risposta, è possibile trasmettere un'immagine, un file audio, un'informazione video e qualsiasi altro tipo di dati supportato dal cliente. Il contenuto del campo di intestazione Content-type indica al client come gestire la risorsa ricevuta.
Di seguito è riportato un esempio di risposta del server alla richiesta fornita nella sezione precedente. Il corpo della risposta contiene il testo originale del documento HTML.
Server: Microsoft-IIS / 5.1
X-Powered-By: ASP.NET
Tipo di contenuto: testo / html
Intervalli di accettazione: byte
ETag: "b66a667f948c92: 8a5"
Lunghezza contenuto: 426