Vom învăța să rezumam. Nu, acestea nu sunt încă rezultatele studiului SQL, ci rezultatele valorilor coloanelor din tabelele bazei de date. Funcțiile de agregare SQL acționează asupra valorilor coloanei pentru a produce o singură valoare de rezultat. Cele mai frecvent utilizate funcții de agregare SQL sunt SUM, MIN, MAX, AVG și COUNT. Este necesar să se facă distincția între două cazuri de utilizare a funcțiilor agregate. În primul rând, funcțiile de agregare sunt folosite singure și returnează o singură valoare rezultată. În al doilea rând, funcțiile de agregare sunt utilizate cu clauza SQL GROUP BY, adică cu gruparea după câmpuri (coloane) pentru a obține valorile rezultate din fiecare grup. Să luăm în considerare mai întâi cazurile de utilizare a funcțiilor agregate fără grupare.
Funcția SQL SUM
Funcția SQL SUM returnează suma valorilor unei coloane dintr-un tabel al bazei de date. Poate fi aplicat numai coloanelor ale căror valori sunt numere. Interogările SQL pentru a obține suma rezultată încep astfel:
SELECTAȚI SUMA (COLUMN_NAME)...
Această expresie este urmată de FROM (TABLE_NAME) și apoi poate fi specificată o condiție folosind clauza WHERE. În plus, DISTINCT poate fi specificat în fața numelui coloanei, ceea ce înseamnă că vor fi numărate doar valorile unice. În mod implicit, toate valorile sunt luate în considerare (pentru aceasta, puteți specifica în mod specific nu DISTINCT, ci TOATE, dar cuvântul TOATE este opțional).
Exemplul 1. Există o bază de date a companiei cu date despre diviziile și angajații acesteia. Tabelul Staff, pe lângă toate, are o coloană cu date despre salariile angajaților. Selecția din tabel este următoarea (pentru a mări imaginea, faceți clic pe ea cu butonul stâng al mouse-ului):
Pentru a obține suma tuturor salariilor, folosim următoarea interogare:
SELECTAȚI SUMA (Salariu) FROM Personal
Această interogare va returna 287664.63.
Si acum . În exerciții, începem deja să complicăm sarcinile, aducându-le mai aproape de cele întâlnite în practică.
Funcția SQL MIN
Funcția SQL MIN funcționează și pe coloanele ale căror valori sunt numere și returnează minimul tuturor valorilor din coloană. Această funcție are o sintaxă similară cu sintaxa Funcții SUM.
Exemplul 3. Baza de date și tabelul sunt aceleași ca în exemplul 1.
Este necesar să aflați salariul minim al angajaților departamentului cu numărul 42. Pentru a face acest lucru, scrieți următoarea solicitare:
Solicitarea va returna valoarea 10505.90.
Și din nou exercițiu de autoajutorare... În acest exercițiu și în alte câteva exerciții, veți avea nevoie nu numai de tabelul Staff, ci și de tabelul Org, care conține date despre diviziile companiei:

Exemplul 4. Tabelul Org este adăugat la tabelul Staff, care conține date despre diviziile companiei. Afișați numărul minim de ani în care un singur angajat a lucrat într-un departament situat în Boston.
Funcția SQL MAX
Funcția SQL MAX funcționează în mod similar și are o sintaxă similară, care este utilizată atunci când trebuie să definiți valoare maximă dintre toate valorile coloanei.
Exemplul 5.
Este necesar să aflați salariul maxim al angajaților departamentului numărul 42. Pentru a face acest lucru, scrieți următoarea solicitare:
Solicitarea va returna valoarea 18352.80
Este timpul exerciții de auto-rezolvare.
Exemplul 6. Lucrăm din nou cu două mese - Staff și Org. Tipăriți numele departamentului și comisioanele maxime câștigate de un angajat dintr-un departament aparținând Diviziei de Est. Utilizare JOIN (aderă la mese) .
Funcția SQL AVG
Sintaxa de mai sus pentru funcțiile descrise anterior este valabilă și pentru funcția SQL AVG. Această funcție returnează media tuturor valorilor dintr-o coloană.
Exemplul 7. Baza de date și tabelul sunt aceleași ca în exemplele anterioare.
Să presupunem că doriți să aflați experiența medie de muncă a angajaților departamentului numărul 42. Pentru a face acest lucru, scrieți următoarea interogare:
Rezultatul va fi o valoare de 6,33
Exemplul 8. Lucrăm cu o singură masă - Personal. Retragerea salariului mediu al angajaților cu o experiență de 4 până la 6 ani.
Funcția SQL COUNT
Funcția SQL COUNT returnează numărul de înregistrări dintr-un tabel de bază de date. Dacă specificați SELECT COUNT (COLUMN_NAME) ... în interogare, rezultatul va fi numărul de înregistrări excluzând acele înregistrări în care valoarea coloanei este NULL (nedefinită). Dacă utilizați un asterisc ca argument și începeți o interogare SELECT COUNT (*) ..., rezultatul va fi numărul tuturor înregistrărilor (rândurilor) din tabel.
Exemplul 9. Baza de date și tabelul sunt aceleași ca în exemplele anterioare.
Este necesar să se afle numărul tuturor angajaților care primesc comisioane. Numărul de angajați ale căror valori ale coloanei Comm nu sunt NULL va returna următoarea interogare:
SELECTARE NUMĂR (Comm) FROM Staff
Rezultatul este 11.
Exemplul 10. Baza de date și tabelul sunt aceleași ca în exemplele anterioare.
Dacă trebuie să aflați numărul total de înregistrări dintr-un tabel, atunci folosim o interogare cu un asterisc ca argument pentru funcția COUNT:
SELECTAȚI NUMĂRUL (*) DIN Personal
Rezultatul este 17.
În urmatoarele exercițiu de autoajutorare va trebui să utilizați o subinterogare.
Exemplul 11. Lucrăm cu o singură masă - Personal. Afișați numărul de angajați din departamentul de planificare (Plains).
Funcții agregate cu SQL GROUP BY (grupare)
Acum să ne uităm la utilizarea funcțiilor agregate în combinație cu clauza SQL GROUP BY. Clauza SQL GROUP BY este utilizată pentru a grupa valorile rezultatului după coloanele tabelului bazei de date.
Exemplul 12. Există o bază de date a portalului de anunțuri. Conține tabelul Anunțuri, care conține date despre anunțurile trimise pentru săptămână. Coloana Categorie conține informații despre categorii mari reclame (de exemplu, Imobiliare) și coloana Părți - despre părți mai mici incluse în categorii (de exemplu, părțile Apartamente și Cabane fac parte din categoria Imobiliare). Coloana Unități conține date despre numărul de anunțuri trimise, iar coloana Bani conține suma de bani primită pentru trimiterea anunțurilor.
| Categorie | Parte | Unități | Bani |
| Transport | Vehicule cu motor | 110 | 17600 |
| Proprietatea | Apartamente | 89 | 18690 |
| Proprietatea | cabane | 57 | 11970 |
| Transport | Motociclete | 131 | 20960 |
| Materiale de construcții | Scânduri | 68 | 7140 |
| Inginerie Electrică | televizoare | 127 | 8255 |
| Inginerie Electrică | Frigidere | 137 | 8905 |
| Materiale de construcții | Regips | 112 | 11760 |
| Timp liber | Cărți | 96 | 6240 |
| Proprietatea | Case | 47 | 9870 |
| Timp liber | Muzică | 117 | 7605 |
| Timp liber | Jocuri | 41 | 2665 |
Folosind instrucțiunea SQL GROUP BY, găsiți suma de bani câștigată din difuzarea anunțurilor din fiecare categorie. Scriem următoarea cerere.
Lecția va acoperi subiectul sql redenumirea unei coloane (câmpuri) folosind cuvântul funcției AS; a acoperit, de asemenea, subiectul funcțiilor agregate în sql. Vor fi analizate exemple specifice de cereri
Puteți redenumi numele coloanelor în interogări. Acest lucru face rezultatele mai lizibile.
În SQL, redenumirea câmpurilor este asociată cu utilizarea lui cuvânt cheie AS care este folosit pentru a redenumi numele câmpurilor din seturile de rezultate
Sintaxă:
SELECTAȚI<имя поля>LA FEL DE<псевдоним>DIN...
Să ne uităm la un exemplu de redenumire în SQL:
Exemplu DB „Institut”: Afișați numele profesorilor și salariile acestora, pentru acei profesori ale căror salarii sunt sub 15000, redenumiți câmpul zarplata în "Salariu mic"
✍ Soluție:
Redenumirea coloanelor în SQL este adesea necesară la calcularea valorilor asociate cu mai multe câmpuri Mese. Să luăm în considerare un exemplu:
Exemplu DB „Institut”: Din tabelul profesorilor, scoateți câmpul de nume și calculați suma salariului și a bonusului, denumind câmpul „Salariu_ premiu”
✍ Soluție:
| 1 2 | SELECT numele, (zarplata + premia) AS zarplata_premia FROM profesori; |
SELECT numele, (zarplata + premia) AS zarplata_premia FROM profesori;
Rezultat:
Funcții agregate în SQL
Funcțiile agregate în sql sunt folosite pentru a obține totaluri și a calcula expresii:
Toate funcțiile agregate returnează o singură valoare.
Funcțiile COUNT, MIN și MAX se aplică oricărui tip de date.
Funcțiile SUM și AVG sunt utilizate numai pentru câmpurile numerice.
Există o diferență între funcțiile COUNT (*) și COUNT (): a doua nu ia în considerare valorile NULL la numărare.
Important: atunci când lucrați cu funcții agregate în SQL, se folosește un cuvânt special LA FEL DE
Exemplu DB „Institut”: Obțineți valoarea celui mai mare salariu dintre profesori, afișați rezultatul ca „Max_zp”
✍ Soluție:
| SELECT MAX (zarplata) AS max_zp FROM profesori; |
SELECT MAX (zarplata) AS max_zp FROM profesori;
Rezultate:
Să luăm în considerare un exemplu mai complex de utilizare a funcțiilor agregate în sql.
✍ Soluție:
Clauza GROUP BY în SQL
Clauza group by din sql este de obicei folosită împreună cu funcțiile de agregare.
Funcțiile agregate sunt efectuate pe toate rândurile de interogare rezultate. Dacă interogarea conține o clauză GROUP BY, fiecare set de rânduri specificat în clauza GROUP BY constituie un grup și funcțiile de agregare sunt executate pentru fiecare grup separat.
Luați în considerare un exemplu cu tabelul de lecții: 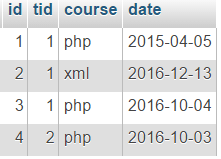
Exemplu:
Important: Astfel, ca urmare a utilizării GROUP BY, toate rândurile de ieșire ale interogării sunt împărțite în grupuri caracterizate de aceleași combinații de valori în aceste coloane (adică, funcțiile de agregare sunt efectuate pentru fiecare grup separat).
Trebuie avut în vedere că atunci când sunt grupate după un câmp care conține valori NULL, toate astfel de înregistrări se vor încadra într-un singur grup.
Pentru diferite tipuri de imprimante, definiți-le cost mediuși cantitatea (adică separat pentru laser, jet de cerneală și matrice). Utilizați funcții agregate. Rezultatul ar trebui să arate astfel:

Având instrucțiune SQL
Clauza HAVING din SQL este necesară pentru a valida valori, care se obţin folosind funcţia de agregare după grupare(după folosirea GROUP BY). O astfel de verificare nu poate fi inclusă într-o clauză WHERE.
Exemplu: Magazin de calculatoare DB... Calculați prețul mediu al computerelor cu aceeași viteză a procesorului. Calculați numai pentru acele grupuri al căror preț mediu este mai mic de 30.000.


- Funcții agregate sunt folosite ca numele câmpurilor din instrucțiunea SELECT, cu o singură excepție: iau numele câmpului ca argument. Cu functii SUMĂși AVG poate fi folosit doar câmpuri numerice... Cu functii COUNT, MAX și MIN pot fi utilizate atât câmpuri numerice, cât și câmpuri de caractere. Când este utilizat cu câmpuri de caractere MAXși MIN le va traduce în echivalentul ASCII și le va procesa în ordine alfabetică... Unele SGBD-uri permit utilizarea agregatelor imbricate, dar aceasta este o abatere de la standardul ANSI cu toate consecințele care decurg.


De exemplu, puteți calcula numărul de studenți care au promovat examene la fiecare disciplină. Pentru a face acest lucru, trebuie să executați o interogare grupată după câmpul „Disciplina” și să afișați ca rezultat numele disciplinei și numărul de linii din grup pentru această disciplină. Utilizarea caracterului * ca argument pentru funcția COUNT înseamnă că toate liniile din grup sunt numărate.
SELECTAȚI R1. Disciplina, COUNT (*)
GRUPARE PRIN R1.Disciplina;
Rezultat:

SELECTARE R1 Disciplina, COUNT (*)
UNDE R1. IS NOT NULL scor
GRUPARE PRIN R1.Disciplina;
Rezultat:

nu vor fi incluse în setul de tupluri înainte de grupare, astfel încât numărul de tupluri din grupa la disciplina „Teoria informației” va fi cu 1 mai mic.
Un rezultat similar poate fi obținut dacă scrieți cererea în felul următor:
SELECTAȚI R1. Disciplina, COUNT (R1. Evaluare)
GRUPARE PRIN R1. Disciplina;
Funcţie COUNT (NUME ATRIBUT) numără numărul de valori definite dintr-un grup, spre deosebire de o funcție NUMARA (*), care numără numărul de linii din grup. Într-adevăr, în grupa cu disciplina „Teoria informației” vor fi 4 rânduri, dar doar 3 valori specifice atributului „Evaluare”.

Reguli pentru manipularea valorilor nule în funcțiile agregate
Dacă orice valori din coloană sunt egale NUL sunt excluse la calcularea rezultatului funcției.
Dacă toate valorile dintr-o coloană sunt egale NUL, atunci Max Min Sum Mediu = NULL, numărare = 0 (zero).
Dacă masa este goală, număr (*) = 0 .
Funcțiile agregate pot fi utilizate și fără operația de grupare preliminară, în acest caz întreaga relație este considerată ca un grup și poate fi calculată o valoare per grup pentru acest grup.
Reguli de interpretare a funcţiilor agregate
Funcțiile agregate pot fi incluse în lista de rezultate și apoi sunt aplicate întregului tabel.
SELECT MAX (Scor) din R1 va acorda ratingul maxim la sesiune;
SELECTAȚI SUMA din R1 va da suma tuturor evaluărilor pe sesiune;
SELECTAȚI AVG (Scor) din R1 va acorda un punctaj mediu pentru întreaga sesiune.
 2; Rezultat: "width =" 640 "
2; Rezultat: "width =" 640 " Referindu-ne din nou la baza de date Session (tabelele R1), vom afla numărul de examene promovate cu succes:
SELECTARE NUMĂR (*) As Închiriat _ examene
UNDE Clasa 2;
Rezultat:

Argumentul funcțiilor agregate poate fi coloane separate de tabele. Pentru a calcula, de exemplu, numărul de valori distincte ale unei anumite coloane dintr-un grup, este necesar să folosiți cuvântul cheie DISTINCT împreună cu numele coloanei. Să calculăm numărul de note diferite primite pentru fiecare disciplină:
SELECTARE R1 Disciplina, COUNT (Evaluare DISTINCT R1)
UNDE R1. IS NOT NULL scor
GRUPARE PRIN R1.Disciplina;
Rezultat:

Același rezultat se obține dacă excludeți condiția explicită din partea WHERE, caz în care interogarea va arăta astfel:
SELECTAȚI R1. Disciplina, COUNT (DIstinct R1. Evaluare)
GRUPARE PRIN R1. Disciplina;
Funcţie COUNT (DIstinct R1.Evaluare) consideră doar sigur variat valorile.
Pentru a se obține rezultatul dorit în acest caz, este necesar să se facă o transformare preliminară a tipului de date din coloana „Scor”, aducându-l la un tip real, apoi rezultatul calculării mediei nu va fi un întreg. În acest caz, cererea va arăta astfel:
 2 Grupați după R2. Grupa, R1. Disciplina; Aici, funcția CAST () convertește coloana „Scor” într-un tip de date valid. "lățime =" 640 "
2 Grupați după R2. Grupa, R1. Disciplina; Aici, funcția CAST () convertește coloana „Scor” într-un tip de date valid. "lățime =" 640 " Selectați R2.Group, R1.Discipline, Count (*) ca Total, AVG (distribuit (Scor zecimal (3,1))) ca Average_point
De la R1, R2
unde R1. Nume complet = R2. Nume și R1. scorul nu este nul
și R1. Clasa 2
Grupați după R2. Grupa, R1. Disciplina;
Aici funcția DISTRIBUIE () convertește coloana Scor într-un tip de date valid.

Nu puteți utiliza funcții agregate în clauza WHERE deoarece condițiile din această secțiune sunt evaluate în termeni de un singur rând, iar funcțiile agregate sunt evaluate în termeni de grupuri de rânduri.
Clauza GROUP BY vă permite să definiți un subset de valori dintr-un anumit câmp în termenii unui alt câmp și să aplicați o funcție de agregare subsetului. Acest lucru face posibilă combinarea câmpurilor și a funcțiilor agregate într-o singură clauză SELECT. Funcțiile de agregare pot fi utilizate atât în expresia pentru ieșirea rezultatelor rândului SELECT, cât și în expresia pentru procesarea grupurilor HAVING generate. În acest caz, fiecare funcție agregată este calculată pentru fiecare grup selectat. Valorile obținute la calcularea funcțiilor agregate pot fi utilizate pentru afișarea rezultatelor corespunzătoare sau pentru starea de selecție a grupurilor.
Să construim o interogare care să afișeze grupurile în care s-au obținut mai mult de un deuce la o disciplină la examene:
 unu; Rezultat: "width =" 640 "
unu; Rezultat: "width =" 640 " SELECTARE R2. grup
DE LA R1, R2
UNDE R1. Nume complet = R2. Nume AND
Scorul R1 = 2
GRUPA DE R2. Grupa, R1. Disciplina
AVÂND număr (*) 1;
Rezultat:

Avem o DB „Banca”, formată dintr-un tabel F, care stochează relația F, care conține informații despre conturile din sucursalele unei anumite bănci:
Găsiți soldul total al contului în sucursale. Este posibil să se facă o interogare separată pentru fiecare dintre ele selectând SUM (Remaining) din tabel pentru fiecare ramură, dar operația gruparea GROUP BY le va pune pe toate într-o singură comandă:
SELECTAȚI Ramura , SUMA ( Rest )
GRUP PE Filiala;
A SE GRUPA CU aplică funcții agregate în mod independent pentru fiecare grup identificat prin valoarea câmpului Filială. Grupul este format din linii cu aceeași valoare de câmp Branch și funcția SUMĂ se aplică separat pentru fiecare astfel de grup, adică soldul total al contului este calculat separat pentru fiecare sucursală. Valoarea câmpului căruia i se aplică A SE GRUPA CU, are, prin definiție, o singură valoare per grup de ieșire, la fel ca rezultatul unei funcții agregate.
 5.000; Argumentele din clauza HAVING urmează aceleași reguli ca și în clauza SELECT, care utilizează GROUP BY. Acestea trebuie să aibă o valoare pentru fiecare grup de ieșiri. "lățime =" 640 "
5.000; Argumentele din clauza HAVING urmează aceleași reguli ca și în clauza SELECT, care utilizează GROUP BY. Acestea trebuie să aibă o valoare pentru fiecare grup de ieșiri. "lățime =" 640 " Să presupunem că selectați doar acele ramuri, ale căror valori totale ale soldurilor conturilor depășesc 5.000 USD, precum și soldurile totale pentru ramurile selectate. Pentru a afișa sucursale cu solduri totale de peste 5.000 USD, trebuie să utilizați clauza HAVING. Clauza HAVING definește criteriile folosite pentru a elimina anumite grupuri din rezultat, la fel ca clauza WHERE pentru rândurile individuale.
Comanda corectă ar fi următoarea:
SELECTARE Sucursala, SUMA (Sold)
A SE GRUPA CU Ramura
AVÂND SUMA ( Rest ) 5 000;
Argumente într-o propoziție AVÂND respectați aceleași reguli ca în propoziție SELECTAȚI unde este folosit A SE GRUPA CU... Acestea trebuie să aibă o valoare pentru fiecare grup de ieșiri.

Următoarea comandă va fi interzisă:
SELECTARE Sucursala, SUMA (Sold)
GRUP PE Filiala
AVÂND Data deschiderii = 27.12.2004 ;
Camp Data deschiderii nu poate fi folosit într-o propoziție AVÂND deoarece poate avea mai mult de o valoare per grup de afișare. Pentru a evita o astfel de situație, propunerea AVÂND ar trebui să se refere numai la agregate și câmpuri selectate A SE GRUPA CU... Există o modalitate corectă de a face interogarea de mai sus:
SELECTARE Sucursala, SUMA (Sold)
WHERE Data deschiderii = '27 / 12/2004 '
GRUP PE Filiala;

Sensul acestei interogări este următorul: găsiți suma soldurilor pentru fiecare ramură de conturi deschisă la 27 decembrie 2004.
După cum sa menționat mai devreme, HAVING poate folosi doar argumente care au aceeași valoare pentru fiecare grup de ieșire. În practică, referințele la funcțiile agregate sunt cele mai generale, dar câmpurile selectate cu GROUP BY sunt și ele valabile. De exemplu, dorim să vedem soldurile totale ale conturilor sucursalelor din Sankt Petersburg, Pskov și Uryupinsk:
SELECTARE Sucursala, SUMA (Sold)
DE LA F, Q
UNDE F. Filiala = Q. Filiala
GRUP PE Filiala
HAVING Branch IN („Sankt Petersburg”, „Pskov”, „Uriupinsk”);
100.000; Dacă soldul total este mai mare de 100.000 USD, atunci îl vom vedea în raportul rezultat, altfel vom obține un raport gol. "lățime =" 640 "
Prin urmare, în expresiile aritmetice ale predicatelor incluse în condiția de selecție a clauzei HAVING, puteți utiliza direct doar specificațiile coloanelor specificate ca coloane de grupare în clauza GROUP BY. Restul coloanelor pot fi specificate numai în specificațiile funcțiilor agregate COUNT, SUM, AVG, MIN și MAX, care calculează în în acest caz niste valoare agregată pentru întregul grup de linii. Rezultatul executării clauzei HAVING este un tabel grupat care conține doar acele grupuri de rânduri pentru care rezultatul evaluării condiției de selecție în partea HAVING este TRUE. În special, dacă clauza HAVING este prezentă într-o interogare care nu conține GROUP BY, atunci rezultatul execuției sale va fi fie un tabel gol, fie rezultatul executării secțiunilor anterioare. expresie de tabel considerată ca un grup fără coloane de grupare. Să ne uităm la un exemplu. Să presupunem că vrem să ieșim valoare totală solduri pentru toate filialele, dar numai dacă este mai mare de 100.000 USD. În acest caz, cererea noastră nu va conține operațiuni de grupare, ci va conține o secțiune HAVING și va arăta astfel:
SELECTAȚI SUMA ( Rest )
AVÂND SUMA ( Rest ) 100 000;
Dacă soldul total este mai mare de 100.000 USD, atunci îl vom vedea în raportul rezultat, altfel vom obține un raport gol.

Standardul ISO definește următoarele cinci functii de agregare:
NUMARA- returnează numărul de valori din coloana specificată;
SUMĂ- returnează suma valorilor din coloana specificată;
AVG- returnează valoarea medie în coloana specificată;
MIN- returnează valoarea minimă în coloana specificată;
MAX- returnează valoarea maximă în coloana specificată.
Toate aceste funcții operează pe valori dintr-o singură coloană a tabelului și returnează o singură valoare. Funcțiile COUNT, MIN și MAX se aplică atât câmpurilor numerice, cât și nenumerice, în timp ce funcțiile SUM și AVG pot fi utilizate numai în cazul câmpurilor numerice. Cu excepția COUNT (*), atunci când se evaluează rezultatele oricăror funcții, toate valorile nule sunt mai întâi excluse, după care operația necesară este aplicată numai valorilor rămase ale coloanei non-nule. Opțiunea COUNT (*) este ocazie speciala folosind funcția COUNT - scopul acesteia este de a număra toate rândurile din tabel, indiferent dacă acesta conține valori goale, duplicate sau orice alte valori. Dacă doriți să eliminați valorile duplicate înainte de a utiliza funcția de agregare, plasați cuvântul cheie DISTINCT în fața numelui coloanei în definiția funcției. Standardul ISO permite utilizarea cuvântului cheie ALL pentru a indica în mod explicit că eliminarea valorilor duplicate nu este necesară, deși acest cuvânt cheie este asumat în mod implicit dacă nu este specificat niciun alt calificator. Cuvântul cheie DISTINCT este lipsit de sens pentru funcțiile MIN și MAX. Cu toate acestea, utilizarea sa poate afecta rezultatele execuției funcțiilor SUM și AVG, așa că ar trebui să luați în considerare în prealabil dacă ar trebui să fie prezent în fiecare caz specific. În plus, cuvântul cheie DISTINCT poate fi specificat cel mult o dată în fiecare solicitare.
Trebuie remarcat faptul că funcțiile agregate pot fi utilizate doar într-o listă SELECT și într-o clauză HAVING (vezi secțiunea 5.3.4). În toate celelalte cazuri, utilizarea acestor funcții este invalidă. Dacă lista SELECT conține o funcție de agregare, iar textul interogării nu conține o clauză GROUP BY care furnizează agregarea datelor în grupuri, atunci niciunul dintre elementele listei SELECT nu poate include referințe de coloană, cu excepția cazului în care această coloană este utilizată ca parametru al functia de agregare. De exemplu, următoarea solicitare este nevalidă:
SELECTAȚIpersonal nu,NUMARA (salariu)
DINPersonal;
Eroarea este că această solicitare nu conține construcția A SE GRUPA CU, iar accesul la coloana staffNo din lista SELECT se realizează fără a utiliza funcția de agregare.
Exemplul 13. Utilizarea funcției COUNT (*).Determinați câte proprietăți de închiriere au o rată de închiriere de peste 350 GBP pe lună,
SELECTARE NUMĂR(*) CA număr
DINPropertyForRent
UNDEchirie> 350;
Clauza WHERE se limitează la numărarea numai a articolelor de închiriat care depășesc 350 GBP pe lună. Numărul total de proprietăți închiriate care se întâlnesc condiția specificată, poate fi determinat folosind funcția de agregare COUNT. Rezultatele executării interogării sunt prezentate în tabel. 23.
Tabelul 23
| numara |
Exemplul 14. Folosind funcția COUNT (DISTINCT).Determinați câte proprietăți de închiriere diferite au fost vizualizate de clienți în mai 2001.
SELECTAȚI NUMĂR (DISTINCTpropertyNo) AS count
DINVizionare
Din nou, limitarea rezultatelor interogării la o analiză numai a acelor contracte de închiriere care au fost vizualizate în mai 2001 se realizează prin utilizarea unei clauze WHERE. Numărul total de obiecte examinate care îndeplinesc condiția specificată poate fi determinat folosind funcția de agregare COUNT. Cu toate acestea, deoarece același obiect poate fi vizualizat de clienți diferiți de mai multe ori, trebuie să specificați cuvântul cheie DISTINCT în definiția funcției pentru a exclude valorile duplicate din calcul. Rezultatele executării interogării sunt prezentate în tabel. 24.
Tabelul 24
Exemplul 16. Utilizarea funcțiilor MIN, MAXnAVG.Calculați valoarea salariului minim, maxim și mediu.
SELECTARE MIN(salariu) LA FEL DE min, MAX(salariu) LA FEL DE max, AVG(salariu) LA FEL DE medie
DINPersonal;
În acest exemplu, trebuie să procesați informații despre tot personalul companiei, deci nu trebuie să utilizați o clauză WHERE. Valorile necesare pot fi calculate folosind funcțiile MIN, MAX și AVG aplicate coloanei de salarii din tabelul Staff. Rezultatele executării interogării sunt prezentate în tabel. 26.
Tabelul 26.
Rezultatul interogării
| min | max | medie |
| 9000.00 | 30000.00 | 17000.00 |
Rezultate de grupare (clauza GROUP BY). Exemplele de date rezumative de mai sus sunt similare cu rândurile rezumate care se găsesc de obicei la sfârșitul rapoartelor. În totaluri, toate datele detaliate ale raportului sunt comprimate într-o singură linie de rezumat. Cu toate acestea, de foarte multe ori este necesar să se formeze subtotaluri în rapoarte. În acest scop, o clauză GROUP BY poate fi specificată în instrucțiunea SELECT. Este apelată o interogare care conține o clauză GROUP BY interogare de grupareîntrucât grupează datele obţinute în urma operaţiei SELECT, după care un singur linie de rezumat... Coloanele listate în clauza GROUP BY sunt denumite coloane grupate. Standardul ISO cere ca clauzele SELECT și GROUP BY să fie strâns legate. Când utilizați clauza GROUP BY într-o instrucțiune SELECT, fiecare articol din lista SELECT trebuie să aibă singurul sens pentru întregul grup.În plus, o clauză SELECT poate include doar următoarele tipuri de elemente:
Numele coloanelor;
funcții de agregare;
constante;
Expresii care includ combinații ale celor de mai sus.
Toate numele coloanelor enumerate în lista SELECT trebuie să apară și în clauza GROUP BY, cu excepția cazului în care numele coloanei este utilizat numai în funcția de agregare. Opusul nu este întotdeauna adevărat - clauza GROUP BY poate conține nume de coloane care nu sunt în lista SELECT. Dacă clauza WHERE este folosită împreună cu clauza GROUP BY, atunci este procesată mai întâi și sunt grupate numai acele rânduri care îndeplinesc condiția de căutare. Standardul ISO specifică că atunci când se realizează gruparea, toate valorile lipsă sunt tratate ca fiind egale. Dacă două rânduri de tabel din aceeași coloană de grupare conțin valori nule și valori identice în toate celelalte coloane grupate nevide, acestea sunt plasate în același grup.
Exemplul 17. Utilizarea clauzei GROUP BY.Determinați numărul de personal care lucrează în fiecare dintre departamentele companiei, precum și salariile totale ale acestora.
SELECTAȚIramurăNu, NUMARA(personalNu) LA FEL DE numara, SUMĂ(salariu) LA FEL DE sumă
DINPersonal
A SE GRUPA CUramuraNr
COMANDA PENTRUramurăNu;
Nu este necesar să includeți numele de coloană staffNo și salariu în clauza GROUP BY, deoarece acestea apar doar în lista SELECT cu funcții agregate. În același timp, coloana branchNo din lista clauzei SELECT nu este asociată cu nicio funcție de agregare și, din acest motiv, trebuie specificată în clauza GROUP BY. Rezultatele executării interogării sunt prezentate în tabel. 27.
Tabelul 27
Rezultatul interogării
| ramuraNr | Numara | Sumă |
| B003 | 54000.00 | |
| B005 | 39000.00 | |
| B007 | 9000.00 |
Conceptual, la procesarea acestei cereri, se parcurg următorii pași.
1. Rândurile din tabelul de personal sunt împărțite în grupuri în conformitate cu valorile din numărul coloanei departamentului companiei. În cadrul fiecăreia dintre grupuri, există date despre întreg personalul unuia dintre departamentele companiei. În exemplul nostru, vor fi create trei grupuri, așa cum se arată în Fig. unu.
2. Pentru fiecare dintre grupuri se calculează numărul total de rânduri, egal cu numărul de angajați din departament, precum și suma valorilor din coloana de salarii, care este suma salariilor tuturor. angajații departamentului care ne interesează. Un singur rând rezumat este apoi generat pentru întregul grup de rânduri sursă.
3. Rândurile rezultate din tabelul rezultat sunt sortate în ordinea crescătoare a numărului de ramură indicat în coloana branchNo.
| ramuraNr | personalNr | Salariu |
| V00Z | SG37 | 12000.00 |
| V00Z | SG14 | 18000.00 |
| V00Z | SG5 | 24000.00 |
| B005 | SL21 | 30000.00 |
| B005 | SL41 | 9000.00 |
| B007 | SA9 | 9000.00 |
| COUNT (nr personal) | SUMA (salariu) |
| 54000.00 | |
| 39000.00 | |
| 9000.00 |
Orez. 1. Trei grupuri de înregistrări create la executarea unei interogări
Standardul SQL permite plasarea subinterogărilor în lista SELECT. Prin urmare, interogarea de mai sus poate fi reprezentată și după cum urmează:
SELECTAȚIramurăNu, (SELECTARE COUNT (nr personal)LA FEL DE numara
DINPersonalul s
UNDEs.branchNo = b.branchNo),
(SELECT SUM (salariu) AS sumă
DINPersonalul s
UNDEs.branchNo = b.branchNo)
DINFiliala b
COMANDA PENTRUramurăNu;
Dar în această versiune a interogării, pentru fiecare dintre departamentele companiei descrise în tabelul Filiale, sunt generate două rezultate ale calculării funcțiilor de agregare, prin urmare, în unele cazuri, pot apărea rânduri care conțin valori zero.
Constrângeri de grupare (clauza HAVING). Clauza HAVING este destinată să fie utilizată împreună cu clauza GROUP BY pentru a specifica constrângerile specificate pentru a le selecta. grupuri, care va fi plasat în tabelul de interogări rezultat. Deși clauzele HAVING și WHERE au sintaxă similară, scopul lor este diferit. Clauza WHERE este concepută pentru a selecta rânduri individuale pentru a umple tabelul de interogări rezultat, în timp ce clauza HAVING este utilizată pentru a selecta grupuri, plasat în tabelul de interogări rezultat. Standardul ISO impune ca numele coloanelor utilizate în clauza HAVING să apară în lista articolelor GROUP BY sau să fie utilizate în funcțiile agregate. În practică, termenii de căutare dintr-o clauză HAVING includ întotdeauna cel puțin o funcție agregată; în caz contrar, aceste condiții de căutare trebuie plasate într-o clauză WHERE și aplicate pentru selectarea rândurilor individuale. (Rețineți că funcțiile agregate nu pot fi folosite într-o clauză WHERE.) Clauza HAVING nu este o parte necesară a limbajului SQL - orice interogare scrisă folosind clauza HAVING poate fi reprezentată diferit fără a o folosi.
Exemplul 18. Folosind construcția HAVING.Pentru fiecare departament al companiei cu mai mult de un personal, determinați numărul de angajați și cuantumul salariilor acestora.
SELECTAȚIramurăNu, COUN T (nr personal) LA FEL DE numara, SUMĂ(salariu) LA FEL DE sumă
DINPersonal
A SE GRUPA CUramuraNr
AVÂND NUMĂRARE(nr personal)> 1
COMANDA PENTRUramurăNu;
Acest exemplu este similar cu cel precedent, dar aici sunt folosite restricții suplimentare, ceea ce indică faptul că ne interesează doar informații despre acele departamente ale companiei în care lucrează mai mult de o persoană. O cerință similară este impusă grupurilor, astfel încât clauza HAVING ar trebui utilizată în interogare. Rezultatele executării interogării sunt prezentate în tabel. 28.
Tabelul 28
| ramurăNumăr sumă |
| V00Z 3 54000,00 |
| B005 2 39000,00 |
Subinterogări.În această secțiune, vom discuta despre utilizarea instrucțiunilor SELECT complete încorporate în corpul altuia instrucțiunea SELECT. Extern(a doua) instrucțiune SELECT folosește rezultatul execuției intern(primul) operator care să determine conținutul rezultatului final al întregii operațiuni. Interogările interioare pot fi găsite în clauzele WHERE și HAVING ale instrucțiunii exterioare SELECT - în acest caz, ele sunt denumite subinterogări, sau interogări imbricate.În plus, instrucțiunile interne SELECT pot fi utilizate în instrucțiunile INSERT, UPDATE și DELETE . Există trei tipuri de subinterogări.
Subinterogare scalară returnează valoarea selectată din intersecția unei coloane cu un rând, adică singurul sens. În principiu, o subinterogare scalară poate fi utilizată oriunde este necesară o singură valoare. Exemple de subinterogări scalare sunt prezentate în exemplele 13 și 14.
Subinterogare șir returnează valorile mai multor coloane ale unui tabel, dar ca un singur rând. O subinterogare de șir poate fi utilizată oriunde este folosit un constructor de valoare șir - de obicei predicate. O variantă a subinterogării șir este prezentată în exemplul 15.
Subinterogare de tabel returnează valorile uneia sau mai multor coloane ale unui tabel repartizate pe mai mult de un rând. O subinterogare de tabel poate fi utilizată oriunde poate fi specificat un tabel, de exemplu, ca operand al unui predicat IN.
Exemplul 19. Utilizarea unei subinterogări cu verificarea egalității. Inventa o listă a personalului care lucrează în filiala companiei situată la adresa Main St1 463.
SELECTAȚI
DINPersonal
UNDEbranchNo = (SELECTARE branchNo
DINRamura
UNDEstrada = "163 Main S t");
O declarație internă SELECT (SELECT branchNo FROM Branch ...) este utilizată pentru a determina numărul sucursalei companiei situate la 163 Main St. (Există un singur astfel de departament într-o companie, deci acest exemplu este un exemplu de subinterogare scalară.) Odată ce se obține numărul de departament dorit, se execută o subinterogare externă pentru a prelua detaliile lucrătorilor din acel departament. Cu alte cuvinte, operator interior SELECT returnează un tabel cu o singură valoare „BOOV. Acesta este numărul sucursalei companiei situată la 163 Main St1. Ca rezultat, instrucțiunea SELECT exterioară devine după cum urmează:
SELECTAȚIpersonalNu, fNume, INume, poziție
DINPersonal
UNDEbranchNu = "B0031;
Rezultatele acestei interogări sunt prezentate în tabel. 29.
Tabelul 29
Rezultatul interogării
| personalNr | fNume | INume | poziţie |
| SG37 | Ann | Fag | Asistent |
| SG14 | David | Vad | supraveghetor |
| SG5 | Susan | Marca | Administrator |
O subinterogare este un instrument pentru crearea unui tabel temporar, al cărui conținut este preluat și procesat de un operator extern. O subinterogare poate fi specificată imediat după operatorii de comparare (adică operatorii =,<, >, <=, >=, <>) într-o clauză WHERE sau HAVING. Textul subinterogării trebuie să fie cuprins între paranteze.
Exemplul 20. Utilizarea subinterogărilor cu funcții agregate. Listați toți angajații cu salarii peste medie, indicând cât de mult salariul lor este mai mare decât salariul mediu pentru întreprindere.
SELECTAȚIpersonalNu, fNume, INume, funcție, salariu - ( SELECTARE AVG(salariu) DIN Personal) LA FEL DE salDiff
DINPersonal
UNDEsalariu> ( SELECTARE AVG(salariu) DIN S t a f f);
Trebuie menționat că nu se poate în mod direct include în expresie de interogare„UNDE salariu> AVG (salariu)”, din moment ce folosirea agregatului funcțiile din clauza WHERE sunt interzise. Pentru a obține rezultatul dorit, creați o subinterogare care calculează salariul mediu anual și apoi utilizați-o într-o declarație SELECT externă pentru a prelua informații despre acei angajați din companie ale căror salarii sunt mai mari decât această medie. Cu alte cuvinte, subinterogarea returnează valoarea salariu mediu pentru companie pe an, egal cu 17.000 GBP.
Rezultatul acestei subinterogări scalare este utilizat într-o instrucțiune exterioară SELECT atât pentru a calcula variația salariilor față de medie, cât și pentru a selecta informațiile despre angajați. Prin urmare, instrucțiunea SELECT exterioară devine:
SELECTAȚIpersonalNu, fNume, INume, funcție, salariu - 17000 La fel de salDiff
DINPersonal
UNDEsalariu> 17000;
Rezultatele executării interogării sunt prezentate în tabel. treizeci.
Tabelul 30.
Rezultatul interogării
| personalNr | fNume | INume | poziţie | salDiff |
| SL21 | Ioan | alb | Administrator | 13000.00 |
| SG14 | David | Vad | supraveghetor | 1000.00 |
| SG5 | Susan | Marca | Administrator | 7000.00 |
Aplicați la subinterogări urmând reguli si restrictii.
1. Clauza ORDER BY nu trebuie folosită în subinterogări, deși poate apărea în instrucțiunea exterioară SELECT.
2. Lista SELECT a unei subinterogări trebuie să constea din numele coloanelor individuale sau expresii compuse din acestea, cu excepția cazului în care cuvântul cheie EXISTS este utilizat în subinterogare.
3. În mod implicit, numele coloanelor dintr-o subinterogare se referă la tabelul numit în clauza FROM a subinterogării. Cu toate acestea, vă puteți referi și la coloanele din tabel specificate în clauza FROM a interogării externe utilizând nume calificate de coloane (așa cum este descris mai jos).
4. Dacă subinterogarea este unul dintre cei doi operanzi implicați în operația de comparare, atunci subinterogarea trebuie specificată în partea dreaptă a acestei operațiuni. De exemplu, următorul exemplu de scriere a unei interogări din exemplul anterior este incorect deoarece subinterogarea este plasată în partea stângă a operației de comparare cu valoarea coloanei de salariu.
SELECTAȚI
DINPersonal
UNDE(SELECTARE MEDIA (salariu) FROM Personal)< salary;
Exemplul 21... Subinterogări imbricate și utilizarea predicatului IN. Faceți o listă cu proprietățile de închiriere de care sunt responsabili angajații în sucursala situată la 163 Main st1.
SELECTAȚIproprietateNr, strada, oras, cod postal, tip, camere, inchiriere
DINPropertyForRent
capitolul 5... Limbajul SQL: manipularea datelor 189
UNDEstaffNo IN (SELECTARE personalNo
DINPersonal
UNDEbrancliNo = (SELECTARE branchNr
DINRamura
UNDEstrada = "163 Main S t"));
Prima interogare, cea mai internă, are scopul de a determina numărul sucursalei companiei situate la 463 Main St ". A doua interogare intermediară preia informații despre personalul care lucrează în acest departament. În acest caz, sunt mai multe rânduri de date. selectat și deci în interogarea externă nu poți folosi operatorul de comparație =.Trebuie să folosești în schimb cuvântul cheie IN. Interogarea exterioară preia informații despre contractele de închiriere de care sunt responsabili angajații companiei, datele despre care au fost obținute ca urmare a interogării intermediare.Rezultatele interogării sunt prezentate în tabel.31.
Tabelul 31
Rezultatul interogării
| proprietateNr | stradă | oraș | cod poștal | tip | camere | chirie |
| PG16 | 5 Novar Dr | Glasgow | G129AX | Apartament | ||
| PG36 | 2 Manor Rd | Glasgow | G324QX | Apartament | ||
| PG21 | 18 Dale Rd | Glasgow | G12 | Casa |
Cuvinte cheie ORICE și TOATE. Cuvintele cheie ANY și ALL pot fi utilizate cu subinterogări care returnează o singură coloană de numere. Dacă subinterogarea este precedată de cuvântul cheie ALL, condiția de comparare este îndeplinită numai dacă este îndeplinită pentru toate valorile din coloana rezultat a subinterogării. Dacă textul subinterogării este precedat de cuvântul cheie ORICE, atunci condiția de comparare va fi considerată îndeplinită dacă este îndeplinită pentru cel puțin una (una sau mai multe) valori din coloana rezultată a subinterogării. Dacă subinterogarea are ca rezultat o valoare nulă, atunci condiția de comparare pentru cuvântul cheie ALL va fi considerată îndeplinită, iar pentru cuvântul cheie ORICE, va fi considerată neîndeplinită. Conform standardului ISO, puteți utiliza suplimentar cuvântul cheie SOME, care este un sinonim pentru cuvântul cheie ANY.
Exemplul 22. Folosind cuvintele cheie ANY și SOME. Găsiți toți angajații al căror salariu depășește cel puțin salariul unu un angajat al unei sucursale a firmei cu numărul „booz”.
SELECTAȚIpersonalNu, fNume, INume, funcție, salariu
DINPersonal
UNDEsalariu> UNELE (SELECTARE salariu
DINPersonal
UNDEbranchNu = "B003");
Deși această interogare poate fi scrisă folosind o subinterogare care determină salariul minim al personalului din departament cu numărul „BOOZ”, după care subinterogarea externă poate selecta informații despre tot personalul companiei ale căror salarii depășesc această valoare (vezi Exemplul 20) , este posibilă o altă abordare.care constă în folosirea cuvintelor cheie SOME / ANY. În acest caz, interogarea internă creează un set de valori (12000, 18000, 24000), iar interogarea exterioară selectează informații despre acei angajați al căror salariu este mai mare decât oricare dintre valorile din acest
set (de fapt, mai mult decât valoarea minimă - 12000). Această metodă alternativă poate fi considerată mai naturală decât definirea salariului minim în subinterogare. Dar, în ambele cazuri, sunt generate aceleași rezultate ale interogării, care sunt prezentate în tabel. 32 .
Tabelul 32
Rezultatul interogării
| personalNr | fNume | INume | poziţie | salariu |
| SL21 | Ioan | alb | Administrator | 30000.00 |
| SG14 | David | Vad | supraveghetor | 18000.00 |
| SG5 | Susan | Marca | Administrator | 24000.00 |
Exemplul 23. Folosind cuvântul cheie ALL. Găsiți toți angajații ale căror salarii sunt mai mari decât salariile oricărui angajat din filiala de băuturi a companiei.
SELECTAȚIpersonalNu, fNume, INarae, functie, salariu
DINPersonal
UNDEsalariu> TOATE(SELECTARE salariul
DINPersonal
UNDEbranchNu = "BOG3");
În general, această solicitare este similară cu cea anterioară. Și în acest caz, s-ar putea folosi o subinterogare care determină valoarea maximă a salariului personalului departamentului sub numărul „WOOZ”, apoi, folosind o interogare externă, selectați informații despre toți angajații companiei ale căror salarii depășesc această valoare. Cu toate acestea, în acest exemplu a fost aleasă o abordare folosind cuvântul cheie ALL. Rezultatele executării interogării sunt prezentate în tabel. 33 .
Tabelul 33
Rezultatul interogării
| personalNr | INume | fNume | poziţie | salariu |
| SL21 | alb | Ioan | Administrator | 30000,00 |
Interogări cu mai multe tabele. Toate exemplele de mai sus au aceeași limitare importantă: coloanele plasate în tabelul rezultat sunt întotdeauna selectate dintr-un singur tabel. Cu toate acestea, în multe cazuri acest lucru nu este suficient. Pentru a combina coloane din mai multe tabele sursă în tabelul rezultat, trebuie să efectuați operația conexiuni.În SQL, o operație de îmbinare este utilizată pentru a combina informațiile din două tabele formând perechi de rânduri legate selectate din fiecare tabel. Perechile de rânduri plasate în tabelul combinat sunt compilate în funcție de egalitatea valorilor coloanelor specificate incluse în ele.
Dacă aveți nevoie să obțineți informații din mai multe tabele, puteți fie să aplicați o subinterogare, fie să efectuați o îmbinare între tabele. Dacă tabelul de interogări rezultat trebuie să conțină coloane din tabele sursă diferite, atunci este recomandabil să utilizați mecanismul de îmbinare a tabelului. Pentru a efectua o îmbinare, este suficient să specificați numele a două sau mai multe tabele în clauza FROM, separându-le cu virgule, și apoi să includeți în interogare clauza WHERE care definește coloanele folosite pentru unirea tabelelor specificate. În plus, în loc de nume de tabel, puteți utiliza pseudonime, atribuite acestora în clauza FROM. În acest caz, numele tabelelor și aliasurile atribuite acestora trebuie separate prin spații. Aliasurile pot fi folosite pentru a califica numele coloanelor ori de câte ori există ambiguitate cu privire la tabelul căruia îi aparține o anumită coloană. În plus, alias-urile pot fi folosite pentru a abreviera numele tabelelor. Dacă este definit un alias pentru un tabel, acesta poate fi folosit oriunde care necesită numele acelui tabel.
Exemplul 24. Conexiune simplă. Enumerați numele tuturor clienților care au vizualizat cel puțin o proprietate închiriată și au oferit feedback cu privire la aceasta.
SELECTAȚIc.clientNo, fName, INname, propertyNo, comentariu
DINClient c, Vizualizare v
UNDEc.clientNu = v.clientNu;
Acest raport necesită informații atât din tabelul Client, cât și din tabelul de vizualizare, așa că vom folosi mecanismul de alăturare a tabelului atunci când construim interogarea. Clauza SELECT listează toate coloanele care ar trebui plasate în tabelul de interogări rezultat. Rețineți că coloana cu numărul clientului (clientNo) necesită o rafinare, deoarece o astfel de coloană poate fi prezentă și într-un alt tabel care participă la unire. Prin urmare, este necesar să indicăm în mod explicit ce valori de tabel ne interesează. (În acest exemplu, ați putea la fel de bine să selectați valorile pentru coloana clientNo din tabelul de vizualizare). Numele este specificat prin prefixarea numelui coloanei cu numele tabelului corespunzător (sau aliasul acestuia). În exemplul nostru, este folosită valoarea „c”, specificată ca alias pentru tabelul Client. Pentru a forma rândurile rezultate, se folosesc acele rânduri ale tabelelor sursă care au o valoare identică în coloana clientNo. Această condiție este determinată prin setarea condiției de căutare cu.clientNo = v.clientNo. Sunt numite coloane similare din tabelele originale coloane compatibile. Operația descrisă este echivalentă cu operația egalitatea se unește algebră relațională. Rezultatele executării interogării sunt prezentate în tabel. 34.
Tabelul 34
Rezultatul interogării
| clientNr | fNume | INume | proprietateNr | cometariu |
| CR56 | Aline | Stewart | PG36 | |
| CR56 | Aline | Stewart | PA14 | prea mic |
| CR56 | Aline | Stewart | PG4 | |
| CR62 | Maria | Tregear | PA14 | nicio sufragerie |
| CR76 | Ioan | Kay | PG4 | prea îndepărtat |
Cel mai adesea, interogările cu mai multe tabele sunt efectuate pe două tabele conectate printr-o relație unu-la-mai multe (1: *) sau părinte-copil. În exemplul de mai sus, care implică accesarea tabelelor Client și Vizualizare, acestea din urmă sunt conectate doar printr-o astfel de relație. Fiecare rând al tabelului de vizualizare (copil) este asociat cu un singur rând al tabelului Client (părinte), în timp ce același rând al tabelului Client (părinte) poate fi asociat
cu multe rânduri din tabelul de vizualizare (copil). Perechile de rânduri care sunt generate atunci când interogarea este executată sunt rezultatul tuturor combinațiilor valide de rânduri din tabelele copil și părinte. Secțiunea 3.2.5 a detaliat cum în bază relațională date, cheile primare și externe ale tabelelor creează o relație „părinte-copil”. Tabelul care conține cheia străină este de obicei un copil, în timp ce tabelul care conține cheia primară va fi întotdeauna părintele. Pentru a utiliza o relație părinte-copil într-o interogare SQL, trebuie să specificați o condiție de căutare în care vor fi comparate cheile străine și primare. Exemplul 24 compară cheia primară a tabelului Client (cu. ClientNo) cu cheia externă a tabelului de vizualizare (v. ClientNo).
Standardul SQL oferă în plus următoarele moduri definiții ale unui compus dat:
DINClient cu A TE ALATURA Vizualizare v PE c.clientNo = v.clientNu
DINClientul J OIN Vizionare UTILIZAREA clientNr
DINClient UNIUNEA NATURALĂ Vizionare
În fiecare caz, clauza FROM înlocuiește clauzele originale FROM și WHERE. Cu toate acestea, prima opțiune creează un tabel cu două coloane clientNo identice, în timp ce în celelalte două cazuri, tabelul rezultat va conține doar o coloană clientNo.
Exemplul 25. Sortarea rezultatelor unirii tabelelor. Pentru fiecare ramură a companiei, enumerați numerele de personal și numele angajaților care se ocupă de orice facilități închiriate și, de asemenea, indicați facilitățile pentru
la care ei raspund.
SELECTAȚIs.branchNo, s.staffNo, fName, INname, propertyNo
DINPersonal, PropertyForRent p
UNDEs.staffNo = p.staffNo
COMANDA PENTRUs.branchNo, s.staffNo, propertyNo;
Pentru a face rezultatele mai ușor de citit, rezultatul este sortat folosind numărul departamentului ca cheie principală de sortare și numărul personalului și numărul proprietății ca chei minore. Rezultatele executării interogării sunt prezentate în tabel. 35.
Tabelul 35
Rezultatul interogării
| ramuraNr | PersonalNr | fNume | INume | proprietateNr |
| CARE | SG14 | David | Vad | PG16 |
| CARE | SG37 | Ann | Fag | PG21 |
| CARE | SG37 | Ann | Fag | PG36 |
| BOO5 | SL41 | Maria | Lee | PL94 |
| SBI7 | SA9 | Julie | Howe | PA14 |
Exemplul 26. O îmbinare a trei tabele. Pentru fiecare sucursală a companiei, enumerați numerele de personal și numele angajaților care se ocupă de orice facilități închiriate, indicând orașul în care se află filiala și numerele facilităților pentru care fiecare angajat este responsabil.
SELECTAȚI b.filialaNr, b.oraș, s.staffNr, fNume, INume, proprietateNr
DIN Filiala b, Staff s, PropertyForRent p
UNDE b.branchNo = s.branchNo ȘI s.staffNo = p.staffNo
COMANDA PENTRU b.branchNo, s.staffNo, propertyNo;
Coloanele din cele trei tabele sursă - Branch, Staff și PropertyForRent - trebuie să fie plasate în tabelul rezultat, așa că ar trebui să alăturați aceste tabele în interogarea dvs. Tabelele Sucursale și Personal pot fi legate folosind clauza b.branchNo = * s .branchNo, care va lega sucursalele companiei de personalul care lucrează în acestea. Tabelele Staff și PropertyForRent pot fi legate folosind condiția s.staffNo = p.staffNo. Ca urmare, fiecare angajat va fi asociat cu proprietățile de închiriere pentru care este responsabil. Rezultatele executării interogării sunt prezentate în tabel. 36.
Tabelul 36
Interogarea rezultatelor
| ramuraNr | oraș | personal Mo | fNume | INume | proprietateNr |
| B003 | Glasgow | SG14 | David | Vad | PG16 |
| B003 | Glasgow | SG37 | Ann | Fag | PG21 |
| B003 | Glasgow | SG37 | Ann | Fag | PG36 |
| B005 | Londra | SL41 | Julie | Lee | PL94 |
| B007 | Aberdeen | SA9 | Maria | Howe | PA14 |
Rețineți că standardul SQL vă permite să utilizați Opțiune alternativă formulări ale clauzelor FROM și WHERE:
DIN(Sucursala b ÎNSCRIEȚI-vă personalului UTILIZAND filialaNu) LA FEL DE bs
A TE ALATURAProprietateForRent p UTILIZAREA personalNr
Exemplul 27. Gruparea după mai multe coloane. Determinați numărul de proprietăți de închiriere pentru care este responsabil fiecare angajat.
SELECTAȚIs.branchNu, S.staffNu, NUMARA(*) LA FEL DE numara
DIN Staff s, PropertyForRent p
UNDE S.staffNo = p.staffNo
A SE GRUPA CUs.branchNu, s.staffNr
COMANDA PENTRUs.branchNu, s.staffNu;
Pentru a întocmi raportul solicitat, în primul rând, trebuie să aflați care dintre angajații companiei este responsabil pentru obiectele închiriate. Această sarcină poate fi rezolvată prin alăturarea tabelelor Staff și PropertyForRent de către coloana staffNo din clauzele FROM / WHERE. Apoi este necesar să se formeze grupuri formate din numărul departamentului și numerele de personal ale angajaților săi, pentru care să se aplice clauza GROUP BY. În cele din urmă, tabelul rezultat trebuie sortat prin specificarea unei clauze ORDER BY. Rezultatele executării interogării sunt prezentate în tabel. 37.
Tabelul 37
Rezultatul interogării
| ramuraNr | personalNr | numara |
| V00Z | SG14 | |
| V00Z | SG37 | |
| B005 | SL41 | |
| B007 | SA9 |
A face legături. O îmbinare este un subset al unei combinații mai generale de date din două tabele, numite carteziană... Produsul cartezian a două tabele este un alt tabel, format din toate perechile posibile de rânduri care alcătuiesc ambele tabele. Setul de coloane din tabelul rezultat este toate coloanele din primul tabel urmate de toate coloanele din al doilea tabel. Dacă introduceți o interogare pe două tabele fără a specifica o clauză WHERE, rezultatul executării interogării în mediul SQL va fi produsul cartezian al acestor tabele. În plus, standardul ISO prevede format special Instrucțiunea SELECT care calculează produsul cartezian a două tabele:
SELECTAȚI (* j columnList]
FROM tableNamel CROSS JOINCaNeulte2
Luați în considerare din nou un exemplu în care tabelele client și Vizualizare sunt conectate folosind coloana comună clientNr. Când lucrați cu tabele, al căror conținut este dat în Tabel. 3.6 și 3.8, produsul cartezian al acestor tabele va fi de 20 de rânduri (4 rânduri în tabelul Client x 5 rânduri în tabelul de vizualizare = 20 de rânduri). Acest lucru este echivalent cu emiterea interogării utilizate în Exemplul 5.24, dar fără a aplica clauza WHERE. Procedura de generare a unui tabel care conține rezultatele unirii a două tabele folosind instrucțiunea SELECT este următoarea.
1. Se formează un produs cartezian al tabelelor specificate în clauza FROM.
2. Dacă interogarea conține o clauză WHERE, aplicați condițiile de căutare fiecărui rând din tabelul de produse carteziene și stocați numai acele rânduri din tabel care îndeplinesc condițiile specificate. În ceea ce privește algebra relațională, această operație se numește prescripţie Produs cartezian.
3. Pentru fiecare rând rămas se determină valoarea fiecărui element specificat în lista SELECT, în urma căreia se formează un rând separat al tabelului rezultat.
4. Dacă clauza SELECT DISTINCT este prezentă în interogarea originală, toate rândurile duplicat sunt eliminate din tabelul rezultat.
5. Dacă interogarea în curs de executare conține o clauză ORDER BY,
© 2015-2019 site
Toate drepturile aparțin autorilor lor. Acest site nu pretinde autor, dar oferă o utilizare gratuită.
Data creării paginii: 2016-08-07
Următoarele subsecțiuni descriu alte clauze SELECT care pot fi utilizate în interogări, precum și funcții agregate și seturi de instrucțiuni. Lasă-mă să-ți reamintesc acest moment am acoperit utilizarea clauzei WHERE, iar în acest articol ne vom uita la clauzele GROUP BY, ORDER BY și HAVING și vom oferi câteva exemple despre modul în care aceste clauze pot fi utilizate împreună cu funcțiile agregate care sunt acceptate în Transact -SQL.
Clauza GROUP BY
Propoziție A SE GRUPA CU grupează setul de rânduri selectat pentru a obține un set de rânduri rezumative pe baza valorilor uneia sau mai multor coloane sau expresii. Un caz de utilizare simplu pentru clauza GROUP BY este prezentat în exemplul de mai jos:
UTILIZAȚI SampleDb; SELECTARE Job FROM Works_On GROUP BY Job;
În acest exemplu, posturile de angajați sunt eșantionate și grupate.
În exemplul de mai sus, clauza GROUP BY creează un grup separat pentru toată lumea. valori posibile(inclusiv NULL) a coloanei Job.
Utilizarea coloanelor în clauza GROUP BY trebuie să îndeplinească anumite condiții. În special, fiecare coloană din lista de selecție a interogării trebuie să apară și în clauza GROUP BY. Această cerință nu se aplică constantelor și coloanelor care fac parte dintr-o funcție de agregare. (Funcțiile agregate sunt discutate în subsecțiunea următoare.) Acest lucru are sens deoarece numai coloanele din clauza GROUP BY au o valoare garantată per grup.
Un tabel poate fi grupat după orice combinație a coloanelor sale. Exemplul de mai jos demonstrează gruparea rândurilor din tabelul Works_on pe două coloane:
UTILIZAȚI SampleDb; SELECTARE ProjectNumber, Job FROM Works_On GROUP BY ProjectNumber, Job;
Rezultatul acestei interogări:

Pe baza rezultatelor interogării, puteți vedea că există nouă grupuri cu diferite combinații de număr și titlu de proiect. Secvența de nume de coloane din clauza GROUP BY nu trebuie să fie aceeași cu cea din lista de coloane SELECT.
Funcții agregate
Funcțiile agregate sunt folosite pentru a obține valorile sumei. Toate funcțiile agregate pot fi împărțite în următoarele categorii:
funcții agregate obișnuite;
funcții agregate statistice;
funcții agregate definite de utilizator;
funcţii agregate analitice.
Aici ne vom uita la primele trei tipuri de funcții agregate.
Funcții agregate obișnuite
Transact-SQL acceptă următoarele șase funcții agregate: MIN, MAX, SUMĂ, AVG, NUMARA, COUNT_BIG.
Toate funcțiile agregate efectuează calcule pe un singur argument, care poate fi fie o coloană, fie o expresie. (Singura excepție este a doua formă a două funcții, COUNT și COUNT_BIG, și anume COUNT (*) și, respectiv, COUNT_BIG (*).) Orice funcție agregată evaluează la o valoare constantă care apare într-o coloană separată de rezultat.
Funcțiile agregate sunt specificate în lista de coloane a unei instrucțiuni SELECT, care poate conține și o clauză GROUP BY. Dacă instrucțiunea SELECT nu include o clauză GROUP BY și lista de coloane select conține cel puțin o funcție de agregare, atunci nu trebuie să conțină coloane simple (altele decât coloanele utilizate ca argumente pentru funcția de agregare). Prin urmare, codul din exemplul de mai jos este incorect:
UTILIZAȚI SampleDb; SELECTAȚI Nume, MIN (Id) FROM Angajat;
Aici, coloana LastName din tabelul Employee nu ar trebui să fie în lista de coloane select, deoarece nu este un argument pentru funcția de agregare. Pe de altă parte, lista de coloane selectate poate conține nume de coloane care nu sunt argumente pentru funcția de agregare dacă acele coloane sunt folosite ca argumente pentru clauza GROUP BY.
Un argument de funcție agregată poate fi precedat de unul dintre cele două cuvinte cheie posibile:
TOATEIndică faptul că calculele sunt efectuate pentru toate valorile din coloană. Aceasta este valoarea implicită.
DISTINCTSpecifică faptul că numai valorile unice ale coloanei sunt utilizate pentru calcule.
Funcțiile agregate MIN și MAX
Funcțiile agregate MIN și MAX calculează cele mai mici și, respectiv, cele mai mari valori dintr-o coloană. Dacă interogarea conține o clauză WHERE, funcțiile MIN și MAX returnează cele mai mici și cele mai mari valori ale rândului care corespund condițiilor specificate. Exemplul de mai jos demonstrează utilizarea funcției de agregare MIN:
UTILIZAȚI SampleDb; - Returnează 2581 SELECT MIN (Id) AS „Valoarea minimă a ID” FROM Employee;
Rezultatul returnat în exemplul de mai sus nu este foarte informativ. De exemplu, numele de familie al angajatului care deține acest număr este necunoscut. Dar nu puteți obține acest nume de familie în mod obișnuit, deoarece, așa cum am menționat mai devreme, nu puteți specifica în mod explicit coloana LastName. Pentru a obține numele de familie al acestui angajat împreună cu cel mai mic număr de personal al angajatului, se folosește o subinterogare. Exemplul de mai jos demonstrează utilizarea unei astfel de subinterogări, în care subinterogarea conține instrucțiunea SELECT din exemplul anterior:
Rezultatul executării interogării:

Utilizarea funcției de agregare MAX este prezentată în exemplul de mai jos:
Funcțiile MIN și MAX pot accepta șiruri și date ca argumente. În cazul unui argument șir, valorile sunt comparate folosind ordinea reală de sortare. Pentru toate argumentele de date temporare de tip dată, cea mai mică valoare a coloanei va fi cea mai mare data devreme, iar cel mai recent este cel mai mare.
Cuvântul cheie DISTINCT poate fi folosit cu funcțiile MIN și MAX. Toate valorile NULL sunt eliminate din coloanele lor de argument înainte de a utiliza funcțiile agregate MIN și MAX.
Funcția agregată SUM
Agregat Funcția SUM calculează suma totală a valorilor coloanei. Argumentul acestei funcții agregate trebuie să fie întotdeauna de tip de date numerice. Utilizarea funcției de agregare SUM este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; SELECT SUM (Buget) „Buget total” FROM Proiect;
Acest exemplu calculează bugetele totale pentru toate proiectele. Rezultatul executării interogării:

În acest exemplu, funcția agregată grupează toate valorile bugetului proiectului și determină totalul acestora. Din acest motiv, interogarea conține o funcție implicită de grupare (ca toate interogările similare). Funcția de grupare implicită din exemplul de mai sus poate fi specificată în mod explicit, așa cum se arată în exemplul de mai jos:
UTILIZAȚI SampleDb; SELECT SUM (Buget) „Bugetul total” FROM Project GROUP BY ();
Utilizarea parametrului DISTINCT elimină orice valori duplicate din coloană înainte de a aplica funcția SUM. De asemenea, eliminați toate valorile NULL înainte de a aplica această funcție de agregare.
Funcția agregată AVG
Agregat Funcția AVG returnează media aritmetică a tuturor valorilor dintr-o coloană. Argumentul acestei funcții agregate trebuie să fie întotdeauna de tip de date numerice. Înainte de utilizare Funcții AVG toate valorile NULL sunt eliminate din argumentul său.
Utilizarea funcției de agregare AVG este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; - Returnează 133833 SELECT AVG (Buget) „Buget mediu pentru un proiect” FROM Proiect;
Aici se calculează media valoare aritmetică buget pentru toate bugetele.
Agregați funcțiile COUNT și COUNT_BIG
Agregat Funcția COUNT are două forme diferite:
COUNT (nume_coloană) COUNT (*)
Prima formă a funcției numără numărul de valori din coloana col_name. Dacă interogarea folosește cuvântul cheie DISTINCT, toate valorile coloanelor duplicat sunt eliminate înainte ca funcția COUNT să fie utilizată. Această formă a funcției COUNT nu ia în considerare valorile NULL atunci când se numără numărul de valori ale coloanei.
Utilizarea primei forme a funcției de agregare COUNT este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; SELECTARE ProjectNumber, COUNT (DISTINCT Job) "Jobs in Project" FROM Works_on GROUP BY ProjectNumber;
Aici este numărat numărul de poziții diferite pentru fiecare proiect. Rezultatul acestei interogări:

După cum puteți vedea din interogarea din exemplu, valorile NULL nu au fost luate în considerare de funcția COUNT. (Suma tuturor valorilor din coloana jobului este 7, nu 11 așa cum ar trebui să fie.)
A doua formă a funcției COUNT, adică. funcția COUNT (*) numără numărul de rânduri dintr-un tabel. Și dacă instrucțiunea SELECT a interogării cu funcția COUNT (*) conține o clauză WHERE cu o condiție, funcția returnează numărul de rânduri care satisfac condiția specificată. Spre deosebire de prima versiune a funcției COUNT, a doua formă nu ignoră valorile NULL, deoarece această funcție operează pe șiruri, nu pe coloane. Exemplul de mai jos demonstrează utilizarea funcției COUNT (*):
UTILIZAȚI SampleDb; SELECTARE Job CA „Tipul locului de muncă”, COUNT (*) „Este nevoie de muncitori” FROM Works_on GROUP BY Job;
Aici este numărat numărul de postări din toate proiectele. Rezultatul executării interogării:

COUNT_BIG funcție aceeași funcție ca COUNT. Singura diferență dintre cele două este tipul de rezultat pe care îl returnează: COUNT_BIG returnează întotdeauna valori BIGINT, în timp ce COUNT returnează valori de date INTEGER.
Funcții agregate statistice
Următoarele funcții alcătuiesc grupul de funcții agregate statistice:
VARCalculează varianța statistică a tuturor valorilor dintr-o coloană sau expresie.
VARPCalculează varianța statistică a populației tuturor valorilor dintr-o coloană sau expresie.
STDEVCalculează abaterea standard (care este calculată ca Rădăcină pătrată din varianța corespunzătoare) a tuturor valorilor coloanei sau expresiei.
STDEVPCalculează abaterea standard a colecției tuturor valorilor dintr-o coloană sau expresie.
Funcții agregate definite de utilizator
Motorul de baze de date suportă, de asemenea, implementarea funcțiilor definite de utilizator. Această capacitate permite utilizatorilor să suplimenteze funcțiile agregate ale sistemului cu funcții pe care le pot implementa și instala ei înșiși. Aceste funcții reprezintă o clasă specială de funcții definite de utilizator și sunt discutate în detaliu mai târziu.
clauza HAVING
Într-o propoziție AVÂND definește o condiție care se aplică unui grup de rânduri. Astfel, această clauză are aceeași semnificație pentru grupurile de rânduri ca și clauza WHERE pentru conținutul tabelului corespunzător. Sintaxa pentru clauza HAVING este următoarea:
AVÂND stare
Aici parametrul condiție reprezintă o condiție și conține funcții sau constante agregate.
Utilizarea clauzei HAVING împreună cu funcția de agregare COUNT (*) este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; - Returnează „p3” SELECT ProjectNumber FROM Works_on GROUP BY ProjectNumber HAVING COUNT (*)
În acest exemplu, sistemul folosește clauza GROUP BY pentru a grupa toate rândurile după valorile din coloana ProjectNumber. Numărul de rânduri din fiecare grup este apoi numărat și sunt selectate grupuri care conțin mai puțin de patru rânduri (trei sau mai puține).
Clauza HAVING poate fi folosită și fără funcții agregate, așa cum se arată în exemplul de mai jos:
UTILIZAȚI SampleDb; - Va returna „Consultant” SELECTARE Job FROM Works_on GROUP BY Job HAVING Job LIKE „К%”;
Acest exemplu grupează rândurile tabelului Works_on după titlul postului și elimină joburile care nu încep cu litera „K”.
Clauza HAVING poate fi folosită și fără clauza GROUP BY, deși aceasta nu este o practică obișnuită. În acest caz, toate rândurile tabelului sunt returnate în același grup.
clauza ORDER BY
Propoziție COMANDA PENTRU determină ordinea de sortare a rândurilor din setul de rezultate returnat de interogare. Această clauză are următoarea sintaxă:
Ordinea de sortare este specificată în parametrul col_name. Col_number este un indicator alternativ al ordinii de sortare care identifică coloanele în ordinea în care apar în lista de selectare a instrucțiunii SELECT (1 este prima coloană, 2 este a doua coloană și așa mai departe). Parametrul ASC definește o ordine crescătoare și parametrul DESC- în aval. Valoarea implicită este ASC.
Numele coloanelor din clauza ORDER BY nu trebuie să fie neapărat în lista de coloane selectate. Dar acest lucru nu se aplică interogărilor precum SELECT DISTINCT, deoarece în astfel de interogări, numele coloanelor specificate în clauza ORDER BY trebuie să apară și în lista coloanelor selectate. În plus, această clauză nu poate conține nume de coloane din tabele care nu sunt specificate în clauza FROM.
După cum puteți vedea din sintaxa clauzei ORDER BY, sortarea setului de rezultate se poate face pe mai multe coloane. Această sortare este prezentată în exemplul de mai jos:
Acest exemplu selectează numere de departamente și nume de familie și prenume ale angajaților pentru angajații ale căror numere de personal sunt mai mici de 20.000, precum și sortate după nume și prenume. Rezultatul acestei interogări:

Coloanele din clauza ORDER BY pot fi specificate nu după numele lor, ci în ordine în lista de selecție. În consecință, propoziția din exemplul de mai sus poate fi rescrisă după cum urmează:
Astfel de cale alternativă specificarea coloanelor după poziția lor în loc de nume este utilizată dacă criteriul de ordonare conține o funcție de agregare. (O altă modalitate este să folosiți numele coloanelor, care apar apoi în clauza ORDER BY.) Cu toate acestea, în clauza ORDER BY, se recomandă să specificați coloanele după numele lor, mai degrabă decât după numere, pentru a facilita actualizarea interogării. dacă trebuie să adăugați sau să eliminați coloane din lista de selectare. Specificarea coloanelor din clauza ORDER BY după numerele lor este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; SELECTARE ProjectNumber, COUNT (*) „Număr de angajați” FROM Works_on GROUP BY ProjectNumber ORDER BY 2 DESC;
Aici, pentru fiecare proiect, se selectează numărul proiectului și numărul de angajați care participă la acesta, ordonând rezultatul în ordine descrescătoare după numărul de angajați.
Transact-SQL plasează valorile NULL în partea de sus a listei când sunt sortate în ordine crescătoare, iar valorile NULL la sfârșitul listei când sunt sortate în ordine descrescătoare.
Utilizarea clauzei ORDER BY pentru paginarea rezultatelor
Afișarea rezultatelor interogării pe pagina curentă poate fi implementată fie în aplicație personalizată, sau instruiți serverul de baze de date să facă acest lucru. În primul caz, toate rândurile bazei de date sunt trimise către aplicație, a cărei sarcină este să selecteze rândurile necesare și să le afișeze. În al doilea caz, din partea serverului, doar rândurile necesare pentru pagina curenta... După cum v-ați putea aștepta, crearea paginii pe server oferă de obicei performanță mai bună de cand doar liniile necesare pentru afișare sunt trimise clientului.
Pentru a sprijini crearea paginii pe partea serverului în SQL Server 2012 introduce două noi clauze SELECT: OFFSET și FETCH. Aplicarea acestor două propoziții este demonstrată în exemplul de mai jos. Aici, din baza de date AdventureWorks2012 (pe care o găsiți în sursă), extrage ID-ul companiei, titlul postului și ziua de naștere a tuturor angajatelor, sortate după titlul postului în ordine crescătoare. Setul de rânduri rezultat este împărțit în pagini de 10 rânduri și este afișată o a treia pagină:
Într-o propoziție DECALAJ specifică numărul de linii de rezultat care trebuie sărit în rezultatul afișat. Această sumă este calculată după ce rândurile sunt sortate cu clauza ORDER BY. Într-o propoziție FETCH NEXT specifică numărul de WHERE și rândurile sortate de returnat. Parametrul acestei clauze poate fi o constantă, o expresie sau rezultatul unei alte interogări. Clauza FETCH NEXT este similară cu clauza FETCH MAINTI.
Scopul principal atunci când se creează pagini pe partea serverului este acela de a putea implementa formulare comune de pagină folosind variabile. Această sarcină poate fi realizată prin pachetul SQL Server.
Declarația SELECT și proprietatea IDENTITY
proprietatea IDENTITATE vă permite să determinați valorile pentru o anumită coloană a tabelului sub forma unui contor incremental automat. Coloanele cu un tip de date numerice, cum ar fi TINYINT, SMALLINT, INT și BIGINT pot avea această proprietate. Pentru o astfel de coloană de tabel, Motorul de bază de date generează automat valori secvențiale începând cu valoarea de pornire specificată. Astfel, proprietatea IDENTITY poate fi folosită pentru a crea fără ambiguitate valori numerice pentru coloana selectată.
Un tabel poate conține o singură coloană cu proprietatea IDENTITY. Proprietarul tabelului are capacitatea de a specifica valoarea inițială și creșterea, așa cum se arată în exemplul de mai jos:
UTILIZAȚI SampleDb; CREATE TABLE Product (Id INT IDENTITY (10000, 1) NOT NULL, Name NVARCHAR (30) NOT NULL, Price MONEY) INSERT INTO Product (Nume, Price) VALUES ("Produs1", 10), ("Product2", 15) , ("Produs3", 8), ("Produs4", 15), ("Produs5", 40); - Va returna 10004 SELECT IDENTITYCOL FROM Product WHERE Nume = "Product5"; - Analog cu declarația anterioară SELECT $ identity FROM Product WHERE Nume = "Product5";
Acest exemplu creează mai întâi un tabel Product care conține o coloană Id cu o proprietate IDENTITY. Valorile din coloana Id sunt create automat de sistem, începând de la 10.000 și crescând într-un pas pentru fiecare valoare ulterioară: 10.000, 10.001, 10.002 etc.
Mai multe funcții de sistem și variabile sunt asociate cu proprietatea IDENTITY. De exemplu, codul de exemplu folosește variabila de sistem $ identitate... După cum puteți vedea din rezultatele rulării acestui cod, această variabilă este referită automat la proprietatea IDENTITY. Puteți folosi și în schimb functia sistemului IDENTITYCOL.
Valoarea inițială și incrementul coloanei cu proprietatea IDENTITATE pot fi găsite folosind funcțiile IDENT_SEEDși IDENT_INCR respectiv. Aceste funcții se aplică după cum urmează:
UTILIZAȚI SampleDb; SELECT IDENT_SEED ("Produs"), IDENT_INCR ("Produs")
După cum sa menționat, valorile IDENTITATE sunt setate automat de către sistem. Dar utilizatorul își poate specifica în mod explicit valorile pentru anumite șiruri de caractere prin alocarea parametrului IDENTITY_INSERT valoarea ON înainte de a introduce valoarea explicită:
SETARE IDENTITATE INSERT numele tabelului
Deoarece parametrul IDENTITY_INSERT poate fi utilizat pentru a seta orice valoare, inclusiv valori duplicate, pe o coloană cu proprietatea IDENTITY, proprietatea IDENTITY de obicei nu impune unicitatea valorilor coloanei. Prin urmare, constrângerile UNIQUE sau PRIMARY KEY ar trebui aplicate pentru a impune unicitatea valorilor coloanei.
Când inserați valori într-un tabel după ce ați activat IDENTITY_INSERT, sistemul creează următoarea valoare în coloana IDENTITY, incrementând cea mai mare valoare curentă din acea coloană.
Instrucțiunea CREATE SEQUENCE
Utilizarea proprietății IDENTITY are câteva dezavantaje semnificative, dintre care cele mai semnificative sunt:
proprietatea este limitată la tabelul specificat;
noua valoare a coloanei nu poate fi obtinuta in nici un alt mod, decat prin aplicarea acesteia;
proprietatea IDENTITY poate fi specificată numai la crearea unei coloane.
Din aceste motive, SQL Server 2012 introduce secvențe care au aceeași semantică ca proprietatea IDENTITY, dar nu au dezavantajele enumerate anterior. În acest context, o secvență se referă la funcționalitatea unei baze de date care vă permite să specificați valori de contor pentru diferite obiecte de bază de date, cum ar fi coloane și variabile.
Secvențele sunt create folosind instrucțiunea CREAȚI SECVENȚA... Instrucțiunea CREATE SEQUENCE este definită în Standardul SQLși este suportat de alte sisteme de baze de date relaționale, cum ar fi IBM DB2 și Oracle.
Exemplul de mai jos arată cum să creați o secvență în SQL Server:
UTILIZAȚI SampleDb; CREATE SECVENCE dbo.Sequence1 AS INT START CU 1 INCREMENTARE CU 5 MINVALUE 1 MAXVALUE 256 CYCLE;
În exemplul de mai sus, valorile Sequence1 sunt generate automat de sistem, începând de la o valoare de 1 și în trepte de 5 pentru fiecare valoare succesivă. Astfel, în clauza START este indicată valoarea inițială, iar în Oferta INCREMENTARE- Etapa. (Pasul poate fi fie pozitiv, fie negativ.)
În următoarele două propoziții opționale MINVALUEși MAXVALUE specifică valoarea minimă și maximă a obiectului secvență. (Rețineți că MINVALUE trebuie să fie mai mic sau egal cu valoarea initiala, iar valoarea MAXVALUE nu poate fi mai mare decât limita superioară a tipului de date specificat pentru secvență.) În clauza CICLU indică faptul că secvența se repetă de la început atunci când valoarea maximă (sau minimă pentru o secvență cu pas negativ) este depășită. În mod implicit, această clauză este setată la NO CYCLE, ceea ce înseamnă că depășirea valorii maxime sau minime a secvenței ridică o excepție.
Caracteristica principală a secvențelor este independența lor față de tabele, adică. ele pot fi utilizate cu orice obiect de bază de date, cum ar fi coloanele de tabel sau variabile. (Această proprietate are un efect pozitiv asupra stocării și, prin urmare, asupra performanței. O anumită secvență nu trebuie să fie stocată; doar ultima ei valoare este stocată.)
Sunt create noi valori ale secvenței cu NEXT VALUE FOR expresii, a cărui aplicare este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; - Returnează 1 SELECT NEXT VALUE FOR dbo.sequence1; - Returnează 6 (pasul următor) SELECT NEXT VALUE FOR dbo.sequence1;
Puteți folosi expresia NEXT VALUE FOR pentru a atribui rezultatul unei secvențe unei variabile sau unei celule de coloană. Exemplul de mai jos ilustrează utilizarea acestei expresii pentru a atribui rezultate unei coloane:
UTILIZAȚI SampleDb; CREATE TABLE Product (Id INT NOT NULL, Name NVARCHAR (30) NOT NULL, Price MONEY) INSERT INTO Product VALUES (NEXT VALUE FOR dbo.sequence1, "Product1", 10); INSERT INTO Product VALUES (URMĂTORUL VALOARE PENTRU dbo.sequence1, „Product2”, 15); -...
Exemplul de mai sus creează mai întâi un tabel numit Produs cu patru coloane. Apoi, două instrucțiuni INSERT inserează două rânduri în acest tabel. Primele două celule ale primei coloane vor fi 11 și 16.
Exemplul de mai jos demonstrează utilizarea vizualizării catalogului sys.secvente pentru a vizualiza valoarea curentă a unei secvențe fără a o folosi:
De obicei, expresia NEXT VALUE FOR este utilizată într-o instrucțiune INSERT pentru a instrui sistemul să insereze valorile generate. Această expresie poate fi folosită și ca parte a unei interogări pe mai multe linii folosind clauza OVER.
Pentru a modifica o proprietate a unei secvențe existente, aplicați Instrucțiunea ALTER SEQUENCE... Una dintre cele mai importante utilizări pentru această declarație este opțiunea RESTART WITH, care resetează secvența specificată. Exemplul de mai jos demonstrează utilizarea instrucțiunii ALTER SEQUENCE pentru a reseta aproape toate proprietățile Sequence1:
UTILIZAȚI SampleDb; ALTER SEQUENCE dbo.sequence1 RESTART CU 100 INCREMENTARE CU 50 MINVALUE 50 MAXVALUE 200 FĂRĂ CICLU;
Secvența este ștearsă folosind instrucțiunea SECVENȚA DE CĂDERARE.
Setați operatori
Pe lângă operatorii discutați mai devreme, Transact-SQL acceptă alți trei operatori de set: UNION, INTERSECT și EXCEPT.
operator UNION
operator UNION combină rezultatele a două sau mai multe interogări într-un singur set de rezultate care include toate rândurile care aparțin tuturor interogărilor din uniune. În consecință, rezultatul unirii celor două tabele este un tabel nou care conține toate rândurile din unul sau ambele tabele originale.
Forma generală a operatorului UNION arată astfel:
select_1 UNION select_2 (select_3])...
Opțiunile select_1, select_2, ... sunt instrucțiuni SELECT care creează unirea. Dacă se utilizează parametrul ALL, sunt afișate toate rândurile, inclusiv duplicatele. În instrucțiunea UNION, parametrul ALL are aceeași semnificație ca în SELECT, cu o diferență: pentru SELECT, acest parametru este implicit, iar pentru UNION, trebuie specificat explicit.
În forma sa originală, SampleDb nu este potrivit pentru demonstrarea utilizării operatorului UNION. Prin urmare, în această secțiune este creat un nou tabel EmployeeEnh, care este identic tabelul existent Angajat, dar are o coloană suplimentară Oraș. Această coloană indică locul de reședință al angajaților.
Crearea tabelului EmployeeEnh ne oferă o oportunitate de a demonstra utilizarea clauzei. ÎNîn instrucțiunea SELECT. Instrucțiunea SELECT INTO efectuează două operații. Mai întâi, este creat un nou tabel cu coloanele listate în lista SELECT. Apoi, rândurile din tabelul original sunt inserate în noul tabel. Numele noului tabel este specificat în clauza INTO, iar numele tabelului sursă este specificat în clauza FROM.
Exemplul de mai jos arată crearea tabelului EmployeeEnh din tabelul Employee:
UTILIZAȚI SampleDb; SELECT * INTO EmployeeEnh FROM Employee; ALTER TABLE EmployeeEnh ADD City NCHAR (40) NULL;
În acest exemplu, instrucțiunea SELECT INTO creează tabelul EmployeeEnh, inserează toate rândurile din tabelul sursă Employee în acesta, iar apoi instrucțiunea ALTER TABLE adaugă coloana City la noul tabel. Dar coloana Oraș adăugată nu conține nicio valoare. Valorile pot fi inserate în această coloană prin Mediul de management Studio sau cu următorul cod:
UTILIZAȚI SampleDb; UPDATE EmployeeEnh SET City = "Kazan" WHERE Id = 2581; UPDATE EmployeeEnh SET City = „Moscova” WHERE Id = 9031; UPDATE EmployeeEnh SET City = "Ekaterinburg" WHERE Id = 10102; UPDATE EmployeeEnh SET City = "Sankt Petersburg" WHERE Id = 18316; UPDATE EmployeeEnh SET City = "Krasnodar" WHERE Id = 25348; UPDATE EmployeeEnh SET City = "Kazan" WHERE Id = 28559; UPDATE EmployeeEnh SET City = "Perm" WHERE Id = 29346;
Acum suntem gata să demonstrăm utilizarea declarației UNION. Exemplul de mai jos arată o interogare pentru a crea o îmbinare între tabelele EmployeeEnh și Department folosind această declarație:
UTILIZAȚI SampleDb; SELECTAȚI Orașul AS „ORAS” FROM EmployeeEnh UNION SELECTAȚI Locația FROM Departament;
Rezultatul acestei interogări:
Numai tabelele compatibile pot fi alăturate folosind declarația UNION. Prin tabele compatibile, înțelegem că ambele liste de coloane din selecție trebuie să conțină același număr de coloane, iar coloanele corespunzătoare trebuie să aibă tipuri de date compatibile. (În ceea ce privește compatibilitatea, tipurile de date INT și SMALLINT nu sunt compatibile.)
Rezultatul concatenării poate fi ordonat numai folosind clauza ORDER BY din ultima instrucțiune SELECT, așa cum se arată în exemplul de mai jos. Clauzele GROUP BY și HAVING pot fi utilizate cu instrucțiuni individuale SELECT, dar nu în cadrul uniunii în sine.
Interogarea din acest exemplu selectează angajați care fie lucrează în departamentul d1, fie care au început să lucreze la un proiect înainte de 1 ianuarie 2008.
Operatorul UNION acceptă opțiunea ALL. Această opțiune nu elimină duplicatele din setul de rezultate. Un operator OR poate fi utilizat în locul operatorului UNION dacă toate instrucțiunile SELECT unite de unul sau mai mulți operatori UNION se referă la același tabel. În acest caz, setul de instrucțiuni SELECT este înlocuit cu o singură instrucțiune SELECT cu un set de instrucțiuni OR.
Operatorii INTERSECT și EXCEPT
Alți doi operatori pentru lucrul cu seturi, INTERSECTși CU EXCEPTIA, definiți intersecția și respectiv diferența. Sub intersecție, în acest context, există un set de rânduri care aparțin ambelor tabele. Și diferența dintre două tabele este definită ca toate valorile care aparțin primului tabel și nu sunt prezente în al doilea. Exemplul de mai jos demonstrează utilizarea operatorului INTERSECT:
Transact-SQL nu acceptă utilizarea parametrului ALL cu operatorii INTERSECT sau EXCEPT. Utilizarea operatorului EXCEPT este prezentată în exemplul de mai jos:
Trebuie amintit că acești trei operatori de set au o prioritate de execuție diferită: operatorul INTERSECT are cea mai mare prioritate, urmat de EXCEPȚIA declarației iar operatorul UNION are cea mai mică prioritate. Neatenție la prioritatea execuției atunci când se utilizează multiple diferiți operatori lucrul cu seturi poate produce rezultate neașteptate.
expresii CASE
În domeniul programării aplicațiilor de baze de date, uneori este necesară modificarea prezentării datelor. De exemplu, oamenii pot fi subdivizați în funcție de clasa lor socială, folosind valorile 1, 2 și 3, desemnând bărbați, femei și, respectiv, copii. Această tehnică de programare poate reduce timpul necesar implementării programului. expresie CASE Transact-SQL vă permite să implementați cu ușurință acest tip de codificare.
Spre deosebire de majoritatea limbajelor de programare, CASE nu este o declarație, ci o expresie. Prin urmare, o expresie CASE poate fi folosită aproape oriunde Transact-SQL permite utilizarea expresiilor. Expresia CASE are două forme:
expresie CASE simplă;
expresia de căutare CASE.
Sintaxa pentru o expresie CASE simplă este următoarea:
O instrucțiune cu o expresie CASE simplă caută mai întâi în lista tuturor expresiilor din clauza CÂND prima expresie care se potrivește cu expresia_1 și apoi execută cea corespunzătoare THEN clauza... Dacă nu există o expresie potrivită în lista CÂND, atunci clauza ELSE.
Sintaxa pentru o expresie de căutare CASE este următoarea:
În acest caz, caută prima condiție de calificare și apoi execută clauza THEN corespunzătoare. Dacă niciuna dintre condiții nu îndeplinește cerințele, se execută clauza ELSE. Utilizarea expresiei de căutare CASE este prezentată în exemplul de mai jos:
UTILIZAȚI SampleDb; SELECTAȚI Nume Proiect, CAZUL CÂND Buget> 0 ȘI Buget 100000 ȘI Buget 150000 ȘI Buget
Rezultatul acestei interogări:

Acest exemplu ponderează bugetele tuturor proiectelor și afișează ponderile calculate împreună cu numele proiectelor corespunzătoare.
Exemplul de mai jos arată o altă modalitate de a utiliza o expresie CASE în care clauza WHEN conține subinterogări care fac parte din expresie:
UTILIZAȚI SampleDb; SELECTAȚI Numele Proiectului, CAZUL CÂND p1.Buget (SELECTARE AVG (p2.Buget) FROM Proiectul p2) THEN „peste medie” END „Categoria bugetară” FROM Proiectul p1;
Rezultatul acestei interogări este următorul: