Naučimo da sumiramo. Ne, ovo nisu rezultati učenja SQL-a, već rezultati vrijednosti stupaca tablica baze podataka. SQL agregatne funkcije rade na vrijednostima stupca kako bi proizvele jednu vrijednost rezultata. Najčešće korištene SQL agregatne funkcije su SUM, MIN, MAX, AVG i COUNT. Postoje dva slučaja u kojima treba koristiti agregatne funkcije. Prvo, agregatne funkcije se koriste same i vraćaju jednu vrijednost rezultata. Drugo, agregatne funkcije se koriste sa SQL GROUP BY klauzulom, odnosno sa grupiranjem po poljima (kolonama) kako bi se dobile rezultirajuće vrijednosti u svakoj grupi. Razmotrimo prvo slučajeve korištenja agregatnih funkcija bez grupiranja.
SQL SUM funkcija
SQL SUM funkcija vraća zbroj vrijednosti stupca u tablici baze podataka. Može se primijeniti samo na stupce čije su vrijednosti brojevi. SQL upiti za dobivanje rezultujuće sume počinju ovako:
ODABIR ZBIR (NAZIV STUPCA) ...
Nakon ovog izraza slijedi FROM (TABLE_NAME), a zatim se uvjet može specificirati korištenjem klauzule WHERE. Osim toga, DISTINCT može biti prefiksiran imenu kolone kako bi se naznačilo da će se uzeti u obzir samo jedinstvene vrijednosti. Prema zadanim postavkama, sve vrijednosti se uzimaju u obzir (za to možete posebno navesti ne DISTINCT, već SVE, ali riječ SVE je opcionalna).
Primjer 1 Postoji baza podataka kompanije sa podacima o njenim odeljenjima i zaposlenima. Tabela Osoblje takođe ima kolonu sa podacima o platama zaposlenih. Izbor iz tabele ima sledeći oblik (za uvećanje slike kliknite na nju levim tasterom miša):
Da biste dobili zbir svih plata, koristite sljedeći upit:
ODABERITE SUMU (Platu) OD osoblja
Ovaj upit će vratiti vrijednost 287664.63.
I sada . U vježbama već počinjemo da komplikujemo zadatke, približavajući ih onima koji se susreću u praksi.
SQL MIN funkcija
SQL MIN funkcija također radi na stupcima čije su vrijednosti brojevi i vraća minimum svih vrijednosti u stupcu. Ova funkcija ima istu sintaksu kao SUM funkcije.
Primjer 3 Baza podataka i tabela su iste kao u primjeru 1.
Potrebno je saznati minimalnu plaću za zaposlene u odjeljenju broj 42. Da biste to učinili, napišite sljedeći upit:
Upit će vratiti vrijednost 10505.90.
I opet vježba za samoopredjeljenje. U ovoj i nekim drugim vežbama, biće vam potrebna ne samo tabela osoblja, već i tabela organizacije koja sadrži podatke o divizijama kompanije:

Primjer 4 Tabela Org se dodaje tabeli Osoblje, koja sadrži podatke o divizijama kompanije. Navedite minimalni broj godina koje je jedan zaposlenik radio u odjelu koji se nalazi u Bostonu.
SQL MAX funkcija
SQL MAX funkcija radi slično i ima sličnu sintaksu, koja se koristi kada je potrebno odrediti maksimalna vrijednost među svim vrijednostima stupaca.
Primjer 5
Potrebno je saznati maksimalnu platu zaposlenih u odjeljenju broj 42. Da biste to učinili, napišite sljedeći upit:
Upit će vratiti vrijednost 18352.80
Sada je vrijeme vježbe za samoopredjeljenje.
Primjer 6 Opet radimo sa dva stola - Staff i Org. Iskazati naziv odjela i maksimalan iznos provizija koji primi jedan zaposlenik u odjeljenju koji pripada grupi odjela (Odsjek) Istočni. Koristi JOIN (spajanje tablica) .
SQL AVG funkcija
Ono što je rečeno o sintaksi za prethodno opisane funkcije važi i za SQL AVG funkciju. Ova funkcija vraća prosjek svih vrijednosti u stupcu.
Primjer 7 Baza podataka i tabela su iste kao u prethodnim primjerima.
Neka je potrebno saznati prosječan radni staž zaposlenih u odjeljenju broj 42. Da bismo to učinili, pišemo sljedeći upit:
Rezultat će biti 6,33
Primjer 8 Radimo sa jednim stolom - Osoblje. Prikažite prosečnu platu zaposlenih sa iskustvom od 4 do 6 godina.
SQL COUNT funkcija
SQL COUNT funkcija vraća broj zapisa u tablici baze podataka. Ako navedete SELECT COUNT(COLUMNAME) ... u upitu, tada će rezultat biti broj zapisa bez uzimanja u obzir onih zapisa u kojima je vrijednost stupca NULL (nedefinirana). Ako koristite zvjezdicu kao argument i pokrenete upit SELECT COUNT(*) ..., rezultat će biti broj svih zapisa (redova) u tabeli.
Primjer 9 Baza podataka i tabela su iste kao u prethodnim primjerima.
Želite znati broj svih zaposlenih koji primaju provizije. Broj zaposlenih čije vrijednosti Comm stupca nisu NULL vratit će sljedeći upit:
SELECT COUNT(Comm) OD osoblja
Rezultat će biti vrijednost 11.
Primjer 10 Baza podataka i tabela su iste kao u prethodnim primjerima.
Ako želite znati ukupan broj zapisa u tablici, onda koristite upit sa zvjezdicom kao argument funkciji COUNT:
ODABIR BROJ(*) IZ osoblja
Rezultat će biti vrijednost 17.
Sljedeći vježba za samoopredjeljenje morate koristiti potupit.
Primjer 11. Radimo sa jednim stolom - Osoblje. Prikažite broj zaposlenih u odjeljenju Plains.
Agregatne funkcije sa SQL GROUP BY
Pogledajmo sada korištenje agregatnih funkcija zajedno sa SQL GROUP BY klauzulom. SQL GROUP BY klauzula se koristi za grupiranje rezultirajućih vrijednosti po stupcima u tablici baze podataka.
Primjer 12. Postoji baza podataka portala oglasa. Ima tabelu Oglasi koja sadrži podatke o oglasima koji su poslani za sedmicu. Stupac Kategorija sadrži informacije o velike kategorije oglasi (npr. Nekretnine), i kolona Dijelovi - o manjim dijelovima koji su uključeni u kategoriju (npr. dijelovi Apartmani i vikendice su dijelovi kategorije Nekretnine). Kolona Jedinice sadrži podatke o broju dostavljenih oglasa, a kolona Novac iznos novca zarađen za slanje oglasa.
| Kategorija | dio | Jedinice | Novac |
| Transport | motorna vozila | 110 | 17600 |
| Nekretnina | Apartmani | 89 | 18690 |
| Nekretnina | Dachas | 57 | 11970 |
| Transport | Motocikli | 131 | 20960 |
| građevinski materijal | Ploče | 68 | 7140 |
| elektrotehnike | televizori | 127 | 8255 |
| elektrotehnike | Frižideri | 137 | 8905 |
| građevinski materijal | Regips | 112 | 11760 |
| Slobodno vrijeme | Knjige | 96 | 6240 |
| Nekretnina | Kuće | 47 | 9870 |
| Slobodno vrijeme | Muzika | 117 | 7605 |
| Slobodno vrijeme | Igre | 41 | 2665 |
Koristeći klauzulu SQL GROUP BY, pronađite količinu novca generiranu slanjem oglasa u svakoj kategoriji. Pišemo sljedeći zahtjev.
Lekcija će pokriti temu sql-a o preimenovanju kolone (polja) koristeći servisnu riječ AS; razmatra se i tema agregatnih funkcija u sql-u. Analizirat će se konkretni primjeri zahtjeva
Nazivi kolona u upitima mogu se preimenovati. Ovo čini rezultate čitljivijim.
U SQL-u, preimenovanje polja je povezano s upotrebom AS ključna riječ, koji se koristi za preimenovanje imena polja u skupovima rezultata
sintaksa:
SELECT<имя поля>AS<псевдоним>OD…
Razmotrimo primjer preimenovanja u SQL-u:
Primjer baze podataka "Institut": Prikažite imena nastavnika i njihove plate, za one nastavnike čija je plata ispod 15000 preimenujte polje zarplata u "niska_plata"
✍ Rješenje:
Preimenovanje stupaca u SQL-u je često potrebno prilikom izračunavanja vrijednosti povezanih s više polja stolovi. Razmotrimo primjer:
Primjer baze podataka "Institut": Iz tabele nastavnika prikažite polje za ime i izračunajte zbir plate i bonusa, dajući naziv polju "plata_bonus"
✍ Rješenje:
| 1 2 | SELECT ime, (zarplata+ premia) AS zarplata_premia OD nastavnika; |
SELECT ime, (zarplata+premia) AS zarplata_premia FROM nastavnika;
rezultat:
Agregatne funkcije u SQL-u
Agregatne funkcije u sql-u se koriste za dobivanje ukupnih vrijednosti i procjenu izraza:
Sve agregatne funkcije vraćaju jednu vrijednost.
Funkcije COUNT, MIN i MAX primjenjuju se na bilo koji tip podataka.
Funkcije SUM i AVG koriste se samo za numerička polja.
Postoji razlika između funkcija COUNT(*) i COUNT(): ova druga ne uzima u obzir NULL vrijednosti prilikom izračunavanja.
Bitan: kada se radi sa agregatnim funkcijama u SQL-u, koristi se funkcijska riječ AS
Primjer baze podataka "Institut": Dobijte vrijednost najveće plate među nastavnicima, prikažite ukupan kao "max_zp"
✍ Rješenje:
| SELECT MAX (zarplata) AS max_zp FROM nastavnika; |
SELECT MAX(zarplata) AS max_sal FROM nastavnika;
Rezultati:
Razmotrite složeniji primjer korištenja agregatnih funkcija u sql-u.
✍ Rješenje:
GROUP BY klauzula u SQL-u
Grupa po naredbi u sql-u se obično koristi u sprezi sa agregatnim funkcijama.
Agregatne funkcije se izvršavaju na svim rezultujućim nizovima upita. Ako upit sadrži GROUP BY klauzulu, svaki skup redova naveden u GROUP BY klauzuli čini grupu, a agregatne funkcije se izvršavaju za svaku grupu posebno.
Razmotrimo primjer s tabelom lekcija: 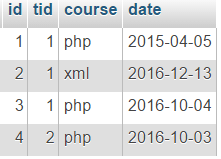
primjer:
Bitan: Dakle, kao rezultat korištenja GROUP BY, svi izlazni redovi upita podijeljeni su u grupe koje karakterizira ista kombinacija vrijednosti u ovim stupcima (odnosno, agregatne funkcije se izvode za svaku grupu posebno).
Istovremeno, treba uzeti u obzir da će pri grupisanju po polju koje sadrži NULL -vrijednosti svi takvi zapisi pasti u jednu grupu.
Za različite tipove štampača, identifikujte ih prosječna cijena i količinu (tj. odvojeno za laser, inkjet i matricu). Koristite agregatne funkcije. Rezultat bi trebao izgledati ovako:

Imati SQL izjavu
Klauzula HAVING u SQL-u je potrebna za provjeru vrijednosti, koji se dobijaju pomoću agregatne funkcije nakon grupisanja(nakon upotrebe GROUP BY). Takav ček ne može biti sadržan u klauzuli WHERE.
primjer: DB Computer Store. Izračunajte prosječnu cijenu računara sa istom brzinom procesora. Pokrenite kalkulaciju samo za one grupe čija je prosječna cijena manja od 30.000.


- Agregatne funkcije se koriste kao imena polja u SELECT izrazu, s jednim izuzetkom: uzimaju ime polja kao argument. Sa karakteristikama SUMA I AVG može se koristiti samo numerička polja. Sa karakteristikama COUNT, MAX i MIN mogu se koristiti i numerička i karakterna polja. Kada se koristi sa znakovnim poljima MAX I MINće ih prevesti u ekvivalent ASCII koda i obraditi ih u abecedni red. Neki DBMS dozvoljavaju ugniježđene agregate, ali ovo je odstupanje od ANSI standarda, sa svim njegovim implikacijama.


Na primjer, možete izračunati broj studenata koji su polagali ispite u svakoj disciplini. Da biste to učinili, potrebno je izvršiti upit grupiran po polju "Subject" i kao rezultat prikazati naziv discipline i broj redova u grupi za ovu disciplinu. Upotreba znaka * kao argumenta funkciji COUNT znači brojati sve redove u grupi.
SELECT R1. Disciplina, COUNT(*)
GRUPA PO R1 Disciplina;
rezultat:

SELECT R1.Disciplina, COUNT (*)
GDJE R1. Evaluacija NIJE NULL
GRUPA PO R1 Disciplina;
rezultat:

neće upasti u skup torki prije grupisanja, pa će broj torki u grupi za disciplinu "Teorija informacija" biti 1 manji.
Sličan rezultat se može dobiti ako se upit napiše na sljedeći način:
SELECT R1. Disciplina, COUNT(R1. Rezultat)
GRUPA PO R1. Disciplina;
Funkcija COUNT (NAZIV ATRIBUTA) broji broj definiranih vrijednosti u grupi, za razliku od funkcije COUNT(*), koji broji broj redova u grupi. Zaista, u grupi sa disciplinom "Teorija informacija" bit će 4 reda, ali samo 3 određene vrijednosti atributa "Evaluacija".

Pravila za rukovanje NULL vrijednostima u agregatnim funkcijama
Ako su bilo koje vrijednosti u koloni jednake NULL kada se računa rezultat funkcije, oni su isključeni.
Ako su sve vrijednosti u koloni jednake NULL, onda Maks. Min. zbroj pros = NULL , count = 0 (nula).
Ako je tabela prazna, count(*) = 0 .
Agregatne funkcije se mogu koristiti i bez operacije prethodnog grupisanja, u kom slučaju se cijela relacija tretira kao jedna grupa, a jedna vrijednost po grupi se može izračunati za ovu grupu.
Pravila za tumačenje agregatnih funkcija
Agregatne funkcije mogu biti uključene u izlaznu listu i zatim se primjenjuju na cijelu tablicu.
SELECT MAX(Score) od R1 daće maksimalnu ocjenu na sjednici;
SELECT SUM(Score) iz R1će dati zbir svih ocjena za sesiju;
SELECT AVG(Score) iz R1će dati prosječnu ocjenu tokom cijele sesije.
 2; Rezultat: "width="640"
2; Rezultat: "width="640" Ponovo se pozivajući na bazu podataka „Session“ (tabele R1), nalazimo broj uspješno položenih ispita:
ODABIR BROJ(*) Iznajmljeno _ ispiti
WHERE rezultat 2;
rezultat:

Agregatne funkcije mogu uzeti pojedinačne stupce tablica kao argumente. Da bi se izračunao, na primjer, broj različitih vrijednosti za određenu kolonu u grupi, ključna riječ DISTINCT mora se koristiti zajedno s nazivom kolone. Izračunajmo broj različitih ocjena dobijenih u svakoj disciplini:
SELECT R1.Discipline, COUNT (DISTINCT R1.Score)
GDJE R1. Evaluacija NIJE NULL
GRUPA PO R1 Disciplina;
rezultat:

Isti rezultat se dobija ako se isključi eksplicitni uslov u dijelu WHERE, u kom slučaju će upit izgledati ovako:
SELECT R1. Disciplina, COUNT(DISTINCT R1. Score)
GRUPA PO R1. Disciplina;
Funkcija COUNT(RAZLIČITI R1.Score) računa se samo izvesno razne vrijednosti.
Da bi se u ovom slučaju dobio željeni rezultat, potrebno je izvršiti preliminarnu konverziju tipa podataka kolone “Score”, dovodeći je do realnog tipa, tada rezultat izračunavanja prosjeka neće biti cijeli broj. U ovom slučaju, zahtjev će izgledati ovako:
 2 Grupirajte po R2. Grupa, R1. Disciplina; Ovdje funkcija CAST() pretvara stupac Score u važeći tip podataka. "width="640"
2 Grupirajte po R2. Grupa, R1. Disciplina; Ovdje funkcija CAST() pretvara stupac Score u važeći tip podataka. "width="640" Odaberite R2.Grupa, R1.Subject,Count(*) kao Total, AVG(cast(Score as decimal(3,1))) kao Average_Score
Od R1,R2
gdje je R1. Puno ime = R2. Puno ime i R1. evaluacija nije ništavna
i R1. Razred 2
Grupirajte po R2. Grupa, R1. Disciplina;
Evo funkcije CAST() pretvara kolonu Score u važeći tip podataka.

Ne možete koristiti agregatne funkcije u klauzuli WHERE jer se uvjeti u ovom odjeljku procjenjuju u smislu jednog reda, dok se agregatne funkcije procjenjuju u smislu grupa redova.
Klauzula GROUP BY vam omogućava da definirate podskup vrijednosti u određenom polju u smislu drugog polja i primijenite agregatnu funkciju na podskup. Ovo omogućava kombiniranje polja i agregatnih funkcija u jednoj SELECT klauzuli. Agregatne funkcije se mogu koristiti kako u izlaznom izrazu rezultata SELECT reda, tako iu izrazu uslova za obradu formiranih HAVING grupa. U ovom slučaju, svaka agregatna funkcija se izračunava za svaku odabranu grupu. Vrijednosti dobivene u proračunu agregatnih funkcija mogu se koristiti za prikaz odgovarajućih rezultata ili za uvjete odabira grupe.
Napravimo upit koji prikazuje grupe u kojima je primljeno više od jedne dvojke u jednoj disciplini na ispitima:
 jedan; Rezultat: "width="640"
jedan; Rezultat: "width="640" SELECT R2. Grupa
OD R1, R2
GDJE R1. Puno ime = R2. Puno ime AND
R1.Score = 2
GRUPA PO R2.Grupa, R1.Disciplina
IMATI broj(*) 1;
rezultat:

Imamo bazu podataka "Banka", koja se sastoji od jedne tabele F, u kojoj se čuva relacija F, koja sadrži podatke o računima u filijalama određene banke:
Pronađite ukupno stanje na računima u filijalama. Moguće je napraviti poseban upit za svaku od njih odabirom SUM (Stanje) iz tabele za svaku granu, ali operacija GRUPA BY će vam omogućiti da ih sve stavite u jednu naredbu:
SELECT Filijala , SUMA( Ostatak )
GROUP BY Ogranak;
GROUP BY primjenjuje agregatne funkcije nezavisno za svaku grupu identificiranu vrijednošću polja Grana. Grupa se sastoji od redova sa istom vrijednošću u polju Grana i funkcije SUMA primjenjuje se posebno za svaku takvu grupu, odnosno ukupno stanje računa se obračunava posebno za svaku filijalu. Vrijednost polja na koje se odnosi GROUP BY, ima po definiciji samo jednu vrijednost po izlaznoj grupi, baš kao rezultat agregatne funkcije.
 5000; Argumenti u klauzuli HAVING slijede ista pravila kao u klauzuli SELECT gdje se koristi GROUP BY. Moraju imati jednu vrijednost po izlaznoj grupi. "width="640"
5000; Argumenti u klauzuli HAVING slijede ista pravila kao u klauzuli SELECT gdje se koristi GROUP BY. Moraju imati jednu vrijednost po izlaznoj grupi. "width="640" Pretpostavimo da odaberete samo one filijale čija su ukupna stanja na računu veća od 5.000 USD, kao i ukupna stanja za odabrane filijale. Za prikaz filijala sa ukupnim stanjem preko 5.000 USD, koristite klauzulu HAVING. Klauzula HAVING specificira kriterije koji se koriste za uklanjanje određenih grupa iz izlaza, baš kao što klauzula WHERE radi za pojedinačne redove.
Ispravna naredba bi bila:
SELECT Ogranak, SUM (Stanje)
GROUP BY Filijala
IMATI SUMU ( Ostatak ) 5 000;
Argumenti u rečenici HAVING podliježu istim pravilima kao u prijedlogu SELECT gdje se koristi GROUP BY. Moraju imati jednu vrijednost po izlaznoj grupi.

Sljedeća komanda će biti zabranjena:
SELECT Ogranak,SUM(Stanje)
GRUPA PO Ogranku
IMAJUĆI Datum otvaranja = 27/12/2004 ;
Polje Datum otvaranja ne može se koristiti u rečenici HAVING, jer može imati više od jedne vrijednosti po izlaznoj grupi. Da bi se izbjegla ova situacija, prijedlog HAVING treba da se odnosi samo na agregate i odabrana polja GROUP BY. Postoji ispravan način da se uputi gornji zahtjev:
SELECT Ogranak,SUM(Stanje)
WHERE OpenDate = '27/12/2004'
GROUP BY Ogranak;

Značenje ovog upita je sljedeće: pronaći zbir stanja za svaku filijalu računa otvorenih 27. decembra 2004. godine.
Kao što je ranije rečeno, HAVING može uzeti samo argumente koji imaju jednu vrijednost po izlaznoj grupi. U praksi, reference na agregatne funkcije su najčešće, ali polja odabrana pomoću GROUP BY su također važeća. Na primjer, želimo vidjeti ukupna stanja na računima filijala u Sankt Peterburgu, Pskovu i Uryupinsku:
SELECT Ogranak, SUM (Stanje)
OD F,Q
GDJE F. Grana = Q. Grana
GRUPA PO Ogranku
HAVING Ogranak U ('Sankt Peterburg', 'Pskov', 'Urjupinsk');
100.000; Ako je ukupni saldo veći od 100.000$, tada ćemo ga vidjeti u rezultirajućem odnosu, inače ćemo dobiti praznu relaciju. "width="640"
Stoga, u aritmetičkim izrazima predikata uključenih u klauzulu za odabir klauzule HAVING, mogu se direktno koristiti samo specifikacije stupaca specificiranih kao grupiranje stupaca u klauzuli GROUP BY. Preostale kolone se mogu specificirati samo unutar specifikacija agregatnih funkcija COUNT, SUM, AVG, MIN i MAX koje procjenjuju na ovaj slučaj neki agregatna vrijednost za cijelu grupu redova. Rezultat izvršavanja sekcije HAVING je grupisana tabela koja sadrži samo one grupe redova za koje je rezultat izračunavanja uslova izbora u delu HAVING TRUE. Konkretno, ako je klauzula HAVING prisutna u upitu koji ne sadrži GROUP BY, tada će rezultat njegovog izvršenja biti ili prazna tabela ili rezultat izvršenja prethodnih sekcija tabelarni izraz A, tretira se kao jedna grupa bez grupisanih kolona. Razmotrimo primjer. Recimo da želimo izlaz ukupan iznos stanja za sve grane, ali samo ako je više od 100 000 USD. U ovom slučaju, naš upit neće sadržavati operacije grupisanja, već će sadržavati odjeljak HAVING i izgledat će ovako:
ODABIR SUM( Ostatak )
IMATI SUM( Ostatak ) 100 000;
Ako je ukupni saldo veći od 100.000$, tada ćemo ga vidjeti u rezultirajućem odnosu, inače ćemo dobiti praznu relaciju.

ISO standard definira sljedećih pet funkcije agregiranja:
COUNT– vraća broj vrijednosti u navedenoj koloni;
SUMA– vraća zbir vrijednosti u navedenoj koloni;
AVG– vraća prosječnu vrijednost u navedenoj koloni;
MIN– vraća minimalnu vrijednost u navedenoj koloni;
MAX- vraća maksimalnu vrijednost u navedenoj koloni.
Sve ove funkcije rade na vrijednostima u jednoj koloni tablice i vraćaju jednu vrijednost. Funkcije COUNT, MIN i MAX primjenjuju se i na numerička i na nenumerička polja, dok se funkcije SUM i AVG mogu koristiti samo za numerička polja. Sa izuzetkom COUNT(*), prilikom izračunavanja rezultata bilo koje funkcije, prvo se isključuju sve nulte vrijednosti, nakon čega se potrebna operacija primjenjuje samo na preostale vrijednosti kolone koje nisu nule. Opcija COUNT(*) je posebna prigoda koristeći funkciju COUNT - njena svrha je da prebroji sve redove u tabeli, bez obzira da li sadrže prazne, duple ili bilo koje druge vrednosti. Ako želite eliminirati duple vrijednosti prije korištenja agregatne funkcije, morate prethoditi imenu stupca u definiciji funkcije ključnom riječi DISTINCT. ISO standard dozvoljava korištenje ključne riječi ALL da eksplicitno naznači da eliminacija duplih vrijednosti nije potrebna, iako se ova ključna riječ pretpostavlja po defaultu ako nisu specificirani drugi kvalifikatori. Ključna riječ DISTINCT nema značenje za funkcije MIN i MAX. Međutim, njegova upotreba može uticati na rezultate funkcija SUM i AVG, tako da biste trebali unaprijed razmisliti da li treba biti prisutan u svakom konkretnom slučaju. Također, ključna riječ DISTINCT može biti specificirana najviše jednom u svakom upitu.
Imajte na umu da se agregatne funkcije mogu koristiti samo u SELECT listi za odabir i u klauzuli HAVING (pogledajte odjeljak 5.3.4). U svim ostalim slučajevima upotreba ovih funkcija nije dozvoljena. Ako SELECT lista sadrži funkciju agregacije, a u tijelu upita nema klauzule GROUP BY koja obezbjeđuje grupisanje podataka, tada nijedan od elemenata SELECT liste za odabir ne može uključivati reference na stupce, osim ako se ta kolona ne koristi kao agregatna funkcija parametar. Na primjer, sljedeći upit je nevažeći:
SELECTosobljeNe,COUNT (plata)
ODosoblje;
Greška je u tome što u ovom upitu nema konstrukcije GROUP BY, a stupcu staffNo na SELECT listi se pristupa bez upotrebe funkcije agregacije.
Primjer 13: Upotreba funkcije COUNT(*).Odredite koliko nekretnina za iznajmljivanje ima stopu zakupa veću od £350 mjesečno,
SELECT COUNT(*) AS count
ODpropertyforrent
GDJEnajam > 350;
Ograničenje brojanja samo onih iznajmljenih objekata čija je najamnina veća od £350 mjesečno implementirano je korištenjem klauzule WHERE. Ukupan broj iznajmljenih nekretnina koje ispunjavaju specificirano stanje, može se odrediti pomoću agregatne funkcije COUNT. Rezultati izvršenja upita prikazani su u tabeli. 23.
Tabela 23
| count |
Primjer 14. Korištenje funkcije COUNT(DISTINCT).Odredite koliko su različitih nekretnina za iznajmljivanje pregledali klijenti u maju 2001.
ODABIR BROJ(DISTINCTpropertyNo) AS count
ODGledanje
Opet, ograničavanje rezultata upita na raščlanjivanje samo onih iznajmljivanja koji su pregledani u maju 2001. postiže se korištenjem klauzule WHERE. Ukupan broj pregledanih objekata koji ispunjavaju specificirani uvjet može se odrediti korištenjem funkcije agregiranja COUNT. Međutim, budući da se isti objekt može vidjeti više puta od strane različitih klijenata, ključna riječ DISTINCT mora biti specificirana u definiciji funkcije kako bi se izuzele duple vrijednosti iz izračunavanja. Rezultati izvršenja upita prikazani su u tabeli. 24.
Tabela 24
Primjer 16. Upotreba funkcija MIN, MAXnAVG.Izračunajte vrijednost minimalne, maksimalne i prosječne plate.
ODABIR MIN(plata) AS min, MAX(plata) AS max, AVG(plata) AS avg
ODosoblje;
U ovom primjeru, želite obraditi informacije o svim ljudima u vašoj kompaniji, tako da ne morate koristiti klauzulu WHERE. Tražene vrijednosti se mogu izračunati pomoću funkcija MIN, MAX i AVG primijenjenih na kolonu plata u tabeli osoblja. Rezultati izvršenja upita prikazani su u tabeli. 26.
Tabela 26
Rezultat upita
| min | max | avg |
| 9000.00 | 30000.00 | 17000.00 |
Rezultati grupisanja (GROUP BY konstrukcija). Gore navedeni primjeri sažetih podataka slični su redovima sažetka koji se obično stavljaju na kraj izvještaja. Kao rezultat toga, svi detaljni podaci izvještaja su komprimirani u jedan sažetak. Međutim, vrlo često se u izvještajima traži formiranje međuzbroja. U tu svrhu, klauzula GROUP BY može biti specificirana u SELECT izrazu. Poziva se upit koji sadrži klauzulu GROUP BY grupni upit, budući da grupiše podatke dobijene kao rezultat SELECT operacije, nakon čega se kreira jedna grupa za svaku pojedinačnu grupu. sažetak. Pozivaju se stupci navedeni u klauzuli GROUP BY grupisane kolone. ISO standard zahtijeva da klauzule SELECT i GROUP BY budu blisko povezane. Kada koristite klauzulu GROUP BY u SELECT izrazu, svaka stavka liste na SELECT listi odabira mora imati jedina vrijednost za cijelu grupu.Štaviše, SELECT konstrukcija može uključivati samo sljedeće tipove elemenata:
Imena kolona;
funkcije agregiranja;
konstante;
Izrazi koji uključuju kombinacije gornjih elemenata.
Sva imena stupaca na SELECT listi također se moraju pojaviti u klauzuli GROUP BY, osim ako se ime stupca koristi samo u agregatnoj funkciji. Suprotna izjava nije uvijek tačna - klauzula GROUP BY može sadržavati nazive stupaca koji se ne nalaze na listi SELECT. Ako se klauzula WHERE koristi zajedno sa klauzulom GROUP BY, tada se prvo obrađuje i grupišu se samo oni redovi koji zadovoljavaju uvjet pretraživanja. ISO standard navodi da kada se izvrši grupisanje, sve nedostajuće vrijednosti se tretiraju kao jednake. Ako dva reda tablice u istoj koloni za grupisanje sadrže NULL vrijednosti i identične vrijednosti u svim drugim nepraznim kolonama grupiranja, oni se stavljaju u istu grupu.
Primjer 17: Upotreba klauzule GROUP BY.Odredite broj zaposlenih koji rade u svakom od odjeljenja kompanije, kao i njihove ukupne plate.
SELECTogranci br, COUNT(nema osoblja) AS broji, SUMA(plata) AS suma
ODOsoblje
GROUP BYbr
POREDAK PObr.grana;
Nema potrebe uključiti nazive stupaca staffNo i salary u listu elemenata GROUP BY, jer se oni pojavljuju samo na SELECT listi sa agregatnim funkcijama. U isto vrijeme, stupac branchNo na popisu klauzule SELECT nije pridružen nijednoj funkciji agregacije i iz tog razloga mora biti specificiran u klauzuli GROUP BY. Rezultati izvršenja upita prikazani su u tabeli. 27.
Tabela 27
Rezultat upita
| br | Count | suma |
| B003 | 54000.00 | |
| B005 | 39000.00 | |
| B007 | 9000.00 |
Konceptualno, prilikom obrade ovog zahtjeva izvode se sljedeće radnje.
1. Redovi tabele Osoblje se raspoređuju u grupe prema vrednostima u koloni broja filijale kompanije. Unutar svake od grupa nalaze se podaci o cijelom osoblju jednog od odjela kompanije. U našem primjeru biće kreirane tri grupe, kao što je prikazano na sl. jedan.
2. Za svaku od grupa izračunava se ukupan broj redova koji je jednak broju zaposlenih u odeljenju, kao i zbir vrednosti u koloni zarada, koji je zbir zarada svih zaposlenih u odeljenju za koje smo zainteresovani. Tada se generira jedan sažeti red za cijelu grupu izvornih redova.
3. Primljeni redovi rezultirajuće tablice sortiraju se uzlaznim redoslijedom prema broju grane navedenog u stupcu br.
| br | broj osoblja | Plata |
| B00Z | SG37 | 12000.00 |
| B00Z | SG14 | 18000.00 |
| B00Z | SG5 | 24000.00 |
| B005 | SL21 | 30000.00 |
| B005 | SL41 | 9000.00 |
| B007 | SA9 | 9000.00 |
| COUNT (broj osoblja) | SUM (plata) |
| 54000.00 | |
| 39000.00 | |
| 9000.00 |
Rice. 1. Tri grupe zapisa kreirane prilikom izvršavanja upita
SQL standard dozvoljava postavljanje podupita u SELECT listu odabira. Stoga se gornji upit može predstaviti i na sljedeći način:
SELECTbr. grane, (ODABIR BROJ (broj osoblja)AS count
ODosoblje s
GDJEs.br.grana = b.br.grana),
(IZABIR ZBIR (plata) KAO zbroj
ODosoblje s
GDJEs.br.grana = b.br.grana)
ODogranak b
POREDAK PObr.grana;
Ali u ovoj verziji upita, za svaku od grana kompanije opisanu u tablici Branch, generiraju se dva rezultata izračunavanja funkcija agregacije, tako da se u nekim slučajevima mogu pojaviti redovi koji sadrže nulte vrijednosti.
Ograničenja grupisanja (HAVING konstrukcija). HAVING klauzula je namijenjena da se koristi zajedno s klauzulom GROUP BY za specificiranje ograničenja za odabir onih grupe, koji će biti postavljen u rezultujuću tabelu upita. Iako klauzule HAVING i WHERE imaju sličnu sintaksu, njihova svrha je drugačija. Klauzula WHERE je dizajnirana za odabir pojedinačnih redova namijenjenih da popune rezultirajuću tablicu upita, a konstrukcija HAVING se koristi za odabir grupe, postavljen u rezultujuću tabelu upita. ISO standard zahtijeva da nazivi stupaca koji se koriste u klauzuli HAVING moraju biti prisutni na listi elemenata GROUP BY ili da se koriste u agregatnim funkcijama. U praksi, uslovi pretraživanja u klauzuli HAVING uvijek uključuju barem jednu funkciju agregacije; u suprotnom, ovi pojmovi za pretragu bi trebali biti smješteni u klauzulu WHERE i primijenjeni na odabir pojedinačnih redova. (Zapamtite da se agregatne funkcije ne mogu koristiti u klauzuli WHERE.) Klauzula HAVING nije neophodan dio SQL jezika—bilo koji upit napisan korištenjem klauzule HAVING može se drugačije predstaviti bez korištenja.
Primjer 18: Korištenje konstrukcije HAVING.Za svaku filijalu kompanije sa više zaposlenih odredite broj zaposlenih i visinu njihovih zarada.
SELECTogranci br, COUN T (br. osoblja) AS broji, SUMA(plata) AS suma
ODOsoblje
GROUP BYbr
HAVING COUNT(broj osoblja) > 1
POREDAK PObr.grana;
Ovaj primjer je sličan prethodnom, ali koristi dodatna ograničenja kako bi naznačio da nas zanimaju samo podaci o onim odjelima kompanije koji zapošljavaju više od jedne osobe. Sličan zahtjev se primjenjuje na grupe, tako da bi upit trebao koristiti konstrukciju HAVING. Rezultati izvršenja upita prikazani su u tabeli. 28.
Tabela 28
| grana Nema zbroja |
| V00Z 3 54000,00 |
| B005 2 39000,00 |
Podupiti. U ovom odeljku ćemo raspravljati o upotrebi kompletnih SELECT izraza ugrađenih u telo drugog SELECT izraz. Eksterni(drugi) SELECT izraz koristi rezultat izvršenja interni(prvi) iskaz za određivanje sadržaja konačnog rezultata cijele operacije. Unutrašnji upiti mogu biti u klauzulama WHERE i HAVING vanjskog SELECT izraza, u kom slučaju se pozivaju potupiti ili ugniježđeni upiti. Također, interni SELECT izrazi se mogu koristiti u INSERT, UPDATE i DELETE izrazima . Postoje tri vrste podupita.
Skalarni podupit vraća vrijednost odabranu iz preseka jedne kolone sa jednim redom, tj. pojedinačna vrijednost. U principu, skalarni podupit se može koristiti gdje god je potrebna jedna vrijednost. Varijante skalarnih potupita prikazane su u primjerima 13 i 14.
String potupit vraća vrijednosti više kolona tabele, ali kao jedan red. Potupit stringova može se koristiti bilo gdje gdje se koristi konstruktor vrijednosti niza—obično predikati. Varijanta podupita stringova prikazana je u primjeru 15.
Podupit tabele vraća vrijednosti jedne ili više kolona tabele koja obuhvata više od jednog reda. Potupit tablice se može koristiti gdje god je tablica dopuštena, kao što je operand IN predikata.
Primjer 19: Korištenje podupita s testom jednakosti. Compose spisak osoblja koje radi u filijali kompanije, koja se nalazi u glavnoj ulici 4631.
SELECT
ODOsoblje
GDJEbr. grane = (ODABIR br
ODgrana
GDJEulica = "163 Main S t ");
Interna SELECT izjava (SELECT branchNo FROM Branch ...) je dizajnirana da odredi broj podružnice kompanije koja se nalazi u "163 Main St". (Postoji samo jedna takva podružnica kompanije, tako da je ovaj primjer primjer skalarnog podupita.) Nakon dobijanja željenog broja podružnice, izvršava se eksterni podupit za dohvaćanje detaljnih informacija o zaposlenima u toj grani. Drugim riječima, interni operater SELECT vraća tabelu koja se sastoji od jedne vrijednosti "BOOV". Ovo je broj podružnice kompanije koja se nalazi na "163 Main St1. Kao rezultat, vanjski SELECT izraz postaje:
SELECTbroj osoblja, fIme, Iname, pozicija
ODOsoblje
GDJEbr. grane = "B0031;
Rezultati ovog upita prikazani su u tabeli. 29.
Tabela 29
Rezultat upita
| broj osoblja | fName | IName | pozicija |
| SG37 | Ann | Beech | Asistent |
| SG14 | David | Ford | Supervizor |
| SG5 | Susan | brand | menadžer |
Potupit je alat za kreiranje privremene tabele, čiji sadržaj se preuzima i obrađuje eksternim izrazom. Potupit, može se specificirati direktno nakon operatora poređenja (tj. operatori =,<, >, <=, >=, <>) u klauzuli WHERE ili HAVING. Tekst potupita mora biti zatvoren u zagradama.
Primjer 20. Korištenje potupita sa agregatnim funkcijama. Napravite spisak svih zaposlenih koji su plaćeni iznad prosjeka, navodeći koliko je njihova plata veća od prosječne plate u preduzeću.
SELECTbroj osoblja, fIme, Ime, pozicija, plata - ( SELECT AVG(plata) OD osoblje) AS salDiff
ODOsoblje
GDJEplata > ( SELECT AVG(plata) OD S t a f f) ;
Treba napomenuti da se ne može direktno uključiti u izraz upita"GDJE plata > AVG(plata)", od upotrebe agregiranja funkcije u klauzuli WHERE nisu dozvoljene. Da biste postigli željeni rezultat, trebali biste kreirati potupit koji izračunava prosječnu godišnju platu, a zatim ga koristiti u vanjskom SELECT izrazu za odabir informacija o onim zaposlenima u kompaniji čija plata prelazi ovaj prosjek. Drugim riječima, potupit vraća vrijednost prosečna plata po kompaniji godišnje, jednako £17,000.
Rezultat izvršavanja ovog skalarnog podupita koristi se u vanjskom SELECT izrazu i za izračunavanje odstupanja plata od prosjeka i za odabir informacija o zaposlenicima. Dakle, vanjski SELECT izraz postaje:
SELECTbroj osoblja, ime, ime, pozicija, plata - 17000 As salDiff
ODOsoblje
GDJEplata > 17000;
Rezultati izvršenja upita prikazani su u tabeli. trideset.
Tabela 30
Rezultat upita
| broj osoblja | fName | IName | pozicija | salDiff |
| SL21 | John | Bijelo | menadžer | 13000.00 |
| SG14 | David | Ford | Supervizor | 1000.00 |
| SG5 | Susan | brand | menadžer | 7000.00 |
Primjenjuju se potupiti slijedeći pravila i ograničenja.
1. Potupiti ne bi trebali koristiti klauzulu ORDER BY, iako ona može biti prisutna u vanjskom SELECT izrazu.
2. SELECT lista potupita mora se sastojati od pojedinačnih imena stupaca ili izraza sastavljenih od njih, osim ako potupit ne koristi ključnu riječ EXISTS.
3. Po defaultu, imena stupaca u potupitu odnose se na tablicu čije je ime navedeno u FROM klauzuli potupita. Međutim, također je dozvoljeno upućivanje na stupce tablice specificirane u FROM klauzuli vanjskog upita korištenjem kvalificiranih naziva stupaca (kao što je opisano u nastavku).
4. Ako je potupit jedan od dva operanda uključena u operaciju poređenja, onda potupit mora biti specificiran na desnoj strani ove operacije. Na primjer, notacija upita iz prethodnog primjera u nastavku nije tačna jer je potupit postavljen na lijevu stranu operacije poređenja u odnosu na vrijednost kolone plaće.
SELECT
ODOsoblje
GDJE(ODABERITE PROSJEK (plata) OD osoblja)< salary;
Primjer 21. Ugniježđeni potupiti i upotreba IN predikata. Napravite spisak nekretnina za izdavanje za koje se zaposleni u filijali kompanije nalaze u ulici „Glavna 163.1.
SELECTbroj nekretnine, ulica, grad, poštanski broj, tip, sobe, najam
ODpropertyforrent
Poglavlje 5. SQL jezik: manipulacija podacima 189
GDJEbroj osoblja IN (ODABIR br. osoblja
ODOsoblje
GDJEbrancliNo = (ODABIR br. grane
ODgrana
GDJEulica = "Glavna ulica 163")) ;
Prvi, najviše interni, upit je dizajniran da odredi broj filijale kompanije koja se nalazi u glavnoj ulici 463. Drugi, srednji, upit odabire informacije o osoblju koje radi u ovoj ekspozituri. U ovom slučaju, više od jednog reda podaci su odabrani i stoga ne možete koristiti operator poređenja =. Umjesto toga morate koristiti ključnu riječ IN. Eksternim upitom se biraju podaci o zakupljenim objektima za koje su odgovorni zaposleni u kompaniji, a podaci o kojima se dobija kao rezultat intermedijarnog upita. Rezultati upita prikazani su u tabeli 31.
Tabela 31
Rezultat upita
| imovine br | ulica | grad | poštanski broj | tip | sobe | najam |
| PG16 | 5 Novar Dr | Glasgow | G129AX | Stan | ||
| PG36 | 2 Manor Road | Glasgow | G324QX | Stan | ||
| PG21 | 18 Dale Road | Glasgow | G12 | kuća |
Ključne riječi BILO i SVE. Ključne riječi ANY i ALL mogu se koristiti s potupitima koji vraćaju jednu kolonu brojeva. Ako podupitu prethodi ključna riječ ALL, uvjet usporedbe se smatra istinitim samo ako je istinit za sve vrijednosti u koloni rezultata potupita. Ako tekstu podupita prethodi ključna riječ ANY, tada će se smatrati da je uvjet poređenja ispunjen ako je zadovoljen za najmanje jednu (jednu ili više) vrijednosti u rezultirajućem stupcu potupita. Ako potupit rezultira praznom vrijednošću, tada će se za ključnu riječ SVE smatrati da je uvjet poređenja ispunjen, a za BILO KOJU ključnu riječ će se smatrati neuspjelim. Prema ISO standardu, možete dodatno koristiti ključnu riječ SOME, koja je sinonim za BILO KOJU ključnu riječ.
Primjer 22. Koristeći ključne riječi ANY i SOME. Pronađite sve zaposlene čija je plata barem veća od plate jedan uposlenik filijale firme pod brojem "booz".
SELECTbroj osoblja, fIme, INime, pozicija, plata
ODOsoblje
GDJEplata > NEKI(ODABIR plata
ODOsoblje
GDJEbranchNo="B003");
Iako se ovaj upit može napisati korištenjem podupita koji specificira minimalnu plaću za osoblje odjeljenja pod brojem "WHO", nakon čega vanjski podupit može odabrati informacije o svim zaposlenicima kompanije čija plata prelazi ovu vrijednost (vidi primjer 20), moguć je i drugi pristup, koji se sastoji u upotrebi ključnih riječi NEKI/BILO KOJI. U ovom slučaju, unutrašnji potupit generiše skup vrijednosti (12000, 18000, 24000), a vanjski upit odabire detalje onih radnika čija je plata veća od bilo koje vrijednosti u ovom
set (u stvari, više od minimalne vrijednosti - 12000). Ova alternativna metoda se može smatrati prirodnijom od definiranja minimalne plaće u potupitu. Ali u oba slučaja, generišu se isti rezultati izvršenja upita, koji su predstavljeni u tabeli. 32 .
Tabela 32
Rezultat upita
| broj osoblja | fName | IName | pozicija | plata |
| SL21 | John | Bijelo | menadžer | 30000.00 |
| SG14 | David | Ford | Supervizor | 18000.00 |
| SG5 | Susan | brand | menadžer | 24000.00 |
Primjer 23. Korištenje ključne riječi SVE. Brojem "booz" pronađite sve zaposlene čije su plate veće od plata bilo kog zaposlenog u filijali kompanije.
SELECTbroj osoblja, fIme, INarae, pozicija, plata
ODOsoblje
GDJEplata > SVE(ODABIR plata
ODOsoblje
GDJEbr. grane = "BOG3");
Općenito, ovaj upit je sličan prethodnom. I u ovom slučaju bilo bi moguće koristiti podupit koji određuje maksimalnu vrijednost plate osoblja odjeljenja pod brojem „BOOS“, a zatim eksternim upitom odabrati podatke o svim zaposlenima kompanije čiji plata prelazi ovu vrijednost. Međutim, u ovaj primjer bira se pristup koji koristi ključnu riječ ALL. Rezultati izvršenja upita prikazani su u tabeli. 33 .
Tabela 33
Rezultat upita
| broj osoblja | IName | fName | pozicija | plata |
| SL21 | Bijelo | John | menadžer | 30000,00 |
Upiti sa više tablica. Svi gore razmotreni primjeri imaju isto važno ograničenje: kolone smještene u rezultirajuću tablicu uvijek se biraju iz jedne tabele. Međutim, u mnogim slučajevima to nije dovoljno. Da biste spojili stupce iz nekoliko izvornih tablica u rezultirajuću tablicu, morate izvršiti operaciju veze. U SQL-u se operacija spajanja koristi za kombiniranje informacija iz dvije tablice formiranjem parova povezanih redova odabranih iz svake tablice. Parovi redova postavljeni u kombinovanu tabelu sastavljeni su od jednakosti vrednosti navedenih kolona uključenih u njih.
Ako trebate dohvatiti informacije iz više tabela, možete koristiti podupit ili se pridružiti tablicama. Ako rezultirajuća tablica upita mora sadržavati stupce iz različitih izvornih tabela, tada je preporučljivo koristiti mehanizam spajanja tablice. Da biste izvršili spajanje, dovoljno je navesti imena dvije ili više tablica u klauzuli FROM, odvajajući ih zarezima, a zatim uključiti klauzulu WHERE u upit sa definicijom kolona koje se koriste za spajanje navedenih tabela. Osim toga, umjesto imena tablica, možete koristiti alijasi, dodijeljen im u konstrukciji FROM. U ovom slučaju, imena tablica i pseudonimi koji su im dodijeljeni moraju biti odvojeni razmacima. Pseudonimi se mogu koristiti za kvalificiranje imena stupaca kad god postoji nejasnoća u pogledu toga kojoj tablici kolona pripada. Osim toga, aliasi se mogu koristiti za skraćivanje imena tablica. Ako je pseudonim definiran za tablicu, može se koristiti bilo gdje gdje je potrebno ime te tablice.
Primjer 24. Jednostavna veza. Napravite listu imena svih klijenata koji su već pogledali barem jednu nekretninu za iznajmljivanje i dali svoje mišljenje o ovom pitanju.
SELECTc.clientNo, fName, INName, propertyNo, komentar
ODKlijent c, Pregled v
GDJEc.clientNo = v.clientNo;
Ovaj izvještaj treba da predstavi informacije i iz tablice klijenta i iz tabele pregleda, tako da ćemo prilikom izrade upita koristiti mehanizam spajanja tablice. SELECT konstrukcija navodi sve kolone koje treba staviti u tablicu rezultata upita. Imajte na umu da kolona broja klijenta (clientNo) mora biti kvalificirana, budući da takva kolona također može biti prisutna u drugoj tabeli koja učestvuje u pridruživanju. Stoga je potrebno eksplicitno naznačiti koje vrijednosti tabele nas zanimaju. (U ovom primjeru, možda ste i odabrali vrijednosti stupca clientNo iz tablice Pregled). Kvalifikacija imena se vrši prefiksom imena kolone sa imenom odgovarajuće tabele (ili njenim alias-om). U našem primjeru, vrijednost "c" se koristi kao pseudonim za tablicu Client. Za formiranje rezultirajućih redova koriste se oni redovi izvornih tabela koji imaju identičnu vrijednost u stupcu clientNo. Ovaj uvjet se određuje specificiranjem uvjeta pretraživanja c.clientNo=v.clientNo. Pozivaju se slične kolone izvornih tabela podudarne kolone. Opisana operacija je ekvivalentna operaciji pridružuje se jednakošću relacione algebre. Rezultati izvršenja upita prikazani su u tabeli. 34.
Tabela 34
Rezultat upita
| klijent br | fName | IName | imovine br | komentar |
| CR56 | Aline | Stewart | PG36 | |
| CR56 | Aline | Stewart | PA14 | premali |
| CR56 | Aline | Stewart | PG4 | |
| CR62 | Mary | Tregear | PA14 | nema trpezarije |
| CR76 | John | Kej | PG4 | previše udaljeno |
Najčešće se upiti za više tablica izvode na dvije tabele povezane odnosom jedan-prema-više (1:*) ili odnosom roditelj-dijete. U gornjem primjeru, koji uključuje pristup tablicama Client i Viewing, potonje su povezane upravo takvim odnosom. Svaki red pregledne tabele (dijete) je pridružen samo jednom redu tabele klijenta (roditelj), dok se isti red tabele klijenata (roditelj) može pridružiti
sa mnogo redova tabele za gledanje (dijete). Parovi redova koji se generiraju prilikom izvršavanja upita rezultat su svih valjanih kombinacija redova u podređenoj i nadređenoj tablici. Odjeljak 3.2.5 detaljno opisuje kako relacione baze podataka podataka, primarni i strani ključ tabela stvaraju odnos "roditelj-dijete". Tabela koja sadrži strani ključ je obično podređena, dok će tabela koja sadrži primarni ključ uvijek biti nadređena. Da biste koristili odnos roditelj-dijete u SQL upitu, morate navesti uvjet pretraživanja koji uspoređuje strani i primarni ključ. Primjer 24 upoređuje primarni ključ tablice Client (v. clientNo) sa stranim ključem pregledne tablice (v. clientNo).
SQL standard dodatno pruža na sledeće načine definicije za ovo jedinjenje:
ODKlijent sa PRIDRUŽITE SE Pregled v ON c.clientNo = v.clientNo
ODKlijent J OIN Gledanje KORIŠĆENJE klijent br
ODklijent NATURAL JOIN Gledanje
U svakom slučaju, klauzula FROM zamjenjuje originalne klauzule FROM i WHERE. Međutim, u prvom slučaju kreira se tabela sa dve identične kolone clientNo, dok će u druga dva slučaja rezultujuća tabela sadržati samo jednu kolonu clientNo.
Primjer 25. Sortiraj rezultate spajanja tablice. Za svaku filijalu kompanije navedite kadrovske brojeve i imena zaposlenih koji su odgovorni za bilo koji od zakupljenih objekata i navedite objekte za
na koje odgovaraju.
SELECTbr. filijale, br. osoblja, fName, INName, br
ODStaff s, PropertyForRent str
GDJEs.staffNo = p.staffNo
POREDAK PObr. filijale, br. osoblja, br. imovine;
Da bi se rezultati lakše čitali, izlaz se sortira koristeći broj odjela kao glavni ključ sortiranja i broj osoblja i broj imovine kao sporedne ključeve. Rezultati izvršenja upita prikazani su u tabeli. 35.
Tabela 35
Rezultat upita
| br | Broj osoblja | fName | IName | imovine br |
| SZO | SG14 | David | Ford | PG16 |
| SZO | SG37 | Ann | Beech | PG21 |
| SZO | SG37 | Ann | Beech | PG36 |
| BOO5 | SL41 | Mary | Lee | PL94 |
| SBI7 | SA9 | Julie | howe | PA14 |
Primjer 26. Spajanje tri stola. Za svaku filijalu kompanije navedite kadrovske brojeve i imena zaposlenih odgovornih za sve iznajmljene objekte, uključujući grad u kojem se filijala nalazi, i brojeve objekata za koje je svaki zaposlenik odgovoran.
SELECT b.br.filijale, b.grad, broj osoblja, fNaziv, INaziv, broj imovine
OD Filijala b, Osoblje s, PropertyForRent str
GDJE b.branchNo = s.branchNo I s.staffNo = p.staffNo
POREDAK PO b.br.filijale, br.s.osoblja, br. imovine;
Rezultirajuća tabela mora sadržati kolone iz tri izvorne tabele - Branch, Staff i PropertyForRent - tako da se upit mora pridružiti ovim tabelama. Tabele ogranaka i osoblja mogu se spojiti pomoću uslova b.branchNo=*s .branchNo, koji će povezati filijale kompanije sa osobljem koje u njima radi. Tablice Staff i PropertyForRent mogu se spojiti korištenjem uslova s.staffNo=p.staffNo. Kao rezultat, svaki radnik će biti povezan sa onim iznajmljenim objektima za koje je odgovoran. Rezultati izvršenja upita prikazani su u tabeli. 36.
Tabela 36
Query Results
| br | grad | staffMo | fName | IName | imovine br |
| B003 | Glasgow | SG14 | David | Ford | PG16 |
| B003 | Glasgow | SG37 | Ann | Beech | PG21 |
| B003 | Glasgow | SG37 | Ann | Beech | PG36 |
| B005 | London | SL41 | Julie | Lee | PL94 |
| B007 | Aberdeen | SA9 | Mary | howe | PA14 |
Imajte na umu da vam SQL standard dozvoljava korištenje Alternativna opcija izjave klauzula FROM i WHERE:
OD(Ogranak b PRIDRUŽITE se osoblju s KORIŠTENJEM podružnice) AS bs
PRIDRUŽITE SEPropertyForRent str KORIŠĆENJE broj osoblja
Primjer 27. Grupiranje po više kolona. Odredite broj zakupljenih objekata za koji je odgovoran svaki zaposlenik kompanije.
SELECTbr. filijale, br. COUNT(*) AS count
FROM Staff s, PropertyForRent str
GDJE S.staffNo = p.staffNo
GROUP BYbr. filijale, br
POREDAK PObr. filijale, br. osoblja;
Za izradu potrebnog izvještaja, prije svega, potrebno je saznati ko je od zaposlenih u kompaniji odgovoran za zakupljene objekte. Ovaj problem se može riješiti spajanjem tablica Staff i PropertyForRent u stupcu staffNo u klauzulama FROM/WHERE. Zatim je potrebno formirati grupe koje se sastoje od broja filijale i broja zaposlenih u njoj, za šta treba koristiti konstrukciju GROUP BY. Konačno, rezultirajuća tabela mora biti sortirana pomoću ORDER BY klauzule. Rezultati izvršenja upita prikazani su u tabeli. 37.
Tabela 37
Rezultat upita
| br | broj osoblja | count |
| B00Z | SG14 | |
| B00Z | SG37 | |
| B005 | SL41 | |
| B007 | SA9 |
Uspostavljanje veza. Spoj je podskup općenitije kombinacije podataka iz dvije tablice tzv Kartezijanski. Dekartov proizvod dvije tabele je druga tabela koja se sastoji od svih mogućih parova redova koji su deo obe tabele. Rezultirajući skup kolona tablice su svi stupci prve tablice nakon kojih slijede svi stupci druge tablice. Ako unesete upit na dvije tablice bez specificiranja klauzule WHERE, rezultat upita u SQL okruženju bit će kartezijanski proizvod ovih tablica. Osim toga, ISO standard predviđa poseban format SELECT izraz koji vam omogućava da izračunate kartezijanski proizvod dvije tablice:
SELECT(* j lista kolona]
IZ tabeleNaziv CROSS JOINCayeUlte2
Razmotrimo ponovo primjer u kojem se povezivanje klijenta i tabela Pregleda vrši korištenjem zajedničke kolone clientNo. Pri radu sa tabelama čiji je sadržaj dat u tabeli. 3.6 i 3.8, kartezijanski proizvod ovih tabela će imati 20 redova (4 reda klijentske tabele x 5 redova tabele za pregled = 20 redova). Ovo je ekvivalentno izdavanju upita korištenog u primjeru 5-24, ali bez klauzule WHERE. Procedura za generiranje tablice koja sadrži rezultate spajanja dvije tablice pomoću SELECT izraza je sljedeća.
1. Formira se kartezijanski proizvod tablica navedenih u FROM konstrukciji.
2. Ako upit sadrži klauzulu WHERE, primijenite uslove pretraživanja na svaki red kartezijanske tabele proizvoda i pohranite samo one redove u tabeli koji zadovoljavaju date uslove. U smislu relacijske algebre, ova operacija se zove ograničenje kartezijanski proizvod.
3. Za svaki preostali red određuje se vrijednost svakog elementa navedenog u SELECT listi, kao rezultat čega se formira poseban red rezultirajuće tablice.
4. Ako je konstrukcija SELECT DISTINCT prisutna u originalnom upitu, svi dupli redovi se uklanjaju iz rezultirajuće tablice.
5. Ako upit koji se izvršava sadrži ORDER BY klauzulu,
©2015-2019 stranica
Sva prava pripadaju njihovim autorima. Ova stranica ne tvrdi autorstvo, ali omogućava besplatno korištenje.
Datum kreiranja stranice: 07.08.2016
Sljedeći pododjeljci opisuju druge klauzule izraza SELECT koje se mogu koristiti u upitima, kao i agregatne funkcije i skupove izraza. Dozvolite mi da vas podsjetim sadašnji trenutak pogledali smo upotrebu klauzule WHERE, au ovom članku ćemo pogledati klauzule GROUP BY, ORDER BY i HAVING i dati neke primjere korištenja ovih klauzula u sprezi sa agregatnim funkcijama koje su podržane u Transact-u. SQL.
GROUP BY ponuda
Rečenica GROUP BY grupiše odabrani skup redova da proizvede skup sažetih redova na osnovu vrijednosti jedne ili više kolona ili izraza. Jednostavna upotreba klauzule GROUP BY prikazana je u primjeru ispod:
USE SampleDb; SELECT Job FROM Works_On GROUP BY Job;
U ovom primjeru, pozicije zaposlenika su odabrane i grupisane.
U gornjem primjeru, klauzula GROUP BY stvara posebnu grupu za sve moguće vrijednosti(uključujući NULL vrijednost) stupca Zadatak.
Upotreba stupaca u klauzuli GROUP BY mora ispunjavati određene uvjete. Konkretno, svaka kolona na listi odabira upita također se mora pojaviti u klauzuli GROUP BY. Ovaj zahtjev se ne odnosi na konstante i stupce koji su dio agregatne funkcije. (O agregatnim funkcijama se govori u sljedećem pododjeljku.) Ovo ima smisla jer samo kolone u klauzuli GROUP BY imaju zagarantovanu jednu vrijednost po grupi.
Tabela se može grupirati prema bilo kojoj kombinaciji svojih kolona. Primjer ispod pokazuje grupiranje redova Works_on tablice u dvije kolone:
USE SampleDb; SELECT ProjectNumber, Job FROM Works_On GROUP BY ProjectNumber, Job;
Rezultat ovog upita je:

Na osnovu rezultata upita možete vidjeti da postoji devet grupa s različitim kombinacijama broja projekta i pozicije. Redoslijed naziva stupaca u klauzuli GROUP BY ne mora biti isti kao na listi stupaca SELECT.
Agregatne funkcije
Agregatne funkcije se koriste za dobivanje ukupnih vrijednosti. Sve agregatne funkcije mogu se podijeliti u sljedeće kategorije:
obične agregatne funkcije;
statističke agregatne funkcije;
agregatne funkcije definirane od strane korisnika;
analitičke agregatne funkcije.
Ovdje ćemo pogledati prve tri vrste agregatnih funkcija.
Obične agregatne funkcije
Transact-SQL jezik podržava sljedećih šest agregatnih funkcija: MIN, MAX, SUMA, AVG, COUNT, COUNT_BIG.
Sve agregatne funkcije izvode kalkulacije na jednom argumentu, koji može biti ili stupac ili izraz. (Jedini izuzetak je drugi oblik dvije funkcije COUNT i COUNT_BIG, odnosno COUNT(*) i COUNT_BIG(*).) Rezultat bilo koje agregatne funkcije je konstantna vrijednost prikazana u zasebnoj koloni rezultata.
Agregatne funkcije su specificirane u listi stupaca izraza SELECT, koja također može sadržavati klauzulu GROUP BY. Ako nema GROUP BY klauzule u SELECT izrazu, a lista stupaca za odabir sadrži barem jednu agregatnu funkciju, onda ne smije sadržavati jednostavne stupce (osim stupaca koji služe kao argumenti agregatnoj funkciji). Stoga je kod u primjeru ispod netačan:
USE SampleDb; SELECT Prezime, MIN(Id) FROM Employee;
Ovdje kolona Prezime u tablici Employee ne bi trebala biti na listi za odabir stupaca jer nije argument agregatne funkcije. S druge strane, lista za odabir stupaca može sadržavati imena stupaca koja nisu argumenti agregatnoj funkciji ako su ti stupci argumenti klauzule GROUP BY.
Argumentu agregatne funkcije može prethoditi jedna od dvije moguće ključne riječi:
SVEOdređuje da se proračuni izvode za sve vrijednosti u koloni. Ovo je zadana vrijednost.
DISTINCTOdređuje da se za proračune koriste samo jedinstvene vrijednosti stupaca.
Agregatne funkcije MIN i MAX
Agregatne funkcije MIN i MAX izračunavaju najmanju i najveću vrijednost stupca, respektivno. Ako upit sadrži klauzulu WHERE, funkcije MIN i MAX vraćaju najmanju i najveću vrijednost redaka koji ispunjavaju navedene uvjete. Primjer u nastavku pokazuje upotrebu agregatne funkcije MIN:
USE SampleDb; -- Vraća 2581 SELECT MIN(Id) AS "Min Id" FROM Employee;
Rezultat vraćen u gornjem primjeru nije baš informativan. Na primjer, ime zaposlenika koji posjeduje ovaj broj nije poznato. Međutim, nije moguće dobiti ovo prezime na uobičajen način, jer, kao što je ranije spomenuto, eksplicitno navođenje stupca Prezime nije dozvoljeno. Da bi se dobilo prezime ovog zaposlenog uz najmanji kadrovski broj zaposlenog, koristi se potupit. Sljedeći primjer pokazuje upotrebu takvog potupita, gdje potupit sadrži naredbu SELECT iz prethodnog primjera:
Rezultat izvršenja upita:

Upotreba MAX agregatne funkcije prikazana je u primjeru ispod:
Funkcije MIN i MAX također mogu uzeti nizove i datume kao argumente. U slučaju argumenta string, vrijednosti se uspoređuju koristeći stvarni redoslijed sortiranja. Za sve argumente privremenih podataka tipa "datum", najmanja vrijednost stupca će biti najveća rani datum, a najveći - najnoviji.
Možete koristiti ključnu riječ DISTINCT sa funkcijama MIN i MAX. Prije nego što se koriste agregatne funkcije MIN i MAX, sve NULL vrijednosti se isključuju iz njihovih kolona argumenata.
Agregatna funkcija SUM
Agregat Funkcija SUM izračunava ukupan zbir vrijednosti stupca. Argument ove agregatne funkcije uvijek mora biti numeričkog tipa podataka. Upotreba agregatne funkcije SUM prikazana je u primjeru ispod:
USE SampleDb; SELECT SUM (Budget) "Summary budget" IZ projekta;
Ovaj primjer izračunava ukupan zbir budžeta svih projekata. Rezultat izvršenja upita:

U ovom primjeru, agregatna funkcija grupiše sve vrijednosti budžeta projekta i određuje njihov ukupan iznos. Iz tog razloga, upit sadrži implicitnu funkciju grupiranja (kao i svi slični upiti). Implicitna funkcija grupisanja iz gornjeg primjera može se eksplicitno specificirati, kao što je prikazano u primjeru ispod:
USE SampleDb; SELECT SUM (Budžet) "Ukupni budžet" IZ Project GROUP BY();
Korištenje opcije DISTINCT eliminira sve duple vrijednosti u stupcu prije primjene funkcije SUM. Slično, sve NULL vrijednosti se uklanjaju prije primjene ove agregatne funkcije.
AVG agregatna funkcija
Agregat AVG funkcija vraća aritmetičku sredinu svih vrijednosti u koloni. Argument ove agregatne funkcije uvijek mora biti numeričkog tipa podataka. Prije upotrebe AVG funkcije sve NULL vrijednosti su uklonjene iz njegovog argumenta.
Upotreba AVG agregatne funkcije prikazana je u primjeru ispod:
USE SampleDb; -- Vraća 133833 SELECT AVG (budžet) "Prosečan budžet po projektu" IZ projekta;
Ovdje se izračunava prosjek. aritmetička vrijednost budžet za sve budžete.
Agregatne funkcije COUNT i COUNT_BIG
Agregat COUNT funkcija ima dva različita oblika:
COUNT(naziv_kolca) COUNT(*)
Prvi oblik funkcije broji broj vrijednosti u stupcu col_name. Ako se u upitu koristi ključna riječ DISTINCT, sve duplicirane vrijednosti stupaca se uklanjaju prije nego što se primijeni funkcija COUNT. Ovaj oblik funkcije COUNT ne uzima u obzir NULL vrijednosti kada se broji broj vrijednosti u stupcu.
Upotreba prvog oblika agregatne funkcije COUNT prikazana je u primjeru ispod:
USE SampleDb; SELECT ProjectNumber, COUNT(DISTINCT Job) "Radi u projektu" FROM Works_on GROUP BY ProjectNumber;
Ovdje se računa broj različitih pozicija za svaki projekat. Rezultat ovog upita je:

Kao što možete vidjeti iz primjera upita, NULL vrijednosti nisu uzete u obzir od strane funkcije COUNT. (Zbroj svih vrijednosti u stupcu posla pokazao se kao 7, a ne 11, kako bi trebao biti.)
Drugi oblik funkcije COUNT, tj. funkcija COUNT(*) broji broj redova u tabeli. A ako izraz SELECT upita s funkcijom COUNT(*) sadrži klauzulu WHERE s uvjetom, funkcija vraća broj redova koji zadovoljavaju navedeni uvjet. Za razliku od prvog oblika funkcije COUNT, drugi oblik ne zanemaruje NULL vrijednosti jer ova funkcija djeluje na redove, a ne na stupce. Primjer ispod pokazuje korištenje funkcije COUNT(*):
USE SampleDb; SELECT Posao KAO "Vrsta posla", COUNT(*) "Potrebni radnici" FROM Works_on GRUPA PO POSAO;
Ovdje se računa broj pozicija u svim projektima. Rezultat izvršenja upita:

COUNT_BIG funkcija slično funkciji COUNT. Jedina razlika između njih je tip rezultata koji vraćaju: funkcija COUNT_BIG uvijek vraća BIGINT vrijednosti, dok funkcija COUNT vraća INTEGER vrijednosti podataka.
Statističke agregatne funkcije
Sljedeće funkcije čine grupu statističkih agregatnih funkcija:
VARIzračunava statističku varijansu svih vrijednosti predstavljenih u stupcu ili izrazu.
VARPIzračunava statističku varijansu populacije svih vrijednosti predstavljenih u stupcu ili izrazu.
STDEVIzračunava standardnu devijaciju (koja se izračunava kao Kvadratni korijen iz odgovarajuće varijanse) svih vrijednosti stupca ili izraza.
STDEVPIzračunava standardnu devijaciju ukupnosti svih vrijednosti u stupcu ili izrazu.
Korisnički definirane agregatne funkcije
Database Engine također podržava implementaciju korisnički definiranih funkcija. Ova mogućnost omogućava korisnicima da prošire sistemske agregatne funkcije funkcijama koje mogu sami implementirati i instalirati. Ove funkcije predstavljaju posebnu klasu korisnički definiranih funkcija i o njima se kasnije govori detaljnije.
HAVING ponudu
U rečenici HAVING definira uvjet koji se primjenjuje na grupu redova. Dakle, ova klauzula ima isto značenje za grupe redova kao klauzula WHERE za sadržaj odgovarajuće tabele. Sintaksa klauzule HAVING je sljedeća:
HAVING stanje
Ovdje parametar uvjeta predstavlja uvjet i sadrži agregatne funkcije ili konstante.
Upotreba klauzule HAVING sa agregatnom funkcijom COUNT(*) prikazana je u primjeru ispod:
USE SampleDb; -- Vrati "p3" SELECT ProjectNumber FROM Works_on GRUPA PO Broju projekta IMA COUNT(*)
U ovom primjeru, koristeći klauzulu GROUP BY, sistem grupiše sve redove na osnovu vrijednosti u stupcu ProjectNumber. Nakon toga, broj redova u svakoj grupi se broji i odabiru grupe koje sadrže manje od četiri reda (tri ili manje).
Klauzula HAVING se također može koristiti bez agregatnih funkcija, kao što je prikazano u primjeru ispod:
USE SampleDb; -- Vraća "Konsultant" ODABIR POSAO IZ Works_on GRUPE PO POSLU KOJI IMA POSAO KAO "K%";
Ovaj primjer grupiše redove u tabeli Works_on po poziciji i eliminiše one pozicije koje ne počinju slovom "K".
Klauzula HAVING se također može koristiti bez klauzule GROUP BY, iako to nije uobičajena praksa. U ovom slučaju, svi redovi tabele se vraćaju u istoj grupi.
NARUČI PO ponudi
Rečenica POREDAK PO definira redoslijed sortiranja redova u skupu rezultata koji je vratio upit. Ova rečenica ima sljedeću sintaksu:
Redoslijed sortiranja je specificiran u parametru col_name. Parametar col_number je alternativni specificator redoslijeda sortiranja koji specificira stupce redoslijedom kojim se pojavljuju na listi odabira izraza SELECT (1 je prvi stupac, 2 je drugi stupac, itd.). ASC parametar definira sortiranje uzlaznim redoslijedom, i DESC parametar- silazno. Podrazumevano je ASC.
Imena stupaca u klauzuli ORDER BY ne moraju biti na popisu stupaca za odabir. Ali ovo se ne odnosi na SELECT DISTINCT upite, jer u takvim upitima, nazivi stupaca specificirani u ORDER BY klauzuli također moraju biti specificirani u listi za odabir stupaca. Osim toga, ova klauzula ne može sadržavati nazive stupaca iz tablica koje nisu navedene u klauzuli FROM.
Kao što možete vidjeti iz sintakse ORDER BY klauzule, skup rezultata se može sortirati na više kolona. Ovo sortiranje je prikazano u primjeru ispod:
Ovaj primjer odabire brojeve odjela i prezimena i imena zaposlenika za zaposlenike čiji je broj osoblja manji od 20.000 i sortira prema prezimenu i imenu. Rezultat ovog upita je:

Kolone u ORDER BY klauzuli mogu se specificirati ne njihovim imenima, već redoslijedom na listi za odabir. Shodno tome, rečenica u gornjem primjeru može se prepisati na sljedeći način:
Takve alternativni način specificiranje stupaca po njihovoj poziciji umjesto imena koristi se ako kriterij naručivanja sadrži agregatnu funkciju. (Drugi način je da koristite nazive stupaca, koji se tada pojavljuju u ORDER BY klauzuli.) Međutim, u ORDER BY klauzuli, preporučuje se da se stupci specificiraju svojim imenima, a ne brojevima, kako bi se olakšalo ažuriranje pitajte da li kolone treba dodati ili ukloniti sa liste odabira. Određivanje stupaca u ORDER BY klauzuli njihovim brojevima prikazano je u primjeru ispod:
USE SampleDb; SELECT ProjectNumber, COUNT(*) "Broj zaposlenih" FROM Works_on GROUP BY ProjectNumber ORDER BY 2 DESC;
Ovdje se za svaki projekat odabire broj projekta i broj zaposlenih koji u njemu učestvuju, sortirajući rezultat u opadajućem redoslijedu prema broju zaposlenih.
Transact-SQL stavlja NULL vrijednosti na početak liste kada se sortira u rastućem redoslijedu, a na kraj liste kada se sortira u opadajućem redoslijedu.
Korištenje ORDER BY klauzule za paginiranje rezultata
Prikazivanje rezultata upita na trenutnoj stranici može se implementirati u korisnička aplikacija, ili naložite poslužitelju baze podataka da to učini. U prvom slučaju, svi redovi baze podataka se šalju aplikaciji, čiji je zadatak da odabere tražene redove i prikaže ih. U drugom slučaju, na strani servera, samo redovi potrebni za trenutna stranica. Kao što možete očekivati, stranica na strani servera obično pruža bolje performanse, jer klijentu se šalju samo redovi potrebni za prikaz.
Za podršku kreiranju stranice na strani servera u SQL Server 2012 uvodi dvije nove klauzule izraza SELECT: OFFSET i FETCH. Primjena ove dvije rečenice prikazana je u primjeru ispod. Ovdje se iz AdventureWorks2012 baze podataka (koju možete pronaći u izvorima) preuzimaju poslovni ID, naziv radnog mjesta i rođendan svih zaposlenica, sortirajući rezultat po nazivu posla uzlaznim redoslijedom. Rezultirajući skup redova se dijeli na stranice od 10 redova i prikazuje se treća stranica:
U rečenici OFFSET specificira broj redova rezultata koje treba preskočiti u prikazanom rezultatu. Ovaj broj se izračunava nakon što se redovi sortiraju prema ORDER BY klauzuli. U rečenici DETCH NEXT specificira broj odgovarajućih WHERE i sortiranih redova koje treba vratiti. Parametar ove klauzule može biti konstanta, izraz ili rezultat drugog upita. Klauzula FETCH NEXT je slična klauzuli PETCH FETCH.
Glavni cilj pri kreiranju stranica na strani servera je biti u mogućnosti implementirati uobičajene forme stranica koristeći varijable. Ovaj zadatak možete izvršiti preko SQL Server paketa.
SELECT izraz i svojstvo IDENTITY
IDENTITY Nekretnina omogućava vam da definirate vrijednosti za određenu kolonu tabele kao brojač koji se automatski povećava. Stupci numeričkog tipa podataka kao što su TINYINT, SMALLINT, INT i BIGINT mogu imati ovo svojstvo. Za takvu kolonu tabele, Database Engine automatski generiše sekvencijalne vrednosti počevši od navedene početne vrednosti. Dakle, svojstvo IDENTITY se može koristiti za kreiranje jedinstvenog numeričke vrijednosti za odabranu kolonu.
Tablica može sadržavati samo jedan stupac sa svojstvom IDENTITY. Vlasnik tabele ima mogućnost da odredi početnu vrednost i inkrement, kao što je prikazano u donjem primeru:
USE SampleDb; KREIRAJ TABELU Proizvod (Id INT IDENTITY(10000, 1) NOT NULL, Ime NVARCHAR(30) NOT NULL, Cijena NOVAC) UMETNI U PROIZVOD(Naziv, Cijena) VRIJEDNOSTI ("Item1", 10), ("Item2", 15) , ("Item3", 8), ("Item4", 15), ("Item5", 40); -- Vraća 10004 SELECT IDENTITYCOL FROM Product WHERE Naziv = "Proizvod5"; -- Slično prethodnom izrazu SELECT $identity FROM Product WHERE Ime = "Proizvod5";
Ovaj primjer prvo kreira tablicu proizvoda koja sadrži stupac Id sa svojstvom IDENTITY. Vrijednosti u koloni Id sistem automatski generiše, počevši od 10.000 i povećavajući se za jedan za svaku narednu vrijednost: 10.000, 10.001, 10.002 itd.
Nekoliko sistemskih funkcija i varijabli pridruženo je svojstvu IDENTITY. Na primjer, primjer koda koristi $identity sistemska varijabla. Kao što možete vidjeti iz izlaza ovog koda, ova varijabla automatski referencira svojstvo IDENTITY. Možete koristiti i umjesto toga funkcija sistema IDENTITYCOL.
Početna vrijednost i prirast stupca sa svojstvom IDENTITY mogu se pronaći pomoću funkcija IDENT_SEED I IDENT_INCR respektivno. Ove funkcije se primjenjuju na sljedeći način:
USE SampleDb; SELECT IDENT_SEED("Proizvod"), IDENT_INCR("Proizvod")
Kao što je već spomenuto, IDENTITY vrijednosti postavlja sistem automatski. Ali korisnik može eksplicitno odrediti svoje vrijednosti za određene redove postavljanjem parametra IDENTITY_INSERT ON prije umetanja eksplicitne vrijednosti:
SET IDENTITY INSERT ime tablice ON
Budući da se opcija IDENTITY_INSERT može postaviti na bilo koju vrijednost za stupac svojstva IDENTITY, uključujući i duplikat vrijednosti, svojstvo IDENTITY obično ne provodi jedinstvenost vrijednosti stupca. Stoga, ograničenja UNIQUE ili PRIMARY KEY trebaju se koristiti za provođenje jedinstvenosti vrijednosti stupca.
Kada umetnete vrijednosti u tabelu nakon što je IDENTITY_INSERT postavljen na uključeno, sistem kreira sljedeću vrijednost kolone IDENTITY, povećavajući najveću trenutnu vrijednost te kolone.
CREATE SEQUENCE izraz
Upotreba svojstva IDENTITY ima nekoliko značajnih nedostataka, od kojih su najznačajniji sljedeći:
aplikacija svojstva je ograničena na navedenu tabelu;
nova vrijednost kolone se ne može dobiti ni na koji drugi način osim njenom primjenom;
svojstvo IDENTITY se može specificirati samo prilikom kreiranja stupca.
Iz ovih razloga, SQL Server 2012 uvodi sekvence koje imaju istu semantiku kao svojstvo IDENTITY, ali bez prethodno navedenih nedostataka. U ovom kontekstu, sekvenca je funkcionalnost baze podataka koja vam omogućava da odredite vrijednosti brojača za različite objekte baze podataka, kao što su stupci i varijable.
Sekvence se kreiraju pomoću instrukcije CREATE SEQUEENCE. Naredba CREATE SEQUENCE je definirana u SQL standard i podržan je od drugih sistema relacijskih baza podataka kao što su IBM DB2 i Oracle.
Primjer ispod pokazuje kako kreirati sekvencu u SQL Serveru:
USE SampleDb; CREATE SEQUENCE dbo.Sequence1 KAO INT POČINJE SA 1 POVEĆANJEM ZA 5 MIN VRIJEDNOSTI 1 MAKSIMALNA VRIJEDNOST 256 CIKLUS;
U gornjem primjeru, vrijednosti za Sequence1 sistem generira automatski, počevši od vrijednosti 1 i povećavajući se za 5 za svaku narednu vrijednost. Dakle, u ponuda START početna vrijednost je navedena, i INCREMENT ponuda- korak. (Korak može biti pozitivan ili negativan.)
U sljedeće dvije fakultativne rečenice MINVRIJEDNOST I MAXVALUE navedene su minimalne i maksimalne vrijednosti objekta sekvence. (Imajte na umu da MINVALUE mora biti manji ili jednak početna vrijednost, i MAXVALUE ne mogu biti veći od gornje granice tipa podataka specificiranog za sekvencu.) U klauzuli CIKLUS označava da se sekvenca ponavlja od početka kada se prekorači maksimalna (ili minimalna za sekvencu sa negativnim korakom) vrijednost. Po defaultu, ova klauzula je postavljena na NO CYCLE, što znači da prekoračenje maksimalne ili minimalne vrijednosti sekvence uzrokuje izuzetak.
Glavna karakteristika sekvenci je njihova nezavisnost od tabela, tj. mogu se koristiti sa bilo kojim objektom baze podataka kao što su stupci tablice ili varijable. (Ovo svojstvo ima pozitivan učinak na pohranu, a samim tim i na performanse. Određeni niz ne mora biti pohranjen; pohranjuje se samo njegova posljednja vrijednost.)
Nove vrijednosti sekvence se kreiraju sa SLJEDEĆA VRIJEDNOST ZA izraze, čija je upotreba prikazana u primjeru ispod:
USE SampleDb; -- Vraća 1 SELECT SLJEDEĆU VRIJEDNOST ZA dbo.sequence1; -- Vraća 6 (sljedeći korak) SELECT SLEDEĆU VRIJEDNOST ZA dbo.sequence1;
Možete koristiti izraz SLJEDEĆA VRIJEDNOST FOR da dodijelite rezultat niza varijabli ili ćeliji stupca. Donji primjer pokazuje upotrebu ovog izraza za dodjelu rezultata koloni:
USE SampleDb; CREATE TABLE Proizvod (Id INT NOT NULL, Naziv NVARCHAR(30) NOT NULL, Cijena NOVAC) UMETNI U VRIJEDNOSTI proizvoda (SLJEDEĆA VRIJEDNOST ZA dbo.sequence1, "Proizvod1", 10); UMETNI U VRIJEDNOSTI proizvoda (SLJEDEĆA VRIJEDNOST ZA dbo.sequence1, "Proizvod2", 15); -- ...
Gornji primjer prvo kreira tablicu proizvoda sa četiri stupca. Zatim, dva INSERT izraza ubacuju dva reda u ovu tabelu. Prve dvije ćelije u prvoj koloni imat će vrijednosti 11 i 16.
Primjer ispod pokazuje korištenje kataloškog pogleda sys.sequences da vidite trenutnu vrijednost sekvence bez korištenja:
Obično se izraz NEXT VALUE FOR koristi u INSERT izrazu da prisili sistem da ubaci generirane vrijednosti. Ovaj izraz se također može koristiti kao dio upita u više redova pomoću klauzule OVER.
Za promjenu svojstva postojeće sekvence, koristite ALTER SEQUENCE izraz. Jedna od najvažnijih upotreba ove izjave je opcija RESTART WITH, koja resetira navedeni niz. Sljedeći primjer pokazuje upotrebu naredbe ALTER SEQUENCE za resetiranje gotovo svih svojstava Sequence1:
USE SampleDb; ALTER SEQUENCE dbo.sequence1 RESTART SA 100 POVEĆANJA ZA 50 MIN VRIJEDNOSTI 50 MAKSIMALNE VRIJEDNOSTI 200 BEZ CIKLUSA;
Izbrišite sekvencu koristeći instrukciju DROP SEQUENCE.
Postavite operatore
Pored operatora o kojima smo ranije govorili, Transact-SQL podržava još tri operatora skupa: UNION, INTERSECT i EXCEPT.
UNION operater
UNION operater kombinuje rezultate dva ili više upita u jedan skup rezultata koji uključuje sve redove koji pripadaju svim upitima u spoju. Shodno tome, rezultat spajanja dvije tabele je nova tabela koja sadrži sve redove uključene u jednu od originalnih tabela ili obe ove tabele.
Opšti oblik UNION operatora izgleda ovako:
select_1 UNION select_2(select_3])...
Opcije select_1, select_2, ... su SELECT izjave koje kreiraju spoj. Ako se koristi opcija SVE, prikazuju se svi redovi, uključujući duplikate. U operatoru UNION, parametar ALL ima isto značenje kao u SELECT listi za odabir, s jednom razlikom: za SELECT listu odabira, ovaj parametar se primjenjuje po defaultu, ali za UNION operator mora biti specificiran eksplicitno.
U svom izvornom obliku, SampleDb baza podataka nije prikladna za demonstraciju upotrebe UNION operatora. Stoga, ovaj odjeljak kreira novu tabelu, EmployeeEnh, koja je identična postojeća tabela Zaposlenik, ali ima dodatnu kolonu Grad. Ova kolona pokazuje gdje zaposleni žive.
Kreiranje tabele EmployeeEnh pruža nam priliku da demonstriramo upotrebu klauzule INTO u SELECT izrazu. Naredba SELECT INTO izvodi dvije operacije. Prvo, kreira se nova tabela sa stupcima navedenim na listi za odabir SELECT. Zatim se redovi originalne tabele ubacuju u novu tabelu. Ime nove tablice je navedeno u INTO klauzuli, a ime izvorne tablice navedeno je u klauzuli FROM.
Primjer ispod prikazuje kreiranje tabele EmployeeEnh iz tabele Employee:
USE SampleDb; SELECT * INTO EmployeeEnh FROM Employee; ALTER TABLE EmployeeEnh DODAJ Grad NCHAR(40) NULL;
U ovom primjeru, naredba SELECT INTO kreira tablicu EmployeeEnh, u nju umeće sve redove iz izvorne tablice Employee, a zatim naredba ALTER TABLE dodaje stupac City u novu tablicu. Ali dodana kolona Grad ne sadrži nikakve vrijednosti. Vrijednosti u ovu kolonu mogu se umetnuti pomoću Environment Management Studio ili sa sljedećim kodom:
USE SampleDb; UPDATE EmployeeEnh SET City="Kazan" WHERE Id=2581; UPDATE EmployeeEnh SET City = "Moskva" GDJE Id = 9031; UPDATE EmployeeEnh SET Grad = "Jekaterinburg" GDJE Id = 10102; UPDATE EmployeeEnh SET Grad = "Sankt Peterburg" GDJE Id = 18316; UPDATE EmployeeEnh SET Grad = "Krasnodar" GDJE Id = 25348; UPDATE EmployeeEnh SET City="Kazan" GDJE Id=28559; UPDATE EmployeeEnh SET City="Perm" WHERE Id=29346;
Sada smo spremni da demonstriramo upotrebu izjave UNIJE. Primjer u nastavku prikazuje upit za kreiranje spajanja između EmployeeEnh i Department tablica koristeći ovu naredbu:
USE SampleDb; ODABERITE Grad KAO "Grad" IZ UNIONA EmployeeEnh ODABIRITE lokaciju IZ Odjela;
Rezultat ovog upita je:
Samo kompatibilne tablice mogu se spojiti pomoću UNION izraza. Pod kompatibilnim tabelama podrazumijevamo da obje liste kolona u selekciji moraju sadržavati isti broj kolona i da odgovarajuće kolone moraju imati kompatibilne tipove podataka. (U smislu kompatibilnosti, tipovi podataka INT i SMALLINT nisu kompatibilni.)
Rezultat spajanja može se poredati samo korištenjem ORDER BY klauzule u posljednjem SELECT izrazu, kao što je prikazano u primjeru ispod. GROUP BY i HAVING klauzule se mogu koristiti sa pojedinačnim SELECT naredbama, ali ne unutar samog spoja.
Upit u ovom primjeru dohvaća zaposlenike koji ili rade u odjelu d1 ili su počeli raditi na projektu prije 1. januara 2008.
UNION operator podržava opciju SVE. Kada se koristi ova opcija, duplikati se ne uklanjaju iz skupa rezultata. OR operator se može koristiti umjesto UNION operatora ako se svi SELECT izrazi spojeni s jednim ili više UNION operatora odnose na istu tablicu. U ovom slučaju, skup SELECT izraza je zamijenjen jednim SELECT izrazom sa skupom OR naredbi.
INTERSECT i EXCEPT iskazi
Dva druga operatera za rad sa setovima, INTERSECT I OSIM, definiraju sjecište i razliku, respektivno. Ispod presjeka u ovom kontekstu je skup redova koji pripadaju objema tablicama. A razlika između dvije tablice definira se kao sve vrijednosti koje pripadaju prvoj tablici, a nisu prisutne u drugoj. Donji primjer pokazuje upotrebu INTERSECT izraza:
Transact-SQL ne podržava upotrebu opcije ALL s naredbom INTERSECT ili EXCEPT. Upotreba izraza EXCEPT prikazana je u primjeru ispod:
Imajte na umu da ova tri operatora skupa imaju različit prioritet izvršenja: operator INTERSECT ima najveći prioritet, a slijedi ga EXCEPT izjava, a UNION operator ima najmanji prioritet. Nepažnja prema prioritetu izvršenja kada se koristi višestruko različiti operateri rad sa setovima može dovesti do neočekivanih rezultata.
CASE izrazi
U oblasti aplikativnog programiranja baze podataka, ponekad je potrebno modificirati prezentaciju podataka. Na primjer, ljudi se mogu podijeliti tako što ih kodiraju prema njihovoj društvenoj pripadnosti, koristeći vrijednosti 1, 2 i 3, koje označavaju muškarce, žene, odnosno djecu. Ova tehnika programiranja može smanjiti vrijeme potrebno za implementaciju programa. CASE izraz Transact-SQL jezik olakšava implementaciju ovog tipa kodiranja.
Za razliku od većine programskih jezika, CASE nije izjava, već izraz. Stoga se izraz CASE može koristiti gotovo svuda gdje Transact-SQL jezik dozvoljava upotrebu izraza. Izraz CASE ima dva oblika:
jednostavan CASE izraz;
izraz za pretragu CASE.
Sintaksa za jednostavan CASE izraz je sljedeća:
Naredba s jednostavnim CASE izrazom prvo pretražuje listu svih izraza u WHEN klauzula prvi izraz koji odgovara izrazu_1, a zatim izvršava odgovarajući THEN klauzula. Ako na listi WHEN ne postoji odgovarajući izraz, onda ELSE klauzula.
Sintaksa za CASE izraz za pretraživanje je:
U ovom slučaju se traži prvi uvjet podudaranja, a zatim se izvršava odgovarajuća klauzula THEN. Ako nijedan od uslova ne odgovara zahtjevima, ELSE klauzula se izvršava. Upotreba izraza za pretragu CASE prikazana je u primjeru ispod:
USE SampleDb; SELECT ProjectName, CASE WHEN Budžet > 0 I Budžet 100000 I Budžet 150000 I Budžet
Rezultat ovog upita je:

Ovaj primjer ponderira budžete svih projekata i prikazuje njihove izračunate težine zajedno sa odgovarajućim nazivima projekata.
Primjer ispod pokazuje drugi način korištenja izraza CASE, gdje klauzula WHEN sadrži potupite koji su dio izraza:
USE SampleDb; SELECT ProjectName, CASE WHEN p1.Budget (IZABRAJTE AVG(p2.Budget) IZ Projekta p2) ONDA "Iznad proseka" KRAJ "Kategorija budžeta" IZ Projekta p1;
Rezultat ovog upita je sljedeći: