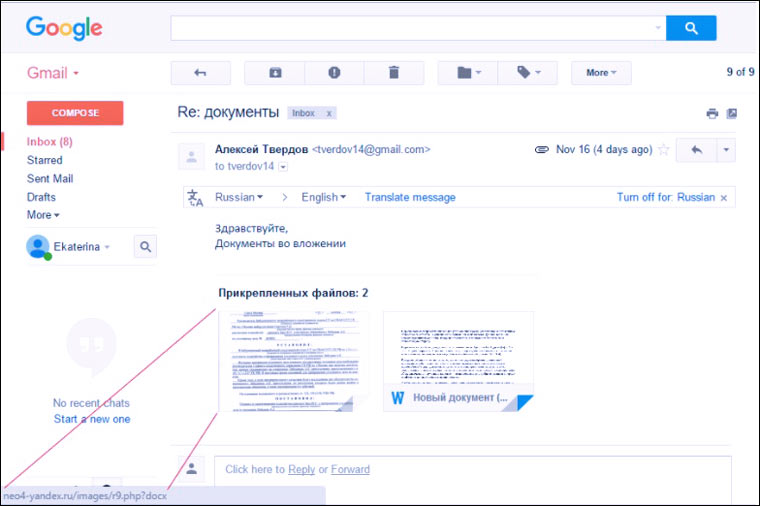
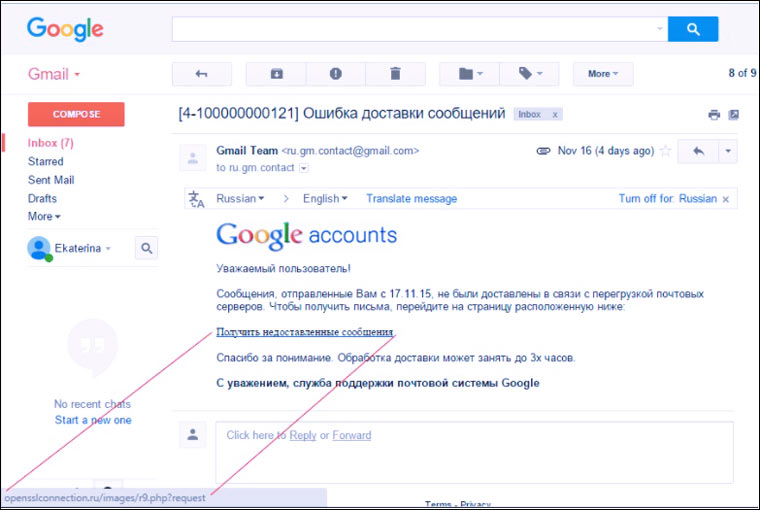
: Gjithmonë kam dashur ta kuptoj këtë, por rëndësia e saj ishte aq e vogël sa gjithmonë kishte një arsye për të mos e bërë :)
A keni pyetur veten: URL - çfarë është ajo?
Gjithmonë e hasja këtë, por ende nuk doja të kuptoja se cili është ndryshimi midis termave URI, URL, URN, dhe më pas papritmas një postim (për fat të keq, ai tashmë është zhytur në harresë), vendosa - do ta lexoj veten time dhe do t'u tregoj të tjerëve, megjithëse, siç u përmend më lart, kjo nuk do të ndryshojë asgjë, por ndonjëherë më pëlqen të luaj fjalët, prandaj lexoni përkthyesin shpjegues:
A e keni vënë re ndonjëherë shiritin e adresave në shfletuesin tuaj? Çfarë është kjo? URI, URL apo URN? Shumë prej nesh nuk bëjnë dallime midis URI, URL, URN dhe disa prej nesh nuk i kanë dëgjuar as termat URI dhe URN, të gjithë përdorin vetëm termin URL. Le të përpiqemi ta kuptojmë së bashku.
Shpjegimi i shkurtesave
URI - Identifikuesi Uniform i Burimit (i unifikuar identifikues burim)
URL - Gjetësi i Uniform i Burimeve (i unifikuar lokalizues burim)
URN - Emri i burimit Unifromm (unifikuar emri burim)
Kujdes, këtu e vërteta fshihet në gjërat e vogla, por deri më tani asgjë nuk është e qartë, një lloj rrëmujë. Le të shkojmë më tej.
Përkufizimi
URI: Tregon emrin dhe adresën e një burimi në rrjet. Zakonisht ndahet në URL dhe URN, kështu që URL dhe URN janë pjesë e URI-së.
URL: Adresa e disa burimeve në ueb. URL-ja identifikon vendndodhjen e burimit dhe mënyrën se si aksesohet.
URN: Emri i disa burimeve në ueb. Kuptimi i URN është se ai identifikon vetëm emrin e një artikulli specifik, i cili mund të gjendet në shumë vende specifike.
Nuk ka asgjë më të mirë se një shembull specifik.
URI = http: //site/2009/09/uri-url-urn.html
URL = http: // sajti
URN = /2009/09/uri-url-urn.html
Le të përmbledhim
URI është koncepti i një identifikuesi abstrakt, ndërsa URL dhe URN janë zbatime konkrete të adresës dhe emrit.
Shpresoj që të gjithë të kuptojnë gjithçka. Jini të shkolluar!
Perceptimi i secilit prej nesh është individual, prandaj - argumentoni dhe lexoni diskutimet në komentet e artikullit, ka shumë gjëra interesante.
Mosmarrëveshjet për këtë çështje - si të shkruani URL-në saktë, me ose pa një vijë të pjerrët pasuese? - ishin dhe do të jenë. Argumentimi është i larmishëm dhe shpesh kontradiktor. Dhe ka dy lloje të kthimit për një hyrje të pasaktë të URL-së. Nga ana e motorëve të kërkimit, këto janë gjoja dënime për faqet e kopjuara. Nga pikëpamja e performancës, supozohet se ky është një ridrejtim shtesë në faqen e saktë të regjistrimit, i krijuar automatikisht nga serveri.
Megjithatë, duke analizuar specifikimet teknike të standardeve të Internetit, në veçanti dokumentin "RFC 1738 - Uniform Resource Locators (URL)", duhet të pranojmë se të dy versionet e regjistrimit të adresave të burimeve në internet janë zyrtarisht të sakta, dhe sanksioni për përdorimin e një ose një version tjetër nuk është asgjë më shumë se një motor kërkimi i çuditshëm ose histori pseudo-SEO-schnick.
Nga pikëpamja e shkurtësisë, opsioni pa një vijë të pjerrët në fund duket të jetë më i saktë, pavarësisht nëse lidhja juaj është një "skedar" në server apo një "dosje", prova indirekte e së cilës do të demonstrohet më poshtë. Por nuk ka asnjë deklaratë të vetme në dokument që një opsion tjetër është i pasaktë ose i referohet një burimi krejtësisht të ndryshëm.
Nuk do t'ju shkarkoj një përkthim me shumë faqe të RFC-së së përmendur, pasi, së pari, qëllimi i pyetjes ishte prerja në fund të URL-së, dhe së dyti, publikimi u drejtohet përdoruesve të zakonshëm të motorëve, përfshirë ata që nuk i interesojnë të gjitha detajet, presin shpjegime të shkurtra dhe prova mbi themelin. Prandaj, unë do të citoj pjesë nga ky dokument si provë dhe do të shpjegoj. Kushdo që nuk është i interesuar për këtë mund të shikojë menjëherë rezultatin në fund të artikullit.
Sintaksa e përgjithshme e URL-së
Gjëja e parë që duhet tërhequr vëmendjen tuaj është fragmenti nga paragrafi 2. Sintaksa e përgjithshme e URL-së. Në secilin rast, unë do të citoj një fragment të tekstit në gjuhën origjinale, e ndjekur nga një përkthim në Rusisht.
URL-të përdoren për të "vendosur" burimet, duke ofruar një identifikim abstrakt të vendndodhjes së burimit. URL-të përdoren për të "lokalizuar" burimet, duke ofruar një identifikim abstrakt të vendndodhjes së burimit.
Kjo do të thotë, vetë URL-ja është një abstraksion i pastër. Fakti që nga pamja e jashtme mund të na duket i ngjashëm me emrin e një skedari ose dosjeje, nuk do të thotë aspak një referencë fizike ndaj një skedari të tillë, dhe jo të ndonjë skedari tjetër në hapësirën e skedarit të serverit. Kjo do të thuhet drejtpërdrejt në dokumentin e mëposhtëm.
Shënimi Në përgjithësi, në lidhje me lidhjet http, është në parim e gabuar të thuhet se për shembull
- http://domain.com/path/subpath/filename.txt- gjoja tregon për një dosje
- http://domain.com/path/subpath/- gjoja tregon për një dosje
- http://domain.com/path - supozohet se tregon gabimisht një dosje
Ne thjesht e thonim këtë, sepse është e përshtatshme të lidhësh lidhje me skedarët në sit. Në realitet, të gjitha këto lidhje tregojnë për disa burime, pa treguar në asnjë mënyrë llojin e burimit. Ajo që fshihet pas çdo burimi, domethënë, çfarë lloj skedari ose dosjeje reale dhe çfarë lloji i përmbajtjes do të shërbehet përmes një lidhjeje të tillë, përcaktohet tashmë nga konfigurimi i serverit.
Është e rëndësishme të kuptohet se në lidhje nuk ka një gjë të tillë si "skedar", "dosje", "nënfolder", "tekst", "foto", "html", "skript", "stil fletë" etj. Asnjë prerje në fund ose mungesa e saj nuk do të thotë absolutisht asgjë derisa lidhja të transformohet brenda serverit, dhe ai vetë vendos se ku tregon në të vërtetë lidhja dhe çfarë lloji të përmbajtjes fshihet pas saj. Kjo është e vetmja zgjidhje që lidhet me arkitekturën e brendshme të serverit.
Skemat hierarkike
Më poshtë është një fragment nga paragrafi 2.3 Skemat hierarkike dhe lidhjet relative (skemat hierarkike dhe lidhjet relative).
Disa skema URL (të tilla si skemat ftp, http dhe skedarët) përmbajnë emra që mund të konsiderohen hierarkikë; komponentët e hierarkisë ndahen me "/". Disa skema URL (si ftp, http dhe file) përmbajnë emra që mund të konsiderohen hierarkikë; anëtarët e hierarkisë ndahen me simbolin "/".
Kjo do të thotë, argumentohet se në skema të caktuara adresash, përmbajtja e një lokalizuesi të burimeve nuk ndalohet të konsiderohet hierarkike dhe ende nuk është përcaktuar që hierarkia të jetë e barabartë me ndonjë formë, le të themi, skedar.
Sintaksa e përgjithshme e skemës së rrjetit
Më poshtë është një fragment nga paragrafi 3.1. Sintaksa e zakonshme e skemës së internetit
//
Shënimi Kjo, meqë ra fjala, është përgjigja e një pyetjeje që rrjedh nga ajo që po shqyrtojmë. Shpesh ata debatojnë për këtë çështje: si t'i jepni saktë një lidhje një domeni (host) - pa një prerje në fund apo me një prerje?
Si ta bëni atë siç duhet http://domain.com/ apo http://domain.com?
Dhe kështu e kaq e drejtë. Thjesht prerja e parë pas emrit të hostit synon të ndajë emrin e rrugës nga emri i hostit. I njëjti paragraf i dokumentit e thotë kështu:
Url-rruga Pjesa tjetër e lokalizuesit përbëhet nga të dhëna specifike për skemën dhe njihet si "rruga url". Ai jep detajet se si mund të aksesohet burimi i specifikuar. Vini re se "/" midis hostit (ose portit) dhe shtegut url NUK është pjesë e shtegut url. Pjesa tjetër e lokalizuesit përbëhet nga të dhëna specifike të skemës dhe njihet si "rruga url". Ai jep detaje se si mund të aksesohet burimi i specifikuar. Vini re se karakteri "/" midis hostit (ose portit) dhe shtegut të URL-së nuk është pjesë e shtegut të url-së.
Ne nuk ishim të detyruar me një fjalë ta vendosnim këtë karakter pasues ose të mos e vendosnim kur shtegu i url-së është një varg bosh (siç do të thoshim shumë prej nesh kur URL-ja i referohet rrënjës së sajtit). Askush nuk ka të drejtë të të vendosë penalitete "për dy marrjen e faqes kryesore", sepse sipas specifikimit, në të dyja rastet ju e lidhni URL-në me të njëjtin burim.
Le te vazhdojme një fragment tjetër nga i njëjti paragraf.
Sintaksa e rrugës url varet nga skema që përdoret, si dhe mënyra në të cilën interpretohet. Sintaksa për url-path varet nga skema e përdorur, si dhe nga mënyra se si interpretohet.
Ky është një tjetër konfirmim se çdo skemë lokatore ka konceptin e saj të "hierarkisë" dhe mënyrën e interpretimit të saj.
Hierarkia
Për disa sisteme skedarësh, "/" e përdorur për të treguar strukturën hierarkike të URL-së korrespondon me ndarësin e përdorur për të ndërtuar një hierarki të emrit të skedarit, dhe kështu, emri i skedarit do të duket i ngjashëm me shtegun e URL-së. Kjo NUK do të thotë që URL-ja është një emër skedari Unix. Karakteri "/" përdoret për të treguar strukturën hierarkike të URL-së sipas kufirit të përdorur në ndërtimin e hierarkisë së emrave të skedarëve, dhe kështu, në disa sisteme skedarësh, emri i skedarit duket si një shteg URL. Por kjo nuk do të thotë që URL-ja është një emër skedari i ngjashëm me Unix-in.Megjithëse ky paragraf i referohet skemës ftp, megjithatë ai zbatohet për skemat e tjera (http, gopher, prospero, e kështu me radhë). Vetëm në skemën e skedarëve, simboli i pjerrët logjikisht tregon njësoj si në emrat e skedarëve, për shembull skedari: //server_or_device/path/subpath/filename.txt.
Http
Një URL HTTP merr formën: http://
Shënimi Ai gjithashtu thotë se ju mund të specifikoni një lidhje pa një vijë të pjerrët pasuese. Në këtë rast, ne po flisnim për një situatë kur shtegu i lidhjes është bosh - tregon rrënjën e hostit.
Shënim zyrtar
Së fundi, një fragment nga paragrafi 5. BNF për skemat specifike të URL-ve.
Këtu, pjesët opsionale tregohen në kllapa katrore. Një yll përpara një kllapa tregon 0 ose më shumë përsëritje të të njëjtit fragment siç tregohet në kllapa. Shiriti vertikal duhet të kuptohet si OSE.
Hostport = host [":" port] ... ... httpurl = "http: //" hostport ["/" hpath ["?" kërko]] hpath= hsegment * ["/" hsegment] hsegment = * [uchar | ";" | ":" | "@" | "&" | "="] kërkim = * [uchar | ";" | ":" | "@" | "&" | "="] ... ... lowalfa = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" hialfa = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "Unë" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | "Q" | "R" | "S" | "T" | "U" | "V" | "W" | "X" | "Y" | "Z" alfa = ulëtalfa | shifra hialfa = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" kasafortë = "$" | "-" | "_" | "." | "+" shtesë = "!" | "*" | "" "|" ("|") "|", "hex = shifra |" A "|" B "|" C "|" D "|" E "|" F "|" a "|" b " | "c" | "d" | "e" | "f" ikje = "%" hex hex e parezervuar = alfa | shifra | e sigurt | uchar shtesë = e parezervuar | ikje
Vini re se si elementi hpath - rruga e lidhjes - është formuar saktësisht sipas rregullave. Elementet e segmentit të rrugës - segmentet - ndahen me një vijë të pjerrët. Sikur të lë të kuptohet për idenë e rëndësishme që pjerrësia e ndan shtegun në pjesë hierarkike dhe është gjithmonë brenda. Në parim, është e mundur që elementi i fundit i segmentit mund të jetë një varg bosh (kjo rrjedh nga përkufizimi i tij), dhe më pas një prerje mbyllëse shfaqet në mënyrë të pavullnetshme në fund të URL-së.
konkluzioni
Ndarja e një shtegu në segmente duke përdorur një karakter të pjerrët nënkupton praninë e emrave jo bosh të këtyre segmenteve. Prandaj, një lidhje me një prerje në fund duket e palogjikshme (megjithëse jo e ndaluar) në kuptimin që duket se tregon një segment të caktuar të fundit të shtegut, por, për më tepër, nuk e emërton këtë segment në asnjë mënyrë. Pikërisht si lidhje e palogjikshme (por edhe jo e ndaluar). http://domain.com/level1////levelX, i cili nuk emërton segmente të ndërmjetme të shtegut, nëse shtegu konsiderohet jo si një grup parametrash, por si një strukturë hierarkike.
Në gjuhën e folur, përmbajtja semantike e dy lidhjeve mund të shpjegohet si më poshtë:
- - adresat në pikën fillestare të paracaktuar të nivelit të dytë të hierarkisë
- - adreson një pikë të papërcaktuar brenda nivelit të dytë të hierarkisë, pra sikur serverit i është caktuar detyra që "ne po i drejtohemi nivelit të dytë të hierarkisë dhe ju vetë përcaktoni se cilën pikë në këtë nivel e konsideroni si të paracaktuar. fillestar".
Nga të gjitha ato që u tha më sipër rrjedh, e cila është e ngjashme me mënyrën se si lidhet
- http://domain.com
- http://domain.com/
adresoni vizitorin në rrënjën e faqes, dhe për shembull lidhjet
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
adresoni vizitorin në nivelin e dytë të hierarkisë së burimeve. Dhe fakti që një server i caktuar mund të interpretojë vijën e pjerrët në fund në mënyrën e vet dhe të fillojë të ridrejtojë nga brenda në pikën fillestare të paracaktuar të nivelit - të themi, në skedarin index.html, ky është tashmë një rast i veçantë i një konfigurimi specifik . Ashtu si në zbatimin e një sistemi URL të lexueshëm nga njeriu, të gjitha regjistrimet e ridrejtimit duke përdorur modulin e serverit mod_rewrite përcaktojnë konceptin e tyre (të qenësishëm në një motor specifik) të një strukture hierarkike URL, në të cilën elementët e rrugës mund të barazohen për të kërkuar parametra dhe kanë nuk ka të bëjë me strukturën e skedarit të sitit ( shembulli klasik: http://domain.com/ru/path, elementi ru është parametri i gjuhës aktuale, jo një dosje në sit).
Dua të theksoj se kjo është njohuri e brendshme e serverit, për shkak të konfigurimit të tij, si dhe motorit të instaluar në faqe. Një shërbim i jashtëm, le të themi i njëjti motor kërkimi, nuk mund të bëjë hamendje dhe nuk e ka idenë nëse dhe si ndryshojnë lidhjet me dhe pa një vijë të pjerrët, përveç nëse serveri i faqes është konfiguruar posaçërisht për të shfaqur përmbajtje të ndryshme në lidhje të tilla.
Për informacionin tuaj
Në nivel zbatimi, çështja e prerjeve në skajet nuk është e një rëndësie thelbësore, për të cilën ka shumë konfirmime nga portalet eminente. Në disa, të gjitha lidhjet përfundojnë me një të pjerrët, në të tjerët - pa një prerje. Gjëja kryesore është që përmbajtja në lidhje nuk rezulton të jetë e ndryshme, dhe për Yandex gjithashtu duhet të regjistroni ridrejtimin 301 nga ato lidhje që nuk i përdorni (të themi, ato që përfundojnë me një të pjerrët), tek ato që ju përdorni. Fakti është se, sipas deklaratave të pakonfirmuara nga shërbimi mbështetës Yandex, ky motor kërkimi supozohet se mund të bëjë gabime dhe të mos "ngjisë" (mbani mend në dijeninë e tyre) ose, me njëfarë vonese, të ngjisë adresat pa prerje në një.

Këtu është një shembull i zbatimit të një ridrejtimi të tillë duke përdorur skedarin root .htaccess:
# nëse url-ja e hyrjes përfundon me një vijë të pjerrët (em, s), # vendosni ridrejtimin e 301-të në faqen pa vijë të pjerrët RewriteCond% (REQUEST_URI) ^ /. + / $ RewriteRule ^ (. *?) / + $ http: / /% (HTTP_HOST) / 1 $
Google (përsëri, sipas informacionit të pa konfirmuar nga eksperimenti), këto ridrejtime nuk janë të rëndësishme, pasi duket se është në gjendje të ngjitë adresa të tilla saktë dhe pa ridrejtime.
Mbani mend Ka mjaft njerëz që e konsiderojnë veten specialistë të SEO. Por jo të gjithë janë. Për më tepër, tema e SEO shpesh spekulohet pa njohuri dhe arsye të duhura, vetëm me shpresën se jeni injorant në këtë fushë, ndaj është e lehtë të besoni në ndonjë "petë". Kur ju thuhet se disa nga faqet tuaja "dolën jashtë indeksit", përdorni një rekomandim shumë të mirë nga Yandex: Ju mund të mësoni për gabimet e indeksimit, nëse ka, në shërbimin Yandex.Webmaster. Në këtë shërbim, gjithmonë mund të shihni një listë të faqeve tuaja në kërkim dhe një listë të faqeve të përjashtuara nga kërkimi për ndonjë arsye. Google ka një shërbim të ngjashëm. Besojini kësaj dijeje dhe jo mendimit të pseudospecialistëve, të cilët diku dëgjuan diçka jashtë rrugës, dhe mbi këtë bazë ju rekomandojnë të bëni atë që ata mendojnë se është e vetmja gjë e duhur.
Këtu Një postim shumë interesant, Fakte pak të njohura SEO, i publikuar në prill 2017. Ai paraqet një studim të madh me shumë pamje nga ekrani, i cili filloi me synimin për të testuar vlefshmërinë e disa gjykimeve të njohura në fushën e promovimit të motorëve të kërkimit dhe duke përdorur shembuj të qartë për të përcjellë rezultatet tek pronari mesatar i faqes. I njëjti studim i tregon njëkohësisht lexuesit të ri një sërë veçorish të dukshme, të rëndomta dhe mjaft të paqarta, por ende befasuese të rezultateve të kërkimit organik në kërkimet e Google dhe Yandex.
Këtu Ndërsa lidhja e mëposhtme nuk ka pothuajse asnjë lidhje me SEO, ajo do të jetë ende tërheqëse për mjeshtrat e SEO që kërkojnë porosi shtesë tani. Një ofertë komerciale është postuar nën lidhjen, djemtë kanë gjetur një mënyrë interesante për të përdorur faqen. Një biznesi privat i ofrohet të krijojë një billboard në internet bazuar në një temë të veçantë, nën kontrollin e së cilës faqja, ose më saktë ekrani i saj i parë, duket si një shtrirje baneri në tabelat e reklamave në natyrë. Në smartphone, ktheva ekranin, shtrirja u bë vertikale dhe zë të gjithë zonën e ekranit, u kthye prapa, u bë horizontale dhe përsëri në të gjithë ekranin. Dhe nën ekranin e parë ka një shtojcë teksti, ku përdoruesit zakonisht nuk lëvizin, por motori i kërkimit e sheh mirë këtë tekst. Pra, pikat më të shkathëta të biznesit rajonal i blejnë vetë këto tabela të lira në internet si një alternativë fitimprurëse ndaj reklamave kontekstuale dhe Rrjetit të Ekranit Yandex dhe Google. Dhe për të qëndruar sa më shumë në indeksin e kërkimit lokal, ata janë gati të rrahin para në të njëjtën kohë në një tufë SEO-tekstesh për të promovuar mburojën e tyre, e cila mban erë të një sasie jo acide. Duke gjykuar nga thashethemet, porositë për 30 kilogramë rubla po rrëshqasin, dhe meqenëse djemtë i transferojnë ato tek partnerët e SEO, këtu mund të ndërtoni ura partneriteti dhe të merrni fitime të mira.
Ju mund të humbni jo vetëm në pyll, por edhe në internet. Dhe kjo mund të jetë për shkak të rrugës ose adresës së gabuar që çon në burim. Nuk e dini se çfarë është një URL? Më pas, përpara se të nisim një udhëtim të mëtejshëm nëpër hapësirën virtuale, le të merremi me sistemin e adresave të emailit.
Çfarë është URL
URL-ja është një standard i pranuar përgjithësisht për regjistrimin e një adrese dhe për të treguar vendndodhjen e një burimi në internet. Nga anglishtja emri i saj ( Gjetësi Uniform i Burimeve) përkthehet si një gjetës uniform i burimeve. Ju mund të gjeni një dekodim të mëparshëm të shkurtesës URL - Gjetësi universal i burimeve (gjetës i burimeve universale). Por të dy kuptimet plotësojnë konceptin e URL-së në vend që të kundërshtojnë njëri-tjetrin.
Formati bazë i strukturës së URL-së është si më poshtë:
://:@:/?#
- më shpesh nënkuptohet protokolli.
login - emri i përdoruesit i përdorur për autorizimin në burim.
fjalëkalimi - fjalëkalimi i përdoruesit për autorizim.
host - emri i domenit të hostit.
port - port pritës i përdorur gjatë lidhjes.
URL - rruga ku ndodhet burimi i kërkuar në server.
parametrat dhe ankorimi- vlera e variablave dhe identifikuesi në një burim specifik.
Kalimi i vlerës së variablave në një varg pyetjesh është i mundur vetëm duke përdorur metodën GET.
Le të shqyrtojmë formatin e URL-së së faqes së burimit të kërkuar me shembuj praktikë. Në anën e klientit, URL-ja shfaqet në shiritin e adresave të shfletuesit:
Opsionet më të zakonshme janë:
- http: // ru.wikipedia.org/wiki/Home_page- http ( protokolli i transferimit të hipertekstit);
- https://ru.wikipedia.org/wiki/Home_page- https përdoret si metodë transmetimi. Është një formë e sigurt e protokollit http që përdor enkriptimin (SSL ose TLS);
- fttp: //wikipedia.org/wiki/file.txt- protokolli i transferimit të skedarëve fttp;
- http://mail.ru/script.php?num=10&type=new&v=text- kalimi i vlerave të variablave në vargun e pyetjeve duke përdorur metodën GET.
Çdo format URL është kryesisht një varg karakteresh. Mund të përfshijë:
2; letra.
2; Numrat arabë (0-9).
2; Karaktere të rezervuara ("+", "=", "!" Dhe të tjerë).
2; Karaktere speciale - le të ndalemi në to në më shumë detaje.
Përdorimi i karaktereve speciale në URL
Natyrisht, karaktere të tilla shumë "të veçanta" nuk përdoren në URL. Por ka disa:
- ? - shërben për ndarjen e bllokut me parametrat e transmetuar në linjën e pyetësorit;
- & - ndan parametrat e kaluar nga njëri-tjetri;
- = - ndan variablin në parametër nga vlera e tij;
- : - shërben për të ndarë protokollin nga pjesa tjetër e URL-së;
- # - karakteri përdoret në pjesën lokale të adresës. Ju lejon t'i referoheni një pjese të caktuar të faqes së kërkuar;
- @ - tregohet në të dhënat e regjistrimit të përdoruesit dhe kur transferoni të dhëna duke përdorur protokollin mailto.
Por kjo është e gjitha vetëm teori. Prandaj, para se të mësojmë pjesën tjetër, le të shohim një shembull të vogël praktik.
Shembull ilustrues
Për qartësi, le të marrim një formular kaq të thjeshtë regjistrimi:
Këtu është kodi i tij: