Impareremo a riassumere. No, questi non sono ancora i risultati dello studio di SQL, ma i risultati dei valori delle colonne delle tabelle del database. Le funzioni aggregate SQL agiscono sui valori delle colonne per produrre un singolo valore di risultato. Le funzioni di aggregazione SQL più comunemente utilizzate sono SUM, MIN, MAX, AVG e COUNT. È necessario distinguere tra due casi di utilizzo di funzioni aggregate. Innanzitutto, le funzioni aggregate vengono utilizzate da sole e restituiscono un singolo valore risultante. In secondo luogo, le funzioni aggregate vengono utilizzate con la clausola SQL GROUP BY, ovvero con il raggruppamento per campi (colonne) per ottenere i valori dei risultati in ciascun gruppo. Consideriamo prima i casi di utilizzo di funzioni aggregate senza raggruppamento.
Funzione SOMMA SQL
La funzione SQL SUM restituisce la somma dei valori di una colonna in una tabella di database. Può essere applicato solo alle colonne i cui valori sono numeri. Le query SQL per ottenere la somma risultante iniziano in questo modo:
SELEZIONA SOMMA (COLUMN_NAME) ...
Questa espressione è seguita da FROM (TABLE_NAME), quindi è possibile specificare una condizione utilizzando la clausola WHERE. Inoltre, DISTINCT può essere specificato davanti al nome della colonna, il che significa che verranno conteggiati solo i valori univoci. Per impostazione predefinita, vengono presi in considerazione tutti i valori (per questo, è possibile specificare specificamente non DISTINCT, ma ALL, ma la parola ALL è facoltativa).
Esempio 1. C'è un database dell'azienda con i dati sulle sue divisioni e dipendenti. La tabella Personale, oltre a tutto, ha una colonna con i dati sugli stipendi dei dipendenti. La selezione dalla tabella è la seguente (per ingrandire l'immagine cliccarci sopra con il tasto sinistro del mouse):
Per ottenere la somma di tutti gli stipendi, utilizziamo la seguente query:
SELEZIONA SOMMA (stipendio) DA Personale
Questa query restituirà 287664.63.
E adesso . Negli esercizi, stiamo già iniziando a complicare i compiti, avvicinandoli a quelli che si incontrano nella pratica.
Funzione SQL MIN
La funzione SQL MIN funziona anche su colonne i cui valori sono numeri e restituisce il minimo di tutti i valori nella colonna. Questa funzione ha una sintassi simile alla sintassi SOMMA funzioni.
Esempio 3. Il database e la tabella sono gli stessi dell'esempio 1.
È necessario scoprire il salario minimo dei dipendenti del dipartimento con il numero 42. Per fare ciò, scrivi la seguente richiesta:
La richiesta restituirà il valore 10505.90.
E di nuovo esercizio di auto-aiuto... In questo e in altri esercizi, avrai bisogno non solo della tabella Staff, ma anche della tabella Org, che contiene i dati sulle divisioni dell'azienda:

Esempio 4. La tabella Org viene aggiunta alla tabella Staff, che contiene i dati sulle divisioni dell'azienda. Visualizza il numero minimo di anni in cui un singolo dipendente ha lavorato in un dipartimento situato a Boston.
Funzione SQL MAX
La funzione SQL MAX funziona in modo simile e ha una sintassi simile, che viene utilizzata quando è necessario definire valore massimo tra tutti i valori di colonna.
Esempio 5.
È necessario scoprire lo stipendio massimo dei dipendenti del dipartimento numero 42. Per fare ciò, scrivi la seguente richiesta:
La richiesta restituirà il valore 18352.80
È tempo esercizi per l'autosoluzione.
Esempio 6. Stiamo lavorando di nuovo con due tabelle: Staff e Org. Stampa il nome del reparto e le provvigioni massime guadagnate da un dipendente in un reparto appartenente alla Divisione Orientale. Uso UNISCITI (unisci tabelle) .
Funzione SQL AVG
La sintassi precedente per le funzioni descritte in precedenza è vera anche per la funzione SQL AVG. Questa funzione restituisce la media di tutti i valori in una colonna.
Esempio 7. Il database e la tabella sono gli stessi degli esempi precedenti.
Supponiamo di voler scoprire l'esperienza lavorativa media dei dipendenti del dipartimento numero 42. Per fare ciò, scrivi la seguente query:
Il risultato sarà un valore di 6.33
Esempio 8. Lavoriamo con un tavolo - Staff. Ritirare lo stipendio medio dei dipendenti con un'esperienza da 4 a 6 anni.
Funzione SQL COUNT
La funzione SQL COUNT restituisce il numero di record in una tabella di database. Se specifichi SELECT COUNT (COLUMN_NAME) ... nella query, il risultato sarà il numero di record esclusi i record in cui il valore della colonna è NULL (non definito). Se si utilizza un asterisco come argomento e si avvia una query SELECT COUNT (*) ..., il risultato sarà il numero di tutti i record (righe) nella tabella.
Esempio 9. Il database e la tabella sono gli stessi degli esempi precedenti.
È necessario conoscere il numero di tutti i dipendenti che ricevono commissioni. Il numero di dipendenti i cui valori della colonna Comm non sono NULL restituirà la seguente query:
SELEZIONA COUNT (Comm) DA Staff
Il risultato è 11.
Esempio 10. Il database e la tabella sono gli stessi degli esempi precedenti.
Se hai bisogno di scoprire il numero totale di record in una tabella, usiamo una query con un asterisco come argomento della funzione COUNT:
SELEZIONA COUNT (*) FROM Staff
Il risultato è 17.
Nel prossimo esercizio di auto-aiuto dovrai usare una sottoquery.
Esempio 11. Lavoriamo con un tavolo - Staff. Visualizza il numero di dipendenti nel reparto di pianificazione (pianure).
Funzioni di aggregazione con SQL GROUP BY (raggruppamento)
Ora diamo un'occhiata all'utilizzo delle funzioni aggregate in combinazione con la clausola SQL GROUP BY. La clausola SQL GROUP BY viene utilizzata per raggruppare i valori dei risultati in base alle colonne della tabella del database.
Esempio 12. C'è un database del portale di annunci. Contiene la tabella Annunci, che contiene i dati sugli annunci inviati per la settimana. La colonna Categoria contiene informazioni su grandi categorie annunci pubblicitari (ad esempio, Immobili) e la colonna Parti - sulle parti più piccole incluse nelle categorie (ad esempio, le parti Appartamenti e Cottage fanno parte della categoria Immobili). La colonna Unità contiene i dati sul numero di annunci inviati e la colonna Denaro contiene l'importo ricevuto per l'invio degli annunci.
| Categoria | Parte | Unità | I soldi |
| Trasporto | Veicoli a motore | 110 | 17600 |
| La proprietà | Appartamenti | 89 | 18690 |
| La proprietà | Cottage | 57 | 11970 |
| Trasporto | Motociclette | 131 | 20960 |
| Materiali da costruzione | tavole | 68 | 7140 |
| Ingegnere elettrico | televisori | 127 | 8255 |
| Ingegnere elettrico | Frigoriferi | 137 | 8905 |
| Materiali da costruzione | Regips | 112 | 11760 |
| Tempo libero | libri | 96 | 6240 |
| La proprietà | case | 47 | 9870 |
| Tempo libero | Musica | 117 | 7605 |
| Tempo libero | Giochi | 41 | 2665 |
Utilizzando l'istruzione SQL GROUP BY, trova la quantità di denaro guadagnata dalla pubblicazione di annunci in ciascuna categoria. Scriviamo la seguente richiesta.
La lezione tratterà l'argomento sql rinominare una colonna (campi) utilizzando la parola funzione AS; trattato anche il tema delle funzioni aggregate in sql. Saranno analizzati esempi specifici di richieste
È possibile rinominare i nomi delle colonne nelle query. Questo rende i risultati più leggibili.
In SQL, la ridenominazione dei campi è associata all'uso di parola chiave AS che viene utilizzato per rinominare i nomi dei campi nei set di risultati
Sintassi:
SELEZIONARE<имя поля>COME<псевдоним>A PARTIRE DAL ...
Diamo un'occhiata a un esempio di ridenominazione in SQL:
Esempio DB "Istituto": Visualizza i nomi degli insegnanti e i loro stipendi, per quegli insegnanti i cui stipendi sono inferiori a 15000, rinomina il campo zarplata in "Bassi salari"
Soluzione:
Rinominare le colonne in SQL è spesso necessario quando si calcolano i valori associati a più campi tabelle. Consideriamo un esempio:
Esempio DB "Istituto": Dalla tabella insegnanti, emettere il campo nome e calcolare l'importo dello stipendio e del bonus, nominando il campo "Premio_stipendio"
Soluzione:
| 1 2 | SELEZIONA nome, (zarplata + premia) AS zarplata_premia FROM insegnanti; |
SELEZIONA nome, (zarplata + premia) AS zarplata_premia FROM insegnanti;
Risultato:
Funzioni aggregate in SQL
Le funzioni aggregate in sql vengono utilizzate per ottenere i totali e calcolare le espressioni:
Tutte le funzioni aggregate restituiscono un singolo valore.
Le funzioni COUNT, MIN e MAX si applicano a qualsiasi tipo di dati.
Le funzioni SOMMA e AVG vengono utilizzate solo per i campi numerici.
C'è una differenza tra le funzioni COUNT (*) e COUNT (): la seconda non tiene conto dei valori NULL durante il conteggio.
Importante: quando si lavora con funzioni aggregate in SQL, viene utilizzata una parola speciale COME
Esempio DB "Istituto": Ottieni il valore dello stipendio più alto tra gli insegnanti, visualizza il risultato come "Max_zp"
Soluzione:
| SELEZIONA MAX (zarplata) AS max_zp DA insegnanti; |
SELEZIONA MAX (zarplata) AS max_zp DA insegnanti;
Risultati:
Consideriamo un esempio più complesso di utilizzo di funzioni aggregate in sql.
Soluzione:
Clausola GROUP BY in SQL
La clausola group by in sql viene solitamente utilizzata in combinazione con le funzioni aggregate.
Le funzioni aggregate vengono eseguite su tutte le righe di query risultanti. Se la query contiene una clausola GROUP BY, ogni insieme di righe specificato nella clausola GROUP BY costituisce un gruppo e vengono eseguite le funzioni aggregate per ogni gruppo separatamente.
Considera un esempio con la tabella delle lezioni: 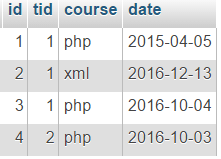
Esempio:
Importante: Pertanto, come risultato dell'utilizzo di GROUP BY, tutte le righe di output della query sono divise in gruppi caratterizzati dalle stesse combinazioni di valori in queste colonne (ovvero, le funzioni aggregate vengono eseguite separatamente per ciascun gruppo).
Va tenuto presente che quando raggruppati da un campo contenente valori NULL, tutti i record di questo tipo rientreranno in un gruppo.
Per diversi tipi di stampanti, definirle costo medio e la quantità (vale a dire, separatamente per laser, getto d'inchiostro e matrice). Utilizzare le funzioni aggregate. Il risultato dovrebbe essere simile a questo:

Avere un'istruzione SQL
La clausola HAVING in SQL è necessaria per convalidare i valori, che si ottengono utilizzando la funzione di aggregazione dopo il raggruppamento(dopo aver utilizzato GROUP BY). un tale controllo non può essere contenuto in una clausola WHERE.
Esempio: Negozio di computer DB... Calcola il prezzo medio dei computer con la stessa velocità del processore. Calcola solo per quei gruppi il cui prezzo medio è inferiore a 30.000.


- Funzioni aggregate sono usati come i nomi dei campi nell'istruzione SELECT, con un'eccezione: prendono il nome del campo come argomento. Con funzioni SOMMA e AVG può essere utilizzato solo campi numerici... Con funzioni CONTEGGIO, MAX e MIN possono essere utilizzati sia campi numerici che caratteri. Se utilizzato con i campi di caratteri MAX e MIN li tradurrà nell'equivalente ASCII e li elaborerà in ordine alfabetico... Alcuni DBMS consentono l'utilizzo di aggregati nidificati, ma questa è una deviazione dallo standard ANSI con tutte le conseguenze che ne conseguono.


Ad esempio, puoi calcolare il numero di studenti che hanno superato gli esami in ciascuna disciplina. Per fare ciò, è necessario eseguire una query raggruppata per il campo "Disciplina" e visualizzare come risultato il nome della disciplina e il numero di righe nel gruppo per questa disciplina. L'utilizzo del carattere * come argomento della funzione COUNT significa che vengono contate tutte le righe del gruppo.
SELEZIONA R1. Disciplina, CONTE (*)
GRUPPO PER R1 Disciplina;
Risultato:

SELEZIONA R1 Disciplina, CONTA (*)
DOVE R1. NON È NULL punteggio
GRUPPO PER R1 Disciplina;
Risultato:

non saranno incluse nell'insieme di tuple prima del raggruppamento, quindi il numero di tuple nel gruppo per la disciplina "Teoria dell'informazione" sarà 1 in meno.
Un risultato simile si può ottenere scrivendo la richiesta nel seguente modo:
SELEZIONA R1. Disciplina, COUNT (R1. Valutazione)
GRUPPO PER R1. Disciplina;
Funzione CONTEGGIO (NOME ATTRIBUTO) conta il numero di valori definiti in un gruppo, al contrario di una funzione CONTARE (*), che conta il numero di righe nel gruppo. Infatti, nel gruppo con la disciplina "Teoria dell'informazione" ci saranno 4 righe, ma solo 3 valori specifici dell'attributo "Valutazione".

Regole per la gestione dei valori null nelle funzioni aggregate
Se alcuni valori nella colonna sono uguali NULLO sono esclusi nel calcolo del risultato della funzione.
Se tutti i valori in una colonna sono uguali NULLO, poi Max Min Somma Avg = NULLO, conteggio = 0 (zero).
Se la tabella è vuota, conteggio (*) = 0 .
Le funzioni aggregate possono essere utilizzate anche senza l'operazione di raggruppamento preliminare, in questo caso l'intera relazione viene considerata come un gruppo e per questo gruppo è possibile calcolare un valore per gruppo.
Regole per interpretare le funzioni aggregate
Le funzioni aggregate possono essere incluse nell'elenco di output e quindi applicate all'intera tabella.
SELEZIONA MAX (Punteggio) da R1 darà il voto massimo alla sessione;
SELEZIONA SOMMA da R1 fornirà la somma di tutte le valutazioni per sessione;
SELEZIONA MEDIA (Punteggio) da R1 darà un punteggio medio per l'intera sessione.
 2; Risultato: "larghezza =" 640 "
2; Risultato: "larghezza =" 640 " Facendo nuovamente riferimento al database della Sessione (tabelle R1), troveremo il numero di esami superati con successo:
SELEZIONA CONTEGGIO (*) As affittato _ esami
DOVE Grado 2;
Risultato:

L'argomento delle funzioni aggregate può essere singole colonne di tabelle. Per calcolare, ad esempio, il numero di valori distinti di una determinata colonna in un gruppo, è necessario utilizzare la parola chiave DISTINCT insieme al nome della colonna. Calcoliamo il numero di voti diversi ricevuti per ogni disciplina:
SELECT R1 Disciplina, COUNT (DISTINCT R1 Evaluation)
DOVE R1. NON È NULL punteggio
GRUPPO PER R1 Disciplina;
Risultato:

Lo stesso risultato si ottiene escludendo la condizione esplicita nella parte WHERE, nel qual caso la query sarà simile a questa:
SELEZIONA R1. Disciplina, CONTE (DISTINTO R1. Valutazione)
GRUPPO PER R1. Disciplina;
Funzione CONTEGGIO (DISTINTO R1.Valutazione) considera solo certo vari i valori.
Affinché in questo caso si ottenga il risultato desiderato, è necessario effettuare una trasformazione preliminare del tipo di dati della colonna "Punteggio", portandolo in un tipo reale, quindi il risultato del calcolo della media non sarà un numero intero. In questo caso, la richiesta sarà simile a questa:
 2 Raggruppa per R2. Gruppo, R1. Disciplina; Qui, la funzione CAST() converte la colonna "Punteggio" in un tipo di dati valido. "larghezza =" 640 "
2 Raggruppa per R2. Gruppo, R1. Disciplina; Qui, la funzione CAST() converte la colonna "Punteggio" in un tipo di dati valido. "larghezza =" 640 " Seleziona R2.Group, R1.Discipline, Count (*) come Total, AVG (cast (punteggio come decimal (3,1))) come Average_point
Da R1, R2
dove R1. Nome completo = R2. Nome e R1. il punteggio non è nullo
e R1. Grado 2
Raggruppa per R2. Gruppo, R1. Disciplina;
Ecco la funzione LANCIO () converte la colonna Punteggio in un tipo di dati valido.

Non è possibile utilizzare funzioni aggregate nella clausola WHERE perché le condizioni in questa sezione vengono valutate in termini di una singola riga e le funzioni aggregate vengono valutate in termini di gruppi di righe.
La clausola GROUP BY consente di definire un sottoinsieme dei valori in un determinato campo in termini di un altro campo e applicare una funzione di aggregazione al sottoinsieme. Ciò rende possibile combinare campi e funzioni aggregate in un'unica clausola SELECT. Le funzioni aggregate possono essere utilizzate sia nell'espressione per l'output dei risultati della riga SELECT, sia nell'espressione per l'elaborazione dei gruppi HAVING generati. In questo caso, ogni funzione aggregata viene calcolata per ogni gruppo selezionato. I valori ottenuti durante il calcolo delle funzioni aggregate possono essere utilizzati per visualizzare i risultati corrispondenti o per la condizione di selezione dei gruppi.
Costruiamo una query che visualizzi i gruppi in cui è stato ottenuto più di un deuce in una disciplina negli esami:
 uno; Risultato: "larghezza =" 640 "
uno; Risultato: "larghezza =" 640 " SELEZIONA R2. Gruppo
DA R1, R2
DOVE R1. Nome completo = R2. Nome AND
Punteggio R1 = 2
RAGGRUPPARE PER R2.Gruppo, R1.Disciplina
AVERE conteggio (*) 1;
Risultato:

Abbiamo un DB "Banca", costituito da una tabella F, che memorizza la relazione F, contenente informazioni sui conti nelle filiali di una determinata banca:
Trova il saldo totale del conto nelle filiali. È possibile effettuare una query separata per ciascuno di essi selezionando SUM (Restante) dalla tabella per ogni ramo, ma l'operazione raggruppamento GRUPPO BY li metterà tutti in un comando:
SELEZIONARE Ramo , SOMMA ( Resto )
GRUPPO PER Filiale;
RAGGRUPPA PER applica le funzioni aggregate in modo indipendente per ogni gruppo identificato dal valore del campo Ramo. Il gruppo è composto da righe con lo stesso valore di campo Ramo e la funzione SOMMA si applica separatamente per ciascuno di questi gruppi, ovvero il saldo totale del conto viene calcolato separatamente per ciascuna filiale. Il valore del campo a cui si applica RAGGRUPPA PER, ha, per definizione, un solo valore per gruppo di output, così come il risultato di una funzione aggregata.
 5.000; Gli argomenti nella clausola HAVING seguono le stesse regole della clausola SELECT, che utilizza GROUP BY. Devono avere un valore per gruppo di output. "larghezza =" 640 "
5.000; Gli argomenti nella clausola HAVING seguono le stesse regole della clausola SELECT, che utilizza GROUP BY. Devono avere un valore per gruppo di output. "larghezza =" 640 " Supponiamo di selezionare solo quelle filiali, i cui valori totali dei saldi dei conti superano $ 5.000, nonché i saldi totali per le filiali selezionate. Per visualizzare le filiali con saldi totali superiori a $ 5.000, è necessario utilizzare la clausola HAVING. La clausola HAVING definisce i criteri utilizzati per rimuovere gruppi specifici dall'output, proprio come fa la clausola WHERE per le singole righe.
Il comando corretto sarebbe il seguente:
SELEZIONA Ramo, SOMMA (Saldo)
RAGGRUPPA PER Ramo
AVENDO SOMMA ( Resto ) 5 000;
Argomenti in una frase AVENDO obbedire alle stesse regole della frase SELEZIONARE dove si usa? RAGGRUPPA PER... Devono avere un valore per gruppo di output.

Il seguente comando sarà proibito:
SELEZIONA Ramo, SOMMA (Saldo)
GRUPPO PER Filiale
AVERE Data di apertura = 27/12/2004 ;
Campo Data di apertura non può essere usato in una frase AVENDO perché può avere più di un valore per gruppo di output. Per evitare una situazione del genere, la proposta AVENDO dovrebbe fare riferimento solo agli aggregati e ai campi selezionati RAGGRUPPA PER... C'è un modo corretto per fare la query di cui sopra:
SELEZIONA Ramo, SOMMA (Saldo)
DOVE Data di apertura = '27 / 12/2004 '
GRUPPO PER Filiale;

Il significato di questa query è il seguente: trovare l'importo dei saldi per ogni ramo di conti aperto il 27 dicembre 2004.
Come affermato in precedenza, HAVING può utilizzare solo argomenti che hanno lo stesso valore per gruppo di output. In pratica i riferimenti alle funzioni aggregate sono i più generici, ma sono validi anche i campi selezionati con GROUP BY. Ad esempio, vogliamo vedere i saldi totali dei conti delle filiali a San Pietroburgo, Pskov e Uryupinsk:
SELEZIONA Ramo, SOMMA (Saldo)
DA F, Q
DOVE F. Ramo = Q. Ramo
GRUPPO PER Filiale
HAVING Branch IN ("San Pietroburgo", "Pskov", "Uryupinsk");
100.000; Se il saldo totale è superiore a $ 100.000, lo vedremo nel rapporto risultante, altrimenti otterremo un rapporto vuoto. "larghezza =" 640 "
Pertanto, nelle espressioni aritmetiche dei predicati inclusi nella condizione di selezione della clausola HAVING, è possibile utilizzare direttamente solo le specifiche delle colonne specificate come colonne di raggruppamento nella clausola GROUP BY. Il resto delle colonne può essere specificato solo all'interno delle specifiche delle funzioni aggregate COUNT, SUM, AVG, MIN e MAX, che calcolano in in questo caso alcuni valore aggregato per l'intero gruppo di linee. Il risultato dell'esecuzione della clausola HAVING è una tabella raggruppata contenente solo quei gruppi di righe per i quali il risultato della valutazione della condizione di selezione nella parte HAVING è TRUE. In particolare, se la clausola HAVING è presente in una query che non contiene GROUP BY, il risultato della sua esecuzione sarà una tabella vuota o il risultato dell'esecuzione delle sezioni precedenti espressione tabellare considerato come un gruppo senza colonne di raggruppamento. Diamo un'occhiata a un esempio. Diciamo che vogliamo produrre importo totale saldi per tutte le filiali, ma solo se è superiore a $ 100.000. In questo caso, la nostra richiesta non conterrà operazioni di raggruppamento, ma conterrà una sezione HAVING e avrà il seguente aspetto:
SELEZIONA SOMMA ( Resto )
AVENDO SOMMA ( Resto ) 100 000;
Se il saldo totale è superiore a $ 100.000, lo vedremo nel rapporto risultante, altrimenti otterremo un rapporto vuoto.

Lo standard ISO definisce i seguenti cinque funzioni di aggregazione:
CONTARE- restituisce il numero di valori nella colonna specificata;
SOMMA- restituisce la somma dei valori nella colonna specificata;
AVG- restituisce il valore medio nella colonna specificata;
MIN- restituisce il valore minimo nella colonna specificata;
MAX- restituisce il valore massimo nella colonna specificata.
Tutte queste funzioni operano sui valori in una singola colonna della tabella e restituiscono un unico valore. Le funzioni COUNT, MIN e MAX si applicano sia a campi numerici che non numerici, mentre le funzioni SUM e AVG possono essere utilizzate solo nel caso di campi numerici. Ad eccezione di COUNT (*), quando si valutano i risultati di qualsiasi funzione, tutti i valori null vengono prima esclusi, dopodiché l'operazione richiesta viene applicata solo ai restanti valori di colonna non null. L'opzione COUNT (*) è occasione speciale utilizzando la funzione COUNT - il suo scopo è contare tutte le righe nella tabella, indipendentemente dal fatto che contenga valori vuoti, duplicati o altri. Se desideri eliminare i valori duplicati prima di utilizzare la funzione di aggregazione, inserisci la parola chiave DISTINCT davanti al nome della colonna nella definizione della funzione. Lo standard ISO consente l'uso della parola chiave ALL per indicare esplicitamente che non è richiesta l'eliminazione dei valori duplicati, sebbene questa parola chiave venga assunta per impostazione predefinita se non viene specificato altro qualificatore. La parola chiave DISTINCT non ha significato per le funzioni MIN e MAX. Tuttavia, il suo utilizzo può influenzare i risultati dell'esecuzione delle funzioni SUM e AVG, quindi dovresti considerare in anticipo se dovrebbe essere presente in ogni caso specifico. Inoltre, la parola chiave DISTINCT può essere specificata al massimo una volta in ogni richiesta.
Va notato che le funzioni aggregate possono essere utilizzate solo in un elenco SELECT e in una clausola HAVING (vedere la sezione 5.3.4). In tutti gli altri casi, l'uso di queste funzioni non è valido. Se l'elenco SELECT contiene una funzione di aggregazione e il testo della query non contiene una clausola GROUP BY che fornisce l'aggregazione dei dati in gruppi, nessuno degli elementi dell'elenco SELECT può includere riferimenti di colonna, a meno che questa colonna non venga utilizzata come parametro di la funzione di aggregazione. Ad esempio, la seguente richiesta non è valida:
SELEZIONAREpersonaleNo,CONTARE (stipendio)
A PARTIRE DALPersonale;
L'errore è che questa richiesta non contiene la costruzione RAGGRUPPA PER e l'accesso alla colonna staffNo nell'elenco SELECT viene eseguito senza utilizzare la funzione di aggregazione.
Esempio 13. Utilizzo della funzione COUNT (*).Determina quante proprietà in affitto hanno un canone di locazione superiore a £ 350 al mese,
SELEZIONA CONTEGGIO(*) AS conteggio
A PARTIRE DALProprietàIn Affitto
DOVEaffitto > 350;
La clausola WHERE è limitata al conteggio dei soli articoli a noleggio che superano £ 350 al mese. Il numero totale di proprietà in affitto che soddisfano la condizione specificata, può essere determinato utilizzando la funzione di aggregazione COUNT. I risultati dell'esecuzione della query sono presentati nella tabella. 23.
Tabella 23
| contare |
Esempio 14. Utilizzo della funzione CONTEGGIO (DISTINTA).Determina quante diverse proprietà in affitto sono state visualizzate dai clienti nel maggio 2001.
SELEZIONA CONTEGGIO (DISTINT)propertyNo) AS count
A PARTIRE DALVisualizzazione
Anche in questo caso, la limitazione dei risultati dell'interrogazione all'analisi dei soli contratti di locazione visualizzati nel maggio 2001 è ottenuta mediante l'uso di una clausola WHERE. Il numero totale di oggetti esaminati che soddisfano la condizione specificata può essere determinato utilizzando la funzione di aggregazione COUNT. Tuttavia, poiché lo stesso oggetto può essere visualizzato più volte da client diversi, è necessario specificare la parola chiave DISTINCT nella definizione della funzione per escludere i valori duplicati dal calcolo. I risultati dell'esecuzione della query sono presentati nella tabella. 24.
Tavolo 24
Esempio 16. Utilizzo delle funzioni MIN, MAXnAVG.Calcola il valore del salario minimo, massimo e medio.
SELEZIONA MIN(stipendio) COME minimo, MAX(stipendio) COME massimo, AVG(stipendio) COME medio
A PARTIRE DALPersonale;
In questo esempio, è necessario elaborare le informazioni su tutto il personale dell'azienda, quindi non è necessario utilizzare una clausola WHERE. I valori richiesti possono essere calcolati utilizzando le funzioni MIN, MAX e AVG applicate alla colonna stipendio della tabella Personale. I risultati dell'esecuzione della query sono presentati nella tabella. 26.
Tabella 26.
Il risultato della query
| min | max | medio |
| 9000.00 | 30000.00 | 17000.00 |
Risultati del raggruppamento (clausola GROUP BY). Gli esempi di dati di riepilogo sopra riportati sono simili alle righe di riepilogo che si trovano solitamente alla fine dei report. Nei totali, tutti i dati dettagliati del report sono compressi in un'unica riga di riepilogo. Tuttavia, molto spesso è necessario formare subtotali nei report. A tal fine, è possibile specificare una clausola GROUP BY nell'istruzione SELECT. Viene chiamata una query che contiene una clausola GROUP BY query di raggruppamento poiché raggruppa i dati ottenuti a seguito dell'operazione SELECT, dopodiché un singolo riga riassuntiva... Le colonne elencate nella clausola GROUP BY sono denominate colonne raggruppate. Lo standard ISO richiede che le clausole SELECT e GROUP BY siano strettamente correlate. Quando si utilizza la clausola GROUP BY in un'istruzione SELECT, ogni elemento dell'elenco nell'elenco SELECT deve avere l'unico significato per l'intero gruppo. Inoltre, una clausola SELECT può includere solo i seguenti tipi di elementi:
Nomi delle colonne;
funzioni di aggregazione;
Costanti;
Espressioni che includono combinazioni di quanto sopra.
Tutti i nomi di colonna elencati nell'elenco SELECT devono essere visualizzati anche nella clausola GROUP BY, a meno che il nome di colonna non venga utilizzato solo nella funzione di aggregazione. Non è sempre vero il contrario: la clausola GROUP BY può contenere nomi di colonne che non sono nell'elenco SELECT. Se la clausola WHERE viene utilizzata insieme alla clausola GROUP BY, viene elaborata per prima e vengono raggruppate solo le righe che soddisfano la condizione di ricerca. Lo standard ISO specifica che quando viene eseguito il raggruppamento, tutti i valori mancanti vengono trattati come uguali. Se due righe della tabella nella stessa colonna di raggruppamento contengono valori null e valori identici in tutte le altre colonne raggruppate non vuote, vengono inserite nello stesso gruppo.
Esempio 17. Utilizzo della clausola GROUP BY.Determinare il numero del personale che lavora in ciascuno dei dipartimenti dell'azienda, nonché i loro stipendi totali.
SELEZIONAREfilialeNo, CONTARE(personale n.) COME contare, SOMMA(stipendio) COME somma
A PARTIRE DALPersonale
RAGGRUPPA PERfilialeNo
ORDINATO DAramo n.;
Non è necessario includere i nomi delle colonne staffNo e stipendio nella clausola GROUP BY, poiché compaiono solo nell'elenco SELECT con funzioni aggregate. Allo stesso tempo, la colonna branchNo nell'elenco della clausola SELECT non è associata ad alcuna funzione di aggregazione e, per questo motivo, deve essere specificata nella clausola GROUP BY. I risultati dell'esecuzione della query sono presentati nella tabella. 27.
Tabella 27
Il risultato della query
| filialeNo | Contare | Somma |
| B003 | 54000.00 | |
| B005 | 39000.00 | |
| B007 | 9000.00 |
Concettualmente, durante l'elaborazione di questa richiesta, vengono eseguiti i seguenti passaggi.
1. Le righe della tabella Personale sono divise in gruppi in base ai valori nel numero di colonna del dipartimento dell'azienda. All'interno di ciascuno dei gruppi, ci sono dati su tutto il personale di uno dei dipartimenti dell'azienda. Nel nostro esempio, verranno creati tre gruppi, come mostrato in Fig. uno.
2. Per ciascuno dei gruppi viene calcolato il numero totale di righe, pari al numero di dipendenti del dipartimento, nonché la somma dei valori nella colonna stipendio, che è la somma dei salari di tutti dipendenti del reparto che ci interessa. Viene quindi generata una singola riga di riepilogo per l'intero gruppo di righe di origine.
3. Le righe risultanti della tabella risultante vengono ordinate in ordine crescente del numero del ramo indicato nella colonna branchNo.
| filialeNo | personaleNo | Stipendio |
| V00Z | SG37 | 12000.00 |
| V00Z | SG14 | 18000.00 |
| V00Z | SG5 | 24000.00 |
| B005 | SL21 | 30000.00 |
| B005 | SL41 | 9000.00 |
| B007 | SA9 | 9000.00 |
| CONTE (personale n.) | SOMMA (stipendio) |
| 54000.00 | |
| 39000.00 | |
| 9000.00 |
Riso. 1. Tre gruppi di record creati durante l'esecuzione di una query
Lo standard SQL consente di inserire sottoquery nell'elenco SELECT. Pertanto, la query di cui sopra può anche essere rappresentata come segue:
SELEZIONAREbranchNo, (SELEZIONARE COUNT (personaleNo)COME contare
A PARTIRE DALPersonale s
DOVEs.ramoNo = b.ramoNo),
(SELEZIONARE SOMMA (stipendio) COME somma
A PARTIRE DALPersonale s
DOVEs.ramoNo = b.ramoNo)
A PARTIRE DALramo b
ORDINATO DAramo n.;
Ma in questa versione della query, per ciascuno dei reparti aziendali descritti nella tabella Branch, vengono generati due risultati del calcolo delle funzioni di aggregazione, quindi, in alcuni casi, possono apparire righe contenenti valori zero.
Vincoli di raggruppamento (clausola HAVING). La clausola HAVING è destinata ad essere utilizzata insieme alla clausola GROUP BY per specificare i vincoli specificati per selezionarli gruppi, che verrà inserito nella tabella di query risultante. Sebbene le clausole HAVING e WHERE abbiano una sintassi simile, il loro scopo è diverso. La clausola WHERE è progettata per selezionare singole righe per riempire la tabella di query risultante, mentre la clausola HAVING viene utilizzata per selezionare gruppi, inserito nella tabella di query risultante. Lo standard ISO richiede che i nomi delle colonne utilizzati nella clausola HAVING appaiano nell'elenco degli elementi GROUP BY o che vengano utilizzati nelle funzioni aggregate. In pratica, i termini di ricerca in una clausola HAVING includono sempre almeno una funzione aggregata; in caso contrario, queste condizioni di ricerca devono essere inserite in una clausola WHERE e applicate per selezionare singole righe. (Ricorda che le funzioni aggregate non possono essere utilizzate in una clausola WHERE.) La clausola HAVING non è una parte necessaria del linguaggio SQL: qualsiasi query scritta utilizzando la clausola HAVING può essere rappresentata in modo diverso senza utilizzarla.
Esempio 18. Utilizzo della costruzione HAVING.Per ogni dipartimento dell'azienda con più di un personale, determinare il numero di dipendenti e l'importo dei loro stipendi.
SELEZIONAREfilialeNo, COUN T (personale n.) COME contare, SOMMA(stipendio) COME somma
A PARTIRE DALPersonale
RAGGRUPPA PERfilialeNo
AVERE IL CONTO(numero personale)> 1
ORDINATO DAramo n.;
Questo esempio è simile al precedente, ma qui vengono utilizzate ulteriori restrizioni, indicando che siamo interessati solo alle informazioni su quei reparti dell'azienda in cui lavora più di una persona. Un requisito simile è imposto ai gruppi, quindi la clausola HAVING dovrebbe essere utilizzata nella query. I risultati dell'esecuzione della query sono presentati nella tabella. 28.
Tabella 28
| ramoNessun conteggio somma |
| V00Z 3 54000.00 |
| B005 2 39000.00 |
Subquery. In questa sezione, discuteremo l'uso di istruzioni SELECT complete incorporate nel corpo di un altro Istruzione SELECT. Esterno la (seconda) istruzione SELECT usa il risultato dell'esecuzione interno(primo) operatore per determinare il contenuto del risultato finale dell'intera operazione. Le query interne possono essere trovate nelle clausole WHERE e HAVING dell'istruzione SELECT esterna - in questo caso, sono denominate sottoquery, o query nidificate. Inoltre, le istruzioni SELECT interne possono essere utilizzate nelle istruzioni INSERT, UPDATE e DELETE . Esistono tre tipi di sottoquery.
Sottoquery scalare restituisce il valore selezionato dall'intersezione di una colonna con una riga, ad es. l'unico significato. In linea di principio, una sottoquery scalare può essere utilizzata ovunque sia richiesto un singolo valore. Esempi di sottoquery scalari sono mostrati negli Esempi 13 e 14.
Sottoquery di stringhe restituisce i valori di più colonne in una tabella, ma come una singola riga. È possibile utilizzare una sottoquery di stringhe ovunque venga utilizzato un costruttore di valori di stringa, in genere predicati. Una variante della sottoquery di stringhe è mostrata nell'esempio 15.
Sottoquery della tabella restituisce i valori di una o più colonne di una tabella distribuiti su più di una riga. È possibile utilizzare una sottoquery di tabella ovunque sia possibile specificare una tabella, ad esempio come operando di un predicato IN.
Esempio 19. Utilizzo di una sottoquery con controllo di uguaglianza. Trucco un elenco del personale che lavora nella filiale dell'azienda situata a 463 Main St1.
SELEZIONARE
A PARTIRE DALPersonale
DOVEbranchNo = (SELECT branchNo
A PARTIRE DALRamo
DOVEstrada = "163 S t principale");
Un'istruzione SELECT interna (SELECT branchNo FROM Branch ...) viene utilizzata per determinare il numero di filiale dell'azienda situata in 163 Main St. (C'è solo un reparto di questo tipo in un'azienda, quindi questo esempio è un esempio di sottoquery scalare.) Una volta ottenuto il numero di reparto desiderato, viene eseguita una sottoquery esterna per recuperare i dettagli dei lavoratori in quel reparto. In altre parole, operatore interno SELECT restituisce una tabella con un unico valore "BOOV. Questo è il numero del ramo d'azienda situato in 163 Main St1. Di conseguenza, l'istruzione SELECT esterna diventa la seguente:
SELEZIONAREstaffNo, fNome, INome, posizione
A PARTIRE DALPersonale
DOVEbranchN = "B0031;
I risultati di questa query sono presentati nella tabella. 29.
Tabella 29
Il risultato della query
| personaleNo | fNome | Nomino | posizione |
| SG37 | Anna | Faggio | Assistente |
| SG14 | David | Guado | Supervisore |
| SG5 | Susan | Marca | Gestore |
Una sottoquery è uno strumento per creare una tabella temporanea, il cui contenuto viene recuperato ed elaborato da un operatore esterno. Una sottoquery può essere specificata subito dopo gli operatori di confronto (cioè operatori =,<, >, <=, >=, <>) in una clausola WHERE o HAVING. Il testo della sottoquery deve essere racchiuso tra parentesi.
Esempio 20. Utilizzo di sottoquery con funzioni di aggregazione. Elencare tutti i dipendenti con stipendi superiori alla media, indicando quanto il loro stipendio è superiore allo stipendio medio dell'impresa.
SELEZIONAREstaffNo, fName, IName, posizione, stipendio - ( SELEZIONA MEDIA(stipendio) A PARTIRE DAL Personale) COME salDiff
A PARTIRE DALPersonale
DOVEstipendio> ( SELEZIONA MEDIA(stipendio) A PARTIRE DAL Personale);
Va notato che non si può direttamente incluso in espressione di query"WHERE stipendio> AVG (stipendio)", poiché l'uso dell'aggregazione le funzioni nella clausola WHERE sono vietate. Per ottenere il risultato desiderato, creare una sottoquery che calcoli lo stipendio medio annuo e quindi utilizzarla in un'istruzione SELECT esterna per recuperare informazioni sui dipendenti dell'azienda i cui stipendi sono superiori a questa media. In altre parole, la sottoquery restituisce il valore stipendio medio per l'azienda all'anno, pari a £ 17.000.
Il risultato di questa sottoquery scalare viene utilizzato in un'istruzione SELECT esterna sia per calcolare la varianza dei salari dalla media sia per selezionare le informazioni sui dipendenti. Pertanto, l'istruzione SELECT esterna diventa:
SELEZIONAREstaffNo, fName, IName, posizione, stipendio - 17000 Come salDiff
A PARTIRE DALPersonale
DOVEstipendio > 17000;
I risultati dell'esecuzione della query sono presentati nella tabella. trenta.
Tabella 30.
Il risultato della query
| personaleNo | fNome | Nomino | posizione | salDiff |
| SL21 | John | bianco | Gestore | 13000.00 |
| SG14 | David | Guado | Supervisore | 1000.00 |
| SG5 | Susan | Marca | Gestore | 7000.00 |
Applica alle sottoquery seguenti regole e restrizioni.
1. La clausola ORDER BY non deve essere utilizzata nelle sottoquery, sebbene possa apparire nell'istruzione SELECT esterna.
2. L'elenco SELECT di una sottoquery deve essere costituito dai nomi delle singole colonne o da espressioni composte da esse, a meno che nella sottoquery non venga utilizzata la parola chiave EXISTS.
3. Per impostazione predefinita, i nomi delle colonne in una sottoquery si riferiscono alla tabella indicata nella clausola FROM della sottoquery. Tuttavia, puoi anche fare riferimento alle colonne della tabella specificata nella clausola FROM della query esterna utilizzando nomi di colonna qualificati (come descritto di seguito).
4. Se la sottoquery è uno dei due operandi coinvolti nell'operazione di confronto, allora la sottoquery deve essere specificata sul lato destro di questa operazione. Ad esempio, l'esempio seguente di scrittura di una query dall'esempio precedente non è corretto perché la sottoquery viene posizionata sul lato sinistro dell'operazione di confronto con il valore della colonna stipendio.
SELEZIONARE
A PARTIRE DALPersonale
DOVE(SELEZIONARE AVG (stipendio) DA Personale)< salary;
Esempio 21... Subquery nidificate e utilizzo del predicato IN. Fai un elenco delle proprietà in affitto di cui sono responsabili i dipendenti nella filiale situata in 163 Main st1.
SELEZIONAREproprietàNo, via, città, codice postale, tipo, stanze, affitto
A PARTIRE DALProprietàIn Affitto
Capitolo 5... Il linguaggio SQL: manipolazione dei dati 189
DOVEstaffNo IN (SELECT staffNo
A PARTIRE DALPersonale
DOVEbranchNo = (SELECT branchNo
A PARTIRE DALRamo
DOVEstrada = "163 S t principale"));
La prima query, la più interna, ha lo scopo di determinare il numero della filiale dell'azienda situata in 463 Main St ". La seconda query intermedia recupera informazioni sul personale che lavora in questo dipartimento. In questo caso, più di una riga di dati è selezionato e quindi nella query esterna non è possibile utilizzare l'operatore di confronto =. È necessario utilizzare invece la parola chiave IN. La query esterna recupera informazioni sui contratti di locazione di cui sono responsabili i dipendenti dell'azienda, i cui dati sono stati ottenuti come risultato della query intermedia. I risultati della query sono mostrati nella tabella. 31.
Tabella 31
Il risultato della query
| proprietàNo | strada | città | codice postale | genere | camere | affitto |
| PG16 | 5 Novar Dr | Glasgow | G129AX | Piatto | ||
| PG36 | 2 Manor Rd | Glasgow | G324QX | Piatto | ||
| PG21 | 18 Dale Rd | Glasgow | G12 | Casa |
Parole chiave QUALSIASI e TUTTO. Le parole chiave ANY e ALL possono essere utilizzate con sottoquery che restituiscono una singola colonna di numeri. Se la sottoquery è preceduta dalla parola chiave ALL, la condizione di confronto è soddisfatta solo se è soddisfatta per tutti i valori nella colonna dei risultati della sottoquery. Se il testo della sottoquery è preceduto dalla parola chiave ANY, la condizione di confronto sarà considerata soddisfatta se è soddisfatta per almeno uno (uno o più) valori nella colonna risultante della sottoquery. Se la sottoquery restituisce un valore nullo, la condizione di confronto per la parola chiave ALL sarà considerata soddisfatta e per la parola chiave ANY sarà considerata non soddisfatta. Secondo lo standard ISO, puoi anche utilizzare la parola chiave SOME, che è sinonimo della parola chiave ANY.
Esempio 22. Usando le parole chiave QUALSIASI e ALCUNI. Trova tutti i dipendenti il cui stipendio supera almeno lo stipendio uno un dipendente di una filiale dell'azienda con il numero "booz".
SELEZIONAREstaffNo, fNome, INome, posizione, stipendio
A PARTIRE DALPersonale
DOVEstipendio> ALCUNI (SELEZIONARE stipendio
A PARTIRE DALPersonale
DOVEbranchNo = "B003");
Sebbene questa query possa essere scritta utilizzando una sottoquery che determina il salario minimo del personale del dipartimento con il numero "BOOZ", dopo di che la sottoquery esterna può selezionare informazioni su tutto il personale dell'azienda i cui stipendi superano questo valore (vedi Esempio 20) , è possibile un altro approccio, che consiste nell'utilizzare le parole chiave SOME / ANY. In questo caso, la sottoquery interna crea un insieme di valori (12000, 18000, 24000) e la query esterna seleziona le informazioni su quei dipendenti il cui stipendio è maggiore di uno qualsiasi dei valori in questo
impostato (in realtà più del valore minimo - 12000). Questo metodo alternativo può essere considerato più naturale rispetto alla definizione del salario minimo nella sottoquery. Ma in entrambi i casi, vengono generati gli stessi risultati della query, presentati nella tabella. 32 .
Tabella 32
Il risultato della query
| personaleNo | fNome | Nomino | posizione | stipendio |
| SL21 | John | bianco | Gestore | 30000.00 |
| SG14 | David | Guado | Supervisore | 18000.00 |
| SG5 | Susan | Marca | Gestore | 24000.00 |
Esempio 23. Usando la parola chiave ALL. Trova tutti i dipendenti il cui salario è maggiore del salario di qualsiasi dipendente nel ramo alcolico dell'azienda.
SELEZIONAREstaffNo, fName, INarae, posizione, stipendio
A PARTIRE DALPersonale
DOVEstipendio> TUTTO(SELEZIONA stipendio
A PARTIRE DALPersonale
DOVEbranchNo = "BOG3");
In generale, questa richiesta è simile alla precedente. E in questo caso, si potrebbe utilizzare una sottoquery che determina il valore massimo dello stipendio del personale del dipartimento sotto il numero "WOOZ", quindi, utilizzando una query esterna, selezionare le informazioni su tutti i dipendenti dell'azienda i cui stipendi superano questo valore. Tuttavia, in questo esempioè stato scelto un approccio che utilizza la parola chiave ALL. I risultati dell'esecuzione della query sono presentati nella tabella. 33 .
Tabella 33
Il risultato della query
| personaleNo | Nomino | fNome | posizione | stipendio |
| SL21 | bianco | John | Gestore | 30000,00 |
Query multi-tabella. Tutti gli esempi precedenti hanno la stessa importante limitazione: le colonne poste nella tabella risultante sono sempre selezionate da un'unica tabella. Tuttavia, in molti casi questo non è sufficiente. Per combinare colonne di diverse tabelle di origine nella tabella risultante, è necessario eseguire l'operazione connessioni. In SQL, un'operazione di join viene utilizzata per combinare le informazioni da due tabelle formando coppie di righe collegate selezionate da ciascuna tabella. Le coppie di righe inserite nella tabella combinata vengono compilate in base all'uguaglianza dei valori delle colonne specificate incluse in esse.
Se è necessario ottenere informazioni da più tabelle, è possibile applicare una sottoquery o eseguire un'unione tra tabelle. Se la tabella di query risultante deve contenere colonne di tabelle di origine diverse, è consigliabile utilizzare il meccanismo di unione delle tabelle. Per eseguire un join è sufficiente specificare i nomi di due o più tabelle nella clausola FROM, separandoli con virgole, e quindi includere nella query la clausola WHERE che definisce le colonne utilizzate per unire le tabelle specificate. Inoltre, al posto dei nomi delle tabelle, puoi usare alias, assegnato loro nella clausola FROM. In questo caso i nomi delle tabelle e gli alias ad esse assegnati devono essere separati da spazi. Gli alias possono essere utilizzati per qualificare i nomi delle colonne ogni volta che potrebbero esserci ambiguità sulla tabella a cui appartiene una particolare colonna. Inoltre, gli alias possono essere utilizzati per abbreviare i nomi delle tabelle. Se un alias è definito per una tabella, può essere utilizzato ovunque che richieda il nome di quella tabella.
Esempio 24. Collegamento semplice. Elenca i nomi di tutti i clienti che hanno visualizzato almeno una proprietà in affitto e hanno fornito un feedback su di essa.
SELEZIONAREc.clientNo, fNome, INome, proprietàNo, commento
A PARTIRE DALCliente c, Visualizzazione v
DOVEc.clientNo = v.clientNo;
Questo report richiede informazioni sia dalla tabella Client che dalla tabella Viewing, quindi utilizzeremo il meccanismo di join della tabella durante la creazione della query. La clausola SELECT elenca tutte le colonne da inserire nella tabella di query risultante. Si noti che la colonna del numero del cliente (clientNo) necessita di un perfezionamento, poiché tale colonna potrebbe essere presente in un'altra tabella che partecipa al join. Pertanto, è necessario indicare esplicitamente a quali valori di tabella siamo interessati. (In questo esempio, potresti anche aver selezionato i valori per la colonna clientNo dalla tabella di visualizzazione). Il nome viene specificato anteponendo al nome della colonna il nome della tabella corrispondente (o il suo alias). Nel nostro esempio viene utilizzato il valore "c", specificato come alias per la tabella Client. Per formare le righe risultanti, vengono utilizzate quelle righe delle tabelle di origine che hanno un valore identico nella colonna clientNo. Questa condizione è determinata impostando la condizione di ricerca con.clientNo = v.clientNo. Vengono chiamate colonne simili nelle tabelle originali colonne compatibili. L'operazione descritta equivale all'operazione l'uguaglianza si unisce algebra relazionale. I risultati dell'esecuzione della query sono presentati nella tabella. 34.
Tabella 34
Il risultato della query
| clienteNo | fNome | Nomino | proprietàNo | commento |
| CR56 | Aline | Stewart | PG36 | |
| CR56 | Aline | Stewart | PA14 | troppo piccolo |
| CR56 | Aline | Stewart | PG4 | |
| CR62 | Maria | Tregear | PA14 | niente sala da pranzo |
| CR76 | John | Kay | PG4 | troppo remoto |
Molto spesso, le query multitabella vengono eseguite su due tabelle collegate da una relazione uno a molti (1: *) o padre-figlio. Nell'esempio sopra, che prevede l'accesso alle tabelle Client e Viewing, queste ultime sono collegate proprio da tale relazione. Ogni riga della tabella Visualizzazione (figlio) è collegata a una sola riga nella tabella Cliente (genitore), mentre è possibile collegare la stessa riga nella tabella Cliente (genitore).
con molte righe della tabella di visualizzazione (figlio). Le coppie di righe generate durante l'esecuzione della query sono il risultato di tutte le combinazioni valide di righe nelle tabelle figlio e padre. La sezione 3.2.5 ha dettagliato come in base relazionale data, le chiavi primaria ed esterna delle tabelle creano una relazione "genitore-figlio". La tabella che contiene la chiave esterna è solitamente una figlia, mentre la tabella che contiene la chiave primaria sarà sempre la madre. Per utilizzare una relazione padre-figlio in una query SQL, è necessario specificare una condizione di ricerca in cui verranno confrontate le chiavi esterne e primarie. L'Esempio 24 confronta la chiave primaria della tabella Client (con. ClientNo) con la chiave esterna della tabella Viewing (v. ClientNo).
Lo standard SQL fornisce inoltre seguenti modi definizioni di un dato composto:
A PARTIRE DALCliente con GIUNTURA Visualizzazione v IN POI c.clientNo = v.clientNo
A PARTIRE DALcliente J OIN Visualizzazione UTILIZZANDO clienteNo
A PARTIRE DALCliente UNIONE NATURALE Visualizzazione
In ogni caso, la clausola FROM sostituisce le clausole FROM e WHERE originali. Tuttavia, la prima opzione crea una tabella con due colonne clientNo identiche, mentre negli altri due casi la tabella risultante conterrà solo una colonna clientNo.
Esempio 25. Ordinamento dei risultati dell'unione delle tabelle. Per ogni filiale dell'azienda, elencare i numeri del personale e i nominativi dei dipendenti che si occupano di eventuali strutture in locazione, nonché indicare le strutture per
cui rispondono.
SELEZIONAREs.ramoNo, s.staffNo, fNome, INome, proprietàNo
A PARTIRE DALPersonale, PropertyForRent p
DOVEs.staffNo = p.staffNo
ORDINATO DAs.ramoNo, s.personaleNo, proprietàNo;
Per facilitare la lettura dei risultati, l'output viene ordinato utilizzando il numero del reparto come chiave di ordinamento principale e il numero del personale e il numero della proprietà come chiavi secondarie. I risultati dell'esecuzione della query sono presentati nella tabella. 35.
Tavolo 35
Il risultato della query
| filialeNo | StaffNo | fNome | Nomino | proprietàNo |
| CHI | SG14 | David | Guado | PG16 |
| CHI | SG37 | Anna | Faggio | PG21 |
| CHI | SG37 | Anna | Faggio | PG36 |
| BOO5 | SL41 | Maria | Lee | PL94 |
| SBI7 | SA9 | Julie | Come? | PA14 |
Esempio 26. Un join di tre tabelle. Per ogni filiale dell'azienda, elencare i numeri del personale ei nominativi dei dipendenti responsabili delle eventuali strutture in locazione, indicando la città in cui si trova la filiale e il numero delle strutture di cui ciascun dipendente è responsabile.
SELEZIONARE b.branchNo, b.city, s.staffNo, fName, IName, propertyNo
A PARTIRE DAL Ramo b, Personale, PropertyForRent p
DOVE b.branchNo = s.branchNo AND s.staffNo = p.staffNo
ORDINATO DA b.n.ramo, s.n.personale, n.proprietà;
Le colonne delle tre tabelle di origine - Branch, Staff e PropertyForRent - devono essere inserite nella tabella risultante, quindi dovresti unire queste tabelle nella tua query. Le tabelle Branch e Staff possono essere collegate utilizzando la clausola b.branchNo = * s .branchNo, che collegherà le filiali dell'azienda al personale che vi opera. Le tabelle Staff e PropertyForRent possono essere collegate utilizzando la condizione s.staffNo = p.staffNo. Di conseguenza, ogni dipendente sarà associato agli immobili in affitto di cui è responsabile. I risultati dell'esecuzione della query sono presentati nella tabella. 36.
Tabella 36
Risultati della query
| filialeNo | città | staffMo | fNome | Nomino | proprietàNo |
| B003 | Glasgow | SG14 | David | Guado | PG16 |
| B003 | Glasgow | SG37 | Anna | Faggio | PG21 |
| B003 | Glasgow | SG37 | Anna | Faggio | PG36 |
| B005 | Londra | SL41 | Julie | Lee | PL94 |
| B007 | Aberdeen | SA9 | Maria | Come? | PA14 |
Nota che lo standard SQL ti consente di usare Opzione alternativa formulazioni delle clausole FROM e WHERE:
A PARTIRE DAL(Ramo b UNISCITI al personale UTILIZZANDO il numero di filiale) COME bs
GIUNTURAPropertyForRent p UTILIZZANDO personaleNo
Esempio 27. Raggruppamento per più colonne. Determinare il numero di proprietà in affitto di cui è responsabile ciascun dipendente.
SELEZIONAREs.ramoNo, S.personaleNo, CONTARE(*) COME contare
DA Staff s, PropertyForRent p
WHERE S.staffNo = p.staffNo
RAGGRUPPA PERs.branchNo, s.staffNo
ORDINATO DAs.ramoNo, s.personaleNo;
Per redigere il rapporto richiesto, prima di tutto, è necessario scoprire quale dei dipendenti dell'azienda è responsabile degli oggetti locati. Questo compito può essere risolto unendo le tabelle Staff e PropertyForRent dalla colonna staffNo nelle clausole FROM / WHERE. Quindi è necessario formare dei gruppi composti dal numero di reparto e dal numero di personale dei suoi dipendenti, per i quali deve essere applicata la clausola GROUP BY. Infine, la tabella risultante deve essere ordinata specificando una clausola ORDER BY. I risultati dell'esecuzione della query sono presentati nella tabella. 37.
Tabella 37
Il risultato della query
| filialeNo | personaleNo | contare |
| V00Z | SG14 | |
| V00Z | SG37 | |
| B005 | SL41 | |
| B007 | SA9 |
Fare collegamenti. Un join è un sottoinsieme di una combinazione più generale di dati da due tabelle, chiamata cartesiano... Il prodotto cartesiano di due tabelle è un'altra tabella, costituita da tutte le possibili coppie di righe che compongono entrambe le tabelle. L'insieme di colonne nella tabella risultante è costituito da tutte le colonne della prima tabella seguite da tutte le colonne della seconda tabella. Se si immette una query su due tabelle senza specificare una clausola WHERE, il risultato dell'esecuzione della query in ambiente SQL sarà il prodotto cartesiano di queste tabelle. Inoltre, lo standard ISO prevede formato speciale Istruzione SELECT che calcola il prodotto cartesiano di due tabelle:
SELECT (* j elenco colonne]
FROM nometabella CROSS JOINCaNeulte2
Consideriamo ancora un esempio in cui le tabelle client e Viewing sono unite utilizzando la colonna comune clientNo. Quando si lavora con tabelle, il cui contenuto è riportato in Table. 3.6 e 3.8, il prodotto cartesiano di queste tabelle sarà di 20 righe (4 righe nella tabella Cliente x 5 righe nella tabella di visualizzazione = 20 righe). Ciò equivale a inviare la query usata nell'Esempio 5.24, ma senza applicare la clausola WHERE. La procedura per generare una tabella contenente i risultati dell'unione di due tabelle utilizzando l'istruzione SELECT è la seguente.
1. Viene formato un prodotto cartesiano delle tabelle specificate nella clausola FROM.
2. Se la query contiene una clausola WHERE, applicare le condizioni di ricerca a ciascuna riga della tabella dei prodotti cartesiani e memorizzare solo le righe della tabella che soddisfano le condizioni specificate. In termini di algebra relazionale, questa operazione è chiamata limitazione Prodotto cartesiano.
3. Per ogni riga rimanente, viene determinato il valore di ciascun elemento specificato nell'elenco SELECT, a seguito del quale viene formata una riga separata della tabella risultante.
4. Se la clausola SELECT DISTINCT è presente nella query originale, tutte le righe duplicate vengono rimosse dalla tabella risultante.
5. Se la query in esecuzione contiene una clausola ORDER BY,
© 2015-2019 sito
Tutti i diritti appartengono ai loro autori. Questo sito non rivendica la paternità, ma fornisce l'uso gratuito.
Data di creazione della pagina: 2016-08-07
Le seguenti sottosezioni descrivono altre clausole SELECT che possono essere utilizzate nelle query, nonché funzioni aggregate e set di istruzioni. Lascia che te lo ricordi questo momento abbiamo trattato l'uso della clausola WHERE e in questo articolo esamineremo le clausole GROUP BY, ORDER BY e HAVING e forniremo alcuni esempi di come queste clausole possono essere utilizzate insieme alle funzioni aggregate supportate in Transact -SQL.
Clausola GROUP BY
Frase RAGGRUPPA PER raggruppa il set di righe selezionato per ottenere un insieme di righe di riepilogo in base ai valori di una o più colonne o espressioni. Un semplice caso d'uso per la clausola GROUP BY è mostrato nell'esempio seguente:
USA SampleDb; SELEZIONA Lavoro DA Lavori_On GRUPPO PER Lavoro;
In questo esempio, le posizioni dei dipendenti vengono campionate e raggruppate.
Nell'esempio sopra, la clausola GROUP BY crea un gruppo separato per tutti. valori possibili(incluso NULL) della colonna Lavoro.
L'utilizzo di colonne nella clausola GROUP BY deve soddisfare determinate condizioni. In particolare, ogni colonna dell'elenco di selezione della query deve comparire anche nella clausola GROUP BY. Questo requisito non si applica alle costanti e alle colonne che fanno parte di una funzione aggregata. (Le funzioni aggregate sono discusse nella prossima sottosezione.) Questo ha senso perché solo le colonne nella clausola GROUP BY hanno un valore garantito per gruppo.
Una tabella può essere raggruppata in base a qualsiasi combinazione delle sue colonne. L'esempio seguente mostra il raggruppamento di righe nella tabella Works_on da due colonne:
USA SampleDb; SELEZIONA NumeroProgetto, Lavoro FROM Lavori_On GROUP BY NumeroProgetto, Lavoro;
Il risultato di questa query:

In base ai risultati della query, puoi vedere che ci sono nove gruppi con diverse combinazioni di numero di progetto e titolo. La sequenza dei nomi delle colonne nella clausola GROUP BY non deve essere la stessa dell'elenco delle colonne SELECT.
Funzioni aggregate
Le funzioni aggregate vengono utilizzate per ottenere valori di somma. Tutte le funzioni aggregate possono essere suddivise nelle seguenti categorie:
funzioni aggregate ordinarie;
funzioni di aggregazione statistica;
funzioni aggregate definite dall'utente;
funzioni di aggregazione analitica.
Qui esamineremo i primi tre tipi di funzioni aggregate.
Funzioni aggregate regolari
Transact-SQL supporta le sei funzioni aggregate seguenti: MIN, MAX, SOMMA, AVG, CONTARE, COUNT_BIG.
Tutte le funzioni aggregate eseguono calcoli su un singolo argomento, che può essere una colonna o un'espressione. (L'unica eccezione è la seconda forma di due funzioni, COUNT e COUNT_BIG, rispettivamente COUNT (*) e COUNT_BIG (*).) Qualsiasi funzione aggregata restituisce un valore costante che viene visualizzato in una colonna separata del risultato.
Le funzioni aggregate sono specificate nell'elenco di colonne di un'istruzione SELECT, che può anche contenere una clausola GROUP BY. Se l'istruzione SELECT non include una clausola GROUP BY e l'elenco delle colonne di selezione contiene almeno una funzione di aggregazione, non deve contenere colonne semplici (diverse dalle colonne utilizzate come argomenti per la funzione di aggregazione). Pertanto, il codice nell'esempio seguente non è corretto:
USA SampleDb; SELECT Cognome, MIN (Id) FROM Impiegato;
Qui, la colonna Cognome della tabella Impiegato non dovrebbe essere nell'elenco di colonne di selezione perché non è un argomento per la funzione di aggregazione. D'altra parte, l'elenco di colonne di selezione può contenere nomi di colonna che non sono argomenti per la funzione di aggregazione se tali colonne vengono utilizzate come argomenti per la clausola GROUP BY.
L'argomento di una funzione aggregata può essere preceduto da una delle due possibili parole chiave:
TUTTOIndica che i calcoli vengono eseguiti su tutti i valori nella colonna. Questa è l'impostazione predefinita.
DISTINTOSpecifica che per i calcoli vengono utilizzati solo valori di colonna univoci.
Funzioni aggregate MIN e MAX
Le funzioni aggregate MIN e MAX calcolano rispettivamente i valori più piccolo e più grande in una colonna. Se la query contiene una clausola WHERE, le funzioni MIN e MAX restituiscono i valori di riga più piccoli e più grandi che corrispondono alle condizioni specificate. L'esempio seguente mostra l'uso della funzione di aggregazione MIN:
USA SampleDb; - Restituisce 2581 SELECT MIN (Id) AS "Valore Id minimo" FROM Impiegato;
Il risultato restituito nell'esempio sopra non è molto informativo. Ad esempio, il cognome del dipendente che possiede questo numero è sconosciuto. Ma non puoi ottenere questo cognome nel solito modo, perché, come accennato in precedenza, non puoi specificare esplicitamente la colonna LastName. Per ottenere il cognome di questo dipendente insieme al numero di personale più basso del dipendente, viene utilizzata una sottoquery. L'esempio seguente mostra l'uso di tale sottoquery, dove la sottoquery contiene l'istruzione SELECT dell'esempio precedente:
Il risultato dell'esecuzione della query:

L'uso della funzione di aggregazione MAX è mostrato nell'esempio seguente:
Le funzioni MIN e MAX possono anche accettare stringhe e date come argomenti. Nel caso di un argomento stringa, i valori vengono confrontati utilizzando l'ordinamento effettivo. Per tutti gli argomenti di dati temporanei di tipo data, il valore della colonna più piccolo sarà il più appuntamento anticipato, e il più recente è il più grande.
La parola chiave DISTINCT può essere utilizzata con le funzioni MIN e MAX. Tutti i valori NULL vengono rimossi dalle colonne degli argomenti prima di utilizzare le funzioni aggregate MIN e MAX.
Funzione di aggregazione SOMMA
Aggregato Funzione SOMMA calcola la somma totale dei valori della colonna. L'argomento di questa funzione di aggregazione deve essere sempre di tipo numerico. L'uso della funzione di aggregazione SUM è mostrato nell'esempio seguente:
USA SampleDb; SELEZIONA SOMMA (Budget) "Budget totale" DA Progetto;
Questo esempio calcola i budget totali per tutti i progetti. Il risultato dell'esecuzione della query:

In questo esempio, la funzione di aggregazione raggruppa tutti i valori del budget del progetto e ne determina il totale. Per questo motivo, la query contiene una funzione di raggruppamento implicita (come tutte le query simili). La funzione di raggruppamento implicita dell'esempio precedente può essere specificata in modo esplicito, come mostrato nell'esempio seguente:
USA SampleDb; SELEZIONA SOMMA (Budget) "Budget totale" FROM Progetto GRUPPO PER ();
L'utilizzo del parametro DISTINCT rimuove eventuali valori duplicati nella colonna prima di applicare la funzione SUM. Allo stesso modo, rimuovere tutti i valori NULL prima di applicare questa funzione di aggregazione.
Funzione di aggregazione AVG
Aggregato Funzione AVG restituisce la media aritmetica di tutti i valori in una colonna. L'argomento di questa funzione di aggregazione deve essere sempre di tipo numerico. Prima di usare Funzioni AVG tutti i valori NULL vengono rimossi dal suo argomento.
L'utilizzo della funzione di aggregazione AVG è mostrato nell'esempio seguente:
USA SampleDb; - Restituisce 133833 SELECT AVG (Budget) "Budget medio per un progetto" FROM Project;
Qui è dove viene calcolata la media valore aritmetico budget per tutti i budget.
Funzioni aggregate COUNT e COUNT_BIG
Aggregato Funzione COUNT ha due diverse forme:
COUNT (col_name) COUNT (*)
La prima forma della funzione conta il numero di valori nella colonna col_name. Se la query utilizza la parola chiave DISTINCT, tutti i valori di colonna duplicati vengono rimossi prima che venga utilizzata la funzione COUNT. Questa forma della funzione COUNT non tiene conto dei valori NULL durante il conteggio del numero di valori di colonna.
L'uso della prima forma della funzione di aggregazione COUNT è mostrato nell'esempio seguente:
USA SampleDb; SELECT ProjectNumber, COUNT (DISTINCT Job) "Lavori in Project" FROM Works_on GROUP BY ProjectNumber;
Qui è dove viene conteggiato il numero di posizioni diverse per ogni progetto. Il risultato di questa query:

Come puoi vedere dalla query nell'esempio, i valori NULL non sono stati presi in considerazione dalla funzione COUNT. (La somma di tutti i valori nella colonna del lavoro è 7, non 11 come dovrebbe essere.)
La seconda forma della funzione COUNT, ad es. la funzione COUNT (*) conta il numero di righe in una tabella. E se l'istruzione SELECT della query con la funzione COUNT (*) contiene una clausola WHERE con una condizione, la funzione restituisce il numero di righe che soddisfano la condizione specificata. A differenza della prima versione della funzione COUNT, la seconda forma non ignora i valori NULL perché questa funzione opera su stringhe, non colonne. L'esempio seguente mostra l'uso della funzione COUNT (*):
USA SampleDb; SELECT Job AS "Tipo di lavoro", COUNT (*) "Lavoratori necessari" FROM Works_on GROUP BY Job;
Qui è dove viene conteggiato il numero di post in tutti i progetti. Il risultato dell'esecuzione della query:

COUNT_BIG funzione stessa funzione di COUNT. L'unica differenza tra i due è nel tipo di risultato che restituiscono: COUNT_BIG restituisce sempre valori BIGINT, mentre COUNT restituisce valori di dati INTEGER.
Funzioni statistiche aggregate
Le seguenti funzioni costituiscono il gruppo delle funzioni aggregate statistiche:
VARCalcola la varianza statistica di tutti i valori in una colonna o espressione.
VARPCalcola la varianza statistica della popolazione di tutti i valori in una colonna o espressione.
STDEVCalcola la deviazione standard (che viene calcolata come Radice quadrata dalla varianza corrispondente) di tutti i valori della colonna o dell'espressione.
STDEVPCalcola la deviazione standard della raccolta di tutti i valori in una colonna o espressione.
Funzioni aggregate definite dall'utente
Il Motore di database supporta anche l'implementazione di funzioni definite dall'utente. Questa capacità consente agli utenti di integrare le funzioni aggregate del sistema con funzioni che possono implementare e installare autonomamente. Queste funzioni rappresentano una classe speciale di funzioni definite dall'utente e vengono discusse in dettaglio in seguito.
clausola HAVING
In una frase AVENDO definisce una condizione che viene applicata a un gruppo di righe. Pertanto, questa clausola ha lo stesso significato per i gruppi di righe della clausola WHERE per il contenuto della tabella corrispondente. La sintassi per la clausola HAVING è la seguente:
AVERE condizione
Qui il parametro condition rappresenta una condizione e contiene funzioni aggregate o costanti.
L'uso della clausola HAVING in combinazione con la funzione di aggregazione COUNT (*) è mostrato nell'esempio seguente:
USA SampleDb; - Restituisce "p3" SELECT ProjectNumber FROM Works_on GROUP BY ProjectNumber HAVING COUNT (*)
In questo esempio, il sistema utilizza la clausola GROUP BY per raggruppare tutte le righe in base ai valori nella colonna ProjectNumber. Viene quindi contato il numero di righe in ciascun gruppo e vengono selezionati i gruppi contenenti meno di quattro righe (tre o meno).
La clausola HAVING può essere utilizzata anche senza funzioni aggregate, come mostrato nell'esempio seguente:
USA SampleDb; - Restituirà "Consulente" SELECT Job FROM Works_on GROUP BY Job HAVING Job LIKE "К%";
Questo esempio raggruppa le righe della tabella Works_on per titolo di lavoro ed elimina i lavori che non iniziano con la lettera "K".
La clausola HAVING può essere utilizzata anche senza la clausola GROUP BY, sebbene questa non sia una pratica comune. In questo caso, tutte le righe della tabella vengono restituite nello stesso gruppo.
Clausola ORDER BY
Frase ORDINATO DA determina l'ordinamento delle righe nel set di risultati restituito dalla query. Questa clausola ha la seguente sintassi:
L'ordinamento è specificato nel parametro col_name. Col_number è un indicatore di ordinamento alternativo che identifica le colonne nell'ordine in cui vengono visualizzate nell'elenco di selezione dell'istruzione SELECT (1 è la prima colonna, 2 è la seconda colonna e così via). Parametro ASC definisce un ordine crescente, e Parametro DESC- a valle. L'impostazione predefinita è ASC.
I nomi delle colonne nella clausola ORDER BY non devono necessariamente essere nell'elenco delle colonne selezionate. Ma questo non si applica a query come SELECT DISTINCT, poiché in tali interrogazioni, i nomi delle colonne specificati nella clausola ORDER BY devono comparire anche nell'elenco delle colonne selezionate. Inoltre, questa clausola non può contenere nomi di colonne di tabelle non specificate nella clausola FROM.
Come puoi vedere dalla sintassi della clausola ORDER BY, l'ordinamento del set di risultati può essere eseguito su più colonne. Questo ordinamento è mostrato nell'esempio seguente:
Questo esempio seleziona i numeri di reparto, i cognomi e i nomi dei dipendenti per i dipendenti il cui numero di personale è inferiore a 20.000, nonché ordinati per cognome e nome. Il risultato di questa query:

Le colonne nella clausola ORDER BY possono essere specificate non con i loro nomi, ma in ordine nell'elenco di selezione. Di conseguenza, la frase nell'esempio precedente può essere riscritta come segue:
Tale modo alternativo la specificazione delle colonne in base alla loro posizione anziché ai nomi viene utilizzata se il criterio di ordinamento contiene una funzione aggregata. (Un altro modo consiste nell'utilizzare i nomi delle colonne, che vengono quindi visualizzati nella clausola ORDER BY.) Tuttavia, nella clausola ORDER BY, si consiglia di specificare le colonne in base ai loro nomi anziché ai numeri, per semplificare l'aggiornamento della query se è necessario aggiungere o rimuovere colonne nell'elenco di selezione. La specifica delle colonne nella clausola ORDER BY in base ai loro numeri è mostrata nell'esempio seguente:
USA SampleDb; SELECT ProjectNumber, COUNT (*) "Numero di dipendenti" FROM Works_on GRUPPO PER ProjectNumber ORDER BY 2 DESC;
Qui, per ogni progetto, vengono selezionati il numero del progetto e il numero di dipendenti che vi partecipano, ordinando il risultato in ordine decrescente per il numero di dipendenti.
Transact-SQL inserisce i valori NULL all'inizio dell'elenco se ordinati in ordine crescente e i valori NULL alla fine dell'elenco se ordinati in ordine decrescente.
Utilizzo della clausola ORDER BY per impaginare i risultati
La visualizzazione dei risultati della query nella pagina corrente può essere implementata in applicazione personalizzata o istruire il server del database a farlo. Nel primo caso, tutte le righe del database vengono inviate all'applicazione, il cui compito è selezionare le righe richieste e visualizzarle. Nel secondo caso, lato server, solo le righe necessarie per pagina corrente... Come ci si potrebbe aspettare, la creazione di pagine lato server di solito fornisce prestazioni migliori da al cliente vengono inviate solo le righe necessarie per la visualizzazione.
Per supportare la creazione di pagine lato server in server SQL Il 2012 introduce due nuove clausole SELECT: OFFSET e FETCH. L'applicazione di queste due frasi è dimostrata nell'esempio seguente. Qui, dal database AdventureWorks2012 (che puoi trovare nella fonte), estrae l'ID aziendale, il titolo di lavoro e la data di nascita di tutte le dipendenti di sesso femminile, ordinati per titolo di lavoro in ordine crescente. Il set di righe risultante viene suddiviso in pagine di 10 righe e viene visualizzata una terza pagina:
In una frase COMPENSARE specifica il numero di righe di risultato da saltare nel risultato visualizzato. Questo importo viene calcolato dopo che le righe sono state ordinate con la clausola ORDER BY. In una frase PRENDI SUCCESSIVO specifica il numero di WHERE e di righe ordinate da restituire. Il parametro di questa clausola può essere una costante, un'espressione o il risultato di un'altra query. La clausola FETCH NEXT è simile alla clausola PRENDI PRIMA.
L'obiettivo principale durante la creazione di pagine sul lato server è essere in grado di implementare moduli di pagina comuni utilizzando le variabili. Questa attività può essere eseguita tramite il pacchetto SQL Server.
Dichiarazione SELECT e proprietà IDENTITY
IDENTITÀ proprietà consente di determinare i valori per una colonna specifica della tabella sotto forma di contatore incrementale automatico. Le colonne di un tipo di dati numerici come TINYINT, SMALLINT, INT e BIGINT possono avere questa proprietà. Per tale colonna della tabella, Motore di database genera automaticamente valori sequenziali a partire dal valore iniziale specificato. Pertanto, la proprietà IDENTITY può essere utilizzata per creare univoca valori numerici per la colonna selezionata.
Una tabella può contenere solo una colonna con la proprietà IDENTITY. Il proprietario della tabella ha la possibilità di specificare il valore iniziale e l'incremento, come mostrato nell'esempio seguente:
USA SampleDb; CREATE TABLE Prodotto (Id INT IDENTITY (10000, 1) NOT NULL, Name NVARCHAR (30) NOT NULL, Price MONEY) INSERT INTO Product (Name, Price) VALUES ("Prodotto1", 10), ("Prodotto2", 15) , ("Prodotto3", 8), ("Prodotto4", 15), ("Prodotto5", 40); - Restituirà 10004 SELECT IDENTITYCOL FROM Product WHERE Name = "Product5"; - Analogo all'istruzione precedente SELECT $ identity FROM Product WHERE Name = "Product5";
Questo esempio crea prima una tabella Product che contiene una colonna Id con una proprietà IDENTITY. I valori nella colonna Id vengono creati automaticamente dal sistema, partendo da 10.000 e aumentando di un passo per ogni valore successivo: 10.000, 10.001, 10.002, ecc.
Diverse funzioni e variabili di sistema sono associate alla proprietà IDENTITY. Ad esempio, il codice di esempio usa variabile di sistema $ identità... Come puoi vedere dai risultati dell'esecuzione di questo codice, questa variabile fa automaticamente riferimento alla proprietà IDENTITY. Puoi anche usare invece funzione di sistema IDENTITÀ'.
Il valore iniziale e l'incremento della colonna con la proprietà IDENTITY possono essere trovati usando le funzioni IDENT_SEED e IDENT_INCR rispettivamente. Queste funzioni vengono applicate come segue:
USA SampleDb; SELECT IDENT_SEED ("Prodotto"), IDENT_INCR ("Prodotto")
Come accennato, i valori di IDENTITÀ vengono impostati automaticamente dal sistema. Ma l'utente può specificare esplicitamente i propri valori per determinate stringhe assegnando al parametro IDENTITY_INSERT il valore ON prima di inserire il valore esplicito:
IMPOSTA IDENTITÀ INSERISCI nome tabella ON
Poiché il parametro IDENTITY_INSERT può essere utilizzato per impostare qualsiasi valore, inclusi i valori duplicati, su una colonna con la proprietà IDENTITY, la proprietà IDENTITY in genere non impone l'unicità dei valori della colonna. Pertanto, i vincoli UNIQUE o PRIMARY KEY devono essere applicati per imporre l'unicità dei valori di colonna.
Quando si inseriscono valori in una tabella dopo aver attivato IDENTITY_INSERT, il sistema crea il valore successivo nella colonna IDENTITY, incrementando il valore corrente più alto in quella colonna.
Dichiarazione CREATE SEQUENCE
L'utilizzo della proprietà IDENTITY presenta diversi inconvenienti significativi, i più significativi dei quali sono:
la proprietà è limitata alla tabella specificata;
il nuovo valore della colonna non può essere ottenuto in altro modo se non applicandolo;
la proprietà IDENTITY può essere specificata solo durante la creazione di una colonna.
Per questi motivi, SQL Server 2012 introduce sequenze che hanno la stessa semantica della proprietà IDENTITY, ma senza gli svantaggi elencati in precedenza. In questo contesto, una sequenza si riferisce alla funzionalità di un database che consente di specificare i valori del contatore per diversi oggetti del database, come colonne e variabili.
Le sequenze vengono create utilizzando l'istruzione CREA SEQUENZA... L'istruzione CREATE SEQUENCE è definita in Standard SQL ed è supportato da altri sistemi di database relazionali come IBM DB2 e Oracle.
L'esempio seguente mostra come creare una sequenza in SQL Server:
USA SampleDb; CREATE SEQUENCE dbo.Sequence1 AS INT INIZIA CON 1 INCREMENTO DI 5 MINVALUE 1 MAXVALUE 256 CYCLE;
Nell'esempio sopra, i valori di Sequenza1 sono generati automaticamente dal sistema, partendo da un valore di 1 e con incrementi di 5 per ogni valore successivo. Così, in la clausola START viene indicato il valore iniziale, e in INCREMENTO offerta- fare un passo. (Il passo può essere positivo o negativo.)
Nelle prossime due frasi opzionali VALORE MINIMO e VALOREMAX specifica il valore minimo e massimo dell'oggetto sequenza. (Nota che MINVALUE deve essere minore o uguale a valore iniziale e il valore MAXVALUE non può essere maggiore del limite superiore del tipo di dati specificato per la sequenza.) Nella clausola CICLO indica che la sequenza viene ripetuta dall'inizio quando viene superato il valore massimo (o minimo per una sequenza con passo negativo). Per impostazione predefinita, questa clausola è impostata su NO CYCLE, il che significa che il superamento del valore di sequenza massimo o minimo genera un'eccezione.
La caratteristica principale delle sequenze è la loro indipendenza dalle tabelle, ad es. possono essere utilizzati con qualsiasi oggetto di database come colonne di tabella o variabili. (Questa proprietà ha un effetto positivo sull'archiviazione e, quindi, sulle prestazioni. Non è necessario archiviare una sequenza specifica, viene archiviato solo il suo ultimo valore.)
I nuovi valori di sequenza vengono creati con PROSSIMO VALORE PER le espressioni, la cui applicazione è mostrata nell'esempio seguente:
USA SampleDb; - Restituisce 1 SELECT NEXT VALUE FOR dbo.sequence1; - Restituisce 6 (passo successivo) SELECT NEXT VALUE FOR dbo.sequence1;
È possibile utilizzare l'espressione NEXT VALUE FOR per assegnare il risultato di una sequenza a una variabile oa una cella di colonna. L'esempio seguente illustra l'uso di questa espressione per assegnare risultati a una colonna:
USA SampleDb; CREATE TABLE Prodotto (Id INT NOT NULL, Nome NVARCHAR (30) NOT NULL, Price MONEY) INSERT INTO Product VALUES (NEXT VALUE FOR dbo.sequence1, "Product1", 10); INSERT INTO Product VALUES (NEXT VALUE FOR dbo.sequence1, "Product2", 15); - ...
L'esempio sopra crea prima una tabella chiamata Product con quattro colonne. Successivamente, due istruzioni INSERT inseriscono due righe in questa tabella. Le prime due celle della prima colonna saranno 11 e 16.
L'esempio seguente mostra l'uso della vista del catalogo sys.sequences per visualizzare il valore corrente di una sequenza senza utilizzarlo:
In genere, l'espressione NEXT VALUE FOR viene utilizzata in un'istruzione INSERT per indicare al sistema di inserire i valori generati. Questa espressione può essere utilizzata anche come parte di una query su più righe utilizzando la clausola OVER.
Per modificare una proprietà di una sequenza esistente, applica Dichiarazione ALTER SEQUENCE... Uno degli usi più importanti di questa istruzione è con l'opzione RESTART WITH, che reimposta la sequenza specificata. L'esempio seguente mostra l'uso dell'istruzione ALTER SEQUENCE per reimpostare quasi tutte le proprietà di Sequence1:
USA SampleDb; ALTER SEQUENCE dbo.sequence1 RIAVVIA CON 100 INCREMENTA DI 50 VALORE MIN 50 VALORE MAX 200 NESSUN CICLO;
La sequenza viene cancellata usando l'istruzione SEQUENZA DI CADUTA.
Imposta operatori
Oltre agli operatori discussi in precedenza, Transact-SQL supporta altri tre operatori di insiemi: UNION, INTERSECT ed EXCEPT.
operatore UNION
operatore UNION combina i risultati di due o più query in un unico set di risultati che include tutte le righe appartenenti a tutte le query nell'unione. Di conseguenza, il risultato dell'unione delle due tabelle è una nuova tabella contenente tutte le righe in una o entrambe le tabelle originali.
La forma generale dell'operatore UNION si presenta così:
select_1 UNION select_2 (select_3]) ...
Le opzioni select_1, select_2, ... sono istruzioni SELECT che creano il join. Se viene utilizzato il parametro ALL, vengono visualizzate tutte le righe, inclusi i duplicati. Nell'istruzione UNION, il parametro ALL ha lo stesso significato di SELECT, ma con una differenza: questo è il valore predefinito per SELECT, ma deve essere specificato esplicitamente per UNION.
Nella sua forma originale, SampleDb non è adatto per dimostrare l'uso dell'operatore UNION. Pertanto in questa sezione viene creata una nuova tabella EmployeeEnh che è identica tabella esistente Dipendente ma ha una colonna Città aggiuntiva. In questa colonna è indicato il luogo di residenza dei dipendenti.
La creazione della tabella EmployeeEnh ci offre l'opportunità di dimostrare l'uso della clausola. IN nell'istruzione SELECT. L'istruzione SELECT INTO esegue due operazioni. Innanzitutto, viene creata una nuova tabella con le colonne elencate nell'elenco SELECT. Quindi le righe della tabella originale vengono inserite nella nuova tabella. Il nome della nuova tabella è specificato nella clausola INTO e il nome della tabella di origine è specificato nella clausola FROM.
L'esempio seguente mostra la creazione della tabella EmployeeEnh dalla tabella Employee:
USA SampleDb; SELEZIONA * IN ImpiegatoEnh FROM Impiegato; ALTER TABLE ImpiegatoEnh ADD Città NCHAR (40) NULL;
In questo esempio, l'istruzione SELECT INTO crea la tabella EmployeeEnh, inserisce in essa tutte le righe della tabella di origine Employee e quindi l'istruzione ALTER TABLE aggiunge la colonna City alla nuova tabella. Ma la colonna Città aggiunta non contiene alcun valore. I valori possono essere inseriti in questa colonna da Ambiente di gestione Studio o con il seguente codice:
USA SampleDb; UPDATE EmployeeEnh SET City = "Kazan" WHERE Id = 2581; UPDATE EmployeeEnh SET City = "Mosca" WHERE Id = 9031; UPDATE EmployeeEnh SET City = "Ekaterinburg" WHERE Id = 10102; UPDATE EmployeeEnh SET City = "San Pietroburgo" WHERE Id = 18316; UPDATE EmployeeEnh SET City = "Krasnodar" WHERE Id = 25348; UPDATE EmployeeEnh SET City = "Kazan" WHERE Id = 28559; UPDATE EmployeeEnh SET City = "Perm" WHERE Id = 29346;
Siamo ora pronti a dimostrare l'uso della dichiarazione UNION. L'esempio seguente mostra una query per creare un join tra le tabelle EmployeeEnh e Department utilizzando questa istruzione:
USA SampleDb; SELECT City AS "Città" FROM ImpiegatoEnh UNION SELECT Location FROM Dipartimento;
Il risultato di questa query:
È possibile unire solo tabelle compatibili utilizzando l'istruzione UNION. Per tabelle compatibili intendiamo che entrambi gli elenchi di colonne nella selezione devono contenere lo stesso numero di colonne e le colonne corrispondenti devono avere tipi di dati compatibili. (In termini di compatibilità, i tipi di dati INT e SMALLINT non sono compatibili.)
Il risultato della concatenazione può essere ordinato solo utilizzando la clausola ORDER BY nell'ultima istruzione SELECT, come mostrato nell'esempio seguente. Le clausole GROUP BY e HAVING possono essere utilizzate con singole istruzioni SELECT, ma non all'interno del join stesso.
La query in questo esempio seleziona i dipendenti che lavorano nel reparto d1 o che hanno iniziato a lavorare a un progetto prima del 1 gennaio 2008.
L'operatore UNION supporta l'opzione ALL. Questa opzione non rimuove i duplicati dal set di risultati. Un operatore OR può essere utilizzato al posto dell'operatore UNION se tutte le istruzioni SELECT unite da uno o più operatori UNION fanno riferimento alla stessa tabella. In questo caso, l'insieme di istruzioni SELECT viene sostituito da una singola istruzione SELECT con un insieme di istruzioni OR.
Operatori INTERSECT e EXCEPT
Altri due operatori per lavorare con gli insiemi, INTERSEZIONE e TRANNE, definiscono rispettivamente l'intersezione e la differenza. Sotto l'intersezione, in questo contesto, c'è un insieme di righe che appartengono a entrambe le tabelle. E la differenza tra due tabelle è definita come tutti i valori che appartengono alla prima tabella e non sono presenti nella seconda. L'esempio seguente mostra l'uso dell'operatore INTERSECT:
Transact-SQL non supporta l'utilizzo del parametro ALL con gli operatori INTERSECT o EXCEPT. L'uso dell'operatore EXCEPT è mostrato nell'esempio seguente:
Si ricorda che questi tre operatori di insieme hanno precedenza di esecuzione diversa: l'operatore INTERSECT ha la precedenza più alta, seguito da TRANNE dichiarazione e l'operatore UNION ha la precedenza più bassa. Disattenzione alla priorità di esecuzione quando si utilizzano più diversi operatori lavorare con i set può produrre risultati imprevisti.
Espressioni CASE
Nel campo della programmazione di applicazioni di database, a volte è necessario modificare la presentazione dei dati. Ad esempio, le persone possono essere suddivise per classe sociale, utilizzando i valori 1, 2 e 3, che denotano rispettivamente uomini, donne e bambini. Questa tecnica di programmazione può ridurre il tempo necessario per implementare il programma. Espressione CASE Transact-SQL consente di implementare facilmente questo tipo di codifica.
A differenza della maggior parte dei linguaggi di programmazione, CASE non è un'istruzione, ma un'espressione. Pertanto, un'espressione CASE può essere utilizzata quasi ovunque Transact-SQL consente l'utilizzo di espressioni. L'espressione CASE ha due forme:
semplice espressione CASE;
espressione di ricerca CASO.
La sintassi per una semplice espressione CASE è la seguente:
Un'istruzione con una semplice espressione CASE cerca prima l'elenco di tutte le espressioni in clausola QUANDO la prima espressione che corrisponde a expression_1 e quindi esegue la corrispondente THEN clausola... Se non ci sono espressioni corrispondenti nell'elenco WHEN, allora clausola ELSE.
La sintassi per un'espressione di ricerca CASE è la seguente:
In questo caso, cerca la prima condizione di qualificazione, quindi esegue la clausola THEN corrispondente. Se nessuna delle condizioni soddisfa i requisiti, viene eseguita la clausola ELSE. L'uso dell'espressione di ricerca CASE è mostrato nell'esempio seguente:
USA SampleDb; SELEZIONA NomeProgetto, CASO QUANDO Budget> 0 AND Budget 100000 AND Budget 150000 AND Budget
Il risultato di questa query:

Questo esempio pesa i budget di tutti i progetti e visualizza i pesi calcolati insieme ai nomi dei progetti corrispondenti.
L'esempio seguente mostra un altro modo per utilizzare un'espressione CASE in cui la clausola WHEN contiene sottoquery che fanno parte dell'espressione:
USA SampleDb; SELECT ProjectName, CASE WHEN p1.Budget (SELECT AVG (p2.Budget) FROM Project p2) THEN "sopra la media" END "Categoria budget" FROM Project p1;
Il risultato di questa query è il seguente:



