GROUP BY ponuda(Izjava SELECT) omogućuje grupiranje podataka (redova) prema vrijednosti stupca ili više stupaca ili izraza. Rezultat će biti skup sažetih redaka.
Svaki stupac na popisu za odabir mora biti prisutan u klauzuli GROUP BY, osim za konstante i stupce koji su operandi agregatnih funkcija.
Tablica se može grupirati bilo kojom kombinacijom svojih stupaca.
Agregatne funkcije koriste se za dobivanje jedne zbirne vrijednosti iz grupe redaka. Sve agregatne funkcije izvode izračune na jednom argumentu, koji može biti ili stupac ili izraz. Rezultat bilo koje agregatne funkcije je konstantna vrijednost prikazana u zasebnom stupcu rezultata.
Agregatne funkcije navedene su u popisu stupaca izraza SELECT, koji također može sadržavati klauzulu GROUP BY. Ako u izrazu SELECT nema klauzule GROUP BY, a popis stupaca za odabir sadrži barem jednu agregatnu funkciju, tada ne smije sadržavati jednostavne stupce. S druge strane, popis za odabir stupaca može sadržavati nazive stupaca koji nisu argumenti agregatnoj funkciji ako su ti stupci argumenti klauzule GROUP BY.
Ako upit sadrži klauzulu WHERE, agregatne funkcije izračunavaju vrijednost za rezultate odabira.
Funkcije agregata MIN i MAX izračunajte najmanju i najveću vrijednost stupca, respektivno. Argumenti mogu biti brojevi, nizovi i datumi. Sve NULL vrijednosti uklanjaju se prije izračuna (tj. ne uzimaju se u obzir).
Agregatna funkcija SUM izračunava ukupan zbroj vrijednosti stupca. Argumenti mogu biti samo brojevi. Korištenje opcije DISTINCT eliminira sve duplicirane vrijednosti u stupcu prije primjene funkcije SUM. Slično, sve NULL vrijednosti se uklanjaju prije primjene ove agregatne funkcije.
AVG agregatna funkcija vraća prosjek svih vrijednosti u stupcu. Argumenti također mogu biti samo brojevi, a sve NULL vrijednosti se uklanjaju prije evaluacije.
Zbirna funkcija COUNT ima dva različita oblika:
- COUNT( col_name) - broji broj vrijednosti u stupcu col_name, NULL vrijednosti se zanemaruju
- COUNT(*) - broji broj redaka u tablici, NULL vrijednosti se također uzimaju u obzir
Ako se u upitu koristi ključna riječ DISTINCT, sve duplicirane vrijednosti stupaca se uklanjaju prije nego što se primijeni funkcija COUNT.
COUNT_BIG funkcija slično funkciji COUNT. Jedina razlika između njih je vrsta rezultata koji vraćaju: funkcija COUNT_BIG uvijek vraća BIGINT vrijednosti, dok funkcija COUNT vraća INTEGER vrijednosti podataka.
V IMATI ponudu definira uvjet koji se primjenjuje na grupu redaka. Ima isto značenje za grupe redaka kao klauzula WHERE za sadržaj odgovarajuće tablice (WHERE se primjenjuje prije grupiranja, HAVING nakon).
Sljedeći pododjeljci opisuju druge ponude SELECT izjava, koji se može koristiti u upitima, kao i agregatne funkcije i skupovi operatora. Dopustite mi da vas podsjetim sadašnji trenutak pogledali smo upotrebu klauzule WHERE, au ovom ćemo članku pogledati klauzule GROUP BY, ORDER BY i HAVING i dati neke primjere korištenja ovih klauzula u sprezi sa agregatnim funkcijama koje su podržane u Transact-u. SQL.
GROUP BY ponuda
Rečenica GRUPA PO grupira odabrani skup redaka kako bi se proizveo skup sažetih redaka na temelju vrijednosti jednog ili više stupaca ili izraza. Jednostavna upotreba klauzule GROUP BY prikazana je u primjeru ispod:
KORISTITE SampleDb; SELECT Job FROM Works_On GROUP BY Job;
U ovom primjeru, pozicije zaposlenika su odabrane i grupirane.
U gornjem primjeru, klauzula GROUP BY stvara zasebnu grupu za sve moguće vrijednosti (uključujući NULL) stupca Zadatak.
Korištenje stupaca u klauzuli GROUP BY mora ispunjavati određene uvjete. Konkretno, svaki stupac na popisu odabira upita također se mora pojaviti u klauzuli GROUP BY. Ovaj se zahtjev ne odnosi na konstante i stupce koji su dio agregatne funkcije. (O agregatnim funkcijama raspravlja se u sljedećem pododjeljku.) Ovo ima smisla jer samo stupci u klauzuli GROUP BY imaju zajamčenu jednu vrijednost po grupi.
Tablica se može grupirati bilo kojom kombinacijom svojih stupaca. Primjer u nastavku pokazuje grupiranje redaka tablice Works_on u dva stupca:
KORISTITE SampleDb; SELECT ProjectNumber, Job FROM Works_On GRUPA PO Broj projekta, posao;
Rezultat ovog upita je:

Na temelju rezultata upita možete vidjeti da postoji devet grupa s različitim kombinacijama broja projekta i pozicije. Slijed naziva stupaca u klauzuli GROUP BY ne mora biti isti kao na popisu stupaca SELECT.
Agregatne funkcije
Agregatne funkcije se koriste za dobivanje ukupnih vrijednosti. Sve agregatne funkcije mogu se podijeliti u sljedeće kategorije:
obične agregatne funkcije;
statističke agregatne funkcije;
agregatne funkcije definirane od strane korisnika;
analitičke agregatne funkcije.
Ovdje ćemo pogledati prve tri vrste agregatnih funkcija.
Obične agregatne funkcije
Transact-SQL jezik podržava sljedećih šest agregatnih funkcija: MIN, MAX, IZNOS, PROSJEČAN, RAČUNATI, COUNT_BIG.
Sve agregatne funkcije izvode izračune na jednom argumentu, koji može biti ili stupac ili izraz. (Jedina iznimka je drugi oblik dviju funkcija COUNT i COUNT_BIG, odnosno COUNT(*) i COUNT_BIG(*).) Rezultat bilo koje agregatne funkcije je konstantna vrijednost prikazana u zasebnom stupcu rezultata.
Agregatne funkcije navedene su u popisu stupaca izraza SELECT, koji također može sadržavati klauzulu GROUP BY. Ako u izrazu SELECT nema klauzule GROUP BY, a popis stupaca za odabir sadrži barem jednu agregatnu funkciju, tada ne smije sadržavati jednostavne stupce (osim stupaca koji služe kao argumenti agregatnoj funkciji). Stoga je kod u primjeru u nastavku netočan:
KORISTITE SampleDb; SELECT Prezime, MIN(Id) FROM Employee;
Ovdje stupac Prezime u tablici Employee ne bi trebao biti na popisu za odabir stupca jer nije argument agregatne funkcije. S druge strane, popis za odabir stupaca može sadržavati nazive stupaca koji nisu argumenti agregatnoj funkciji ako su ti stupci argumenti klauzule GROUP BY.
Argumentu agregatne funkcije može prethoditi jedna od dvije moguće ključne riječi:
SVIOdređuje da se izračuni izvode za sve vrijednosti u stupcu. Ovo je zadana vrijednost.
RAZLIČITOdređuje da se za izračune koriste samo jedinstvene vrijednosti stupaca.
Funkcije agregata MIN i MAX
Agregatne funkcije MIN i MAX izračunavaju najmanju i najveću vrijednost stupca, respektivno. Ako upit sadrži klauzulu WHERE, funkcije MIN i MAX vraćaju najmanju i najveću vrijednost redaka koji zadovoljavaju navedene kriterije. Primjer u nastavku prikazuje upotrebu agregatne funkcije MIN:
KORISTITE SampleDb; -- Vraća 2581 SELECT MIN(Id) AS "Min Id" FROM Employee;
Rezultat vraćen u gornjem primjeru nije baš informativan. Na primjer, ime zaposlenika koji posjeduje ovaj broj nije poznato. Međutim, nije moguće dobiti ovo prezime na uobičajen način, jer, kao što je ranije spomenuto, eksplicitno navođenje stupca Prezime nije dopušteno. Kako bi se dobilo prezime ovog zaposlenika uz najmanji broj osoblja zaposlenika koristi se podupit. Sljedeći primjer pokazuje upotrebu takvog potupita, gdje potupit sadrži naredbu SELECT iz prethodnog primjera:
Rezultat izvršenja upita:

Korištenje agregatne funkcije MAX prikazano je u primjeru u nastavku:
Funkcije MIN i MAX također mogu uzeti nizove i datume kao argumente. U slučaju argumenta niza, vrijednosti se uspoređuju koristeći stvarni redoslijed sortiranja. Za argumente svih vremenskih podataka tipa datum, najmanja vrijednost stupca bit će najraniji datum, a najveća vrijednost stupca bit će najnoviji datum.
Možete koristiti ključnu riječ DISTINCT s funkcijama MIN i MAX. Prije nego što se koriste agregatne funkcije MIN i MAX, sve NULL vrijednosti su isključene iz njihovih stupaca argumenta.
Agregatna funkcija SUM
Agregat Funkcija SUM izračunava ukupan zbroj vrijednosti stupca. Argument ove agregatne funkcije uvijek mora biti numeričkog tipa podataka. Upotreba agregatne funkcije SUM prikazana je u primjeru u nastavku:
KORISTITE SampleDb; SELECT SUM (Budget) "Sažetak proračuna" IZ projekta;
Ovaj primjer izračunava ukupan zbroj proračuna svih projekata. Rezultat izvršenja upita:

U ovom primjeru, agregatna funkcija grupira sve vrijednosti proračuna projekta i određuje njihov ukupni iznos. Iz tog razloga, upit sadrži implicitnu funkciju grupiranja (kao i svi slični upiti). Implicitna funkcija grupiranja iz gornjeg primjera može se eksplicitno specificirati, kao što je prikazano u primjeru u nastavku:
KORISTITE SampleDb; SELECT SUM (Proračun) "Ukupni proračun" IZ Project GROUP BY();
Korištenje opcije DISTINCT eliminira sve duplicirane vrijednosti u stupcu prije primjene funkcije SUM. Slično, sve NULL vrijednosti se uklanjaju prije primjene ove agregatne funkcije.
AVG agregatna funkcija
Agregat AVG funkcija vraća aritmetičku sredinu svih vrijednosti u stupcu. Argument ove agregatne funkcije uvijek mora biti numeričkog tipa podataka. Prije upotrebe funkcije AVG, sve NULL vrijednosti se uklanjaju iz njezinog argumenta.
Upotreba AVG agregatne funkcije prikazana je u primjeru u nastavku:
KORISTITE SampleDb; -- Vraća 133833 SELECT AVG (proračun) "Prosječni proračun po projektu" IZ projekta;
Ovdje se izračunava aritmetička sredina proračuna za sve proračune.
Agregatne funkcije COUNT i COUNT_BIG
Agregat COUNT funkcija ima dva različita oblika:
COUNT(naziv_stupca) COUNT(*)
Prvi oblik funkcije broji broj vrijednosti u stupcu col_name. Ako se u upitu koristi ključna riječ DISTINCT, sve duplicirane vrijednosti stupaca se uklanjaju prije nego što se primijeni funkcija COUNT. Ovaj oblik funkcije COUNT ne uzima u obzir NULL vrijednosti kada se broji broj vrijednosti u stupcu.
Upotreba prvog oblika agregatne funkcije COUNT prikazana je u primjeru u nastavku:
KORISTITE SampleDb; SELECT ProjectNumber, COUNT(DISTINCT Job) "Radi u projektu" FROM Works_on GROUP BY ProjectNumber;
Ovdje se broji broj različitih pozicija za svaki projekt. Rezultat ovog upita je:

Kao što možete vidjeti iz primjera upita, NULL vrijednosti nisu uzete u obzir od strane funkcije COUNT. (Zbroj svih vrijednosti u stupcu posla pokazao se 7, a ne 11, kako bi trebao biti.)
Drugi oblik funkcije COUNT, t.j. funkcija COUNT(*) broji broj redaka u tablici. Što ako uputa SELECT upit s funkcijom COUNT(*) sadrži klauzulu WHERE s uvjetom, funkcija vraća broj redaka koji zadovoljava navedeno stanje. Za razliku od prvog oblika funkcije COUNT, drugi oblik ne zanemaruje NULL vrijednosti jer ova funkcija djeluje na retke, a ne na stupce. Primjer u nastavku pokazuje upotrebu funkcije COUNT(*):
KORISTITE SampleDb; SELECT Job AS "Vrsta posla", COUNT(*) "Potrebni radnici" FROM Works_on GRUPA PO POSAO;
Ovdje se broji broj pozicija u svim projektima. Rezultat izvršenja upita:

COUNT_BIG funkcija slično funkciji COUNT. Jedina razlika između njih je vrsta rezultata koji vraćaju: funkcija COUNT_BIG uvijek vraća BIGINT vrijednosti, dok funkcija COUNT vraća INTEGER vrijednosti podataka.
Statističke agregatne funkcije
Sljedeće funkcije čine skupinu statističkih agregatnih funkcija:
VARIzračunava statističku varijansu svih vrijednosti predstavljenih u stupcu ili izrazu.
VARPIzračunava statističku varijansu populacije svih vrijednosti predstavljenih u stupcu ili izrazu.
STDEVIzračunava standardnu devijaciju (koja se izračunava kao Korijen iz odgovarajuće varijance) svih vrijednosti stupca ili izraza.
STDEVPIzračunava standardnu devijaciju ukupnosti svih vrijednosti u stupcu ili izrazu.
Korisnički definirane agregatne funkcije
Database Engine također podržava implementaciju korisnički definiranih funkcija. Ova mogućnost omogućuje korisnicima da prošire agregatne funkcije sustava funkcijama koje mogu sami implementirati i instalirati. Ove funkcije predstavljaju posebnu klasu korisnički definiranih funkcija i kasnije će se detaljnije raspravljati.
IMATI ponudu
U rečenici IMATI definira uvjet koji se primjenjuje na grupu redaka. Dakle, ova klauzula ima isto značenje za grupe redaka kao klauzula WHERE za sadržaj odgovarajuće tablice. Sintaksa IMATI ponude Sljedeći:
IMATI stanje
Ovdje parametar uvjeta predstavlja uvjet i sadrži agregatne funkcije ili konstante.
Upotreba klauzule HAVING sa agregatnom funkcijom COUNT(*) prikazana je u primjeru u nastavku:
KORISTITE SampleDb; -- Vrati "p3" SELECT ProjectNumber FROM Works_on GRUPA PO Broju projekta IMA COUNT(*)
U ovom primjeru, koristeći klauzulu GROUP BY, sustav grupira sve retke na temelju vrijednosti u stupcu ProjectNumber. Nakon toga se broji broj redaka u svakoj skupini i odabiru grupe koje sadrže manje od četiri reda (tri ili manje).
Klauzula HAVING također se može koristiti bez agregatnih funkcija, kao što je prikazano u primjeru u nastavku:
KORISTITE SampleDb; -- Vraća "Konsultant" ODABIR POSAO IZ Works_on GRUPE PO POSLU KOJI IMA POSAO KAO "K%";
Ovaj primjer grupira retke u tablici Works_on po poziciji i eliminira one pozicije koje ne počinju slovom "K".
Klauzula HAVING također se može koristiti bez klauzule GROUP BY, iako to nije uobičajena praksa. U ovom slučaju, svi redovi tablice se vraćaju u istoj grupi.
NARUČI PO ponudi
Rečenica NARUDŽITE PO definira redoslijed sortiranja redaka u skupu rezultata koje je vratio upit. Ova rečenica ima sljedeću sintaksu:
Redoslijed sortiranja naveden je u parametru col_name. Parametar col_number je alternativni specificator redoslijeda sortiranja koji specificira stupce redoslijedom kojim se pojavljuju na popisu odabira izraza SELECT (1 je prvi stupac, 2 je drugi stupac i tako dalje). ASC parametar definira sortiranje uzlaznim redoslijedom, i DESC parametar- silazni. Zadana postavka je ASC.
Nazivi stupaca u klauzuli ORDER BY ne moraju biti na popisu stupaca za odabir. Ali to se ne odnosi na SELECT DISTINCT upite, jer u takvim upitima, nazivi stupaca navedeni u klauzuli ORDER BY također moraju biti navedeni u popisu stupaca za odabir. Osim toga, ova klauzula ne može sadržavati nazive stupaca iz tablica koje nisu navedene u klauzuli FROM.
Kao što možete vidjeti iz sintakse ORDER BY klauzule, skup rezultata može se sortirati na više stupaca. Ovo sortiranje je prikazano u primjeru ispod:
Ovaj primjer odabire brojeve odjela i prezimena i imena zaposlenika za zaposlenike čiji je broj osoblja manji od 20.000, te sortira prema prezimenu i imenu. Rezultat ovog upita je:

Stupci u klauzuli ORDER BY mogu se specificirati ne njihovim nazivima, već redoslijedom na popisu odabira. Prema tome, rečenica u gornjem primjeru može se prepisati na sljedeći način:
Takav alternativni način specificiranje stupaca po njihovoj poziciji umjesto imena koristi se ako kriterij naručivanja sadrži agregatnu funkciju. (Drugi način je korištenje naziva stupaca koji se zatim pojavljuju u klauzuli ORDER BY.) Međutim, u klauzuli ORDER BY preporučuje se da se stupci specificiraju svojim nazivima, a ne brojevima, kako bi se olakšalo ažuriranje upitati treba li stupce dodati ili ukloniti s popisa za odabir. Određivanje stupaca u klauzuli ORDER BY njihovim brojevima prikazano je u primjeru ispod:
KORISTITE SampleDb; SELECT ProjectNumber, COUNT(*) "Broj zaposlenika" FROM Works_on GROUP BY ProjectNumber ORDER BY 2 DESC;
Ovdje se za svaki projekt odabire broj projekta i broj zaposlenika koji u njemu sudjeluju, sortirajući rezultat silaznim redoslijedom prema broju zaposlenika.
Transact-SQL stavlja NULL vrijednosti na početak popisa kada se sortira uzlaznim redoslijedom, a na kraj popisa kada se sortira u silaznom redoslijedu.
Korištenje klauzule ORDER BY za paginiranje rezultata
Prikaz rezultata upita na trenutnoj stranici može se implementirati u korisnička aplikacija, ili dajte upute poslužitelju baze podataka da to učini. U prvom slučaju svi se retki baze podataka šalju aplikaciji, čiji je zadatak odabrati tražene retke i prikazati ih. U drugom slučaju, na strani poslužitelja, samo redovi potrebni za Trenutna stranica. Kao što možete očekivati, stranica na strani poslužitelja obično pruža bolju izvedbu, jer klijentu se šalju samo redovi potrebni za prikaz.
Za podršku kreiranju stranice na strani poslužitelja u SQL Server 2012 uvodi dvije nove klauzule izraza SELECT: OFFSET i FETCH. Primjena ove dvije rečenice prikazana je u primjeru u nastavku. Ovdje se iz baze podataka AdventureWorks2012 (koju možete pronaći u izvorima) preuzimaju poslovni ID, naziv radnog mjesta i rođendan svih zaposlenica, sortirajući rezultat prema nazivu radnog mjesta uzlaznim redoslijedom. Rezultirajući skup redaka dijeli se na stranice od 10 redaka i prikazuje se treća stranica:
U rečenici OFFSET određuje broj redaka rezultata koje treba preskočiti u prikazanom rezultatu. Ovaj se broj izračunava nakon što su retki razvrstani po klauzuli ORDER BY. U rečenici DOVEDI SLJEDEĆE specificira broj podudarnih WHERE i sortiranih redaka koje treba vratiti. Parametar ove klauzule može biti konstanta, izraz ili rezultat drugog upita. Klauzula FETCH NEXT slična je klauzuli PRVI DOUZMI.
Glavni cilj pri stvaranju stranica na strani poslužitelja je biti u mogućnosti implementirati uobičajene obrasce stranica pomoću varijabli. Ovaj zadatak možete izvršiti putem paketa SQL Server.
SELECT izraz i svojstvo IDENTITY
IDENTITY svojstvo omogućuje vam da definirate vrijednosti za određeni stupac tablice kao brojač koji se automatski povećava. Stupci numeričkog tipa podataka kao što su TINYINT, SMALLINT, INT i BIGINT mogu imati ovo svojstvo. Za takav stupac tablice, Database Engine automatski generira sekvencijalne vrijednosti počevši od navedene početne vrijednosti. Dakle, svojstvo IDENTITY može se koristiti za stvaranje jedinstvenog brojčane vrijednosti za odabrani stupac.
Tablica može sadržavati samo jedan stupac sa svojstvom IDENTITY. Vlasnik tablice ima mogućnost odrediti početnu vrijednost i prirast, kao što je prikazano u primjeru ispod:
KORISTITE SampleDb; IZRADI TABLICU Proizvod (Id INT IDENTITY(10000, 1) NOT NULL, Naziv NVARCHAR(30) NOT NULL, Cijena NOVAC) UMETNI U PROIZVOD(Naziv, Cijena) VRIJEDNOSTI ("Item1", 10), ("Item2", 15) , ("Item3", 8), ("Item4", 15), ("Item5", 40); -- Vraća 10004 SELECT IDENTITYCOL FROM Product WHERE Naziv = "Proizvod5"; -- Slično prethodnoj naredbi SELECT $identity FROM Product WHERE Naziv = "Proizvod5";
Ovaj primjer prvo stvara tablicu proizvoda koja sadrži stupac Id sa svojstvom IDENTITY. Vrijednosti u stupcu Id sustav generira automatski, počevši od 10.000 i povećavajući se za jedan za svaku sljedeću vrijednost: 10.000, 10.001, 10.002 itd.
Nekoliko funkcija sustava i varijabli pridruženo je svojstvu IDENTITY. Na primjer, primjer koda koristi varijabla sustava $identity. Kao što možete vidjeti iz izlaza ovog koda, ova varijabla automatski upućuje na svojstvo IDENTITY. Umjesto toga možete koristiti i funkciju sustava IDENTITYCOL.
Početna vrijednost i prirast stupca sa svojstvom IDENTITY mogu se pronaći pomoću funkcija IDENT_SEED i IDENT_INCR odnosno. Ove funkcije se primjenjuju na sljedeći način:
KORISTITE SampleDb; SELECT IDENT_SEED("Proizvod"), IDENT_INCR("Proizvod")
Kao što je već spomenuto, vrijednosti IDENTITY postavlja sustav automatski. Ali korisnik može eksplicitno odrediti svoje vrijednosti za određene retke postavljanjem parametra IDENTITY_INSERT ON prije umetanja eksplicitne vrijednosti:
SET IDENTITY INSERT naziv tablice UKLJUČENO
Budući da se opcija IDENTITY_INSERT može postaviti na bilo koju vrijednost za stupac svojstva IDENTITY, uključujući duplikat vrijednosti, svojstvo IDENTITY obično ne provodi jedinstvenost vrijednosti stupca. Stoga se ograničenja UNIQUE ili PRIMARY KEY trebaju koristiti za provođenje jedinstvenosti vrijednosti stupca.
Kada umetnete vrijednosti u tablicu nakon što je IDENTITY_INSERT postavljen na uključeno, sustav stvara sljedeću vrijednost stupca IDENTITY, povećavajući najveću trenutnu vrijednost tog stupca.
Izjava CREATE SEQUENCE
Korištenje svojstva IDENTITY ima nekoliko značajnih nedostataka, od kojih su najznačajniji sljedeći:
primjena svojstva ograničena je na navedenu tablicu;
nova vrijednost stupca ne može se dobiti ni na koji drugi način osim njezinom primjenom;
svojstvo IDENTITY može se specificirati samo pri izradi stupca.
Iz tih razloga, SQL Server 2012 uvodi sekvence koje imaju istu semantiku kao svojstvo IDENTITY, ali bez prethodno navedenih nedostataka. U ovom kontekstu, sekvenca je funkcionalnost baze podataka koja vam omogućuje da odredite vrijednosti brojača za različite objekte baze podataka, kao što su stupci i varijable.
Sekvence se stvaraju pomoću upute STVORITE SEKVENCIJU. Izraz CREATE SEQUENCE definiran je u SQL standardu i podržan je od drugih sustava relacijskih baza podataka kao što su IBM DB2 i Oracle.
Primjer u nastavku pokazuje kako stvoriti slijed u SQL Serveru:
KORISTITE SampleDb; CREATE SEQUEENCE dbo.Sequence1 KAO INT POČINJE S 1 PORAVANJEM ZA 5 MINVRIJEDNOSTI 1 MAKSIMALNA VRIJEDNOST 256 CIKLUS;
U gornjem primjeru, vrijednosti za Sequence1 sustav generira automatski, počevši od vrijednosti 1 i povećavajući se za 5 za svaku sljedeću vrijednost. Dakle, u ponudi START početna vrijednost je navedena, i INCREMENT ponuda- korak. (Korak može biti pozitivan ili negativan.)
U sljedeće dvije neobavezne rečenice MINVRIJEDNOST i MAXVRIJEDNOST minimum i maksimalna vrijednost objekt sekvence. (Imajte na umu da vrijednost MINVALUE mora biti manja ili jednaka početnoj vrijednosti, a vrijednost MAXVALUE ne može biti veća od gornje granice vrste podataka specificirane za slijed.) U klauzuli CIKLUS označava da se slijed ponavlja od početka kada se prekorači maksimalna (ili minimalna za niz s negativnim korakom) vrijednost. Prema zadanim postavkama, ova je klauzula postavljena na NO CYCLE, što znači da prekoračenje maksimalne ili minimalne vrijednosti sekvence uzrokuje iznimku.
Glavna značajka sekvenci je njihova neovisnost od tablica, t.j. mogu se koristiti s bilo kojim objektom baze podataka kao što su stupci tablice ili varijable. (Ovo svojstvo ima pozitivan učinak na pohranu, a time i na izvedbu. Ne treba pohranjivati određeni niz; pohranjuje se samo njegova posljednja vrijednost.)
Nove vrijednosti sekvence se kreiraju s SLJEDEĆA VRIJEDNOST ZA izraze, čija je upotreba prikazana u primjeru u nastavku:
KORISTITE SampleDb; -- Vraća 1 ODABIR SLJEDEĆE VRIJEDNOSTI ZA dbo.sequence1; -- Vraća 6 (sljedeći korak) ODABIR SLJEDEĆE VRIJEDNOSTI ZA dbo.sequence1;
Možete koristiti izraz SLJEDEĆA VRIJEDNOST FOR da biste rezultat niza dodijelili varijabli ili ćeliji stupca. Primjer u nastavku pokazuje upotrebu ovog izraza za dodjelu rezultata stupcu:
KORISTITE SampleDb; CREATE TABLE Proizvod (Id INT NOT NULL, Naziv NVARCHAR(30) NOT NULL, Cijena NOVAC) UMETNI U VRIJEDNOSTI proizvoda (SLJEDEĆA VRIJEDNOST ZA dbo.sequence1, "Proizvod1", 10); UMETNI U VRIJEDNOSTI proizvoda (SLJEDEĆA VRIJEDNOST ZA dbo.sequence1, "Proizvod2", 15); -- ...
Gornji primjer prvo stvara tablicu proizvoda s četiri stupca. Zatim dva INSERT izraza umeću dva retka u ovu tablicu. Prve dvije ćelije u prvom stupcu imat će vrijednosti 11 i 16.
Primjer u nastavku prikazuje upotrebu kataloškog prikaza sys.sekvence za prikaz trenutne vrijednosti niza bez upotrebe:
Obično se izraz NEXT VALUE FOR koristi u izrazu INSERT da prisili sustav da umetne generirane vrijednosti. Ovaj izraz se također može koristiti kao dio upita s više redaka pomoću klauzule OVER.
Za promjenu svojstva postojeće sekvence, koristite Izjava ALTER SEQUENCE. Jedna od najvažnijih upotreba ove izjave je opcija RESTART WITH, koja resetira navedeni slijed. Sljedeći primjer pokazuje upotrebu izraza ALTER SEQUENCE za resetiranje gotovo svih svojstava Sequence1:
KORISTITE SampleDb; ALTER SEQUENCE dbo.sequence1 RESTART SA 100 POVEĆANJA ZA 50 MIN VRIJEDNOSTI 50 MAKSIMALNE VRIJEDNOSTI 200 BEZ CIKLUSA;
Izbrišite sekvencu pomoću upute DROP SEKVENCA.
Postavite operatore
Uz operatore o kojima smo ranije govorili, Transact-SQL podržava još tri operatora skupa: UNION, INTERSECT i EXCEPT.
UNION operater
UNION operater kombinira rezultate dvaju ili više upita u jedan skup rezultata koji uključuje sve retke koji pripadaju svim upitima u spoju. Sukladno tome, rezultat spajanja dviju tablica je nova tablica koja sadrži sve retke uključene u jednu od izvornih tablica ili obje ove tablice.
Opći oblik UNION operatora izgleda ovako:
select_1 UNION select_2(select_3])...
Opcije select_1, select_2, ... su SELECT izjave koje stvaraju spajanje. Ako se koristi opcija SVE, prikazuju se svi reci, uključujući duplikate. U operatoru UNION, parametar ALL ima isto značenje kao u popisu odabira SELECT, s jednom razlikom: za popis odabira SELECT ovaj se parametar primjenjuje prema zadanim postavkama, ali za operator UNION mora biti eksplicitno specificiran.
U svom izvornom obliku, SampleDb baza podataka nije prikladna za demonstriranje korištenja UNION operatora. Stoga ovaj odjeljak stvara novu tablicu EmployeeEnh koja je identična postojećoj tablici Employee, ali ima dodatni stupac Grad. Ovaj stupac pokazuje gdje zaposlenici žive.
Kreiranje tablice EmployeeEnh pruža nam priliku da demonstriramo upotrebu klauzule U u naredbi SELECT. Naredba SELECT INTO izvodi dvije operacije. Najprije se kreira nova tablica sa stupcima navedenim na popisu odabira SELECT. Zatim se redovi izvorne tablice ubacuju u novu tablicu. Ime nove tablice navedeno je u INTO klauzuli, a ime izvorne tablice navedeno je u klauzuli FROM.
Primjer u nastavku prikazuje kreiranje tablice EmployeeEnh iz tablice Employee:
KORISTITE SampleDb; SELECT * INTO EmployeeEnh FROM Employee; ALTER TABLE EmployeeEnh DODAJ Grad NCHAR(40) NULL;
U ovom primjeru, izraz SELECT INTO kreira tablicu EmployeeEnh, u nju umeće sve retke iz izvorne tablice Employee, a zatim izraz ALTER TABLE dodaje stupac Grad u novu tablicu. No dodani stupac Grad ne sadrži nikakve vrijednosti. Vrijednosti u ovaj stupac mogu se umetnuti pomoću Upravljanje okolišem Studio ili sa sljedećim kodom:
KORISTITE SampleDb; UPDATE EmployeeEnh SET City="Kazan" GDJE Id=2581; AŽURIRANJE EmployeeEnh SET Grad = "Moskva" GDJE Id = 9031; AŽURIRANJE EmployeeEnh SET Grad = "Jekaterinburg" GDJE Id = 10102; AŽURIRANJE EmployeeEnh SET Grad = "Sankt Peterburg" GDJE Id = 18316; UPDATE EmployeeEnh SET Grad = "Krasnodar" GDJE Id = 25348; AŽURIRAJ EmployeeEnh SET City="Kazan" GDJE Id=28559; UPDATE EmployeeEnh SET City="Perm" GDJE Id=29346;
Sada smo spremni pokazati korištenje izjave UNION. Primjer u nastavku prikazuje upit za stvaranje spajanja između tablica EmployeeEnh i Department pomoću ove izjave:
KORISTITE SampleDb; ODABERITE Grad KAO "Grad" IZ UNIONA EmployeeEnh ODABIRITE lokaciju IZ Odjela;
Rezultat ovog upita je:
Pomoću naredbe UNION mogu se spojiti samo kompatibilne tablice. Pod kompatibilnim tablicama podrazumijevamo da oba popisa stupaca u odabiru moraju sadržavati isti broj stupaca, te da odgovarajući stupci moraju imati kompatibilne tipove podataka. (U smislu kompatibilnosti, tipovi podataka INT i SMALLINT nisu kompatibilni.)
Rezultat spajanja može se poredati samo korištenjem ORDER BY klauzule u posljednjem SELECT izrazu, kao što je prikazano u primjeru ispod. GROUP BY i HAVING klauzule se mogu koristiti sa zasebne upute SELECT, ali ne u samom spoju.
Upit u ovom primjeru dohvaća zaposlenike koji ili rade u odjelu d1 ili su počeli raditi na projektu prije 1. siječnja 2008.
Operator UNION podržava opciju SVE. Kada se koristi ova opcija, duplikati se ne uklanjaju iz skupa rezultata. Operator OR se može koristiti umjesto UNION operatora ako se svi izrazi SELECT spojeni s jednim ili više UNION operatora odnose na istu tablicu. U ovom slučaju, skup naredbi SELECT zamjenjuje se jednim izrazom SELECT sa skupom izraza OR.
INTERSECT i EXCEPT iskazi
Dva druga operatora za rad sa skupovima, PRESJEKATI i OSIM, definirati sjecište i razliku, respektivno. Ispod presjeka u ovom kontekstu nalazi se skup redaka koji pripadaju objema tablicama. A razlika dviju tablica definirana je kao sve vrijednosti koje pripadaju prvoj tablici, a nisu prisutne u drugoj. Primjer u nastavku pokazuje upotrebu izraza INTERSECT:
Transact-SQL ne podržava upotrebu opcije ALL ni s izrazom INTERSECT ni s izrazom EXCEPT. Upotreba izraza EXCEPT prikazana je u primjeru ispod:
Imajte na umu da ova tri operatora skupa imaju različit prioritet izvršenja: INTERSECT izjava ima najveći prioritet, slijedi operator EXCEPT, a operator UNION ima najmanji prioritet. Nepažnja prema prioritetu izvršenja kada se koristi višestruko različiti operateri rad sa setovima može dovesti do neočekivanih rezultata.
CASE izrazi
U području aplikacijskog programiranja baze podataka ponekad je potrebno modificirati prikaz podataka. Na primjer, ljudi se mogu podijeliti tako da ih kodiraju prema njihovoj društvenoj pripadnosti, koristeći vrijednosti 1, 2 i 3, označavajući muškarce, žene, odnosno djecu. Ova tehnika programiranja može smanjiti vrijeme potrebno za implementaciju programa. CASE izraz Transact-SQL jezik olakšava implementaciju ove vrste kodiranja.
Za razliku od većine programskih jezika, CASE nije izjava, već izraz. Stoga se izraz CASE može koristiti gotovo svugdje gdje Transact-SQL jezik dopušta korištenje izraza. Izraz CASE ima dva oblika:
jednostavan CASE izraz;
izraz za pretraživanje CASE.
Sintaksa za jednostavan CASE izraz je sljedeća:
Naredba s jednostavnim CASE izrazom prvo pretražuje popis svih izraza klauzula WHEN prvi izraz koji odgovara izrazu_1, a zatim izvršava odgovarajući TADA klauzula. Ako na popisu WHEN ne postoji odgovarajući izraz, onda ELSE klauzula.
Sintaksa za CASE izraz za pretraživanje je:
V ovaj slučaj traži se prvi podudarni uvjet, a zatim se izvršava odgovarajuća klauzula THEN. Ako nijedan od uvjeta ne odgovara zahtjevima, izvršava se klauzula ELSE. Upotreba izraza za pretraživanje CASE prikazana je u primjeru ispod:
KORISTITE SampleDb; ODABIR Naziv projekta, SLUČAJ KADA Proračun > 0 I Proračun 100000 I Proračun 150000 I Proračun
Rezultat ovog upita je:

Ovaj primjer ponderira proračune svih projekata i prikazuje njihove izračunate težine zajedno s odgovarajućim nazivima projekta.
Primjer u nastavku pokazuje drugi način korištenja izraza CASE, gdje klauzula WHEN sadrži potupite koji su dio izraza:
KORISTITE SampleDb; ODABERITE Naziv projekta, SLUČAJ KADA p1.Proračun (ODABRAJTE PROSJ.(p2.Proračun) IZ Projekta p2) ONDA "Iznad prosjeka" KRAJ "Kategorija proračuna" IZ Projekta p1;
Rezultat ovog upita je sljedeći:

Lekcija će pokriti temu sql-a o preimenovanju stupca (polja) korištenjem servisne riječi AS; razmatra se i tema agregatnih funkcija u sql-u. Analizirat će se konkretni primjeri zahtjeva
Nazivi stupaca u upitima mogu se preimenovati. To čini rezultate čitljivijim.
V SQL jezik preimenovanje polja povezano je s korištenjem ključna riječ KAO, koji se koristi za preimenovanje naziva polja u skupovima rezultata
Sintaksa:
IZABERI<имя поля>KAO<псевдоним>OD…
Razmotrimo primjer preimenovanja u SQL-u:
Primjer baze podataka "Institut": Prikažite imena nastavnika i njihove plaće, za one nastavnike čija je plaća manja od 15000 preimenujte polje zarplata u "niska plaća"
✍ Rješenje:
Preimenovanje stupaca u SQL-u često je potrebno prilikom izračunavanja vrijednosti povezanih s više polja tablice. Razmotrimo primjer:
Primjer baze podataka "Institut": Iz tablice učitelja prikažite polje imena i izračunajte zbroj plaće i bonusa, imenujući polje "plaća_bonus"
✍ Rješenje:
| 1 2 | SELECT naziv, (zarplata+ premia) AS zarplata_premia OD učitelja; |
SELECT naziv, (zarplata+premia) AS zarplata_premia OD učitelja;
Proizlaziti:
Agregatne funkcije u SQL-u
Agregatne funkcije u sql-u koriste se za dobivanje ukupnih vrijednosti i procjenu izraza:
Sve agregatne funkcije vraćaju jednu vrijednost.
Funkcije COUNT, MIN i MAX primjenjuju se na bilo koju vrstu podataka.
Funkcije SUM i AVG koriste se samo za numerička polja.
Postoji razlika između funkcija COUNT(*) i COUNT(): potonja ne uzima u obzir NULL vrijednosti prilikom izračunavanja.
Važno: pri radu sa agregatnim funkcijama u SQL-u koristi se funkcijska riječ KAO
Primjer baze podataka "Institut": Dobijte vrijednost najveće plaće među nastavnicima, prikažite ukupni kao "max_zp"
✍ Rješenje:
| SELECT MAX (zarplata) AS max_zp FROM učitelja; |
SELECT MAX(zarplata) AS max_sal FROM učitelja;
Rezultati:
Razmotrite više složen primjer korištenjem agregatnih funkcija u sql-u.
✍ Rješenje:
GROUP BY klauzula u SQL-u
Grupa po naredbi u sql-u obično se koristi zajedno sa agregatnim funkcijama.
Agregatne funkcije se izvode na svim rezultirajućim nizovima upita. Ako upit sadrži klauzulu GROUP BY, svaki skup redaka naveden u klauzuli GROUP BY čini grupu, a agregatne funkcije se izvršavaju za svaku grupu posebno.
Razmotrimo primjer s tablicom lekcija: 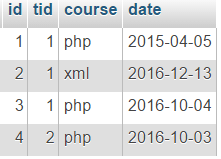
Primjer:
Važno: Dakle, kao rezultat korištenja GROUP BY, svi izlazni reci upita podijeljeni su u grupe koje karakterizira ista kombinacija vrijednosti u tim stupcima (to jest, agregatne funkcije se izvode za svaku grupu zasebno).
Pritom treba uzeti u obzir da će pri grupiranju po polju koje sadrži NULL -vrijednosti svi takvi zapisi pasti u jednu grupu.
Za različite vrste pisača, identificirajte ih Prosječna cijena i količinu (tj. zasebno za laser, inkjet i matricu). Koristite agregatne funkcije. Rezultat bi trebao izgledati ovako:

Imati SQL izjavu
Klauzula HAVING u SQL-u potrebna je za provjeru vrijednosti, koji se dobivaju pomoću agregatne funkcije nakon grupiranja(nakon korištenja GROUP BY). Takav ček ne može biti sadržan u klauzuli WHERE.
Primjer: Trgovina računala DB. Izračunajte prosječnu cijenu računala s istom brzinom procesora. Pokrenite izračun samo za one grupe čija je prosječna cijena manja od 30.000.
po vrijednosti stupca Disciplina . Dobit ćemo 4 grupe, za koje možemo izračunati neke grupne vrijednosti, kao što je broj torki u grupi, maksimalna ili minimalna vrijednost stupca Score.| Funkcija | Proizlaziti |
|---|---|
| RAČUNATI | Broj redaka ili vrijednosti polja koje nisu prazne koje je upit odabrao |
| IZNOS | Zbroj svih odabranih vrijednosti danog polja |
| PROSJEČAN | Aritmetička sredina svih odabranih vrijednosti u danom polju |
| MIN | Najmanja od svih odabranih vrijednosti za ovo polje |
| MAX | Najveća od svih odabranih vrijednosti za ovo polje |
| R1 | |||
|---|---|---|---|
| Puno ime | Disciplina | Razred | |
| Grupa 1 | Petrov F.I. | Baza podataka | 5 |
| Sidorov K.A. | Baza podataka | 4 | |
| Mironov A.V. | Baza podataka | 2 | |
| Stepanova K.E. | Baza podataka | 2 | |
| Krylova T. S. | Baza podataka | 5 | |
| Vladimirov V. A. | Baza podataka | 5 | |
| Grupa 2 | Sidorov K.A. | Teorija informacija | 4 |
| Stepanova K.E. | Teorija informacija | 2 | |
| Krylova T. S. | Teorija informacija | 5 | |
| Mironov A.V. | Teorija informacija | Null | |
| Grupa 3 | Trofimov P. A. | Mreže i telekomunikacije | 4 |
| Ivanova E. A. | Mreže i telekomunikacije | 5 | |
| Utkina N.V. | Mreže i telekomunikacije | 5 | |
| Grupa 4 | Vladimirov V. A. | Engleski jezik | 4 |
| Trofimov P. A. | Engleski jezik | 5 | |
| Ivanova E. A. | Engleski jezik | 3 | |
| Petrov F.I. | Engleski jezik | 5 | |
Agregatne funkcije koriste se kao nazivi polja u SELECT izrazu, s jednom iznimkom: uzimaju ime polja kao argument. Samo s funkcijama SUM i AVG numerička polja. I numerička i znakovna polja mogu se koristiti s funkcijama COUNT, MAX i MIN. Kada se koriste sa znakovnim poljima, MAX i MIN će ih prevesti u njihov ASCII ekvivalent i obraditi ih kao abecedni red. Neki DBMS-ovi dopuštaju ugniježđene agregate, ali ovo je odstupanje od ANSI standarda, sa svim njegovim implikacijama.
Na primjer, možete izračunati broj studenata koji su polagali ispite u svakoj disciplini. Da biste to učinili, morate izvršiti upit grupiran po polju "Subject" i kao rezultat prikazati naziv discipline i broj redaka u grupi za ovu disciplinu. Korištenje znaka * kao argumenta funkciji COUNT znači brojati sve retke u grupi.
ODABIR R1.Disciplina, COUNT(*) IZ R1 GRUPA PO R1.Disciplina
Proizlaziti:
Ako želimo izbrojati broj studenata koji su položili ispit u bilo kojoj disciplini, tada moramo isključiti null vrijednosti iz izvornog omjera prije grupiranja. U ovom slučaju zahtjev će izgledati ovako:
Dobivamo rezultat:
U ovom slučaju, linija s učenikom
| Mironov A.V. | Teorija informacija | Null |
|---|
neće pasti u skup torki prije grupiranja, tako da je broj torki u grupi za disciplinu " Teorija informacija"bit će 1 manje.
Može se primijeniti agregatne funkcije također bez operacije prethodnog grupiranja, u kojem slučaju se cijela relacija smatra jednom grupom i za ovu grupu može se izračunati jedna vrijednost po grupi.
Pozivajući se opet na bazu podataka "Session" (tablice R1, R2, R3), nalazimo broj uspješno položenih ispita:
Ovo se naravno razlikuje od odabira polja, budući da se uvijek vraća jedna vrijednost, bez obzira na to koliko redaka ima u tablici. Argument agregatne funkcije mogu postojati odvojeni stupci tablica. Ali da biste izračunali, na primjer, broj različitih vrijednosti određenog stupca u grupi, morate koristiti ključnu riječ DISTINCT zajedno s nazivom stupca. Izračunajmo broj različitih ocjena dobivenih u svakoj disciplini:
Proizlaziti:
Rezultat može uključivati vrijednost polja grupiranja i nekoliko agregatne funkcije, a više polja se mogu koristiti u uvjetima grupiranja. U ovom slučaju, grupe se formiraju prema skupu specificiranih polja grupiranja. Agregatne operacije mogu se primijeniti za spajanje više izvornih tablica. Na primjer, postavimo pitanje: odredite za svaku grupu i svaku disciplinu broj onih koji su uspješno položili ispit i prosječan rezultat za disciplinu.
Proizlaziti:
Ne možemo koristiti agregatne funkcije u klauzuli WHERE, jer se predikati vrednuju u smislu jednog retka, i agregatne funkcije- u smislu grupa redova.
Klauzula GROUP BY omogućuje vam definiranje podskupa vrijednosti u određenom polju u smislu drugog polja i primjenu agregatne funkcije na podskup. To omogućuje kombiniranje polja i agregatne funkcije u jednoj klauzuli SELECT. Agregatne funkcije može se koristiti i u izlaznom izrazu rezultata SELECT retka i u izrazu uvjeta obrade za formirane grupe IMAJUĆI . U ovom slučaju, svaka se agregatna funkcija izračunava za svaku odabranu skupinu. Vrijednosti koje proizlaze iz izračuna agregatne funkcije, može se koristiti za prikaz odgovarajućih rezultata ili za uvjetovanje odabira grupa.
Napravimo upit koji prikazuje grupe u kojima je primljeno više od jedne dvojke u jednoj disciplini na ispitima:
U budućnosti, kao primjer, nećemo raditi s bazom podataka "Session", već s bazom podataka "Banka", koja se sastoji od jedne tablice F , koja pohranjuje relaciju F koja sadrži podatke o računima u poslovnicama određene banke:
F = (N, puno ime, podružnica, datum otvaranja, datum zatvaranja, stanje); Q = (Podružnica, Grad);
jer je na temelju toga moguće jasnije ilustrirati rad sa agregatnim funkcijama i grupiranjem.
Na primjer, pretpostavimo da želimo pronaći ukupno stanje računa u poslovnicama. Možete napraviti zaseban upit za svaku od njih odabirom SUM(Stanje) iz tablice za svaku granu. GROUP BY će ih, međutim, sve staviti u jednu naredbu:
SELECT Grana, ZBIR (Stanje) FROM F GRUPA PO Ogranak;
Primjenjuje se GROUP BY agregatne funkcije neovisno za svaku grupu definiranu vrijednošću polja Grana. Grupa se sastoji od redaka sa istu vrijednost polja Podružnica, i
ISO standard definira sljedećih pet funkcije agregiranja:
RAČUNATI– vraća broj vrijednosti u navedenom stupcu;
IZNOS– vraća zbroj vrijednosti u navedenom stupcu;
PROSJEČAN– vraća prosječnu vrijednost u navedenom stupcu;
MIN– vraća minimalnu vrijednost u navedenom stupcu;
MAX- vraća maksimalnu vrijednost u navedenom stupcu.
Sve ove funkcije rade na vrijednostima u jednom stupcu tablice i vraćaju jednu vrijednost. Funkcije COUNT, MIN i MAX primjenjuju se i na numerička i na nenumerička polja, dok se funkcije SUM i AVG mogu koristiti samo za numerička polja. Uz iznimku COUNT(*), prilikom izračunavanja rezultata bilo koje funkcije, prvo se isključuju sve nulte vrijednosti, nakon čega se potrebna operacija primjenjuje samo na preostale vrijednosti stupca koje nisu nule. Varijanta COUNT (*) posebna je upotreba funkcije COUNT - njezina je svrha prebrojati sve retke u tablici, bez obzira sadržavaju li null, duplikate ili bilo koju drugu vrijednost. Ako želite eliminirati duplicirane vrijednosti prije korištenja agregatne funkcije, morate ispred naziva stupca u definiciji funkcije staviti ključnu riječ DISTINCT. ISO standard dopušta korištenje ključne riječi ALL kako bi se eksplicitno naznačilo da eliminacija dupliciranih vrijednosti nije potrebna, iako se ova ključna riječ pretpostavlja prema zadanim postavkama ako nisu navedeni drugi kvalifikatori. Ključna riječ DISTINCT nema značenje za funkcije MIN i MAX. Međutim, njegova uporaba može utjecati na rezultate funkcija SUM i AVG, stoga biste trebali unaprijed razmisliti treba li biti prisutan u svakom konkretnom slučaju. Također, ključna riječ DISTINCT može se navesti najviše jednom u svakom upitu.
Imajte na umu da se funkcije agregacije mogu koristiti samo na popisu odabira SELECT i u klauzuli HAVING (pogledajte odjeljak 5.3.4). U svim ostalim slučajevima uporaba ovih funkcija nije dopuštena. Ako popis SELECT sadrži funkciju agregacije, a tijelo upita ne sadrži klauzulu GROUP BY koja pruža grupiranje podataka, tada nijedan od elemenata SELECT popisa za odabir ne može uključivati reference stupaca, osim ako se ovaj stupac ne koristi kao agregatna funkcija parametar. Na primjer, sljedeći upit je nevažeći:
IZABERIosobljeNe,RAČUNATI (plaća)
IZosoblje;
Greška je u tome što je u dati zahtjev nedostaje dizajn GRUPA PO, a stupcu staffNo na popisu SELECT pristupa se bez upotrebe agregatne funkcije.
Primjer 13: Korištenje funkcije COUNT(*).Odredite koliko nekretnina za iznajmljivanje ima stopu najma veću od £350 mjesečno,
ODABIR BROJ(*) AS count
IZvlasništvo zanajam
GDJEnajam > 350;
Ograničenje brojanja samo onih iznajmljenih objekata čija je najamnina veća od £350 mjesečno provodi se korištenjem klauzule WHERE. Ukupni broj iznajmljenih objekata koji zadovoljavaju navedeni uvjet može se odrediti pomoću funkcije agregiranja COUNT. Rezultati izvršenja upita prikazani su u tablici. 23.
Tablica 23
| računati |
Primjer 14. Korištenje funkcije COUNT(DISTINCT).Odredite koliko su različitih nekretnina za iznajmljivanje pregledali klijenti u svibnju 2001.
ODABIR BROJA (RAZLIČITsvojstvoNe) AS count
IZPregledavanje
Opet, ograničavanje rezultata upita na raščlanjivanje samo onih iznajmljivanja koje su pregledane u svibnju 2001. postiže se korištenjem klauzule WHERE. Ukupan broj pregledanih objekata koji zadovoljavaju navedeni uvjet može se odrediti pomoću funkcije zbrajanja COUNT. Međutim, budući da se isti objekt može vidjeti više puta od strane različitih klijenata, ključna riječ DISTINCT mora biti navedena u definiciji funkcije kako bi se iz izračunavanja isključile duplicirane vrijednosti. Rezultati izvršenja upita prikazani su u tablici. 24.
Tablica 24
Primjer 16. Korištenje funkcija MIN, MAXnAVG.Izračunajte vrijednost minimalne, maksimalne i prosječne plaće.
ODABIR MIN(plaća) KAO min, MAX(plaća) KAO max, PROSJEČAN(plaća) KAO prosječno
IZosoblje;
U ovom primjeru morate obraditi podatke o cijelom osoblju u tvrtki, tako da ne morate koristiti klauzulu WHERE. Tražene vrijednosti mogu se izračunati pomoću funkcija MIN, MAX i AVG primijenjenih na stupac plaća u tablici Osoblje. Rezultati izvršenja upita prikazani su u tablici. 26.
Tablica 26
Rezultat upita
| min | maks | prosječno |
| 9000.00 | 30000.00 | 17000.00 |
Rezultati grupiranja (konstrukt GROUP BY). Gornji primjeri sažetih podataka slični su recima sažetka koji se obično nalaze na kraju izvješća. Kao rezultat, svi detaljni podaci izvješća su komprimirani u jedan sažetak. Međutim, vrlo često se u izvješćima traži formiranje i međuzbrojeva. U tu svrhu, klauzula GROUP BY može se navesti u izrazu SELECT. Poziva se upit koji sadrži klauzulu GROUP BY grupni upit, jer grupira podatke koji su rezultat operacije SELECT, nakon čega se kreira jedan sažeti red za svaku pojedinačnu grupu. Pozivaju se stupci navedeni u klauzuli GROUP BY grupiranim stupcima. ISO standard zahtijeva da klauzule SELECT i GROUP BY budu usko povezane. Kada koristite klauzulu GROUP BY u izrazu SELECT, svaka stavka popisa na popisu odabira SELECT mora imati jedina vrijednost za cijelu grupu.Štoviše, konstrukcija SELECT može uključivati samo sljedeće vrste elemenata:
Nazivi stupaca;
funkcije agregiranja;
konstante;
Izrazi koji uključuju kombinacije gornjih elemenata.
Svi nazivi stupaca na popisu SELECT također se moraju pojaviti u klauzuli GROUP BY, osim ako se naziv stupca koristi samo u agregatnoj funkciji. Suprotna izjava nije uvijek istinita - klauzula GROUP BY može sadržavati nazive stupaca koji se ne nalaze na popisu SELECT. Ako se klauzula WHERE koristi zajedno s klauzulom GROUP BY, tada se prvo obrađuje i grupiraju se samo oni reci koji zadovoljavaju uvjet pretraživanja. ISO standard navodi da se prilikom grupiranja sve vrijednosti koje nedostaju tretiraju kao jednake. Ako dva retka tablice u istom stupcu grupiranja sadrže NULL vrijednosti i identične vrijednosti u svim ostalim nepraznim stupcima grupiranja, oni se stavljaju u istu grupu.
Primjer 17: Korištenje klauzule GROUP BY.Odredite broj zaposlenika koji rade u svakom od odjela tvrtke, kao i njihove ukupne plaće.
IZABERIgrane br, RAČUNATI(broj osoblja) KAO računati, IZNOS(plaća) KAO iznos
IZOsoblje
GRUPA POposlovnica br
NARUDŽITE POgrana br;
Nema potrebe uključiti nazive stupaca staffNo i plaću u popis GROUP BY, jer se oni pojavljuju samo na popisu SELECT sa agregatnim funkcijama. Istodobno, stupac branchNo na popisu klauzule SELECT nije pridružen nijednoj funkciji agregacije i iz tog razloga mora biti specificiran u klauzuli GROUP BY. Rezultati izvršenja upita prikazani su u tablici. 27.
Tablica 27
Rezultat upita
| poslovnica br | Računati | iznos |
| B003 | 54000.00 | |
| B005 | 39000.00 | |
| B007 | 9000.00 |
Konceptualno, prilikom obrade ovog zahtjeva izvode se sljedeće radnje.
1. Redovi tablice Osoblje raspoređeni su u grupe prema vrijednostima u stupcu broja podružnice tvrtke. Unutar svake od grupa nalaze se podaci o cijelom osoblju jednog od odjela tvrtke. U našem primjeru će se stvoriti tri grupe, kao što je prikazano na sl. jedan.
2. Za svaku od grupa izračunava se ukupan broj redaka koji je jednak broju zaposlenih u odjelu, kao i zbroj vrijednosti u stupcu plaća, koji je zbroj plaća svih djelatnika odjela za koje smo zainteresirani. Zatim se generira jedan redak sažetka za cijelu grupu izvornih redaka.
3. Primljeni redovi rezultirajuće tablice sortirani su uzlaznim redoslijedom prema broju grane navedenom u stupcu br. grane.
| poslovnica br | broj osoblja | Plaća |
| B00Z | SG37 | 12000.00 |
| B00Z | SG14 | 18000.00 |
| B00Z | SG5 | 24000.00 |
| B005 | SL21 | 30000.00 |
| B005 | SL41 | 9000.00 |
| B007 | SA9 | 9000.00 |
| COUNT (broj osoblja) | SUM (plata) |
| 54000.00 | |
| 39000.00 | |
| 9000.00 |
Riža. 1. Tri grupe zapisa stvorene prilikom izvršavanja upita
SQL standard dopušta postavljanje podupita na popis odabira SELECT. Stoga se gornji upit može predstaviti i na sljedeći način:
IZABERIbr. grane, (ODABIR COUNT(broj osoblja)KAO računati
IZosoblje s
GDJEs.br.grana = b.br.grana),
(ODABIR SUM(plaća) KAO zbroj
IZosoblje s
GDJEs.br.grana = b.br.grana)
IZgrana b
NARUDŽITE POgrana br;
No, u ovoj verziji upita, za svaku od podružnica tvrtke opisanu u tablici Podružnice, generiraju se dva rezultata izračuna agregacijskih funkcija, pa se u nekim slučajevima mogu pojaviti retki koji sadrže nulte vrijednosti.
Ograničenja grupiranja (HAVING konstrukcija). Klauzula HAVING namijenjena je za korištenje zajedno s klauzulom GROUP BY za određivanje ograničenja za odabir onih grupe, koji će biti smješten u rezultirajuću tablicu upita. Iako klauzule HAVING i WHERE imaju sličnu sintaksu, njihova je svrha drugačija. Klauzula WHERE dizajnirana je za odabir pojedinačnih redaka namijenjenih ispunjavanju rezultirajuće tablice upita, a konstrukcija HAVING koristi se za odabir grupe, smještene u rezultirajuću tablicu upita. ISO standard zahtijeva da nazivi stupaca koji se koriste u klauzuli HAVING moraju biti prisutni na popisu elemenata GROUP BY ili korišteni u agregatnim funkcijama. U praksi uvjeti pretraživanja u klauzuli HAVING uvijek uključuju barem jednu funkciju združivanja; u suprotnom bi se ti pojmovi za pretraživanje trebali staviti u klauzulu WHERE i primijeniti na odabir pojedinačnih redaka. (Zapamtite da se agregatne funkcije ne mogu koristiti u klauzuli WHERE.) Klauzula HAVING nije nužan dio SQL jezika—bilo koji upit napisan korištenjem klauzule HAVING može se na drugi način predstaviti bez korištenja.
Primjer 18: Korištenje konstrukcije HAVING.Za svaku podružnicu tvrtke s više od jednog zaposlenika odredite broj zaposlenih i visinu njihove plaće.
IZABERIgrane br, BROJ T (broj osoblja) KAO računati, IZNOS(plaća) KAO iznos
IZOsoblje
GRUPA POposlovnica br
IMATI BROJ(broj osoblja) > 1
NARUDŽITE POgrana br;
Ovaj primjer je sličan prethodnom, ali koristi dodatna ograničenja kako bi naznačio da nas zanimaju samo podaci o onim odjelima tvrtke koji zapošljavaju više osoba. Sličan zahtjev vrijedi i za grupe, pa bi upit trebao koristiti konstrukciju HAVING. Rezultati izvršenja upita prikazani su u tablici. 28.
Tablica 28
| grana Bez brojanja zbroj |
| V00Z 3 54000,00 |
| B005 2 39000,00 |
Podupiti. U ovom ćemo odjeljku raspravljati o upotrebi potpunih SELECT izraza ugrađenih u tijelo drugog SELECT izraza. Vanjski(Drugi) SELECT izraz koristi rezultat izvršenja unutarnje(prva) izjava za određivanje sadržaja konačnog rezultata cijele operacije. Unutarnji upiti mogu biti u klauzulama WHERE i HAVING vanjskog SELECT izraza, u kojem slučaju se nazivaju podupita ili ugniježđeni upiti. Također, interni SELECT izrazi se mogu koristiti u izrazima INSERT, UPDATE i DELETE . Postoje tri vrste potupita.
Skalarni podupit vraća vrijednost odabranu iz sjecišta jednog stupca s jednim redom, t.j. pojedinačna vrijednost. U principu, skalarni se podupit može koristiti gdje god je potrebna jedna vrijednost. Varijante skalarnih potupita prikazane su u primjerima 13 i 14.
Podupit niza vraća vrijednosti više stupaca tablice, ali kao jedan redak. Podupit niza može se koristiti bilo gdje gdje se koristi konstruktor vrijednosti niza — obično predikati. Varijanta potupita niza prikazana je u primjeru 15.
Podupit tablice vraća vrijednosti jednog ili više stupaca tablice koja obuhvaća više od jednog reda. Podupit tablice može se koristiti gdje god je tablica dopuštena, kao što je operand predikata IN.
Primjer 19: Korištenje podupita s testom jednakosti.Šminka popis osoblja koje radi u podružnici tvrtke koja se nalazi na adresi Main St1 463.
IZABERI
IZOsoblje
GDJEbr. grane = (ODABIR br. grane
IZpodružnica
GDJEulica = "163 Main S t ");
Interni SELECT izraz (SELECT branchNo FROM Branch ...) dizajniran je za određivanje broja podružnice tvrtke koja se nalazi na adresi "163 Main St". (Postoji samo jedna takva grana, pa je ovaj primjer primjer skalarnog podupita.) Nakon dobivanja željenog broja grane, izvršava se vanjski podupit za odabir detaljima o zaposlenicima ovog odjela. Drugim riječima, interni operater SELECT vraća tablicu koja se sastoji od jedne vrijednosti "BOOV". Ovo je broj podružnice tvrtke koja se nalazi na "163 Main St1. Kao rezultat toga, vanjski SELECT izraz postaje:
IZABERIbroj osoblja, fName, Iname, pozicija
IZOsoblje
GDJEbr. grane = "B0031;
Rezultati ovog upita prikazani su u tablici. 29.
Tablica 29
Rezultat upita
| broj osoblja | fNaziv | Iname | položaj |
| SG37 | Ann | Bukva | pomoćnik |
| SG14 | David | Ford | Nadglednik |
| SG5 | Susan | marka | menadžer |
Potupit je alat za stvaranje privremene tablice čiji se sadržaj dohvaća i obrađuje vanjskim izrazom. Potupit, može se navesti izravno nakon operatora usporedbe (tj. operatori =,<, >, <=, >=, <>) u klauzuli WHERE ili HAVING. Tekst potupita mora biti zatvoren u zagradama.
Primjer 20. Korištenje potupita sa agregatnim funkcijama. Napravite popis svih zaposlenika koji su plaćeni iznad prosjeka i naznačite koliko je njihova plaća veća od prosječne plaće u poduzeću.
IZABERIbroj osoblja, fIme, Iime, pozicija, plaća - ( ODABIR PROSJ(plaća) IZ osoblje) KAO salDiff
IZOsoblje
GDJEplaća > ( ODABIR PROSJ(plaća) IZ S t a f) ;
Treba napomenuti da se ne može izravno uključiti u izraz upita"GDJE plaća > AVG(plata)", budući da je upotreba agregiranja funkcije u klauzuli WHERE nisu dopuštene. Da biste postigli željeni rezultat, trebali biste kreirati potupit koji izračunava prosječnu godišnju plaću, a zatim ga koristiti u vanjskom SELECT naredbi za odabir informacija o onim zaposlenicima u tvrtki čija plaća prelazi ovaj prosjek. Drugim riječima, podupit vraća prosječnu godišnju plaću tvrtke, koja iznosi 17.000 funti.
Rezultat izvršavanja ovog skalarnog podupita koristi se u vanjskom izrazu SELECT i za izračunavanje odstupanja plaća od prosječne razine i za odabir informacija o zaposlenicima. Dakle, vanjski SELECT izraz postaje:
IZABERIbroj osoblja, fIme, Iname, pozicija, plaća - 17000 Kao salDiff
IZOsoblje
GDJEplaća > 17000;
Rezultati izvršenja upita prikazani su u tablici. trideset.
Tablica 30
Rezultat upita
| broj osoblja | fNaziv | Iname | položaj | salDiff |
| SL21 | Ivan | Bijeli | menadžer | 13000.00 |
| SG14 | David | Ford | Nadglednik | 1000.00 |
| SG5 | Susan | marka | menadžer | 7000.00 |
Primjenjuju se potupiti slijedeći pravila i ograničenja.
1. Potupiti ne bi trebali koristiti klauzulu ORDER BY, iako ona može biti prisutna u vanjskom izrazu SELECT.
2. Popis SELECT podupita mora se sastojati od pojedinačnih naziva stupaca ili izraza sastavljenih od njih, osim ako se ključna riječ EXISTS ne koristi u potupitu.
3. Prema zadanim postavkama, nazivi stupaca u potupitu odnose se na tablicu čije je ime navedeno u klauzuli FROM potupita. Međutim, također je dopušteno upućivanje na stupce tablice navedene u FROM klauzuli vanjskog upita korištenjem kvalificiranih naziva stupaca (kao što je opisano u nastavku).
4. Ako je potupit jedan od dva operanda uključena u operaciju usporedbe, tada se potupit mora navesti na desnoj strani ove operacije. Na primjer, zapis upita iz prethodnog primjera u nastavku nije točan jer je potupit postavljen na lijevu stranu operacije usporedbe u odnosu na vrijednost stupca plaće.
IZABERI
IZOsoblje
GDJE(ODABERITE PROSJ. (plaću) OD osoblja)< salary;
Primjer 21. Ugniježđeni potupiti i upotreba IN predikata. Napravite popis nekretnina za iznajmljivanje za koje zaposlenici podružnice tvrtke koja se nalazi na adresi „Glavna 163.1.
IZABERIbroj imovine, ulica, grad, poštanski broj, vrsta, sobe, najam
IZvlasništvo zanajam
Poglavlje 5. SQL jezik: manipulacija podacima 189
GDJEbroj osoblja IN (ODABIR br. osoblja
IZOsoblje
GDJEbrancliNo = (ODABIR br. grane
IZpodružnica
GDJEulica = "Glavna ulica 163")) ;
Prvi, najviše interni, upit je dizajniran da odredi broj podružnice tvrtke koja se nalazi na adresi Main St. 463. Drugi, srednji, upit odabire podatke o osoblju koje radi u ovoj podružnici. U ovom slučaju, više od jednog reda podaci su odabrani i stoga ne možete koristiti operator usporedbe =. Umjesto toga morate koristiti ključnu riječ IN. Vanjski upit dohvaća informacije o zakupljenim objektima za koje su odgovorni zaposlenici tvrtke, a podaci o kojima su dobiveni kao rezultat posredni upit. Rezultati upita prikazani su u tablici. 31.
Tablica 31
Rezultat upita
| vlasništvo br | ulica | Grad | poštanski broj | tip | sobe | najam |
| PG16 | 5 Novar Dr | Glasgow | G129AX | Ravan | ||
| PG36 | 2 Manor Road | Glasgow | G324QX | Ravan | ||
| PG21 | 18 Dale Road | Glasgow | G12 | kuća |
Ključne riječi BILO i SVE. Ključne riječi ANY i ALL mogu se koristiti s potupitima koji vraćaju jedan stupac brojeva. Ako podupitu prethodi ključna riječ ALL, smatra se da je uvjet usporedbe ispunjen samo ako je istinit za sve vrijednosti u stupcu rezultata potupita. Ako tekstu podupita prethodi ključna riječ ANY, tada će se uvjet usporedbe smatrati ispunjenim ako je zadovoljen za barem jednu (jednu ili više) vrijednosti u rezultirajućem stupcu potupita. Ako podzahtjev rezultira prazna vrijednost, tada će se za ključnu riječ ALL uvjet usporedbe smatrati ispunjenim, a za BILO KOJU ključnu riječ smatrat će se neuspjelim. Prema ISO standardu, možete dodatno koristiti ključnu riječ SOME, koja je sinonim za ključnu riječ BILO.
Primjer 22. Koristeći ključne riječi ANY i SOME. Pronađite sve zaposlenike čija je plaća barem veća od plaće jedan djelatnik podružnice poduzeća pod brojem "booz".
IZABERIosobljeNe, fIme, Iime, pozicija, plaća
IZOsoblje
GDJEplaća > NEKI(ODABIR plaće
IZOsoblje
GDJEgranaNo="B003");
Iako se ovaj upit može napisati korištenjem podupita koji specificira minimalnu plaću za osoblje odjela pod brojem "WHO", nakon čega vanjski podupit može odabrati podatke o svim zaposlenicima tvrtke čija plaća prelazi ovu vrijednost (vidi primjer 20), moguć je i drugi pristup, koji se sastoji u korištenju ključnih riječi NEKI/BILO KOJI. U ovom slučaju, unutarnji potupit generira skup vrijednosti (12000, 18000, 24000), a vanjski upit odabire detalje onih radnika čija je plaća veća od bilo koje vrijednosti u ovom
set (u stvari, više od minimalne vrijednosti - 12000). Kao alternativna metoda može se smatrati prirodnijim od definiranja minimalne plaće u potupitu. Ali u oba slučaja proizvode isti rezultati izvršenje zahtjeva, koji su prikazani u tablici. 32 .
Tablica 32
Rezultat upita
| broj osoblja | fNaziv | Iname | položaj | plaća |
| SL21 | Ivan | Bijeli | menadžer | 30000.00 |
| SG14 | David | Ford | Nadglednik | 18000.00 |
| SG5 | Susan | marka | menadžer | 24000.00 |
Primjer 23. Korištenje ključne riječi SVE. Pronađite sve zaposlenike čije su plaće veće od plaće bilo kojeg zaposlenika u podružnici tvrtke s brojem "booz".
IZABERIosobljeNe, fIme, INarae, pozicija, plaća
IZOsoblje
GDJEplaća > SVI(ODABIR plaće
IZOsoblje
GDJEbr. grane = "BOG3");
Općenito, ovaj je upit sličan prethodnom. I u ovom slučaju bilo bi moguće koristiti podupit koji određuje maksimalnu vrijednost plaće osoblja odjela pod brojem "BOOS", a zatim eksternim upitom odabrati podatke o svim zaposlenicima tvrtke čiji plaća prelazi ovu vrijednost. Međutim, u ovaj primjer bira se pristup koji koristi ključnu riječ ALL. Rezultati izvršenja upita prikazani su u tablici. 33 .
Tablica 33
Rezultat upita
| broj osoblja | Iname | fNaziv | položaj | plaća |
| SL21 | Bijeli | Ivan | menadžer | 30000,00 |
Upiti za više tablica. Svi gore razmotreni primjeri imaju isto važno ograničenje: stupci smješteni u rezultirajuću tablicu uvijek se biraju iz jedne tablice. Međutim, u mnogim slučajevima to nije dovoljno. Da biste spojili stupce iz nekoliko izvornih tablica u rezultirajuću tablicu, morate izvesti operaciju veze. U SQL-u se operacija spajanja koristi za kombiniranje informacija iz dvije tablice formiranjem parova povezanih redaka odabranih iz svake tablice. Parovi redaka smješteni u kombiniranu tablicu sastavljeni su od jednakosti vrijednosti navedenih stupaca uključenih u njih.
Ako trebate dohvatiti informacije iz više tablica, možete koristiti podupit ili se pridružiti tablicama. Ako rezultirajuća tablica upita mora sadržavati stupce iz različitih izvornih tablica, tada je preporučljivo koristiti mehanizam spajanja tablice. Za izvođenje spajanja dovoljno je navesti nazive dviju ili više tablica u klauzuli FROM, odvajajući ih zarezima, a zatim uključiti klauzulu WHERE u upit s definicijom stupaca koji se koriste za spajanje navedenih tablica. Osim toga, umjesto imena tablica, možete koristiti aliasi, dodijeljena im u konstrukciji FROM. U ovom slučaju, nazivi tablica i pseudonimi koji su im dodijeljeni moraju biti odvojeni razmacima. Aliasi se mogu koristiti za kvalificiranje naziva stupaca kad god postoji nejasnoća o tome kojoj tablici stupac pripada. Osim toga, aliasi se mogu koristiti za skraćivanje naziva tablica. Ako je za tablicu definiran pseudonim, može se koristiti bilo gdje gdje je potrebno ime te tablice.
Primjer 24. Jednostavna veza. Napravite popis imena svih klijenata koji su već pregledali barem jednu nekretninu za iznajmljivanje i dali svoje mišljenje o ovom pitanju.
IZABERIc.clientNo, fName, INName, propertyNo, comment
IZKlijent c, Pregled v
GDJEc.clientNo = v.clientNo;
Ovo izvješće treba predstaviti informacije i iz tablice klijenta i iz tablice pregleda, tako da ćemo prilikom izrade upita koristiti mehanizam spajanja tablice. Konstrukcija SELECT navodi sve stupce koji bi trebali biti smješteni u tablicu rezultata upita. Imajte na umu da stupac broja klijenta (clientNo) mora biti kvalificiran, budući da takav stupac također može biti prisutan u drugoj tablici koja sudjeluje u pridruživanju. Stoga je potrebno eksplicitno naznačiti koje vrijednosti tablice nas zanimaju. (U ovom primjeru, možda ste i odabrali vrijednosti stupca clientNo iz tablice Viewing). Kvalifikacija naziva se izvodi tako da se nazivu stupca doda prefiks naziva odgovarajuće tablice (ili njezinog aliasa). U našem primjeru, vrijednost "c" navedena je kao pseudonim za tablicu Client. Za formiranje rezultirajućih redaka koriste se oni reci izvornih tablica koji imaju identičnu vrijednost u stupcu clientNo. Ovaj uvjet se određuje navođenjem uvjeta pretraživanja c.clientNo=v.clientNo. Pozivaju se slični stupci izvornih tablica podudarni stupci. Opisana operacija je ekvivalentna operaciji pridružuje se jednakošću relacijske algebre. Rezultati izvršenja upita prikazani su u tablici. 34.
Tablica 34
Rezultat upita
| klijent br | fNaziv | Iname | vlasništvo br | komentar |
| CR56 | Aline | Stewart | PG36 | |
| CR56 | Aline | Stewart | PA14 | premalen |
| CR56 | Aline | Stewart | PG4 | |
| CR62 | Marija | Tregear | PA14 | nema blagovaonice |
| CR76 | Ivan | Kay | PG4 | previše udaljeno |
Najčešće se upiti s više tablica izvode na dvije tablice povezane odnosom jedan-prema-više (1:*) ili odnosom roditelj-dijete. U gornjem primjeru, koji uključuje pristup tablicama Client i Viewing, potonje su povezane upravo takvim odnosom. Svaki red pregledne tablice (dijete) pridružen je samo jednom retku tablice klijenta (roditelj), dok se isti red tablice klijenta (roditelj) može pridružiti
s mnogo redaka Pregledne tablice (dijete). Parovi redaka koji se generiraju prilikom izvršavanja upita rezultat su svih valjanih kombinacija redaka u podređenim i nadređenim tablicama. Odjeljak 3.2.5 opisuje kako relacijske baze podataka podataka, primarni i strani ključ tablica stvaraju odnos "roditelj-dijete". Tablica koja sadrži strani ključ obično je podređena, dok će tablica koja sadrži primarni ključ uvijek biti nadređena. Da biste koristili odnos roditelj-dijete u SQL upitu, morate navesti uvjet pretraživanja koji uspoređuje strani i primarni ključ. Primjer 24 uspoređuje primarni ključ tablice Client (v. clientNo) sa stranim ključem pregledne tablice (v. clientNo).
SQL standard dodatno pruža sljedeće načine definiranja ovu vezu:
IZKlijent sa PRIDRUŽITI Pregled v NA c.br.klijent = v.br.klijent
IZKlijent J OIN Pregledavanje UPOTREBA klijent br
IZklijent PRIRODNO PRIDRUŽENJE Pregledavanje
U svakom slučaju, klauzula FROM zamjenjuje izvorne klauzule FROM i WHERE. Međutim, u prvom slučaju se kreira tablica s dva identična stupca clientNo, dok će u druga dva slučaja rezultirajuća tablica sadržavati samo jedan stupac clientNo.
Primjer 25. Razvrstaj rezultate spajanja tablice. Za svaku podružnicu tvrtke navedite kadrovske brojeve i imena zaposlenika koji su odgovorni za sve iznajmljene objekte i navedite objekte za
na koje odgovaraju.
IZABERIbr.s.podružnice, br.s.osoblja, fName, INName, br
IZStaff s, PropertyForRent str
GDJEs.broj osoblja = p.broj osoblja
NARUDŽITE PObr. podružnice, br. osoblja, br. imovine;
Kako bi se rezultati lakše čitali, izlaz se sortira korištenjem broja odjela kao glavnog ključa sortiranja i broja osoblja i broja imovine kao sporednih ključeva. Rezultati izvršenja upita prikazani su u tablici. 35.
Tablica 35
Rezultat upita
| poslovnica br | Broj osoblja | fNaziv | Iname | vlasništvo br |
| TKO | SG14 | David | Ford | PG16 |
| TKO | SG37 | Ann | Bukva | PG21 |
| TKO | SG37 | Ann | Bukva | PG36 |
| BOO5 | SL41 | Marija | Lee | PL94 |
| SBI7 | SA9 | Julie | kako | PA14 |
Primjer 26. Spajanje tri stola. Za svaku podružnicu tvrtke navedite broj osoblja i imena zaposlenika odgovornih za sve iznajmljene objekte, uključujući grad u kojem se podružnica nalazi, te brojeve objekata za koje je svaki zaposlenik odgovoran.
IZABERI b.br.podružnice, b.grad, broj osoblja, fNaziv, Inaziv, br
IZ Podružnica b, Osoblje s, PropertyForRent str
GDJE b.br.grana = s.br.ogranka I s.broj osoblja = p.br.osoblja
NARUDŽITE PO b.br.grana, br.s.osoblja, br. imovine;
Rezultirajuća tablica mora sadržavati stupce iz tri izvorne tablice - Branch, Staff i PropertyForRent - tako da se upit mora pridružiti tim tablicama. Tablice podružnica i osoblje mogu se spojiti pomoću uvjeta b.branchNo=*s .branchNo, koji će povezati podružnice tvrtke s osobljem koje u njima radi. Tablice Staff i PropertyForRent mogu se spojiti pomoću uvjeta s.staffNo=p.staffNo. Kao rezultat, svaki će radnik biti povezan s onim iznajmljenim objektima za koje je odgovoran. Rezultati izvršenja upita prikazani su u tablici. 36.
Tablica 36
Rezultati upita
| poslovnica br | Grad | osobljeMo | fNaziv | Iname | vlasništvo br |
| B003 | Glasgow | SG14 | David | Ford | PG16 |
| B003 | Glasgow | SG37 | Ann | Bukva | PG21 |
| B003 | Glasgow | SG37 | Ann | Bukva | PG36 |
| B005 | London | SL41 | Julie | Lee | PL94 |
| B007 | Aberdeen | SA9 | Marija | kako | PA14 |
Imajte na umu da SQL standard dopušta alternativnu formulaciju klauzula FROM i WHERE:
IZ(Podružnica b PRIDRUŽITE osoblju s KORIŠTENJEM podružnice br.) KAO bs
PRIDRUŽITIPropertyForRent str UPOTREBA broj osoblja
Primjer 27. Grupiranje po više stupaca. Odredite broj zakupljenih objekata za koji je odgovoran svaki zaposlenik tvrtke.
IZABERIbr. podružnice, br. osoblja, RAČUNATI(*) KAO računati
FROM Staff s, PropertyForRent str
GDJE S.broj osoblja = p.broj osoblja
GRUPA POs.br.podružnice, br
NARUDŽITE PObr.s.podružnice, br.s.osoblje;
Za izradu potrebnog izvješća, prije svega, potrebno je saznati tko je od zaposlenika tvrtke odgovoran za zakupljene objekte. Ovaj se problem može riješiti spajanjem tablica Staff i PropertyForRent u stupcu staffNo u klauzulama FROM/WHERE. Zatim je potrebno formirati grupe koje se sastoje od broja podružnice i broja osoblja njenih zaposlenika, za što treba koristiti konstrukciju GROUP BY. Konačno, rezultirajuća tablica mora se sortirati pomoću ORDER BY klauzule. Rezultati izvršenja upita prikazani su u tablici. 37.
Tablica 37
Rezultat upita
| poslovnica br | broj osoblja | računati |
| B00Z | SG14 | |
| B00Z | SG37 | |
| B005 | SL41 | |
| B007 | SA9 |
Uspostavljanje veza. Spoj je podskup općenitije kombinacije podataka iz dvije tablice tzv kartezijanski. Kartezijanski proizvod dviju tablica je druga tablica koja se sastoji od svih mogućih parova redaka koji su dio obje tablice. Rezultirajući skup stupaca tablice su svi stupci prve tablice nakon kojih slijede svi stupci druge tablice. Ako unesete upit u dvije tablice bez navođenja klauzule WHERE, rezultat upita u SQL okruženju bit će kartezijanski proizvod ovih tablica. Osim toga, ISO standard pruža poseban format za izraz SELECT koji vam omogućuje izračunavanje kartezijanskog proizvoda dviju tablica:
SELECT(* j popis stupaca]
IZ tabliceNaziv CROSS JOINCayeUlte2
Razmotrimo ponovno primjer u kojem se spajanje tablica klijenta i preglednih tablica izvodi pomoću zajedničkog stupca clientNo. Pri radu s tablicama čiji je sadržaj dan u tablici. 3.6 i 3.8, kartezijanski proizvod ovih tablica imat će 20 redaka (4 reda tablice klijenta x 5 reda pregledne tablice = 20 redaka). Ovo je ekvivalentno izdavanju upita korištenog u primjeru 5-24, ali bez klauzule WHERE. Procedura za generiranje tablice koja sadrži rezultate spajanja dviju tablica pomoću naredbe SELECT je kako slijedi.
1. Formira se kartezijanski proizvod tablica navedenih u konstrukciji FROM.
2. Ako upit sadrži klauzulu WHERE, primijenite uvjete pretraživanja na svaki red kartezijanske tablice proizvoda i pohranite samo one retke u tablici koji zadovoljavaju zadane uvjete. U smislu relacijske algebre, ova operacija se zove ograničenje kartezijanski proizvod.
3. Za svaki preostali red utvrđuje se vrijednost svakog elementa navedenog na popisu SELECT, što rezultira posebnim redom rezultirajuće tablice.
4. Ako je konstrukcija SELECT DISTINCT prisutna u izvornom upitu, svi duplicirani reci se uklanjaju iz rezultirajuće tablice.
5. Ako upit koji se izvršava sadrži klauzulu ORDER BY,
©2015-2019 stranica
Sva prava pripadaju njihovim autorima. Ova stranica ne tvrdi autorstvo, ali pruža besplatno korištenje.
Datum izrade stranice: 07.08.2016