Članak daje odgovore na sljedeća pitanja:
- Kako usporediti dvije tablice u Excelu?
- Kako usporediti složene tablice u Excelu?
- Kako usporediti tablice u Excelu pomoću funkcije VLOOKUP()?
- Kako formirati jedinstvene identifikatore reda ako je njihova jedinstvenost inicijalno određena skupom vrijednosti u nekoliko stupaca?
- Kako popraviti vrijednosti ćelija u formulama prilikom kopiranja formula?
Prilikom rada s velikom količinom informacija, korisnik se može suočiti s takvim zadatkom kao što je usporedba dva tabelarnih izvora podataka. Prilikom pohranjivanja podataka u jedinstveni računovodstveni sustav (na primjer, sustavi temeljeni na 1C Enterprise, sustavi koji koriste SQL baze podataka), mogućnosti ugrađene u sustav ili DBMS mogu se koristiti za usporedbu podataka. U pravilu je za to dovoljno uključiti programera koji će napisati upit u bazu podataka ili programski mehanizam za izvješća. Iskusni korisnik koji ima vještinu pisanja 1C ili SQL upita također može obraditi upit.
Problemi počinju kada je potrebno hitno izvršiti zadatak usporedbe podataka, a uključivanje programera i pravovremeno pisanje zahtjeva ili programskog izvješća može prekoračiti rokove postavljene za rješavanje zadatka. Drugi jednako čest problem je potreba za usporedbom informacija iz različitih izvora. U ovom slučaju, izjava zadatka za programera zvučat će kao integracija dvaju sustava. Rješenje takvog problema će zahtijevati veću kvalifikaciju programera i također će oduzeti više vremena nego razvoj u jednom sustavu.
Za rješavanje navedenih problema idealna tehnika je korištenje uređivača proračunskih tablica Microsoft Excel za usporedbu podataka. Većina uobičajenih upravljačkih i reguliranih računovodstvenih sustava podržava izvoz u Excel format. Ovaj zadatak će zahtijevati samo određenu kvalifikaciju korisnika za rad s ovim uredskim paketom i neće zahtijevati vještine programiranja.
Razmislite o rješavanju problema usporedbe tablica u Excelu pomoću primjera. Imamo dvije tablice s popisima stanova. Izvori istovara - 1C Enterprise (računovodstvo za izgradnju) i tablica u Excelu (računovodstvo za prodaju). Tablice se u Excel radnoj knjizi nalaze na prvom, odnosno drugom listu.
Pred nama je zadatak usporedbe tih popisa po adresama. U prvoj tablici - svi stanovi u kući. U drugoj tablici - samo prodani stanovi i ime kupca. Krajnji cilj je da se u prvoj tablici za svaki stan ispiše ime kupca (za one stanove koji su prodani). Zadatak je kompliciran činjenicom da je adresa stana u svakoj tablici adresa zgrade i sastoji se od nekoliko polja: 1) adresa zgrade (kuće), 2) odjeljak (ulaz), 3) kat, 4) broj na katu (na primjer, od 1 do 4).
Da bismo usporedili dvije Excel tablice, moramo osigurati da u obje tablice svaki redak bude identificiran s jednim poljem, a ne s četiri. Takvo polje možete dobiti kombiniranjem vrijednosti četiri adresna polja s funkcijom Concatenate(). Svrha funkcije Concatenate() je spojiti više tekstualnih vrijednosti u jedan niz. Vrijednosti u funkciji navedene su kroz simbol ";". Kao vrijednosti mogu djelovati i adrese ćelija i proizvoljni tekst navedeni u navodnicima.
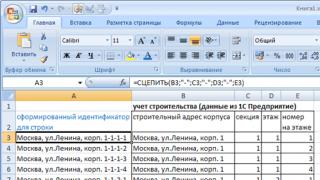
Korak 1. Umetnite prazan stupac "A" na početku prve tablice i u ćeliju tog stupca nasuprot prvog retka s podacima upišite formulu:
=SPAJANJE(B3,"-";C3;"-";D3;"-";E3)
Za praktičnost vizualne percepcije između vrijednosti spojenih ćelija postavili smo simbole "-".
Korak 2 Kopirajte formulu u sljedeće ćelije u stupcu A.

Korak 4 Za usporedbu Excel tablica po vrijednostima koristite funkciju VLOOKUP(). Svrha funkcije VLOOKUP() je traženje vrijednosti u krajnjem lijevom stupcu tablice i vraćanje vrijednosti ćelije u navedenom stupcu istog retka. Prvi parametar je željena vrijednost. Drugi parametar je tablica u kojoj će se vrijednost tražiti. Treći parametar je broj stupca iz čije će ćelije biti vraćena vrijednost u pronađenom retku. Četvrti parametar je vrsta pretraživanja: false - točno podudaranje, true - približno podudaranje.
Budući da bi izlazne informacije trebale biti smještene u prvu tablicu (u njoj su bila potrebna imena kupaca), u nju ćemo napisati formulu. Formulirajmo formulu u slobodnom stupcu desno od tablice nasuprot prvom redu podataka:
=VLOOKUP(A3;Sheet2!$A$3:$F$10;6;FALSE)
Prilikom kopiranja formula, "pametni" Excel automatski mijenja adresiranje ćelija. U našem slučaju mijenjat će se željena vrijednost za svaki red: A3, A4 itd., a adresa tablice u kojoj se traži mora ostati nepromijenjena. Da bismo to učinili, popravljamo ćelije u adresnom parametru tablice sa simbolima "$". Umjesto "Sheet2!A3:F10" radimo "Sheet2!$A$3:$F$10".
Neka postoje dvije tablice vrijednosti koje imaju isti sastav i tipove stupaca. Potrebno je usporediti ove tablice kako bi se utvrdile razlike, dostupni između njih.
Razmišljajući o uvjetima problema prema najčešćim okolnostima, dodatno utvrđujemo da:
- Različiti redoslijed istih redaka u dvije tablice ne čini tablice različitima (u problemima gdje je redoslijed redova značajan, uvijek možete dodati stupac s brojem retka kako biste uočili njihovu permutaciju);
- U jednoj tablici ne mogu postojati dva identična retka (a ako postoje, uvijek možete preklopiti sve stupce s brojem identičnih redaka u dodanom stupcu - to će pojednostaviti tumačenje rezultata usporedbe).
- Tablice se uspoređuju izravnom usporedbom vrijednosti njihovih elemenata ili referenci. Ako elementi tablice sadrže zbirke, tada se uspoređuju samo reference na zbirke bez pokušaja utvrđivanja jednakosti njihovog sadržaja.
Drugo usavršavanje automatski dovodi do činjenice da će tablica uvijek imati jedan ili više stupaca, čija će vrijednost (kombinacija vrijednosti) biti jedinstvena i može poslužiti kao identifikator reda. Takav stupac (skup stupaca) može se nazvati ključem: jednostavnim u slučaju jednog stupca ili složenim u složenijem slučaju. I još bolje, po analogiji s registrima, spomenuti se stupci nazivaju dimenzijama tablice, a preostali se nazivaju resursima.
Označavanje stupaca-dimenzija omogućuje, prilikom usporedbe tablica, utvrđivanje ne samo činjenice brisanja ili dodavanja retka, već i činjenice promjene retka ako su se resursi promijenili u istom skupu dimenzija.
Na primjer, kada se uspoređuju tablice vrijednosti dobivene iz bilance stanja računa za računovodstvo sirovina i materijala, mjere će biti stupci koji sadrže nomenklaturu i skladište, a sredstva će biti stanja i prometi računa. A kada se uspoređuju tablični dijelovi "Proizvodi", mjere će biti nomenklatura, karakteristika i serija, a resursi - svi ostali detalji ovog tabličnog dijela. I tada će se usporedbom verzija tabelarnih dijelova moći reći da je takva i takva nomenklatura uklonjena ili dodana, a takva i takva promijenjena.
Prilikom postavljanja problema određujemo i oblik prikaza rezultata usporedbe. Ovo je rješenje koje je najosjetljivije na kritike. Budući da o tome ovisi rezultat natjecanja metoda. Jedna forma može odgovarati jednoj metodi, druga drugoj, treća trećoj, a vježba, zbog raznolikosti zadataka i situacija, ne pomaže odgovoru.
Nakon dugog oklijevanja donesena je sljedeća odluka: rezultat usporedbe dviju tablica Table0 i Table1 trebala bi biti tablica "Razlika" iste strukture kao i uspoređivane tablice. "Razlika" treba sadržavati različite retke dviju tablica (izbrisano, dodano, promijenjeno). U tom slučaju u dodatnom stupcu "Znak" treba stajati oznaka: 0 - ako je linija u Tablici 0 i 1 - ako je linija u Tablici 1. Ovo se može protumačiti kao 0 - redak uklonjen, 1 - dodan ili 0 - redak prije promjene, 1 - poslije. Osim toga (pažnja!), redovi s istim mjernim vrijednostima trebaju se nalaziti jedan ispod drugog, što implementira prikladan način za vizualnu kontrolu za "povezivanje" redaka prije i nakon promjene.
Na primjer, ako usporedimo tablicu "Ocjena 7" s tablicom "Ocjena 8" koristeći predloženu metodu, tada treba dobiti tablicu "Razlika".
| 7. razred | 8. razred | Razlika | ||||||
| Artikal | Razred | Artikal | Razred | Artikal | Razred | Znak | ||
| Pjevanje | 5 | Književnost | 5 | Pjevanje | 5 | 0 | ||
| Književnost | 5 | Algebra | 4 | Algebra | 5 | 0 | ||
| Algebra | 5 | Fizika | 5 | Algebra | 4 | 1 | ||
| Fizika | 5 | Kemija | 4 | Kemija | 4 | 1 |
Pa, zadnji. Ne tako često, ali ipak postoje slučajevi kada se uspoređuju tablice koje su već sortirane po ključnim poljima. Dodajmo ovaj uvjet problemu kako bismo proširili skup testiranih algoritama metodom koja je posebno skrojena za ovaj slučaj.
2. Kriteriji ocjenjivanja i metode ispitivanja
Prirodno je izabrati vrijeme za usporedbu kao glavni kriterij ocjenjivanja. Dodatni kriterij može biti jednostavnost funkcije usporedbe. Vrijeme izvršenja usporedbe može se mjeriti obradom posebno stvorenom za tu svrhu. Predlaže se subjektivna procjena jednostavnosti funkcija.
Obrada stvorena za testiranje generira tablicu vrijednosti sa zadanim brojem redaka i stupaca i zadanim brojem dimenzija. Tip podataka elemenata odabire se s ograničenog popisa primitivnih tipova: niz, broj i datum, također možete postaviti duljinu vrijednosti. Vrijednosti elemenata tablice generiraju se nasumično. Promjenom prve tablice formira se druga. Broj izmjena dan je kao postotak broja redaka u prvoj tablici pomoću tri različita pokazatelja: postotak brisanja, izmjene i dodavanja. Broj ponavljanja također je postavljen kako bi se odredilo prosječno vrijeme rada metode. Sve ispitne metode izvode se jedna za drugom na istim ispitnim tablicama. Obrada korištena u testiranju priložena je ovoj publikaciji kako bi se rezultati mogli unakrsno provjeriti na drugom hardveru iu drugom softverskom okruženju.
3. Kratak opis uspoređivanih metoda
Za detaljno testiranje odabrano je ukupno sedam različitih metoda:
3.1. Konvolucija i sortiranje
Bit metode je kombinirati tablice dodavanjem u petlju jednog retka od prve tablice do druge. Zatim se dodaje dodatni stupac "Broj" za naknadno brojanje identičnih redaka. Izračun se vrši konvolucijom preko svih stupaca. Time se određuju isti i različiti reci u prvoj i drugoj tablici. Oni redovi koji su se nalazili jedan po jedan u kombiniranoj tablici prepisuju se u tablicu razlika, koja se zatim razvrstava po dimenzijama tako da redovi prije i poslije promjena budu sljedeći. Ovdje je kod za ovu funkciju
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export AllColumns = ""; Za svaki stupac tablice0.Columns Loop AllColumns = AllColumns + ", " + Column.Name Kraj petlje; Svi stupci = Prosj.(Svi stupci, 2); Tablica = Tablica1.Kopiraj(); Table.Columns.Add("Znak", NewTypeDescription("Broj")); Table.FillValues(1, "Sign"); Za svaki red iz tablice0 Loop FillPropertyValues(Table.Add(), Row) EndCycle; Table.Columns.Add("Račun"); Table.FillValues(1, "Račun"); Table.Collapse(AllColumns, "Sign, Count"); Odgovor = Table.Copy(New Structure("Account", 1), AllColumns + ", Sign"); Odgovor.Sortiraj(Dimenzije); Povratni odgovor EndFunction
3.2 Trik, preklapanje i sortiranje
Ova funkcija je mala modifikacija prethodne funkcije zbog činjenice da dodavanje prve tablice u drugu ne ide po redovima, već po stupcima. Ovo, u određenom rasponu uvjeta, ubrzava operaciju spajanja tablice.
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export AllColumns = ""; Za svaki stupac tablice0.Columns Loop AllColumns = AllColumns + ", " + Column.Name Kraj petlje; Svi stupci = Prosj.(Svi stupci, 2); Tablica = Tablica1.Kopiraj(); Table.Columns.Add("Znak", NewTypeDescription("Broj")); Table.FillValues(1, "Sign"); Za e = 1 By Table0.Quantity() Loop Table.Insert(0) EndCycle; Za ë = 0 By Table0.Columns.Quantity() - 1 petlja Table.LoadColumn(Table0.UnloadColumn(ë), ë) Kraj ciklusa; Table.Columns.Add("Račun"); Table.FillValues(1, "Račun"); Table.Collapse(AllColumns, "Sign, Count"); Odgovor = Table.Copy(New Structure("Account", 1), AllColumns + ", Sign"); Odgovor.Sortiraj(Dimenzije); Povratni odgovor EndFunction
3.3. Pridružite se indeksom
Ova je funkcija izgrađena na jednostavnoj i jasnoj ideji. Prolazi kroz retke prve tablice. Za svaki redak pokušava se pronaći redak u drugoj tablici koji mu odgovara po vrijednosti dimenzije pomoću metode "Pronađi retke". Resursi pronađenih redaka se zatim uspoređuju radi odstupanja, pronađeni redak u drugoj tablici označen je nulom, da bi se zatim odabrali neoznačeni "pojedinačni" reci koji nisu prisutni u prvoj tablici. Kako bi metoda FindRows brzo radila, jedan indeks se stvara za drugu tablicu u cijelom skupu dimenzija.
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Izvoz odabira = Nova struktura(Dimenzije); Resursi = Novi niz; For IndexColumns = 0 By Table0.Columns.Count() - 1 Loop If NOT Selection.Property(Table0.Columns[IndexColumns].Name) Then Resources.Add(IndexColumns) EndIf EndCycle; Table1.Columns.Add("Znak", NewTypeDescription("Broj")); Table1.FillValues(1, "Sign"); NewIndex = Table1.Indexes.Add(Dimensions); Razlika = Table1.CopyColumns(); Za svaki redak0 iz tablice0 petlja FillPropertyValues(Selection, Row0); Redovi1 = Tablica1.PronađiRedove(Odabir); If Rows1.Count() = 0 Then FillPropertyValues(Difference.Add(), Row0) Inače Red1 = Rows1; Za svaki resurs iz petlje resursa If String0[resurs]<>Line1[Resource] Then FillPropertyValues(Difference.Add(), Line0); FillPropertyValues(Difference.Add(), Line1); Prekid EndIf Kraj petlje; String1.Sign = 0 EndIf EndLoop; Za svaki redak1 iz tablice1.Pronađi redove(Nova struktura("Znak", 1)) Petlja FillPropertyValues(Difference.Add(), Red1); EndCycle; Table1.Columns.Delete("Sign"); Table1.Indexes.Delete(NewIndex); Vrati razliku EndFunction
3.4. Veza sukladnosti
Ova funkcija algoritamski ponavlja prethodnu, osim što se umjesto običnog indeksa koristi "sam-made" indeks temeljen na podudaranju. Da bi se to postiglo, druga se tablica prethodno obilazi, zbog čega se reference na njezine retke pohranjuju u stablo pretraživanja izgrađeno na temelju podudaranja
Funkcija DifferenceTableValues_(Table0, Table1, RowDimensions) Export Table1.Columns.Add("Sign", NewTypeDescription("Number")); Table1.FillValues(1, "Sign"); DimensionStructure = Nova struktura(DimensionString); Dimenzije = Novi niz; Resursi = Novi niz; For Index = 0 By Table0.Columns.Count() - 1 LoopColumnName = Table0.Columns[Index].Name; If DimensionStructure.Property(ColumnName) Then Dimensions.Add(Index) Else Resources.Add(Index) EndIf EndCycle; DimensionPlus = Dimenzije[Dimensions.Count() - 1]; Dimenzije.Delete(Measurements.Quantity() - 1); HashMap = Nova utakmica; Za svaki redak1 iz tablice1 Korijen petlje = HashMap; Za svaku dimenziju iz dimenzije LoopKeyPart = redak1[dimenzija]; Grana = korijen[Ključni dio]; If Branch = Nedefinirano Then Branch = New Match; Root[KeyPart] = Branch EndIf; Korijen = završni ciklus grane; PartKey = Niz1[DimenzijaPlus]; Root[KeyPart] = String1 EndCycle; Dimenzije.Dodaj(DimenzijaPlus); Razlika = Table1.CopyColumns(); Za svaki redak0 iz tablice0 Korijen petlje = HashMap; Za svaku dimenziju iz dimenzije LoopKeyPart = String0[dimenzija]; Grana = korijen[Ključni dio]; If Branch = Undefined Then FillPropertyValues(Difference.Add(), Line0); Prekid EndIf; Korijen = završni ciklus grane; Ako grana<>Nedefinirano Zatim za svaki resurs iz petlje resursa If String0[resurs]<>Branch[Resource] Then FillPropertyValues(Difference.Add(), Line0); FillPropertyValues(Difference.Add(), Grana); Prekid EndIf Kraj petlje; Branch.Sign = 0 EndIf EndCycle; Za svaki redak1 iz tablice1.Pronađi redove(Nova struktura("Znak", 1)) Petlja FillPropertyValues(Difference.Add(), Red1); EndCycle; Table1.Columns.Delete("Sign"); Vrati razliku EndFunction
3.5. spajanje
Ova funkcija pretpostavlja da su uspoređene tablice poredane po ključnim dimenzijama. Tijekom rada, redovi dviju tablica se redom čitaju, uspoređuju jedni s drugima, tako da je rezultat spojena uređena tablica bez identičnih redaka.
Funkcija DifferenceTableValues_(Table0, Table1, RowDimensions) Export Table1.Columns.Add("Sign", NewTypeDescription("Number")); Table1.FillValues(1, "Sign"); Razlika = Table1.CopyColumns(); DimensionStructure = Nova struktura(DimensionString); Dimenzije = Novi niz; Resursi = Novi niz; For Index = 0 By Table0.Columns.Count() - 1 LoopColumnName = Table0.Columns[Index].Name; If DimensionStructure.Property(ColumnName) Then Dimensions.Add(Index) Else Resources.Add(Index) EndIf EndCycle; Usporedba = Nova usporedba vrijednosti; Indeks1 = Tablica0.Broj() - 1; Indeks2 = Tablica1.Broj() - 1; Redak1 = Tablica0[Indeks1]; Redak2 = Tablica1[Indeks2]; Dok je istinita petlja za svaku dimenziju iz dimenzije LoopCompareResult = Comparison.Compare(Red1[Dimenzija], Red2[Dimenzija]); IfComparisonResult<>0 Zatim prekinuti EndIf Kraj petlje; IfComparisonResult = 0 Onda za svaki resurs iz petlje resursa If String1[Resource]<>Line2[Resource] Then FillPropertyValues(Difference.Add(), Line1); FillPropertyValues(Difference.Add(), Line2); Prekid EndIf Kraj petlje; Indeks1 = Indeks1 - 1; Indeks2 = Indeks2 - 1; Ako Min(indeks1, indeks2)< 0 Тогда Прервать КонецЕсли; Строка1 = Таблица0[Индекс1]; Строка2 = Таблица1[Индекс2]; ИначеЕсли РезультатСравнения >0 Zatim FillPropertyValues(Difference.Add(), Line1); Indeks1 = Indeks1 - 1; Ako Index1< 0 Тогда Прервать КонецЕсли; Строка1 = Таблица0[Индекс1] Иначе ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2); Индекс2 = Индекс2 - 1; Если Индекс2 < 0 Тогда Прервать КонецЕсли; Строка2 = Таблица1[Индекс2] КонецЕсли КонецЦикла; Пока Индекс1 >= 0 Petlja Red1 = Tablica0[Indeks1]; FillPropertyValues(Difference.Add(), Line1); Indeks1 = Indeks1 - 1 završni ciklus; Dok Indeks2 >= 0 Petlja Red2 = Tablica1[Indeks2]; FillPropertyValues(Difference.Add(), Line2); Indeks2 = Indeks2 - 1 završni ciklus; Table1.Columns.Delete("Sign"); Vrati razliku EndFunction
3.6. Upit - potpuno pridruživanje
Funkcija se temelji na prosljeđivanju dvije tablice u upit, gdje su spojene jednakošću vrijednosti u dimenzijama. Mala komplikacija povezana je s naknadnim "čišćenjem" u dva reda redaka,razlikuju u resursima.
Funkcija StrPart(String, Delimiter) ExportDelimiterPosition = Find(String, Delimiter); If SeparatorPosition = 0 Then Response = New Array; Odgovor.Dodaj(niz); Inače Odgovor = StrParts(Average(String, SeparatorPosition + StrLength(Separator)), Separator); Answer.Insert(0, Middle(String, 1, SeparatorPosition - 1)) EndIf; Povratni odgovor EndFunction Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export Query = New Query("SELECT | 0 AS Sign(), T.Field() |PUT T0 |FROM | &Table0 AS T |; | |//////////////////////////////////////////// ////////////////////////////////////////////////////////////////////////////////////////////// |SELECT |1 AS Sign(), T.Field() |PUT T1 |FROM | &Tablica 1 AS T |; | |/////////////////////////////////////// //////////////////////////////////// |SELECT |0 AS Znak |PUT Znakovi | |CONNECT | |SELECT |1 |; |///////////// ////////////////////////////////////////////////////////// |SELECT() | SELECT Signs.Sign | WHEN 0 | THEN T0.Field | ALSE T1.Field | END AS Polje,() | Signs.Sign |FROM | T0 AS T0 | POTPUNA VEZA T1 KAO T1 | UKLJUČENO (ISTINA) | () I T0.Polje = T1.Polje(), | Znakovi KAO Znakovi |WHERE | (() T0.Polje JE NULL I Znak.Sign = 1 | ILI T1.Polje JE NULL I Znak.Sign = 0 | () ILI T0.Polje<>T1.Polje()) | |NARUČI OD | ()Field"); DimensionStructure = Nova struktura(Dimensions); Sections = StrParts(Query.Text, "()"); Query.Text = Sections; Za svaki stupac iz tablice1.Columns Loop Query.Text = Query.Text + StrReplace(Sections, "Field", Column.Name) EndCycle; Query.Text = Query .Text + Sec za svaki stupac iz Table1.Columns Loop Query.Text = Query.Text + StrReplace(Sections, "Field", Column.Name) EndCycle; Query.Text = Query.Text + Sections; Za svaki stupac iz Table1.Columns Loop Query.Text = Query.Text + StrReplace(Sections, "Field", Stupac. Naziv) EndCycle; Query.Text = Query.Text + Sekcije; Za svaki element FromDimensionStructure ciklus Query.Text = Query.Text + StrReplace(Sections, "Field", Element.Key) EndCycle; Query.Text = Query.Text + Sections; Query.Text = Query.Text + StrReplace(Sections, "Fi eld ", Table1.Columns.Name); Za svaki stupac iz Table1.Columns Loop If NOT Struktura dimenzije.Property(Column.Name) Then Query.Text = Query.Text + StrReplace(Sections, "Field", Column.Name) EndIf EndCycle; Upit.Tekst = Upit.Tekst + Odjeljci; Query.Text = Query.Text + StrReplace(Odjeljci, "Polje", Dimenzije); Query.SetParameter("Tablica0", Tablica0); Query.SetParameter("Tablica1", Tablica1); Return Request.Execute().Upload() EndFunction
3.7. Zahtjev - grupiranje
Ova je funkcija izgrađena točno na istoj ideji kao funkcija 3.1, samo implementirana unutar zahtjeva
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export Query = New Query("SELECT | 0 AS Sign, | T.Field |PUT T0 |FROM | &Table0 AS T |; | |////////////////////////////////////////////////// //////// //////////////////// |SELECT |1 AS Sign, |T.Field |PUT T1 |FROM |&Table1 AS T |; |///////////////////////////////////////////////////// //////////////////// //////// |SELECT | T.Sign, | T.Field |PUT T |FROM | T0 AS T | |JOIN SVI | |SELECT | T.Sign, | T.Field |FROM | T1 AS T |; | |////////////////////////////////////////////////////////// ///////////////////////////. Svi stupci = ""; Za svaki stupac iz Table1.Columns Loop AllColumns = AllColumns + ", T." + Column.Name EndCycle; Query.Text = StrReplace(Query.Text, "T.Field", Avg(AllColumns, 2)); Query.Text = StrReplace(Query.Text, "Field//", Dimensions); Query.SetParameter("Tablica0", Tablica0); Query.SetParameter("Tablica1", Tablica1); Return Request.Execute().Upload() EndFunction
Sve ovdje predstavljene funkcije pažljivo su podešene kako bi se postigla maksimalna izvedba. Uzimajući u obzir iskustvo stečeno tijekom zajedničkog ugađanja na funkcijskom forumu za jednodimenzionalni slučaj. No, to nije rađeno tako pažljivo kao tamo, pa se možda iz nekih funkcija može iscijediti još koja performansa.
4. Rezultati ispitivanja
4.1 Utjecaj broja redaka
Istražujemo ovisnost vremena usporedbe o broju redaka u tablicama. Da bismo to učinili, koristimo sljedeće parametre testa. Broj redaka je 20000, 40000, 60000, 80000, 100000, broj stupaca je 10, broj ključnih stupaca je 1, tip podataka je niz, duljina niza je 10, postotak brisanja, promjena, dodavanja je 5, broj ponavljanja testa je 2. Dobivamo sljedeću ovisnost, što je prikladnije za predstaviti u obliku grafikona.
Ova je ovisnost za većinu metoda gotovo linearna! Tako i treba biti. Vrijeme izvršenja metode FindRows u prisutnosti indeksa ne ovisi o broju redaka, tako da se spajanje na indeksu izvodi u linearnom vremenu. Isto vrijedi i kada koristite podudaranje i spajanje. U potpunom spajanju, upit najvjerojatnije koristi hash podudaranje za spajanje tablica jednake veličine.
Nelinearnost vremena sortiranja s obzirom na mali broj različitih redaka malo odstupa od izravne ovisnosti za konvoluciju. Stvari su gore za metodu koja koristi uniju kopiranjem stupaca - upravo ova metoda kopiranja uvodi značajnu nelinearnost uz blagu nelinearnost sortiranja. Zbog toga se gubi korist korištenja "trika" spajanja tablica na više od 60.000 redaka.
4.2 Utjecaj duljine vrijednosti
Ispitajmo sada ovisnost vremena o duljini vrijednosti niza. Postavimo broj redaka na 50000. Ostali parametri su isti kao u 4.1. Rezultat se prikazuje u obliku stupčastog grafikona. Bolje prikazuje omjer vremena izvođenja različitih metoda i omogućuje vam da istaknete vodeću, što je u većini slučajeva metoda konvolucije.

Vidi se da se ovisnost vremena o metodi praktički ne mijenja kada se promijeni duljina niza. Raste samo vrijeme izvršenja upita.
Kako bi ovaj grafikon bio što informativniji u odnosu na metode upita, ovdje je u posebnim dimenzijama istaknuto vrijeme unosa tablica u upit. Da biste to učinili, stvorena je lažna funkcija koja samo izvršava unos tablica u upit i ne obavlja nikakav drugi posao. Dugo vrijeme za unos tablica pokazuje da je tehnici upita vrlo teško konkurirati vodećim metodama. U mnogim slučajevima, voditelji su već završili svoj posao u trenutku kada su izvorni podaci u upitu.
4.3 Utjecaj tipova podataka
Sljedeće zanimljivo pitanje je odnos metoda prema tipovima podataka. To je prikazano na sljedećem dijagramu. I ovdje je broj redaka 50000, duljina niza i numerička vrijednost je 10. Ostalo je isto kao u 4.1.

To pokazuje da vrsta podataka ima najveći utjecaj na vrijeme upitnih metoda. Grupiranje je bolje za brojeve. I datumi se vrlo dobro obrađuju prema zahtjevima.
4.3 Utjecaj broja stupaca
Druga ovisnost je ovisnost vremena usporedbe o broju stupaca. To je prikazano na sljedećem dijagramu. Broj redaka ovdje je 50 000, vrsta podataka je niz duljine 10, postotak dodavanja, izobličenja i brisanja svaki je 5. Jedan ključni stupac.

Vidi se da broj stupaca ne mijenja uvelike usporednu brzinu metoda. Najviše od svega, povećanje broja stupaca usporava upite.
4.4 Utjecaj broja mjerenja
Zanimljivija je ovisnost o broju ključnih stupaca prikazana u nastavku. Broj redaka ovdje je 50 000, vrsta podataka je niz duljine 10, postotak dodavanja, izobličenja i brisanja svaki je 5. Ukupno ima 10 stupaca.

Može se vidjeti da je metoda koja se temelji na dopisivanju, koja je prije pokazala dobre rezultate, sada autsajder. Spajanje također postaje gore. Ali pretraživanje po indeksu se poboljšava - zbog činjenice da ima manje stupaca za usporedbu.
4.5 Učinak razlika u veličini tablice
Sada obratimo pozornost na asimetriju metoda 1 - 4 (konvolucije i spajanja) s obzirom na veličine tablica koje se uspoređuju. Sve ove metode imaju koristi od toga što je prva tablica manja! To potvrđuje sljedeća tablica, koja pokazuje vrijeme usporedbe dviju tablica od 50 000 i 40 000 redaka različitim redoslijedom.

Na gornjem dijagramu primjetan je zanimljiv artefakt. S obzirom na broj redaka i stupaca, ispada da je isplativije proći kroz 50 000 redaka do tablice od 40 000 redaka nego obrnuto. Možda je to zbog osobitosti raspodjele memorije za tablicu vrijednosti.
4.6 Utjecaj broja razlika
I, na kraju, ispitat ćemo ovisnost vremena usporedbe o stupnju razlike između tablica. Može se vidjeti da kako se postotak odstupanja povećava, vrijeme izvođenja konvolucije usporava. Budući da nelinearnost sortiranja počinje igrati ulogu.

4.7 Utjecaj hardverskog i softverskog okruženja
Testovi su obavljeni na platformi 8.3.5.1248 na prijenosnom računalu VGN-Z51MRG. Dobivene ovisnosti općenito su potvrđene na drugoj opremi, ali postoje neke značajke koje još nisu generalizirane.
5. Zaključci
5.1. Najjednostavnija metoda konvolucije pokazuje se najproduktivnijom u većini slučajeva. Treba ga koristiti kao univerzalnu metodu, ali ne u posebnim slučajevima.
5.2 S malom veličinom (do 50 000 redaka), možete dobiti dodatno ubrzanje konvolucije primjenom kopiranja stupaca prilikom spajanja tablica (metoda 3.2).
5.3 U posebnom slučaju jednog ključnog stupca, značajnog broja razlika i značajne razlike u veličinama tablice, potrebno je koristiti spajanje podudaranja. Isto treba učiniti čak i ako postoji nekoliko ključnih tablica, ali se usporedba vrši s istom tablicom, za koju se možete unaprijed pripremiti "stablo odlučivanja" na temelju podudaranja,prilagođen njegovim karakteristikama.
5.4 U posebnom slučaju nekoliko ključnih stupaca sa značajnim brojem razlika i nerazvrstanih uspoređenih tablica, trebate koristiti metodu spajanja indeksa.
5.5 Za najveću učinkovitost metoda 1-4 potrebno je odabrati ispravan redoslijed navođenja tablica prilikom usporedbe.
5.6 U posebnom slučaju sortiranih uspoređenih tablica sa značajnim brojem razlika, treba koristiti spajanje.
5.7. U posebnom slučaju velikih (ovisnih o hardveru) i približno jednakih tablica, koje osim toga imaju značajne razlike i sastoje se od kratkih redaka i iznimno malog broja stupaca, moguće je koristiti upite.
5.8 Ako u tablicama dominiraju numerički podaci, datumi, srednji i dugi nizovi, tada bi upiti za usporedbu tablica trebali koristiti grupiranje, a samo za vrlo kratke nizove, potpuno spajanje.
6. Opći zaključci
6.1 U svakom slučaju, prije donošenja odlučnog izbora, bolje je, ako je moguće, usporediti nekoliko metoda u stvarnim uvjetima njihove primjene. Na primjer, pomoću obrade priložene članku.
6.2 Uzimanje u obzir osobitosti podataka u tablicama omogućuje ciljanu dodatnu optimizaciju većine gore navedenih metoda. Za to postoje mnoge mogućnosti koje ostaju izvan raspona razmatranih pitanja.
6.3 Unos tablica vrijednosti u upite može potrajati značajno vrijeme, što u većini slučajeva poništava učinkovitost njihove upotrebe u zadacima kada se podaci uzimaju iz memorije, a ne iz baze podataka. Bezumno korištenje upita u ovom problemu je štetna zabluda.
6.4 Vrijeme rada metode FindRows u prisutnosti indeksa na stupcima uključenim u odabir ne ovisi o veličini tablice vrijednosti. Prema tome, ispravna procjena izvedbe za metodu usporedbe tablice koja koristi indeksno spajanje je O(N).
, koji je predložio, implementirao i otklonio pogreške u svojim metodama za jednodimenzionalni slučaj, napravio mnoge korisne ispravke i razmatranja, a također je aktivno sudjelovao u svim raspravama. Posebno zahvaljujemo sponzorima iste podružnice i - za zanimljivo pitanje.Nakon instaliranja dodatka, imat ćete novu karticu s naredbom za poziv funkcije. Kada kliknete na naredbu Usporedba raspona pojavljuje se dijaloški okvir za unos parametara.
Ova vam makronaredba omogućuje usporedbu tablica bilo koje veličine i s bilo kojim brojem stupaca. Tablice se mogu uspoređivati u jednom, dva ili tri stupca odjednom.
Dijaloški okvir je podijeljen u dva dijela: lijevi za prvu tablicu i desni za drugu.
Za usporedbu tablica učinite sljedeće:
- Navedite raspone tablice.
- Postavite potvrdni okvir (kvačica/kvačica) ispod odabranog raspona tablica ako tablica uključuje zaglavlje (redak zaglavlja).
- Odaberite stupce lijeve i desne tablice za usporedbu (ako rasponi tablice ne uključuju zaglavlja, stupci će biti numerirani).
- Navedite vrstu usporedbe.
- Odaberite izlaznu opciju.
Vrsta usporedbe tablice
 Program vam omogućuje odabir nekoliko vrsta usporedbe tablica:
Program vam omogućuje odabir nekoliko vrsta usporedbe tablica:
Pronađite retke u jednoj tablici koji nedostaju u drugoj tablici
Kada je odabrana ova vrsta usporedbe, program traži retke u jednoj tablici koji nedostaju u drugoj. Ako uspoređujete tablice po nekoliko stupaca, tada će rezultat rada biti redovi u kojima postoji razlika u barem jednom od stupaca.
Pronađite odgovarajuće linije
Kada je odabrana ova vrsta usporedbe, program pronalazi retke koji se podudaraju u prvoj i drugoj tablici. Podudarni retci su oni u kojima se vrijednosti u odabranim usporednim stupcima (1, 2, 3) jedne tablice u potpunosti podudaraju s vrijednostima stupaca druge tablice.
Primjer programa u ovom načinu rada prikazan je desno na slici.
Uparite tablice na temelju odabranih
U ovom načinu usporedbe, ispred svakog retka prve tablice (odabranog kao glavnog), kopiraju se podaci odgovarajućeg retka druge tablice. Ako nema odgovarajućih redaka, red nasuprot glavne tablice ostaje prazan.
Uspoređivanje tablica s četiri ili više stupaca
Ako vam nedostaje funkcionalnost programa i trebate spojiti tablice na četiri ili više stupaca, to možete riješiti na sljedeći način:
- Napravite prazan stupac u tablicama.
- U novim stupcima pomoću formule = SPOJITI spojite stupce s kojima želite usporediti.
Tako ćete završiti s 1 stupcem koji sadrži vrijednosti više stupaca. Pa, već znate kako spojiti jedan stupac.

1. Izjava problema
Neka postoje dvije tablice vrijednosti koje imaju isti sastav i tipove stupaca. Potrebno je usporediti ove tablice kako bi se utvrdile razlike, dostupni između njih.
Razmišljajući o uvjetima problema prema najčešćim okolnostima, dodatno utvrđujemo da:
- Različiti redoslijed istih redaka u dvije tablice ne čini tablice različitima (u problemima gdje je redoslijed redova značajan, uvijek možete dodati stupac s brojem retka kako biste uočili njihovu permutaciju);
- U jednoj tablici ne mogu postojati dva identična retka (a ako postoje, uvijek možete preklopiti sve stupce s brojem identičnih redaka u dodanom stupcu - to će pojednostaviti tumačenje rezultata usporedbe).
- Tablice se uspoređuju izravnom usporedbom vrijednosti njihovih elemenata ili referenci. Ako elementi tablice sadrže zbirke, tada se uspoređuju samo reference na zbirke bez pokušaja utvrđivanja jednakosti njihovog sadržaja.
Drugo usavršavanje automatski dovodi do činjenice da će tablica uvijek imati jedan ili više stupaca, čija će vrijednost (kombinacija vrijednosti) biti jedinstvena i može poslužiti kao identifikator reda. Takav stupac (skup stupaca) može se nazvati ključem: jednostavnim u slučaju jednog stupca ili složenim u složenijem slučaju. I još bolje, po analogiji s registrima, spomenuti se stupci nazivaju dimenzijama tablice, a preostali se nazivaju resursima.
Označavanje stupaca-dimenzija omogućuje, prilikom usporedbe tablica, utvrđivanje ne samo činjenice brisanja ili dodavanja retka, već i činjenice promjene retka ako su se resursi promijenili u istom skupu dimenzija.
Na primjer, kada se uspoređuju tablice vrijednosti dobivene iz bilance stanja računa za računovodstvo sirovina i materijala, mjere će biti stupci koji sadrže nomenklaturu i skladište, a sredstva će biti stanja i prometi računa. A kada se uspoređuju tablični dijelovi "Proizvodi", mjere će biti nomenklatura, karakteristika i serija, a resursi - svi ostali detalji ovog tabličnog dijela. I tada će se usporedbom verzija tabelarnih dijelova moći reći da je takva i takva nomenklatura uklonjena ili dodana, a takva i takva promijenjena.
Prilikom postavljanja problema određujemo i oblik prikaza rezultata usporedbe. Ovo je rješenje koje je najosjetljivije na kritike. Budući da o tome ovisi rezultat natjecanja metoda. Jedna forma može odgovarati jednoj metodi, druga drugoj, treća trećoj, a vježba, zbog raznolikosti zadataka i situacija, ne pomaže odgovoru.
Nakon dugog oklijevanja donesena je sljedeća odluka: rezultat usporedbe dviju tablica Table0 i Table1 trebala bi biti tablica "Razlika" iste strukture kao i uspoređivane tablice. "Razlika" treba sadržavati različite retke dviju tablica (izbrisano, dodano, promijenjeno). U tom slučaju u dodatnom stupcu "Znak" treba stajati oznaka: 0 - ako je linija u Tablici 0 i 1 - ako je linija u Tablici 1. Ovo se može protumačiti kao 0 - redak uklonjen, 1 - dodan ili 0 - redak prije promjene, 1 - poslije. Osim toga (pažnja!), redovi s istim mjernim vrijednostima trebaju se nalaziti jedan ispod drugog, što implementira prikladan način za vizualnu kontrolu za "povezivanje" redaka prije i nakon promjene.
Na primjer, ako usporedimo tablicu "Ocjena 7" s tablicom "Ocjena 8" koristeći predloženu metodu, tada treba dobiti tablicu "Razlika".
| 7. razred | 8. razred | Razlika | ||||||
| Artikal | Razred | Artikal | Razred | Artikal | Razred | Znak | ||
| Pjevanje | 5 | Književnost | 5 | Pjevanje | 5 | 0 | ||
| Književnost | 5 | Algebra | 4 | Algebra | 5 | 0 | ||
| Algebra | 5 | Fizika | 5 | Algebra | 4 | 1 | ||
| Fizika | 5 | Kemija | 4 | Kemija | 4 | 1 |
Pa, zadnji. Ne tako često, ali ipak postoje slučajevi kada se uspoređuju tablice koje su već sortirane po ključnim poljima. Dodajmo ovaj uvjet problemu kako bismo proširili skup testiranih algoritama metodom koja je posebno skrojena za ovaj slučaj.
2. Kriteriji ocjenjivanja i metode ispitivanja
Prirodno je izabrati vrijeme za usporedbu kao glavni kriterij ocjenjivanja. Dodatni kriterij može biti jednostavnost funkcije usporedbe. Vrijeme izvršenja usporedbe može se mjeriti obradom posebno stvorenom za tu svrhu. Predlaže se subjektivna procjena jednostavnosti funkcija.
Obrada stvorena za testiranje generira tablicu vrijednosti sa zadanim brojem redaka i stupaca i zadanim brojem dimenzija. Tip podataka elemenata odabire se s ograničenog popisa primitivnih tipova: niz, broj i datum, također možete postaviti duljinu vrijednosti. Vrijednosti elemenata tablice generiraju se nasumično. Promjenom prve tablice formira se druga. Broj izmjena dan je kao postotak broja redaka u prvoj tablici pomoću tri različita pokazatelja: postotak brisanja, izmjene i dodavanja. Broj ponavljanja također je postavljen kako bi se odredilo prosječno vrijeme rada metode. Sve ispitne metode izvode se jedna za drugom na istim ispitnim tablicama. Obrada korištena u testiranju priložena je ovoj publikaciji kako bi se rezultati mogli unakrsno provjeriti na drugom hardveru iu drugom softverskom okruženju.
3. Kratak opis uspoređivanih metoda
Za detaljno testiranje odabrano je ukupno sedam različitih metoda:
3.1. Konvolucija i sortiranje
Bit metode je kombinirati tablice dodavanjem u petlju jednog retka od prve tablice do druge. Zatim se dodaje dodatni stupac "Broj" za naknadno brojanje identičnih redaka. Izračun se vrši konvolucijom preko svih stupaca. Time se određuju isti i različiti reci u prvoj i drugoj tablici. Oni redovi koji su se nalazili jedan po jedan u kombiniranoj tablici prepisuju se u tablicu razlika, koja se zatim razvrstava po dimenzijama tako da redovi prije i poslije promjena budu sljedeći. Ovdje je kod za ovu funkciju
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export AllColumns = ""; Za svaki stupac tablice0.Columns Loop AllColumns = AllColumns + ", " + Column.Name Kraj petlje; Svi stupci = Prosj.(Svi stupci, 2); Tablica = Tablica1.Kopiraj(); Table.Columns.Add("Znak", NewTypeDescription("Broj")); Table.FillValues(1, "Sign"); Za svaki red iz tablice0 Loop FillPropertyValues(Table.Add(), Row) EndCycle; Table.Columns.Add("Račun"); Table.FillValues(1, "Račun"); Table.Collapse(AllColumns, "Sign, Count"); Odgovor = Table.Copy(New Structure("Account", 1), AllColumns + ", Sign"); Odgovor.Sortiraj(Dimenzije); Povratni odgovor EndFunction
3.2 Trik, preklapanje i sortiranje
Ova funkcija je mala modifikacija prethodne funkcije zbog činjenice da dodavanje prve tablice u drugu ne ide po redovima, već po stupcima. Ovo, u određenom rasponu uvjeta, ubrzava operaciju spajanja tablice.
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export AllColumns = ""; Za svaki stupac tablice0.Columns Loop AllColumns = AllColumns + ", " + Column.Name Kraj petlje; Svi stupci = Prosj.(Svi stupci, 2); Tablica = Tablica1.Kopiraj(); Table.Columns.Add("Znak", NewTypeDescription("Broj")); Table.FillValues(1, "Sign"); Za e = 1 By Table0.Quantity() Loop Table.Insert(0) EndCycle; Za ë = 0 By Table0.Columns.Quantity() - 1 petlja Table.LoadColumn(Table0.UnloadColumn(ë), ë) Kraj ciklusa; Table.Columns.Add("Račun"); Table.FillValues(1, "Račun"); Table.Collapse(AllColumns, "Sign, Count"); Odgovor = Table.Copy(New Structure("Account", 1), AllColumns + ", Sign"); Odgovor.Sortiraj(Dimenzije); Povratni odgovor EndFunction
3.3. Pridružite se indeksom
Ova je funkcija izgrađena na jednostavnoj i jasnoj ideji. Prolazi kroz retke prve tablice. Za svaki redak pokušava se pronaći redak u drugoj tablici koji mu odgovara po vrijednosti dimenzije pomoću metode “Pronađi retke”. Resursi pronađenih redaka se zatim uspoređuju radi odstupanja, pronađeni redak u drugoj tablici označava se nulom, kako bi se zatim odabrali neoznačeni "pojedinačni" reci koji nedostaju u prvoj tablici. Kako bi metoda FindRows brzo radila, jedan indeks se stvara za drugu tablicu u cijelom skupu dimenzija.
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Izvoz odabira = Nova struktura(Dimenzije); Resursi = Novi niz; For IndexColumns = 0 By Table0.Columns.Count() - 1 Loop If NOT Selection.Property(Table0.Columns[IndexColumns].Name) Then Resources.Add(IndexColumns) EndIf EndCycle; Table1.Columns.Add("Znak", NewTypeDescription("Broj")); Table1.FillValues(1, "Sign"); NewIndex = Table1.Indexes.Add(Dimensions); Razlika = Table1.CopyColumns(); Za svaki redak0 iz tablice0 petlja FillPropertyValues(Selection, Row0); Redovi1 = Tablica1.PronađiRedove(Odabir); If Rows1.Count() = 0 Then FillPropertyValues(Difference.Add(), Row0) Inače Red1 = Rows1; Za svaki resurs iz petlje resursa If String0[resurs]<>Line1[Resource] Then FillPropertyValues(Difference.Add(), Line0); FillPropertyValues(Difference.Add(), Line1); Prekid EndIf Kraj petlje; String1.Sign = 0 EndIf EndLoop; Za svaki redak1 iz tablice1.Pronađi redove(Nova struktura("Znak", 1)) Petlja FillPropertyValues(Difference.Add(), Red1); EndCycle; Table1.Columns.Delete("Sign"); Table1.Indexes.Delete(NewIndex); Vrati razliku EndFunction
3.4. Veza sukladnosti
Ova funkcija algoritamski ponavlja prethodnu, osim što se umjesto uobičajenog indeksa koristi "samostalno napravljen" indeks na temelju podudaranja. Da bi se to postiglo, druga se tablica prethodno obilazi, zbog čega se reference na njezine retke pohranjuju u stablo pretraživanja izgrađeno na temelju podudaranja
Funkcija DifferenceTableValues_(Table0, Table1, RowDimensions) Export Table1.Columns.Add("Sign", NewTypeDescription("Number")); Table1.FillValues(1, "Sign"); DimensionStructure = Nova struktura(DimensionString); Dimenzije = Novi niz; Resursi = Novi niz; For Index = 0 By Table0.Columns.Count() - 1 LoopColumnName = Table0.Columns[Index].Name; If DimensionStructure.Property(ColumnName) Then Dimensions.Add(Index) Else Resources.Add(Index) EndIf EndCycle; DimensionPlus = Dimenzije[Dimensions.Count() - 1]; Dimenzije.Delete(Measurements.Quantity() - 1); HashMap = Nova utakmica; Za svaki redak1 iz tablice1 Korijen petlje = HashMap; Za svaku dimenziju iz dimenzije LoopKeyPart = redak1[dimenzija]; Grana = korijen[Ključni dio]; If Branch = Nedefinirano Then Branch = New Match; Root[KeyPart] = Branch EndIf; Korijen = završni ciklus grane; PartKey = Niz1[DimenzijaPlus]; Root[KeyPart] = String1 EndCycle; Dimenzije.Dodaj(DimenzijaPlus); Razlika = Table1.CopyColumns(); Za svaki redak0 iz tablice0 Korijen petlje = HashMap; Za svaku dimenziju iz dimenzije LoopKeyPart = String0[dimenzija]; Grana = korijen[Ključni dio]; If Branch = Undefined Then FillPropertyValues(Difference.Add(), Line0); Prekid EndIf; Korijen = završni ciklus grane; Ako grana<>Nedefinirano Zatim za svaki resurs iz petlje resursa If String0[resurs]<>Branch[Resource] Then FillPropertyValues(Difference.Add(), Line0); FillPropertyValues(Difference.Add(), Grana); Prekid EndIf Kraj petlje; Branch.Sign = 0 EndIf EndCycle; Za svaki redak1 iz tablice1.Pronađi redove(Nova struktura("Znak", 1)) Petlja FillPropertyValues(Difference.Add(), Red1); EndCycle; Table1.Columns.Delete("Sign"); Vrati razliku EndFunction
3.5. spajanje
Ova funkcija pretpostavlja da su uspoređene tablice poredane po ključnim dimenzijama. Tijekom rada, redovi dviju tablica se redom čitaju, uspoređuju jedni s drugima, tako da je rezultat spojena uređena tablica bez identičnih redaka.
Funkcija DifferenceTableValues_(Table0, Table1, RowDimensions) Export Table1.Columns.Add("Sign", NewTypeDescription("Number")); Table1.FillValues(1, "Sign"); Razlika = Table1.CopyColumns(); DimensionStructure = Nova struktura(DimensionString); Dimenzije = Novi niz; Resursi = Novi niz; For Index = 0 By Table0.Columns.Count() - 1 LoopColumnName = Table0.Columns[Index].Name; If DimensionStructure.Property(ColumnName) Then Dimensions.Add(Index) Else Resources.Add(Index) EndIf EndCycle; Usporedba = Nova usporedba vrijednosti; Indeks1 = Tablica0.Broj() - 1; Indeks2 = Tablica1.Broj() - 1; Redak1 = Tablica0[Indeks1]; Redak2 = Tablica1[Indeks2]; Dok je istinita petlja za svaku dimenziju iz dimenzije LoopCompareResult = Comparison.Compare(Red1[Dimenzija], Red2[Dimenzija]); IfComparisonResult<>0 Zatim prekinuti EndIf Kraj petlje; IfComparisonResult = 0 Onda za svaki resurs iz petlje resursa If String1[Resource]<>Line2[Resource] Then FillPropertyValues(Difference.Add(), Line1); FillPropertyValues(Difference.Add(), Line2); Prekid EndIf Kraj petlje; Indeks1 = Indeks1 - 1; Indeks2 = Indeks2 - 1; Ako Min(indeks1, indeks2)< 0 Тогда Прервать КонецЕсли; Строка1 = Таблица0[Индекс1]; Строка2 = Таблица1[Индекс2]; ИначеЕсли РезультатСравнения >0 Zatim FillPropertyValues(Difference.Add(), Line1); Indeks1 = Indeks1 - 1; Ako Index1< 0 Тогда Прервать КонецЕсли; Строка1 = Таблица0[Индекс1] Иначе ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2); Индекс2 = Индекс2 - 1; Если Индекс2 < 0 Тогда Прервать КонецЕсли; Строка2 = Таблица1[Индекс2] КонецЕсли КонецЦикла; Пока Индекс1 >= 0 Petlja Red1 = Tablica0[Indeks1]; FillPropertyValues(Difference.Add(), Line1); Indeks1 = Indeks1 - 1 završni ciklus; Dok Indeks2 >= 0 Petlja Red2 = Tablica1[Indeks2]; FillPropertyValues(Difference.Add(), Line2); Indeks2 = Indeks2 - 1 završni ciklus; Table1.Columns.Delete("Sign"); Vrati razliku EndFunction
3.6. Upit - potpuno pridruživanje
Funkcija se temelji na prosljeđivanju dvije tablice u upit, gdje su spojene jednakošću vrijednosti u dimenzijama. Mala komplikacija povezana je s naknadnim "čišćenjem" u dva reda redaka,razlikuju u resursima.
Funkcija StrPart(String, Delimiter) ExportDelimiterPosition = Find(String, Delimiter); If SeparatorPosition = 0 Then Response = New Array; Odgovor.Dodaj(niz); Inače Odgovor = StrParts(Average(String, SeparatorPosition + StrLength(Separator)), Separator); Answer.Insert(0, Middle(String, 1, SeparatorPosition - 1)) EndIf; Povratni odgovor EndFunction Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export Query = New Query("SELECT | 0 AS Sign(), T.Field() |PUT T0 |FROM | &Table0 AS T |; | |//////////////////////////////////////////// ////////////////////////////////////////////////////////////////////////////////////////////// |SELECT |1 AS Sign(), T.Field() |PUT T1 |FROM | &Tablica 1 AS T |; | |/////////////////////////////////////// //////////////////////////////////// |SELECT |0 AS Znak |PUT Znakovi | |CONNECT | |SELECT |1 |; |///////////// ////////////////////////////////////////////////////////// |SELECT() | SELECT Signs.Sign | WHEN 0 | THEN T0.Field | ALSE T1.Field | END AS Polje,() | Signs.Sign |FROM | T0 AS T0 | POTPUNA VEZA T1 KAO T1 | UKLJUČENO (ISTINA) | () I T0.Polje = T1.Polje(), | Znakovi KAO Znakovi |WHERE | (() T0.Polje JE NULL I Znak.Sign = 1 | ILI T1.Polje JE NULL I Znak.Sign = 0 | () ILI T0.Polje<>T1.Polje()) | |NARUČI OD | ()Field"); DimensionStructure = Nova struktura(Dimensions); Sections = StrParts(Query.Text, "()"); Query.Text = Sections; Za svaki stupac iz tablice1.Columns Loop Query.Text = Query.Text + StrReplace(Sections, "Field", Column.Name) EndCycle; Query.Text = Query .Text + Sec za svaki stupac iz Table1.Columns Loop Query.Text = Query.Text + StrReplace(Sections, "Field", Column.Name) EndCycle; Query.Text = Query.Text + Sections; Za svaki stupac iz Table1.Columns Loop Query.Text = Query.Text + StrReplace(Sections, "Field", Stupac. Naziv) EndCycle; Query.Text = Query.Text + Sekcije; Za svaki element FromDimensionStructure ciklus Query.Text = Query.Text + StrReplace(Sections, "Field", Element.Key) EndCycle; Query.Text = Query.Text + Sections; Query.Text = Query.Text + StrReplace(Sections, "Fi eld ", Table1.Columns.Name); Za svaki stupac iz Table1.Columns Loop If NOT Struktura dimenzije.Property(Column.Name) Then Query.Text = Query.Text + StrReplace(Sections, "Field", Column.Name) EndIf EndCycle; Upit.Tekst = Upit.Tekst + Odjeljci; Query.Text = Query.Text + StrReplace(Odjeljci, "Polje", Dimenzije); Query.SetParameter("Tablica0", Tablica0); Query.SetParameter("Tablica1", Tablica1); Return Request.Execute().Upload() EndFunction
3.7. Upit - grupiranje
Ova je funkcija izgrađena točno na istoj ideji kao funkcija 3.1, samo implementirana unutar zahtjeva
Funkcija DifferenceTableValues(Table0, Table1, Dimensions) Export Query = New Query("SELECT | 0 AS Sign, | T.Field |PUT T0 |FROM | &Table0 AS T |; | |////////////////////////////////////////////////// //////// //////////////////// |SELECT |1 AS Sign, |T.Field |PUT T1 |FROM |&Table1 AS T |; |///////////////////////////////////////////////////// //////////////////// //////// |SELECT | T.Sign, | T.Field |PUT T |FROM | T0 AS T | |JOIN SVI | |SELECT | T.Sign, | T.Field |FROM | T1 AS T |; | |////////////////////////////////////////////////////////// ///////////////////////////. Svi stupci = ""; Za svaki stupac iz Table1.Columns Loop AllColumns = AllColumns + ", T." + Column.Name EndCycle; Query.Text = StrReplace(Query.Text, "T.Field", Avg(AllColumns, 2)); Query.Text = StrReplace(Query.Text, "Field//", Dimensions); Query.SetParameter("Tablica0", Tablica0); Query.SetParameter("Tablica1", Tablica1); Return Request.Execute().Upload() EndFunction
Sve ovdje predstavljene funkcije pažljivo su podešene kako bi se postigla maksimalna izvedba. Uzimajući u obzir iskustvo stečeno tijekom zajedničkog ugađanja na funkcijskom forumu za jednodimenzionalni slučaj. No, to nije rađeno tako pažljivo kao tamo, pa se možda iz nekih funkcija može iscijediti još koja performansa.
4. Rezultati ispitivanja
4.1 Utjecaj broja redaka
Istražujemo ovisnost vremena usporedbe o broju redaka u tablicama. Da bismo to učinili, koristimo sljedeće parametre testa. Broj redaka je 20000, 40000, 60000, 80000, 100000, broj stupaca je 10, broj ključnih stupaca je 1, tip podataka je niz, duljina niza je 10, postotak brisanja, promjena, dodavanja je 5, broj ponavljanja testa je 2. Dobivamo sljedeću ovisnost, što je prikladnije za predstaviti u obliku grafikona.

Ova je ovisnost za većinu metoda gotovo linearna! Tako i treba biti. Vrijeme izvršenja metode FindRows u prisutnosti indeksa ne ovisi o broju redaka, tako da se spajanje na indeksu izvodi u linearnom vremenu. Isto vrijedi i kada koristite podudaranje i spajanje. U potpunom spajanju, upit najvjerojatnije koristi hash podudaranje za spajanje tablica jednake veličine.
Nelinearnost vremena sortiranja s obzirom na mali broj različitih redaka malo odstupa od izravne ovisnosti za konvoluciju. Još gora je metoda koja koristi uniju kopiranjem stupaca - upravo ova metoda kopiranja uvodi značajnu nelinearnost uz blagu nelinearnost sortiranja. Zbog toga se gubi korist korištenja "trika" spajanja tablica na više od 60.000 redaka.
4.2 Utjecaj duljine vrijednosti
Ispitajmo sada ovisnost vremena o duljini vrijednosti niza. Postavimo broj redaka na 50000. Ostali parametri su isti kao u 4.1. Rezultat se prikazuje u obliku stupčastog grafikona. Bolje prikazuje omjer vremena izvođenja različitih metoda i omogućuje vam da istaknete vodeću, što je u većini slučajeva metoda konvolucije.

Vidi se da se ovisnost vremena o metodi praktički ne mijenja kada se promijeni duljina niza. Raste samo vrijeme izvršenja upita.
Kako bi ovaj grafikon bio što informativniji u odnosu na metode upita, ovdje je u posebnim dimenzijama istaknuto vrijeme unosa tablica u upit. Da biste to učinili, stvorena je lažna funkcija koja samo izvršava unos tablica u upit i ne obavlja nikakav drugi posao. Dugo vrijeme za unos tablica pokazuje da je tehnici upita vrlo teško konkurirati vodećim metodama. U mnogim slučajevima, voditelji su već završili svoj posao u trenutku kada su izvorni podaci u upitu.
4.3 Utjecaj tipova podataka
Sljedeće zanimljivo pitanje je odnos metoda prema tipovima podataka. To je prikazano na sljedećem dijagramu. I ovdje je broj redaka 50000, duljina niza i numerička vrijednost je 10. Ostalo je isto kao u 4.1.

To pokazuje da vrsta podataka ima najveći utjecaj na vrijeme upitnih metoda. Grupiranje je bolje za brojeve. I datumi se vrlo dobro obrađuju prema zahtjevima.
4.3 Utjecaj broja stupaca
Druga ovisnost je ovisnost vremena usporedbe o broju stupaca. To je prikazano na sljedećem dijagramu. Broj redaka ovdje je 50 000, vrsta podataka je niz duljine 10, postotak dodavanja, izobličenja i brisanja svaki je 5. Jedan ključni stupac.

Vidi se da broj stupaca ne mijenja uvelike usporednu brzinu metoda. Najviše od svega, povećanje broja stupaca usporava upite.
4.4 Utjecaj broja mjerenja
Zanimljivija je ovisnost o broju ključnih stupaca prikazana u nastavku. Broj redaka ovdje je 50 000, vrsta podataka je niz duljine 10, postotak dodavanja, izobličenja i brisanja svaki je 5. Ukupno ima 10 stupaca.

Može se vidjeti da je metoda koja se temelji na dopisivanju, koja je prije pokazala dobre rezultate, sada autsajder. Spajanje također postaje gore. Ali pretraživanje po indeksu se poboljšava - zbog činjenice da ima manje stupaca za usporedbu.
4.5 Učinak razlika u veličini tablice
Sada obratimo pozornost na asimetriju metoda 1 - 4 (konvolucije i spajanja) s obzirom na veličine tablica koje se uspoređuju. Sve ove metode imaju koristi od toga što je prva tablica manja! To potvrđuje sljedeća tablica, koja pokazuje vrijeme usporedbe dviju tablica od 50 000 i 40 000 redaka različitim redoslijedom.

Na gornjem dijagramu primjetan je zanimljiv artefakt. S obzirom na broj redaka i stupaca, ispada da je isplativije proći kroz 50 000 redaka do tablice od 40 000 redaka nego obrnuto. Možda je to zbog osobitosti raspodjele memorije za tablicu vrijednosti.
4.6 Utjecaj broja razlika
I, na kraju, ispitat ćemo ovisnost vremena usporedbe o stupnju razlike između tablica. Može se vidjeti da kako se postotak odstupanja povećava, vrijeme izvođenja konvolucije usporava. Budući da nelinearnost sortiranja počinje igrati ulogu.

4.7 Utjecaj hardverskog i softverskog okruženja
Testovi su obavljeni na platformi 8.3.5.1248 na prijenosnom računalu VGN-Z51MRG. Dobivene ovisnosti općenito su potvrđene na drugoj opremi, ali postoje neke značajke koje još nisu generalizirane.
5. Zaključci
5.1. Najjednostavnija metoda konvolucije pokazuje se najproduktivnijom u većini slučajeva. Treba ga koristiti kao univerzalnu metodu, ali ne u posebnim slučajevima.
5.2 S malom veličinom (do 50 000 redaka), možete dobiti dodatno ubrzanje konvolucije primjenom kopiranja stupaca prilikom spajanja tablica (metoda 3.2).
5.3 U posebnom slučaju jednog ključnog stupca, značajnog broja razlika i značajne razlike u veličinama tablice, potrebno je koristiti spajanje podudaranja. Isto treba učiniti čak i ako postoji nekoliko ključnih tablica, ali se usporedba vrši s istom tablicom, za koju se možete unaprijed pripremiti “stablo odlučivanja” na temelju podudaranja,prilagođen njegovim karakteristikama.
5.4 U posebnom slučaju nekoliko ključnih stupaca sa značajnim brojem razlika i nerazvrstanih uspoređenih tablica, trebate koristiti metodu spajanja indeksa.
5.5 Za najveću učinkovitost metoda 1-4 potrebno je odabrati ispravan redoslijed navođenja tablica prilikom usporedbe.
5.6 U posebnom slučaju sortiranih uspoređenih tablica sa značajnim brojem razlika, treba koristiti spajanje.
5.7. U posebnom slučaju velikih (ovisnih o hardveru) i približno jednakih tablica, koje osim toga imaju značajne razlike i sastoje se od kratkih redaka i iznimno malog broja stupaca, moguće je koristiti upite.
5.8 Ako u tablicama dominiraju numerički podaci, datumi, srednji i dugi nizovi, tada bi upiti za usporedbu tablica trebali koristiti grupiranje, a samo za vrlo kratke nizove, potpuno spajanje.
6. Opći zaključci
6.1 U svakom slučaju, prije donošenja odlučnog izbora, bolje je, ako je moguće, usporediti nekoliko metoda u stvarnim uvjetima njihove primjene. Na primjer, pomoću obrade priložene članku.
6.2 Uzimanje u obzir osobitosti podataka u tablicama omogućuje ciljanu dodatnu optimizaciju većine gore navedenih metoda. Za to postoje mnoge mogućnosti koje ostaju izvan raspona razmatranih pitanja.
6.3 Unos tablica vrijednosti u upite može potrajati značajno vrijeme, što u većini slučajeva poništava učinkovitost njihove upotrebe u zadacima kada se podaci uzimaju iz memorije, a ne iz baze podataka. Nepromišljeno korištenje upita u ovom problemu je štetna zabluda.
6.4 Vrijeme rada metode FindRows u prisutnosti indeksa na stupcima uključenim u odabir ne ovisi o veličini tablice vrijednosti. Prema tome, ispravna procjena izvedbe za metodu usporedbe tablice koja koristi indeksno spajanje je O(N).
, koji je predložio, implementirao i otklonio pogreške u svojim metodama za jednodimenzionalni slučaj, napravio mnoge korisne ispravke i razmatranja, a također je aktivno sudjelovao u svim raspravama. Posebno zahvaljujemo sponzorima iste podružnice i - za zanimljivo pitanje.Usporedimo dvije tablice s gotovo istom strukturom. Tablice se razlikuju u vrijednostima u zasebnim recima, neki nazivi redaka nalaze se u jednoj tablici, ali ne moraju biti u drugoj.
Neka na plahtama siječnja I veljača postoje dvije tablice s prometima za razdoblje za dotične račune.

Kao što se može vidjeti na slikama, tablice se razlikuju:
- Prisutnost (odsutnost) linija (imena računa). Na primjer, u tablici na listu siječnja nema ocjene 26 (vidi primjer datoteke), au tablici na listu veljača Nedostaje račun 10 i njegovi podračuni.
- Različite vrijednosti u linijama. Na primjer, na kontu 57 ne poklapaju se prometi za siječanj i veljaču.
Ako su strukture tablice približno iste (većina naziva računa (redova) je ista, broj i nazivi stupaca su isti), tada se mogu usporediti dvije tablice. Usporedimo na dva načina: jedan je lakši za implementaciju, drugi je jasniji.
Jednostavan način za usporedbu 2 tablice
Prvo, odredimo koji su redovi (nazivi računa) prisutni u jednoj tablici, ali ih nema u drugoj. Zatim ćemo u tablici u kojoj nedostaje manje redaka (u najpotpunijoj tablici) prikazati usporedni izvještaj, a to je razlika u stupcima (razlika prometa za siječanj i veljaču).
Glavni nedostatak ovog pristupa je da izvješće o usporedbi tablice ne uključuje retke koji nedostaju u najpotpunijoj tablici. Na primjer, u našem slučaju, najpotpunija tablica je tablica na listu siječnja, u kojoj nema ocjene 26 iz veljačke tablice.

Da biste utvrdili koja je od dvije tablice najpotpunija, potrebno je odgovoriti na 2 pitanja: Koji računi u tablici za veljaču nedostaju u onoj za siječanj? i Koji računi u tablici za siječanj nedostaju u tablici za siječanj?
To se može učiniti pomoću formula (vidi stupac E): = IF(END(VLOOKUP(A7,siječanj!$A$7:$A$81,1,0)),"Ne","Da") i = IF(END(VLOOKUP(A7,Feb!$A$7:$A$77,1,0)),"Ne","Da")
Usporedba prometa na računima vršit će se pomoću formula: = IF(END(VLOOKUP($A7,feb!$A$7:$C77,2,0)),0,VLOOKUP($A7,feb!$A$7:$C77,2,0))-B7 i = IF(END(VLOOKUP($A7,feb!$A$7:$C77,3,0)),0,VLOOKUP($A7,feb!$A$7:$C77,3,0))-C7
Ako ne postoji odgovarajući red, funkcija VLOOKUP() vraća pogrešku #N/A, koja se rješava kombinacijom funkcija UND() i IF(), zamjenjujući pogrešku s 0 (ako nema retka) ili s vrijednošću iz odgovarajućeg stupca.
Koristite za označavanje odstupanja (na primjer, crvenom bojom).
Vizualniji način za usporedbu 2 tablice (ali složeniji)
Analogno problemu riješenom u članku, možete napraviti popis naziva računa koji uključuje SVE nazive računa iz obje tablice (bez ponavljanja). Zatim prikažite razliku po stupcima.

Za ovo vam je potrebno:
- Uz = IFERROR(IFERROR(INDEX(siječanj,MATCH(0,COUNTIF(A$4:$A4,siječanj),0)), INDEX(veljača,MATCH(0,COUNTI(A$4:$A4,veljača),0))),"") formirati u stupcu A popis računa iz obje tablice (bez ponavljanja);
- Uz = IFERROR(INDEX(List, MATCH(SMALL(COUNTIF(List, "<"&Список); СТРОКА()-СТРОКА($B$4)); СЧЁТЕСЛИ(Список; "<"&Список); 0));"") , gdje je Lista - popis računa iz obje tablice (stupac A), računa dobivenih u prethodnoj fazi;
- Pomoću formule = IF(AND(VLOOKUP($B5;siječanj!$A$7:$C$81,2;0));0;VLOOKUP($B5;siječanj!$A$7:$C$81;2;0))- IF(AND(VLOOKUP($B5;veljača!$A$7:$C$77;2;0));0;VLOOKUP($B5;veljača!$A$ 7:$C$77;2 ;0)) usporedite promete po računu;
- Koristi se za označavanje odstupanja bojom, kao i za označavanje računa koji se javljaju samo u jednoj tablici (npr. na gornjoj slici plavom bojom označeni su konti sadržani samo u tablici za siječanj, a žutom bojom samo konti iz tablice za veljaču).