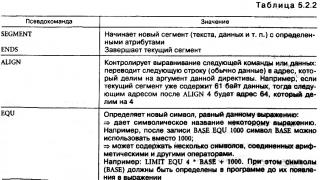
[از روش ها]
تعریف 9.22 Linker (لینکر) "برنامه ای است که برای ارتباط بین فایل های شی تولید شده توسط کامپایلر و فایل های کتابخانه ای که بخشی از سیستم برنامه نویسی هستند طراحی شده است.
یک فایل شی نمی تواند راه اندازی شود تا زمانی که همه ماژول ها و بخش ها در آن پیوند داده شوند. خروجی لینکر یک فایل اجرایی است. این فایل شامل متن برنامه به زبان کد ماشین می باشد. هنگام تلاش برای ایجاد یک فایل اجرایی، پیوند دهنده ممکن است در صورتی که هیچ مؤلفه ای را پیدا نکند یک پیام خطا نشان دهد.
ابتدا، پیوند دهنده یک بخش برنامه را از اولین ماژول شی انتخاب می کند و یک آدرس شروع به آن اختصاص می دهد. بخش های برنامه ماژول های شی باقیمانده آدرس های مربوط به آدرس شروع را به ترتیب متوالی دریافت می کنند. در این حالت می توان آدرس های بخش های برنامه را تراز کرد. همزمان با ادغام متون بخش های برنامه، بخش های داده، جداول شناسه ها و زمان های خارجی ادغام می شوند. پیوندهای مقطعی مجاز است.
روند حل پیوندها به محاسبه مقادیر ثابت آدرس رویه ها، توابع و متغیرها با در نظر گرفتن حرکات بخش ها نسبت به ابتدای ماژول برنامه مونتاژ شده کاهش می یابد. اگر همزمان ارجاعاتی به متغیرهای خارجی که در لیست ماژولهای شی نیستند یافت شود، ویرایشگر پیوند جستجوی آنها را در کتابخانه سازماندهی میکند؛ مؤلفه مورد نیاز یافت نمیشود، یک پیام خطا ایجاد میشود.
به طور معمول، پیوند دهنده ساده ترین واحد برنامه را تشکیل می دهد که به عنوان یک واحد ایجاد می شود. با این حال، در موارد پیچیده تر، پیوند دهنده می تواند ماژول های دیگری ایجاد کند: ماژول های برنامه همپوشانی، ماژول های شی کتابخانه و ماژول های کتابخانه پیوند پویا.
لینکر (همچنین ویرایشگر پیوند، پیوند دهنده - از ویرایشگر پیوند انگلیسی، لینکر) - برنامه ای که پیوند را انجام می دهد - یک یا چند ماژول شی را به عنوان ورودی می گیرد و یک ماژول اجرایی را با استفاده از آنها مونتاژ می کند.
برای پیوند دادن ماژول ها، پیوند دهنده از جداول نام ایجاد شده توسط کامپایلر در هر یک از ماژول های شی استفاده می کند. این نام ها می توانند دو نوع باشند:
نام های تعریف شده یا صادر شده - توابع و متغیرهایی که در یک ماژول معین تعریف شده و برای استفاده توسط ماژول های دیگر ارائه شده است.
نام های تعریف نشده یا وارد شده - توابع و متغیرهایی که ماژول به آنها اشاره می کند، اما آنها را به صورت داخلی تعریف نمی کند.
وظیفه پیوند دهنده حل کردن ارجاع به نام های تعریف نشده در هر ماژول است. برای هر نام وارد شده، تعریف آن در ماژول های دیگر یافت می شود، ذکر نام با آدرس آن جایگزین می شود.
پیوند دهنده معمولاً بررسی نوع یا شمارش پارامترهای رویه و عملکرد را انجام نمی دهد. اگر لازم است ماژولهای شی برنامههایی که به زبانهای تایپ شده قوی نوشته شدهاند ترکیب شوند، باید قبل از شروع پیوند، بررسیهای لازم توسط یک ابزار اضافی انجام شود.
پیوند دهنده (یا پیوند دهنده) برای پیوند دادن فایل های شی تولید شده توسط کامپایلر و همچنین فایل های کتابخانه ای که بخشی از سیستم برنامه نویسی هستند طراحی شده است.
یک فایل شی (یا مجموعه ای از فایل های شی) تا زمانی که همه ماژول ها و بخش های موجود در آن به هم مرتبط نباشند نمی توانند اجرا شوند. این همان کاری است که پیوند دهنده (لینکر) انجام می دهد. نتیجه کار او یک فایل واحد به نام ماژول بوت است.
یک ماژول بار یک ماژول برنامه مناسب برای بارگذاری و اجرا است که از یک ماژول شی در هنگام ویرایش پیوندها به دست می آید و یک برنامه را در قالب دنباله ای از دستورالعمل های ماشین نشان می دهد.
اگر هنگام تلاش برای جمعآوری فایلهای شی در یک واحد، نتواند مؤلفه لازم را پیدا کند، پیوند دهنده ممکن است یک پیام خطا ایجاد کند.
عملکرد پیوند دهنده بسیار ساده است. با انتخاب یک بخش برنامه از اولین ماژول شی و اختصاص یک آدرس شروع به آن شروع می شود. بخش های برنامه ماژول های شی باقیمانده آدرس های مربوط به آدرس شروع را به ترتیب متوالی دریافت می کنند. در این حالت، عملکرد تراز کردن آدرس های شروع بخش های برنامه نیز قابل انجام است. همزمان با ادغام متون بخش های برنامه، بخش های داده، جداول شناسه ها و نام های خارجی ادغام می شوند. پیوندهای مقطعی مجاز است.
روند حل پیوندها به محاسبه مقادیر ثابت آدرس رویه ها، توابع و متغیرها با در نظر گرفتن حرکات بخش ها نسبت به ابتدای ماژول برنامه مونتاژ شده کاهش می یابد. اگر در همان زمان ارجاعاتی به متغیرهای خارجی یافت شود که در لیست ماژول های شی نیستند، ویرایشگر پیوند جستجوی آنها را در کتابخانه های موجود در سیستم برنامه نویسی سازماندهی می کند. اگر کامپوننت مورد نیاز در کتابخانه یافت نشد، یک پیام خطا ایجاد می شود.
به طور معمول، پیوند دهنده ساده ترین واحد برنامه را تشکیل می دهد که به عنوان یک واحد ایجاد می شود. با این حال، در موارد پیچیده تر، پیوند دهنده می تواند ماژول های دیگری ایجاد کند: ماژول های برنامه همپوشانی، ماژول های شی کتابخانه و ماژول های کتابخانه پیوند پویا.
اکثر ماژول های شی در سیستم های برنامه نویسی مدرن بر اساس آدرس های نسبی بنا شده اند. کامپایلری که فایلهای شی را تولید میکند و سپس پیونددهندهای که آنها را در یک کل واحد ترکیب میکند، نمیتواند دقیقاً بداند که برنامه در زمان اجرای آن در کدام ناحیه حافظه واقعی رایانه قرار دارد. بنابراین، آنها با آدرس های واقعی سلول های RAM کار نمی کنند، بلکه با برخی از آدرس های نسبی کار می کنند. چنین آدرسهایی از نقطهای مشروط بهعنوان ابتدای منطقه حافظه اشغال شده توسط برنامه بهدستآمده محاسبه میشوند (معمولاً این نقطه شروع اولین ماژول برنامه است).
البته هیچ برنامه ای در این آدرس های نسبی قابل اجرا نیست. بنابراین، ماژولی مورد نیاز است که تبدیل آدرسهای نسبی به آدرسهای واقعی (مطلق) را مستقیماً در لحظه راهاندازی برنامه برای اجرا انجام دهد. این فرآیند ترجمه آدرس نامیده می شود و توسط ماژول خاصی به نام لودر انجام می شود.
با این حال، بوت لودر همیشه بخشی جدایی ناپذیر از سیستم برنامه نویسی نیست، زیرا عملکردهایی که انجام می دهد بسیار وابسته به معماری سیستم کامپیوتری هدف است که در آن برنامه ایجاد شده توسط سیستم برنامه نویسی در حال اجرا است. در اولین مراحل توسعه سیستم عامل، لودرها به عنوان ماژول های جداگانه وجود داشتند که ترجمه آدرس را انجام می دادند و برنامه را برای اجرا آماده می کردند - آنها به اصطلاح "تصویر وظیفه" را ایجاد کردند. چنین طرحی برای بسیاری از سیستم عامل ها معمولی بود (به عنوان مثال، برای RTOS در یک کامپیوتر نوع SM-1، OS RSX/11 یا RAFOS در یک کامپیوتر نوع SM-4 و غیره). هر بار که برنامه برای اجرا آماده می شد، می توان تصویر کار را در رسانه خارجی ذخیره کرد یا دوباره ایجاد کرد.
با توسعه معماری امکانات محاسباتی رایانه، امکان انجام ترجمه آدرس به طور مستقیم در زمانی که برنامه برای اجرا راه اندازی شد، فراهم شد. برای انجام این کار لازم بود که در فایل اجرایی جدولی مناسب حاوی لیستی از پیوندها به آدرس هایی که باید ترجمه شوند در فایل اجرایی گنجانده شود. در زمان راه اندازی فایل اجرایی، سیستم عامل این جدول را پردازش کرد و آدرس های نسبی را به آدرس های مطلق تبدیل کرد. برای مثال، چنین طرحی برای سیستم عاملی مانند MS-DOS معمول است. در این طرح، هیچ ماژول بارگیری وجود ندارد (در واقع، بخشی از سیستم عامل است) و سیستم برنامه نویسی فقط مسئول تهیه جدول ترجمه آدرس است - این عملکرد توسط پیوند دهنده انجام می شود.
در سیستم عامل های مدرن، روش های پیچیده ای برای ترجمه آدرس وجود دارد که به طور مستقیم در طول اجرای برنامه کار می کنند. این روش ها مبتنی بر قابلیت های ذاتی در معماری سیستم های محاسباتی هستند. روشهای ترجمه آدرس را میتوان بر اساس سازماندهی حافظه بخش، صفحه، و بخش-صفحه باشد. سپس برای انجام ترجمه آدرس، جداول سیستم مربوطه باید در زمان راه اندازی برنامه آماده شود. این توابع به طور کامل بر روی ماژول های سیستم عامل قرار می گیرند، بنابراین در سیستم های برنامه نویسی انجام نمی شوند.
مقالات برای خواندن:
چگونه از سیستم عامل چینی به Miui 9 Stable Global ارتقا دهیم؟ باز کردن قفل بوت لودر
این مقاله
سازماندهی جدول اسامی نمادین در اسمبلر.
این جدول حاوی اطلاعاتی درباره نمادها و معانی آنها است که توسط اسمبلر در اولین پاس جمع آوری شده است. اسمبلر در گذر دوم به جدول نمادها دسترسی پیدا می کند. راه هایی را برای سازماندهی جدولی از نام های نمادین در نظر بگیرید. بیایید یک جدول را به عنوان یک حافظه تداعی تصور کنیم که مجموعه ای از جفت ها را ذخیره می کند: یک نام نمادین - یک مقدار. حافظه انجمنی با نام باید ارزش خود را تولید کند. به جای یک نام و یک مقدار، یک اشاره گر به نام و یک اشاره گر به مقدار می تواند ظاهر شود.
مونتاژ متوالی
جدول نماد به عنوان نتیجه اولین پاس به صورت آرایه ای از جفت نام-مقدار نمایش داده می شود. جستجو برای کاراکتر مورد نیاز با اسکن متوالی جدول تا تعیین یک تطابق انجام می شود. برنامه نویسی این روش بسیار آسان است، اما کند است.
به ترتیب نام.
نام ها بر اساس حروف الفبا از پیش مرتب شده اند. برای جستجوی نام ها از الگوریتم هرس باینری استفاده می شود که نام مورد نیاز را با نام عنصر میانی جدول مقایسه می کند. اگر نماد مورد نظر از نظر حروف الفبا نزدیکتر از عنصر میانی باشد، در نیمه اول جدول و اگر دورتر باشد، در نیمه دوم جدول قرار دارد. اگر نام مورد نظر با نام عنصر میانی مطابقت داشته باشد، جستجو به پایان می رسد.
الگوریتم هرس باینری سریعتر از اسکن جدول متوالی است، اما عناصر جدول باید به ترتیب حروف الفبا باشند.
رمزگذاری کش
با این روش، بر اساس جدول اصلی، یک تابع کش ساخته می شود که نام ها را به اعداد صحیح در محدوده 0 تا k-1 نگاشت می کند (شکل 5.2.1، a). یک تابع کش می تواند، برای مثال، تابعی برای ضرب تمام ارقام یک نام باشد که با یک کد اسکی نشان داده شده است، یا هر تابع دیگری که توزیع یکنواختی از مقادیر را ارائه می دهد. پس از آن، یک جدول کش ایجاد می شود که حاوی k ردیف (اسلات) است. هر خط حاوی (مثلاً به ترتیب حروف الفبا) نام هایی است که مقادیر تابع کش یکسانی دارند (شکل 5.2.1، b) یا شماره شکاف. اگر n نام کاراکتر در جدول کش وجود داشته باشد، میانگین تعداد نام ها در هر شکاف n/k است. با n = k، به طور متوسط، تنها یک جستجو برای یافتن نام نماد مورد نظر مورد نیاز است. با تغییر k می توانید اندازه جدول (تعداد اسلات) و سرعت جستجو را تغییر دهید. لینک و دانلود. برنامه را می توان به عنوان مجموعه ای از رویه ها (زیر روال ها) نشان داد. مونتاژ کننده به نوبه خود پخشیکی پس از دیگری، ایجاد ماژول های شیو قرار دادن آنها در حافظه برای به دست آوردن یک کد باینری اجرایی باید یافت و متصلتمام مراحل ترجمه شده
توابع پیوند و دانلود توسط برنامه های خاصی به نام انجام می شود لینکرها، لینکرها، لودرها، لینکرهایا پیوند دهنده ها
 بنابراین، دو مرحله برای آمادگی کامل برای اجرای برنامه منبع مورد نیاز است (شکل 5.2.2):
بنابراین، دو مرحله برای آمادگی کامل برای اجرای برنامه منبع مورد نیاز است (شکل 5.2.2):
● ترجمه اجرا شده توسط کامپایلر یا اسمبلر برای هر رویه منبع به منظور به دست آوردن یک ماژول شی. در طول ترجمه، یک انتقال انجام می شود از اصلزبان به مرخصی روزانهزبانی که دستورات و نمادهای متفاوتی دارد.
● پیوند ماژول های شی، که توسط پیوند دهنده برای به دست آوردن یک باینری اجرایی انجام می شود. ترجمه جداگانه رویه ها به دلیل خطاهای احتمالی یا نیاز به تغییر رویه ها ایجاد می شود. در این موارد، شما باید همه ماژولهای شی را دوباره پیوند دهید. از آنجایی که پیوند دادن بسیار سریعتر از ترجمه است، انجام این دو مرحله (ترجمه و پیوند دادن) باعث صرفه جویی در زمان در هنگام اصلاح برنامه می شود. این امر به ویژه برای برنامه هایی که شامل صدها یا هزاران ماژول هستند بسیار مهم است. در سیستمعاملهای MS-DOS، Windows و NT، ماژولهای شی دارای پسوند «.obj» و برنامههای باینری اجرایی پسوند «.exe» هستند. در یک سیستم یونیکس، ماژول های شی دارای پسوند ".o" هستند و برنامه های باینری قابل اجرا پسوند ندارند.
توابع پیوند دهنده
قبل از شروع اولین پاس اسمبلی، شمارنده آدرس دستورالعمل روی 0 تنظیم می شود. این مرحله معادل با فرض این است که ماژول شی در هنگام اجرا در مکان 0 باشد.
هدف از چیدمان استیک نقشه دقیق از فضای آدرس مجازی برنامه اجرایی در داخل لینکر ایجاد کنید و همه ماژول های شی را در آدرس های مناسب قرار دهید.
 ویژگی های چیدمان چهار ماژول شی را در نظر بگیرید (شکل 5.2.3، a)، با این فرض که هر یک از آنها در سلولی با آدرس 0 قرار دارد و با یک دستورالعمل انتقال BRANCH به یک دستورالعمل MOVE در همان ماژول شروع می شود. قبل از اجرای یک برنامه، پیوند دهنده ماژول های شی را در حافظه اصلی قرار می دهد و نقشه ای از باینری اجرایی را تشکیل می دهد. به طور معمول، بخش کوچکی از حافظه که از آدرس صفر شروع می شود برای بردارهای وقفه، تعامل با سیستم عامل و اهداف دیگر استفاده می شود.
ویژگی های چیدمان چهار ماژول شی را در نظر بگیرید (شکل 5.2.3، a)، با این فرض که هر یک از آنها در سلولی با آدرس 0 قرار دارد و با یک دستورالعمل انتقال BRANCH به یک دستورالعمل MOVE در همان ماژول شروع می شود. قبل از اجرای یک برنامه، پیوند دهنده ماژول های شی را در حافظه اصلی قرار می دهد و نقشه ای از باینری اجرایی را تشکیل می دهد. به طور معمول، بخش کوچکی از حافظه که از آدرس صفر شروع می شود برای بردارهای وقفه، تعامل با سیستم عامل و اهداف دیگر استفاده می شود.
بنابراین، همانطور که در شکل نشان داده شده است. 5.2.3، b، برنامه ها از آدرس صفر شروع نمی شوند، بلکه از آدرس 100 شروع می شوند. از آنجایی که هر مدول شی در شکل. 5.2.3، اما فضای آدرس جداگانه ای را اشغال می کند، مشکل تخصیص مجدد حافظه وجود دارد. تمام دستورات دسترسی به حافظه به دلیل آدرس دهی نادرست اجرا نمی شوند. به عنوان مثال، فرمان فراخوانی ماژول شی B (شکل 5.2.3، b) که در سلول با آدرس 300 ماژول شی A مشخص شده است (شکل 5.2.3، a) به دو دلیل اجرا نخواهد شد:
● دستور CALL B در سلولی با آدرس متفاوت (300، نه 200) است. ● از آنجایی که هر رویه جداگانه ترجمه می شود، اسمبلر نمی تواند تعیین کند که کدام آدرس را در دستور CALL B وارد کند. آدرس ماژول شی B قبل از پیوند مشخص نیست. چنین مشکلی نامیده می شود مشکل لینک خارجیهر دو علت با استفاده از پیوند دهنده حذف می شوند، که فضاهای آدرس ماژول شی جداگانه را در یک فضای آدرس خطی واحد ادغام می کند، که برای آن:
● جدولی از ماژول های شی و طول آنها می سازد.
● بر اساس این جدول آدرس های شروع را به هر ماژول شی اختصاص می دهد.
به حافظهو به هر یک از آنها یک ثابت جابجایی اضافه می کند که برابر با آدرس شروع این ماژول (در این مورد 100) است.
● تمام دستوراتی را که به آنها دسترسی دارید را پیدا می کند به رویه هاو آدرس این رویه ها را در آنها درج می کند.  در زیر جدول ماژول های شی (جدول 5.2.6) ساخته شده در مرحله اول آمده است. نام، طول و آدرس شروع هر ماژول را می دهد. فضای آدرس پس از تکمیل تمام مراحل توسط پیوند دهنده در جدول 1 نشان داده شده است. 5.2.6 و در شکل. 5.2.3، ج. ساختار ماژول شی. ماژول های شی از بخش های زیر تشکیل شده اند:
در زیر جدول ماژول های شی (جدول 5.2.6) ساخته شده در مرحله اول آمده است. نام، طول و آدرس شروع هر ماژول را می دهد. فضای آدرس پس از تکمیل تمام مراحل توسط پیوند دهنده در جدول 1 نشان داده شده است. 5.2.6 و در شکل. 5.2.3، ج. ساختار ماژول شی. ماژول های شی از بخش های زیر تشکیل شده اند:
● نام ماژول،برخی اطلاعات اضافی (به عنوان مثال، طول قسمت های مختلف ماژول، تاریخ مونتاژ)؛
● لیست نمادهای تعریف شده در ماژول(اسامی نمادین) همراه با معانی آنها. این نمادها توسط ماژول های دیگر قابل دسترسی هستند. برنامه نویس زبان اسمبلی، با استفاده از دستورالعمل PUBLIC، مشخص می کند که نام نمادها به عنوان نقاط ورودی در نظر گرفته می شوند.
● لیست نمادهای استفاده شده،که در ماژول های دیگر تعریف شده اند. این فهرست همچنین اسامی نمادین استفاده شده توسط دستورات ماشین خاصی را نشان می دهد. این به پیوند دهنده اجازه می دهد تا آدرس های صحیح را در دستوراتی که از نام های خارجی استفاده می کنند وارد کند. این به یک رویه اجازه میدهد تا با اعلام (با استفاده از دستورالعمل EXTERN) نام رویههای فراخوانده شده خارجی، سایر رویههای ترجمه شده را فراخوانی کند. در برخی موارد، نقاط ورودی و پیوندهای خارجی در یک جدول ترکیب می شوند.
● دستورالعمل ها و ثابت های ماشین؛
● فرهنگ لغت جنبشدستورالعمل هایی که حاوی آدرس های حافظه هستند باید دارای یک ثابت حرکتی باشند (شکل 5.2.3 را ببینید). خود پیوند دهنده نمی تواند تعیین کند که کدام کلمات حاوی دستورالعمل های ماشینی و کدام کلمات حاوی ثابت هستند. بنابراین، این جدول حاوی اطلاعاتی در مورد آدرس هایی است که باید جابجا شوند. این می تواند یک جدول بیت باشد، که در آن برای هر بیت یک آدرس بالقوه قابل جابجایی وجود دارد، یا یک لیست صریح از آدرس هایی که باید جابجا شوند.
● انتهای ماژول، آدرس شروع اجرا،و چک جمعبرای شناسایی خطاهای ایجاد شده در هنگام خواندن ماژول. توجه داشته باشید که دستورالعمل ها و ثابت های ماشینتنها بخشی از ماژول شی که برای اجرا در حافظه بارگذاری می شود. قسمتهای باقیمانده قبل از شروع اجرای برنامه توسط پیوند دهنده استفاده میشوند و دور ریخته میشوند. اکثر لینکرها استفاده می کنند دوعبور:
● ابتدا، همه ماژولهای شی خوانده میشوند و جدولی از نامها و طولهای ماژول ساخته میشود، و همچنین یک جدول نمادها، که شامل تمام نقاط ورودی و مراجع خارجی است.
● سپس ماژول ها دوباره خوانده می شوند، در حافظه منتقل می شوند و پیوند داده می شوند. در مورد برنامه های جابجایی مشکل جابجایی برنامه های مرتبط و درون حافظه به این دلیل است که پس از جابجایی آنها آدرس های ذخیره شده در جداول اشتباه می شود. برای تصمیم گیری در مورد جابجایی برنامه ها، باید زمان صحافی نهایی را بدانید نام های نمادینبا مطلق آدرس های حافظه فیزیکی
زمان تصمیم گیریلحظه تعیین آدرس در حافظه اصلی مربوط به نام نمادین نامیده می شود. گزینه های مختلفی برای زمان تصمیم گیری در مورد الزام آور وجود دارد: چه زمانی املا شده استبرنامه زمانی که برنامه جریان، کامپایل، آپلودیا چه زمانی تیم،حاوی آدرس انجام.روشی که در بالا مورد بحث قرار گرفت، نام های نمادین را با آدرس های فیزیکی مطلق مرتبط می کند. به همین دلیل، برنامه ها پس از پیوند قابل جابجایی نیستند.
دو مرحله برای پیوند وجود دارد:
● اولینمرحله ای که در آن نام های نمادیندر تماس با آدرس های مجازیهنگامی که پیوند دهنده فضاهای آدرس ماژول شی جداگانه را به یک فضای آدرس خطی منفرد پیوند می دهد، در واقع یک فضای آدرس مجازی ایجاد می کند.
● دومینمرحله زمانی که آدرس های مجازیدر تماس با آدرس های فیزیکیفقط پس از عملیات دوم می توان فرآیند اتصال را تکمیل شده در نظر گرفت. لازم است شرایط حرکت برنامهوجود مکانیزمی است که به شما امکان می دهد نگاشت آدرس های مجازی را به آدرس های حافظه فیزیکی اصلی تغییر دهید (مرحله دوم را به طور مکرر انجام دهید). این مکانیسم ها عبارتند از:
● صفحه بندی. فضای آدرس نشان داده شده در شکل. 5.2.3، c، حاوی آدرسهای مجازی است که از قبل تعریف شدهاند و با نامهای نمادین A، B، C و D مطابقت دارند. آدرسهای فیزیکی آنها به محتوای جدول صفحه بستگی دارد. بنابراین، برای جابجایی یک برنامه در حافظه اصلی، کافی است فقط جدول صفحه آن را تغییر دهید، نه خود برنامه را.
● استفاده کنید حرکت ثبت ناماین ثبت به یک آدرس فیزیکی اشاره می کند شروع کنیدبرنامه فعلی، قبل از انتقال برنامه توسط سیستم عامل بارگیری می شود. از طریق سخت افزار، محتویات ثبت حرکت به تمام آدرس های حافظه قبل از بارگذاری در حافظه اضافه می شود. فرآیند انتقال برای هر برنامه کاربر "شفاف" است. ویژگی مکانیسم: بر خلاف صفحه بندی، کل برنامه باید حرکت کند. اگر رجیسترهای جداگانه (یا بخشهای حافظه مانند پردازندههای اینتل) برای جابجایی کد و جابجایی دادهها وجود داشته باشد، برنامه باید به عنوان دو جزء منتقل شود.
● مکانیسم تجدید نظر می کندبه حافظه نسبت به شمارنده برنامه با این مکانیسم، در هنگام جابجایی برنامه فقط شمارنده برنامه در حافظه اصلی به روز می شود. برنامه ای که در آن تمام دسترسی های حافظه با شمارنده برنامه مرتبط هستند (یا مطلق هستند، مثلاً دسترسی به رجیسترهای دستگاه های ورودی/خروجی در آدرس های مطلق)، نامیده می شود. برنامه مستقل از موقعیتچنین برنامه ای را می توان در هر نقطه از فضای آدرس مجازی بدون پیکربندی آدرس ها قرار داد. لینک دهی پویا
روش اتصال که در بالا مورد بحث قرار گرفت یکی دارد خصوصیات عجیب و غریب:ارتباط با تمام رویه های مورد نیاز برنامه قبل از شروع برنامه برقرار می شود. یک روش منطقی تر برای پیوند دادن رویه های جداگانه کامپایل شده، نامیده می شود پویاالزام آور، شامل برقراری ارتباط با هر رویه در طول اولین تماس است. اولین بار در سیستم MULTICS استفاده شد. 
پیوند پویا در سیستمMULTICS. برای هر برنامهدرست شد بخش پیوند،حاوی بلوکی از اطلاعات برای هر رویه (شکل 5.2.4).
اطلاعات شامل:
● کلمه "آدرس غیر مستقیم" که برای آدرس مجازی رویه محفوظ است.
● نام رویه (EARTH، FIRE، و غیره)، که به عنوان رشته ای از کاراکترها ذخیره می شود. با پیوند پویا، فراخوانیهای رویهها در زبان مبدأ به دستوراتی ترجمه میشوند که با استفاده از آدرسدهی غیرمستقیم، به کلمه «آدرس غیر مستقیم» بلوک مربوطه اشاره میکنند (شکل 5.2.4). کامپایلر این کلمه را نیز پر می کند آدرس نامعتبر،یا مجموعه ای خاص از بیت هاکه باعث ایجاد وقفه در سیستم می شود (مانند تله ها).بعد از آن:
● پیوند دهنده نام رویه (به عنوان مثال، EARTH) را پیدا می کند و شروع به جستجوی دایرکتوری کاربر برای رویه کامپایل شده با آن نام می کند.
● رویه یافت شده یک آدرس مجازی «Address EARTH» (معمولاً در بخش خودش) اختصاص داده میشود که روی آدرس نامعتبر نوشته میشود، همانطور که در شکل نشان داده شده است. 5.2.4;
● سپس دستوری که باعث خطا شده است دوباره اجرا می شود. این به برنامه اجازه می دهد تا در جایی که قبل از قطع شدن سیستم بود ادامه یابد. همه فراخوانهای بعدی به رویه EARTH بدون خطا اجرا میشوند، زیرا بخش bind اکنون به جای کلمه «آدرس غیرمستقیم» آدرس مجازی واقعی «EARTH Address» را دارد. بنابراین، پیوند دهنده تنها زمانی درگیر می شود که برخی از رویه ها برای اولین بار فراخوانی شوند. بعد از آن دیگر نیازی به تماس با لینک دهنده نیست.
لینک سازی پویا در ویندوز
برای پیوند، از کتابخانه های پیوند پویا (Dynamic Link Library - DLL) استفاده می شود که حاوی رویه ها و (یا) داده ها هستند. کتابخانه ها به صورت فایل هایی با پسوندهای ".dll"، ".drv" (برای کتابخانه های درایور - کتابخانه های درایور) و ".fon" (برای کتابخانه های فونت - کتابخانه های فونت) قالب بندی می شوند. آنها اجازه می دهند رویه ها و داده های خود را بین چندین برنامه (فرآیند) به اشتراک بگذارند. بنابراین، رایجترین شکل یک DLL یک کتابخانه است که شامل مجموعهای از رویههای بارگذاری شده با حافظه است که میتواند توسط چندین برنامه به طور همزمان قابل دسترسی باشد. به عنوان مثال، در شکل. شکل 5.2.5 چهار فرآیند را نشان می دهد که یک فایل DLL حاوی رویه های A، B، C و D را به اشتراک می گذارند. برنامه های 1 و 2 از روش A استفاده می کنند. برنامه 3 - رویه D، برنامه 4 - رویه B.  فایل DLL توسط پیوند دهنده از مجموعه ای از فایل های ورودی ساخته می شود. اصل ساخت شبیه به ساخت کدهای باینری اجرایی است. تفاوت در این است که وقتی فایل DLL ساخته می شود، یک پرچم خاص به لینک دهنده ارسال می شود تا گزارش دهد که DLL ایجاد شده است. فایلهای DLL معمولاً از مجموعهای از روالهای کتابخانهای ساخته میشوند که ممکن است چندین پردازنده به آن نیاز داشته باشند. نمونههای رایج فایلهای DLL، رابطهای کتابخانه فراخوانی سیستم ویندوز و کتابخانههای گرافیکی بزرگ هستند. استفاده از فایل های DDL به شما امکان می دهد:
فایل DLL توسط پیوند دهنده از مجموعه ای از فایل های ورودی ساخته می شود. اصل ساخت شبیه به ساخت کدهای باینری اجرایی است. تفاوت در این است که وقتی فایل DLL ساخته می شود، یک پرچم خاص به لینک دهنده ارسال می شود تا گزارش دهد که DLL ایجاد شده است. فایلهای DLL معمولاً از مجموعهای از روالهای کتابخانهای ساخته میشوند که ممکن است چندین پردازنده به آن نیاز داشته باشند. نمونههای رایج فایلهای DLL، رابطهای کتابخانه فراخوانی سیستم ویندوز و کتابخانههای گرافیکی بزرگ هستند. استفاده از فایل های DDL به شما امکان می دهد:
● صرفه جویی در حافظه و فضای دیسک. به عنوان مثال، اگر یک کتابخانه به هر برنامه ای که از آن استفاده می کند پیوند داده شود، آن کتابخانه در بسیاری از باینری های اجرایی در حافظه و دیسک ظاهر می شود. اگر از فایل های DLL استفاده می کنید، هر کتابخانه یک بار روی دیسک و یک بار در حافظه ظاهر می شود.
● به روز رسانی رویه های کتابخانه را آسان تر می کند و علاوه بر این، به روز رسانی را حتی پس از کامپایل و پیوند برنامه هایی که از آنها استفاده می کنند، انجام می دهد.
● با توزیع فایل های DLL جدید (مثلاً از طریق اینترنت) خطاهای شناسایی شده را برطرف کنید. نیازی به تغییر در برنامه های باینری اصلی ندارد. تفاوت اصلیبین یک فایل DLL و یک برنامه باینری اجرایی این است که فایل DLL:
● نمی تواند به تنهایی شروع و اجرا شود زیرا برنامه میزبان ندارد.
● حاوی اطلاعات دیگری در هدر است.
● چندین رویه اضافی دارد که به رویه های موجود در کتابخانه مربوط نمی شوند، مانند رویه هایی برای تخصیص حافظه و مدیریت منابع دیگری که فایل DLL به آن نیاز دارد. یک برنامه می تواند به دو طریق به یک فایل DLL پیوند دهد: استفاده از پیوند ضمنی و استفاده از پیوند صریح. در الزام آور ضمنیبرنامه کاربر به صورت ایستا به یک فایل خاص به نام مرتبط است کتابخانه وارداتی
این کتابخانه توسط ابزار، یا ایجاد شده است سودمندی،با استخراج اطلاعات خاص از یک فایل DLL. کتابخانه واردات لینکر به یک برنامه کاربر اجازه دسترسی به یک فایل DLL را می دهد و می تواند به چندین کتابخانه وارداتی مرتبط شود. ویندوز، در پیوند ضمنی، برنامه ای را که برای اجرا بارگذاری می شود، کنترل می کند. سیستم تشخیص می دهد که برنامه از کدام فایل های DLL استفاده می کند و آیا همه فایل های مورد نیاز از قبل در حافظه هستند یا خیر. فایل های از دست رفته بلافاصله در حافظه بارگذاری می شوند.
سپس تغییرات مناسبی در ساختار دادههای کتابخانههای وارداتی ایجاد میشود تا بتوان مکان رویههای فراخوانی شده را تعیین کرد. این تغییرات در فضای آدرس مجازی برنامه نگاشت می شوند و پس از آن برنامه کاربر می تواند رویه های موجود در فایل های DLL را به گونه ای فراخوانی کند که گویی به صورت ایستا به آن لینک شده اند و آن را اجرا کند.
در الزام آور صریحهیچ کتابخانه وارداتی مورد نیاز نیست و هیچ فایل DLL نیازی به بارگیری همزمان با برنامه کاربر ندارد. در عوض، برنامه کاربر:
● یک تماس صریح در زمان اجرا برای پیوند به فایل DLL برقرار می کند.
● سپس تماس های اضافی برای دریافت آدرس رویه های مورد نیاز خود برقرار می کند.
● پس از آن برنامه آخرین تماس را برای شکستن پیوند با فایل DLL برقرار می کند.
● هنگامی که آخرین فرآیند پیوند خود را با یک فایل DLL می شکند، این فایل را می توان از حافظه حذف کرد. توجه داشته باشید که با پیوند پویا، رویه ای در یک فایل DLL روی رشته برنامه فراخوانی اجرا می شود و از پشته برنامه فراخوانی برای متغیرهای محلی خود استفاده می کند. یک تفاوت اساسی بین عملکرد یک رویه با اتصال پویا (از استاتیک) روش برقراری اتصال است.
دیوید دریسدیل، راهنمای مبتدیان برای پیوند دهنده ها
(http://www.lurklurk.org/linkers/linkers.html).
هدف این مقاله کمک به برنامه نویسان C و C++ است که جوهر کاری که لینکر انجام می دهد را درک کنند. من این موضوع را در چند سال گذشته برای بسیاری از همکاران توضیح دادهام و در نهایت به این نتیجه رسیدم که زمان آن رسیده است که این مطالب را روی کاغذ بیاورم تا در دسترستر باشد (و بنابراین نیازی به توضیح مجدد آن نیست). [به روز رسانی مارس 2009: اطلاعات بیشتر در مورد ویژگی های طرح بندی ویندوز، و جزئیات بیشتر در مورد قانون یک تعریف اضافه شد.
یک مثال معمولی از اینکه چرا از من کمک خواسته شده است خطای پیوند زیر است:
g++ -o test1 test1a.o test1b.o
test1a.o(.text+0x18): در تابع «main»:
: مرجع تعریف نشده به "findmax(int, int)"
collect2: ld 1 وضعیت خروج را برگرداند
اگر واکنش شما "احتمالاً "C" خارجی را فراموش کرده است، به احتمال زیاد همه چیزهایی که در این مقاله ارائه شده است را می دانید.
- تعاریف: در یک فایل C چیست؟
- کامپایلر C چه کاری انجام می دهد
- آنچه پیوند دهنده انجام می دهد: قسمت 1
- سیستم عامل چه کاری انجام می دهد
- پیوند دهنده چه می کند: قسمت 2
- C++ برای تکمیل تصویر
- کتابخانه های بارگذاری شده پویا
- علاوه بر این
تعاریف: در یک فایل C چیست؟
این فصل یادآوری مختصری از اجزای مختلف یک فایل C است. اگر همه چیز در فهرست زیر برای شما منطقی است، احتمالاً می توانید این فصل را نادیده بگیرید و مستقیماً به فصل بعدی بروید.
ابتدا باید تفاوت بین یک اعلان و یک تعریف را درک کنید.
یک تعریف یک نام را با یک پیاده سازی مرتبط می کند که می تواند کد یا داده باشد:
- تعریف متغیر به کامپایلر دستور می دهد تا مقداری از حافظه را رزرو کند، شاید مقدار خاصی به آن بدهد.
- تعریف تابع باعث می شود کامپایلر برای آن تابع کد تولید کند.
این اعلان به کامپایلر می گوید که یک تابع یا تعریف متغیر (با یک نام خاص) در جای دیگری از برنامه وجود دارد، احتمالاً در یک فایل C دیگر. (توجه داشته باشید که یک تعریف نیز یک اعلامیه است - در واقع، این یک اعلان است که در آن "جای دیگر" برنامه با تعریف فعلی یکسان است.)
دو نوع تعریف برای متغیرها وجود دارد:
- متغیرهای جهانی، که در طول چرخه عمر برنامه ("میزبانی استاتیک") وجود دارند و در عملکردهای مختلف موجود هستند.
- متغیرهای محلی، که فقط در یک تابع اجرایی ("میزبان محلی") وجود دارند و فقط در خود آن تابع در دسترس هستند.
در این مورد، اصطلاح "در دسترس" باید به این صورت درک شود که "می توان با نام مرتبط با متغیر در زمان تعریف دسترسی داشت".
چند مورد خاص وجود دارد که در نگاه اول واضح به نظر نمی رسند:
- متغیرهای محلی ساکندر واقع جهانی هستند زیرا در طول عمر برنامه وجود دارند، حتی اگر فقط در یک تابع قابل مشاهده باشند.
- متغیرهای جهانی ایستاجهانی نیز هستند، تنها با این تفاوت که فقط در همان فایلی که در آن تعریف شده اند در دسترس هستند.
شایان ذکر است که با تعریف یک تابع به عنوان استاتیک، به سادگی تعداد مکان هایی را که می توان از آنها به تابع داده شده با نام اشاره کرد، کاهش می دهد.
برای متغیرهای سراسری و محلی، میتوانیم تشخیص دهیم که متغیر مقداردهی اولیه شده است یا نه، یعنی. آیا فضای اختصاص داده شده برای یک متغیر در حافظه با یک مقدار خاص پر می شود یا خیر.
در نهایت، ما می توانیم اطلاعاتی را در حافظه ذخیره کنیم که به صورت پویا با استفاده از malloc یا new تخصیص داده شده است. در این مورد، نمی توان به حافظه اختصاص داده شده با نام اشاره کرد، بنابراین لازم است از اشاره گرها - متغیرهای نامگذاری شده حاوی آدرس یک ناحیه حافظه بدون نام استفاده شود. این قسمت از حافظه را می توان با رایگان یا حذف نیز آزاد کرد. در این صورت با «جایگاه پویا» سروکار داریم.
به طور خلاصه:
|
جهانی |
محلی |
پویا |
||||
|
عدم شروع |
عدم شروع |
|||||
|
اعلامیه |
int fn(int x); |
extern int x; |
extern int x; |
|||
|
تعریف |
int fn(int x) { ... } |
int x = 1; (محدوده فایل) |
intx; (دامنه - فایل) |
int x = 1; (حوزه - عملکرد) |
intx; (حوزه - عملکرد) |
int*p = malloc(sizeof(int)); |
احتمالاً ساده ترین راه برای یادگیری این است که فقط به برنامه نمونه نگاه کنید.
/* تعریف یک متغیر جهانی بدون مقدار اولیه */
int x_global_uninit;
/* یک متغیر جهانی اولیه را تعریف کنید */
int x_global_init = 1;
/* یک متغیر سراسری بدون مقدار اولیه تعریف کنید که به آن
static int y_global_uninit;
/* تعریف یک متغیر جهانی اولیه که به آن
* فقط با نام در این فایل C قابل ارجاع است */
static int y_global_init = 2;
/* اعلان یک متغیر سراسری که در جایی تعریف شده است
* در جای دیگر برنامه */
extern int z_global;
/* اعلان تابعی که در جای دیگری تعریف شده است
* برنامه ها (با این وجود می توانید "اکسترن" را در جلو اضافه کنید
* لازم نیست) */
int fn_a(int x, int y);
/* تعریف تابع. با این حال، علامت گذاری به عنوان ثابت، می تواند باشد
* فقط با نام در این فایل C تماس بگیرید. */
static int fn_b(int x)
بازگشت x+1;
/* تعریف تابع. */
/* پارامتر تابع به عنوان یک متغیر محلی در نظر گرفته می شود. */
int fn_c (int x_local)
/* یک متغیر محلی بدون مقدار اولیه تعریف کنید */
int y_local_uninit;
/* یک متغیر محلی اولیه را تعریف کنید */
int y_local_init = 3;
/* کدی که به متغیرهای محلی و سراسری دسترسی دارد،
* و همچنین توابع بر اساس نام */
X_global_uninit = fn_a(x_local، x_global_init);
Y_local_uninit = fn_a(x_local، y_local_init);
Y_local_uninit += fn_b(z_global);
بازگشت (x_global_uninit + y_local_uninit)؛
کامپایلر C چه کاری انجام می دهد
وظیفه کامپایلر C تبدیل متنی است که (معمولاً) برای انسان قابل درک است به چیزی که رایانه آن را می فهمد. به عنوان خروجی، کامپایلر یک فایل شی تولید می کند. در پلتفرم های یونیکس، این فایل ها معمولاً پسوند .o دارند. در ویندوز، پسوند.obj. محتویات یک فایل شی اساساً دو چیز است:
تعریف تابع تطبیق کد در فایل C
داده های مربوط به تعریف متغیرهای سراسری در فایل C (برای متغیرهای جهانی اولیه، مقدار اولیه متغیر نیز باید در فایل شی ذخیره شود).
کد و داده ها، در این مورد، نام های مرتبط با آنها خواهند داشت - نام توابع یا متغیرهایی که با تعریف آنها مرتبط هستند.
کد شی دنبالهای از دستورالعملهای ماشین (ترکیب مناسب) است که با دستورات C نوشته شده توسط برنامهنویس مطابقت دارد: همه آنهایی که if و while و حتی goto هستند. این طلسم ها باید نوعی اطلاعات را دستکاری کنند، و اطلاعات باید در جایی باشد - این همان چیزی است که ما به متغیرها نیاز داریم. کد ممکن است به کدهای دیگری نیز اشاره داشته باشد (به ویژه به سایر توابع C در برنامه).
هر جا که کد به یک متغیر یا تابع اشاره می کند، کامپایلر تنها در صورتی به آن اجازه می دهد که اعلان آن متغیر یا تابع را قبلا دیده باشد. اعلامیه قولی است مبنی بر اینکه این تعریف در جای دیگری از برنامه وجود دارد.
وظیفه پیوند دهنده تأیید این وعده ها است. با این حال، کامپایلر با تمام این وعده ها وقتی یک فایل شی تولید می کند، چه می کند؟
اساسا کامپایلر فضاهای خالی را ترک می کند. یک فضای خالی (پیوند) یک نام دارد، اما مقدار مربوط به این نام هنوز مشخص نیست.
با در نظر گرفتن این موضوع، میتوانیم فایل شی مربوط به برنامه بالا را به صورت زیر رندر کنیم:
تجزیه یک فایل شی
تا به حال همه چیز را در سطح بالایی در نظر گرفته ایم. با این حال، دیدن این که چگونه در عمل کار می کند مفید است. ابزار اصلی برای ما دستور nm خواهد بود که اطلاعاتی در مورد نمادهای یک فایل شی در پلت فرم یونیکس می دهد. در ویندوز، دستور dumpbin با گزینه /symbols تقریباً معادل است. همچنین Binutil های گنو به ویندوز منتقل شده اند که شامل nm.exe می شود.
بیایید ببینیم که چه nm خروجی برای فایل شی به دست آمده از مثال بالا ما دارد:
نمادها از c_parts.o:
Name Value Class Type Size Section Line
fn_a | | U | NOTTYPE| | |*UND*
z_global | | U | NOTTYPE| | |*UND*
fn_b |00000000| t | FUNC|00000009| |.متن
x_global_init |00000000| D | OBJECT|00000004| |.داده
y_global_unit |00000000| b | OBJECT|00000004| |.bss
x_global_uninit |00000004| ج | OBJECT|00000004| |*COM*
y_global_init |00000004| d | OBJECT|00000004| |.داده
fn_c|00000009| T | FUNC|00000055| |.متن
نتیجه ممکن است در پلتفرم های مختلف کمی متفاوت به نظر برسد (برای جزئیات، صفحات man را بررسی کنید)، اما اطلاعات کلیدی کلاس هر کاراکتر و اندازه آن است (در صورت وجود). کلاس می تواند مقادیر متفاوتی داشته باشد:
- کلاس U مخفف ارجاعات نامشخص است، آن «فضاهای خالی» که در بالا ذکر شد. دو شی برای این کلاس وجود دارد: fn_a و z_global. (برخی نسخه های nm ممکن است بخشی را خروجی دهند که در این مورد *UND* یا UNDEF خواهد بود.)
- کلاس های t و T به کد تعریف شده اشاره می کنند. تفاوت بین t و T این است که آیا تابع محلی (t) در فایل است یا نه (T)، یعنی. آیا تابع به عنوان ثابت اعلام شده است. مجدداً، در برخی از سیستم ها، ممکن است بخشی مانند .text نشان داده شود.
- کلاس های d و D حاوی متغیرهای جهانی اولیه هستند. در این حالت متغیرهای استاتیک متعلق به کلاس d هستند. اگر اطلاعات بخش موجود باشد، .data خواهد بود.
- برای متغیرهای سراسری اولیه، اگر ثابت باشند، b و در غیر این صورت B یا C میگیریم. بخش در این مورد به احتمال زیاد .bss یا *COM* خواهد بود.
همچنین می توانید کاراکترهایی را ببینید که بخشی از کد منبع C نیستند. ما روی این موضوع تمرکز نخواهیم کرد، زیرا معمولاً بخشی از مکانیزم داخلی کامپایلر است تا برنامه شما همچنان بتواند بعداً پیوند داده شود.
هدف این مقاله کمک به برنامه نویسان C و C++ است که جوهر کاری که لینکر انجام می دهد را درک کنند. من این موضوع را در چند سال گذشته برای بسیاری از همکاران توضیح دادهام و در نهایت به این نتیجه رسیدم که زمان آن رسیده است که این مطالب را روی کاغذ بیاورم تا در دسترستر باشد (و بنابراین نیازی به توضیح مجدد آن نیست). [به روز رسانی مارس 2009: اطلاعات بیشتر در مورد ویژگی های طرح بندی ویندوز، و جزئیات بیشتر در مورد قانون یک تعریف اضافه شد.
یک مثال معمولی از اینکه چرا از من کمک خواسته شده است خطای پیوند زیر است:
g++ -o test1 test1a.o test1b.o test1a.o(.text+0x18): در تابع "main": : مرجع تعریف نشده به "findmax(int, int)" collect2: ld 1 وضعیت خروج را برگرداند
اگر واکنش شما "احتمالاً "C" خارجی را فراموش کرده است، به احتمال زیاد همه چیزهایی که در این مقاله ارائه شده است را می دانید.
تعاریف: در یک فایل C چیست؟
این فصل یادآوری مختصری از اجزای مختلف یک فایل C است. اگر همه چیز برای شما منطقی است، احتمالاً می توانید این فصل را نادیده بگیرید و مستقیماً به آن بروید.ابتدا باید تفاوت بین یک اعلان و یک تعریف را درک کنید. تعریفیک نام را با یک پیاده سازی مرتبط می کند که می تواند کد یا داده باشد:
- تعریف متغیر به کامپایلر دستور می دهد تا مقداری از حافظه را رزرو کند، شاید مقدار خاصی به آن بدهد.
- تعریف تابع باعث می شود کامپایلر برای آن تابع کد تولید کند.
دو نوع تعریف برای متغیرها وجود دارد:
- متغیرهای جهانی، که در طول چرخه عمر برنامه ("میزبانی استاتیک") وجود دارند و در عملکردهای مختلف موجود هستند.
- متغیرهای محلی، که فقط در یک تابع اجرایی ("میزبان محلی") وجود دارند و فقط در خود آن تابع در دسترس هستند.
چند مورد خاص وجود دارد که در نگاه اول واضح به نظر نمی رسند:
- متغیرهای محلی استاتیک در واقع متغیرهای سراسری هستند زیرا در طول عمر برنامه وجود دارند، حتی اگر فقط در یک تابع قابل مشاهده باشند.
- متغیرهای static global نیز سراسری هستند، تنها با این تفاوت که آنها فقط در همان فایلی که در آن تعریف شده اند قابل دسترسی هستند.
برای متغیرهای سراسری و محلی، میتوانیم تشخیص دهیم که متغیر مقداردهی اولیه شده است یا نه، یعنی. آیا فضای اختصاص داده شده برای یک متغیر در حافظه با یک مقدار خاص پر می شود یا خیر.
در نهایت، میتوانیم اطلاعاتی را در حافظه ذخیره کنیم که به صورت پویا با malloc یا new تخصیص داده میشوند. در این مورد، نمی توان به حافظه اختصاص داده شده با نام اشاره کرد، بنابراین لازم است از اشاره گرها - متغیرهای نامگذاری شده حاوی آدرس یک ناحیه حافظه بدون نام استفاده شود. این قسمت از حافظه را می توان با رایگان یا حذف نیز آزاد کرد. در این صورت با «جایگاه پویا» سروکار داریم.
به طور خلاصه:
احتمالاً ساده ترین راه برای یادگیری این است که فقط به برنامه نمونه نگاه کنید.
/* تعریف یک متغیر جهانی بدون مقدار اولیه */ int x_global_uninit; /* یک متغیر جهانی اولیه تعریف کنید */ int x_global_init = 1; /* یک متغیر جهانی بدون مقدار اولیه تعریف کنید که * فقط در این فایل C با نام قابل ارجاع باشد */ static int y_global_uninit; /* یک متغیر سراسری اولیه تعریف کنید که * فقط با نام در این فایل C قابل ارجاع باشد */ static int y_global_init = 2; /* اعلان یک متغیر سراسری که در جایی * در جای دیگر برنامه تعریف شده است */ extern int z_global; /* اعلان تابعی که در جای دیگری از برنامه تعریف شده است * (شما می توانید پیشوند "extern" را انتخاب کنید، اما این * اختیاری است) */ int fn_a(int x, int y); /* تعریف تابع. با این حال، هنگامی که ثابت علامت گذاری می شود، می توان * را با نام فقط در آن فایل C فراخوانی کرد. */ static int fn_b(int x) ( x+1; ) /* تعریف تابع. */ /* پارامتر تابع به عنوان یک متغیر محلی در نظر گرفته می شود. */ int fn_c(int x_local) ( /* تعریف یک متغیر محلی بدون مقدار اولیه */ int y_local_uninit؛ /* تعریف یک متغیر محلی اولیه */ int y_local_init = 3؛ /* کدی که به متغیرهای محلی و جهانی دسترسی دارد، * همچنین به عنوان توابع توسط */ x_global_uninit = fn_a (x_local، x_global_init)؛ y_local_uninit = fn_a(x_local، y_local_init); y_local_uninit += fn_b(z_global)؛ بازگشت (x_global_uninit + y_local);
کامپایلر C چه کاری انجام می دهد
وظیفه کامپایلر C تبدیل متنی است که (معمولاً) برای انسان قابل درک است به چیزی که رایانه آن را می فهمد. خروجی کامپایلر فایل شی. در پلتفرم های یونیکس، این فایل ها معمولاً پسوند .o دارند. در ویندوز، پسوند.obj. محتویات یک فایل شی اساساً دو چیز است:کد و داده ها، در این مورد، نام های مرتبط با آنها خواهند داشت - نام توابع یا متغیرهایی که با تعریف آنها مرتبط هستند.
کد شی دنبالهای از دستورالعملهای ماشین (ترکیب مناسب) است که با دستورالعملهای C نوشته شده توسط برنامهنویس مطابقت دارد: همه آنهایی که اگر "s و while" و حتی goto باشند. این طلسم ها باید نوعی اطلاعات را دستکاری کنند، و اطلاعات باید در جایی باشد - این همان چیزی است که ما به متغیرها نیاز داریم. کد ممکن است به کدهای دیگری نیز اشاره داشته باشد (به ویژه به سایر توابع C در برنامه).
هر جا کد به متغیر یا تابعی اشاره می کند، کامپایلر تنها در صورتی به آن اجازه می دهد که آن متغیر یا تابع را قبلا دیده باشد. اعلامیه قولی است مبنی بر اینکه این تعریف در جای دیگری از برنامه وجود دارد.
وظیفه پیوند دهنده تأیید این وعده ها است. با این حال، کامپایلر با تمام این وعده ها وقتی یک فایل شی تولید می کند، چه می کند؟
اساسا کامپایلر فضاهای خالی را ترک می کند. یک فضای خالی (پیوند) یک نام دارد، اما مقدار مربوط به این نام هنوز مشخص نیست.
با در نظر گرفتن این موضوع، می توانیم فایل شی مربوط به را به صورت زیر نمایش دهیم: 
تجزیه یک فایل شی
تا به حال همه چیز را در سطح بالایی در نظر گرفته ایم. با این حال، دیدن این که چگونه در عمل کار می کند مفید است. ابزار اصلی برای ما تیم خواهد بود نانومتر، که اطلاعاتی در مورد نمادهای یک فایل شی در پلت فرم یونیکس می دهد. برای دستور ویندوز دامپبینبا گزینه /symbols تقریبا معادل است. ابزارهای GNU binutils نیز وجود دارد که شامل nm.exe میشود.بیایید ببینیم که چه nm خروجی برای فایل شی به دست آمده از:
نمادها از c_parts.o: Name Value Class نوع اندازه خط بخش fn_a | | U | NOTTYPE| | |*UND*z_global | | U | NOTTYPE| | |*UND* fn_b |00000000| t | FUNC|00000009| |.text x_global_init |00000000| D | OBJECT|00000004| |.data y_global_uninit |00000000| b | OBJECT|00000004| |.bss x_global_uninit |00000004| ج | OBJECT|00000004| |*COM* y_global_init |00000004| d | OBJECT|00000004| |.داده fn_c |00000009| T | FUNC|00000055| |.متن
نتیجه ممکن است در پلتفرم های مختلف کمی متفاوت به نظر برسد (برای جزئیات بیشتر به man "s مراجعه کنید)، اما اطلاعات کلیدی کلاس هر کاراکتر و اندازه آن است (در صورت وجود). کلاس می تواند مقادیر متفاوتی داشته باشد:
- کلاس Uبه ارجاعات نامعین اشاره دارد، همان «فضاهای خالی» که در بالا ذکر شد. دو شی برای این کلاس وجود دارد: fn_a و z_global. (برخی از نسخه های nm ممکن است خروجی داشته باشند بخش، که می شود *UND*یا UNDEFدر این مورد.)
- کلاس ها تیو تیبه کدی که تعریف شده است اشاره کنید. تفاوت بین تیو تیاین است که آیا تابع محلی است ( تی) در فایل یا نه ( تی) ، یعنی آیا تابع به عنوان ثابت اعلام شده است. مجدداً، در برخی از سیستم ها، ممکن است یک بخش نشان داده شود، مانند .متن.
- کلاس ها دو Dشامل متغیرهای جهانی اولیه است. در این حالت متغیرهای استاتیک متعلق به کلاس هستند د. اگر اطلاعات بخش موجود باشد، خواهد بود .داده ها.
- برای متغیرهای جهانی اولیه، ما دریافت می کنیم باگر ساکن باشند و بیا سیدر غیر این صورت. بخش در این مورد به احتمال زیاد خواهد بود .bssیا *COM*.
آنچه پیوند دهنده انجام می دهد: قسمت 1
قبلاً اشاره کردیم که اعلان یک تابع یا متغیر قولی به کامپایلر است که تعریفی از آن تابع یا متغیر در جای دیگری از برنامه وجود دارد و این وظیفه پیوند دهنده است که به آن وعده عمل کند. با نگاه کردن به، می توانیم این فرآیند را به عنوان "پر کردن جاهای خالی" توصیف کنیم.بیایید این را با یک مثال توضیح دهیم و علاوه بر فایل C، به فایل C دیگری نیز نگاه کنیم.
/* متغیر جهانی اولیه */ int z_global = 11; /* دومین متغیر جهانی با نام y_global_init، اما هر دو ثابت هستند */ static int y_global_init = 2; /* اعلام یک متغیر جهانی دیگر */ extern int x_global_init; int fn_a(int x, int y) ( return(x+y); ) int main(int argc, char *argv) (const char *message = "سلام، دنیا"؛ بازگشت fn_a(11,12)؛ ) 
بر اساس هر دو نمودار، میتوانیم ببینیم که همه نقاط میتوانند متصل شوند (اگر نه، پیوند دهنده یک پیام خطا میفرستد). هر چیزی جای خود را دارد و هر مکانی چیز خود را دارد. همچنین، پیوند دهنده می تواند تمام فضاهای خالی را همانطور که در اینجا نشان داده شده است پر کند (در سیستم های یونیکس، فرآیند پیوند معمولاً با دستور فراخوانی می شود. ld).

برای C، همه چیز کمتر روشن است. باید دقیقاً یک تعریف برای هر تابع و متغیر جهانی اولیه وجود داشته باشد، اما تعریف یک متغیر بدون مقدار اولیه را می توان به عنوان تعریف موقت. بنابراین زبان C به فایلهای منبع مختلف اجازه میدهد (یا حداقل آن را منع نمیکند) که حاوی یک پیش تعریف از یک شی باشند.
با این حال، لینککنندهها باید بتوانند با زبانهایی غیر از C و C++ نیز سروکار داشته باشند، که الزاماً قانون تک تعریف برای آنها وجود ندارد. برای مثال، طبیعی است که Fortran یک کپی از هر متغیر جهانی در هر فایلی که به آن ارجاع می دهد داشته باشد. سپس پیوند دهنده باید با انتخاب یک کپی (بزرگترین نماینده در صورت متفاوت بودن اندازه) موارد تکراری را حذف کند و همه موارد را دور بیندازد. استراحت گاهی اوقات به این مدل به دلیل کلمه کلیدی Fortran COMMON، "مدل مشترک" طرح بندی نامیده می شود.
در نتیجه، برای پیوند دهنده های یونیکس کاملاً معمول است که از کاراکترهای تکراری شکایت نکنند، حداقل اگر آنها نویسه های تکراری متغیرهای جهانی اولیه هستند (این مدل پیوند گاهی اوقات به عنوان "مدل پیوند آرام" نامیده می شود [ تقریبا ترجمهاین ترجمه رایگان من از مدل ref/def آرام است. پیشنهادات بهتر استقبال می شود]). اگر این شما را آزار میدهد (و احتمالاً باید باشد)، برای یافتن یک گزینه --work-properly- که رفتار آن را رام میکند، به اسناد پیوند دهنده خود مراجعه کنید. به عنوان مثال، در زنجیره ابزار گنو، گزینه کامپایلر -fno-common باعث میشود که به جای ایجاد بلوکهای مشترک (COMMON) یک متغیر بدون مقدار اولیه در بخش BBS قرار گیرد.
سیستم عامل چه کاری انجام می دهد
اکنون که پیوند دهنده یک فایل اجرایی تولید کرده است و به هر مرجع نماد تعریف مناسبی می دهد، می توانید مکث کوتاهی داشته باشید تا متوجه شوید که سیستم عامل هنگام اجرای برنامه چه می کند.راه اندازی برنامه، البته، مستلزم اجرای کد ماشین است، یعنی. بدیهی است که سیستم عامل باید کد ماشین فایل اجرایی را از هارد دیسک به RAM منتقل کند، جایی که CPU می تواند آن را دریافت کند. به این بخش ها قطعه کد (بخش کد یا بخش متن) می گویند.
کد بدون داده به خودی خود بی فایده است. بنابراین تمام متغیرهای سراسری نیز نیاز به مکانی در حافظه کامپیوتر دارند. با این حال، بین متغیرهای جهانی اولیه و بدون مقدار اولیه تفاوت وجود دارد. متغیرهای اولیه دارای مقادیر شروع خاصی هستند که باید در فایل های شی و اجرایی نیز ذخیره شوند. هنگامی که برنامه در هنگام راه اندازی شروع می شود، سیستم عامل این مقادیر را در فضای مجازی برنامه، در بخش داده کپی می کند.
برای متغیرهای بدون مقدار اولیه، سیستم عامل ممکن است فرض کند که همه آنها 0 به عنوان مقدار اولیه خود دارند، یعنی. نیازی به کپی کردن هیچ مقداری نیست. تکه ای از حافظه که به صفر مقدار دهی اولیه می شود به عنوان بخش bss شناخته می شود.
این بدان معناست که فضایی برای متغیرهای سراسری را می توان در یک فایل اجرایی ذخیره شده روی دیسک کنار گذاشت. برای متغیرهای اولیه، مقادیر اولیه آنها باید حفظ شود، اما برای متغیرهای اولیه، فقط اندازه آنها باید حفظ شود.

همانطور که ممکن است متوجه شده باشید، تا کنون تمام بحث در مورد فایل های شی و پیوند دهنده فقط در مورد متغیرهای جهانی بوده است. در حالی که ما به متغیرهای محلی و حافظه اشغال شده پویا اشاره نکردیم.
این داده نیازی به مداخله پیوند دهنده ندارد زیرا طول عمر آن در طول اجرای برنامه شروع می شود و به پایان می رسد - مدت ها بعد از اینکه پیوند دهنده کار خود را انجام داده باشد. با این حال، برای تکمیل، به اختصار بیان می کنیم که:
- متغیرهای محلی در ناحیه ای از حافظه به نام قرار دارند پشته، که با فراخوانی و اجرای توابع مختلف رشد و کوچک می شود.
- حافظه تخصیص یافته به صورت پویا از ناحیه ای از حافظه به نام گرفته شده است پشتهو تابع malloc دسترسی به فضای آزاد در آن ناحیه را کنترل می کند.

پیوند دهنده چه کاری انجام می دهد؟ قسمت 2
اکنون که به آنچه پیوند دهنده انجام می دهد نگاه کردیم، می توانیم جزئیات پیچیده تر را بررسی کنیم - تقریباً به همان ترتیب زمانی که آنها به پیوند دهنده اضافه شده اند.مشاهدات اصلی که بر عملکردهای پیوند دهنده تأثیر می گذارد این است: اگر تعدادی از برنامه های مختلف تقریباً کارهای مشابهی را انجام دهند (چاپ روی صفحه، خواندن فایل ها از هارد دیسک و غیره)، پس واضح است که جداسازی این کد در یک کد منطقی است. مکان خاصی را در اختیار دیگران قرار دهید تا از آن استفاده کنند.
یکی از راه حل های ممکن استفاده از فایل های شی یکسان است، اما نگهداری کل مجموعه فایل های ... شی در یک مکان به راحتی قابل دسترسی است. کتابخانه.
انحراف فنی: این فصل یک ویژگی مهم پیوند دهنده را کاملاً حذف می کند: حمل و نقل(جابجایی). برنامه های مختلف اندازه های متفاوتی دارند، به عنوان مثال. اگر یک کتابخانه مشترک به فضای آدرس برنامه های مختلف نگاشت شود، آدرس های متفاوتی خواهد داشت. این به نوبه خود به این معنی است که تمام توابع و متغیرهای موجود در کتابخانه در مکان های مختلف قرار خواهند گرفت. حال، اگر همه دسترسیهای آدرس نسبی باشند ("مقدار +1020 بایت از اینجا") به جای مطلق ("مقدار در 0x102218BF")، مشکلی نیست، اما همیشه اینطور نیست. در چنین مواردی، تمام آدرس های مطلق باید با یک افست مناسب اضافه شوند - این است جابجایی. من قصد ندارم دوباره به این موضوع بازگردم، اما اضافه میکنم که از آنجایی که تقریباً همیشه از برنامهنویس C/C++ پنهان است، بسیار نادر است که مشکلات پیوند ناشی از مشکلات تغییر مسیر باشد.
کتابخانه های ایستا
ساده ترین پیاده سازی یک کتابخانه است ایستاکتابخانه در فصل قبل ذکر شد که امکان اشتراک گذاری (اشتراک گذاری) کد به سادگی با استفاده مجدد از فایل های شی وجود دارد. این ماهیت کتابخانه های ایستا است.در سیستم های یونیکس، معمولاً دستور ساخت یک کتابخانه استاتیک است ar، و فایل کتابخانه حاصل دارای پسوند *.a است. همچنین، این فایلها معمولاً با پیشوند «lib» در نام خود قرار میگیرند و با گزینه «-l» و به دنبال آن نام کتابخانه بدون پیشوند و پسوند به پیوند دهنده ارسال میشوند (یعنی «-fred» فایل را انتخاب میکند. "libfred.a").
(در گذشته برای کتابخانه های استاتیک به برنامه ای به نام ranlib نیز نیاز بود تا لیستی از نمادها را در ابتدای کتابخانه تولید کند. این روزها ابزارهای ar خودشان این کار را انجام می دهند.)
در ویندوز، کتابخانه های استاتیک دارای پسوند .LIB هستند و توسط ابزارهای LIB ساخته می شوند، با این حال این می تواند گمراه کننده باشد زیرا همان پسوند برای "کتابخانه وارداتی" استفاده می شود که فقط موارد موجود در DLL را فهرست می کند - ببینید.
همانطور که پیوند دهنده از طریق مجموعه فایل های شی تکرار می شود تا آنها را با هم ترکیب کند، لیستی از نمادها را حفظ می کند که هنوز نمی توانند پیاده سازی شوند. هنگامی که تمام فایل های شی صریح پردازش شدند، پیوند دهنده اکنون مکان جدیدی برای جستجوی نمادهای باقی مانده در لیست - در کتابخانه دارد. اگر یک نماد تحقق نیافته در یکی از اشیاء کتابخانه تعریف شود، آن شی اضافه می شود، درست مانند اینکه کاربر به لیست فایل های شی اضافه شده است، و پیوند ادامه می یابد.
به ریزه کاری آنچه از کتابخانه اضافه می شود توجه کنید: اگر تعریفی از نماد لازم است، پس کل شیءشامل تعریف نماد خواهد شد. این بدان معنی است که این فرآیند می تواند یک گام به جلو و یک گام به عقب باشد - یک شی تازه اضافه شده می تواند یک مرجع تعریف نشده را حل کند یا مجموعه ای کامل از مراجع حل نشده جدید را معرفی کند.
یکی دیگر از جزئیات مهم این است سفارشمناسبت ها؛ کتابخانه ها تنها زمانی وارد می شوند که پیوند عادی کامل شده و در آن پردازش شوند باشهاز چپ به راست. این بدان معنی است که اگر آخرین شیء بازیابی شده از کتابخانه به نمادی از کتابخانه نیاز داشته باشد که ابتدا در خط فرمان پیوند قرار می گیرد، پیوند دهنده آن را به طور خودکار پیدا نمی کند.
بیایید برای روشن شدن وضعیت مثالی بزنیم. فرض کنید فایلهای شی زیر و یک خط فرمان پیوند حاوی a.o، b.o، -lx و -ly را داریم.
هنگامی که پیوند دهنده a.o و b.o را پردازش کرد، ارجاعات به b2 و a3 حل می شوند، در حالی که x12 و y22 هنوز حل نشده خواهند بود. در این مرحله، پیوند دهنده اولین libx.a را برای نشانههای از دست رفته بررسی میکند و متوجه میشود که میتواند x1.o را برای ارجاع به x12 شامل شود. با این حال، با انجام این کار، x23 و y12 به لیست مراجع تعریف نشده اضافه می شوند (لیست اکنون مانند y22، x23، y12 است).
پیوند دهنده هنوز با libx.a سروکار دارد، بنابراین مرجع x23 به راحتی با گنجاندن x2.o از libx.a جبران می شود. با این حال، این y11 را به لیست تعریف نشده (که تبدیل به y22، y12، y11 شد) اضافه می کند. هیچ یک از این پیوندها با استفاده از libx.a قابل حل نیستند، بنابراین پیوند دهنده با liby.a اشتباه گرفته می شود.
در اینجا هم همین اتفاق می افتد و پیوند دهنده شامل y1.o و y2.o می شود. یک مرجع به y21 به عنوان اولین شی اضافه می شود، اما از آنجایی که y2.o به هر حال شامل خواهد شد، این مرجع به سادگی حل می شود. نتیجه این فرآیند این است که همه مراجع تعریف نشده حل می شوند و برخی (و نه همه) اشیاء کتابخانه در فایل اجرایی نهایی گنجانده می شوند.
توجه داشته باشید که اگر مثلاً b.o به y32 نیز اشاره داشته باشد، وضعیت تا حدودی متفاوت است. اگر اینطور بود، پیوند libx.a نیز رخ میداد، اما پردازش liby.a شامل y3.o میشد. با گنجاندن این شی، x31 را به لیست نمادهای حل نشده اضافه می کنیم و این مرجع حل نشده باقی می ماند - در این مرحله، پیوند دهنده قبلاً پردازش libx.a را به پایان رسانده است و بنابراین دیگر تعریف این نماد را پیدا نمی کند (در x3. o).
(به هر حال، این مثال یک وابستگی دایره ای بین کتابخانه های libx.a و liby.a دارد؛ این معمولاً بد است)
کتابخانه های مشترک پویا
برای کتابخانه های محبوب مانند کتابخانه استاندارد C (معمولاً libc)، یک کتابخانه ایستا بودن دارای این عیب مشخص است که هر برنامه اجرایی یک کپی از همان کد خواهد داشت. در واقع، اگر هر فایل اجرایی یک کپی از printf، fopen و موارد مشابه داشته باشد، فضای دیسک به طور غیرضروری زیادی اشغال میشود.یک اشکال کمتر آشکار این است که در یک برنامه پیوند استاتیک، کد برای همیشه ثابت می شود. اگر کسی اشکالی را در printf پیدا کرده و رفع کند، هر برنامه باید دوباره پیوند داده شود تا کد تصحیح شده را دریافت کند.
برای غلبه بر این مشکلات و مشکلات دیگر، کتابخانه های به اشتراک گذاشته شده به صورت پویا (معمولاً .so یا .dll در ویندوز و .dylib در Mac OS X) معرفی شده اند. برای این نوع کتابخانه، پیوند دهنده لزوماً همه نقاط را به هم متصل نمی کند. در عوض، پیوند دهنده کوپنی مانند "IOU" (من به شما بدهکارم = به شما بدهکارم) صادر می کند و نقد کردن این کوپن را تا اجرای برنامه به تاخیر می اندازد.
نتیجه این است که اگر پیوند دهنده تشخیص دهد که تعریف یک نماد خاص در یک کتابخانه مشترک است، آن تعریف را در فایل اجرایی نهایی شامل نمی شود. در عوض، پیوند دهنده نام نماد و کتابخانه ای را که قرار است نماد از آنجا آمده باشد، یادداشت می کند.
هنگامی که برنامه ای برای اجرا فراخوانی می شود، سیستم عامل اطمینان حاصل می کند که قسمت های باقی مانده از فرآیند پیوند به موقع قبل از شروع اجرای برنامه کامل شده است. قبل از فراخوانی تابع اصلی، یک نسخه کوچک از پیوند دهنده (که اغلب ld.so نامیده می شود) لیست وعده ها را طی می کند و عمل پیوند نهایی را در محل انجام می دهد - قرار دادن کد کتابخانه و اتصال همه نقاط.
این بدان معناست که هیچ فایل اجرایی حاوی کپی کد printf نیست. اگر نسخه جدیدی از printf در دسترس باشد، می توان آن را به سادگی با تغییر libc.so استفاده کرد - دفعه بعد که برنامه اجرا می شود، printf جدید فراخوانی می شود.
تفاوت بزرگ دیگری بین نحوه کار کتابخانه های پویا در مقایسه با کتابخانه های ایستا وجود دارد و این در دانه بندی پیوند آشکار می شود. اگر نماد خاصی از یک کتابخانه پویا خاص (مثلا printf از libc.so) گرفته شود، کل محتویات کتابخانه در فضای آدرس برنامه قرار می گیرد. این تفاوت اصلی با کتابخانه های ایستا است، جایی که فقط اشیاء خاص مربوط به یک نماد تعریف نشده اضافه می شوند.
به بیان دیگر، کتابخانه های اشتراکی خود توسط پیوند دهنده (به جای تشکیل انبوهی از اشیاء، همانطور که ar انجام می دهد) ایجاد می شوند که حاوی پیوندهایی بین اشیاء در خود کتابخانه است. برای تکرار، nm یک ابزار مفید برای نشان دادن آنچه در حال وقوع است است: زیرا هنگامی که در نسخه استاتیک کتابخانه اجرا می شود چندین خروجی برای هر فایل شی به صورت جداگانه تولید می کند، اما برای نسخه مشترک کتابخانه، liby.so تنها یک خروجی دارد. نماد تعریف نشده x31 . همچنین، در مثال با ترتیب گنجاندن کتابخانه ها در انتها، هیچ مشکلی وجود نخواهد داشت: افزودن ارجاع به y32 در b.c تغییری در پی نخواهد داشت، زیرا تمام محتویات y3.o و x3.o قبلاً وجود داشته است. استفاده شده است.
بنابراین، یکی دیگر از ابزارهای مفید ldd است. در یک پلتفرم یونیکس، تمام کتابخانه های مشترکی را که باینری اجرایی (یا کتابخانه مشترک دیگر) به آنها وابسته است، همراه با نشانی از جایی که این کتابخانه ها را می توان یافت، فهرست می کند. برای اینکه برنامه با موفقیت شروع شود، لودر باید همه این کتابخانه ها را به همراه تمام وابستگی های آنها پیدا کند. (به طور معمول، لودر به دنبال کتابخانه ها در لیست دایرکتوری های مشخص شده در متغیر محیطی LD_LIBRARY_PATH می گردد.)
/usr/bin:ldd xeyes linux-gate.so.1 => (0xb7efa000) libXext.so.6 => /usr/lib/libXext.so.6 (0xb7edb000) libXmu.so.6 => /usr/lib /libXmu.so.6 (0xb7ec6000) libXt.so.6 => /usr/lib/libXt.so.6 (0xb7e77000) libX11.so.6 => /usr/lib/libX11.so.6 (0xb7d93000) libSM .so.6 => /usr/lib/libSM.so.6 (0xb7d8b000) libICE.so.6 => /usr/lib/libICE.so.6 (0xb7d74000) libm.so.6 => /lib/libm .so.6 (0xb7d4e000) libc.so.6 => /lib/libc.so.6 (0xb7c05000) libXau.so.6 => /usr/lib/libXau.so.6 (0xb7c01000) libxcb-xlib.so 0.0 => /usr/lib/libxcb-xlib.so.0 (0xb7bff000) libxcb.so.1 => /usr/lib/libxcb.so.1 (0xb7be8000) libdl.so.2 => /lib/libdl .so.2 (0xb7be4000) /lib/ld-linux.so.2 (0xb7efb000) libXdmcp.so.6 => /usr/lib/libXdmcp.so.6 (0xb7bdf000)
دلیل جزئیات بیشتر این است که سیستمعاملهای مدرن به اندازه کافی هوشمند هستند که به شما امکان میدهند کارهای بیشتری از ذخیره موارد تکراری روی دیسک انجام دهید، که کتابخانههای استاتیک از آن رنج میبرند. فرآیندهای اجرایی متفاوتی که از یک کتابخانه مشترک استفاده میکنند نیز میتوانند یک بخش کد را به اشتراک بگذارند (اما نه یک بخش داده یا یک بخش bss - برای مثال، در هنگام استفاده از strtok، دو فرآیند مختلف میتوانند در مکانهای مختلف باشند). برای دستیابی به این هدف، کل کتابخانه باید یکباره مورد بررسی قرار گیرد، به طوری که همه مراجع داخلی به طور منحصر به فرد ردیف شوند. در واقع، اگر یکی از فرآیندهای a.o و c.o و دیگری b.o و c.o را انتخاب کند، سیستم عامل قادر به استفاده از هیچ تطابقی نخواهد بود.
DLL ویندوز
اگرچه اصول کلی کتابخانه های اشتراکی تقریباً در هر دو پلتفرم یونیکس و ویندوز یکسان است، هنوز جزئیات کمی وجود دارد که مبتدیان می توانند درگیر آنها شوند.نمادهای صادر شده
بزرگترین تفاوت این است که در کتابخانه های ویندوز، نمادها وجود ندارند صادر می شودبطور خودکار. در یونیکس، تمام نمادها در تمام فایل های شی که به یک کتابخانه مشترک پیوند داده شده اند برای کاربر آن کتابخانه قابل مشاهده هستند. در ویندوز، برنامه نویس باید به صراحت کاراکترهای خاصی را قابل مشاهده کند، به عنوان مثال. آنها را صادر کنندسه راه برای صادر کردن یک نماد و یک DLL ویندوز وجود دارد (و هر سه روش را می توان در یک کتابخانه ترکیب کرد).
- در کد منبع، نماد را به عنوان __declspec(dllexport) اعلام کنید، چیزی شبیه به این:
__declspec(dllexport) int my_exported_function(int x، double y) - هنگام اجرای دستور لینکر، از گزینه صادرات LINK.EXE استفاده کنید: نماد_به_صادرات
LINK.EXE /dll /export:my_exported_function - فایل تعریف ماژول (DEF) را به پیوند دهنده (با استفاده از گزینه /DEF): def_file) با گنجاندن یک بخش EXPORT در آن فایل که شامل نمادهایی است که باید صادر شوند.
صادرات my_exported_function my_other_exported_function
.LIB و سایر فایل های مرتبط با کتابخانه
ما به مشکل دوم با کتابخانه های ویندوز رسیده ایم: اطلاعات مربوط به نمادهای صادر شده که پیوند دهنده باید به بقیه نمادها پیوند دهد در خود DLL موجود نیست. در عوض، این اطلاعات در فایل .LIB مربوطه موجود است.فایل LIB مرتبط با DLL، نمادهای (صادراتی) در DLL را همراه با مکان آنها توصیف می کند. هر باینری که از DLL استفاده می کند باید به فایل .LIB دسترسی داشته باشد تا نمادها را به درستی پیوند دهد.
برای گیجکنندهتر کردن همه چیز، پسوند .LIB برای کتابخانههای استاتیک نیز استفاده میشود.
در واقع، تعدادی فایل مختلف وجود دارد که می توانند به نوعی به کتابخانه های ویندوز مرتبط شوند. همراه با فایل .LIB و همچنین فایل (اختیاری) .DEF، می توانید تمام فایل های زیر مرتبط با کتابخانه ویندوز خود را مشاهده کنید.
این یک تفاوت بزرگ در یونیکس است، جایی که تقریباً تمام اطلاعات موجود در همه این فایل های اضافی به سادگی به خود کتابخانه اضافه می شود.
نمادهای وارداتی
علاوه بر الزام DLL ها برای اعلام صریح، ویندوز همچنین به باینری هایی که از کد کتابخانه استفاده می کنند اجازه می دهد تا نمادها را به صراحت اعلام کنند. این مورد نیاز نیست، اما به دلیل ویژگی های تاریخی ویندوزهای 16 بیتی، مقداری بهینه سازی سرعت را فراهم می کند.ما می توانیم این لیست ها را دوباره با استفاده از nm دنبال کنیم. فایل C++ زیر را در نظر بگیرید:
کلاس Fred ( خصوصی: int x؛ int y؛ عمومی: Fred() : x(1)، y(2) () Fred(int z): x(z)، y(3) ()); فرد فرد; فرد theOtherFred(55);
برای این کد ( نهتزئین شده) خروجی nm به شکل زیر است:
نمادها از global_obj.o: Name Value Class نوع اندازه خط بخش __gxx_personality_v0| | U | NOTTYPE| | |*UND* __Initialization_and_destruction_static_0(int, int) |00000000| t | FUNC|00000039| |.text Fred::Fred(int) |00000000| w | FUNC|00000017| |.text._ZN4FredC1Ei Fred::Fred() |00000000| w | FUNC|00000018| |.text._ZN4FredC1Ev theFred |00000000| b | OBJECT|00000008| |.bss theOtherFred |00000008| b | OBJECT|00000008| سازنده های جهانی |.bss کلید شده به theFred |0000003a| t | FUNC|0000001a| |.متن
طبق معمول، ما می توانیم یک سری چیزهای مختلف را در اینجا ببینیم، اما یکی از جالب ترین آنها برای ما ورودی های کلاس است. دبلیو(به معنی نماد "ضعیف") و همچنین ورودی هایی با نام بخشی مانند ".gnu.linkonce.t. چیز". اینها نشانگرهایی برای سازنده های شی جهانی هستند، و ما می بینیم که فیلد "Name" مربوطه نشان می دهد که ما واقعاً می توانیم در آنجا انتظار داشته باشیم - هر یک از دو سازنده درگیر هستند.
قالب ها
ما قبلاً سه پیاده سازی مختلف از تابع max را نشان داده ایم که هر کدام انواع مختلفی از آرگومان ها را می گیرند. با این حال، می بینیم که کد بدنه تابع در هر سه حالت یکسان است. و ما می دانیم که کپی کردن یک کد یک شکل بد از برنامه نویسی است.C++ مفاهیم را معرفی می کند قالب(الگوها)، که به شما امکان می دهد از کد زیر برای همه موارد به طور همزمان استفاده کنید. ما می توانیم یک فایل هدر max_template.h را تنها با یک کپی از حداکثر کد تابع ایجاد کنیم:
قالب
و این فایل را در فایل منبع قرار دهید تا عملکرد الگو را امتحان کنید:
#include "max_template.h" int main() ( int a=1; int b=2; int c; c = max(a,b); // کامپایلر به طور خودکار تعیین می کند که حداکثر نیاز است
این کد ++C از حداکثر استفاده می کند
هر یک از این نمونه های مختلف کد ماشین متفاوتی تولید می کند. بنابراین، در زمانی که برنامه در نهایت پیوند می شود، کامپایلر و پیوند دهنده باید اطمینان حاصل کنند که کد هر نمونه از الگوی استفاده شده در برنامه گنجانده شده است (و هیچ نمونه الگوی استفاده نشده ای در آن گنجانده نشده است، تا اندازه برنامه زیاد نشود).
چگونه انجام می شود؟ معمولاً دو راه وجود دارد: یا نازک کردن نمونههای تکراری، یا به تعویق انداختن نمونهسازی به مرحله پیوند (من معمولاً از این رویکردها به عنوان راه هوشمند و راه خورشید یاد میکنم).
روش نازک کردن نمونههای مکرر به این معنی است که هر فایل شی حاوی کد تمام قالبهایی است که با آنها مواجه میشویم. به عنوان مثال، برای فایل فوق، محتوای فایل شی به شکل زیر است:
نمادها از max_template.o: Name Value Class نوع اندازه خط بخش __gxx_personality_v0 | | U | NOTTYPE| | |*UND*حداکثر دو برابر
و ما شاهد حضور هر دو نمونه max هستیم
هر دو تعریف به عنوان علامت گذاری شده اند شخصیت های ضعیف، و این بدان معنی است که پیوند دهنده، هنگام ایجاد فایل اجرایی نهایی، می تواند تمام نمونه های تکراری یک الگو را بیرون بیاورد و تنها یکی را باقی بگذارد (و در صورت صلاحدید، می تواند بررسی کند که آیا همه نمونه های تکراری الگو واقعاً به الگو نگاشت می شوند یا خیر. همان کد). بزرگترین نقطه ضعف این روش افزایش اندازه هر فایل شی منفرد است.
رویکرد دیگر (که در Solaris C++ استفاده میشود) این است که به هیچ وجه تعاریف الگو را در فایلهای آبجکت لحاظ نکنید، بلکه آنها را به عنوان نمادهای تعریف نشده علامتگذاری کنید. وقتی نوبت به مرحله پیوند میرسد، پیوند دهنده میتواند تمام نمادهای تعریفنشده را که در واقع به نمونههای الگو تعلق دارند جمعآوری کند و سپس کد ماشین را برای هر یک از آنها تولید کند.
این قطعاً حجم هر فایل شی را کاهش میدهد، اما نقطه ضعف این روش این است که پیوند دهنده باید محل قرارگیری کد منبع را دنبال کند و باید بتواند کامپایلر C++ را در زمان پیوند اجرا کند (که میتواند کل را کاهش دهد. روند)
کتابخانه های بارگذاری شده پویا
آخرین ویژگی که در اینجا به آن خواهیم پرداخت، بارگذاری پویا کتابخانه های مشترک است. در ما دیدیم که چگونه استفاده از کتابخانه های مشترک پیوند نهایی را تا زمانی که برنامه واقعا اجرا شود به تاخیر می اندازد. در سیستم عامل های مدرن، این حتی در مراحل بعدی امکان پذیر است.این کار توسط یک جفت فراخوانی سیستمی dlopen و dlsym انجام می شود (معادل های ویندوز به ترتیب LoadLibrary و GetProcAddress نامیده می شوند). اولین مورد نام کتابخانه مشترک را می گیرد و آن را در فضای آدرس فرآیند در حال اجرا بارگذاری می کند. البته ممکن است این کتابخانه دارای نمادهای حل نشده نیز باشد، بنابراین فراخوانی dlopen ممکن است باعث بارگیری کتابخانه های مشترک دیگر شود.
Dlopen این انتخاب را ارائه می دهد که یا حذف همه موارد حل نشده به محض بارگیری کتابخانه (RTLD_NOW) یا حل نمادها در صورت نیاز (RTLD_LAZY). روش اول به این معنی است که تماس dlopen ممکن است مدت زیادی طول بکشد، اما راه دوم خطر خاصی را ایجاد می کند که یک مرجع نامشخص در طول اجرای برنامه پیدا می شود که قابل حل نیست - در این مرحله برنامه خاتمه می یابد.
البته، نمادهای یک کتابخانه بارگذاری شده پویا نمی توانند نام داشته باشند. با این حال، این به سادگی حل می شود، همانطور که سایر مشکلات برنامه نویسی حل می شوند، با افزودن یک لایه اضافی از راه حل ها. در این حالت از نشانگر فضای کاراکتری استفاده می شود. فراخوانی dlsym یک پارامتر تحت اللفظی می گیرد که نام نمادی را که باید پیدا شود می دهد و یک اشاره گر را به محل آن برمی گرداند (یا اگر نماد پیدا نشد NULL).
تعامل با C++
فرآیند بارگذاری پویا به اندازه کافی ساده است، اما چگونه با ویژگی های مختلف C++ که بر رفتار کلی پیوند دهنده تأثیر می گذارد، تعامل دارد؟اولین مشاهده مربوط به تزئین اسامی است. هنگام فراخوانی dlsym، نام نمادی که باید پیدا شود، ارسال می شود. بنابراین باید نسخه قابل مشاهده پیوند دهنده نام باشد، یعنی. نام تزئین شده
از آنجایی که فرآیند تزئین می تواند از پلت فرمی به پلتفرم دیگر و کامپایلری به کامپایلر دیگر متفاوت باشد، این بدان معناست که یافتن نماد C++ به صورت پویا با یک روش عمومی تقریبا غیرممکن است. حتی اگر فقط با یک کامپایلر کار میکنید و در دنیای درونی آن جستجو میکنید، مشکلات دیگری وجود دارد - علاوه بر توابع ساده مانند C، یک سری چیزهای دیگر (جدول روش مجازی و موارد مشابه) وجود دارد که باید مراقب آنها باشید. از بیش از حد.
برای خلاصه کردن موارد فوق، معمولاً بهتر است یک نقطه ورودی خارجی "C" داشته باشیم که بتوان آن را با dlsym پیدا کرد. این نقطه ورودی می تواند یک روش کارخانه ای باشد که نشانگرها را به تمام نمونه های کلاس C++ برمی گرداند و امکان دسترسی به تمام جذابیت های کلاس را فراهم می کند. C++.
کامپایلر ممکن است به خوبی با سازندههای شی سراسری در کتابخانهای که توسط dlopen بارگذاری شده است سروکار داشته باشد، زیرا چند کاراکتر خاص وجود دارد که میتوان به کتابخانه اضافه کرد، که توسط پیوند دهنده (چه در زمان بارگذاری و چه در زمان اجرا) فراخوانی میشوند. کتابخانه به صورت پویا بارگیری یا تخلیه می شود - پس از آن فراخوانی های لازم برای سازنده ها وجود دارد یا تخریب کننده ها می توانند در اینجا رخ دهند. در یونیکس، اینها توابع _init و _fini هستند، یا در سیستمهای جدیدتر با استفاده از جعبه ابزار گنو، توابعی با برچسب __attribute__((سازنده)) یا __خصیصه__((نابودگر)) وجود دارد. در ویندوز، تابع مربوطه DllMain با پارامتر fdwReason DWORD روی DLL_PROCESS_ATTACH یا DLL_PROCESS_DETACH تنظیم شده است.
به عنوان نکته پایانی، بارگذاری پویا یک کار عالی در "ناقص کردن نمونه های تکراری" در هنگام نمونه سازی الگوها انجام می دهد. و همه چیز با "به تعویق انداختن نمونه سازی" مبهم به نظر می رسد، زیرا "مرحله پیوند" پس از اجرای برنامه (و احتمالاً در ماشین دیگری که منبع را ذخیره نمی کند) رخ می دهد. برای یافتن راهی برای خروج از این وضعیت به مستندات کامپایلر و لینک کننده مراجعه کنید.
علاوه بر این
این مقاله به عمد بسیاری از جزئیات را در مورد نحوه عملکرد لینکر حذف کرده است، زیرا من معتقدم که محتوای نوشته شده 95٪ از مشکلات روزمره ای را که یک برنامه نویس هنگام پیوند دادن برنامه خود با آن مواجه است، پوشش می دهد.اگر می خواهید بیشتر بدانید، می توانید از لینک های زیر اطلاعات کسب کنید:
با تشکر فراوان از Mike Capp و Ed Wilson برای پیشنهادات مفید در مورد این صفحه.
حق چاپ 2004-2005، 2009-2010 دیوید دریسدیل
اجازه کپی، توزیع و/یا اصلاح این سند تحت شرایط مجوز مستندات آزاد گنو، نسخه 1.1 یا هر نسخه بعدی منتشر شده توسط بنیاد نرم افزار آزاد اعطا می شود. بدون بخشهای ثابت، بدون متنهای جلویی، و بدون متنهای پشت جلدی. یک کپی از مجوز موجود است.
برچسب ها: اضافه کردن برچسب