Regresiona analiza u Microsoft Excel-u je najsveobuhvatniji vodič za korištenje MS Excel-a za rješavanje problema regresijske analize u poslovnoj inteligenciji. Konrad Carlberg jasno objašnjava teorijske probleme čije će vam poznavanje pomoći da izbjegnete mnoge greške kako sami radite regresijsku analizu tako i kada procjenjujete rezultate analiza koje su izvršili drugi ljudi. Sav materijal, od jednostavnih korelacija i t-testova do višestruke analize kovarijanse, zasnovan je na stvarnim primjerima i popraćen je detaljnim opisom relevantnih postupaka korak po korak.
Ova knjiga govori o detaljima Excelovih regresijskih funkcija, istražuje implikacije svake opcije i svakog argumenta i objašnjava kako pouzdano primijeniti tehnike regresije u poljima koja se kreću od medicinskog istraživanja do finansijske analize.
Konrad Carlberg. Regresiona analiza u Microsoft Excel-u. - M.: Dijalektika, 2017. - 400 str.
Preuzmite bilješku u formatu ili, primjere u formatu
Poglavlje 1. Procjena varijabilnosti podataka
Statističari imaju na raspolaganju mnogo indikatora varijabilnosti (varijabilnosti). Jedan od njih je zbir kvadrata odstupanja pojedinačnih vrijednosti od srednje vrijednosti. Excel za ovo koristi funkciju SQUADROT(). Ali češće se koristi disperzija. Varijanca je srednja vrijednost kvadrata odstupanja. Varijanca je neosjetljiva na broj vrijednosti u skupu podataka koji se proučava (dok se zbir kvadrata odstupanja povećava s brojem mjerenja).
Excel nudi dvije funkcije koje vraćaju varijansu: VARP.D() i VARP.V():
- Koristite funkciju VAR.G() ako vrijednosti koje treba obraditi čine populaciju. Odnosno, vrijednosti sadržane u rasponu su jedine vrijednosti koje vas zanimaju.
- Koristite funkciju VAR.V() ako vrijednosti koje treba obraditi čine uzorak iz veće populacije. Pretpostavlja se da postoje dodatne vrijednosti čiju varijansu također možete procijeniti.
Ako se vrijednost kao što je srednja vrijednost ili koeficijent korelacije izračunava na osnovu opće populacije, onda se naziva parametar. Slična vrijednost izračunata na osnovu uzorka naziva se statistika. Odbrojavanje odstupanja od prosjeka u ovom skupu ćete dobiti zbir kvadrata odstupanja manjeg iznosa nego da ih računate od bilo koje druge vrijednosti. Slična izjava vrijedi i za disperziju.
Što je veličina uzorka veća, to je tačnija izračunata vrijednost statistike. Ali ne postoji uzorak manji od veličine populacije za koji možete biti sigurni da je vrijednost statistike ista kao i vrijednost parametra.
Recimo da imate skup od 100 visina čija se srednja vrijednost razlikuje od srednje vrijednosti stanovništva, koliko god razlika bila mala. Kada izračunate varijansu za uzorak, dobit ćete neku vrijednost, recimo 4. Ova vrijednost je manja od bilo koje druge vrijednosti koja se može dobiti izračunavanjem odstupanja svake od 100 vrijednosti rasta od bilo koje vrijednosti osim uzorka srednja vrijednost, uključujući pravu srednju vrijednost za opću populaciju. Stoga će se izračunata varijansa razlikovati, i to u manjoj mjeri, od varijanse koju biste dobili da ste nekako znali i koristili ne srednju vrijednost uzorka, već parametar populacije.
Srednji zbir kvadrata određen za uzorak daje nižu procjenu varijanse populacije. Ovako izračunata varijansa se zove raseljeni evaluacija. Ispada da je za eliminaciju pristrasnosti i dobijanje nepristrasne procjene dovoljno podijeliti zbir kvadrata odstupanja ne sa n, gdje n je veličina uzorka, i n - 1.
Vrijednost n - 1 naziva se broj (broj) stepeni slobode. Postoje različiti načini za izračunavanje ove vrijednosti, iako svi uključuju ili oduzimanje nekog broja od veličine uzorka ili prebrojavanje broja kategorija u koje opservacije spadaju.
Suština razlike između funkcija DISP.G() i DISP.V() je sljedeća:
- U funkciji VARI.G(), zbir kvadrata je podijeljen sa brojem opservacija i stoga predstavlja pristrasnu procjenu varijanse, pravu srednju vrijednost.
- U funkciji VAR.B() zbroj kvadrata se dijeli sa brojem opažanja minus 1, tj. brojem stepena slobode, što daje tačniju, nepristrasnu procenu varijanse populacije iz koje je uzorak izvučen.
standardna devijacija (engleski) standardna devijacija, SD) je kvadratni korijen varijanse:
Kvadratura odstupanja prevodi mjernu skalu u drugu metriku, koja je kvadrat originalne: metri - u kvadratne metre, dolari - u kvadratne dolare, itd. Standardna devijacija je kvadratni korijen varijanse i tako nas vraća na izvorne jedinice. Što je zgodnije.
Često je potrebno izračunati standardnu devijaciju nakon što su podaci podvrgnuti nekoj manipulaciji. I iako su u ovim slučajevima rezultati nesumnjivo standardne devijacije, oni se obično nazivaju standardne greške. Postoji nekoliko tipova standardnih grešaka, uključujući standardnu grešku merenja, standardnu grešku proporcije i standardnu grešku srednje vrednosti.
Recimo da prikupljate podatke o visini 25 nasumično odabranih odraslih muškaraca u svakoj od 50 država. Zatim izračunavate prosječnu visinu odraslih muškaraca u svakoj državi. Rezultirajućih 50 srednjih vrijednosti se mogu smatrati zapažanjima. Iz ovoga možete izračunati njihovu standardnu devijaciju, koja je standardna greška srednje vrijednosti. Rice. 1. omogućava vam da uporedite distribuciju 1250 originalnih pojedinačnih vrednosti (podaci o visini 25 muškaraca u svakoj od 50 država) sa distribucijom prosečnih vrednosti od 50 država. Formula za procjenu standardne greške srednje vrijednosti (tj. standardne devijacije srednje vrijednosti, a ne pojedinačnih zapažanja):
![]()
gdje je standardna greška srednje vrijednosti; s je standardna devijacija originalnih zapažanja; n je broj opservacija u uzorku.

Rice. 1. Varijacija u prosječnim vrijednostima od države do države je mnogo manja od varijacije pojedinačnih zapažanja
U statistici postoji konvencija o upotrebi grčkih i latiničnih slova za označavanje statističkih veličina. Uobičajeno je da se parametri opće populacije označavaju grčkim slovima, a statistike uzorka latiničnim slovima. Dakle, ako govorimo o standardnoj devijaciji populacije, pišemo je kao σ; ako se uzme u obzir standardna devijacija uzorka, koristimo oznaku s. Što se tiče simbola za prosjeke, oni se međusobno ne slažu tako dobro. Srednja vrijednost stanovništva označava se grčkim slovom μ. Međutim, simbol X̅ se tradicionalno koristi za predstavljanje srednje vrijednosti uzorka.
z-score izražava poziciju opažanja u distribuciji u jedinicama standardne devijacije. Na primjer, z = 1,5 znači da je opservacija udaljena 1,5 standardnih devijacija od srednje vrijednosti, prema višim vrijednostima. Termin z-score koristi se za individualne evaluacije, tj. za mjerenja pripisana pojedinačnim elementima uzorka. Za takve statistike (npr. državni prosjek), koristi se termin. z-vrijednost:

gdje je X̅ srednja vrijednost uzorka, μ je srednja vrijednost opće populacije, standardna greška srednje vrijednosti skupa uzoraka:
![]()
gdje je σ standardna greška opće populacije (pojedinačna mjerenja), n je veličina uzorka.
Pretpostavimo da ste instruktor golfa. Već duže vrijeme možete mjeriti domet udarca i znate da je prosjek 205 jardi, a standardna devijacija 36 jardi. Ponuđen vam je novi štap, tvrdeći da će povećati vaš domet za 10 jardi. Zamolite svakog od sljedećeg 81 posjetitelja kluba da se oproba s novim klubom i snimi njihov raspon. Ispostavilo se da je prosječni domet udarca novom palicom 215 jardi. Kolika je vjerovatnoća da je razlika od 10 jardi (215 - 205) posljedica isključivo greške uzorkovanja? Ili drugačije rečeno, kolika je vjerovatnoća da, u većem testu, novi klub neće pokazati povećanje dometa u odnosu na trenutni dugoročni prosjek od 205 jardi?
Ovo možemo testirati generiranjem z-vrijednosti. Standardna greška srednje vrijednosti:
![]()
Tada z-vrijednost:

Moramo pronaći vjerovatnoću da će srednja vrijednost uzorka biti udaljena 2,5σ od srednje vrijednosti populacije. Ako je vjerovatnoća mala, onda razlike nisu zbog slučajnosti, već zbog kvaliteta novog kluba. U Excelu ne postoji gotova funkcija za određivanje vjerovatnoće z-skora. Međutim, možete koristiti formulu =1-NORM.ST.DIST(z-vrijednost, TRUE), gdje NORM.ST.DIST() vraća područje ispod normalne krive lijevo od z-vrijednosti (slika 2) .

Rice. 2. Funkcija NORM.S.DIST() vraća područje ispod krive lijevo od z-vrijednosti; Da biste uvećali sliku, kliknite desnim tasterom miša na nju i izaberite Otvorite sliku u novoj kartici
Drugi argument funkcije NORM.S.DIST() može imati dvije vrijednosti: TRUE - funkcija vraća područje ispod krive lijevo od tačke specificirane prvim argumentom; FALSE - Funkcija vraća visinu krivulje u tački datoj prvim argumentom.
Ako srednja vrijednost (μ) i standardna devijacija (σ) populacije nisu poznate, koristi se t-vrijednost (vidi ). Strukture z- i t-skora razlikuju se po tome što se standardna devijacija s dobijena iz rezultata uzorka koristi za pronalaženje t-vrijednosti, a ne poznate vrijednosti parametra populacije σ. Normalna kriva ima jedan oblik, a oblik raspodjele t-vrijednosti varira ovisno o broju stupnjeva slobode df (od engleskog. stepena slobode) uzorka koji predstavlja. Broj stepeni slobode uzorka je n - 1, gdje n- veličina uzorka (slika 3).

Rice. 3. Oblik t-distribucija koje nastaju kada je parametar σ nepoznat razlikuje se od oblika normalne raspodjele
Excel ima dvije funkcije za t-distribuciju, koja se naziva i Studentova t-distribucija: STUDENT.DIST() vraća područje ispod krive lijevo od date t-vrijednosti, a STUDENT.DIST.Tx() desno.
Poglavlje 2. Korelacija
Korelacija je mjera zavisnosti između elemenata skupa uređenih parova. Korelacija je okarakterisana Pearsonovi koeficijenti korelacije– r. Koeficijent može imati vrijednosti u rasponu od -1,0 do +1,0.

gdje S x I Sy su standardne devijacije varijabli X I Y, Sxy– kovarijansa:

U ovoj formuli, kovarijansa je podijeljena standardnim devijacijama varijabli X I Y, čime se uklanjaju efekti skaliranja koji se odnose na jedinicu iz kovarijanse. Excel koristi funkciju CORREL(). Ime ove funkcije ne sadrži kvalifikacione elemente G i C, koji se koriste u nazivima funkcija kao što su STDEV(), VARV() ili COVARIANCE(). Iako koeficijent korelacije uzorka daje pristrasnu procjenu, razlog za pristrasnost je drugačiji nego u slučaju varijanse ili standardne devijacije.
Ovisno o veličini općeg koeficijenta korelacije (često se označava grčkim slovom ρ ), koeficijent korelacije r daje pristrasnu procjenu, s efektom pristranosti koji se povećava sa smanjenjem veličine uzorka. Ipak, ne pokušavamo da ispravimo ovu pristrasnost na isti način kao što smo, na primjer, to učinili prilikom izračunavanja standardne devijacije, kada smo u odgovarajuću formulu zamenili ne broj opažanja, već broj stupnjeva slobode. U stvarnosti, broj opservacija korištenih za izračunavanje kovarijanse nema utjecaja na veličinu.
Standardni koeficijent korelacije je dizajniran da se koristi sa varijablama koje su međusobno povezane linearnim odnosom. Prisustvo nelinearnosti i/ili grešaka u podacima (outliers) dovode do netačnog izračuna koeficijenta korelacije. Dijagrami raspršenja se preporučuju za dijagnosticiranje problema s podacima. Ovo je jedini tip grafikona u Excelu koji i horizontalnu i vertikalnu os tretira kao osi vrednosti. Linijski grafikon, s druge strane, definiše jednu od kolona kao osu kategorije, što iskrivljuje sliku podataka (Sl. 4).

Rice. 4. Čini se da su linije regresije iste, ali uporedite njihove jednačine jedna s drugom
Opažanja korištena za izgradnju linijskog grafikona su jednako udaljena duž horizontalne ose. Oznake podjela duž ove ose su samo oznake, a ne numeričke vrijednosti.
Iako korelacija često znači da postoji uzročna veza, ona se ne može koristiti kao dokaz da postoji. Statistika se ne koristi da pokaže da li je teorija istinita ili netačna. Isključiti suprotstavljena objašnjenja rezultata opservacija staviti planirane eksperimente. Statistika se također koristi za sumiranje informacija prikupljenih tokom takvih eksperimenata i za kvantificiranje vjerovatnoće da odluka može biti pogrešna s obzirom na bazu dokaza.
Poglavlje 3 Jednostavna regresija
Ako su dvije varijable povezane, tako da je vrijednost koeficijenta korelacije veća od, recimo, 0,5, tada je moguće (sa određenom tačnošću) predvidjeti nepoznatu vrijednost jedne varijable iz poznate vrijednosti druge. Da biste dobili predviđene vrijednosti cijene, na osnovu podataka datih na sl. 5, možete koristiti bilo koji od nekoliko mogućih načina, ali gotovo sigurno nećete koristiti onaj prikazan na sl. 5. Ipak, trebali biste ga pročitati, jer nijedan drugi način ne može tako jasno pokazati odnos između korelacije i predviđanja kao ovaj. Na sl. 5, u rasponu B2:C12, je slučajni uzorak od deset kuća i daje podatke o površini svake kuće (u kvadratnim stopama) i njenoj prodajnoj cijeni.

Rice. 5. Predviđanja prodajnih cijena formiraju pravu liniju
Pronađite srednje vrijednosti, standardne devijacije i koeficijent korelacije (opseg A14:C18). Izračunajte z-rezultate površine (E2:E12). Na primjer, ćelija E3 sadrži formulu: =(B3-$B$14)/$B$15. Izračunajte z-rezultate prognozirane cijene (F2:F12). Na primjer, ćelija F3 sadrži formulu: =E3*$B$18. Pretvorite z-rezultate u cijene u dolarima (H2:H12). U ćeliji HZ, formula je: =F3*$C$15+$C$14.
Imajte na umu da predviđena vrijednost uvijek ima tendenciju pomjeranja prema srednjoj vrijednosti, koja je 0. Što je koeficijent korelacije bliži nuli, to je predviđeni z-score bliži nuli. U našem primjeru koeficijent korelacije između površine i prodajne cijene je 0,67, a prognozirana cijena je 1,0*0,67, tj. 0,67. Ovo odgovara višku vrijednosti u odnosu na prosječnu vrijednost, jednakom dvije trećine standardne devijacije. Ako bi koeficijent korelacije bio jednak 0,5, onda bi prognozirana cijena bila 1,0 * 0,5, tj. 0.5. Ovo odgovara višku vrijednosti iznad prosječne vrijednosti, jednakom samo polovini standardne devijacije. Kad god se vrijednost koeficijenta korelacije razlikuje od idealne, tj. veće od -1,0 i manje od 1,0, procjena prediktorske varijable treba da bude bliža njenoj srednjoj vrijednosti nego procjena prediktorske (nezavisne) varijable njenoj vlastitoj. Ovaj fenomen se naziva regresija na srednju vrijednost ili jednostavno regresija.
U Excelu postoji nekoliko funkcija za određivanje koeficijenata jednadžbe regresijske linije (u Excelu se to zove linija trenda) y=kx + b. Za utvrđivanje k služi funkciji
=SLOPE(poznate_y-vrijednosti; poznate_x-vrijednosti)
Evo at je predviđena varijabla, i X je nezavisna varijabla. Morate striktno slijediti ovaj redoslijed varijabli. Nagib linije regresije, koeficijent korelacije, standardne devijacije varijabli i kovarijansa su usko povezani (slika 6). Funkcija INTERCEPT() vraća vrijednost odsječenu linijom regresije na okomitoj osi:
= INTERCUT(poznate_y-vrijednosti; poznate_x-vrijednosti)

Rice. 6. Odnos između standardnih devijacija pretvara kovarijansu u koeficijent korelacije i nagib linije regresije
Imajte na umu da broj x i y vrijednosti koje se pružaju funkcijama SLOPE() i INTERCEPT() kao argumentima mora biti isti.
U regresionoj analizi koristi se još jedan važan indikator - R 2 (R-kvadrat), odnosno koeficijent determinacije. Određuje kakav doprinos ukupnoj varijabilnosti podataka daje odnos između X I at. Excel za to ima funkciju QVPIRSON(), koja uzima potpuno iste argumente kao i funkcija CORREL().
Kaže se da dvije varijable sa koeficijentom korelacije različitom od nule objašnjavaju varijansu ili imaju objašnjenu varijansu. Obično se objašnjena varijansa izražava u postocima. Dakle R 2 = 0,81 znači da je objašnjeno 81% varijanse (raspršenosti) dvije varijable. Preostalih 19% je rezultat slučajnih fluktuacija.
Excel ima funkciju TREND koja pojednostavljuje proračune. TREND() funkcija:
- uzima poznate vrijednosti koje dajete X i poznate vrijednosti at;
- izračunava nagib linije regresije i konstante (segment);
- vraća prediktivne vrijednosti at određeno primjenom regresione jednadžbe na poznate vrijednosti X(Sl. 7).
Funkcija TREND() je funkcija niza (ako do sada niste naišli na takve funkcije, preporučujem je).

Rice. 7. Upotreba funkcije TREND() omogućava vam da ubrzate i pojednostavite proračune u usporedbi s korištenjem para funkcija SLOPE() i INTERCEPT()
Da biste unijeli funkciju TREND() kao formulu niza u ćelijama G3:G12, odaberite raspon G3:G12, unesite formulu TREND (SZ:S12;VZ:B12), pritisnite i držite tipke
Funkcija TREND() ima još dva argumenta: nove_vrijednosti_x I konst. Prvi vam omogućava da napravite prognozu za budućnost, a drugi može natjerati liniju regresije da prođe kroz ishodište (vrijednost TRUE govori Excelu da koristi izračunatu konstantu, FALSE vrijednost - konstanta = 0). Excel vam omogućava da nacrtate liniju regresije na grafikonu tako da prolazi kroz ishodište. Počnite crtanjem dijagrama raspršenosti, a zatim kliknite desnim tasterom miša na jedan od markera serije podataka. Izaberite stavku u kontekstnom meniju koji se otvori. Dodajte liniju trenda; odaberite opciju Linearno; ako je potrebno, skrolujte nadole po panelu, označite polje Postavite raskrsnicu; provjerite je li njegov pridruženi okvir za tekst postavljen na 0.0.
Ako imate tri varijable i želite da odredite korelaciju između dvije od njih isključujući utjecaj treće, možete koristiti parcijalna korelacija. Pretpostavimo da vas zanima odnos između procenta stanovnika grada koji su završili fakultet i broja knjiga u gradskim bibliotekama. Prikupili ste podatke za 50 gradova, ali... Problem je što oba ova parametra mogu zavisiti od blagostanja stanovnika određenog grada. Naravno, veoma je teško naći drugih 50 gradova koje karakteriše potpuno isti nivo blagostanja stanovnika.
Primjenom statističkih metoda za uklanjanje utjecaja bogatstva i na bibliotečku podršku i na fakultetsko obrazovanje, mogli biste bolje kvantificirati odnos između varijabli koje vas zanimaju, odnosno broja knjiga i broja diplomaca. Ova uslovna korelacija između dvije varijable, kada su vrijednosti drugih varijabli fiksne, naziva se djelomična korelacija. Jedan od načina da se to izračuna je korištenje jednadžbe:

Gdje rCB . W- koeficijent korelacije između varijabli Fakultet (fakultet) i Books (knjige) sa isključenim uticajem (fiksna vrijednost) varijable Bogatstvo (bogatstvo); rCB- koeficijent korelacije između varijabli Fakultet i knjige; rCW- koeficijent korelacije između varijabli Fakultet i socijalna zaštita; rb.w.- koeficijent korelacije između varijabli Knjige i Blagostanje.
S druge strane, parcijalna korelacija se može izračunati na osnovu rezidualne analize, tj. razlike između predviđenih vrijednosti i njihovih povezanih stvarnih opažanja (obje metode su prikazane na slici 8).

Rice. 8. Parcijalna korelacija kao rezidualna korelacija
Da biste pojednostavili izračunavanje matrice koeficijenata korelacije (B16: E19), koristite Excel paket za analizu (meni Podaci –> Analiza –> Analiza podataka). Podrazumevano, ovaj paket nije aktivan u Excelu. Da biste ga instalirali, prođite kroz meni File –> Parametri –> dodaci. Na dnu prozora koji se otvara Parametriexcel pronađite polje Kontrola, izaberite dodaciexcel, kliknite Idi. Označite polje pored dodatka Paket analiza. Kliknite na A Analiza podataka, odaberite opciju Korelacija. Navedite $B$2:$D$13 kao interval unosa, označite polje Oznake u prvom redu, navedite $B$16:$E$19 kao izlazni interval.
Druga mogućnost je da se definiše polu-parcijalna korelacija. Na primjer, istražujete utjecaj visine i starosti na težinu. Dakle, imate dvije prediktorske varijable, visinu i starost, i jednu prediktorsku varijablu, težinu. Želite da isključite uticaj jedne prediktorske varijable na drugu, ali ne i na prediktorsku varijablu:
![]()
gdje je H - visina (visina), W - težina (težina), A - starost (starost); Indeks poludjelimičnog koeficijenta korelacije koristi zagrade da naznači koja se varijabla eliminira i iz koje varijable. U ovom slučaju, oznaka W(H.A) označava da se efekat varijable Starost uklanja iz varijable Visina, ali ne i iz varijable Težina.
Mogao bi se steći utisak da tema o kojoj se raspravlja nije od većeg značaja. Na kraju krajeva, najvažnije je koliko tačno funkcioniše opšta regresiona jednačina, dok se čini da je problem relativnih doprinosa pojedinačnih varijabli ukupnoj objašnjenoj varijansi sekundaran. Međutim, to nije slučaj. Čim počnete da razmišljate da li da koristite bilo koju promenljivu u jednačini višestruke regresije, pitanje postaje važno. Može uticati na ocjenu ispravnosti izbora modela za analizu.
Poglavlje 4. Funkcija LINEST().
Funkcija LINEST() vraća 10 statistika regresijske analize. Funkcija LINEST() je funkcija niza. Da biste je unijeli, odaberite raspon koji sadrži pet redova i dvije kolone, upišite formulu i pritisnite
LINEST(B2:B21,A2:A21,TRUE,TRUE)

Rice. 9. LINEST() funkcija: a) odaberite raspon D2:E6, b) unesite formulu kao što je prikazano na traci formule, c) kliknite
Funkcija LINEST() vraća:
- koeficijent regresije (ili nagib, ćelija D2);
- segment (ili konstanta, ćelija E3);
- standardne greške koeficijenta regresije i konstanti (opseg D3:E3);
- koeficijent determinacije R 2 za regresiju (ćelija D4);
- standardna greška procjene (ćelija E4);
- F-test za potpunu regresiju (ćelija D5);
- broj stepeni slobode za preostali zbir kvadrata (ćelija E5);
- regresijski zbir kvadrata (ćelija D6);
- rezidualni zbir kvadrata (ćelija E6).
Pogledajmo svaku od ovih statistika i njihove interakcije.
standardna greška u našem slučaju, ovo je standardna devijacija izračunata za greške uzorkovanja. Odnosno, radi se o situaciji u kojoj opšta populacija ima jednu statistiku, a uzorak drugu. Deljenjem koeficijenta regresije standardnom greškom dobijate vrednost od 2,092/0,818 = 2,559. Drugim riječima, koeficijent regresije od 2,092 je dvije i po standardne greške udaljen od nule.
Ako je koeficijent regresije nula, tada je najbolja procjena predviđene varijable njena srednja vrijednost. Dvije i po standardne greške je prilično velika vrijednost i možete sa sigurnošću pretpostaviti da koeficijent regresije za populaciju ima vrijednost različitu od nule.
Možete odrediti vjerovatnoću dobivanja koeficijenta regresije uzorka od 2,092 ako je njegova stvarna vrijednost u populaciji 0,0 koristeći funkciju
STUDENT.DIST.PH (t-test = 2.559; broj stupnjeva slobode = 18)
Općenito, broj stupnjeva slobode = n - k - 1, gdje je n broj opservacija, a k broj prediktorskih varijabli.
Ova formula vraća vrijednost od 0,00987 ili zaokruženu na 1%. To nam govori sljedeće: ako je koeficijent regresije za populaciju 0%, onda je vjerovatnoća da se dobije uzorak od 20 osoba za koje je izračunata vrijednost koeficijenta regresije 2,092 skromnih 1%.
F-test (ćelija D5 na slici 9) obavlja istu funkciju u odnosu na punu regresiju kao i t-test u odnosu na koeficijent jednostavne parne regresije. F-test se koristi za testiranje da li je koeficijent determinacije R 2 za regresiju zaista dovoljno velik da odbaci hipotezu da ima vrijednost od 0,0 u populaciji, što ukazuje na odsustvo varijanse objašnjene prediktorskom i prediktorskom varijablom . Kada postoji samo jedna prediktorska varijabla, F-test je tačno jednak kvadratu t-testa.
Do sada smo razmatrali intervalne varijable. Ako imate varijable koje mogu poprimiti više vrijednosti koje su jednostavna imena, kao što su muškarac i žena ili gmaz, vodozemac i riba, predstavite ih kao numerički kod. Takve varijable se nazivaju nominalnim.
R2 statistika kvantificira udio objašnjene varijanse.
Standardna greška procjene. Na sl. U tabeli 4.9 prikazane su predviđene vrijednosti varijable Weight, dobijene na osnovu njenog odnosa sa varijablom Height. Opseg E2:E21 sadrži vrijednosti reziduala za varijablu Težina. Preciznije, ovi reziduali se nazivaju greškama – otuda slijedi termin standardna greška procjene.

Rice. 10. I R 2 i standardna greška procjene izražavaju tačnost predviđanja dobijenih korištenjem regresije
Što je manja standardna greška procjene, to je tačnija jednadžba regresije i što bliže očekujete da se bilo kakvo predviđanje iz jednačine podudara sa stvarnim opažanjem. Standardna greška procjene pruža način da se kvantificiraju ova očekivanja. Težina 95% ljudi određene visine bit će u rasponu:
(visina * 2.092 - 3.591) ± 2.092 * 21.118
F-statistika je omjer međugrupne varijanse prema unutargrupnoj varijansi. Ovaj naziv je uveo statističar George Snedecor u čast Sir, koji je razvio analizu varijanse (ANOVA, Analysis of Variance) početkom 20. vijeka.
Koeficijent determinacije R 2 izražava proporciju ukupnog zbira kvadrata povezanih sa regresijom. Vrijednost (1 - R 2) izražava proporciju ukupnog zbira kvadrata povezanih sa rezidualima - greške predviđanja. F-test se može dobiti pomoću funkcije LINEST (ćelija F5 na slici 11), koristeći sume kvadrata (opseg G10:J11), koristeći razlomke varijanse (opseg G14:J15). Formule se mogu proučavati u priloženom Excel datoteci.

Rice. 11. Izračunavanje F-kriterijuma
Kada se koriste nominalne varijable, koristi se lažno kodiranje (slika 12). Za kodiranje vrijednosti prikladno je koristiti vrijednosti 0 i 1. Vjerovatnoća F se izračunava pomoću funkcije:
F.DIST.PH(K2;I2;I3)
Ovdje funkcija F.DIST.RT() vraća vjerovatnoću dobijanja F-testa nakon centralne F-distribucije (slika 13) za dva skupa podataka sa stupnjevima slobode datim u ćelijama I2 i I3, vrijednost što je isto kao i vrijednost data u ćeliji K2.

Rice. 12. Regresiona analiza korištenjem lažnih varijabli

Rice. 13. Centralna F-distribucija za λ = 0
Poglavlje 5 Višestruka regresija
Kada pređete sa jednostavne parne regresije sa jednom promenljivom prediktora na višestruku regresiju, dodajete jednu ili više prediktorskih varijabli. Spremite vrijednosti varijabli prediktora u susjedne stupce, kao što su kolone A i B za dva prediktora ili A, B i C za tri prediktora. Prije nego unesete formulu koja uključuje funkciju LINEST(), odaberite pet redova i onoliko kolona koliko ima prediktorskih varijabli, plus još jedan za konstantu. U slučaju regresije sa dvije prediktorske varijable, može se koristiti sljedeća struktura:
LINEST(A2: A41; B2: C41;; TRUE)
Slično, u slučaju tri varijable:
LINEST(A2:A61;B2:D61;;TRUE)
Recimo da želite da proučavate mogući uticaj starosti i ishrane na nivoe LDL, lipoproteina niske gustine za koje se smatra da su odgovorni za formiranje aterosklerotskih plakova koji uzrokuju aterotrombozu (Slika 14).

Rice. 14. Višestruka regresija
R 2 višestruke regresije (prikazano u ćeliji F13) je veći od R 2 bilo koje jednostavne regresije (E4, H4). Višestruka regresija koristi više prediktorskih varijabli u isto vrijeme. U ovom slučaju, R2 se skoro uvijek povećava.
Za bilo koju jednostavnu jednačinu linearne regresije sa jednom prediktorskom varijablom, uvijek će postojati savršena korelacija između vrijednosti prediktora i vrijednosti prediktorske varijable, jer se u takvoj jednadžbi vrijednosti prediktora množe s jednom konstantom i još jedna konstanta se dodaje svakom proizvodu. Ovaj efekat nije sačuvan u višestrukoj regresiji.
Prikaz rezultata koje vraća LINEST() za višestruku regresiju (Slika 15). Koeficijenti regresije se prikazuju kao dio rezultata koje vraća LINEST() obrnutim redoslijedom varijabli(G–H–I odgovara C–B–A).

Rice. 15. Koeficijenti i njihove standardne greške su prikazane obrnutim redoslijedom na radnom listu.
Principi i procedure koje se koriste u regresionoj analizi sa jednom varijablom prediktora lako se prilagođavaju da bi se uzele u obzir više prediktorskih varijabli. Ispostavilo se da veliki dio ove adaptacije ovisi o eliminaciji utjecaja prediktorskih varijabli jedne na drugu. Ovo poslednje je povezano sa privatnim i poluprivatnim korelacijama (slika 16).

Rice. 16. Višestruka regresija se može izraziti kroz parnu regresiju reziduala (pogledajte formule u Excel datoteci)
U Excelu postoje funkcije koje pružaju informacije o t- i F-distribucijama. Funkcije čija imena uključuju dio DIST, kao što su STUDENT.DIST() i F.DIST(), uzimaju t- ili F-test kao argument i vraćaju vjerovatnoću promatranja navedene vrijednosti. Funkcije čija imena uključuju OBR dio, kao što su STUDENT.INV() i F.INV(), uzimaju vrijednost vjerovatnoće kao argument i vraćaju vrijednost kriterija koja odgovara navedenoj vjerovatnoći.
Budući da tražimo kritične vrijednosti t-distribucije koja odsiječe rubove njenih repnih regija, prosljeđujemo 5% kao argument jednoj od STUDENT.INV() funkcija, koja vraća vrijednost koja odgovara ovoj vjerovatnoći (sl. 17, 18).

Rice. 17. Dvostrani t-test

Rice. 18. Jednostrani t-test
Uspostavljanjem pravila odlučivanja u slučaju jednostrane alfa regije, povećavate statističku snagu testa. Ako ste, kada započnete eksperiment, sigurni da imate sve razloge da očekujete pozitivan (ili negativan) koeficijent regresije, tada biste trebali izvršiti jednostrani test. U ovom slučaju, vjerovatnoća da ćete donijeti ispravnu odluku, odbacivši hipotezu o nultom koeficijentu regresije u populaciji, bit će veća.
Statističari radije koriste taj termin usmjereni test umjesto termina test sa jednim repom i termin neusmjereni test umjesto termina dvostrani test. Termini usmjereni i neusmjereni su poželjniji jer naglašavaju tip hipoteze, a ne prirodu repova distribucije.
Pristup procjeni uticaja prediktora na osnovu poređenja modela. Na sl. 19 prikazuje rezultate regresione analize koja testira doprinos varijable Dijeta regresijskoj jednačini.

Rice. 19. Poređenje dva modela provjeravanjem razlika u njihovim rezultatima
Rezultati LINEST() (opseg H2:K6) povezani su sa onim što ja nazivam punim modelom, koji regresira LDL varijablu na dijetu, godine i HDL. U rasponu H9:J13, proračuni su prikazani bez uzimanja u obzir prediktorske varijable Dijeta. Ja to zovem limitiranim modelom. U punom modelu, 49,2% varijanse LDL zavisne varijable objašnjava se prediktorskim varijablama. U ograničenom modelu, samo 30,8% LDL-a objašnjava se godinama i HDL-om. Gubitak R 2 zbog isključenja varijable Dijeta iz modela je 0,183. U rasponu G15:L17 napravljeni su proračuni koji pokazuju da je samo sa vjerovatnoćom od 0,0288 uticaj varijable Dijeta slučajan. U preostalih 97,1% dijeta utiče na LDL.
Poglavlje 6. Pretpostavke i upozorenja u vezi sa regresionom analizom
Termin "pretpostavka" nije striktno definiran, a način na koji se koristi sugerira da ako pretpostavka nije ispunjena, onda su rezultati cjelokupne analize u najmanju ruku upitni ili eventualno nevažeći. U stvari, to nije tako, iako svakako postoje slučajevi u kojima kršenje pretpostavke iz temelja mijenja sliku. Glavne pretpostavke su: a) reziduali varijable Y normalno su raspoređeni u bilo kojoj tački u X duž linije regresije; b) Y vrijednosti su linearno zavisne od X vrijednosti; c) varijansa reziduala je približno ista u svakoj tački X; d) nema veze između ostataka.
Ako pretpostavke ne igraju značajnu ulogu, statističari govore o robusnosti analize u odnosu na kršenje pretpostavke. Konkretno, kada koristite regresiju za testiranje razlika između srednjih vrijednosti grupe, pretpostavka da su Y vrijednosti - a time i reziduali - normalno raspoređeni, ne igra značajnu ulogu: testovi su robusni u odnosu na kršenje pretpostavka normalnosti. Važno je analizirati podatke koristeći grafikone. Na primjer, uključeno u dodatak Analiza podataka alat Regresija.
Ako podaci ne odgovaraju pretpostavkama linearne regresije, na raspolaganju su vam i drugi nelinearni pristupi. Jedna od njih je logistička regresija (slika 20). Blizu gornje i donje granice prediktorske varijable, linearna regresija rezultira nerealnim predviđanjima.

Rice. 20. Logistička regresija
Na sl. Na slici 6.8 prikazani su rezultati dvije metode analize podataka koje imaju za cilj istraživanje veze između godišnjeg prihoda i vjerovatnoće kupovine kuće. Očigledno, vjerovatnoća kupovine će se povećati s povećanjem prihoda. Grafikoni olakšavaju uočavanje razlika između rezultata koji predviđaju vjerovatnoću kupovine kuće putem linearne regresije i rezultata koje biste mogli dobiti koristeći drugačiji pristup.
Statističkim jezikom rečeno, odbacivanje nulte hipoteze kada je ona zapravo istinita naziva se greškom tipa I.
U dodatku Analiza podataka nudi se zgodan alat za generisanje slučajnih brojeva, koji omogućava korisniku da odredi željeni oblik distribucije (na primjer, normalan, binom ili Poisson), kao i srednju vrijednost i standardnu devijaciju.
Razlike između funkcija porodice STUDENT.DIST(). Počevši od Excel 2010, dostupna su tri različita oblika funkcije koja vraćaju dio distribucije lijevo i/ili desno od date vrijednosti t-testa. Funkcija STUDENT.DIST() vraća udio površine ispod krivulje distribucije lijevo od vrijednosti t-testa koju navedete. Recimo da imate 36 opservacija, tako da je broj stupnjeva slobode za analizu 34, a vrijednost t-testa je 1,69. U ovom slučaju, formula
STUDENT.DIST(+1.69;34;TRUE)
vraća vrijednost od 0,05 ili 5% (Slika 21). Treći argument za STUDENT.DIST() može biti TRUE ili FALSE. Ako je postavljeno na TRUE, funkcija vraća kumulativnu površinu ispod krive lijevo od datog t-testa, izraženu kao razlomak. Ako je FALSE, funkcija vraća relativnu visinu krivulje u tački koja odgovara t-testu. Druge verzije funkcije STUDENT.DIST() - STUDENT.DIST.PX() i STUDENT.DIST.2X() - uzimaju samo vrijednost t-testa i broj stupnjeva slobode kao argumente i ne zahtijevaju treći argument .

Rice. 21. Tamnije osjenčano područje u lijevom repu distribucije odgovara proporciji površine ispod krive lijevo od velike pozitivne vrijednosti t-testa.
Da biste odredili područje desno od t-testa, koristite jednu od formula:
1 - STUDENT.DIST (1, 69; 34; TRUE)
STUDENT.DIST.PH(1.69;34)
Ukupna površina ispod krive mora biti 100%, tako da oduzimanjem od 1 udjela površine lijevo od vrijednosti t-testa koju vraća funkcija daje dio površine desno od vrijednosti t-testa. Možda će vam biti bolje da direktno dobijete proporciju površine za koju ste zainteresovani koristeći funkciju STUDENT.DIST.RH(), gde RH označava desni rep distribucije (slika 22).

Rice. 22. 5% alfa područja za usmjereni test
Upotreba funkcija STUDENT.DIST() ili STUDENT.DIST.PH() implicira da ste odabrali usmjerenu radnu hipotezu. Hipoteza usmjerenog rada, u kombinaciji sa postavljanjem alfa vrijednosti na 5%, znači da stavljate svih 5% u desni rep distribucija. Morat ćete odbiti nultu hipotezu samo ako je vjerovatnoća da se dobije vrijednost vašeg t-testa 5% ili manja. Hipoteze usmjerene obično rezultiraju osjetljivijim statističkim testovima (ova veća osjetljivost se također naziva i veća statistička moć).
Kod neusmjerenog testa, alfa vrijednost ostaje na istom nivou od 5%, ali će distribucija biti drugačija. Budući da morate dozvoliti dva ishoda, vjerovatnoća lažnog pozitivnog rezultata mora biti raspoređena između dva repa distribucije. Općenito je prihvaćeno da se ova vjerovatnoća ravnomjerno raspoređuje (slika 23).

Koristeći istu dobivenu vrijednost t-testa i isti broj stupnjeva slobode kao u prethodnom primjeru, koristite formulu
STUDENT DIST.2X(1.69;34)
Bez posebnog razloga, funkcija STUDENT.DIST.2X() vraća kod greške #BROJ! ako joj je data negativna vrijednost t-testa kao prvi argument.
Ako uzorci sadrže različite brojeve podataka, koristite t-test sa dva uzorka s različitim varijacijama uključenim u paket Analiza podataka.
Poglavlje 7 Korištenje regresije za testiranje razlika između grupnih srednjih vrijednosti
Varijable koje su ranije nazivane prediktivnim varijablama u ovom poglavlju će se u ovom poglavlju nazivati varijablama ishoda, a termin faktorske varijable će se koristiti umjesto prediktorskih varijabli.
Najjednostavniji pristup kodiranju nominalne varijable je lažno kodiranje(Sl. 24).

Rice. 24. Regresiona analiza zasnovana na lažnom kodiranju
Kada koristite lažno kodiranje bilo koje vrste, treba se pridržavati sljedećih pravila:
- Broj kolona rezerviranih za nove podatke mora biti jednak broju minus nivoa faktora
- Svaki vektor predstavlja jedan nivo faktora.
- Subjekti na jednom nivou, koji je često kontrolna grupa, primaju kod 0 na svim vektorima.
Formula u ćelijama F2:H6 =LINEST(A2:A22;C2:D22;;TRUE) vraća statistiku regresije. Za poređenje, na sl. 24 prikazuje rezultate tradicionalne analize varijanse koju vraća alat Jednosmjerna analiza varijanse nadgradnje Analiza podataka.
Kodiranje efekata. U drugoj vrsti kodiranja tzv kodiranje efekata, srednja vrijednost svake grupe se upoređuje sa srednjom vrijednosti grupe. Ovaj aspekt kodiranja efekata nastaje zbog upotrebe -1 umjesto 0 kao koda za grupu koja prima isti kod u svim vektorima koda (Slika 25).

Rice. 25. Kodiranje efekata
Kada se koristi lažno kodiranje, vrijednost konstante koju vraća LINEST() je srednja vrijednost grupe kojoj su dodijeljeni nulti kodovi u svim vektorima (obično kontrolnoj grupi). U slučaju kodiranja efekata, konstanta je jednaka ukupnom prosjeku (ćelija J2).
Opšti linearni model je koristan način da se konceptualiziraju komponente vrijednosti rezultirajuće varijable:
Y ij = μ + α j + ε ij
Upotreba grčkih slova umjesto latiničnih u ovoj formuli naglašava činjenicu da se odnosi na populaciju iz koje su uzeti uzorci, ali se može prepisati kako bi se naznačilo da se odnosi na uzorke izvučene iz objavljene populacije:
Y ij = Y̅ + a j + e ij
Ideja je da se svako opažanje Y ij može posmatrati kao zbir sljedeće tri komponente: ukupna srednja vrijednost, μ; efekat obrade j, i j ; vrijednost e ij , koja predstavlja odstupanje pojedinačnog kvantitativnog indikatora Y ij od kombinovane vrijednosti ukupne srednje vrijednosti i efekta j-tog tretmana (slika 26). Cilj regresijske jednadžbe je minimiziranje sume kvadrata reziduala.

Rice. 26. Zapažanja dekomponirana na komponente opšteg linearnog modela
Faktorska analiza. Ako se istražuje odnos između rezultirajuće varijable i dva ili više faktora istovremeno, onda se u ovom slučaju govori o upotrebi faktorske analize. Dodavanje jednog ili više faktora jednosmjernoj analizi varijanse može povećati statističku moć. U jednosmjernoj ANOVA, varijacija varijable ishoda koja se ne može pripisati faktoru uključena je u rezidualni srednji kvadrat. Ali može biti da je ova varijacija sa povezana sa drugim faktorom. Tada se ova varijacija može ukloniti iz srednje kvadratne greške, čije smanjenje dovodi do povećanja vrijednosti F-testa, a time i do povećanja statističke snage testa. nadgradnja Analiza podataka uključuje alat koji omogućava obradu dva faktora istovremeno (slika 27).

Rice. 27. Alat Dvosmjerna analiza varijanse s paketom analize ponavljanja
Alat za analizu varijanse koji se koristi na ovoj slici je koristan po tome što vraća srednju vrijednost i varijansu rezultirajuće varijable, kao i vrijednost brojača za svaku grupu uključenu u dizajn. Table Analiza varijanse prikazuje dva parametra koja nisu u izlazu jednosmjerne verzije alata ANOVA. Obratite pažnju na izvore varijacija Uzorak I kolone u redovima 27 i 28. Izvor varijacije kolone odnosi se na rod. Izvor varijacije Uzorak odnosi se na bilo koju varijablu čije vrijednosti zauzimaju različite redove. Na sl. 27, vrijednosti za CourseLech1 grupu su u redovima 2-6, CourseLech2 grupu su u redovima 7-11, a CourseLech3 grupu su u redovima 12-16.
Glavna stvar je da su i Pol (označene Kolone u ćeliji E28) i Tretman (označen Uzorak u ćeliji E27) uključeni u ANOVA tabelu kao izvori varijacija. Prosjeci za muškarce se razlikuju od prosjeka za žene, a to stvara izvor varijacija. Prosjeci za tri tretmana se također razlikuju - evo još jednog izvora varijacija. Postoji i treći izvor, Interakcija, koji se odnosi na kombinovani efekat varijabli Rod i Tretman.
Poglavlje 8
Analiza kovarijanse, ili ANCOVA (analiza kovarijacije), smanjuje pristrasnost i povećava statističku moć. Da vas podsjetim da su jedan od načina za procjenu pouzdanosti regresijske jednačine F-testovi:
F = MS regresija/MS rezidual
gdje je MS (Mean Square) srednji kvadrat, a indeksi Regresija i Residual označavaju regresiju i rezidualne komponente, respektivno. MS rezidual se izračunava pomoću formule:
MS rezidualni = SS rezidualni / df rezidualni
gdje je SS (Sum of Squares) zbir kvadrata, a df je broj stupnjeva slobode. Kada dodate kovarijansu u jednadžbu regresije, neki dio ukupnog zbira kvadrata nije uključen u SS ResiduaI, već u SS Regresiju. Ovo dovodi do smanjenja SS Residual l, a time i MS Residual. Što je manji MS rezidual, veći je F-test i veća je vjerovatnoća da ćete odbaciti nultu hipotezu da nema razlike između srednjih vrijednosti. Kao rezultat, vi preraspoređujete volatilnost rezultirajuće varijable. U ANOVA, kada se kovarijansa ne uzme u obzir, varijabilnost prelazi u grešku. Ali u ANCOVA, dio varijabilnosti koji je prethodno pripisan grešci se dodjeljuje kovarijati i postaje dio SS regresije.
Razmotrimo primjer gdje se isti skup podataka analizira prvo sa ANOVA, a zatim sa ANCOVA (Slika 28).

Rice. 28. ANOVA analiza pokazuje da su rezultati dobijeni pomoću regresione jednadžbe nepouzdani
Studija uspoređuje relativne efekte fizičke vježbe, koja razvija snagu mišića, i kognitivne vježbe (križaljke) koja aktivira moždanu aktivnost. Ispitanici su nasumično raspoređeni u dvije grupe tako da su na početku eksperimenta obje grupe bile u istim uslovima. Nakon tri mjeseca mjerene su kognitivne karakteristike ispitanika. Rezultati ovih mjerenja prikazani su u koloni B.
Raspon A2:C21 sadrži početne podatke proslijeđene funkciji LINEST() za izvođenje analize korištenjem kodiranja efekata. Rezultati funkcije LINEST() prikazani su u rasponu E2:F6, gdje ćelija E2 prikazuje koeficijent regresije povezan s vektorom udara. Ćelija E8 sadrži t-test = 0,93, a ćelija E9 testira pouzdanost ovog t-testa. Vrijednost u ćeliji E9 ukazuje da je vjerovatnoća da se naiđe na razliku između srednjih vrijednosti grupe uočene u ovom eksperimentu 36% ako su srednje vrijednosti grupe jednake u populaciji. Samo nekolicina smatra da je ovaj rezultat statistički značajan.
Na sl. Slika 29 pokazuje šta se dešava kada se kovarijat doda analizi. U ovom slučaju, dodao sam starost svakog subjekta u skup podataka. Koeficijent determinacije R 2 za jednadžbu regresije koja koristi kovarijatu je 0,80 (ćelija F4). Vrijednost R 2 u rasponu F15:G19, u kojem sam reprodukovao rezultate ANOVA dobijene bez korištenja kovarijate, iznosi samo 0,05 (ćelija F17). Stoga, jednadžba regresije koja uključuje kovarijatu predviđa vrijednosti varijable kognitivnog rezultata mnogo preciznije nego koristeći samo vektor uticaja. Za ANCOVA, vjerovatnoća da će se nasumično dobiti vrijednost F-testa prikazana u ćeliji F5 je manja od 0,01%.

Rice. 29. ANCOVA vraća potpuno drugačiju sliku
Statistička obrada podataka se također može izvršiti pomoću dodatka PAKET ANALIZE(Sl. 62).
Od predloženih stavki odaberite stavku " REGRESIJA” i kliknite na njega lijevom tipkom miša. Zatim kliknite na OK.
Prozor prikazan na sl. 63.

Alat za analizu « REGRESIJA» se koristi za uklapanje grafa u skup opažanja koristeći metodu najmanjih kvadrata. Regresija se koristi za analizu učinka na jednu zavisnu varijablu vrijednosti jedne ili više nezavisnih varijabli. Na primjer, na sportske performanse sportiste utiče nekoliko faktora, uključujući godine, visinu i težinu. Moguće je izračunati stepen uticaja svakog od ova tri faktora na performanse jednog sportiste, a zatim pomoću dobijenih podataka predvideti učinak drugog sportiste.
Alat Regresija koristi funkciju LINEST.
REGRESS dijaloški okvir
Oznake Potvrdite izbor u polju za potvrdu ako prvi red ili prva kolona raspona unosa sadrži naslove. Poništite ovaj potvrdni okvir ako nema zaglavlja. U ovom slučaju će se automatski generirati odgovarajuća zaglavlja za podatke izlazne tablice.
Nivo pouzdanosti Potvrdite izbor u polju za potvrdu da biste uključili dodatni nivo u tabelu ukupnih rezultata. U odgovarajuće polje unesite nivo pouzdanosti koji želite da primenite, pored podrazumevanog nivoa pouzdanosti od 95%.
Konstanta - nula Označite kvadratić da linija regresije prođe kroz nultu vrijednost.
Izlazni opseg Unesite referencu na gornju lijevu ćeliju izlaznog raspona. Odredite najmanje sedam kolona za izlaznu tabelu rezultata, koja će uključivati: rezultate analize varijanse, koeficijente, standardnu grešku izračunavanja Y, standardne devijacije, broj posmatranja, standardne greške za koeficijente.
Novi radni list Označite ovo polje za otvaranje novog radnog lista u radnoj svesci i umetanje rezultata analize počevši od ćelije A1. Ako je potrebno, unesite naziv za novi list u polje nasuprot odgovarajućeg položaja radio dugmeta.
Nova radna sveska Označite ovo polje da biste kreirali novu radnu svesku u kojoj će rezultati biti dodati na novi list.
Ostaci Označite potvrdni okvir da biste uključili ostatke u izlaznu tablicu.
Standardizirani reziduali Označite polje za potvrdu da biste uključili standardizirane ostatke u izlaznu tablicu.
Residual Plot Označite polje za iscrtavanje reziduala za svaku nezavisnu varijablu.
Fit Plot Označite potvrdni okvir za iscrtavanje predviđenih vrijednosti naspram uočenih vrijednosti.
Grafikon normalne vjerovatnoće Označite polje za iscrtavanje normalne vjerovatnoće.
Funkcija LINEST
Da biste izvršili proračune, odaberite ćeliju u kojoj želimo da prikažemo prosječnu vrijednost pomoću kursora i pritisnite tipku = na tastaturi. Zatim u polju Ime navedite željenu funkciju, na primjer PROSJEČNO(Sl. 22).
Funkcija LINEST izračunava statistiku za seriju koristeći metodu najmanjih kvadrata za izračunavanje prave linije koja najbolje aproksimira dostupne podatke, a zatim vraća niz koji opisuje rezultirajuću ravnu liniju. Također možete kombinirati funkciju LINEST s drugim funkcijama za izračunavanje drugih vrsta modela koji su linearni u nepoznatim parametrima (čiji su nepoznati parametri linearni), uključujući polinomske, logaritamske, eksponencijalne i nizove stepena. Budući da se vraća niz vrijednosti, funkcija mora biti navedena kao formula niza.
Jednačina za pravu liniju je:
y=m 1 x 1 +m 2 x 2 +…+b (u slučaju nekoliko raspona x vrijednosti),
gdje je zavisna vrijednost y funkcija nezavisne vrijednosti x, vrijednosti m su koeficijenti koji odgovaraju svakoj nezavisnoj varijabli x, a b je konstanta. Imajte na umu da y, x i m mogu biti vektori. Funkcija LINEST vraća niz (mn;mn-1;…;m 1 ;b). LINEST može također vratiti dodatnu statistiku regresije.
LINEST(poznate_y-vrijednosti; poznate_x-vrijednosti; konst; statistika)
Poznate_y vrijednosti - skup y vrijednosti koje su već poznate za relaciju y=mx+b.
Ako niz poznatog_y ima jednu kolonu, onda se svaki stupac niza poznatog_x tumači kao zasebna varijabla.
Ako niz poznatog_y ima jedan red, tada se svaki red niza poznatog_x tumači kao zasebna varijabla.
Poznate_x vrijednosti - opcioni skup x vrijednosti koje su već poznate za relaciju y=mx+b.
Poznati_x niz može sadržavati jedan ili više skupova varijabli. Ako se koristi samo jedna varijabla, tada nizovi_poznate_y_vrijednosti i poznate_x_vrijednosti mogu biti bilo kojeg oblika - sve dok imaju istu dimenziju. Ako se koristi više od jedne varijable, tada poznati_y mora biti vektor (tj. visok jedan red ili širok jedan stupac).
Ako je niz_poznat_x izostavljen, onda se pretpostavlja da je ovaj niz (1;2;3;...) iste veličine kao i niz_poznat_y.
Const je logička vrijednost koja određuje da li konstanta b mora biti 0.
Ako je argument "const" TRUE ili izostavljen, tada se konstanta b procjenjuje normalno.
Ako je argument "const" FALSE, tada se pretpostavlja da je vrijednost b 0 i vrijednosti m se biraju na takav način da je relacija y=mx zadovoljena.
Statistics je Boolean vrijednost koja pokazuje da li treba vratiti dodatnu statistiku regresije.
Ako je statistika TRUE, LINEST vraća dodatnu statistiku regresije. Vraćeni niz će izgledati ovako: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Ako je statistika FALSE ili je izostavljena, LINEST vraća samo koeficijente m i konstantu b.
Dodatna statistika regresije (Tabela 17)
| Vrijednost | Opis |
| se1,se2,...,sen | Standardne vrijednosti greške za koeficijente m1,m2,...,mn. |
| seb | Standardna greška za konstantu b (seb = #N/A ako je 'const' FALSE). |
| r2 | Faktor determinacije. Stvarne vrijednosti y se upoređuju sa vrijednostima dobijenim iz jednačine prave linije; na osnovu rezultata poređenja izračunava se koeficijent determinizma, normalizovan sa 0 na 1. Ako je jednak 1, postoji potpuna korelacija sa modelom, odnosno nema razlike između stvarne i procenjene vrednosti od y. Inače, ako je koeficijent determinizma 0, nema smisla koristiti jednadžbu regresije za predviđanje y vrijednosti. Za više informacija o tome kako izračunati r2, pogledajte "Napomene" na kraju ovog odjeljka. |
| sey | Standardna greška za procjenu y. |
| F | F-statistička ili F-opažena vrijednost. F statistika se koristi za određivanje da li je posmatrani odnos između zavisnih i nezavisnih varijabli slučajan. |
| df | Stepeni slobode. Stupnjevi slobode su korisni za pronalaženje F-kritičnih vrijednosti u statističkoj tabeli. Da biste odredili nivo pouzdanosti modela, morate uporediti vrijednosti u tabeli sa F-statistikom koju vraća LINEST. Pogledajte "Napomene" na kraju ovog odjeljka za više informacija o izračunavanju df. Primjer 4 ispod pokazuje upotrebu F i df. |
| ssreg | Regresijski zbir kvadrata. |
| ssresid | Preostali zbir kvadrata. Za više informacija o izračunavanju ssreg i ssresid, pogledajte "Napomene" na kraju ovog odjeljka. |
Slika ispod pokazuje redoslijed kojim se vraćaju dodatne statistike regresije (Slika 64).

napomene:
Bilo koja prava linija se može opisati svojim nagibom i presekom sa y-osom:
Nagib (m): da biste odredili nagib prave, koji se obično označava sa m, potrebno je da uzmete dve tačke na pravoj (x 1 ,y 1) i (x 2 ,y 2); nagib će biti jednak (y 2 -y 1) / (x 2 -x 1).
Y-presek (b): Y-presek prave, koji se obično označava sa b, je vrednost y za tačku u kojoj linija seče y-osu.
Jednačina prave linije ima oblik y=mx+b. Ako su poznate vrijednosti m i b, tada se bilo koja tačka na pravoj može izračunati zamjenom vrijednosti y ili x u jednadžbu. Također možete koristiti funkciju TREND.
Ako postoji samo jedna nezavisna varijabla x, možete dobiti nagib i y-presjek direktno koristeći sljedeće formule:
Nagib: INDEX(LINEST(poznati_y, poznati_x), 1)
Y-presjek: INDEX(LINEST(poznati_y, poznati_x), 2)
Preciznost aproksimacije korištenjem prave linije izračunate pomoću funkcije LINEST ovisi o stupnju rasipanja podataka. Što su podaci bliži pravoj liniji, to je tačniji model koji koristi LINEST. Funkcija LINEST koristi metodu najmanjih kvadrata za određivanje najboljeg uklapanja podataka. Kada postoji samo jedna nezavisna varijabla x, m i b se izračunavaju pomoću sljedećih formula:

gdje su x i y srednje vrijednosti uzorka, na primjer x = PROSJEK (poznati_x) i y = PROSJEK (poznati_y).
Funkcije uklapanja LINEST i LGRFPRIBL mogu izračunati ravnu ili eksponencijalnu krivu koja najbolje odgovara podacima. Međutim, oni ne daju odgovor na pitanje koji je od dva rezultata pogodniji za rješavanje problema. Također možete izračunati funkciju TREND(poznate_y-vrijednosti; poznate_x-vrijednosti) funkciju za ravnu liniju ili funkciju GROWTH(poznate_y-vrijednosti; poznate_x-vrijednosti) funkciju za eksponencijalnu krivu. Ove funkcije, ako ne navedete argument new_x_values, vraćaju niz izračunatih y vrijednosti za stvarne x vrijednosti prema pravoj liniji ili krivulji. Zatim možete uporediti izračunate vrijednosti sa stvarnim vrijednostima. Takođe možete napraviti grafikone za vizuelno poređenje.
Prilikom izvođenja regresione analize, Microsoft Excel izračunava, za svaku tačku, kvadrat razlike između predviđene vrijednosti y i stvarne vrijednosti y. Zbir ovih kvadrata razlika naziva se rezidualni zbir kvadrata (ssresid). Microsoft Excel zatim izračunava ukupan zbir kvadrata (sstotal). Ako je const = TRUE ili ako ovaj argument nije naveden, ukupan zbir kvadrata će biti jednak zbroju kvadrata razlika stvarnih y vrijednosti i srednjih y vrijednosti. Ako je const = FALSE, zbir kvadrata će biti jednak zbroju kvadrata realnih y vrijednosti (bez oduzimanja srednje vrijednosti y od količnika y). Nakon toga, regresijski zbir kvadrata se može izračunati na sljedeći način: ssreg = sstotal - ssresid. Što je manji rezidualni zbir kvadrata, to je veća vrijednost koeficijenta determinizma r2, što pokazuje koliko dobro jednačina dobijena regresionom analizom objašnjava odnose između varijabli. Koeficijent r2 je jednak ssreg/sstotal.
U nekim slučajevima, jedan ili više X stupaca (neka Y i X vrijednosti budu u kolonama) nemaju dodatnu prediktivnu vrijednost u drugim kolonama X. Drugim riječima, brisanjem jednog ili više X stupaca može doći do Y vrijednosti izračunati sa istom preciznošću. U ovom slučaju, redundantni X stupci će biti isključeni iz regresijskog modela. Ovaj fenomen se naziva "kolinearnost" jer se redundantni stupci X mogu predstaviti kao zbir nekoliko neredundantnih kolona. LINEST provjerava kolinearnost i uklanja sve redundantne X stupce iz regresijskog modela ako ih pronađe. Uklonjeni X stupci mogu se identificirati u LINEST izlazu faktorom 0 i se vrijednošću 0. Uklanjanje jedne ili više kolona kao suvišnih mijenja vrijednost df jer ovisi o broju X stupaca koji se stvarno koriste u svrhe predviđanja. Pogledajte primjer 4 u nastavku za više detalja o izračunavanju df. Kada se df promijeni zbog uklanjanja suvišnih kolona, mijenjaju se i vrijednosti sey i F. Često se ne preporučuje korištenje kolinearnosti. Međutim, treba ga koristiti ako neke kolone X sadrže 0 ili 1 kao indikator koji pokazuje da li je subjekt eksperimenta u zasebnoj grupi. Ako je const = TRUE ili ako ovaj argument nije specificiran, LINEST umeće dodatni X stupac za simulaciju točke presjeka. Ako postoji kolona sa vrijednostima 1 za muškarce i 0 za žene, a postoji kolona sa vrijednostima 1 za žene i 0 za muškarce, tada se posljednja kolona uklanja jer se njene vrijednosti mogu dobiti iz kolona "muški indikator".
Izračunavanje df za slučajeve kada X kolona nije uklonjeno iz modela zbog kolinearnosti je kako slijedi: ako postoji k poznatih_x stupaca i const = TRUE ili nije specificirano, onda je df = n - k - 1. Ako je const = FALSE, onda je df = n -k. U oba slučaja, uklanjanje X stupaca zbog kolinearnosti povećava vrijednost df za 1.
Formule koje vraćaju nizove moraju se unijeti kao formule niza.
Prilikom unosa niza konstanti kao argumenta known_x_values, na primjer, koristite tačku i zarez da odvojite vrijednosti u istom redu, a dvotočku za razdvajanje redaka. Znakovi za razdvajanje mogu se razlikovati ovisno o postavkama u prozoru "Jezik i standardi" na kontrolnoj tabli.
Imajte na umu da y vrijednosti predviđene jednadžbom regresije možda neće biti tačne ako su izvan raspona vrijednosti y koje su korištene za definiranje jednačine.
Glavni algoritam koji se koristi u funkciji LINEST, razlikuje se od glavnog algoritma funkcija INCLINE I ODJELJAK. Razlike između algoritama mogu dovesti do različitih rezultata za nesigurne i kolinearne podatke. Na primjer, ako su točke podataka argumenta poznatog_y 0, a podatkovne točke argumenta poznatog_x 1, tada:
Funkcija LINEST vraća vrijednost jednaku 0. Algoritam funkcije LINEST koristi se za vraćanje odgovarajućih vrijednosti za kolinearne podatke, u kom slučaju se može pronaći barem jedan odgovor.
Funkcije SLOPE i INTERCEPT vraćaju grešku #DIV/0!. Algoritam funkcija SLOPE i INTERCEPT se koristi za pronalaženje samo jednog odgovora, au ovom slučaju može biti nekoliko.
Pored izračunavanja statistike za druge vrste regresije, LINEST se može koristiti za izračunavanje raspona za druge vrste regresije unosom funkcija varijabli x i y kao niza varijabli x i y za LINEST. Na primjer, sljedeća formula:
LINEST(y-vrijednosti, x-vrijednosti^COLUMN($A:$C))
radi sa jednom kolonom od Y vrijednosti i jednom kolonom od X vrijednosti kako bi izračunao aproksimaciju kocke (polinom 3. stepena) sljedećeg oblika:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Formula se može modificirati za izračunavanje drugih tipova regresije, ali u nekim slučajevima su potrebna prilagođavanja izlaznih vrijednosti i druge statistike.
IN excel postoji još brži i pogodniji način za crtanje linearne regresije (pa čak i glavne vrste nelinearnih regresija, pogledajte dolje). Ovo se može uraditi ovako:
1) odaberite kolone sa podacima X I Y(moraju biti tim redoslijedom!);
2) poziv Čarobnjak za karte i izaberite u grupi Tip – tačkasta i odmah pritisnite Spreman;
3) bez poništavanja izbora dijagrama, izaberite stavku glavnog menija koja se pojavi Dijagram, u kojem trebate odabrati stavku Dodajte liniju trenda;
4) u dijalogu koji se pojavi linija trenda tab Tip izaberite Linearno;
5) tab Parametri prekidač se može aktivirati Pokažite jednačinu na grafikonu, što će vam omogućiti da vidite jednačinu linearne regresije (4.4), u kojoj će se izračunati koeficijenti (4.5).
6) U istoj kartici možete aktivirati prekidač Stavite na dijagram vrijednost pouzdanosti aproksimacije (R^2). Ova vrijednost je kvadrat koeficijenta korelacije (4.3) i pokazuje koliko dobro izračunata jednačina opisuje eksperimentalnu ovisnost. Ako R 2 je blizu jedinice, tada teorijska regresijska jednadžba dobro opisuje eksperimentalnu ovisnost (teorija se dobro slaže s eksperimentom), a ako R 2 je blizu nule, onda ova jednadžba nije prikladna za opisivanje eksperimentalne ovisnosti (teorija se ne slaže s eksperimentom).
Kao rezultat izvođenja opisanih radnji, dobit ćete dijagram s grafom regresije i njegovom jednadžbom.
§4.3. Glavne vrste nelinearne regresije
Parabolična i polinomska regresija.
Parabolic zavisnost vrednosti Y od vrijednosti X zavisnost izražena kvadratnom funkcijom (parabola 2. reda) naziva se:
Ova jednačina se zove parabolična regresija Y na X. Parametri ali, b, od pozvao koeficijenti paraboličke regresije. Izračunavanje koeficijenata paraboličke regresije je uvijek glomazno, pa se preporučuje korištenje računara za proračune.
Jednačina (4.8) paraboličke regresije je poseban slučaj općenitije regresije koja se naziva polinom. polinom zavisnost vrednosti Y od vrijednosti X naziva se zavisnost izražena polinomom n-ti red:
gdje su brojevi a i (i=0,1,…, n) su pozvani koeficijenti polinomske regresije.
Regresija snage.
Snaga zavisnost vrednosti Y od vrijednosti X naziva se zavisnost oblika:
Ova jednačina se zove jednadžba regresije snage Y na X. Parametri ali I b pozvao koeficijenti regresije snage.
ln=ln a+b ln x. (4.11)
Ova jednadžba opisuje pravu liniju u ravni sa logaritamskim koordinatnim osa ln x i ln. Stoga je kriterij primjenjivosti regresije stepena zahtjev da tačke logaritama empirijskih podataka ln x i i ln i bili najbliži pravoj liniji (4.11).
eksponencijalna regresija.
uzorno(ili eksponencijalna) zavisnost količine Y od vrijednosti X naziva se zavisnost oblika:
(ili ). (4.12)
Ova jednačina se zove eksponencijalna jednačina(ili eksponencijalna) regresija Y na X. Parametri ali(ili k) I b pozvao eksponencijalna(ili eksponencijalna) regresija.
Ako uzmemo logaritam obje strane jednadžbe regresije moći, dobićemo jednačinu
ln = x ln a+ln b(ili ln = k x+ln b). (4.13)
Ova jednadžba opisuje linearnu ovisnost logaritma jedne veličine ln od druge veličine x. Stoga je kriterij primjenjivosti regresije snage zahtjev da empirijski podaci ukazuju na istu veličinu x i i logaritmi druge vrijednosti ln i bili najbliži pravoj liniji (4.13).
logaritamska regresija.
Logaritamski zavisnost vrednosti Y od vrijednosti X naziva se zavisnost oblika:
=a+b ln x. (4.14)
Ova jednačina se zove logaritamska regresija Y na X. Parametri ali I b pozvao koeficijenti logaritamske regresije.
hiperbolička regresija.
Hyperbolic zavisnost vrednosti Y od vrijednosti X naziva se zavisnost oblika:
Ova jednačina se zove jednadžba hiperboličke regresije Y na X. Parametri ali I b pozvao koeficijenti hiperboličke regresije a određuju se metodom najmanjih kvadrata. Primjenom ove metode dolazi se do formula:
U formulama (4.16-4.17) sumiranje se vrši preko indeksa i od jednog do broja zapažanja n.
Nažalost, in excel ne postoji funkcija koja izračunava koeficijente hiperboličke regresije. U onim slučajevima kada se ne zna pouzdano da su izmjerene vrijednosti povezane inverznom proporcionalnošću, preporučljivo je tražiti jednadžbu regresije snage umjesto jednačine hiperboličke regresije, tako da u excel postoji procedura za pronalaženje. Ako se između izmjerenih vrijednosti pretpostavi hiperbolička zavisnost, tada će se njeni regresijski koeficijenti morati izračunati korištenjem pomoćnih proračunskih tablica i operacijama sumiranja pomoću formula (4.16-4.17).
Regresija u Excelu
Statistička obrada podataka može se izvršiti i pomoću dodatka Analysis paketa u podstavci menija "Servis". U Excel 2003, ako otvorite SERVIS, ne možemo pronaći karticu ANALIZA PODATAKA, a zatim kliknite lijevu tipku miša da otvorite karticu DODATCI i suprotna tačka PAKET ANALIZE klikom na levi taster miša stavite kvačicu (slika 17).
Rice. 17. Prozor DODATCI
Nakon toga, meni SERVIS pojavljuje se kartica ANALIZA PODATAKA.
U programu Excel 2007 za instalaciju PAKETA ANALIZA potrebno je da kliknete na dugme URED u gornjem levom uglu lista (Sl. 18a). Zatim kliknite na dugme EXCEL OPCIJE. U prozoru koji se pojavi EXCEL OPCIJE levi klik na stavku DODATCI a u desnom dijelu padajuće liste odaberite stavku PAKET ANALIZE. Zatim kliknite na uredu.




Rice. 18. Instalacija PAKETA ANALIZA u Excel 2007
Da biste instalirali Analysis Pack, kliknite na dugme IDE, na dnu otvorenog prozora. Prozor prikazan na sl. 12. Označite polje pored PAKET ANALIZE. U kartici PODACI pojaviće se dugme ANALIZA PODATAKA(Sl. 19).

Od predloženih stavki odaberite stavku " REGRESIJA” i kliknite na njega lijevom tipkom miša. Zatim kliknite na OK.

Prozor prikazan na sl. 21

Alat za analizu « REGRESIJA» se koristi za uklapanje grafa u skup opažanja koristeći metodu najmanjih kvadrata. Regresija se koristi za analizu učinka na jednu zavisnu varijablu vrijednosti jedne ili više nezavisnih varijabli. Na primjer, na sportske performanse sportiste utiče nekoliko faktora, uključujući godine, visinu i težinu. Moguće je izračunati stepen uticaja svakog od ova tri faktora na performanse jednog sportiste, a zatim pomoću dobijenih podataka predvideti učinak drugog sportiste.
Alat Regresija koristi funkciju LINEST.
REGRESS dijaloški okvir
Oznake Potvrdite izbor u polju za potvrdu ako prvi red ili prva kolona raspona unosa sadrži naslove. Poništite ovaj potvrdni okvir ako nema zaglavlja. U ovom slučaju će se automatski generirati odgovarajuća zaglavlja za podatke izlazne tablice.
Nivo pouzdanosti Potvrdite izbor u polju za potvrdu da biste uključili dodatni nivo u tabelu ukupnih rezultata. U odgovarajuće polje unesite nivo pouzdanosti koji želite da primenite, pored podrazumevanog nivoa pouzdanosti od 95%.
Konstanta - nula Označite kvadratić da linija regresije prođe kroz nultu vrijednost.
Izlazni opseg Unesite referencu na gornju lijevu ćeliju izlaznog raspona. Odredite najmanje sedam kolona za izlaznu tabelu rezultata, koja će uključivati: rezultate analize varijanse, koeficijente, standardnu grešku izračunavanja Y, standardne devijacije, broj posmatranja, standardne greške za koeficijente.
Novi radni list Označite ovo polje za otvaranje novog radnog lista u radnoj svesci i umetanje rezultata analize počevši od ćelije A1. Ako je potrebno, unesite naziv za novi list u polje nasuprot odgovarajućeg položaja radio dugmeta.
Nova radna sveska Označite ovo polje da biste kreirali novu radnu svesku u kojoj će rezultati biti dodati na novi list.
Ostaci Označite potvrdni okvir da biste uključili ostatke u izlaznu tablicu.
Standardizirani reziduali Označite polje za potvrdu da biste uključili standardizirane ostatke u izlaznu tablicu.
Residual Plot Označite polje za iscrtavanje reziduala za svaku nezavisnu varijablu.
Fit Plot Označite potvrdni okvir za iscrtavanje predviđenih vrijednosti naspram uočenih vrijednosti.
Grafikon normalne vjerovatnoće Označite polje za iscrtavanje normalne vjerovatnoće.
Funkcija LINEST
Da biste izvršili proračune, odaberite ćeliju u kojoj želimo da prikažemo prosječnu vrijednost pomoću kursora i pritisnite tipku = na tastaturi. Zatim u polju Ime navedite željenu funkciju, na primjer PROSJEČNO(Sl. 22).

Rice. 22 Pronalaženje funkcija u programu Excel 2003
Ako je na terenu NAME naziv funkcije se ne pojavljuje, zatim kliknite lijevom tipkom miša na trokut pored polja, nakon čega će se pojaviti prozor sa listom funkcija. Ako ove funkcije nema na listi, kliknite levim tasterom miša na stavku na listi DRUGE FUNKCIJE, pojavit će se okvir za dijalog. FUNCTION MASTER, u kojem pomoću vertikalnog pomicanja odaberite željenu funkciju, odaberite je kursorom i kliknite na uredu(Sl. 23).

Rice. 23. Čarobnjak za funkcije
Za traženje funkcije u Excelu 2007 može se otvoriti bilo koja kartica u meniju, a zatim za izvođenje proračuna, odaberite ćeliju u kojoj želimo da prikažemo prosječnu vrijednost pomoću kursora i pritisnite tipku = na tastaturi. Zatim, u polju Ime navedite funkciju PROSJEČNO. Prozor za izračunavanje funkcije sličan je onom u programu Excel 2003.
Također možete odabrati karticu Formule i kliknuti lijevom tipkom miša na dugme u " INSERT FUNCTION» (Sl. 24), pojavit će se prozor FUNCTION MASTER, čiji je prikaz sličan Excel 2003. Takođe, u meniju možete odmah odabrati kategoriju funkcija (nedavno korištene, finansijske, logičke, tekstualne, datum i vrijeme, matematičke, druge funkcije), u kojima ćemo pretraživati za željenu funkciju.




Rice. 24 Odabir funkcije u Excelu 2007
Funkcija LINEST izračunava statistiku za seriju koristeći metodu najmanjih kvadrata za izračunavanje prave linije koja najbolje aproksimira dostupne podatke, a zatim vraća niz koji opisuje rezultirajuću ravnu liniju. Također možete kombinirati funkciju LINEST s drugim funkcijama za izračunavanje drugih vrsta modela koji su linearni u nepoznatim parametrima (čiji su nepoznati parametri linearni), uključujući polinomske, logaritamske, eksponencijalne i nizove stepena. Budući da se vraća niz vrijednosti, funkcija mora biti navedena kao formula niza.
Jednačina za pravu liniju je:
(u slučaju višestrukih raspona x vrijednosti),
gdje je zavisna vrijednost y funkcija nezavisne vrijednosti x, vrijednosti m su koeficijenti koji odgovaraju svakoj nezavisnoj varijabli x, a b je konstanta. Imajte na umu da y, x i m mogu biti vektori. Funkcija LINEST vraća niz ![]() . LINEST može također vratiti dodatnu statistiku regresije.
. LINEST može također vratiti dodatnu statistiku regresije.
LINEST(poznate_y-vrijednosti; poznate_x-vrijednosti; konst; statistika)
Poznate_y vrijednosti - skup y vrijednosti koje su već poznate za relaciju.
Ako niz poznatog_y ima jednu kolonu, onda se svaki stupac niza poznatog_x tumači kao zasebna varijabla.
Ako niz poznatog_y ima jedan red, tada se svaki red niza poznatog_x tumači kao zasebna varijabla.
Poznati_x je opcioni skup x-ova koji su već poznati za relaciju.
Poznati_x niz može sadržavati jedan ili više skupova varijabli. Ako se koristi samo jedna varijabla, tada nizovi_poznate_y_vrijednosti i poznate_x_vrijednosti mogu biti bilo kojeg oblika - sve dok imaju istu dimenziju. Ako se koristi više od jedne varijable, tada poznati_y mora biti vektor (tj. visok jedan red ili širok jedan stupac).
Ako je niz_poznat_x izostavljen, onda se pretpostavlja da je ovaj niz (1;2;3;...) iste veličine kao i niz_poznat_y.
Const je logička vrijednost koja određuje da li konstanta b mora biti 0.
Ako je argument "const" TRUE ili izostavljen, tada se konstanta b procjenjuje normalno.
Ako je argument "const" FALSE, tada se pretpostavlja da je vrijednost b 0, a vrijednosti m se biraju na takav način da je relacija zadovoljena.
Statistics je Boolean vrijednost koja pokazuje da li treba vratiti dodatnu statistiku regresije.
Ako je statistika TRUE, LINEST vraća dodatnu statistiku regresije. Vraćeni niz će izgledati ovako: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Ako je statistika FALSE ili je izostavljena, LINEST vraća samo koeficijente m i konstantu b.
Dodatna statistika regresije.
Slika ispod pokazuje redoslijed po kojem se vraćaju dodatne statistike regresije.

napomene:
Bilo koja prava linija se može opisati svojim nagibom i presekom sa y-osom:
Nagib (m): Da biste odredili nagib prave, koji se obično označava sa m, trebate uzeti dvije točke na pravoj i ; nagib će biti ![]() .
.
Y-presek (b): Y-presek prave, koji se obično označava sa b, je vrednost y za tačku u kojoj linija seče y-osu.
Jednačina prave linije ima oblik . Ako su poznate vrijednosti m i b, tada se bilo koja tačka na pravoj može izračunati zamjenom vrijednosti y ili x u jednadžbu. Također možete koristiti funkciju TREND.
Ako postoji samo jedna nezavisna varijabla x, možete dobiti nagib i y-presjek direktno koristeći sljedeće formule:
Nagib: INDEX(LINEST(poznati_y, poznati_x), 1)
Y-presjek: INDEX(LINEST(poznati_y, poznati_x), 2)
Preciznost aproksimacije korištenjem prave linije izračunate pomoću funkcije LINEST ovisi o stupnju rasipanja podataka. Što su podaci bliži pravoj liniji, to je tačniji model koji koristi LINEST. Funkcija LINEST koristi metodu najmanjih kvadrata za određivanje najboljeg uklapanja podataka. Kada postoji samo jedna nezavisna varijabla x, m i b se izračunavaju pomoću sljedećih formula:

gdje su x i y srednje vrijednosti uzorka, na primjer x = PROSJEK (poznati_x) i y = PROSJEK (poznati_y).
Funkcije uklapanja LINEST i LGRFPRIBL mogu izračunati ravnu ili eksponencijalnu krivu koja najbolje odgovara podacima. Međutim, oni ne daju odgovor na pitanje koji je od dva rezultata pogodniji za rješavanje problema. Također možete izračunati funkciju TREND(poznate_y-vrijednosti; poznate_x-vrijednosti) funkciju za ravnu liniju ili funkciju GROWTH(poznate_y-vrijednosti; poznate_x-vrijednosti) funkciju za eksponencijalnu krivu. Ove funkcije, ako ne navedete argument new_x_values, vraćaju niz izračunatih y vrijednosti za stvarne x vrijednosti prema pravoj liniji ili krivulji. Zatim možete uporediti izračunate vrijednosti sa stvarnim vrijednostima. Takođe možete napraviti grafikone za vizuelno poređenje.
Prilikom izvođenja regresione analize, Microsoft Excel izračunava, za svaku tačku, kvadrat razlike između predviđene vrijednosti y i stvarne vrijednosti y. Zbir ovih kvadrata razlika naziva se rezidualni zbir kvadrata (ssresid). Microsoft Excel zatim izračunava ukupan zbir kvadrata (sstotal). Ako je const = TRUE ili ako ovaj argument nije naveden, ukupan zbir kvadrata će biti jednak zbroju kvadrata razlika stvarnih y vrijednosti i srednjih y vrijednosti. Ako je const = FALSE, zbir kvadrata će biti jednak zbroju kvadrata realnih y vrijednosti (bez oduzimanja srednje vrijednosti y od količnika y). Nakon toga, regresijski zbir kvadrata se može izračunati na sljedeći način: ssreg = sstotal - ssresid. Što je manji rezidualni zbir kvadrata, to je veća vrijednost koeficijenta determinizma r2, što pokazuje koliko dobro jednačina dobijena regresionom analizom objašnjava odnose između varijabli. Koeficijent r2 je jednak ssreg/sstotal.
U nekim slučajevima, jedan ili više X stupaca (neka Y i X vrijednosti budu u kolonama) nemaju dodatnu prediktivnu vrijednost u drugim kolonama X. Drugim riječima, brisanjem jednog ili više X stupaca može doći do Y vrijednosti izračunati sa istom preciznošću. U ovom slučaju, redundantni X stupci će biti isključeni iz regresijskog modela. Ovaj fenomen se naziva "kolinearnost" jer se redundantni stupci X mogu predstaviti kao zbir nekoliko neredundantnih kolona. LINEST provjerava kolinearnost i uklanja sve redundantne X stupce iz regresijskog modela ako ih pronađe. Uklonjeni X stupci mogu se identificirati u LINEST izlazu faktorom 0 i se vrijednošću 0. Uklanjanje jedne ili više kolona kao suvišnih mijenja vrijednost df jer ovisi o broju X stupaca koji se stvarno koriste u svrhe predviđanja. Pogledajte primjer 4 u nastavku za više detalja o izračunavanju df. Kada se df promijeni zbog uklanjanja suvišnih kolona, mijenjaju se i vrijednosti sey i F. Često se ne preporučuje korištenje kolinearnosti. Međutim, treba ga koristiti ako neke kolone X sadrže 0 ili 1 kao indikator koji pokazuje da li je subjekt eksperimenta u zasebnoj grupi. Ako je const = TRUE ili ako ovaj argument nije specificiran, LINEST umeće dodatni X stupac za simulaciju točke presjeka. Ako postoji kolona sa vrijednostima 1 za muškarce i 0 za žene, a postoji kolona sa vrijednostima 1 za žene i 0 za muškarce, tada se posljednja kolona uklanja jer se njene vrijednosti mogu dobiti iz kolona "muški indikator".
Izračunavanje df za slučajeve kada X kolona nije uklonjeno iz modela zbog kolinearnosti je kako slijedi: ako postoji k poznatih_x stupaca i const = TRUE ili nije specificirano, onda je df = n - k - 1. Ako je const = FALSE, onda je df = n -k. U oba slučaja, uklanjanje X stupaca zbog kolinearnosti povećava vrijednost df za 1.
Formule koje vraćaju nizove moraju se unijeti kao formule niza.
Prilikom unosa niza konstanti kao argumenta known_x_values, na primjer, koristite tačku i zarez da odvojite vrijednosti u istom redu, a dvotočku za razdvajanje redaka. Znakovi za razdvajanje mogu se razlikovati ovisno o postavkama u prozoru "Jezik i standardi" na kontrolnoj tabli.
Imajte na umu da y vrijednosti predviđene jednadžbom regresije možda neće biti tačne ako su izvan raspona vrijednosti y koje su korištene za definiranje jednačine.
Glavni algoritam koji se koristi u funkciji LINEST, razlikuje se od glavnog algoritma funkcija INCLINE I ODJELJAK. Razlike između algoritama mogu dovesti do različitih rezultata za nesigurne i kolinearne podatke. Na primjer, ako su točke podataka argumenta poznatog_y 0, a podatkovne točke argumenta poznatog_x 1, tada:
Funkcija LINEST vraća vrijednost jednaku 0. Algoritam funkcije LINEST koristi se za vraćanje odgovarajućih vrijednosti za kolinearne podatke, u kom slučaju se može pronaći barem jedan odgovor.
Funkcije SLOPE i INTERCEPT vraćaju grešku #DIV/0!. Algoritam funkcija SLOPE i INTERCEPT se koristi za pronalaženje samo jednog odgovora, au ovom slučaju može biti nekoliko.
Pored izračunavanja statistike za druge vrste regresije, LINEST se može koristiti za izračunavanje raspona za druge vrste regresije unosom funkcija varijabli x i y kao niza varijabli x i y za LINEST. Na primjer, sljedeća formula:
LINEST(y-vrijednosti, x-vrijednosti^COLUMN($A:$C))
radi sa jednom kolonom od Y vrijednosti i jednom kolonom od X vrijednosti kako bi izračunao aproksimaciju kocke (polinom 3. stepena) sljedećeg oblika:
Formula se može modificirati za izračunavanje drugih tipova regresije, ali u nekim slučajevima su potrebna prilagođavanja izlaznih vrijednosti i druge statistike.
Po mom mišljenju, kao studentu, ekonometrija je jedna od najprimijenjenijih nauka od svih sa kojima sam uspio da se upoznam u zidovima svog univerziteta. Uz pomoć njega, zaista, moguće je riješiti primijenjene probleme na nivou preduzeća. Koliko će ova rješenja biti efikasna je treće pitanje. Suština je da će većina znanja ostati teorija, ali ekonometrija i regresijska analiza su i dalje vrijedni proučavanja s posebnom pažnjom.
Šta objašnjava regresiju?
Pre nego što počnemo da razmatramo funkcije MS Excel-a koje nam omogućavaju da rešimo ove probleme, želeo bih da vam na prste objasnim šta, u suštini, podrazumeva regresionu analizu. Tako će vam biti lakše polagati ispit, a što je najvažnije, bit će zanimljivije učiti predmet.
Nadamo se da ste upoznati sa konceptom funkcije iz matematike. Funkcija je odnos između dvije varijable. Kada se jedna varijabla promijeni, nešto se dešava drugoj. Mijenjamo X, odnosno Y mijenjamo. Funkcije opisuju različite zakone. Poznavajući funkciju, možemo zamijeniti proizvoljne vrijednosti za X i vidjeti kako se Y mijenja.
Ovo je od velike važnosti, budući da je regresija pokušaj da se uz pomoć određene funkcije objasne naizgled nesistemski i haotični procesi. Tako je, na primjer, moguće otkriti odnos između kursa dolara i nezaposlenosti u Rusiji.
Ako se ovaj obrazac može otkriti, onda ćemo prema funkciji koju smo dobili u toku proračuna moći napraviti prognozu kolika će biti stopa nezaposlenosti pri N-om kursu dolara prema rublji.
Ovaj odnos će se zvati korelacija. Regresiona analiza uključuje izračunavanje koeficijenta korelacije, koji će objasniti čvrstoću odnosa između varijabli koje razmatramo (kurs dolara i broj radnih mjesta).
Ovaj koeficijent može biti pozitivan ili negativan. Njegove vrijednosti se kreću od -1 do 1. Shodno tome, možemo uočiti visoku negativnu ili pozitivnu korelaciju. Ako bude pozitivan, onda će povećanje dolara biti praćeno otvaranjem novih radnih mjesta. Ako je negativan, onda će porast kursa biti praćen smanjenjem broja radnih mesta.
Regresija je nekoliko vrsta. Može biti linearna, parabolična, eksponencijalna, eksponencijalna, itd. Odabir modela vršimo ovisno o tome koja će regresija odgovarati konkretno našem slučaju, koji će model biti što bliži našoj korelaciji. Razmotrimo ga na primjeru problema i riješimo ga u MS Excel-u.
Linearna regresija u MS Excel-u
Za rješavanje problema linearne regresije potrebna vam je funkcija analize podataka. Možda vam nije omogućeno, pa ga morate aktivirati.
- Kliknite na dugme "Datoteka";
- Odaberite stavku "Opcije";
- Kliknite na pretposljednju karticu "Dodaci" na lijevoj strani;

- Ispod ćemo vidjeti natpis "Upravljanje" i dugme "Idi". Pritisnemo ga;
- Stavite kvačicu na "Paket analize";
- Pritisnemo "ok".

Primjer zadatka
Aktivirana je funkcija analize serije. Hajde da rešimo sledeći problem. Imamo uzorak podataka za više godina o broju vanrednih situacija na teritoriji preduzeća i broju zaposlenih radnika. Moramo identificirati odnos između ove dvije varijable. Postoji varijabla za objašnjenje X, što je broj radnika, i varijabla za objašnjenje, Y, koja predstavlja broj hitnih slučajeva. Podijelimo početne podatke u dvije kolone.
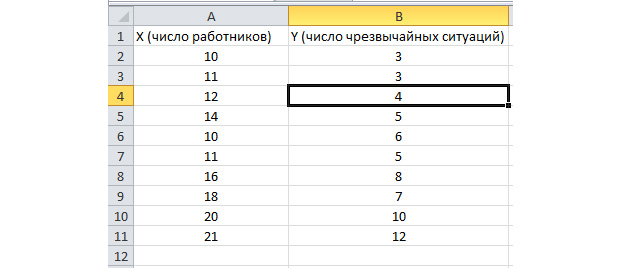
Idite na karticu "Podaci" i odaberite "Analiza podataka"
Odaberite "Regresija" sa liste koja se pojavi. U intervalima unosa Y i X odaberite odgovarajuće vrijednosti.

Pritisnemo "OK". Analiza je urađena, au novom listu ćemo vidjeti rezultate.
Najznačajnije vrijednosti za nas označene su na donjoj slici.
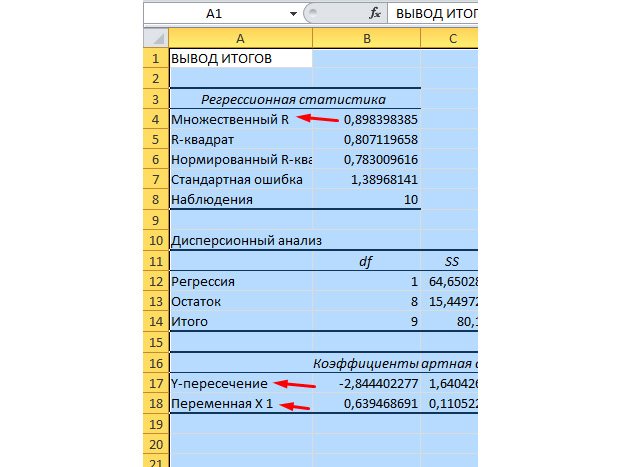
Višestruki R je koeficijent determinacije. Ima složenu formulu za izračunavanje i pokazuje koliko možemo vjerovati našem koeficijentu korelacije. Shodno tome, što je ova vrijednost veća, što je veće povjerenje, to je naš model u cjelini uspješniji.
Y-presjek i X1 presjek su koeficijenti naše regresije. Kao što je već spomenuto, regresija je funkcija i ima određene koeficijente. Dakle, naša funkcija će izgledati ovako: Y = 0,64 * X-2,84.
Šta nam to daje? Ovo nam daje priliku da napravimo predviđanje. Recimo da želimo da zaposlimo 25 radnika za preduzeće i trebamo otprilike da zamislimo koliki će biti broj hitnih slučajeva. Zamjenjujemo ovu vrijednost u našu funkciju i dobivamo rezultat Y = 0,64 * 25 - 2,84. Oko 13 vanrednog stanja ćemo nastupiti.
Hajde da vidimo kako to radi. Pogledajte sliku ispod. Stvarne vrijednosti za uključene zaposlenike zamjenjuju se u funkciju koju smo dobili. Pogledajte koliko su vrijednosti bliske stvarnim igračima.

Također možete izgraditi polje korelacije tako što ćete označiti područje y i x, kliknuti na karticu "insert" i odabrati dijagram raspršenja.

Tačke su raštrkane, ali se uglavnom kreću prema gore kao da je u sredini prava linija. Ovu liniju možete dodati i tako što ćete otići na karticu "Izgled" u MS Excel-u i odabrati stavku "Linija trenda"
Dvaput kliknite na liniju koja se pojavi i vidjet ćete šta je ranije rečeno. Možete promijeniti tip regresije ovisno o tome kako izgleda vaše polje korelacije.
Možda ćete otkriti da tačke crtaju parabolu, a ne ravnu liniju, i možda ćete želeti da izaberete drugu vrstu regresije.

Zaključak
Nadamo se da vam je ovaj članak dao bolje razumijevanje šta je regresijska analiza i čemu služi. Sve ovo je od velike praktične važnosti.


