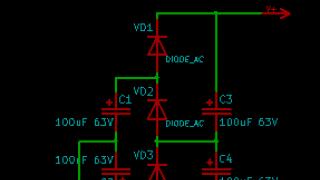
SMP архитектура
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.
Память является способом передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP архитектура называется симметричной.
Основные преимущества SMP-систем:
Простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают абсолютно независимо друг от друга - однако, можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания.
Легкость в эксплуатации. Как правило, SMP-системы используют систему охлаждения, основанную на воздушном кондиционировании, что облегчает их техническое обслуживание.
Относительно невысокая цена.
Недостатки:
Системы с общей памятью, построенные на системной шине, плохо масштабируемы
Этот важный недостаток SMP-системы не позволяет считать их по-настоящему перспективными. Причины плохой масштабируемости состоят в том, что в данный момент шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти.
MPP архитектура
MPP архитектура (massive parallel processing) - массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), два коммуникационных процессора (рутера) или сетевой адаптер, иногда - жесткие диски и/или другие устройства ввода/вывода.

Главное преимущество:
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодняшний день устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки:
Отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами.
каждый процессор может использовать только ограниченный объем локального банка памяти.
вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
PVP архитектура
PVP (Parallel Vector Process) - параллельная архитектура с векторными процессорами.
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гб/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дороги, эти машины не будут являться общедоступными.
Кластерная архитектура
Кластер представляет собой два или больше компьютеров (часто называемых узлами), объединяемых при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающих перед пользователями в качестве единого информационно-вычислительного ресурса. В качестве узлов кластера могут быть выбраны серверы, рабочие станции и даже обычные персональные компьютеры. Преимущество кластеризации для повышения работоспособности становится очевидным в случае сбоя какого-либо узла: при этом другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе.
Зако́н Амдала (англ. Amdahl"s law , иногда также Закон Амдаля-Уэра ) - иллюстрирует ограничение ростапроизводительности вычислительной системы с увеличением количества вычислителей. Джин Амдалсформулировал закон в 1967 году, обнаружив простое по существу, но непреодолимое по содержанию ограничение на рост производительности при распараллеливании вычислений: «В случае, когда задача разделяется на несколько частей, суммарное время её выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента». Согласно этому закону, ускорение выполнения программы за счётраспараллеливания её инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.
Предположим, что необходимо решить некоторую вычислительную задачу. Предположим, что её алгоритм таков, что доля от общего объёма вычислений может быть получена только последовательными расчётами, а, соответственно, доля может быть распараллелена идеально (то есть время вычисления будет обратно пропорционально числу задействованных узлов ). Тогда ускорение, которое может быть получено на вычислительной системе из процессоров, по сравнению с однопроцессорным решением не будет превышать величины

Иллюстрация
Таблица показывает, во сколько раз быстрее выполнится программа с долей последовательных вычислений при использовании процессоров. . Так, если половина кода - последовательная, то общий прирост никогда не превысит двух.
]Идейное значение
Закон Амдала показывает, что прирост эффективности вычислений зависит от алгоритма задачи и ограничен сверху для любой задачи с . Не для всякой задачи имеет смысл наращивание числа процессоров в вычислительной системе.
Более того, если учесть время, необходимое для передачи данных между узлами вычислительной системы, то зависимость времени вычислений от числа узлов будет иметь максимум. Это накладывает ограничение на масштабируемость вычислительной системы, то есть означает, что с определенного момента добавление новых узлов в систему будет увеличивать время расчёта задачи.
Для MIMD-систем в настоящее время общепризнанна классификация, основанная на используемых способах организации оперативной памяти в этих системах. По этой классификации, прежде всего, различают мультипроцессорные вычислительные системы (или мультипроцессоры) или вычислительные системы с разделяемой памятью (multiprocessors, common memory systems, shared-memory systems) и мультикомпьютерные вычислительные системы (мультикомпьютеры) или вычислительные системы с распределенной памятью (multicomputers, distributed memory systems). Структура мультипроцессорной и мультикомпьютерной систем приведена рис. 1, где - процессор, - модуль памяти.
Рис. 1. а) - структура мультипроцессора; б) – структура мультикомпьютера.
Мультипроцессоры.
В мультипроцессорах адресное пространство всех процессоров является единым. Это значит, что если в программах нескольких процессоров мультипроцессора встречается одна и та же переменная, то для получения или изменения значения этой переменной эти процессоры будут обращаться в одну физическую ячейку общей памяти. Это обстоятельство имеет как положительные, так и отрицательные последствия.
С одной стороны, не нужно физически перемещать данные между коммутирующими программами, что исключает затраты времени на межпроцессорный обмен.
С другой стороны, так как одновременное обращение нескольких процессоров к общим данным может привести к получению неверных результатов, необходимы системы синхронизации параллельных процессов и обеспечения когерентности памяти. Поскольку процессорам необходимо очень часто обращаться к общей памяти, требования к пропускной способности коммуникационной среды чрезвычайно высоки.
Последнее обстоятельство ограничивает число процессоров в мультипроцессорах несколькими десятками. Остроту проблемы доступа к общей памяти частично удается снять разделением памяти на блоки, которые позволяют распараллелить обращения к памяти от различных процессоров.
Отметим еще одно преимущество мультипроцессоров – мультипроцессорная система функционирует под управлением единственной копией операционной системы (обычно, UNIX-подобной) и не требует индивидуальной настройки каждого процессорного узла.
Однородные мультипроцессоры с равноправным (симметричным) доступом к общей оперативной памяти принято называть SMP-системами (системами с симметричной мультипроцессорной архитектурой). SMP-системы появились как альтернатива дорогим мультипроцессорным системам на базе векторно-конвейерных процессоров и векторно-параллельных процессоров (см. Рис.2).
Мультикомпьютеры.
Вследствие простоты своей архитектуры наибольшее распространение в настоящее время получили мультикомпьютеры. Мультикомпьютеры не имеют общей памяти. Поэтому межпроцессорный обмен в таких системах осуществляется обычно через коммуникационную сеть с помощью передачи сообщений.
Каждый процессор в мультикомпьютере имеет независимое адресное пространство. Поэтому наличие переменной с одним и тем же именем в программах разных процессоров, приводит к обращению к физически разным ячейкам собственной памяти этих процессоров. Это обстоятельство требует физического перемещения данных между коммутирующими программами в разных процессорах. Чаще всего основная часть обращений производится каждым процессором к собственной памяти. Поэтому требования к коммутационной среде ослабляются. В результате число процессоров в мультикомпьютерных системах может достигать нескольких тысяч, десятков тысяч и даже сотен тысяч.
Пиковая производительность крупнейших систем с общей памятью ниже пиковой производительности крупнейших систем с распределенной памятью; стоимость систем с общей памятью выше стоимости аналогичных по производительности систем с распределенной памятью.
Однородные мультикомпьютеры с распределенной памятью называются вычислительными системами с массивно-параллельной архитектурой (MPP-системами) - см. рис.2.
Нечто среднее между SMP-системами и MPP-системами представляют собой NUMA-системы.
Кластерные системы (вычислительные кластеры).
Кластерные системы (вычислительные кластеры) представляют собой более дешевый вариант MPP-систем. Вычислительный кластер состоит из совокупности персональных компьютеров или рабочих станций), объединенных локальной сетью в качестве коммуникационной среды. Детально вычислительные кластеры рассмотрены позже.
Рис. 2. Классификация мультипроцессоров и мультикомпьютеров.
SMP-системы
Все процессоры SMP-системы имеют симметричный доступ к памяти, т.е. память SMP-системы представляет собой UMA-память. Под симметричностью понимается следующее: равные права всех процессоров на доступ к памяти; одна и та же адресация для всех элементов памяти; равное время доступа всех процессоров системы к памяти (без учета взаимных блокировок).
Общая структура SMP-системы приведена на рис. 3. Коммуникационная среда SMP-системы строится на основе какой-либо высокоскоростной системной шины или высокоскоростного коммутатора. Кроме одинаковых процессоров и общей памяти M к этой же шине или коммутатору подключаются устройства ввода-вывода.
За кажущейся простотой SMP-систем скрываются значительные проблемы, связанные в основном с оперативной памятью. Дело в том, что в настоящее время скорость работы оперативной памяти значительно отстает от скорости работы процессора. Для того чтобы сгладить этот разрыв, современные процессоры снабжаются высокоскоростной буферной памятью (кэш-памятью). Скорость доступа к этой памяти в несколько десятков раз превышает скорость доступа к основной памяти процессора. Однако наличие кэш-памяти нарушается принцип равноправного доступа к любой точке памяти, поскольку данные, находящиеся в кэш-памяти одного процессора, недоступны для других процессоров. Поэтому после каждой модификации копии переменной, находящейся в кэш-памяти какого-либо процессора, необходимо производить синхронную модификацию самой этой переменной, расположенной в основной памяти. В современных SMP-системах когерентность кэш-памяти поддерживается аппаратно или операционной системой.
Рис. 3. Общая структура SMP-системы
Наиболее известными SMP-системами являются SMP-cерверы и рабочие станции IBM, HP, Compaq, Dell, Fujitsu и др. SMP-система функционирует под управлением единой операционной системой (чаще всего – UNIX и подобной ей).
Из-за ограниченной пропускной способности коммуникационной среды SMP-системы плохо масштабируются. В настоящее время в реальных системах используется не более нескольких десятков процессоров.
Известным неприятным свойством SMP-систем является то, что их стоимость растет быстрее, чем производительность при увеличении числа процессоров в системе.
MPP-системы.
MPP-системы строится из процессорных узлов, содержащих процессор, локальный блок оперативной памяти, коммуникационный процессор или сетевой адаптер, иногда - жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры (см. рис. 4.). Доступ к блоку оперативной памяти данного модуля имеет только процессор этого же модуля. Модули взаимодействуют между собой через некоторую коммуникационную среду. Используются два варианта работы операционной системы на MPP-системах. В одном варианте полноценная операционная система функционирует только на управляющей ЭВМ, а на каждом отдельном модуле работает сильно урезанный вариант операционной системы, поддерживающий только базовые функции ядра операционной системы. Во втором варианте на каждом модуле работает полноценная UNIX-подобная операционная система. Заметим, что необходимость наличия (в том или ином виде) на каждом процессоре MPP-системы операционной системы, позволяет использовать только ограниченный объем памяти каждого из процессоров.
По сравнению с SMP-системами, архитектура MPP-системы устраняет одновременно как проблему конфликтов при обращении к памяти, так и проблему когерентности кэш-памяти.
Главным преимуществом MPP-систем является хорошая масштабируемость. Так супер-ЭВМ серии CRAY T3E, способны масштабироваться до 2048 процессоров. Практически все рекорды по производительности на сегодняшний день установлены именно на MPP-системах, состоящих из нескольких тысяч процессоров.
Рис. 4. Общая структура MPP-системы.
С другой стороны, отсутствие общей памяти заметно снижает скорость межпроцессорного обмена в MPP-системах. Это обстоятельство для MPP-систем выводит на первый план проблему эффективности коммуникационной среды.
Кроме того, в MPP-системах требуется специальная техника программирования для реализации обмена данными между процессорами. Этим объясняется высокая цена программного обеспечения для MPP-систем. Этим же объясняется то, что написание эффективных параллельных программ для MPP-систем представляет собой более сложную задачу, чем написание таких же программ для SMP-систем. Для широкого круга задач, для которые известны хорошо зарекомендовавшие себя последовательные алгоритмы, не удается построить эффективные параллельные алгоритмы для MPP-систем.
NUMA-системы.
Логически общий доступ к данным может быть обеспечен и при физически распределенной памяти. При этом расстояние между различными процессорами и различными элементами памяти, вообще говоря, различно и длительность доступа различных процессоров к различным элементам памяти различна. Т.е. память таких систем представляет собой NUMA-память.
NUMA-система обычно строится на основе однородных процессорных узлов, состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью некоторой высокоскоростной коммуникационной среды (см. рис. 5). Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу, NUMA-система представляет собой MPP-систему, где в качестве отдельных вычислительных элементов используются SMP-узлы.
Среди NUMA-систем выделяют следующие типы систем:
- COMA-системы , в которых в качестве оперативной памяти используется только локальная кэш-память процессоров (cache-only memory architecture - COMA);
- CC-NUMA-системы , в которых аппаратно обеспечивается когерентность локальной кэш-памяти разных процессоров (cache-coherent NUMA - CC-NUMA);
- NCC-NUMA-системы , в которых аппаратно не поддерживается когерентность локальной КЭШ памяти разных процессоров (non-cache coherent NUMA - NCC-NUMA). К данному типу относится, например, система Cray T3E.
Рис. 5. Общая структура NUMA-системы.
Логическая общедоступность памяти в NUMA-системах, с одной стороны, позволяет работать с единым адресным пространством, а, с другой стороны, позволяет достаточно просто обеспечить высокую масштабируемость системы. Данная технология позволяет в настоящее время создавать системы, содержащие до нескольких сот процессоров.
NUMA-системы серийно производятся многими компьютерными фирмами как многопроцессорные серверы и прочно удерживают лидерство в классе малых суперкомпьютеров.
15.02.1995 В. Пятенок
Однопроцессорная архитектура Модифицированная однопроцессорная архитектура SMP-архитектура Архитектура SMP-маршрутизатора, предложенная Wellfleet Обзор архитектуры Детали обработки пакетов Резюме Литература Маршрутизаторы в своем развитии использовали три различных архитектуры: однопроцессорную, модифицированную однопроцессорную и симметричную многопроцессорную. Все три разрабатывались с учетом требований поддержки высококритичных применений.
Маршрутизаторы в своем развитии использовали три различных архитектуры: однопроцессорную, модифицированную однопроцессорную и симметричную многопроцессорную. Все три разрабатывались с учетом требований поддержки высококритичных применений. Однако основные из этих требований, а именно высокую, масштабируемую производительность, а также высокий уровень готовности, включая полную устойчивость к отказам и восстановление неработоспособных компонентов ("горячее резервирование"), они способны удовлетворить не в одинаковой степени. В статье рассматриваются достоинства симметричной многопроцессорной архитектуры.
Однопроцессорная архитектура
Однопроцессорная архитектура использует несколько сетевых интерфейсных модулей - это позволяет добиться дополнительной гибкости в конфигурировании узлов. Сетевые интерфейсные модули соединяются с единым центральным процессором через общую системную шину. На этот единственный процессор ложится забота о выполнении всех задач обработки. А задачи эти при современном уровне развития корпоративных сетей сложны и многообразны: фильтрация и продвижение пакетов, необходимая модификация заголовков пакетов, обновления таблиц маршрутизации и сетевых адресов, интерпретация служебных управляющих пакетов, ответы на SNMP-запросы, формирование управляющих пакетов, предоставление иных специфических сервисов типа спуфинга (spoofing), то есть задания специальных фильтров, позволяющих добиться улучшенных характеристик безопасности и производительности сети.
Подобное традиционное архитектурное решение реализовать наиболее просто. Впрочем, несложно и предположить те ограничения, которым будут подвержены производительность и готовность такой системы.
Действительно, все пакеты от всех сетевых интерфейсов должны обрабатываться единственным центральным процессором. По мере того как добавляются дополнительные сетевые интерфейсы, производительность заметно снижается. Кроме того, каждый пакет должен дважды пропутешествовать по шине - от модуля-"источника" к процессору, а-затем от процессора к модулю-"приемнику". Пакет проделывает этот путь, даже если он предназначается тому же самому сетевому интерфейсу, с которого он поступил. Это также приводит к существенному падению производительности при увеличении числа модулей сетевых интерфейсов. Таким образом, налицо классическое "бутылочное горлышко".
Невелика и надежность. Если произойдет сбой центрального процессора, то нарушится работоспособность маршрутизатора в целом. Кроме того, для такой архитектуры невозможно реализовать "горячее восстановление" из резерва поврежденных элементов системы.
В современных реализациях этой архитектуры маршрутизаторов для того, чтобы разрешить ограничения производительности, как правило, используют достаточно мощный RISC-процессор и высокоскоростную системную шину. Это чисто силовая попытка решить проблему - увеличенная производительность за большие начальные вложения. Однако такие реализации не обеспечивают масштабирования производительности, а уровень их надежности наперед задан надежностью процессора.
Модифицированная однопроцессорная архитектура
Для того чтобы преодолеть часть указанных выше недостатков однопроцессорной архитектуры, придумана ее модификация. Нижележащая архитектура сохранена: интерфейсные модули соединены с единственным процессором через общую системную шину. Однако в каждый из сетевых интерфейсных модулей включается специальный периферийный процессор - для того, чтобы хотя бы частично разгрузить центральный процессор.
Периферийные процессоры - это, как правило, разрядно-модульные (bit-slace) или универсальные микропроцессоры, фильтрующие и маршрутизирующие пакеты, предназначающиеся сетевому интерфейсу того же модуля, с которого они и поступили в маршрутизатор. (К сожалению, во многих доступных в настоящий момент реализациях этого можно добиться в отношении пакетов только некоторых типов, таких как кадры Ethernet, но не IEEE 802.3.
Центральный же процессор по-прежнему отвечает за те задачи, которые нельзя переложить на периферийный процессор (в том числе маршрутизацию между модулями, общесистемные операции, администрирование и управление). Поэтому достигаемая таким образом оптимизация производительности достаточно ограничена (справедливости ради следует отметить, что в ряде случаев при надлежащем проектировании сети можно добиться неплохих результатов). В то же время, несмотря на некоторое сокращение количества передаваемых по системной шине пакетов, она по-прежнему остается весьма узким местом.
Включение в архитектуру периферийных процессоров не повышает уровень готовности маршрутизатора в целом.
SMP-архитектура
Симметрично-многопроцессорная архитектура лишена недостатков, свойственных вышеупомянутым архитектурам. В этом случае вычислительные мощности полностью распределены между всеми сетевыми интерфейсными модулями.
Каждый сетевой интерфейсный модуль обладает своим собственным, предназначенным только для него процессорным модулем, который выполняет все задачи, связанные с маршрутизацией. При этом все таблицы маршрутизации, другая необходимая информация, а также реализующее протоколы программное обеспечение реплицированы (то есть скопированы) на каждый процессорный модуль. Когда процессорный модуль получает информацию о маршрутизации, он обновляет собственную таблицу, а затем распространяет обновления по всем другим процессорным модулям.
Такая архитектура, безусловно, обеспечивает практически линейную (если пренебречь расходами на репликацию и пропускной способностью канала связи между модулями) масштабируемость. Это, в свою очередь, означает перспективу значительного расширения сети без заметного падения производительности. При необходимости требуется всего лишь добавить дополнительный сетевой интерфейсный модуль - ведь центральный процессор в этой архитектуре попросту отсутствует.
Все пакеты обрабатываются локальными процессорами. Внешние (то есть предназначенные другим модулям) пакеты передаются по каналу связи между процессорами только однажды. Это ведет к существенному снижению трафика внутри маршрутизатора.
Что касается готовности, система не будет выходить из строя, если сломается одиночный процессорный модуль. Эта поломка скажется только на тех сегментах сети, которые соединены с поврежденным процессорным модулем. Кроме того, поврежденный модуль может быть заменен на работоспособный модуль без выключения маршрутизатора и без всякого воздействия на все остальные модули.
Преимущества SMP-архитектуры признаны производителями компьютеров. В течение ряда последних лет появилось много подобных платформ, и только ограниченное число стандартных операционных систем, способных в полной мере реализовать преимущества аппаратуры, сдерживало их распространение. Используют SMP-архитектуру при создании специализированных вычислительных устройств и другие производители, в том числе производители активных сетевых устройств.
В оставшейся части мы подробнее рассмотрим технические детали архитектуры SMP-маршрутизатора, разработанной компанией Wellfleet .
Архитектура SMP-маршрутизатора, предложенная Wellfleet
Компания Wellfleet , один из ведущих производителей маршрутизаторов и мостов, конечно же, не пожалела средств на оценку и тестирование различных архитектур маршрутизаторов, поддерживающих различные протоколы глобальных и локальных сетей над различными физическими носителями и рассчитанных на различные условия трафика. Итоги этих исследований были сформулированы в виде перечня требований, учитываемых при проектировании маршрутизаторов, предназначенных для построения корпоративных сетевых сред для высококритичных применений. Приведем часть из этих требований - те, которые на наш взгляд обосновывают использование многопроцессорной архитектуры.
1. Необходимость в масштабируемой производительности, высоком уровне готовности, гибкости конфигурирования диктует использование SMP-архитектуры.
2. Уровень требований многопротокольной маршрутизации к вычислительной мощности (особенно при использовании современных протоколов маршрутизации наподобие TCP/IP OSPF) может быть обеспечен только современными мощными 32-разрядными микропроцессорами. При этом, поскольку маршрутизация предполагает параллельное обслуживание большого числа сходных запросов, необходимо быстрое переключение между различными процессами, для чего требуется исключительно низкая задержка при переключении контекста, а также интегрированная кэш-память.
3. Для хранения поддерживающего протоколы и управляющего программного обеспечения, таблиц маршрутизации и адресов, статистической и другой информации нужна достаточно большая емкость памяти.
4. Чтобы обеспечить максимальную скорость передачи между сетями и обрабатывающими модулями маршрутизатора, требуются высокоскоростные сетевые интерфейсные контроллеры и контролллеры межпроцессорного взаимодействия с интегрированными возможностями прямого доступа к памяти (DMA - Direct Memory Access).
5. Минимизация задержек требует наличия обладающих высокой пропускной способностью 32-разрядных каналов данных и адресов для всех ресурсов.
6. Требования повышения уровня готовности включают распределение вычислительной мощности, избыточные подсистемы питания и, как дополнительную, но очень важную возможность, дублированные каналы межпроцессорного взаимодействия.
7. Необходимость охватить широкий спектр сетевых сред - от одиночного удаленного узла или сети рабочей группы до организации высокопроизводительной, обладающей высокой готовностью магистралью - требует использования масштабируемой многопроцессорной архитектуры.
Обзор архитектуры
На рисунке 2 схематически изображена симметрично-многопроцессорная архитектура, используемая во всех модульных маршрутизаторах, производимых компанией Wellfleet. Можно выделить три основных архитектурных элемента: модули связи, процессорные модули и межпроцессное соединение.
Модули связи обеспечивают физические сетевые интерфейсы, допускающие соединения с локальными и глобальными сетями практически любых типов. Каждый модуль связи напрямую присоединен к предназначенному именно ему процессорному модулю посредством интеллектуального интерфейса связи (ILI - Intelligent Link Interface). Пакеты, получаемые модулем связи, передаются в подключенный к нему процессорный модуль через собственное, прямое соединение. Процессор определяет, какому сетевому интерфейсу предназначаются эти пакеты, и либо перенаправляет их на другой сетевой интерфейс того же модуля связи, либо, по высокоскоростному межпроцессорному соединению, в другой процессорный модуль, который передаст этот пакет присоединенному к нему модулю связи.
Остановимся детальнее на структуре каждого из компонентов.
Процессорный модуль включает в себя:
Собственно центральный процессор;
Локальную память, в которой хранятся протоколы и таблицы маршрутизации, таблицы адресов и другая информация, локальным образом используемая ЦПУ;
Глобальную память, играющую роль буфера для "транзитных" пакетов данных, поступающих от модуля связи в присоединенный к нему процессорный модуль или от других процессорных модулей (глобальной она называется потому, что видима и доступна для всех процессорных модулей);
ОМА-процессор, обеспечивающий возможность прямого доступа к памяти при передаче пакетов между буферами глобальной памяти, размещенными в различных процессорных модулях;
Интерфейс связи, предоставляющий соединение с соответствующим модулем связи;
Внутренние каналы данных шириной 32 разряда, соединяющие все вышеперечисленные ресурсы и призванные обеспечить максимально возможную пропускную способность и минимальное время задержек; предусмотрены множественные каналы, что обеспечивает одновременное выполнение операций разными вычислительными устройствами (например, ЦПУ и DMA-процессором) и гарантирует отсутствие узких мест, замедляющих перенаправление и обработку пакетов.
Различные модели маршрутизаторов Wellfleet используют процессорные модули АСЕ (Advanced Communication Engine), основанные на процессорах Motorola 68020 или 68030, либо модули Fast Routing Engine (FRE), основанные на МС68040.
В состав модуля связи входят:
Коннекторы, обеспечивающие интерфейс со специфическими сетями (например, синхронный, Ethernet, Token Ring FDDI);
Контроллеры связи, передающие пакеты между физическим сетевым интерфейсом и глобальной памятью, используя DMA-канал; контроллеры связи также предназначены для конкретного типа сетевого интерфейса и способны передавать пакеты со скоростью, совпадающей со скоростью проволоки;
Фильтры (дополнительная возможность для модулей связей для FDDI и Ethernet), выполняющие предварительную фильтрацию входящих пакетов, сохраняя вычислительные ресурсы для содержательной обработки файлов.
В качестве канала межпроцессорной связи часто используется стандартная шина VMEbus, обеспечивающая совокупную пропускную способность 320 Мбит/сек.
В старших же моделях применяется разработанный самой компанией Wellfleet интерфейс Parallel Packet Express (РРХ) с полосой пропускания 1 Гбит/сек, использующий четыре независимых, обладающих избыточностью 256 Мбит/сек канала данных с динамическим распределением загрузки. Это обеспечивает высокую общую производительность и позволяет добиться того, что в архитектуре нет единой точки сбоя. Каждый процессорный модуль присоединен ко всем четырем каналам и имеет возможность выбрать любой из них. Конкретный канал выбирается случайно, для каждого пакета, что должно обеспечить равномерное распределение трафика между всеми доступными каналами. Если один из каналов данных PPX становится недоступным, загрузка автоматически распределяется между оставшимися.
Детали обработки пакетов
Поступающие пакеты получает, в зависимости от сети, тот или иной контроллер связи. Если в конфигурацию модуля связи включен дополнительный фильтр, часть пакетов отбрасывается, а другая часть принимается. Принятые пакеты помещаются контроллером связи в буфер глобальной памяти непосредственно присоединенного к нему процессорного модуля. Для быстрой передачи пакетов в каждый контроллер связи включен канал прямого доступа к памяти.
Поступив в глобальную память, пакеты извлекаются центральным процессором для маршрутизации. ЦПУ определяет выходной сетевой интерфейс, должным образом модифицирует пакет и возвращает его в глобальную память. Затем выполняется одно из двух действий:
1. Пакет перенаправляется в сетевой интерфейс непосредственно присоединенного к нему модуля. Контроллер связи выходного сетевого интерфейса получает от ЦПУ инструкции выбрать пакеты из глобальной памяти и отправить их в сеть.
2. Пакет перенаправляется в сетевой интерфейс другого модуля связи. DMA-процессор получает инструкции от ЦПУ отправить пакеты в другой процессорный модуль и загружает их по межпроцессорному соединению в глобальную память процессорного модуля, присоединенного к выходному сетевому интерфейсу. Контроллер связи выходного сетевого интерфейса выбирает пакеты из глобальной памяти и отправляет их в сеть.
Решения относительно маршрутизации принимаются ЦПУ независимо от друтих процессорных модулей. Каждый процессорный модуль поддерживает в своей локальной памяти независимую базу данных маршрутизации и адресов, обновляемую в тех случаях, когда модуль получает информацию об изменениях в таблицах маршрутизации или в адресах (в этом случае изменения рассылаются и во все остальные процессорные модули).
Одновременная работа контроллера связи, ЦПУ и DMA-процессора позволяет добиться общей высокой производительности. (Подчеркнем, что все это происходит в устройстве, где обработка распараллеливается по нескольким многопроцессорным модулям). Например, можно представить себе такую ситуацию, когда контроллер связи помещает пакеты в глобальную память, в то время как центральный процессор обновляет таблицу маршрутизации в локальной памяти, а DMA-процессор помещает пакет в межпроцессорное соединение.
Резюме
Сам по себе факт проникновения компьютерных технологий, разработанных для одной области применений, в другие, смежные, не нов. Однако каждый конкретный пример привлекает внимание специалистов. В рассмотренной в данной статье архитектуре маршрутизаторов, кроме идеи симметричной многопроцессорности, призванной обеспечить масштабируемую производительность и высокий уровень готовности, использованы также механизм дублированных каналов данных между процессорами (с теми же целями), а также идея репликации (или тиражирования) данных, применение которой более характерно для индустрии распределенных СУБД .
Литература
Symmetric Multiprocessor Architecture. Wellfleet Communications, 10/1993.
Г.Г. Барон, Г.М. Ладыженский. "Технология тиражирования данных в распределенных системах" , "Открытые системы", Весна 1994.
*) Компания Wellfleet осенью прошлого года объединилась с другим лидером сетевых технологий, SunOptics Communications. Объединение привело к созданию нового сетевого гиганта - компании Bay Networks (прим. ред.)
UMA – Uniform Memory Access

5. SMP-архитектура используется в cерверах и РС на базе процессоров Intel, AMD, Sun, IBM, HP
(+) : простота, «отработанность» базовых принципов
(-) : весь обмен м/д процессором и памятью осущ. по 1 шине – узкое горлышко арх-ры – ограничение производительности, масштабируемости.
Пример:
MPP – архитектура: Massive parallel processing
Система с массовым параллелизмом. В основе лежал транспьютер – мощный универсальный процессор, особенностью которого было наличие 4 линков (коммуникационные каналы связи). Каждый линк состоит из двух частей, служащих для передачи информации в противоположных направлениях, и используется для соединения транспьютеров между собой и подключения внешних устройств. Архитектура: множество узлов, каждые узел – ОП+ЦП


Классическая МРР-архитектура: каждый узел соединен с 4 узлами по каналу «точка-точка».
 Пример:
Intel Peragon
Пример:
Intel Peragon
Кластерная архитектура
Реализация объединения машин, представляющегося единым целым для ОС, системного ПО, прикладных программами пользователей.
Типы кластеров
- Системы высокой надежности/готовности (High Availability Systems, HA).
- Системы для высокопроизводительных вычислений (High Performance, HP, Compute clusters).
- Многопоточные системы.
- Load-balancing clusters. (распределение вычислительной нагрузки)
Пример: архитектура кластера theHIVE
 5. NUMA архитектура Non Uniform Memory Access – неоднородный доступ к памяти
5. NUMA архитектура Non Uniform Memory Access – неоднородный доступ к памяти
Каждый процессор имеет доступ к своей и к чужой памяти (для доступа в чужую память используется коммутационная сеть или даже проц чужого узла). Доступ к памяти чужого узла может поддерживаться аппаратно: спец. контроллеры.
- : дорого, плохая масштабируемость.
Сейчас: NUMA осущ доступ к чужой памяти программно.
Вычислительная система NUMA состоит из набора узлов (содержит один или несколько процессоров, на нем работает единственная копия ОС), которые соединены между собой коммутатором либо быстродействующей сетью.
Топология связей разбивается на несколько уровней. Каждый из уровней предоставляет соединения в группах с небольшим числом узлов. Такие группы рассматриваются как единые узлы на более высоком уровне.
ОП физически распределена, но логически общедоступна.
В зависимости от пути доступа к элементу данных, время, затрачиваемое на эту операцию, может существенно различаться.
Примеры конкретных реализаций: cc-NUMA, СОМА, NUMA-Q
Пример: HP Integrity SuperDome
Упрощенные блок-схемы SMP (а) и MPP (б)

- Пять основных архитектур высокопроизводительных ВС, их краткая характеристика, примеры. Сравнение кластерной архитектуры и NUMA.
В кластере каждый процессор имеет доступ только в своей памяти, в NUMA не только к своей, но и к чужой (для доступа в чужую память используется коммутационная сеть и процессор чужого узла).
- SMP архитектура. Принципы организации. Достоинства, недостатки. Масштабируемость в «узком» и «широком» смысле. Область применения, примеры ВС на SMP.
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.


1. SMP-система строится на основе высокоскоростной системной шины, к слотам которой подключаются функциональные блоки трех типов: процессоры (ЦП), оперативная память (ОП), подсистема ввода/вывода (I/O).
2. Память является способом передачи сообщений между процессорами.
3. Все вычислительные устройства при обращении к ОП имеют равные права и одну и ту же адресацию для всех ячеек памяти.
4. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами.
5. SMP используется в cерверах и рабочих станциях на базе процессоров Intel, AMD, Sun, IBM, HP.
6. SMP-система работает под управлением единой ОС (либо UNIX-подобной, либо Windows). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Принципы организации:
SMP система состоит из нескольких однородных процессоров и массива общей памяти.
Один из часто используемых в SMP архитектурах подходов для формирования масштабируемой, общедоступной системы памяти, состоит в однородной организации доступа к памяти посредством организации масштабируемого канала память-процессоры.
Каждая операция доступа к памяти интерпретируется как транзакция по шине процессоры-память.
В SMP каждый процессор имеет по крайней мере одну собственную кэш-память (а возможно, и несколько). Можно сказать, что SMP система - это один компьютер с несколькими равноправными процессорами.
Когерентность кэшей поддерживается аппаратными средствами.
Все остальное - в одном экземпляре: одна память, одна подсистема ввода/вывода, одна операционная система.
Слово "равноправный" означает, что каждый процессор может делать все, что любой другой. Каждый процессор имеет доступ ко всей памяти, может выполнять любую операцию ввода/вывода, прерывать другие процессоры.
Масштабируемость:
В «узком» смысле: возможность подключения аппаратных средств в некоторых пределах (процессоры, память, интерфейсы).
В «широком» смысле: линейный рост показателя производительности при увеличении аппаратных средств.
Достоинства:
Простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают абсолютно независимо друг от друга - однако, можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти.
Легкость в эксплуатации. Как правило, SMP-системы используют систему охлаждения, основанную на воздушном кондиционировании, что облегчает их техническое обслуживание.
Относительно невысокая цена.
Преимущество, связанное с параллелизмом. Неявно производимая аппаратурой SMP пересылка данных между кэшами является наиболее быстрым и самым дешевым средством коммуникации в любой параллельной архитектуре общего назначения. Поэтому при наличии большого числа коротких транзакций (свойственных, например, банковским приложениям), когда приходится часто синхронизовать доступ к общим данным, архитектура SMP является наилучшим выбором; любая другая архитектура работает хуже.
Архитектура SMP наиболее безопасна. Из этого не следует, что передача данных между кэшами желательна. Параллельная программа всегда будет выполняться тем быстрее, чем меньше взаимодействуют ее части. Но если эти части должны взаимодействовать часто, то программа будет работать быстрее на SMP.
Недостатки:
SMP-cистемы плохо масштабируемы:
1. Системная шина имеет ограниченную (хоть и высокую) пропускную способность и ограниченное число слотов, так называемое «узкое горлышко».
2. В каждый момент времени шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Когда произойдет такой конфликт, зависит от скорости связи и от количества вычислительных элементов.
Все это препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах эффективно можно использовать не более 8-16-32 процессоров.
Область применения: для работы с банковскими приложениями
Пример: Архитектура Sun Fire T2000. Архитектура UltraSPARC T1.
- SMP архитектура. Совершенствование и модификация SMP архитектуры. SMP в современных многоядерных процессорах. Когерентность КЭШа.
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.
Совершенствование и модификация SMP:
Пример: Архитектура QBB серверных систем серии GS DEC

 С целью увеличения производительности шины произведена попытка убрать шину, но оставить общий доступ к памяти --> переход и замена общей шины локальным коммутатором (или системой коммутаторов): каждый процессор в каждый момент времени скоммутирован с 4 банками памяти.
С целью увеличения производительности шины произведена попытка убрать шину, но оставить общий доступ к памяти --> переход и замена общей шины локальным коммутатором (или системой коммутаторов): каждый процессор в каждый момент времени скоммутирован с 4 банками памяти.
Каждый проц работает с каким-то банком памяти,
Переключается на другой банк памяти
Начинает работу с другим банком памяти.
Рис. 3.1.
Память служит, в частности, для передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP - архитектура называется симметричной. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами. SMP -система строится на основе высокоскоростной системной шины ( SGI PowerPath, Sun Gigaplane, DEC TurboLaser), к слотам которой подключаются функциональные блоки типов: процессоры (ЦП), подсистема ввода/вывода ( I/O ) и т. п. Для подсоединения к модулям I/O используются уже более медленные шины ( PCI , VME64 ). Наиболее известными SMP -системами являются SMP -cерверы и рабочие станции на базе процессоров Intel ( IBM , HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Основные преимущества SMP -систем:
- простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают независимо друг от друга. Однако можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют довольно эффективные средства автоматического распараллеливания;
- простота эксплуатации. Как правило, SMP-системы используют систему кондиционирования, основанную на воздушном охлаждении, что облегчает их техническое обслуживание;
- относительно невысокая цена.
Недостатки:
- системы с общей памятью плохо масштабируются.
Этот существенный недостаток SMP -систем не позволяет считать их по -настоящему перспективными. Причиной плохой масштабируемости является то, что в данный момент шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти . Вычислительные элементы начинают друг другу мешать. Когда произойдет такой конфликт , зависит от скорости связи и от количества вычислительных элементов. В настоящее время конфликты могут происходить при наличии 8-24 процессоров. Кроме того, системная шина имеет ограниченную (хоть и высокую) пропускную способность (ПС) и ограниченное число слотов. Все это очевидно препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах можно задействовать не более 32 процессоров. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA -архитектуры. При работе с SMP -системами используют так называемую парадигму программирования с разделяемой памятью (shared memory paradigm ).
MPP-архитектура
MPP (massive parallel processing) – массивно-параллельная архитектура . Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры (рутеры) или сетевые адаптеры , иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры (см. рис.3.2). Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами. Используются два варианта работы операционной системы (ОС) на машинах MPP -архитектуры. В одном полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно.

Рис. 3.2.
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость : в отличие от SMP -систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти , в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (