Analiza e regresionit në Microsoft Excel është udhëzuesi më gjithëpërfshirës për përdorimin e MS Excel për të zgjidhur problemet e analizës së regresionit në inteligjencën e biznesit. Konrad Carlberg shpjegon qartë çështjet teorike, njohja e të cilave do t'ju ndihmojë të shmangni shumë gabime si kur bëni vetë analizën e regresionit, ashtu edhe kur vlerësoni rezultatet e analizave të kryera nga njerëz të tjerë. I gjithë materiali, nga korrelacionet e thjeshta dhe t-testet deri tek analiza e shumëfishtë e kovariancës, bazohet në shembuj realë dhe shoqërohet me një përshkrim të detajuar të procedurave përkatëse hap pas hapi.
Ky libër diskuton hollësitë dhe rezultatet e funksioneve të regresionit të Excel-it, shqyrton implikimet e secilit opsion dhe çdo argumenti dhe shpjegon se si të zbatohen me besueshmëri teknikat e regresionit në fusha që variojnë nga kërkimi mjekësor deri tek analiza financiare.
Konrad Carlberg. Analiza e regresionit në Microsoft Excel. - M.: Dialektika, 2017. - 400 f.
Shkarkoni shënimin në ose format, shembuj në format
Kapitulli 1. Vlerësimi i ndryshueshmërisë së të dhënave
Statisticienët kanë në dispozicion shumë tregues të variacionit (ndryshueshmërisë). Një prej tyre është shuma e devijimeve në katror të vlerave individuale nga mesatarja. Excel përdor funksionin SQUADROT() për këtë. Por më shpesh përdoret dispersioni. Varianca është mesatarja e katrorëve të devijimeve. Varianca është e pandjeshme ndaj numrit të vlerave në grupin e të dhënave në studim (ndërsa shuma e devijimeve në katror rritet me numrin e matjeve).
Excel ofron dy funksione që kthejnë variancën: VARP.D() dhe VARP.V():
- Përdorni funksionin VAR.G() nëse vlerat që do të përpunohen formojnë një popullatë. Kjo do të thotë, vlerat e përmbajtura në gamë janë vlerat e vetme për të cilat ju interesojnë.
- Përdorni funksionin VAR.V() nëse vlerat që do të përpunohen formojnë një mostër nga një popullsi më e madhe. Supozon se ka vlera shtesë, variancën e të cilave mund ta vlerësoni gjithashtu.
Nëse një vlerë si mesatarja ose koeficienti i korrelacionit llogaritet në bazë të popullatës së përgjithshme, atëherë quhet parametër. Një vlerë e ngjashme e llogaritur në bazë të një kampioni quhet statistikë. Numërimi mbrapsht i devijimeve nga mesatarja në këtë grup, do të merrni shumën e devijimeve në katror të një sasie më të vogël sesa nëse do t'i numëronit nga ndonjë vlerë tjetër. Një deklaratë e ngjashme është e vërtetë për shpërndarjen.
Sa më e madhe të jetë madhësia e kampionit, aq më e saktë është vlera e llogaritur e statistikës. Por nuk ka asnjë mostër më të vogël se madhësia e popullsisë për të cilën mund të jeni të sigurt se vlera e statistikës përputhet me vlerën e parametrit.
Le të themi se keni një grup prej 100 lartësish, mesatarja e të cilave ndryshon nga mesatarja e popullsisë, sado i vogël të jetë ndryshimi. Kur llogaritni variancën për kampionin, do të merrni një vlerë, të themi 4. Kjo vlerë është më e vogël se çdo vlerë tjetër që mund të merret duke llogaritur devijimin e secilës prej 100 vlerave të rritjes nga çdo vlerë tjetër përveç mostrës. mesatare, duke përfshirë mesataren e vërtetë për popullatën e përgjithshme. Prandaj, varianca e llogaritur do të ndryshojë, dhe në një masë më të vogël, nga varianca që do të merrnit nëse disi do ta dinit dhe do të përdornit jo mesataren e mostrës, por parametrin e popullsisë.
Shuma mesatare e katrorëve të përcaktuar për kampionin ofron një vlerësim më të ulët të variancës së popullatës. Varianca e llogaritur në këtë mënyrë quhet të zhvendosur vlerësimi. Rezulton se për të eliminuar paragjykimet dhe për të marrë një vlerësim të paanshëm, mjafton të pjesëtohet shuma e devijimeve në katror jo me n, ku nështë madhësia e kampionit, dhe n - 1.
Vlera n - 1 quhet numri (numri) i shkallëve të lirisë. Ka mënyra të ndryshme për të llogaritur këtë vlerë, megjithëse të gjitha ato përfshijnë ose zbritjen e një numri nga madhësia e kampionit ose numërimin e numrit të kategorive në të cilat përfshihen vëzhgimet.
Thelbi i ndryshimit midis funksioneve DISP.G() dhe DISP.V() është si më poshtë:
- Në funksionin VARI.G(), shuma e katrorëve pjesëtohet me numrin e vëzhgimeve dhe për këtë arsye paraqet vlerësimin e njëanshëm të variancës, mesataren e vërtetë.
- Në funksionin VAR.B(), shuma e katrorëve pjesëtohet me numrin e vëzhgimeve minus 1, d.m.th. nga numri i shkallëve të lirisë, i cili jep një vlerësim më të saktë dhe të paanshëm të variancës së popullatës nga e cila është nxjerrë kampioni.
devijimi standard (anglisht) devijimi standard, SD) është rrënja katrore e variancës:
Devijimet katrore e përkthen shkallën e matjes në një metrikë tjetër, e cila është katrori i asaj origjinale: metra - në metra katrorë, dollarë - në dollarë katrorë, etj. Devijimi standard është rrënja katrore e variancës, dhe kështu na kthen në njësitë origjinale. Cili është më i përshtatshëm.
Shpesh është e nevojshme të llogaritet devijimi standard pasi të dhënat i janë nënshtruar disa manipulimeve. Dhe megjithëse në këto raste rezultatet janë padyshim devijime standarde, ato zakonisht quhen gabimet standarde. Ekzistojnë disa lloje të gabimeve standarde, duke përfshirë gabimin standard të matjes, gabimin standard të proporcionit dhe gabimin standard të mesatares.
Le të themi se mbledhni të dhëna për gjatësinë e 25 meshkujve të rritur të zgjedhur rastësisht në secilin prej 50 shteteve. Më pas, ju llogaritni gjatësinë mesatare të meshkujve të rritur në çdo shtet. 50 vlerat mesatare që rezultojnë mund të konsiderohen si vëzhgime. Nga kjo, ju mund të llogarisni devijimin standard të tyre, që është gabim standard i mesatares. Oriz. 1. ju lejon të krahasoni shpërndarjen e 1250 vlerave origjinale individuale (të dhëna për lartësinë e 25 burrave në secilin nga 50 shtetet) me shpërndarjen e vlerave mesatare prej 50 shtetesh. Formula për vlerësimin e gabimit standard të mesatares (d.m.th. devijimi standard i mesatares, jo vëzhgime individuale):
![]()
ku është gabimi standard i mesatares; sështë devijimi standard i vëzhgimeve origjinale; nështë numri i vëzhgimeve në kampion.

Oriz. 1. Ndryshimi në vlerat mesatare nga shteti në shtet është shumë më i vogël se ndryshimi i vëzhgimeve individuale
Ekziston një konventë në statistika në lidhje me përdorimin e shkronjave greke dhe latine për të treguar sasitë statistikore. Është e zakonshme të përcaktohen parametrat e popullsisë së përgjithshme me shkronja greke dhe statistikat e mostrës me shkronja latine. Prandaj, nëse flasim për devijimin standard të popullatës, e shkruajmë si σ; nëse merret parasysh devijimi standard i mostrës, atëherë përdorim shënimin s. Sa i përket simboleve për mesataret, ato nuk përputhen aq mirë me njëri-tjetrin. Mesatarja e popullsisë shënohet me shkronjën greke μ. Megjithatë, simboli X̅ përdoret tradicionalisht për të përfaqësuar mesataren e mostrës.
z-rezultati shpreh pozicionin e vëzhgimit në shpërndarjen në njësi të devijimit standard. Për shembull, z = 1.5 do të thotë që vëzhgimi është 1.5 devijime standarde larg mesatares, drejt vlerave më të larta. Afati z-rezultati përdoret për vlerësime individuale, d.m.th. për matjet që i atribuohen elementeve individuale të kampionit. Për statistika të tilla (p.sh., mesatarja e shtetit), përdoret termi. z-vlera:

ku X̅ është vlera mesatare e kampionit, μ është vlera mesatare e popullatës së përgjithshme, është gabimi standard i mesatareve të grupit të mostrave:
![]()
ku σ është gabimi standard i popullatës së përgjithshme (matjet individuale), nështë madhësia e kampionit.
Supozoni se jeni një instruktor golfi. Ju keni qenë në gjendje të matni diapazonin e goditjes për një kohë të gjatë dhe e dini se mesatarja është 205 jardë dhe devijimi standard është 36 jard. Ju është ofruar një klub i ri, duke pretenduar se do të rrisë gamën tuaj me 10 jard. Ju i kërkoni secilit nga 81 vizitorët e ardhshëm të klubit të provojnë me një klub të ri dhe të regjistrojnë gamën e tyre. Doli se diapazoni mesatar i një goditjeje me një klub të ri është 215 jard. Sa është probabiliteti që një diferencë prej 10 jardësh (215 - 205) të jetë për shkak të gabimit të kampionimit? Ose për ta thënë ndryshe, sa është probabiliteti që, në një provë më të madhe, një klub i ri nuk do të shfaqë një rritje në distancë krahasuar me mesataren aktuale afatgjatë prej 205 jardësh?
Ne mund ta testojmë këtë duke gjeneruar një vlerë z. Gabim standard i mesatares:
![]()
Pastaj vlera z:

Duhet të gjejmë probabilitetin që mesatarja e kampionit të jetë 2.5σ larg mesatares së popullatës. Nëse probabiliteti është i vogël, atëherë diferencat nuk janë për shkak të rastësisë, por të cilësisë së klubit të ri. Nuk ka asnjë funksion të gatshëm në Excel për të përcaktuar probabilitetin e një rezultati z. Megjithatë, mund të përdorni formulën =1-NORM.ST.DIST(z-vlera, TRUE), ku NORM.ST.DIST() kthen zonën nën kurbën normale në të majtë të vlerës z (Figura 2) .

Oriz. 2. Funksioni NORM.S.DIST() kthen zonën nën kurbë në të majtë të vlerës z; Për të zmadhuar një imazh, klikoni me të djathtën mbi të dhe zgjidhni Hapni imazhin në skedën e re
Argumenti i dytë i funksionit NORM.S.DIST() mund të marrë dy vlera: TRUE - funksioni kthen zonën nën kurbë në të majtë të pikës së specifikuar nga argumenti i parë; FALSE - Funksioni kthen lartësinë e kurbës në pikën e dhënë nga argumenti i parë.
Nëse mesatarja (μ) dhe devijimi standard (σ) i popullatës nuk dihen, përdoret vlera t (shih). Strukturat e rezultateve z dhe t ndryshojnë në atë që devijimi standard s i marrë nga rezultatet e mostrës përdoret për të gjetur vlerën t, në vend të vlerës së njohur të parametrit të popullatës σ. Kurba normale ka një formë të vetme, dhe forma e shpërndarjes së vlerave t ndryshon në varësi të numrit të shkallëve të lirisë df (nga anglishtja. shkallët e lirisë) të kampionit që përfaqëson. Numri i shkallëve të lirisë së kampionit është n - 1, ku n- madhësia e mostrës (Fig. 3).

Oriz. 3. Forma e shpërndarjeve t që lindin kur parametri σ është i panjohur ndryshon nga forma e shpërndarjes normale.
Excel ka dy funksione për shpërndarjen t, të quajtur edhe shpërndarje t Studentit: STUDENT.DIST() kthen zonën nën kurbë në të majtë të vlerës së dhënë t dhe STUDENT.DIST.Tx() në të djathtë.
Kapitulli 2. Korrelacioni
Korrelacioni është një masë e varësisë midis elementeve të një grupi çiftesh të renditura. Korrelacioni karakterizohet Koeficientët e korrelacionit të Pearson– r. Koeficienti mund të marrë vlera në rangun nga -1.0 në +1.0.

ku S x dhe Sy janë devijimet standarde të variablave X dhe Y, Sxy- kovarianca:

Në këtë formulë, kovarianca ndahet me devijimet standarde të variablave X dhe Y, duke hequr kështu efektet e shkallëzimit të lidhura me njësinë nga kovarianca. Excel përdor funksionin CORREL(). Emri i këtij funksioni nuk përmban elementët kualifikues G dhe C, të cilët përdoren në emrat e funksioneve si STDEV(), VARV(), ose COVARIANCE(). Megjithëse koeficienti i korrelacionit të mostrës ofron një vlerësim të njëanshëm, arsyeja e paragjykimit është e ndryshme sesa në rastin e variancës ose devijimit standard.
Në varësi të madhësisë së koeficientit të korrelacionit të përgjithshëm (shpesh shënohet me shkronjën greke ρ ), koeficienti i korrelacionit r jep një vlerësim të njëanshëm, me efektin e njëanshmërisë që rritet me zvogëlimin e madhësisë së kampionit. Sidoqoftë, ne nuk përpiqemi ta korrigjojmë këtë paragjykim në të njëjtën mënyrë siç, për shembull, e bëmë kur llogaritëm devijimin standard, kur zëvendësuam jo numrin e vëzhgimeve, por numrin e shkallëve të lirisë në formulën përkatëse. Në realitet, numri i vëzhgimeve të përdorura për të llogaritur kovariancën nuk ka asnjë efekt në madhësinë.
Koeficienti standard i korrelacionit është projektuar për t'u përdorur me variabla që lidhen me njëra-tjetrën nga një marrëdhënie lineare. Prania e jolinearitetit dhe / ose gabimeve në të dhëna (të jashtme) çon në një llogaritje të gabuar të koeficientit të korrelacionit. Grafikat e shpërndarjes rekomandohen për diagnostikimin e problemeve të të dhënave. Ky është i vetmi lloj grafiku në Excel që trajton boshtet horizontale dhe vertikale si boshte vlerash. Grafiku i linjës, nga ana tjetër, përcakton njërën nga kolonat si bosht të kategorisë, i cili shtrembëron pamjen e të dhënave (Fig. 4).

Oriz. 4. Vijat e regresionit duken të njëjta, por krahasoni ekuacionet e tyre me njëra-tjetrën
Vëzhgimet e përdorura për të ndërtuar grafikun e vijës janë të barabarta përgjatë boshtit horizontal. Etiketat e ndarjes përgjatë këtij boshti janë vetëm etiketa, jo vlera numerike.
Ndërsa korrelacioni shpesh nënkupton se ekziston një marrëdhënie shkakësore, ajo nuk mund të përdoret si provë që është. Statistikat nuk përdoren për të demonstruar nëse një teori është e vërtetë apo e rreme. Për të përjashtuar shpjegimet konkurruese të rezultateve të vëzhgimeve të vendosura eksperimentet e planifikuara. Statistikat përdoren gjithashtu për të përmbledhur informacionin e mbledhur gjatë eksperimenteve të tilla dhe për të përcaktuar mundësinë që vendimi të jetë i gabuar duke pasur parasysh bazën e provave.
Kapitulli 3 Regresioni i thjeshtë
Nëse dy ndryshore janë të lidhura, të tilla që vlera e koeficientit të korrelacionit është më e madhe se, le të themi, 0.5, atëherë është e mundur të parashikohet (me njëfarë saktësie) vlera e panjohur e njërës ndryshore nga vlera e njohur e tjetrës. Për të marrë vlerat e parashikuara të çmimit, bazuar në të dhënat e dhëna në fig. 5, ju mund të përdorni ndonjë nga disa mënyra të mundshme, por pothuajse me siguri nuk do të përdorni atë të treguar në fig. 5. Megjithatë, duhet ta lexoni, sepse asnjë mënyrë tjetër nuk ju lejon të demonstroni marrëdhënien midis korrelacionit dhe parashikimit aq qartë sa kjo. Në fig. 5, në rangun B2:C12, është një kampion i rastësishëm prej dhjetë shtëpish dhe ofron të dhëna për sipërfaqen e secilës shtëpi (në metra katrorë) dhe çmimin e shitjes së saj.

Oriz. 5. Parashikimet e çmimeve të shitjes formojnë një vijë të drejtë
Gjeni mesataren, devijimet standarde dhe koeficientin e korrelacionit (vargu A14:C18). Llogaritni pikët z të zonës (E2:E12). Për shembull, qeliza E3 përmban formulën: =(B3-$B$14)/$B$15. Llogaritni z-rezultatet e çmimit të parashikuar (F2:F12). Për shembull, qeliza F3 përmban formulën: =E3*$B$18. Konvertoni rezultatet z në çmimet e dollarit (H2:H12). Në qelizën HZ, formula është: =F3*$C$15+$C$14.
Vini re se vlera e parashikuar gjithmonë tenton të zhvendoset drejt mesatares së 0. Sa më afër zeros të jetë koeficienti i korrelacionit, aq më afër zeros është z-rezultati i parashikuar. Në shembullin tonë, koeficienti i korrelacionit ndërmjet sipërfaqes dhe çmimit të shitjes është 0,67, dhe çmimi i parashikuar është 1,0*0,67, d.m.th. 0,67. Kjo korrespondon me një tejkalim të vlerës mbi vlerën mesatare, e barabartë me dy të tretat e devijimit standard. Nëse koeficienti i korrelacionit do të ishte i barabartë me 0,5, atëherë çmimi i parashikuar do të ishte 1,0 * 0,5, d.m.th. 0.5. Kjo korrespondon me një tejkalim të vlerës mbi vlerën mesatare, e barabartë me vetëm gjysmën e devijimit standard. Sa herë që vlera e koeficientit të korrelacionit ndryshon nga idealja, d.m.th. më i madh se -1.0 dhe më pak se 1.0, vlerësimi i variablit parashikues duhet të jetë më afër vlerës së tij mesatare sesa vlerësimi i variablit parashikues (i pavarur) me të tijën. Ky fenomen quhet regresion në mesatare, ose thjesht regresion.
Ekzistojnë disa funksione në Excel për të përcaktuar koeficientët e ekuacionit të linjës së regresionit (në Excel quhet linjë trendi) y=kx + b. Për përcaktimin k shërben funksionin
=SLOPE (vlera_y-të njohura; vlerat e njohura-x)
Këtu nëështë variabli i parashikuar, dhe Xështë një variabël i pavarur. Ju duhet të ndiqni rreptësisht këtë renditje të variablave. Pjerrësia e vijës së regresionit, koeficienti i korrelacionit, devijimet standarde të variablave dhe kovarianca janë të lidhura ngushtë (Fig. 6). Funksioni INTERCEPT() kthen vlerën e prerë nga vija e regresionit në boshtin vertikal:
= INTERCUT (njohur_y-vlera; njohur_x-vlera)

Oriz. 6. Raporti ndërmjet devijimeve standarde konverton kovariancën në një koeficient korrelacioni dhe pjerrësinë e vijës së regresionit
Vini re se numri i vlerave x dhe y të dhëna për funksionet SLOPE() dhe INTERCEPT() si argumente duhet të jetë i njëjtë.
Në analizën e regresionit, përdoret një tregues tjetër i rëndësishëm - R 2 (R-katror), ose koeficienti i përcaktimit. Ai përcakton se çfarë kontributi në ndryshueshmërinë e përgjithshme të të dhënave jepet nga marrëdhënia ndërmjet X dhe në. Excel ka funksionin QVPIRSON() për të, i cili merr saktësisht të njëjtat argumente si funksioni CORREL().
Dy variabla me një koeficient korrelacioni jo zero mes tyre thuhet se shpjegojnë variancën ose kanë shpjeguar variancën. Në mënyrë tipike, varianca e shpjeguar shprehet si përqindje. Kështu që R 2 = 0.81 do të thotë se shpjegohet 81% e variancës (shpërndarjes) së dy variablave. 19% e mbetur janë për shkak të luhatjeve të rastësishme.
Excel ka një funksion TREND që thjeshton llogaritjet. Funksioni TREND():
- merr vlerat e njohura që ju jepni X dhe vlerat e njohura në;
- njehson pjerrësinë e vijës së regresionit dhe konstantes (segmentit);
- kthen vlerat parashikuese në përcaktohet duke zbatuar ekuacionin e regresionit në vlerat e njohura X(Fig. 7).
Funksioni TREND() është një funksion grupi (nëse nuk keni hasur në funksione të tilla më parë, ju rekomandoj).

Oriz. 7. Përdorimi i funksionit TREND() ju lejon të shpejtoni dhe thjeshtoni llogaritjet në krahasim me përdorimin e një çifti funksionesh SLOPE() dhe INTERCEPT()
Për të futur funksionin TREND() si formulë grupi në qelizat G3:G12, zgjidhni diapazonin G3:G12, futni formulën TREND (SZ:S12;VZ:B12), shtypni dhe mbani butonat
Funksioni TREND() ka dy argumente të tjera: vlerat e reja_x dhe konst. E para ju lejon të ndërtoni një parashikim për të ardhmen, dhe e dyta mund të detyrojë vijën e regresionit të kalojë përmes origjinës (Vlera TRUE i thotë Excel-it të përdorë konstanten e llogaritur, vlerën FALSE - konstante = 0). Excel ju lejon të vizatoni një vijë regresioni në një grafik në mënyrë që të kalojë përmes origjinës. Filloni duke vizatuar një grafik shpërndarjeje, më pas kliko me të djathtën në një nga shënuesit e serisë së të dhënave. Zgjidhni artikullin në menynë e kontekstit që hapet. Shtoni linjën e trendit; zgjidhni një opsion Linear; nëse është e nevojshme, lëvizni poshtë panelit, kontrolloni kutinë Vendosni një kryqëzim; sigurohuni që kutia e tekstit të lidhur me të është vendosur në 0.0.
Nëse keni tre variabla dhe dëshironi të përcaktoni korrelacionin midis dy prej tyre duke përjashtuar ndikimin e të tretës, mund të përdorni korrelacion i pjesshëm. Supozoni se jeni të interesuar në lidhjen midis përqindjes së banorëve të qytetit që kanë përfunduar fakultetin dhe numrit të librave në bibliotekat e qytetit. Ju keni mbledhur të dhëna për 50 qytete, por... Problemi është se të dy këta parametra mund të varen nga mirëqenia e banorëve të një qyteti të caktuar. Sigurisht, është shumë e vështirë të gjesh 50 qytete të tjera të karakterizuara nga saktësisht i njëjti nivel mirëqenieje të banorëve.
Duke aplikuar metoda statistikore për të hequr ndikimin e pasurisë si në mbështetjen e bibliotekës ashtu edhe në arsimin universitar, ju mund të përcaktoni më mirë marrëdhënien midis variablave që ju interesojnë, përkatësisht numrit të librave dhe numrit të të diplomuarve. Ky korrelacion i kushtëzuar midis dy variablave, kur vlerat e ndryshoreve të tjera janë fikse, quhet korrelacion i pjesshëm. Një mënyrë për ta llogaritur atë është përdorimi i ekuacionit:

ku rCB . W- koeficienti i korrelacionit ndërmjet variablave Kolegj (Kolegj) dhe Libra (Libra) me ndikimin e përjashtuar (vlera fikse) të variablës Pasuria (Pasuria); rCB- koeficienti i korrelacionit ndërmjet variablave Kolegj dhe Libra; rCW- koeficienti i korrelacionit ndërmjet variablave Kolegj dhe Mirëqenie; rb.w.- koeficienti i korrelacionit ndërmjet variablave Libra dhe Mirëqenie.
Nga ana tjetër, korrelacioni i pjesshëm mund të llogaritet në bazë të analizës së mbetur, d.m.th. dallimet midis vlerave të parashikuara dhe vëzhgimeve aktuale të lidhura me to (të dyja metodat janë paraqitur në Figurën 8).

Oriz. 8. Korrelacioni i pjesshëm si korrelacion i mbetur
Për të thjeshtuar llogaritjen e matricës së koeficientëve të korrelacionit (B16: E19), përdorni paketën e analizës Excel (menuja Të dhënat –> Analiza –> Analiza e të dhënave). Si parazgjedhje, kjo paketë nuk është aktive në Excel. Për ta instaluar, kaloni nëpër menu Skedari –> Opsione –> shtesa. Në fund të dritares që hapet Opsioneshkëlqejnë gjeni fushën Kontrolli, zgjidhni shtesashkëlqejnë, kliko Shkoni. Kontrolloni kutinë pranë shtesës Paketa e analizës. Klikoni A analiza e të dhënave, zgjidhni një opsion Korrelacioni. Specifikoni $B$2:$D$13 si intervalin e hyrjes, kontrolloni kutinë Etiketat në rreshtin e parë, specifikoni $B$16:$E$19 si intervalin e daljes.
Një mundësi tjetër është të përcaktohet një korrelacion gjysmë i pjesshëm. Për shembull, ju po hulumtoni efektin e gjatësisë dhe moshës në peshë. Pra, ju keni dy variabla parashikues, gjatësinë dhe moshën, dhe një variabël parashikues, peshën. Ju dëshironi të përjashtoni ndikimin e një ndryshoreje parashikuese në një tjetër, por jo në variablin parashikues:
![]()
ku H - Lartësia (Lartësia), W - Pesha (Pesha), A - Mosha (Mosha); Indeksi i koeficientit të korrelacionit gjysmë të pjesshëm përdor kllapa për të treguar se cila variabël po eliminohet dhe nga cila variabël. Në këtë rast, shënimi W(H.A) tregon se efekti i ndryshores Age hiqet nga ndryshorja Height, por jo nga ndryshorja Pesha.
Mund të krijohet përshtypja se çështja në diskutim nuk ka ndonjë rëndësi të madhe. Në fund të fundit, gjëja më e rëndësishme është se sa saktë funksionon ekuacioni i përgjithshëm i regresionit, ndërsa problemi i kontributeve relative të variablave individualë në variancën totale të shpjeguar duket se është dytësor. Megjithatë, ky nuk është rasti. Sapo filloni të mendoni nëse do të përdorni apo jo ndonjë variabël në ekuacionin e regresionit të shumëfishtë, çështja bëhet e rëndësishme. Mund të ndikojë në vlerësimin e korrektësisë së zgjedhjes së modelit për analizë.
Kapitulli 4. Funksioni LINEST().
Funksioni LINEST() kthen 10 statistika të analizës së regresionit. Funksioni LINEST() është një funksion vargu. Për ta futur atë, zgjidhni një gamë që përmban pesë rreshta dhe dy kolona, shkruani formulën dhe shtypni
LINEST(B2:B21,A2:A21,E VËRTETË, E VËRTETË)

Oriz. 9. Funksioni LINEST(): a) zgjidhni diapazonin D2:E6, b) vendosni formulën siç tregohet në shiritin e formulave, c) klikoni
Funksioni LINEST() kthen:
- koeficienti i regresionit (ose pjerrësia, qeliza D2);
- segment (ose konstante, qeliza E3);
- gabimet standarde të koeficientit dhe konstanteve të regresionit (vargu D3:E3);
- koeficienti i përcaktimit R2 për regresion (qeliza D4);
- gabim standard i vlerësimit (qeliza E4);
- F-test për regresion të plotë (qeliza D5);
- numri i shkallëve të lirisë për shumën e mbetur të katrorëve (qeliza E5);
- shuma e regresionit të katrorëve (qeliza D6);
- shuma e mbetur e katrorëve (qeliza E6).
Le të shohim secilën nga këto statistika dhe ndërveprimet e tyre.
gabim standard në rastin tonë, ky është devijimi standard i llogaritur për gabimet e kampionimit. Kjo do të thotë, kjo është një situatë ku popullata e përgjithshme ka një statistikë, dhe kampioni ka një tjetër. Pjestimi i koeficientit të regresionit me gabimin standard ju jep një vlerë prej 2.092/0.818 = 2.559. Me fjalë të tjera, një koeficient regresioni prej 2.092 është dy gabime e gjysmë standarde larg zeros.
Nëse koeficienti i regresionit është zero, atëherë vlerësimi më i mirë i variablit të parashikuar është mesatarja e tij. Dy gabime standarde e gjysmë janë një numër mjaft i madh dhe mund të supozoni me siguri se koeficienti i regresionit për popullatën ka një vlerë jo zero.
Ju mund të përcaktoni probabilitetin e marrjes së një koeficienti të regresionit të mostrës prej 2,092 nëse vlera e tij aktuale në popullatë është 0,0 duke përdorur funksionin
STUDENT.DIST.PH (t-test = 2.559; numri i shkallëve të lirisë = 18)
Në përgjithësi, numri i shkallëve të lirisë = n - k - 1, ku n është numri i vëzhgimeve dhe k është numri i variablave parashikues.
Kjo formulë kthen një vlerë prej 0,00987, ose e rrumbullakosur deri në 1%. Ai na tregon si më poshtë: nëse koeficienti i regresionit për popullatën është 0%, atëherë probabiliteti për të marrë një kampion prej 20 personash për të cilin vlera e llogaritur e koeficientit të regresionit është 2.092 është një 1% modeste.
F-testi (qeliza D5 në figurën 9) kryen të njëjtin funksion në lidhje me një regresion të plotë si testi t në lidhje me koeficientin e regresionit të thjeshtë çift. Testi F përdoret për të testuar nëse koeficienti i përcaktimit R 2 për regresionin është me të vërtetë mjaft i madh për të hedhur poshtë hipotezën se ai ka një vlerë prej 0.0 në popullatë, e cila tregon mungesën e variancës të shpjeguar nga variabli parashikues dhe parashikues. . Kur ka vetëm një ndryshore parashikuese, testi F është saktësisht i barabartë me katrorin e testit t.
Deri më tani, ne kemi marrë në konsideratë variablat e intervalit. Nëse keni variabla që mund të marrin vlera të shumta që janë emra të thjeshtë, si Burri dhe Gruaja ose Zvarraniku, Amfib dhe Peshku, përfaqësojini ato si një kod numerik. Variabla të tillë quhen nominale.
Statistikat e R2 kuantifikon proporcionin e variancës së shpjeguar.
Gabimi standard i vlerësimit. Në fig. Tabela 4.9 tregon vlerat e parashikuara të ndryshores Pesha, të marra në bazë të marrëdhënies së saj me variablin Height. Gama E2:E21 përmban vlerat e mbetjeve për variablin Pesha. Më saktësisht, këto mbetje quhen gabime - prandaj vijon termi gabim standard i vlerësimit.

Oriz. 10. Si R2 ashtu edhe gabimi standard i vlerësimit shprehin saktësinë e parashikimeve të marra duke përdorur regresionin
Sa më i vogël të jetë gabimi standard i vlerësimit, aq më i saktë është ekuacioni i regresionit dhe aq më afër prisni që çdo parashikim nga ekuacioni të përputhet me vëzhgimin aktual. Gabimi standard i vlerësimit ofron një mënyrë për të përcaktuar sasinë e këtyre pritjeve. Pesha e 95% e njerëzve me një gjatësi të caktuar do të jetë në intervalin:
(lartësia * 2,092 - 3,591) ± 2,092 * 21,118
F-statistikaështë raporti i variancës ndërgrupore me variancën brendagrupore. Ky emër u prezantua nga statisticieni George Snedecor për nder të Sir, i cili zhvilloi analizën e variancës (ANOVA, Analysis of Variance) në fillim të shekullit të 20-të.
Koeficienti i përcaktimit R 2 shpreh proporcionin e shumës totale të katrorëve të lidhur me regresionin. Vlera (1 - R 2) shpreh proporcionin e shumës totale të katrorëve të lidhur me mbetjet - gabimet e parashikimit. Testi F mund të merret duke përdorur funksionin LINEST (qeliza F5 në Fig. 11), duke përdorur shumat e katrorëve (varg G10:J11), duke përdorur fraksionet e variancës (varg G14:J15). Formulat mund të studiohen në skedarin e bashkangjitur Excel.

Oriz. 11. Llogaritja e kriterit F
Kur përdoren variabla nominale, përdoret kodimi dummy (Fig. 12). Për të koduar vlerat, është e përshtatshme të përdoren vlerat 0 dhe 1. Probabiliteti F llogaritet duke përdorur funksionin:
F.DIST.PH(K2;I2;I3)
Këtu, funksioni F.DIST.RT() kthen probabilitetin e marrjes së një testi F pas shpërndarjes qendrore F (Fig. 13) për dy grupe të dhënash me shkallët e lirisë të dhëna në qelizat I2 dhe I3, vlera e e cila është e njëjtë me vlerën e dhënë në qelizën K2.

Oriz. 12. Analiza e regresionit duke përdorur variablat dummy

Oriz. 13. Shpërndarja F qendrore për λ = 0
Kapitulli 5 Regresioni i shumëfishtë
Kur kaloni nga një regresion i thjeshtë në çift me një ndryshore parashikuese në një regresion të shumëfishtë, ju shtoni një ose më shumë variabla parashikues. Ruani vlerat e variablave parashikues në kolonat ngjitur, si kolonat A dhe B për dy parashikues, ose A, B dhe C për tre parashikues. Përpara se të futni një formulë që përfshin funksionin LINEST(), zgjidhni pesë rreshta dhe aq kolona sa ka variabla parashikues, plus një tjetër për një konstante. Në rastin e regresionit me dy ndryshore parashikuese, mund të përdoret struktura e mëposhtme:
LINEST(A2: A41; B2: C41;; E VËRTETË)
Në mënyrë të ngjashme, në rastin e tre variablave:
LINEST(A2:A61;B2:D61;;E VËRTETË)
Le të themi se dëshironi të studioni efektin e mundshëm të moshës dhe dietës në nivelet e LDL, lipoproteinat me densitet të ulët që mendohet se janë përgjegjëse për formimin e pllakave aterosklerotike që shkaktojnë aterotrombozë (Figura 14).

Oriz. 14. Regresioni i shumëfishtë
R 2 i regresionit të shumëfishtë (i treguar në qelizën F13) është më i madh se R 2 i çdo regresioni të thjeshtë (E4, H4). Regresioni i shumëfishtë përdor variabla të shumta parashikuese në të njëjtën kohë. Në këtë rast, R 2 pothuajse gjithmonë rritet.
Për çdo ekuacion të thjeshtë të regresionit linear me një variabël parashikues, gjithmonë do të ketë një korrelacion të përsosur midis vlerave të parashikuesit dhe vlerave të ndryshores parashikuese, pasi në një ekuacion të tillë vlerat e parashikuesit shumëzohen me një konstante dhe çdo produkt i shtohet një konstante tjetër. Ky efekt nuk ruhet në regresion të shumëfishtë.
Shfaqja e rezultateve të kthyera nga LINEST() për regresion të shumëfishtë (Figura 15). Koeficientët e regresionit shfaqen si pjesë e rezultateve të kthyera nga LINEST() në rend të kundërt të variablave(G–H–I korrespondon me C–B–A).

Oriz. 15. Koeficientët dhe gabimet standarde të tyre shfaqen në rend të kundërt në fletën e punës.
Parimet dhe procedurat e përdorura në analizën e regresionit me një ndryshore të vetme parashikuese përshtaten lehtësisht për të llogaritur variabla të shumëfishta parashikuese. Rezulton se shumë nga kjo përshtatje varet nga eliminimi i ndikimit të variablave parashikues mbi njëri-tjetrin. Kjo e fundit shoqërohet me korrelacione private dhe gjysmë private (Fig. 16).

Oriz. 16. Regresioni i shumëfishtë mund të shprehet përmes regresionit në çift të mbetjeve (shih formulat në skedarin Excel)
Në Excel, ka funksione që ofrojnë informacion në lidhje me shpërndarjet t- dhe F. Funksionet emrat e të cilëve përfshijnë një pjesë DIST, si STUDENT.DIST() dhe F.DIST(), marrin një test t- ose F si argument dhe kthejnë probabilitetin e vëzhgimit të vlerës së specifikuar. Funksionet emrat e të cilëve përfshijnë një pjesë OBR, si STUDENT.INV() dhe F.INV(), marrin një vlerë probabiliteti si argument dhe kthejnë një vlerë kriteri që korrespondon me probabilitetin e specifikuar.
Meqenëse ne jemi duke kërkuar për vlera kritike të shpërndarjes t që prenë skajet e rajoneve të bishtit të saj, ne kalojmë 5% si argument në një nga funksionet STUDENT.INV(), i cili kthen një vlerë që korrespondon me këtë probabilitet. (Fig. 17, 18).

Oriz. 17. T-test me dy bisht

Oriz. 18. T-test me një bisht
Duke vendosur një rregull vendimi në rastin e një rajoni alfa me një bisht, ju rritni fuqinë statistikore të testit. Nëse, kur filloni eksperimentin tuaj, jeni të sigurt se keni çdo arsye për të pritur një koeficient regresioni pozitiv (ose negativ), atëherë duhet të kryeni një test me një bisht. Në këtë rast, probabiliteti që ju të merrni vendimin e duhur, duke hedhur poshtë hipotezën e një koeficienti regresioni zero në popullatë, do të jetë më i lartë.
Statisticienët preferojnë të përdorin termin test i drejtuar në vend të termit test me bisht të vetëm dhe afati test i padrejtuar në vend të termit test me dy bisht. Termat e drejtuar dhe jo-drejtues janë të preferueshëm sepse theksojnë llojin e hipotezës sesa natyrën e bishtave të shpërndarjes.
Një qasje për vlerësimin e ndikimit të parashikuesve bazuar në krahasimin e modeleve. Në fig. 19 tregon rezultatet e një analize regresioni që teston kontributin e variablit Diet në ekuacionin e regresionit.

Oriz. 19. Krahasimi i dy modeleve duke kontrolluar ndryshimet në rezultatet e tyre
Rezultatet e LINEST() (varg H2:K6) lidhen me atë që unë e quaj modeli i plotë, i cili regreson variablin LDL në dietë, moshë dhe HDL. Në diapazonin H9:J13, llogaritjet paraqiten pa marrë parasysh variablin parashikues Diet. Unë e quaj atë modeli i kufizuar. Në modelin e plotë, 49.2% e variancës në variablin e varur LDL shpjegohet nga variablat parashikues. Në modelin e kufizuar, vetëm 30.8% e LDL shpjegohet nga Mosha dhe HDL. Humbja e R 2 për shkak të përjashtimit të variablit Diet nga modeli është 0.183. Në intervalin G15:L17, janë bërë llogaritjet që tregojnë se vetëm me një probabilitet prej 0,0288 ndikimi i ndryshores Diet është i rastësishëm. Në pjesën e mbetur prej 97.1%, dieta ka një efekt në LDL.
Kapitulli 6. Supozimet dhe vërejtjet në lidhje me analizën e regresionit
Termi "supozim" nuk është i përcaktuar në mënyrë strikte, dhe mënyra se si përdoret sugjeron që nëse supozimi nuk përmbushet, atëherë rezultatet e të gjithë analizës janë të paktën të dyshimta ose ndoshta të pavlefshme. Në fakt, nuk është kështu, megjithëse sigurisht që ka raste kur shkelja e supozimit ndryshon rrënjësisht pamjen. Supozimet kryesore janë: a) mbetjet e ndryshores Y zakonisht shpërndahen në çdo pikë në X përgjatë vijës së regresionit; b) Vlerat Y varen në mënyrë lineare nga vlerat X; c) varianca e mbetjeve është afërsisht e njëjtë në secilën pikë X; d) nuk ka lidhje midis mbetjeve.
Nëse supozimet nuk luajnë një rol të rëndësishëm, statisticienët flasin për qëndrueshmërinë e analizës në lidhje me shkeljen e supozimit. Në veçanti, kur përdorni regresionin për të testuar dallimet midis mesatareve të grupit, supozimi se vlerat Y - dhe rrjedhimisht mbetjet - shpërndahen normalisht, nuk luan një rol të rëndësishëm: testet janë të forta në lidhje me shkeljen e supozimi i normalitetit. Është e rëndësishme të analizohen të dhënat duke përdorur grafikët. Për shembull, i përfshirë në shtesë Analiza e të dhënave mjet Regresioni.
Nëse të dhënat nuk përputhen me supozimet e regresionit linear, ka qasje të tjera jolineare në dispozicionin tuaj. Një prej tyre është regresioni logjistik (Fig. 20). Pranë kufirit të sipërm dhe të poshtëm të ndryshores parashikuese, regresioni linear rezulton në parashikime joreale.

Oriz. 20. Regresioni logjistik
Në fig. Figura 6.8 tregon rezultatet e dy metodave të analizës së të dhënave që synojnë të hetojnë lidhjen midis të ardhurave vjetore dhe gjasave për të blerë një shtëpi. Natyrisht, probabiliteti për të bërë një blerje do të rritet me rritjen e të ardhurave. Grafikët e bëjnë të lehtë identifikimin e dallimeve midis rezultateve që parashikojnë gjasat për të blerë një shtëpi përmes regresionit linear dhe rezultateve që mund të merrni duke përdorur një qasje të ndryshme.
Në gjuhën statistikore, refuzimi i hipotezës zero kur ajo është në fakt e vërtetë quhet gabim i tipit I.
Në shtesën Analiza e të dhënave ofron një mjet të dobishëm për gjenerimin e numrave të rastësishëm, duke i lejuar përdoruesit të specifikojë formën e dëshiruar të shpërndarjes (për shembull, Normal, Binomial ose Poisson), si dhe devijimin mesatar dhe standard.
Dallimet midis funksioneve të familjes STUDENT.DIST(). Duke filluar me Excel 2010, janë të disponueshme tre forma të ndryshme të një funksioni që kthejnë fraksionin e një shpërndarjeje majtas dhe/ose djathtas të një vlere të dhënë të testit t. Funksioni STUDENT.DIST() kthen proporcionin e zonës nën kurbën e shpërndarjes në të majtë të vlerës së testit t që specifikoni. Le të themi se keni 36 vëzhgime, kështu që numri i shkallëve të lirisë për të analizuar është 34 dhe vlera e testit t është 1,69. Në këtë rast, formula
STUDENT.DIST(+1,69;34; E VËRTETË)
kthen një vlerë prej 0.05, ose 5% (Figura 21). Argumenti i tretë për STUDENT.DIST() mund të jetë TRUE ose FALSE. Nëse vendoset në TRUE, funksioni kthen zonën kumulative nën lakore në të majtë të testit t të dhënë, të shprehur si fraksion. Nëse është FALSE, funksioni kthen lartësinë relative të kurbës në pikën që korrespondon me testin t. Versione të tjera të funksionit STUDENT.DIST() - STUDENT.DIST.PX() dhe STUDENT.DIST.2X() - marrin vetëm vlerën e testit t dhe numrin e shkallëve të lirisë si argumente dhe nuk kërkojnë një argument të tretë .

Oriz. 21. Zona me hije më të errët në bishtin e majtë të shpërndarjes korrespondon me proporcionin e zonës nën kurbë në të majtë të vlerës së madhe pozitive të testit t.
Për të përcaktuar zonën në të djathtë të testit t, përdorni një nga formulat:
1 - STUDENT.DIST (1, 69; 34; E VËRTETË)
STUDENT.DIST.PH(1.69;34)
Sipërfaqja totale nën kurbë duhet të jetë 100%, kështu që zbritja nga 1 e fraksionit të sipërfaqes në të majtë të vlerës së testit t të kthyer nga funksioni jep fraksionin e sipërfaqes në të djathtë të vlerës së testit t. Ju mund ta gjeni të preferueshme që të merrni drejtpërdrejt proporcionin e zonës që ju intereson duke përdorur funksionin STUDENT.DIST.RH(), ku RH nënkupton bishtin e djathtë të shpërndarjes (Fig. 22).

Oriz. 22. 5% sipërfaqe alfa për testin e drejtimit
Përdorimi i funksioneve STUDENT.DIST() ose STUDENT.DIST.PH() nënkupton që ju keni zgjedhur një hipotezë pune të drejtuar. Hipoteza e punës me drejtim, e kombinuar me vendosjen e vlerës alfa në 5%, do të thotë që ju vendosni të gjitha 5% në bishtin e djathtë të shpërndarjeve. Ju do të duhet të refuzoni hipotezën zero vetëm nëse probabiliteti që vlera juaj e testit t të merret është 5% ose më pak. Hipotezat e drejtimit zakonisht rezultojnë në teste statistikore më të ndjeshme (kjo ndjeshmëri më e madhe quhet edhe fuqi më e madhe statistikore).
Me një test të padrejtuar, vlera alfa mbetet në të njëjtin nivel 5%, por shpërndarja do të jetë e ndryshme. Për shkak se ju duhet të lejoni dy rezultate, probabiliteti i një pozitive false duhet të shpërndahet midis dy bishtave të shpërndarjes. Në përgjithësi pranohet që kjo probabilitet të shpërndahet në mënyrë të barabartë (Fig. 23).

Duke përdorur të njëjtën vlerë të fituar të testit t dhe të njëjtin numër shkallësh lirie si në shembullin e mëparshëm, përdorni formulën
STUDENT DIST.2X(1.69;34)
Pa ndonjë arsye të veçantë, funksioni STUDENT.DIST.2X() kthen kodin e gabimit #NUM! nëse i jepet një vlerë negative t-test si argument i parë.
Nëse mostrat përmbajnë numra të ndryshëm të dhënash, përdorni testin t-test me dy mostra me varianca të ndryshme të përfshira në paketë Analiza e të dhënave.
Kapitulli 7 Përdorimi i regresionit për të testuar dallimet ndërmjet mesatareve në grup
Variablat e përmendur më parë si variabla parashikuese do të referohen në këtë kapitull si variabla të rezultatit dhe termi variabla faktor do të përdoret në vend të variablave parashikues.
Qasja më e thjeshtë për të koduar një ndryshore nominale është kodim bedel(Fig. 24).

Oriz. 24. Analiza e regresionit bazuar në kodimin dummy
Kur përdorni kodim dummy të çdo lloji, duhet të ndiqen rregullat e mëposhtme:
- Numri i kolonave të rezervuara për të dhëna të reja duhet të jetë i barabartë me numrin e niveleve të faktorëve minus
- Çdo vektor përfaqëson një nivel faktori.
- Subjektet në një nivel, që shpesh është grupi i kontrollit, marrin kodin 0 në të gjithë vektorët.
Formula në qelizat F2:H6 =LINEST(A2:A22;C2:D22;;TRUE) kthen statistikat e regresionit. Për krahasim, në Fig. 24 tregon rezultatet e analizës tradicionale të variancës të kthyera nga mjeti Analiza njëkahëshe e variancës superstrukturat Analiza e të dhënave.
Kodimi i efekteve. Në një lloj tjetër kodimi të quajtur kodimi i efekteve, krahasohet mesatarja e secilit grup me mesataren e mesatares së grupit. Ky aspekt i kodimit të efekteve është për shkak të përdorimit të -1 në vend të 0 si kod për një grup që merr të njëjtin kod në të gjithë vektorët e kodit (Figura 25).

Oriz. 25. Kodimi i efektit
Kur përdoret kodimi dummy, vlera e konstantës së kthyer nga LINEST() është mesatarja e grupit të caktuar zero kode në të gjithë vektorët (zakonisht grupi i kontrollit). Në rastin e kodimit të efekteve, konstanta është e barabartë me mesataren e përgjithshme (qeliza J2).
Modeli i përgjithshëm linear është një mënyrë e dobishme për të konceptuar komponentët e vlerës së variablit që rezulton:
Y ij = μ + α j + ε ij
Përdorimi i shkronjave greke në vend të shkronjave latine në këtë formulë thekson faktin se i referohet popullatës nga e cila janë nxjerrë mostrat, por mund të rishkruhet për të treguar se i referohet mostrave të nxjerra nga popullata e publikuar:
Y ij = Y̅ + a j + e ij
Ideja është që çdo vëzhgim Y ij mund të shihet si shuma e tre komponentëve të mëposhtëm: mesatarja e përgjithshme, μ; efekti i përpunimit j, dhe j; vlera e e ij , e cila paraqet devijimin e treguesit sasior individual Y ij nga vlera e kombinuar e mesatares së përgjithshme dhe efektit të trajtimit j (Fig. 26). Qëllimi i ekuacionit të regresionit është të minimizojë shumën e katrorëve të mbetjeve.

Oriz. 26. Vëzhgime të zbërthyera në komponentë të një modeli të përgjithshëm linear
Analiza e faktorëve. Nëse lidhja ndërmjet variablit që rezulton dhe dy ose më shumë faktorëve në të njëjtën kohë është duke u hetuar, atëherë në këtë rast flitet për përdorimin e analizës së faktorëve. Shtimi i një ose më shumë faktorëve në një analizë të njëanshme të variancës mund të rrisë fuqinë statistikore. Në ANOVA njëkahëshe, ndryshimi në variablin e rezultatit që nuk mund t'i atribuohet një faktori përfshihet në katrorin mesatar të mbetur. Por mund të ndodhë që ky ndryshim të lidhet me një faktor tjetër. Më pas, ky variacion mund të hiqet nga gabimi mesatar katror, ulja e të cilit çon në një rritje të vlerave të testit F, dhe rrjedhimisht në një rritje të fuqisë statistikore të testit. superstrukturë Analiza e të dhënave përfshin një mjet që siguron përpunimin e dy faktorëve në të njëjtën kohë (Fig. 27).

Oriz. 27. Paketa e analizës së instrumenteve të dyanshme të analizës së variancës me përsëritje
Mjeti i analizës së variancës i përdorur në këtë figurë është i dobishëm në atë që kthen mesataren dhe variancën e variablit që rezulton, si dhe vlerën e numëruesit për secilin grup të përfshirë në dizajn. Tabela Analiza e variancës shfaq dy parametra që nuk janë në dalje të versionit njëkahësh të mjetit ANOVA. Kushtojini vëmendje burimeve të variacionit Mostra dhe kolonat në rreshtat 27 dhe 28. Burimi i variacionit kolonat i referohet gjinisë. Burimi i variacionit Mostra i referohet çdo ndryshoreje, vlerat e së cilës zënë rreshta të ndryshëm. Në fig. 27, vlerat për grupin CourseLech1 janë në rreshtat 2-6, grupi CourseLech2 janë në rreshtat 7-11 dhe grupi CourseLech3 janë në rreshtat 12-16.
Çështja kryesore është se si Gjinia (etiketuar Kolonat në qelizën E28) ashtu edhe Trajtimi (etiketuar Kampion në qelizën E27) përfshihen në tabelën ANOVA si burime variacioni. Mesatarja për meshkujt është e ndryshme nga ajo e femrave, dhe kjo krijon një burim variacionesh. Mesatarja për të tre trajtimet gjithashtu ndryshojnë - këtu është një burim tjetër ndryshimi. Ekziston edhe një burim i tretë, Ndërveprimi, i cili i referohet efektit të kombinuar të variablave Gjinia dhe Trajtimi.
Kapitulli 8
Analiza e Kovariancës, ose ANCOVA (Analysis of Covariation), redukton paragjykimet dhe rrit fuqinë statistikore. Më lejoni t'ju kujtoj se një nga mënyrat për të vlerësuar besueshmërinë e ekuacionit të regresionit janë testet F:
F = MS Regresioni/MS Reziduale
ku MS (Mean Square) është katrori mesatar, dhe indekset Regression dhe Residual tregojnë respektivisht komponentët e regresionit dhe ato të mbetura. MS Reziduali llogaritet duke përdorur formulën:
MS Residual = SS Residual / df Residual
ku SS (Shuma e katrorëve) është shuma e katrorëve, dhe df është numri i shkallëve të lirisë. Kur shtoni kovariancën në një ekuacion regresioni, një pjesë e shumës totale të katrorëve nuk përfshihet në SS ResiduaI, por në Regresionin SS. Kjo çon në një ulje të SS Residual l, dhe si rrjedhim, MS Residual. Sa më i vogël të jetë MS Residual, aq më i madh është F-testi dhe aq më shumë ka gjasa që të refuzoni hipotezën zero se nuk ka dallim midis mesatareve. Si rezultat, ju rishpërndani paqëndrueshmërinë e ndryshores që rezulton. Në ANOVA, kur nuk merret parasysh kovarianca, ndryshueshmëria shkon në gabim. Por në ANCOVA, pjesa e ndryshueshmërisë që i atribuohet më parë gabimit i caktohet bashkëvariatit dhe bëhet pjesë e regresionit SS.
Merrni parasysh një shembull ku i njëjti grup të dhënash analizohet fillimisht me ANOVA dhe më pas me ANCOVA (Figura 28).

Oriz. 28. Analiza ANOVA tregon se rezultatet e marra duke përdorur ekuacionin e regresionit janë jo të besueshme
Studimi krahason efektet relative të ushtrimeve fizike, të cilat zhvillojnë forcën e muskujve, dhe ushtrimeve njohëse (puzzles me fjalëkryqe), që aktivizojnë aktivitetin e trurit. Subjektet u ndanë rastësisht në dy grupe në mënyrë që në fillim të eksperimentit, të dy grupet të ishin në të njëjtat kushte. Pas tre muajsh, u matën karakteristikat njohëse të subjekteve. Rezultatet e këtyre matjeve janë paraqitur në kolonën B.
Gama A2:C21 përmban të dhënat fillestare që i kalohen funksionit LINEST() për të kryer analiza duke përdorur kodimin e efekteve. Rezultatet e funksionit LINEST() tregohen në diapazonin E2:F6, ku qeliza E2 shfaq koeficientin e regresionit të lidhur me vektorin e ndikimit. Qeliza E8 përmban një test t = 0,93 dhe qeliza E9 teston besueshmërinë e këtij testi t. Vlera në qelizën E9 tregon se probabiliteti për të hasur diferencën midis mesatareve të grupit të vëzhguar në këtë eksperiment është 36% nëse mesataret e grupit janë të barabarta në popullatë. Vetëm disa e konsiderojnë këtë rezultat si të rëndësishëm statistikisht.
Në fig. Figura 29 tregon se çfarë ndodh kur analizës i shtohet një variacion. Në këtë rast, unë shtova moshën e çdo subjekti në grupin e të dhënave. Koeficienti i përcaktimit R 2 për ekuacionin e regresionit që përdor kovariatin është 0.80 (qeliza F4). Vlera R 2 në diapazonin F15:G19, në të cilën unë riprodhova rezultatet ANOVA të marra pa përdorur variantin, është vetëm 0.05 (qeliza F17). Prandaj, një ekuacion i regresionit që përfshin një kovariate parashikon vlerat e ndryshores së rezultatit njohës shumë më saktë sesa përdorimi i vektorit të ndikimit vetëm. Për ANCOVA, probabiliteti i marrjes së rastësishme të vlerës së testit F të shfaqur në qelizën F5 është më pak se 0,01%.

Oriz. 29. ANCOVA sjell një tablo krejt tjetër
Përpunimi statistikor i të dhënave mund të kryhet gjithashtu duke përdorur shtesën PAKETA E ANALIZËS(Fig. 62).
Nga artikujt e propozuar, zgjidhni artikullin " REGRESIONI” dhe klikoni mbi të me butonin e majtë të miut. Tjetra, klikoni OK.
Dritarja e paraqitur në Fig. 63.

Mjeti i analizës « REGRESIONI» përdoret për të përshtatur një grafik në një grup vëzhgimesh duke përdorur metodën e katrorëve më të vegjël. Regresioni përdoret për të analizuar ndikimin në një ndryshore të vetme të varur të vlerave të një ose më shumë variablave të pavarur. Për shembull, performanca atletike e një atleti ndikohet nga disa faktorë, duke përfshirë moshën, gjatësinë dhe peshën. Është e mundur të llogaritet shkalla e ndikimit të secilit prej këtyre tre faktorëve në performancën e një atleti, dhe më pas të përdoren të dhënat e marra për të parashikuar performancën e një atleti tjetër.
Vegla Regresioni përdor funksionin LINEST.
Kutia e dialogut REGRESS
Etiketat Zgjidhni kutinë e zgjedhjes nëse rreshti i parë ose kolona e parë e diapazonit të hyrjes përmban tituj. Fshi këtë kuti të kontrollit nëse nuk ka tituj. Në këtë rast, titujt e përshtatshëm për të dhënat e tabelës dalëse do të gjenerohen automatikisht.
Niveli i besueshmërisë Zgjidhni kutinë e kontrollit për të përfshirë një nivel shtesë në tabelën totale të prodhimit. Në fushën përkatëse, vendosni nivelin e besimit që dëshironi të aplikoni, përveç nivelit të paracaktuar të besimit 95%.
Konstante - zero Kontrolloni kutinë për të bërë që vija e regresionit të kalojë përmes origjinës.
Gama e daljes Futni një referencë në qelizën e sipërme majtas të diapazonit të daljes. Ndani të paktën shtatë kolona për tabelën e rezultateve të rezultateve, e cila do të përfshijë: rezultatet e analizës së variancës, koeficientët, gabimin standard të llogaritjes Y, devijimet standarde, numrin e vëzhgimeve, gabimet standarde për koeficientët.
Fletë pune e re Zgjidhni këtë kuti për të hapur një fletë të re pune në librin e punës dhe për të futur rezultatet e analizës duke filluar nga qeliza A1. Nëse është e nevojshme, vendosni një emër për fletën e re në fushën përballë pozicionit të duhur të butonit të radios.
Libri i ri i punës Kontrolloni këtë kuti për të krijuar një libër të ri pune në të cilin rezultatet do të shtohen në një fletë të re.
Mbetjet Zgjidhni kutinë e kontrollit për të përfshirë mbetjet në tabelën e daljes.
Mbetjet e standardizuara Zgjidhni kutinë e kontrollit për të përfshirë mbetjet e standardizuara në tabelën e daljes.
Komploti i mbetur Kontrolloni kutinë për të vizatuar mbetjet për çdo variabël të pavarur.
Fit Plot Zgjidhni kutinë e kontrollit për të paraqitur vlerat e parashikuara kundrejt vlerave të vëzhguara.
Skema e probabilitetit normal Kontrolloni kutinë për të paraqitur probabilitetin normal.
Funksioni LINEST
Për të kryer llogaritjet, zgjidhni qelizën në të cilën duam të shfaqim vlerën mesatare me kursorin dhe shtypni butonin = në tastierë. Më pas, në fushën Emri, specifikoni funksionin e dëshiruar, për shembull MESATAR(Fig. 22).
Funksioni LINEST llogarit statistikat për një seri duke përdorur metodën e katrorëve më të vegjël për të llogaritur një vijë të drejtë që përafron më mirë të dhënat e disponueshme dhe më pas kthen një grup që përshkruan vijën e drejtë që rezulton. Ju gjithashtu mund të kombinoni funksionin LINEST me funksione të tjera për të llogaritur lloje të tjera modelesh që janë lineare në parametra të panjohur (parametrat e panjohur të të cilëve janë linearë), duke përfshirë seritë polinomiale, logaritmike, eksponenciale dhe të fuqisë. Për shkak se një grup vlerash është kthyer, funksioni duhet të specifikohet si një formulë grupi.
Ekuacioni për një vijë të drejtë është:
y=m 1 x 1 +m 2 x 2 +…+b (në rastin e disa vargjeve të vlerave x),
ku vlera e varur y është një funksion i vlerës së pavarur x, vlerat m janë koeficientët që korrespondojnë me çdo ndryshore të pavarur x, dhe b është një konstante. Vini re se y, x dhe m mund të jenë vektorë. Funksioni LINEST kthen një grup (mn;mn-1;…;m 1 ;b). LINEST gjithashtu mund të kthejë statistika shtesë të regresionit.
LINEST(njohur_y-vlera; njohur_x-vlera; konst; statistika)
Vlerat e njohura_y - grupi i vlerave y që tashmë njihen për relacionin y=mx+b.
Nëse grupi i njohur_y ka një kolonë, atëherë çdo kolonë e grupit të njohur_x interpretohet si një ndryshore e veçantë.
Nëse grupi i njohur_y ka një rresht, atëherë çdo rresht i grupit të njohur_x interpretohet si një ndryshore e veçantë.
Vlerat e njohura_x - një grup opsional i vlerave x që janë tashmë të njohura për relacionin y=mx+b.
Vargu i njohur_x mund të përmbajë një ose më shumë grupe variablash. Nëse përdoret vetëm një variabël, atëherë vargjet_known_y_vlerat dhe të njohura_x_vlerat mund të jenë të çdo forme - për sa kohë që kanë të njëjtin dimension. Nëse përdoret më shumë se një ndryshore, atëherë know_y's duhet të jetë një vektor (d.m.th., një rresht i lartë ose një kolonë i gjerë).
Nëse array_known_x hiqet, atëherë ky grup (1;2;3;...) supozohet të jetë i njëjtë me madhësinë e grupit_known_y.
Const është një vlerë boolean që specifikon nëse konstanta b kërkohet të jetë 0.
Nëse argumenti "const" është TRUE ose i anashkaluar, atëherë konstanta b vlerësohet normalisht.
Nëse argumenti "const" është FALSE, atëherë vlera e b supozohet të jetë 0 dhe vlerat e m zgjidhen në atë mënyrë që relacioni y=mx të plotësohet.
Statistikat është një vlerë Boolean që tregon nëse statistikat shtesë të regresionit duhet të kthehen.
Nëse statistikat janë të vërteta, LINEST kthen statistika shtesë të regresionit. Vargu i kthyer do të duket kështu: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Nëse statistikat janë FALSE ose janë lënë jashtë, LINEST kthen vetëm koeficientët m dhe konstanten b.
Statistikat shtesë të regresionit (Tabela 17)
| Vlera | Përshkrim |
| se1,se2,...,sen | Vlerat standarde të gabimit për koeficientët m1, m2,..., mn. |
| seb | Gabimi standard për konstanten b (seb = #N/A nëse 'const' është FALSE). |
| r2 | Faktori përcaktues. Vlerat aktuale të y krahasohen me vlerat e marra nga ekuacioni i vijës së drejtë; bazuar në rezultatet e krahasimit, llogaritet koeficienti i determinizmit, i normalizuar nga 0 në 1. Nëse është i barabartë me 1, atëherë ka një korrelacion të plotë me modelin, d.m.th. nuk ka dallim midis vlerave aktuale dhe të vlerësuar nga y. Përndryshe, nëse koeficienti i determinizmit është 0, nuk ka kuptim të përdoret ekuacioni i regresionit për të parashikuar vlerat y. Për më shumë informacion se si të llogaritni r2, shihni "Vërejtje" në fund të këtij seksioni. |
| sey | Gabimi standard për vlerësimin y. |
| F | F-statistikë ose vlerë F-vëzhguar. Statistika F përdoret për të përcaktuar nëse një marrëdhënie e vëzhguar midis variablave të varur dhe të pavarur është e rastësishme. |
| df | Shkallët e lirisë. Shkallët e lirisë janë të dobishme për gjetjen e vlerave F-kritike në një tabelë statistikore. Për të përcaktuar nivelin e besimit të modelit, duhet të krahasoni vlerat në tabelë me statistikën F të kthyer nga LINEST. Shihni "Vërejtje" në fund të këtij seksioni për më shumë informacion rreth llogaritjes së df. Shembulli 4 më poshtë tregon përdorimin e F dhe df. |
| ssreg | Shuma e regresionit të katrorëve. |
| ssresid | Shuma e mbetur e katrorëve. Për më shumë informacion rreth llogaritjes së ssreg dhe ssresid, shihni "Vërejtje" në fund të këtij seksioni. |
Figura më poshtë tregon rendin në të cilin kthehen statistikat shtesë të regresionit (Figura 64).

Shënime:
Çdo vijë e drejtë mund të përshkruhet nga pjerrësia dhe kryqëzimi i saj me boshtin y:
Pjerrësia (m): për të përcaktuar pjerrësinë e një vije, zakonisht të shënuar me m, duhet të merrni dy pika në vijë (x 1 ,y 1) dhe (x 2 ,y 2); pjerrësia do të jetë e barabartë me (y 2 -y 1) / (x 2 -x 1).
Kryqëzimi Y (b): Kryqëzimi y i një drejtëze, që zakonisht shënohet me b, është vlera y për pikën ku drejtëza kryqëzon boshtin y.
Ekuacioni drejtvizor ka formën y=mx+b. Nëse dihen vlerat e m dhe b, atëherë çdo pikë në vijë mund të llogaritet duke zëvendësuar vlerat e y ose x në ekuacion. Ju gjithashtu mund të përdorni funksionin TREND.
Nëse ka vetëm një ndryshore të pavarur x, mund të merrni pjerrësinë dhe ndërprerjen y drejtpërdrejt duke përdorur formulat e mëposhtme:
Pjerrësia: INDEX(LINEST(njohur_y, njohur_x), 1)
Ndërprerja Y: INDEX (LINEST (të njohura_y, të njohura_x), 2)
Saktësia e përafrimit duke përdorur vijën e drejtë të llogaritur nga funksioni LINEST varet nga shkalla e shpërndarjes së të dhënave. Sa më afër të jenë të dhënat me një vijë të drejtë, aq më i saktë është modeli i përdorur nga LINEST. Funksioni LINEST përdor metodën e katrorëve më të vegjël për të përcaktuar përshtatjen më të mirë me të dhënat. Kur ka vetëm një ndryshore të pavarur x, m dhe b llogariten duke përdorur formulat e mëposhtme:

ku x dhe y janë mesataret e mostrës, për shembull x = MESATAR (të njohura_x) dhe y = MESATAR (të njohura_y).
Funksionet e përshtatjes LINEST dhe LGRFPRIBL mund të llogarisin një kurbë të drejtë ose eksponenciale që i përshtatet më së miri të dhënave. Megjithatë, ata nuk i përgjigjen pyetjes se cili nga dy rezultatet është më i përshtatshëm për zgjidhjen e problemit. Ju gjithashtu mund të llogaritni funksionin TREND (njohur_y-vlerat; njohur_x-vlerat) për një vijë të drejtë, ose funksionin GROWTH (njohur_y-vlerat; njohur_x-vlerat) për një kurbë eksponenciale. Këto funksione, nëse hiqen nga argumenti new_x_values, kthejnë një grup vlerash të llogaritura y për vlerat aktuale x sipas një vije të drejtë ose kurbë. Më pas mund të krahasoni vlerat e llogaritura me vlerat aktuale. Ju gjithashtu mund të ndërtoni tabela për krahasim vizual.
Kur kryen një analizë regresioni, Microsoft Excel llogarit, për çdo pikë, katrorin e diferencës midis vlerës së parashikuar y dhe vlerës aktuale y. Shuma e këtyre diferencave në katror quhet shuma e mbetur e katrorëve (ssresid). Microsoft Excel më pas llogarit shumën totale të katrorëve (sstotal). Nëse const = TRUE ose nëse ky argument nuk specifikohet, shuma totale e katrorëve do të jetë e barabartë me shumën e diferencave në katror të vlerave reale y dhe vlerave mesatare y. Nëse const = FALSE, shuma e katrorëve do të jetë e barabartë me shumën e katrorëve të vlerave reale y (pa zbritur mesataren y nga herësi y). Pas kësaj, shuma e regresionit të katrorëve mund të llogaritet si më poshtë: ssreg = sstotal - ssresid. Sa më e vogël të jetë shuma e mbetur e katrorëve, aq më e madhe është vlera e koeficientit të determinizmit r2, që tregon se sa mirë ekuacioni i marrë duke përdorur analizën e regresionit shpjegon marrëdhëniet midis variablave. Koeficienti r2 është i barabartë me ssreg/sstotal.
Në disa raste, një ose më shumë kolona X (le vlerat Y dhe X të jenë në kolona) nuk kanë vlerë parashikuese shtesë në kolonat e tjera X. Me fjalë të tjera, fshirja e një ose më shumë kolonave X mund të rezultojë në vlera Y llogaritur me të njëjtën saktësi. Në këtë rast, kolonat e tepërta X do të përjashtohen nga modeli i regresionit. Ky fenomen quhet "kolinearitet" sepse kolonat e tepërta të X mund të përfaqësohen si shuma e disa kolonave jo të tepërta. LINEST kontrollon për kolinearitet dhe heq çdo kolonë X të tepërt nga modeli i regresionit nëse gjen ndonjë. Kolonat X të hequra mund të identifikohen në daljen LINEST me një faktor 0 dhe një vlerë se 0. Heqja e një ose më shumë kolonave si të tepërta ndryshon vlerën e df sepse varet nga numri i kolonave X të përdorura aktualisht për qëllime parashikuese. Shih shembullin 4 më poshtë për më shumë detaje mbi llogaritjen e df. Kur df ndryshon për shkak të heqjes së kolonave të tepërta, ndryshojnë edhe vlerat e sey dhe F. Shpesh nuk rekomandohet përdorimi i kolinearitetit. Megjithatë, duhet të përdoret nëse disa kolona X përmbajnë 0 ose 1 si një tregues që tregon nëse subjekti i eksperimentit është në një grup të veçantë. Nëse const = TRUE ose nëse ky argument nuk është specifikuar, LINEST fut një kolonë X shtesë për të simuluar pikën e kryqëzimit. Nëse ka një kolonë me vlerat 1 për meshkujt dhe 0 për femrat, dhe ka një kolonë me vlerat 1 për femrat dhe 0 për meshkujt, atëherë kolona e fundit hiqet sepse vlerat e saj mund të merren nga kolona "treguesi mashkull".
Llogaritja e df për rastet kur X kolonat nuk hiqen nga modeli për shkak të kolinearitetit është si më poshtë: nëse ka k kolona të njohura_x dhe const = TRUE ose jo e specifikuar, atëherë df = n - k - 1. Nëse const = FALSE, atëherë df = n - k. Në të dyja rastet, heqja e kolonave X për shkak të kolinearitetit rrit vlerën e df me 1.
Formulat që kthejnë vargje duhet të futen si formula vargjesh.
Kur futni një grup konstantesh si një argument të njohur_x_values, për shembull, përdorni një pikëpresje për të ndarë vlerat në të njëjtën linjë dhe një pikëpresje për të ndarë linjat. Karakteret ndarëse mund të ndryshojnë në varësi të cilësimeve në dritaren "Gjuha dhe standardet" në panelin e kontrollit.
Vini re se vlerat y të parashikuara nga ekuacioni i regresionit mund të mos jenë të sakta nëse janë jashtë gamës së vlerave y që janë përdorur për të përcaktuar ekuacionin.
Algoritmi kryesor i përdorur në funksion LINEST, ndryshon nga algoritmi kryesor i funksioneve PJERRJE dhe SEGMENTI I LINJËS. Dallimet midis algoritmeve mund të çojnë në rezultate të ndryshme për të dhëna të pasigurta dhe kolineare. Për shembull, nëse pikat e të dhënave të argumentit të njohur_y janë 0 dhe pikat e të dhënave të argumentit të njohur_x janë 1, atëherë:
Funksioni LINEST kthen një vlerë të barabartë me 0. Algoritmi i funksionit LINEST përdoret për të kthyer vlera të përshtatshme për të dhënat kolineare, në të cilin rast mund të gjendet të paktën një përgjigje.
Funksionet SLOPE dhe INTERCEPT kthejnë gabimin #DIV/0!. Algoritmi i funksioneve SLOPE dhe INTERCEPT përdoret për të gjetur vetëm një përgjigje, dhe në këtë rast mund të ketë disa.
Përveç llogaritjes së statistikave për llojet e tjera të regresionit, LINEST mund të përdoret për të llogaritur intervalet për llojet e tjera të regresionit duke futur funksione të ndryshoreve x dhe y si një seri ndryshoresh x dhe y për LINEST. Për shembull, formula e mëposhtme:
LINEST(y-vlera, x-vlera^COLUMN($A:$C))
punon me një kolonë të vlerave Y dhe një kolonë me vlera X për të llogaritur një përafrim të kubit (polinom i shkallës së 3-të) të formës së mëposhtme:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Formula mund të modifikohet për të llogaritur llojet e tjera të regresionit, por në disa raste kërkohen rregullime në vlerat e prodhimit dhe statistika të tjera.
AT shkëlqejnë ekziston një mënyrë edhe më e shpejtë dhe më e përshtatshme për të hartuar një regresion linear (dhe madje edhe llojet kryesore të regresioneve jolineare, shih më poshtë). Kjo mund të bëhet si kjo:
1) zgjidhni kolonat me të dhëna X dhe Y(ata duhet të jenë në atë renditje!);
2) telefononi Magjistari i grafikut dhe zgjidhni në një grup Lloji – me pika dhe shtypni menjëherë Gati;
3) pa hequr zgjedhjen e diagramit, zgjidhni artikullin e menysë kryesore që shfaqet Diagramë, në të cilën duhet të zgjidhni artikullin Shtoni linjën e trendit;
4) në dialogun që shfaqet linjë trendi skedën Lloji zgjidhni Linear;
5) skeda Opsione ndërprerësi mund të aktivizohet Trego ekuacionin në tabelë, i cili do t'ju lejojë të shihni ekuacionin e regresionit linear (4.4), në të cilin do të llogariten koeficientët (4.5).
6) Në të njëjtën skedë, mund të aktivizoni çelësin Vendosni në diagram vlerën e besueshmërisë së përafrimit (R^2). Kjo vlerë është katrori i koeficientit të korrelacionit (4.3) dhe tregon se sa mirë ekuacioni i llogaritur përshkruan varësinë eksperimentale. Nese nje R 2 është afër unitetit, atëherë ekuacioni teorik i regresionit përshkruan mirë varësinë eksperimentale (teoria pajtohet mirë me eksperimentin), dhe nëse R 2 është afër zeros, atëherë ky ekuacion nuk është i përshtatshëm për të përshkruar varësinë eksperimentale (teoria nuk pajtohet me eksperimentin).
Si rezultat i kryerjes së veprimeve të përshkruara, do të merrni një diagram me një grafik regresioni dhe ekuacionin e tij.
§4.3. Llojet kryesore të regresionit jolinear
Regresioni parabolik dhe polinom.
Parabolike varësia e vlerës Y nga vlera X varësia e shprehur nga një funksion kuadratik (parabola e rendit të dytë) quhet:
Ky ekuacion quhet regresioni parabolik Y në X. Opsione a, b, me thirrur koeficientët e regresionit parabolik. Llogaritja e koeficientëve të regresionit parabolik është gjithmonë e rëndë, prandaj rekomandohet përdorimi i një kompjuteri për llogaritjet.
Ekuacioni (4.8) i regresionit parabolik është një rast i veçantë i një regresioni më të përgjithshëm të quajtur polinom. polinom varësia e vlerës Y nga vlera X quhet varësia e shprehur me polinomin n- urdhri:
ku janë numrat a i (i=0,1,…, n) quhen koeficientët e regresionit polinom.
Regresioni i fuqisë.
Fuqia varësia e vlerës Y nga vlera X quhet varësi e formës:
Ky ekuacion quhet ekuacioni i regresionit të fuqisë Y në X. Opsione a dhe b thirrur koeficientët e regresionit të fuqisë.
ln=ln a+b ln x. (4.11)
Ky ekuacion përshkruan një vijë të drejtë në rrafsh me boshte koordinative logaritmike ln x dhe ln. Prandaj, kriteri për zbatueshmërinë e regresionit të fuqisë është kërkesa që pikat e logaritmeve të të dhënave empirike ln x i dhe ln i ishin më afër vijës së drejtë (4.11).
regresioni eksponencial.
shembullore(ose eksponenciale) varësia e sasisë Y nga vlera X quhet varësi e formës:
(ose ). (4.12)
Ky ekuacion quhet ekuacioni eksponencial(ose eksponenciale) regresioni Y në X. Opsione a(ose k) dhe b thirrur eksponenciale(ose eksponenciale) regresioni.
Nëse marrim logaritmin e të dy anëve të ekuacionit të regresionit të fuqisë, marrim ekuacionin
ln = x ln a+ln b(ose ln = k x+ln b). (4.13)
Ky ekuacion përshkruan varësinë lineare të logaritmit të një sasie ln nga një sasi tjetër x. Prandaj, kriteri për zbatueshmërinë e regresionit të fuqisë është kërkesa që të dhënat empirike të tregojnë të njëjtën madhësi x i dhe logaritme të një vlere tjetër ln i ishin më afër vijës së drejtë (4.13).
regresioni logaritmik.
Logaritmike varësia e vlerës Y nga vlera X quhet varësi e formës:
=a+b ln x. (4.14)
Ky ekuacion quhet regresioni logaritmik Y në X. Opsione a dhe b thirrur koeficientët e regresionit logaritmik.
regresioni hiperbolik.
Hiperbolike varësia e vlerës Y nga vlera X quhet varësi e formës:
Ky ekuacion quhet ekuacioni i regresionit hiperbolik Y në X. Opsione a dhe b thirrur koeficientët e regresionit hiperbolik dhe përcaktohen me metodën e katrorëve më të vegjël. Zbatimi i kësaj metode çon në formulat:
Në formulat (4.16-4.17), përmbledhja kryhet mbi indeksin i nga një në numrin e vëzhgimeve n.
Fatkeqësisht, në shkëlqejnë nuk ka asnjë funksion që llogarit koeficientët e regresionit hiperbolik. Në ato raste kur nuk dihet me siguri se vlerat e matura janë të lidhura me proporcion të zhdrejtë, rekomandohet të kërkohet ekuacioni i regresionit të fuqisë në vend të ekuacionit të regresionit hiperbolik, kështu që në shkëlqejnë ekziston një procedurë për gjetjen e saj. Nëse supozohet një varësi hiperbolike midis vlerave të matura, atëherë koeficientët e tij të regresionit do të duhet të llogariten duke përdorur tabela llogaritëse ndihmëse dhe operacionet e mbledhjes duke përdorur formulat (4.16-4.17).
Regresioni në Excel
Përpunimi statistikor i të dhënave mund të kryhet edhe duke përdorur paketën shtesë të Analizës në nën-artikullin e menysë "Shërbimi". Në Excel 2003, nëse hapni SHËRBIMI, nuk mund ta gjejmë skedën ANALIZA E TË DHËNAVE, më pas klikoni butonin e majtë të miut për të hapur skedën SHTESAT dhe pika e kundërt PAKETA E ANALIZËS duke klikuar butonin e majtë të miut, vendosni një shenjë (Fig. 17).
Oriz. 17. Dritare SHTESAT
Pas kësaj, menyja SHËRBIMI shfaqet skeda ANALIZA E TË DHËNAVE.
Në Excel 2007 për të instaluar ANALIZA E PAKETËS duhet të klikoni në butonin OFFICE në këndin e sipërm të majtë të fletës (Fig. 18a). Tjetra, klikoni në butonin OPTIONS EXCEL. Në dritaren që shfaqet OPTIONS EXCEL kliko me të majtën mbi artikull SHTESAT dhe në pjesën e djathtë të listës rënëse, zgjidhni artikullin PAKETA E ANALIZËS. Tjetra, klikoni mbi Ne rregull.




Oriz. 18. Instalimi ANALIZA E PAKETËS në Excel 2007
Për të instaluar Paketën e Analizës, klikoni butonin SHKO, në fund të dritares së hapur. Dritarja e paraqitur në Fig. 12. Kontrolloni kutinë pranë PAKETA E ANALIZËS. Në skedën TË DHËNAT do të shfaqet butoni ANALIZA E TË DHËNAVE(Fig. 19).

Nga artikujt e propozuar, zgjidhni artikullin " REGRESIONI” dhe klikoni mbi të me butonin e majtë të miut. Tjetra, klikoni OK.

Dritarja e paraqitur në Fig. 21

Mjeti i analizës « REGRESIONI» përdoret për të përshtatur një grafik në një grup vëzhgimesh duke përdorur metodën e katrorëve më të vegjël. Regresioni përdoret për të analizuar ndikimin në një ndryshore të vetme të varur të vlerave të një ose më shumë variablave të pavarur. Për shembull, performanca atletike e një atleti ndikohet nga disa faktorë, duke përfshirë moshën, gjatësinë dhe peshën. Është e mundur të llogaritet shkalla e ndikimit të secilit prej këtyre tre faktorëve në performancën e një atleti, dhe më pas të përdoren të dhënat e marra për të parashikuar performancën e një atleti tjetër.
Vegla Regresioni përdor funksionin LINEST.
Kutia e dialogut REGRESS
Etiketat Zgjidhni kutinë e zgjedhjes nëse rreshti i parë ose kolona e parë e diapazonit të hyrjes përmban tituj. Fshi këtë kuti të kontrollit nëse nuk ka tituj. Në këtë rast, titujt e përshtatshëm për të dhënat e tabelës dalëse do të gjenerohen automatikisht.
Niveli i besueshmërisë Zgjidhni kutinë e kontrollit për të përfshirë një nivel shtesë në tabelën totale të prodhimit. Në fushën përkatëse, vendosni nivelin e besimit që dëshironi të aplikoni, përveç nivelit të paracaktuar të besimit 95%.
Konstante - zero Kontrolloni kutinë për të bërë që vija e regresionit të kalojë përmes origjinës.
Gama e daljes Futni një referencë në qelizën e sipërme majtas të diapazonit të daljes. Ndani të paktën shtatë kolona për tabelën e rezultateve të rezultateve, e cila do të përfshijë: rezultatet e analizës së variancës, koeficientët, gabimin standard të llogaritjes Y, devijimet standarde, numrin e vëzhgimeve, gabimet standarde për koeficientët.
Fletë pune e re Zgjidhni këtë kuti për të hapur një fletë të re pune në librin e punës dhe për të futur rezultatet e analizës duke filluar nga qeliza A1. Nëse është e nevojshme, vendosni një emër për fletën e re në fushën përballë pozicionit të duhur të butonit të radios.
Libri i ri i punës Kontrolloni këtë kuti për të krijuar një libër të ri pune në të cilin rezultatet do të shtohen në një fletë të re.
Mbetjet Zgjidhni kutinë e kontrollit për të përfshirë mbetjet në tabelën e daljes.
Mbetjet e standardizuara Zgjidhni kutinë e kontrollit për të përfshirë mbetjet e standardizuara në tabelën e daljes.
Komploti i mbetur Kontrolloni kutinë për të vizatuar mbetjet për çdo variabël të pavarur.
Fit Plot Zgjidhni kutinë e kontrollit për të paraqitur vlerat e parashikuara kundrejt vlerave të vëzhguara.
Skema e probabilitetit normal Kontrolloni kutinë për të paraqitur probabilitetin normal.
Funksioni LINEST
Për të kryer llogaritjet, zgjidhni qelizën në të cilën duam të shfaqim vlerën mesatare me kursorin dhe shtypni butonin = në tastierë. Më pas, në fushën Emri, specifikoni funksionin e dëshiruar, për shembull MESATAR(Fig. 22).

Oriz. 22 Gjetja e funksioneve në Excel 2003
Nëse në terren EMRI emri i funksionit nuk shfaqet, pastaj kliko me të majtën në trekëndëshin pranë fushës, pas së cilës do të shfaqet një dritare me një listë funksionesh. Nëse ky funksion nuk është në listë, atëherë kliko me të majtën mbi artikullin në listë FUNKSIONET E TJERA, do të shfaqet një kuti dialogu. MJESHTRI I FUNKSIONIT, në të cilën, duke përdorur lëvizjen vertikale, zgjidhni funksionin e dëshiruar, zgjidhni atë me kursorin dhe klikoni mbi Ne rregull(Fig. 23).

Oriz. 23. Funksioni Wizard
Për të kërkuar një funksion në Excel 2007, çdo skedë mund të hapet në meny, më pas për të kryer llogaritjet, zgjedhim qelizën në të cilën dëshirojmë të shfaqim vlerën mesatare me kursorin dhe shtypim tastin = në tastierë. Më pas, në fushën Emri, specifikoni funksionin MESATAR. Dritarja për llogaritjen e funksionit është e ngjashme me atë në Excel 2003.
Ju gjithashtu mund të zgjidhni skedën Formulat dhe të klikoni me të majtën në butonin në " INSERT FUNKSIONIN» (Fig. 24), do të shfaqet një dritare MJESHTRI I FUNKSIONIT, pamja e të cilit është e ngjashme me Excel 2003. Gjithashtu, në meny, mund të zgjidhni menjëherë kategorinë e funksioneve (të përdorura së fundi, financiare, logjike, tekst, datë dhe orë, matematikore, funksione të tjera), në të cilën do të kërkojmë për funksionin e dëshiruar.




Oriz. 24 Zgjedhja e funksionit në Excel 2007
Funksioni LINEST llogarit statistikat për një seri duke përdorur metodën e katrorëve më të vegjël për të llogaritur një vijë të drejtë që përafron më mirë të dhënat e disponueshme dhe më pas kthen një grup që përshkruan vijën e drejtë që rezulton. Ju gjithashtu mund të kombinoni funksionin LINEST me funksione të tjera për të llogaritur lloje të tjera modelesh që janë lineare në parametra të panjohur (parametrat e panjohur të të cilëve janë linearë), duke përfshirë seritë polinomiale, logaritmike, eksponenciale dhe të fuqisë. Për shkak se një grup vlerash është kthyer, funksioni duhet të specifikohet si një formulë grupi.
Ekuacioni për një vijë të drejtë është:
(në rast të vargjeve të shumta të vlerave x),
ku vlera e varur y është një funksion i vlerës së pavarur x, vlerat m janë koeficientët që korrespondojnë me çdo ndryshore të pavarur x, dhe b është një konstante. Vini re se y, x dhe m mund të jenë vektorë. Funksioni LINEST kthen një grup ![]() . LINEST gjithashtu mund të kthejë statistika shtesë të regresionit.
. LINEST gjithashtu mund të kthejë statistika shtesë të regresionit.
LINEST(njohur_y-vlera; njohur_x-vlera; konst; statistika)
Vlerat e njohura_y - grupi i vlerave y që njihen tashmë për relacionin.
Nëse grupi i njohur_y ka një kolonë, atëherë çdo kolonë e grupit të njohur_x interpretohet si një ndryshore e veçantë.
Nëse grupi i njohur_y ka një rresht, atëherë çdo rresht i grupit të njohur_x interpretohet si një ndryshore e veçantë.
Known_x's është një grup opsional i x që janë tashmë të njohur për relacionin.
Vargu i njohur_x mund të përmbajë një ose më shumë grupe variablash. Nëse përdoret vetëm një variabël, atëherë vargjet_known_y_vlerat dhe të njohura_x_vlerat mund të jenë të çdo forme - për sa kohë që kanë të njëjtin dimension. Nëse përdoret më shumë se një ndryshore, atëherë know_y's duhet të jetë një vektor (d.m.th., një rresht i lartë ose një kolonë i gjerë).
Nëse array_known_x hiqet, atëherë ky grup (1;2;3;...) supozohet të jetë i njëjtë me madhësinë e grupit_known_y.
Const është një vlerë boolean që specifikon nëse konstanta b kërkohet të jetë 0.
Nëse argumenti "const" është TRUE ose i anashkaluar, atëherë konstanta b vlerësohet normalisht.
Nëse argumenti "const" është FALSE, atëherë vlera e b supozohet të jetë 0 dhe vlerat e m zgjidhen në atë mënyrë që relacioni të jetë i kënaqur.
Statistikat është një vlerë Boolean që tregon nëse statistikat shtesë të regresionit duhet të kthehen.
Nëse statistikat janë të vërteta, LINEST kthen statistika shtesë të regresionit. Vargu i kthyer do të duket kështu: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Nëse statistikat janë FALSE ose janë lënë jashtë, LINEST kthen vetëm koeficientët m dhe konstanten b.
Statistikat shtesë të regresionit.
Figura më poshtë tregon rendin në të cilin kthehen statistikat shtesë të regresionit.

Shënime:
Çdo vijë e drejtë mund të përshkruhet nga pjerrësia dhe kryqëzimi i saj me boshtin y:
Pjerrësia (m): Për të përcaktuar pjerrësinë e një vije, zakonisht të shënuar me m, duhet të merrni dy pika në vijë dhe ; pjerrësia do të jetë ![]() .
.
Kryqëzimi Y (b): Kryqëzimi y i një drejtëze, që zakonisht shënohet me b, është vlera y për pikën ku drejtëza kryqëzon boshtin y.
Ekuacioni drejtvizor ka formën . Nëse dihen vlerat e m dhe b, atëherë çdo pikë në vijë mund të llogaritet duke zëvendësuar vlerat e y ose x në ekuacion. Ju gjithashtu mund të përdorni funksionin TREND.
Nëse ka vetëm një ndryshore të pavarur x, mund të merrni pjerrësinë dhe ndërprerjen y drejtpërdrejt duke përdorur formulat e mëposhtme:
Pjerrësia: INDEX(LINEST(njohur_y, njohur_x), 1)
Ndërprerja Y: INDEX (LINEST (të njohura_y, të njohura_x), 2)
Saktësia e përafrimit duke përdorur vijën e drejtë të llogaritur nga funksioni LINEST varet nga shkalla e shpërndarjes së të dhënave. Sa më afër të jenë të dhënat me një vijë të drejtë, aq më i saktë është modeli i përdorur nga LINEST. Funksioni LINEST përdor metodën e katrorëve më të vegjël për të përcaktuar përshtatjen më të mirë me të dhënat. Kur ka vetëm një ndryshore të pavarur x, m dhe b llogariten duke përdorur formulat e mëposhtme:

ku x dhe y janë mesataret e mostrës, për shembull x = MESATAR (të njohura_x) dhe y = MESATAR (të njohura_y).
Funksionet e përshtatjes LINEST dhe LGRFPRIBL mund të llogarisin një kurbë të drejtë ose eksponenciale që i përshtatet më së miri të dhënave. Megjithatë, ata nuk i përgjigjen pyetjes se cili nga dy rezultatet është më i përshtatshëm për zgjidhjen e problemit. Ju gjithashtu mund të llogaritni funksionin TREND (njohur_y-vlerat; njohur_x-vlerat) për një vijë të drejtë, ose funksionin GROWTH (njohur_y-vlerat; njohur_x-vlerat) për një kurbë eksponenciale. Këto funksione, nëse hiqen nga argumenti new_x_values, kthejnë një grup vlerash të llogaritura y për vlerat aktuale x sipas një vije të drejtë ose kurbë. Më pas mund të krahasoni vlerat e llogaritura me vlerat aktuale. Ju gjithashtu mund të ndërtoni tabela për krahasim vizual.
Kur kryen një analizë regresioni, Microsoft Excel llogarit, për çdo pikë, katrorin e diferencës midis vlerës së parashikuar y dhe vlerës aktuale y. Shuma e këtyre diferencave në katror quhet shuma e mbetur e katrorëve (ssresid). Microsoft Excel më pas llogarit shumën totale të katrorëve (sstotal). Nëse const = TRUE ose nëse ky argument nuk specifikohet, shuma totale e katrorëve do të jetë e barabartë me shumën e diferencave në katror të vlerave reale y dhe vlerave mesatare y. Nëse const = FALSE, shuma e katrorëve do të jetë e barabartë me shumën e katrorëve të vlerave reale y (pa zbritur mesataren y nga herësi y). Pas kësaj, shuma e regresionit të katrorëve mund të llogaritet si më poshtë: ssreg = sstotal - ssresid. Sa më e vogël të jetë shuma e mbetur e katrorëve, aq më e madhe është vlera e koeficientit të determinizmit r2, që tregon se sa mirë ekuacioni i marrë duke përdorur analizën e regresionit shpjegon marrëdhëniet midis variablave. Koeficienti r2 është i barabartë me ssreg/sstotal.
Në disa raste, një ose më shumë kolona X (le vlerat Y dhe X të jenë në kolona) nuk kanë vlerë parashikuese shtesë në kolonat e tjera X. Me fjalë të tjera, fshirja e një ose më shumë kolonave X mund të rezultojë në vlera Y llogaritur me të njëjtën saktësi. Në këtë rast, kolonat e tepërta X do të përjashtohen nga modeli i regresionit. Ky fenomen quhet "kolinearitet" sepse kolonat e tepërta të X mund të përfaqësohen si shuma e disa kolonave jo të tepërta. LINEST kontrollon për kolinearitet dhe heq çdo kolonë X të tepërt nga modeli i regresionit nëse gjen ndonjë. Kolonat X të hequra mund të identifikohen në daljen LINEST me një faktor 0 dhe një vlerë se 0. Heqja e një ose më shumë kolonave si të tepërta ndryshon vlerën e df sepse varet nga numri i kolonave X të përdorura aktualisht për qëllime parashikuese. Shih shembullin 4 më poshtë për më shumë detaje mbi llogaritjen e df. Kur df ndryshon për shkak të heqjes së kolonave të tepërta, ndryshojnë edhe vlerat e sey dhe F. Shpesh nuk rekomandohet përdorimi i kolinearitetit. Megjithatë, duhet të përdoret nëse disa kolona X përmbajnë 0 ose 1 si një tregues që tregon nëse subjekti i eksperimentit është në një grup të veçantë. Nëse const = TRUE ose nëse ky argument nuk është specifikuar, LINEST fut një kolonë X shtesë për të simuluar pikën e kryqëzimit. Nëse ka një kolonë me vlerat 1 për meshkujt dhe 0 për femrat, dhe ka një kolonë me vlerat 1 për femrat dhe 0 për meshkujt, atëherë kolona e fundit hiqet sepse vlerat e saj mund të merren nga kolona "treguesi mashkull".
Llogaritja e df për rastet kur X kolonat nuk hiqen nga modeli për shkak të kolinearitetit është si më poshtë: nëse ka k kolona të njohura_x dhe const = TRUE ose jo e specifikuar, atëherë df = n - k - 1. Nëse const = FALSE, atëherë df = n - k. Në të dyja rastet, heqja e kolonave X për shkak të kolinearitetit rrit vlerën e df me 1.
Formulat që kthejnë vargje duhet të futen si formula vargjesh.
Kur futni një grup konstantesh si një argument të njohur_x_values, për shembull, përdorni një pikëpresje për të ndarë vlerat në të njëjtën linjë dhe një pikëpresje për të ndarë linjat. Karakteret ndarëse mund të ndryshojnë në varësi të cilësimeve në dritaren "Gjuha dhe standardet" në panelin e kontrollit.
Vini re se vlerat y të parashikuara nga ekuacioni i regresionit mund të mos jenë të sakta nëse janë jashtë gamës së vlerave y që janë përdorur për të përcaktuar ekuacionin.
Algoritmi kryesor i përdorur në funksion LINEST, ndryshon nga algoritmi kryesor i funksioneve PJERRJE dhe SEGMENTI I LINJËS. Dallimet midis algoritmeve mund të çojnë në rezultate të ndryshme për të dhëna të pasigurta dhe kolineare. Për shembull, nëse pikat e të dhënave të argumentit të njohur_y janë 0 dhe pikat e të dhënave të argumentit të njohur_x janë 1, atëherë:
Funksioni LINEST kthen një vlerë të barabartë me 0. Algoritmi i funksionit LINEST përdoret për të kthyer vlera të përshtatshme për të dhënat kolineare, në të cilin rast mund të gjendet të paktën një përgjigje.
Funksionet SLOPE dhe INTERCEPT kthejnë gabimin #DIV/0!. Algoritmi i funksioneve SLOPE dhe INTERCEPT përdoret për të gjetur vetëm një përgjigje, dhe në këtë rast mund të ketë disa.
Përveç llogaritjes së statistikave për llojet e tjera të regresionit, LINEST mund të përdoret për të llogaritur intervalet për llojet e tjera të regresionit duke futur funksione të ndryshoreve x dhe y si një seri ndryshoresh x dhe y për LINEST. Për shembull, formula e mëposhtme:
LINEST(y-vlera, x-vlera^COLUMN($A:$C))
punon me një kolonë të vlerave Y dhe një kolonë me vlera X për të llogaritur një përafrim të kubit (polinom i shkallës së 3-të) të formës së mëposhtme:
Formula mund të modifikohet për të llogaritur llojet e tjera të regresionit, por në disa raste kërkohen rregullime në vlerat e prodhimit dhe statistika të tjera.
Për mendimin tim, si student, ekonometria është një nga shkencat më të aplikuara nga të gjitha ato që kam arritur të njihem brenda mureve të universitetit tim. Me ndihmën e tij, në të vërtetë, është e mundur të zgjidhen problemet e aplikuara në një shkallë ndërmarrjeje. Sa efektive do të jenë këto zgjidhje është pyetja e tretë. Përfundimi është se shumica e njohurive do të mbeten teori, por ekonometria dhe analiza e regresionit ia vlen të studiohen me vëmendje të veçantë.
Çfarë e shpjegon regresionin?
Para se të fillojmë të shqyrtojmë funksionet e MS Excel që na lejojnë t'i zgjidhim këto probleme, do të doja t'ju shpjegoja me gishta se çfarë, në thelb, përfshin analizën e regresionit. Kështu që do të jetë më e lehtë për ju të merrni provimin, dhe më e rëndësishmja, do të jetë më interesante të studioni lëndën.
Shpresojmë se jeni njohur me konceptin e një funksioni nga matematika. Një funksion është një marrëdhënie midis dy variablave. Kur një variabël ndryshon, diçka i ndodh një tjetri. Ne ndryshojmë X, dhe Y ndryshon, përkatësisht. Funksionet përshkruajnë ligje të ndryshme. Duke ditur funksionin, ne mund të zëvendësojmë vlera arbitrare për X dhe të shohim se si ndryshon Y.
Kjo ka një rëndësi të madhe, pasi regresioni është një përpjekje për të shpjeguar, me ndihmën e një funksioni të caktuar, procese në dukje josistematike dhe kaotike. Kështu, për shembull, është e mundur të zbulohet marrëdhënia midis kursit të këmbimit të dollarit dhe papunësisë në Rusi.
Nëse kjo rregullsi mund të zbulohet, atëherë sipas funksionit të marrë nga ne gjatë llogaritjeve, ne do të jemi në gjendje të bëjmë një parashikim se cila do të jetë norma e papunësisë në kursin e N-të të këmbimit të dollarit kundrejt rublës.
Kjo marrëdhënie do të quhet korrelacion. Analiza e regresionit përfshin llogaritjen e koeficientit të korrelacionit, i cili do të shpjegojë ngushtësinë e marrëdhënies midis variablave që po shqyrtojmë (kursin e këmbimit të dollarit dhe numrin e vendeve të punës).
Ky koeficient mund të jetë pozitiv ose negativ. Vlerat e tij variojnë nga -1 në 1. Prandaj, mund të vërejmë një korrelacion të lartë negativ ose pozitiv. Nëse do të jetë pozitive, atëherë rritja e dollarit do të pasohet nga shfaqja e vendeve të reja të punës. Nëse është negative, atëherë rritja e kursit do të pasohet me ulje të vendeve të punës.
Regresioni është i disa llojeve. Mund të jetë linear, parabolik, eksponencial, eksponencial, etj. Zgjedhjen e modelit e bëjmë varësisht se cili regresion do t'i korrespondojë konkretisht rastit tonë, cili model do të jetë sa më afër korrelacionit tonë. Le ta shqyrtojmë atë në shembullin e problemit dhe ta zgjidhim atë në MS Excel.
Regresioni linear në MS Excel
Për të zgjidhur problemet e regresionit linear, ju nevojitet funksionaliteti i Analizës së të Dhënave. Mund të mos jetë i aktivizuar për ju, ndaj duhet ta aktivizoni.
- Klikoni në butonin "File";
- Zgjidhni artikullin "Opsionet";
- Klikoni në skedën e parafundit "Shtesa" në anën e majtë;

- Më poshtë do të shohim mbishkrimin "Menaxhimi" dhe butonin "Shko". Ne shtypim mbi të;
- Vendosni një shenjë në "Paketën e Analizës";
- Shtypim "ok".

Shembull i detyrës
Funksioni i analizës së grupit është aktivizuar. Le të zgjidhim problemin e mëposhtëm. Ne kemi një mostër të të dhënave për disa vite për numrin e situatave emergjente në territorin e ndërmarrjes dhe numrin e punëtorëve të punësuar. Ne duhet të identifikojmë marrëdhënien midis këtyre dy variablave. Ekziston një variabël shpjegues X, që është numri i punëtorëve, dhe një ndryshore shpjeguese, Y, që është numri i emergjencave. Le të shpërndajmë të dhënat fillestare në dy kolona.
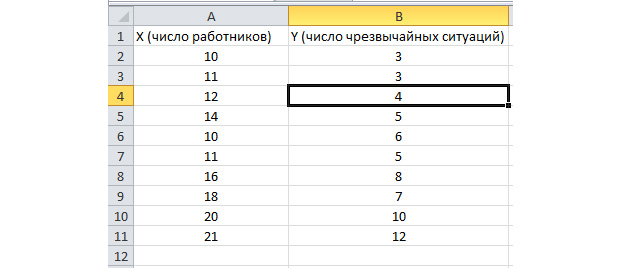
Shkoni te skedari "Të dhënat" dhe zgjidhni "Analiza e të dhënave"
Zgjidhni "Regresion" nga lista që shfaqet. Në intervalet e hyrjes Y dhe X, zgjidhni vlerat e duhura.

Ne shtypim "OK". Analiza është bërë, dhe në fletën e re do të shohim rezultatet.
Vlerat më domethënëse për ne janë shënuar në figurën më poshtë.
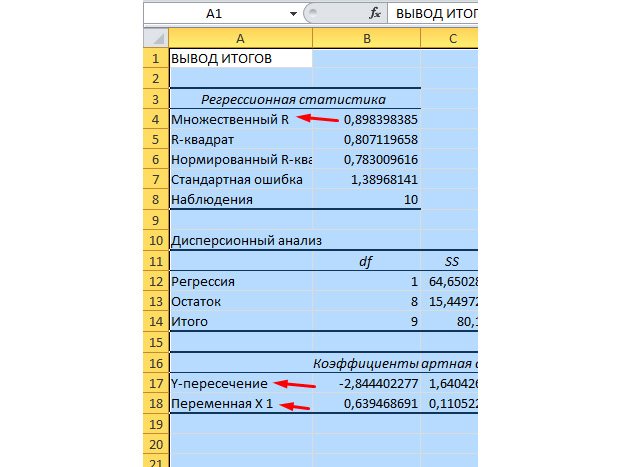
R shumëfishi është koeficienti i përcaktimit. Ka një formulë komplekse llogaritjeje dhe tregon se sa mund t'i besojmë koeficientit tonë të korrelacionit. Prandaj, sa më e madhe të jetë kjo vlerë, aq më i madh është besimi, aq më i suksesshëm është modeli ynë në tërësi.
Ndërprerja Y dhe Kryqëzimi X1 janë koeficientët e regresionit tonë. Siç është përmendur tashmë, regresioni është një funksion dhe ka koeficientë të caktuar. Kështu, funksioni ynë do të duket si: Y = 0.64 * X-2.84.
Çfarë na jep? Kjo na jep mundësinë për të bërë një parashikim. Le të themi se duam të punësojmë 25 punonjës për një ndërmarrje dhe duhet të imagjinojmë afërsisht sa do të jetë numri i emergjencave. Ne e zëvendësojmë këtë vlerë në funksionin tonë dhe marrim rezultatin Y = 0.64 * 25 - 2.84. Afërsisht 13 gjendje të jashtëzakonshme do të kemi.
Le të shohim se si funksionon. Hidhini një sy fotos më poshtë. Vlerat aktuale për punonjësit e përfshirë zëvendësohen në funksionin që kemi marrë. Shihni sa afër janë vlerat me lojtarët e vërtetë.

Ju gjithashtu mund të ndërtoni një fushë korrelacioni duke theksuar zonën y dhe x, duke klikuar në skedën "insert" dhe duke zgjedhur grafikun e shpërndarjes.

Pikat janë të shpërndara, por në përgjithësi lëvizin lart sikur të ketë një vijë të drejtë në mes. Dhe gjithashtu mund ta shtoni këtë rresht duke shkuar te skeda "Layout" në MS Excel dhe duke zgjedhur artikullin "Trend Line".
Klikoni dy herë në rreshtin që shfaqet dhe do të shihni atë që u tha më parë. Ju mund të ndryshoni llojin e regresionit në varësi të asaj se si duket fusha juaj e korrelacionit.
Ju mund të zbuloni se pikat vizatojnë një parabolë dhe jo një vijë të drejtë dhe mund të dëshironi të zgjidhni një lloj tjetër regresioni.

konkluzioni
Shpresojmë, ky artikull ju ka dhënë një kuptim më të mirë se çfarë është analiza e regresionit dhe për çfarë shërben. E gjithë kjo ka një rëndësi të madhe praktike.