Unicode (në anglisht Unicode) është një standard kodimi i karaktereve. E thënë thjesht, kjo është një tabelë e korrespondencës së karaktereve të tekstit (, shkronja, elementet e pikësimit) kodet binare. Kompjuteri kupton vetëm sekuencën e zeros dhe njëshit. Në mënyrë që ai të dijë se çfarë saktësisht duhet të shfaqë në ekran, është e nevojshme të caktohet një numër unik për secilin personazh. Në vitet tetëdhjetë, karakteret u koduan në një bajt, domethënë në tetë bit (çdo bit është 0 ose 1). Kështu, rezultoi se një tabelë (aka kodim ose grup) mund të mbajë vetëm 256 karaktere. Kjo mund të mos mjaftojë as për një gjuhë. Prandaj, u shfaqën shumë kodime të ndryshme, konfuzioni me të cilin shpesh çonte në faktin se në vend të tekstit të lexueshëm, në ekran u shfaqën disa krakozyabry të çuditshme. Kërkohej një standard i vetëm, i cili u bë Unicode. Kodimi më i përdorur është UTF-8 (Unicode Transformation Format), i cili përdor 1 deri në 4 bajt për të shfaqur një karakter.
Simbolet
Karakteret në tabelat Unicode numërohen me numra heksadecimal. Për shembull, shkronja e madhe cirilike M është caktuar U + 041C. Kjo do të thotë se ai qëndron në kryqëzimin e rreshtit 041 dhe kolonës C. Ju thjesht mund ta kopjoni dhe më pas ta ngjisni diku. Për të mos gërmuar nëpër një listë shumë kilometrash, duhet të përdorni kërkimin. Duke shkuar në faqen e simboleve, do të shihni numrin e tij në Unicode dhe mënyrën se si është vizatuar në fonte të ndryshme. Ju gjithashtu mund ta futni vetë shenjën në shiritin e kërkimit, edhe nëse në vend të tij vizatohet një katror, të paktën për të gjetur se çfarë ishte. Gjithashtu, në këtë faqe ka grupe të veçanta (dhe - të rastësishme) të të njëjtit lloj ikonash, të mbledhura nga seksione të ndryshme, për lehtësinë e përdorimit.
Standardi Unicode është ndërkombëtar. Ai përfshin shenja nga pothuajse të gjitha shkrimet në botë. Përfshirë ato që nuk përdoren më. Hieroglifet egjiptiane, runat gjermanike, shkrimet maja, kuneiformat dhe alfabetet e shteteve antike. Paraqiten dhe përcaktimi i masave dhe peshave, notimi muzikor, konceptet matematikore.
Vetë Konsorciumi Unicode nuk shpik personazhe të rinj. Në tabela shtohen ato ikona që gjejnë aplikimin e tyre në shoqëri. Për shembull, shenja rubla u përdor në mënyrë aktive për gjashtë vjet përpara se të shtohej në Unicode. Piktogramet emoji (emoticons) gjithashtu u përdorën gjerësisht për herë të parë në Japoni dhe përpara se të përfshiheshin në kodim. Por markat tregtare dhe logot e kompanisë nuk shtohen në parim. Madje po aq e zakonshme sa Apple Apple apo flamuri i Windows. Sot, në versionin 8.0, janë të koduara rreth 120 mijë karaktere.
Për të përdorur me kompetencë ASCII, është e nevojshme të zgjerohen njohuritë në këtë fushë dhe për mundësitë e kodimit.
Cfare eshte?
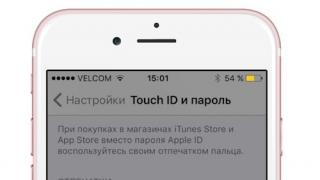
ASCII është një tabelë koduese e karaktereve të printueshme (shih pamjen e ekranit # 1) e shtypur në një tastierë kompjuteri për të transferuar informacione dhe disa kode. Me fjalë të tjera, alfabeti dhe shifrat dhjetore janë të koduara në simbolet përkatëse që përfaqësojnë dhe mbajnë informacionin e nevojshëm.
Kodimi ASCII u zhvillua në Amerikë, kështu që tabela standarde e kodimit zakonisht përfshin alfabetin anglez me numra, për një total prej rreth 128 karaktere. Por atëherë lind një pyetje e drejtë: çfarë të bëjmë nëse nevojitet kodimi i alfabetit kombëtar?
Versione të tjera të tabelës ASCII janë zhvilluar për të adresuar këto çështje. Për shembull, për gjuhët me një strukturë gjuhësore të huaj, shkronjat e alfabetit anglez ose u hoqën, ose u shtuan karaktere shtesë në formën e një alfabeti kombëtar. Pra, në kodimin ASCII mund të ketë shkronja ruse për përdorim kombëtar (shih pamjen e ekranit # 2).

Ku përdoret sistemi i kodimit ASCII?
Ky sistem kodimi është i nevojshëm jo vetëm për të shtypur informacionin e tekstit në tastierë. Përdoret gjithashtu në grafikë. Për shembull, në programin ASCII Art Maker, imazhet grafike të shtesave të ndryshme përbëhen nga një spektër karakteresh ASCII (shih pamjen e ekranit # 3).

Si rregull, programe të tilla mund të ndahen në ato që kryejnë funksionin e redaktuesve grafikë, duke e kthyer imazhin në tekst, dhe ato që e shndërrojnë imazhin në grafikë ASCII. Emoticon i njohur (ose siç quhet edhe " fytyrë njerëzore e qeshur") Është gjithashtu një shembull i një karakteri kodues.
Kjo metodë e kodimit mund të jetë gjithashtu e dobishme kur shkruani ose krijoni një dokument HTML. Për shembull, ju futni një grup specifik dhe të nevojshëm karakteresh dhe kur shikoni vetë faqen, një karakter që korrespondon me këtë kod do të shfaqet në ekran.
Ndër të tjera, ky lloj kodimi është i nevojshëm kur krijoni një faqe shumëgjuhëshe, sepse karakteret që nuk përfshihen në këtë apo atë tabelë kombëtare do të duhet të zëvendësohen me kode ASCII. Nëse lexuesi është i lidhur drejtpërdrejt me teknologjitë e informacionit dhe komunikimit (TIK), atëherë do të jetë e dobishme që ai të njihet me sisteme të tilla si:
- Set portativ i karaktereve;
- personazhet e kontrollit;
- EBCDIC;
- VISCII;
- YUSCII;
- Unicode;
- arti ASCII;
- KOI-8.
Karakteristikat e tabelës ASCII
Si me çdo program të sistemuar, ASCII ka vetitë e veta karakteristike. Kështu, për shembull, sistemi i numrave dhjetorë (shifrat nga 0 në 9) konvertohet në sistemin e numrave binar (d.m.th., çdo shifër dhjetore konvertohet në binar 288 = 1001000, përkatësisht).
Shkronjat e vendosura në kolonat e sipërme dhe të poshtme ndryshojnë nga njëra-tjetra vetëm pak, gjë që redukton ndjeshëm nivelin e kompleksitetit të kontrollit dhe redaktimit të rastit.
Me të gjitha këto veti, kodimi ASCII funksionon si tetë bit, megjithëse fillimisht ishte parashikuar si shtatë bit.
Aplikimi i ASCII në programet e Microsoft Office:
Nëse është e nevojshme, ky opsion për kodimin e informacionit mund të përdoret në Microsoft Notepad dhe Microsoft Office Word. Brenda këtyre aplikacioneve, dokumenti mund të ruhet në formatin ASCII, por në këtë rast nuk do të jetë e mundur të përdoren disa funksione gjatë shtypjes.
Në veçanti, zgjedhja me shkronja të zeza dhe të zeza nuk do të jetë e disponueshme, sepse kodimi ruan vetëm kuptimin e informacionit të shtypur, dhe jo pamjen dhe formën e përgjithshme. Ju mund të shtoni kode të tilla në një dokument duke përdorur aplikacionet e mëposhtme të softuerit:
- Microsoft Excel;
- Microsoft FrontPage;
- Microsoft InfoPath
- Microsoft OneNote
- Microsoft Outlook;
- Microsoft PowerPoint;
- Projekti Microsoft.
Duhet të kihet parasysh se gjatë shtypjes së kodit ASCII në këto aplikacione, duhet të mbani të shtypur tastin ALT të tastierës.
Sigurisht, të gjitha kodet e nevojshme kërkojnë një studim më të gjatë dhe më të detajuar, por kjo është përtej qëllimit të artikullit tonë të sotëm. Shpresoj që ta gjeni vërtet të dobishme.
Deri herën tjetër!
Mire keq
Siç e dini, një kompjuter ruan informacionin në formë binare, duke e paraqitur atë si një sekuencë njësh dhe zero. Për të përkthyer informacionin në një formë që është e përshtatshme për perceptimin njerëzor, çdo sekuencë unike e numrave zëvendësohet me simbolin përkatës kur shfaqet.
Një nga sistemet për lidhjen e kodeve binare me karakteret e printueshme dhe të kontrollit është
Në nivelin aktual të zhvillimit të teknologjisë kompjuterike, përdoruesi nuk kërkohet të dijë kodin e çdo simboli specifik. Sidoqoftë, një kuptim i përgjithshëm se si kryhet kodimi është jashtëzakonisht i dobishëm, dhe për disa kategori specialistësh madje i nevojshëm.
Krijimi i ASCII
Në formën e tij origjinale, kodimi u zhvillua në 1963 dhe më pas u përditësua dy herë brenda 25 viteve.
Në versionin origjinal, tabela e karaktereve ASCII përfshinte 128 karaktere, më vonë u shfaq një version i zgjeruar, ku u ruajtën 128 karakteret e para dhe karakteret që mungonin më parë iu caktuan kodeve me bitin e tetë të përfshirë.
Për shumë vite, ky kodim ka qenë më i popullarizuari në botë. Në vitin 2006, Latin 1252 zuri pozitën udhëheqëse, dhe nga fundi i 2007 e deri më sot, Unicode ka mbajtur me vendosmëri pozicionin drejtues.
Përfaqësimi kompjuterik ASCII
Çdo karakter ASCII ka kodin e tij prej 8 karakteresh që përfaqësojnë zero ose një. Numri minimal në një paraqitje të tillë është zero (tetë zero në sistemin binar), që është kodi i elementit të parë në tabelë.
Dy kode në tabelë u rezervuan për kalimin midis standardit US-ASCII dhe versionit të tij kombëtar.

Pasi ASCII filloi të përfshijë jo 128, por 256 karaktere, një variant i kodimit u përhap gjerësisht, në të cilin versioni origjinal i tabelës u ruajt në 128 kodet e para me një bit të 8-të zero. Shenjat e shkrimit kombëtar ruheshin në gjysmën e sipërme të tabelës (pozicionet 128-255).
Përdoruesi nuk ka nevojë të dijë drejtpërdrejt kodet e karaktereve ASCII. Zakonisht mjafton që një zhvillues softuerësh të dijë numrin e një elementi në një tabelë në mënyrë që të llogarisë kodin e tij duke përdorur një sistem binar, nëse është e nevojshme.
Gjuha ruse
Pas zhvillimit të kodimeve për gjuhët skandinave, kineze, koreane, greke etj. në fillim të viteve 70, edhe Bashkimi Sovjetik filloi të krijojë versionin e tij. Së shpejti, u zhvillua një version i kodimit 8-bit i quajtur KOI8, i cili ruan 128 kodet e para të karaktereve ASCII dhe cakton të njëjtin numër pozicionesh për shkronjat e alfabetit kombëtar dhe karaktere shtesë.
Para prezantimit të Unicode, KOI8 dominonte segmentin rus të internetit. Kishte opsione kodimi për alfabetin rus dhe ukrainas.
Problemet ASCII
Meqenëse numri i elementeve edhe në tabelën e zgjeruar nuk i kalonte 256, nuk ekzistonte mundësia e vendosjes së disa skripteve të ndryshme në një kodim. Në vitet '90, problemi i "crocozyabr" u shfaq në Runet, kur tekstet e shtypura me karaktere ruse ASCII u shfaqën gabimisht.
Problemi ishte se kodet e varianteve të ndryshme ASCII nuk përputheshin me njëri-tjetrin. Kujtoni që pozicionet 128-255 mund të përmbajnë karaktere të ndryshme, dhe kur ndryshoni një kodim cirilik në një tjetër, të gjitha shkronjat e tekstit u zëvendësuan me të tjera që kishin një numër identik në një version tjetër të kodimit.
Gjendja e tanishme
Me ardhjen e Unicode, popullariteti i ASCII ra ndjeshëm.
Arsyeja për këtë qëndron në faktin se kodimi i ri bëri të mundur akomodimin e shenjave të pothuajse të gjitha gjuhëve të shkruara. Në këtë rast, 128 karakteret e para ASCII korrespondojnë me të njëjtat karaktere në Unicode.

Në vitin 2000, ASCII ishte kodimi më i popullarizuar në internet dhe përdorej në 60% të faqeve të internetit të indeksuara nga Google. Deri në vitin 2012, pjesa e faqeve të tilla kishte rënë në 17%, dhe Unicode (UTF-8) zuri vendin e kodimit më të njohur.
Kështu, ASCII është një pjesë e rëndësishme e historisë së teknologjisë së informacionit, por përdorimi i tij në të ardhmen shihet si jopremtues.
Excel për Office 365 Word për Office 365 Outlook për Office 365 PowerPoint për Office 365 Publisher për Office 365 Excel 2019 Word 2019 Outlook 2019 PowerPoint 2019 OneNote 2016 Publisher 2019 Visio Professional 2019 Visio Standard 2019 Excel 2016 Word 2016 Outlook 2016 PowerPoint 2016 OneNote 2013 Publisher 2016 Visio 2013 Visio Professional 2016 Visio Standard 2016 Excel 2013 Word 2013 Outlook 2013 PowerPoint 2013 Publisher 2013 Excel 2010 Word 2010 Outlook 2010 PowerPoint 2010 OneNote 2010 Publisher 2010 Visio 2010 Excel 2007 Word 2007 Outlook 2007 PowerPoint 2007 Publisher 2007 Access 2007 Visio 2007 OneNote 2007 Office 2010 Visio Standard 2007 Visio Standard 2010 Më të vogla
Në këtë artikull
Futni një karakter ASCII ose Unicode në një dokument
Nëse ju duhet të futni vetëm disa karaktere ose simbole të veçanta, mund të përdorni ose shkurtoret e tastierës. Për një listë të karaktereve ASCII, shihni tabelat e mëposhtme ose artikullin Fut alfabetet kombëtare duke përdorur shkurtoret e tastierës.
Shënime:
Fut karaktere ASCII
Për të futur një karakter ASCII, shtypni dhe mbani tastin ALT ndërsa futni kodin e karakterit. Për shembull, për të futur një simbol të shkallës (º), shtypni dhe mbani tastin Alt, më pas futni 0176 në tastierën numerike.
Përdorni tastierën numerike për të futur numra në vend të numrave në tastierën kryesore. Nëse duhet të futni numra në tastierën numerike, sigurohuni që treguesi NUM LOCK të jetë i ndezur.
Futja e karaktereve Unicode
Për të futur një karakter Unicode, futni kodin e karakterit, më pas shtypni ALT dhe X në sekuencë. Për shembull, për të futur një shenjë dollari ($), futni 0024 dhe shtypni ALT dhe X me radhë. Për të gjitha kodet e karaktereve të Unicode, shihni.
E rëndësishme: Disa programe të Microsoft Office, të tilla si PowerPoint dhe InfoPath, nuk mbështesin konvertimin e kodeve të Unicode në karaktere. Nëse keni nevojë të futni një karakter Unicode në një nga këto programe, përdorni.
Shënime:
Nëse shihni karakterin e gabuar të Unicode pasi shtypni ALT + X, zgjidhni kodin e duhur dhe më pas shtypni përsëri ALT + X.
Për më tepër, "U +" duhet të futet përpara kodit. Për shembull, nëse futni "1U + B5" dhe shtypni Alt + X, shfaqet teksti "1µ", dhe nëse futni "1B5" dhe shtypni Alt + X, shfaqet karakteri "Ƶ".
Duke përdorur tabelën e simboleve
Symbol Map është një program i integruar në Microsoft Windows që ju lejon të shikoni simbolet e disponueshme për një font të zgjedhur.
Duke përdorur një tabelë simbolesh, mund të kopjoni simbole individuale ose një grup simbolesh në kujtesën e fragmenteve dhe t'i ngjisni në çdo program që mund t'i shfaqë ato simbole. Hapja e tabelës së simboleve
Në Windows 10 Futni fjalën "simbol" në kutinë e kërkimit në shiritin e detyrave dhe zgjidhni një tabelë simbolesh nga rezultatet e kërkimit.
Në Windows 8 Futni fjalën "karakter" në ekranin bazë dhe zgjidhni një tabelë karakteresh nga rezultatet e kërkimit.
Në Windows 7 Shtyp butonin Filloni, zgjidhni në mënyrë sekuenciale Të gjitha programet, Standard, Shërbimi dhe klikoni tabela e simboleve.
Karakteret janë grupuar sipas fontit. Klikoni në listën e shkronjave për të zgjedhur grupin e duhur të karaktereve. Për të zgjedhur një simbol, klikoni mbi të dhe më pas klikoni Zgjidhni... Për të futur një simbol, klikoni me të djathtën në vendndodhjen e dëshiruar në dokument dhe zgjidhni Fut.
Kodet e simboleve të përdorura shpesh
Për një listë të plotë të karaktereve, shihni kompjuterin tuaj, tabelën e kodit të karaktereve ASCII ose tabelat e grupeve të karaktereve Unicode.
|
Glyph |
Glyph |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Njësitë monetare |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simbolet ligjore |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simbolet e matematikës |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Thyesat |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simbolet e pikësimit dhe dialekteve |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Forma simbole |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Kodet diakritike të përdorura zakonishtPër një listë të plotë të glifeve dhe kodeve përkatëse, shihni.
|
Sipas Unionit Ndërkombëtar të Telekomunikacionit, në vitin 2016, tre miliardë e gjysmë njerëz përdorën internetin me rregullsi të ndryshme. Shumica e tyre as që e mendojnë faktin se çdo mesazh i dërguar prej tyre nëpërmjet kompjuterëve apo pajisjeve celulare, si dhe tekstet që shfaqen në të gjitha llojet e monitorëve, në fakt janë kombinime të 0 dhe 1. Ky prezantim i informacionit quhet kodim. . Ai siguron dhe lehtëson shumë ruajtjen, përpunimin dhe transmetimin e tij. Në vitin 1963, u zhvillua kodimi amerikan ASCII, të cilit i kushtohet ky artikull.
Prezantimi i informacionit në kompjuter
Nga pikëpamja e çdo kompjuteri elektronik, teksti është një koleksion karakteresh individuale. Këto përfshijnë jo vetëm shkronjat, duke përfshirë shkronjat e mëdha, por edhe shenjat e pikësimit dhe numrat. Përveç kësaj, përdoren karaktere speciale "=", "&", "(" dhe hapësira.
Tërësia e simboleve që përbëjnë tekstin quhet alfabet dhe numri i tyre quhet kardinalitet (shënohet si N). Për ta përcaktuar atë, përdoret shprehja N = 2 ^ b, ku b është numri i biteve ose pesha informative e një karakteri të caktuar.
Është vërtetuar se një alfabet me një kapacitet prej 256 karakteresh mund të përfaqësojë të gjitha karakteret e nevojshme.
Meqenëse 256 është fuqia e 8-të e dy, pesha e çdo karakteri është 8 bit.
Njësia matëse prej 8 bitësh quhet 1 bajt, kështu që është zakon të thuhet se çdo karakter në një tekst të ruajtur në një kompjuter merr një bajt memorie.

Si bëhet kodimi
Çdo tekst futet në kujtesën e një kompjuteri personal me anë të tasteve të tastierës në të cilat janë shkruar numra, shkronja, shenja pikësimi dhe simbole të tjera. Ato transferohen në RAM në një kod binar, domethënë, çdo karakter shoqërohet me një kod dhjetor të njohur për njerëzit, nga 0 në 255, që korrespondon me një kod binar - nga 00000000 në 11111111.
Kodimi i karaktereve me byte i lejon procesorit të tekstit të aksesojë secilin karakter veç e veç. Në të njëjtën kohë, 256 karaktere janë të mjaftueshme për të përfaqësuar çdo informacion të karakterit.

Kodimi i karaktereve ASCII
Kjo shkurtesë në anglisht qëndron për kodin për shkëmbimin e informacionit.
Edhe në agimin e kompjuterizimit, u bë e qartë se ju mund të gjeni një shumëllojshmëri të gjerë mënyrash për të koduar informacionin. Megjithatë, për të transferuar informacion nga një kompjuter në tjetrin, kërkohej të zhvillohej një standard i vetëm. Pra, në vitin 1963, një tabelë kodimi ASCII u shfaq në Shtetet e Bashkuara. Në të, çdo simbol i alfabetit të kompjuterit shoqërohet me numrin e tij rendor në paraqitjen binar. Fillimisht, ASCII u përdor vetëm në Shtetet e Bashkuara dhe më vonë u bë standardi ndërkombëtar për PC.
Kodet ASCII ndahen në 2 pjesë. Vetëm gjysma e parë e kësaj tabele konsiderohet Standard Ndërkombëtar. Ai përfshin karaktere me numra rendorë nga 0 (i koduar si 00000000) deri në 127 (kodi 01111111).
Numër serik | Kodimi i tekstit ASCII | Simboli |
0000 0000 - 0001 1111 | Karakteret me N nga 0 në 31 quhen karaktere kontrolli. Funksioni i tyre është të "udhëzojnë" procesin e shfaqjes së tekstit në një monitor ose pajisje printimi, duke dhënë një sinjal zanor etj. |
|
0010 0000 - 0111 1111 | Karaktere me N nga 32 në 127 (pjesa standarde e tabelës) - shkronja të mëdha dhe të vogla të alfabetit latin, 10 shifra, shenja pikësimi, si dhe kllapa të ndryshme, simbole tregtare dhe të tjera. Karakteri 32 tregon një hapësirë. |
|
1000 0000 - 1111 1111 | Karakteret me N nga 128 në 255 (pjesë alternative e tabelës ose faqe kodi) mund të kenë variante të ndryshme, secila prej të cilave ka numrin e vet. Faqja e kodit përdoret për të specifikuar alfabetet kombëtare që janë të ndryshëm nga latinishtja. Në veçanti, është me ndihmën e tij që kryhet kodimi ASCII për karakteret ruse. |
Në tabelën e kodimit, shkronjat e mëdha dhe ndiqni njëra pas tjetrës sipas rendit alfabetik, dhe numrat - sipas renditjes rritëse të vlerave. Ky parim vlen edhe për alfabetin rus.
Personazhet e kontrollit
Tabela e kodimit ASCII u krijua fillimisht për të marrë dhe transmetuar informacion në një pajisje të tillë që nuk është përdorur për një kohë të gjatë, siç është teletypi. Në këtë drejtim, në grupin e karaktereve janë përfshirë karaktere jo të printueshme, të përdorura si komanda për të kontrolluar këtë pajisje. Komanda të ngjashme u përdorën në metoda të tilla të mesazheve para kompjuterike si kodi Morse, etj.
Karakteri më i zakonshëm "teletipi" është NUL (00, "zero"). Përdoret ende në shumicën e gjuhëve programuese deri më sot, duke treguar një terminator të linjës.

Ku përdoret kodimi ASCII?
Kodi standard i SHBA-së nevojitet për më shumë sesa thjesht futjen e informacionit të tekstit nga tastiera. Përdoret gjithashtu në grafikë. Në mënyrë të veçantë, në ASCII Art Maker, imazhet e zgjerimeve të ndryshme përfaqësojnë një spektër karakteresh ASCII.
Produkte të tilla janë dy llojesh: ato kryejnë funksionin e redaktuesve grafikë duke konvertuar imazhet në tekst dhe duke konvertuar "fotografitë" në grafikë ASCII. Për shembull, emoticon i famshëm është një shembull kryesor i një karakteri kodues.
ASCII mund të përdoret gjithashtu kur krijoni një dokument HTML. Në këtë rast, mund të futni një grup të caktuar karakteresh dhe kur shikoni faqen, në ekran do të shfaqet një karakter që korrespondon me këtë kod.
ASCII është gjithashtu i nevojshëm për krijimin e faqeve shumëgjuhëshe, pasi karakteret që nuk përfshihen në një tabelë specifike kombëtare zëvendësohen me kode ASCII.

Disa veçori
Për të koduar informacionin e tekstit në kodimin ASCII, fillimisht u përdorën 7 bit (njëri mbeti bosh), por sot funksionon si 8-bit.
Shkronjat në kolonën e sipërme dhe të poshtme ndryshojnë nga njëra-tjetra vetëm me një bit të vetëm. Kjo redukton shumë kompleksitetin e kontrollit.
Përdorimi i ASCII në Microsoft Office
Nëse është e nevojshme, ky lloj kodimi teksti mund të përdoret në redaktuesit e tekstit të Microsoft si Notepad dhe Office Word. Sidoqoftë, kur shkruani në këtë rast, nuk do të jetë e mundur të përdorni disa funksione. Për shembull, ju nuk do të jeni në gjendje të bëni bold, sepse ASCII ruan vetëm kuptimin e informacionit, duke injoruar pamjen dhe formën e tij të përgjithshme.

Standardizimi
Organizata ISO ka miratuar standardet ISO 8859. Ky grup përcakton kodimet me tetë bit për grupe të ndryshme gjuhësore. Në mënyrë të veçantë, ISO 8859-1 është Extended ASCII, e cila është një tabelë për Shtetet e Bashkuara dhe Evropën Perëndimore. Dhe ISO 8859-5 është një tabelë e përdorur për alfabetin cirilik, duke përfshirë gjuhën ruse.
Për një sërë arsyesh historike, standardi ISO 8859-5 ka qenë në përdorim për një kohë shumë të shkurtër.
Për gjuhën ruse, për momentin, përdoren në të vërtetë kodimet:
- CP866 (Kodi Faqe 866) ose DOS, i cili shpesh quhet kodimi alternativ GOST. Ajo u përdor në mënyrë aktive deri në mesin e viteve '90 të shekullit të kaluar. Për momentin, praktikisht nuk është përdorur.
- KOI-8. Kodimi u zhvillua në vitet 1970-80, dhe për momentin është një standard i pranuar përgjithësisht për mesazhet postare në Runet. Përdoret gjerësisht në OS të familjes Unix, duke përfshirë Linux. Versioni "rus" i KOI-8 quhet KOI-8R. Përveç kësaj, ka versione për gjuhë të tjera cirilike, si për shembull ukrainisht.
- Kodi Faqe 1251 (CP 1251, Windows - 1251). Zhvilluar nga Microsoft për të ofruar mbështetje për gjuhën ruse në mjedisin Windows.
Avantazhi kryesor i standardit të parë CP866 ishte ruajtja e karaktereve pseudografike në të njëjtat pozicione si në Extended ASCII. Kjo bëri të mundur ekzekutimin pa ndryshime të programeve tekstuale të prodhuara nga jashtë, si p.sh. Norton Commander i mirënjohur. Për momentin, CP866 përdoret për programet e zhvilluara nën Windows që funksionojnë në modalitetin e tekstit në ekran të plotë ose në dritaret e tekstit, duke përfshirë FAR Manager.
Tekstet kompjuterike të shkruara në kodimin CP866 janë mjaft të rralla kohët e fundit, por është pikërisht ky kodim që përdoret për emrat e skedarëve rusë në Windows.
"Unicode"
Për momentin, është ky kodim që ka marrë përdorimin më të përhapur. Kodet Unicode ndahen në zona. E para (U + 0000 në U + 007F) përfshin karaktere ASCII me kode. Kjo pasohet nga zonat e shenjave të shkrimeve të ndryshme kombëtare, si dhe shenjat e pikësimit dhe simbolet teknike. Përveç kësaj, disa nga kodet "Unicode" janë të rezervuara në rast se ka nevojë për të përfshirë karaktere të reja në të ardhmen.

Tani e dini se në ASCII, çdo karakter përfaqësohet si një kombinim i 8 zerave dhe njësheve. Për jo-specialistët, ky informacion mund të duket i panevojshëm dhe jo interesant, por a nuk doni të dini se çfarë po ndodh "në trurin" e kompjuterit tuaj?!