NË shkëlqejnë ekziston një mënyrë edhe më e shpejtë dhe më e përshtatshme për të hartuar një regresion linear (dhe madje edhe llojet kryesore të regresioneve jolineare, shih më poshtë). Kjo mund të bëhet si kjo:
1) zgjidhni kolonat me të dhëna X Dhe Y(ata duhet të jenë në atë renditje!);
2) telefononi Magjistari i grafikut dhe zgjidhni në një grup Lloji – me pika dhe shtypni menjëherë Gati;
3) pa hequr zgjedhjen e diagramit, zgjidhni artikullin e menysë kryesore që shfaqet Diagramë, në të cilën duhet të zgjidhni artikullin Shtoni linjën e trendit;
4) në dialogun që shfaqet linjë trendi skedën Lloji zgjidhni Linear;
5) skeda Parametrat ndërprerësi mund të aktivizohet Trego ekuacionin në tabelë, i cili do t'ju lejojë të shihni ekuacionin e regresionit linear (4.4), në të cilin do të llogariten koeficientët (4.5).
6) Në të njëjtën skedë, mund të aktivizoni çelësin Vendosni në diagram vlerën e besueshmërisë së përafrimit (R^2). Kjo vlerë është katrori i koeficientit të korrelacionit (4.3) dhe tregon se sa mirë ekuacioni i llogaritur përshkruan varësinë eksperimentale. Nëse R 2 është afër unitetit, atëherë ekuacioni teorik i regresionit përshkruan mirë varësinë eksperimentale (teoria pajtohet mirë me eksperimentin), dhe nëse R 2 është afër zeros, atëherë ky ekuacion nuk është i përshtatshëm për të përshkruar varësinë eksperimentale (teoria nuk pajtohet me eksperimentin).
Si rezultat i kryerjes së veprimeve të përshkruara, do të merrni një diagram me një grafik regresioni dhe ekuacionin e tij.
§4.3. Llojet kryesore të regresionit jolinear
Regresioni parabolik dhe polinom.
Parabolike varësia e vlerës Y nga vlera X varësia e shprehur nga një funksion kuadratik (parabola e rendit të dytë) quhet:
Ky ekuacion quhet regresioni parabolik Y në X. Parametrat por, b, nga thirrur koeficientët e regresionit parabolik. Llogaritja e koeficientëve të regresionit parabolik është gjithmonë e rëndë, kështu që rekomandohet përdorimi i një kompjuteri për llogaritjet.
Ekuacioni (4.8) i regresionit parabolik është një rast i veçantë i një regresioni më të përgjithshëm të quajtur polinom. polinom varësia e vlerës Y nga vlera X quhet varësia e shprehur me polinomin n- urdhri:
ku janë numrat a i (i=0,1,…, n) quhen koeficientët e regresionit polinom.
Regresioni i fuqisë.
Fuqia varësia e vlerës Y nga vlera X quhet varësi e formës:
Ky ekuacion quhet ekuacioni i regresionit të fuqisë Y në X. Parametrat por Dhe b thirrur koeficientët e regresionit të fuqisë.
ln=ln a+b ln x. (4.11)
Ky ekuacion përshkruan një vijë të drejtë në rrafsh me boshte koordinative logaritmike ln x dhe ln. Prandaj, kriteri për zbatueshmërinë e regresionit të fuqisë është kërkesa që pikat e logaritmeve të të dhënave empirike ln x i dhe ln i ishin më afër vijës së drejtë (4.11).
regresioni eksponencial.
shembullore(ose eksponenciale) varësia e sasisë Y nga vlera X quhet varësi e formës:
(ose ). (4.12)
Ky ekuacion quhet ekuacioni eksponencial(ose eksponenciale) regresioni Y në X. Parametrat por(ose k) Dhe b thirrur eksponenciale(ose eksponenciale) regresioni.
Nëse marrim logaritmin e të dy anëve të ekuacionit të regresionit të fuqisë, marrim ekuacionin
ln = x ln a+ln b(ose ln = k x+ln b). (4.13)
Ky ekuacion përshkruan varësinë lineare të logaritmit të një sasie ln nga një sasi tjetër x. Prandaj, kriteri për zbatueshmërinë e regresionit të fuqisë është kërkesa që të dhënat empirike të tregojnë të njëjtën madhësi x i dhe logaritme të një vlere tjetër ln i ishin më afër vijës së drejtë (4.13).
regresioni logaritmik.
Logaritmike varësia e vlerës Y nga vlera X quhet varësi e formës:
=a+b ln x. (4.14)
Ky ekuacion quhet regresioni logaritmik Y në X. Parametrat por Dhe b thirrur koeficientët e regresionit logaritmik.
regresioni hiperbolik.
Hiperbolike varësia e vlerës Y nga vlera X quhet varësi e formës:
Ky ekuacion quhet ekuacioni i regresionit hiperbolik Y në X. Parametrat por Dhe b thirrur koeficientët e regresionit hiperbolik dhe përcaktohen me metodën e katrorëve më të vegjël. Zbatimi i kësaj metode çon në formulat:
Në formulat (4.16-4.17), përmbledhja kryhet mbi indeksin i nga një në numrin e vëzhgimeve n.
Fatkeqësisht, në shkëlqejnë nuk ka asnjë funksion që llogarit koeficientët e regresionit hiperbolik. Në ato raste kur nuk dihet me siguri se vlerat e matura janë të lidhura me proporcion të zhdrejtë, rekomandohet të kërkohet ekuacioni i regresionit të fuqisë në vend të ekuacionit të regresionit hiperbolik, kështu që në shkëlqejnë ekziston një procedurë për gjetjen e saj. Nëse supozohet një varësi hiperbolike midis vlerave të matura, atëherë koeficientët e tij të regresionit do të duhet të llogariten duke përdorur tabela llogaritëse ndihmëse dhe operacionet e mbledhjes duke përdorur formulat (4.16-4.17).
Regresioni në Excel
Përpunimi statistikor i të dhënave mund të kryhet edhe duke përdorur paketën shtesë të Analizës në nën-artikullin e menysë "Shërbimi". Në Excel 2003, nëse hapni SHËRBIMI, nuk mund ta gjejmë skedën ANALIZA E TË DHËNAVE, më pas klikoni butonin e majtë të miut për të hapur skedën SHTESAT dhe pika e kundërt PAKETA E ANALIZËS duke klikuar butonin e majtë të miut, vendosni një shenjë (Fig. 17).
Oriz. 17. Dritare SHTESAT
Pas kësaj, menyja SHËRBIMI shfaqet skeda ANALIZA E TË DHËNAVE.
Në Excel 2007 për të instaluar ANALIZA E PAKETËS duhet të klikoni në butonin OFFICE në këndin e sipërm të majtë të fletës (Fig. 18a). Tjetra, klikoni në butonin OPTIONS EXCEL. Në dritaren që shfaqet OPTIONS EXCEL kliko me të majtën mbi artikull SHTESAT dhe në pjesën e djathtë të listës rënëse, zgjidhni artikullin PAKETA E ANALIZËS. Tjetra, klikoni mbi Ne rregull.




Oriz. 18. Instalimi ANALIZA E PAKETËS në Excel 2007
Për të instaluar Paketën e Analizës, klikoni butonin SHKO, në fund të dritares së hapur. Dritarja e paraqitur në Fig. 12. Kontrolloni kutinë pranë PAKETA E ANALIZËS. Në skedën TË DHËNAT do të shfaqet butoni ANALIZA E TË DHËNAVE(Fig. 19).

Nga artikujt e propozuar, zgjidhni artikullin " REGRESIONI” dhe klikoni mbi të me butonin e majtë të miut. Tjetra, klikoni OK.

Dritarja e paraqitur në Fig. 21

Mjeti i analizës « REGRESIONI» përdoret për të përshtatur një grafik në një grup vëzhgimesh duke përdorur metodën e katrorëve më të vegjël. Regresioni përdoret për të analizuar efektin në një ndryshore të vetme të varur të vlerave të një ose më shumë variablave të pavarur. Për shembull, performanca atletike e një atleti ndikohet nga disa faktorë, duke përfshirë moshën, gjatësinë dhe peshën. Është e mundur të llogaritet shkalla e ndikimit të secilit prej këtyre tre faktorëve në performancën e një atleti, dhe më pas të përdoren të dhënat e marra për të parashikuar performancën e një atleti tjetër.
Vegla Regresioni përdor funksionin LINEST.
Kutia e dialogut REGRESS
Etiketat Zgjidhni kutinë e zgjedhjes nëse rreshti i parë ose kolona e parë e diapazonit të hyrjes përmban tituj. Fshi këtë kuti të kontrollit nëse nuk ka tituj. Në këtë rast, titujt e përshtatshëm për të dhënat e tabelës dalëse do të gjenerohen automatikisht.
Niveli i besueshmërisë Zgjidhni kutinë e kontrollit për të përfshirë një nivel shtesë në tabelën totale të prodhimit. Në fushën përkatëse, vendosni nivelin e besimit që dëshironi të aplikoni, përveç nivelit të paracaktuar të besimit 95%.
Konstante - zero Kontrolloni kutinë për të bërë që vija e regresionit të kalojë përmes origjinës.
Gama e daljes Futni një referencë në qelizën e sipërme majtas të diapazonit të daljes. Ndani të paktën shtatë kolona për tabelën e rezultateve të rezultateve, e cila do të përfshijë: rezultatet e analizës së variancës, koeficientët, gabimin standard të llogaritjes Y, devijimet standarde, numrin e vëzhgimeve, gabimet standarde për koeficientët.
Fletë pune e re Zgjidhni këtë kuti për të hapur një fletë të re pune në librin e punës dhe për të futur rezultatet e analizës duke filluar nga qeliza A1. Nëse është e nevojshme, vendosni një emër për fletën e re në fushën përballë pozicionit të duhur të butonit të radios.
Libri i ri i punës Kontrolloni këtë kuti për të krijuar një libër të ri pune në të cilin rezultatet do të shtohen në një fletë të re.
Mbetjet Zgjidhni kutinë e kontrollit për të përfshirë mbetjet në tabelën e daljes.
Mbetjet e standardizuara Zgjidhni kutinë e kontrollit për të përfshirë mbetjet e standardizuara në tabelën e daljes.
Komploti i mbetur Kontrolloni kutinë për të vizatuar mbetjet për çdo variabël të pavarur.
Fit Plot Zgjidhni kutinë e kontrollit për të paraqitur vlerat e parashikuara kundrejt vlerave të vëzhguara.
Skema e probabilitetit normal Kontrolloni kutinë për të paraqitur probabilitetin normal.
Funksioni LINEST
Për të kryer llogaritjet, zgjidhni qelizën në të cilën duam të shfaqim vlerën mesatare me kursorin dhe shtypni tastin = në tastierë. Më pas, në fushën Emri, specifikoni funksionin e dëshiruar, për shembull MESATAR(Fig. 22).

Oriz. 22 Gjetja e funksioneve në Excel 2003
Nëse në terren EMRI emri i funksionit nuk shfaqet, pastaj kliko me të majtën në trekëndëshin pranë fushës, pas së cilës do të shfaqet një dritare me një listë funksionesh. Nëse ky funksion nuk është në listë, atëherë kliko me të majtën mbi artikullin në listë FUNKSIONET E TJERA, do të shfaqet një kuti dialogu. MJESHTRI I FUNKSIONIT, në të cilën, duke përdorur lëvizjen vertikale, zgjidhni funksionin e dëshiruar, zgjidhni atë me kursorin dhe klikoni mbi Ne rregull(Fig. 23).

Oriz. 23. Funksioni Wizard
Për të kërkuar një funksion në Excel 2007, çdo skedë mund të hapet në meny, më pas për të kryer llogaritjet, zgjedhim qelizën në të cilën dëshirojmë të shfaqim vlerën mesatare me kursorin dhe shtypim tastin = në tastierë. Më pas, në fushën Emri, specifikoni funksionin MESATAR. Dritarja për llogaritjen e funksionit është e ngjashme me atë në Excel 2003.
Ju gjithashtu mund të zgjidhni skedën Formulat dhe të klikoni me të majtën në butonin në " INSERT FUNKSIONIN» (Fig. 24), do të shfaqet një dritare MJESHTRI I FUNKSIONIT, pamja e të cilit është e ngjashme me Excel 2003. Gjithashtu, në meny, mund të zgjidhni menjëherë kategorinë e funksioneve (të përdorura së fundi, financiare, logjike, tekst, datë dhe orë, matematikore, funksione të tjera), në të cilën do të kërkojmë për funksionin e dëshiruar.




Oriz. 24 Zgjedhja e funksionit në Excel 2007
Funksioni LINEST llogarit statistikat për një seri duke përdorur metodën e katrorëve më të vegjël për të llogaritur një vijë të drejtë që përafron më mirë të dhënat e disponueshme dhe më pas kthen një grup që përshkruan vijën e drejtë që rezulton. Ju gjithashtu mund të kombinoni funksionin LINEST me funksione të tjera për të llogaritur lloje të tjera modelesh që janë lineare në parametra të panjohur (parametrat e panjohur të të cilëve janë linearë), duke përfshirë seritë polinomiale, logaritmike, eksponenciale dhe të fuqisë. Për shkak se një grup vlerash është kthyer, funksioni duhet të specifikohet si një formulë grupi.
Ekuacioni për një vijë të drejtë është:
(në rast të vargjeve të shumta të vlerave x),
ku vlera e varur y është një funksion i vlerës së pavarur x, vlerat m janë koeficientët që korrespondojnë me çdo ndryshore të pavarur x dhe b është një konstante. Vini re se y, x dhe m mund të jenë vektorë. Funksioni LINEST kthen një grup ![]() . LINEST gjithashtu mund të kthejë statistika shtesë të regresionit.
. LINEST gjithashtu mund të kthejë statistika shtesë të regresionit.
LINEST(njohur_y-vlera; njohur_x-vlera; konst; statistika)
Vlerat e njohura_y - grupi i vlerave y që njihen tashmë për relacionin.
Nëse grupi i njohur_y ka një kolonë, atëherë çdo kolonë e grupit të njohur_x interpretohet si një ndryshore e veçantë.
Nëse grupi i njohur_y ka një rresht, atëherë çdo rresht i grupit të njohur_x interpretohet si një ndryshore e veçantë.
Known_x's është një grup opsional i x që janë tashmë të njohur për relacionin.
Vargu i njohur_x mund të përmbajë një ose më shumë grupe variablash. Nëse përdoret vetëm një variabël, atëherë vargjet_known_y_vlerat dhe të njohura_x_vlerat mund të jenë të çdo forme - për sa kohë që kanë të njëjtin dimension. Nëse përdoret më shumë se një ndryshore, atëherë know_y's duhet të jetë një vektor (d.m.th., një rresht i lartë ose një kolonë i gjerë).
Nëse array_known_x hiqet, atëherë ky grup (1;2;3;...) supozohet të jetë i njëjtë me madhësinë e grupit_known_y.
Const është një vlerë boolean që specifikon nëse konstanta b kërkohet të jetë 0.
Nëse argumenti "const" është TRUE ose i anashkaluar, atëherë konstanta b vlerësohet normalisht.
Nëse argumenti "const" është FALSE, atëherë vlera e b supozohet të jetë 0 dhe vlerat e m zgjidhen në atë mënyrë që relacioni të jetë i kënaqur.
Statistikat është një vlerë Boolean që tregon nëse statistikat shtesë të regresionit duhet të kthehen.
Nëse statistikat janë të vërteta, LINEST kthen statistika shtesë të regresionit. Vargu i kthyer do të duket kështu: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Nëse statistikat janë FALSE ose janë lënë jashtë, LINEST kthen vetëm koeficientët m dhe konstanten b.
Statistikat shtesë të regresionit.
Figura më poshtë tregon rendin në të cilin kthehen statistikat shtesë të regresionit.

Shënime:
Çdo vijë e drejtë mund të përshkruhet nga pjerrësia dhe kryqëzimi i saj me boshtin y:
Pjerrësia (m): Për të përcaktuar pjerrësinë e një vije, zakonisht të shënuar me m, duhet të merrni dy pika në vijë dhe ; pjerrësia do të jetë ![]() .
.
Kryqëzimi Y (b): Kryqëzimi y i një drejtëze, që zakonisht shënohet me b, është vlera y për pikën ku drejtëza kryqëzon boshtin y.
Ekuacioni drejtvizor ka formën . Nëse dihen vlerat e m dhe b, atëherë çdo pikë në vijë mund të llogaritet duke zëvendësuar vlerat e y ose x në ekuacion. Ju gjithashtu mund të përdorni funksionin TREND.
Nëse ka vetëm një ndryshore të pavarur x, mund të merrni pjerrësinë dhe ndërprerjen y drejtpërdrejt duke përdorur formulat e mëposhtme:
Pjerrësia: INDEX(LINEST(njohur_y, njohur_x), 1)
Ndërprerja Y: INDEX (LINEST (të njohura_y, të njohura_x), 2)
Saktësia e përafrimit duke përdorur vijën e drejtë të llogaritur nga funksioni LINEST varet nga shkalla e shpërndarjes së të dhënave. Sa më afër të jenë të dhënat me një vijë të drejtë, aq më i saktë është modeli i përdorur nga LINEST. Funksioni LINEST përdor metodën e katrorëve më të vegjël për të përcaktuar përshtatjen më të mirë me të dhënat. Kur ka vetëm një ndryshore të pavarur x, m dhe b llogariten duke përdorur formulat e mëposhtme:

ku x dhe y janë mesataret e mostrës, për shembull x = MESATAR (të njohura_x) dhe y = MESATAR (të njohura_y).
Funksionet e përshtatjes LINEST dhe LGRFPRIBL mund të llogarisin një kurbë të drejtë ose eksponenciale që i përshtatet më së miri të dhënave. Megjithatë, ata nuk i përgjigjen pyetjes se cili nga dy rezultatet është më i përshtatshëm për zgjidhjen e problemit. Ju gjithashtu mund të llogarisni funksionin TREND (njohur_y-vlerat; njohur_x-vlerat) për një vijë të drejtë, ose funksionin GROWTH (njohur_y-vlerat; njohur_x-vlerat) për një kurbë eksponenciale. Këto funksione, nëse hiqen nga argumenti new_x_values, kthejnë një grup vlerash të llogaritura y për vlerat aktuale x sipas një vije të drejtë ose kurbë. Më pas mund të krahasoni vlerat e llogaritura me vlerat aktuale. Ju gjithashtu mund të ndërtoni tabela për krahasim vizual.
Kur kryen një analizë regresioni, Microsoft Excel llogarit, për çdo pikë, katrorin e diferencës midis vlerës së parashikuar y dhe vlerës aktuale y. Shuma e këtyre diferencave në katror quhet shuma e mbetur e katrorëve (ssresid). Microsoft Excel më pas llogarit shumën totale të katrorëve (sstotal). Nëse const = TRUE ose nëse ky argument nuk specifikohet, shuma totale e katrorëve do të jetë e barabartë me shumën e diferencave në katror të vlerave reale y dhe vlerave mesatare y. Nëse const = FALSE, shuma e katrorëve do të jetë e barabartë me shumën e katrorëve të vlerave reale y (pa zbritur mesataren y nga herësi y). Pas kësaj, shuma e regresionit të katrorëve mund të llogaritet si më poshtë: ssreg = sstotal - ssresid. Sa më e vogël të jetë shuma e mbetur e katrorëve, aq më e madhe është vlera e koeficientit të determinizmit r2, që tregon se sa mirë ekuacioni i marrë duke përdorur analizën e regresionit shpjegon marrëdhëniet midis variablave. Koeficienti r2 është i barabartë me ssreg/sstotal.
Në disa raste, një ose më shumë kolona X (le vlerat Y dhe X të jenë në kolona) nuk kanë vlerë parashikuese shtesë në kolonat e tjera X. Me fjalë të tjera, fshirja e një ose më shumë kolonave X mund të rezultojë në vlera Y llogaritur me të njëjtën saktësi. Në këtë rast, kolonat e tepërta X do të përjashtohen nga modeli i regresionit. Ky fenomen quhet "kolinearitet" sepse kolonat e tepërta të X mund të përfaqësohen si shuma e disa kolonave jo të tepërta. LINEST kontrollon për kolinearitet dhe heq çdo kolonë X të tepërt nga modeli i regresionit nëse gjen ndonjë. Kolonat X të hequra mund të identifikohen në daljen LINEST me një faktor 0 dhe një vlerë se 0. Heqja e një ose më shumë kolonave si të tepërta ndryshon vlerën e df sepse varet nga numri i kolonave X të përdorura aktualisht për qëllime parashikuese. Shih shembullin 4 më poshtë për më shumë detaje mbi llogaritjen e df. Kur df ndryshon për shkak të heqjes së kolonave të tepërta, ndryshojnë edhe vlerat e sey dhe F. Shpesh nuk rekomandohet përdorimi i kolinearitetit. Megjithatë, duhet të përdoret nëse disa kolona X përmbajnë 0 ose 1 si një tregues që tregon nëse subjekti i eksperimentit është në një grup të veçantë. Nëse const = TRUE ose nëse ky argument nuk është specifikuar, LINEST fut një kolonë X shtesë për të simuluar pikën e kryqëzimit. Nëse ka një kolonë me vlerat 1 për meshkujt dhe 0 për femrat, dhe ka një kolonë me vlerat 1 për femrat dhe 0 për meshkujt, atëherë kolona e fundit hiqet sepse vlerat e saj mund të merren nga kolona "treguesi mashkull".
Llogaritja e df për rastet kur X kolonat nuk hiqen nga modeli për shkak të kolinearitetit është si më poshtë: nëse ka k kolona të njohura_x dhe const = TRUE ose jo e specifikuar, atëherë df = n - k - 1. Nëse const = FALSE, atëherë df = n -k. Në të dyja rastet, heqja e kolonave X për shkak të kolinearitetit rrit vlerën e df me 1.
Formulat që kthejnë vargje duhet të futen si formula vargjesh.
Kur futni një grup konstantesh si një argument të njohur_x_values, për shembull, përdorni një pikëpresje për të ndarë vlerat në të njëjtën linjë dhe një pikëpresje për të ndarë linjat. Karakteret ndarëse mund të ndryshojnë në varësi të cilësimeve në dritaren "Gjuha dhe standardet" në panelin e kontrollit.
Vini re se vlerat y të parashikuara nga ekuacioni i regresionit mund të mos jenë të sakta nëse janë jashtë gamës së vlerave y që janë përdorur për të përcaktuar ekuacionin.
Algoritmi kryesor i përdorur në funksion LINEST, ndryshon nga algoritmi kryesor i funksioneve PJERRJE Dhe SEKSIONI. Dallimet midis algoritmeve mund të çojnë në rezultate të ndryshme për të dhëna të pasigurta dhe kolineare. Për shembull, nëse pikat e të dhënave të argumentit të njohur_y janë 0 dhe pikat e të dhënave të argumentit të njohur_x janë 1, atëherë:
Funksioni LINEST kthen një vlerë të barabartë me 0. Algoritmi i funksionit LINEST përdoret për të kthyer vlera të përshtatshme për të dhënat kolineare, në të cilin rast mund të gjendet të paktën një përgjigje.
Funksionet SLOPE dhe INTERCEPT kthejnë gabimin #DIV/0!. Algoritmi i funksioneve SLOPE dhe INTERCEPT përdoret për të gjetur vetëm një përgjigje, dhe në këtë rast mund të ketë disa.
Përveç llogaritjes së statistikave për llojet e tjera të regresionit, LINEST mund të përdoret për të llogaritur intervalet për llojet e tjera të regresionit duke futur funksione të ndryshoreve x dhe y si një seri ndryshoresh x dhe y për LINEST. Për shembull, formula e mëposhtme:
LINEST(y-vlera, x-vlera^COLUMN($A:$C))
punon me një kolonë të vlerave Y dhe një kolonë me vlera X për të llogaritur një përafrim të kubit (polinom i shkallës së 3-të) të formës së mëposhtme:
Formula mund të modifikohet për të llogaritur llojet e tjera të regresionit, por në disa raste kërkohen rregullime në vlerat e prodhimit dhe statistika të tjera.
Për mendimin tim, si student, ekonometria është një nga shkencat më të aplikuara nga të gjitha ato që kam arritur të njihem brenda mureve të universitetit tim. Me ndihmën e tij, në të vërtetë, është e mundur të zgjidhen problemet e aplikuara në një shkallë ndërmarrjeje. Sa efektive do të jenë këto zgjidhje është pyetja e tretë. Përfundimi është se shumica e njohurive do të mbeten teori, por ekonometria dhe analiza e regresionit ia vlen të studiohen me vëmendje të veçantë.
Çfarë e shpjegon regresionin?
Para se të fillojmë të shqyrtojmë funksionet e MS Excel që na lejojnë t'i zgjidhim këto probleme, do të doja t'ju shpjegoja me gishta se çfarë përfshin në thelb analizën e regresionit. Kështu që do të jetë më e lehtë për ju të merrni provimin, dhe më e rëndësishmja, do të jetë më interesante të studioni lëndën.
Shpresojmë se jeni njohur me konceptin e një funksioni nga matematika. Një funksion është një marrëdhënie midis dy variablave. Kur një variabël ndryshon, diçka i ndodh një tjetri. Ne ndryshojmë X, dhe Y ndryshon, përkatësisht. Funksionet përshkruajnë ligje të ndryshme. Duke ditur funksionin, ne mund të zëvendësojmë vlera arbitrare për X dhe të shohim se si ndryshon Y.
Kjo ka një rëndësi të madhe, pasi regresioni është një përpjekje për të shpjeguar, me ndihmën e një funksioni të caktuar, procese në dukje josistematike dhe kaotike. Kështu, për shembull, është e mundur të zbulohet marrëdhënia midis kursit të këmbimit të dollarit dhe papunësisë në Rusi.
Nëse ky model mund të zbulohet, atëherë sipas funksionit që kemi marrë gjatë llogaritjeve, ne do të jemi në gjendje të bëjmë një parashikim se cila do të jetë norma e papunësisë në kursin e N-të të këmbimit të dollarit ndaj rublës.
Kjo marrëdhënie do të quhet korrelacion. Analiza e regresionit përfshin llogaritjen e koeficientit të korrelacionit, i cili do të shpjegojë ngushtësinë e marrëdhënies midis variablave që po shqyrtojmë (kursin e këmbimit të dollarit dhe numrin e vendeve të punës).
Ky koeficient mund të jetë pozitiv ose negativ. Vlerat e tij variojnë nga -1 në 1. Prandaj, mund të vërejmë një korrelacion të lartë negativ ose pozitiv. Nëse do të jetë pozitive, atëherë rritja e dollarit do të pasohet nga shfaqja e vendeve të reja të punës. Nëse është negative, atëherë rritja e kursit do të pasohet me ulje të vendeve të punës.
Regresioni është i disa llojeve. Mund të jetë linear, parabolik, eksponencial, eksponencial, etj. Zgjedhjen e modelit e bëjmë varësisht se cili regresion do t'i korrespondojë konkretisht rastit tonë, cili model do të jetë sa më afër korrelacionit tonë. Le ta shqyrtojmë atë në shembullin e problemit dhe ta zgjidhim atë në MS Excel.
Regresioni linear në MS Excel
Për të zgjidhur problemet e regresionit linear, ju nevojitet funksionaliteti i Analizës së të Dhënave. Mund të mos jetë i aktivizuar për ju, ndaj duhet ta aktivizoni.
- Klikoni në butonin "File";
- Zgjidhni artikullin "Opsionet";
- Klikoni në skedën e parafundit "Shtesa" në anën e majtë;

- Më poshtë do të shohim mbishkrimin "Menaxhimi" dhe butonin "Shko". Ne shtypim mbi të;
- Vendosni një shenjë në "Paketën e Analizës";
- Shtypim "ok".

Shembull i detyrës
Funksioni i analizës së grupit është aktivizuar. Le të zgjidhim problemin e mëposhtëm. Ne kemi një mostër të të dhënave për disa vite për numrin e situatave emergjente në territorin e ndërmarrjes dhe numrin e punëtorëve të punësuar. Ne duhet të identifikojmë marrëdhënien midis këtyre dy variablave. Ekziston një variabël shpjegues X, që është numri i punëtorëve, dhe një ndryshore shpjeguese, Y, që është numri i emergjencave. Le të shpërndajmë të dhënat fillestare në dy kolona.
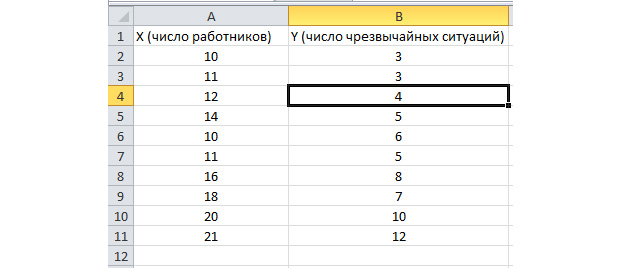
Shkoni te skedari "Të dhënat" dhe zgjidhni "Analiza e të dhënave"
Zgjidhni "Regresion" nga lista që shfaqet. Në intervalet e hyrjes Y dhe X, zgjidhni vlerat e duhura.
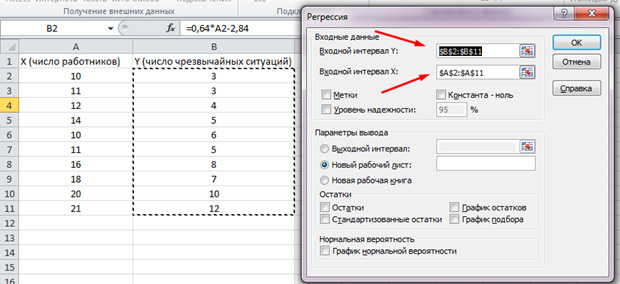
Ne shtypim "OK". Analiza është bërë, dhe në fletën e re do të shohim rezultatet.
Vlerat më domethënëse për ne janë shënuar në figurën më poshtë.
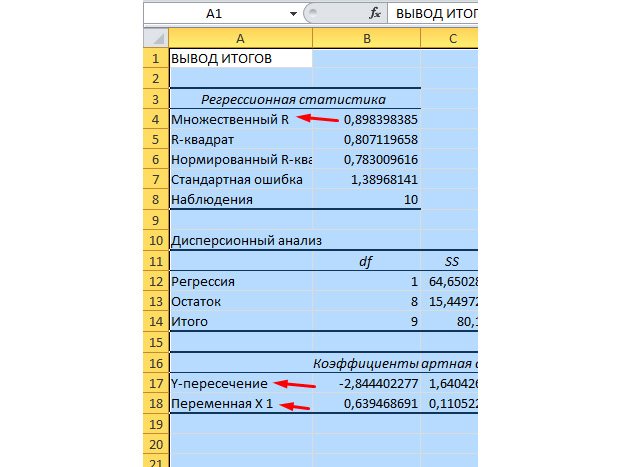
R shumëfishi është koeficienti i përcaktimit. Ka një formulë komplekse llogaritjeje dhe tregon se sa mund t'i besojmë koeficientit tonë të korrelacionit. Prandaj, sa më e madhe të jetë kjo vlerë, aq më i madh është besimi, aq më i suksesshëm është modeli ynë në tërësi.
Ndërprerja Y dhe Kryqëzimi X1 janë koeficientët e regresionit tonë. Siç është përmendur tashmë, regresioni është një funksion dhe ka koeficientë të caktuar. Kështu, funksioni ynë do të duket si: Y = 0.64 * X-2.84.
Çfarë na jep? Kjo na jep mundësinë për të bërë një parashikim. Le të themi se duam të punësojmë 25 punonjës për një ndërmarrje dhe duhet të imagjinojmë afërsisht sa do të jetë numri i emergjencave. Ne e zëvendësojmë këtë vlerë në funksionin tonë dhe marrim rezultatin Y = 0.64 * 25 - 2.84. Afërsisht 13 gjendje të jashtëzakonshme do të kemi.
Le të shohim se si funksionon. Hidhini një sy fotos më poshtë. Vlerat aktuale për punonjësit e përfshirë zëvendësohen në funksionin që kemi marrë. Shihni sa afër janë vlerat me lojtarët e vërtetë.

Ju gjithashtu mund të ndërtoni një fushë korrelacioni duke theksuar zonën y dhe x, duke klikuar në skedën "insert" dhe duke zgjedhur grafikun e shpërndarjes.

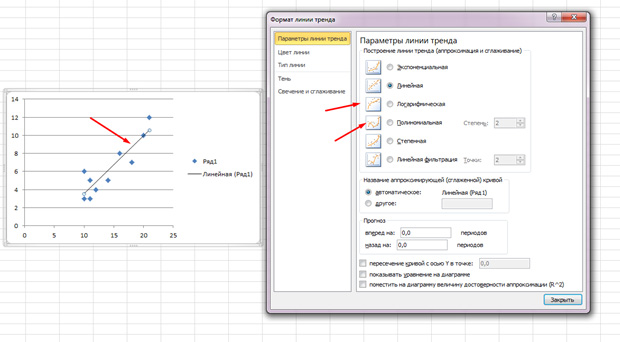
Pikat janë të shpërndara, por në përgjithësi lëvizin lart sikur të ketë një vijë të drejtë në mes. Dhe gjithashtu mund ta shtoni këtë rresht duke shkuar te skeda "Layout" në MS Excel dhe duke zgjedhur artikullin "Trend Line".
Klikoni dy herë në rreshtin që shfaqet dhe do të shihni atë që u tha më parë. Ju mund të ndryshoni llojin e regresionit në varësi të asaj se si duket fusha juaj e korrelacionit.
Ju mund të zbuloni se pikat vizatojnë një parabolë dhe jo një vijë të drejtë dhe mund të dëshironi të zgjidhni një lloj tjetër regresioni.
konkluzioni
Shpresojmë, ky artikull ju ka dhënë një kuptim më të mirë se çfarë është analiza e regresionit dhe për çfarë shërben. E gjithë kjo ka një rëndësi të madhe praktike.
Metoda e regresionit linear na lejon të përshkruajmë një vijë të drejtë që përshtatet më mirë me një seri çiftesh të renditura (x, y). Ekuacioni për një vijë të drejtë, i njohur si ekuacioni linear, është dhënë më poshtë:
ŷ është vlera e pritur e y për një vlerë të dhënë të x,
x është një ndryshore e pavarur,
a - segment në boshtin y për një vijë të drejtë,
b është pjerrësia e drejtëzës.
Në figurën më poshtë, ky koncept është paraqitur grafikisht:
Figura e mësipërme tregon një vijë të përshkruar nga ekuacioni ŷ =2+0.5x. Segmenti i drejtëzës në boshtin y është pika ku drejtëza pret boshtin y; në rastin tonë, a = 2. Pjerrësia e vijës, b, raporti i rritjes së vijës me gjatësinë e vijës, ka një vlerë prej 0,5. Një pjerrësi pozitive do të thotë që vija ngrihet nga e majta në të djathtë. Nëse b = 0, vija është horizontale, që do të thotë se nuk ka lidhje ndërmjet variablave të varur dhe të pavarur. Me fjalë të tjera, ndryshimi i vlerës së x nuk ndikon në vlerën e y.
ŷ dhe y shpesh ngatërrohen. Grafiku tregon 6 çifte pikash të renditura dhe një vijë, sipas ekuacionit të dhënë

Kjo figurë tregon pikën që i korrespondon çiftit të renditur x = 2 dhe y = 4. Vini re se vlera e pritshme e y sipas vijës në X= 2 është ŷ. Këtë mund ta konfirmojmë me ekuacionin e mëposhtëm:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Vlera y është pika aktuale dhe vlera ŷ është vlera e pritshme y duke përdorur një ekuacion linear për një vlerë të dhënë x.
Hapi tjetër është përcaktimi i ekuacionit linear që korrespondon maksimalisht me grupin e çifteve të renditura, për këtë folëm në artikullin e mëparshëm, ku përcaktuam formën e ekuacionit me .
Përdorimi i Excel për të përcaktuar regresionin linear
Për të përdorur mjetin e analizës së regresionit të integruar në Excel, duhet të aktivizoni shtesën Paketa e analizës. Mund ta gjeni duke klikuar në skedën Skedari –> Opsionet(2007+), në dialogun që shfaqet Parametratshkëlqejnë shkoni te skeda Shtesa. Në fushë Kontrolli zgjidhni shtesashkëlqejnë dhe klikoni Shkoni. Në dritaren që shfaqet, kontrolloni kutinë pranë paketa e analizës, klikoni NE RREGULL.

Në skedën Të dhënat në një grup Analiza do të shfaqet një buton i ri Analiza e të dhënave.

Për të demonstruar se si funksionon shtesa, le të përdorim të dhënat , ku një djalë dhe një vajzë ndajnë një tavolinë në banjë. Futni të dhënat për shembullin tonë të banjës në kolonat A dhe B të një flete bosh.
Shkoni te skeda Të dhënat, në një grup Analiza klikoni Analiza e të dhënave. Në dritaren që shfaqet Analiza e të dhënave zgjidhni Regresioni siç tregohet në figurë dhe klikoni OK.

Vendosni parametrat e kërkuar të regresionit në dritare Regresioni, siç tregohet në foto:

Klikoni NE RREGULL. Figura më poshtë tregon rezultatet e marra:

Këto rezultate janë në përputhje me ato që kemi marrë nga llogaritjet e pavarura në.
Ndërtimi i një regresioni linear, vlerësimi i parametrave të tij dhe rëndësia e tyre mund të bëhet shumë më shpejt kur përdorni paketën e analizës Excel (Regresion). Le të shqyrtojmë interpretimin e rezultateve të marra në rastin e përgjithshëm ( k variablat shpjegues) sipas shembullit 3.6.
Tabela statistikat e regresionit jepen vlerat:
Të shumëfishta R – koeficienti i korrelacionit të shumëfishtë;
R- katrore– koeficienti i përcaktimit R 2 ;
Normalizuar R - katrore- rregulluar R 2 i rregulluar për numrin e shkallëve të lirisë;
gabim standardështë gabimi standard i regresionit S;
Vëzhgimet - numri i vëzhgimeve n.
Tabela Analiza e variancës dhënë:
1. Kolona df - numri i shkallëve të lirisë, i barabartë me
për vargun Regresioni df = k;
për vargun Pjesa e mbeturdf = n – k – 1;
për vargun Totaldf = n– 1.
2. Kolona SS- shuma e devijimeve në katror, e barabartë me
për vargun Regresioni ;
për vargun Pjesa e mbetur ;
për vargun Total .
3. Kolona ZNJ variancat e përcaktuara nga formula ZNJ = SS/df:
për vargun Regresioni– varianca e faktorëve;
për vargun Pjesa e mbeturështë varianca e mbetur.
4. Kolona F - vlera e llogaritur F-kriteret e llogaritura me formulë
F = ZNJ(regresion)/ ZNJ(mbetja).
5. Kolona Rëndësia F është vlera e nivelit të rëndësisë që korrespondon me të llogaritur F-statistikat .
Rëndësia F= FRIST( F- statistikat, df(regresioni), df(mbetja)).
Nëse rëndësia F < стандартного уровня значимости, то R 2 është statistikisht i rëndësishëm.
| Koeficientët | gabim standard | t-statistikat | p-vlera | fundi 95% | 95% e lartë | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Kjo tabelë tregon:
1. Shanset– vlerat e koeficientit a, b.
2. Gabim standard janë gabimet standarde të koeficientëve të regresionit S a, Sb.
3. t- statistikat– vlerat e llogaritura t - kriteret e llogaritura me formulën:
t-statistika = Koeficientët / Gabim standard.
4.R-vlera (rëndësia t) është vlera e nivelit të rëndësisë që korrespondon me të llogaritur t- statistikat.
R-vlera = STUDRASP(t- statistikat, df(mbetja)).
Nëse R-kuptim< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. 95% e poshtme dhe 95% e lartë janë kufijtë e poshtëm dhe të sipërm të intervaleve të besimit 95% për koeficientët e ekuacionit teorik të regresionit linear.
| TERHEQJA E MBETUR | ||
| Vrojtim | Parashikuar y | Mbetet e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
Tabela TERHEQJA E MBETUR treguar:
në një kolonë Vrojtim– numri i vëzhgimit;
në një kolonë parashikuar y janë vlerat e llogaritura të ndryshores së varur;
në një kolonë Mbetet e është diferenca midis vlerave të vëzhguara dhe të llogaritura të ndryshores së varur.
Shembulli 3.6. Të dhënat e disponueshme (njësi arb.) për shpenzimet ushqimore y dhe të ardhurat për frymë x për nëntë grupe familjesh:
| x | |||||||||
| y |
Duke përdorur rezultatet e paketës së analizës Excel (Regresioni), analizojmë varësinë e kostove të ushqimit nga vlera e të ardhurave për frymë.
Rezultatet e analizës së regresionit zakonisht shkruhen si:
![]()
ku në kllapa janë gabimet standarde të koeficientëve të regresionit.
Koeficientët e regresionit por = 65,92 dhe b= 0,107. Drejtimi i komunikimit ndërmjet y Dhe x përcakton shenjën e koeficientit të regresionit b= 0,107, d.m.th. marrëdhënia është e drejtpërdrejtë dhe pozitive. Koeficient b= 0.107 tregon se me një rritje të të ardhurave për frymë me 1 arb. njësi kostot e ushqimit rriten me 0,107 konv. njësi
Le të vlerësojmë rëndësinë e koeficientëve të modelit të marrë. Rëndësia e koeficientëve ( a, b) kontrollohet kundër t- test:
p-vlera ( a) = 0,00080 < 0,01 < 0,05
p-vlera ( b) = 0,00016 < 0,01 < 0,05,
pra koeficientët ( a, b) janë të rëndësishme në nivelin 1%, dhe aq më tepër në nivelin 5% të rëndësisë. Kështu, koeficientët e regresionit janë të rëndësishëm dhe modeli është adekuat me të dhënat origjinale.
Rezultatet e vlerësimit të regresionit janë të pajtueshme jo vetëm me vlerat e marra të koeficientëve të regresionit, por edhe me një pjesë të grupit të tyre (intervali i besimit). Me një probabilitet prej 95%, intervalet e besimit për koeficientët janë (38,16 - 93,68) për a dhe (0,0728 - 0,142) për b.
Cilësia e modelit vlerësohet nga koeficienti i përcaktimit R 2 .
Vlera R 2 = 0,884 do të thotë se faktori i të ardhurave për frymë mund të shpjegojë 88,4% të variacionit (shpërndarjes) në shpenzimet ushqimore.
Rëndësia R 2 kontrolluar nga F- test: rëndësi F = 0,00016 < 0,01 < 0,05, следовательно, R 2 është i rëndësishëm në nivelin 1%, dhe aq më tepër në nivelin 5% të rëndësisë.
Në rastin e regresionit linear në çift, koeficienti i korrelacionit mund të përkufizohet si ![]() . Vlera e përftuar e koeficientit të korrelacionit tregon se lidhja ndërmjet shpenzimeve ushqimore dhe të ardhurave për frymë është shumë e ngushtë.
. Vlera e përftuar e koeficientit të korrelacionit tregon se lidhja ndërmjet shpenzimeve ushqimore dhe të ardhurave për frymë është shumë e ngushtë.