Până la jumătatea anului 2015, internetul global conectase deja 3,2 miliarde de utilizatori, adică aproape 43,8% din populația planetei. Spre comparație: acum 15 ani, doar 6,5% din populație erau utilizatori de Internet, adică numărul utilizatorilor a crescut de peste 6 ori! Dar ceea ce este mai impresionant nu sunt indicatorii cantitativi, ci calitativi ai extinderii implementării tehnologiilor Internet în diverse domenii ale activității umane: de la comunicațiile globale ale rețelelor sociale până la lucruri de uz casnic pe Internet. Internetul mobil a oferit utilizatorilor posibilitatea de a fi online în afara biroului și acasă: pe drum, în afara orașului, în natură.
În prezent, există sute de sisteme de căutare a informațiilor pe Internet. Cele mai populare dintre ele sunt disponibile pentru marea majoritate a utilizatorilor deoarece sunt gratuite și ușor de utilizat: Google, Yandex, Nigma, Yahoo!, Bing..... Pentru utilizatorii mai experimentați, interfețe „căutare avansată” și „specializate”. sunt disponibile căutări în rețea socială. , conform fluxurilor de știri și reclame de cumpărare și vânzare... Dar toate aceste minunate motoare de căutare au un dezavantaj semnificativ, pe care l-am notat deja mai sus ca un avantaj: sunt gratuite.
Dacă investitorii investesc miliarde de dolari în dezvoltarea motoarelor de căutare, atunci apare o întrebare complet adecvată: de unde câștigă bani?
Și câștigă bani, în special, oferind ca răspuns la solicitările utilizatorilor nu atât informații care ar fi utile din punctul de vedere al utilizatorului, cât cele pe care proprietarii motoarelor de căutare le consideră utile utilizatorului. Acest lucru se realizează prin manipularea ordinii în care sunt prezentate listele de răspunsuri la interogările de căutare ale utilizatorilor. Aici există publicitate deschisă pentru anumite resurse de pe Internet și manipulare ascunsă a relevanței răspunsurilor bazate pe interesele comerciale, politice și ideologice ale proprietarilor motoarelor de căutare.
Prin urmare, printre specialiștii profesioniști în căutarea de informații pe Internet, problema pertinenței rezultatelor motoarelor de căutare este foarte relevantă.
Pertinența este corespondența documentelor găsite de un sistem de regăsire a informațiilor cu nevoile de informații ale utilizatorului, indiferent de cât de complet și cât de exact este exprimată această nevoie de informații în textul cererii de informații în sine. Acesta este raportul dintre cantitatea de informații utile și cantitatea totală de informații primite. În linii mari, aceasta este eficiența căutării.
Specialiștii care efectuează căutări calificate de informații pe Internet trebuie să depună anumite eforturi pentru a filtra rezultatele căutării, eliminând „zgomotul” informațiilor inutile. Și pentru aceasta se folosesc instrumente de căutare la nivel profesional.
Unul dintre aceste sisteme profesionale este programul rusesc FileForFiles și SiteSputnik (SiteSputnik).
Dezvoltator Alexey Mylnikov din Volgograd.
„Programul FileForFiles & SiteSputnik (SiteSputnik) este conceput pentru a organiza și automatiza căutarea profesională, colectarea și monitorizarea informațiilor postate pe Internet. O atenție deosebită este acordată obținerii de noi informații primite pe subiecte de interes. Au fost implementate mai multe funcții de analiză a informațiilor."
Monitorizarea și clasificarea fluxurilor de informații
Mai întâi câteva cuvinte despre monitorizarea fluxurilor de informații, al cărui caz special este monitorizarea mass-media și a rețelelor sociale:
- utilizatorul indică Sursele care pot conține informațiile necesare și Regulile de selectare a acestor informații;
- programul descarcă link-uri noi din surse, eliberează conținutul lor de gunoi și repetări și le aranjează în secțiuni conform Regulilor.
Pentru a vedea în direct un proces de monitorizare simplu, dar real, care implică 6 surse și 4 rubrici:- deschideți versiunea Demo a programului;
- apoi, în fereastra care apare, faceți clic pe butonul Împreună;
- și atunci când Site-ul webSputnik veți realiza acest proiect în timp real, dvs.:
— în lista „Clean Stream” veți vedea toate informațiile noi de la Surse,
— în secțiunea „Post-cerere” - numai știri economice și financiare care îndeplinesc regula,
- în rubricile „Despre Președinte”, „Despre Premieră” și „Banca Centrală”, - informații referitoare la obiectele relevante.
În proiecte reale, puteți utiliza aproape orice număr de surse și rubrici.
Puteți crea primele proiecte de lucru în câteva ore și le puteți îmbunătăți în timpul funcționării.
Procesarea informațiilor descrise este disponibilă în pachetul SiteSputnik Pro+News și mai sus.
2. Căutare simplă și în lot, colectare de informații
Pentru a se familiariza cu posibilitățile SiteSputnik Pro(versiunea de bază a programului) :
- deschideți versiunea Demo a programului;
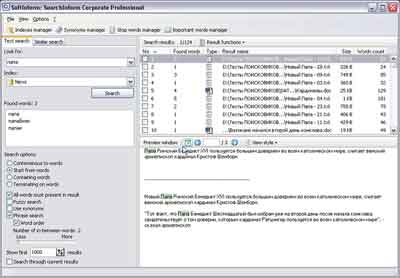
- introduceți prima dvs. solicitare, de exemplu, numele dvs. complet, așa cum am făcut eu:
și faceți clic pe butonul Căutare.
- Programul (vezi semnul pe care SiteSputnik l-a construit) va sonda în câteva secunde 7 surse, se vor deschide în ele 24 pagini de căutare, va găsi 227 linkuri relevante, va elimina linkurile duplicate iar din restul 156 unic lista de link-uri "O asociere".
Total: număr de linkuri unice - 156 , linkuri duplicat - 46 %.
Nume
Sursă
Ordonat
pagini
Descărcat
pagini
Găsite
link-uri
Timp
căutare
Eficienţă
căutare
Legături
Nou
Eficienţă
NouYandex 5 5 50 0:00:05 32% 0 0 5 5 44 0:00:03 28% 0 0 Yahoo 5 5 50 0:00:05 32% 0 0 Hoinar 5 4 56 0:00:07 36% 0 0 MSN (Bing) 5 3 23 0:00:04 15% 0 0 Yandex.Blogs 5 1 1 0:00:01 1% 0 0 Google.Bloguri 5 1 3 0:00:01 2% 0 0 Total: 35 24 227 0:00:26 — 0 0 - (! ) Repetați cererea după câteva ore sau zile și veți vedea numai link-uri noi care au apărut în Surse pentru această perioadă de timp. În ultimele două coloane ale tabelului puteți vedea câte link-uri noi a adus fiecare Sursă și eficiența acesteia în ceea ce privește „noutatea”. Când o interogare este executată de mai multe ori, o listă care conține numai link-uri noi , este creat în raport cu toate execuțiile anterioare ale acestei solicitări. S-ar părea că aceasta este o funcție elementară și necesară, dar autorul nu cunoaște un singur program în care să fie implementată.
- (!! ) Capacitățile descrise sunt acceptate nu numai pentru cereri individuale, ci și pentru întreg solicită pachete :
Pachetul pe care îl vedeți constă din șapte interogări diferite care colectează informații despre Vasily Shukshin din mai multe surse, inclusiv motoarele de căutare, Wikipedia, căutare exactă în știrile Yandex, metacăutare și căutare de mențiuni pe posturile TV și radio. La scenariu TV și Radio include: „Channel One”, „TV Russia”, NTV, RBC TV, „Echo of Moscow”, compania de radio „Mayak”, ... și alte surse de informații. Fiecare sursă are propria sa căutare sau profunzime de navigare în pagini. Este listat în a treia coloană.
Căutarea în lot vă permite să efectuați căutări complete cu un singur clic colectare de informații pe o anumită temă.
Listă separată link-uri noi, la execuții repetate ale pachetului, va conține doar link-uri care nu au fost găsite anterior.
Amintește-ți ce și când ai întrebat pe internet și ce ți-a răspuns Nu este nevoie- totul este salvat automat în biblioteci și în bazele de date de programe.
Repet că capabilitățile descrise în acest paragraf sunt incluse în întregime în pachet SiteSpunik Pro.
Mai multe detalii în instrucțiuni: SiteSputnik Pro pentru începători.
3. Monitorizare obiecte și căutare
Destul de des Utilizatorul se confruntă cu următoarea sarcină. Trebuie să aflați ce este pe Internet despre un anumit obiect: o persoană sau o companie. De exemplu, atunci când angajați un nou angajat sau când apare o nouă contraparte, știți întotdeauna numele complet, numele companiei, numerele de telefon, INN, OGRN sau OGRNIP, puteți lua, de asemenea, ICQ, Skype și alte câteva date. Apoi, folosind un apel la o funcție specială a programului Site-ul webSputnik "Colectarea de informații despre obiect" (echipament SiteSputnik Pro+Obiecte):Introduceți datele pe care le cunoașteți și cu un singur clic de mouse le efectuați exacteȘi deplin căutați link-uri care conțin informații specificate. Căutarea se efectuează pe mai multe motoare de căutare simultan, folosind toate detaliile simultan, folosind mai multe combinații posibile de detalii de înregistrare simultan: amintiți-vă cum puteți nota un număr de telefon în diferite moduri. După o anumită perioadă de timp, fără să faci o muncă de rutină plictisitoare, vei primi o listă de link-uri, curățată de repetări și, cel mai important, ordonată în funcție de relevanța obiectului pe care-l cauți. Relevanța (semnificația) este atinsă datorită faptului că primele în rezultatele căutării SiteSputnik vor fi acele link-uri pe care cantitate mare detaliile pe care le-ați specificat și nu cele care au mutat în sus în rezultatele motorului de căutare ale webmasterului.
Important .
Programul SiteSputnik este mai bun decât alte programe la extragere real, dar nu oficial informații despre Obiect. De exemplu, în baza de date oficială a unui operator de telefonie mobilă se poate înregistra că telefonul îi aparține lui Vasily Terekhin, dar, în realitate, acest telefon conține informații că Alexander a vândut o mașină Ford Focus în 2013, care reprezintă informații suplimentare care trebuie luate în considerare.Monitorizarea căutării .
Monitorizarea căutării înseamnă următoarele. Dacă trebuie să urmăriți apariția link-uri noi, de un obiect dat sau arbitrar pachet de interogări, atunci trebuie doar să repetați periodic căutarea corespunzătoare. La fel ca pentru o cerere simplă, programul SiteSputnik va crea o listă „Nouă”, în care va plasa doar acele linkuri care nu au fost găsite în niciuna dintre căutările anterioare.Monitorizarea căutării interesant nu numai în sine. Poate fi implicat în monitorizarea mass-media, rețelele socialeși alte surse de știri, care a fost menționat mai sus la paragraful 1. Spre deosebire de alte programe, în care se pot obține informații noi doar din fluxurile RSS, în program Site-ul webSputnik poate fi folosit pentru aceasta căutări integrate în site-uri web Și motoare de căutare . De asemenea, posibil emulare(auto-creare) mai multe feed-uri RSS din pagini arbitrare, mai mult, emularea unui feed RSS la cerere și chiar a unui lot de solicitări.
- Pentru a profita la maximum de program, utilizați funcțiile sale principale, și anume:
- solicitați pachete, pachete cu parametri, utilizați Assembler (asambler), operațiunea „Imbinare analitică” a rezultatelor mai multor sarcini, dacă este necesar, aplicați funcții de căutare de bază pe Internetul invizibil;
- conectați-vă sursele la sursele de informații integrate în program : alte motoare de căutare și căutări integrate în site-uri, fluxuri RSS existente create de dvs propriile fluxuri RSS Cu arbitrar pagini, utilizați funcția de căutare pentru surse noi;
- utilizați următoarele tipuri de caracteristici monitorizarea: Mass-media, rețele sociale și alte surse, monitorizare comentarii la știri și mesaje, urmăriți apariția informațiilor noi pe paginile existente;
- se angajează Categorii , Funcții externe, Task Scheduler, listă de corespondență, mai multe computere, Project Instructor, instalare alarma Pentru a vă anunța despre apariția unor evenimente semnificative, utilizați celelalte funcții enumerate mai jos.
4. Programul SiteSputnik (SiteSputnik): opțiuni și caracteristici
- Program SiteSputnik se îmbunătățește constant în următoarele domenii: „Trebuie să găsesc totul și cu garanție”.
„Software de interogare pentru internet”, - o altă definiție a Utilizatorului pentru atribuirea programului.A. Funcții pentru căutarea și colectarea informațiilor.
. Solicitați pachet - executarea mai multor interogări simultan, combinând rezultatele căutării sau separat. Când se generează rezultatul combinat, linkurile găsite în mod repetat sunt eliminate. Mai multe detalii despre pachete pot fi găsite în introducerea la SiteSputnik și vizual în videoclip: o incheieturaȘi separa executarea cererilor. Nu există analogi în evoluțiile interne și externe.
. Pachete cu parametri. Orice interogări și pachete de interogări concepute pentru a rezolva sarcinile de căutare standard, de exemplu, căutarea după număr de telefon, nume complet sau e-mail, - poate fi parametrizat, salvat și executat dintr-o bibliotecă de interogări gata făcute cu înlocuirea valorilor actuale (necesare) ale parametrilor. Fiecare pachet cu parametri este propriul său special formular de căutare avansată . Poate folosi nu unul, ci mai multe motoare de căutare. Puteți crea formulare care sunt foarte complexe în scopul lor funcțional. Este extrem de important ca forme pot fi create de utilizatori înșiși, fără participarea autorului sau programatorului programului. Acest lucru este scris foarte simplu în instrucțiuni, mai multe detalii într-o publicație separată despre parametrizarea căutării și pe forum, clar în videoclip: căutați toate opțiunile pentru înregistrarea unui număr deodată telefon mobil si dupa mai multe optiuni de inregistrare a adresei E-mail. Nu există analogi.
. Asamblator NOU- asamblarea unei sarcini de căutare din mai multe gata făcute : cereri, pachete de solicitări și pachete de parametri. Pachetele pot conține alte pachete în textul lor. Adâncimea de cuibărire a pachetelor este nelimitată. Puteți crea mai multe sarcini de căutare, de exemplu, despre mai multe entități juridice și persoane fizice, și puteți finaliza aceste sarcini simultan. Mai multe detalii pe forum și într-o publicație separată despre Assembler, clar la video. Nu există analogi.
. Metacăutare - executarea unei cereri specifice simultan la o „profunzime” dată de căutare pentru fiecare dintre ele. Metacăutarea este posibilă folosind motoarele de căutare încorporate, care includ Yandex, Rambler, Google, Yahoo, MSN (Bing), Mail, Yandex și blogurile Google și instrumente de căutare conectate. Lucrul cu mai multe motoare de căutare arată ca și cum lucrezi un singur motor de căutare . Linkurile regăsite sunt șterse. Metacăutare vizuală pe trei rețele sociale conectate: VKontakte, Twitter și Youtube - afișat pe video.
. Metacăutare pe site - combinarea căutării pe site în Google, Yahoo, Yandex, MSN (Bing). Clar pe video.
. Metacăutare în documente de birou - combinarea căutării în fișiere PDF, XLS, DOC, RTF, PPT, FLASH în Google, Yahoo, Yandex, MSN (Bing). Puteți alege orice combinație de formate de fișiere.
. Metacăutare pentru copii cache link-uri în Yandex, Google, Yahoo, MSN (Bing). Este compilată o listă, fiecare articol din care conține toate fragmentele găsite pentru fiecare link de către fiecare motor de căutare. Nu există analogi.
. Căutare profundă pentru Yandex, Google și Rambler vă permit să combinați într-o singură listă toate linkurile din căutarea obișnuită și, respectiv, toate linkurile din listele „Mai multe de pe site”, „Rezultate suplimentare de pe site” și „Căutare pe site (Total ...)”. Citiți mai multe despre căutarea profundă pe forum. Nu există analogi.
. Căutare precisă și completă . Aceasta înseamnă următoarele. Pe de o parte, fiecare interogare poate fi executată pe aceea și numai pe sursa în al cărei limbaj de interogare este scrisă. Acest căutare exactă. Pe de altă parte, poate exista un număr arbitrar de astfel de solicitări și surse. Aceasta oferă căutare completă. Citiți mai multe într-o postare separată despre căutarea procedurală. Nu există analogi.
. Căutând pe internetul invizibil .
Include următoarele caracteristici de bază:
B. Funcții de monitorizare a informațiilor.Un pachet special de cereri care pot fi îmbunătățite de către Utilizator,
- căutați linkuri invizibile folosind un păianjen,
- căutați legături invizibile în vecinătatea unui link sau a unui folder vizibil după „imagine și asemănare”,
- căutări speciale pentru foldere deschise,
- căutați link-uri și foldere invizibile cu nume standard folosind dicționare speciale,
- utilizarea propriilor căutări integrate în site-uri.Mai multe detalii într-o publicație separată pe SiteSputnik Invisible. Funcțiile de bază sunt „bine cunoscute în cercuri înguste”, dar modul în care sunt utilizate nu are analogi. Esența acestei metode este de a construi o hartă a site-ului vizibilă de pe Internet (cu alte cuvinte, materializarea Internetului vizibil), și numai pe baza unor link-uri vizibile și căutarea de link-uri invizibile în raport cu acestea. Căutarea link-urilor deja vizibile folosind metode „invizibile” nu este efectuată.
. Monitorizarea pentru apariția pe Internet nou link-uri pe o anumită temă. Monitorizarea aspectului nou link-urile pot fi folosite folosind numere întregi solicită pachete , care implică oricare dintre metodele de căutare menționate mai sus, mai degrabă decât primele pagini individuale ale motorului de căutare. Unire și intersecție implementate nou link-uri din mai multe căutări separate. Mai multe detalii în publicația despre monitorizare (vezi § 1) și pe forum. Nu există analogi.
. Prelucrarea colectivă a informațiilor . Creare rețea corporativă sau profesională pentru colectarea, monitorizarea și analiza colectivă a informațiilor. Participanții și creatorii unei astfel de rețele sunt angajați ai corporației, membri ai unei comunități profesionale sau grupuri de interese. Locația geografică a participanților nu contează. Mai multe detalii într-o publicație separată despre organizarea unei rețele pentru colectarea colectivă, monitorizarea și analiza informațiilor.
. Monitorizarea link-uri (pagini web) pentru a detecta modificări în conținutul acestora (conținut). Versiune beta. Modificările găsite sunt evidențiate cu culori și simboluri speciale. Mai multe detalii într-o publicație separată despre monitorizare (a se vedea § 2 și 3).
ÎN. Funcții de analiză a informațiilor.
. Categorii de materiale deja descris mai sus. Mai multe detalii pot fi găsite într-o publicație separată despre Rubrici. Regulile de introducere a rubrici vă permit să specificați cuvintele cheie și distanța dintre ele, să setați „ȘI”, „SAU” și „NU” logic, să aplicați o structură de paranteze pe mai multe niveluri și dicționare (inserați fișiere) la care pot fi aplicate operațiuni logice.
. Tehnologia VF - extinderea aproape arbitrară a posibilității de clasificare a materialelor prin implementarea unor funcții externe care sunt integrate organic în Regulile de introducere a rubricilor și pot fi implementate de programator în mod independent, fără participarea autorului programului.
. Analiza numerica ocuparea Rubriks, montaj alarma și notificarea apariției unor evenimente semnificative prin evidențierea rubricilor în culoare și/sau trimiterea unui raport de alarmă prin e-mail.
. Relevanța faptică. Există o opțiune de a aranja legăturile în ordine aproape de semnificaţie aceste linkuri in raport cu problema in curs de rezolvare, ocolind trucurile webmasterilor care folosesc diverse metode pentru a creste clasamentul site-urilor in motoarele de cautare. Acest lucru se realizează prin analiza rezultatelor executării mai multor interogări „diverse” pe un anumit subiect. În sensul literal al cuvântului, link-uri care conțin maximum de informații solicitate . Citiți mai multe în descrierea modului de a găsi furnizorul optim și pe forum. Nu există analogi.
. Calcularea relațiilor obiectelor - cauta link-uri, resurse (site-uri), foldere si domenii pe care obiectele sunt mentionate simultan. Cele mai comune obiecte sunt oamenii și firmele. Pentru a căuta conexiuni, pot fi folosite toate instrumentele de program menționate pe această pagină SiteSputnik, ceea ce crește semnificativ eficiența muncii pe care o desfășurați. Operația se efectuează pe orice număr de obiecte. Mai multe detalii în introducerea programului, precum și în descrierea noii funcții „obiectele și conexiunile lor”. Nu există analogi.
. Formarea, integrarea și intersecția fluxurilor de informații pe o varietate de subiecte, comparație de fire. Mai multe detalii într-o postare separată pe fire.
. Construirea de hărți web site-uri, resurse, foldere și obiecte căutate pe baza linkurilor găsite pe Internet folosind Google, Yahoo, Yandex, MSN (Bing) și Altavista care aparțin site-ului. Experții pot afla: este vizibil "suplimentar" informații de pe Internet pe site-urile lor web, precum și site-urile web ale concurenților de cercetare pe acest subiect. Harta site-ului web este materializarea internetului vizibil . Mai multe detalii într-o publicație separată despre construirea de hărți web, vizual la video. Nu există analogi.
. Găsirea de noi surse de informare pe un anumit subiect, care poate fi apoi folosit pentru a urmări apariția unor noi informații relevante. Mai multe detalii la.
G. Funcții de service.
. Planificator de sarcini oferă muncă Programat: efectuează anumite funcții ale programului la un moment dat. Mai multe detalii într-o publicație separată despre Planificator.
. Instructor de proiect NOU- acesta este un asistent crearea si intretinerea Proiecte de căutare, colectare, monitorizare și analiză a informațiilor (categorizare și semnalizare). Mai multe detalii pe forum.
. Arhivare automată. ÎN baze de date Toate rezultatele muncii tale sunt memorate automat, și anume: solicitări, pachete de solicitări, protocoale de căutare și monitorizare, orice alte funcții de mai sus și rezultatele executării acestora. Poate sa structura lucrați pe subiecte și subteme.
. Bază de date include sortare, căutare simplă și căutare personalizată prin interogare SQL. Pentru acesta din urmă, există un vrăjitor pentru alcătuirea interogărilor SQL. Folosind aceste instrumente, puteți găsi și revizui munca pe care ați făcut-o ieri, luna trecută, acum un an, puteți defini un subiect ca criteriu de căutare sau puteți stabili un alt criteriu de căutare pe baza conținutului bazei de date.
. Limitări tehnice motoare de căutare. Unele limitări, cum ar fi lungimea șirului de interogare, pot fi depășite. Acesta asigură executarea nu a uneia, ci a mai multor interogări, combinând rezultatele căutării sau separat. Puteți citi despre o modalitate de a depăși încălcarea legii aditivității pentru motoarele de căutare majore. Pentru un cuvânt sau o expresie cuprinsă între ghilimele, este implementată o căutare cu majuscule și minuscule în motoarele de căutare, în special căutarea prin abreviere.
Incorporat browser . Navigator după pagină. Multicolor marker pentru a evidenția cuvinte cheie și arbitrare. Bilistarea și N-listing din documentele generate.
. Descărcare fluxurile de știri într-un tabel concentrat pe import în Excel, MySQL, Access, Kronos și alte aplicații.
5. Instalarea și lansarea Programului, cerințele computerului.
Pentru a instala și rula programul:
- Descărcați fișierul, copiați folderul FileForFiles de pe acesta pe hard disk, de exemplu, în D:\;
- Versiunea demo a programului va fi instalat si se va deschide.
Programul va funcționa pe orice computer cu orice versiune de Windows instalată.Ce este asta
DuckDuckGo este un motor de căutare open source destul de cunoscut. Serverele sunt situate în SUA. Pe lângă propriul robot, motorul de căutare folosește rezultate din alte surse: Yahoo, Bing, Wikipedia.
Cu atât mai bine
DuckDuckGo se poziționează ca un motor de căutare care oferă confidențialitate și confidențialitate maximă. Sistemul nu colectează date despre utilizator, nu stochează jurnalele (fără istoric de căutare), iar utilizarea cookie-urilor este cât se poate de limitată.
DuckDuckGo nu colectează și nu partajează informații personale de la utilizatori. Aceasta este politica noastră de confidențialitate.
Gabriel Weinberg, fondatorul DuckDuckGoDe ce ai nevoie de asta
Toate motoarele de căutare majore încearcă să personalizeze rezultatele căutării pe baza datelor despre persoana din fața monitorului. Acest fenomen se numește „bule de filtrare”: utilizatorul vede doar acele rezultate care sunt în concordanță cu preferințele sale sau pe care sistemul le consideră ca atare.
Formează o imagine obiectivă care nu depinde de comportamentul tău trecut pe Internet și elimină publicitatea tematică Google și Yandex bazată pe interogările tale. Cu DuckDuckGo este ușor să căutați informații în limbi străine, în timp ce Google și Yandex în mod implicit acordă preferință site-urilor în limba rusă, chiar dacă interogarea este introdusă într-o altă limbă.
Ce este asta
not Evil este un sistem care caută în rețeaua Tor anonimă. Pentru a-l folosi, trebuie să accesați această rețea, de exemplu, lansând un .
not Evil nu este singurul motor de căutare de acest gen. Există LOOK (căutarea implicită în browserul Tor, accesibilă de pe internetul obișnuit) sau TORCH (unul dintre cele mai vechi motoare de căutare din rețeaua Tor) și altele. Ne-am hotărât pe not Evil din cauza indicii clare de la Google (doar uitați-vă la pagina de pornire).
Cu atât mai bine
Căută unde Google, Yandex și alte motoare de căutare sunt în general închise.
De ce ai nevoie de asta
Rețeaua Tor conține multe resurse care nu pot fi găsite pe internetul care respectă legea. Iar numărul acestora va crește pe măsură ce controlul guvernului asupra conținutului internetului se va înăspri. Tor este un fel de rețea din Internet cu propriile rețele sociale, trackere de torrent, media, platforme de tranzacționare, bloguri, biblioteci și așa mai departe.
3. YaCy
Ce este asta
YaCy este un motor de căutare descentralizat care funcționează pe principiul rețelelor P2P. Fiecare computer pe care este instalat modulul software principal scanează Internetul independent, adică este analog cu un robot de căutare. Rezultatele obținute sunt colectate într-o bază de date comună care este utilizată de toți participanții YaCy.
Cu atât mai bine
Este dificil de spus dacă acest lucru este mai bun sau mai rău, deoarece YaCy este o abordare complet diferită a organizării căutării. Absența unui singur server și a unei companii proprietare face ca rezultatele să fie complet independente de preferințele oricui. Autonomia fiecărui nod elimină cenzura. YaCy este capabil să caute pe web profund și rețele publice neindexate.
De ce ai nevoie de asta
Dacă sunteți un susținător al software-ului open source și al unui internet gratuit, care nu este supus influenței agențiilor guvernamentale și a marilor corporații, atunci YaCy este alegerea dvs. Poate fi folosit și pentru a organiza o căutare în cadrul unei rețele corporative sau autonome. Și chiar dacă YaCy nu este foarte util în viața de zi cu zi, este o alternativă demnă la Google în ceea ce privește procesul de căutare.
4. Pipl
Ce este asta
Pipl este un sistem conceput pentru a căuta informații despre o anumită persoană.
Cu atât mai bine
Autorii lui Pipl susțin că algoritmii lor specializați caută mai eficient decât motoarele de căutare „obișnuite”. În special, se acordă prioritate profilurilor de rețele sociale, comentariilor, listelor de membri și diferitelor baze de date care publică informații despre persoane, cum ar fi bazele de date cu hotărâri judecătorești. Conducerea lui Pipl în acest domeniu este confirmată de evaluările de la Lifehacker.com, TechCrunch și alte publicații.
De ce ai nevoie de asta
Dacă aveți nevoie să găsiți informații despre o persoană care locuiește în SUA, atunci Pipl va fi mult mai eficient decât Google. Bazele de date ale instanțelor ruse sunt aparent inaccesibile motorului de căutare. Prin urmare, el nu se descurcă atât de bine cu cetățenii ruși.
Ce este asta
FindSounds este un alt motor de căutare specializat. Caută diverse sunete în surse deschise: casă, natură, mașini, oameni și așa mai departe. Serviciul nu acceptă interogări în limba rusă, dar există o listă impresionantă de etichete în limba rusă pe care le puteți folosi pentru a căuta.
Cu atât mai bine
Ieșirea conține doar sunete și nimic în plus. În setări puteți seta formatul dorit și calitatea sunetului. Toate sunetele găsite sunt disponibile pentru descărcare. Există o căutare după model.
De ce ai nevoie de asta
Dacă trebuie să găsiți rapid sunetul unei împușcături de muschetă, loviturile unei ciocănitoare care alăptează sau strigătul lui Homer Simpson, atunci acest serviciu este pentru dvs. Și am ales acest lucru numai din interogările disponibile în limba rusă. În engleză spectrul este și mai larg.
Serios, un serviciu specializat necesită un public specializat. Dar dacă îți este de folos și ție?
Ce este asta
Wolfram|Alpha este un motor de căutare computațional. În loc de link-uri către articole care conțin cuvinte cheie, oferă un răspuns gata făcut la cererea utilizatorului. De exemplu, dacă introduceți „comparați populațiile din New York și San Francisco” în formularul de căutare în limba engleză, Wolfram|Alpha va afișa imediat tabele și grafice cu comparația.
Cu atât mai bine
Acest serviciu este mai bun decât altele pentru a găsi fapte și a calcula date. Wolfram|Alpha colectează și organizează cunoștințele disponibile pe Web dintr-o varietate de domenii, inclusiv știință, cultură și divertisment. Dacă această bază de date conține un răspuns gata făcut la o interogare de căutare, sistemul îl afișează; dacă nu, calculează și afișează rezultatul. În acest caz, utilizatorul nu vede decât nimic de prisos.
De ce ai nevoie de asta
Dacă sunteți student, analist, jurnalist sau cercetător, de exemplu, puteți utiliza Wolfram|Alpha pentru a găsi și a calcula date legate de munca dvs. Serviciul nu înțelege toate solicitările, dar se dezvoltă constant și devine mai inteligent.
Ce este asta
Motorul de metacăutare Dogpile afișează o listă combinată de rezultate din rezultatele căutării de la Google, Yahoo și alte sisteme populare.
Cu atât mai bine
În primul rând, Dogpile afișează mai puține anunțuri. În al doilea rând, serviciul folosește un algoritm special pentru a găsi și afișa cele mai bune rezultate din diferite motoare de căutare. Potrivit dezvoltatorilor Dogpile, sistemele lor generează cele mai complete rezultate de căutare de pe întregul Internet.
De ce ai nevoie de asta
Dacă nu puteți găsi informații pe Google sau pe alt motor de căutare standard, căutați-o în mai multe motoare de căutare simultan folosind Dogpile.
Ce este asta
BoardReader este un sistem de căutare de text în forumuri, servicii de întrebări și răspunsuri și alte comunități.
Cu atât mai bine
Serviciul vă permite să restrângeți câmpul de căutare la platformele sociale. Datorită filtrelor speciale, puteți găsi rapid postări și comentarii care se potrivesc criteriilor dvs.: limbă, data publicării și numele site-ului.
De ce ai nevoie de asta
BoardReader poate fi util pentru specialiștii în PR și pentru alți specialiști media care sunt interesați de opinia maselor asupra anumitor probleme.
In cele din urma
Viața motoarelor de căutare alternative este adesea trecătoare. Lifehacker l-a întrebat pe fostul director general al filialei ucrainene Yandex, Serghei Petrenko, despre perspectivele pe termen lung ale unor astfel de proiecte.
Serghei Petrenko
Fost director general al Yandex.Ukraine.
În ceea ce privește soarta motoarelor de căutare alternative, este simplu: să fie proiecte foarte de nișă cu un public restrâns, deci fără perspective comerciale clare sau, dimpotrivă, cu claritatea deplină a absenței lor.
Dacă te uiți la exemplele din articol, poți vedea că astfel de motoare de căutare fie sunt specializate într-o nișă îngustă, dar populară, care, poate, încă nu a crescut suficient pentru a fi vizibilă pe radarele Google sau Yandex, fie testează. o ipoteză originală în clasament, care nu este încă aplicabilă în căutarea obișnuită.
De exemplu, dacă o căutare pe Tor se dovedește brusc a fi solicitată, adică rezultatele de acolo sunt necesare de cel puțin un procent din publicul Google, atunci, desigur, motoarele de căutare obișnuite vor începe să rezolve problema cum să găsiți-le și arătați-le utilizatorului. Dacă comportamentul publicului arată că pentru o proporție semnificativă de utilizatori într-un număr semnificativ de interogări, rezultatele oferite fără a lua în considerare factorii în funcție de utilizator par mai relevante, atunci Yandex sau Google vor începe să producă astfel de rezultate.
„Fii mai bun” în contextul acestui articol nu înseamnă „fii mai bun în orice”. Da, în multe aspecte, eroii noștri sunt departe de Yandex (chiar departe de Bing). Dar fiecare dintre aceste servicii oferă utilizatorului ceva ce giganții industriei de căutare nu pot oferi. Cu siguranță cunoști și tu proiecte similare. Distribuie cu noi - haideți să discutăm.
Introducere
În prezent, Internetul reunește sute de milioane de servere care găzduiesc miliarde de site-uri diferite și fișiere individuale care conțin diferite tipuri de informații. Acesta este un depozit uriaș de informații. Există diferite metode de căutare a informațiilor pe Internet.
Căutați după adresa cunoscută. Adresele necesare sunt preluate din directoare. Cunoscând adresa, trebuie doar să o introduceți în bara de adrese a browserului.
Exemplul 1. www.gov.ru este un server al autorităților guvernamentale ruse.
Construirea unei adrese de către utilizator. Cunoscând sistemul de formare a adreselor de Internet, puteți construi adrese atunci când căutați site-uri Web.
La cuvântul cheie (numele unei companii, întreprinderi, organizații sau un simplu substantiv englezesc), trebuie să adăugați un domeniu tematic sau geografic și trebuie să vă conectați intuiția.
Exemplul 2. Adresele paginilor web comerciale:
www.samsung.com (compania SAMSUNG),
www.mtv.com (știri muzicale MTV).
Exemplul 3. Adresele instituțiilor de învățământ:
www.ntu.edu (Universitatea Națională din SUA).
Motoarele de căutare pe internet
Au fost dezvoltate sisteme speciale de regăsire a informațiilor pentru a căuta informații pe Internet. Motoarele de căutare au o adresă obișnuită și sunt afișate ca o pagină Web care conține instrumente speciale pentru organizarea căutărilor (șir de căutare, director de subiecte, link-uri). Pentru a apela un motor de căutare, introduceți pur și simplu adresa acestuia în bara de adrese a browserului.
Potrivit serviciului de statistică LiveInternet.ru, distribuția motoarelor de căutare în Rusia este aproximativ după cum urmează:
2) Google – 35,0%
3) Caută Mail.ru – 8,3%
4) Rambler – 0,9%
După metoda de organizare a informațiilor, sistemele de recuperare a informațiilor se împart în două tipuri: clasificare (rubricatoare) și dicționar.
Categorii (clasificatoare)- motoarele de căutare care utilizează o organizare ierarhică (arboresc) a informațiilor. Când caută informații, utilizatorul caută prin titluri tematice, restrângând treptat câmpul de căutare (de exemplu, dacă trebuie să găsiți sensul unui cuvânt, mai întâi trebuie să găsiți un dicționar în clasificator și apoi să găsiți cuvântul dorit în aceasta).
Dicţionar search engines- Acestea sunt sisteme software și hardware automate puternice. Cu ajutorul lor, informațiile sunt vizualizate (scanate) pe Internet. Datele despre locația acestei sau acelea informații sunt introduse în directoare speciale de index. Ca răspuns la o solicitare, se efectuează o căutare în funcție de șirul de interogare. Drept urmare, utilizatorului i se oferă acele adrese (URL-uri) la care a fost găsit cuvântul sau grupul de cuvinte căutat în momentul scanării. Selectând oricare dintre adresele de linkuri propuse, puteți merge la documentul găsit. Majoritatea motoarelor de căutare moderne sunt mixte.
Cele mai cunoscute și populare motoare de căutare:
Există sisteme specializate în căutarea resurselor informaționale în diverse domenii.
https://my.mail.ru
https://ru-ru.facebook.com
https://twitter.com
https://www.tumblr.com
https://www.instagram.com etc.
Motoare de căutare subiecte:
Software de căutare:
Cataloage (colecții tematice de link-uri cu adnotări):
http://www.atrus.ru
Reguli de executare a cererilor
Secțiunea de ajutor a fiecărui motor de căutare oferă informații despre cum să căutați și cum să construiți un șir de interogare. Mai jos sunt informații despre un limbaj de interogare tipic, „mediu”.
Cerere simplă
Introduceți un cuvânt care definește subiectul de căutare. De exemplu, în motorul de căutare Rambler.ru este suficient să introduceți: automatizare.
Se gasesc documente care contin cuvintele specificate in cerere. Toate formele de cuvinte rusești sunt recunoscute; de regulă, majusculele sunt ignorate.
Puteți utiliza caracterul „*” sau „?” în interogare. Semn "?" într-un cuvânt cheie, un caracter este înlocuit, în locul căruia poate fi înlocuită orice literă, iar semnul „*” este o secvență de caractere.
De exemplu, interogarea automat* vă va permite să găsiți documente care includ cuvintele automat, automatizare etc.
Cerere complexă
Adesea este nevoie de combinarea cuvintelor cheie pentru a obține informații mai specifice. În acest caz, sunt utilizate cuvinte de legătură suplimentare, funcții, operatori, simboluri, combinații de operatori, separați prin paranteze.
De exemplu, interogarea muzică & (beatles beatles) înseamnă că utilizatorul caută documente care conțin cuvintele muzică și beatles sau muzică și beatles.
Lista motoarelor de căutare și directoarelor
Abordare Descriere www.excite.com Motor de căutare cu recenzii și ghiduri de site www.alta-vista.com Server de căutare, capabilități avansate de căutare disponibile www.hotbot.com Server de căutare www.ifoseek.com Server de căutare (ușor de utilizat) www.ipl.org Internet Publik library, o bibliotecă publică care funcționează în cadrul proiectului World Village www.wisewire.com WiseWire - organizație de căutare folosind inteligența artificială www.webcrawler.com WebCrawler - server de căutare, ușor de utilizat www.yahoo.com CatalogWeb și interfață pentru accesarea căutării full-text pe serverul AltaVista www.aport.ru Aport - server de căutare în limba rusă www.yandex.ru Yandex - server de căutare în limba rusă www.rambler.ru Rambler - server de căutare în limba rusă Resurse de ajutor pe internet www.yellow.com Pagini Galbene Internet monk.newmail.ru Motoare de căutare de diverse profiluri www.top200.ru Top 200 de site-uri web www.allru.net www.ru Catalogul resurselor rusești de internet www.allru.net/z09.htm Resurse educaționale www.students.ru Server student rus www.cdo.ru/index_new.asp Centrul de învățare la distanță www.open.ac.uk Universitatea Deschisă din Marea Britanie www.ntu.edu Universitatea Națională din SUA www.translate.ru Traducător electronic de text www.pomorsu.ru/guide.library.html Lista de link-uri către biblioteci de rețea www.elibrary.ru Biblioteca științifică electronică www.citforum.ru Biblioteca digitala www.infamed.com/psy Teste psihologice www.pokoleniye.ru Site-ul internet al Federației pentru Educație pe Internet www.metod.narod.ru Resurse educaționale www.spb.osi.ru/ic/distant Învățare la distanță pe internet www.examen.ru Examene și teste www.kbsu.ru/~book/ Manual de informatică Mega.km.ru Enciclopedii și dicționare Căutare profesională de informații pe Internet
Căutarea de informații este una dintre cele mai comune și, în același timp, cele mai dificile sarcini cu care trebuie să se confrunte orice utilizator pe Internet. Cu toate acestea, dacă pentru un membru obișnuit al comunității online cunoașterea metodelor de regăsire eficientă a informațiilor este o calitate dezirabilă, dar departe de a fi obligatorie, atunci pentru profesioniștii în informații abilitatea de a naviga rapid resursele de pe Internet și de a găsi sursele necesare este una dintre calificările de bază. aptitudini.
Motivul dificultăților care apar la căutarea informațiilor pe Internet este determinat de doi factori principali. În primul rând, numărul de surse de pe Internet este extrem de mare. La sfârșitul anului 2001, cele mai aproximative estimări indicau o cifră estimată de 7,5 miliarde de documente aflate pe servere din întreaga lume. În al doilea rând, gama de informații de pe Internet nu este doar colosală ca volum, ci și extrem de dinamică. În jumătate de minut petrecut citind primele rânduri ale acestei secțiuni, în universul virtual au apărut aproximativ o sută de documente noi sau modificate, zeci au fost mutate la adrese noi, iar câteva au încetat să mai existe pentru totdeauna. Internetul nu „doarme” niciodată, la fel cum planeta noastră nu „doarme”, de-a lungul căruia un val de activitate umană de afaceri se rotește în mod continuu în conformitate exactă cu schimbarea fusurilor orare.
Spre deosebire de o colecție stabilă și controlată de documente dintr-o bibliotecă, pe Internet avem de-a face cu o matrice informațională gigantică și în continuă schimbare, căutarea datelor în care este un proces foarte, foarte complex. Situația amintește adesea foarte bine de problema binecunoscută a găsirii unui ac într-un car de fân, iar uneori informații de mare valoare rămân nerevendicate doar din cauza dificultății de a le găsi.
Majoritatea utilizatorilor rețelelor globale de calculatoare au abilități de cercetare a informațiilor într-o măsură sau alta. Atât amatorii, cât și profesioniștii folosesc adesea aceleași instrumente. Cu toate acestea, rezultatele căutărilor și timpul petrecut cu acestea variază foarte mult.
Scopul acestei secțiuni este de a vă familiariza în detaliu cu instrumentele și metodele de regăsire a informațiilor și de a dezvolta abilități stabile de căutare profesională pe Internet pentru toate tipurile de date: de la texte în orice format, la video și animație.
CAUTARE INFORMATII PROFESIONALE PE INTERNET
Căutarea pe Internet este un element important al lucrului pe Internet. Numărul exact de resurse web de pe internetul modern este puțin probabil să fie cunoscut de oricine cu siguranță. În orice caz, numărul este de miliarde. Pentru a putea folosi informațiile necesare la un moment dat, indiferent de muncă sau de divertisment, trebuie mai întâi să le găsești în acest ocean de resurse alimentat constant.
Pentru ca o căutare pe Internet să aibă succes, trebuie îndeplinite două condiții: interogările trebuie bine formulate și trebuie adresate în locuri adecvate. Cu alte cuvinte, utilizatorului i se cere, pe de o parte, să își poată traduce interesele de căutare în limba interogării de căutare și, pe de altă parte, o bună cunoaștere a motoarelor de căutare, a instrumentelor de căutare disponibile, a avantajelor acestora și dezavantaje, care îi vor permite să aleagă cele mai potrivite instrumente de căutare în fiecare caz specific.
În prezent, nu există o singură resursă care să satisfacă toate cerințele de căutare pe Internet. Prin urmare, dacă îți iei căutarea în serios, trebuie inevitabil să folosești diferite instrumente, folosind fiecare în cazul cel mai potrivit.
De bază Instrumente de căutare pe internetpot fi împărțite în următoarele grupe principale:
Motoare de căutare;
directoare web;
Resurse de ajutor;
Programe locale pentru căutarea pe Internet.
Cele mai populare instrumente de căutare suntmotoare de căutare– așa-numitele motoare de căutare pe Internet (motoare de căutare). Primii trei lideri la scară globală sunt destul de stabili - Google, Yahoo! și Bing. În multe țări, propriile lor motoare de căutare locale, optimizate pentru a lucra cu conținut local, sunt adăugate la această listă. Cu ajutorul lor, teoretic puteți găsi orice cuvânt specific pe paginile a milioane de site-uri. Din punctul de vedere al utilizatorului, principalul dezavantaj al motoarelor de căutare este prezența inevitabilăzgomot informaționalîn rezultate. Acesta este numele obișnuit pentru rezultatele care sunt incluse în lista de căutare dintr-un motiv sau altul și nu corespund solicitării.
În ciuda multor diferențe, toate motoarele de căutare pe Internet funcționează pe principii similare și, din punct de vedere tehnic, constau din subsisteme similare. Prima parte structurală a unui motor de căutare sunt programele speciale utilizate pentru căutarea automată și indexarea ulterioară a paginilor web. Astfel de programe sunt de obicei numite păianjeni sau roboți. Ei se uită la codul paginilor web, găsesc link-uri situate pe ele și, prin urmare, descoperă noi pagini web. Există o modalitate alternativă de a include un site în index. Multe motoare de căutare oferă proprietarilor de resurse posibilitatea de a adăuga în mod independent un site la baza lor de date. Cu toate acestea, paginile web sunt apoi descărcate, analizate și indexate. Ele evidențiază elemente structurale, găsesc cuvinte cheie și determină conexiunile acestora cu alte site-uri și pagini web. Se efectuează și alte operațiuni, al căror rezultat este formarea unei baze de date cu index al motorului de căutare. Această bază de date este al doilea element principal al oricărui motor de căutare. În prezent, nu există o singură bază de date index absolut completă care să conțină informații despre tot conținutul de pe Internet. Deoarece diferite motoare de căutare utilizează diferite programe de căutare în pagini web și își construiesc indexul folosind diferiți algoritmi, bazele de date cu indexuri ale motoarelor de căutare pot varia semnificativ. Unele site-uri sunt indexate de mai multe motoare de căutare, dar există întotdeauna un anumit procent de resurse incluse în baza de date a unui singur motor de căutare. Prezența unei părți a indexului atât de originală și care nu se suprapune în fiecare motor de căutare ne permite să tragem o concluzie practică importantă: dacă utilizați un singur motor de căutare, chiar și cel mai mare, veți pierde cu siguranță un anumit procent de link-uri utile .
Următoarea parte a motorului de căutare pe Internet este programul propriu-zis de căutare și sortare. Aceste programe rezolvă două sarcini principale: în primul rând, găsesc pagini și fișiere în baza de date care se potrivesc cu cererea primită și apoi sortează matricea de date rezultată în conformitate cu diverse criterii. Succesul în atingerea obiectivelor de căutare depinde în mare măsură de eficacitatea muncii lor.
Ultimul element al unui motor de căutare pe Internet este interfața cu utilizatorul. Pe lângă cerințele obișnuite de estetică și comoditate pentru orice site web, interfețele motoarelor de căutare au o altă cerință importantă: trebuie să ofere diverse instrumente pentru compunerea și clarificarea interogărilor, precum și sortarea și filtrarea rezultatelor. Avantajele motoarelor de căutare sunt acoperirea excelentă a surselor, actualizarea relativ rapidă a conținutului bazei de date și o selecție bună de funcții suplimentare.
Instrumentul principal de lucru cu motoarele de căutare este o interogare.
Pentru căutări pe internet se folosesc și aplicații speciale care sunt instalate pe computerul local. Acestea pot fi fie programe simple, fie mai degrabă complexe complexe pentru căutarea și analiza datelor. Cele mai comune sunt pluginurile de căutare pentru browsere, panourile de browser concepute pentru a funcționa cu un anumit serviciu de căutare și pachetele de metacăutare cu capabilități de analiză a rezultatelor.
directoare web – acestea sunt resurse în care site-urile sunt împărțite în categorii tematice. Dacă utilizatorul lucrează cu motoarele de căutare doar prin interogări, atunci în catalog este posibil să vizualizeze secțiuni tematice în întregime. A doua diferență fundamentală între directoare și motoarele de căutare automate este că, de regulă, oamenii sunt direct implicați în completarea lor, vizualizarea resurselor și clasificarea site-ului într-o categorie sau alta. Directoarele web sunt de obicei împărțite în universale și tematice. Cele universale încearcă să acopere cât mai multe subiecte. Puteți găsi orice acolo: de la site-uri web despre poezie până la resurse informatice. Cu alte cuvinte, lărgimea lor de căutare este maximă. Directoarele tematice sunt specializate într-un anumit subiect, oferind o adâncime maximă de căutare prin reducerea lărgimii acoperirii resurselor.
Avantajele directoarelor sunt calitatea relativ ridicată a resurselor, deoarece fiecare site din el este vizualizat și selectat de către o persoană. Gruparea tematică a site-urilor vă permite să aranjați convenabil site-uri cu subiecte similare. Acest mod de operare este bun pentru a descoperi site-uri care sunt noi pentru tine pe o temă de interes - este mai precis decât utilizarea unui motor de căutare. Este recomandat să folosiți cataloage web pentru prima cunoaștere cu orice domeniu, precum și pentru căutarea unor interogări vagi - veți avea ocazia să „rătăciți” prin secțiunile catalogului și să determinați mai precis de ce aveți nevoie exact.
Dezavantajele directoarelor web sunt cunoscute. În primul rând, aceasta este o reîncărcare lentă a bazei de date, deoarece includerea unui site în catalog necesită participarea umană. În ceea ce privește eficiența, un director web nu este un rival cu motoarele de căutare. În plus, directoarele web sunt semnificativ inferioare motoarele de căutare în ceea ce privește dimensiunea bazei de date.
Când vorbim despre căutarea pe Internet, nu putem ignora o serie de termeni care sunt strâns legați de acest domeniu și sunt adesea folosiți pentru a descrie și evalua motoarele de căutare. De exemplu: lățime și adăncime Căutare pe internet. O căutare amplă este aceea care captează cât mai multe surse de informații. În acest caz, se consideră suficientă cel puțin o mențiune a unuia sau a altuia site potrivit solicitării. Profunzimea de căutare se referă la detaliile indexării și căutării ulterioare a fiecărei resurse specifice. De exemplu, multe motoare de căutare abordează indexarea diferitelor site-uri în mod diferit. Site-urile mari și populare sunt indexate în cea mai mare măsură; roboții încearcă să nu rateze o singură pagină dintr-o astfel de resursă. În același timp, pe alte site-uri, pot fi indexate doar pagina de titlu și câteva pagini de conținut. Aceste circumstanțe afectează în mod firesc căutările ulterioare. Căutarea profundă funcționează pe principiul „este mai bine să includeți informații inutile în rezultate decât să pierdeți orice date relevante pentru subiectul de căutare”.
Destul de des poți întâlni concepte precum globală și locală Căutare pe internet. Căutările locale pe Internet țin cont de locația geografică a utilizatorului și dau preferință rezultatelor care sunt într-un fel legate de o anumită țară sau localitate. În timpul unei căutări globale, aceste informații nu sunt luate în considerare, iar căutarea se efectuează în toate resursele disponibile.
Când compuneți o interogare pe motoarele de căutare de pe Internet, funcționează diferite moduri de căutare. Modurile de căutare tipice găsite pe majoritatea mașinilor de internet includ: simplu si avansat căutare. O căutare simplă vă permite să specificați doar o funcție de căutare într-o singură solicitare. Căutarea avansată face posibilă crearea unei interogări din mai multe condiții, legându-le cu operatori logici.
Pentru a rafina interogările de căutare, diverse filtre . Filtrele sunt acelea sau alte mijloace auxiliare pentru alcătuirea unei interogări care nu se referă la partea de conținut a condițiilor de interogare, dar limitează rezultatele căutării printr-o caracteristică formală. Deci, de exemplu, atunci când folosește un filtru de tip de fișier la căutare, utilizatorul nu furnizează sistemului informații legate de subiectul solicitării sale, ci pur și simplu limitează rezultatele obținute la un anumit tip de fișier specificat în condiția solicitării sale.
Pentru majoritatea utilizatorilor, motoarele de căutare universale sunt principalele și adesea singurele mijloace de căutare pe Internet. Ele oferă o bună acoperire a surselor, precum și un set de instrumente suficiente pentru a rezolva problemele de căutare de bază.
Piața motoarelor de căutare universale este destul de mare. Am încercat să analizăm cele mai cunoscute motoare de căutare și am prezentat rezultatele în Tabelul 1.
Atunci când alegeți un motor de căutare universal, calitatea resurselor găsite cu ajutorul acestuia joacă un rol important. Puteți determina motorul de căutare preferat pentru anumite sarcini folosind „metoda marcatorului”. Esența sa este că mai întâi este alcătuită o anumită interogare de căutare tematică, după care un grup de oameni - experți în acest domeniu - este chestionat pentru a identifica, în opinia lor, cele mai bune resurse de internet pe tema aleasă. Pe baza datelor sondajului, este generată o listă de site-uri de marcare care sunt garantate a fi relevante pentru cerere și conțin informații de înaltă calitate. Solicitarea este apoi trimisă către motoarele de căutare testate. Logica evaluării este simplă: cu cât site-urile de marcare sunt localizate mai sus în rezultatele căutării, cu atât o anumită resursă este mai potrivită pentru căutarea informațiilor despre un subiect de testare.
A spune că în vremea noastră de tehnologie a informației și de creșterea nesfârșită a volumului de date disponibile atât pentru un individ, cât și pentru societate, există multe probleme cu prelucrarea informațiilor și căutarea acesteia este deja o blasfemie. Cine nu ridică acest subiect? Și pentru a nu vă împovăra cu judecăți subiective și, parțial, obiective, extrase din diverse surse de informare cu privire la problemă, voi trece direct la rezolvarea acesteia. Astăzi vom vorbi despre căutare. Adică despre programe și sisteme informaționale serioase care caută documentele și datele de care avem nevoie.
Actualizați „căutarea directă”
Nu cu mult timp în urmă, când copacii erau mari și nu existau prea multe informații chiar și în rețeaua locală a întreprinderii, orice căutare era efectuată prin simpla căutare într-o mână de fișiere disponibile și verificarea succesivă a numelor și conținutului acestora. O astfel de căutare se numește directă, iar programele (utilitățile) care utilizează tehnologia de căutare directă sunt prezente în mod tradițional în toate sistemele de operare și pachetele de instrumente. Dar nici puterea computerelor moderne nu este suficientă pentru o căutare rapidă și adecvată în volume gigantice de date în timpul căutării directe. Căutarea în câteva sute de documente de pe un disc și căutarea într-o bibliotecă imensă și în câteva zeci de cutii poștale sunt două lucruri diferite. Prin urmare, programele de căutare directă astăzi trec în mod clar în fundal - când vine vorba de instrumente universale.
Desigur, acest tip de căutare nu a fost solicitat de mult timp în sectorul corporativ. Volumele nu sunt aceleași. Și, prin urmare, de mulți ani, și recent în mod clar, tehnologiile capabile să caute rapid și precis documente de diverse formate și din diverse surse sunt mai mult decât relevante. Nu cu mult timp în urmă, „părintele” Microsoft, Bill Gates, aparent invidios pe succesul fenomenal al motorului de căutare pe internet Google, a anunțat, la una dintre conferințele de presă, dorința industriei software (și nu numai) de a contribui în toate modurile posibile, dezvoltarea și aprofundarea creării de motoare și tehnologii de căutare. Dar este prea devreme pentru a crea vreun program de lucru fenomenal de la Microsoft sau un server competitiv pe Internet (MSN încă nu ajunge la Google). Prin urmare, să ne întoarcem la evoluțiile existente. Index, interogare, relevanță
Tehnologiile moderne se bazează pe două procese fundamentale. În primul rând, indexează informațiile disponibile și procesează cererea cu rezultatul ulterioar. În ceea ce privește primul, orice program (fie el un motor de căutare desktop, un sistem de informații corporative sau un motor de căutare pe Internet) își creează propria zonă de căutare. Adică prelucrează documente și generează un index al acestor documente (o structură organizată care conține informații despre datele prelucrate). În viitor, indexul creat este folosit pentru lucru - obținând rapid o listă de documente necesare conform solicitării. Ceea ce urmează, deși deloc simplu din punct de vedere tehnologic, este destul de înțeles de utilizatorul obișnuit. Programul procesează cererea (folosind o expresie cheie) și afișează o listă de documente care conțin această expresie cheie. Întrucât informația este conținută într-un index structurat, procesarea interogărilor este mult mai rapidă (de zeci și sute de ori!) decât în cazul căutării directe (selectarea documentelor se realizează nu prin enumerarea fișierelor, ci prin analiza informațiilor text în index).
Programul afișează documentele găsite în lista rezultată în funcție de relevanță - conformitatea documentului cu textul de interogare. În diferite tehnologii, desigur, există diferite metode pentru căutarea și determinarea relevanței unui document (numărul de „apariții” unui cuvânt și frecvența de mențiune a acestuia în document, raportul dintre acești parametri și numărul total de cuvinte în document, distanța dintre cuvintele expresiei de interogare din fișierele căutate și așa mai departe). Pe baza acestor parametri, se determină „greutatea” documentului și, în funcție de aceasta, un anumit fișier apare în lista de rezultate la o anumită poziție. În cazul căutării pe Internet, situația este și mai complicată. Într-adevăr, în acest caz, trebuie luați în considerare mulți alți factori (page Rank-ul Google este un exemplu în acest sens). Dar acesta este un subiect pentru un articol separat, așa că nu vom atinge Internetul. Revizuirea motoarelor de căutare
Acest material examinează capacitățile mai multor programe de căutare populare care se laudă atât cu viteze decente, cât și cu funcționalitate bună. Dar să te arăți în broșuri este una, dar să stai sub privirea unui expert este cu totul altceva. Și nu mai existau experți, nici un birou plin de oameni cărora le plăcea să joace software-ul pentru uzabilitate. Pe computerul experimental a fost instalat un set de programe (Athlon 2,2 MHz, cu RAM 1 GB, 160 GB hard disk IDE Seagate 7200 rpm și Windows XP): dtSearch Desktop, Ishcheika Prof Deluxe, Google Desktop Search, SearchInform , Copernic Desktop Search, Desktop ISYS. Pentru teste, a fost compilată o bază de date text de documente în formate doc, txt și html cu o dimensiune totală nici mai mult, nici mai mică, ci de 20 gigaocteți. Un grup de camarazi sub conducerea umilului tău servitor a testat, comparat și împărtășit impresiile lor subiective despre fiecare software. Citiți mai jos un rezumat al constatărilor. dtSearch Desktop
Un program care, potrivit dezvoltatorilor, se pretinde a fi cel mai rapid, mai convenabil și cel mai bun motor de căutare. Ca, în general, toți ceilalți din această recenzie. Interfața dtSearch este destul de simplă, dar unele ferestre sau file sunt oarecum supraîncărcate cu elemente, ceea ce face să pară dificil de utilizat. Dar, în realitate, nu există dificultăți deosebite. Singurul punct cu adevărat neplăcut este lipsa de suport a software-ului pentru limba rusă (în ciuda faptului că programul poate căuta documente în mai multe limbi, interfața sa este exclusiv engleză).
Dar dtSearch este unul dintre puținele programe care pot indexa paginile web la o „adâncime” specificată de utilizator (deși, ținând cont de „cumpărarea suplimentară” a kit-ului de completare dtSearch Spider). Aceasta este în plus față de suportarea fișierelor de disc de diferite formate de text și e-mailuri din cutia poștală Outlook. În același timp, programul nu poate funcționa cu baze de date, care sunt o bucată atât de gustoasă pentru motoarele de căutare din cauza volumelor mari de informații conținute în ele și a distribuției lor largi în companii și, prin urmare, în rețelele corporative. Viteza de indexare a documentelor dtSearch s-a dovedit a fi la nivelul potrivit. Privind în viitor, voi spune că acest program a făcut față indexării unei cantități date de informații la un nivel cu un alt concurent - iSYS - și a împărtășit cu acesta locul doi în lista celor mai rapide sisteme. dtSearch a indexat un test de 20 gigaocteți de informații în 6 ore și 13 minute, creând un index de 7,9 GB pentru nevoile ulterioare de căutare.
În ceea ce privește capacitățile de căutare, aici sunt la nivelul potrivit. În primul rând, dtSearch are o căutare morfologică (căutarea unui cuvânt în toate formele sale morfologice). Folosind această oportunitate, te eliberezi de, să zicem, gânduri precum „în ce caz a fost folosit un anumit cuvânt în documentul de care aveam nevoie?” Utilizarea căutării morfologice este aproape întotdeauna justificată, așa că ar trebui să fie prezentă în orice motor de căutare profesional.
Căutarea după sunet este o caracteristică non-standard chiar și pentru motoarele de căutare profesionale. Esența sa este că programul va căuta cuvinte care sună la fel cu cuvântul introdus. Și cea mai bună parte este că această funcție funcționează și pentru limba rusă! De exemplu, când tastați cuvântul „ureche” într-o interogare de căutare, veți vedea nu numai cuvintele „ureche”, ci și „ureche” ca rezultat.
Căutarea cu corectarea erorilor este o funcție foarte importantă. Este folosit pentru a căuta cuvinte care conțin erori sintactice - acestea pot fi fie greșeli de scriere, fie erori în documente obținute folosind sisteme de recunoaștere a caracterelor, de exemplu. Un exemplu simplu - căutați cuvântul tastatură. Unele documente conțin cuvântul „tastatură”, este evident că, de fapt, acesta este cuvântul „tastatură”, persoana tocmai a făcut o greșeală de tipar când a tastat. Deci, o căutare de corectare a erorilor va detecta și include un document cu cuvântul „tastatură” în rezultat. Există, de asemenea, o setare în dtSearch care vă permite să determinați gradul de posibile caractere eronate.
Căutați folosind sinonime. Această caracteristică folosește o listă de sinonime pentru diferite cuvinte. Deci, de exemplu, introducând cuvântul „rapid”, programul va găsi și cuvintele „de mare viteză” și altele care sunt sinonime pentru cuvântul „rapid”, dacă, desigur, sunt prezente în lista de sinonime. . O listă gata făcută de sinonime nu este furnizată cu programul dtSearch, cu toate acestea, este posibil să utilizați liste pe Internet (în consecință, este necesară o conexiune, ceea ce nu este întotdeauna convenabil) sau vă puteți crea propria listă de sinonime .
În plus față de capabilitățile enumerate, dtSearch poate căuta folosind expresii formate din cuvinte conectate prin operații logice. Fiecărui cuvânt dintr-o interogare i se poate atribui propria „greutate”, adică semnificația. O opțiune utilă este să folosești un dicționar format din cuvinte neimportante pentru a nu ține cont de ele la căutare, dar și acest dicționar este gol și va trebui să-l completezi singur.
În continuare, să ne uităm la capacitățile programului atunci când lucrați în rețea. De fapt, dtSearch nu oferă capabilități specifice pentru lucrul cu rețeaua. Cu toate acestea, este foarte posibil să îl utilizați online. Alternativ, puteți crea un fel de index și îl puteți pune într-un folder public (partajat). Programul în sine poate fi instalat pe computerul fiecărui utilizator sau poate fi, de asemenea, plasat într-un folder deschis pentru acces public, iar comenzile rapide pot fi create într-un mod special pentru fiecare utilizator separat, folosind parametrii de linie de comandă, al căror scop este descris în fișierul de ajutor furnizat împreună cu programul. De asemenea, este posibil să instalați automat programul în rețea folosind un fișier MSI. Aceasta va lua în considerare setările pentru fiecare utilizator conectat.
În general, este un program bun din categoria motoarelor de căutare profesionale. Se poate califica pentru o evaluare bună, dar câștigarea încrederii și a respectului din partea utilizatorilor poate să nu fie ușor pentru dtSearch din cauza anumitor factori (nu totul este bine cu interfața, utilizatorii ruși sunt defavorizați, nu există caracteristici strălucitoare pentru lucrul cu rețeaua) . În ceea ce privește căutarea directă a documentelor, programul nu a avut probleme cu textul rusesc. Ca nu existau nici unul cu morfologia declarata, sau cu o cautare neclara. Sistemul a găsit destul de adecvat documentele necesare atât printr-o simplă interogare de un singur cuvânt, cât și folosind câteva paragrafe sau un document ca frază cheie.
Site-ul oficial:
Dimensiunea distribuției: 23 Mb Bloodhound Prof DeluxePe baza numelui, puteți ghici că există suport pentru limba rusă în acest program. Acest lucru este deja frumos. În ceea ce privește interfața, în general, este oarecum neobișnuită, dar în aparență este foarte atractivă. Un alt lucru este comoditatea. Un criteriu foarte controversat, dar totuși, probabil, o soluție cu mai multe ferestre nu este cea mai de succes opțiune (solicitarea este introdusă într-o fereastră, rezultatul este afișat în alta și altele asemenea).
Snoop folosește aceiași indexuri pentru a efectua o căutare rapidă, dar indexarea este mult mai lentă decât alte programe. Acest lucru este foarte ciudat, mai ales având în vedere că capabilitățile sale de procesare a interogărilor de căutare sunt foarte slabe și, prin urmare, structura indexului nu este complexă. Cel mai probabil, acest lucru se datorează unor algoritmi neoptimizați. Acest program sa dovedit a fi un outsider clar în ceea ce privește viteza de indexare și căutare: timpul petrecut pentru crearea unui index este de șase ori mai mare decât cel al dtSearch și iSYS. Indexarea a 20 de gigaocteți de texte pentru câine a dus la 38 de ore și 46 de minute de lucru. Și „zona de căutare” creată a ocupat aceeași dimensiune pe hard disk ca și datele originale, cu un mic minus - 19 gigaocteți.
Bloodhound poate fi prezentat ca o alternativă la căutarea standard în Windows; este puțin probabil să fie capabil de mai mult. Faptul că sarcina principală a lui Snooper este cea mai simplă căutare a fișierelor este indicat nu numai de numărul mic de funcții de analiză a textului interogărilor de căutare și de o căutare avansată după atributele fișierului, ci chiar și de o fereastră de rezultate care oferă legături directe către fișierele găsite, precum și către folderele care conțin aceste fișiere. Fereastra de rezultate nu este foarte informativă în sensul că puteți citi întreg fișierul găsit doar rulând-l, adică nu are un vizualizator de fișiere încorporat. Dar este afișat un fragment din fișierul în care a fost găsit cuvântul căutat; în general, această schemă de afișare amintește foarte mult de motoarele de căutare de pe Internet.
Vorbind despre capacitățile specifice de procesare a interogărilor de căutare, este de remarcat faptul că nu există un „text de căutare”; maximul care poate fi căutat este o frază, chiar dacă nu există un câmp de introducere a textului cu mai multe linii. Cu toate acestea, puteți analiza fraza introdusă, iar Snoop ne oferă aici un set de căutare standard: operații logice, căutare cu mască și căutare citate... nu foarte mult. Programul conține câteva rudimente de căutare morfologică, dar este probabil atât de grosier încât cel mai probabil interferează cu funcționarea corectă (în timpul testelor, au fost observate multe erori cu utilizarea incorectă a morfologiei).
Dar programul vă permite să specificați atributele fișierului atunci când căutați (data documentului, numele fișierului, numele folderului), iar în aceste interogări puteți utiliza și același set de căutare. De asemenea, puteți căuta litere specificând parametrii (De la, Subiect... etc.).
Deci, ne-am dat seama de căutarea în sine, ce mai este interesant despre program, pentru care a primit atât de multe premii, conform informațiilor de pe site-ul oficial? Este greu de spus ce este atât de special la ea; cel mai probabil, interfața Bloodhound este atractivă (exact ca aspect, ca să nu mai vorbim de utilizare).
Operațiunile cu indici sunt foarte standard; o caracteristică plăcută este capacitatea de a actualiza indecșii într-un program. În plus, indexurile pot fi utilizate și online. De acum încolo avem nevoie de mai multe detalii.
În ciuda caracterului primitiv al interogărilor de căutare, programul poate fi folosit pentru a căuta fișiere, astfel încât utilizarea sa poate fi justificată în rețele. Deși aceasta este o întindere, deoarece într-o rețea mare, prioritatea este căutarea rapidă a datelor folosind interogări de căutare complexe din cauza cantității uriașe de informații - și există în mod clar probleme cu viteza de căutare și program. Trebuie să spun că munca cu rețeaua de la Izhishika este gândită așa cum ar trebui. O aplicație separată este concepută special pentru aceasta - Bloodhound Server. Funcționează la fel ca și simplu Snooper (au un singur motor de căutare), doar pentru documentele aflate pe un server central sau pe resurse partajate în rețeaua corporativă. Snooper Server creează noi indecși pe resursele partajate sau le folosește pe cele create anterior. Orice utilizator al rețelei corporative se poate conecta la Serverul de căutare și îl poate folosi pentru a accesa orice document (situat în indexul curent) folosind un browser de Internet. De acord, această schemă este extrem de convenabilă: se dovedește că fișierele din propria rețea pot fi căutate în același mod ca și informațiile de pe Internet, de exemplu, prin Google.
Evaluând toate avantajele și dezavantajele acestui program, concluzia sugerează că capabilitățile sale nu sunt, cel mai probabil, suficiente pentru rețelele corporative (în ciuda organizării bune a lucrului cu rețeaua), dar pentru un computer de acasă sau chiar pentru o rețea de acasă este , în principiu, s-ar putea să apară. Deși nici viteza de lucru și nici capacitățile de căutare nu inspiră optimism...
Site oficial în limba rusă:
Dimensiunea distribuției: 6 MbGoogle Desktop Search + GDS EnterpriseDesigur, nu am putea ignora un dezvoltator atât de faimos. Numele Google spune deja multe. Oamenii care folosesc cel mai puternic motor de căutare de pe Internet de ani de zile vor decide, fără nicio îndoială, să instaleze acest motor de căutare special pe computerul lor. Gândește-te: Google pe computerul tău de acasă! Cu toate acestea, fără a ceda provocărilor cu un brand promovat pe scară largă, să încercăm sobru, și cel mai important obiectiv, să luăm în considerare capacitățile motorului de căutare „desktop” de la Google.
Primul lucru care vă atrage atenția este lipsa propriei sale cochilii pentru program. Google Desktop Search este încă situat în fereastra browserului, respectiv, întreaga interfață a versiunii desktop a fost moștenită de la software-ul de la fratele său mai mare de Internet. Dacă acest lucru este bun sau rău, este un aspect discutabil: unor oameni le place minimalismul în designul acestui motor de căutare, în timp ce alții doresc să vadă o aplicație cu drepturi depline, plină cu tot felul de butoane și așa mai departe.
Ce vă atrage atenția imediat după design? Și faptul că același Google Desktop Search începe să indexeze totul pe computer, fără nicio cerere! Și cel mai interesant este că este imposibil să selectați căile de indexare folosind Google Desktop Search. Va trebui să descărcați un program separat (TweakGDS), care vă va permite să extindeți oarecum setările Google Desktop, inclusiv specificarea locurilor necesare pentru indexare. Deși, până când vă dați seama de toate acestea, acesta va indexa deja un hard disk standard, astfel încât această setare este mai probabil să fie necesară atunci când lucrați cu cantități mari de date, ceea ce este foarte important atunci când este utilizat în rețelele corporative (versiunile Enterprise) . Cu toate acestea, nu este un fapt că, după descărcarea TweakGDS, problemele tale vor fi rezolvate. La urma urmei, necesită Microsoft .NET Framework și Microsoft Scripting Runtime pentru a funcționa. Da... instalarea, precum și accesul la setări, ar fi putut fi simplificate, deși dezvoltatorii pot înțelege probabil: de ce să scrieți ceva nou când există un motor de căutare gata făcut, l-au portat pe computerul local și l-au lăsat utilizatorul „se bucură” și un nume celebru va face o altă capodoperă din „asta”. Haide, să încheiem această digresiune lirică și să trecem la căutare.
În ceea ce privește analiza interogărilor de căutare și livrarea rezultatelor, aici totul este absolut identic cu Google pe Internet: același sistem de afișare a rezultatelor, același set standard de operații logice pentru interogările de căutare. În general, Google Desktop Search, ca și programul anterior, este destinat exclusiv căutării fișierelor - desigur, nu are un vizualizator intern pentru aceste fișiere. Numărul de formate de fișiere acceptate de Google Desktop Search este destul de suficient și, de asemenea, este plăcut că caută paginile de Internet vizitate, preluând date din cache. Vitezele de căutare și indexare sunt destul de acceptabile. Adevărat, pentru uz casnic. Google Desktop Search a făcut față cu o cantitate impresionantă de 20 de gigaocteți de texte în 8 ore și 17 minute. Petrecerea mai multor zile procesând informații din rețeaua corporativă a unei întreprinderi mari nu este ceva ce orice administrator de sistem ar dori să facă. În plus: dimensiunea indexului creat a fost la același nivel (4,5 GB) cu un alt motor de căutare testat în această recenzie - SearchInform.
Marele avantaj (sau dezavantaj - tu hotărăști) al Google Desktop Search este că acceptă pluginuri, care se pot schimba mult în bine. Un alt lucru este că conectarea pluginurilor și configurarea lor complică atât de mult sarcina de a instala un motor de căutare, încât începi să te întrebi dacă toate acestea sunt necesare atunci când poți instala un program normal, cu drepturi depline, în care totul va fi deja prezent. La urma urmei, pentru a utiliza fiecare caracteristică, va trebui să instalați un nou plugin. Chiar și pentru ca programul să funcționeze pe deplin cu arhive, este nevoie de un gadget separat. Este fascinant și seducător faptul că toate aceste module suplimentare sunt gratuite. Cu toate acestea, dacă nu țineți cont de versiunea desktop a motorului de căutare, atunci configurarea competentă a GDS Enterprise s-ar putea să nu fie în puterea dvs. - la urma urmei, nu degeaba specialiștii de la Google își oferă serviciile pentru configurarea propriilor lor. software pentru rețeaua dvs. pentru doar 10.000 USD.
Dacă parcurgeți procedura de configurare și instalare (sau plătiți 10.000 USD unei echipe de răspuns rapid de la Google), veți înțelege că complexitatea instalării este mai mult decât compensată de setările foarte flexibile atunci când sunt utilizate în rețelele corporative. Un aspect important al utilizării Google Desktop într-o rețea corporativă este utilizarea politicilor de grup, ceea ce face posibilă setarea setărilor pentru fiecare utilizator.
Pentru a rezuma, cea mai rezonabilă utilizare a acestui program este un computer de acasă sau de la serviciu. La urma urmei, pentru un computer obișnuit, este suficient doar să instalați programul - va face restul singur (nici măcar nu vă va întreba nimic).
Cu toate acestea, Google Desktop Search Enterprise va fi acceptabilă în cazurile în care există o nevoie urgentă de configurare flexibilă a politicii de rețea pentru a utiliza motorul de căutare, în timp ce capacitatea de a procesa interogări de căutare va fi pe locul al doilea ca importanță și timp (sau bani). ) cheltuiți pentru configurarea programului vor fi pe primul loc.
Site-ul oficial:
Dimensiunea distribuției, inclusiv TweakGDS: 1,2 MbCopernic Desktop SearchClick pe poza pentru marire
Interfața programului evocă emoții extrem de pozitive - totul este făcut în conformitate cu standardele general acceptate, nimic de prisos, într-un cuvânt, un design plăcut. Pentru un începător, înțelegerea interfeței Copernic Desktop Search va fi foarte ușoară. Deși, este oarecum confuz faptul că designerii au creat clar interfața programului ținând cont de faptul că programul va funcționa în tema standard Windows XP. Când utilizați tema clasică, programul nu arată atât de frumos. Dar aceasta este mai mult o chestiune de gust.
La prima lansare, programul vă solicită să creați indecși pentru căutare. Mi s-a părut oarecum neobișnuit ca, după selectarea folderelor pentru indexare, programul să nu ofere apăsarea niciunui buton, cum ar fi „Începe indexarea”, iar indexarea nu începe automat, doar atunci s-a observat că Copernic încerca să înceapă indexarea în timp ce computerul era inactiv. Va trebui să aprofundați puțin în opțiunile programului pentru a configura totul corect. Trebuie remarcat faptul că există posibilități destul de largi pentru configurarea creării automate a indexului: un planificator încorporat, capacitatea de a indexa în timp ce computerul este inactiv, în fundal, cu prioritate scăzută. Indexarea nu a fost prea rapidă - 10 ore și 51 de minute - aceasta este mai lentă decât în alte motoare de căutare (cu excepția Bloodhound, dar Copernic este încă cu un ordin de mărime mai rapid decât dezvoltarea tehnologiilor iSleuthHound.
Acum despre structura indexului. În general, nu are nimic special în asta. Este posibil să selectați tipuri de fișiere, atât în formă generală, cât și detaliată. Adică, inițial poți alege ceea ce vrei să indexezi - Documente, Imagini, Videoclipuri, Muzică. În cealaltă filă a ferestrei de opțiuni, veți putea selecta anumite tipuri de fișiere după extensie. În plus, puteți configura indexul astfel încât, de exemplu, imaginile mai mici de 16x16 în dimensiune să nu fie indexate sau fișierele de sunet cu o lungime mai mică de 10 secunde să nu fie indexate. Pe lângă indexarea fișierelor din foldere, Copernic poate lucra cu e-mailuri și contacte din agenda Microsoft Outlook și Microsoft Outlook Express și este posibilă indexarea Favoritelor și Istoricul din Internet Explorer.
În ceea ce privește capacitățile de căutare, acestea sunt foarte slabe aici. În timpul testelor, a fost chiar dezvăluit că programul nu caută documente în formatele txt și html în limba rusă, permițându-vă să le găsiți numai după titluri și nu după conținut. Singurul lucru pe care îl oferă programul pentru a îmbunătăți eficiența căutării este utilizarea unui set standard de operații logice și, chiar și atunci, această caracteristică a fost descoperită experimental, deoarece nu a fost documentată. Apropo, nici ajutorul programului nu este în regulă - este disponibil numai prin Internet, ceea ce, vedeți, este foarte incomod și nu există prea multe informații de ajutor pe Internet. Aparent, dezvoltatorii au decis că interfața simplă a programului nu implică prezența unui ajutor normal. Continuând conversația despre capabilitățile de căutare, trebuie remarcat faptul că, în ciuda analizei slabe a interogărilor, programul oferă un sistem de căutare interesant - utilizatorul poate selecta tipul de fișiere (imagini, videoclipuri, muzică etc.), introduce o căutare interogați și selectați atributele specifice tipului de fișier selectat. De exemplu, pentru fișierele de sunet, acestea pot fi valori din etichetele mp3 (artist, album, dată etc.), pentru imagini, de exemplu, puteți selecta dimensiunea acestora (după rezoluție), în general, fiecare tip are propriile setări. După căutarea unui anumit tip de fișier, programul va afișa o listă foarte informativă în fereastra de rezultate, iar dacă solicitarea dvs. include fișiere de alte tipuri, le puteți deschide făcând clic pe un anumit link.
Separat, merită menționat fereastra de afișare a rezultatelor. Sub lista fișierelor găsite, este afișat conținutul acestor fișiere (o schemă similară este adesea folosită în clienții de e-mail). Adevărat, vizualizarea textului se poate face numai în format nativ și nu există un mod de afișare a textului simplu, care nu este întotdeauna convenabil, deoarece deschiderea unui document în acest caz durează mai mult. Dar, având în vedere că Copernic poate căuta imagini și muzică, este posibil să vizualizați aceste fișiere multimedia.
Sunt descrise principiile de bază de funcționare ale acestui program, acum să vedem ce ne poate oferi Copernic Desktop Search pentru lucrul cu rețeaua... În principiu, puteți viziona foarte mult timp, dar cu greu veți putea vedea nimic . Cu alte cuvinte, acest program nu a fost destinat să fie bazat pe rețea. Copernic Desktop Search este un motor de căutare exclusiv pentru acasă.
Evident, singura (cea mai logică) aplicație a acestui program este un computer de acasă. Aici va face față pe deplin tuturor interogărilor simple de căutare ale utilizatorilor, constând din unul sau două cuvinte, va găsi informațiile necesare, precum și împărțirea căutării în funcție de tipul de fișier și suport pentru fișiere multimedia, împreună cu indexarea de fundal în modul cu prioritate scăzută, cuplată cu un mod plăcut. interfață, oferă programului puterea de a câștiga încredere în rândul utilizatorilor fără experiență.
Site-ul oficial
Dimensiunea distribuției: 2,6 MbISYS DesktopClick pe poza pentru marire
Un program foarte puternic. În ceea ce privește nivelul său de echipare cu tot felul de funcții, este undeva aproape de următorul sistem de căutare SearchInform de pe listă. Mai mult, dimensiunea fișierului de instalare este mai mare de 40Mb! Este greu de spus ce ar putea fi strâns în astfel de dimensiuni, deoarece același SearchInform, cu funcționalitate similară, ocupă 15Mb.
Nici aici procesul de instalare nu este foarte plăcut, sau mai degrabă nici măcar procesul de instalare. Chiar înainte de a descărca programul, vi se va cere să vă înregistrați, altfel nu există nicio cale. Apoi, interfața. Este făcut foarte frumos, nimic inutil nu atrage atenția, totuși, acestea sunt impresiile unei persoane care este deja oarecum obișnuită cu asta. Nu va fi ușor pentru un începător să-și dea seama unde și ce se află, unde să facă clic și unde să caute în cele din urmă. Este foarte recomandat să citiți ajutorul înainte de a începe lucrul - veți economisi o mulțime de nervi și timp. La orice altceva se adaugă lipsa completă de suport pentru limba rusă în program. Nu e bun. În plus, ferestrele de aici nu sunt supraîncărcate cu comenzi, dar a trebuit să plătim pentru asta cu mai multe module și utilizarea de ferestre suplimentare. De exemplu, interogările de căutare sunt introduse prin lansarea unui program, iar gestionarea indexului se realizează folosind un alt program. Interogările de căutare sunt introduse aici și în ferestre pop-up separate. Este greu de spus care este mai bun - o interfață supraîncărcată sau ferestre multiple omniprezente; mai degrabă, este o chestiune de gust.
Când vine vorba de crearea de indexuri, programul oferă caracteristici pentru a simplifica procesul de setare a opțiunilor pentru un nou index. Aceste caracteristici includ mai multe șabloane gata făcute pentru crearea de indexuri pentru folderul „Documentele mele”, „Poștă”, „Poștă și documente”, „Folder specific”, „Dosar cu o selecție de tipuri de fișiere”, etc. Astfel de șabloane simplifică crearea de indici pe prima etapă. Utilitatea pentru lucrul cu indici nu are o interfață foarte bună, ceea ce este intimidant cu o oarecare complexitate (aceasta este o evaluare foarte subiectivă, să fiu sincer), totuși, dacă te uiți la ea, oferă multe opțiuni utile și, în general , utilizarea sa nu cauzează prea multe dificultăți. ISYS Desktop poate indexa date din diverse surse de date și oferă, de asemenea, multe setări flexibile pentru o astfel de indexare. Caracteristicile suplimentare de indexare includ: suport pentru SQL, FTP, TRIM Context, WORLDOX 2002, scripturi. La crearea unui index, dacă ați selectat elementul „Folder cu selecție de tipuri de fișiere”, aveți posibilitatea de a selecta tipuri de fișiere pentru indexare manual (prin extensie). Trebuie spus că pur și simplu există un număr mare de tipuri de fișiere acceptate, dar nu veți putea adăuga propriul tip (extensie) la lista existentă. De asemenea, puteți observa prezența unui planificator de indexare. Crearea unui index și procesarea a 20 de gigaocteți de informații au luat ISYS Desktop 6 ore și 13 minute, arătând în cele din urmă un timp bun și dimensiunea fișierului creat - 7,9 GB.
Capacitățile de căutare ale acestui program sunt destul de bune. Ceea ce este folosit în ISYS este mult mai puternic decât suportul convențional pentru operațiuni logice. Printre capabilitățile avansate de căutare, programul oferă utilizarea de sinonime și un filtru de sortare (după cale, nume și data creării fișierului). Setul de operatori logici este ceva mai larg decât setul standard. Pe lângă operațiile logice, programul vă permite să lucrați cu mulți alți operatori, care, în principiu, pot înlocui unele tipuri de căutare; de exemplu, căutarea cu analizare poate fi înlocuită complet prin utilizarea operatorilor speciali. Am fost foarte surprins că programul nu are o căutare folosind morfologie. Aceasta este o omisiune gravă, deoarece eficiența căutării este mult îmbunătățită atunci când se utilizează analiza morfologică. În plus, nu există o listă de cuvinte semnificative, dar există o listă extinsă de cuvinte nesemnificative. De asemenea, sunt anunțate funcții de căutare precum „căutare aproximativă” și „analiza euristică”.
ISYS oferă o gamă de mai multe tipuri de interogări de căutare, și anume tipuri vizuale. Acest lucru se face folosind diferite tipuri de ferestre pentru introducerea interogărilor de căutare, cu toate acestea, de fapt, nici o singură fereastră nu permite utilizarea altor tehnologii decât cele enumerate mai sus.
Rezultatele căutării sunt foarte informative și sunt afișate ca o listă de documente sortate după relevanță. O previzualizare a documentului selectat este afișată mai jos. Spre deosebire de Copernic Desktop Search, previzualizarea aici este disponibilă doar sub formă de text simplu; nu a fost posibilă afișarea documentelor în formatul lor nativ, fie că este Word, Html sau PDF, deși acest lucru, în principiu, nu este prea critic. Programul vă permite să împărțiți documentele găsite în grupuri în funcție de anumite criterii (în mod implicit, acestea sunt împărțite în funcție de relevanță). De asemenea, puteți vizualiza documente deja găsite selectând foldere individuale (acest lucru este convenabil când rezultatul produce un număr foarte mare de documente).
Utilizarea programului într-o rețea corporativă este, de asemenea, foarte justificată, deoarece oferă oportunități bune de organizare a căutării în rețea. Sistemul de căutare se bazează pe crearea unui index public care conține date indexate din resurse online disponibile public.
De fapt, programul de la ISYS este demn de atenție, cel puțin familiarizarea cu el. Acest program este un proiect matur cu un număr mare de funcții (nu întotdeauna și nu toată lumea, desigur, are nevoie de ele, dar totuși). Șansele ca programul să înregistreze unele îmbunătățiri în ceea ce privește procesarea interogărilor de căutare sunt necunoscute, dar în acest moment poate fi recomandat pentru utilizare aproape universală. Și având în vedere că este încă prea greu pentru sistemele de acasă, principalele locuri pentru instalarea lui sunt rețelele corporative.
Site-ul oficial:
Dimensiunea distribuției: 40 MbSearchInformClick pe poza pentru marire
Probabil că nu merită să începeți imediat cu o descriere a interfeței SearchInform. Ar trebui mai întâi să descriem procesul de instalare, sau mai degrabă unul dintre detaliile acestuia: nu puteți instala programul fără o conexiune la Internet. Faptul este că înainte de prima lansare, programul necesită înregistrarea utilizatorului (gratuit) și trimite toate datele introduse către server. Aparent, dezvoltatorii au trebuit să ia astfel de măsuri în lupta împotriva pirateriei, dar acest lucru nu a avut un efect pozitiv asupra ușurinței instalării.
Interfața programului este proiectată în conformitate cu toate regulile general acceptate, cu toate acestea, la prima vedere, este oarecum greoaie. Folosind programul pentru prima dată, pare că este prea complicat, uneori nu este ușor să ne amintim în ce meniu sau pe ce filă se află opțiunea dorită, totuși, cu o utilizare mai îndelungată, interfața nu mai pare atât de teribil de complicată . Principalul lucru este să citiți mai întâi certificatul.
După ce ați înțeles puțin interfața, puteți începe să creați un index. Procesul în sine este foarte simplu, iar viteza de indexare, chiar și oculară, este semnificativ mai mare decât toate celelalte motoare de căutare din recenzie. Numerele de test clare arată că SearchInform este de două ori mai rapid decât dtSearch și iSYS în ceea ce privește viteza de indexare! Programul a indexat datele furnizate în valoare de 20 gigaocteți într-un timp record de 3 ore și 17 minute. Și dimensiunea indexului creat s-a dovedit a fi cea mai mică de 4,4 GB - cu 100 de megaocteți mai puțin decât Google Desktop Search.
Programul suportă, pe lângă fișierele și folderele obișnuite, și indexarea e-mail-urilor, conectarea și indexarea bazelor de date (!) și a altor surse externe (DMS, CRM), imediat în timpul indexării puteți specifica un dicționar pentru efectuarea unei căutări morfologice, precum și toate atributele. pot fi fișiere indexate. După crearea indexului, atunci când încercați să efectuați prima căutare de testare a documentelor, puteți deveni oarecum confuz: „există două tipuri de căutare aici, dar de care am nevoie?” După cum am menționat mai devreme, principalul lucru este să citiți ajutorul, apoi totul va deveni clar. Programul poate efectua de fapt două tipuri de căutări - căutarea expresiei și căutarea documentelor similare ca conținut cu textul interogării.
O descriere a tuturor funcțiilor principale pentru analizarea unei interogări de căutare a fost dată mai sus, așa că acum vom enumera doar capacitățile de căutare oferite de acest program. Să începem cu căutarea expresiilor: bineînțeles, căutarea morfologică, căutarea citatelor, operații logice, căutarea cu analiza cuvintelor (căutare la începutul cuvântului, la sfârșit, în partea din mijloc, sau o potrivire completă), căutare mixtă de citate ( când toate cuvintele din interogare trebuie să fie prezente în document, dar nu neapărat în ordinea introdusă), căutarea cu corectarea erorilor, utilizarea sinonimelor, „căutare aproape de citare” (căutați fraza introdusă ca citare, dar alte cuvinte pot să fie prezent între cuvintele introduse), etc. Unele dintre opțiunile enumerate au propriile setări specifice. În plus, este posibil să folosiți un dicționar de cuvinte neimportante, iar programul are deja o listă gata făcută a acestor cuvinte; puteți utiliza și un dicționar de cuvinte prioritare pentru căutare (desigur, va trebui să o completați tu).
Aici, în principiu, am trecut în revistă pe scurt toate caracteristicile principale ale căutării de expresii.
Să trecem la luarea în considerare a caracteristicilor acestui program - căutarea de documente similare. Dezvoltatorii susțin că aceasta nu este în niciun caz o simplă căutare de text, este tocmai o „căutare a celor similare” - exact așa este descris peste tot, dar ei bine, o puteți numi cum doriți - principalul aspect este . O căutare rapidă pe Internet poate dezvălui rapid că așa-numita „căutare similară” este o nouă dezvoltare în domeniul analizei textului. Acest sistem vă permite să găsiți texte care sunt similare în conținut semantic. Cel mai plăcut lucru a fost că, după efectuarea interogărilor de căutare test, s-a dovedit că teoria coincide destul de bine cu practica! Programul caută de fapt documente cu conținut similar și le afișează într-o listă, sortându-le după procent de asemănare.
În continuare, să ne uităm la ce oferă SearchInform (în special, versiunea sa corporativă SearchInform Corporate) pentru a lucra într-o rețea corporativă. Există două tipuri de aplicații: partea server și partea utilizator. Partea de server procesează independent indecșii specificați, iar utilizatorii îi pot folosi pentru căutare, în funcție de drepturile de acces care le sunt atribuite. Utilizatorii pot fi configurați automat folosind conturi Windows (în termeni profesionali, SearchInform folosește autentificarea NTFS Windows) sau manual (utilizatorii vor trebui adăugați separat). Fiecărui utilizator i se poate permite sau refuza accesul la anumiți indexuri, iar utilizatorii pot fi, de asemenea, combinați în grupuri. În general, setările SearchInform pentru lucrul în rețea sunt înaintea Google în ceea ce privește flexibilitatea și Ishhound Server în ceea ce privește comoditatea și simplitatea.
Site-ul oficial:
Dimensiunea distribuției: 14,7 Mb Comparația vitezelor de indexare
Sistem de căutare Timp de indexare Dimensiunea indexului Bloodhound Prof Deluxe 4.5 38 ore 46 minute 19 GB Isys Desktop 7.0 6 ore 13 minute 7,9 GB DtSearch 7.0 6 ore 3 minute 8,6 GB Google Desktop Search Enterprise 8 ore 17 minute 4,5 GB Copernic Desktop Search * 10 ore 51 minute 7 GB SearchInform 1.5.02 3 ore 17 minute 4,4 GB * Majoritatea documentelor.html și .txt care conțin text rusesc, deși au fost indexate, au fost imposibil de găsit decât după numele lor.
Toate programele sunt demne de atenție.
Pe baza testelor și a unei examinări atente a fiecărui program prezentat în recenzie, se pot trage anumite concluzii. Deci, Google Desktop Search Copernic Desktop Search este destul de potrivit pentru utilizatorul neexperimentat ca sistem de căutare a informațiilor de acasă. Aceștia fac față bine interogărilor simple, nu supraîncărcă utilizatorul cu setări și, în plus, sunt complet gratuit. Încercarea Google de a intra pe piața motoarelor de căutare corporative nu este încă foarte justificată: pentru ca acesta să funcționeze corect, programul trebuie să fie echipat cu module suplimentare și este departe de a fi ușor de configurat. Prin urmare, denumirile care se explică de la sine Desktop Search, Copernic și Google își rezervă în spatele lor nișa motoarelor de căutare „desktop”.
Soluții adevărate, mai puternice - dtSearch, iSYS și SearchInform, de asemenea, nu sunt sigure și oferă utilizatorilor versiunile lor „desktop”. Dar la un preț rezonabil, spre deosebire de software-ul gratuit de la Google și Copernic. Desigur, trebuie să plătiți pentru putere, viteză și funcționalitate. Dar accentul principal al dezvoltatorilor dtSearch, iSYS și SearchInform este, desigur, pe sectorul corporativ. Rețeaua, funcționalitatea, indexarea și viteza de căutare sunt cele care disting aceste produse de „concurenții” lor. Pe baza rezultatelor testului, favoritul a fost identificat - SearchInform. Programul oferă posibilitatea de a căuta documente similare, are cele mai rapide viteze de indexare și căutare și are un set bun de funcții.