V excela există o modalitate și mai rapidă și mai convenabilă de a reprezenta o regresie liniară (și chiar principalele tipuri de regresii neliniare, vezi mai jos). Acest lucru se poate face astfel:
1) selectați coloanele cu date Xși Y(trebuie să fie în ordinea aceea!);
2) sunați Chart Wizardși selectați într-un grup Un fel – punctatși apăsați imediat Gata;
3) fără a deselecta diagrama, selectați elementul din meniul principal care apare Diagramă, în care ar trebui să selectați elementul Adăugați linia de tendință;
4) în caseta de dialog care apare linie de tendință fila Un fel Selectați Liniar;
5) fila Parametrii comutatorul poate fi activat Arată ecuația pe diagramă, care vă va permite să vedeți ecuația de regresie liniară (4.4), în care se vor calcula coeficienții (4.5).
6) În aceeași filă, puteți activa comutatorul Puneți pe diagramă valoarea încrederii de aproximare (R^2). Această valoare este pătratul coeficientului de corelație (4.3) și arată cât de bine ecuația calculată descrie dependența experimentală. Dacă R 2 este aproape de unitate, atunci ecuația de regresie teoretică descrie bine dependența experimentală (teoria este de acord cu experimentul) și dacă R 2 este aproape de zero, atunci această ecuație nu este potrivită pentru a descrie dependența experimentală (teoria nu este de acord cu experimentul).
Ca urmare a efectuării acțiunilor descrise, veți obține o diagramă cu un grafic de regresie și ecuația acestuia.
§4.3. Principalele tipuri de regresie neliniară
Regresia parabolica si polinomiala.
Parabolic dependenta de valoare Y din valoare X dependența exprimată printr-o funcție pătratică (parabolă de ordinul 2) se numește:
Această ecuație se numește regresie parabolica Y pe X. Parametrii A, b, Cu numit coeficienții de regresie parabolic. Calculul coeficienților de regresie parabolic este întotdeauna greoi, de aceea se recomandă utilizarea unui computer pentru calcule.
Ecuația (4.8) a regresiei parabolice este un caz special al unei regresii mai generale numită polinom. polinom dependenta de valoare Y din valoare X se numește dependență exprimată prin polinom n-a comanda:
unde sunt numerele un i (i=0,1,…, n) sunt numite coeficienții de regresie polinomială.
Regresia puterii.
Putere dependenta de valoare Y din valoare X se numește dependență de forma:
Această ecuație se numește ecuația de regresie a puterii Y pe X. Parametrii Ași b numit coeficienții de regresie a puterii.
ln=ln A+b ln X. (4.11)
Această ecuație descrie o dreaptă în plan cu axe de coordonate logaritmice ln Xși ln. Prin urmare, criteriul de aplicabilitate a regresiei puterii este cerința ca punctele logaritmilor datelor empirice ln x iși ln i erau cel mai aproape de linia dreaptă (4.11).
regresie exponenţială.
exemplar(sau exponenţială) dependenţa cantităţii Y din valoare X se numește dependență de forma:
(sau ). (4,12)
Această ecuație se numește ecuație exponențială(sau exponenţială) regresie Y pe X. Parametrii A(sau k) și b numit exponenţială(sau exponenţială) regresie.
Dacă luăm logaritmul ambelor părți ale ecuației de regresie a puterii, obținem ecuația
ln = X ln A+ln b(sau ln = k x+ln b). (4.13)
Această ecuație descrie dependența liniară a logaritmului unei mărimi ln față de o altă mărime X. Prin urmare, criteriul de aplicabilitate a regresiei puterii este cerința ca datele empirice să aibă aceeași mărime x işi logaritmi de altă valoare ln i erau cel mai aproape de linia dreaptă (4.13).
regresie logaritmică.
Logaritmic dependenta de valoare Y din valoare X se numește dependență de forma:
=A+b ln X. (4.14)
Această ecuație se numește regresie logaritmică Y pe X. Parametrii Ași b numit coeficienții de regresie logaritmică.
regresie hiperbolica.
Hiperbolic dependenta de valoare Y din valoare X se numește dependență de forma:
Această ecuație se numește ecuația de regresie hiperbolică Y pe X. Parametrii Ași b numit coeficienții de regresie hiperbolicși sunt determinate prin metoda celor mai mici pătrate. Aplicarea acestei metode conduce la formulele:
În formulele (4.16-4.17), însumarea se realizează peste indice i de la unu la numărul de observaţii n.
Din păcate, în excela nu există nicio funcţie care să calculeze coeficienţii regresiei hiperbolice. În acele cazuri în care nu se știe cu siguranță că valorile măsurate sunt legate de proporționalitate inversă, se recomandă să se caute ecuația de regresie a puterii în locul ecuației de regresie hiperbolică, deci în excela există o procedură pentru a-l găsi. Dacă se presupune o dependență hiperbolică între valorile măsurate, atunci coeficienții săi de regresie vor trebui să fie calculați folosind tabele de calcul auxiliare și operații de însumare folosind formule (4.16-4.17).
Regresia în Excel
Prelucrarea datelor statistice poate fi efectuată și folosind pachetul de analiză suplimentar din sub-articolul din meniul „Serviciu”. În Excel 2003, dacă deschideți SERVICIU, nu putem găsi fila ANALIZA DATELOR, apoi faceți clic pe butonul stâng al mouse-ului pentru a deschide fila SUPLIMENTARE si punctul opus PACHET DE ANALIZĂ făcând clic pe butonul stâng al mouse-ului, puneți o bifă (Fig. 17).
Orez. 17. Fereastra SUPLIMENTARE
După aceea, meniul SERVICIU apare fila ANALIZA DATELOR.
În Excel 2007 pentru a instala ANALIZA PACHET trebuie să faceți clic pe butonul OFFICE din colțul din stânga sus al foii (Fig. 18a). Apoi, faceți clic pe butonul OPȚIUNI EXCEL. În fereastra care apare OPȚIUNI EXCEL clic stânga pe element SUPLIMENTARE iar în partea dreaptă a listei derulante, selectați elementul PACHET DE ANALIZĂ. Apoi, faceți clic pe O.K.




Orez. 18. Instalare ANALIZA PACHETîn Excel 2007
Pentru a instala pachetul de analiză, faceți clic pe butonul MERGE,în partea de jos a ferestrei deschise. Fereastra prezentată în fig. 12. Bifați caseta de lângă PACHET DE ANALIZĂ.În fila DATE va apărea butonul ANALIZA DATELOR(Fig. 19).

Din articolele propuse, selectați articolul " REGRESIE” și faceți clic pe el cu butonul stâng al mouse-ului. Apoi, faceți clic pe OK.

Fereastra prezentată în fig. 21

Instrument de analiză « REGRESIE» este folosit pentru a potrivi un grafic la un set de observații folosind metoda celor mai mici pătrate. Regresia este utilizată pentru a analiza efectul asupra unei singure variabile dependente al valorilor uneia sau mai multor variabile independente. De exemplu, performanța atletică a unui atlet este influențată de mai mulți factori, inclusiv vârsta, înălțimea și greutatea. Este posibil să se calculeze gradul de influență a fiecăruia dintre acești trei factori asupra performanței unui sportiv, iar apoi să se utilizeze datele obținute pentru a prezice performanța altui sportiv.
Instrumentul de regresie folosește funcția LINIST.
Caseta de dialog REGRES
Etichete Selectați caseta de selectare dacă primul rând sau prima coloană a intervalului de intrare conține titluri. Debifați această casetă de validare dacă nu există antete. În acest caz, anteturile adecvate pentru datele din tabelul de ieșire vor fi generate automat.
Nivel de fiabilitate Selectați caseta de selectare pentru a include un nivel suplimentar în tabelul cu totaluri de ieșire. În câmpul corespunzător, introduceți nivelul de încredere pe care doriți să îl aplicați, în plus față de nivelul de încredere implicit de 95%.
Constant - zero Bifați caseta pentru ca linia de regresie să treacă prin origine.
Interval de ieșire Introduceți o referință la celula din stânga sus a intervalului de ieșire. Alocați cel puțin șapte coloane pentru tabelul de rezultate, care va include: rezultatele analizei varianței, coeficienții, eroarea standard de calcul Y, abaterile standard, numărul de observații, erorile standard pentru coeficienți.
Foaie de lucru nouă Bifați această casetă pentru a deschide o nouă foaie de lucru în registrul de lucru și introduceți rezultatele analizei pornind de la celula A1. Dacă este necesar, introduceți un nume pentru noua foaie în câmpul opus poziției corespunzătoare a butonului radio.
Nou registru de lucru Bifați această casetă pentru a crea un nou registru de lucru în care rezultatele vor fi adăugate la o nouă foaie.
Reziduuri Selectați caseta de selectare pentru a include reziduurile în tabelul de ieșire.
Reziduuri standardizate Selectați caseta de validare pentru a include reziduurile standardizate în tabelul de ieșire.
Graficul rezidual Bifați caseta pentru a reprezenta grafic reziduurile pentru fiecare variabilă independentă.
Fit Plot Selectați caseta de validare pentru a reprezenta un grafic valorile prezise în raport cu valorile observate.
Graficul de probabilitate normală Bifați caseta pentru a reprezenta probabilitatea normală.
Funcţie LINIST
Pentru a efectua calcule, selectați celula în care dorim să afișăm valoarea medie cu cursorul și apăsați tasta = de pe tastatură. Apoi, în câmpul Nume, specificați funcția dorită, de exemplu IN MEDIE(Fig. 22).

Orez. 22 Găsirea funcțiilor în Excel 2003
Dacă în câmp NUME numele functiei nu apare, apoi click stanga pe triunghiul de langa camp, dupa care va aparea o fereastra cu o lista de functii. Dacă această funcție nu este în listă, faceți clic stânga pe elementul din listă ALTE FUNCȚII, va apărea o casetă de dialog. MASTER FUNCȚIE, în care, folosind derularea verticală, selectați funcția dorită, selectați-o cu cursorul și faceți clic pe O.K(Fig. 23).

Orez. 23. Asistent de funcții
Pentru a căuta o funcție în Excel 2007, în meniu se poate deschide orice filă, apoi pentru a efectua calcule, selectați celula în care dorim să afișăm valoarea medie cu cursorul și apăsați tasta = de pe tastatură. Apoi, în câmpul Nume, specificați funcția IN MEDIE. Fereastra pentru calcularea funcției este similară cu cea din Excel 2003.
De asemenea, puteți selecta fila Formule și faceți clic stânga pe butonul din „ FUNCȚIE DE INSERARE» (Fig. 24), va apărea o fereastră MASTER FUNCȚIE, a cărui vizualizare este similară cu Excel 2003. De asemenea, în meniu, puteți selecta imediat categoria de funcții (utilizate recent, financiare, logice, text, dată și oră, matematice, alte funcții), în care vom căuta pentru funcția dorită.




Orez. 24 Selectarea funcției în Excel 2007
Funcţie LINIST calculează statistici pentru o serie folosind metoda celor mai mici pătrate pentru a calcula o linie dreaptă care aproximează cel mai bine datele disponibile și apoi returnează o matrice care descrie linia dreaptă rezultată. De asemenea, puteți combina funcția LINIST cu alte funcții pentru a calcula alte tipuri de modele care sunt liniare în parametri necunoscuți (ai căror parametri necunoscuți sunt liniari), inclusiv serii polinomiale, logaritmice, exponențiale și de putere. Deoarece este returnată o matrice de valori, funcția trebuie specificată ca formulă matrice.
Ecuația pentru o dreaptă este:
(în cazul mai multor intervale de valori x),
unde valoarea dependentă y este o funcție a valorii independente x, valorile m sunt coeficienții corespunzători fiecărei variabile independente x, iar b este o constantă. Rețineți că y, x și m pot fi vectori. Funcţie LINIST returnează o matrice ![]() . LINIST poate returna, de asemenea, statistici de regresie suplimentare.
. LINIST poate returna, de asemenea, statistici de regresie suplimentare.
LINIST(valori-y-cunoscute; valori-x-cunoscute; const; statistici)
Known_y values - setul de valori y care sunt deja cunoscute pentru relație.
Dacă matricea cunoscută_y are o coloană, atunci fiecare coloană a matricei cunoscute_x este interpretată ca o variabilă separată.
Dacă tabloul cunoscut_y are un rând, atunci fiecare rând al matricei cunoscut_x este interpretat ca o variabilă separată.
Known_x's este un set opțional de x-uri care sunt deja cunoscute pentru relație.
Matricea cunoscută_x poate conține unul sau mai multe seturi de variabile. Dacă este utilizată o singură variabilă, atunci arrays_known_y_values și cunoscute_x_values pot fi de orice formă - atâta timp cât au aceeași dimensiune. Dacă este folosită mai mult de o variabilă, atunci cunoscutele_y trebuie să fie un vector (adică un rând înalt sau o lățime de coloană).
Dacă array_known_x este omis, atunci această matrice (1;2;3;...) se presupune că are aceeași dimensiune cu array_known_y.
Const este o valoare booleană care specifică dacă constanta b trebuie să fie 0.
Dacă argumentul „const” este TRUE sau omis, atunci constanta b este evaluată normal.
Dacă argumentul „const” este FALS, atunci valoarea lui b se presupune a fi 0, iar valorile lui m sunt selectate în așa fel încât relația să fie satisfăcută.
Statistics este o valoare booleană care indică dacă trebuie returnate statistici suplimentare de regresie.
Dacă statisticile este TRUE, LINEST returnează statistici de regresie suplimentare. Matricea returnată va arăta astfel: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Dacă statistica este FALSĂ sau omisă, LINEST returnează numai coeficienții m și constanta b.
Statistici suplimentare de regresie.
Figura de mai jos arată ordinea în care sunt returnate statisticile de regresie suplimentare.

Note:
Orice linie dreaptă poate fi descrisă prin panta și intersecția cu axa y:
Panta (m): Pentru a determina panta unei drepte, notată de obicei cu m, trebuie să luați două puncte pe linie și ; panta va fi ![]() .
.
Intersecția Y (b): Intersecția y a unei linii, de obicei notat cu b, este valoarea y pentru punctul în care linia intersectează axa y.
Ecuația dreptei are forma . Dacă valorile lui m și b sunt cunoscute, atunci orice punct de pe linie poate fi calculat prin înlocuirea valorilor lui y sau x în ecuație. De asemenea, puteți utiliza funcția TREND.
Dacă există o singură variabilă independentă x, puteți obține direct panta și intersecția cu y folosind următoarele formule:
Pantă: INDEX(LINEST(y_cunoscute, x_cunoscute), 1)
Intersecție cu Y: INDEX(LINEST(y_cunoscute, x_cunoscute), 2)
Precizia aproximării folosind linia dreaptă calculată de funcția LINEST depinde de gradul de împrăștiere a datelor. Cu cât datele sunt mai aproape de o linie dreaptă, cu atât modelul folosit de LINEST este mai precis. Funcția LINEST folosește metoda celor mai mici pătrate pentru a determina cea mai bună potrivire la date. Când există o singură variabilă independentă x, m și b sunt calculate folosind următoarele formule:

unde x și y sunt mediile eșantionului, de exemplu x = MEDIE(x_cunoscute) și y = MEDIE (y_cunoscute).
Funcțiile de potrivire LINEST și LGRFPRIBL pot calcula o curbă dreaptă sau exponențială care se potrivește cel mai bine datelor. Cu toate acestea, ele nu răspund la întrebarea care dintre cele două rezultate este mai potrivită pentru rezolvarea problemei. De asemenea, puteți calcula funcția TREND(valori-y-cunoscute; valori-x-cunoscute) pentru o linie dreaptă sau funcția GROWTH(valori-y-cunoscute; valori-x-cunoscute) pentru o curbă exponențială. Aceste funcții, dacă nu specificați un argument new_x_values, returnează o matrice de valori y calculate pentru valorile efective x conform unei linii drepte sau curbe. Puteți compara apoi valorile calculate cu valorile reale. De asemenea, puteți crea diagrame pentru comparație vizuală.
La efectuarea unei analize de regresie, Microsoft Excel calculează, pentru fiecare punct, pătratul diferenței dintre valoarea y prezisă și valoarea y reală. Suma acestor diferențe pătrate se numește suma reziduală a pătratelor (ssresid). Microsoft Excel calculează apoi suma totală de pătrate (sstotal). Dacă const = TRUE sau dacă acest argument nu este specificat, suma totală a pătratelor va fi egală cu suma diferențelor pătrate ale valorilor reale y și ale valorilor medii y. Dacă const = FALS, suma pătratelor va fi egală cu suma pătratelor valorilor reale ale y (fără a scădea media y din câtul y). După aceea, suma de regresie a pătratelor poate fi calculată după cum urmează: ssreg = sstotal - ssresid. Cu cât suma reziduală a pătratelor este mai mică, cu atât valoarea coeficientului de determinism r2 este mai mare, ceea ce indică cât de bine explică ecuația obținută prin analiza de regresie relațiile dintre variabile. Coeficientul r2 este egal cu ssreg/sstotal.
În unele cazuri, una sau mai multe coloane X (să fie valorile Y și X în coloane) nu au o valoare predictivă suplimentară în celelalte coloane X. Cu alte cuvinte, ștergerea uneia sau mai multor coloane X poate avea ca rezultat valori Y calculate cu aceeași precizie. În acest caz, coloanele X redundante vor fi excluse din modelul de regresie. Acest fenomen se numește „colinearitate” deoarece coloanele redundante ale lui X pot fi reprezentate ca suma mai multor coloane neredundante. LINEST verifică coliniaritatea și elimină orice coloane X redundante din modelul de regresie dacă găsește vreuna. Coloanele X eliminate pot fi identificate în ieșirea LINEST printr-un factor de 0 și o valoare se de 0. Eliminarea uneia sau mai multor coloane ca redundante modifică valoarea df deoarece depinde de numărul de coloane X utilizate efectiv în scopuri predictive. Consultați exemplul 4 de mai jos pentru mai multe detalii despre calcularea df. Când df se modifică din cauza eliminării coloanelor redundante, se modifică și valorile lui sey și F. Adesea nu este recomandată utilizarea coliniarității. Cu toate acestea, ar trebui utilizat dacă unele coloane X conțin 0 sau 1 ca indicator care indică dacă subiectul experimentului se află într-un grup separat. Dacă const = TRUE sau dacă acest argument nu este specificat, LINEST inserează o coloană X suplimentară pentru a simula punctul de intersecție. Dacă există o coloană cu valorile 1 pentru bărbați și 0 pentru femei și există o coloană cu valorile 1 pentru femei și 0 pentru bărbați, atunci ultima coloană este eliminată deoarece valorile sale pot fi obținute din coloana „indicator masculin”.
Calculul df pentru cazurile în care X coloane nu sunt eliminate din model din cauza coliniarității este următorul: dacă există k cunoscute_x coloane și const = TRUE sau nespecificat, atunci df = n - k - 1. Dacă const = FALSE, atunci df = n -k. În ambele cazuri, eliminarea coloanelor X din cauza coliniarității crește valoarea df cu 1.
Formulele care returnează matrice trebuie introduse ca formule matrice.
Când introduceți o matrice de constante ca argument know_x_values, de exemplu, utilizați un punct și virgulă pentru a separa valorile pe aceeași linie și două puncte pentru a separa liniile. Caracterele de separare pot varia în funcție de setările din fereastra „Limbă și standarde” din panoul de control.
Rețineți că valorile y prezise de ecuația de regresie pot să nu fie corecte dacă se află în afara intervalului de valori y care au fost utilizate pentru a defini ecuația.
Algoritmul principal utilizat în funcție LINIST, diferă de algoritmul principal al funcțiilor ÎNCLINAŢIEși SECȚIUNE. Diferențele dintre algoritmi pot duce la rezultate diferite pentru date incerte și coliniare. De exemplu, dacă punctele de date ale argumentului cunoscut_y sunt 0 și punctele de date ale argumentului cunoscut_x sunt 1, atunci:
Funcţie LINIST returnează o valoare egală cu 0. Algoritmul funcției LINIST este folosit pentru a returna valori adecvate pentru datele coliniare, caz în care poate fi găsit cel puțin un răspuns.
Funcțiile SLOPE și INTERCEPT returnează eroarea #DIV/0!. Algoritmul funcțiilor SLOPE și INTERCEPT este folosit pentru a găsi un singur răspuns, iar în acest caz pot fi mai multe.
Pe lângă calcularea statisticilor pentru alte tipuri de regresie, LINEST poate fi utilizat pentru a calcula intervale pentru alte tipuri de regresie prin introducerea funcțiilor variabilelor x și y ca o serie de variabile x și y pentru LINEST. De exemplu, următoarea formulă:
LINIE(valori-y, valori-x^COLUMN($A:$C))
funcționează cu o coloană de valori Y și o coloană de valori X pentru a calcula o aproximare a unui cub (polinom de gradul 3) de următoarea formă:
Formula poate fi modificată pentru a calcula alte tipuri de regresie, dar în unele cazuri sunt necesare ajustări ale valorilor de ieșire și alte statistici.
După părerea mea, ca student, econometria este una dintre cele mai aplicate științe cu care am reușit să mă familiarizez între zidurile universității mele. Cu ajutorul acestuia, într-adevăr, este posibil să se rezolve probleme aplicate la scară întreprindere. Cât de eficiente vor fi aceste soluții este a treia întrebare. Concluzia este că majoritatea cunoștințelor vor rămâne teorie, dar econometria și analiza de regresie merită totuși studiate cu o atenție deosebită.
Ce explică regresia?
Înainte de a începe să luăm în considerare funcțiile MS Excel care ne permit să rezolvăm aceste probleme, aș dori să vă explic pe degete ce implică, în esență, analiza regresiei. Deci îți va fi mai ușor să dai examenul și, cel mai important, va fi mai interesant să studiezi subiectul.
Sperăm că sunteți familiarizat cu conceptul de funcție din matematică. O funcție este o relație între două variabile. Când o variabilă se schimbă, i se întâmplă ceva cu alta. Schimbăm modificările X, respectiv Y. Funcțiile descriu diverse legi. Cunoscând funcția, putem înlocui valorile arbitrare pentru X și vedem cum se schimbă Y.
Acest lucru este de mare importanță, deoarece regresia este o încercare de a explica, cu ajutorul unei anumite funcții, procese aparent nesistematice și haotice. Deci, de exemplu, este posibil să dezvăluiți relația dintre cursul de schimb al dolarului și șomaj în Rusia.
Dacă acest model poate fi detectat, atunci, conform funcției pe care am obținut-o în cursul calculelor, vom putea face o prognoză a ratei șomajului la cursul N-a al dolarului față de rublă.
Această relație se va numi corelație. Analiza de regresie presupune calcularea coeficientului de corelare, care va explica strânsoarea relației dintre variabilele pe care le avem în vedere (cursul de schimb al dolarului și numărul de locuri de muncă).
Acest coeficient poate fi pozitiv sau negativ. Valorile sale variază de la -1 la 1. În consecință, putem observa o corelație negativă sau pozitivă ridicată. Dacă este pozitiv, atunci creșterea dolarului va fi urmată de apariția de noi locuri de muncă. Dacă este negativă, atunci creșterea cursului de schimb va fi urmată de o scădere a locurilor de muncă.
Regresia este de mai multe tipuri. Poate fi liniar, parabolic, exponențial, exponențial etc. Alegem modelul în funcție de care regresie va corespunde în mod specific cazului nostru, care model va fi cât mai aproape de corelația noastră. Să o luăm în considerare pe exemplul problemei și să o rezolvăm în MS Excel.
Regresia liniară în MS Excel
Pentru a rezolva probleme de regresie liniară, aveți nevoie de funcționalitatea de analiză a datelor. Este posibil să nu fie activat pentru dvs., așa că trebuie să îl activați.
- Faceți clic pe butonul „Fișier”;
- Selectați elementul „Opțiuni”;
- Faceți clic pe penultima filă „Suplimente” din partea stângă;

- Mai jos vom vedea inscripția „Management” și butonul „Go”. Apăsăm pe el;
- Bifați „Pachetul de analiză”;
- Apăsăm „ok”.

Exemplu de sarcină
Funcția de analiză a lotului este activată. Să rezolvăm următoarea problemă. Avem un eșantion de date de câțiva ani privind numărul de situații de urgență pe teritoriul întreprinderii și numărul de lucrători angajați. Trebuie să identificăm relația dintre aceste două variabile. Există o variabilă explicativă X, care este numărul de lucrători, și o variabilă explicativă, Y, care este numărul de urgențe. Să distribuim datele inițiale în două coloane.
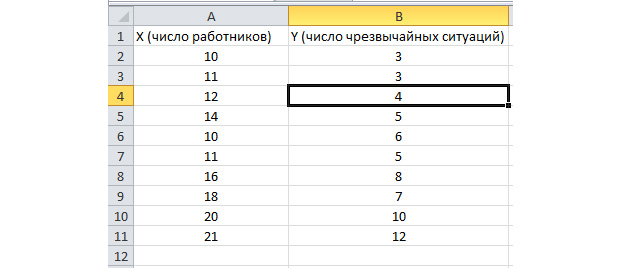
Accesați fila „Date” și selectați „Analiza datelor”
Selectați „Regresie” din lista care apare. În intervalele de intrare Y și X, selectați valorile corespunzătoare.
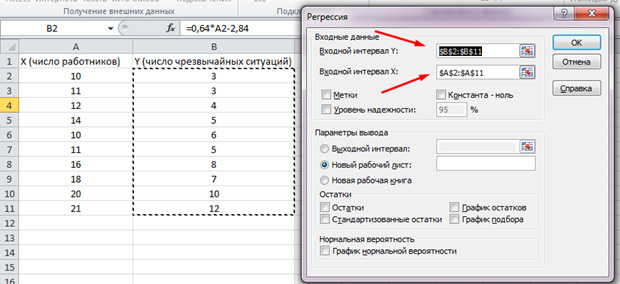
Apăsăm „OK”. Analiza este făcută, iar în noua fișă vom vedea rezultatele.
Cele mai semnificative valori pentru noi sunt marcate în figura de mai jos.
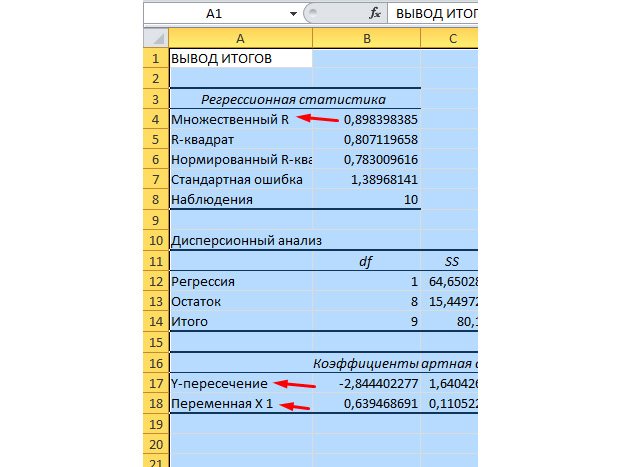
Multiplu R este coeficientul de determinare. Are o formulă de calcul complexă și arată cât de mult putem avea încredere în coeficientul nostru de corelație. Prin urmare, cu cât această valoare este mai mare, cu atât este mai mare încrederea, cu atât modelul nostru în ansamblu este mai de succes.
Y-Intercept și X1 Intersection sunt coeficienții regresiei noastre. După cum am menționat deja, regresia este o funcție și are anumiți coeficienți. Astfel, funcția noastră va arăta astfel: Y = 0,64 * X-2,84.
Ce ne oferă? Acest lucru ne oferă posibilitatea de a face o predicție. Să presupunem că vrem să angajăm 25 de angajați pentru o întreprindere și trebuie să ne imaginăm aproximativ care va fi numărul de urgențe. Inlocuim aceasta valoare in functia noastra si obtinem rezultatul Y = 0,64 * 25 - 2,84. Aproximativ 13 vom avea stare de urgență.
Să vedem cum funcționează. Aruncă o privire la poza de mai jos. Valorile efective pentru angajații implicați sunt înlocuite în funcția pe care am obținut-o. Vedeți cât de aproape sunt valorile de jucătorii adevărați.

De asemenea, puteți construi un câmp de corelare evidențiind zonele y și x, făcând clic pe fila „inserare” și selectând graficul de dispersie.

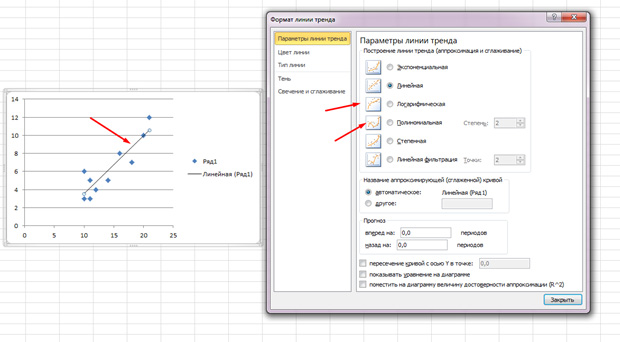
Punctele sunt împrăștiate, dar în general se deplasează în sus, ca și cum ar fi o linie dreaptă în mijloc. De asemenea, puteți adăuga această linie accesând fila „Aspect” din MS Excel și selectând elementul „Linie de tendință”
Faceți dublu clic pe linia care apare și veți vedea ce s-a spus mai devreme. Puteți schimba tipul de regresie în funcție de cum arată câmpul de corelare.
Este posibil să descoperiți că punctele desenează o parabolă mai degrabă decât o linie dreaptă și poate doriți să alegeți un alt tip de regresie.
Concluzie
Sperăm că acest articol v-a oferit o mai bună înțelegere a ce este analiza de regresie și pentru ce este aceasta. Toate acestea au o mare importanță practică.
Metoda regresiei liniare ne permite să descriem o linie dreaptă care se potrivește cel mai bine unei serii de perechi ordonate (x, y). Ecuația pentru o linie dreaptă, cunoscută sub numele de ecuație liniară, este dată mai jos:
ŷ este valoarea așteptată a lui y pentru o valoare dată a lui x,
x este o variabilă independentă,
a - segment pe axa y pentru o linie dreaptă,
b este panta dreptei.
În figura de mai jos, acest concept este reprezentat grafic:
Figura de mai sus arată o dreaptă descrisă de ecuația ŷ =2+0,5x. Segmentul de linie de pe axa y este punctul în care linia intersectează axa y; în cazul nostru, a = 2. Panta dreptei, b, raportul dintre ridicarea dreptei și lungimea dreptei, are o valoare de 0,5. O pantă pozitivă înseamnă că linia se ridică de la stânga la dreapta. Dacă b = 0, linia este orizontală, ceea ce înseamnă că nu există nicio relație între variabilele dependente și cele independente. Cu alte cuvinte, modificarea valorii lui x nu afectează valoarea lui y.
ŷ și y sunt adesea confundate. Graficul prezintă 6 perechi ordonate de puncte și o dreaptă, conform ecuației date

Această figură arată punctul corespunzător perechii ordonate x = 2 și y = 4. Rețineți că valoarea așteptată a lui y conform dreptei de la X= 2 este ŷ. Putem confirma acest lucru cu următoarea ecuație:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Valoarea y este punctul real, iar valoarea ŷ este valoarea y așteptată folosind o ecuație liniară pentru o valoare x dată.
Următorul pas este determinarea unei ecuații liniare care să corespundă maxim unui set de perechi ordonate, despre asta am vorbit în articolul anterior, unde am determinat forma ecuației prin .
Utilizarea Excel pentru a defini regresia liniară
Pentru a utiliza instrumentul de analiză de regresie încorporat în Excel, trebuie să activați programul de completare Pachet de analize. Îl puteți găsi făcând clic pe filă Fișier –> Opțiuni(2007+), în dialogul care apare Parametriiexcela accesați fila Suplimente.În câmp Control alege suplimenteexcelași faceți clic Merge.În fereastra care apare, bifați caseta de lângă pachet de analize, clic O.K.

În fila Date in grup Analiză va apărea un nou buton Analiza datelor.

Pentru a demonstra cum funcționează programul de completare, să folosim datele , unde un tip și o fată împart o masă în baie. Introduceți datele pentru exemplul nostru de baie în coloanele A și B ale unei foi goale.
Accesați fila Date, in grup Analiză clic Analiza datelor.În fereastra care apare Analiza datelor Selectați Regresia așa cum se arată în figură și faceți clic pe OK.

Setați parametrii de regresie necesari în fereastră Regresia, așa cum se arată în imagine:

Clic O.K.În figura de mai jos sunt prezentate rezultatele obținute:

Aceste rezultate sunt în concordanță cu cele pe care le-am obținut prin calcule independente în .
Construirea unei regresii liniare, estimarea parametrilor acesteia și a semnificației acestora se poate face mult mai rapid atunci când se utilizează pachetul de analiză Excel (Regresie). Să luăm în considerare interpretarea rezultatelor obținute în cazul general ( k variabile explicative) conform Exemplului 3.6.
Masa statistici de regresie valorile sunt date:
Multiplu R – coeficientul de corelație multiplă;
R- pătrat- coeficient de determinare R 2 ;
Normalizat R - pătrat- ajustat R 2 ajustat pentru numărul de grade de libertate;
eroare standard este eroarea standard a regresiei S;
Observatii - numărul de observații n.
Masa Analiza variatiei dat:
1. Coloana df - numărul de grade de libertate, egal cu
pentru sfoară Regresia df = k;
pentru sfoară Restdf = n – k – 1;
pentru sfoară Totaldf = n– 1.
2. Coloana SS- suma abaterilor pătrate, egală cu
pentru sfoară Regresia ;
pentru sfoară Rest ;
pentru sfoară Total .
3. Coloana DOMNIȘOARĂ varianțe determinate de formulă DOMNIȘOARĂ = SS/df:
pentru sfoară Regresia– varianța factorilor;
pentru sfoară Rest este varianța reziduală.
4. Coloana F - valoarea calculată F-criterii calculate prin formula
F = DOMNIȘOARĂ(regresie)/ DOMNIȘOARĂ(rest).
5. Coloana Semnificaţie F este valoarea nivelului de semnificație corespunzătoare valorii calculate F-statistici .
Semnificaţie F= FRIST( F- statistici, df(regresie), df(rest)).
Dacă semnificație F < стандартного уровня значимости, то R 2 este semnificativ statistic.
| Coeficienți | eroare standard | t-statistici | valoarea p | jos 95% | Top 95% | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Acest tabel arată:
1. Cote– valorile coeficientului A, b.
2. Eroare standard sunt erorile standard ale coeficienților de regresie S a, Sb.
3. t- statistici– valori calculate t -criterii calculate prin formula:
t-statistic = Coeficienți / Eroare standard.
4.R-valoare (semnificație t) este valoarea nivelului de semnificație corespunzător celui calculat t- statistici.
R-valoare = STUDRASP(t-statistici, df(rest)).
Dacă R-sens< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. 95% de jos și 95% de sus sunt limitele inferioare și superioare ale intervalelor de încredere de 95% pentru coeficienții ecuației teoretice de regresie liniară.
| RETRAGERE RĂMĂSĂ | ||
| Observare | A prezis y | Rămâne e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
Masa RETRAGERE RĂMĂSĂ indicat:
într-o coloană Observare– numărul de observație;
într-o coloană prezis y sunt valorile calculate ale variabilei dependente;
într-o coloană Rămășițe e este diferența dintre valorile observate și calculate ale variabilei dependente.
Exemplul 3.6. Date disponibile (unități arb.) privind cheltuielile alimentare yși venitul pe cap de locuitor X pentru nouă grupuri de familii:
| X | |||||||||
| y |
Folosind rezultatele pachetului de analiză Excel (Regresie), analizăm dependența costurilor cu alimentele de valoarea venitului pe cap de locuitor.
Rezultatele analizei de regresie sunt de obicei scrise astfel:
![]()
unde între paranteze sunt erorile standard ale coeficienților de regresie.
Coeficienți de regresie A = 65,92 și b= 0,107. Direcția de comunicare între yși X determină semnul coeficientului de regresie b= 0,107, adică relația este directă și pozitivă. Coeficient b= 0,107 arată că cu o creștere a venitului pe cap de locuitor cu 1 arb. unitati costurile cu alimente cresc cu 0,107 conv. unitati
Să estimăm semnificația coeficienților modelului obținut. Semnificația coeficienților ( a, b) este verificată împotriva t- Test:
valoarea p ( A) = 0,00080 < 0,01 < 0,05
valoarea p ( b) = 0,00016 < 0,01 < 0,05,
de aici coeficienții ( a, b) sunt semnificative la nivelul de 1% și cu atât mai mult la nivelul de semnificație de 5%. Astfel, coeficienții de regresie sunt semnificativi și modelul este adecvat datelor originale.
Rezultatele estimării regresiei sunt compatibile nu numai cu valorile obținute ale coeficienților de regresie, ci și cu o parte din setul acestora (interval de încredere). Cu o probabilitate de 95%, intervalele de încredere pentru coeficienți sunt (38,16 - 93,68) pentru Aşi (0,0728 - 0,142) pentru b.
Calitatea modelului este evaluată prin coeficientul de determinare R 2 .
Valoare R 2 = 0,884 înseamnă că factorul venit pe cap de locuitor poate explica 88,4% din variația (împrăștierea) cheltuielilor cu alimente.
Semnificaţie R 2 verificat de F- test: semnificație F = 0,00016 < 0,01 < 0,05, следовательно, R 2 este semnificativ la nivelul de 1% și cu atât mai mult la nivelul de semnificație de 5%.
În cazul regresiei liniare pe perechi, coeficientul de corelație poate fi definit ca ![]() . Valoarea obținută a coeficientului de corelație indică faptul că relația dintre cheltuielile alimentare și venitul pe cap de locuitor este foarte strânsă.
. Valoarea obținută a coeficientului de corelație indică faptul că relația dintre cheltuielile alimentare și venitul pe cap de locuitor este foarte strânsă.