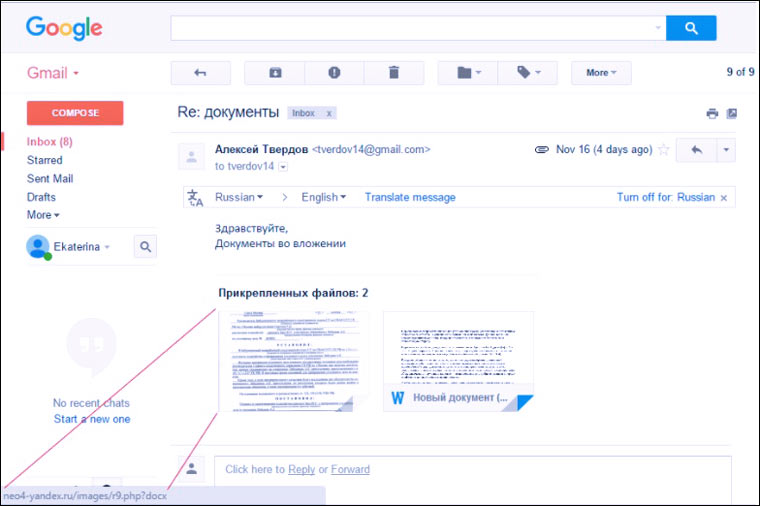
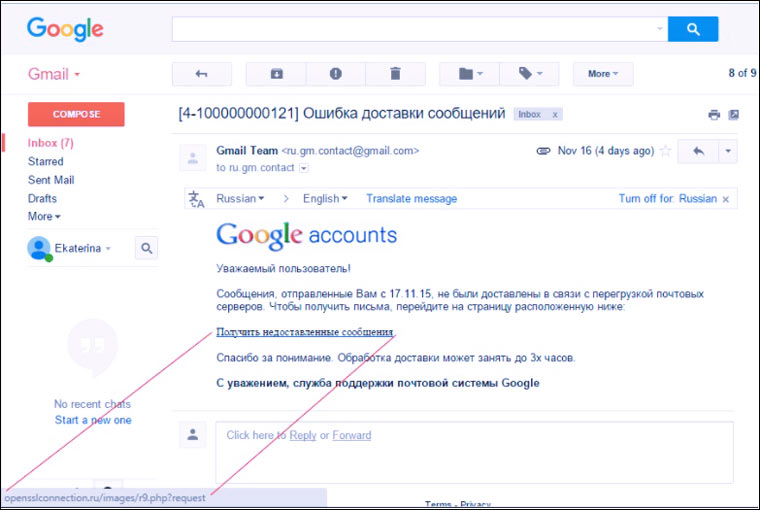
: Întotdeauna am vrut să înțeleg asta, dar semnificația lui era atât de mică încât a existat întotdeauna un motiv să nu o fac :)
Te-ai întrebat: URL - ce este?
Mereu dau peste asta, dar tot nu am vrut să înțeleg care este diferența dintre termenii URI, URL, URN și apoi dintr-o dată o postare (din păcate, a căzut deja în uitare), m-am hotărât - o voi citi eu însumi și voi spune altora, deși, așa cum am menționat mai sus, acest lucru nu va schimba nimic, dar uneori îmi place să joc cuvintele, așa că citiți traducătorul explicativ:
Ați observat vreodată bara de adrese din browser? Ce este asta? URI, URL sau URN? Mulți dintre noi nu fac diferența între URI, URL, URN, iar unii dintre noi nici măcar nu au auzit termenii URI și URN, toată lumea folosește doar termenul URL. Să încercăm să ne dăm seama împreună.
Explicația abrevierilor
URI - Identificator uniform de resurse (unificat identificator resursă)
URL - Localizator uniform de resurse (unificat localizator resursă)
URN - Numele resursei Unifrorm (unificat Nume resursă)
Atentie, aici adevarul se ascunde in lucrurile marunte, dar pana acum nimic nu este clar, un fel de mizerie. Să mergem mai departe.
Definiție
URI: indică numele și adresa unei resurse din rețea. De obicei, este împărțit în URL și URN, astfel încât URL și URN fac parte din URI.
URL: adresa unei resurse de pe web. URL-ul identifică locația resursei și modul în care este accesată.
URN: Numele unei resurse de pe web. Semnificația URN este că identifică doar numele unui anumit articol, care poate fi găsit în multe locații specifice.
Nu există nimic mai bun decât un exemplu concret.
URI = http://site/2009/09/uri-url-urn.html
URL = http: // site
URN = /2009/09/uri-url-urn.html
Să rezumam
URI este conceptul de identificator abstract, în timp ce URL și URN sunt implementări concrete ale adresei și numelui.
Sper ca toata lumea sa inteleaga totul. Fii alfabetizat!
Percepția fiecăruia dintre noi este individuală, prin urmare - argumentați și citiți discuțiile din comentariile la articol, sunt multe lucruri interesante.
Litigii cu privire la această problemă - cum să scrieți corect adresa URL, cu sau fără bară oblică? - au fost si vor fi. Argumentarea este variată și adesea contradictorie. Și există două tipuri de rambursare pentru o intrare URL incorectă. Din partea motoarelor de căutare, se presupune că acestea sunt penalități pentru paginile duplicat. Din punct de vedere al performanței, se presupune că aceasta este o redirecționare suplimentară către pagina de înregistrare corectă, generată automat de server.
Totuși, analizând specificațiile tehnice ale standardelor de internet, în special documentul „RFC 1738 - Uniform Resource Locators (URL)”, trebuie să admitem că ambele versiuni ale înregistrării adresei resursei web sunt corecte din punct de vedere formal, iar sancțiunea pentru utilizarea una sau alta versiune nu este altceva decât un motor de căutare ciudat sau povești pseudo-SEO.
Din punct de vedere al conciziei, opțiunea fără bară oblică la final pare a fi mai corectă, indiferent dacă linkul tău este un „fișier” de pe server sau un „dosar”, dovadă indirectă a faptului că va fi demonstrată mai jos. Dar nu există o singură declarație în document că o altă opțiune este incorectă sau se referă la o resursă complet diferită.
Nu vă voi descărca o traducere de mai multe pagini a RFC-ului menționat, deoarece, în primul rând, scopul întrebării au fost barele oblice la sfârșitul adresei URL, iar în al doilea rând, publicația se adresează utilizatorilor obișnuiți ai motoarelor, inclusiv celor care nu sunt interesați de toate detaliile, așteaptă scurte explicații și dovezi pe fond. În consecință, voi cita fragmente din acest document ca dovezi și voi explica. Oricine nu este interesat de acest lucru se poate uita imediat la rezultatul de la sfârșitul articolului.
Sintaxa URL generală
Primul lucru asupra căruia vă atrageți atenția este fragmentul din paragraful 2. Sintaxa URL generală. În fiecare caz, voi cita un fragment din text în limba originală, urmat de o traducere în rusă.
URL-urile sunt folosite pentru a „localiza” resurse, oferind o identificare abstractă a locației resursei. URL-urile sunt folosite pentru a „localiza” resurse, oferind o identificare abstractă a locației resursei.
Adică, URL-ul în sine este o abstractizare pură. Faptul că ne poate părea în exterior asemănător cu numele unui fișier sau folder nu înseamnă deloc o referire fizică la un astfel de fișier și nu la un alt fișier din spațiul de fișiere al serverului. Acest lucru va fi menționat direct în documentul de mai jos.
NotaÎn general, în ceea ce privește linkurile http, este în principiu incorect să spunem că de exemplu
- http://domain.com/path/subpath/filename.txt- se presupune că indică un dosar
- http://domain.com/path/subpath/- se presupune că indică către un folder
- http://domain.com/path - se presupune că indică un folder incorect
Tocmai spuneam asta, pentru că este convenabil să asociem link-uri cu fișierele de pe site. În realitate, toate aceste legături indică unele resurse, fără a denota în niciun fel tipul de resursă. Ce se ascunde în spatele fiecărei resurse, adică ce fel de fișier sau folder real și ce tip de conținut va fi servit printr-un astfel de link, este deja determinat de configurația serverului.
Este important să înțelegeți că în link-uri nu există „fișier”, „dosar”, „subfolder”, „text”, „imagine”, „html”, „script”, „foaia de stil” și așa mai departe. Nicio bară oblică la sfârșit sau absența acesteia nu înseamnă absolut nimic până când linkul este transformat în interiorul serverului și el însuși decide unde indică de fapt linkul și ce tip de conținut este ascuns în spatele acestuia. Aceasta este singura soluție legată de arhitectura internă a serverului.
Scheme ierarhice
În continuare este un extras din paragraful 2.3 Scheme ierarhice și legături relative (scheme ierarhice și legături relative).
Unele scheme URL (cum ar fi ftp, http și schemele de fișiere) conțin nume care pot fi considerate ierarhice; componentele ierarhiei sunt separate prin „/”. Unele scheme URL (cum ar fi ftp, http și fișier) conțin nume care pot fi considerate ierarhice; membrii ierarhiei sunt separați prin simbolul „/”.
Adică, se susține că în anumite scheme de adrese, conținutul unui localizator de resurse nu este interzis să fie considerat ierarhic și nu s-a stipulat încă că ierarhia este echivalentă cu orice formă, să zicem, fișier.
Sintaxa generală a schemei de rețea
Următorul este un extras din paragraful 3.1. Sintaxa Common Internet Scheme
//
Nota Acesta, de altfel, este răspunsul la o întrebare derivată din cea pe care o luăm în considerare. Adesea se ceartă pe această problemă: cum să dați corect un link către un domeniu (gazdă) - fără o bară oblică la sfârșit sau cu o bară oblică?
Cum să o faci corect http://domain.com/ sau http://domain.com?
Și așa și așa corect. Pur și simplu prima bară oblică după numele de gazdă are scopul de a separa calea de numele de gazdă. Același paragraf al documentului spune așa:
Url-path Restul locatorului constă din date specifice schemei și este cunoscut ca „url-path”. Furnizează detalii despre cum poate fi accesată resursa specificată. Rețineți că „/” dintre gazdă (sau port) și calea URL NU face parte din calea URL. Restul locatorului constă din date specifice schemei și este cunoscut sub numele de „url-path”. Acesta oferă detalii despre cum poate fi accesată resursa specificată. Rețineți că caracterul „/” dintre gazdă (sau port) și calea URL nu face parte din calea URL.
Nu am fost obligați de un cuvânt să punem acest caracter final sau să nu îl punem atunci când url-path este un șir gol (cum ar spune mulți dintre noi când URL-ul se referă la rădăcina site-ului). Nimeni nu are dreptul să-ți impună penalități „pentru două preluări ale paginii principale”, pentru că conform specificației, în ambele cazuri link-ul URL la aceeași resursă.
Hai sa continuăm un alt fragment din același paragraf.
Sintaxa url-path depinde de schema utilizată, la fel ca și de modul în care este interpretată. Sintaxa pentru url-path depinde de schema utilizată, precum și de modul în care este interpretată.
Aceasta este o altă confirmare că fiecare schemă de localizare are propriul concept de „ierarhie” și modul de interpretare a acesteia.
Ierarhie
Pentru unele sisteme de fișiere, „/” folosit pentru a desemna structura ierarhică a adresei URL corespunde delimitatorului utilizat pentru a construi o ierarhie a numelor de fișier și, astfel, numele fișierului va arăta similar cu calea URL. Aceasta NU înseamnă că adresa URL este un nume de fișier Unix. Caracterul „/” este folosit pentru a indica structura ierarhică a URL-ului conform delimitatorului utilizat în construirea ierarhiei numelor de fișiere și astfel, pe unele sisteme de fișiere, numele fișierului arată ca o cale URL. Dar asta nu înseamnă că adresa URL este un nume de fișier asemănător Unix.Deși acest paragraf se referă la schema ftp, se aplică totuși și altor scheme (http, gopher, prospero și așa mai departe). Numai în schema de fișiere, simbolul slash denotă în mod logic la fel ca și în numele fișierelor, de exemplu fișier: //server_or_device/path/subpath/filename.txt.
Http
O adresă URL HTTP are forma: http: //
Nota De asemenea, afirmă că puteți specifica un link fără o bară oblică finală. În acest caz, vorbeam despre o situație în care calea linkului este goală - indică către rădăcina gazdei.
Notație formală
În sfârșit, un extras din paragraful 5. BNF pentru scheme URL specifice.
Aici, piesele opționale sunt afișate între paranteze drepte. Un asterisc în fața unei paranteze indică 0 sau mai multe repetări ale aceluiași fragment, așa cum este indicat în paranteze. Bara verticală trebuie înțeleasă ca SAU.
Hostport = host [":" port] ... ... httpurl = "http: //" hostport ["/" hpath ["?" căutare]] hpath= hsegment * ["/" hsegment] hsegment = * [uchar | ";" | „:” | „@” | „&” | "="] căutare = * [uchar | ";" | „:” | „@” | „&” | "="] ... ... lowalpha = "a" | „b” | „c” | „d” | „e” | „f” | „g” | „h” | „eu” | „j” | „k” | "l" | "m" | „n” | „o” | „p” | „q” | „r” | „s” | „t” | „u” | „v” | „w” | "x" | „y” | "z" hialpha = "A" | „B” | „C” | „D” | „E” | „F” | „G” | „H” | „Eu” | „J” | „K” | „L” | „M” | „N” | „O” | „P” | „Q” | „R” | „S” | „T” | „U” | „V” | „W” | „X” | „Y” | „Z” alfa = lowalpha | cifră hialpha = "0" | „1” | „2” | „3” | „4” | „5” | „6” | „7” | „8” | „9” sigur = „$” | „-” | „_” | "." | "+" extra = "!" | „*” | "" "|" ("|") "|", "hex = cifră |" A "|" B "|" C "|" D "|" E "|" F "|" a "|" b " | "c" | "d" | "e" | "f" escape = "%" hex hex nerezervat = alfa | cifră | sigur | extra uchar = nerezervat | escape
Observați cum elementul hpath - calea linkului - este format exact conform regulilor. Elementele hsegmentului de cale - segmente - sunt separate printr-o bară oblică. Ca și cum ar sugera ideea importantă că slash-ul împarte calea în părți ierarhice și este întotdeauna în interior. În principiu, este posibil ca ultimul element hsegment să fie un șir gol (asta decurge din definiția sa), iar apoi o bară oblică de închidere să apară involuntar la sfârșitul URL-ului.
Concluzie
Împărțirea unei căi în segmente folosind un caracter oblic implică prezența unor nume nevide ale acestor segmente. În consecință, o legătură cu o bară oblică la capăt pare ilogică (deși nu interzisă) în sensul că pare să indice un anumit ultim segment al căii, dar, în plus, nu denumește în niciun fel acest segment. Exact ca link ilogic (dar nici interzis). http://domain.com/level1////levelX, care nu denumește segmente intermediare ale căii, dacă calea este considerată nu ca un set de parametri, ci ca o structură ierarhică.
În limbajul colocvial, conținutul semantic al celor două legături poate fi explicat astfel:
- - adrese la punctul de plecare implicit al celui de-al doilea nivel al ierarhiei
- - abordează un punct nedefinit în cadrul celui de-al doilea nivel al ierarhiei, adică de parcă serverului i se atribuie sarcina că „ne adresăm celui de-al doilea nivel al ierarhiei, iar tu însuți determinați ce punct considerați în acest nivel ca implicit iniţială".
Din tot ce s-a spus mai sus rezultă, care este similar cu modul în care se leagă
- http://domain.com
- http://domain.com/
adresa vizitatorului la rădăcina site-ului și, de exemplu, link-uri
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
adresa vizitatorului la al doilea nivel al ierarhiei resurselor. Și faptul că un anumit server poate interpreta slash-ul de la sfârșit în felul său și poate începe redirecționarea intern către punctul de pornire implicit al nivelului - să zicem, la fișierul index.html, acesta este deja un caz special al unei anumite configurații . La fel ca în implementarea unui sistem URL care poate fi citit de om, toate înregistrările de redirecționare care utilizează modulul server mod_rewrite își definesc propriul concept (inerent unui motor specific) al unei structuri URL ierarhice, în care elementele de cale pot fi echivalate cu parametrii de solicitare și au nimic de-a face cu structura de fișiere a site-ului (exemplu clasic: http://domain.com/ru/path, elementul ru este parametrul limbii curente, nu un folder de pe site).
Aș dori să subliniez că aceasta este cunoștințele interne ale serverului, datorită configurației sale, precum și a motorului instalat pe site. Un serviciu extern, să zicem același motor de căutare, nu poate face presupuneri și nu are idee dacă și cum diferă legăturile cu și fără bară oblică, cu excepția cazului în care serverul site-ului a fost configurat special astfel încât să afișeze conținut diferit pe astfel de link-uri.
Pentru informația dumneavoastră
La nivel de implementare, problema barelor oblice la capete nu este de o importanță fundamentală, fapt pentru care există multe confirmări în rândul portalurilor eminente. Pe unele, toate linkurile se termină cu o bară oblică, pe altele - fără o oblică. Principalul lucru este că conținutul de pe link-uri nu se dovedește a fi diferit, iar pentru Yandex trebuie, de asemenea, să înregistrați a 301-a redirecționare de la acele link-uri pe care nu le utilizați (să zicem, cele care se termină cu o bară oblică), la cele care să utilizați. Cert este că, conform declarațiilor neconfirmate ale serviciului de asistență Yandex, acest motor de căutare poate face greșeli și nu poate „lipi” (amintiți-vă în cunoștințele lor) sau, cu o oarecare întârziere, lipiți adresele slash-fără-slash într-una singură.

Iată un exemplu de implementare a unei astfel de redirecționări folosind fișierul rădăcină .htaccess:
# dacă adresa URL de intrare se termină cu o bară oblică (em, s), # setați a 301-a redirecționare către pagină fără o bară oblică RewriteCond% (REQUEST_URI) ^ /. + / $ RewriteRule ^ (. *?) / + $ http: / /% (HTTP_HOST) / $ 1
Google (din nou, conform informațiilor neconfirmate prin experiment), aceste redirecționări nu sunt importante, deoarece pare să poată lipi astfel de adrese corect și fără redirecționări.
Tine minte Sunt destul de mulți oameni care se consideră specialiști SEO. Dar nu toate sunt. Mai mult decât atât, subiectul SEO este adesea speculat fără cunoștințe și temeiuri adecvate, doar în așteptarea că ești ignorant în acest domeniu, așa că este ușor să crezi în orice „fidea”. Când vi se spune că unele dintre paginile dvs. „au ieșit din index”, utilizați o recomandare foarte bună de la Yandex: puteți afla despre erorile de indexare, dacă există, în serviciul Yandex.Webmaster. În acest serviciu, puteți vedea întotdeauna o listă a paginilor dvs. aflate în căutare și o listă a paginilor excluse din căutare dintr-un motiv oarecare. Google are un serviciu similar. Aveți încredere în aceste cunoștințe, și nu în părerea pseudo-specialiștilor, care undeva au auzit ceva din drum, și pe această bază vă recomandăm să faceți ceea ce cred ei că este singurul lucru corect.
Aici O postare foarte interesantă, Little Known SEO Facts, lansată în aprilie 2017. Prezintă un studiu amplu cu multe capturi de ecran, care a început cu scopul de a testa validitatea mai multor judecăți populare în domeniul promovării motoarelor de căutare și de a folosi exemple clare pentru a transmite rezultatele proprietarului mediu de site. Același studiu demonstrează simultan tânărului cititor o serie de caracteristici evidente, banale și chiar discrete, dar totuși surprinzătoare ale rezultatelor căutării organice în căutările Google și Yandex.
Aici Deși următorul link nu are aproape nimic de-a face cu SEO, va fi în continuare atractiv pentru maeștrii SEO care caută comenzi suplimentare chiar acum. Sub link este postată o ofertă comercială, băieții au găsit o modalitate interesantă de a folosi site-ul. O afacere privată este oferită pentru a crea un panou online bazat pe o temă specială, sub controlul căreia site-ul, sau mai degrabă primul său ecran, arată ca un banner întins pe panouri de publicitate în aer liber. Pe smartphone, am întors ecranul, întinderea a devenit verticală și ocupă întreaga zonă a ecranului, s-a întors înapoi, a devenit orizontal și din nou pe întregul ecran. Iar sub primul ecran se află un apendice de text, unde utilizatorii de obicei nu derulează, dar motorul de căutare vede bine acest text. Așadar, cei mai agile pin-up ai afacerilor regionale își cumpără singuri aceste panouri publicitare online ieftine ca o alternativă profitabilă la publicitatea contextuală și la Rețeaua de display Yandex și Google. Și pentru a se petrece cât mai mult posibil în indexul local de căutare, sunt gata să trimită bani dintr-o dată la o grămadă de seo-texte pentru a-și promova scutul, care miroase a neacid. Judecând după zvonuri, comenzile pentru 30 de kilograme de ruble sunt în scădere și, din moment ce băieții le externalizează către parteneri SEO, aici puteți construi punți de parteneriat și puteți obține câștiguri bune.
Te poți pierde nu numai în pădure, ci și online. Și acest lucru se poate datora căii sau adresei greșite care duce la resursă. Nu știi ce este o adresă URL? Apoi, înainte de a începe o nouă călătorie prin spațiul virtual, să ne ocupăm de sistemul de adrese de e-mail.
Ce este URL-ul
URL-ul este un standard general acceptat pentru înregistrarea unei adrese și indicarea locației unei resurse pe Internet. Din engleză numele său ( Localizator uniform de resurse) este tradus ca un localizator uniform de resurse. Puteți găsi o decodare anterioară a abrevierei URL - Universal Resource Locator (localizator universal de resurse). Dar ambele sensuri completează conceptul de URL, mai degrabă decât să se contrazică reciproc.
Formatul de bază al structurii URL este următorul:
://:@:/?#
- cel mai adesea se referă la protocol.
login - nume de utilizator folosit pentru autorizarea resursei.
parola - parola de utilizator pentru autorizare.
gazdă - numele de domeniu al gazdei.
port - port gazdă utilizat în timpul conexiunii.
URL - calea unde se află resursa solicitată pe server.
parametrii și ancora- valoarea variabilelor și identificatorul unei anumite resurse.
Transmiterea valorii variabilelor într-un șir de interogare este posibilă numai folosind metoda GET.
Să luăm în considerare formatul URL-ului paginii resursei solicitate cu exemple practice. Pe partea clientului, adresa URL este afișată în bara de adrese a browserului:
Cele mai comune opțiuni sunt:
- http://ru.wikipedia.org/wiki/Home_page- http ( protocol de transfer hipertext);
- https://ru.wikipedia.org/wiki/Home_page- https este folosit ca metodă de transmitere. Este o formă sigură a protocolului http care utilizează criptare (SSL sau TLS);
- ftp: //wikipedia.org/wiki/file.txt- protocol de transfer de fișiere ftp;
- http://mail.ru/script.php?num=10&type=new&v=text- trecerea valorilor variabilelor în șirul de interogare folosind metoda GET.
Orice format URL este în primul rând un șir de caractere. Poate include:
2; Scrisori.
2; Cifre arabe (0-9).
2; Caractere rezervate ("+", "=", "!" Și altele).
2; Personaje speciale - să ne oprim asupra lor mai detaliat.
Utilizarea caracterelor speciale în adrese URL
Desigur, astfel de caractere prea „speciale” nu sunt folosite în URL. Dar sunt mai multe:
- ? - servește la separarea blocului cu parametrii transmisi în linia de interogare;
- & - separă parametrii trecuți unul de celălalt;
- = - separă variabila din parametru de valoarea acesteia;
- : - servește la separarea protocolului de restul URL-ului;
- # - caracterul este folosit în partea locală a adresei. Vă permite să faceți referire la o anumită parte a paginii solicitate;
- @ - este indicat în datele de înregistrare ale utilizatorului și la transferul de date folosind protocolul mailto.
Dar toate acestea sunt doar teorie. Prin urmare, înainte de a învăța restul, să ne uităm la un mic exemplu practic.
Exemplu ilustrativ
Pentru claritate, să luăm un formular de înregistrare atât de simplu:
Iată codul său: