Analisi di regressione in Microsoft Excel: la guida più completa all'utilizzo di MS Excel per risolvere problemi di analisi di regressione nel campo dell'analisi aziendale. Konrad Carlberg spiega chiaramente le questioni teoriche, la cui conoscenza ti aiuterà a evitare molti errori sia quando conduci tu stesso l'analisi di regressione sia quando valuti i risultati dell'analisi eseguita da altre persone. Tutto il materiale, dalle correlazioni semplici e dai test t all'analisi multipla della covarianza, si basa su esempi reali ed è accompagnato da procedure dettagliate passo dopo passo.
Il libro discute le peculiarità e le controversie delle funzioni di regressione di Excel, esamina le implicazioni di ciascuna opzione e argomento e spiega come applicare in modo affidabile metodi di regressione in aree che vanno dalla ricerca medica all'analisi finanziaria.
Konrad Carlberg. Analisi di regressione in Microsoft Excel. – M.: Dialettica, 2017. – 400 p.
Scarica la nota in formato o, esempi in formato
Capitolo 1: Valutazione della variabilità dei dati
Gli statistici hanno molte misure di variazione a loro disposizione. Uno di questi è la somma dei quadrati delle deviazioni dei singoli valori dalla media. In Excel viene utilizzata la funzione QUADRATO(). Ma la varianza è più spesso utilizzata. La dispersione è la media delle deviazioni quadrate. La varianza è insensibile al numero di valori presenti nell'insieme di dati in studio (mentre la somma dei quadrati delle deviazioni aumenta con il numero di misurazioni).
Excel offre due funzioni che restituiscono la varianza: DISP.G() e DISP.V():
- Utilizzare la funzione DISP.G() se i valori da elaborare formano una popolazione. Cioè, i valori contenuti nell'intervallo sono gli unici valori che ti interessano.
- Utilizzare la funzione DISP.B() se i valori da elaborare formano un campione di una popolazione più ampia. Si presuppone che esistano valori aggiuntivi di cui è possibile stimare anche la varianza.
Se una quantità come una media o un coefficiente di correlazione viene calcolata da una popolazione, viene chiamata parametro. Una quantità simile calcolata sulla base di un campione è chiamata statistica. Conteggio delle deviazioni dalla media in un dato insieme, otterrai una somma di deviazioni quadrate di grandezza inferiore rispetto a quelle contate da qualsiasi altro valore. Una affermazione simile vale per la varianza.
Maggiore è la dimensione del campione, più accurato sarà il valore statistico calcolato. Ma non esiste una dimensione del campione inferiore alla dimensione della popolazione per la quale si possa essere certi che il valore statistico corrisponda al valore del parametro.
Supponiamo che tu abbia un insieme di 100 altezze la cui media differisce dalla media della popolazione, non importa quanto piccola sia la differenza. Calcolando la varianza per un campione, otterrai un valore, diciamo 4. Questo valore è inferiore a qualsiasi altro valore che può essere ottenuto calcolando la deviazione di ciascuno dei 100 valori di altezza rispetto a qualsiasi valore diverso dalla media del campione , anche rispetto alla media reale della popolazione generale. Pertanto, la varianza calcolata sarà diversa, e più piccola, dalla varianza che otterresti se in qualche modo scoprissi e utilizzassi un parametro della popolazione anziché una media campionaria.
La somma media dei quadrati determinata per il campione fornisce una stima inferiore della varianza della popolazione. La varianza così calcolata si chiama spostato valutazione. Si scopre che per eliminare la distorsione e ottenere una stima imparziale, è sufficiente dividere la somma delle deviazioni al quadrato non per N, Dove N- dimensione del campione e n-1.
Grandezza n-1è chiamato numero (numero) di gradi di libertà. Esistono diversi modi per calcolare questa quantità, sebbene tutti implichino la sottrazione di un numero dalla dimensione del campione o il conteggio del numero di categorie in cui rientrano le osservazioni.
L'essenza della differenza tra le funzioni DISP.G() e DISP.V() è la seguente:
- Nella funzione VAR.G(), la somma dei quadrati è divisa per il numero di osservazioni e quindi rappresenta una stima distorta della varianza, la vera media.
- Nella funzione DISP.B(), la somma dei quadrati viene divisa per il numero di osservazioni meno 1, ovvero dal numero di gradi di libertà, che fornisce una stima più accurata e imparziale della varianza della popolazione da cui è stato estratto il campione.
Deviazione standard deviazione standard, SD) – è la radice quadrata della varianza:
La quadratura delle deviazioni trasforma la scala di misura in un'altra metrica, che è il quadrato di quella originale: metri - in metri quadrati, dollari - in dollari quadrati, ecc. La deviazione standard è la radice quadrata della varianza e quindi ci riporta alle unità di misura originali. Il che è più conveniente.
Spesso è necessario calcolare la deviazione standard dopo che i dati sono stati sottoposti a qualche manipolazione. E sebbene in questi casi i risultati siano senza dubbio deviazioni standard, di solito vengono chiamate errori standard. Esistono diversi tipi di errori standard, inclusi errore standard di misurazione, errore standard di proporzione ed errore standard della media.
Supponiamo che tu abbia raccolto dati sull'altezza per 25 uomini adulti selezionati casualmente in ciascuno dei 50 stati. Successivamente, calcoli l'altezza media dei maschi adulti in ciascuno stato. I 50 valori medi risultanti possono a loro volta essere considerati osservazioni. Da questo, potresti calcolare la loro deviazione standard, che è errore standard della media. Riso. 1. confronta la distribuzione di 1.250 valori individuali grezzi (dati di altezza per 25 uomini in ciascuno dei 50 stati) con la distribuzione delle medie di 50 stati. La formula per stimare l'errore standard della media (ovvero la deviazione standard delle medie, non le singole osservazioni):
![]()
dove è l'errore standard della media; S– deviazione standard delle osservazioni originali; N– numero di osservazioni nel campione.

Riso. 1. La variazione delle medie da stato a stato è significativamente inferiore alla variazione delle singole osservazioni.
In statistica esiste una convenzione riguardante l'uso delle lettere greche e latine per rappresentare quantità statistiche. È consuetudine indicare i parametri della popolazione generale con lettere greche e campionare le statistiche con lettere latine. Pertanto, quando parliamo di deviazione standard della popolazione, la scriviamo come σ; se si considera la deviazione standard del campione, allora usiamo la notazione s. Per quanto riguarda i simboli per designare le medie, non sono così d'accordo tra loro. La media della popolazione è indicata con la lettera greca μ. Tuttavia, il simbolo X̅ è tradizionalmente utilizzato per rappresentare la media campionaria.
punteggio z esprime la posizione di un'osservazione nella distribuzione in unità di deviazione standard. Ad esempio, z = 1,5 significa che l'osservazione è a 1,5 deviazioni standard dalla media. Termine punteggio z utilizzato per valutazioni individuali, ad es. per le dimensioni assegnate ai singoli elementi del campione. Il termine usato per riferirsi a tali statistiche (come la media statale) punteggio z:

dove X̅ è la media campionaria, μ è la media della popolazione, è l'errore standard delle medie di un insieme di campioni:
![]()
dove σ è l'errore standard della popolazione (misure individuali), N- misura di prova.
Diciamo che lavori come istruttore in un golf club. Sei stato in grado di misurare la distanza dei tuoi tiri per un lungo periodo di tempo e sai che la media è di 205 iarde e la deviazione standard è di 36 iarde. Ti viene offerta una nuova mazza, sostenendo che aumenterà la distanza del tuo colpo di 10 iarde. Chiedi a ciascuno dei successivi 81 frequentatori del club di effettuare un tiro di prova con un nuovo club e di registrare la distanza dello swing. Si è scoperto che la distanza media con il nuovo club era di 215 iarde. Qual è la probabilità che una differenza di 10 iarde (215 – 205) sia dovuta esclusivamente ad un errore di campionamento? O per dirla in un altro modo: qual è la probabilità che, in test più approfonditi, il nuovo bastone non dimostri un aumento della distanza di colpire rispetto alla media a lungo termine esistente di 205 iarde?
Possiamo verificarlo generando un punteggio z. Errore standard della media:
![]()
Quindi punteggio z:

Dobbiamo trovare la probabilità che la media campionaria si discosti di 2,5σ dalla media della popolazione. Se la probabilità è piccola, le differenze non sono dovute al caso, ma alla qualità del nuovo club. Excel non dispone di una funzione già pronta per determinare la probabilità del punteggio z. Tuttavia, è possibile utilizzare la formula =1-NORM.ST.DIST(z-score,TRUE), dove la funzione NORM.ST.DIST() restituisce l'area sotto la curva normale a sinistra del punteggio z (Figura 2).

Riso. 2. La funzione NORM.ST.DIST() restituisce l'area sotto la curva a sinistra del valore z; Per ingrandire l'immagine, fare clic destro su di essa e selezionare Apri l'immagine in una nuova scheda
Il secondo argomento della funzione NORM.ST.DIST() può assumere due valori: TRUE – la funzione restituisce l'area dell'area sotto la curva a sinistra del punto specificato dal primo argomento; FALSO – la funzione restituisce l'altezza della curva nel punto specificato dal primo argomento.
Se la media della popolazione (μ) e la deviazione standard (σ) non sono note, viene utilizzato il valore t (vedi dettagli). Le strutture z-score e t-score differiscono in quanto per trovare il t-score viene utilizzata la deviazione standard s ottenuta dai risultati del campione anziché il valore noto del parametro della popolazione σ. La curva normale ha una forma unica e la forma della distribuzione del valore t varia a seconda del numero di gradi di libertà df. gradi di libertà) del campione che rappresenta. Il numero di gradi di libertà del campione è uguale a n-1, Dove N- dimensione del campione (Fig. 3).

Riso. 3. La forma delle distribuzioni t che si presentano nei casi in cui il parametro σ è sconosciuto differisce dalla forma della distribuzione normale
Excel dispone di due funzioni per la distribuzione t, chiamata anche distribuzione di Student: STUDENT.DIST() restituisce l'area sotto la curva a sinistra di un determinato valore t e STUDENT.DIST.PH() restituisce l'area sotto la curva a sinistra di un dato valore t e STUDENT.DIST.PH() restituisce l'area sotto la curva Giusto.
Capitolo 2. Correlazione
La correlazione è una misura della dipendenza tra gli elementi di un insieme di coppie ordinate. La correlazione è caratterizzata Coefficienti di correlazione di Pearson-R. Il coefficiente può assumere valori compresi tra –1,0 e +1,0.

Dove Sx E Sì– deviazioni standard delle variabili X E Y, Sxy– covarianza:

In questa formula, la covarianza viene divisa per le deviazioni standard delle variabili X E Y, rimuovendo così gli effetti di ridimensionamento relativi alle unità dalla covarianza. Excel utilizza la funzione CORRELAZIONE(). Il nome di questa funzione non contiene gli elementi qualificanti à e Â, che vengono utilizzati nei nomi di funzioni come STANDARDEV(), VARIANCE() o COVARIANCE(). Sebbene il coefficiente di correlazione campionaria fornisca una stima distorta, la ragione della distorsione è diversa rispetto al caso della varianza o della deviazione standard.
A seconda della grandezza del coefficiente di correlazione generale (spesso indicato con la lettera greca ρ ), coefficiente di correlazione R produce una stima distorta, il cui effetto aumenta al diminuire delle dimensioni del campione. Tuttavia, non cerchiamo di correggere questo errore nello stesso modo in cui, ad esempio, abbiamo fatto quando abbiamo calcolato la deviazione standard, quando abbiamo sostituito nella formula corrispondente non il numero di osservazioni, ma il numero di gradi di libertà. In realtà, il numero di osservazioni utilizzate per calcolare la covarianza non ha alcun effetto sulla grandezza.
Il coefficiente di correlazione standard è destinato all'uso con variabili correlate tra loro da una relazione lineare. La presenza di non linearità e/o errori nei dati (outlier) portano ad un calcolo errato del coefficiente di correlazione. Per diagnosticare problemi relativi ai dati, si consiglia di creare grafici a dispersione. Questo è l'unico tipo di grafico in Excel che tratta sia l'asse orizzontale che quello verticale come assi dei valori. Un grafico a linee definisce una delle colonne come asse delle categorie, il che distorce l'immagine dei dati (Fig. 4).

Riso. 4. Le linee di regressione sembrano uguali, ma confrontano le loro equazioni tra loro
Le osservazioni utilizzate per costruire il grafico a linee sono disposte equidistanti lungo l'asse orizzontale. Le etichette di divisione lungo questo asse sono solo etichette, non valori numerici.
Sebbene la correlazione spesso significhi che esiste una relazione di causa-effetto, non può essere utilizzata per dimostrare che sia così. Le statistiche non vengono utilizzate per dimostrare se una teoria è vera o falsa. Per escludere spiegazioni concorrenti per i risultati osservativi, mettere esperimenti previsti. Le statistiche vengono utilizzate per riassumere le informazioni raccolte durante tali esperimenti e per quantificare la probabilità che la decisione presa possa essere errata data la base di prove disponibile.
Capitolo 3: Regressione semplice
Se due variabili sono correlate tra loro, in modo che il valore del coefficiente di correlazione supera, diciamo, 0,5, allora in questo caso è possibile prevedere (con una certa precisione) il valore sconosciuto di una variabile dal valore noto dell'altra . Per ottenere valori di prezzo previsti sulla base dei dati mostrati in Fig. 5, potete utilizzare uno qualsiasi dei diversi metodi possibili, ma quasi certamente non utilizzerete quello mostrato in Fig. 5. Tuttavia, dovresti familiarizzare con esso, perché nessun altro metodo ti consente di dimostrare la connessione tra correlazione e previsione in modo così chiaro come questo. Nella fig. 5 nell'intervallo B2:C12 mostra un campione casuale di dieci case e fornisce dati sulla superficie di ciascuna casa (in metri quadrati) e sul suo prezzo di vendita.

Riso. 5. I valori dei prezzi di vendita previsti formano una linea retta
Trova le medie, le deviazioni standard e il coefficiente di correlazione (intervallo A14:C18). Calcolare i punteggi z dell'area (E2:E12). Ad esempio, la cella E3 contiene la formula: =(B3-$B$14)/$B$15. Calcolare i punteggi z del prezzo previsto (F2:F12). Ad esempio, la cella F3 contiene la formula: =ЕЗ*$В$18. Convertire i punteggi z in prezzi in dollari (H2:H12). Nella cella NZ la formula è: =F3*$C$15+$C$14.
Si noti che il valore previsto tende sempre a spostarsi verso la media di 0. Quanto più vicino è il coefficiente di correlazione a zero, tanto più vicino a zero è il punteggio z previsto. Nel nostro esempio il coefficiente di correlazione tra superficie e prezzo di vendita è 0,67 e il prezzo previsto è 1,0 * 0,67, ovvero 0,67. Ciò corrisponde ad un eccesso di valore sopra la media pari a due terzi di una deviazione standard. Se il coefficiente di correlazione fosse pari a 0,5, il prezzo previsto sarebbe 1,0 * 0,5, ovvero 0,5. Ciò corrisponde ad un eccesso di valore sopra la media pari solo a metà della deviazione standard. Ogni volta che il valore del coefficiente di correlazione differisce dal valore ideale, ad es. maggiore di -1,0 e inferiore a 1,0, il punteggio della variabile prevista dovrebbe essere più vicino alla sua media rispetto al punteggio della variabile predittrice (indipendente) alla propria. Questo fenomeno è chiamato regressione alla media o semplicemente regressione.
Excel dispone di diverse funzioni per determinare i coefficienti di un'equazione della linea di regressione (in Excel è chiamata linea di tendenza) y =kx + B. Per determinare K serve alla funzione
=PENDENZA(valori_y_noti, valori_x_noti)
Qui Aè la variabile prevista e X- variabile indipendente. È necessario seguire rigorosamente questo ordine di variabili. La pendenza della linea di regressione, il coefficiente di correlazione, le deviazioni standard delle variabili e la covarianza sono strettamente correlati (Figura 6). La funzione INTERMEPT() restituisce il valore intercettato dalla retta di regressione sull'asse verticale:
=LIMIT(valori_y_conosciuti, valori_x_conosciuti)

Riso. 6. La relazione tra deviazioni standard converte la covarianza in un coefficiente di correlazione e la pendenza della retta di regressione
Tieni presente che il numero di valori xey forniti come argomenti alle funzioni SLOPE() e INTERCEPT() deve essere lo stesso.
Nell'analisi di regressione viene utilizzato un altro indicatore importante: R 2 (R-quadrato) o il coefficiente di determinazione. Determina quale contributo alla variabilità complessiva dei dati viene fornito dalla relazione tra X E A. In Excel esiste una funzione chiamata CVPIERSON(), che accetta esattamente gli stessi argomenti della funzione CORREL().
Si dice che due variabili con un coefficiente di correlazione diverso da zero spieghino la varianza o abbiano spiegato la varianza. In genere la varianza spiegata è espressa in percentuale. COSÌ R 2 = 0,81 significa che viene spiegato l'81% della varianza (dispersione) di due variabili. Il restante 19% è dovuto a fluttuazioni casuali.
Excel ha una funzione TENDENZA che semplifica i calcoli. Funzione TENDENZA():
- accetta i valori noti forniti X e valori conosciuti A;
- calcola la pendenza della retta di regressione e la costante (intercetta);
- restituisce i valori previsti A, determinato applicando un'equazione di regressione a valori noti X(Fig. 7).
La funzione TENDENZA() è una funzione di array (se non hai mai incontrato tali funzioni prima, lo consiglio).

Riso. 7. L'utilizzo della funzione TENDENZA() consente di velocizzare e semplificare i calcoli rispetto all'utilizzo della coppia di funzioni PENDENZA() e INTERCETTA()
Per inserire la funzione TENDENZA() come formula di matrice nelle celle G3:G12, seleziona l'intervallo G3:G12, inserisci la formula TENDENZA(NW:C12;B3:B12), tieni premuti i tasti
La funzione TENDENZA() ha altri due argomenti: nuovi_valori_x E cost. Il primo consente di fare una previsione per il futuro e il secondo può forzare il passaggio della linea di regressione attraverso l'origine (un valore TRUE indica a Excel di utilizzare la costante calcolata, un valore FALSE indica a Excel di utilizzare una costante = 0 ). Excel ti consente di tracciare una linea di regressione su un grafico in modo che passi attraverso l'origine. Inizia disegnando un grafico a dispersione, quindi fai clic con il pulsante destro del mouse su uno degli indicatori della serie di dati. Seleziona la voce nel menu contestuale che si apre Aggiungi una linea di tendenza; seleziona un'opzione Lineare; se necessario, scorrere il pannello e selezionare la casella Imposta l'intersezione; Assicurati che la casella di testo associata sia impostata su 0.0.
Se hai tre variabili e vuoi determinare la correlazione tra due di esse, eliminando l'influenza della terza, puoi utilizzare correlazione parziale. Supponiamo che tu sia interessato al rapporto tra la percentuale di residenti di una città che hanno completato l'università e il numero di libri nelle biblioteche della città. Hai raccolto dati per 50 città, ma... Il problema è che entrambi questi parametri possono dipendere dal benessere dei residenti di una determinata città. Certo, è molto difficile trovare altre 50 città caratterizzate esattamente dallo stesso livello di benessere dei residenti.
Utilizzando metodi statistici per controllare l’influenza della ricchezza sia sul sostegno finanziario delle biblioteche che sull’accessibilità universitaria, si potrebbe ottenere una quantificazione più precisa della forza della relazione tra le variabili di interesse, vale a dire il numero di libri e il numero di laureati. Tale correlazione condizionale tra due variabili, quando i valori delle altre variabili sono fissi, è chiamata correlazione parziale. Un modo per calcolarlo è utilizzare l'equazione:

Dove RC.B. . W- coefficiente di correlazione tra le variabili College e Libri escludendo l'influenza (valore fisso) della variabile Ricchezza; RC.B.- coefficiente di correlazione tra le variabili Università e Libri; RCW- coefficiente di correlazione tra le variabili College e Welfare; RB.W.- coefficiente di correlazione tra le variabili Libri e Welfare.
D'altro canto, la correlazione parziale può essere calcolata sulla base dell'analisi dei residui, vale a dire differenze tra i valori previsti e i risultati associati delle osservazioni effettive (entrambi i metodi sono presentati in Fig. 8).

Riso. 8. Correlazione parziale come correlazione dei residui
Per semplificare il calcolo della matrice dei coefficienti di correlazione (B16:E19), utilizzare il pacchetto di analisi Excel (menu Dati –> Analisi –> Analisi dei dati). Per impostazione predefinita, questo pacchetto non è attivo in Excel. Per installarlo, passare attraverso il menu File –> Opzioni –> Componenti aggiuntivi. Nella parte inferiore della finestra aperta OpzioniEccellere trova il campo Controllo, Selezionare Componenti aggiuntiviEccellere, fare clic Andare. Seleziona la casella accanto al componente aggiuntivo Pacchetto di analisi. Fare clic su A analisi dei dati, selezionare l'opzione Correlazione. Specificare $B$2:$D$13 come intervallo di input e selezionare la casella Etichette nella prima riga, specificare $B$16:$E$19 come intervallo di output.
Un'altra possibilità è determinare la correlazione semiparziale. Ad esempio, stai studiando gli effetti dell'altezza e dell'età sul peso. Pertanto, hai due variabili predittive: altezza ed età, e una variabile predittiva: peso. Si desidera escludere l'influenza di una variabile predittore su un'altra, ma non sulla variabile predittore:
![]()
dove H – Altezza, W – Peso, A – Età; L'indice del coefficiente di correlazione semiparziale utilizza parentesi per indicare quale variabile viene rimossa e da quale variabile. In questo caso, la notazione W(H.A) indica che l'effetto della variabile Età viene rimosso dalla variabile Altezza, ma non dalla variabile Peso.
Può sembrare che la questione in discussione non sia di significativa importanza. Dopotutto, ciò che conta di più è la precisione con cui funziona l’equazione di regressione complessiva, mentre il problema dei contributi relativi delle singole variabili alla varianza totale spiegata sembra essere di secondaria importanza. Tuttavia, questo non è il caso. Una volta che inizi a chiederti se valga la pena utilizzare una variabile in un'equazione di regressione multipla, la questione diventa importante. Può influenzare la valutazione della correttezza della scelta del modello per l'analisi.
Capitolo 4. Funzione REGR.LIN()
La funzione REGR.LIN() restituisce 10 statistiche di regressione. La funzione REGR.LIN() è una funzione di matrice. Per inserirlo, seleziona un intervallo contenente cinque righe e due colonne, digita la formula e fai clic
REGR.LIN(B2:B21;A2:A21;VERO;VERO)

Riso. 9. Funzione REGR.LIN(): a) seleziona l'intervallo D2:E6, b) inserisci la formula come mostrato nella barra della formula, c) fai clic su
La funzione REGR.LIN() restituisce:
- coefficiente di regressione (o pendenza, cella D2);
- segmento (o costante, cella E3);
- errori standard del coefficiente e della costante di regressione (intervallo D3:E3);
- coefficiente di determinazione R 2 per la regressione (cella D4);
- errore standard di stima (cella E4);
- Test F per la regressione completa (cella D5);
- numero di gradi di libertà per la somma residua dei quadrati (cella E5);
- somma dei quadrati di regressione (cella D6);
- somma residua dei quadrati (cella E6).
Diamo un'occhiata a ciascuna di queste statistiche e al modo in cui interagiscono.
Errore standard nel nostro caso si tratta della deviazione standard calcolata per gli errori di campionamento. Cioè, questa è una situazione in cui la popolazione generale ha una statistica e il campione ne ha un'altra. Dividendo il coefficiente di regressione per l'errore standard si ottiene un valore di 2,092/0,818 = 2,559. In altre parole, un coefficiente di regressione pari a 2,092 è a due errori standard e mezzo di distanza da zero.
Se il coefficiente di regressione è zero, la migliore stima della variabile prevista è la sua media. Due errori standard e mezzo sono piuttosto grandi e si può tranquillamente presumere che il coefficiente di regressione per la popolazione sia diverso da zero.
È possibile determinare la probabilità di ottenere un coefficiente di regressione campione pari a 2,092 se il suo valore effettivo nella popolazione è 0,0 utilizzando la funzione
STUDENT.DIST.PH (criterio t = 2.559; numero di gradi di libertà = 18)
In generale, il numero di gradi di libertà = n – k – 1, dove n è il numero di osservazioni e k è il numero di variabili predittive.
Questa formula restituisce 0,00987 o arrotondato all'1%. Ci dice che se il coefficiente di regressione per la popolazione è 0%, allora la probabilità di ottenere un campione di 20 persone per il quale il coefficiente di regressione stimato è 2,092 è un modesto 1%.
Il test F (cella D5 nella Fig. 9) esegue le stesse funzioni in relazione alla regressione completa del test t in relazione al coefficiente di regressione semplice a coppie. Il test F viene utilizzato per verificare se il coefficiente di determinazione R 2 per una regressione è sufficientemente grande da rifiutare l'ipotesi che nella popolazione abbia un valore pari a 0,0, il che indica che non esiste alcuna varianza spiegata dal predittore e dalla variabile prevista. Quando è presente una sola variabile predittrice, il test F è esattamente uguale al test t al quadrato.
Finora abbiamo considerato le variabili di intervallo. Se disponi di variabili che possono assumere più valori, che rappresentano nomi semplici, ad esempio Uomo e Donna o Rettile, Anfibio e Pesce, rappresentale come codice numerico. Tali variabili sono chiamate nominali.
Statistiche R2 quantifica la proporzione della varianza spiegata.
Errore standard di stima. Nella fig. La Figura 4.9 presenta i valori previsti della variabile Peso, ottenuti sulla base della sua relazione con la variabile Altezza. L'intervallo E2:E21 contiene i valori residui per la variabile Peso. Più precisamente, questi residui sono chiamati errori – da qui il termine errore standard di stima.

Riso. 10. Sia R 2 che l'errore standard della stima esprimono l'accuratezza delle previsioni ottenute mediante la regressione
Quanto più piccolo è l'errore standard della stima, tanto più accurata sarà l'equazione di regressione e quanto più ci si aspetterà che la previsione prodotta dall'equazione corrisponda all'osservazione effettiva. L’errore standard di stima fornisce un modo per quantificare queste aspettative. Il peso del 95% delle persone con una certa altezza sarà compreso nell'intervallo:
(altezza * 2.092 – 3.591) ± 2.092 * 21.118
Statistica Fè il rapporto tra la varianza tra gruppi e la varianza all'interno del gruppo. Questo nome è stato introdotto dallo statistico George Snedecor in onore di Sir, che ha sviluppato l'analisi della varianza (ANOVA, Analysis of Variance) all'inizio del XX secolo.
Il coefficiente di determinazione R 2 esprime la proporzione della somma totale dei quadrati associati alla regressione. Il valore (1 – R 2) esprime la proporzione della somma totale dei quadrati associata ai residui - errori di previsione. Il test F può essere ottenuto utilizzando la funzione REGR.LIN (cella F5 nella Fig. 11), utilizzando somme di quadrati (intervallo G10:J11), utilizzando proporzioni della varianza (intervallo G14:J15). Le formule possono essere studiate nel file Excel allegato.

Riso. 11. Calcolo del criterio F
Quando si utilizzano variabili nominali, viene utilizzata la codifica fittizia (Figura 12). Per codificare i valori, è conveniente utilizzare i valori 0 e 1. La probabilità F viene calcolata utilizzando la funzione:
DIST.F.PH(K2;I2;I3)
Qui la funzione F.DIST.PH() restituisce la probabilità di ottenere un criterio F che obbedisce alla distribuzione F centrale (Fig. 13) per due insiemi di dati con i numeri di gradi di libertà indicati nelle celle I2 e I3, il cui valore coincide con il valore indicato nella cella K2.

Riso. 12. Analisi di regressione mediante variabili dummy

Riso. 13. Distribuzione F centrale a λ = 0
Capitolo 5. Regressione multipla
Quando si passa dalla semplice regressione a coppie con una variabile predittrice alla regressione multipla, si aggiungono una o più variabili predittive. Memorizzare i valori delle variabili predittore in colonne adiacenti, come le colonne A e B nel caso di due predittori, o A, B e C nel caso di tre predittori. Prima di immettere una formula che include la funzione REGR.LIN(), selezionare cinque righe e tante colonne quante sono le variabili predittrici, più un'altra per la costante. Nel caso di regressione con due variabili predittive è possibile utilizzare la seguente struttura:
REGR.LIN(A2: A41; B2: C41;;VERO)
Allo stesso modo nel caso di tre variabili:
REGR.LIN(A2:A61;B2:D61;;VERO)
Supponiamo che tu voglia studiare i possibili effetti dell'età e della dieta sui livelli di LDL: lipoproteine a bassa densità, che si ritiene siano responsabili della formazione di placche aterosclerotiche, che causano l'aterotrombosi (Fig. 14).

Riso. 14. Regressione multipla
L'R 2 della regressione multipla (riflesso nella cella F13) è maggiore dell'R 2 di qualsiasi regressione semplice (E4, H4). La regressione multipla utilizza più variabili predittive contemporaneamente. In questo caso R2 aumenta quasi sempre.
Per qualsiasi equazione di regressione lineare semplice con una variabile predittrice, ci sarà sempre una perfetta correlazione tra i valori previsti e i valori della variabile predittrice perché l'equazione moltiplica i valori predittivi per una costante e aggiunge un'altra costante a ogni prodotto. Questo effetto non persiste nella regressione multipla.
Visualizzazione dei risultati restituiti dalla funzione REGR.LIN() per la regressione multipla (Figura 15). I coefficienti di regressione vengono restituiti come parte dei risultati restituiti dalla funzione REGR.LIN() in ordine inverso delle variabili(G–H–I corrisponde a C–B–A).

Riso. 15. I coefficienti e i relativi errori standard vengono visualizzati in ordine inverso sul foglio di lavoro.
I principi e le procedure utilizzati nell'analisi di regressione di variabili predittive singole possono essere facilmente adattati per tenere conto di più variabili predittive. Si scopre che gran parte di questo adattamento dipende dall'eliminazione dell'influenza reciproca delle variabili predittive. Quest'ultimo è associato a correlazioni parziali e semiparziali (Fig. 16).

Riso. 16. La regressione multipla può essere espressa attraverso la regressione a coppie dei residui (vedere il file Excel per le formule)
In Excel sono presenti funzioni che forniscono informazioni sulle distribuzioni t e F. Le funzioni i cui nomi includono la parte DIST, come STUDENT.DIST() e F.DIST(), accettano un test t o un test F come argomento e restituiscono la probabilità di osservare un valore specificato. Le funzioni i cui nomi includono la parte OBR, come STUDENT.INV() e F.INR(), accettano un valore di probabilità come argomento e restituiscono un valore di criterio corrispondente alla probabilità specificata.
Poiché stiamo cercando valori critici della distribuzione t che tagliano i bordi delle sue regioni di coda, passiamo 5% come argomento a una delle funzioni STUDENT.INV(), che restituisce il valore corrispondente a questa probabilità (Fig. 17, 18).

Riso. 17. Test t a due code

Riso. 18. Test t a una coda
Stabilendo una regola decisionale per la regione alfa a coda singola, si aumenta la potenza statistica del test. Se, quando inizi un esperimento, sei sicuro di avere tutte le ragioni per aspettarti un coefficiente di regressione positivo (o negativo), allora dovresti eseguire un test a coda singola. In questo caso, la probabilità di prendere la decisione giusta rifiutando l’ipotesi di un coefficiente di regressione pari a zero nella popolazione sarà maggiore.
Gli statistici preferiscono usare il termine prova diretta invece del termine test a coda singola e termine prova non orientata invece del termine test a due code. I termini diretto e non diretto sono preferiti perché enfatizzano il tipo di ipotesi piuttosto che la natura delle code della distribuzione.
Un approccio per valutare l'impatto dei predittori basato sul confronto dei modelli. Nella fig. La Figura 19 presenta i risultati di un'analisi di regressione che verifica il contributo della variabile Dieta all'equazione di regressione.

Riso. 19. Confrontare due modelli testando le differenze nei loro risultati
I risultati della funzione REGR.LIN() (intervallo H2:K6) sono correlati a quello che chiamo modello completo, che regredisce la variabile LDL sulle variabili Dieta, Età e HDL. L'intervallo H9:J13 presenta i calcoli senza tenere conto della variabile predittrice Dieta. Lo chiamo il modello limitato. Nel modello completo, il 49,2% della varianza nella variabile dipendente LDL era spiegata dalle variabili predittive. Nel modello ristretto, solo il 30,8% delle LDL è spiegato dalle variabili Età e HDL. La perdita in R2 dovuta all'esclusione della variabile Dieta dal modello è 0,183. Nell'intervallo G15:L17 vengono effettuati calcoli che mostrano che solo con una probabilità pari a 0,0288 l'effetto della variabile Dieta è casuale. Nel restante 97,1%, la dieta ha un effetto sulle LDL.
Capitolo 6: Presupposti e precauzioni per l'analisi di regressione
Il termine "presupposto" non è definito in modo sufficientemente rigoroso e il modo in cui viene utilizzato suggerisce che se il presupposto non viene soddisfatto, i risultati dell'intera analisi sono quanto meno discutibili o forse non validi. In realtà non è così, anche se ci sono certamente casi in cui la violazione di un presupposto cambia radicalmente il quadro. Ipotesi di base: a) i residui della variabile Y sono normalmente distribuiti in qualsiasi punto X lungo la retta di regressione; b) i valori Y dipendono linearmente dai valori X; c) la dispersione dei residui è circa la stessa in ciascun punto X; d) non esiste dipendenza tra i residui.
Se le ipotesi non svolgono un ruolo significativo, gli statistici affermano che l’analisi è resistente alla violazione delle ipotesi. In particolare, quando si utilizza la regressione per testare le differenze tra le medie dei gruppi, l’ipotesi che i valori Y – e quindi i residui – siano distribuiti normalmente non gioca un ruolo significativo: i test sono robusti alle violazioni dell’ipotesi di normalità. È importante analizzare i dati utilizzando i grafici. Ad esempio, incluso nel componente aggiuntivo Analisi dei dati attrezzo Regressione.
Se i dati non soddisfano i presupposti della regressione lineare, sono a disposizione approcci diversi dalla regressione lineare. Uno di questi è la regressione logistica (Fig. 20). In prossimità dei limiti superiore e inferiore della variabile predittrice, la regressione lineare produce previsioni non realistiche.

Riso. 20. Regressione logistica
Nella fig. La Figura 6.8 mostra i risultati di due metodi di analisi dei dati volti a esaminare la relazione tra reddito annuo e probabilità di acquistare una casa. Ovviamente, la probabilità di effettuare un acquisto aumenterà con l'aumentare del reddito. I grafici facilitano l'individuazione delle differenze tra i risultati che la regressione lineare prevede sulla probabilità di acquistare una casa e i risultati che potresti ottenere utilizzando un approccio diverso.
Nel gergo statistico, rifiutare l'ipotesi nulla quando in realtà è vera è chiamato errore di tipo I.
Nel componente aggiuntivo Analisi dei dati offre un comodo strumento per generare numeri casuali, consentendo all'utente di specificare la forma desiderata della distribuzione (ad esempio, Normale, Binomiale o Poisson), nonché la media e la deviazione standard.
Differenze tra le funzioni della famiglia STUDENT.DIST(). A partire da Excel 2010, sono disponibili tre diverse forme della funzione che restituiscono la proporzione della distribuzione a sinistra e/o a destra di un determinato valore del test t. La funzione STUDENT.DIST() restituisce la frazione dell'area sotto la curva di distribuzione a sinistra del valore del test t specificato. Supponiamo di avere 36 osservazioni, quindi il numero di gradi di libertà per l'analisi è 34 e il valore del test t = 1,69. In questo caso la formula
DIST.STUDENTE(+1.69,34,VERO)
restituisce il valore 0,05, ovvero 5% (Figura 21). Il terzo argomento della funzione STUDENT.DIST() può essere VERO o FALSO. Se impostata su TRUE, la funzione restituisce l'area cumulativa sotto la curva a sinistra del test t specificato, espressa come proporzione. Se è FALSO, la funzione restituisce l'altezza relativa della curva nel punto corrispondente al test t. Altre versioni della funzione STUDENT.DIST() - STUDENT.DIST.PH() e STUDENT.DIST.2X() - accettano solo il valore t-test e il numero di gradi di libertà come argomenti e non richiedono la specifica di un terzo discussione.

Riso. 21. L'area ombreggiata più scura nella coda sinistra della distribuzione corrisponde alla proporzione dell'area sotto la curva a sinistra di un valore t-test ampio e positivo
Per determinare l'area a destra del test t, utilizzare una delle formule:
1 — DIST.STIODENT (1, 69;34;VERO)
STUDENTE.DIST.PH(1,69;34)
L'intera area sotto la curva deve essere 100%, quindi sottraendo da 1 la frazione dell'area a sinistra del valore del test t restituita dalla funzione si ottiene la frazione dell'area a destra del valore del test t. Potresti trovare preferibile ottenere direttamente la frazione di area che ti interessa utilizzando la funzione STUDENT.DIST.PH(), dove PH indica la coda destra della distribuzione (Fig. 22).

Riso. 22. Regione alfa del 5% per il test direzionale
L'utilizzo delle funzioni STUDENT.DIST() o STUDENT.DIST.PH() implica che si sia scelta un'ipotesi di lavoro direzionale. L'ipotesi di lavoro direzionale combinata con l'impostazione del valore alfa al 5% significa posizionare tutto il 5% nella coda destra delle distribuzioni. Dovrai rifiutare l'ipotesi nulla solo se la probabilità che ottieni il valore del test t è pari o inferiore al 5%. Le ipotesi direzionali generalmente danno luogo a test statistici più sensibili (questa maggiore sensibilità è anche chiamata maggiore potere statistico).
In un test non indirizzato, il valore alfa rimane allo stesso livello del 5%, ma la distribuzione sarà diversa. Poiché è necessario consentire due risultati, la probabilità di un falso positivo deve essere distribuita tra le due code della distribuzione. È generalmente accettato distribuire equamente questa probabilità (Fig. 23).

Utilizzando lo stesso valore t-test ottenuto e lo stesso numero di gradi di libertà dell'esempio precedente, utilizzare la formula
DIST.STUDENTE.2Х(1.69;34)
Per nessun motivo particolare, la funzione STUDENT.DIST.2X() restituisce il codice di errore #NUM! se le viene fornito un valore t-test negativo come primo argomento.
Se i campioni contengono quantità diverse di dati, utilizzare il test t a due campioni con varianze diverse incluso nel pacchetto Analisi dei dati.
Capitolo 7: Utilizzo della regressione per testare le differenze tra le medie dei gruppi
Le variabili che in precedenza apparivano sotto il nome di variabili predittive verranno chiamate variabili di risultato in questo capitolo e verrà utilizzato il termine variabili fattore al posto del termine variabili predittive.
L'approccio più semplice per codificare una variabile nominale è codifica fittizia(Fig. 24).

Riso. 24. Analisi di regressione basata sulla codifica dummy
Quando si utilizza una codifica fittizia di qualsiasi tipo, è necessario seguire le seguenti regole:
- Il numero di colonne riservate per i nuovi dati deve essere uguale al numero di livelli di fattore meno
- Ciascun vettore rappresenta un livello di fattore.
- I soggetti in uno dei livelli, che spesso è il gruppo di controllo, sono codificati 0 in tutti i vettori.
La formula nelle celle F2:H6 =LINES(A2:A22,C2:D22,;VERO) restituisce le statistiche di regressione. Per confronto, in Fig. La Figura 24 mostra i risultati dell'ANOVA tradizionale restituiti dallo strumento. ANOVA unidirezionale componenti aggiuntivi Analisi dei dati.
Codifica degli effetti. In un altro tipo di codifica chiamato codifica degli effetti, La media di ciascun gruppo viene confrontata con la media delle medie del gruppo. Questo aspetto della codifica degli effetti è dovuto all'uso di -1 invece di 0 come codice per il gruppo, che riceve lo stesso codice in tutti i vettori di codice (Figura 25).

Riso. 25. Codifica degli effetti
Quando viene utilizzata la codifica fittizia, il valore costante restituito da LINEST() è la media del gruppo a cui vengono assegnati codici zero in tutti i vettori (solitamente il gruppo di controllo). Nel caso della codifica degli effetti la costante è pari alla media complessiva (cella J2).
Il modello lineare generale è un modo utile per concettualizzare le componenti del valore di una variabile di risultato:
Y ij = μ + α j + ε ij
L'uso di lettere greche in questa formula invece di lettere latine sottolinea il fatto che si riferisce alla popolazione da cui vengono estratti i campioni, ma può essere riscritta per indicare che si riferisce a campioni estratti da una determinata popolazione:
Y ij = Y̅ + a j + e ij
L'idea è che ogni osservazione Y ij può essere vista come la somma delle seguenti tre componenti: la media generale, μ; effetto del trattamento j e j ; valore e ij, che rappresenta lo scostamento dell'indicatore quantitativo individuale Y ij dal valore combinato della media generale e dall'effetto del j-esimo trattamento (Fig. 26). L'obiettivo dell'equazione di regressione è ridurre al minimo la somma dei quadrati dei residui.

Riso. 26. Osservazioni scomposte in componenti di un modello lineare generale
Analisi fattoriale. Se la relazione tra la variabile di risultato e due o più fattori viene studiata contemporaneamente, in questo caso si parla di utilizzo dell'analisi fattoriale. L'aggiunta di uno o più fattori a un'ANOVA unidirezionale può aumentare la potenza statistica. Nell'analisi della varianza unidirezionale, la varianza della variabile di risultato che non può essere attribuita a un fattore è inclusa nel quadrato medio residuo. Ma può darsi che questa variazione sia legata ad un altro fattore. Quindi questa variazione può essere rimossa dall'errore quadratico medio, una diminuzione della quale porta ad un aumento dei valori del test F, e quindi ad un aumento del potere statistico del test. Sovrastruttura Analisi dei dati include uno strumento che elabora due fattori contemporaneamente (Fig. 27).

Riso. 27. Strumento Analisi bidirezionale della varianza con ripetizioni del Pacchetto Analisi
Lo strumento ANOVA utilizzato in questa figura è utile perché restituisce la media e la varianza della variabile di risultato, nonché il controvalore, per ciascun gruppo incluso nel disegno. Sul tavolo Analisi della varianza visualizza due parametri non presenti nell'output della versione a fattore singolo dello strumento ANOVA. Prestare attenzione alle fonti di variazione Campione E Colonne nelle righe 27 e 28. Fonte della variazione Colonne si riferisce al genere. Fonte di variazione Campione si riferisce a qualsiasi variabile i cui valori occupano linee diverse. Nella fig. 27 valori per il gruppo KursLech1 si trovano nelle righe 2-6, il gruppo KursLech2 nelle righe 7-11 e il gruppo KursLechZ nelle righe 12-16.
Il punto principale è che entrambi i fattori, Sesso (etichetta Colonne nella cella E28) e Trattamento (etichetta Campione nella cella E27), sono inclusi nella tabella ANOVA come fonti di variazione. I mezzi per gli uomini sono diversi da quelli per le donne, e questo crea una fonte di variazione. Anche i mezzi per i tre trattamenti differiscono, fornendo un'altra fonte di variazione. Esiste anche una terza fonte, Interazione, che fa riferimento all'effetto combinato delle variabili Sesso e Trattamento.
Capitolo 8. Analisi della covarianza
L'analisi della covarianza, o ANCOVA (Analisi della covarianza), riduce i bias e aumenta il potere statistico. Lascia che ti ricordi che uno dei modi per valutare l'affidabilità di un'equazione di regressione sono i test F:
F = Regressione SM/Residuo SM
dove MS (Mean Square) è la media del quadrato e gli indici Regressione e Residuo indicano rispettivamente la regressione e le componenti residue. Il residuo MS viene calcolato utilizzando la formula:
Residuo MS = Residuo SS / Residuo df
dove SS (somma dei quadrati) è la somma dei quadrati e df è il numero di gradi di libertà. Quando aggiungi la covarianza a un'equazione di regressione, una parte della somma totale dei quadrati non viene inclusa in SS ResiduaI, ma in SS Regression. Ciò porta ad una diminuzione del residuo SS e quindi del residuo MS. Minore è il residuo MS, maggiore è il test F e maggiore è la probabilità di rifiutare l'ipotesi nulla di assenza di differenza tra le medie. Di conseguenza, ridistribuisci la variabilità della variabile di risultato. Nell'ANOVA, quando non si tiene conto della covarianza, la variabilità diventa errore. Ma in ANCOVA, parte della variabilità precedentemente attribuita al termine di errore viene assegnata a una covariata e diventa parte della regressione SS.
Consideriamo un esempio in cui lo stesso set di dati viene analizzato prima con ANOVA e poi con ANCOVA (Figura 28).

Riso. 28. L'analisi ANOVA indica che i risultati ottenuti dall'equazione di regressione non sono affidabili
Lo studio confronta gli effetti relativi dell'esercizio fisico, che sviluppa la forza muscolare, e dell'esercizio cognitivo (facendo cruciverba), che stimola l'attività cerebrale. I soggetti sono stati assegnati in modo casuale a due gruppi in modo che entrambi i gruppi fossero esposti alle stesse condizioni all'inizio dell'esperimento. Dopo tre mesi, è stata misurata la prestazione cognitiva dei soggetti. I risultati di queste misurazioni sono mostrati nella colonna B.
L'intervallo A2:C21 contiene i dati di origine passati alla funzione LINEST() per eseguire l'analisi utilizzando la codifica degli effetti. I risultati della funzione REGR.LIN() sono forniti nell'intervallo E2:F6, dove la cella E2 visualizza il coefficiente di regressione associato al vettore di impatto. La cella E8 contiene t-test = 0,93 e la cella E9 verifica l'affidabilità di questo t-test. Il valore contenuto nella cella E9 indica che la probabilità di incontrare la differenza tra le medie dei gruppi osservata in questo esperimento è del 36% se le medie dei gruppi sono uguali nella popolazione. Pochi considerano questo risultato statisticamente significativo.
Nella fig. La Figura 29 mostra cosa succede quando si aggiunge una covariata all'analisi. In questo caso, ho aggiunto l'età di ciascun soggetto al set di dati. Il coefficiente di determinazione R 2 per l'equazione di regressione che utilizza la covariata è 0,80 (cella F4). Il valore R 2 nell'intervallo F15:G19, in cui ho replicato i risultati ANOVA ottenuti senza la covariata, è solo 0,05 (cella F17). Pertanto, un'equazione di regressione che include la covariata prevede i valori della variabile Punteggio cognitivo in modo molto più accurato rispetto all'utilizzo del solo vettore Impatto. Per ANCOVA, la probabilità di ottenere per caso il valore del test F visualizzato nella cella F5 è inferiore allo 0,01%.

Riso. 29. L'ANCOVA ripropone un quadro completamente diverso
L'elaborazione dei dati statistici può essere effettuata anche utilizzando un componente aggiuntivo PACCHETTO ANALISI(Fig. 62).
Tra gli articoli suggeriti, seleziona la voce “ REGRESSIONE" e cliccaci sopra con il tasto sinistro del mouse. Quindi, fare clic su OK.
Apparirà una finestra come mostrato in Fig. 63.

Strumento di analisi " REGRESSIONE» viene utilizzato per adattare un grafico a un insieme di osservazioni utilizzando il metodo dei minimi quadrati. La regressione viene utilizzata per analizzare l'effetto su una singola variabile dipendente dei valori di una o più variabili indipendenti. Ad esempio, diversi fattori influenzano le prestazioni atletiche di un atleta, tra cui età, altezza e peso. È possibile calcolare il grado in cui ciascuno di questi tre fattori influenza le prestazioni di un atleta e quindi utilizzare tali dati per prevedere le prestazioni di un altro atleta.
Lo strumento Regressione utilizza la funzione LINEST.
Finestra di dialogo REGRESSIONE
Etichette Selezionare la casella di controllo se la prima riga o la prima colonna dell'intervallo di input contiene intestazioni. Deselezionare questa casella di controllo se non sono presenti intestazioni. In questo caso verranno create automaticamente le intestazioni adatte per i dati della tabella di output.
Livello di affidabilità Selezionare la casella di controllo per includere un livello aggiuntivo nella tabella di riepilogo dell'output. Nel campo apposito, inserire il livello di confidenza da applicare, oltre al livello predefinito del 95%.
Costante - zero Selezionare la casella di controllo per forzare il passaggio della linea di regressione attraverso l'origine.
Intervallo di output Immettere il riferimento alla cella in alto a sinistra dell'intervallo di output. Fornire almeno sette colonne per la tabella di riepilogo dell'output, che includerà: risultati ANOVA, coefficienti, errore standard del calcolo Y, deviazioni standard, numero di osservazioni, errori standard per i coefficienti.
Nuovo foglio di lavoro Selezionare questa opzione per aprire un nuovo foglio di lavoro nella cartella di lavoro e incollare i risultati dell'analisi, iniziando dalla cella A1. Se necessario, inserisci un nome per il nuovo foglio nel campo situato di fronte al pulsante di opzione corrispondente.
Nuova cartella di lavoro Selezionare questa opzione per creare una nuova cartella di lavoro con i risultati aggiunti a un nuovo foglio di lavoro.
Residui Selezionare la casella di controllo per includere i residui nella tabella di output.
Residui standardizzati Selezionare la casella di controllo per includere i residui standardizzati nella tabella di output.
Grafico dei residui Selezionare la casella di controllo per tracciare i residui per ciascuna variabile indipendente.
Adatta grafico Selezionare la casella di controllo per tracciare i valori previsti rispetto a quelli osservati.
Grafico della probabilità normale Selezionare la casella di controllo per tracciare un grafico di probabilità normale.
Funzione LINEST
Per effettuare i calcoli, selezioniamo con il cursore la cella in cui vogliamo visualizzare il valore medio e premiamo il tasto = sulla tastiera. Successivamente, nel campo Nome, indicare ad esempio la funzione desiderata MEDIA(Fig. 22).
Funzione LINEST calcola le statistiche per una serie utilizzando il metodo dei minimi quadrati per calcolare la linea retta che meglio approssima i dati disponibili e quindi restituisce una matrice che descrive la linea retta risultante. Puoi anche combinare la funzione LINEST con altre funzioni per calcolare altri tipi di modelli lineari in parametri sconosciuti (i cui parametri sconosciuti sono lineari), comprese le serie polinomiali, logaritmiche, esponenziali e di potenze. Poiché viene restituito un array di valori, la funzione deve essere specificata come formula di matrice.
L'equazione per una linea retta è:
y=m 1 x 1 +m 2 x 2 +…+b (in caso di più intervalli di valori x),
dove il valore dipendente y è una funzione del valore indipendente x, i valori m sono i coefficienti corrispondenti a ciascuna variabile indipendente x e b è una costante. Nota che y, x e m possono essere vettori. Funzione LINEST restituisce array(mn;mn-1;…;m 1 ;b). LINEST può anche restituire statistiche di regressione aggiuntive.
LINEST(valori_noti_y; valori_noti_x; const; statistiche)
Known_y_values - un insieme di valori y già noti per la relazione y=mx+b.
Se l'arrayknown_y_values ha una colonna, ciascuna colonna nell'arrayknown_x_values viene trattata come una variabile separata.
Se l'arrayknown_y_values ha una riga, ciascuna riga nell'arrayknown_x_values viene trattata come una variabile separata.
I valori x_conosciuti sono un insieme facoltativo di valori x già noti per la relazione y=mx+b.
L'arrayknown_x_values può contenere uno o più set di variabili. Se viene utilizzata una sola variabile, gli array Known_y_values e Known_x_values possono avere qualsiasi forma, purché abbiano la stessa dimensione. Se viene utilizzata più di una variabile, alloraknown_y_values deve essere un vettore (ovvero un intervallo alto una riga o largo una colonna).
Se array_known_x_values viene omesso, si presuppone che l'array (1;2;3;...) abbia le stesse dimensioni di array_known_values_y.
Const è un valore booleano che specifica se la costante b deve essere uguale a 0.
Se l'argomento "const" è VERO o omesso, la costante b viene valutata come al solito.
Se l'argomento “const” è FALSE, allora il valore di b è impostato su 0 e i valori di m sono selezionati in modo tale che la relazione y=mx sia soddisfatta.
Statistiche: un valore booleano che indica se devono essere restituite statistiche di regressione aggiuntive.
Se la statistica è VERA, REGR.LIN restituisce ulteriori statistiche di regressione. L'array restituito sarà simile a questo: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Se la statistica è FALSA o omessa, REGR.LIN restituisce solo i coefficienti me la costante b.
Ulteriori statistiche di regressione (Tabella 17)
| Grandezza | Descrizione |
| se1,se2,...,sen | Valori di errore standard per i coefficienti m1,m2,...,mn. |
| seb | Valore dell'errore standard per la costante b (seb = #N/A se const è FALSE). |
| r2 | Coefficiente di determinismo. Vengono confrontati i valori effettivi di y e i valori ottenuti dall'equazione della retta; Sulla base dei risultati del confronto, viene calcolato il coefficiente di determinismo, normalizzato da 0 a 1. Se è uguale a 1, allora esiste una correlazione completa con il modello, ovvero non c'è differenza tra i valori effettivi e quelli stimati di y. Nel caso opposto, se il coefficiente di determinazione è 0, non ha senso utilizzare l’equazione di regressione per prevedere i valori di y. Per ulteriori informazioni su come calcolare r2, consultare le “Note” alla fine di questa sezione. |
| guarda | Errore standard per la stima di y. |
| F | Valore statistico F o valore osservato F. La statistica F viene utilizzata per determinare se la relazione osservata tra una variabile dipendente e indipendente è dovuta al caso. |
| df | Gradi di libertà. I gradi di libertà sono utili per trovare valori F-critici in una tabella statistica. Per determinare il livello di confidenza del modello, si confrontano i valori nella tabella con la statistica F restituita dalla funzione REGR.LIN. Per ulteriori informazioni sul calcolo del df, vedere le “Note” alla fine di questa sezione. Successivamente, l'Esempio 4 mostra l'uso dei valori F e df. |
| ssreg | Somma di regressione dei quadrati. |
| ssresid | Somma residua dei quadrati. Per ulteriori informazioni sul calcolo di ssreg e ssresid, vedere le "Note" alla fine di questa sezione. |
La figura seguente mostra l'ordine in cui vengono restituite le statistiche di regressione aggiuntive (Figura 64).

Appunti:
Qualsiasi linea retta può essere descritta dalla sua pendenza e dall'intersezione con l'asse y:
Pendenza (m): Per determinare la pendenza di una linea, solitamente indicata con m, è necessario prendere due punti sulla linea (x 1 ,y 1) e (x 2 ,y 2); la pendenza sarà uguale a (y 2 -y 1)/(x 2 -x 1).
Intercetta Y (b): l'intercetta y di una linea, solitamente indicata con b, è il valore y per il punto in cui la linea interseca l'asse y.
L'equazione della retta è y=mx+b. Se i valori di m e b sono noti, qualsiasi punto sulla linea può essere calcolato sostituendo i valori di y o x nell'equazione. Puoi anche utilizzare la funzione TENDENZA.
Se esiste una sola variabile indipendente x, puoi ottenere la pendenza e l'intercetta y direttamente utilizzando le seguenti formule:
Pendenza: INDICE(LINEST(valori_y_noti; valori_x_noti); 1)
Intercetta Y: INDICE(LINEST(valori_y_noti; valori_x_noti); 2)
La precisione dell'approssimazione utilizzando la linea retta calcolata dalla funzione REGR.LIN dipende dal grado di dispersione dei dati. Quanto più i dati sono vicini a una linea retta, tanto più accurato sarà il modello utilizzato dalla funzione REGR.LIN. La funzione REGR.LIN utilizza i minimi quadrati per determinare l'adattamento migliore ai dati. Quando esiste una sola variabile indipendente x, m e b vengono calcolati utilizzando le seguenti formule:

dove xey sono medie campione, ad esempio x = MEDIA(x_conosciute) e y = MEDIA(y_conosciute).
Le funzioni di adattamento REGR.LIN e LGRFPRIBL possono calcolare la linea retta o la curva esponenziale che meglio si adatta ai dati. Tuttavia non rispondono alla domanda su quale dei due risultati sia più adatto a risolvere il problema. Puoi anche valutare la funzione TENDENZA (y_conosciuta; x_conosciuta) per una linea retta o la funzione GROW(y_conosciuta; x_conosciuta) per una curva esponenziale. Queste funzioni, a meno che non vengano specificati new_x-values, restituiscono un array di valori y calcolati per i valori x effettivi lungo una linea o curva. È quindi possibile confrontare i valori calcolati con i valori effettivi. Puoi anche creare grafici per il confronto visivo.
Quando si esegue l'analisi di regressione, Microsoft Excel calcola, per ogni punto, il quadrato della differenza tra il valore y previsto e il valore y effettivo. La somma di queste differenze al quadrato è chiamata somma residua dei quadrati (ssresid). Microsoft Excel calcola quindi la somma totale dei quadrati (sstotal). Se const = TRUE o il valore di questo argomento non è specificato, la somma totale dei quadrati sarà uguale alla somma dei quadrati delle differenze tra i valori y effettivi e i valori y medi. Quando const = FALSE, la somma totale dei quadrati sarà uguale alla somma dei quadrati dei valori reali y (senza sottrarre il valore y medio dal valore y parziale). La somma dei quadrati della regressione può quindi essere calcolata come segue: ssreg = sstotal - ssresid. Minore è la somma residua dei quadrati, maggiore è il valore del coefficiente di determinazione r2, che mostra quanto bene l'equazione ottenuta utilizzando l'analisi di regressione spiega le relazioni tra le variabili. Il coefficiente r2 è pari a ssreg/sstotal.
In alcuni casi, una o più colonne X (lascia che i valori Y e X siano nelle colonne) non hanno alcun valore predicativo aggiuntivo in altre colonne X. In altre parole, la rimozione di una o più colonne X può comportare il calcolo dei valori Y con la stessa precisione. In questo caso, le colonne X ridondanti verranno escluse dal modello di regressione. Questo fenomeno è chiamato “collinearità” perché le colonne ridondanti di X possono essere rappresentate come la somma di più colonne non ridondanti. La funzione REGR.LIN verifica la collinearità e rimuove eventuali colonne X ridondanti dal modello di regressione se le rileva. Le colonne X rimosse possono essere identificate nell'output di REGR.LIN con un fattore pari a 0 e un valore se pari a 0. La rimozione di una o più colonne come ridondanti modifica il valore di df perché dipende dal numero di colonne X effettivamente utilizzate per scopi predittivi. Per ulteriori informazioni sul calcolo di df, vedere l'Esempio 4 di seguito. Quando df cambia a causa della rimozione delle colonne ridondanti, cambiano anche i valori di sey e F. Non è consigliabile utilizzare spesso la collinearità. Tuttavia, dovrebbe essere utilizzato se alcune colonne X contengono 0 o 1 come indicatore che indica se il soggetto dell'esperimento appartiene a un gruppo separato. Se const = TRUE o non viene specificato un valore per questo argomento, REGR.LIN inserisce un'ulteriore colonna X per modellare il punto di intersezione. Se è presente una colonna con valori pari a 1 per gli uomini e 0 per le donne, ed è presente una colonna con valori pari a 1 per le donne e 0 per gli uomini, l'ultima colonna viene rimossa perché è possibile ottenere i suoi valori dalla colonna "indicatore maschile".
Il calcolo di df per i casi in cui X colonne non vengono rimosse dal modello a causa della collinearità avviene come segue: se ci sono k colonne conosciute_x e il valore const = TRUE o non specificato, allora df = n – k – 1. Se const = FALSO, allora df = n - k. In entrambi i casi, la rimozione delle colonne X a causa della collinearità aumenta il valore df di 1.
Le formule che restituiscono matrici devono essere immesse come formule di matrice.
Quando si immette un array di costanti come argomento, ad esempio,known_x_values, è necessario utilizzare un punto e virgola per separare i valori sulla stessa riga e i due punti per separare le righe. I caratteri separatori possono variare a seconda delle impostazioni nella finestra Lingua e impostazioni nel Pannello di controllo.
Va notato che i valori y previsti dall'equazione di regressione potrebbero non essere corretti se non rientrano nell'intervallo dei valori y utilizzati per definire l'equazione.
Algoritmo di base utilizzato nella funzione LINEST, differisce dall'algoritmo della funzione principale INCLINAZIONE E SEGMENTO. La differenza tra gli algoritmi può portare a risultati diversi con dati incerti e collineari. Ad esempio, se i punti dati dell'argomento Know_y_values sono 0 e i punti dati dell'argomento Known_x_values sono 1, allora:
Funzione LINEST restituisce un valore pari a 0. Algoritmo della funzione LINEST viene utilizzato per restituire valori adeguati per dati collineari e in questo caso è possibile trovare almeno una risposta.
Le funzioni PENDENZA e LINEA restituiscono l'errore #DIV/0! L'algoritmo delle funzioni PENDENZA e INTERCETTA viene utilizzato per trovare una sola risposta, ma in questo caso potrebbero essercene diverse.
Oltre a calcolare le statistiche per altri tipi di regressione, REGR.LIN può essere utilizzato per calcolare intervalli per altri tipi di regressione inserendo funzioni delle variabili x e y come serie delle variabili x e y per REGR.LIN. Ad esempio, la seguente formula:
REGR.LIN(valori_y, valori_x^COLUMN($A:$C))
funziona avendo una colonna di valori Y e una colonna di valori X per calcolare un'approssimazione del cubo (polinomio di 3° grado) della seguente forma:
y=m1x+m2x2 +m3x3 +b
La formula può essere modificata per calcolare altri tipi di regressione, ma in alcuni casi potrebbe essere necessario modificare i valori di output e altre statistiche.
IN Eccellere Esiste un modo ancora più veloce e conveniente per tracciare la regressione lineare (e anche i principali tipi di regressioni non lineari, come discusso di seguito). Questo può essere fatto come segue:
1) seleziona le colonne con i dati X E Y(dovrebbero essere in quest'ordine!);
2) chiamare Mago dei grafici e seleziona nel gruppo Tipo – Macchiare e premere immediatamente Pronto;
3) senza deselezionare lo schema, selezionare la voce del menu principale che appare Diagramma, in cui dovresti selezionare l'elemento Aggiungi una linea di tendenza;
4) nella finestra di dialogo che appare Linea di tendenza nella scheda Tipo scegliere Lineare;
5) nella tab Opzioni puoi attivare l'interruttore Mostra l'equazione nel diagramma, che ti permetterà di vedere l'equazione di regressione lineare (4.4), in cui verranno calcolati i coefficienti (4.5).
6) Nella stessa scheda è possibile attivare l'interruttore Posiziona il valore di affidabilità di approssimazione (R ^ 2) sul diagramma. Questo valore è il quadrato del coefficiente di correlazione (4.3) e mostra quanto bene l'equazione calcolata descrive la dipendenza sperimentale. Se R 2 è vicino all'unità, allora l'equazione di regressione teorica descrive bene la dipendenza sperimentale (la teoria concorda bene con l'esperimento), e se R 2 è vicino a zero, allora questa equazione non è adatta a descrivere la dipendenza sperimentale (la teoria non concorda con l'esperimento).
Come risultato dell'esecuzione delle azioni descritte, otterrai un diagramma con un grafico di regressione e la sua equazione.
§4.3. Principali tipi di regressione non lineare
Regressione parabolica e polinomiale.
Parabolico dipendenza del valore Y dalla dimensione X si chiama dipendenza espressa da una funzione quadratica (parabola del 2° ordine):
Questa equazione si chiama equazione di regressione parabolica Y SU X. Opzioni UN, B, Con sono chiamati coefficienti di regressione parabolica. Il calcolo dei coefficienti di regressione parabolica è sempre complicato, quindi si consiglia di utilizzare un computer per i calcoli.
L'equazione (4.8) della regressione parabolica è un caso speciale di una regressione più generale chiamata polinomiale. Polinomio dipendenza del valore Y dalla dimensione X si chiama dipendenza espressa da un polinomio N-esimo ordine:
dove sono i numeri e io (io=0,1,…, N) sono chiamati coefficienti di regressione polinomiale.
Regressione di potenza.
Energia dipendenza del valore Y dalla dimensione Xè chiamata dipendenza della forma:
Questa equazione si chiama equazione di regressione di potenza Y SU X. Opzioni UN E B sono chiamati coefficienti di regressione di potenza.
ln = ln UN+B ln X. (4.11)
Questa equazione descrive una linea retta su un piano con assi di coordinate logaritmiche ln X e ln. Pertanto, il criterio per l'applicabilità della regressione di potenza è il requisito che i punti dei logaritmi dei dati empirici ln x io e ln sì io erano più vicini alla linea retta (4.11).
Regressione esponenziale.
Indicativo(O esponenziale) dipendenza del valore Y dalla dimensione Xè chiamata dipendenza della forma:
(O ). (4.12)
Questa equazione si chiama equazione esponenziale(O esponenziale) regressione Y SU X. Opzioni UN(O K) E B sono chiamati coefficienti esponenziali(O esponenziale) regressione.
Se prendiamo il logaritmo di entrambi i lati dell'equazione di regressione di potenza, otteniamo l'equazione
ln = X ln UN+ln B(o ln = kx+ln B). (4.13)
Questa equazione descrive la dipendenza lineare del logaritmo di una quantità ln da un'altra quantità X. Pertanto, il criterio per l'applicabilità della regressione di potenza è il requisito che i dati empirici abbiano lo stesso valore x io e logaritmi di un'altra quantità ln sì io erano più vicini alla linea retta (4.13).
Regressione logaritmica.
Logaritmico dipendenza del valore Y dalla dimensione Xè chiamata dipendenza della forma:
=UN+B ln X. (4.14)
Questa equazione si chiama Equazione di regressione logaritmica Y SU X. Opzioni UN E B sono chiamati coefficienti di regressione logaritmica.
Regressione iperbolica.
Iperbolico dipendenza del valore Y dalla dimensione Xè chiamata dipendenza della forma:
Questa equazione si chiama equazione di regressione iperbolica Y SU X. Opzioni UN E B sono chiamati coefficienti di regressione iperbolica e sono determinati con il metodo dei minimi quadrati. L'applicazione di questo metodo porta alle formule:
Nelle formule (4.16-4.17), la somma viene effettuata sull'indice io da uno al numero di osservazioni N.
Sfortunatamente, dentro Eccellere non ci sono funzioni che calcolano i coefficienti di regressione iperbolica. Nei casi in cui non è noto che le quantità misurate sono correlate mediante proporzionalità inversa, si consiglia di cercare un'equazione di regressione su potenza anziché l'equazione di regressione iperbolica, quindi in Eccellere C'è una procedura per trovarlo. Se si assume una dipendenza iperbolica tra le quantità misurate, i suoi coefficienti di regressione dovranno essere calcolati utilizzando tabelle di calcolo ausiliarie e operazioni di somma utilizzando le formule (4.16-4.17).
Regressione in Excel
L'elaborazione dei dati statistici può essere effettuata anche utilizzando il componente aggiuntivo Pacchetto Analisi nella sottovoce del menu “Servizi”. In Excel 2003, se apri SERVIZIO, non riusciamo a trovare la scheda ANALISI DEI DATI, quindi fare clic con il pulsante sinistro del mouse per aprire la scheda SOVRASTRUTTURE e opposto al punto PACCHETTO ANALISI Fare clic con il pulsante sinistro del mouse per inserire un segno di spunta (Fig. 17).
Riso. 17. Finestra SOVRASTRUTTURE
Successivamente nel menu SERVIZIO viene visualizzata la scheda ANALISI DEI DATI.
In Excel 2007 da installare PACCHETTO ANALISIè necessario cliccare sul pulsante UFFICIO nell'angolo in alto a sinistra del foglio (Fig. 18a). Successivamente, fare clic sul pulsante IMPOSTAZIONI EXCEL. Nella finestra che appare IMPOSTAZIONI EXCEL fare clic con il tasto sinistro del mouse sull'elemento SOVRASTRUTTURE e nella parte destra dell'elenco a discesa seleziona l'elemento PACCHETTO ANALISI. Quindi fare clic su OK.




Riso. 18. Installazione PACCHETTO ANALISI nell'Excel 2007
Per installare il pacchetto di analisi, fare clic sul pulsante ANDARE, situato nella parte inferiore della finestra aperta. Apparirà una finestra come mostrato in Fig. 12. Metti un segno di spunta davanti a PACCHETTO ANALISI. Nella scheda DATI apparirà un pulsante ANALISI DEI DATI(Fig. 19).

Tra gli articoli suggeriti, seleziona la voce “ REGRESSIONE" e cliccaci sopra con il tasto sinistro del mouse. Quindi, fare clic su OK.

Apparirà una finestra come mostrato in Fig. 21

Strumento di analisi " REGRESSIONE» viene utilizzato per adattare un grafico a un insieme di osservazioni utilizzando il metodo dei minimi quadrati. La regressione viene utilizzata per analizzare l'effetto su una singola variabile dipendente dei valori di una o più variabili indipendenti. Ad esempio, diversi fattori influenzano le prestazioni atletiche di un atleta, tra cui età, altezza e peso. È possibile calcolare il grado in cui ciascuno di questi tre fattori influenza le prestazioni di un atleta e quindi utilizzare tali dati per prevedere le prestazioni di un altro atleta.
Lo strumento Regressione utilizza la funzione LINEST.
Finestra di dialogo REGRESSIONE
Etichette Selezionare la casella di controllo se la prima riga o la prima colonna dell'intervallo di input contiene intestazioni. Deselezionare questa casella di controllo se non sono presenti intestazioni. In questo caso verranno create automaticamente le intestazioni adatte per i dati della tabella di output.
Livello di affidabilità Selezionare la casella di controllo per includere un livello aggiuntivo nella tabella di riepilogo dell'output. Nel campo apposito, inserire il livello di confidenza da applicare, oltre al livello predefinito del 95%.
Costante - zero Selezionare la casella di controllo per forzare il passaggio della linea di regressione attraverso l'origine.
Intervallo di output Immettere il riferimento alla cella in alto a sinistra dell'intervallo di output. Fornire almeno sette colonne per la tabella di riepilogo dell'output, che includerà: risultati ANOVA, coefficienti, errore standard del calcolo Y, deviazioni standard, numero di osservazioni, errori standard per i coefficienti.
Nuovo foglio di lavoro Selezionare questa opzione per aprire un nuovo foglio di lavoro nella cartella di lavoro e incollare i risultati dell'analisi, iniziando dalla cella A1. Se necessario, inserisci un nome per il nuovo foglio nel campo situato di fronte al pulsante di opzione corrispondente.
Nuova cartella di lavoro Selezionare questa opzione per creare una nuova cartella di lavoro con i risultati aggiunti a un nuovo foglio di lavoro.
Residui Selezionare la casella di controllo per includere i residui nella tabella di output.
Residui standardizzati Selezionare la casella di controllo per includere i residui standardizzati nella tabella di output.
Grafico dei residui Selezionare la casella di controllo per tracciare i residui per ciascuna variabile indipendente.
Adatta grafico Selezionare la casella di controllo per tracciare i valori previsti rispetto a quelli osservati.
Grafico della probabilità normale Selezionare la casella di controllo per tracciare un grafico di probabilità normale.
Funzione LINEST
Per effettuare i calcoli, selezioniamo con il cursore la cella in cui vogliamo visualizzare il valore medio e premiamo il tasto = sulla tastiera. Successivamente, nel campo Nome, indicare ad esempio la funzione desiderata MEDIA(Fig. 22).

Riso. 22 Trovare funzioni in Excel 2003
Se sul campo NOME non appare il nome della funzione, quindi fare clic con il tasto sinistro del mouse sul triangolo accanto al campo, dopodiché apparirà una finestra con l'elenco delle funzioni. Se questa funzione non è nell'elenco, fare clic con il tasto sinistro del mouse sulla voce dell'elenco ALTRE FUNZIONI, Apparirà una finestra di dialogo MAESTRO DELLE FUNZIONI, in cui, utilizzando lo scorrimento verticale, selezionare la funzione desiderata, evidenziarla con il cursore e cliccare su OK(Fig. 23).

Riso. 23. Procedura guidata funzione
Per cercare una funzione in Excel 2007 si può aprire una qualsiasi scheda del menu, quindi per effettuare i calcoli selezionare con il cursore la cella in cui vogliamo visualizzare il valore medio e premere il tasto = sulla tastiera. Successivamente, nel campo Nome, specificare la funzione MEDIA. La finestra per il calcolo della funzione è simile a quella mostrata in Excel 2003.
Puoi anche selezionare la scheda Formule e fare clic con il pulsante sinistro del mouse sul pulsante nel menu " FUNZIONE INSERIMENTO"(Fig. 24), apparirà una finestra MAESTRO DELLE FUNZIONI, il cui aspetto è simile a Excel 2003. Inoltre nel menu è possibile selezionare immediatamente una categoria di funzioni (usate di recente, finanziarie, logiche, testo, data e ora, matematiche, altre funzioni) in cui cercheremo il desiderato funzione.




Riso. 24 Selezione di una funzione in Excel 2007
Funzione LINEST calcola le statistiche per una serie utilizzando il metodo dei minimi quadrati per calcolare la linea retta che meglio approssima i dati disponibili e quindi restituisce una matrice che descrive la linea retta risultante. Puoi anche combinare la funzione LINEST con altre funzioni per calcolare altri tipi di modelli lineari in parametri sconosciuti (i cui parametri sconosciuti sono lineari), comprese le serie polinomiali, logaritmiche, esponenziali e di potenze. Poiché viene restituito un array di valori, la funzione deve essere specificata come formula di matrice.
L'equazione per una linea retta è:
(in caso di più intervalli di valori x),
dove il valore dipendente y è una funzione del valore indipendente x, i valori m sono i coefficienti corrispondenti a ciascuna variabile indipendente x e b è una costante. Nota che y, x e m possono essere vettori. Funzione LINEST restituisce un array ![]() . LINEST può anche restituire statistiche di regressione aggiuntive.
. LINEST può anche restituire statistiche di regressione aggiuntive.
LINEST(valori_noti_y; valori_noti_x; const; statistiche)
Known_y_values - l'insieme di valori y già noti per la relazione.
Se l'arrayknown_y_values ha una colonna, ciascuna colonna nell'arrayknown_x_values viene trattata come una variabile separata.
Se l'arrayknown_y_values ha una riga, ciascuna riga nell'arrayknown_x_values viene trattata come una variabile separata.
I valori x_conosciuti sono un insieme facoltativo di valori x già noti per la relazione.
L'arrayknown_x_values può contenere uno o più set di variabili. Se viene utilizzata una sola variabile, gli array Known_y_values e Known_x_values possono avere qualsiasi forma, purché abbiano la stessa dimensione. Se viene utilizzata più di una variabile, alloraknown_y_values deve essere un vettore (ovvero un intervallo alto una riga o largo una colonna).
Se array_known_x_values viene omesso, si presuppone che l'array (1;2;3;...) abbia le stesse dimensioni di array_known_values_y.
Const è un valore booleano che specifica se la costante b deve essere uguale a 0.
Se l'argomento "const" è VERO o omesso, la costante b viene valutata come al solito.
Se l'argomento “const” è FALSE, il valore di b viene impostato su 0 e i valori di m vengono selezionati in modo tale che la relazione sia soddisfatta.
Statistiche: un valore booleano che indica se devono essere restituite statistiche di regressione aggiuntive.
Se la statistica è VERA, REGR.LIN restituisce ulteriori statistiche di regressione. L'array restituito sarà simile a questo: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Se la statistica è FALSA o omessa, REGR.LIN restituisce solo i coefficienti me la costante b.
Ulteriori statistiche di regressione.
La figura seguente mostra l'ordine in cui vengono restituite le statistiche di regressione aggiuntive.

Appunti:
Qualsiasi linea retta può essere descritta dalla sua pendenza e dall'intersezione con l'asse y:
Pendenza (m): Per determinare la pendenza di una linea, solitamente indicata con m, prendi due punti sulla linea e ; la pendenza sarà uguale a ![]() .
.
Intercetta Y (b): l'intercetta y di una linea, solitamente indicata con b, è il valore y per il punto in cui la linea interseca l'asse y.
L'equazione della retta ha la forma . Se i valori di m e b sono noti, qualsiasi punto sulla linea può essere calcolato sostituendo i valori di y o x nell'equazione. Puoi anche utilizzare la funzione TENDENZA.
Se esiste una sola variabile indipendente x, puoi ottenere la pendenza e l'intercetta y direttamente utilizzando le seguenti formule:
Pendenza: INDICE(LINEST(valori_y_noti; valori_x_noti); 1)
Intercetta Y: INDICE(LINEST(valori_y_noti; valori_x_noti); 2)
La precisione dell'approssimazione utilizzando la linea retta calcolata dalla funzione REGR.LIN dipende dal grado di dispersione dei dati. Quanto più i dati sono vicini a una linea retta, tanto più accurato sarà il modello utilizzato dalla funzione REGR.LIN. La funzione REGR.LIN utilizza i minimi quadrati per determinare l'adattamento migliore ai dati. Quando esiste una sola variabile indipendente x, m e b vengono calcolati utilizzando le seguenti formule:

dove xey sono medie campione, ad esempio x = MEDIA(x_conosciute) e y = MEDIA(y_conosciute).
Le funzioni di adattamento REGR.LIN e LGRFPRIBL possono calcolare la linea retta o la curva esponenziale che meglio si adatta ai dati. Tuttavia non rispondono alla domanda su quale dei due risultati sia più adatto a risolvere il problema. Puoi anche valutare la funzione TENDENZA (y_conosciuta; x_conosciuta) per una linea retta o la funzione GROW(y_conosciuta; x_conosciuta) per una curva esponenziale. Queste funzioni, a meno che non vengano specificati new_x-values, restituiscono un array di valori y calcolati per i valori x effettivi lungo una linea o curva. È quindi possibile confrontare i valori calcolati con i valori effettivi. Puoi anche creare grafici per il confronto visivo.
Quando si esegue l'analisi di regressione, Microsoft Excel calcola, per ogni punto, il quadrato della differenza tra il valore y previsto e il valore y effettivo. La somma di queste differenze al quadrato è chiamata somma residua dei quadrati (ssresid). Microsoft Excel calcola quindi la somma totale dei quadrati (sstotal). Se const = TRUE o il valore di questo argomento non è specificato, la somma totale dei quadrati sarà uguale alla somma dei quadrati delle differenze tra i valori y effettivi e i valori y medi. Quando const = FALSE, la somma totale dei quadrati sarà uguale alla somma dei quadrati dei valori reali y (senza sottrarre il valore y medio dal valore y parziale). La somma dei quadrati della regressione può quindi essere calcolata come segue: ssreg = sstotal - ssresid. Minore è la somma residua dei quadrati, maggiore è il valore del coefficiente di determinazione r2, che mostra quanto bene l'equazione ottenuta utilizzando l'analisi di regressione spiega le relazioni tra le variabili. Il coefficiente r2 è pari a ssreg/sstotal.
In alcuni casi, una o più colonne X (lascia che i valori Y e X siano nelle colonne) non hanno alcun valore predicativo aggiuntivo in altre colonne X. In altre parole, la rimozione di una o più colonne X può comportare il calcolo dei valori Y con la stessa precisione. In questo caso, le colonne X ridondanti verranno escluse dal modello di regressione. Questo fenomeno è chiamato “collinearità” perché le colonne ridondanti di X possono essere rappresentate come la somma di più colonne non ridondanti. La funzione REGR.LIN verifica la collinearità e rimuove eventuali colonne X ridondanti dal modello di regressione se le rileva. Le colonne X rimosse possono essere identificate nell'output di REGR.LIN con un fattore pari a 0 e un valore se pari a 0. La rimozione di una o più colonne come ridondanti modifica il valore di df perché dipende dal numero di colonne X effettivamente utilizzate per scopi predittivi. Per ulteriori informazioni sul calcolo di df, vedere l'Esempio 4 di seguito. Quando df cambia a causa della rimozione delle colonne ridondanti, cambiano anche i valori di sey e F. Non è consigliabile utilizzare spesso la collinearità. Tuttavia, dovrebbe essere utilizzato se alcune colonne X contengono 0 o 1 come indicatore che indica se il soggetto dell'esperimento appartiene a un gruppo separato. Se const = TRUE o non viene specificato un valore per questo argomento, REGR.LIN inserisce un'ulteriore colonna X per modellare il punto di intersezione. Se è presente una colonna con valori pari a 1 per gli uomini e 0 per le donne, ed è presente una colonna con valori pari a 1 per le donne e 0 per gli uomini, l'ultima colonna viene rimossa perché è possibile ottenere i suoi valori dalla colonna "indicatore maschile".
Il calcolo di df per i casi in cui X colonne non vengono rimosse dal modello a causa della collinearità avviene come segue: se ci sono k colonne conosciute_x e il valore const = TRUE o non specificato, allora df = n – k – 1. Se const = FALSO, allora df = n - k. In entrambi i casi, la rimozione delle colonne X a causa della collinearità aumenta il valore df di 1.
Le formule che restituiscono matrici devono essere immesse come formule di matrice.
Quando si immette un array di costanti come argomento, ad esempio,known_x_values, è necessario utilizzare un punto e virgola per separare i valori sulla stessa riga e i due punti per separare le righe. I caratteri separatori possono variare a seconda delle impostazioni nella finestra Lingua e impostazioni nel Pannello di controllo.
Va notato che i valori y previsti dall'equazione di regressione potrebbero non essere corretti se non rientrano nell'intervallo dei valori y utilizzati per definire l'equazione.
Algoritmo di base utilizzato nella funzione LINEST, differisce dall'algoritmo della funzione principale INCLINAZIONE E SEGMENTO. La differenza tra gli algoritmi può portare a risultati diversi con dati incerti e collineari. Ad esempio, se i punti dati dell'argomento Know_y_values sono 0 e i punti dati dell'argomento Known_x_values sono 1, allora:
Funzione LINEST restituisce un valore pari a 0. Algoritmo della funzione LINEST viene utilizzato per restituire valori adeguati per dati collineari e in questo caso è possibile trovare almeno una risposta.
Le funzioni PENDENZA e LINEA restituiscono l'errore #DIV/0! L'algoritmo delle funzioni PENDENZA e INTERCETTA viene utilizzato per trovare una sola risposta, ma in questo caso potrebbero essercene diverse.
Oltre a calcolare le statistiche per altri tipi di regressione, REGR.LIN può essere utilizzato per calcolare intervalli per altri tipi di regressione inserendo funzioni delle variabili x e y come serie delle variabili x e y per REGR.LIN. Ad esempio, la seguente formula:
REGR.LIN(valori_y, valori_x^COLUMN($A:$C))
funziona avendo una colonna di valori Y e una colonna di valori X per calcolare un'approssimazione del cubo (polinomio di 3° grado) della seguente forma:
La formula può essere modificata per calcolare altri tipi di regressione, ma in alcuni casi potrebbe essere necessario modificare i valori di output e altre statistiche.
Secondo me, da studente, l'econometria è una delle scienze più applicate che ho potuto conoscere tra le mura della mia università. Con il suo aiuto è infatti possibile risolvere problemi applicati su scala aziendale. La terza domanda è quanto saranno efficaci queste decisioni. La conclusione è che la maggior parte della conoscenza rimarrà teorica, ma l’econometria e l’analisi di regressione meritano comunque di essere studiate con particolare attenzione.
Cosa spiega la regressione?
Prima di iniziare a considerare le funzioni di MS Excel che ci permettono di risolvere questi problemi, vorrei spiegarvi in dettaglio cosa comporta, in sostanza, l'analisi di regressione. Ciò ti renderà più facile superare l'esame e, soprattutto, sarà più interessante studiare l'argomento.
Spero che tu abbia familiarità con il concetto di funzione matematica. Una funzione è la relazione tra due variabili. Quando una variabile cambia, succede qualcosa ad un’altra. Cambiamo X e Y cambia di conseguenza. Le funzioni descrivono varie leggi. Conoscendo la funzione, possiamo sostituire valori arbitrari di X e vedere come cambia Y.
Ciò è di grande importanza perché la regressione è un tentativo di spiegare, a prima vista, processi non sistematici e caotici utilizzando una determinata funzione. Ad esempio, è possibile identificare la relazione tra il tasso di cambio del dollaro e la disoccupazione in Russia.
Se questo modello può essere scoperto, allora usando la funzione che abbiamo ottenuto durante i calcoli, saremo in grado di fare una previsione di quale sarà il tasso di disoccupazione all'ennesimo tasso di cambio del dollaro rispetto al rublo.
Questa relazione verrà chiamata correlazione. L’analisi di regressione prevede il calcolo di un coefficiente di correlazione che spiegherà la stretta relazione tra le variabili che stiamo considerando (il tasso di cambio del dollaro e il numero di posti di lavoro).
Questo coefficiente può essere positivo o negativo. I suoi valori vanno da -1 a 1. Di conseguenza, possiamo osservare un'elevata correlazione negativa o positiva. Se è positivo, l’aumento del tasso di cambio del dollaro sarà seguito dalla creazione di nuovi posti di lavoro. Se è negativo, significa che un aumento del tasso di cambio sarà seguito da una diminuzione dei posti di lavoro.
Esistono diversi tipi di regressione. Può essere lineare, parabolico, di potenza, esponenziale, ecc. Scegliamo un modello a seconda di quale regressione corrisponderà specificamente al nostro caso, quale modello sarà il più vicino possibile alla nostra correlazione. Esaminiamolo utilizzando un problema di esempio e risolviamolo in MS Excel.
Regressione lineare in MS Excel
Per risolvere problemi di regressione lineare, avrai bisogno della funzionalità di analisi dei dati. Potrebbe non essere abilitato per te, quindi devi attivarlo.
- Fare clic sul pulsante “File”;
- Seleziona la voce “Opzioni”;
- Fare clic sulla penultima scheda “Componenti aggiuntivi” sul lato sinistro;

- Di seguito vedremo la scritta “Gestione” e il pulsante “Vai”. Cliccaci sopra;
- Seleziona la casella “Pacchetto analisi”;
- Fare clic su "ok".

Compito di esempio
La funzione di analisi batch è attivata. Risolviamo il seguente problema. Disponiamo di un campione di dati da diversi anni sul numero di situazioni di emergenza sul territorio dell'impresa e sul numero di lavoratori occupati. Dobbiamo identificare la relazione tra queste due variabili. C'è una variabile esplicativa X - questo è il numero di lavoratori e una variabile esplicativa - Y - questo è il numero di incidenti di emergenza. Distribuiamo i dati di origine in due colonne.
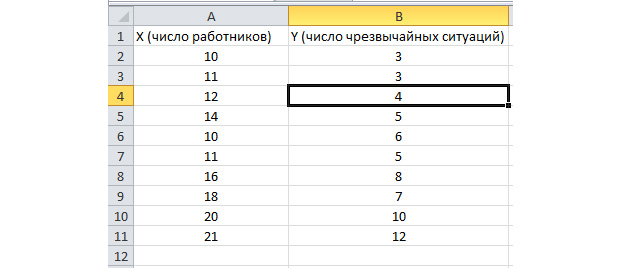
Andiamo nella scheda “dati” e selezioniamo “Analisi dei dati”
Nell'elenco visualizzato, seleziona "Regressione". Negli intervalli di input Y e X selezioniamo i valori appropriati.

Fare clic su "Ok". L'analisi è completata e vedremo i risultati in un nuovo foglio.
I valori per noi più significativi sono evidenziati nella figura sottostante.
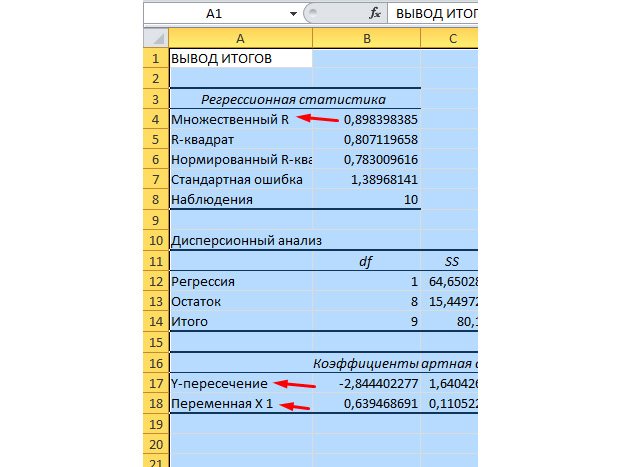
Multiplo R è il coefficiente di determinazione. Ha una formula di calcolo complessa e mostra quanto puoi fidarti del nostro coefficiente di correlazione. Di conseguenza, quanto più alto è questo valore, tanto maggiore è la fiducia, tanto più efficace sarà il nostro modello nel suo complesso.
Y-Intercept e X1-Intercept sono i nostri coefficienti di regressione. Come già accennato, la regressione è una funzione e ha determinati coefficienti. Pertanto, la nostra funzione sarà simile a: Y = 0,64*X-2,84.
Cosa ci dà questo? Questo ci dà l’opportunità di fare una previsione. Diciamo che vogliamo assumere 25 lavoratori per un'impresa e dobbiamo immaginare approssimativamente quale sarà il numero di incidenti di emergenza. Sostituiamo questo valore nella nostra funzione e otteniamo il risultato Y = 0,64 * 25 – 2,84. Avremo circa 13 emergenze.
Vediamo come funziona. Date un'occhiata alla foto qui sotto. La funzione che abbiamo ottenuto contiene i valori effettivi per i dipendenti coinvolti. Guarda quanto sono vicini i valori ai giocatori reali.

Puoi anche costruire un campo di correlazione selezionando l'area delle Y e delle X, facendo clic sulla scheda "inserisci" e selezionando il grafico a dispersione.

I punti sono sparsi, ma generalmente si muovono verso l'alto, come se ci fosse una linea retta al centro. E puoi anche aggiungere questa linea andando alla scheda “Layout” in MS Excel e selezionando “Linea di tendenza”
Fai doppio clic sulla riga che appare e vedrai quanto menzionato prima. Puoi modificare il tipo di regressione a seconda dell'aspetto del campo di correlazione.
Potresti avere la sensazione che i punti disegnano una parabola anziché una linea retta e che sarebbe meglio scegliere un diverso tipo di regressione.

Conclusione
Si spera che questo articolo ti abbia fornito una maggiore comprensione di cos'è l'analisi di regressione e perché è necessaria. Tutto ciò è di grande importanza pratica.