Contenuto (contenuto in inglese - contenuto) - informazioni, ovvero testo, immagini, video, file che si trovano sul sito.Dovrebbe essere:
- Fornire la risposta più completa e comprensibile, risolvendo il problema di una persona: che si tratti di rallegrarsi, porre fine a un dilemma difficile o acquistare un prodotto di qualità.
- Senza utilizzare frammenti nascosti come:
- testo dello stesso colore con lo sfondo,
- il testo è nascosto dietro l'immagine,
- la dimensione del carattere è 0.
- i pensieri principali sono evidenziati a colori o in grassetto per consentire all'utente di concentrarsi su di essi. Non dimenticare che le pagine web non vengono lette ma intraviste.
- attraverso la struttura dell'articolo,
- le frasi sono combinate in paragrafi tra i quali c'è una riga vuota,
- liste usate, citazioni, tabelle,
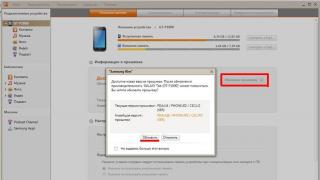
- immagini applicate, infografiche, video, registrazioni audio. Le immagini giocano un ruolo importante. Quindi, un lettore di questo blog ha chiesto di tradurre i simboli nello screenshot, che mostrava l'editor di Blogger.
La duplicazione del contenuto può essere osservata non solo quando si inseriscono dati su siti diversi, ma anche quando si ripetono informazioni su due o più di un progetto web. Ecco un esperimento su devvver.ru sul negativo dei duplicati interni e su come i concorrenti possono trarne vantaggio.
Considera quali strumenti abbiamo nella lotta contro questo disturbo.
Link alle pagine
L'unico il modo al cento per cento per impedire l'indicizzazione di una pagina è non pubblicare collegamenti ad essa e non aggiungerla ai componenti aggiuntivi Yandex, Google eccetera.
File Robots.txt
Un file di testo robots.txt (ad esempio) è un ottimo strumento per la gestione dell'indicizzazione. Aiuta Yandex, Google. Ma se Google trova un collegamento a un URL che è chiuso in robots.txt, lo aggiungerà ai risultati della ricerca.
Per questo motivo, devi entrare qui solo quei documenti web che non possono essere raggiunti in altro modo, Per esempio, . Ed ovviamente, Mappa del sito per un'indicizzazione migliore e più rapida delle pagine più popolari.
Intestazione HTTP
L'URL non verrà indicizzato se mostra 404 o 301. E per Google, anche quando la linea è presente
X-Robots-Tag: noindex
Tag meta robot
esso strumento principale perché funziona allo stesso modo per Yandex e Google. Nella pagina, il cui accesso al contenuto dovrebbe essere negato, è indicato:
Rel = attributo "canonico"
Obbligatorio l'attributo rel = "canonical" suggerisce quello preferito da diversi documenti web con contenuti molto simili, ad esempio http: //site/2010/07/kontent..html? showComment. Il secondo motore di ricerca lo ignorerà perché sottoporrà alla riga:
Yandex.Webmaster

supporto = "stampa"
Non è necessario creare una versione stampata separata. Gli stili possono essere regolati con.
Rimozione di duplicati nell'indice per errore
Nonostante le misure adottate, i robot di ricerca possono indicizzare le pagine indesiderate. Facendo una richiesta
Visualizza tutte le SERP, in particolare quelle con risultati Google omessi. Idealmente, questa iscrizione non dovrebbe essere: 
I risultati omessi devono essere rimossi manualmente. Per Yandex utilizzeremo il modulo di eliminazione della pagina e per Google dobbiamo andare su "Strumenti per i Webmaster" - "Ottimizzazione" - "Rimuovi URL" - "Crea una nuova richiesta di eliminazione".
Il contenuto duplicato è uno dei problemi principali con un basso posizionamento nei motori di ricerca. Questo problema è causato dalla presenza nel sito di pagine completamente o parzialmente identiche tra loro. Naturalmente, per i motori di ricerca, la presenza di pagine spazzatura sul sito è un problema serio, dal momento che devi spendere la potenza del server per la loro elaborazione. Non ha senso che i motori di ricerca sprechino risorse fisiche indicizzando tali contenuti inutili. Pertanto, lottano con tali siti, imponendo loro un filtro o sottovalutando la classifica, il che porta a posizioni basse per le query promosse.
Duplicati e SEO
La presenza di pagine duplicate sul sito comporta quanto segue:
- Il potere di collegamento utile viene spruzzato su queste pagine inutili.
- La pagina duplicata dopo il successivo aggiornamento sposta la pagina di destinazione e perde posizione.
- Il contenuto duplicato riduce l'unicità di tutte le pagine su cui è ospitato.
- Poiché il motore di ricerca combatte tali pagine, rimuovendole dalla ricerca, può escludere anche la pagina promossa.
Classificazione duplicata e soluzioni per eliminarli
I duplicati possono essere completi e parziali. I duplicati completi sono quando le pagine sono completamente identiche. Di conseguenza, i duplicati parziali si verificano quando le pagine non corrispondono completamente. I duplicati completi vengono eliminati tramite robots.txt e impostando i reindirizzamenti 301. I duplicati parziali vengono eliminati apportando le modifiche necessarie sul sito.
Ecco un elenco di liste di controllo che devi seguire per identificare e risolvere il problema dei duplicati:
- Cerca i duplicati della pagina principale del sito. Ad esempio, potrebbero essere presenti le seguenti opzioni della home page: http://www.domen.com/, http://www.domen.com/index.php, http://www.domen.com, http: / /domen.com/, https://www.domen.com/, http://www.domen.com/index.html. Come puoi vedere, ci sono molte opzioni, ma l'opzione ottimale è http://www.domen.com/. Per eliminare le copie rimanenti della pagina principale, vengono utilizzati un reindirizzamento 301 e una chiusura in robots.txt (nel caso di costruzioni come https://www.domen.com/.
- Controllando la fondamentale (regola d'oro della SEO): ogni pagina dovrebbe essere accessibile solo da un URL. Gli indirizzi non devono variare come segue: http://www.domen.com/stranica1/stranica2/ e http://www.domen.com/stranica2/stranica1/.
- Verifica della presenza di variabili nell'url. Loro, nell'indirizzo della pagina, non dovrebbero essere. Ad esempio, la generazione di URL come: http://www.domen.ru/index.php?dir=4567&id=515 è un errore. La seguente opzione URL sarà corretta: http://www.domen.ru/dir/4567/id/515.
- Verifica della presenza di identificatori di sessione negli URL. Ad esempio, URL come http://www.domen.ru/dir/4567/id/515.php?PHPSESSID=3451 non sono consentiti. Tali URL contengono un numero infinito di copie di ogni pagina. Pertanto, è necessario chiudere tutti gli ID di sessione in robots.txt.
Molti proprietari di siti si concentrano principalmente sul rendere il contenuto unico rispetto ad altre risorse. Tuttavia, non trascurare la presenza di contenuti duplicati all'interno dello stesso sito. Questo ha anche un forte impatto sulle classifiche.
Che cos'è il contenuto duplicato?
Duplicato, o duplicato, il contenuto è un grande blocco di testo che coincide all'interno del sito su pagine diverse. Questo non è necessariamente fatto con intenti dannosi: spesso si verifica per motivi tecnici, che sono discussi in dettaglio di seguito.
Il pericolo è che i contenuti spesso duplicati non possano essere visti ad occhio nudo, ma il motore di ricerca lo vede perfettamente e reagisce di conseguenza.
Da dove vengono i contenuti duplicati e dove sono più comuni
Le ragioni principali di questo fenomeno:
- Modifica della struttura del sito;
- Uso intenzionale per uno scopo specifico (ad esempio, una versione cartacea);
- Azioni errate di programmatori e webmaster;
- Problemi CMS.
Ad esempio, si verifica una situazione comune: replytocom (risposta a un commento) in WordPress genera automaticamente nuove pagine con URL diversi, ma non contenuti.
Di solito, si notano contenuti duplicati durante la creazione di annunci di articoli su altre pagine del sito, la pubblicazione di recensioni, nonché con le stesse descrizioni di prodotti, categorie, titoli.

Perché i contenuti duplicati sono dannosi
Il contenuto duplicato ha un analogo dal regno dell'economia: scoperto bancario. Questo è l'unico posto in cui viene speso il cosiddetto budget di scansione. Questo è il numero di pagine di una risorsa che un motore di ricerca può scansionare per un determinato periodo di tempo. La risorsa è molto preziosa ed è meglio spenderla su pagine davvero importanti e pertinenti che su dozzine di duplicati di testo identico.
Pertanto, il contenuto duplicato degrada il posizionamento nei motori di ricerca. Inoltre, i collegamenti naturali vengono persi e la potenza del collegamento è distribuita in modo non corretto all'interno del sito. Sostituisce anche le pagine veramente rilevanti.
Come trovare contenuti duplicati sul sito (manualmente, programmi e servizi)
Esistono programmi speciali per l'analisi delle risorse. Di questi, gli utenti evidenziano in particolare Netpeak Spider. Cerca copie complete delle pagine, corrispondenze per titolo o descrizione, titoli. Un'altra opzione è Screaming Frog, che ha funzionalità simili e infatti differisce solo nell'interfaccia. C'è anche l'applicazione Link Sleuth di Xenu, che funziona in modo simile a un motore di ricerca ed è in grado di setacciare il sito alla ricerca di duplicati con una qualità abbastanza elevata.

Sfortunatamente, non ci sono strumenti in grado di tracciare completamente tutto il testo duplicato. Pertanto, molto probabilmente, dovrai eseguire un controllo manuale. Ecco un elenco di possibili fattori che causano il problema:

Capito come trovare contenuti duplicati. E i migliori aiutanti nel combatterlo sono i reindirizzamenti 301, i tag URL canonici, le istruzioni robots.txt e i parametri Nofollow e Noindex come parte del meta tag robots.
Uno dei modi rapidi per verificare se ci sono contenuti duplicati sul sito è una ricerca avanzata in Yandex o Google. Devi inserire l'indirizzo del sito e una parte di testo dalla pagina che hai deciso di controllare. È inoltre possibile utilizzare numerosi programmi per verificare l'unicità del testo:
- Testo.Ru;
- eTXT anti-plagio;
- Advego Plagiatus;
- Contenuto-Guarda.

Come gestire e ripulire i contenuti duplicati
Lo stesso sistema di aiuto di Google fornisce una serie di suggerimenti per prevenire il verificarsi di questo problema.
- 301. In caso di modifiche strutturali alla risorsa, è necessario indicare il redirect 301 nel file htaccess.
- Utilizzare un unico standard di riferimento.
- Il contenuto specifico della regione è posizionato meglio nei domini di primo livello che nei sottodomini o nelle sottodirectory.
- Imposta il tuo metodo di indicizzazione preferito utilizzando Search Console.
- Non utilizzare modelli. Invece di inserire il testo di protezione del copyright su ogni pagina, è meglio creare un collegamento che porti a una pagina separata con questo testo.
- Quando sviluppi nuove pagine, assicurati che siano chiuse dall'indicizzazione fino a quando non sono pronte.
- Comprendi esattamente come vengono visualizzati i tuoi contenuti: potrebbero esserci differenze nella visualizzazione nei blog e nei forum.
- Se ci sono molti articoli simili sul sito, è meglio combinare il loro contenuto in un tutt'uno o unificarli.
I motori di ricerca non prevedono alcuna sanzione in relazione ai siti che hanno contenuti duplicati per motivi tecnici (al contrario di quelli che lo fanno deliberatamente per manipolare i risultati di ricerca o fuorviare i visitatori).
Dopo che i duplicati sono stati rimossi, resta da rimuoverli dai risultati della ricerca. Yandex lo fa da solo, a condizione che il file robots.txt sia configurato correttamente. Per quanto riguarda Google: lì dovrai registrare manualmente le regole nel Webmaster, nella scheda "Parametri URL".
Conclusione
La lotta ai contenuti duplicati su un sito Web è un aspetto importante dell'attività di qualsiasi proprietario di un sito Web. Ci sono alcune ragioni per il suo verificarsi e ci sono altrettanti modi per eliminarlo.
Resta comunque la regola principale: postare esclusivamente contenuti originali, indipendentemente dal tipo di sito. Anche se è un grande negozio online con migliaia di pagine.
RICEVI ANNUNCI DI POST SIMILI VIA MAIL
Iscriviti e ricevi, non più di una volta alla settimana, qualcosa di interessante dal mondo del marketing su Internet, SEO, promozione siti web, negozi online, guadagno sui siti web.
Il contenuto duplicato di solito si riferisce a grandi blocchi di informazioni all'interno di uno o più domini, il cui contenuto è completamente lo stesso o molto simile. Di norma, in questo caso, lo scopo non è quello di indurre in errore l'utente. I contenuti duplicati possono essere utilizzati senza intenti dannosi, ad esempio:
- pagine del forum nelle versioni regolari di siti e versioni per dispositivi mobili;
- prodotti nel negozio online visualizzati quando si fa clic su URL diversi;
- versioni delle pagine per la stampa.
Se il tuo sito contiene più pagine con quasi gli stessi contenuti, puoi specificare il tuo URL preferito per Google. Questo può essere fatto in diversi modi. Questa procedura è chiamata "normalizzazione".
Tuttavia, in alcuni casi, il contenuto viene deliberatamente duplicato su diversi domini al fine di manipolare il posizionamento nei motori di ricerca o aumentare il traffico. L'utilizzo di tecniche ingannevoli come questa può lasciare un'impressione negativa sugli utenti, poiché vedranno gran parte dello stesso contenuto ripetitivo nei risultati di ricerca.
Google fa del suo meglio per indicizzare e visualizzare pagine con informazioni univoche. Ad esempio, se il tuo sito ha una versione "standard" e una versione "stampata" di ogni articolo che non è contrassegnato con il meta tag noindex, solo uno di essi apparirà nei risultati di ricerca. Nelle rare occasioni in cui Google ritiene che vengano visualizzati contenuti duplicati per manipolare le classifiche o fuorviare gli utenti, aggiorneremo l'indice e le classifiche dei siti in questione. Di conseguenza, il posizionamento del sito potrebbe diminuire o il sito potrebbe essere completamente rimosso dall'indice di Google e non sarà più disponibile per la ricerca.
Di seguito sono riportate le istruzioni su come evitare problemi di contenuto duplicato e consentire agli utenti di visualizzare i contenuti desiderati.
- Usa 301. Se hai modificato la struttura del tuo sito, utilizza un reindirizzamento 301 ("reindirizzamento permanente") nel tuo file .htaccess per reindirizzare rapidamente gli utenti, il crawler di Google e vari spider. (Per Apache, questo può essere fatto tramite il file .htaccess. Per IIS, tramite la console di amministrazione.)
- Sii coerente... Cerca di utilizzare i collegamenti interni in modo coerente. Ad esempio, non collegare a http://www.example.com/page/, http://www.example.com/page e http://www.example.com/page/index.htm.
- Usa domini di primo livello... Per aiutarci a selezionare la versione più appropriata di un documento, utilizza i domini di primo livello quando possibile per visualizzare contenuti specifici del paese. Ad esempio, si consiglia di inserire contenuti relativi alla Russia sul sito http://www.example.ru e non sul sito http://www.example.com/ru o http://en.example. com.
- Fai attenzione quando fai syndication... Se fornisci i tuoi contenuti ad altri siti, con ogni query di ricerca Google mostrerà sempre la versione che ritiene più appropriata per gli utenti. Questa versione non è necessariamente la stessa che sceglieresti tu. Tuttavia, vale la pena assicurarsi che tutti i siti che ospitano i tuoi contenuti dispongano di un collegamento all'articolo originale. Puoi anche chiedere ai proprietari dei siti che utilizzano il tuo materiale in syndication di bloccarlo utilizzando il meta tag noindex in modo che i motori di ricerca non includano le loro versioni nell'indice.
- Utilizza Search Console per informare Google del tuo metodo di indicizzazione preferito. In particolare, puoi specificare il dominio principale (ad esempio http://www.example.com o http://example.com).
- Evita le ripetizioni... Ad esempio, invece di inserire l'intero testo del copyright in fondo a ogni pagina, includi solo le nozioni di base con un collegamento alla pagina dettagliata. Puoi anche utilizzare lo strumento Parametri URL per scegliere il modo preferito in cui Google gestisce i parametri URL.
- Non utilizzare stub software. Gli utenti non sono interessati alle pagine vuote. Ad esempio, non pubblicare pagine il cui contenuto non è ancora pronto. Se non puoi fare a meno delle pagine segnaposto, bloccale con il meta tag noindex in modo che non vengano indicizzate.
- Esplora il tuo sistema di gestione dei contenuti... Acquisisci familiarità con il modo in cui i contenuti vengono visualizzati sul tuo sito. Blog, forum e altri sistemi simili spesso visualizzano lo stesso contenuto in più formati. Ad esempio, un post del blog potrebbe apparire nella pagina principale del blog, in una pagina con archivi o in una pagina con altri post, e sempre con lo stesso titolo.
- Riduci la quantità di contenuti correlati... Se il tuo sito ha molte pagine simili, aggiungi contenuti unici a ciascuna di esse o combinale in una. Supponiamo di avere un sito di viaggi con pagine separate per due città che presentano le stesse informazioni. Puoi invece inserire una pagina con una descrizione di entrambe le città o aggiungere materiali unici a ciascuna.
Google sconsiglia di impedire ai crawler dei motori di ricerca di accedere a contenuti duplicati utilizzando un file robots.txt o altri mezzi. Se i motori di ricerca non sono in grado di eseguire la scansione di pagine con tali contenuti, non saranno in grado di rilevare automaticamente che URL diversi hanno lo stesso contenuto e li tratteranno come pagine univoche. È meglio consentire la scansione di questi URL, ma contrassegnarli come copie esatte utilizzando un collegamento rel = "canonico", uno strumento di elaborazione dei parametri URL o reindirizzamenti 301. Se avere più copie rallenta notevolmente la scansione della pagina, regolare la velocità di scansione in Console di ricerca.
La presenza di contenuti duplicati sul sito non costituisce una base per intraprendere alcuna azione in relazione ad esso. Tali misure vengono applicate solo se eseguite con l'obiettivo di fuorviare gli utenti o manipolare i risultati della ricerca. Se hai problemi con i contenuti duplicati ma non hai seguito i suggerimenti di cui sopra, sceglieremo la versione del contenuto da mostrare nei risultati di ricerca a nostra discrezione.
Tuttavia, se i nostri risultati di controllo mostrano che hai usato l'inganno e il tuo sito è stato rimosso dai nostri risultati di ricerca, controlla attentamente il tuo sito. Consulta la nostra Guida per i webmaster e apporta le modifiche necessarie. Dopo esserti accertato che il sito soddisfi i requisiti, inviaci una richiesta.
In alcuni casi, gli algoritmi di Google possono selezionare l'URL di un sito di terze parti che ha pubblicato copie dei tuoi contenuti senza autorizzazione. Se il tuo contenuto è stato pubblicato su un altro sito in violazione del copyright, chiedi al proprietario di rimuovere quel contenuto. Puoi anche chiedere a Google di rimuovere la pagina in violazione dai risultati di ricerca. Per fare ciò, è necessario presentare un avviso di violazione del Digital Millennium Copyright Act statunitense.
È stato utile?
Come puoi migliorare questo articolo?
Il contenuto duplicato degrada l'indicizzazione del sito
"Strade diverse portano a luoghi diversi e solo una di esse è corretta".
Ciao amici! Da tempo ho intenzione di divulgare questo argomento sulle pagine del mio sito, quindi, dopo aver studiato molto materiale sulla duplicazione dei contenuti e le sue cause, conseguenze e modi per eliminare questo fenomeno negativo, ho deciso di esprimere i miei pensieri su questo problema sulla mia modesta risorsa.
Sii paziente e studia attentamente tutti i consigli dell'articolo, quindi controlla lo stato delle tue risorse. Se vuoi vedere un eccellente posizionamento delle pagine dei tuoi siti nei motori di ricerca, seguili rigorosamente.
Senza pretendere di essere tutti i modi possibili per eliminare le cause dei contenuti duplicati, propongo tuttavia di studiare i punti più importanti di questo problema.
Se un utente normale (e talvolta lo stesso webmaster) potrebbe non notare il contenuto duplicato del sito, i motori di ricerca lo determineranno immediatamente. La loro reazione sarà inequivocabile: il contenuto di queste pagine cesserà di essere unico... E già questo non va bene, in quanto influenzerà negativamente la loro classifica.
Inoltre, duplicazione offusca il peso del collegamento, a un post specifico, che, pur ottimizzando, hai cercato di promuovere al TOP, come una landing page. I duplicati rovineranno semplicemente tutti i tentativi di ottimizzazione e l'effetto di collegamento sarà minimo.
Cosa sono i contenuti duplicati?
1. Contenuti copiati da qualcuno o personalmente da te e pubblicati su risorse di terze parti.
Puoi leggere molti articoli su Internet su come gestire i contenuti rubati, una delle opzioni è il mio articolo. È possibile sterminarlo è una domanda retorica e oggi, secondo me, non ci sono soluzioni cardinali a questo problema su Internet. Ci sono solo alcuni trucchi più o meno efficaci.
2. Contenuto duplicato, che viene creato dal webmaster con le proprie mani.
Duplicato completo (o incompleto) quando si distribuiscono informazioni (o come vengono chiamate - annunci) su siti e forum speciali. Se vuoi ottenere un duplicato della tua registrazione su Internet - duplicalo su una risorsa decente - il risultato, quasi sempre, sarà immediato. Un duplicato è possibile direttamente sulle pagine del sito. Hai mai visto due pagine identiche sulla tua risorsa quando ne hai creata solo una? Perché succede? Motivi per modificare le note o salvare quelle non finite nelle bozze e quindi, inavvertitamente, creare un duplicato. Il webmaster, senza accorgersene lui stesso e poi non sfogliando tutti i suoi record, per non trovare un duplicato, vive felice e contento, non sospettando di avere "gemelli", "terzetti", ecc.
3. Duplicazione per motivi tecnici - il verificarsi di duplicati in cui la colpa è del CMS.
Questi errori derivano dal fatto che gli sviluppatori CMS non pensano come i browser o gli spider di ricerca, ma pensano come si addice agli sviluppatori di motori di siti web; molti peccano in questo - Joomla, per esempio.
Lascia che ti spieghi un po'. Supponiamo di avere un articolo con una frase chiave "Contenuto duplicato"... Dovrebbe trovarsi in una pagina con il seguente indirizzo:, http: //domain.ru/ duplicazione del contenuto /, ma lo stesso contenuto può essere visualizzato, ad esempio, in questo modo: http: //domain.ru/article-category/ duplicazione del contenuto /... E se teniamo conto anche di altre duplicazioni, pagine, ad esempio: http: //domain.ru/ duplicazione del contenuto /? source = rss... Tutti questi URL sono indirizzi diversi per ciascuno, ma lo stesso per l'utente (lettore). Queste differenze consentono al webmaster di risalire alla provenienza dell'utente, ma possono essere dannose se non vengono effettuate le necessarie impostazioni di indicizzazione.
È noto che i siti Web funzionano grazie al sistema di database esistente. C'è solo una versione di un articolo specifico (ID) nel database, ma gli script del sito lo consentono stampa questo articolo dal database su pagine diverse (url)... Ma i motori di ricerca hanno bisogno di un documento (URL) - solo che è un identificatore univoco e nient'altro!
4. Prese sfocate.
Un particolare tipo di duplicazione, che si trova principalmente nei negozi online, dove le pagine con le schede prodotto differiscono solo per poche frasi con le descrizioni, e tutto il resto del contenuto, composto da blocchi end-to-end e altri elementi, è il stesso. È difficile dare la colpa al webmaster, anche se ci sono alcune opzioni per eliminarli.
Quindi, abbiamo capito le cause e le conseguenze dei contenuti duplicati. Ora passiamo alla risoluzione dei problemi. Prima di tutto, scopriamolo
Come posso trovare pagine duplicate?
1. Metodo manuale.
1) Se il tuo contenuto non è troppo grande, scorri semplicemente la pagina nel pannello di amministrazione "Tutte le voci”E, se vengono trovati duplicati, elimina quelli non necessari.
2) Per scoprire la presenza di duplicati è possibile utilizzare i servizi dei motori di ricerca "Yandex-webmaster" o Google Webmaster Tools.
Ad esempio, in Strumenti per i Webmaster apri la pagina "Strumenti per webmaster" - "Ottimizzazione" - "Ottimizzazione HTML": se ci sono errori e duplicati, la procedura guidata ti mostrerà tutto. Gestisci i clic, elimina errori e duplicati, allo stesso tempo.
3) Utilizzare direttamente le finestre di ricerca del sistema (metodo approssimativo). Inserisci per ognuno di essi un record del modulo sito: domain.ru e confrontare i loro risultati. Se non sono molto diversi, la tua duplicazione non è poi così male.
4) C'è un modo efficace per trovare i duplicati: cercare tra i frammenti di testo. Questo è fatto semplicemente: nella casella di ricerca di qualsiasi sistema, inserisci un frammento di testo della tua voce (articolo) della dimensione di 10-20 parole (preferibilmente dal centro) e analizza il risultato. La presenza di due o più pagine nella SERP significa che ci sono duplicati per questa opera. In caso contrario, puoi essere un po' felice :).
È difficile se il sito ha accumulato molte pagine. La verifica di cui sopra può diventare un compito intollerabile. Se vuoi ridurre al minimo le tue spese di tempo, usa il programma Detective del collegamento di Xenu.
Chi ha bisogno di un link per scaricare il file di questo programma, disiscriversi nei commenti, lo invierò alla sua e-mail.Per controllare il sito, è necessario aprire un nuovo progetto selezionando "Controlla URL" dal menu "File", inserire l'indirizzo e fare clic su "OK". Successivamente, il programma inizierà a elaborare tutti gli URL del sito. Alla fine del controllo, devi esportare i dati ricevuti in un qualsiasi editor conveniente e iniziare a cercare i duplicati.
Quindi, abbiamo capito quali (principali) ragioni portano a contenuti duplicati. Ora definiamo i modi per eliminarlo.
Modi per eliminare i contenuti duplicati
Gli URL canonici sono una soluzione concettuale al problema
Se non hai la possibilità di () rimuovere i duplicati, il problema può essere risolto utilizzando il tag canonica l (usato per copie fuzzy). Il tag canonico è adatto anche per le versioni pagine da stampare e in altri casi simili. È usato in modo molto semplice: rel = "canonical" è specificato per tutte le copie, ma non per la pagina principale, che è la più rilevante. Il codice dovrebbe assomigliare a questo: link rel = "canonical" href = "http: //domain.ru/copy page" /, ed essere all'interno del tag head.
Per gli utenti con il motore WordPress, c'è una grande opportunità di fare tutto questo automaticamente installando il plugin all in one seo pack o simili. Nelle impostazioni, questa operazione è impostata dalle etichette:

Impostazione delle funzioni di non autorizzazione nel file robots.txt del tuo sito
Sebbene configurare pagine proibitive per l'indicizzazione non sia sempre un modo efficace per evitare duplicati, poiché i motori di ricerca a volte riescono a bypassarli, un robot.txt correttamente configurato faciliterà notevolmente il compito di evitarli.
INSIEME Awwwo senzawww
Come appariranno le pagine del tuo sito, utilizzando solo http o http.www? L'incertezza creerà duplicazioni. Immediatamente dopo aver creato il sito, determina quale protocollo di trasporto ipertestuale utilizzerai. Per fare ciò, nel pannello dei webmaster di Yandex e Google, metti la tua scelta (in Google, questo può essere fatto per entrambe le versioni, ma dovrai confermare i diritti su entrambi gli indirizzi). Puoi lasciarlo come predefinito o su "scelta di un robot di ricerca", ma è meglio che sia definito chiaramente.
Configurare un reindirizzamento
Un reindirizzamento 301 è ottimo per incollare pagine di copia con URL che hanno o non hanno www. Come hai già capito (vedi lo screenshot sopra), anche l'impostazione di un reindirizzamento su WordPress è semplificata utilizzando un plug-in. In effetti, se tu e il robot di ricerca avete "deciso" la vostra scelta - con o senza www, ci sarà un dominio principale, non è necessario impostare un reindirizzamento per tutte le pagine. Tuttavia, l'argomento dell'impostazione di un reindirizzamento e della sua opportunità è un argomento per un articolo separato.
Risultati e conclusioni
- non consentire la duplicazione di pagine (contenuto) sulle tue risorse, poiché i duplicati portano a una grave diminuzione della pertinenza delle pagine, il che rende difficile portarle nelle posizioni di testa nei risultati di ricerca (TOP);
- i problemi con contenuti duplicati per la maggior parte hanno una soluzione: usa tutti i mezzi possibili per questo;
- monitorare costantemente il processo di indicizzazione dei tuoi contenuti e non creare duplicati su di essi
Questo è tutto, caro lettore. Se hai qualcosa da aggiungere o correggermi, fai una domanda - cogli l'occasione!
Non proprio l'argomento, ma sui gemelli.
(Visitato 28 volte, 1 visite oggi)