Do sredine 2015. globalna internetska mreža povezala je već 3,2 milijarde korisnika, odnosno gotovo 43,8% svjetske populacije. Za usporedbu: prije 15 godina samo je 6,5% stanovništva bilo korisnika interneta, odnosno broj korisnika se povećao za više od 6 puta! Ali impresivniji nisu kvantitativni, već kvalitativni pokazatelji ekspanzije uvođenja internetskih tehnologija u različitim područjima ljudske djelatnosti: od globalnih komunikacija društvenih mreža do kućnih internetskih stvari. Mobilni internet omogućio je korisnicima da budu online izvan ureda i kod kuće: na cesti, izvan grada u prirodi.
Trenutno postoje stotine sustava za pretraživanje informacija na Internetu. Najpopularniji od njih dostupni su velikoj većini korisnika jer su besplatni i jednostavni za korištenje: Google, Yandex, Nigma, Yahoo!, Bing ..... Iskusniji korisnici imaju sučelja za "napredno pretraživanje", specijalizirana "društvena mreža" pretraživanja , prema tokovima vijesti i oglasima o prodaji i kupnji ... Ali sve ove divne tražilice imaju značajan nedostatak, koji sam već naveo kao prednost gore: besplatne su.
Ako investitori ulažu milijarde dolara u razvoj tražilica, onda se postavlja sasvim relevantno pitanje: gdje zarađuju novac?
A posebno zarađuju na tome što na zahtjeve korisnika daju ne samo informacije koje bi bile korisne s korisničkog stajališta, već i informacije koje vlasnici tražilica smatraju korisnima za korisnika. To se postiže manipuliranjem redoslijeda izdavanja popisa odgovora na upite pretraživanja korisnika. Ovdje je i otvoreno oglašavanje određenih internetskih resursa, i skriveno žongliranje relevantnosti odgovora na temelju komercijalnih, političkih i ideoloških interesa vlasnika tražilica.
Stoga je među profesionalnim stručnjacima za pretraživanje informacija na Internetu vrlo aktualan problem relevantnosti rezultata tražilica.
Relevantnost je korespondencija dokumenata koje pronalazi sustav za pronalaženje informacija informacijskim potrebama korisnika, bez obzira na to koliko je ta potreba za informacijama potpuno i točno izražena u samom tekstu zahtjeva za informacijama. Ovo je omjer količine korisnih informacija i ukupne količine primljenih informacija. Grubo govoreći, ovo je učinkovitost pretraživanja.
Stručnjaci koji provode kvalificirano pretraživanje informacija na Internetu moraju uložiti određene napore kako bi filtrirali rezultate pretraživanja, filtrirajući nepotrebnu informacijsku "buku". A za to se koriste alati za pretraživanje na profesionalnoj razini.
Jedan od takvih profesionalnih sustava je ruski program FileForFiles & SiteSputnik (SiteSputnik).
Programer Alexey Mylnikov iz Volgograda.
"Program FileForFiles & SiteSputnik (SiteSputnik) osmišljen je za organiziranje i automatizaciju profesionalnog pretraživanja, prikupljanja i praćenja informacija objavljenih na Internetu. Posebna se pozornost pridaje dobivanju novih informacija o temama od interesa. Implementirano je nekoliko funkcija analize informacija."
Praćenje i kategorizacija tokova informacija
Prvo, nekoliko riječi o praćenje protoka informacija, čiji je poseban slučaj praćenje medija i društvenih mreža:
- korisnik naznači Izvore koji mogu sadržavati tražene podatke, te Pravila za odabir tih podataka;
- program preuzima svježe poveznice s Izvora, oslobađa njihov sadržaj od smeća i ponavljanja te ih razvrstava u naslove u skladu s Pravilima.
Da biste uživo vidjeli jednostavan, ali stvaran proces praćenja, koji uključuje 6 izvora i 4 naslova:- otvorite Demo verziju programa;
- zatim u prozoru koji se pojavi kliknite na gumb zajednički;
- i kada SiteSputnik izvršit ćete ovaj Projekt u stvarnom vremenu, vi:
- na popisu "Clean stream" vidjet ćete sve nove informacije iz izvora,
— u odjeljku "Nakon zahtjeva" - samo ekonomske i financijske vijesti koje zadovoljavaju pravilo,
- u naslovima "O predsjedniku", "O premijeru" i "Središnjoj banci" - informacije o predmetima.
U stvarnim projektima možete koristiti gotovo bilo koji broj izvora i naslova.
Svoje prve radne projekte možete izraditi za nekoliko sati, njihovo poboljšanje je u procesu rada.
Opisana obrada informacija dostupna je u paketu SiteSputnik Pro+News i novijim.
2. Jednostavno i grupno pretraživanje, prikupljanje informacija
Kako bi se upoznali s mogućnostima SiteSputnik Pro(osnovna verzija programskog paketa) :
- otvorite Demo verziju programa;
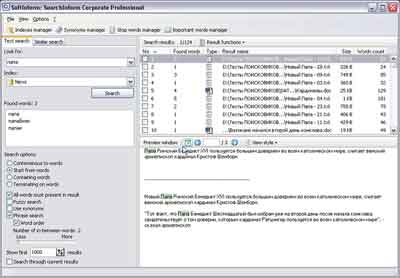
- unesite svoj prvi zahtjev, na primjer, svoje puno ime, kao što sam ja učinio:
i kliknite na gumb traži.
- Program (vidi znak koji je napravio SiteSputnik) za nekoliko sekundi će ispitati 7 izvora, otkrit će u njima 24 pretražite stranice, pronađite 227 relevantne poveznice ukloniti suvišne veze a od ostatka 156 jedinstvena linkovi će se prikazati "Unija".
Ukupno: broj jedinstvenih veza - 156 , ponovljene veze - 46 %.
Ime
izvor
Naručeno
stranicama
Preuzeto
stranicama
Pronađeno
poveznice
Vrijeme
traži
učinkovitosti
traži
Linkovi
Novi
učinkovitosti
NoviYandex 5 5 50 0:00:05 32% 0 0 5 5 44 0:00:03 28% 0 0 Yahoo 5 5 50 0:00:05 32% 0 0 Lutalica 5 4 56 0:00:07 36% 0 0 MSN (Bing) 5 3 23 0:00:04 15% 0 0 Yandex.Blogovi 5 1 1 0:00:01 1% 0 0 Google.Blogovi 5 1 3 0:00:01 2% 0 0 Ukupno: 35 24 227 0:00:26 — 0 0 - (! ) Ponovite svoj zahtjev za nekoliko sati ili dana i vidjet ćete samo na zasebnom popisu nove veze , koji se pojavio u izlazu Izvora za ovo vremensko razdoblje. U posljednja dva stupca tablice možete vidjeti koliko je svaki Izvor donio novih linkova i njegovu učinkovitost u smislu "noviteta". Kada se upit izvršava više puta, popis koji sadrži samo nove veze , kreira se u odnosu na sva prethodna izvršenja ovog upita. Čini se da je to elementarna i neophodna funkcija, ali autoru nije poznat nijedan program u kojem se ona implementira.
- (!! ) Opisane značajke podržane su ne samo za pojedinačne zahtjeve, već i za cijele zatražite pakete :
Paket koji vidite sastoji se od sedam različitih upita koji prikupljaju informacije o Vasiliju Šukšinu iz nekoliko izvora, uključujući tražilice, Wikipediju, točnu pretragu u Yandex vijestima, metapretragu i traženje spominjanja na TV i radio postajama. Na scenarij TV i Radio uključuje: Prvi kanal, TV Rusija, NTV, RBC TV, Ekho Moskvy, radio tvrtku Mayak, ... i druge izvore informacija. Svaki izvor ima svoju dubinu pretraživanja ili pregledavanja stranica. Naveden je u trećem stupcu.
Skupno pretraživanje omogućuje opsežnu pretragu jednim klikom prikupljanje informacija na zadanu temu.
Zasebna lista nove veze, pri ponovljenim izvršavanjima paketa, sadržavat će samo reference koje prije nisu pronađene.
Sjetite se što ste i kada pitali internet i što vam je odgovorio nema potrebe- sve se automatski sprema u knjižnice i baze podataka programa.
Ponavljam da su značajke opisane u ovom odlomku u potpunosti uključene u paket. SiteSpunik Pro.
Pročitajte više u uputama: SiteSputnik Pro za početnike.
3. Pretraga objekata i praćenje
Često se korisnik suočava sa sljedećim zadatkom. Morate saznati što je na internetu o određenom objektu: osobi ili tvrtki. Na primjer, kada zapošljavate novog zaposlenika ili kada se pojavi nova strana, uvijek znate puno ime, naziv tvrtke, brojeve telefona, TIN, PSRN ili PSRNIP, možete uzeti i ICQ, Skype i neke druge podatke. Nadalje, korištenjem poziva posebne funkcije programa SiteSputnik "Prikupljanje informacija o objektu“ (oprema SiteSputnik Pro+Objekti):Unesite podatke koje znate i jednim klikom miša, točne i puna tražiti poveznice koje sadrže dane informacije. Pretraživanje se izvodi na nekoliko tražilica odjednom, koristeći sve detalje odjednom, koristeći nekoliko mogućih kombinacija detalja odjednom: zapamtite kako možete napisati telefonski broj na različite načine. Nakon određenog vremenskog razdoblja, bez dosadnih rutinskih poslova, dobit ćete popis poveznica, očišćen od ponavljanja i, što je najvažnije, poredanu po važnosti za predmet koji tražite. Relevantnost (značajnost) postiže se činjenicom da će prvi u izdavanju SiteSputnika biti oni linkovi na kojima se velika količina pojedinosti koje ste naveli, a ne one koji su promovirali rezultate webmasterove tražilice.
Važno .
Program SiteSputnik može ekstrahirati bolje od drugih programa stvaran, ali ne službeno informacije o Objektu. Na primjer, u službenoj bazi podataka mobilnog operatera može biti zabilježeno da telefon pripada Vasiliju Terekhinu, ali u stvarnosti ovaj telefon "visi" informaciju da je Alexander prodao automobil Ford Focus 2013., što je dodatna informacija za razmišljanje.Praćenje pretraživanja .
Praćenje pretraživanja znači sljedeće. Ako želite pratiti izgled nove veze, po danom objektu ili proizvoljan hrpu zahtjeva, tada samo trebate povremeno ponavljati odgovarajuću pretragu. Kao i za jednostavan upit, Program SiteSputnikće kreirati "Novi" popis, u koji će smjestiti samo one poveznice koje nisu pronađene niti u jednom od prethodnih pretraživanja.Praćenje pretraživanja zanimljiva ne samo sama po sebi. Može biti uključeno u praćenje medija, društvene mreže i drugih izvora vijesti, što je spomenuto u stavku 1. Za razliku od drugih programa u kojima je moguće ukloniti nove informacije samo iz RSS feedova, program SiteSputnik može se koristiti za ovo pretraživanja na mjestu i tražilice . Također moguće oponašanje(samostvaranje) nekoliko RSS feedovi s proizvoljnih stranica, štoviše, emulacija RSS feeda na zahtjev, pa čak i niz zahtjeva.
- Da biste maksimalno iskoristili program, koristite njegove glavne značajke, a to su:
- zatražiti pakete, pakete s parametrima, koristiti Assembler (sakupljač), rad "Analitičke unije" rezultata nekoliko zadataka, po potrebi primijeniti osnovne funkcije pretraživanja na nevidljivom Internetu;
- povežite svoje izvore s izvorima informacija ugrađenim u program : druge tražilice i pretraživanja na licu mjesta, postojeće RSS feedove koje ste kreirali vlastiti RSS feedovi s proizvoljan stranice, primijeniti pretragu za novim izvorima;
- iskoristite sljedeće mogućnosti praćenje: Masovni mediji, društvene mreže i drugi izvori, praćenje komentari na vijesti i poruke, pratiti pojavu novih informacija na postojećim stranicama;
- angažirati se Kategorije , Vanjske značajke, Planer zadataka, Popis pošte, Više računala, Instruktor projekta, Instalacija alarm da biste obavijestili o pojavi značajnih događaja, koristite druge funkcije navedene u nastavku.
4. Program SiteSputnik (SiteSputnik): mogućnosti i značajke
- Program SiteSputnik stalno se poboljšava u smjeru: "Moram pronaći sve i uz garanciju".
"Program za ispitivanje interneta", je još jedna definicija Korisnika kojemu se dodijeli program.ALI. Funkcije pretraživanja i prikupljanja informacija.
. Zatražite paket - izvršavanje nekoliko upita odjednom s kombinacijom rezultata pretraživanja ili zasebno. Prilikom generiranja kombiniranog rezultata, ponovno pronađene veze se uklanjaju. Više o paketima - u uvodu u SiteSputnik, vizualno - u videu: zglob i odvojeno izvršavanje upita. Nema analoga u domaćem i inozemnom razvoju.
. Paketi s opcijama. Bilo koji zahtjevi i paketi zahtjeva dizajnirani za rješavanje standardnih zadataka pretraživanja, na primjer, pretraživanje po telefon, ime ili e-mail, - može se parametrirati, spremati i izvršavati iz biblioteke gotovih zahtjeva uz zamjenu stvarnih (potrebnih) vrijednosti parametara. Svaki paket s parametrima je poseban obrazac za napredno pretraživanje . Može koristiti ne jednu, već nekoliko tražilica. Moguće je izraditi oblike koji su po svojoj funkcionalnoj namjeni vrlo složeni. Izuzetno je važno da oblicima mogu kreirati sami korisnici, bez sudjelovanja autora programa ili programera. Vrlo je jednostavno o tome piše u uputama, više detalja u zasebnoj publikaciji o parametrizaciji pretraživanja i na forumu, jasno na videu: tražite sve opcije unosa brojeva odjednom mobitel te po nekoliko opcija za pisanje adrese E-mail. Nema analoga.
. asembler NOVI- sastavljanje zadatka pretraživanja od nekoliko gotovih : zahtjeve, pakete zahtjeva i pakete parametara. Paketi mogu sadržavati druge pakete u svom tekstu. Dubina gniježđenja paketa je neograničena. Možete kreirati nekoliko zadataka pretraživanja, na primjer, o nekoliko pravnih i fizičkih osoba, i izvršavati te zadatke u isto vrijeme. Više detalja na forumu i u zasebnoj publikaciji o Assembleru, jasno na video. Nema analoga.
. Metatraga - izvršavanje određenog upita istovremeno za zadanu "dubinu" pretraživanja za svaki od njih. Metatraga je moguća na ugrađenim tražilicama, koje uključuju Yandex, Rambler, Google, Yahoo, MSN (Bing), Mail, Yandex i Google blogove te na povezanim alatima za pretraživanje. Rad s nekoliko tražilica izgleda kao da radite s vama jedna tražilica . Ponovno pronađene veze su uklonjene. Prikazana je vizualna metapretraga na tri povezane društvene mreže: VKontakte, Twitter i Youtube video.
. Metatraga web mjesta - objedinjavanje pretraživanja web stranica u Google, Yahoo, Yandex, MSN (Bing). Jasno uključeno video.
. Metatraga u uredskim dokumentima - kombiniranje pretraživanja u PDF, XLS, DOC, RTF, PPT, FLASH datotekama u Google, Yahoo, Yandex, MSN (Bing). Možete odabrati bilo koju kombinaciju formata datoteka.
. Kopije predmemorije metapretrage veze u Yandex, Google, Yahoo, MSN (Bing). Sastavlja se popis u kojem se u svakom odlomku skupljaju svi isječci koje je svaka tražilica pronašla za svaku poveznicu. Nema analoga.
. Duboka pretraga za Yandex, Google i Rambler, omogućuje vam da u jedan popis spojite sve veze iz uobičajenog pretraživanja i sve veze, redom, iz "Više s web-mjesta", "Dodatni rezultati s web-mjesta" i "Traži na web-mjestu (Ukupno ...)" popisi. Pročitajte više o dubokom pretraživanju na forumu. Nema analoga.
. Točna i potpuna pretraga . To znači sljedeće. S jedne strane, svaki se upit može izvršiti na tom i samo onom izvoru, na čijem je jeziku upita napisan. Ovo je točna pretraga. S druge strane, takvih zahtjeva i izvora može postojati proizvoljan broj. Ovo osigurava punu pretragu. Više detalja u zasebnom postu o proceduralnim pretragama. Nema analoga.
. Pretraživanje nevidljivog weba .
Uključuje sljedeće osnovne značajke:
B. Funkcije praćenja informacija.Poseban paket zahtjeva koji Korisnik može poboljšati,
- tražiti nevidljive veze pomoću pauka (pauka),
- pretraživati nevidljive veze u blizini vidljive veze ili mape prema "slici i sličnosti",
- posebna pretraživanja otvorenih mapa,
- tražiti nevidljive veze i mape sa standardnim nazivima pomoću posebnih rječnika,
- korištenje vlastitih pretraživanja ugrađenih u web stranice.Više detalja u zasebnoj publikaciji na SiteSputnik Invisible. Osnovne funkcije su "dobro poznate u uskim krugovima", ali način na koji se koriste nema analoga. Bit ove metode je izgradnja mape web stranice vidljive s Interneta (drugim riječima, materijalizacija vidljivog Interneta), a samo na temelju vidljivih poveznica i u odnosu na njih, traženje nevidljivih poveznica. Pretraga već vidljivih poveznica "nevidljivim" metodama se ne provodi.
. Praćenje za pojavljivanje na internetu novi poveznice na zadanu temu. Monitor izgled novi veze se mogu koristiti u cijelosti zatražite pakete , koji uključuju bilo koju od gore navedenih metoda pretraživanja, a ne pojedinačne prve stranice tražilica. Provedeni spoj i raskrižje novi veze iz nekoliko zasebnih pretraživanja. Više pojedinosti u publikaciji praćenja (vidi § 1) i na forumu. Nema analoga.
. Kolektivna obrada informacija . Stvaranje korporativnu ili profesionalnu mrežu za kolektivno prikupljanje, praćenje i analizu informacija. Sudionici i kreatori takve mreže su zaposlenici korporacije, članovi stručne zajednice ili interesne skupine. Geografski položaj sudionika nije bitan. Više detalja u zasebnoj publikaciji o organizaciji mreže kolektivnog prikupljanja, praćenja i analize informacija.
. Praćenje poveznice (web stranice) za otkrivanje promjena u njihovom sadržaju (sadržaju). Beta verzija. Pronađene promjene označene su bojom i posebnim znakovima. Više pojedinosti u zasebnoj publikaciji praćenja (vidi § 2. i 3.).
NA. Funkcije analize informacija.
. Kategorija materijala već gore opisano. Više detalja - u zasebnoj publikaciji o Rubrikama. Pravila pogodaka rubrike omogućuju vam da odredite ključne riječi i udaljenost između njih, postavite logičko "I", "ILI" i "NE", primijenite strukturu zagrada na više razina i rječnike (umetnite datoteke) na koje možete primijeniti logičke operacije.
. VF tehnologija - gotovo proizvoljno proširenje mogućnosti kategorizacije materijala kroz implementaciju vanjskih funkcija koje su organski ugrađene u Pravila za ulazak u Rubrike i koje programer može implementirati samostalno bez sudjelovanja autora programa.
. Numerička analiza popunjenost Rubrike, instalacija signaliziranje te obavijesti o nastupu značajnih događaja isticanjem Rubrika i/ili slanjem izvješća o alarmu e-poštom.
. stvarna relevantnost. Postoji mogućnost slaganja linkova po redu blizu značaja ove poveznice u odnosu na problem koji se rješava, zaobilazeći trikove webmastera koji raznim metodama povećavaju rang stranica u tražilicama. To se postiže analizom rezultata nekoliko "raznolikih" upita na zadanu temu. Izračunati, u pravom smislu riječi, poveznice koje sadrže maksimalno tražene informacije . Više pročitajte u opisu kako pronaći najboljeg dobavljača i na forumu. Nema analoga.
. Računalni objektni odnosi - tražiti poveznice, resurse (stranice), mape i domene koje istovremeno spominju objekte. Najčešći objekti su ljudi i firme. Za traženje veza mogu se koristiti svi programski alati spomenuti na ovoj stranici. SiteSputnikšto značajno povećava učinkovitost vašeg rada. Operacija se izvodi na bilo kojem broju objekata. Više detalja u uvodu programa, kao i u opisu nove značajke "objekti i njihovi odnosi". Nema analoga.
. Formiranje, udruživanje i sjecište informacijskih tokova o raznim temama, odgovarajućim tokovima. Više detalja u zasebnom postu.
. Izrada web karata web-mjesta, resursi, mape i pretraženi objekti na temelju poveznica pronađenih na Internetu pomoću poveznica Google, Yahoo, Yandex, MSN (Bing) i Altavista koje pripadaju web-mjestu. Stručnjaci mogu saznati ako možete vidjeti "ekstra" informacije s interneta na njihovim stranicama, kao i istražiti stranice konkurenata na ovu temu. Mapa web stranice je materijalizacija vidljivog interneta . Više detalja u zasebnoj publikaciji o izgradnji web karata, jasno na video. Nema analoga.
. Tražite nove izvore informacija na zadanu temu, što se zatim može primijeniti za praćenje pojave novih relevantnih informacija. Više pročitajte na.
G. Servisne funkcije.
. Planer zadataka pruža posao Zakazano: obavlja navedene funkcije programa u određeno vrijeme. Pročitajte više u zasebnom postu o Scheduleru.
. Instruktor projekta NOVI je asistent stvaranje i održavanje Projekti pretraživanja, prikupljanja, praćenja i analize informacija (kategorizacija i signalizacija). Pročitajte više na forumu.
. Automatsko arhiviranje. NA baze podataka automatski se pohranjuju svi rezultati vašeg rada, i to: zahtjevi, paketi zahtjeva, protokoli pretraživanja i praćenja, sve druge gore navedene funkcije i rezultati njihovog izvršavanja. Limenka struktura rad na temama i podtemama.
. Baza podataka uključuje sortiranja, jednostavna pretraživanja i proizvoljna pretraživanja prema SQL upitu. Za potonje postoji čarobnjak za sastavljanje SQL upita. Pomoću ovih alata možete pronaći i upoznati se s poslom koji ste radili jučer, prošli mjesec, prije godinu dana, definirati temu kao kriterij pretraživanja ili postaviti drugi kriterij pretraživanja za sadržaj baze podataka.
. Tehnička ograničenja tražilice. Neka ograničenja, kao što je duljina niza upita, mogu se prevladati. Osigurano je izvršavanje ne jednog, već nekoliko upita s kombinacijom rezultata pretraživanja ili zasebno. Možete pročitati o načinu prevladavanja kršenja zakona aditivnosti za glavne tražilice. Za jednu riječ ili jednu frazu, uzetu u navodnike, u tražilicama se implementira pretraživanje osjetljivo na velika i mala slova, posebno pretraživanje skraćenica.
ugrađeni preglednik . Navigator po stranicama. Višebojni marker za isticanje ključnih i proizvoljnih riječi. Bilisting i N-listing iz generiranih dokumenata.
. Istovar hrani se u tabelarni prikaz usmjeren na uvoz u Excel, MySQL, Access, Kronos i druge aplikacije.
5. Instalacija i pokretanje Programa, zahtjevi računala.
Da biste instalirali i pokrenuli program:
- Preuzmite datoteku, kopirajte mapu FileForFiles iz nje na svoj tvrdi disk, na primjer D:\;
- Demo verzija programa će biti instaliran i otvorit će se.
Program će raditi na svakom računalu na kojem je instaliran Windows bilo koje verzije.Što je
DuckDuckGo je prilično poznata tražilica otvorenog koda. Poslužitelji se nalaze u SAD-u. Osim vlastitog robota, tražilica koristi rezultate drugih izvora: Yahoo, Bing, Wikipedia.
Bolji
DuckDuckGo se pozicionira kao ultimativno pretraživanje privatnosti i privatnosti. Sustav ne prikuplja nikakve podatke o korisniku, ne pohranjuje zapisnike (bez povijesti pretraživanja), korištenje kolačića je maksimalno ograničeno.
DuckDuckGo ne prikuplja niti dijeli osobne podatke korisnika. Ovo je naša politika privatnosti.
Gabriel Weinberg, osnivač DuckDuckGoZašto ti ovo treba
Sve glavne tražilice pokušavaju personalizirati rezultate pretraživanja na temelju podataka o osobi ispred monitora. Taj se fenomen naziva "mjehurić filtra": korisnik vidi samo one rezultate koji su u skladu s njegovim preferencijama ili koje sustav takvima smatra.
Formira objektivnu sliku koja ne ovisi o vašem dosadašnjem ponašanju na webu te se rješava Google i Yandex tematskog oglašavanja na temelju vaših zahtjeva. Uz pomoć DuckDuckGo lako je pretraživati informacije na stranim jezicima, dok Google i Yandex prema zadanim postavkama preferiraju stranice na ruskom jeziku, čak i ako je upit upisan na drugom jeziku.
Što je
not Evil je sustav koji pretražuje anonimnu Tor mrežu. Da biste ga koristili, morate otići na ovu mrežu, na primjer, pokretanjem specijaliziranog .
not Evil nije jedina tražilica te vrste. Postoji LOOK (zadano pretraživanje u Tor pregledniku, dostupno s običnog interneta) ili TORCH (jedna od najstarijih tražilica na Tor mreži) i drugi. Odlučili smo se da nije Evil zbog nepogrešive aluzije na Google (samo pogledajte početnu stranicu).
Bolji
On traži gdje je Googleu, Yandexu i drugim tražilicama u načelu zabranjen pristup.
Zašto ti ovo treba
Na mreži Tor postoji mnogo resursa koji se ne mogu pronaći na Internetu koji poštuje zakon. A njihov će broj rasti kako se kontrola vlasti nad sadržajem weba pooštrava. Tor je svojevrsna mreža unutar weba sa svojim društvenim mrežama, torrent trackerima, medijima, tržnicama, blogovima, knjižnicama i tako dalje.
3. YaCy
Što je
YaCy je decentralizirana tražilica koja radi na principu P2P mreža. Svako računalo na kojem je instaliran glavni softverski modul samostalno skenira internet, odnosno analogno je robotu za pretraživanje. Dobiveni rezultati prikupljaju se u zajedničku bazu podataka koju koriste svi sudionici YaCyja.
Bolji
Ovdje je teško reći je li to bolje ili gore, budući da je YaCy potpuno drugačiji pristup organizaciji pretraživanja. Nedostatak jednog poslužitelja i vlasničke tvrtke čini rezultate potpuno neovisnim o nečijim preferencijama. Autonomija svakog čvora isključuje cenzuru. YaCy je sposoban pretraživati duboki web i neindeksirane javne mreže.
Zašto ti ovo treba
Ako ste pobornik softvera otvorenog koda i besplatnog interneta na koji ne utječu državne agencije i velike korporacije, YaCy je vaš izbor. Također se može koristiti za organiziranje pretraživanja unutar korporativne ili druge autonomne mreže. I iako YaCy nije baš koristan u svakodnevnom životu, on je dostojna alternativa Googleu u smislu procesa pretraživanja.
4. Pipl
Što je
Pipl je sustav dizajniran za traženje informacija o određenoj osobi.
Bolji
Autori Pipl tvrde da njihovi specijalizirani algoritmi pretražuju učinkovitije od "običnih" tražilica. Posebno su prioritetni profili na društvenim mrežama, komentari, popisi članova i razne baze podataka u kojima se objavljuju podaci o ljudima, poput baze podataka sudskih odluka. Piplovo vodstvo u ovom području potvrđuju Lifehacker.com, TechCrunch i druge publikacije.
Zašto ti ovo treba
Ako trebate pronaći informacije o osobi koja živi u SAD-u, onda će Pipl biti puno učinkovitiji od Googlea. Baze podataka ruskih sudova očito su nedostupne tražilici. Stoga se ne nosi tako dobro s građanima Rusije.
Što je
FindSounds je još jedna specijalizirana tražilica. Pretražuje otvorene izvore za različite zvukove: kuća, priroda, automobili, ljudi itd. Usluga ne podržava zahtjeve na ruskom, ali postoji impresivan popis oznaka na ruskom jeziku koje možete tražiti.
Bolji
U izdavanju samo zvukova i ništa više. U postavkama možete postaviti željeni format i kvalitetu zvuka. Svi pronađeni zvukovi dostupni su za preuzimanje. Postoji pretraga uzorka.
Zašto ti ovo treba
Ako trebate brzo pronaći zvuk pucnjave muškete, udarac djetlića koji siše ili krik Homera Simpsona, onda je ova usluga za vas. A mi smo ovo odabrali samo iz dostupnih upita na ruskom jeziku. Na engleskom je spektar još širi.
Ozbiljno, specijalizirana usluga podrazumijeva specijaliziranu publiku. No, hoće li i vama dobro doći?
Što je
Wolfram|Alpha je računalna tražilica. Umjesto poveznica na članke koji sadrže ključne riječi, daje gotov odgovor na zahtjev korisnika. Na primjer, ako u obrazac za pretraživanje unesete "usporedi stanovništvo New Yorka i San Francisca" na engleskom, Wolfram|Alpha će odmah prikazati tablice i grafikone s usporedbom.
Bolji
Ova je usluga bolja od ostalih za pronalaženje činjenica i izračunavanje podataka. Wolfram|Alpha prikuplja i organizira znanje dostupno na webu iz različitih područja, uključujući znanost, kulturu i zabavu. Ako ova baza podataka sadrži spreman odgovor na upit za pretraživanje, sustav ga prikazuje, ako ne, izračunava i prikazuje rezultat. U ovom slučaju korisnik vidi samo i ništa više.
Zašto ti ovo treba
Ako ste, na primjer, student, analitičar, novinar ili istraživač, možete koristiti Wolfram|Alpha za pronalaženje i izračunavanje podataka povezanih s vašim aktivnostima. Usluga ne razumije sve zahtjeve, ali se stalno razvija i postaje sve pametnija.
Što je
Metatrazilica Dogpile prikazuje kombinirani popis rezultata s Googlea, Yahooa i drugih popularnih tražilica.
Bolji
Prvo, Dogpile prikazuje manje oglasa. Drugo, usluga koristi poseban algoritam za pronalaženje i prikaz najboljih rezultata iz različitih tražilica. Prema programerima Dogpilea, njihov sustav generira najpotpunije izdanje na cijelom Internetu.
Zašto ti ovo treba
Ako ne možete pronaći informacije na Googleu ili nekoj drugoj standardnoj tražilici, potražite ih u nekoliko tražilica odjednom koristeći Dogpile.
Što je
BoardReader je sustav za pretraživanje teksta za forume, usluge pitanja i odgovora i druge zajednice.
Bolji
Usluga vam omogućuje da suzite polje pretraživanja na društvene stranice. Zahvaljujući posebnim filterima, možete brzo pronaći postove i komentare koji odgovaraju vašim kriterijima: jezik, datum objave i naziv stranice.
Zašto ti ovo treba
BoardReader može biti koristan PR stručnjacima i drugim medijskim profesionalcima koje zanima mišljenje masovnih medija o određenim pitanjima.
Konačno
Život alternativnih tražilica često je prolazan. Lifehacker je upitao bivšeg izvršnog direktora ukrajinske podružnice Yandexa Sergeja Petrenka o dugoročnim izgledima za takve projekte.
Sergej Petrenko
Bivši izvršni direktor Yandex.Ukraine.
Što se tiče sudbine alternativnih tražilica, to je jednostavno: biti vrlo nišni projekti s malom publikom, dakle, bez jasnih komercijalnih izgleda, ili, obrnuto, s potpunom jasnoćom njihove odsutnosti.
Ako pogledate primjere u članku, možete vidjeti da su takve tražilice ili specijalizirane za usku, ali traženu nišu, koja, možda samo do sada, nije dovoljno narasla da bi bila uočljiva na radarima Googlea ili Yandexa, ili testiraju izvornu hipotezu u rangiranju, koja još nije primjenjiva u konvencionalnom pretraživanju.
Na primjer, ako se Tor pretraga odjednom pokaže traženom, odnosno barem će postotku Googleove publike biti potrebni rezultati odande, tada će, naravno, obične tražilice početi rješavati problem kako pronaći ih i pokazati korisniku. Ako ponašanje publike pokazuje da se značajan udio korisnika u značajnom broju upita čini relevantnijim rezultatima, podacima bez uzimanja u obzir čimbenika koji ovise o korisniku, tada će Yandex ili Google početi davati takve rezultate.
"Biti bolji" u kontekstu ovog članka ne znači "biti bolji u svemu". Da, u mnogim aspektima naši su junaci daleko od Yandexa (čak i od Binga). No, svaka od ovih usluga korisniku daje nešto što divovi industrije pretraživanja ne mogu ponuditi. Sigurno i vi poznajete slične projekte. Podijelite s nama - razgovarajmo.
Uvod
Trenutno Internet ujedinjuje stotine milijuna poslužitelja na kojima se nalaze milijarde različitih stranica i pojedinačnih datoteka koje sadrže različite vrste informacija. To je ogromno spremište informacija. Postoje različite metode traženja informacija na Internetu.
Traži po poznatoj adresi. Tražene adrese se preuzimaju iz imenika. Poznavajući adresu, dovoljno je unijeti je u adresnu traku preglednika.
Primjer 1. www.gov.ru - poslužitelj državnih organa Rusije.
Konstrukcija adrese od strane korisnika. Poznavajući sustav generiranja internetskih adresa, možete konstruirati adrese kada tražite web stranice.
Ključnoj riječi (naziv tvrtke, poduzeća, organizacije ili obična engleska imenica) potrebno je dodati tematsku ili geografsku domenu, a mora biti povezana intuicija.
Primjer 2 Adrese komercijalnih web stranica:
www.samsung.com (tvrtka SAMSUNG),
www.mtv.com (MTV glazbene vijesti).
Primjer 3. Adrese obrazovnih institucija:
www.ntu.edu (Nacionalno sveučilište SAD).
Internetske tražilice
Za traženje informacija na Internetu razvijeni su posebni sustavi za pronalaženje informacija. Tražilice imaju redovitu adresu i prikazuju se kao web stranica koja sadrži posebne alate za organiziranje pretraživanja (string za pretraživanje, predmetni katalog, poveznice). Da biste pozvali tražilicu, samo unesite njezinu adresu u adresnu traku preglednika.
Prema statističkoj usluzi LiveInternet.ru, distribucija tražilica u Rusiji otprilike je sljedeća:
2) Google - 35,0%
3) Mail.ru pretraga - 8,3%
4) Rambler - 0,9%
Sustavi za pronalaženje informacija dijele se prema načinu organiziranja informacija u dvije vrste: klasifikacijski (rubrikatori) i rječnički.
Rubrikatori (klasifikatori)- tražilice koje koriste hijerarhijsku (stablo) organizaciju informacija. Prilikom traženja informacija korisnik pregledava tematske naslove, postupno sužavajući polje za pretraživanje (na primjer, ako trebate pronaći značenje riječi, tada prvo morate pronaći rječnik u klasifikatoru, a zatim pronaći pravu riječ u tome).
Tražilice za rječnike moćni su automatski softverski i hardverski sustavi. Uz njihovu pomoć pregledavaju se (skeniraju) informacije na Internetu. Podaci o mjestu ove ili one informacije unose se u posebne referentne knjige-indekse. Kao odgovor na zahtjev, vrši se pretraga u skladu sa nizom upita. Kao rezultat, korisniku se nude one adrese (URL-ovi) na kojima je tražena riječ ili grupa riječi pronađena u trenutku skeniranja. Odabirom bilo koje od predloženih poveznica možete ići na pronađeni dokument. Većina modernih tražilica su mješovite.
Najpoznatije i najpopularnije tražilice:
Postoje sustavi koji su specijalizirani za traženje informacijskih izvora u različitim područjima.
https://my.mail.ru
https://ru-ru.facebook.com
https://twitter.com
https://www.tumblr.com
https://www.instagram.com itd.
Subjektne tražilice:
Pretraživanje softvera:
Katalozi (tematske zbirke poveznica s napomenama):
http://www.atrus.ru
Pravila za izvršavanje upita
U svakoj tražilici, u odjeljku Pomoć, možete dobiti informacije o tome kako pretraživati, kako sastaviti niz upita. Ispod su informacije o tipičnom, "prosječnom" jeziku upita.
Jednostavan zahtjev
Unesite jednu riječ koja definira temu pretraživanja. Na primjer, u tražilici Rambler.ru dovoljno je unijeti: automatizacija.
Pronađeni su dokumenti koji sadrže riječi navedene u zahtjevu. Prepoznaju se svi oblici ruskih riječi, u pravilu se zanemaruje velika slova.
U upitu možete koristiti znak "*" ili "?". Znak "?" u ključnoj riječi zamjenjuje se jedan znak, umjesto kojeg se može zamijeniti bilo koje slovo, a znak "*" je niz znakova.
Na primjer, automat za upit* će pronaći dokumente koji uključuju riječi automatski, automatski i tako dalje.
Složen zahtjev
Često postoji potreba za kombiniranjem ključnih riječi kako biste dobili konkretnije informacije. U ovom slučaju koriste se dodatne riječi za povezivanje, funkcije, operatori, simboli, kombinacije operatora odvojenih zagradama.
Na primjer, upit glazba & (beatles beatles) znači da korisnik traži dokumente koji sadrže riječi glazba i beatles ili glazba i beatles.
Popis poslužitelja za pretraživanje i direktorija
Adresa Opis www.excite.com Tražilica s recenzijama čvorova i vodičima www.alta-vista.com Poslužitelj za pretraživanje, dostupne su napredne mogućnosti pretraživanja www.hotbot.com poslužitelj za pretraživanje www.ifoseek.com Search Server (jednostavan za korištenje) www.ipl.org Internet Publik knjižnica, javna knjižnica koja djeluje u sklopu projekta World Village www.wisewire.com WiseWire - organizacija pretraživanja pomoću umjetne inteligencije www.webcrawler.com WebCrawler - poslužitelj za pretraživanje, jednostavan za korištenje www.yahoo.com Web katalog i sučelje za pristup pretraživanju cijelog teksta na AltaVista poslužitelju www.aport.ru Aport - poslužitelj za pretraživanje na ruskom jeziku www.yandex.ru Yandex - poslužitelj za pretraživanje na ruskom jeziku www.rambler.ru Rambler - poslužitelj za pretraživanje na ruskom jeziku Resursi za internetsku pomoć www.žuta.com Internet žute stranice monk.newmail.ru Tražilice raznih profila www.top200.ru 200 najboljih web stranica www.allru.net www.ru Katalog ruskih internetskih resursa www.allru.net/z09.htm Obrazovni resursi www.students.ru Ruski studentski server www.cdo.ru/index_new.asp Centar za učenje na daljinu www.open.ac.uk Otvoreno sveučilište UK www.ntu.edu Američko nacionalno sveučilište www.translate.ru Elektronski prevoditelj teksta www.pomorsu.ru/guide.library.html Popis poveznica na mrežne knjižnice www.elibrary.ru Znanstvena elektronska knjižnica www.citforum.ru Digitalna knjižnica www.infamed.com/psy Psihološki testovi www.pokoleniye.ru Internetska stranica federacije za obrazovanje www.metod.narod.ru Obrazovni resursi www.spb.osi.ru/ic/distant Učenje na daljinu na internetu www.examen.ru Ispiti i testovi www.kbsu.ru/~book/ Udžbenik informatike Mega.km.ru Enciklopedije i rječnici Profesionalno traženje informacija na internetu
Pretraživanje informacija jedan je od najčešćih, a ujedno i najtežih zadataka s kojima se svaki korisnik mora suočiti na webu. Međutim, ako je za običnog člana mrežne zajednice poznavanje učinkovitih metoda pronalaženja informacija poželjna, ali daleko od obvezne kvalitete, onda je za informacijske profesionalce sposobnost brzog snalaženja u internetskim resursima i pronalaženja potrebnih izvora jedan od osnovne kvalifikacijske vještine.
Razlog za poteškoće koje nastaju u pronalaženju informacija na Internetu određuju dva glavna čimbenika. Prvo, broj izvora na webu je iznimno velik. Krajem 2001. najgrublje procjene upućivale su na približnu brojku od 7,5 milijardi dokumenata smještenih na poslužiteljima diljem svijeta. Drugo, količina informacija na webu nije samo kolosalna, već i iznimno dinamična. U pola minute koliko ste proveli čitajući prve retke ovog odjeljka, stotinjak novih ili izmijenjenih dokumenata pojavilo se u virtualnom svemiru, deseci su preseljeni na nove adrese, a jedinice su zauvijek prestale postojati. Internet nikad ne "spava", kao što nikad "ne spava" i naš planet, po kojem se neprestano kotrlja val ljudskih poslovnih aktivnosti točno u skladu s promjenom vremenskih zona.
Za razliku od stabilne i kontrolirane zbirke dokumenata u knjižnici, na webu imamo posla s gigantskim i stalno promjenjivim informacijskim nizom, potraga za podacima u kojem je vrlo, vrlo složen proces. Situacija često vrlo podsjeća na dobro poznatu zadaću pronalaženja igle u plastu sijena, a ponekad informacije velike vrijednosti ostaju nepotražene isključivo zbog poteškoća u pronalaženju.
Većina korisnika globalnih računalnih mreža u jednoj ili drugoj mjeri posjeduje vještine pretraživanja informacija. I amateri i profesionalci često koriste iste alate. Međutim, rezultati pretraživanja i vrijeme provedeno na njima uvelike se razlikuju.
Svrha ovog odjeljka je detaljno se upoznati s alatima i metodama pronalaženja informacija te razviti održive vještine za profesionalno pretraživanje na webu svih vrsta podataka: od tekstova u bilo kojem formatu do videa i animacije.
STRUČNO PRETRAŽIVANJE INFORMACIJA NA INTERNETU
Pretraživanje interneta važan je element rada na webu. Točan broj web-resursa suvremenog Interneta teško je nikome pouzdano poznat. U svakom slučaju, račun ide na milijarde. Kako biste mogli koristiti informacije koje su vam potrebne u ovom trenutku, bilo u poslovne ili zabavne svrhe, najprije ih morate pronaći u ovom oceanu resursa koji se neprestano obnavlja.
Da bi pretraživanje Interneta bilo uspješno, moraju biti ispunjena dva uvjeta: upiti moraju biti dobro formulirani i postavljati ih na prikladna mjesta. Drugim riječima, od korisnika se traži, s jedne strane, sposobnost prevođenja svojih interesa za pretraživanje na jezik upita za pretraživanje, a s druge strane dobro poznavanje tražilica, dostupnih alata za pretraživanje, njihovih prednosti i nedostatke, što će omogućiti odabir najprikladnijih alata za pretraživanje u svakom konkretnom slučaju. .
Trenutno ne postoji niti jedan resurs koji zadovoljava sve zahtjeve za pretraživanje interneta. Stoga, uz ozbiljan pristup pretraživanju, neizbježno morate koristiti različite alate, koristeći svaki u najprikladnijem slučaju.
Glavni alati za pretraživanje internetamogu se podijeliti u sljedeće glavne skupine:
tražilice;
Web imenici;
Referentni izvori;
Lokalni programi za pretraživanje interneta.
Najpopularnija tražilica jetražilice- takozvane internetske tražilice (Search Engines). Prva tri lidera na globalnoj razini prilično su stabilna - to su Google, Yahoo! i Bing. Mnoge zemlje ovom popisu dodaju vlastite lokalne tražilice optimizirane za lokalni sadržaj. Uz njihovu pomoć, teoretski, možete pronaći bilo koju određenu riječ na stranicama mnogih milijuna web-mjesta. Sa stajališta korisnika, glavni nedostatak tražilica je neizbježna prisutnostinformacijski šumu rezultatima. Ovako je uobičajeno nazivati rezultate koji su, iz ovog ili onog razloga, uključeni u popis rezultata koji ne odgovaraju upitu.
Unatoč mnogim razlikama, sve internetske tražilice rade na sličnim principima i, s tehničkog gledišta, sastoje se od sličnih podsustava. Prvi strukturni dio tražilice su posebni programi koji se koriste za automatsko pretraživanje i naknadno indeksiranje web stranica. Takvi se programi obično nazivaju pauci ili botovi. Gledaju kod web stranica, pronalaze poveznice koje se nalaze na njima i tako otkrivaju nove web stranice. Postoji alternativni način uključivanja web mjesta u indeks. Mnoge tražilice nude vlasnicima resursa mogućnost da sami dodaju web mjesto u svoju bazu podataka. Kako god bilo, tada se web stranice preuzimaju, analiziraju i indeksiraju. U njima se ističu strukturni elementi, pronalaze ključne riječi, određuju njihove poveznice s drugim stranicama i web stranicama. Izvode se i druge operacije čiji je rezultat formiranje indeksne baze tražilice. Ova baza je drugi glavni element svake tražilice. Trenutno ne postoji jedna apsolutno cjelovita indeksna baza podataka koja bi sadržavala podatke o svim sadržajima interneta. Budući da različite tražilice koriste različite programe za pretraživanje web stranica i grade svoj indeks korištenjem različitih algoritama, baze indeksa tražilica mogu značajno varirati. Neke stranice indeksira nekoliko tražilica, ali uvijek postoji određeni postotak resursa uključenih u bazu podataka samo jedne tražilice. Činjenica da svaka tražilica ima tako originalan dio indeksa koji se ne preklapa omogućuje vam da donesete važan praktični zaključak: ako koristite samo jednu tražilicu, čak i najveću, sigurno ćete izgubiti određeni postotak korisnih poveznica .
Sljedeći dio internetske tražilice je stvarni program za pretraživanje i sortiranje. Ovi programi rješavaju dva glavna zadatka: prvo pronalaze stranice i datoteke u bazi podataka koje odgovaraju dolaznom zahtjevu, a zatim sortiraju rezultirajući niz podataka prema različitim kriterijima. Uspjeh u postizanju ciljeva potrage uvelike ovisi o učinkovitosti njihova rada.
Posljednji element internetske tražilice je korisničko sučelje. Uz zahtjeve za estetikom i praktičnošću koji su uobičajeni za bilo koju stranicu, postoji još jedan važan zahtjev za sučelja tražilica: moraju ponuditi različite alate za sastavljanje i pročišćavanje upita, kao i sortiranje i filtriranje rezultata. Prednosti tražilica su izvrsna pokrivenost izvora, relativno brzo ažuriranje sadržaja baze podataka i dobar izbor dodatnih značajki.
Glavni alat za rad s tražilicama je upit.
Za pretraživanje interneta također se koriste posebne aplikacije instalirane na lokalnom računalu. To mogu biti i jednostavni programi i prilično složeni kompleksi pretraživanja i analize podataka. Najčešći dodaci preglednika su dodaci preglednika, ploče preglednika dizajnirane za rad s određenim uslugom pretraživanja i paketi metapretraživanja s mogućnostima analize rezultata.
Web imenici - to su resursi u kojima su stranice raspoređene po tematskim kategorijama. Ako korisnik radi s tražilicama samo putem upita, tada katalog ima mogućnost pregleda cijelih tematskih odjeljaka. Druga temeljna razlika između kataloga i automatskih tražilica je u tome što, u pravilu, ljudi izravno sudjeluju u njihovom sadržaju, koji pregledavaju resurse i pripisuju stranicu jednoj ili drugoj kategoriji. Web imenici se obično dijele na univerzalne i tematske. Univerzalni pokušajte pokriti što više tema. U njima možete pronaći sve: od stranica o poeziji do računalnih resursa. Drugim riječima, imaju maksimalnu širinu pretraživanja. Tematski imenici, s druge strane, specijalizirani su za određenu temu, osiguravajući maksimalnu dubinu pretraživanja smanjujući širinu pokrivenosti resursa.
Prednost imenika je relativno visoka kvaliteta resursa, budući da svako mjesto u njemu pregledava i bira osoba. Tematsko grupiranje web-mjesta omogućuje vam prikladno lociranje web-mjesta sličnih tema. Ovaj način rada je dobar za otkrivanje novih stranica za vas na temu od interesa - točniji je od korištenja tražilice. Preporuča se korištenje web imenika za prvo upoznavanje s bilo kojim predmetnim područjem, kao i traženje nejasnih upita - imat ćete priliku "lutati" odjeljcima imenika i točnije odrediti što vam je potrebno.
Nedostaci web imenika su poznati. Prije svega, riječ je o sporom nadopunjavanju baze podataka, budući da je za uključivanje stranice u katalog potrebno sudjelovanje osobe. Što se tiče učinkovitosti, web imenik nije rival tražilicama. Osim toga, web imenici su znatno inferiorniji u odnosu na tražilice po veličini baze podataka.
Kada se govori o pretraživanju Interneta, ne može se zanemariti niz pojmova koji su usko povezani s ovim područjem i često se koriste za opisivanje i ocjenu tražilica. Na primjer:širina i dubina pretraživanje interneta. Široko pretraživanje je pretraživanje koje obuhvaća što više izvora informacija. Istodobno, barem spominjanje određene stranice koja odgovara upitu smatra se dovoljnim. Dubina pretraživanja odnosi se na pojedinosti indeksiranja i naknadnog pretraživanja svakog određenog resursa. Na primjer, mnoge tražilice imaju različite pristupe indeksiranju različitih stranica. Velike i popularne stranice indeksirane su u maksimalnoj mjeri, roboti pokušavaju ne propustiti niti jednu stranicu takvog resursa. Istodobno, na drugim stranicama može se indeksirati samo glavna stranica i nekoliko stranica sadržaja. Ove okolnosti, naravno, utječu na kasniju pretragu. Dubinsko pretraživanje funkcionira po principu "bolje je uključiti suvišne informacije u rezultate nego propustiti bilo koji podatak relevantan za temu pretraživanja."
Sasvim je uobičajeno naići na pojmove kao npr globalno i lokalno pretraživanje interneta. Lokalno pretraživanje interneta uzima u obzir zemljopisni položaj korisnika, a prednost se daje rezultatima koji su na neki način povezani s određenom zemljom ili lokalitetom. Globalna pretraga zanemaruje ove informacije i pretražuje sve dostupne resurse.
Prilikom sastavljanja upita na internetskim tražilicama djeluju različiti načini pretraživanja. Tipični načini pretraživanja koji se nalaze na većini internetskih strojeva uključuju jednostavno i napredno Traži. Jednostavno pretraživanje omogućuje vam da navedete samo jednu značajku pretraživanja u jednom upitu. Napredno pretraživanje omogućuje stvaranje upita iz nekoliko uvjeta povezujući ih logičkim operatorima.
Za pročišćavanje upita za pretraživanje koriste se različite metode. filteri . Filtri su ona ili druga pomoćna sredstva za sastavljanje upita koja se ne odnose na sadržajnu stranu uvjeta upita, ali ograničavaju rezultate pretraživanja na neki formalni znak. Tako, primjerice, prilikom primjene filtera vrste datoteke prilikom pretraživanja, korisnik ne daje sustavu informacije vezane za predmet njegovog zahtjeva, već jednostavno ograničava dobivene rezultate na određenu vrstu datoteke navedenu u uvjetu njegovog zahtjeva.
Za većinu korisnika univerzalne tražilice su glavno, a često i jedino sredstvo pretraživanja interneta. Nude dobru pokrivenost izvora, kao i skup alata dovoljnih za osnovne zadatke pretraživanja.
Tržište univerzalnih tražilica prilično je veliko. Pokušali smo analizirati najpoznatije tražilice, a rezultati su prikazani u obliku tablice 1.
Prilikom odabira univerzalne tražilice, kvaliteta resursa pronađenih uz njezinu pomoć igra važnu ulogu. Pomoću "metode markera" možete odrediti željenu tražilicu za određene zadatke. Njegova bit leži u činjenici da se prvo sastavlja određeni tematski upit za pretraživanje, nakon čega se anketira grupa ljudi - stručnjaka u ovom području kako bi identificirali najbolje, po njihovom mišljenju, internetske resurse na odabranu temu. Na temelju podataka ankete formira se popis markerskih stranica za koje se jamči da su relevantne za upit i sadrže visokokvalitetne informacije. Zatim se zahtjev šalje testiranim tražilicama. Logika evaluacije je jednostavna: što se više mjesta s oznakama nalaze u rezultatima pretraživanja, to je određeni resurs prikladniji za pronalaženje informacija o temi testa.
Reći da u naše vrijeme informacijske tehnologije i beskrajnog rasta količine podataka dostupnih kako pojedincu tako i društvu, postoje brojni problemi s obradom informacija i njihovo traženje je već blasfemija. Tko samo ne pokreće ovu temu. A kako vas ne bih opterećivao subjektivnim, a dijelom i objektivnim prosudbama iz raznih izvora informacija o problemu, prijeći ću izravno na njegovo rješavanje. Razgovarajmo o pretrazi danas. Odnosno o programima i ozbiljnim informacijskim sustavima koji traže dokumente i podatke koji su nam potrebni.
Nadogradite "izravno pretraživanje"
Ne tako davno, kada su stabla bila velika, a nije bilo puno informacija čak ni na lokalnoj mreži poduzeća, svaka se pretraga obavljala jednostavnim sortiranjem kroz pregršt dostupnih datoteka i uzastopnim provjeravanjem njihovih naziva i sadržaja. Takvo pretraživanje naziva se izravno pretraživanje, a programi (uslužni programi) koji koriste tehnologiju izravnog pretraživanja tradicionalno su prisutni u svim operacijskim sustavima i paketima alata. No, ni snaga modernih računala nije dovoljna za brzo i adekvatno pretraživanje golemih količina podataka tijekom izravnog pretraživanja. Pretraživanje nekoliko stotina dokumenata na disku i pretraživanje u ogromnoj biblioteci i nekoliko desetaka poštanskih sandučića dvije su različite stvari. Stoga, programi izravnog pretraživanja danas očito blijede u pozadini - ako govorimo o univerzalnim alatima.
Naravno, u korporativnom sektoru ova vrsta pretraživanja već dugo nije tražena. Volumeni nisu isti. Stoga su već dugi niz godina, a odnedavno nedvojbeno, tehnologije sposobne za brzu i točnu pretragu dokumenata različitih formata i iz različitih izvora više nego relevantne. Ne tako davno, Microsoftov "otac" Bill Gates, zavideći, očito, fenomenalnom uspjehu Googleove internetske tražilice, na jednoj od konferencija za novinare najavio je želju da softver (već i ne samo) na sve moguće načine promovira , razvijati i produbljivati stvaranje tražilica i tehnologija. Ali prije stvaranja bilo kakvog fenomenalnog radnog programa od Microsofta ili konkurentnog poslužitelja na Internetu, još je prerano (MSN još uvijek zaostaje za Googleom). Stoga se okrećemo postojećim razvojima. Indeks, upit, relevantnost
U središtu modernih tehnologija su dva temeljna procesa. Prvo, to je indeksiranje dostupnih informacija i obrada zahtjeva, nakon čega slijedi izlaz rezultata. Što se prvog tiče, svaki program (bilo da se radi o tražilici za stolna računala, korporativnom informacijskom sustavu ili internetskoj tražilici) stvara vlastito područje pretraživanja. Odnosno, obrađuje dokumente i formira indeks tih dokumenata (organiziranu strukturu koja sadrži informacije o obrađenim podacima). U budućnosti se za rad koristi stvoreni indeks - brzo dobivanje popisa potrebnih dokumenata prema zahtjevu. Nadalje, iako nimalo jednostavno u tehnološkom smislu, ali je prosječnom korisniku sasvim razumljivo. Program obrađuje zahtjev (po ključnoj riječi-frazi) i prikazuje popis dokumenata koji sadrže ovu ključnu riječ. Budući da su informacije sadržane u strukturiranom indeksu, obrada upita je mnogo (desetke i stotine puta!) brža nego u slučaju izravnog pretraživanja (odabir dokumenta ne provodi se nabrajanjem datoteka, već analizom tekstualnih informacija u indeks).
Program prikazuje pronađene dokumente u rezultirajućem popisu prema relevantnosti – korespondenciji dokumenta s tekstom upita. U različitim tehnologijama, naravno, postoje različite metode pretraživanja i utvrđivanja relevantnosti dokumenta (broj "pojavljivanja" riječi i njezina učestalost spominjanja u dokumentu, omjer ovih parametara i ukupnog broja riječi u dokumentu, udaljenost između riječi izraza upita u pretraživanim datotekama i tako dalje). Na temelju tih parametara određuje se "težina" dokumenta i ovisno o tome, jedna ili druga datoteka pojavljuje se na popisu rezultata na određenoj poziciji. U slučaju pretraživanja interneta situacija je još složenija. Doista, u ovom slučaju, mnogi drugi čimbenici moraju se uzeti u obzir (Page Rank Google je primjer toga). Ali ovo je tema za poseban članak, pa nećemo dirati internet Pregled tražilica
Ovaj članak govori o mogućnostima nekoliko popularnih programa za pretraživanje koji se mogu pohvaliti i pristojnim brzinama i dobrom funkcionalnošću. No, pokazivati se u letku je jedno, a stajati pred pogledom stručnjaka sasvim je drugo. A stručnjaka nije bilo ni puno ni malo, pun ured ljubitelja koji su se petljali sa softverom za njegovu upotrebljivost. Eksperimentalno računalo (Athlon 2,2 MHz, 1 GB RAM-a, 160 GB Seagate 7200 rpm IDE hard disk i Windows XP sustav) instalirano je sa skupom programa: dtSearch Desktop, Snoop Prof Deluxe, Google Desktop Search, SearchInform , Copernic Desktop Search, ISYS Desktop. Za testove je sastavljena tekstualna baza dokumenata u doc, txt i html formatima ukupne veličine ne više, ni manje, već 20 gigabajta. Grupa suboraca, pod vodstvom vašeg poniznog sluge, testirala je, uspoređivala i podijelila svoje subjektivne dojmove o svakom softveru. U nastavku pročitajte sažetak nalaza. dtSearchDesktop
Program koji, prema riječima programera, tvrdi da je najbrža, najprikladnija i najbolja tražilica. Kao, općenito, i svi ostali u ovom pregledu. Sučelje dtSearch-a je prilično jednostavno, ali neki prozori ili kartice su pomalo preopterećeni elementima, što ostavlja dojam da ih je teško koristiti. Ali u stvari, nema posebnih poteškoća. Jedini stvarno neugodan trenutak je nedostatak podrške za softver na ruskom jeziku (unatoč činjenici da program može pretraživati dokumente na nekoliko jezika, njegovo je sučelje isključivo na engleskom).
No dtSearch je jedan od rijetkih programa koji može indeksirati web stranice na "dubinu" koju je odredio korisnik (međutim, uzimajući u obzir "dodatnu kupnju" u dtSearch Spider kompletu dodataka). Ovo je uz podršku datotekama na disku u različitim tekstualnim formatima i e-porukama iz Outlook poštanskog sandučića. Istovremeno, program ne zna raditi s bazama podataka koje su zbog velike količine informacija koje sadrže i široke distribucije u tvrtkama, a time i u korporativnim mrežama, tako ukusan zalogaj za tražilice. Brzina indeksiranja dtSearch dokumenata bila je na visini. Gledajući unaprijed, reći ću da se ovaj program nosio s indeksiranjem zadane količine informacija na razini s drugim natjecateljem - iSYS -om i s njim podijelio drugo mjesto na listi najbržih sustava. dtSearch je indeksirao test 20 gigabajta informacija u 6 sati i 13 minuta, stvorivši indeks veličine 7,9 GB za potrebe naknadnog pretraživanja.
Što se tiče mogućnosti pretraživanja, ovdje su na visini. Prvo, dtSearch ima morfološko pretraživanje (traženje riječi u svim njezinim morfološkim oblicima). Koristeći se ovom prilikom oslobađate se, recimo, misli poput "u kojem slučaju je određena riječ korištena u dokumentu koji mi treba?". Korištenje morfološkog pretraživanja gotovo je uvijek opravdano, stoga bi trebalo biti prisutno u svakoj profesionalnoj tražilici.
Pretraživanje zvuka je nestandardna značajka čak i za profesionalne pretraživače. Njegova bit leži u činjenici da će program tražiti riječi koje zvuče isto kao i riječ koju ste unijeli. A najbolji dio je što ova značajka radi i za ruski jezik! Na primjer, upisivanje riječi "uho" u upit za pretraživanje rezultirat će ne samo riječima "uho", već i "uho".
Pretraživanje s ispravljanjem pogrešaka vrlo je važna značajka. Koristi se za traženje riječi koje sadrže sintaktičke pogreške - to mogu biti ili tipkarske pogreške ili pogreške u dokumentima dobivenim pomoću sustava za prepoznavanje znakova, na primjer. Jednostavan primjer je da tražite riječ tipkovnica. Neki dokument sadrži riječ "tipkovnica", očito je da je ta riječ zapravo "tipkovnica", samo osoba koja tipka kada tipka. Sada, pretraživanje s ispravljanjem pogrešaka, ovo će otkriti i uključiti dokument s riječju "tipkovnica" u rezultat. Također u dtSearch postoji postavka koja vam omogućuje da odredite stupanj mogućih pogrešnih znakova.
Tražite koristeći sinonime. Ova značajka koristi popis sinonima za različite riječi. Tako će, primjerice, unošenjem riječi "brzo" program pronaći i riječi "velika brzina" i druge koje su sinonimi za riječ "brzo", ako ih ima, naravno, na popisu sinonima . Gotovi popis sinonima ne isporučuje se s programom dtSearch, no moguće je koristiti popise na Internetu (prema tome, potrebna je veza, što nije uvijek zgodno), ili možete kreirati vlastiti popis sinonimi.
Uz navedene značajke, dtSearch može pretraživati pomoću fraza koje se sastoje od riječi povezanih logičkim operacijama. Svakoj riječi u upitu može se dodijeliti vlastita "težina", odnosno značaj. Korisna opcija je korištenje rječnika koji se sastoji od nevažnih riječi kako biste ih zanemarili prilikom pretraživanja, ali je i ovaj rječnik prazan i morat ćete ga sami ispuniti.
Zatim razmotrite mogućnosti programa pri radu na mreži. Zapravo, dtSearch ne nudi nikakve posebne mogućnosti umrežavanja. Međutim, sasvim je moguće koristiti ga na mreži. Alternativno, možete stvoriti neki indeks i staviti ga u javnu (dijeljenu) mapu. Sam program može se instalirati za svakog korisnika na računalo, ili se može postaviti u mapu koja je otvorena za javnost, a prečaci se mogu kreirati na poseban način za svakog korisnika posebno pomoću parametara naredbenog retka, u svrhu što je opisano u datoteci pomoći isporučenoj s programom. Također, moguće je automatski instalirati program na mrežu pomoću MSI datoteke. Ovo će uzeti u obzir postavke za svakog povezanog korisnika.
Općenito - dobar program iz kategorije profesionalnih tražilica. Može se kvalificirati za dobru ocjenu, međutim, stjecanje povjerenja i poštovanja korisnika može biti teško za dtSearch zbog nekoliko čimbenika (nije sve glatko sa sučeljem, ruski korisnici su zakinuti, nema svijetlih značajki za rad s mrežom) . Što se tiče izravnog traženja dokumenata, program nije imao preklapanja s ruskim tekstom. Kako ih nije bilo s deklariranom morfologijom, ili s nejasnom pretragom. Sustav je sasvim adekvatno pronašao potrebne dokumente i jednostavnim zahtjevom u jednoj riječi i korištenjem nekoliko pasusa ili bilo kojeg dokumenta kao ključne fraze.
Službena stranica:
Veličina distribucije: 23 MbSnoop Prof DeluxeNa temelju naziva možete pretpostaviti da u ovom programu postoji podrška za ruski jezik. Već je lijepo. Što se tiče sučelja, općenito je pomalo neobično, ali vrlo atraktivno izgleda. Druga stvar je praktičnost. Vrlo kontroverzan kriterij, ali ipak, vjerojatno, rješenje s više prozora nije najbolja opcija (zahtjev se unosi u jedan prozor, rezultat se prikazuje u drugom itd.).
Bloodhound i dalje koristi iste indekse za brzo pretraživanje, ali indeksiranje je puno sporije od ostalih programa. To je vrlo čudno, pogotovo ako se uzme u obzir da je njegova sposobnost obrade upita pretraživanja vrlo slaba, što znači da struktura indeksa nije komplicirana. Najvjerojatnije je poanta ovdje u neoptimiziranim algoritmima. Pokazalo se da je ovaj program jasan autsajder u indeksiranju i brzini pretraživanja: vrijeme utrošeno na stvaranje indeksa šest je puta duže od vremena istog dtSearch-a i iSYS-a. Indeksiranje 20 gigabajta tekstova za krvoslednika rezultiralo je 38 sati i 46 minuta rada. A stvoreno "područje pretraživanja" zauzimalo je istu veličinu na tvrdom disku kao izvorni podaci s malim minusom - 19 gigabajta.
Bloodhound se može predstaviti kao alternativa standardnom pretraživanju u Windowsima, teško da je sposoban za više. Činjenica da je primarni zadatak Tragača - najjednostavnije pretraživanje datoteka, ne ukazuje samo mali broj funkcija za analizu teksta upita za pretraživanje i napredno pretraživanje po atributima datoteke, već čak i prozor s rezultatima koji daje izravne veze na pronađene datoteke, kao i mape koje sadrže te datoteke. Prozor s rezultatima nije baš informativan u smislu da cijelu pronađenu datoteku možete pročitati samo pokretanjem, odnosno nema ugrađeni preglednik datoteka. No, dan je izvadak iz datoteke, gdje je tražena riječ pronađena, općenito, takva shema prikaza jako podsjeća na internetske tražilice.
Govoreći o specifičnim mogućnostima obrade upita za pretraživanje, vrijedno je napomenuti da ne postoji takva stvar kao što je "traži tekst", maksimum koji se može pretraživati je fraza, makar samo zato što nema višerednog polja za unos teksta. Ipak, možete analizirati unesenu frazu, a Bloodhound nam ovdje nudi standardni skup pretraživanja: logičke operacije, pretraživanje po maski i pretraživanje citata... ne puno. Ima nekih rudimenata morfološkog pretraživanja u programu, ali vjerojatno toliko sirovo da prilično ometa ispravan rad (tijekom testiranja uočeno je puno preklapanja s netočnom upotrebom morfologije).
Ali program vam omogućuje da odredite atribute datoteke (datum dokumenta, naziv datoteke, naziv mape) prilikom pretraživanja, a u tim upitima također možete koristiti isti skup pretraživanja. Također, možete pretraživati poruke navođenjem parametara (Od, Predmet.... itd.).
Dakle, skužili smo samu pretragu, što je još zanimljivo u programu, za koji je dobio toliko nagrada, prema informacijama sa službenih stranica? Teško je reći što je tu toliko posebno, najvjerojatnije je sučelje Bloodhounda pogodno samo za sebe (samo izvana, da ne spominjemo upotrebljivost).
Operacije s indeksima su vrlo standardne, zgodna stvar je mogućnost ažuriranja indeksa po rasporedu. Osim toga, indeksi se mogu koristiti i online. Od sada moramo biti konkretniji.
Unatoč primitivnosti upita za pretraživanje, program se može koristiti za traženje datoteka, pa se njegova upotreba može opravdati u mrežama. Iako s velikim natezanjem, budući da je u velikoj mreži prioritet brzo tražiti podatke pomoću složenih upita za pretraživanje zbog ogromne količine informacija - a očito postoje problemi s brzinom pretraživanja i programa. Moram reći da je rad s mrežom u Bloodhoundu zamišljen kako treba. Za to je posebno dizajnirana posebna aplikacija - Bloodhound Server. Radi na isti način kao i samo Bloodhound (imaju jednu tražilicu), samo za dokumente koji se nalaze na središnjem poslužitelju ili na zajedničkim resursima na korporativnoj mreži. Bloodhound Server stvara nove indekse na zajedničkim resursima ili koristi prethodno stvorene. Svaki korisnik na korporativnoj mreži može se spojiti na Bloodhound Server i koristiti ga za pristup bilo kojem dokumentu (koji se nalazi u trenutnom indeksu) pomoću internetskog preglednika. Slažem se, takva je shema iznimno prikladna: ispada da se datoteke na vlastitoj mreži mogu pretraživati na isti način kao i informacije na Internetu putem, na primjer, Googlea.
Procjenjujući sve prednosti i nedostatke ovog programa, nameće se zaključak da za korporativne mreže njegove mogućnosti najvjerojatnije neće biti dovoljne (usprkos dobroj organizaciji umrežavanja), ali za kućno računalo ili čak za kućnu mrežu jest, u principu može odgovarati. Iako ni brzina rada, ni mogućnosti pretraživanja ne ulijevaju optimizam ...
Službena stranica na ruskom:
Veličina distribucije: 6 MbGoogle Desktop Search + GDS EnterpriseNaravno, nismo mogli zanemariti tako eminentnog programera. Ime Google već dovoljno govori. Ljudi koji već godinama koriste najmoćniju internetsku tražilicu vjerojatno će se bez ikakve sumnje odlučiti instalirati upravo ovu tražilicu na svoje računalo. To je kao da razmišljate: Google na svom kućnom računalu! No, ne podliježući provokacijama s naširoko promoviranim brendom, pokušajmo trezveno, a što je najvažnije objektivno, razmotriti mogućnosti „desktop“ tražilice iz Googlea.
Prva stvar koja vam upada u oči je nedostatak vlastite ljuske za program. Google Desktop Search je još uvijek u prozoru preglednika, odnosno cijelo sučelje desktop verzije prešlo je na softver starijeg internetskog brata. Je li to dobro ili loše je diskutabilno pitanje: netko voli minimalizam u dizajnu ove tražilice, a netko želi vidjeti punopravnu aplikaciju ispunjenu svim vrstama gumba i tako dalje.
Što vam upada u oči odmah nakon dizajna? I činjenica da ovaj isti Google Desktop Search počinje indeksirati sve na računalu, bez ikakve potražnje za tim! I što je najzanimljivije, nemoguće je odabrati putove za indeksiranje pomoću Google Desktop Searcha. Morat ćete preuzeti poseban program (TweakGDS), koji će vam omogućiti da donekle proširite postavke Google Desktopa, uključujući navođenje mjesta potrebnih za indeksiranje. Iako, dok sve shvatite, on će već indeksirati standardni tvrdi disk, pa je ova postavka potrebna više pri radu s velikim količinama podataka, što je vrlo važno kada se koristi u korporativnim mrežama (Enterprise verzija). Međutim, nije činjenica da će nakon preuzimanja TweakGDS-a vaši problemi biti riješeni. Uostalom, za rad su mu potrebni Microsoft .NET Framework i Microsoft Scripting Runtime. Da... instalacija, kao i pristup postavkama, mogli su biti lakši, iako, vjerojatno, programeri mogu razumjeti: zašto pisati nešto novo kada već postoji gotova tražilica, prenijeta na lokalno računalo i neka korisnik "uživa" , a poznato ime će od "ovoga" napraviti još jedno remek-djelo. Hajde, završimo ovu lirsku digresiju i prijeđimo na potragu.
Što se tiče analize upita pretraživanja i izdavanja rezultata, ovdje je sve apsolutno identično Googleu na Internetu: isti sustav za prikaz rezultata, isti standardni skup logičkih operacija za upite pretraživanja. Općenito, Google Desktop Search, kao i prethodni program, dizajniran je isključivo za pretraživanje datoteka - naravno, ne postoji interni preglednik za te datoteke. Broj formata datoteka koje podržava Google Desktop Search sasvim je dovoljan, a lijepo je i što pretražuje posjećene internetske stranice, uzimajući podatke iz predmemorije. Brzine pretraživanja i indeksiranja su sasvim prihvatljive. Istina, za kućnu upotrebu. S impresivnih 20 gigabajta tekstova, Google Desktop Search uspio je za 8 sati i 17 minuta. Provedite nekoliko dana obrađujući informacije iz korporativne mreže velikog poduzeća ne smiješi se niti jednom administratoru sustava. Pozitivna strana: veličina stvorenog indeksa pokazala se na razini (4,5 GB) s drugom tražilicom testiranom u ovoj recenziji - SearchInform.
Velika prednost (ili propust - vi odlučujete) Google Desktop Searcha je ta što podržava dodatke koji mogu promijeniti puno stvari na bolje. Druga stvar je što povezivanje dodataka i njihovo konfiguriranje toliko komplicira zadatak instaliranja tražilice da se počnete pitati je li sve to potrebno kada možete instalirati normalan, punopravni program u kojem će već sve biti prisutno. Uostalom, da biste koristili svaku značajku, morat ćete instalirati novi dodatak. Čak i da bi program u potpunosti radio s arhivama, potreban je zaseban losion. Fascinira i zavodi besplatno svim tim dodatnim modulima. Međutim, ako ne uzmete u obzir verziju tražilice za stolno računalo, kompetentno postavljanje GDS Enterprisea možda neće biti u vašoj moći - ne uzalud Googleovi stručnjaci nude svoje usluge za postavljanje vlastitog softvera za vašu mrežu za samo 10.000 dolara.
Ako ipak ovladate procedurom postavljanja i instalacije (ili platite 10.000 USD Googleovom timu za brzi odgovor), shvatit ćete da je složenost instalacije više nego nadoknađena vrlo fleksibilnim postavkama kada se koriste u korporativnim mrežama. Važan aspekt rada Google Desktopa u korporativnoj mreži je korištenje grupnih pravila, što omogućuje postavljanje postavki za svakog korisnika.
Sumirajući, treba reći da je najrazumnija upotreba ovog programa kućno ili radno računalo. Doista, za obično računalo, dovoljno je samo instalirati program - on će sam učiniti ostalo (neće vas ni o čemu pitati).
Međutim, Google Desktop Search Enterprise će biti prihvatljiv u slučajevima kada postoji hitna potreba za fleksibilnim postavkama mrežnih pravila za korištenje tražilice, dok će mogućnost obrade upita za pretraživanje biti na drugom mjestu po važnosti, a vremenu (ili novcu) potrošeno na postavljanje programa doći će na prvo mjesto.
Službena stranica:
Veličina distribucije s TweakGDS: 1,2 MbCopernic Desktop SearchKliknite na sliku za povećanje
Sučelje programa izaziva iznimno pozitivne emocije - sve je urađeno u skladu s općeprihvaćenim standardima, ništa suvišno, jednom riječju, ugodan dizajn. Početniku će biti vrlo lako razumjeti sučelje Copernic Desktop Searcha. Iako je pomalo neugodno što su dizajneri eksplicitno kreirali sučelje programa, uzimajući u obzir činjenicu da će program raditi u standardnoj Windows XP temi. Kada koristite istu klasičnu temu, program ne izgleda tako lijepo. Ali ovo je više stvar ukusa.
Pri prvom pokretanju program nudi izradu indeksa za pretraživanje. Činilo se pomalo neuobičajenim da nakon odabira mapa za indeksiranje, program ne nudi pritisnuti bilo koju tipku, poput "Pokreni indeksiranje", dok se indeksiranje ne pokreće automatski, tek tada se primijetilo da Copernic pokušava pokrenuti indeksiranje kada je računalo u stanju mirovanja . Morat ćete malo kopati po opcijama programa kako biste sve ispravno postavili. Treba napomenuti da postoje prilično široke mogućnosti za postavljanje automatskog stvaranja indeksa: ugrađeni planer, mogućnost indeksiranja kada je računalo u stanju mirovanja, u pozadini, s niskim prioritetom. Indeksiranje nije bilo prebrzo - 10 sati i 51 minutu - to je sporije nego u drugim tražilicama (osim Bloodhounda, no Copernic je za red veličine brži od razvoja iSleuthHound Technologies.
Sada o strukturi indeksa. Općenito, u tome nema ništa posebno. Moguće je odabrati vrste datoteka, kako u generaliziranom, tako iu detaljnom obliku. Odnosno, u početku možete odabrati što želite indeksirati - dokumente, slike, videozapise, glazbu. Na drugoj kartici prozora s opcijama bit će moguće odabrati određene vrste datoteka prema ekstenziji. Dodatno, možete konfigurirati indeks na način da se, na primjer, slike manje od 16x16 ne indeksiraju ili zvučne datoteke kraće od 10 sekundi ne indeksiraju. Osim indeksiranja datoteka iz mapa, Copernic može raditi s e-mailovima i kontaktima iz adresara Microsoft Outlooka i Microsoft Outlook Expressa, moguće je indeksirati Favorite i Povijest iz Internet Explorera.
Što se tiče mogućnosti pretraživanja, one su ovdje vrlo slabe. Tijekom testova čak je otkriveno da program ne traži dokumente u txt i html formatima na ruskom jeziku, što vam omogućuje da ih pronađete samo po naslovima, a nikako po sadržaju. Jedino što program pruža za poboljšanje učinkovitosti pretraživanja je korištenje standardnog skupa logičkih operacija, a čak i tada je ova značajka otkrivena eksperimentalno, budući da nije dokumentirana. Usput, pomoć programa također nije u redu - dostupna je samo putem interneta, što je, vidite, vrlo nezgodno, a na mreži nema previše pomoćnih informacija. Očigledno, programeri su odlučili da jednostavno sučelje programa ne podrazumijeva prisutnost normalne pomoći. Nastavljajući razgovor o mogućnostima pretraživanja, treba napomenuti da, unatoč lošoj analizi upita, program nudi zanimljiv sustav pretraživanja - korisnik može odabrati vrstu datoteka (slike, video, glazbu, itd.), unijeti upit za pretraživanje i odabir atributa koji su specifični za odabranu vrstu datoteke. Na primjer, za zvučne datoteke to mogu biti vrijednosti iz mp3 oznaka (izvođač, album, datum itd.), za slike, na primjer, možete odabrati njihovu veličinu (prema razlučivosti), općenito, svaka vrsta ima svoju vlastite postavke. Nakon pretraživanja određene vrste datoteka, program će prikazati vrlo informativan popis u prozoru s rezultatima, a ako vaš zahtjev uključuje datoteke drugih vrsta, možete ih otvoriti klikom na određenu poveznicu.
Zasebno, vrijedno je spomenuti prozor za prikaz rezultata. Sadržaj tih datoteka prikazan je ispod popisa pronađenih datoteka (slična shema se često koristi u klijentima e-pošte). Istina, tekst se može vidjeti samo u svom izvornom formatu, a nema načina prikaza običnog teksta, što nije uvijek prikladno, jer otvaranje dokumenta u ovom slučaju traje više vremena. No, s obzirom na to da Copernic može pretraživati slike i glazbu, postoji mogućnost pregleda tih multimedijskih datoteka.
Osnovni principi ovog programa su opisani, sada da vidimo što nam Copernic Desktop Search može ponuditi za rad s mrežom... U principu, možete gledati jako dugo, ali malo je vjerojatno da ćete išta vidjeti. Drugim riječima, ovaj program nije zamišljen kao mrežni. Copernic Desktop Search je isključivo kućna tražilica.
Očito, jedina (najlogičnija) upotreba ovog programa je kućno računalo. Ovdje će se sasvim nositi sa svim jednostavnim upitima za pretraživanje korisnika koji se sastoje od jedne ili dvije riječi, pronaći potrebne informacije, te odvajanje pretraživanja po vrsti datoteke i podršku za multimedijske datoteke, uz pozadinsko indeksiranje u načinu rada niskog prioriteta, zajedno s ugodnim sučeljem, samo daju snagu programu da stekne povjerenje među neiskusnim korisnicima.
Službena stranica
Veličina distribucije: 2,6 MbISYS DesktopKliknite na sliku za povećanje
Vrlo moćan program. Po razini opremljenosti sa svim vrstama funkcija nalazi se negdje blizu sljedeće tražilice SearchInform na popisu. Istodobno, veličina instalacijske datoteke je veća od 40Mb! Teško je reći što bi se moglo strpati u takve veličine, jer isti SearchInform, sa sličnom funkcionalnošću, zauzima 15Mb.
Proces instalacije ovdje također nije baš ugodan, odnosno čak ni proces instalacije. Čak i prije preuzimanja programa od vas će se tražiti da se registrirate, inače - ništa. Dalje, sučelje. Napravljen je jako lijepo, ništa suvišno ne upada u oči, međutim, to su dojmovi osobe koja se već pomalo navikla na njega. Početniku neće biti lako shvatiti gdje i što je, gdje kliknuti i gdje na kraju potražiti. Vrlo je preporučljivo pročitati pomoć prije početka rada – uštedite puno živaca i vremena. Na sve ostalo dodaje se i potpuni nedostatak podrške za ruski jezik u programu. Nije dobro. Osim toga, prozori ovdje nisu preopterećeni kontrolama, ali to je došlo po cijenu višemodula i korištenja dodatnih prozora. Na primjer, upiti za pretraživanje unose se pokretanjem jednog programa, a indeksima se upravlja pomoću drugog programa. Ovdje se također unose upiti za pretraživanje u zasebnim okvirima koji se pojavljuju. Teško je reći što je bolje - preopterećeno sučelje ili sveprisutni multi-window, dapače, stvar je ukusa.
Što se tiče izrade indeksa, program nudi opcije za pojednostavljenje procesa postavljanja opcija za novi indeks. Ove značajke uključuju nekoliko gotovih predložaka za izradu indeksa za Moje dokumente, poštu, poštu i dokumente, određenu mapu, mapu s odabranim vrstama datoteka i još mnogo toga. Ovi predlošci olakšavaju stvaranje indeksa u prvoj fazi. Uslužni program za rad s indeksima ima ne baš dobro sučelje koje plaši neke složenosti (ovo je vrlo subjektivna procjena, da budemo iskreni), ali ako ga pogledate, pruža mnogo korisnih opcija i, općenito, njegova upotreba čini ne izazivaju velike poteškoće. ISYS Desktop može indeksirati podatke iz različitih izvora podataka, a također nudi mnoge fleksibilne postavke za takvo indeksiranje. Dodatne značajke indeksiranja uključuju podršku za SQL, FTP, TRIM Context, WORLDOX 2002, skripte. Prilikom izrade indeksa, ako ste odabrali opciju "Mapa s izborom vrsta datoteka", imate priliku odabrati vrste datoteka koje će se indeksirati ručno (prema ekstenzijama). Mora se reći da jednostavno postoji ogroman broj podržanih vrsta datoteka, ali neće biti moguće dodati vlastitu vrstu (proširenje) na postojeći popis. Također možete primijetiti prisutnost planera indeksiranja. ISYS Desktopu je trebalo 6 sati i 13 minuta za izradu indeksa i obradu 20 gigabajta informacija, te je na kraju pokazao dobro vrijeme i veličinu kreirane datoteke - 7,9 GB.
Mogućnosti pretraživanja ovog programa nisu loše. Ono što se koristi u ISYS-u puno je moćnije od uobičajene podrške za logičke operacije. Od naprednih značajki pretraživanja, program nudi korištenje sinonima, sortiranje filtera (po putanji, nazivu i datumu stvaranja datoteke). Skup logičkih operatora je nešto širi od standardnog skupa. Osim logičkih operacija, program vam omogućuje rad s mnogim drugim operatorima koji u principu mogu zamijeniti neke vrste pretraživanja, na primjer, pretraživanje s raščlanjivanjem može se u potpunosti zamijeniti upotrebom posebnih operatora. Bio sam jako iznenađen što program nema pretragu pomoću morfologije. Ovo je ozbiljan propust, budući da je učinkovitost pretraživanja znatno poboljšana korištenjem morfološke analize. Osim toga, ne postoji popis značajnih riječi, ali postoji opsežan popis nebitnih riječi. Također su deklarirane takve funkcije u pretraživanju kao "približno pretraživanje" i "heuristička analiza".
ISYS nudi izbor između nekoliko vrsta upita za pretraživanje, odnosno vizualnih. To se radi pomoću različitih vrsta prozora za unos upita za pretraživanje, međutim, zapravo, nijedan prozor ne dopušta korištenje tehnologija koje nisu gore navedene.
Rezultati pretraživanja su vrlo informativni, prikazuju se kao popis dokumenata poredanih po relevantnosti. Ispod je pregled odabranog dokumenta. Za razliku od Copernic Desktop Searcha, ovdje je pregled dostupan samo u obliku običnog teksta, nije bilo moguće postići prikaz dokumenata u izvornom formatu, bilo Word, Html ili PDF, iako to u principu nije previše kritično. Program vam omogućuje podjelu pronađenih dokumenata u grupe prema određenim kriterijima (prema zadanim postavkama, podijeljeni su po relevantnosti). Također možete vidjeti već pronađene dokumente odabirom pojedinačnih mapa (ovo je korisno kada rezultat proizvodi vrlo velik broj dokumenata).
Korištenje programa u korporativnoj mreži također je sasvim opravdano, jer pruža dobre mogućnosti za organiziranje pretraživanja mreže. Sustav pretraživanja temelji se na stvaranju javnog indeksa, koji sadrži indeksirane podatke iz javnih mrežnih resursa.
Zapravo, program iz ISYS-a je vrijedan pažnje, barem upoznavanja s njim. Ovaj program je zreo projekt s ogromnim brojem funkcija (ne uvijek i ne trebaju ih svi, naravno, ali ipak). Šanse da će program imati neka poboljšanja u obradi upita pretraživanja nisu poznate, ali se trenutno može preporučiti za gotovo univerzalnu upotrebu. A s obzirom da je još uvijek pretežak za kućne sustave, glavna mjesta za njegovu instalaciju su korporativne mreže.
Službena stranica:
Veličina distribucije: 40 MbSearchInformKliknite na sliku za povećanje
Vjerojatno se ne isplati odmah početi s opisom sučelja SearchInform. Prvo bismo trebali opisati proces instalacije, odnosno jedan od njegovih detalja: nećete moći instalirati program bez internetske veze. Činjenica je da prije prvog pokretanja program zahtijeva registraciju korisnika (besplatno) i sve unesene podatke šalje na poslužitelj. Navodno su programeri morali poduzeti takve mjere u borbi protiv piratstva, ali to nije pozitivno utjecalo na jednostavnost instalacije.
Sučelje programa izrađeno je u skladu sa svim općeprihvaćenim pravilima, ali je na prvi pogled pomalo glomazno. Prvim korištenjem programa čini se da je previše komplicirano, ponekad se nije lako sjetiti na kojem izborniku ili kartici se nalazi željena opcija, međutim, duljom uporabom sučelje se više ne čini tako užasno kompliciranim. Glavna stvar je prvo pročitati pomoć.
Nakon što ste se malo pozabavili sučeljem, možete početi stvarati indeks. Sam proces je vrlo jednostavan, a brzina indeksiranja, čak i na oko, puno je veća od svih ostalih tražilica iz recenzije. Jasni testovi pokazuju da je SearchInform dvostruko brži od dtSearch-a i iSYS-a u smislu brzine indeksiranja! Program je indeksirao dostavljene podatke u količini od 20 gigabajta u rekordnom vremenu - 3 sata i 17 minuta. A veličina stvorenog indeksa pokazala se najmanjih 4,4 GB - 100 megabajta manje od Google Desktop Searcha.
Program podržava, osim običnih datoteka i mapa, i indeksiranje e-pošte, povezivanje i indeksiranje baza podataka (!) I drugih vanjskih izvora (DMS, CRM), odmah prilikom indeksiranja možete odrediti rječnik za morfološko pretraživanje, a svi atributi mogu biti indeksirane datoteke. Nakon izrade indeksa, kada pokušate provesti prvu probnu pretragu dokumenata, možete doći do neke zabune: "postoje dvije vrste pretraživanja, ali koja mi treba?". Kao što je ranije spomenuto, glavna stvar je pročitati pomoć, tada će sve postati jasno. Program je doista sposoban izvršiti dvije vrste pretraživanja - pretraživanje po frazi i traženje dokumenata koji su po sadržaju slični tekstu upita.
Opis svih glavnih funkcija za analizu upita za pretraživanje dat je gore, pa ćemo sada navesti samo mogućnosti pretraživanja koje pruža ovaj program. Počnimo s pretraživanjem izraza: naravno, morfološko pretraživanje, pretraživanje citata, logičke operacije, pretraživanje raščlanjivanja riječi (traži po početku riječi, do kraja, po srednjem dijelu ili potpuno podudaranje), mješovito pretraživanje citata (kada sve riječi iz upita moraju biti prisutne u dokumentu, ali ne nužno unesenim redoslijedom), pretraživanja za ispravljanje pogrešaka, korištenje sinonima, "pretraga gotovo citata" (traži unesenu frazu kao citat, ali može postojati i drugi riječi između unesenih riječi) itd. Neke od navedenih opcija imaju svoje specifične postavke. Osim toga, moguće je koristiti rječnik beznačajnih riječi, a program već ima gotov popis tih riječi, možete koristiti i rječnik prioritetnih riječi za pretraživanje (naravno, morat ćete ga ispuniti sami).
Ovdje smo, u principu, ukratko prošli kroz sve glavne značajke pretraživanja izraza.
Prijeđimo na razmatranje značajki ovog programa - traženje sličnih dokumenata. Programeri tvrde da ovo nipošto nije jednostavna pretraga teksta, to je upravo "potraga za sličnim" - tako to svugdje opisuju, ali dobro, možete to zvati kako god želite - glavno je. Kratka internetska pretraga može brzo otkriti da je takozvana "slična pretraga" novi razvoj u području analize teksta. Ovaj sustav vam omogućuje da pronađete tekstove koji su slični u smislu semantičkog sadržaja. Najugodnije je bilo to što se nakon provođenja testnih upita za pretraživanje pokazalo da je teorija sasvim u skladu s praksom! Program doista traži dokumente slične po sadržaju i prikazuje ih na popisu, razvrstane prema postotku sličnosti.
Dalje, pogledajmo što SearchInform nudi (posebno njegovu korporativnu verziju SearchInform Corporate) za rad u korporativnoj mreži. Postoje dvije vrste aplikacija: na strani poslužitelja i na strani korisnika. Poslužiteljski dio samostalno obrađuje navedene indekse, a korisnici ih mogu koristiti za pretraživanje, ovisno o pravima pristupa koja su im dodijeljena. Korisnici se mogu konfigurirati automatski pomoću Windows računa (profesionalno rečeno, SearchInform koristi Windows NTFS autentifikaciju) ili ručno (korisnici će se morati dodati pojedinačno). Svakom korisniku može biti dopušten ili odbijen pristup određenim indeksima, također možete kombinirati korisnike u grupe. Općenito, SearchInform-ove mrežne postavke su ispred Googlea u pogledu fleksibilnosti, a Snoop Servera u smislu praktičnosti i jednostavnosti.
Službena stranica:
Veličina distribucije: 14,7 Mb Usporedba brzine indeksiranja
Sustav pretraživanja Vrijeme indeksiranja Veličina indeksa Bloodhound Pro Deluxe 4.5 38 sati 46 minuta 19 GB Isys Desktop 7.0 6 sati 13 minuta 7,9 GB DtSearch 7.0 6 sati 3 minute 8,6 GB Google Desktop Search Enterprise 8 sati 17 minuta 4,5 GB Copernic Desktop Search * 10 sati 51 minuta 7 GB SearchInform 1.5.02 3 sata 17 minuta 4,4 GB * Većinu .html i .txt dokumenata koji sadrže ruski tekst, iako su bili indeksirani, bilo je nemoguće pronaći osim po njihovim imenima. Sažetak
Svi programi su vrijedni pažnje.
Na temelju testova i pažljivog pregleda svakog programa predstavljenog u pregledu, mogu se izvući određeni zaključci. Dakle, Google Desktop Search Copernic Desktop Search je sasvim prikladan za neiskusnog korisnika kao sustav za pretraživanje kućnih informacija. Oni dobro rade s jednostavnim zahtjevima, ne opterećuju korisnika puno postavkama i, štoviše, potpuno su besplatni. Googleov pokušaj da uđe na tržište korporativnih tražilica još nije snažno opravdan: za punopravni rad, program mora biti obješen dodatnim modulima, a nije ga lako postaviti. Stoga, govoreći imena Desktop Searcha, tog Copernica, tog Googlea ostavljaju iza sebe nišu "desktop" tražilica.
Istina, moćnija rješenja - dtSearch, iSYS i SearchInform također nisu iznebuha i nude korisnicima svoje "desktop" verzije. Ali po razumnoj cijeni, za razliku od besplatnog softvera iz Googlea i Copernica. Naravno, morate platiti snagu, brzinu i funkcionalnost. No, programeri dtSearch, iSYS i SearchInform svoj glavni fokus, naravno, usmjeravaju na korporativni sektor. Umrežavanje, funkcionalnost, indeksiranje i brzina pretraživanja - to je ono što ove proizvode razlikuje od njihovih "konkurenta". Prema rezultatima testa, određen je favorit - SearchInform. Program pruža mogućnost pretraživanja sličnih dokumenata, ima najveću brzinu indeksiranja i pretraživanja te ima dobar skup funkcija.