V Excel postoji još brži i prikladniji način za crtanje linearne regresije (pa čak i osnovne vrste nelinearnih regresija, kao što je objašnjeno u nastavku). To se može učiniti na sljedeći način:
1) odaberite stupce s podacima x i Y(moraju biti tim redoslijedom!);
2) poziv Čarobnjak za karte i odaberite u grupi Vrsta – Točka i odmah pritisnite Spreman;
3) bez ispuštanja odabira s dijagrama, odaberite prikazanu stavku glavnog izbornika Dijagram, u kojem biste trebali odabrati stavku Dodajte liniju trenda;
4) u dijaloškom okviru koji se pojavi Linija trenda u kartici Vrsta Odaberi Linearni;
5) u kartici Mogućnosti prekidač se može aktivirati Prikaži jednadžbu u grafikonu, što će vam omogućiti da vidite jednadžbu linearne regresije (4.4), u kojoj će se izračunati koeficijenti (4.5).
6) U istoj kartici možete aktivirati prekidač Postavite aproksimacijski pouzdanost (R ^ 2) na dijagram... Ova veličina je kvadrat koeficijenta korelacije (4.3) i pokazuje koliko dobro izračunata jednadžba opisuje eksperimentalnu ovisnost. Ako R 2 je blizu jedinice, tada teorijska regresijska jednadžba dobro opisuje eksperimentalnu ovisnost (teorija se dobro slaže s eksperimentom), a ako R 2 je blizu nuli, onda ova jednadžba nije prikladna za opisivanje eksperimentalne ovisnosti (teorija se ne slaže s eksperimentom).
Kao rezultat izvođenja opisanih radnji, dobit ćete dijagram s regresijskim grafom i njegovom jednadžbom.
§4.3. Glavne vrste nelinearne regresije
Parabolička i polinomska regresija.
Parabolični ovisnost količine Y na vrijednost NS naziva se ovisnost izražena kvadratnom funkcijom (parabola 2. reda):
Ova se jednadžba zove jednadžba paraboličke regresije Y na NS... Mogućnosti a, b, s se zovu koeficijenti paraboličke regresije... Izračunavanje koeficijenata paraboličke regresije uvijek je glomazno pa se za izračune preporučuje korištenje računala.
Jednadžba (4.8) paraboličke regresije poseban je slučaj općenitije regresije koja se naziva polinom. Polinom ovisnost količine Y na vrijednost NS naziva se ovisnost izražena polinomom n-ti red:
gdje su brojevi i ja (i=0,1,…, n) se zovu koeficijenti polinomske regresije.
Regresija snage.
Eksponencijalno ovisnost količine Y na vrijednost NS ovisnost oblika naziva se:
Ova se jednadžba zove jednadžba regresije snage Y na NS... Mogućnosti a i b se zovu koeficijenti regresije snage.
ln = ln a+b ln x. (4.11)
Ova jednadžba opisuje ravnu liniju u ravnini s logaritamskim koordinatnim osi ln x i ln. Stoga je kriterij za primjenjivost regresije po stupnju zahtjev da točke logaritama empirijskih podataka ln x i i ln i bili najbliži pravoj liniji (4.11).
Eksponencijalna regresija.
Indikativno(ili eksponencijalna) ovisnošću količine Y na vrijednost NS ovisnost oblika naziva se:
(ili ). (4.12)
Ova se jednadžba zove eksponencijalnu jednadžbu(ili eksponencijalna) regresija Y na NS... Mogućnosti a(ili k) i b se zovu eksponencijalna(ili eksponencijalna) regresije.
Ako uzmemo logaritam obje strane jednadžbe regresije moći, dobit ćemo jednadžbu
ln = x ln a+ In b(ili ln = k x+ In b). (4.13)
Ova jednadžba opisuje linearnu ovisnost logaritma jedne veličine ln o drugoj veličini x... Stoga je kriterij primjenjivosti regresije snage zahtjev da empirijski podaci ukazuju na istu količinu x i a logaritmi druge veličine ln i bili najbliži pravoj liniji (4.13).
Logaritamska regresija.
Logaritamski ovisnost količine Y na vrijednost NS ovisnost oblika naziva se:
=a+b ln x. (4.14)
Ova se jednadžba zove logaritamska regresijska jednadžba Y na NS... Mogućnosti a i b se zovu koeficijenti logaritamske regresije.
Hiperbolička regresija.
Hiperbolični ovisnost količine Y na vrijednost NS ovisnost oblika naziva se:
Ova se jednadžba zove jednadžba hiperboličke regresije Y na NS... Mogućnosti a i b se zovu koeficijenti hiperboličke regresije a određuju se metodom najmanjih kvadrata. Primjena ove metode dovodi do formula:
U formulama (4.16-4.17) zbrajanje se vrši preko indeksa i od jednog do broja opažanja n.
Nažalost u Excel ne postoji funkcija koja izračunava koeficijente hiperboličke regresije. U slučajevima kada nije unaprijed poznato da su mjerene veličine povezane obrnuto proporcionalno, preporuča se da se umjesto jednadžbe hiperboličke regresije traži jednadžba regresije snage, kao u Excel postoji procedura za njegovo pronalaženje. Ako se između izmjerenih vrijednosti pretpostavi hiperbolička ovisnost, tada će se koeficijenti njezine regresije morati izračunati pomoću pomoćnih proračunskih tablica i operacija zbrajanja pomoću formula (4.16-4.17).
Regresija u Excelu
Statistička obrada podataka može se izvesti i pomoću dodatka paketa Analiza u točki izbornika "Usluga". U Excelu 2003, ako otvorite SERVIS, ne nalazimo karticu ANALIZA PODATAKA, a zatim klikom lijeve tipke miša otvorite karticu NADGRADNJE i suprotna točka PAKET ANALIZE klikom na lijevu tipku miša stavite kvačicu (slika 17).
Riža. 17. Prozor NADGRADNJE
Nakon toga u izborniku SERVIS pojavljuje se kartica ANALIZA PODATAKA.
U programu Excel 2007 za instalaciju PAKET ANALIZE potrebno je kliknuti na gumb URED u gornjem lijevom kutu lista (slika 18a). Zatim kliknite na gumb EXCEL PARAMETRI... U prozoru koji se pojavi EXCEL PARAMETRI kliknite lijevom tipkom miša na stavku NADGRADNJE i na desnoj strani padajućeg popisa odaberite stavku PAKET ANALIZE. Zatim kliknite na u redu.




Riža. 18. Instalacija PAKET ANALIZE u Excelu 2007
Da biste instalirali paket za analizu, kliknite na gumb IĆI, koji se nalazi na dnu otvorenog prozora. Prozor prikazan na sl. 12. Stavite kvačicu nasuprot PAKET ANALIZE. U kartici PODACI pojavit će se gumb ANALIZA PODATAKA(slika 19).

Od predloženih stavki odabire stavku " REGRESIJA„I kliknite na njega lijevom tipkom miša. Zatim kliknite OK.

Prozor prikazan na sl. 21

Alat za analizu" REGRESIJA»Upotrebljava se za uklapanje grafa za skup opažanja metodom najmanjih kvadrata. Regresija se koristi za analizu učinka vrijednosti jedne ili više varijabli objašnjenja na pojedinačnu ovisnu varijablu. Na primjer, nekoliko čimbenika utječe na atletske performanse sportaša, uključujući dob, visinu i težinu. Možete izračunati utjecaj svakog od ova tri čimbenika na izvedbu sportaša, a zatim upotrijebiti te podatke za predviđanje učinka drugog sportaša.
Alat Regresija koristi tu funkciju LINEST.
Dijaloški okvir REGRESSION
Oznake Označite potvrdni okvir ako prvi redak ili prvi stupac raspona unosa sadrži zaglavlja. Poništite ovaj potvrdni okvir ako nema naslova. U tom će se slučaju automatski generirati odgovarajuća zaglavlja za podatke izlazne tablice.
Razina pouzdanosti Odaberite potvrdni okvir za uključivanje dodatne razine u tablicu ukupnih rezultata. U odgovarajuće polje unesite razinu pouzdanosti koju želite primijeniti, uz zadanu razinu od 95%.
Konstanta - nula Označite potvrdni okvir kako bi linija regresije prolazila kroz ishodište.
Izlazni razmak Unesite referencu na gornju lijevu ćeliju izlaznog raspona. Dodijelite najmanje sedam stupaca za tablicu ukupnih izlaznih vrijednosti, koja će uključivati: rezultate ANOVA, koeficijente, standardnu pogrešku izračuna Y, standardne devijacije, broj opažanja, standardne pogreške za koeficijente.
Novi radni list Odaberite ovaj prekidač da biste otvorili novi radni list u radnoj knjizi i umetnuli rezultate analize počevši od ćelije A1. Ako je potrebno, unesite naziv za novi list u polje nasuprot odgovarajućeg položaja prekidača.
Nova radna knjiga Pritisnite prekidač na ovu poziciju da biste stvorili novu radnu knjigu u kojoj će se rezultati dodati na novi list.
Ostaci Označite potvrdni okvir da biste uključili ostatke u izlaznu tablicu.
Standardizirani ostaci Označite potvrdni okvir za uključivanje standardiziranih ostataka u izlaznu tablicu.
Iscrtaj ostatke Označite potvrdni okvir za iscrtavanje reziduala za svaku neovisnu varijablu.
Grafikon uklapanja Označite potvrdni okvir za crtanje grafikona predviđenih vrijednosti naspram promatranih vrijednosti.
Grafikon normalne vjerojatnosti Označite okvir za crtanje normalnog grafa vjerojatnosti.
Funkcija LINEST
Za izračune odaberite ćeliju u kojoj želimo prikazati prosječnu vrijednost kursorom i pritisnite tipku = na tipkovnici. Zatim u polju Naziv navedite željenu funkciju, na primjer PROSJEČAN(slika 22).

Riža. 22 Pronalaženje funkcija u Excelu 2003
Ako na terenu IME naziv funkcije se ne pojavljuje, zatim lijevom tipkom miša kliknite na trokut pored polja, nakon čega će se pojaviti prozor s popisom funkcija. Ako ove funkcije nema na popisu, kliknite lijevom tipkom miša na stavku popisa OSTALE FUNKCIJE, pojavit će se dijaloški okvir MAJSTOR FUNKCIJA, u kojem pomoću okomitog pomicanja odaberite željenu funkciju, odaberite je kursorom i kliknite na u redu(slika 23).

Riža. 23. Čarobnjak za funkcije
Za traženje funkcije u Excelu 2007 može se otvoriti bilo koja kartica u izborniku, zatim za izračune odabrati ćeliju u kojoj želimo prikazati prosječnu vrijednost i pritisnuti tipku = na tipkovnici. Zatim u polju Naziv navedite funkciju PROSJEČAN... Prozor za izračun funkcije sličan je onom prikazanom u Excelu 2003.
Također možete odabrati karticu Formule i kliknuti lijevom tipkom na gumb u izborniku " INSERT FUNCTION”(slika 24), pojavit će se prozor MAJSTOR FUNKCIJA, čija je vrsta slična Excel 2003. Također u izborniku možete odmah odabrati kategoriju funkcija (nedavno korištene, financijske, logičke, tekstualne, datum i vrijeme, matematičke, druge funkcije), u kojima ćemo tražiti željenu funkciju.




Riža. 24 Odabir funkcije u Excelu 2007
Funkcija LINEST izračunava statistiku za niz pomoću najmanjih kvadrata za izračunavanje ravne linije koja najbolje odgovara dostupnim podacima, a zatim vraća niz koji opisuje rezultirajuću ravnu liniju. Također možete kombinirati funkciju LINEST s drugim funkcijama za izračunavanje drugih vrsta modela koji su linearni u nepoznatim parametrima (čiji su nepoznati parametri linearni), uključujući polinomske, logaritamske, eksponencijalne i nizove stepena. Budući da se vraća niz vrijednosti, funkcija mora biti navedena kao formula polja.
Jednadžba za ravnu liniju je sljedeća:
(u slučaju više raspona x vrijednosti),
gdje je zavisna vrijednost y funkcija neovisne vrijednosti x, m vrijednosti su koeficijenti koji odgovaraju svakoj nezavisnoj x varijabli, a b je konstanta. Imajte na umu da y, x i m mogu biti vektori. Funkcija LINEST vraća niz ![]() . LINEST može također vratiti dodatnu statistiku regresije.
. LINEST može također vratiti dodatnu statistiku regresije.
LINEST(poznati_y; poznati_x; konst; statistika)
Poznati_y su skup y-vrijednosti koje su već poznate za odnos.
Ako poznati_y ima jedan stupac, tada se svaki stupac u poznatom_x tumači kao zasebna varijabla.
Ako poznati_y ima jedan redak, tada se svaki redak u poznatom_x tumači kao zasebna varijabla.
Poznati_x su izborni skup vrijednosti x koje su već poznate za odnos.
Poznati_x mogu sadržavati jedan ili više skupova varijabli. Ako se koristi samo jedna varijabla, tada poznati_y i poznati_x mogu biti bilo kojeg oblika, sve dok imaju istu dimenziju. Ako se koristi više od jedne varijable, poznati_y mora biti vektor (to jest, visok jedan redak ili širina jednog stupca).
Ako je niz_ poznatih_x izostavljen, tada se pretpostavlja da je ovaj niz (1; 2; 3; ...) iste veličine kao niz_ poznati_y.
Const je Booleova vrijednost koja pokazuje da li konstanta b mora biti 0.
Ako je const TRUE ili izostavljena, konstanta b se procjenjuje na uobičajeni način.
Ako je argument "const" FALSE, tada se vrijednost b postavlja jednaka 0, a vrijednosti m se biraju na takav način da relacija vrijedi.
Statistika je Booleova vrijednost koja pokazuje želite li vratiti dodatnu statistiku za regresiju.
Ako je statistika TRUE, LINEST vraća dodatnu statistiku regresije. Vraćeni niz će izgledati ovako: (mn; mn-1; ...; m1; b: sen; sen-1; ...; se1; seb: r2; sey: F; df: ssreg; ssresid).
Ako je statistika FALSE ili je izostavljena, LINEST vraća samo koeficijente m i konstantu b.
Dodatna statistika regresije.
Slika ispod prikazuje redoslijed kojim se vraćaju dodatne statistike regresije.

Bilješke:
Svaka ravna linija može se opisati svojim nagibom i sjecištem s y-osom:
Nagib (m): Za određivanje nagiba ravne linije, koja se obično označava s m, trebate uzeti dvije točke ravne crte i; nagib će biti ![]() .
.
Y-presjek (b): y-sjecište pravca, obično označeno s b, je y-vrijednost točke u kojoj pravac siječe y-os.
Jednadžba ravne linije ima oblik. Ako znate vrijednosti m i b, možete izračunati bilo koju točku na liniji zamjenom vrijednosti y ili x u jednadžbi. Također možete koristiti funkciju TREND.
Ako postoji samo jedna nezavisna varijabla x, možete izravno dobiti nagib i y-presjek koristeći sljedeće formule:
Nagib: INDEX (LINEST (poznati_y; poznati_x); 1)
Y-raskrižje: INDEX (LINEST (poznati_y; poznati_x); 2)
Točnost aproksimacije LINEST linije ovisi o stupnju raspršenosti podataka. Što su podaci bliži pravoj liniji, to je LINEST model točniji. LINEST koristi metodu najmanjih kvadrata kako bi odredio što najbolje odgovara podacima. Kada postoji samo jedna nezavisna varijabla x, m i b se izračunavaju pomoću sljedećih formula:

gdje su x i y uzorci, na primjer x = PROSJEČAN (poznati_x) i y = PROSJEČNI (poznati_y).
Funkcije uklapanja LINEST i LOGEST mogu izračunati ravnu ili eksponencijalnu krivulju koja najbolje opisuje podatke. Međutim, oni ne daju odgovor na pitanje koji je od dva rezultata prikladniji za rješavanje zadatka. Također možete izračunati TREND (poznati_y; poznati_xovi) za ravnu liniju ili RAST (poznati_y; poznati_xovi) za eksponencijalnu krivulju. Ove funkcije, ako ne navedete new_x_values, vraćaju niz izračunatih y-vrijednosti za stvarne x-vrijednosti duž ravne linije ili krivulje. Izračunate vrijednosti se zatim mogu usporediti sa stvarnim vrijednostima. Također možete izraditi grafikone za vizualnu usporedbu.
S regresijskom analizom, Microsoft Excel izračunava, za svaku točku, kvadrat razlike između predviđene y-vrijednosti i stvarne y-vrijednosti. Zbroj tih kvadrata razlika naziva se rezidualni zbroj kvadrata (ssresid). Microsoft Excel zatim izračunava ukupan zbroj kvadrata (sstotal). Ako je const = TRUE ili izostavljeno, ukupni zbroj kvadrata jednak je zbroju kvadrata razlike između stvarnih vrijednosti y i srednjih vrijednosti y. Kada je const = FALSE, ukupni zbroj kvadrata bit će jednak zbroju kvadrata stvarnih vrijednosti y (bez oduzimanja srednje vrijednosti y od kvocijenta vrijednosti y). Regresijski zbroj kvadrata se tada može izračunati na sljedeći način: ssreg = sstotal - ssresid. Što je rezidualni zbroj kvadrata manji, to je veća vrijednost koeficijenta determinizma r2, što pokazuje koliko dobro jednadžba dobivena regresijskom analizom objašnjava odnos između varijabli. Koeficijent r2 je ssreg / sstotal.
U nekim slučajevima, jedan ili više X stupaca (neka vrijednosti Y i X budu u stupcima) nemaju dodatnu predikativnu vrijednost u drugim stupcima X. Drugim riječima, brisanje jednog ili više X stupaca može rezultirati Y vrijednostima izračunati s istom preciznošću. U ovom slučaju, redundantni X stupci bit će isključeni iz regresijskog modela. Taj se fenomen naziva "kolinearnost" jer se redundantni X stupci mogu predstaviti kao zbroj više neredundantnih stupaca. LINEST provjerava kolinearnost i uklanja sve suvišne X stupce iz regresijskog modela ako ih pronađe. Izbrisani X stupci mogu se identificirati u LINEST izlazu faktorom 0 i se vrijednošću 0. Uklanjanje jednog ili više stupaca kao suvišnih mijenja df vrijednost jer ovisi o broju X stupaca koji se stvarno koriste u svrhe predviđanja. Za više informacija o izračunavanju df, pogledajte primjer 4. Kada se df promijeni zbog uklanjanja suvišnih stupaca, sey i F također se mijenjaju. Kolinearnost se često obeshrabruje. Međutim, treba ga koristiti ako neki od X stupaca sadrže 0 ili 1 kao indikator koji pokazuje je li subjekt eksperimenta u zasebnoj skupini. Ako je const = TRUE ili je izostavljen, LINEST umeće dodatni X stupac za simulaciju točke presjeka. Ako postoji stupac s vrijednostima 1 za muškarce i 0 za žene, a postoji i stupac s vrijednostima 1 za žene i 0 za muškarce, tada se zadnji stupac uklanja jer se njegove vrijednosti mogu dobiveno iz stupca s “indikatorom muškog spola”.
Izračun df za slučajeve kada stupci X nisu uklonjeni iz modela zbog kolinearnosti je sljedeći: ako postoji k stupaca poznatih_x i vrijednost const = TRUE ili nije navedena, tada je df = n - k - 1. Ako const = FALSE, tada je df = n - k. U oba slučaja, uklanjanje X stupaca zbog kolinearnosti povećava df vrijednost za 1.
Formule koje vraćaju nizove moraju se unijeti kao formule polja.
Kada unesete niz konstanti za, na primjer, poznati_x, upotrijebite točku i zarez za odvajanje vrijednosti u istom retku i dvotočku za razdvajanje redaka. Znakovi za razdvajanje razlikuju se ovisno o opcijama postavljenim u prozoru Jezik i standardi na upravljačkoj ploči.
Treba napomenuti da y-vrijednosti predviđene jednadžbom regresije možda neće biti točne ako su izvan raspona y-vrijednosti koje su korištene za definiranje jednadžbe.
Glavni algoritam koji se koristi u funkciji LINEST, razlikuje se od glavnog algoritma funkcija NAGIB i ODJELJAK... Razlike između algoritama mogu dovesti do različitih rezultata za nedefinirane i kolinearne podatke. Na primjer, ako su podatkovne točke poznatih_y 0, a podatkovne točke poznatih_x 1, tada:
Funkcija LINEST vraća vrijednost jednaku 0. Algoritam funkcije LINEST koristi se za vraćanje valjanih vrijednosti za kolinearne podatke, u kojem slučaju se može pronaći barem jedan odgovor.
Funkcije SLOPE i INTERCEPT vraćaju pogrešku # DIV / 0!. Algoritam funkcija SLOPE i INTERCEPT služi za traženje samo jednog odgovora, au ovom slučaju može ih biti nekoliko.
Uz izračun statistike za druge vrste regresije, LINEST se može koristiti za izračunavanje raspona za druge vrste regresije unosom funkcija x i y kao niza x i y za LINEST. Na primjer, sljedeća formula:
LINEST (y-vrijednosti, x-vrijednosti ^ COLUMN ($ A: $ C))
radi tako da ima jedan stupac vrijednosti Y i jedan stupac vrijednosti X za izračunavanje aproksimacije kocki (polinom 3. stupnja) sljedećeg oblika:
Formula se može promijeniti kako bi se izračunale druge vrste regresije, ali u nekim slučajevima su potrebne prilagodbe izlaznih vrijednosti i drugih statistika.
Po mom mišljenju, kao studentu, ekonometrija je jedna od najprimijenjenijih znanosti od svih s kojima sam se uspio upoznati u zidovima svog sveučilišta. Uz nju je, doista, moguće riješiti probleme primijenjene prirode na razini poduzeća. Koliko će ta rješenja biti učinkovita, treće je pitanje. Zaključak je da će većina znanja ostati teorija, ali ekonometrija i regresijska analiza i dalje su vrijedni proučavanja s posebnom pažnjom.
Što objašnjava regresija?
Prije nego počnemo ispitivati funkcije MS Excela koje omogućuju rješavanje ovih problema, želio bih vam na prste objasniti što, u biti, podrazumijeva regresijska analiza. Tako ćete lakše položiti ispit, a što je najvažnije bit će zanimljivije proučavati predmet.
Nadamo se da ste upoznati s konceptom funkcije iz matematike. Funkcija je odnos između dvije varijable. Kada se jedna varijabla promijeni, nešto se događa drugoj. Mijenjamo X, odnosno Y također. Funkcije opisuju različite zakone. Poznavajući funkciju, možemo zamijeniti proizvoljne vrijednosti za X i pogledati kako to mijenja Y.
To je od velike važnosti, budući da je regresija pokušaj da se naizgled nesustavni i kaotični procesi objasne pomoću određene funkcije. Tako je, na primjer, moguće identificirati odnos između tečaja dolara i nezaposlenosti u Rusiji.
Ako se ovaj obrazac može otkriti, tada ćemo pomoću funkcije koju smo dobili tijekom izračuna moći prognozirati kolika će biti stopa nezaposlenosti pri N-om tečaju dolara u odnosu na rublju.
Ovaj odnos će se zvati korelacija. Regresijska analiza uključuje izračun koeficijenta korelacije koji će objasniti čvrstoću odnosa između varijabli koje razmatramo (tečaj dolara i broj radnih mjesta).
Ovaj omjer može biti pozitivan ili negativan. Njegove vrijednosti kreću se od -1 do 1. Sukladno tome, možemo uočiti visoku negativnu ili pozitivnu korelaciju. Ako je pozitivan, onda će porast tečaja dolara biti praćen otvaranjem novih radnih mjesta. Ako je negativan, znači da će porast tečaja biti praćen smanjenjem radnih mjesta.
Postoji nekoliko vrsta regresije. Može biti linearna, parabolična, eksponencijalna itd. Odabiremo model ovisno o tome koja će regresija odgovarati konkretno našem slučaju, koji će model biti što bliži našoj korelaciji. Razmotrimo to na primjeru problema i riješimo ga u MS Excelu.
Linearna regresija u MS Excelu
Za rješavanje problema linearne regresije trebat će vam funkcija analize podataka. Možda vam nije omogućeno, pa ga morate aktivirati.
- Kliknite na gumb "Datoteka";
- Odabiremo stavku "Parametri";
- Kliknite na pretposljednju karticu "Dodaci" s lijeve strane;

- Ispod ćemo vidjeti natpis "Kontrola" i gumb "Idi". Pritisnemo na njega;
- Stavili smo kvačicu na "Paket analize";
- Pritisnemo "ok".

Primjer zadatka
Aktivirana je funkcija analize serije. Riješimo sljedeći problem. Imamo uzorak podataka za više godina o broju izvanrednih situacija na području poduzeća i broju zaposlenih radnika. Moramo identificirati odnos između ove dvije varijable. Postoji varijabla s objašnjenjem X – ovo je broj radnika, a objašnjena varijabla – Y – je broj nesreća. Podijelimo početne podatke u dva stupca.
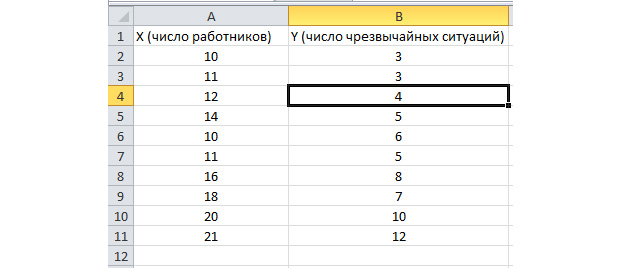
Idemo na karticu "podaci" i odaberite "Analiza podataka"
Na popisu koji se pojavi odaberite "Regresija". U intervalima unosa Y i X odaberite odgovarajuće vrijednosti.
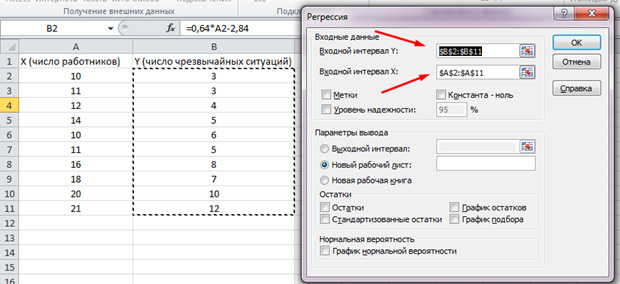
Kliknite "U redu". Analiza je obavljena, a u novom listu ćemo vidjeti rezultate.
Najznačajnije vrijednosti za nas označene su na donjoj slici.
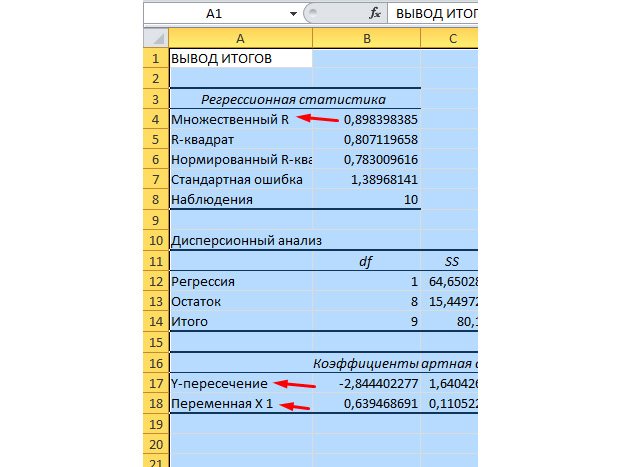
Višestruki R je koeficijent determinacije. Ima složenu formulu za izračun i pokazuje koliko možete vjerovati našem koeficijentu korelacije. Sukladno tome, što je ta vrijednost veća, to je više povjerenja, to je naš model u cjelini uspješniji.
Y-presjek i X1 presjek su koeficijenti naše regresije. Kao što je već spomenuto, regresija je funkcija i ima određene koeficijente. Dakle, naša funkcija će izgledati ovako: Y = 0,64 * X-2,84.
Što nam to daje? To nam omogućuje da napravimo prognozu. Recimo da želimo zaposliti 25 radnika za tvrtku i trebamo si otprilike zamisliti koliki će biti broj nesreća. Tu vrijednost zamjenjujemo u našu funkciju i dobivamo rezultat Y = 0,64 * 25 - 2,84. U našoj zemlji dogodit će se približno 13 izvanrednih situacija.
Pogledajmo kako to radi. Pogledajte sliku ispod. Funkcija koju smo dobili zamjenjuje se stvarnim vrijednostima uključenih zaposlenika. Pogledajte koliko su vrijednosti bliske stvarnim igrama.

Također možete izgraditi korelacijsko polje tako da označite igrače i xs područje, kliknete na karticu "umetni" i odaberete dijagram raspršenja.

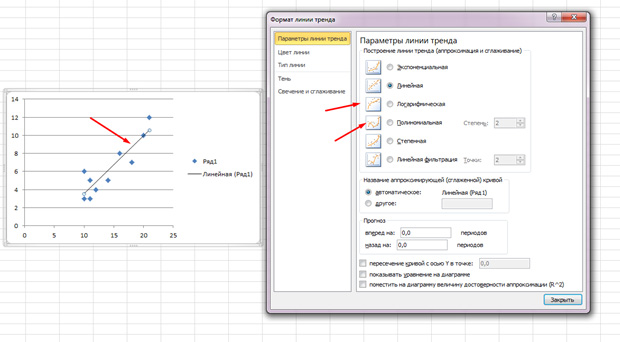
Točke su raštrkane, ali općenito se kreću prema gore, kao da su u ravnoj liniji u sredini. A ovu liniju možete dodati i tako da odete na karticu "Izgled" u MS Excelu i odaberete stavku "Linija trenda"
Dvaput kliknite na liniju koja se pojavi i vidjet ćete ono što je ranije spomenuto. Možete promijeniti vrstu regresije ovisno o tome kako izgleda vaše korelacijsko polje.
Možda smatrate da točke crtaju parabolu, a ne ravnu liniju, te je prikladnije da odaberete drugu vrstu regresije.
Zaključak
Nadamo se da vam je ovaj članak dao bolje razumijevanje što je regresijska analiza i čemu služi. Sve je to od velike praktične važnosti.
Linearna regresija nam omogućuje da opišemo ravnu liniju koja najbolje odgovara nizu uređenih parova (x, y). Jednadžba za ravnu liniju, poznata kao linearna jednadžba, prikazana je u nastavku:
ŷ je očekivana vrijednost y za danu vrijednost x,
x je nezavisna varijabla,
a - segment na y-osi za ravnu liniju,
b - nagib ravne linije.
Slika ispod grafički ilustrira ovaj koncept:
Na gornjoj slici prikazana je linija opisana jednadžbom ŷ = 2 + 0,5x. Segment na y-osi je točka presjeka pravca s y-osi; u našem slučaju a = 2. Nagib pravca, b, omjer uspona pravca i duljine pravca, ima vrijednost 0,5. Pozitivan nagib znači da linija ide gore s lijeva na desno. Ako je b = 0, linija je horizontalna, što znači da ne postoji odnos između zavisnih i nezavisnih varijabli. Drugim riječima, promjena vrijednosti x ne utječe na vrijednost y.
Ŷ i y su često zbunjeni. Na grafikonu je prikazano 6 uređenih parova točaka i pravac prema ovoj jednadžbi

Ova slika prikazuje točku koja odgovara uređenom paru x = 2 i y = 4. Imajte na umu da je očekivana vrijednost y prema liniji na NS= 2 je ŷ. To možemo potvrditi sljedećom jednadžbom:
ŷ = 2 + 0,5x = 2 +0,5 (2) = 3.
Y-vrijednost je stvarna točka, a vrijednost je očekivana y-vrijednost pomoću linearne jednadžbe za danu x-vrijednost.
Sljedeći korak je određivanje linearne jednadžbe koja najviše odgovara skupu uređenih parova, o tome smo govorili u prethodnom članku, gdje smo odredili oblik jednadžbe.
Korištenje Excela za definiranje linearne regresije
Da biste koristili alat za regresijsku analizu ugrađen u Excel, morate aktivirati dodatak Paket analize... Možete ga pronaći klikom na karticu Datoteka -> Opcije(2007+), u dijaloškom okviru koji se pojavi MogućnostiExcel idite na karticu Dodaci. U polju Kontrolirati birati DodaciExcel i kliknite Ići. U prozoru koji se pojavi stavite kvačicu nasuprot Paket analize, pritisnemo U REDU.

U kartici Podaci u grupi Analiza pojavit će se novi gumb Analiza podataka.

Da pokažemo kako dodatak radi, upotrijebimo podatke u kojima momak i djevojka dijele stol u kupaonici. Unesite podatke za naš primjer kade u stupce A i B prazne ploče.
Idite na karticu Podaci, u grupi Analiza klik Analiza podataka. U prozoru koji se pojavi Analiza podataka birati Regresija kao što je prikazano i kliknite OK.

Postavite potrebne parametre regresije u prozoru Regresija, kao što je prikazano na slici:

Klik U REDU. Slika ispod prikazuje dobivene rezultate:

Ovi rezultati su u skladu s onima koje smo dobili vlastitim proračunima.
Izgradnja linearne regresije, procjena njezinih parametara i njihove važnosti može se izvesti puno brže korištenjem paketa za analizu programa Excel (Regression). Razmotrimo tumačenje rezultata dobivenih u općem slučaju ( k objašnjavajuće varijable) prema primjeru 3.6.
U stolu regresijska statistika dane su vrijednosti:
Višestruko R - koeficijent višestruke korelacije;
R- kvadrat- koeficijent odlučnosti R 2 ;
Normalizirano R - kvadrat- prilagođen R 2 ispravljeno za broj stupnjeva slobode;
Standardna pogreška- standardna pogreška regresije S;
Zapažanja - broj zapažanja n.
U stolu ANOVA daju se:
1. Stupac df - broj stupnjeva slobode, jednak
za niz Regresija df = k;
za niz Ostatakdf = n – k – 1;
za niz Ukupnodf = n– 1.
2. Stupac SS - zbroj kvadrata odstupanja jednak
za niz Regresija ;
za niz Ostatak ;
za niz Ukupno .
3. Stupac MS varijance određene formulom MS = SS/df:
za niz Regresija- faktorijalna varijansa;
za niz Ostatak- zaostala varijansa.
4. Stupac F - izračunata vrijednost F-kriterij izračunat po formuli
F = MS(regresija)/ MS(ostatak).
5. Stupac Značaj F - vrijednost razine značajnosti koja odgovara izračunatoj F-statistika .
Značaj F= FDIST ( F- statistika, df(regresija), df(ostatak)).
Ako je značaj F < стандартного уровня значимости, то R 2 je statistički značajno.
| Koeficijenti | Standardna pogreška | t-statistika | P-vrijednost | donjih 95% | Top 95% | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| x | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Ova tablica pokazuje:
1. Izgledi- vrijednosti koeficijenta a, b.
2. Standardna pogreška–Standardne pogreške regresijskih koeficijenata S a, S b.
3. t- statistika- izračunate vrijednosti t - kriteriji izračunati po formuli:
t-statistika = koeficijenti / standardna pogreška.
4.R-vrijednost (značaj t) Odgovara li vrijednost razine značajnosti izračunatoj t- statistika.
R-vrijednost = TDIST(t-statistika, df(ostatak)).
Ako R-značenje< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5... Donjih 95% i gornjih 95%- donja i gornja granica 95% intervala povjerenja za koeficijente teorijske linearne regresijske jednadžbe.
| POVLAČENJE PREOSTALO | ||
| Promatranje | Predviđeno y | Ostaje e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
U stolu POVLAČENJE PREOSTALO naznačeno:
u koloni Promatranje- broj promatranja;
u koloni Predviđeno y - izračunate vrijednosti zavisne varijable;
u koloni Ostaci e - razlika između promatrane i izračunate vrijednosti zavisne varijable.
Primjer 3.6. Postoje podaci (uobičajene jedinice) o troškovima hrane y i dohodak po glavi stanovnika x za devet grupa obitelji:
| x | |||||||||
| y |
Koristeći rezultate Excel paketa analize (Regresija) analizirajmo ovisnost troškova hrane o visini dohotka po stanovniku.
Uobičajeno je rezultate regresijske analize pisati u obliku:
![]()
gdje su standardne pogreške regresijskih koeficijenata naznačene u zagradama.
Regresijski koeficijenti a = 65,92 i b= 0,107. Smjer komunikacije između y i x određuje predznak koeficijenta regresije b= 0,107, tj. veza je izravna i pozitivna. Koeficijent b= 0,107 pokazuje da s povećanjem dohotka po stanovniku za 1 konv. jedinice troškovi hrane rastu za 0,107 konv. jedinice
Procijenimo značaj koeficijenata dobivenog modela. Značaj koeficijenata ( a, b) provjerava t-test:
P-vrijednost ( a) = 0,00080 < 0,01 < 0,05
P-vrijednost ( b) = 0,00016 < 0,01 < 0,05,
dakle, koeficijenti ( a, b) značajni su na razini od 1%, a još više na razini značajnosti od 5%. Dakle, koeficijenti regresije su značajni i model je adekvatan izvornim podacima.
Rezultati procjene regresije su kompatibilni ne samo s dobivenim vrijednostima regresijskih koeficijenata, već i s nekim njihovim skupom (interval pouzdanosti). S vjerojatnošću od 95%, intervali povjerenja za koeficijente su (38,16 - 93,68) za a i (0,0728 - 0,142) for b.
Kvaliteta modela ocjenjuje se koeficijentom determinacije R 2 .
Veličina R 2 = 0,884 znači da se 88,4% varijacije (rasprostiranja) u izdacima za hranu može objasniti faktorom dohotka po glavi stanovnika.
Značaj R 2 provjerava F- test: značaj F = 0,00016 < 0,01 < 0,05, следовательно, R 2 je značajan na razini od 1%, a još više na razini značajnosti od 5%.
U slučaju uparene linearne regresije koeficijent korelacije se može definirati kao ![]() ... Dobivena vrijednost koeficijenta korelacije pokazuje da je odnos između izdataka za hranu i dohotka po stanovniku vrlo blizak.
... Dobivena vrijednost koeficijenta korelacije pokazuje da je odnos između izdataka za hranu i dohotka po stanovniku vrlo blizak.