Makarova N.V.، Volkov V.B. انفورماتیک: کتاب درسی برای دانشگاه ها - سن پترزبورگ: پیتر، 2011. 576 ص.
موضوع 1. ارائه اطلاعات
مفهوم اطلاعات
اصطلاح "اطلاعات" از کلمه لاتین "informatio" گرفته شده است که به معنای "توضیح"، "اطلاعات"، "نمایش" است.
تعاریف زیادی از اطلاعات وجود دارد. بنابراین، یکی از بنیانگذاران نظریه اطلاعات مدرن، نوبرت وینر، اطلاعات را اینگونه تعریف کرد: «اطلاعات، اطلاعات هستند، نه ماده یا انرژی».
چنین تعریفی از طریق نفی کاملاً کامل و جهانی به نظر می رسد، اما استفاده از آن به عنوان ابزاری برای ساخت روش شناسی علمی عملاً غیرممکن است.
در عین حال، رویکردهای روششناختی در فنآوری مدرن رایج شدهاند که به کارگیری مفهوم اطلاعات و ابزارهای پیشنهادی برای مطالعه فرآیندهای رخ داده در سیستمهای فنی، اقتصاد، جامعه، در طبیعت زنده و بیجان را ممکن میسازد.
مشهورترین در میان چنین رویکردهایی، نظریه ریاضی کلود شانون است که امکان اثبات احتمالی قابلیت اطمینان انتقال سیگنال از طریق یک خط ارتباطی را ممکن میسازد. در رویکرد شانون، اطلاعات معیاری برای کاهش عدم قطعیت یک سیستم است.
همچنین یک رویکرد ترمودینامیکی (انرژی) وجود دارد که اطلاعات را راهی برای کاهش آنتروپی سیستم در نظر می گیرد.
کولموگروف، ریاضیدان شوروی، یک رویکرد الگوریتمی را پیشنهاد کرد که ارزیابی اطلاعات را با پیچیدگی الگوریتم مورد نیاز برای پردازش آن ممکن میسازد. همه این رویکردها مفهوم اطلاعات را با دامنه ارتباط تنگاتنگی داشتند.
از منظر فلسفه مادی، اطلاعات بازتابی از دنیای واقعی به کمک اطلاعات (پیام) است. پیام شکلی از نمایش اطلاعات در قالب گفتار، متن، تصاویر، داده های دیجیتال، نمودارها، جداول و غیره است. در مفهوم گسترده، اطلاعات یک مفهوم علمی کلی است که شامل تبادل اطلاعات بین افراد، تبادل سیگنال های بین طبیعت جاندار و بی جان، مردم و وسایل.
اطلاعات- این اطلاعات در مورد اشیاء و پدیده های محیطی، پارامترها، خواص و حالت آنها است که درجه عدم قطعیت و ناقص بودن دانش موجود را کاهش می دهد.
انفورماتیک اطلاعات را به عنوان اطلاعات مفهومی مرتبط با هم در نظر می گیرد، مفاهیمی که ایده های ما را در مورد یک پدیده یا شی در جهان تغییر می دهد. همراه با اطلاعات در علوم کامپیوتر، اغلب از مفهوم داده استفاده می شود. بیایید نشان دهیم که تفاوت آنها چیست.
داده ها را می توان به عنوان علائم یا مشاهدات ثبت شده در نظر گرفت که به دلایلی مورد استفاده قرار نمی گیرند، بلکه فقط ذخیره می شوند. در صورتی که استفاده از این داده ها برای کاهش عدم قطعیت دانش در مورد چیزی ممکن شود، داده ها به اطلاعات تبدیل می شوند.
داده ها- این اطلاعاتی است که به روش خاصی به منظور انتقال، پردازش، بازیابی یا بازیابی کدگذاری شده است.
مثال.ده شماره تلفن را به ترتیب ده عدد روی یک کاغذ بنویسید و به دوست خود نشان دهید. او این ارقام را به عنوان داده درک می کند، زیرا آنها هیچ اطلاعاتی در اختیار او قرار نمی دهند. سپس در کنار هر عدد نام شرکت و نوع فعالیت را قید نمایید. برای دوست شما، اعداد نامفهوم قطعیت پیدا می کنند و از داده ها به اطلاعاتی تبدیل می شوند که بعداً می تواند از آنها استفاده کند.
هنگام کار با اطلاعات، همیشه منبع و مصرف کننده (گیرنده) آن وجود دارد. راه ها و فرآیندهایی که انتقال پیام از منبع اطلاعات به مصرف کننده را تضمین می کند، ارتباطات اطلاعاتی نامیده می شود.
برای مصرف کننده اطلاعات، یک ویژگی بسیار مهم، کفایت آن است.
کفایت اطلاعات سطح معینی از مطابقت تصویر ایجاد شده با کمک اطلاعات دریافتی با یک شی واقعی، فرآیند، پدیده و غیره است.
در زندگی واقعی، موقعیتی به سختی امکان پذیر است که بتوانید روی کفایت کامل اطلاعات حساب کنید. همیشه درجاتی از عدم قطعیت وجود دارد. صحت تصمیم گیری توسط یک فرد به میزان کفایت اطلاعات با وضعیت واقعی یک شی یا فرآیند بستگی دارد.
اقدامات اطلاعاتی (ص 20-25)
کیفیت اطلاعات
کیفیت اطلاعاتمجموعه ای از ویژگی هایی است که توانایی اطلاعات را برای برآوردن نیازهای خاص افراد تعیین می کند.
شاخص های اصلی مصرف کننده کیفیت اطلاعات عبارتند از: نمایندگی، محتوا، کفایت، دسترسی، ارتباط، به موقع بودن، دقت، قابلیت اطمینان، ثبات.
نماینده بودناطلاعات مربوط به صحت انتخاب و شکل گیری آن به منظور انعکاس کافی ویژگی های جسم است. مهمترین نکته در اینجا درستی مفهومی است که مفهوم اصلی بر اساس آن صورت بندی شده است; اعتبار انتخاب ویژگی های اساسی و روابط پدیده نمایش داده شده.
نقض نمایندگی اطلاعات اغلب منجر به خطاهای قابل توجهی می شود.
صمیمیتاطلاعات منعکس کننده ظرفیت معنایی، برابر با نسبت مقدار اطلاعات معنایی در پیام به مقدار داده های در حال پردازش است. با افزایش محتوای اطلاعات، ظرفیت معنایی سیستم اطلاعاتی افزایش می یابد، زیرا برای به دست آوردن همان اطلاعات، نیاز به تبدیل حجم کمتری از داده ها است.
کفایت (کامل)اطلاعات به این معنی است که ترکیب آن (مجموعه شاخص ها) حداقل است، اما برای تصمیم گیری صحیح کافی است. مفهوم کامل بودن اطلاعات با محتوای معنایی (معناشناسی) و عمل شناسی آن مرتبط است. اطلاعات ناقص، یعنی ناکافی برای تصمیم گیری صحیح، و اطلاعات اضافی، اثربخشی تصمیمات اتخاذ شده توسط کاربر را کاهش می دهد.
دسترسیاطلاعات به درک کاربر با اجرای رویه های مناسب برای دریافت و تبدیل آن تضمین می شود. به عنوان مثال، در یک سیستم اطلاعاتی، اطلاعات به فرمی در دسترس و کاربر پسند تبدیل می شود.
ارتباطاطلاعات با درجه حفظ ارزش اطلاعات برای مدیریت در زمان استفاده تعیین می شود و به پویایی تغییرات در ویژگی های آن و همچنین به فاصله زمانی سپری شده از زمان وقوع این اطلاعات بستگی دارد.
به موقع بودناطلاعات به معنای دریافت آن حداکثر تا یک نقطه از پیش تعیین شده در زمان، مطابق با زمان حل کار است.
دقتاطلاعات با درجه نزدیکی اطلاعات دریافتی به وضعیت واقعی شی، فرآیند، پدیده و غیره تعیین می شود. برای اطلاعات نمایش داده شده توسط یک کد دیجیتال، چهار مفهوم طبقه بندی دقت شناخته شده است:
- دقت رسمی با مقدار واحد کمترین رقم قابل توجه عدد اندازه گیری می شود.
- دقت واقعی با مقدار واحد آخرین رقم عدد تعیین می شود که صحت آن تضمین شده است.
- حداکثر دقت دقتی است که می توان تحت شرایط عملیاتی خاص سیستم به دست آورد.
- دقت مورد نیاز با هدف عملکردی نشانگر تعیین می شود.
قابلیت اطمیناناطلاعات با ویژگی آن تعیین می شود تا اشیاء واقعی را با دقت لازم منعکس کند. قابلیت اطمینان اطلاعات با سطح اطمینان دقت مورد نیاز اندازه گیری می شود، یعنی احتمال اینکه مقدار پارامتر نمایش داده شده توسط اطلاعات با مقدار واقعی این پارامتر در دقت مورد نیاز متفاوت باشد.
پایداریاطلاعات نشان دهنده توانایی آن در پاسخگویی به تغییرات داده های منبع بدون به خطر انداختن دقت مورد نیاز است. ثبات اطلاعات و همچنین نمایندگی، به دلیل انتخاب روش انتخاب و شکل گیری آن است.
نمایندگی، معنادار بودن، کفایت، دسترسی، پایداری، به طور کامل در سطح روش شناختی توسعه سیستم های اطلاعاتی تعیین می شود. پارامترهای مربوط بودن، به موقع بودن، دقت و قابلیت اطمینان نیز تا حد زیادی در سطح روش شناختی تعیین می شوند، اما ارزش آنها نیز به طور قابل توجهی تحت تأثیر ماهیت عملکرد سیستم، در درجه اول قابلیت اطمینان آن است. در عین حال، پارامترهای مربوط و دقت به ترتیب با پارامترهای به موقع و قابلیت اطمینان به طور صلب مرتبط هستند.
فرآیندهای اطلاعاتی
فرآیندهای مرتبط با جستجو، ذخیره سازی، انتقال، پردازش و استفاده از اطلاعات را اطلاعاتی می نامند.
جستجو برای اطلاعاتفرآیند بازیابی اطلاعات ذخیره شده است.
مجموعه اطلاعات- این فعالیت سوژه است که در طی آن اطلاعاتی در مورد موضوع مورد علاقه خود دریافت می کند.
ذخیره سازی داده ها- این فرآیند نگهداری اطلاعات اصلی به شکلی است که صدور به موقع داده ها به درخواست کاربران نهایی را تضمین می کند.
روش ذخیره اطلاعات به حامل آن بستگی دارد (کتاب یک کتابخانه است، یک عکس یک موزه است، یک عکس یک آلبوم است). کامپیوتر را می توان وسیله ای برای ذخیره سازی فشرده اطلاعات با قابلیت دسترسی سریع به آن دانست.
انتقال (تبادل) اطلاعاتفرآیندی که در آن یک فرستنده (منبع) اطلاعات را ارسال می کند و یک گیرنده (گیرنده) آن را دریافت می کند.
در فرآیند انتقال اطلاعات، لزوماً یک منبع و یک گیرنده اطلاعات دخالت دارند. بین منبع و گیرنده یک کانال برای انتقال اطلاعات وجود دارد - یک کانال ارتباطی.
ارتباط دادنمجموعه ای از وسایل فنی است که انتقال سیگنال از منبع به گیرنده را تضمین می کند.
رمزگذار- این دستگاهی است که برای تبدیل پیام منبع اصلی به فرمی مناسب برای انتقال طراحی شده است.
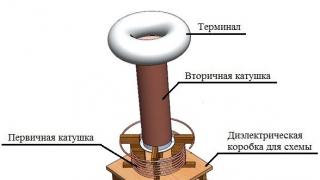
رمزگشا- این وسیله ای برای تبدیل یک پیام رمزگذاری شده به پیام اصلی است (شکل 1.1).
فعالیت افراد همیشه با انتقال اطلاعات مرتبط است. در حین انتقال، اطلاعات می توانند از بین بروند و تحریف شوند، نمونه هایی از جمله اعوجاج صدا در تلفن، تداخل جوی در رادیو، اعوجاج یا خاموشی تصویر در تلویزیون، خطاهای انتقال در تلگراف.
برنج. 1.1. انتقال اطلاعات از طریق یک کانال ارتباطی
کانال های انتقال پیام با پهنای باند و ایمنی نویز مشخص می شوند. کانال های انتقال داده به دو دسته ساده (با انتقال اطلاعات در یک جهت، به عنوان مثال، تلویزیون) و دوبلکس (که از طریق آن می توان اطلاعات را در هر دو جهت انتقال داد، به عنوان مثال، تلفن، تلگراف) تقسیم می شود. چندین پیام را می توان به طور همزمان در یک کانال منتقل کرد. هر یک از این پیام ها با استفاده از فیلترهای خاص برجسته می شوند (از دیگران جدا می شوند). به عنوان مثال، فیلتر کردن بر اساس فرکانس پیام های ارسال شده، همانطور که در کانال های رادیویی انجام می شود، امکان پذیر است. پهنای باند یک کانال با حداکثر تعداد نمادهای ارسال شده روی آن در صورت عدم تداخل تعیین می شود. این مشخصه به خواص فیزیکی کانال بستگی دارد. برای افزایش مصونیت نویز کانال از روش های خاص انتقال پیام استفاده می شود که اثر نویز را کاهش می دهد. به عنوان مثال، کاراکترهای اضافی وارد می شوند. این کاراکترها محتوای واقعی ندارند، اما برای تأیید اعتبار پیام هنگام دریافت استفاده می شوند. از منظر نظریه اطلاعات، هر چیزی که زبان ادبی را رنگارنگ، انعطاف پذیر، سرشار از ظرافت، چندوجهی، چند معنایی می کند، زائد است.
پردازش داده هایک فرآیند مرتب تبدیل آن مطابق با الگوریتم حل مسئله یا قوانین رسمی دیگر است.
پس از رفع مشکل پردازش اطلاعات، نتیجه باید به شکل مورد نیاز برای کاربران نهایی صادر شود. این عملیات در راستای حل مشکل صدور اطلاعات اجرا می شود. صدور اطلاعات، به عنوان یک قاعده، با کمک دستگاه های کامپیوتری خارجی در قالب متون، جداول انجام می شود.
حفاظت از اطلاعات در معنای محدودتر به معنای جلوگیری از دسترسی به اطلاعات توسط افرادی است که مجوز مناسب (دسترسی غیرمجاز، غیرقانونی)، استفاده ناخواسته یا غیرمجاز، تغییر یا تخریب اطلاعات را ندارند.
حفاظت اطلاعات(در معنای وسیع) مجموعه ای از اقدامات سازمانی، قانونی و فنی برای جلوگیری از تهدیدات امنیت اطلاعات و رفع پیامدهای آن است.
مؤثرترین ابزار سازماندهی فرآیندهای اطلاعاتی، سیستم اطلاعاتی مجهز به ورودی، جستجو، قرار دادن، پردازش و تحویل اطلاعات است. وجود چنین ابزارهایی ویژگی اصلی سیستم های اطلاعاتی است که آنها را از انباشته های ساده مواد اطلاعاتی متمایز می کند. به عنوان مثال، یک کتابخانه شخصی که فقط صاحب آن می تواند در آن حرکت کند، یک سیستم اطلاعاتی نیست. اما در کتابخانههای عمومی، ترتیب قرار دادن کتابها همیشه کاملاً مشخص است. با تشکر از او، جستجو و صدور کتاب، و همچنین قرار دادن مجموعه های جدید در قالب روش های استاندارد و رسمی اجرا می شود.
طبقه بندی و ساختار اطلاعات
طبقه بندی- این سیستمی برای توزیع اشیاء (اشیاء، پدیده ها، فرآیندها، مفاهیم) به طبقات مطابق با یک ویژگی خاص است.
مثال.تمام اطلاعات مربوط به دانشگاه را می توان بر اساس اشیاء اطلاعاتی متعددی طبقه بندی کرد که با ویژگی های مشترک مشخص می شوند:
- اطلاعات در مورد دانش آموزان - در قالب یک شی اطلاعاتی "دانشجو"؛
- اطلاعات در مورد معلمان - در قالب یک شی اطلاعاتی "معلم"؛
- اطلاعات مربوط به دانشکده ها - در قالب یک شی اطلاعاتی "دانشکده" و غیره.
خصوصیات یک شی اطلاعاتی توسط پارامترهای اطلاعاتی به نام ویژگی ها تعریف می شود. جزئیات یا به عنوان داده های عددی (به عنوان مثال، وزن، هزینه، سال) یا به عنوان ویژگی ها (به عنوان مثال، رنگ، نام تجاری خودرو، نام خانوادگی) ارائه می شود.
لوازم جانبی- این یک عنصر اطلاعاتی منطقی غیرقابل تقسیم است که ویژگی خاصی از یک شی، فرآیند، پدیده را توصیف می کند.
مثال.اطلاعات مربوط به هر دانشجو در بخش پرسنل دانشگاه با استفاده از جزئیات یکسان سیستماتیک و ارائه شده است:
- نام و نام خانوادگی؛
- سال تولد؛
- محل تولد؛
- آدرس محل سکونت؛
- دانشکده محل تحصیل دانشجو و غیره.
تمام جزئیات ذکر شده ویژگی های شی اطلاعات "Student" را مشخص می کند.
علاوه بر شناسایی ویژگیهای کلی یک شی اطلاعاتی، طبقهبندی برای توسعه قوانین (الگوریتمها) و رویههایی برای پردازش اطلاعات ارائهشده توسط مجموعهای از جزئیات مورد نیاز است.
مثال.الگوریتم پردازش اشیاء اطلاعاتی صندوق کتابخانه به شما امکان می دهد اطلاعاتی در مورد همه کتاب ها در یک موضوع خاص، در مورد نویسندگان، مشترکین و غیره به دست آورید.
الگوریتم پردازش اشیاء اطلاعاتی شرکت به شما امکان می دهد اطلاعاتی در مورد حجم فروش، سود، مشتریان، انواع محصولات و غیره به دست آورید.
الگوریتم های پردازش در هر دو مورد اهداف متفاوتی را دنبال می کنند، اطلاعات متفاوتی را پردازش می کنند و به روش های مختلف پیاده سازی می شوند.
در هر کشوری طبقهبندیکنندههای دولتی، صنعتی و منطقهای ساخته شده و در حال استفاده است. به عنوان مثال، صنایع، تجهیزات، حرفه ها، واحدهای اندازه گیری، اقلام هزینه و غیره طبقه بندی می شوند.
طبقه بندیمجموعه ای سیستماتیک از نام ها و کدهای گروه های طبقه بندی است.
هنگام طبقه بندی، مفاهیم "ویژگی طبقه بندی" و "مقدار ویژگی طبقه بندی" به طور گسترده استفاده می شود که به شما امکان می دهد درجه شباهت یا تفاوت بین اشیاء را تعیین کنید. رویکردی به طبقه بندی با ترکیب این دو مفهوم در یک مفهوم به نام صفت طبقه بندی امکان پذیر است. مترادف یک ویژگی طبقه بندی، پایه تقسیم است.
مثال.به عنوان یک ویژگی طبقه بندی، سن انتخاب شده است که از سه مقدار تشکیل شده است: تا 20 سال، از 20 تا 30 سال، بیش از 30 سال. می توان از سن تا 20 سال، سن 20 تا 30 سال، سن بالای 30 سال به عنوان علائم طبقه بندی استفاده کرد.
سه روش طبقهبندی شی توسعه داده شده است: سلسله مراتبی، وجهی، توصیفی. این روش ها در استراتژی های مختلف برای اعمال ویژگی های طبقه بندی متفاوت هستند.
هر طبقه بندی همیشه نسبی است. یک شیء مشابه را می توان بر اساس ویژگی ها یا معیارهای مختلف طبقه بندی کرد. اغلب شرایطی وجود دارد که بسته به شرایط محیطی، یک شی را می توان به گروه های طبقه بندی مختلف اختصاص داد. این ملاحظات به ویژه هنگام طبقهبندی انواع اطلاعات بدون در نظر گرفتن جهتگیری موضوعی مرتبط هستند، زیرا اغلب میتوانند در شرایط مختلف، توسط مصرفکنندگان مختلف، برای اهداف مختلف مورد استفاده قرار گیرند.
روی میز. 1.1 یکی از طرح های طبقه بندی اطلاعات در حال گردش در یک سازمان (شرکت) را نشان می دهد. این طبقه بندی بر اساس پنج ویژگی رایج است: محل مبدا، مرحله پردازش، روش نمایش، پایداری، عملکرد کنترل.
جدول 1.1. طبقه بندی اطلاعات در حال گردش در سازمان
بر اساس محل وقوع، اطلاعات را می توان به ورودی، خروجی، داخلی و خارجی تقسیم کرد.
اطلاعات ورودی اطلاعاتی است که وارد شرکت یا بخش های آن می شود. اطلاعات خروجی اطلاعاتی است که از یک شرکت به شرکت دیگر، سازمان (بخش) می رسد.
یک اطلاعات یکسان می تواند برای یک شرکت ورودی و برای دیگری که آن را تولید می کند، خروجی باشد. در رابطه با شی کنترل (شرکت یا زیرمجموعه آن: کارگاه، بخش، آزمایشگاه) می توان اطلاعات داخلی و خارجی را تعیین کرد.
اطلاعات داخلی در داخل شی رخ می دهد، خارجی - خارج از شی.
مثال.محتوای مصوبه دولت در مورد تغییر سطح مالیات های اخذ شده برای شرکت از یک سو اطلاعات خارجی و از سوی دیگر ورودی است. اطلاعات شرکت ارسالی به سازمان بازرسی مالیاتی مبنی بر میزان کسورات به بودجه کشور از یک سو اطلاعات خروجی و از سوی دیگر در رابطه با سازمان بازرسی مالیاتی خارجی است.
با توجه به مرحله پردازش، اطلاعات می تواند اولیه، ثانویه، میانی، نتیجه باشد.
اطلاعات اولیه اطلاعاتی هستند که مستقیماً در فرآیند فعالیت شی بوجود می آیند و در مرحله اولیه ثبت می شوند. اطلاعات ثانویه اطلاعاتی هستند که در نتیجه پردازش اطلاعات اولیه به دست می آیند. می تواند متوسط و نتیجه باشد. اطلاعات میانی به عنوان ورودی برای محاسبات بعدی استفاده می شود. اطلاعات حاصل در فرآیند پردازش اطلاعات اولیه و میانی به دست می آید و به توسعه تصمیمات مدیریتی کمک می کند.
مثال. در کارگاه هنری که فنجان رنگ می شود، در پایان هر شیفت، تعداد کل محصولات تولید شده و تعداد فنجان های نقاشی شده توسط هر کارمند ثبت می شود. این اطلاعات اولیه است. در پایان هر ماه، استاد اطلاعات اولیه را جمعبندی میکند. از یک طرف این اطلاعات میانی ثانویه است و از طرف دیگر نتیجه است. داده های نهایی به بخش حسابداری ارسال می شود، جایی که دستمزد هر کارمند بسته به خروجی آنها محاسبه می شود. داده های محاسبه شده به دست آمده، اطلاعات نتیجه است.
با توجه به روش نمایش اطلاعات به متنی و گرافیکی تقسیم می شود.
اطلاعات متنی مجموعه ای از کاراکترهای الفبایی، عددی و خاص است که اطلاعات با آن بر روی یک رسانه فیزیکی (کاغذ، تصویر روی صفحه نمایش) ارائه می شود. اطلاعات گرافیکی انواع مختلفی از نمودارها، نمودارها، نمودارها، نقشه ها و غیره است.
از نظر ثبات، اطلاعات می تواند متغیر (جاری) و ثابت (ثابت شرطی) باشد.
اطلاعات متغیر منعکس کننده ویژگی های کمی و کیفی واقعی فعالیت های تولیدی و اقتصادی شرکت است. می تواند برای هر مورد متفاوت باشد، هم از نظر هدف و هم از نظر کمیت. به عنوان مثال، تعداد محصولات تولید شده در هر شیفت، هزینه های هفتگی برای تحویل مواد اولیه، تعداد ماشین آلات قابل سرویس و غیره. اطلاعات دائمی (مشروط دائمی) اطلاعاتی هستند که دائمی و قابل استفاده مجدد در یک دوره زمانی طولانی هستند. اطلاعات دائمی می تواند مرجع، نظارتی، برنامه ریزی شده باشد:
- اطلاعات مرجع دائمی شامل توصیفی از خواص دائمی شی به شکل علائمی است که برای مدت طولانی پایدار هستند (به عنوان مثال: شماره پرسنل یک کارمند، حرفه کارمند، شماره کارگاه و غیره).
- اطلاعات نظارتی دائمی شامل مقررات محلی، صنعتی و ملی است (به عنوان مثال: میزان مالیات بر درآمد، استاندارد کیفیت محصولات یک نوع خاص، حداقل دستمزد، مقیاس پرداخت برای کارمندان دولت).
- اطلاعات برنامه ریزی دائمی شامل شاخص های برنامه ریزی شده ای است که در شرکت مورد استفاده مجدد قرار می گیرند (به عنوان مثال: طرحی برای تولید تلویزیون، برنامه ای برای آموزش متخصصان با صلاحیت خاص).
با توجه به عملکردهای مدیریت، اطلاعات اقتصادی معمولاً طبقه بندی می شوند و گروه های زیر را متمایز می کنند: برنامه ریزی شده، مرجع، حسابداری و عملیاتی (جاری).
اطلاعات برنامه ریزی شده - اطلاعاتی در مورد پارامترهای شی کنترل برای دوره آینده. این اطلاعات محور تمام فعالیت های شرکت است.
مثال.اطلاعات برنامه ریزی شده شرکت می تواند شامل شاخص هایی مانند برنامه تولید، سود برنامه ریزی شده از فروش، تقاضای مورد انتظار برای محصولات و غیره باشد.
اطلاعات مرجع نظارتی انواع داده های نظارتی و مرجع است. به ندرت به روز می شود.
مثال.اطلاعات مرجع نظارتی در شرکت عبارتند از:
- زمان در نظر گرفته شده برای ساخت یک قطعه معمولی (نرخ کار)؛
- میانگین دستمزد روزانه یک کارگر بر اساس طبقه بندی؛
- حقوق یک کارمند؛
- آدرس تامین کننده یا خریدار و غیره
اطلاعات حساب- این اطلاعاتی است که فعالیت های شرکت را برای یک دوره زمانی خاص گذشته مشخص می کند. بر اساس این اطلاعات می توان اقدامات زیر را انجام داد: تنظیم اطلاعات برنامه ریزی شده، تجزیه و تحلیل فعالیت های تجاری شرکت، تصمیم گیری در مورد مدیریت کارآمدتر و غیره. در عمل، اطلاعات حسابداری، اطلاعات آماری و اطلاعات حسابداری عملیاتی می تواند به عنوان اطلاعات حسابداری عمل کند.
مثال.اطلاعات حسابداری عبارت است از: تعداد محصولات فروخته شده برای یک دوره زمانی معین. میانگین بار روزانه یا از کار افتادن ماشین ها و غیره
اطلاعات عملیاتی (جاری).- این اطلاعاتی است که در مدیریت عملیاتی و توصیف فرآیندهای تولید در دوره زمانی فعلی (مشخص شده) استفاده می شود. الزامات جدی بر اطلاعات عملیاتی از نظر سرعت دریافت و پردازش و همچنین میزان قابلیت اطمینان آن تحمیل می شود. موفقیت شرکت در بازار تا حد زیادی به سرعت و کارآمدی پردازش آن بستگی دارد.
مثال.اطلاعات عملیاتی شامل:
- تعداد قطعات تولید شده در ساعت، شیفت، روز؛
- تعداد محصولات فروخته شده در روز یا یک ساعت خاص؛
- حجم مواد اولیه از تامین کننده در ابتدای روز کاری و غیره.
©2015-2019 سایت
تمامی حقوق متعلق به نویسندگان آنها می باشد. این سایت ادعای نویسندگی ندارد، اما استفاده رایگان را فراهم می کند.
تاریخ ایجاد صفحه: 1395/02/16
تنوع روشها برای ساختاردهی اطلاعات به این دلیل است که راههای زیادی برای نمایش و سازماندهی آنها وجود دارد و اطلاعات به خودی خود میتواند ویژگیهای بسیار متفاوتی داشته باشد. به عنوان مثال، بسیار مهم است که در خروجی/ورودی دادههایی که به طور بالقوه حاوی اطلاعات هستند، چه ابزارهای نمایشی/کانالهای ادراک درگیر هستند، سطح اولیه سازماندهی این دادهها چقدر است، آیا به دسته عددی، متنی تعلق دارند. گرافیک، ویدئو، صدا و غیره. اهدافی که در هنگام اجرای رویه ساختار دهی داده ها (اطلاعات) دنبال می شوند، نقش بسیار مهمی دارند.
انحراف مختصر: قبلاً به تفاوت بین داده و اطلاعات اشاره کردیم و گفتیم که مفهوم "داده" با ارائه اطلاعات در رسانه های مادی مرتبط است و همچنین داده های یک مصرف کننده خاص ممکن است اصلاً حاوی اطلاعات نباشند. اطلاعات است - دانش جدیدی است که توسط گیرنده داده به دست می آید. در اینجا یادآوری این موضوع را مفید می دانیم و از روی عادت، با استفاده از کلمه "اطلاعات"، منظور ما این است که ما هنوز در حال ساختار دادن به داده ها هستیم (اگرچه در سر ما همچنین می توانیم اطلاعات را ساختار دهیم، سعی می کنیم دانش موجود را به صورت ذهنی نظام مند کنیم، روان سازی کنیم).
برای شروع، بیایید وارد شویم طبقه بندی اهداف ساختاردهی اطلاعات . کلاس های هدف زیر را می توان در اینجا تشخیص داد:
کسب دانش کیفی جدید در مورد سیستم/فرآیند؛
تثبیت واقعیت و بومی سازی ناقصی و/یا ناسازگاری مجموعه دانش؛
سیستم سازی، نظم بخشیدن به مجموعه معینی از دانش؛
تأکید یا برجسته کردن یک یا چند جنبه از اطلاعات (به عنوان مثال، زمانی، مکانی، عملکردی و غیره).
کاهش بیش از حد ارائه اطلاعات؛
هماهنگی ارائه اطلاعات با برخی از سیستم های پردازش و تفسیر؛
افزایش دید نمایش اطلاعات؛
تغییر سطح عمومیت/انتزاع توصیفات.
بسته به کلاس هدف، روشها و فناوریهای ساختاردهی اطلاعات تغییر میکنند. اما قبلاً اشاره کردیم که هدف تنها عامل تعیین کننده انتخاب روش ساختاردهی اطلاعات نیست. به همین دلیل لازم است انواع اطلاعاتی که باید ساختاربندی شوند و همچنین نحوه ارائه آن در نظر گرفته شود.
بیایید طبقه بندی انواع اطلاعات را با توجه به ماهیت / محتوا و نحوه استفاده از آنها معرفی کنیم:
اطلاعات در مورد ارزش ها و اهداف (اطلاعات تعیین هدف) مورد استفاده در برنامه ریزی/پیش بینی؛
اطلاعات مربوط به عملکردهای سیستم/فرآیند؛
اطلاعات در مورد ساختار سیستم/فرآیند؛
اطلاعات در مورد دینامیک سیستم/فرآیند؛
اطلاعات در مورد وضعیت سیستم/فرآیند؛
اطلاعات مربوط به وظایف سیستم/فرآیند.
در طبقه بندی فوق، انواع اطلاعات به ترتیب نزولی دوره ثبات/ارتباط قرار می گیرند. با این حال، دو دسته از اطلاعات توصیف کننده ارزش ها، اهداف و مقاصد نسبتاً مستقل از وضعیت، پویایی، ساختار، و عملکردهای سیستم/فرایند هستند، زیرا با اجرای عملکرد هدف گذاری مرتبط هستند. با این حال، می توانیم فرض کنیم که تصمیم به استفاده از چنین طرحی برای ترتیب دادن این دسته از اطلاعات کاملاً موجه است، زیرا امکان حل بسیاری از مسائل کاربردی را فراهم می کند.
در میان چیزهای دیگر، باید ویژگی های طبقه بندی را نیز در نظر گرفت:
- ارتباط اطلاعات با یک شی:
اطلاعات مربوط به شی؛
اطلاعات مربوط به کلاس اشیاء؛
اطلاعات مربوط به محیط زیست؛
- ارتباط اطلاعات با یک مقطع زمانی معین:
اطلاعات مربوط به گذشته؛
اطلاعات مربوط به حال؛
اطلاعات مربوط به آینده؛
- ارتباط اطلاعات با طبقه سازمان ساختاری:
اطلاعات بدون ساختار است.
اطلاعات ساختاریافته؛
اطلاعات سفارش داده شده؛
اطلاعات رسمی شده است.
اکنون، پس از اینکه تصمیم گرفتیم در واقع چه چیزی را باید ساختار دهیم، میتوانیم به بررسی آن بپردازیم روش های ساختاری .
آیا می توان گفت که ساختار اطلاعات/داده ها برای ما جدید یا ناآشنا است؟ - البته که نه. در واقع، تمام اقداماتی که در ابتدای این بخش انجام دادیم، یکی از فرضیه های متعدد فرآیند ساختاردهی اطلاعات بود. در مورد ما، ما درگیر ساختاردهی دانش بودیم - مشکل تغییر سطح سازماندهی دانش را حل می کردیم، سعی می کردیم یک سیستم دانش فشرده بسازیم که بتواند به عنوان مبنایی برای توسعه بیشتر نظریه عمل کند (آمریکایی ها واقعاً کلمه " را دوست دارند. اسکلت / اسکلت» که در چنین مواردی از آن استفاده می کنند).
باید اعتراف کرد که زبان علم در میان آمریکاییها بسیار استعاریتر از زبان ما است، اما استعاره، همانطور که اشاره کردیم، گامی به سوی دانش جدید است. اگر بدانیم چیزی را می توان با چه چیزی مقایسه کرد، احتمالاً بخشی از دانش ما در مورد شیئی که این چیزی را با آن مقایسه می کنیم می تواند به این چیزی منتقل شود. "زبان بزرگ و قدرتمند روسی" ما بسیار آکادمیک تر است و روند تشکیل کلمه بسیار پیچیده است و همیشه به نتیجه مطلوب منتهی نمی شود (تعیین یک کلمه جدید و "اقتصادی"). این بسیار غم انگیز است، زیرا یکی از اولین نشانه های رکود علمی و فرهنگی، توقف واژه سازی و غلبه روند رشد واژگان به دلیل استقراض های خارجی است. باید گفت که حتی موضوع "غرور" ملی روس ها - فحاشی های روسی - از نظر عرضه کلمات توهین آمیز، به نظر می رسد که از اکثر زبان های جهان پایین تر است. اما ما بیشتر از این کلمات استفاده می کنیم - "وطن پرست" با شور و شوق اعتراض خواهد کرد ... خوب، شاید، اما این نیز استدلالی است که به نفع ما نیست.
بنابراین، چرا اهداف ساختاردهی اطلاعات را با دقت طبقه بندی کردیم؟ بله، پس، برای ایجاد همان اسکلت، که بعداً آن را با "تاندون ها"، "ماهیچه ها" مجهز می کنیم و آن را با "پوست" متناسب می کنیم - یعنی آن را با دانش خاص تری تکمیل می کنیم. خوب، ما قبلاً اسکلت را ساخته ایم - وقت آن است که به مرحله بعدی بروید.
اکثر روش های ساختاردهی بر اساس روش طبقه بندی هستند. طبقه بندی یک سیستم سلسله مراتبی سازمان یافته از عناصر اطلاعاتی است که اشیاء / فرآیندهای دنیای واقعی را نشان می دهد و بر اساس شباهت / تفاوت ویژگی های طبقه بندی مرتب شده است که منعکس کننده ویژگی های انتخاب شده اشیاء است. . به عنوان یک قاعده، روش طبقه بندی (طبقه بندی) برای راحتی مطالعه یک حوزه موضوعی خاص (بخشی از دنیای واقعی) انجام می شود. مرسوم است که بین انواع طبقه بندی زیر تمایز قائل می شود:
مصنوعی، با توجه به علائم خارجی انجام می شود که ماهیت اشیاء / فرآیندها را بیان نمی کند، و در خدمت ساده سازی برخی از بسیاری از آنها است.
طبیعی (طبیعی) که بر اساس ویژگی های اساسی انجام می شود که مشترکات داخلی (ماهوی) اشیاء / فرآیندها را مشخص می کند.
طبقه بندی طبیعی ابزار و نتیجه تحقیقات علمی است، زیرا بیانگر نتایج حاصل از مطالعه قانونمندی اشیاء/فرآیندهای طبقه بندی شده است. در حالی که طبقه بندی مصنوعی منحصراً ارزش کاربردی در چارچوب حل یک مشکل خاص دارد. به عنوان مثال، سیب رسیده / نارس - طبقه بندی طبیعی، سیب قرمز / سبز - مصنوعی.
اثربخشی و کیفیت همه کارها به کیفیت روش طبقه بندی در مراحل اولیه مطالعه سیستم های پیچیده (و نه تنها سیستم های پیچیده) بستگی دارد. از همین رو هنگام انجام روش طبقه بندی، رعایت اصول زیر ضروری است :
هنگام انجام هر عملیات تقسیم به کلاس ها (عمل تقسیم) مجاز است فقط از یک پایه طبقه بندی استفاده شود.
حجم کل مفاهیم به دست آمده در نتیجه تقسیم به طبقات باید برابر با حجم مفهوم قابل تقسیم باشد.
مفاهیم حاصل از تقسیم باید متقابل باشد.
تقسیم بندی باید منسجم باشد.
طبقه بندی ها به انواع زیر تقسیم می شوند:
ساده (تک سطحی)، به عنوان مثال، یک دوگانگی، زمانی که یک مفهوم سطح بالا (A) به دو (B و C) تقسیم می شود که شرایط A = B + C و B = نه C (C = نه B) ) برای آنها برآورده می شود;
پیچیده (چند بعدی) معمولاً در قالب جداول یک سازمان پیچیده ارائه می شود که در آن ردیف ها و ستون ها با ویژگی های طبقه بندی مختلف مطابقت دارند، به عنوان مثال، جدول تناوبی عناصر شیمیایی D.I. مندلیف؛
سلسله مراتبی (درخت مانند)، به سختی نیاز به مثال و توضیح دارد.
روش طبقه بندی در یک شکل یا دیگری در حل طیف گسترده ای از مسائل مربوط به ساختار اطلاعات استفاده می شود. عناصر اطلاعاتی سازمان نیافته در معرض گروه بندی، پیوند، روش های تعمیم قرار می گیرند که در نتیجه ساختار یا آشکار می شود (با طبقه بندی طبیعی) یا شکل می گیرد (با طبقه بندی مصنوعی). در کتاب V.F. تورچین "پدیده علم: رویکرد سایبرنتیک به تکامل" لحظه تغییر سطح سازماندهی سیستم نامیده می شود. انتقال متاسیستم (ظهور سیستم سطح بالاتری از سلسله مراتب) که به عنوان یک فرآیند تکاملی در نظر گرفته می شود. به ترتیب، فرآیندهای سنتز طبقه بندی و ساختار جدید اطلاعات را می توان به عنوان فرآیند تکامل دانش در نظر گرفت. . این بدان معنا نیست که دانش جدید در نتیجه انجام فرآیندهای طبقه بندی یا ساختاربندی ظاهر می شود، بلکه به این معنی است که در نتیجه این رویه ها، یک سیستم مدیریت دانش جدید ایجاد می شود ، که دستکاری های مختلف با آنها را بسیار ساده می کند، از جمله جستجوی الگوها و قوانین ناشناس قبلی.
توجه داشته باشید که روش طبقه بندی ارزش ذاتی ندارد و تنها در صورتی آن را به دست می آورد که به دستیابی به مجموعه ای از اهداف کمک کند. سیستم مدیریت دانش ایجاد شده در نتیجه روش طبقه بندی باید مفید باشد - به این معنی که انتخاب معیارهای طبقه بندی نمی تواند دلخواه باشد، بلکه باید با در نظر گرفتن کار در حال حل انجام شود. آنها باید به اهداف فعالیت برسند. در عین حال باید تمایز قائل شد دو نوع / جنبه فعالیت :
فعالیت هایی با هدف دستیابی به هدف نهایی (کلی یا جهانی)؛
فعالیت هایی با هدف حل مشکلات تضمین این فعالیت.
دسته آخر می تواند شامل فعالیت هایی با هدف حل مشکلات ساخت یک مدل مناسب از حوزه موضوعی، اصطلاحنامه آن، ایجاد ابزارهای مورد استفاده برای دستیابی به هدف نهایی باشد.
هنگام ساختاردهی اطلاعات، مشخصات مصرف کننده محصول اطلاعاتی دریافتی باید در نظر گرفته شود. به عبارت دیگر، محصول اطلاعاتی به دست آمده باید الزامات مربوط به سطح جزئیات اطلاعات، نحوه ارائه آن و ترکیب اصطلاحنامه را برآورده کند که حالت بهینه درک محصول اطلاعاتی را تضمین می کند.
پیش از این، هنگام در نظر گرفتن انواع مدلها و روشهای مدلسازی، متوجه شدیم که سطح رسمیسازی بازنمایی دانش میتواند از متن بدون ساختار ارائهشده در زبان طبیعی (NL) تا متن ساختیافته در برخی از زبانهای مصنوعی (رسمی) (FL) متفاوت باشد. زبانهای مصنوعی را میتوان بر اساس سیستمهای رسمی مختلف (منطق رسمی، نظریه مجموعهها، دستگاه رسمی جبری و غیره) ساخت.
بسته به سطح اولیه سازماندهی ساختاری داده های پردازش شده، طبقات زیر را می توان تشخیص داد ( کلاس های وظیفه با توجه به سطح سازماندهی ساختاری اطلاعات در ورودی/خروجی ):
1. وظایف تبدیل یک متن NL بدون ساختار به یک متن NL با تقسیم به عنوان.
2. وظایف تبدیل یک متن NL با تقسیم به عنوان به یک متن NL ساختاریافته با عناصر فرمالیسم منطقی.
3. مشکلات تبدیل یک متن NL ساختار یافته با عناصر فرمالیسم منطقی به یک مدل نمادین با استفاده از فرمالیسم نظریه گراف با علامت گذاری NL رئوس (گره ها) و پیوندها (قوس ها).
4. مسائل تبدیل یک مدل نمادین با استفاده از فرمالیسم نظریه گراف با علامت گذاری NL رئوس (گره ها) و پیوندها (قوس) به یک مدل نمادین با استفاده از فرمالیسم نظریه گراف با علامت گذاری NL رئوس (گره ها) و پیوندها ( قوس ها)؛
5. مشکلات تبدیل یک مدل نمادین با استفاده از فرمالیسم نظریه گراف با برچسب گذاری IL رئوس (گره ها) و پیوندها (قوس) به یک مدل IL نمادین دقیق.
در اصل، در حال حاضر پس از حل مشکل نوع دوم، انتقال از بازنمایی های NL به برخی از سیستم های میانی نشانه گذاری (نام ها) می تواند انجام شود، همانطور که در توسعه برنامه ها انجام می شود. با این حال، چنین انتقالی تنها به شرطی منطقی است که تجزیه به اصطلاحات ابتدایی که خصوصیات و عملکرد اشیاء را بیان می کند قبلاً انجام شده باشد، به طوری که در آینده نیازی به انجام روند بازیابی NL-نمایندگی نباشد. . اگر این شرط رعایت شود، پس حتی یک انتقال خودکار از یک سیستم نامگذاری میانی به یک نمایش IL ممکن می شود (به شرطی که اصطلاحنامه ای در سطح مناسب وجود داشته باشد) . در حالت کلی، عملیات تجزیه دقیق فقط در هنگام حل مشکل نوع چهارم انجام می شود. با این حال، ایجاد یک استاندارد سفت و سخت در اینجا دشوار است، و نمی تواند صلب باشد، زیرا ویژگی های الگوریتم ساختاردهی توسط اهداف فعالیت تعیین می شود.
علاوه بر این، در مواردی که درجه رسمیسازی بهدستآمده الزامات ویژگیهای فعالیت را برآورده نمیکند، توصیف رسمی حاصل میتواند مجدداً مشمول رویههایی شود که قبلاً با توجه به نوع دیگری از نمایندگی انجام شده است.
توجه داشته باشید که اطلاعات ارائه شده به صورت غیر متنی نیز میتواند ساختارمند باشد، با این حال، حتی در اینجا نیز میتوان وظایفی را که از نظر محتوایی با موارد ذکر شده معادل هستند، تشخیص داد.
برای مثال، با در نظر گرفتن آرایهای از تصاویر گرافیکی از قطعات مختلف یک شی/فرآیند، بهعنوان یک آرایه دادههای اولیه، مرتبط با نقاط مختلف زمان و بهدستآمده از زوایای مختلف، میتوانیم حل کنیم. وظیفه ساختاری با استفاده از همان مراحل/وظایف. که برای آن می توانید از یکی از دو استراتژی استفاده کنید:
ترجمه مقدماتی را به یک فرم متنی انجام دهید (تلفیقی از توضیحات دقیق تصاویر در NL با نشان دادن روابط مکانی و زمانی بین اشیاء توصیف شده)، و سپس از روشهای توصیف شده قبلی استفاده کنید.
تصویر را به عنوان نوعی متن، با استفاده از یک سیستم نشانه جایگزین که اجازه می دهد فرآیند ساختار در سیستم نشانه دیگری انجام شود، تفسیر کنید.
مبنای نظری به کارگیری این رویکرد نشانه شناسی است که هر شیوه ارائه اطلاعات را به عنوان نوعی متن تفسیر می کند که با استفاده از یک سیستم نشانه ای معین نمایش داده می شود. برای نمایش گرافیکی اطلاعات، تعدادی روش توسعه داده شده است که امکان انتقال از تصویر رنگی معمولی به کانتور و سایر نمایشهایی را میدهد که فرآیندهای تشخیص و ترجمه را به سایر سیستمهای نشانه ساده میکنند. با این حال، از آنجایی که مدلهای گرافیکی بهدستآمده با روش تثبیت متوالی وضعیت اشیاء در دنیای واقعی قادرند تنها ویژگیهای مکانی-زمانی و اسنادی اشیاء/فرایندهای مشاهدهشده را منعکس کنند، استخراج یک سیستم علت و معلولی روابط از آنها تنها با دخالت یک خارجی (اغلب، متخصص) مدل های تفسیر ممکن می شود.
رایج ترین راه برای حل مشکلات ساختار اطلاعات، مشارکت یک تحلیلگر خبره است. در این مورد، تمام بار تبدیل متن مبدأ را به دوش میکشد: از جستجوی قطعات مرتبط گرفته تا شناسایی سیستمی از روابط منطقی، مکانی، زمانی و رویههای بیشتر برای ترکیب یک مدل رسمی. اگرچه اخیراً به لطف توسعه نشانهشناسی، زبانشناسی، تئوری زبانهای مصنوعی، نظریه سیستمهای هوش مصنوعی، نوروسیبرنتیک و تعدادی دیگر از رشتههای علمی، این صنعت به طور فزایندهای مورد هجوم فناوریها قرار گرفته است، اگر نگوییم خودکار، تحلیل خودکار. و ساختار اطلاعات در میان چنین فناوریهایی، میتوان سیستمهای انتزاع متن خودکار را که برای استخراج تکههای متنی طراحی شدهاند که به وضوح ماهیت متن یا مفاد اصلی آن را بیان میکنند، مشخص کرد. به عنوان یک قاعده، این عملیات با استفاده از الگوهای آماری کشف شده توسط جورج کینگزلی زیپ و به نام انجام می شود. اصل صرفه جویی در تلاش در زبان شناسی یا قانون Zipf (یا به طور کلی تر، قانون زیپ-ماندلبروت ).
بسته به نحوه اجرا، معیارهای آماری را می توان در مرحله اولیه (قبل از پردازش دستوری و منطقی متن)، یا در مرحله نهایی (پس از پیش پردازش، تطبیق فرم کلمه و غیره) بر روی متن اعمال کرد. با این حال، در حال حاضر، بدون پشتیبانی از یک حالت تعاملی (گفتگو با یک متخصص)، کیفیت انتزاع نسبتا پایین است و همیشه رضایت مصرف کننده را جلب نمی کند. صرف نظر از گستره فناوری های مورد استفاده در تجزیه و تحلیل فرم های کلمه (اعم از گرامرهای رسمی، فناوری های شبکه عصبی)، نتایج پردازش معنایی هنوز با نتایجی که یک متخصص قادر به ارائه از پایگاههای دانشی که امروزه ایجاد شدهاند، به عبارتی سادهلوحتر از یک کودک است. دلیل چنین "ساده لوحی" این است که مکانیسم های یادگیری چنین سیستم هایی و روش های سازماندهی دانش در آنها ناقص است و تعداد کانال های کسب دانش بسیار کم است. نمونه های اولیه سیستم های هوشمند خودآموز وجود دارد، اما این سیستم ها هنوز نمی توانند به سطح هوش موجودات هوشمند رشد کنند.
با این حال، بررسی دقیق این موضوعات را به متخصصان حوزه تئوری سیستم های هوش مصنوعی واگذار می کنیم. ما فقط به این نکته توجه می کنیم آثار در زمینه تئوری سیستم های هوش مصنوعی واقعاً شایسته خواندن توسط افراد درگیر در "حوزه تولید اطلاعات" است. . این آثار بسیار جالب هستند، حتی به این دلیل که تلاش هایی برای درک چگونگی انجام فعالیت ذهنی یک فرد، الگوریتم سازی و ساده سازی آن است، که برای یک تحلیلگر متخصص بسیار مهم است. علاوه بر این، حداقل به طور کلی مفید است که بفهمید ابزار شما چگونه کار می کند، پارامترها و ویژگی های عملکرد آن چیست. بنابراین، برای مثال، تعدادی از حوزه های روانشناسی مدرن نه از روانشناسی کلاسیک، بلکه از ترکیبی از نظریه هوش مصنوعی، روانشناسی کلاسیک و نظریه فلسفی دانش رشد کرده اند. و چنین خاستگاه غیرمعمول این نظریه های روانشناختی به هیچ وجه مانع از حل موفقیت آمیز مشکلات یک طرح روانشناختی توسط متخصصان این رشته نمی شود.
روشهای ساختار اولیه اطلاعات به طور گسترده در سنتز پایگاههای داده استفاده میشود و در نشریات مختلف علوم رایانه، بهویژه آنهایی که به طراحی و توسعه پایگاههای اطلاعاتی برای اهداف مختلف اختصاص دارند، به تفصیل مورد بحث قرار میگیرند. در محبوب ترین و در عین حال حرفه ای ترین ارائه، این مشکلات در کتاب نویسنده آمریکایی دیوید واسکویچ در نظر گرفته شده است، که به طور خاص برای افرادی نوشته شده است که فعالیت ها را مدیریت می کنند یا وظایفی را برای متخصصان توسعه نرم افزار تدوین می کنند، اما نیازی به کاوش ندارند. به جزئیات تکنولوژیکی فرآیند. به طور خاص، کتاب Vaskevich راه های مختلف سازماندهی و ساختار داده ها، انواع روابط بین آنها را شرح می دهد، نمونه های گویا را ارائه می دهد، که پس از خواندن آن، به مدیر اجازه می دهد تا تیم توسعه را به درستی مدیریت کند و فرآیند فن آوری را به درستی سازماندهی کند. اما یک بار دیگر تاکید می کنیم: برای ما، این کتاب حاوی اطلاعاتی است که به طور خاص به مشکل ساختار اطلاعات مربوط می شود.
هیچ چیز شگفت انگیزی در این واقعیت وجود ندارد که ما به پایگاه های داده به منظور نشان دادن فرآیندهای ساختاردهی اطلاعات مراجعه می کنیم. پایگاه های داده نیز مدل هستند ، جنبه های خاصی از وجود یک سیستم / فرآیند را توصیف می کند ، بنابراین هنگام ایجاد و طراحی آنها ، از روش های ساختاردهی اطلاعات نیز استفاده می شود که با روش های دیگر فقط در این است که ساختاربندی قبلاً با در نظر گرفتن محدودیت های اعمال شده توسط انجام شده است. پلت فرم تکنولوژیکی در حالت کلی، هنگام ساختاردهی اطلاعات، چنین محدودیت هایی همیشه در نظر گرفته نمی شوند.
به هر حال، اما مجموعه ای از توصیفات حاصل از حوزه موضوعی یا مسئله در مرحله اولیه ساختاردهی اطلاعات باید به شکلی ارائه شود که پردازش بیشتر آن را ساده کند. اگر اطلاعات در نتیجه روش های بازیابی اطلاعات به دست آید (به عنوان مثال، در انواع رسانه های جمعی - از مطبوعات چاپی تا اینترنت)، آرایه اولیه حاصل، به عنوان یک قاعده، ساختارمند نیست و دارای قالب های مختلف است. در این حالت، تحلیلگر با وظیفه ساختاربندی اولیه آرایه پیامها در پیچیدهترین نسخه آن مواجه میشود (در اینجا لازم است اطلاعاتی را از پیامها استخراج کند که مرتبط با اهداف تحقیق، طرحبندی آن و غیره است).
با این حال، اگر ما در مورد جمع آوری اطلاعات از طریق مصاحبه با کارشناسان صحبت می کنیم، ساختار اولیه اطلاعات را می توان در مرحله قبل با توسعه سیستمی از پرسشنامه ها، پرسشنامه ها و سایر ابزارهای سفارش اطلاعات انجام داد. استراتژی مصاحبه با کارشناسان (از جمله طوفان فکری یا بازی های تجاری) می تواند به گونه ای سازماندهی شود که کارشناسان را در موقعیتی قرار دهد که فرآیند قضاوت را به ترتیبی کنترل کند که در آن اطلاعات در ابتدا به گونه ای ساختار یافته باشد که مطابق با شرایط باشد. نیازهای رسمی شدن بعدی آن در برخی موارد، کارشناسان ممکن است با گزینههای از پیش آمادهشده برای حل مسائل، آرایههای دادههای اولیه و سایر موادی که نیاز به ارزیابی و رتبهبندی با مشارکت تجربه آنها دارند، برای ارزیابی ارائه شوند.
در یک مورد (هنگام پرسش و مدیریت رویه سوال یا استراتژی بازی)، اطلاعات مطابق با یک روبریک از پیش تعیین شده استخراج می شود. در مورد دیگر (هنگام ارزیابی گزینه ها)، ساختار سازمان اطلاعات تغییر نمی کند و در شکل از پیش تعیین شده هر سطحی از سازمان ساختاری باقی می ماند. به طور خاص، گزینههای پیشنهادی برای ارزیابی ممکن است بر اساس مطالعاتی که قبلاً بر روی مدلهای شبیهسازی انجام شده است، یا از مصاحبه با گروههای دیگر یا همان گروه از متخصصان بهدست آمده باشد.
برای برجسته کردن ساختار منطقی توضیحات، که قبلاً به سرفصلها (مربوط به گروههای مشابه از اشیاء، فرآیندها، مناطق زمانی و مکانی) تقسیم شدهاند، از روشهای مختلفی استفاده میشود که قابلیتهای زیر را ارائه میکنند:
تخصیص حالت های "گسسته" (برای توصیفات متنی - این با تعریف مجموعه ای از اصطلاحات مورد استفاده برای توصیف حالتی است که برای حل مشکل ضروری است)؛
سفارش به موقع آنها (ساخت سناریوهایی مانند "زودتر - بعد")؛
پیوند علت و معلولی (ساخت سناریوهایی مانند "علت - معلول")؛
اتصال فضایی و دیگران.
در مرحله بعد، بسته به اهداف فعالیت، چنین مدل هایی می توانند تحت فرآیند تجزیه (جزئیات) یا تجمیع (ترکیب یا پیچیدگی) قرار گیرند که در نتیجه توصیف سطح مورد نیاز انتزاع / جزئیات تشکیل می شود. .
مراحل بعدی با معرفی سیستمهای ویژه برای نامگذاری عناصر مدل، تخصیص ویژگیهای نامگذاری شده به آنها، توصیف وابستگیهای عملکردی و غیره انجام میشود. به عنوان مثال، وابستگی های منبع-زمان-نتیجه و سایر موارد را می توان به عنوان وابستگی های عملکردی برای تعدادی کار در نظر گرفت که در مراحل اولیه می توان از آنها برای علامت گذاری قوس های نمودار استفاده کرد و متعاقباً در کدهای برنامه نویسی مدل های شبیه سازی گنجانده شد. یک کلاس خاص از مدل های موقعیتی تشکیل شده است که برای تشخیص اشیا، حالات، روندها و فرآیندهای آنها استفاده می شود. در چنین مدل هایی، یا جنبه ایستا یا پویا وجود/عملکرد سیستم را می توان مطلق کرد. با این حال، ما این رویه ها را در اینجا با جزئیات در نظر نخواهیم گرفت، به خصوص که قبلاً برخی از جنبه های این فعالیت را هنگام در نظر گرفتن کلاس های مربوطه از مدل ها شرح داده ایم.
ساده ترین راه برای تجزیه و تحلیل اطلاعات دریافتی، ساختار آن است. ساختاربندی چیزی نیست جز چیدمان در نظمی خاص یا بر اساس الگوی خاصی. این ترتیب را می توان به روش های مختلفی تعریف کرد. بارزترین مثال، چیدمان اطلاعات به ترتیب زمانی است. به عنوان مثال، اطلاعات از منابع مختلف در مورد یک رویداد خاص به ترتیب از اولین تا آخرین (یا برعکس) مرتب شده است. مطابق با زمانی که توسط این بلوک اطلاعاتی توضیح داده شده است. روش دیگر ساختاردهی اطلاعات، محل قرارگیری هر بلوک اطلاعات در بخشهای مختلف است، بسته به عنصری که این بلوک اطلاعاتی را توصیف میکند. در مرحله بعد، پیشنهاد می کنم با روش های مختلف ساختاردهی اطلاعات با جزئیات بیشتری آشنا شوید. آنها عمدتاً در اصل ایجاد ساختار متفاوت هستند.
چیدمان به ترتیب زمانی، یا ساخت توالی رویدادها
به این روش تاریخی نیز می گویند. تمام داده های دریافتی بر اساس زمان رویدادهای توصیف شده مرتب می شوند.
سپس مشخص می شود:
- آنچه به دنبال آن چیست
- کدام واقعیت کدام رویداد را از پیش تعیین می کند،
- چه چیزی را همراهی می کند و غیره
به عبارت دیگر، گاهشماری وقایع احیا می شود. این یکی از ساده ترین راه ها و در عین حال کاملاً مؤثر است.
ساده ترین مثال استفاده از روش تاریخی (کرونولوژی) مطالعه یک نامزد در هنگام استخدام است. شما چندین منبع دارید: نامزد، کتاب کار او، پرسشنامه ای که پر کرده است. علاوه بر این، می توانید از اینترنت برای شناسایی محل کار او (طبق اطلاعیه ها و اپلیکیشن های به جا مانده از او) یا پایگاه های اطلاعاتی استفاده کنید. با جمع آوری تمام این اطلاعات، چندین توالی (کرونولوژی) ایجاد می کنید:
1) نامزد می خواهد چگونه به نظر برسد (با توجه به رزومه و مشخصات او).
2) واقعاً چگونه بود (طبق کتاب کار او).
3) گزینه کمکی (با توجه به سایر منابع).
راه دیگر برای استفاده از زمانشناسی، ساخت زنجیرهای از رویدادها است. در عین حال، بسیار ارزشمند است که حوادث یا رویدادهای موازی با در نظر گرفتن یک واقعه شناخته شده به یک شکل در نظر گرفته شوند، آنگاه خیلی چیزها روشن می شود. پیوند دادن رویدادها به یک حادثه خاص برای شناسایی واکنش های رفتاری شی مورد استفاده قرار می گیرد، با این حال، این در حال حاضر مدل سازی است، اما از همان روش تاریخی (زمان شناسی رویدادها) برای ثبت و تجزیه و تحلیل استفاده می شود. در یک محیط خاص به این می گویند تحریک. به عنوان مثال، به شی نوعی اطلاعات "سوختن" داده می شود - اطلاعاتی که نیاز به اقدام فوری دارد (ارسال شده از طریق پست، به عنوان شایعه، گزارش رسمی و غیره)، و سپس با دقت مشاهده می شود:
- چه کاری و در چه ترتیبی انجام خواهد داد.
- اول با چه کسی تماس بگیرید.
- اصولاً چگونه به پیام واکنش نشان می دهد و غیره.
این رویداد را می توان بر این اساس ترتیب داد. به عنوان مثال، محدود کردن جسم در حرکت یا اتصال، ایجاد این تصور که عملاً زمانی برای فکر کردن ندارد و غیره. همه چیز بستگی به چیزی دارد که می خواهید بفهمید (آشکار کنید). برای ساده کردن وضعیت، نتیجه را می توان به صورت شماتیک نشان داد. اگر چندین سکانس در یک مقیاس و در یک سبک به تصویر کشیده شوند، آنگاه با ترکیب آنها می توان الگوها، همبستگی ها و غیره را آشکار کرد.
مسائل ساختاردهی اطلاعات به دلیل اشباع بیش از حد فضا از اطلاعات مختلف در دنیای مدرن بسیار مورد تقاضا است. به همین دلیل است که نیاز به تفسیر صحیح و ساختاردهی حجم زیادی از داده ها وجود دارد. بدون این امر نمی توان بر اساس هر دانشی تصمیمات مهم مدیریتی و اقتصادی گرفت.
اطلاعات کلی
روش های زیادی برای ساختاردهی اطلاعات وجود دارد. این به این دلیل است که تعداد زیادی روش برای ارائه و سازماندهی آن وجود دارد. این را باید به خاطر بسپارید، زیرا اطلاعات می توانند از نظر خصوصیات بسیار متفاوت باشند. نقش مهمی را ایفا می کند که چه ابزار یا کانال های ادراک خاصی در ورودی یا خروجی داده ها دخیل است، اطلاعات در ابتدا دارای چه سطحی از ساختار است و اینکه آیا به نوع عددی، گرافیکی، متنی یا دیگر تعلق دارد. مهمترین نقش را هدف نهایی ایفا می کند که برای آن ساختار داده ها ضروری است.
اهداف
تجزیه و تحلیل و ساختاردهی اطلاعات همیشه اهداف خاصی دارد و در واقع تعداد کمی از آنها وجود دارد. نتیجه نهایی تا حد زیادی به تنظیم صحیح هدف بستگی دارد. ما طبقات اصلی اهداف را یادداشت می کنیم:
- کسب دانش جدید در یک فرآیند خاص.
- بررسی اطلاعات برای ناقص بودن یا ناسازگاری.
- نیاز به نظام مند کردن و سازماندهی دانش.
- تمرکز بر جنبه های خاص.
- کاهش اطلاعات برای رهایی از پرخوری.
- به روشی واضح تر و قابل فهم تر
- استفاده از تعمیم و انتزاع در توصیف.
بسته به اینکه چه اهدافی را دنبال می کنیم، فناوری ها و روش های ساختاردهی اعمال می شوند. اما همانطور که می دانیم طبقه بندی عامل نهایی تعیین کننده روش سفارش نیست. به همین دلیل تعیین نوع اطلاعات و نحوه ارائه آن مهم است.
طبقه بندی اطلاعات
طبقه بندی را با توجه به ماهیت و محتوای دانش در نظر بگیرید:
- در مورد اهداف و ارزش ها برای نیازهای برنامه ریزی و پیش بینی.
- درباره ویژگی های کاربردی
- درباره ساختار
- درباره تغییرات پویا
- به طور کلی، در مورد دولت.
- درباره وظایف
این طبقه بندی به ترتیب ارتباط نزولی ارائه شده است. بنابراین، مهم ترین اطلاعات مربوط به اهداف است، زیرا بر اساس آن است که نیازهای نهایی کاربر تعیین می شود. کلاسهای باقیمانده نسبتاً مستقل از یکدیگر هستند، آنها فقط به ما اجازه میدهند دادههای موجود را اصلاح و تکمیل کنیم تا کامل بودن آنها را منعکس کنیم. این قرارگیری کاملا معقول است، زیرا حل مسائل کاربردی را به سرعت و کارآمد ممکن می سازد، اما عملا در حل مسائل پیچیده ای که نیاز به تجزیه و تحلیل کامپیوتری دارند، استفاده نمی شود.
اصول طبقهبندی و ساختاردهی اطلاعات نیز بر اساس ویژگیهای دیگری است:
1. اطلاعات مربوط به چیزی
- به شی.
- به چندین شی
- متوسط.
2. الزام به جنبه زمانی
- گذشته.
- آینده.
- حال حاضر.
3. طبقه سازمان ساختاری
- ساختار یافته.
- بدون ساختار
- سفارش داده شده.
- رسمی شد.
علیرغم پیچیدگی ظاهری همه طبقه بندی ها، می خواهم بگویم که ساختار اطلاعات یک فرآیند ساده است که ما هر روز آن را اجرا می کنیم. مشکل درک این موضوع فقط در این است که ما به این فکر نمی کنیم که این موضوع چقدر چند وجهی و گسترده است، همه کارها را به صورت خودکار انجام می دهیم. اگر از دیدگاه حرفه ای به مطالعه این موضوع بپردازیم، معلوم می شود که ساختار اطلاعات بسیاری از مشکلات را حل می کند و به ما کمک می کند تا سیستم دانش خود را بسازیم و از آن برای توسعه بیشتر یا حل مشکلات در سطح روزمره استفاده کنیم. و در سطح حرفه ای
طبقه بندی چیست؟
گردآوری و ساختاردهی اطلاعات بدون مفهوم طبقه بندی که در پاراگراف های قبلی تا حدی به آن پرداختیم غیرممکن است. اما هنوز ارزش درک این مفهوم را با جزئیات بیشتری دارد. طبقه بندی سیستم معینی از عناصر اطلاعاتی است که اشیا یا فرآیندهای واقعی را مشخص می کند و آنها را بر اساس ویژگی های مشابه یا متفاوتی مرتب می کند. اغلب این روش به منظور راحت تر کردن مطالعه انجام می شود.

دو نوع طبقه بندی وجود دارد. اولین، مصنوعی، با توجه به برخی از ویژگی های خارجی انجام می شود که ماهیت واقعی شی را منعکس نمی کند و به شما امکان می دهد فقط داده های سطحی را ساده کنید. نوع دوم یک طبقه بندی طبیعی یا طبیعی است که با توجه به ویژگی های اساسی که ماهیت اشیاء و فرآیندها را مشخص می کند انجام می شود. این طبقه بندی طبیعی است که ابزاری علمی است که برای مطالعه الگوهای اشیاء و فرآیندها استفاده می شود. در عین حال، نمی توان گفت که طبقه بندی مصنوعی مطلقاً بی فایده است. این امکان حل تعدادی از مشکلات کاربردی را فراهم می کند، اما به خودی خود بسیار محدود است.
نتیجه بیشتر مطالعه تا حد زیادی به نحوه انجام روش طبقه بندی بستگی دارد. این از این واقعیت ناشی می شود که در مراحل اولیه بر اساس ویژگی ها تمایز ایجاد می شود و اگر اشتباهی روی آنها صورت گیرد، تحقیقات بعدی راه را اشتباه می رود.
اصول مهم
تکنیکهای ساختاردهی اطلاعات مستلزم رعایت اصول خاصی است که به شما امکان میدهد از قابلیت اطمینان نتایج اطمینان داشته باشید:
- نیاز به تقسیم هر عملیات به کلاس ها و استفاده از تنها یک ویژگی اساسی. این به شما امکان می دهد اطلاعات غیر ضروری را حذف کنید و روی نکات اصلی تمرکز کنید.
- گروه های حاصل باید از نظر منطقی به هم مرتبط باشند و بر اساس اهمیت، زمان، شدت و غیره به ترتیب خاصی چیده شوند.
قانون میلر
این الگو 7 ± 2 نامیده می شود. این توسط دانشمند و روانشناس آمریکایی جورج میلر پس از انجام تعداد زیادی آزمایش کشف شد. قانون میلر این است که حافظه کوتاه مدت انسان می تواند به طور متوسط 7 حرف الفبا، 5 کلمه ساده، 9 عدد متشکل از 2 رقم و 8 عدد اعشاری را به خاطر بسپارد. به طور متوسط، این نشان دهنده گروهی از 7±2 عنصر است. این قانون در بسیاری از زمینه ها قابل اجرا است، به طور فعال برای آموزش توجه انسان استفاده می شود. اما همچنین برای ساختار اطلاعات، بر اساس میزان توانایی مغز انسان استفاده می شود.

اصل لبه
این تأثیر مبتنی بر این واقعیت است که مغز انسان اطلاعات را در ابتدا یا در انتها بهتر به خاطر می آورد. دانشمندی از آلمان در قرن نوزدهم به مطالعه این اصل مشغول بود. او است که کاشف آن محسوب می شود. جالب است که در کشور ما این اصل را بعد از فیلم ماجراهای استرلیتز که در آن شخصیت اصلی برای تغییر توجه حریف خود از آن استفاده کرد، با این اصل آشنا شدند.
اثر بازسازی
به عبارت دیگر، این اثر را اثر انزوا مینامند و به این معناست که وقتی یک شی از تعدادی شیء مشابه متمایز میشود، بسیار بهتر از سایرین به خاطر میآید. به عبارت دیگر، میتوان گفت که ما بیشتر از همه چیزهایی را که بیشتر به چشم میآید به یاد میآوریم. به طور ناخودآگاه، این اثر کاملاً توسط همه افرادی که می خواهند مورد توجه قرار گیرند استفاده می شود. هر فردی متوجه شد که وقتی برخلاف میل او، توجه لباسهای روشنی که از بین جمعیت برجسته بود، یک خانه عجیب و غریب که از یک خیابان خاکستری به بیرون نگاه میکرد، یا پوششی رنگارنگ از زیر انبوهی از لباسهای یکسان جلب میشد، کار میکرد.
در ساختاردهی اطلاعات، از اثر Restroff استفاده می شود تا اطمینان حاصل شود که گروه های مختلف اطلاعات مشابه یکدیگر نیستند. این به آنها درک آسان سریعتر را می دهد. بنابراین، اگر هر عنصر مبهم و جالب باشد، ما آن را بسیار سریعتر به خاطر خواهیم آورد.
روشهای ساختاردهی اطلاعات
روند مطالعه مغز انسان بیهوده نیست. دانشمندان چندین تکنیک و روش برای ساختاردهی اطلاعات ایجاد کرده اند که حفظ را بسیار راحت تر می کند. ما در مورد روش های اصلی و محبوب صحبت خواهیم کرد.
روش اتاق رومی یا زنجیره سیسرو روشی بسیار ساده اما موثر برای تسلط بر مواد است. این در این واقعیت نهفته است که اشیاء به خاطر سپرده شده باید به صورت ذهنی در اتاق شما یا اتاقی که به خوبی می شناسید قرار داده شوند. شرط اصلی این است که همه موارد باید به ترتیب دقیق چیده شوند. پس از آن، برای به خاطر سپردن اطلاعات لازم، کافی است اتاق را به خاطر بسپارید. این دقیقاً همان کاری است که سیسرو هنگام آماده شدن برای سخنرانی خود انجام داد. او در خانهاش قدم میزد و ذهناً لهجههایی میگفت تا بتواند در جریان سخنرانیاش به نکتهای مهم بازگردد. شما نباید محدود به یک اتاق باشید، می توانید سعی کنید اطلاعات مورد نظر را در یک خیابان آشنا، دسکتاپ یا شی دیگری که با آن آشنا هستید قرار دهید.
روش نقشه ذهنی یا روش Buzan روشی ساده برای نمایش گرافیکی اطلاعات با استفاده از نمودارها است. اغلب این روش را نقشه ذهنی می نامند، زیرا نیاز به ساختن نقشه های انجمنی است. این روش حفظ در چند وقت اخیر بسیار رایج شده است. چنین کارت هایی توسط روانشناسان و مربیان مختلف توصیه می شود تا اهداف را به درستی تعیین کنید و خواسته های واقعی خود را درک کنید. اما هدف اولیه نقشه های ذهنی دقیقا به خاطر سپردن و ساختار سریعتر اطلاعات بود. برای تهیه نمودار زایمان به موارد زیر نیاز دارید:
- مطالبی که می خواهید مطالعه کنید.
- ورق کاغذ بزرگ.
- خودکار و مداد رنگی.
پس از آن، نماد یا تصویری را در مرکز برگه بکشید که با موضوعی که می خواهید به خاطر بسپارید مرتبط است یا ماهیت آن را منعکس می کند. پس از آن، به سمت مرکز، زنجیره های مختلفی از اتصالات را بکشید که یک طرف شی مورد مطالعه را منعکس می کند. در نتیجه، برای به خاطر سپردن اطلاعات لازم، لازم نیست فهرستها را مرور کنید یا نیمی از کتاب درسی را بخوانید. می توانید بلافاصله ایده اصلی را با نگاه کردن به آن در مرکز ورق به خاطر بسپارید و سپس با حرکت در امتداد شاخه های خروجی، دقیقاً آنچه را که نیاز دارید به خاطر بسپارید.

روش های ساختاربندی مرحله ای
به طور طبیعی، ساختار اطلاعات دیجیتال فرآیند پیچیده تری است. کارهایی که با سطوح مختلف عدم قطعیت مشخص می شوند، از دشواری خاصی برخوردارند. برای حل آنها، باید به تعدادی از روش ها متوسل شد که می توانند در روش های ساختاربندی مرحله ای و روش های ریخت شناسی ترکیب شوند. هر دوی این انواع برای استفاده در شرایط عدم قطعیت بالا سازگار شده اند.
اما آنها به طور قابل توجهی متفاوت هستند که در کدام روش استفاده می شود. هدف گروه اول کاهش تدریجی عدم قطعیت مسئله است، در حالی که گروه دوم قصد دارند با ساختن مدلها در یک تکرار آن را حل کنند.
لازم به ذکر است که هنگام استفاده از روش ریخت شناسی، عدم قطعیت ممکن است به هیچ وجه تغییر نکند، به سادگی به سطح دیگری از توصیف منتقل می شود. هر دو روش با بررسی سطح رسمی سازی شروع می شوند. اما اگر برای روش های ساختاردهی گام به گام سطح می تواند هر باشد، برای روش های مورفولوژیکی، تجزیه دقیق و تولید بعدی مدل های ماتریسی مهم است. به عبارت دیگر، میتوان گفت که روشهای ریختشناسی اغلب با فناوری کامپیوتری قدرتمند استفاده میشوند، زیرا مغز انسان قادر به پردازش چنین آرایههای اطلاعاتی نیست.
هدف روشهای ساختاری تدریجی یافتن روابط منطقی است، و روشهای ریختشناسی وظیفه خود را برای یافتن یک نتیجه منطقی تعیین نمیکنند، اما آنها یک تجزیه و تحلیل ترکیبی کامل انجام میدهند و اطلاعات را بهطور کامل و عمیقتر مرتب میکنند.
با این حال، کارایی کار در استفاده از هر دوی این روش ها نهفته است. ساختار اطلاعات دیجیتال نیازمند یک رویکرد یکپارچه است. به همین دلیل است که نه تنها استفاده از در دسترس ترین روش ها، بلکه متوسل شدن به برنامه ریزی، آزمایش و سایر روش های خاص صنعت نیز مهم است.
فناوری ساختاردهی اطلاعات تا حد زیادی به جزئیات کار باید انجام شود بستگی دارد. بنابراین، هنگام ساختاردهی، اول از همه، ویژگی های صنعت در نظر گرفته می شود.
تحلیل و ساختاردهی اطلاعات در زمینه نشانه شناسی بسیار سودمند است. این رویکردی است که هر روشی برای ارائه اطلاعات به عنوان یکی از انواع متن تفسیر میکند. استفاده از سیستم نشانه باعث می شود تا درک اطلاعات تا حد امکان ساده و آسان شود. بنابراین، در نمایش گرافیکی، ما از تعدادی روش استفاده می کنیم که به ما امکان می دهد از تونالیته به کنتراست، از اشباع به روشنایی و غیره حرکت کنیم. همه اینها تشخیص داده ها را ساده کرده و آنها را برای سایر سیستم های نشانه ترجمه می کند. اما از آنجایی که مدلهای گرافیکی تا حدودی محدود هستند، استخراج اطلاعات از آنها با استفاده از یک مدل تفسیری آسانتر است.

ساختار اطلاعات در کتابخانه رسانه رایانه های شخصی و سرورها
ما مسائل مربوط به ساختار را با جزئیات در نظر گرفتیم، اما در زمینه اطلاعات دیجیتال به این موضوع اشاره نکردیم. در دنیای مدرن، فناوری های کامپیوتری اطلاعات در حال ورود به تمام حوزه های زندگی هستند. بنابراین، نادیده گرفتن آنها به سادگی غیرممکن است. اخیراً کتابخانههای رسانهای اطلاعاتی که در مدارس، مؤسسات آموزش عالی و دانشکدههای فنی مورد استفاده قرار میگیرند، توسعه زیادی یافتهاند. کتابخانه های رسانه ای رایانه شخصی و سرور، وسایل کمک آموزشی روش شناختی، ضبط صدا، مجموعه کتاب، فایل های ویدئویی، ارائه های رایانه ای و همچنین پشتیبانی فنی لازم برای نمایش تمام اطلاعات فوق را ترکیب می کنند. امروزه هر مؤسسه آموزشی کتابخانه رسانه ای خود را ایجاد می کند که به طور مرتب با اطلاعات جدید ثبت شده در رسانه های مختلف به روز می شود. این به دانش آموزان اجازه می دهد تا کار مستقل با ارتباطات راه دور و کاتالوگ های الکترونیکی را توسعه دهند. وظایفی که کتابخانه رسانه انجام می دهد به شرح زیر است:
- ساختاردهی اطلاعات با استفاده از مدل های اطلاعاتی برای ذخیره پایان نامه ها، مقالات، ارائه ها و غیره دانشجویی.
- اتوماسیون کامل کار با کتابخانه.
- به روز رسانی و ذخیره سازی مواد آموزشی عمومی آموزشی به صورت الکترونیکی.
- ذخیره منابع و کمک های اطلاعاتی.
- دسترسی نامحدود به منابع شبکه و کتابخانه های الکترونیکی.
- ذخیره و مشاهده فایل های عکس و فیلم یک موسسه آموزشی.
- در صورت درخواست، اطلاعات لازم را جستجو کنید.
- کار عملیاتی با هر منبع اطلاعاتی.
نقش مهمی توسط ساختار ذخیره سازی اطلاعات ایفا می شود. برای انجام این کار، موسسات باید سرورهای قدرتمندی داشته باشند که امنیت و امنیت داده ها را تضمین کنند. به همین دلیل است که باید با صلاحیت و حرفه ای به موضوع رسیدگی شود، زیرا در صورت بروز خطا ممکن است اطلاعات از دست رفته برگردانده نشود.
ساختار اطلاعات در یک کتابخانه رسانه ای رایانه شخصی به تجهیزات رایانه ای قدرتمندی از جمله دستگاه های تلفن همراه، لپ تاپ ها، شارژرها و غیره نیاز دارد. فقط تجهیزات با کیفیت بالا کار تمام عیار با مواد را به طور همزمان برای همه کاربران تضمین می کند. همچنین داشتن یک سرور مرکزی که داده ها در آن ذخیره می شوند بسیار مهم است. اغلب سرورها در کتابخانه ها نصب می شوند. نصب یک شبکه بی سیم به هر معلم یا دانش آموز این امکان را می دهد که بدون خروج از خانه به تمام مواد از یک لپ تاپ دسترسی داشته باشد.
ساختار اطلاعات در پایگاه های داده
پایگاه داده مجموعه خاصی از داده ها است که توسط پرسنل یک شرکت، منطقه، دانشجویان دانشگاه و غیره به اشتراک گذاشته می شود. وظیفه بانک های اطلاعاتی این است که بتوانند حجم زیادی از اطلاعات را ذخیره کرده و آن ها را در صورت تقاضا ارائه کنند.

یک پایگاه داده به خوبی طراحی شده، افزونگی داده ها را به طور کامل حذف می کند، به طوری که خطر ذخیره اطلاعات متناقض به حداقل می رسد. بر این اساس می توان گفت که ایجاد پایگاه های داده در دنیای مدرن دو هدف اصلی دارد - افزایش قابلیت اطمینان داده ها و کاهش افزونگی آنها.
چرخه عمر یک محصول نرم افزاری شامل مراحل طراحی، پیاده سازی و بهره برداری است، اما مرحله اصلی و کلیدی، مرحله طراحی است. اشباع اطلاعات و عملکرد کلی به این بستگی دارد که چقدر خوب فکر شده است، چگونه ارتباطات بین همه عناصر به وضوح تعریف شده است.
یک پایگاه داده خوب طراحی شده باید:
- اطمینان از یکپارچگی داده ها
- کاوش، پیدا کردن و حذف تناقضات.
- درک آسان را ارائه دهید.
- به کاربر اجازه می دهد اطلاعات را ساختار دهد و داده های جدید را وارد کند.
- الزامات عملکرد را برآورده کنید.
قبل از طراحی یک پایگاه داده، تجزیه و تحلیل کامل نیازهای کاربر برای یک محصول نرم افزاری آینده انجام می شود. در عین حال، برنامه نویس ملزم به دانستن قوانین اساسی و عوامل محدود کننده است تا به درستی روابط منطقی بین پرس و جوها ایجاد کند. بسیار مهم است که ویژگی جستجو را به درستی کار کنید تا کاربران بتوانند اطلاعات مورد نظر را با کلمات کلیدی مرتب نشده پیدا کنند. همچنین باید به خاطر داشته باشید که هرچه پایگاه داده اطلاعات بیشتری را در خود ذخیره کند، مسئله عملکرد برای آن مهمتر است، زیرا در حداکثر بارها است که همه کاستی ها قابل مشاهده است.
نقش اطلاعات در دنیای مدرن
روشهای ساختاردهی اطلاعاتی که در نظر گرفتهایم با هدف آسانتر کردن دسترسی به دادهها، ذخیرهسازی آنها به شکل دیجیتال یا مادی است. همه آنها در ذات خود بسیار ساده هستند، اما درک آنها مستلزم درک این نکته است که اطلاعات فقط یک مفهوم انتزاعی است.
اندازه گیری، لمس یا دیدن در هر شکل خاص دشوار است. از نقطه نظر ساختار اطلاعات، هر شی فقط مجموعهای از دادهها و ویژگیهای معینی است که میتوانیم آنها را بازنمایی کنیم و به بخشهای جزئی تقسیم کنیم.
در عین حال، درک تفاوت های کلیدی بین اشیاء مبتنی بر این واقعیت است که ما مقادیر آن را با هنجار یا با شیئی که برای مقایسه استفاده می کنیم مقایسه می کنیم. برای یادگیری نحوه ساختار سریع و مؤثر اطلاعات، مهم است که بدانیم این فقط مجموعه ای از ویژگی ها، ویژگی ها و پارامترهای خاص است. با یادگیری نحوه برخورد و طبقه بندی صحیح آنها می توانید بسیاری از مشکلات روزمره و حرفه ای را حل کنید.

همچنین مهم است که به یاد داشته باشید که اطلاعات همیشه می تواند نوشته شود، به تصویر کشیده شود یا به شکل دیگری ارائه شود. به عبارت دیگر، اگر چیزی را متوجه نشدید، باید این موضوع را به عناصر دقیق تقسیم کنید و در اصل آنها عمیق شوید تا چیزی باقی نماند که نتوان آن را به زبان ساده توضیح داد.
در زندگی روزمره، اکثریت به راحتی با اختراع نقشه های ذهنی و استفاده از ویژگی های مغز خود که توسط دانشمندان کشف شده است، چنین مشکلاتی را حل می کنند. اما از نظر حرفه ای، ساختاردهی اطلاعات هنوز یک کار نسبتاً دشوار است، زیرا مقدار آن هر روز و هر دقیقه در حال افزایش است.
در واقع، کل تکامل انسان فرآیند انباشت دانش است. اما در عین حال، برای کار موثر، لازم است اصول اولیه ساختاردهی اطلاعات را که قبلاً در مورد آنها نیز صحبت کردیم، درک کنیم. تعداد زیادی از آنها وجود ندارد. با این حال، درک کلید پردازش حجم عظیمی از اطلاعات و به خاطر سپردن آنهاست.