تجزیه و تحلیل رگرسیون در مایکروسافت اکسل - جامع ترین راهنمای استفاده از MS Excel برای حل مشکلات تجزیه و تحلیل رگرسیون در زمینه تجزیه و تحلیل کسب و کار. کنراد کارلبرگ به وضوح مسائل نظری را توضیح می دهد که دانش آنها به شما کمک می کند از بسیاری از اشتباهات هم هنگام انجام تحلیل رگرسیون خودتان و هم هنگام ارزیابی نتایج تجزیه و تحلیل انجام شده توسط افراد دیگر جلوگیری کنید. همه مطالب، از همبستگی های ساده و آزمون های تی تا تحلیل کوواریانس چندگانه، بر اساس مثال های دنیای واقعی است و با روش های گام به گام دقیق همراه است.
این کتاب در مورد ویژگیها و اختلافات توابع رگرسیون اکسل بحث میکند، پیامدهای هر گزینه و استدلال را بررسی میکند، و توضیح میدهد که چگونه میتوان روشهای رگرسیون را به طور قابل اعتماد در حوزههایی از تحقیقات پزشکی تا تحلیل مالی اعمال کرد.
کنراد کارلبرگ. تجزیه و تحلیل رگرسیون در مایکروسافت اکسل. – م.: دیالکتیک، 2017. – 400 ص.
یادداشت را با فرمت یا نمونه ها در قالب دانلود کنید
فصل 1: ارزیابی تغییرپذیری داده ها
آماردانان معیارهای زیادی برای تنوع در اختیار دارند. یکی از آنها مجموع انحرافات مجذور مقادیر فردی از میانگین است. در اکسل از تابع SQUARE() برای این کار استفاده می شود. اما واریانس بیشتر مورد استفاده قرار می گیرد. پراکندگی میانگین انحرافات مجذور است. واریانس به تعداد مقادیر در مجموعه داده مورد مطالعه حساس نیست (در حالی که مجموع انحرافات مجذور با تعداد اندازه گیری ها افزایش می یابد).
اکسل دو تابع را ارائه می دهد که واریانس را برمی گرداند: DISP.G() و DISP.V():
- اگر مقادیری که باید پردازش شوند از یک جمعیت تشکیل می دهند، از تابع DISP.G() استفاده کنید. یعنی مقادیر موجود در محدوده تنها مقادیری هستند که شما به آنها علاقه دارید.
- اگر مقادیری که باید پردازش شوند نمونه ای از یک جمعیت بزرگتر را تشکیل می دهند، از تابع DISP.B() استفاده کنید. فرض بر این است که مقادیر اضافی وجود دارد که می توانید واریانس آنها را نیز تخمین بزنید.
اگر کمیتی مانند میانگین یا ضریب همبستگی از یک جامعه محاسبه شود، به آن پارامتر می گویند. مقدار مشابهی که بر اساس یک نمونه محاسبه می شود، آمار نامیده می شود. شمارش انحرافات از میانگیندر یک مجموعه معین، مجموع انحرافات مجذور با بزرگی کمتر از زمانی که آنها را از هر مقدار دیگری بشمارید، دریافت خواهید کرد. یک عبارت مشابه برای واریانس صادق است.
هر چه حجم نمونه بزرگتر باشد، مقدار آماری محاسبه شده دقیق تر است. اما هیچ نمونه ای کوچکتر از حجم جامعه وجود ندارد که بتوانید مطمئن باشید که مقدار آماری با مقدار پارامتر مطابقت دارد.
فرض کنید مجموعه ای از 100 ارتفاع دارید که میانگین آنها با میانگین جمعیت متفاوت است، مهم نیست که تفاوت چقدر کوچک است. با محاسبه واریانس برای یک نمونه، یک مقدار مثلاً 4 دریافت خواهید کرد. این مقدار کوچکتر از هر مقدار دیگری است که می توان با محاسبه انحراف هر یک از 100 مقدار ارتفاع نسبت به هر مقداری غیر از میانگین نمونه به دست آورد. از جمله نسبت به میانگین واقعی جمعیت عمومی. بنابراین، واریانس محاسبه شده متفاوت و کوچکتر از واریانسی خواهد بود که اگر به نحوی از یک پارامتر جمعیت به جای میانگین نمونه استفاده کنید، بدست می آورید.
مجموع میانگین مربعات تعیین شده برای نمونه تخمین کمتری از واریانس جامعه ارائه می دهد. واریانس محاسبه شده به این روش نامیده می شود آوارهارزیابی معلوم می شود که برای از بین بردن تعصب و به دست آوردن یک تخمین بی طرفانه، کافی است مجموع انحرافات را بر مجذور تقسیم کنیم نه بر n، جایی که n- حجم نمونه و n – 1.
اندازه n – 1عدد (تعداد) درجات آزادی نامیده می شود. روشهای مختلفی برای محاسبه این کمیت وجود دارد، اگرچه همه آنها شامل کم کردن مقداری از حجم نمونه یا شمارش تعداد دستههایی است که مشاهدات در آن قرار میگیرند.
ماهیت تفاوت بین توابع DISP.G() و DISP.V() به شرح زیر است:
- در تابع VAR.G()، مجموع مربع ها بر تعداد مشاهدات تقسیم می شود و بنابراین تخمین مغرضانه ای از واریانس، یعنی میانگین واقعی را نشان می دهد.
- در تابع DISP.B() مجموع مربع ها بر تعداد مشاهدات منهای 1 تقسیم می شود، یعنی. با تعداد درجات آزادی، که تخمین دقیق تر و بی طرفانه تری از واریانس جامعه ای که نمونه از آن استخراج شده است، به دست می دهد.
انحراف معیار انحراف معیار، SD) - جذر واریانس است:
مربع کردن انحرافات، مقیاس اندازهگیری را به معیار دیگری تبدیل میکند، که مربع اصلی است: متر - به متر مربع، دلار - به دلار مربع و غیره. انحراف معیار جذر واریانس است و بنابراین ما را به واحدهای اندازه گیری اصلی بازمی گرداند. هر کدوم راحت تره
اغلب لازم است انحراف معیار پس از دستکاری داده ها محاسبه شود. و اگرچه در این موارد نتایج بدون شک انحراف معیار هستند، معمولاً آنها را نامیده میشوند خطاهای استاندارد. چندین نوع خطای استاندارد از جمله خطای استاندارد اندازه گیری، خطای استاندارد نسبت و خطای استاندارد میانگین وجود دارد.
فرض کنید اطلاعات قد را برای 25 مرد بالغ به طور تصادفی در هر یک از 50 ایالت جمع آوری کرده اید. در مرحله بعد، میانگین قد مردان بالغ در هر ایالت را محاسبه می کنید. 50 مقدار میانگین حاصل، به نوبه خود، می توانند مشاهدات در نظر گرفته شوند. از این، شما می توانید انحراف معیار آنها را محاسبه کنید، که این است خطای استاندارد میانگین. برنج. 1. توزیع 1250 ارزش فردی خام (داده های قد برای 25 مرد در هر یک از 50 ایالت) را با توزیع میانگین 50 ایالت مقایسه می کند. فرمول تخمین خطای استاندارد میانگین (یعنی انحراف معیار میانگین، نه مشاهدات فردی):
![]()
خطای استاندارد میانگین کجاست. س- انحراف معیار مشاهدات اصلی؛ n- تعداد مشاهدات در نمونه

برنج. 1. تغییرات میانگین ها از حالتی به حالت دیگر به طور قابل توجهی کمتر از تغییرات در مشاهدات فردی است.
در آمار، قراردادی در مورد استفاده از حروف یونانی و لاتین برای نمایش کمیت های آماری وجود دارد. مرسوم است که پارامترهای جمعیت عمومی را با حروف یونانی و آمار نمونه را با حروف لاتین نشان می دهند. بنابراین، وقتی در مورد انحراف معیار جمعیت صحبت می کنیم، آن را به صورت σ می نویسیم. اگر انحراف استاندارد نمونه در نظر گرفته شود، از علامت s استفاده می کنیم. در مورد نمادهای تعیین میانگین ها، آنها به خوبی با یکدیگر همخوانی ندارند. میانگین جمعیت با حرف یونانی μ نشان داده می شود. با این حال، نماد X به طور سنتی برای نشان دادن میانگین نمونه استفاده می شود.
z-scoreموقعیت یک مشاهده را در توزیع در واحدهای انحراف استاندارد بیان می کند. به عنوان مثال، z = 1.5 به این معنی است که مشاهده 1.5 انحراف استاندارد از میانگین فاصله دارد. مدت، اصطلاح z-scoreبرای ارزیابی های فردی استفاده می شود، یعنی. برای ابعاد اختصاص داده شده به عناصر نمونه جداگانه. اصطلاحی که برای اشاره به چنین آماری استفاده می شود (مانند میانگین دولتی) z-score:

که در آن X میانگین نمونه، μ میانگین جامعه است، خطای استاندارد میانگین مجموعهای از نمونهها است:
![]()
جایی که σ خطای استاندارد جامعه (اندازه گیری های فردی) است. n- اندازهی نمونه.
فرض کنید به عنوان مربی در یک باشگاه گلف کار می کنید. شما توانسته اید فاصله شلیک های خود را در مدت زمان طولانی اندازه گیری کنید و بدانید که میانگین 205 یارد و انحراف معیار 36 یارد است. به شما یک باشگاه جدید پیشنهاد می شود که ادعا می کند مسافت ضربه شما را 10 یارد افزایش می دهد. شما از هر یک از 81 مشتری بعدی باشگاه می خواهید که با یک باشگاه جدید یک عکس آزمایشی بگیرند و فاصله نوسان خود را ثبت کنند. معلوم شد که میانگین فاصله با باشگاه جدید 215 یارد بوده است. احتمال اینکه اختلاف 10 یارد (215 تا 205) صرفاً به دلیل خطای نمونه گیری باشد چقدر است؟ یا به بیان دیگر: احتمال اینکه در آزمایش های گسترده تر، باشگاه جدید افزایش فاصله ضربه را نسبت به میانگین طولانی مدت موجود 205 یارد نشان ندهد چقدر است؟
ما می توانیم این را با ایجاد یک z-score بررسی کنیم. خطای استاندارد میانگین:
![]()
سپس z-score:

ما باید این احتمال را پیدا کنیم که میانگین نمونه 2.5σ از میانگین جامعه فاصله داشته باشد. اگر احتمال کم است، پس تفاوت ها به دلیل شانس نیست، بلکه به دلیل کیفیت باشگاه جدید است. اکسل تابع آماده ای برای تعیین احتمال z-score ندارد. با این حال، می توانید از فرمول =1-NORM.ST.DIST(z-score,TRUE) استفاده کنید، که در آن تابع NORM.ST.DIST() ناحیه زیر منحنی نرمال را در سمت چپ امتیاز z برمی گرداند (شکل 2).

برنج. 2. تابع NORM.ST.DIST() ناحیه زیر منحنی را در سمت چپ مقدار z برمی گرداند. برای بزرگنمایی تصویر روی آن کلیک راست کرده و انتخاب کنید باز کردن تصویر در تب جدید
آرگومان دوم تابع NORM.ST.DIST() می تواند دو مقدار داشته باشد: TRUE - تابع مساحت ناحیه زیر منحنی را در سمت چپ نقطه مشخص شده توسط آرگومان اول برمی گرداند. FALSE - تابع ارتفاع منحنی را در نقطه مشخص شده توسط آرگومان اول برمی گرداند.
اگر میانگین جمعیت (μ) و انحراف معیار (σ) مشخص نباشد، از مقدار t استفاده می شود (جزئیات را ببینید). ساختارهای z-score و t-score از این جهت متفاوت هستند که انحراف استاندارد s به دست آمده از نتایج نمونه برای یافتن نمره t به جای مقدار شناخته شده پارامتر جمعیت σ استفاده می شود. منحنی نرمال دارای یک شکل واحد است و شکل توزیع مقدار t بسته به تعداد درجات آزادی df متفاوت است. درجه آزادی) نمونه ای که نشان می دهد. تعداد درجات آزادی نمونه برابر است با n – 1، جایی که n- اندازه نمونه (شکل 3).

برنج. 3. شکل توزیع های t که در مواردی که پارامتر σ ناشناخته است با شکل توزیع نرمال متفاوت است.
اکسل دارای دو تابع برای توزیع t است که توزیع Student نیز نامیده می شود: STUDENT.DIST () ناحیه زیر منحنی را در سمت چپ مقدار t داده شده برمی گرداند و STUDENT.DIST.PH () منطقه را به درست.
فصل 2. همبستگی
همبستگی معیاری برای وابستگی بین عناصر مجموعه ای از جفت های مرتب شده است. همبستگی مشخص می شود ضرایب همبستگی پیرسون-r. ضریب می تواند مقادیری در محدوده -1.0 تا +1.0 داشته باشد.

جایی که Sxو S y- انحراف معیار متغیرها ایکسو Y, S xy– کوواریانس:

در این فرمول کوواریانس بر انحراف معیار متغیرها تقسیم می شود ایکسو Y، در نتیجه اثرات مقیاس بندی مربوط به واحد را از کوواریانس حذف می کند. اکسل از تابع ()CORREL استفاده می کند. نام این تابع حاوی عناصر واجد شرایط Г و В نیست که در نام توابعی مانند STANDARDEV()، VARIANCE() یا COVARIANCE() استفاده می شود. اگرچه ضریب همبستگی نمونه یک تخمین مغرضانه ارائه میکند، اما دلیل سوگیری با واریانس یا انحراف معیار متفاوت است.
بسته به بزرگی ضریب همبستگی عمومی (اغلب با حرف یونانی نشان داده می شود ρ )، ضریب همبستگی rیک تخمین مغرضانه تولید می کند که با کاهش اندازه نمونه، اثر سوگیری افزایش می یابد. با این حال، ما سعی نمی کنیم این تعصب را به همان روشی که مثلاً هنگام محاسبه انحراف استاندارد انجام دادیم، اصلاح کنیم، زمانی که نه تعداد مشاهدات، بلکه تعداد درجات آزادی را در فرمول مربوطه جایگزین کردیم. در واقع، تعداد مشاهداتی که برای محاسبه کوواریانس استفاده می شود، تأثیری بر بزرگی ندارد.
ضریب همبستگی استاندارد برای استفاده با متغیرهایی در نظر گرفته شده است که با یک رابطه خطی به یکدیگر مرتبط هستند. وجود غیرخطی بودن و/یا خطاها در داده ها (پرت) منجر به محاسبه نادرست ضریب همبستگی می شود. برای تشخیص مشکلات داده ها، ایجاد نمودارهای پراکنده توصیه می شود. این تنها نوع نمودار در اکسل است که هر دو محور افقی و عمودی را به عنوان محورهای ارزش در نظر می گیرد. نمودار خطی یکی از ستون ها را به عنوان محور دسته تعریف می کند که تصویر داده ها را مخدوش می کند (شکل 4).

برنج. 4. خطوط رگرسیون یکسان به نظر می رسند، اما معادلات آنها را با یکدیگر مقایسه کنید
مشاهدات مورد استفاده برای ساخت نمودار خطی به فاصله مساوی در امتداد محور افقی مرتب شده اند. برچسب های تقسیم در امتداد این محور فقط برچسب هستند، نه مقادیر عددی.
اگرچه همبستگی اغلب به این معنی است که یک رابطه علت و معلولی وجود دارد، اما نمی توان از آن برای اثبات این موضوع استفاده کرد. از آمار برای نشان دادن درست یا نادرست بودن یک نظریه استفاده نمی شود. برای حذف توضیحات رقابتی برای نتایج مشاهداتی، قرار دهید آزمایش های برنامه ریزی شده. از آمار برای خلاصه کردن اطلاعات جمعآوریشده در طول چنین آزمایشهایی و برای تعیین کمیت احتمال نادرست بودن تصمیم اتخاذ شده با توجه به شواهد موجود استفاده میشود.
فصل 3: رگرسیون ساده
اگر دو متغیر با یکدیگر مرتبط باشند، به طوری که مقدار ضریب همبستگی مثلاً از 0.5 بیشتر شود، در این صورت می توان مقدار مجهول یک متغیر را از مقدار شناخته شده دیگری پیش بینی کرد (با کمی دقت) . برای به دست آوردن مقادیر قیمت پیش بینی شده بر اساس داده های نشان داده شده در شکل. 5، می توانید از هر یک از چندین روش ممکن استفاده کنید، اما تقریباً مطمئناً از روش نشان داده شده در شکل استفاده نخواهید کرد. 5. با این وجود، باید خود را با آن آشنا کنید، زیرا هیچ روش دیگری به شما اجازه نمی دهد که ارتباط بین همبستگی و پیش بینی را به وضوح این روش نشان دهید. در شکل 5 در محدوده B2:C12 یک نمونه تصادفی از ده خانه را نشان می دهد و داده هایی را در مورد مساحت هر خانه (به فوت مربع) و قیمت فروش آن ارائه می دهد.

برنج. 5. پیش بینی ارزش های قیمت فروش یک خط مستقیم را تشکیل می دهد
میانگین، انحراف معیار و ضریب همبستگی را بیابید (محدوده A14:C18). محاسبه مساحت z-نمرات (E2:E12). به عنوان مثال، سلول E3 حاوی فرمول: =(B3-$B$14)/$B$15 است. امتیازهای z قیمت پیش بینی شده (F2:F12) را محاسبه کنید. به عنوان مثال، سلول F3 حاوی فرمول: =ЕЗ*$В$18 است. تبدیل z-score به قیمت دلار (H2:H12). در سلول NZ فرمول این است: =F3*$C$15+$C$14.
توجه داشته باشید که مقدار پیشبینیشده همیشه به سمت میانگین 0 تغییر میکند. هر چه ضریب همبستگی به صفر نزدیکتر باشد، امتیاز z پیشبینیشده به صفر نزدیکتر است. در مثال ما، ضریب همبستگی بین منطقه و قیمت فروش 0.67 است و قیمت پیشبینی شده 1.0 * 0.67 است، یعنی. 0.67. این مربوط به بیش از مقدار بالاتر از میانگین برابر با دو سوم انحراف استاندارد است. اگر ضریب همبستگی برابر با 0.5 بود، قیمت پیشبینی شده 1.0 * 0.5 خواهد بود، یعنی. 0.5. این مربوط به بیش از مقدار بالاتر از میانگین برابر با تنها نیمی از انحراف استاندارد است. هر گاه مقدار ضریب همبستگی با مقدار ایده آل متفاوت باشد، یعنی. بیشتر از -1.0 و کمتر از 1.0، امتیاز متغیر پیشبینیشده باید به میانگین خود نزدیکتر باشد تا امتیاز متغیر پیشبینیکننده (مستقل) به خودش. این پدیده را رگرسیون به میانگین یا به سادگی رگرسیون می نامند.
اکسل چندین تابع برای تعیین ضرایب معادله خط رگرسیون دارد (که در اکسل خط روند نامیده می شود) y =kx + ب. برای تعیین کعملکرد را ارائه می دهد
=SLOPE (مقادیر_y_مقادیر، مقادیر_x_معروف)
اینجا درمتغیر پیش بینی شده است و ایکس- متغیر مستقل شما باید به شدت از این ترتیب متغیرها پیروی کنید. شیب خط رگرسیون، ضریب همبستگی، انحراف معیار متغیرها و کوواریانس ارتباط نزدیکی با هم دارند (شکل 6). تابع ()INTERMEPT مقدار قطع شده توسط خط رگرسیون در محور عمودی را برمیگرداند:
=LIMIT(مقادیر_y_مقادیر، مقادیر_x_معروف)

برنج. 6. رابطه بین انحرافات استاندارد، کوواریانس را به ضریب همبستگی و شیب خط رگرسیون تبدیل می کند.
توجه داشته باشید که تعداد مقادیر x و y ارائه شده به عنوان آرگومان برای توابع SLOPE() و INTERCEPT() باید یکسان باشد.
در تجزیه و تحلیل رگرسیون، از شاخص مهم دیگری استفاده می شود - R 2 (R-square)، یا ضریب تعیین. تعیین می کند که چه سهمی در تغییرپذیری کلی داده ها توسط رابطه بین ایجاد می شود ایکسو در. در اکسل، تابعی به نام ()CVPIERSON برای آن وجود دارد که دقیقا همان آرگومان های تابع ()CORREL را می گیرد.
گفته می شود دو متغیر با ضریب همبستگی غیر صفر بین آنها واریانس را توضیح می دهند یا واریانس را توضیح می دهند. به طور معمول واریانس توضیح داده شده به صورت درصد بیان می شود. بنابراین آر 2 81/0 = یعنی 81 درصد از واریانس (پراکندگی) دو متغیر توضیح داده شده است. 19 درصد باقی مانده به دلیل نوسانات تصادفی است.
اکسل یک تابع TREND دارد که محاسبات را آسان تر می کند. تابع ()TREND:
- ارزش های شناخته شده ای که شما ارائه می کنید را می پذیرد ایکسو ارزش های شناخته شده در;
- شیب خط رگرسیون و ثابت (برق) را محاسبه می کند.
- مقادیر پیش بینی شده را برمی گرداند در، با اعمال یک معادله رگرسیون برای مقادیر شناخته شده تعیین می شود ایکس(شکل 7).
تابع TREND() یک تابع آرایه است (اگر قبلاً با چنین توابعی مواجه نشده اید، توصیه می کنم).

برنج. 7. استفاده از تابع ()TREND به شما امکان می دهد در مقایسه با استفاده از یک جفت تابع ()SLOPE و INTERCEPT، محاسبات را سرعت بخشیده و ساده کنید.
برای وارد کردن تابع TREND() به عنوان فرمول آرایه در سلول های G3:G12، محدوده G3:G12 را انتخاب کنید، فرمول TREND را وارد کنید (NW:S12;V3:B12)، کلیدها را فشار داده و نگه دارید.
تابع TREND() دو آرگومان دیگر دارد: new_values_xو پایان. اولی به شما امکان می دهد برای آینده پیش بینی کنید، و دومی می تواند خط رگرسیون را مجبور کند از مبدا عبور کند (مقدار TRUE به اکسل می گوید از ثابت محاسبه شده استفاده کند، مقدار FALSE به اکسل می گوید که از یک ثابت = 0 استفاده کند. ). اکسل به شما این امکان را می دهد که یک خط رگرسیون روی یک نمودار بکشید تا از مبدا عبور کند. با رسم نمودار پراکندگی شروع کنید، سپس روی یکی از نشانگرهای سری داده کلیک راست کنید. مورد را در منوی زمینه که باز می شود انتخاب کنید یک خط روند اضافه کنید; یک گزینه را انتخاب کنید خطی; در صورت لزوم، پانل را به پایین اسکرول کنید، کادر را علامت بزنید تقاطع را تنظیم کنید; مطمئن شوید که کادر متنی مربوط به آن روی 0.0 تنظیم شده است.
اگر سه متغیر دارید و میخواهید همبستگی بین دو تا از آنها را تعیین کنید و تأثیر متغیر سوم را حذف کنید، میتوانید از آن استفاده کنید. همبستگی جزئی. فرض کنید به رابطه بین درصد ساکنان یک شهر که دانشگاه را به پایان رسانده اند و تعداد کتاب های موجود در کتابخانه های شهر علاقه مند هستید. شما داده های 50 شهر را جمع آوری کردید، اما... مشکل این است که هر دوی این پارامترها ممکن است به رفاه ساکنان یک شهر خاص بستگی داشته باشد. البته یافتن 50 شهر دیگر که دقیقاً با همان سطح رفاه ساکنان مشخص می شوند بسیار دشوار است.
با استفاده از روش های آماری برای کنترل تأثیر ثروت بر حمایت مالی کتابخانه و مقرون به صرفه بودن دانشگاه، می توانید کمیت دقیق تری از قدرت رابطه بین متغیرهای مورد علاقه، یعنی تعداد کتاب و تعداد فارغ التحصیلان به دست آورید. چنین همبستگی شرطی بین دو متغیر، زمانی که مقادیر سایر متغیرها ثابت باشد، همبستگی جزئی نامیده می شود. یکی از راه های محاسبه آن استفاده از معادله است:

جایی که rC.B. . دبلیو- ضریب همبستگی بین متغیرهای کالج و کتاب با تأثیر (مقدار ثابت) متغیر ثروت مستثنی شده است. rC.B.- ضریب همبستگی بین متغیرهای کالج و کتاب. rCW- ضریب همبستگی بین متغیرهای دانشکده و رفاه. rB.W.- ضریب همبستگی بین متغیرهای کتاب و رفاه.
از سوی دیگر، همبستگی جزئی را می توان بر اساس تجزیه و تحلیل باقیمانده ها محاسبه کرد، یعنی. تفاوت بین مقادیر پیش بینی شده و نتایج مربوط به مشاهدات واقعی (هر دو روش در شکل 8 ارائه شده است).

برنج. 8. همبستگی جزئی به عنوان همبستگی باقیمانده ها
برای ساده کردن محاسبه ماتریس ضرایب همبستگی (B16:E19)، از بسته تحلیل اکسل (منو) استفاده کنید. داده ها –> تحلیل و بررسی –> تحلیل داده ها). به طور پیش فرض، این بسته در اکسل فعال نیست. برای نصب آن، از طریق منو بروید فایل –> گزینه ها –> افزونه ها. در پایین پنجره باز شده گزینه هابرتری داشتنمیدان را پیدا کنید کنترل، انتخاب کنید افزونه هابرتری داشتن، کلیک برو. کادر کنار افزونه را علامت بزنید بسته تحلیلی. A را کلیک کنید تحلیل داده ها، گزینه را انتخاب کنید همبستگی. $B$2:$D$13 را به عنوان فاصله ورودی مشخص کنید، کادر را علامت بزنید برچسب ها در خط اول، $B$16:$E$19 را به عنوان بازه خروجی مشخص کنید.
امکان دیگر تعیین همبستگی نیمه جزئی است. به عنوان مثال، شما در حال بررسی اثرات قد و سن بر وزن هستید. بنابراین، شما دو متغیر پیش بینی - قد و سن، و یک متغیر پیش بینی - وزن دارید. شما می خواهید تأثیر یک متغیر پیش بینی کننده را بر دیگری مستثنی کنید، اما نه بر متغیر پیش بینی کننده:
![]()
که در آن H – قد، W – وزن، A – سن. شاخص ضریب همبستگی نیمه جزئی از پرانتز برای نشان دادن اینکه کدام متغیر و از کدام متغیر حذف می شود استفاده می کند. در این حالت، علامت W(H.A) نشان می دهد که اثر متغیر Age از متغیر Height حذف می شود، اما از متغیر Weight حذف نمی شود.
شاید به نظر برسد که موضوع مورد بحث اهمیت چندانی ندارد. به هر حال، آنچه بیش از همه مهم است این است که معادله رگرسیون کلی چقدر دقیق کار می کند، در حالی که به نظر می رسد مشکل مشارکت نسبی متغیرهای فردی در کل واریانس توضیح داده شده اهمیت ثانویه دارد. به هر حال، این چنین نیست. وقتی شروع به تعجب کردید که آیا یک متغیر اصلاً ارزش استفاده در یک معادله رگرسیون چندگانه را دارد، موضوع مهم می شود. می تواند بر ارزیابی صحت انتخاب مدل برای تحلیل تأثیر بگذارد.
فصل 4. تابع LINEST().
تابع LINEST() 10 آمار رگرسیون را برمی گرداند. تابع LINEST() یک تابع آرایه است. برای وارد کردن آن، یک محدوده شامل پنج سطر و دو ستون را انتخاب کنید، فرمول را تایپ کنید و کلیک کنید
LINEST(B2:B21,A2:A21,TRUE,TRUE)

برنج. 9. تابع LINEST(): الف) محدوده D2:E6 را انتخاب کنید، ب) فرمول را همانطور که در نوار فرمول نشان داده شده است وارد کنید، ج) کلیک کنید
تابع LINEST() برمی گرداند:
- ضریب رگرسیون (یا شیب، سلول D2)؛
- بخش (یا ثابت، سلول E3)؛
- خطاهای استاندارد ضریب رگرسیون و ثابت (محدوده D3:E3).
- ضریب تعیین R2 برای رگرسیون (سلول D4).
- خطای استاندارد برآورد (سلول E4)؛
- آزمون F برای رگرسیون کامل (سلول D5).
- تعداد درجات آزادی برای مجموع باقیمانده مربع ها (سلول E5)؛
- مجموع رگرسیون مربع ها (سلول D6)؛
- مجموع مربع باقی مانده (سلول E6).
بیایید به هر یک از این آمار و نحوه تعامل آنها نگاه کنیم.
خطای استاندارددر مورد ما، انحراف استاندارد محاسبه شده برای خطاهای نمونه گیری است. یعنی این وضعیتی است که جامعه عمومی یک آمار دارد و نمونه آماری دیگر. با تقسیم ضریب رگرسیون بر خطای استاندارد مقدار 2.092/0.818 = 2.559 به شما می رسد. به عبارت دیگر، ضریب رگرسیون 2.092 دو و نیم خطای استاندارد با صفر فاصله دارد.
اگر ضریب رگرسیون صفر باشد، بهترین تخمین متغیر پیشبینیشده میانگین آن است. دو و نیم خطای استاندارد بسیار بزرگ است، و شما می توانید با خیال راحت فرض کنید که ضریب رگرسیون برای جمعیت غیر صفر است.
اگر مقدار واقعی آن در جامعه 0.0 باشد با استفاده از تابع می توانید احتمال به دست آوردن ضریب رگرسیون نمونه 2.092 را تعیین کنید.
STUDENT.DIST.PH (معیار t = 2.559، تعداد درجات آزادی = 18)
به طور کلی، تعداد درجات آزادی = n – k – 1 که n تعداد مشاهدات و k تعداد متغیرهای پیش بینی کننده است.
این فرمول 0.00987 یا به 1% گرد می شود. به ما می گوید که اگر ضریب رگرسیون برای جامعه 0٪ باشد، احتمال به دست آوردن یک نمونه 20 نفری که ضریب رگرسیون تخمین زده شده برای آن 2.092 است، یک درصد متوسط است.
آزمون F (سلول D5 در شکل 9) همان توابع را در رابطه با رگرسیون کامل انجام می دهد که آزمون t در رابطه با ضریب رگرسیون زوجی ساده. آزمون F برای آزمایش اینکه آیا ضریب تعیین R2 برای یک رگرسیون به اندازه کافی بزرگ است برای رد این فرضیه استفاده می شود که در جامعه دارای مقدار 0.0 است، که نشان می دهد هیچ واریانسی توسط متغیر پیش بینی و پیش بینی شده توضیح داده نشده است. هنگامی که تنها یک متغیر پیش بینی وجود دارد، آزمون F دقیقاً برابر با مجذور آزمون t است.
تا اینجا به متغیرهای بازه نگاه کردیم. اگر متغیرهایی دارید که می توانند چندین مقدار بگیرند، که نام های ساده را نشان می دهد، به عنوان مثال، مرد و زن یا خزنده، دوزیستان و ماهی، آنها را به عنوان یک کد عددی نشان دهید. به چنین متغیرهایی اسمی می گویند.
آمار R2نسبت واریانس توضیح داده شده را کمی می کند.
خطای استاندارد برآورددر شکل شکل 4.9 مقادیر پیش بینی شده متغیر Weight را نشان می دهد که بر اساس رابطه آن با متغیر Height به دست آمده است. محدوده E2:E21 حاوی مقادیر باقیمانده برای متغیر Weight است. به طور دقیق تر، این باقیمانده ها خطا نامیده می شوند - از این رو اصطلاح خطای استاندارد تخمین را می گویند.

برنج. 10. هم R2 و هم خطای استاندارد برآورد، دقت پیش بینی های به دست آمده با استفاده از رگرسیون را بیان می کنند.
هرچه خطای استاندارد برآورد کوچکتر باشد، معادله رگرسیون دقیق تر است و انتظار دارید هر پیش بینی تولید شده توسط معادله با مشاهده واقعی مطابقت داشته باشد. خطای استاندارد تخمین راهی برای کمی سازی این انتظارات فراهم می کند. وزن 95 درصد افراد با قد معین در محدوده:
(قد * 2.092 - 3.591) ± 2.092 * 21.118
آمار Fنسبت واریانس بین گروهی به واریانس درون گروهی است. این نام توسط آماردان جورج اسندکور به افتخار آقا معرفی شد، کسی که آنالیز واریانس (ANOVA، آنالیز واریانس) را در آغاز قرن بیستم توسعه داد.
ضریب تعیین R2 نسبت مجموع مجذورهای مرتبط با رگرسیون را بیان می کند. مقدار (1 – R 2) نسبت مجموع مجموع مربع های مرتبط با باقیمانده ها - خطاهای پیش بینی را بیان می کند. آزمون F را می توان با استفاده از تابع LINEST (سلول F5 در شکل 11)، با استفاده از مجموع مربع ها (محدوده G10:J11)، با استفاده از نسبت های واریانس (محدوده G14:J15) به دست آورد. فرمول ها در فایل اکسل پیوست قابل مطالعه است.

برنج. 11. محاسبه معیار F
هنگام استفاده از متغیرهای اسمی، از کدگذاری ساختگی استفاده می شود (شکل 12). برای رمزگذاری مقادیر، استفاده از مقادیر 0 و 1 راحت است. احتمال F با استفاده از تابع محاسبه می شود:
F.DIST.PH(K2;I2;I3)
در اینجا تابع F.DIST.PH() احتمال به دست آوردن یک معیار F را برمی گرداند که از توزیع F مرکزی (شکل 13) برای دو مجموعه داده با تعداد درجات آزادی داده شده در سلول های I2 و I3 تبعیت می کند. که مقدار آن با مقدار داده شده در سلول K2 منطبق است.

برنج. 12. تحلیل رگرسیون با استفاده از متغیرهای ساختگی

برنج. 13. توزیع F مرکزی در λ = 0
فصل 5. رگرسیون چندگانه
وقتی از رگرسیون زوجی ساده با یک متغیر پیشبینیکننده به رگرسیون چندگانه منتقل میشوید، یک یا چند متغیر پیشبینیکننده را اضافه میکنید. مقادیر متغیرهای پیشبینیکننده را در ستونهای مجاور ذخیره کنید، مانند ستونهای A و B در مورد دو پیشبینیکننده، یا A، B و C در مورد سه پیشبینیکننده. قبل از وارد کردن فرمولی که شامل تابع LINEST() است، پنج سطر و به تعداد متغیرهای پیش بینی کننده ستون و یک ستون دیگر برای ثابت انتخاب کنید. در مورد رگرسیون با دو متغیر پیش بینی، می توان از ساختار زیر استفاده کرد:
LINEST(A2: A41؛ B2: C41;; TRUE)
به طور مشابه در مورد سه متغیر:
LINEST(A2:A61,B2:D61,;TRUE)
فرض کنید می خواهید اثرات احتمالی سن و رژیم غذایی بر سطوح LDL را مطالعه کنید - لیپوپروتئین های با چگالی کم، که اعتقاد بر این است که مسئول تشکیل پلاک های آترواسکلروتیک هستند که باعث آتروترومبوز می شوند (شکل 14).

برنج. 14. رگرسیون چندگانه
R2 رگرسیون چندگانه (که در سلول F13 منعکس می شود) از R2 هر رگرسیون ساده (E4, H4) بیشتر است. رگرسیون چندگانه از چندین متغیر پیش بینی به طور همزمان استفاده می کند. در این مورد، R2 تقریباً همیشه افزایش می یابد.
برای هر معادله رگرسیون خطی ساده با یک متغیر پیشبینیکننده، همیشه یک همبستگی کامل بین مقادیر پیشبینیشده و مقادیر متغیر پیشبینیکننده وجود خواهد داشت، زیرا معادله مقادیر پیشبینیکننده را در یک ثابت ضرب میکند و ثابت دیگری را به آن اضافه میکند. هر محصول این اثر در رگرسیون چندگانه باقی نمی ماند.
نمایش نتایج بازگشتی توسط تابع LINEST() برای رگرسیون چندگانه (شکل 15). ضرایب رگرسیون به عنوان بخشی از نتایج بازگردانده شده توسط تابع LINEST () خروجی می شود به ترتیب معکوس متغیرها(G–H–I با C–B–A مطابقت دارد).

برنج. 15. ضرایب و خطاهای استاندارد آنها به ترتیب معکوس در کاربرگ نمایش داده می شود.
اصول و رویههای مورد استفاده در تحلیل رگرسیون متغیر پیشبینیکننده منفرد به راحتی برای محاسبه متغیرهای پیشبینیکننده چندگانه تطبیق داده میشوند. به نظر می رسد که بسیاری از این سازگاری به حذف تأثیر متغیرهای پیش بینی کننده بر یکدیگر بستگی دارد. مورد دوم با همبستگی های جزئی و نیمه جزئی همراه است (شکل 16).

برنج. 16. رگرسیون چندگانه را می توان از طریق رگرسیون زوجی باقیمانده ها بیان کرد (برای فرمول ها به فایل اکسل مراجعه کنید)
در اکسل، توابعی وجود دارند که اطلاعاتی در مورد توزیع های t و F ارائه می دهند. توابعی که نام آنها شامل قسمت DIST است، مانند STUDENT.DIST() و F.DIST()، آزمون t یا F-test را به عنوان آرگومان می گیرند و احتمال مشاهده یک مقدار مشخص را برمی گردانند. توابعی که نام آنها شامل بخش OBR است، مانند STUDENT.INV() و F.INR()، یک مقدار احتمال را به عنوان آرگومان می گیرند و یک مقدار معیار مربوط به احتمال مشخص شده را برمی گردانند.
از آنجایی که ما به دنبال مقادیر بحرانی توزیع t هستیم که لبههای نواحی دم آن را قطع میکند، 5% را به عنوان آرگومان به یکی از توابع ()STUDENT.INV ارسال میکنیم که مقدار مربوط به این احتمال را برمیگرداند. (شکل 17 و 18).

برنج. 17. آزمون t دو دم

برنج. 18. آزمون تی تک دم
با ایجاد یک قانون تصمیم گیری برای منطقه آلفای تک دنباله، قدرت آماری آزمون را افزایش می دهید. اگر وارد آزمایشی میشوید و مطمئن هستید که دلایل زیادی برای انتظار داشتن ضریب رگرسیون مثبت (یا منفی) دارید، باید آزمایش تک دم را انجام دهید. در این صورت احتمال اینکه شما در رد فرضیه ضریب رگرسیون صفر در جامعه تصمیم درستی بگیرید بیشتر خواهد بود.
آماردانان ترجیح می دهند از این اصطلاح استفاده کنند آزمون هدایت شدهبه جای اصطلاح تست تک دمو مدت تست بدون جهتبه جای اصطلاح تست دو دم. اصطلاحات جهت دار و غیر جهت دار ترجیح داده می شوند زیرا بر نوع فرضیه تاکید می کنند تا ماهیت دنباله های توزیع.
رویکردی برای ارزیابی تأثیر پیشبینیکنندهها بر اساس مقایسه مدل.در شکل شکل 19 نتایج یک تحلیل رگرسیونی را نشان می دهد که سهم متغیر رژیم غذایی را در معادله رگرسیون آزمایش می کند.

برنج. 19. مقایسه دو مدل با آزمایش تفاوت در نتایج آنها
نتایج تابع ()LINEST (محدوده H2:K6) مربوط به چیزی است که من آن را مدل کامل می نامم، که متغیر LDL را در متغیرهای رژیم غذایی، سن و HDL پسرفت می کند. محدوده H9:J13 محاسبات را بدون در نظر گرفتن متغیر پیش بینی کننده رژیم غذایی ارائه می کند. من این را مدل محدود می نامم. در مدل کامل، 49.2 درصد از واریانس متغیر وابسته LDL توسط متغیرهای پیش بینی توضیح داده شد. در مدل محدود، تنها 30.8 درصد از LDL توسط متغیرهای Age و HDL توضیح داده می شود. ضرر در R 2 به دلیل حذف متغیر Diet از مدل 0.183 است. در محدوده G15:L17، محاسباتی انجام می شود که نشان می دهد تنها احتمال 0.0288 وجود دارد که تأثیر متغیر Diet تصادفی باشد. در 97.1 درصد باقی مانده، رژیم غذایی بر LDL تأثیر دارد.
فصل ششم: مفروضات و احتیاطات برای تحلیل رگرسیون
اصطلاح "فرض" به اندازه کافی دقیق تعریف نشده است، و نحوه استفاده از آن نشان می دهد که اگر این فرض برآورده نشود، نتایج کل تجزیه و تحلیل حداقل مشکوک یا شاید نامعتبر است. این در واقع چنین نیست، اگرچه مطمئناً مواردی وجود دارد که نقض یک فرض اساساً تصویر را تغییر می دهد. مفروضات اساسی: الف) باقیمانده های متغیر Y معمولاً در هر نقطه X در امتداد خط رگرسیون توزیع می شوند. ب) مقادیر Y به صورت خطی به مقادیر X وابسته هستند. ج) پراکندگی باقیمانده ها در هر نقطه X تقریباً یکسان است. د) هیچ وابستگی بین باقیمانده ها وجود ندارد.
اگر مفروضات نقش مهمی ایفا نکنند، آماردانان می گویند که تجزیه و تحلیل در برابر نقض این فرض قوی است. به ویژه، وقتی از رگرسیون برای آزمایش تفاوت بین میانگینهای گروهی استفاده میکنید، این فرض که مقادیر Y - و در نتیجه باقیماندهها - به طور معمول توزیع میشوند، نقش مهمی بازی نمیکند: آزمونها در برابر نقض فرض نرمال بودن قوی هستند. تجزیه و تحلیل داده ها با استفاده از نمودار مهم است. به عنوان مثال، در افزونه گنجانده شده است تحلیل داده هاابزار پسرفت.
اگر داده ها با مفروضات رگرسیون خطی مطابقت نداشته باشند، روش هایی غیر از رگرسیون خطی در اختیار شماست. یکی از آنها رگرسیون لجستیک است (شکل 20). در نزدیکی مرزهای بالایی و پایینی متغیر پیش بینی کننده، رگرسیون خطی پیش بینی های غیر واقعی ایجاد می کند.

برنج. 20. رگرسیون لجستیک
در شکل شکل 6.8 نتایج دو روش تجزیه و تحلیل داده را با هدف بررسی رابطه بین درآمد سالانه و احتمال خرید خانه نشان می دهد. بدیهی است که با افزایش درآمد، احتمال خرید افزایش می یابد. نمودارها تشخیص تفاوت بین نتایجی را که رگرسیون خطی احتمال خرید خانه را پیشبینی میکند و نتایجی که ممکن است با استفاده از روشی متفاوت بدست آورید را آسان میکند.
در اصطلاح آماردانان، رد فرضیه صفر در حالی که در واقع درست باشد، خطای نوع یک نامیده می شود.
در افزونه تحلیل داده هاابزاری مناسب برای تولید اعداد تصادفی ارائه می دهد که به کاربر امکان می دهد شکل مورد نظر توزیع (به عنوان مثال، Normal، Binomial یا Poisson) و همچنین میانگین و انحراف استاندارد را مشخص کند.
تفاوت بین توابع خانواده ()STUDENT.DIST.با شروع اکسل 2010، سه شکل مختلف از تابع موجود است که نسبت توزیع را به سمت چپ و/یا به راست مقدار داده شده t-test برمی گرداند. تابع ()STUDENT.DIST کسری از ناحیه زیر منحنی توزیع را به سمت چپ مقدار t-test که مشخص کردهاید برمیگرداند. فرض کنید شما 36 مشاهده دارید، بنابراین تعداد درجه آزادی برای تجزیه و تحلیل 34 و مقدار آزمون t = 1.69 است. در این مورد فرمول
STUDENT.DIST(+1.69،34، TRUE)
مقدار 0.05 یا 5% را برمی گرداند (شکل 21). آرگومان سوم تابع ()STUDENT.DIST می تواند TRUE یا FALSE باشد. اگر روی TRUE تنظیم شود، تابع ناحیه تجمعی زیر منحنی را در سمت چپ آزمون t مشخص شده برمیگرداند که به صورت نسبت بیان میشود. اگر FALSE باشد، تابع ارتفاع نسبی منحنی را در نقطه مربوط به آزمون t برمی گرداند. سایر نسخههای تابع STUDENT.DIST () -STUDENT.DIST.PH() و STUDENT.DIST.2X() - فقط مقدار آزمون t و تعداد درجات آزادی را به عنوان آرگومان میگیرند و نیازی به تعیین سومی ندارند. بحث و جدل.

برنج. 21. ناحیه سایه دار تیره تر در دم سمت چپ توزیع مربوط به نسبت سطح زیر منحنی به سمت چپ یک مقدار تست t مثبت بزرگ است.
برای تعیین مساحت سمت راست آزمون t، از یکی از فرمول ها استفاده کنید:
1 — STIODENT.DIST (1, 69;34; True)
STUDENT.DIST.PH (1.69;34)
کل مساحت زیر منحنی باید 100% باشد، بنابراین با کم کردن کسری از مساحت سمت چپ مقدار آزمون t که تابع برمی گرداند، کسری از ناحیه سمت راست مقدار آزمون t را به دست می دهد. ممکن است ترجیح دهید مستقیماً کسری مساحتی را که به آن علاقه دارید با استفاده از تابع ()STUDENT.DIST.PH بدست آورید، جایی که PH به معنای دنباله سمت راست توزیع است (شکل 22).

برنج. 22. 5% منطقه آلفا برای تست جهت
استفاده از توابع STUDENT.DIST() یا STUDENT.DIST.PH() به این معنی است که شما یک فرضیه کاری جهت دار را انتخاب کرده اید. فرضیه کار جهت دار همراه با تنظیم مقدار آلفا بر روی 5٪ به این معنی است که شما همه 5٪ را در دم سمت راست توزیع ها قرار می دهید. فقط در صورتی باید فرضیه صفر را رد کنید که احتمال مقدار آزمون t که به دست می آورید 5% یا کمتر باشد. فرضیه های جهت دار عموماً منجر به آزمون های آماری حساس تری می شوند (به این حساسیت بیشتر، قدرت آماری بیشتر نیز گفته می شود).
در آزمایش بدون جهت، مقدار آلفا در همان سطح 5 درصد باقی می ماند، اما توزیع متفاوت خواهد بود. از آنجا که شما باید دو نتیجه را مجاز کنید، احتمال مثبت کاذب باید بین دو دنباله توزیع توزیع شود. به طور کلی پذیرفته شده است که این احتمال به طور مساوی توزیع شود (شکل 23).

با استفاده از همان مقدار t-test به دست آمده و همان تعداد درجه آزادی مانند مثال قبلی، از فرمول استفاده کنید.
STUDENT.DIST.2Х(1.69;34)
بدون دلیل خاصی، تابع STUDENT.DIST.2X () کد خطای #NUM! را برمی گرداند، اگر مقدار آزمون t منفی به عنوان اولین آرگومان آن داده شود.
اگر نمونه ها دارای مقادیر متفاوتی از داده ها هستند، از آزمون t دو نمونه ای با واریانس های مختلف موجود در بسته استفاده کنید. تحلیل داده ها.
فصل 7: استفاده از رگرسیون برای آزمایش تفاوتهای بین میانگینهای گروهی
متغیرهایی که قبلاً تحت نام متغیرهای پیشبینیکننده ظاهر میشدند در این فصل متغیرهای نتیجه نامیده میشوند و به جای عبارت متغیرهای پیشبینیکننده از عبارت متغیرهای عامل استفاده میشود.
ساده ترین روش برای کدگذاری یک متغیر اسمی است کدنویسی ساختگی(شکل 24).

برنج. 24. تحلیل رگرسیون بر اساس کدگذاری ساختگی
هنگام استفاده از کدنویسی ساختگی از هر نوع، قوانین زیر باید رعایت شود:
- تعداد ستون های رزرو شده برای داده های جدید باید برابر با تعداد سطوح فاکتور منهای باشد
- هر بردار نشان دهنده یک سطح عامل است.
- آزمودنی های یکی از سطوح، که اغلب گروه کنترل است، در همه بردارها کد 0 می شوند.
فرمول موجود در سلولهای F2:H6 =LINEST(A2:A22,C2:D22,;TRUE) آمار رگرسیون را برمیگرداند. برای مقایسه، در شکل. شکل 24 نتایج ANOVA سنتی بازگردانده شده توسط ابزار را نشان می دهد. ANOVA یک طرفهافزونه ها تحلیل داده ها.
کدگذاری افکت هادر نوع دیگری از کدنویسی به نام کدگذاری افکت ها،میانگین هر گروه با میانگین میانگین گروه مقایسه می شود. این جنبه از کدگذاری افکت به دلیل استفاده از -1 به جای 0 به عنوان کد برای گروه است که در همه بردارهای کد کد یکسانی را دریافت می کند (شکل 25).

برنج. 25. کدگذاری افکت ها
هنگامی که از کدگذاری ساختگی استفاده می شود، مقدار ثابتی که توسط LINEST() برگردانده می شود، میانگین گروهی است که در همه بردارها (معمولاً گروه مرجع) کدهای صفر تخصیص داده می شود. در مورد کدگذاری اثرات، ثابت برابر با میانگین کلی (سلول J2) است.
مدل خطی کلی روشی مفید برای مفهوم سازی اجزای مقدار متغیر نتیجه است:
Y ij = μ + α j + ε ij
استفاده از حروف یونانی در این فرمول به جای حروف لاتین بر این واقعیت تأکید دارد که به جمعیتی که نمونهها از آن کشیده شدهاند اشاره دارد، اما میتوان آن را بازنویسی کرد تا نشان دهد که به نمونههایی برگرفته شده از یک جمعیت معین اشاره دارد:
Y ij = Y̅ + a j + e ij
ایده این است که هر مشاهده Y ij را می توان به عنوان مجموع سه جزء زیر مشاهده کرد: میانگین کل، μ. اثر درمان j و j ; مقدار e ij، که نشان دهنده انحراف شاخص کمی Y ij از مقدار ترکیبی میانگین عمومی و اثر درمان j-ام است (شکل 26). هدف از معادله رگرسیون به حداقل رساندن مجموع مجذورهای باقیمانده است.

برنج. 26. مشاهدات تجزیه شده به اجزای یک مدل خطی عمومی
تحلیل عاملیاگر رابطه بین متغیر نتیجه و دو یا چند عامل به طور همزمان مورد مطالعه قرار گیرد، در این مورد ما در مورد استفاده از تحلیل عاملی صحبت می کنیم. افزودن یک یا چند عامل به ANOVA یک طرفه می تواند قدرت آماری را افزایش دهد. در تحلیل واریانس یک طرفه، واریانس در متغیر نتیجه که نمی تواند به یک عامل نسبت داده شود، در مجذور میانگین باقیمانده گنجانده می شود. اما ممکن است این تنوع به عامل دیگری مرتبط باشد. سپس این تغییر را می توان از میانگین مربعات خطا حذف کرد که کاهش آن منجر به افزایش مقادیر آزمون F و در نتیجه افزایش قدرت آماری آزمون می شود. روبنا تحلیل داده هاشامل ابزاری است که دو عامل را به طور همزمان پردازش می کند (شکل 27).

برنج. 27. ابزار تحلیل واریانس دو طرفه با تکرار بسته تحلیلی
ابزار ANOVA استفاده شده در این شکل مفید است زیرا میانگین و واریانس متغیر نتیجه و همچنین مقدار شمارنده را برای هر گروه موجود در طرح برمیگرداند. در جدول تحلیل واریانسدو پارامتر را نشان می دهد که در خروجی نسخه تک عاملی ابزار ANOVA وجود ندارد. به منابع تنوع توجه کنید نمونهو ستون هادر سطرهای 27 و 28. منبع تنوع ستون هابه جنسیت اشاره دارد منبع تنوع نمونهبه هر متغیری اشاره دارد که مقادیر آن خطوط مختلفی را اشغال می کند. در شکل 27 مقدار برای گروه KursLech1 در خطوط 2-6، گروه KursLech2 در خطوط 7-11 و گروه KursLechZ در خطوط 12-16 قرار دارند.
نکته اصلی این است که هر دو عامل، جنسیت (ستونهای برچسب در سلول E28) و درمان (نمونه برچسب در سلول E27)، به عنوان منابع تغییر در جدول ANOVA گنجانده شدهاند. وسیله برای مردان با وسیله برای زنان متفاوت است و این باعث ایجاد تنوع می شود. میانگین سه درمان نیز متفاوت است و منبع دیگری از تنوع را فراهم می کند. منبع سومی نیز به نام تعامل وجود دارد که به اثر ترکیبی متغیرهای جنسیت و درمان اشاره دارد.
فصل 8. تحلیل کوواریانس
تجزیه و تحلیل کوواریانس یا ANCOVA (Analysis of Covariation)، سوگیری را کاهش می دهد و قدرت آماری را افزایش می دهد. یادآوری می کنم که یکی از روش های ارزیابی پایایی معادله رگرسیون، آزمون های F است:
F = MS Regression/MS Residual
که در آن MS (میانگین مربع) میانگین مربع است و شاخص های رگرسیون و باقیمانده به ترتیب مولفه های رگرسیون و باقیمانده را نشان می دهند. MS Residual با استفاده از فرمول محاسبه می شود:
MS Residual = SS Residual / df Residual
که در آن SS (مجموع مربعات) مجموع مربع ها و df تعداد درجات آزادی است. وقتی کوواریانس را به معادله رگرسیون اضافه می کنید، بخشی از مجموع مجذورات نه در SS ResiduaI، بلکه در رگرسیون SS گنجانده می شود. این منجر به کاهش SS Residua l و در نتیجه MS Residual می شود. هر چه MS Residual کوچکتر باشد، آزمون F بزرگتر است و احتمال رد فرضیه صفر مبنی بر عدم تفاوت بین میانگین ها بیشتر می شود. در نتیجه، تغییرپذیری متغیر نتیجه را دوباره توزیع میکنید. در آنالیز واریانس، زمانی که کوواریانس در نظر گرفته نشود، تغییرپذیری به خطا تبدیل می شود. اما در ANCOVA، بخشی از متغیری که قبلاً به عبارت خطا نسبت داده شده بود، به یک متغیر کمکی اختصاص داده می شود و بخشی از رگرسیون SS می شود.
مثالی را در نظر بگیرید که در آن همان مجموعه داده ابتدا با ANOVA و سپس با ANCOVA تجزیه و تحلیل می شود (شکل 28).

برنج. 28. تجزیه و تحلیل ANOVA نشان می دهد که نتایج به دست آمده از معادله رگرسیون غیر قابل اعتماد هستند.
این مطالعه اثرات نسبی ورزش بدنی را که باعث افزایش قدرت عضلانی می شود و ورزش شناختی (انجام جدول کلمات متقاطع) که فعالیت مغز را تحریک می کند، مقایسه می کند. آزمودنی ها به طور تصادفی به دو گروه تقسیم شدند به طوری که هر دو گروه در ابتدای آزمایش در معرض شرایط یکسانی قرار گرفتند. پس از سه ماه، عملکرد شناختی آزمودنیها اندازهگیری شد. نتایج این اندازه گیری ها در ستون B نشان داده شده است.
محدوده A2:C21 حاوی داده های منبع است که به تابع LINEST() برای انجام تجزیه و تحلیل با استفاده از کدگذاری افکت ها ارسال می شود. نتایج تابع LINEST() در محدوده E2:F6 آورده شده است، جایی که سلول E2 ضریب رگرسیون مرتبط با بردار ضربه را نمایش می دهد. سلول E8 حاوی t-test = 0.93 است و سلول E9 پایایی این آزمون t را آزمایش می کند. مقدار موجود در سلول E9 نشان می دهد که اگر میانگین گروه ها در جامعه برابر باشند، احتمال مواجهه با تفاوت میانگین های گروهی مشاهده شده در این آزمایش 36 درصد است. تعداد کمی این نتیجه را از نظر آماری معنی دار می دانند.
در شکل شکل 29 نشان می دهد که وقتی یک متغیر کمکی به تحلیل اضافه می کنید چه اتفاقی می افتد. در این مورد، سن هر موضوع را به مجموعه داده اضافه کردم. ضریب تعیین R 2 برای معادله رگرسیونی که از متغیر کمکی استفاده می کند 80/0 است (سلول F4). مقدار R 2 در محدوده F15:G19، که در آن نتایج ANOVA به دست آمده بدون متغیر کمکی را تکرار کردم، تنها 0.05 است (سلول F17). بنابراین، یک معادله رگرسیونی که شامل متغیر کمکی است، مقادیر متغیر نمره شناختی را بسیار دقیقتر از استفاده از بردار تأثیر به تنهایی پیشبینی میکند. برای ANCOVA، احتمال به دست آوردن مقدار آزمون F نمایش داده شده در سلول F5 به طور تصادفی کمتر از 0.01٪ است.

برنج. 29. ANCOVA تصویر کاملا متفاوتی را به ارمغان می آورد
پردازش داده های آماری نیز می تواند با استفاده از یک افزونه انجام شود بسته تحلیلی(شکل 62).
از میان موارد پیشنهادی، مورد را انتخاب کنید پسرفت"و با دکمه سمت چپ ماوس روی آن کلیک کنید. بعد روی OK کلیک کنید.
پنجره ای ظاهر می شود که در شکل نشان داده شده است. 63.

ابزار تجزیه و تحلیل " پسرفت» برای جا دادن یک نمودار به مجموعه ای از مشاهدات با استفاده از روش حداقل مربعات استفاده می شود. رگرسیون برای تجزیه و تحلیل اثر بر روی یک متغیر وابسته واحد از مقادیر یک یا چند متغیر مستقل استفاده می شود. به عنوان مثال، عوامل متعددی بر عملکرد ورزشی یک ورزشکار تأثیر می گذارد، از جمله سن، قد و وزن. می توان میزان تأثیر هر یک از این سه عامل بر عملکرد ورزشکار را محاسبه کرد و سپس از آن داده ها برای پیش بینی عملکرد ورزشکار دیگر استفاده کرد.
ابزار Regression از تابع استفاده می کند LINEST.
جعبه گفتگوی رگرسیون
برچسب ها اگر سطر اول یا ستون اول محدوده ورودی حاوی عنوان است، کادر بررسی را انتخاب کنید. اگر هدر وجود ندارد، این کادر را پاک کنید. در این صورت سرصفحه های مناسب برای داده های جدول خروجی به صورت خودکار ایجاد خواهند شد.
سطح قابلیت اطمینان کادر را انتخاب کنید تا یک سطح اضافی در جدول خلاصه خروجی گنجانده شود. در قسمت مربوطه، علاوه بر سطح پیشفرض 95 درصد، سطح اطمینانی را که میخواهید اعمال کنید، وارد کنید.
ثابت - صفر کادر را انتخاب کنید تا خط رگرسیون مجبور شود از مبدا عبور کند.
محدوده خروجی مرجع به سلول سمت چپ بالای محدوده خروجی را وارد کنید. حداقل هفت ستون برای جدول خلاصه خروجی ارائه دهید که شامل: نتایج ANOVA، ضرایب، خطای استاندارد محاسبه Y، انحرافات استاندارد، تعداد مشاهدات، خطاهای استاندارد برای ضرایب خواهد بود.
کاربرگ جدید این گزینه را انتخاب کنید تا یک کاربرگ جدید در کتاب کار باز شود و نتایج تجزیه و تحلیل از سلول A1 شروع شود. در صورت لزوم، یک نام برای برگه جدید در فیلد واقع در مقابل دکمه رادیویی مربوطه وارد کنید.
New Workbook این گزینه را برای ایجاد یک کتاب کار جدید با نتایج اضافه شده به کاربرگ جدید انتخاب کنید.
باقیمانده ها کادر را برای قرار دادن باقیمانده ها در جدول خروجی انتخاب کنید.
باقیمانده های استاندارد شده، کادر بررسی را برای گنجاندن باقیمانده های استاندارد شده در جدول خروجی انتخاب کنید.
نمودار باقیمانده برای رسم باقیمانده ها برای هر متغیر مستقل، کادر را انتخاب کنید.
Fit Plot برای رسم مقادیر پیشبینیشده در مقابل مشاهدهشده، کادر را انتخاب کنید.
نمودار احتمال عادیچک باکس را برای رسم نمودار احتمال عادی انتخاب کنید.
تابع LINEST
برای انجام محاسبات، سلولی را که می خواهیم مقدار متوسط را در آن نمایش دهیم، با مکان نما انتخاب کرده و کلید = را روی صفحه کلید فشار دهید. سپس در قسمت Name، برای مثال تابع مورد نظر را مشخص کنید میانگین(شکل 22).
تابع LINESTآمار یک سری را با استفاده از روش حداقل مربعات محاسبه می کند تا خط مستقیمی را که به بهترین وجه به داده های موجود تقریب می کند محاسبه کند و سپس آرایه ای را برمی گرداند که خط مستقیم حاصل را توصیف می کند. شما همچنین می توانید تابع را ترکیب کنید LINESTبا توابع دیگر برای محاسبه انواع مدل های دیگر که در پارامترهای مجهول خطی هستند (که پارامترهای مجهول آن خطی هستند)، از جمله سری های چند جمله ای، لگاریتمی، نمایی و توانی. از آنجا که یک آرایه از مقادیر برگردانده می شود، تابع باید به عنوان یک فرمول آرایه مشخص شود.
معادله یک خط مستقیم:
y=m 1 x 1 +m 2 x 2 +…+b (در مورد چندین محدوده از مقادیر x)،
در جایی که مقدار وابسته y تابعی از مقدار مستقل x است، مقادیر m ضرایب مربوط به هر متغیر مستقل x است و b یک ثابت است. توجه داشته باشید که y، x و m می توانند بردار باشند. تابع LINESTآرایه را برمی گرداند (mn;mn-1;…;m 1;b). LINESTهمچنین ممکن است آمار رگرسیون اضافی را برگرداند.
LINEST(مقادیر_شناخته_y؛ مقادیر_شناخته_x؛ const؛ آمار)
Known_y_values - مجموعه ای از مقادیر y که قبلاً برای رابطه y=mx+b شناخته شده اند.
اگر آرایه Known_y_values دارای یک ستون باشد، هر ستون در آرایه Known_x_values به عنوان یک متغیر جداگانه در نظر گرفته می شود.
اگر آرایه Known_y_values دارای یک ردیف باشد، هر سطر در آرایه Known_x_values به عنوان یک متغیر جداگانه در نظر گرفته می شود.
Known_x-values مجموعه ای اختیاری از مقادیر x هستند که قبلاً برای رابطه y=mx+b شناخته شده اند.
آرایه Known_x_values می تواند شامل یک یا چند مجموعه از متغیرها باشد. اگر فقط از یک متغیر استفاده شود، آرایه های Known_y_values و Known_x_values می توانند هر شکلی داشته باشند - تا زمانی که ابعاد یکسانی داشته باشند. اگر بیش از یک متغیر استفاده می شود، شناخته شده_y_values باید یک بردار باشد (یعنی یک فاصله یک ردیف بالا یا یک ستون عرض).
اگر array_known_x_values حذف شود، آرایه (1;2;3;...) به اندازه array_known_values_y در نظر گرفته می شود.
Const یک مقدار بولی است که مشخص می کند آیا ثابت b باید برابر با 0 باشد یا خیر.
اگر آرگومان "const" درست باشد یا حذف شود، ثابت b طبق معمول ارزیابی می شود.
اگر آرگومان Const FALSE باشد، مقدار b روی 0 تنظیم می شود و مقادیر m به گونه ای انتخاب می شوند که رابطه y=mx برآورده شود.
آمار - یک مقدار بولی که نشان می دهد آیا آمار رگرسیون اضافی باید برگردانده شود یا خیر.
اگر آمار درست باشد، LINEST آمار رگرسیون اضافی را برمیگرداند. آرایه برگشتی به این صورت خواهد بود: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
اگر آمار FALSE یا حذف شده باشد، LINEST فقط ضرایب m و ثابت b را برمی گرداند.
آمار رگرسیون اضافی (جدول 17)
| اندازه | شرح |
| se1,se2,...,sen | مقادیر خطای استاندارد برای ضرایب m1، m2،...، mn. |
| seb | مقدار خطای استاندارد برای ثابت b (seb = #N/A اگر const FALSE باشد). |
| r2 | ضریب جبر. مقادیر واقعی y و مقادیر به دست آمده از معادله خط با هم مقایسه می شوند. بر اساس نتایج مقایسه، ضریب جبر محاسبه می شود، از 0 تا 1 نرمال می شود. اگر برابر با 1 باشد، با مدل همبستگی کامل وجود دارد، یعنی تفاوتی بین مقادیر واقعی و تخمینی وجود ندارد. از y. در حالت مخالف، اگر ضریب تعیین 0 باشد، استفاده از معادله رگرسیون برای پیش بینی مقادیر y فایده ای ندارد. برای اطلاعات بیشتر در مورد نحوه محاسبه r2، به "یادداشت ها" در انتهای این بخش مراجعه کنید. |
| sey | خطای استاندارد برای تخمین y. |
| اف | آماره F یا مقدار مشاهده شده F. از آماره F برای تعیین اینکه آیا رابطه مشاهده شده بین متغیر وابسته و مستقل ناشی از شانس است یا خیر استفاده می شود. |
| df | درجه آزادی. درجات آزادی برای یافتن مقادیر بحرانی F در یک جدول آماری مفید است. برای تعیین سطح اطمینان مدل، مقادیر جدول را با آماره F برگردانده شده توسط تابع LINEST مقایسه می کنید. برای اطلاعات بیشتر در مورد محاسبه df، به "یادداشت ها" در انتهای این بخش مراجعه کنید. بعد، مثال 4 استفاده از مقادیر F و df را نشان می دهد. |
| ssreg | مجموع رگرسیون مربع ها. |
| ssresid | جمع باقیمانده مربع ها. برای اطلاعات بیشتر در مورد محاسبه ssreg و ssresid، به "یادداشت ها" در انتهای این بخش مراجعه کنید. |
شکل زیر ترتیب برگرداندن آمار رگرسیون اضافی را نشان می دهد (شکل 64).

یادداشت:
هر خط مستقیمی را می توان با شیب و تقاطع آن با محور y توصیف کرد:
شیب (m): برای تعیین شیب یک خط که معمولاً با m نشان داده می شود، باید دو نقطه از خط (x 1 ,y 1) و (x 2 ,y 2) بگیرید. شیب برابر با (y 2 -y 1)/(x 2 -x 1) خواهد بود.
مقطع Y (b): مقطع y یک خط که معمولاً با b نشان داده می شود، مقدار y برای نقطه ای است که در آن خط محور y را قطع می کند.
معادله خط مستقیم y=mx+b است. اگر مقادیر m و b مشخص باشد، هر نقطه از خط را می توان با جایگزین کردن مقادیر y یا x در معادله محاسبه کرد. همچنین می توانید از تابع TREND استفاده کنید.
اگر فقط یک متغیر مستقل x وجود داشته باشد، می توانید شیب و قطع y را مستقیماً با استفاده از فرمول های زیر بدست آورید:
شیب: INDEX(LINEST(مقادیر_y_معروف؛ مقادیر_x_معروف؛ 1)
مقطع Y: INDEX(LINEST(مقادیر_y_معروف؛ مقادیر_x_شناخته؛ 2)
دقت تقریب با استفاده از خط مستقیم محاسبه شده توسط تابع LINEST به درجه پراکندگی داده ها بستگی دارد. هر چه داده ها به یک خط مستقیم نزدیکتر باشند، مدل مورد استفاده توسط تابع LINEST دقیق تر است. تابع LINEST از حداقل مربعات برای تعیین بهترین تناسب با داده ها استفاده می کند. هنگامی که فقط یک متغیر مستقل x وجود دارد، m و b با استفاده از فرمول های زیر محاسبه می شوند:

که در آن x و y میانگین های نمونه هستند، به عنوان مثال x = AVERAGE (شناختههای_x) و y = AVERAGE (شناختههای_y).
توابع برازش LINEST و LGRFPRIBL می توانند خط مستقیم یا منحنی نمایی را محاسبه کنند که بهترین تناسب با داده ها را دارد. با این حال، آنها به این سوال پاسخ نمی دهند که کدام یک از این دو نتیجه برای حل مشکل مناسب تر است. همچنین میتوانید تابع TREND(known_y's; شناخته شده_x's) را برای یک خط مستقیم یا تابع GROW (known_y's;known_x's) را برای یک منحنی نمایی ارزیابی کنید. این توابع، مگر اینکه new_x-values مشخص شده باشد، آرایه ای از مقادیر y محاسبه شده را برای مقادیر x واقعی در امتداد یک خط یا منحنی برمی گرداند. سپس می توانید مقادیر محاسبه شده را با مقادیر واقعی مقایسه کنید. همچنین می توانید نمودارهایی را برای مقایسه بصری ایجاد کنید.
هنگام انجام تجزیه و تحلیل رگرسیون، مایکروسافت اکسل برای هر نقطه، مجذور اختلاف بین مقدار y پیش بینی شده و مقدار y واقعی را محاسبه می کند. مجموع این مجذور تفاوت ها را مجموع مجذورات باقیمانده (ssresid) می گویند. سپس مایکروسافت اکسل مجموع مجذورات (sstotal) را محاسبه می کند. اگر const = TRUE یا مقدار این آرگومان مشخص نشده باشد، مجموع مجذورات برابر با مجموع مربعات تفاوت بین مقادیر واقعی y و مقادیر متوسط y خواهد بود. هنگامی که const = FALSE، مجموع مجموع مربع ها برابر با مجموع مربع های مقادیر y واقعی خواهد بود (بدون کسر مقدار متوسط y از مقدار y جزئی). سپس مجموع رگرسیون مربع ها را می توان به صورت زیر محاسبه کرد: ssreg = sstotal - ssresid. هر چه مجموع باقیمانده مربع ها کوچکتر باشد، مقدار ضریب تعیین r2 بیشتر است، که نشان می دهد معادله به دست آمده با استفاده از تحلیل رگرسیون چقدر روابط بین متغیرها را توضیح می دهد. ضریب r2 برابر با ssreg/sstotal است.
در برخی موارد، یک یا چند ستون X (بگذارید مقادیر Y و X در ستونها باشند) در سایر ستونهای X ارزش اعتباری اضافی ندارند. به عبارت دیگر، حذف یک یا چند ستون X ممکن است منجر به مقادیر Y شود که با همان دقت در این حالت، ستونهای X اضافی از مدل رگرسیونی حذف خواهند شد. این پدیده را "هم خطی" می نامند زیرا ستون های اضافی X را می توان به صورت مجموع چندین ستون غیر زائد نشان داد. تابع LINEST همخطی بودن را بررسی می کند و در صورت شناسایی ستون های X اضافی از مدل رگرسیون حذف می کند. ستون های X حذف شده را می توان در خروجی LINEST با ضریب 0 و مقدار se 0 شناسایی کرد. حذف یک یا چند ستون به عنوان اضافی، مقدار df را تغییر می دهد زیرا به تعداد ستون های X که واقعاً برای اهداف پیش بینی استفاده می شوند بستگی دارد. برای اطلاعات بیشتر در مورد محاسبه df، به مثال 4 زیر مراجعه کنید. هنگامی که df به دلیل حذف ستون های اضافی تغییر می کند، مقادیر sey و F نیز تغییر می کنند. استفاده از collinearity اغلب توصیه نمی شود. با این حال، اگر برخی از ستون های X حاوی 0 یا 1 به عنوان شاخصی باشد که نشان می دهد موضوع آزمایش به یک گروه جداگانه تعلق دارد، باید استفاده شود. اگر const = TRUE یا مقداری برای این آرگومان مشخص نشده باشد، LINEST یک ستون X اضافی را برای مدلسازی نقطه تقاطع وارد میکند. اگر ستونی با مقادیر 1 برای مردان و 0 برای زنان وجود دارد و ستونی با مقادیر 1 برای زنان و 0 برای مردان وجود دارد، ستون آخر حذف می شود زیرا می توان مقادیر آن را به دست آورد. از ستون "نشانگر مرد".
محاسبه df برای مواردی که X ستونها به دلیل همخطی بودن از مدل حذف نمیشوند به صورت زیر انجام میشود: اگر k ستون شناخته شده_x وجود داشته باشد و مقدار const = TRUE یا مشخص نشده باشد، df = n – k – 1. اگر const = FALSE، سپس df = n - k. در هر دو مورد، حذف ستون های X به دلیل همخطی بودن، مقدار df را 1 افزایش می دهد.
فرمول هایی که آرایه ها را برمی گرداند باید به عنوان فرمول های آرایه وارد شوند.
وقتی آرایه ای از ثابت ها را به عنوان آرگومان وارد می کنید، به عنوان مثال، شناخته شده_x_values، باید از یک نقطه ویرگول برای جدا کردن مقادیر در همان خط و یک دونقطه برای جدا کردن خطوط استفاده کنید. کاراکترهای جداکننده ممکن است بسته به تنظیمات در پنجره زبان و تنظیمات در کنترل پنل متفاوت باشد.
لازم به ذکر است که مقادیر y پیش بینی شده توسط معادله رگرسیون ممکن است درست نباشد اگر خارج از محدوده مقادیر y که برای تعریف معادله استفاده شده است قرار گیرند.
الگوریتم پایه مورد استفاده در تابع LINEST، با الگوریتم تابع اصلی متفاوت است شیبو بخش خط. تفاوت بین الگوریتم ها می تواند منجر به نتایج متفاوتی با داده های نامشخص و خطی شود. به عنوان مثال، اگر نقاط داده آرگومان Known_y_values 0 و نقاط داده آرگومان Known_x_values 1 باشد، آنگاه:
تابع LINESTمقداری برابر با 0 برمی گرداند. الگوریتم تابع LINESTبرای برگرداندن مقادیر مناسب برای داده های خطی استفاده می شود و در این مورد حداقل یک پاسخ می توان یافت.
توابع SLOPE و LINE خطای #DIV/0! را برمیگردانند. الگوریتم توابع SLOPE و INTERCEPT برای یافتن تنها یک پاسخ استفاده می شود، اما در این مورد ممکن است چندین پاسخ وجود داشته باشد.
علاوه بر محاسبه آمار برای انواع دیگر رگرسیون، LINEST می تواند برای محاسبه محدوده سایر انواع رگرسیون با وارد کردن توابع متغیرهای x و y به عنوان سری از متغیرهای x و y برای LINEST استفاده شود. به عنوان مثال، فرمول زیر:
LINEST(y_values، x_values^COLUMN($A:$C))
با داشتن یک ستون از مقادیر Y و یک ستون از مقادیر X برای محاسبه تقریب مکعب (چند جمله ای درجه 3) به شکل زیر کار می کند:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
فرمول را می توان برای محاسبه انواع دیگر رگرسیون تغییر داد، اما در برخی موارد ممکن است مقادیر خروجی و سایر آمارها نیاز به تنظیم داشته باشند.
که در برتری داشتنراه سریعتر و راحتتری برای رسم رگرسیون خطی (و حتی انواع اصلی رگرسیونهای غیرخطی، همانطور که در زیر بحث میشود) وجود دارد. این میتواند بصورت زیر انجام شود:
1) ستون های دارای داده را انتخاب کنید ایکسو Y(آنها باید به این ترتیب باشند!)
2) تماس بگیرید جادوگر نمودارو در گروه انتخاب کنید تایپ کنید – نقطهو بلافاصله فشار دهید آماده;
3) بدون لغو انتخاب نمودار، آیتم منوی اصلی ظاهر شده را انتخاب کنید نمودار، که در آن باید مورد را انتخاب کنید یک خط روند اضافه کنید;
4) در کادر محاوره ای که ظاهر می شود خط رونددر برگه تایپ کنیدانتخاب کنید خطی;
5) در برگه گزینه هامی توانید سوئیچ را فعال کنید معادله را در نمودار نشان دهید، که به شما امکان می دهد معادله رگرسیون خطی (4.4) را مشاهده کنید که در آن ضرایب (4.5) محاسبه می شود.
6) در همان تب می توانید سوئیچ را فعال کنید مقدار قابلیت اطمینان تقریبی (R^2) را روی نمودار قرار دهید. این مقدار مجذور ضریب همبستگی (4.3) است و نشان می دهد که معادله محاسبه شده چقدر وابستگی تجربی را توصیف می کند. اگر آر 2 نزدیک به وحدت است، سپس معادله رگرسیون نظری وابستگی تجربی را به خوبی توصیف می کند (نظریه به خوبی با آزمایش موافق است) و اگر آر 2 نزدیک به صفر است، پس این معادله برای توصیف وابستگی تجربی مناسب نیست (نظریه با آزمایش موافق نیست).
در نتیجه انجام اقدامات توصیف شده، نموداری با نمودار رگرسیون و معادله آن دریافت خواهید کرد.
§4.3. انواع اصلی رگرسیون غیرخطی
رگرسیون سهموی و چند جمله ای
سهمویوابستگی به ارزش Yاز اندازه ایکسوابستگی نامیده می شود که با یک تابع درجه دوم (پارابولای مرتبه دوم) بیان می شود:
این معادله نامیده می شود معادله رگرسیون سهموی Yبر ایکس. گزینه ها آ, ب, بانامیده می شوند ضرایب رگرسیون سهموی. محاسبه ضرایب رگرسیون سهموی همیشه دست و پا گیر است، بنابراین توصیه می شود از رایانه برای محاسبات استفاده کنید.
معادله (4.8) رگرسیون سهموی یک مورد خاص از یک رگرسیون عمومی تر به نام چند جمله ای است. چند جمله ایوابستگی به ارزش Yاز اندازه ایکسوابستگی بیان شده توسط چند جمله ای نامیده می شود n- مرتبه:
اعداد کجا هستند و من (من=0,1,…, n) نامیده می شوند ضرایب رگرسیون چند جمله ای.
رگرسیون قدرت.
قدرتوابستگی به ارزش Yاز اندازه ایکسوابستگی شکل نامیده می شود:
این معادله نامیده می شود معادله رگرسیون توان Yبر ایکس. گزینه ها آو بنامیده می شوند ضرایب رگرسیون توان.
ln =ln آ+بلوگاریتم ایکس. (4.11)
این معادله یک خط مستقیم را در یک صفحه با محورهای مختصات لگاریتمی ln توصیف می کند. ایکسو ln. بنابراین، معیار کاربردی بودن رگرسیون توانی این شرط است که نقاط لگاریتم داده های تجربی ln x iو ln y مننزدیکترین به خط مستقیم بودند (4.11).
رگرسیون نمایی.
نشان دهنده(یا نمایی) وابستگی به ارزش Yاز اندازه ایکسوابستگی شکل نامیده می شود:
(یا ). (4.12)
این معادله نامیده می شود معادله نمایی(یا نمایی) رگرسیون Yبر ایکس. گزینه ها آ(یا ک) و بنامیده می شوند ضرایب نمایی(یا نمایی) پسرفت.
اگر لگاریتم دو طرف معادله رگرسیون توان را بگیریم، معادله را بدست می آوریم.
ln = ایکسلوگاریتم آ+ln ب(یا ln = k x+ln ب). (4.13)
این معادله وابستگی خطی لگاریتم یک کمیت ln به کمیت دیگر را توصیف می کند. ایکس. بنابراین، ملاک کاربردی بودن رگرسیون توانی این شرط است که داده های تجربی دارای یک مقدار باشند. x iو لگاریتم های کمیت دیگر ln y مننزدیکترین به خط مستقیم بودند (4.13).
رگرسیون لگاریتمی
لگاریتمیوابستگی به ارزش Yاز اندازه ایکسوابستگی شکل نامیده می شود:
=آ+بلوگاریتم ایکس. (4.14)
این معادله نامیده می شود معادله رگرسیون لگاریتمی Yبر ایکس. گزینه ها آو بنامیده می شوند ضرایب رگرسیون لگاریتمی.
رگرسیون هایپربولیک.
هایپربولیکوابستگی به ارزش Yاز اندازه ایکسوابستگی شکل نامیده می شود:
این معادله نامیده می شود معادله رگرسیون هذلولی Yبر ایکس. گزینه ها آو بنامیده می شوند ضرایب رگرسیون هایپربولیکو با روش حداقل مربعات تعیین می شوند. استفاده از این روش به فرمول های زیر منجر می شود:
در فرمول (4.16-4.17) جمع بر روی شاخص انجام می شود مناز یک به تعداد مشاهدات n.
متاسفانه در برتری داشتنهیچ تابعی وجود ندارد که ضرایب رگرسیون هذلولی را محاسبه کند. در مواردی که مشخص نیست مقادیر اندازه گیری شده با نسبت معکوس مرتبط هستند، توصیه می شود به جای معادله رگرسیون هذلولی به دنبال معادله رگرسیون توان بگردید، بنابراین در برتری داشتنروشی برای یافتن آن وجود دارد. اگر یک وابستگی هذلولی بین کمیت های اندازه گیری شده در نظر گرفته شود، ضرایب رگرسیون آن باید با استفاده از جداول محاسبه کمکی و عملیات جمع با استفاده از فرمول های (4.16-4.17) محاسبه شود.
رگرسیون در اکسل
پردازش داده های آماری را می توان با استفاده از افزونه Analysis Package در زیر آیتم منوی "Service" نیز انجام داد. در اکسل 2003، اگر باز کنید سرویس، ما نمی توانیم برگه را پیدا کنیم تحلیل داده ها، سپس روی دکمه سمت چپ ماوس کلیک کنید تا برگه باز شود روبناهاو مقابل نقطه بسته تحلیلیبر روی دکمه سمت چپ ماوس کلیک کنید تا علامت بزنید (شکل 17).
برنج. 17. پنجره روبناها
پس از آن در منو سرویسبرگه ظاهر می شود تحلیل داده ها.
در اکسل 2007 برای نصب بسته تحلیلیباید روی دکمه OFFICE در گوشه سمت چپ بالای برگه کلیک کنید (شکل 18a). بعد، روی دکمه کلیک کنید تنظیمات اکسل. در پنجره ای که ظاهر می شود تنظیمات اکسلروی مورد کلیک چپ کنید روبناهاو در سمت راست لیست کشویی مورد را انتخاب کنید بسته تحلیلی.بعد کلیک کنید خوب.




برنج. 18. نصب و راه اندازی بسته تحلیلیدر اکسل 2007
برای نصب بسته تحلیلی روی دکمه کلیک کنید برو،در پایین پنجره باز قرار دارد. پنجره ای ظاهر می شود که در شکل نشان داده شده است. 12. یک تیک در مقابل قرار دهید بسته تحلیلی.در برگه داده هایک دکمه ظاهر می شود تحلیل داده ها(شکل 19).

از میان موارد پیشنهادی، مورد را انتخاب کنید پسرفت"و با دکمه سمت چپ ماوس روی آن کلیک کنید. بعد روی OK کلیک کنید.

پنجره ای ظاهر می شود که در شکل نشان داده شده است. 21

ابزار تجزیه و تحلیل " پسرفت» برای جا دادن یک نمودار به مجموعه ای از مشاهدات با استفاده از روش حداقل مربعات استفاده می شود. رگرسیون برای تجزیه و تحلیل اثر بر روی یک متغیر وابسته واحد از مقادیر یک یا چند متغیر مستقل استفاده می شود. به عنوان مثال، عوامل متعددی بر عملکرد ورزشی یک ورزشکار تأثیر می گذارد، از جمله سن، قد و وزن. می توان میزان تأثیر هر یک از این سه عامل بر عملکرد ورزشکار را محاسبه کرد و سپس از آن داده ها برای پیش بینی عملکرد ورزشکار دیگر استفاده کرد.
ابزار Regression از تابع استفاده می کند LINEST.
جعبه گفتگوی رگرسیون
برچسب ها اگر سطر اول یا ستون اول محدوده ورودی حاوی عنوان است، کادر بررسی را انتخاب کنید. اگر هدر وجود ندارد، این کادر را پاک کنید. در این صورت سرصفحه های مناسب برای داده های جدول خروجی به صورت خودکار ایجاد خواهند شد.
سطح قابلیت اطمینان کادر را انتخاب کنید تا یک سطح اضافی در جدول خلاصه خروجی گنجانده شود. در قسمت مربوطه، علاوه بر سطح پیشفرض 95 درصد، سطح اطمینانی را که میخواهید اعمال کنید، وارد کنید.
ثابت - صفر کادر را انتخاب کنید تا خط رگرسیون مجبور شود از مبدا عبور کند.
محدوده خروجی مرجع به سلول سمت چپ بالای محدوده خروجی را وارد کنید. حداقل هفت ستون برای جدول خلاصه خروجی ارائه دهید که شامل: نتایج ANOVA، ضرایب، خطای استاندارد محاسبه Y، انحرافات استاندارد، تعداد مشاهدات، خطاهای استاندارد برای ضرایب خواهد بود.
کاربرگ جدید این گزینه را انتخاب کنید تا یک کاربرگ جدید در کتاب کار باز شود و نتایج تجزیه و تحلیل از سلول A1 شروع شود. در صورت لزوم، یک نام برای برگه جدید در فیلد واقع در مقابل دکمه رادیویی مربوطه وارد کنید.
New Workbook این گزینه را برای ایجاد یک کتاب کار جدید با نتایج اضافه شده به کاربرگ جدید انتخاب کنید.
باقیمانده ها کادر را برای قرار دادن باقیمانده ها در جدول خروجی انتخاب کنید.
باقیمانده های استاندارد شده، کادر بررسی را برای گنجاندن باقیمانده های استاندارد شده در جدول خروجی انتخاب کنید.
نمودار باقیمانده برای رسم باقیمانده ها برای هر متغیر مستقل، کادر را انتخاب کنید.
Fit Plot برای رسم مقادیر پیشبینیشده در مقابل مشاهدهشده، کادر را انتخاب کنید.
نمودار احتمال عادیچک باکس را برای رسم نمودار احتمال عادی انتخاب کنید.
تابع LINEST
برای انجام محاسبات، سلولی را که می خواهیم مقدار متوسط را در آن نمایش دهیم، با مکان نما انتخاب کرده و کلید = را روی صفحه کلید فشار دهید. سپس در قسمت Name، برای مثال تابع مورد نظر را مشخص کنید میانگین(شکل 22).

برنج. 22 یافتن توابع در اکسل 2003
اگر در میدان نامنام تابع ظاهر نمی شود، سپس روی مثلث کنار فیلد کلیک چپ کرده و پس از آن پنجره ای با لیستی از توابع ظاهر می شود. اگر این تابع در لیست نیست، روی مورد لیست کلیک چپ کنید توابع دیگر، یک جعبه گفتگو ظاهر خواهد شد FUNCTION Master، که در آن با استفاده از اسکرول عمودی، عملکرد مورد نظر را انتخاب کرده، آن را با مکان نما برجسته کرده و بر روی آن کلیک کنید خوب(شکل 23).

برنج. 23. Function Wizard
برای جستجوی یک تابع در اکسل 2007، هر برگه ای را می توان در منو باز کرد؛ سپس برای انجام محاسبات، سلولی را که می خواهیم مقدار متوسط را در آن نمایش دهیم، با مکان نما انتخاب کرده و کلید = را روی صفحه کلید فشار دهید. سپس در قسمت Name تابع را مشخص کنید میانگین. پنجره محاسبه تابع مشابه پنجره اکسل 2003 است.
همچنین می توانید تب فرمول ها را انتخاب کنید و روی دکمه در منو کلیک چپ کنید. درج تابع"(شکل 24)، یک پنجره ظاهر می شود FUNCTION Masterکه ظاهر آن شبیه به Excel 2003 است. همچنین در منو می توانید بلافاصله دسته ای از توابع (اخیراً استفاده شده، مالی، منطقی، متن، تاریخ و زمان، ریاضی، توابع دیگر) را انتخاب کنید که در آن توابع مورد نظر را جستجو می کنیم. تابع.




برنج. 24 انتخاب یک تابع در اکسل 2007
تابع LINESTآمار یک سری را با استفاده از روش حداقل مربعات محاسبه می کند تا خط مستقیمی را که به بهترین وجه به داده های موجود تقریب می کند محاسبه کند و سپس آرایه ای را برمی گرداند که خط مستقیم حاصل را توصیف می کند. شما همچنین می توانید تابع را ترکیب کنید LINESTبا توابع دیگر برای محاسبه انواع مدل های دیگر که در پارامترهای مجهول خطی هستند (که پارامترهای مجهول آن خطی هستند)، از جمله سری های چند جمله ای، لگاریتمی، نمایی و توانی. از آنجا که یک آرایه از مقادیر برگردانده می شود، تابع باید به عنوان یک فرمول آرایه مشخص شود.
معادله یک خط مستقیم:
(در صورت وجود چندین محدوده از مقادیر x)،
در جایی که مقدار وابسته y تابعی از مقدار مستقل x است، مقادیر m ضرایب مربوط به هر متغیر مستقل x است و b یک ثابت است. توجه داشته باشید که y، x و m می توانند بردار باشند. تابع LINESTآرایه ای را برمی گرداند ![]() . LINESTهمچنین ممکن است آمار رگرسیون اضافی را برگرداند.
. LINESTهمچنین ممکن است آمار رگرسیون اضافی را برگرداند.
LINEST(مقادیر_شناخته_y؛ مقادیر_شناخته_x؛ const؛ آمار)
Known_y_values مجموعه ای از مقادیر y است که قبلاً برای رابطه شناخته شده است.
اگر آرایه Known_y_values دارای یک ستون باشد، هر ستون در آرایه Known_x_values به عنوان یک متغیر جداگانه در نظر گرفته می شود.
اگر آرایه Known_y_values دارای یک ردیف باشد، هر سطر در آرایه Known_x_values به عنوان یک متغیر جداگانه در نظر گرفته می شود.
Known_x-values مجموعه ای اختیاری از مقادیر x هستند که قبلاً برای رابطه شناخته شده اند.
آرایه Known_x_values می تواند شامل یک یا چند مجموعه از متغیرها باشد. اگر فقط از یک متغیر استفاده شود، آرایه های Known_y_values و Known_x_values می توانند هر شکلی داشته باشند - تا زمانی که ابعاد یکسانی داشته باشند. اگر بیش از یک متغیر استفاده می شود، شناخته شده_y_values باید یک بردار باشد (یعنی یک فاصله یک ردیف بالا یا یک ستون عرض).
اگر array_known_x_values حذف شود، آرایه (1;2;3;...) به اندازه array_known_values_y در نظر گرفته می شود.
Const یک مقدار بولی است که مشخص می کند آیا ثابت b باید برابر با 0 باشد یا خیر.
اگر آرگومان "const" درست باشد یا حذف شود، ثابت b طبق معمول ارزیابی می شود.
اگر آرگومان Const FALSE باشد، مقدار b روی 0 تنظیم می شود و مقادیر m به گونه ای انتخاب می شوند که رابطه ارضا شود.
آمار - یک مقدار بولی که نشان می دهد آیا آمار رگرسیون اضافی باید برگردانده شود یا خیر.
اگر آمار درست باشد، LINEST آمار رگرسیون اضافی را برمیگرداند. آرایه برگشتی به این صورت خواهد بود: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
اگر آمار FALSE یا حذف شده باشد، LINEST فقط ضرایب m و ثابت b را برمی گرداند.
آمار رگرسیون اضافی
شکل زیر ترتیب برگشت آمار رگرسیون اضافی را نشان می دهد.

یادداشت:
هر خط مستقیمی را می توان با شیب و تقاطع آن با محور y توصیف کرد:
شیب (m): برای تعیین شیب یک خط، که معمولاً با m نشان داده می شود، دو نقطه روی خط و ; شیب برابر خواهد بود ![]() .
.
مقطع Y (b): مقطع y یک خط که معمولاً با b نشان داده می شود، مقدار y برای نقطه ای است که در آن خط محور y را قطع می کند.
معادله خط مستقیم به شکل . اگر مقادیر m و b مشخص باشد، هر نقطه از خط را می توان با جایگزین کردن مقادیر y یا x در معادله محاسبه کرد. همچنین می توانید از تابع TREND استفاده کنید.
اگر فقط یک متغیر مستقل x وجود داشته باشد، می توانید شیب و قطع y را مستقیماً با استفاده از فرمول های زیر بدست آورید:
شیب: INDEX(LINEST(مقادیر_y_معروف؛ مقادیر_x_معروف؛ 1)
مقطع Y: INDEX(LINEST(مقادیر_y_معروف؛ مقادیر_x_شناخته؛ 2)
دقت تقریب با استفاده از خط مستقیم محاسبه شده توسط تابع LINEST به درجه پراکندگی داده ها بستگی دارد. هر چه داده ها به یک خط مستقیم نزدیکتر باشند، مدل مورد استفاده توسط تابع LINEST دقیق تر است. تابع LINEST از حداقل مربعات برای تعیین بهترین تناسب با داده ها استفاده می کند. هنگامی که فقط یک متغیر مستقل x وجود دارد، m و b با استفاده از فرمول های زیر محاسبه می شوند:

که در آن x و y میانگین های نمونه هستند، به عنوان مثال x = AVERAGE (شناختههای_x) و y = AVERAGE (شناختههای_y).
توابع برازش LINEST و LGRFPRIBL می توانند خط مستقیم یا منحنی نمایی را محاسبه کنند که بهترین تناسب با داده ها را دارد. با این حال، آنها به این سوال پاسخ نمی دهند که کدام یک از این دو نتیجه برای حل مشکل مناسب تر است. همچنین میتوانید تابع TREND(known_y's; شناخته شده_x's) را برای یک خط مستقیم یا تابع GROW (known_y's;known_x's) را برای یک منحنی نمایی ارزیابی کنید. این توابع، مگر اینکه new_x-values مشخص شده باشد، آرایه ای از مقادیر y محاسبه شده را برای مقادیر x واقعی در امتداد یک خط یا منحنی برمی گرداند. سپس می توانید مقادیر محاسبه شده را با مقادیر واقعی مقایسه کنید. همچنین می توانید نمودارهایی را برای مقایسه بصری ایجاد کنید.
هنگام انجام تجزیه و تحلیل رگرسیون، مایکروسافت اکسل برای هر نقطه، مجذور اختلاف بین مقدار y پیش بینی شده و مقدار y واقعی را محاسبه می کند. مجموع این مجذور تفاوت ها را مجموع مجذورات باقیمانده (ssresid) می گویند. سپس مایکروسافت اکسل مجموع مجذورات (sstotal) را محاسبه می کند. اگر const = TRUE یا مقدار این آرگومان مشخص نشده باشد، مجموع مجذورات برابر با مجموع مربعات تفاوت بین مقادیر واقعی y و مقادیر متوسط y خواهد بود. هنگامی که const = FALSE، مجموع مجموع مربع ها برابر با مجموع مربع های مقادیر y واقعی خواهد بود (بدون کسر مقدار متوسط y از مقدار y جزئی). سپس مجموع رگرسیون مربع ها را می توان به صورت زیر محاسبه کرد: ssreg = sstotal - ssresid. هر چه مجموع باقیمانده مربع ها کوچکتر باشد، مقدار ضریب تعیین r2 بیشتر است، که نشان می دهد معادله به دست آمده با استفاده از تحلیل رگرسیون چقدر روابط بین متغیرها را توضیح می دهد. ضریب r2 برابر با ssreg/sstotal است.
در برخی موارد، یک یا چند ستون X (بگذارید مقادیر Y و X در ستونها باشند) در سایر ستونهای X ارزش اعتباری اضافی ندارند. به عبارت دیگر، حذف یک یا چند ستون X ممکن است منجر به مقادیر Y شود که با همان دقت در این حالت، ستونهای X اضافی از مدل رگرسیونی حذف خواهند شد. این پدیده را "هم خطی" می نامند زیرا ستون های اضافی X را می توان به صورت مجموع چندین ستون غیر زائد نشان داد. تابع LINEST همخطی بودن را بررسی می کند و در صورت شناسایی ستون های X اضافی از مدل رگرسیون حذف می کند. ستون های X حذف شده را می توان در خروجی LINEST با ضریب 0 و مقدار se 0 شناسایی کرد. حذف یک یا چند ستون به عنوان اضافی، مقدار df را تغییر می دهد زیرا به تعداد ستون های X که واقعاً برای اهداف پیش بینی استفاده می شوند بستگی دارد. برای اطلاعات بیشتر در مورد محاسبه df، به مثال 4 زیر مراجعه کنید. هنگامی که df به دلیل حذف ستون های اضافی تغییر می کند، مقادیر sey و F نیز تغییر می کنند. استفاده از collinearity اغلب توصیه نمی شود. با این حال، اگر برخی از ستون های X حاوی 0 یا 1 به عنوان شاخصی باشد که نشان می دهد موضوع آزمایش به یک گروه جداگانه تعلق دارد، باید استفاده شود. اگر const = TRUE یا مقداری برای این آرگومان مشخص نشده باشد، LINEST یک ستون X اضافی را برای مدلسازی نقطه تقاطع وارد میکند. اگر ستونی با مقادیر 1 برای مردان و 0 برای زنان وجود دارد و ستونی با مقادیر 1 برای زنان و 0 برای مردان وجود دارد، ستون آخر حذف می شود زیرا می توان مقادیر آن را به دست آورد. از ستون "نشانگر مرد".
محاسبه df برای مواردی که X ستونها به دلیل همخطی بودن از مدل حذف نمیشوند به صورت زیر انجام میشود: اگر k ستون شناخته شده_x وجود داشته باشد و مقدار const = TRUE یا مشخص نشده باشد، df = n – k – 1. اگر const = FALSE، سپس df = n - k. در هر دو مورد، حذف ستون های X به دلیل همخطی بودن، مقدار df را 1 افزایش می دهد.
فرمول هایی که آرایه ها را برمی گرداند باید به عنوان فرمول های آرایه وارد شوند.
وقتی آرایه ای از ثابت ها را به عنوان آرگومان وارد می کنید، به عنوان مثال، شناخته شده_x_values، باید از یک نقطه ویرگول برای جدا کردن مقادیر در همان خط و یک دونقطه برای جدا کردن خطوط استفاده کنید. کاراکترهای جداکننده ممکن است بسته به تنظیمات در پنجره زبان و تنظیمات در کنترل پنل متفاوت باشد.
لازم به ذکر است که مقادیر y پیش بینی شده توسط معادله رگرسیون ممکن است درست نباشد اگر خارج از محدوده مقادیر y که برای تعریف معادله استفاده شده است قرار گیرند.
الگوریتم پایه مورد استفاده در تابع LINEST، با الگوریتم تابع اصلی متفاوت است شیبو بخش خط. تفاوت بین الگوریتم ها می تواند منجر به نتایج متفاوتی با داده های نامشخص و خطی شود. به عنوان مثال، اگر نقاط داده آرگومان Known_y_values 0 و نقاط داده آرگومان Known_x_values 1 باشد، آنگاه:
تابع LINESTمقداری برابر با 0 برمی گرداند. الگوریتم تابع LINESTبرای برگرداندن مقادیر مناسب برای داده های خطی استفاده می شود و در این مورد حداقل یک پاسخ می توان یافت.
توابع SLOPE و LINE خطای #DIV/0! را برمیگردانند. الگوریتم توابع SLOPE و INTERCEPT برای یافتن تنها یک پاسخ استفاده می شود، اما در این مورد ممکن است چندین پاسخ وجود داشته باشد.
علاوه بر محاسبه آمار برای انواع دیگر رگرسیون، LINEST می تواند برای محاسبه محدوده سایر انواع رگرسیون با وارد کردن توابع متغیرهای x و y به عنوان سری از متغیرهای x و y برای LINEST استفاده شود. به عنوان مثال، فرمول زیر:
LINEST(y_values، x_values^COLUMN($A:$C))
با داشتن یک ستون از مقادیر Y و یک ستون از مقادیر X برای محاسبه تقریب مکعب (چند جمله ای درجه 3) به شکل زیر کار می کند:
فرمول را می توان برای محاسبه انواع دیگر رگرسیون تغییر داد، اما در برخی موارد ممکن است مقادیر خروجی و سایر آمارها نیاز به تنظیم داشته باشند.
به نظر من به عنوان یک دانشجو، اقتصاد سنجی یکی از کاربردی ترین علومی است که توانستم در دیوارهای دانشگاهم با آن آشنا شوم. با کمک آن، واقعاً می توان مشکلات کاربردی را در مقیاس سازمانی حل کرد. اینکه این تصمیمات چقدر موثر خواهند بود، سوال سوم است. نکته پایانی این است که بیشتر دانش به صورت تئوری باقی خواهد ماند، اما اقتصاد سنجی و تحلیل رگرسیون همچنان ارزش مطالعه با توجه ویژه را دارند.
رگرسیون چه چیزی را توضیح می دهد؟
قبل از اینکه شروع به بررسی عملکردهای MS Excel کنیم که به ما امکان می دهد این مشکلات را حل کنیم، می خواهم به طور مفصل برای شما توضیح دهم که اساساً تجزیه و تحلیل رگرسیون شامل چه چیزی می شود. با این کار قبولی در آزمون برای شما آسان تر می شود و از همه مهمتر مطالعه موضوع جذاب تر خواهد بود.
امیدوارم با مفهوم تابع از ریاضیات آشنا شده باشید. تابع رابطه بین دو متغیر است. وقتی یک متغیر تغییر می کند، برای دیگری اتفاقی می افتد. ما X را تغییر می دهیم و Y نیز بر این اساس تغییر می کند. توابع قوانین مختلفی را توصیف می کنند. با دانستن تابع، می توانیم مقادیر دلخواه X را جایگزین کنیم و ببینیم که Y چگونه تغییر می کند.
این از اهمیت زیادی برخوردار است زیرا رگرسیون تلاشی است برای توضیح در نگاه اول فرآیندهای غیر سیستماتیک و آشفته با استفاده از یک تابع خاص. به عنوان مثال، می توان رابطه بین نرخ دلار و بیکاری در روسیه را شناسایی کرد.
اگر بتوان این الگو را کشف کرد، با استفاده از تابعی که در طی محاسبات به دست آوردیم، میتوانیم پیشبینی کنیم که نرخ بیکاری در نرخ مبادله دلار N در برابر روبل چقدر خواهد بود.
این رابطه را همبستگی می نامند. تجزیه و تحلیل رگرسیون شامل محاسبه یک ضریب همبستگی است که رابطه نزدیک بین متغیرهای مورد نظر ما (نرخ دلار و تعداد مشاغل) را توضیح می دهد.
این ضریب می تواند مثبت یا منفی باشد. مقادیر آن از -1 تا 1 متغیر است. بر این اساس، می توانیم همبستگی منفی یا مثبت بالایی را مشاهده کنیم. در صورت مثبت بودن افزایش نرخ دلار، ایجاد مشاغل جدید را به دنبال خواهد داشت. اگر منفی باشد یعنی افزایش نرخ ارز کاهش مشاغل را به دنبال دارد.
چندین نوع رگرسیون وجود دارد. می تواند خطی، سهمی، توانی، نمایی و غیره باشد. بسته به اینکه کدام رگرسیون به طور خاص با مورد ما مطابقت داشته باشد، مدلی را انتخاب می کنیم که تا حد ممکن به همبستگی ما نزدیک باشد. بیایید با استفاده از یک مثال به این موضوع نگاه کنیم و آن را در MS Excel حل کنیم.
رگرسیون خطی در MS Excel
برای حل مسائل رگرسیون خطی، به عملکرد تجزیه و تحلیل داده ها نیاز دارید. ممکن است برای شما فعال نباشد، بنابراین باید آن را فعال کنید.
- روی دکمه "File" کلیک کنید؛
- مورد "گزینه ها" را انتخاب کنید؛
- روی تب ماقبل آخر "افزونه ها" در سمت چپ کلیک کنید.

- در زیر کتیبه "Management" و دکمه "Go" را خواهیم دید. روی آن کلیک کنید؛
- کادر «بسته تحلیل» را علامت بزنید؛
- روی "ok" کلیک کنید.

نمونه کار
عملکرد تجزیه و تحلیل دسته ای فعال می شود. بیایید مشکل زیر را حل کنیم. ما نمونه ای از داده ها را برای چندین سال در مورد تعداد موقعیت های اضطراری در قلمرو شرکت و تعداد کارگران شاغل در اختیار داریم. ما باید رابطه بین این دو متغیر را شناسایی کنیم. یک متغیر توضیحی X وجود دارد - این تعداد کارگران است و یک متغیر توضیحی - Y - این تعداد حوادث اضطراری است. بیایید داده های منبع را در دو ستون توزیع کنیم.
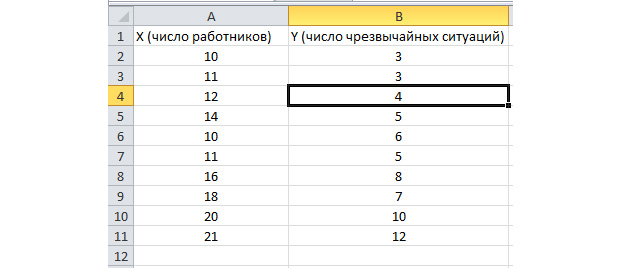
بیایید به برگه "داده" برویم و "تجزیه و تحلیل داده ها" را انتخاب کنیم.
در لیستی که ظاهر می شود، "Regression" را انتخاب کنید. مقادیر مناسب را در بازه های ورودی Y و X انتخاب می کنیم.

روی "OK" کلیک کنید. تجزیه و تحلیل کامل شده است و ما نتایج را در یک برگه جدید خواهیم دید.
مهم ترین مقادیر برای ما در شکل زیر مشخص شده است.
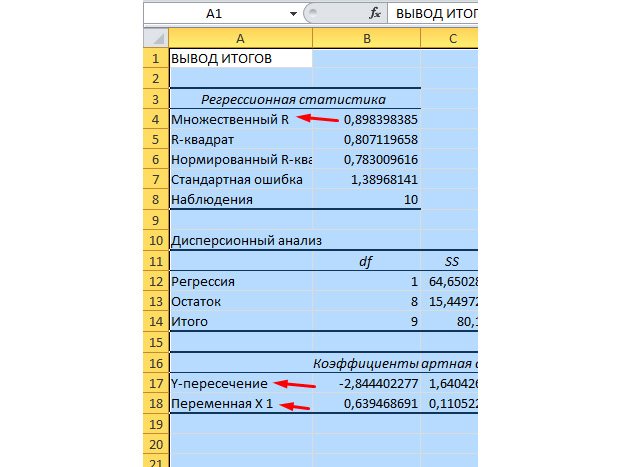
R چندگانه ضریب تعیین است. این یک فرمول محاسبه پیچیده دارد و نشان می دهد که چقدر می توانید به ضریب همبستگی ما اعتماد کنید. بر این اساس، هر چه این مقدار بالاتر باشد، اعتماد بیشتر، مدل ما در کل موفق تر است.
Y-Intercept و X1-Intercept ضرایب رگرسیون ما هستند. همانطور که قبلا ذکر شد، رگرسیون یک تابع است و دارای ضرایب خاصی است. بنابراین، تابع ما به صورت زیر خواهد بود: Y = 0.64 * X-2.84.
این چه چیزی به ما می دهد؟ این به ما فرصت می دهد تا پیش بینی کنیم. فرض کنید می خواهیم 25 کارگر را برای یک شرکت استخدام کنیم و باید تقریباً تصور کنیم که تعداد حوادث اضطراری چقدر خواهد بود. این مقدار را با تابع خود جایگزین می کنیم و نتیجه Y = 0.64 * 25 – 2.84 را می گیریم. تقریبا 13 مورد اضطراری خواهیم داشت.
بیایید ببینیم چگونه کار می کند. به تصویر زیر دقت کنید. تابعی که به دست آوردیم حاوی مقادیر واقعی برای کارکنان درگیر است. ببینید چقدر ارزش ها به بازیکنان واقعی نزدیک است.

همچنین میتوانید با انتخاب ناحیه Y و X، کلیک بر روی زبانه «درج» و انتخاب نمودار پراکندگی، یک فیلد همبستگی ایجاد کنید.

نقاط پراکنده هستند، اما به طور کلی به سمت بالا حرکت می کنند، گویی یک خط مستقیم در وسط وجود دارد. و همچنین می توانید این خط را با رفتن به تب Layout در MS Excel و انتخاب "Trend Line" اضافه کنید.
روی خط ظاهر شده دوبار کلیک کنید و آنچه را که قبلا ذکر شد مشاهده خواهید کرد. بسته به اینکه فیلد همبستگی شما به چه شکل است، می توانید نوع رگرسیون را تغییر دهید.
ممکن است احساس کنید که نقاط به جای یک خط مستقیم، سهمی را ترسیم می کنند و بهتر است نوع دیگری از رگرسیون را انتخاب کنید.

نتیجه
امیدواریم این مقاله به شما درک بیشتری از چیستی تحلیل رگرسیون و چرایی نیاز به آن داده باشد. همه اینها از اهمیت عملی بالایی برخوردار است.