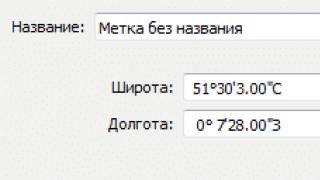
اجازه دهید در اینجا چند پیوند به سایت هایی ارائه دهم که نویسنده و / یا الهام بخش ایدئولوژیک آنها این شخص است - الکساندر ماکارچوک از شهر بوریسوف، بلاروس:
الکساندر برای کار بر روی کامپیوتر از برنامه "جوی استیک صوتی" - توسعه دانشجویان دانشگاه واشنگتن که توسط بنیاد ملی علوم (NSF) تامین می شود، استفاده کرد. به melodi.ee.washington.edu/vj مراجعه کنید
نمی توانستم مقاومت کنم
ضمناً در سایت دانشگاه (http://www.washington.edu/) 90 درصد مطالب در مورد پول است. یافتن چیزی در مورد کار علمی دشوار است. مثلاً در اینجا گزیدههایی از صفحه اول آمده است: «تام، فارغالتحصیل دانشگاه، قارچ میخورد و به زحمت کرایهاش را میداد. اکنون او مدیر ارشد یک شرکت فناوری اطلاعات است و به دانشگاه وام می دهد، "بیگ دیتا به بی خانمان ها کمک می کند"، "شرکت متعهد شده است که 5 میلیون دلار برای ساختمان جدید دانشگاهی بپردازد."
آیا این به تنهایی به چشم من آسیب می زند؟
این برنامه در سال های 2005-2009 ساخته شد و به خوبی روی ویندوز XP کار کرد. در نسخه های جدیدتر ویندوز، برنامه ممکن است یخ بزند، که برای شخصی که نمی تواند از روی صندلی خود بلند شود و آن را دوباره راه اندازی کند غیرقابل قبول است. بنابراین، برنامه باید دوباره انجام شود.
هیچ کد منبعی وجود ندارد، فقط نشریات جداگانه ای وجود دارد که فناوری هایی را که بر اساس آن ها ساخته شده را نشان می دهد (MFCC، MLP - در قسمت دوم در مورد این مطلب بخوانید).
در تصویر و شباهت، برنامه جدیدی نوشته شد (در حدود سه ماه).
در واقع، می توانید ببینید که چگونه کار می کند:
می توانید برنامه را دانلود کنید و/یا کدهای منبع را مشاهده کنید.
برای نصب برنامه نیازی به انجام هیچ عمل خاصی نیست، فقط روی آن کلیک کرده و آن را اجرا کنید. تنها نکته این است که در برخی موارد لازم است که به عنوان مدیر اجرا شود (به عنوان مثال، هنگام کار با صفحه کلید مجازی Comfort Keys Pro):

شاید در اینجا و موارد دیگری که قبلاً انجام دادم تا بتوانم کامپیوتر را بدون دست کنترل کنم قابل ذکر باشد.
اگر توانایی چرخاندن سر خود را دارید، ژیروسکوپ روی سر می تواند جایگزین مناسبی برای eViacam باشد. شما موقعیت یابی سریع و دقیق مکان نما و استقلال نور را دریافت خواهید کرد.
اگر فقط می توانید مردمک چشم ها را حرکت دهید، می توانید از ردیاب نگاه و برنامه برای آن استفاده کنید (ممکن است در صورت استفاده از عینک مشکل باشد).
قسمت دوم. چگونه کار می کند؟
از مطالب منتشر شده در مورد برنامه "جوی استیک صوتی" مشخص شد که به شرح زیر است:- برش جریان صوتی به فریم های 25 میلی ثانیه با همپوشانی 10 میلی ثانیه
- به دست آوردن 13 ضریب مغزی (MFCC) برای هر فریم
- بررسی اینکه یکی از 6 صدای حفظ شده (4 مصوت و 2 صامت) با استفاده از پرسپترون چندلایه (MLP) تلفظ می شود.
- تبدیل صداهای پیدا شده به حرکت/کلیک ماوس
آخرین کار به سادگی با استفاده از تابع SendInput اجرا می شود.
به نظر من کارهای دوم و سوم بیشترین علاقه را دارند. بنابراین.
کار شماره 2. به دست آوردن 13 ضریب مغزی
اگر کسی در این موضوع نباشد - مشکل اصلی تشخیص صدای رایانه این است: مقایسه دو صدا دشوار است، زیرا دو موج صوتی که در طرح کلی متفاوت هستند می توانند از نظر ادراک انسان مشابه به نظر برسند.و در میان کسانی که در تشخیص گفتار دخیل هستند، جستجویی برای "سنگ فیلسوف" وجود دارد - مجموعه ای از ویژگی هایی که به طور واضح موج صوتی را طبقه بندی می کند.
از بین آن دسته از ویژگی هایی که در دسترس عموم است و در کتاب های درسی توضیح داده شده است، پرکاربردترین آن ها ضرایب موسوم به mel-frequency cepstral ضرایب (MFCC) هستند.
تاریخچه آنها به گونه ای است که در ابتدا برای هدف کاملاً متفاوتی در نظر گرفته شده بودند، یعنی سرکوب پژواک در سیگنال (مقاله آموزنده ای در این زمینه توسط آقایان محترم اوپنهایم و شفر نوشته شده است، باشد که شادی در خانه های این مردان نجیب باشد. به A.V. Oppenheim and R.W. Schafer، "از فرکانس تا Quefrency: A History of Cepstrum" مراجعه کنید.
اما نظم و ترتیب انسان به گونه ای است که تمایل دارد از آنچه بهتر می داند استفاده کند. و کسانی که با سیگنالهای گفتاری سروکار داشتند به این فکر افتادند که از یک نمایش فشرده آماده از سیگنال در قالب MFCC استفاده کنند. معلوم شد که به طور کلی کار می کند. (یکی از آشنایان من، متخصص سیستم های تهویه، وقتی از او پرسیدم که چگونه ییلاقی بسازیم، استفاده از کانال های تهویه را پیشنهاد داد. صرفاً به این دلیل که آنها را بهتر از سایر مصالح ساختمانی می شناخت).
آیا MFCC ها طبقه بندی کننده خوبی برای صداها هستند؟ من نمی گویم. همان صدا، که توسط من در میکروفون های مختلف تلفظ می شود، در مناطق مختلف فضای ضرایب MFCC قرار می گیرد و یک طبقه بندی ایده آل آنها را کنار هم می کشد. بنابراین، به ویژه، هنگام تغییر میکروفون، باید برنامه را دوباره آموزش دهید.

این تنها یکی از پیش بینی های فضای 13 بعدی MFCC به 3 بعدی است، اما منظور من را نشان می دهد - نقاط قرمز، بنفش و آبی از میکروفون های مختلف می آیند: (Plantronix، آرایه میکروفون داخلی، Jabra)، اما صدا تلفظ می شود. تنها.
با این حال، از آنجایی که نمی توانم چیز بهتری ارائه دهم، از روش استاندارد نیز استفاده خواهم کرد - محاسبه ضرایب MFCC.
برای اینکه در اجرا اشتباه نشود، در اولین نسخه های برنامه، از کد برنامه معروف CMU Sphinx به عنوان پایه استفاده شد، به طور دقیق تر، پیاده سازی آن در زبان C، به نام pocketsphinx، توسعه یافته در Carnegie. دانشگاه ملون (درود بر هر دو! (ج) Hottabych).
کدهای منبع pocketsphinx باز هستند، اما این بدشانسی است - اگر از آنها استفاده می کنید، باید متنی را در برنامه خود بنویسید (هم در کدهای منبع و هم در ماژول اجرایی) که شامل موارد زیر است:
* این کار تا حدی با بودجه آژانس پروژه های تحقیقاتی دفاع پیشرفته * و بنیاد ملی علوم ایالات متحده * ایالات متحده آمریکا و کنسرسیوم سخنرانی ابوالهول CMU پشتیبانی شد.
به نظر من غیرقابل قبول بود و مجبور شدم کد را دوباره بنویسم. این بر سرعت برنامه تأثیر گذاشت (به هر حال، به هر حال، اگرچه "خوانایی" کد تا حدودی آسیب دید). عمدتاً به دلیل استفاده از کتابخانههای «Intel Performance Primitives» بود، اما او چیزی مانند فیلتر MEL را نیز بهینه کرد. با این وجود، بررسی دادههای آزمایش نشان داد که ضرایب MFCC حاصل کاملاً مشابه ضرایب بهدستآمده با استفاده از ابزار sphinx_fe است.
در برنامه های sphinxbase، محاسبه ضرایب MFCC توسط مراحل زیر انجام می شود:
| گام | تابع پایه اسفینکس | ماهیت عملیات |
|---|---|---|
| 1 | fe_pre_emphasis | بیشتر شمارش قبلی از تعداد فعلی کم می شود (مثلاً 0.97 مقدار آن). یک فیلتر اولیه که فرکانس های پایین را رد می کند. |
| 2 | fe_hamming_window | پنجره همینگ - میرایی را در ابتدا و انتهای قاب معرفی می کند |
| 3 | fe_fft_real | تبدیل فوریه سریع |
| 4 | fe_spec2magnitude | از طیف معمولی، طیف توان را دریافت می کنیم که فاز را از دست می دهد |
| 5 | fe_mel_spec | فرکانس های طیف [مثلا 256 قطعه] را با استفاده از مقیاس MEL و فاکتورهای وزنی به 40 شمع گروه بندی کنید. |
| 6 | fe_mel_cep | لگاریتم را بگیرید و تبدیل DCT2 را به 40 مقدار مرحله قبل اعمال کنید. ما 13 مقدار نتیجه اول را ترک می کنیم. انواع مختلفی از DCT2 (HTK، میراث، کلاسیک) وجود دارد که در ثابتی که ضرایب به دست آمده را با آن تقسیم می کنیم و در یک ثابت خاص برای ضریب صفر تفاوت دارند. شما می توانید هر گزینه ای را انتخاب کنید، این ماهیت را تغییر نمی دهد. |
این مراحل همچنین شامل عملکردهایی هستند که به شما امکان می دهد سیگنال را از نویز و سکوت جدا کنید، مانند fe_track_snr، fe_vad_hangover، اما ما به آنها نیازی نداریم و حواسمان را پرت نمی کنیم.
مراحل زیر برای بدست آوردن ضرایب MFCC انجام شده است:
کار شماره 3. بررسی اینکه یکی از 6 صدای حفظ شده تلفظ می شود
برنامه اصلی Vocal Joystick از یک پرسپترون چندلایه (MLP) برای طبقهبندی استفاده کرد - یک شبکه عصبی بدون زنگها و سوتهای جدید.بیایید ببینیم که استفاده از یک شبکه عصبی در اینجا چقدر موجه است.
به یاد بیاورید که نورون ها در شبکه های عصبی مصنوعی چه می کنند.
اگر نورون دارای N ورودی باشد، نورون فضای N بعدی را به نصف تقسیم می کند. اسلش بک هند با هایپرپلین. در عین حال در یک نیمه از فضا کار می کند (جواب مثبت می دهد) و در نیمه دیگر کار نمی کند.
بیایید به ساده ترین گزینه [تقریبا] نگاه کنیم - یک نورون با دو ورودی. او البته فضای دو بعدی را به نصف تقسیم خواهد کرد.
اجازه دهید مقادیر X1 و X2 ورودی باشند که نورون در ضرایب وزنی W1 و W2 ضرب میکند و عبارت آزاد C را اضافه میکند.

در مجموع، در خروجی نورون (بیایید آن را با Y نشان دهیم) دریافت می کنیم:
Y=X1*W1+X2*W2+C
(بیایید فعلاً از ظرافت های مربوط به توابع سیگموئید بگذریم)
ما در نظر می گیریم که نورون زمانی شلیک می کند که Y>0 باشد. خط مستقیم داده شده توسط معادله 0=X1*W1+X2*W2+C فقط فضا را به قسمتی که Y>0 و قسمتی از Y تقسیم می کند.<0.
بیایید آنچه را که گفته شد با اعداد مشخص نشان دهیم.
اجازه دهید W1=1، W2=1، C=-5.

حالا بیایید ببینیم چگونه می توانیم یک شبکه عصبی را سازماندهی کنیم که در یک منطقه خاص از فضا، به طور نسبی - یک نقطه، کار کند و در همه مکان های دیگر کار نکند.
از شکل مشخص می شود که برای ترسیم یک منطقه در فضای دو بعدی، حداقل به 3 خط، یعنی 3 نورون متصل به آنها نیاز داریم.

ما این سه نورون را با یک لایه دیگر ترکیب می کنیم و یک شبکه عصبی چند لایه (MLP) به دست می آوریم.

و اگر به شبکه عصبی برای کار در دو ناحیه فضا نیاز داشته باشیم، حداقل سه نورون دیگر مورد نیاز خواهد بود (4،5،6 در شکل ها): 
و در اینجا شما نمی توانید بدون لایه سوم انجام دهید: 
و لایه سوم تقریباً یادگیری عمیق است…

اکنون برای کمک به مثال دیگری می پردازیم. اجازه دهید شبکه عصبی ما روی نقاط قرمز یک پاسخ مثبت و روی نقاط آبی پاسخ منفی بدهد.

اگر از من خواسته شود که قرمز را از آبی با خطوط مستقیم برش دهم، این کار را به شکل زیر انجام می دهم:

اما یک شبکه عصبی به طور پیشینی نمی داند که به چه تعداد (نرون) مستقیم نیاز دارد. این پارامتر باید قبل از آموزش شبکه تنظیم شود. و شخص این کار را بر اساس ... شهود یا آزمون و خطا انجام می دهد.
اگر در لایه اول تعداد بسیار کمی نورون (به عنوان مثال سه) انتخاب کنیم، می توانیم یک برش مانند این را دریافت کنیم که خطاهای زیادی ایجاد می کند (ناحیه اشتباه سایه زده می شود):

اما حتی اگر تعداد نورون ها کافی باشد، در نتیجه آموزش، شبکه ممکن است "همگرا نشود"، یعنی زمانی که میزان خطا زیاد است، به یک حالت پایدار و دور از حد مطلوب برسد. مانند اینجا، میله متقاطع بالایی روی دو کوهان قرار می گیرد و آنها را جایی رها نمی کند. و در زیر آن یک منطقه بزرگ است که خطا ایجاد می کند:

باز هم، امکان چنین مواردی به شرایط اولیه تمرین و ترتیب تمرین، یعنی به عوامل تصادفی بستگی دارد:
- نظرت چیه، اون چرخ اگه بشه به مسکو میرسه یا نه؟
- نظر شما چیست، آیا شبکه عصبی همگرا می شود یا خیر؟
یک لحظه ناخوشایند دیگر در ارتباط با شبکه های عصبی وجود دارد. "فراموشی" آنها.
اگر شروع به تغذیه شبکه فقط با نقاط آبی کنید و از تغذیه نقاط قرمز خودداری کنید، آنگاه می تواند به راحتی تکه ای از ناحیه قرمز را برای خود بگیرد و مرزهای خود را به آنجا حرکت دهد:

اگر شبکههای عصبی دارای ایرادات زیادی هستند و یک فرد میتواند مرزها را بسیار کارآمدتر از یک شبکه عصبی ترسیم کند، پس چرا اصلاً از آنها استفاده کنیم؟
و یک جزئیات کوچک اما بسیار مهم وجود دارد.
من به خوبی می توانم قلب قرمز را از پس زمینه آبی با قطعات خط در فضای دو بعدی جدا کنم.
من به خوبی می توانم مجسمه زهره را با هواپیما از فضای سه بعدی اطراف آن جدا کنم.
اما در فضای چهار بعدی، من نمی توانم کاری انجام دهم، ببخشید. و در 13 بعدی - حتی بیشتر.
اما برای یک شبکه عصبی، بعد فضا مانعی ندارد. در فضاهای کم ابعاد به او خندیدم، اما به محض اینکه از حد معمول فراتر رفتم، او به راحتی مرا کتک زد.
با این وجود، این سوال هنوز باز است - با توجه به مضرات شبکه های عصبی فوق، استفاده از یک شبکه عصبی در این کار خاص چقدر موجه است.
بیایید یک لحظه فراموش کنیم که MFCC های ما در فضای 13 بعدی قرار دارند و تصور کنیم که آنها دو بعدی هستند، یعنی نقاطی در یک هواپیما. در این صورت چگونه می توان یک صدا را از دیگری جدا کرد؟
بگذارید نقاط MFCC صدای 1 دارای انحراف استاندارد R1 باشند، که [تقریبا] به این معنی است که نقاطی که از میانگین فاصله زیادی ندارند، مشخص ترین نقاط، در داخل دایره با شعاع R1 قرار دارند. به همین ترتیب، نقاطی که برای صدای 2 به آن اعتماد داریم، در داخل دایره با شعاع R2 قرار دارند.

توجه، سوال این است: کجا می توان یک خط مستقیم کشید که صدای 1 را از صدای 2 جدا کند؟
پاسخ خود را نشان می دهد: در وسط بین مرزهای دایره ها. آیا اعتراضی وجود دارد؟ هیچ اعتراضی وجود ندارد.
تصحیح:در برنامه، این حاشیه، بخش اتصال مراکز دایره ها را به نسبت R1:R2 تقسیم می کند، بنابراین صحیح تر است.


و در نهایت، فراموش نکنیم که جایی در فضا نقطه ای وجود دارد که نشان دهنده سکوت کامل در فضای MFCC است. نه، آن طور که به نظر می رسد 13 صفر نیست. این نکته ای است که نمی تواند انحراف معیار داشته باشد. و خطوط مستقیمی که با آنها آن را از سه صدای خود قطع می کنیم، می توان مستقیماً در امتداد مرزهای دایره ها ترسیم کرد:

در شکل زیر، هر صدا مربوط به قطعه ای از فضا به رنگ خود است، و همیشه می توانیم بگوییم که این یا آن نقطه از فضا به کدام صدا تعلق دارد (یا به هیچ کدام تعلق ندارد):

خوب، خوب، حالا بیایید به یاد بیاوریم که فضا 13 بعدی است، و چیزی که برای کشیدن روی کاغذ خوب بود، اکنون معلوم می شود چیزی است که در مغز انسان نمی گنجد.
بله، اینطور نیست. خوشبختانه در فضایی با هر بعد، مفاهیمی مانند یک نقطه، یک خط، یک [هیپر] صفحه، یک [فوق] کره باقی مانده است.
همه اقدامات مشابه را در فضای 13 بعدی تکرار می کنیم: پراکندگی را پیدا می کنیم، شعاع کره ها را تعیین می کنیم، مراکز آنها را با یک خط مستقیم به هم وصل می کنیم، آن را با یک صفحه [هیپر] در نقطه ای به همان اندازه از کره زمین برش می دهیم. مرزهای [فوق] کره ها
هیچ شبکه عصبی نمی تواند به درستی یک صدا را از دیگری جدا کند.
اما در اینجا باید رزرو انجام شود. همه اینها در صورتی درست است که اطلاعات مربوط به صدا ابری از نقاط باشد که به طور مساوی در همه جهات از میانگین منحرف می شوند، یعنی به خوبی در ابرکره قرار می گیرند. اگر این ابر یک شکل پیچیده بود، به عنوان مثال، یک سوسیس منحنی 13 بعدی، آنگاه تمام استدلال های بالا درست نبود. و شاید با آموزش صحیح، شبکه عصبی بتواند نقاط قوت خود را در اینجا نشان دهد.
اما من آن را به خطر نمی اندازم. و من برای مثال مجموعهای از توزیعهای عادی (GMM) را اعمال میکنم (که اتفاقاً در CMU Sphinx انجام میشود). وقتی بفهمید کدام الگوریتم خاص منجر به نتیجه شده است، همیشه لذت بخش تر است. نه مانند یک شبکه عصبی: Oracle، بر اساس ساعتهای طولانی تهیه اطلاعات آموزشی، به شما میگوید که تصمیم بگیرید که صدای درخواستی صدای شماره ۳ باشد. (مخصوصاً وقتی میخواهند رانندگی ماشین را به یک شبکه عصبی بسپارند، من را آزار میدهد. پس چگونه، در یک موقعیت غیر استاندارد، بفهمم که چرا ماشین به چپ و راست نمیپیچد؟ نورون متعال دستور داد؟).
اما مجموعههایی از توزیعهای عادی در حال حاضر یک موضوع بزرگ جداگانه است که خارج از محدوده این مقاله است.
امیدوارم که مقاله مفید بوده باشد و/یا باعث شده باشد که پیچیدگی های مغز شما به هم بخورد.
Speech Recognition یک ابزار ساده و قدرتمند ویندوز است که به شما امکان می دهد کامپیوتر خود را با استفاده از دستورات صوتی کنترل کنید.
شما می توانید این ویژگی را برای ناوبری، راه اندازی برنامه ها، دیکته متن و بسیاری از کارهای دیگر سفارشی کنید. با این حال، تشخیص گفتار در درجه اول برای افراد دارای معلولیت در نظر گرفته شده است که نمی توانند از ماوس یا صفحه کلید استفاده کنند.
در این راهنما، ما مراحلی را برای راه اندازی و عملکرد ویژگی تشخیص گفتار ارائه می دهیم تا بتوانید رایانه خود را فقط با صدای خود کنترل کنید.
متاسفانه این ابزار نیز مانند کورتانا در منطقه ما بسیار محدود است.

با این حال، می توانید برخی از تنظیمات را در رایانه خود تغییر دهید. برای انجام این کار؛ این موارد را دنبال کنید:

مهم!برای اینکه همه چیز به درستی کار کند، باید نه از یک حساب محلی، بلکه از یک حساب مایکروسافت استفاده کنید! اگر نسخه تک زبانه ای را نصب کرده اید (روی This PC و سپس Properties کلیک راست کنید)، دیگر نمی توانید از Cortana یا ابزار تشخیص گفتار کامل استفاده کنید!
برای راحتی، تمام اقدامات به روسی ترجمه شده و با تصاویر مربوطه به زبان انگلیسی همراه است. یک راه رادیکال تر، اگر همه چیز شکست بخورد، نصب ویندوز برای ایالات متحده است.
موارد زیر را انجام دهید:
- کنترل پنل را باز کنید.

- «دسترسی» را پیدا کنید.

- روی پیوند "راه اندازی تشخیص گفتار" کلیک کنید.


مهم!در اینجا کاربران ما با مشکل روبرو هستند، بنابراین روی پیوند سمت چپ "Text-to-Speech" کلیک کنید و بلافاصله به بخش نحوه تغییر تنظیمات تشخیص گفتار در این مقاله بروید. اگر یک رابط سیستم انگلیسی دارید، با خیال راحت ادامه مراحل را همراه با اسکرین شات به زبان انگلیسی دنبال کنید.
- در صفحه تنظیمات، روی Next کلیک کنید.
- نوع میکروفون مورد استفاده خود را انتخاب کنید.

توجه داشته باشید!میکروفون های رومیزی کامل نیستند، بنابراین مایکروسافت استفاده از یک میکروفون خارجی یا یک هدست اختصاصی را توصیه می کند.
- Next را کلیک کنید. عمل را تکرار کنید.

- متن را با صدای بلند بخوانید تا بررسی کنید که آیا ابزار کار می کند یا خیر. Next را کلیک کنید. عمل را تکرار کنید.

- تشخیص گفتار به اسناد و ایمیل ها دسترسی دارد. این برای بهبود دقت تشخیص بر اساس کلماتی که استفاده می کنید ضروری است. گزینه "Enable Document Viewer" را انتخاب کنید یا اگر نگرانی در مورد حفظ حریم خصوصی دارید آن را خاموش کنید. Next را کلیک کنید.

- حالت فعال سازی را انتخاب کنید: از "حالت فعال سازی دستی" استفاده کنید - تشخیص گفتار دستور "توقف گوش دادن" را غیرفعال می کند. برای روشن کردن مجدد آن، باید دکمه میکروفون را فشار دهید یا از کلید ترکیبی Ctrl + Win استفاده کنید. یا «فعال سازی صوتی ».
ابزار تشخیص زمانی که استفاده نمی شود به حالت خواب می رود. برای روشن کردن مجدد آن، باید فرمان صوتی «شروع گوش دادن» را صدا بزنید. Next را کلیک کنید.

- برای کسب اطلاعات بیشتر در مورد دستورات صوتی که می توانید استفاده کنید، روی دکمه راهنما کلیک کنید. Next را کلیک کنید.

- در صورت تمایل، می توانید گزینه "شروع تشخیص گفتار به طور خودکار" را انتخاب کنید. Next را کلیک کنید.

- برای دسترسی به آموزش مایکروسافت، روی دکمه Start Tutorial کلیک کنید یا Skip را انتخاب کنید. در نتیجه، تنظیمات را تکمیل خواهید کرد.

پس از انجام این مراحل، می توانید با استفاده از دستورات صوتی، از قابلیت تشخیص گفتار استفاده کنید. کنترل ها در بالای صفحه ظاهر می شوند.
توجه داشته باشید!می توانید رابط تشخیص گفتار را در هر نقطه از صفحه بکشید و رها کنید.

نحوه آموزش تشخیص گفتار و بهبود دقت
پس از تکمیل فرآیند آموزش، ابزار تشخیص گفتار باید صدای شما را بهتر درک کند.
نحوه تغییر تنظیمات تشخیص گفتار
اگر نیاز به تغییر تنظیمات دارید، این مراحل را دنبال کنید:
مرحله 1.کنترل پنل را باز کنید.
گام 2روی Accessibility کلیک کنید.
مرحله 3 Speech Recognition را انتخاب کنید.

مرحله 4در قسمت سمت چپ، برای گزینههای گفتار بیشتر، روی پیوند متن کلیک کنید.
مرحله 5در پنجره ویژگی ها در برگه تشخیص گفتار، می توانید اجزای مختلفی از ویژگی را پیکربندی کنید، از جمله:

مرحله 6در تب Text to Speech، میتوانید تنظیمات صدای خود را مدیریت کنید، از جمله:

مرحله 7علاوه بر این، همیشه می توانید منوی زمینه را با دکمه سمت راست ماوس باز کنید و به تمام ویژگی ها و تنظیمات مختلف ابزار تشخیص گفتار دسترسی داشته باشید.

نحوه استفاده از تشخیص گفتار در ویندوز 10
علیرغم فرآیند یادگیری کوچک، تشخیص گفتار از دستورات واضح و آسان برای به خاطر سپردن استفاده می کند. به عنوان مثال، "شروع" منوی مربوطه را باز می کند و "Show Desktop" تمام پنجره ها را به حداقل می رساند.

با کمک عملکرد تشخیص گفتار می توانید کارهای لازم را انجام دهید.
راه اندازی ابزار تشخیص گفتار

روشن و خاموش شدن
برای استفاده از این ویژگی، بسته به پیکربندی خود، دکمه میکروفون را فشار دهید یا بگویید «Start listening».

به همین ترتیب، می توانید با گفتن "Stop" یا با فشار دادن دکمه میکروفون آن را خاموش کنید.
با استفاده از دستورات

برخی از رایج ترین دستورات مورد استفاده عبارتند از:
- "باز کن" (باز کن)- برنامه را پس از گفتن کلمه "Open" و سپس نام برنامه راه اندازی می کند. به عنوان مثال، "Open Mail" یا "Open Firefox"؛
- "تغییر به" (تغییر به)- به برنامه در حال اجرا دیگری بروید. دستور "Switch" و به دنبال آن نام برنامه را بگویید. به عنوان مثال، "Switch to Microsoft Edge"؛
- کنترل پنجره بازبرای مدیریت پنجره فعال، از دستورات Minimize، Maximize و Restore استفاده کنید.
- پیمایش (Scroll).به شما امکان می دهد صفحه را اسکرول کنید. فقط از دستورات «Scroll down» یا «Scroll up»، «Scroll left» یا «Scroll right» استفاده کنید. همچنین می توانید یک اسکرول طولانی را مشخص کنید. به عنوان مثال، بگویید: "Scroll down two pages" ("Scroll down two pages");
- بستن برنامه ها (بستن).بگویید «Close» به دنبال آن نام برنامه در حال اجرا. به عنوان مثال، "Close Word" ("Close Word");
- کلیک کنید (کلیک کنید).در داخل برنامه، می توانید از دستور "Click" و سپس نام عنصر استفاده کنید. به عنوان مثال، در Word می توانید بگویید "Click Layout" و تشخیص گفتار برگه "Layout" را باز می کند. به طور مشابه، می توانید از دستورات "دوبار کلیک" ("دوبار کلیک") یا "راست کلیک" ("کلیک راست") استفاده کنید.
- مطبوعات. این دستور کلیدهای میانبر را راه اندازی می کند. به عنوان مثال، برای باز کردن Action Center، بگویید "Press Windows A".
استفاده از دیکته
تشخیص گفتار همچنین شامل قابلیت تبدیل صدا به متن با استفاده از ویژگی دیکته است و به صورت خودکار کار می کند.

دستیار مایکروسافت با نام Cortana
مایکروسافت برای برآورده کردن انتظارات کاربران و نشان دادن رقابت پذیری در مقایسه با شرکت هایی مانند اپل، گوگل یا آمازون، دستیار هوشمند خود، کورتانا را معرفی کرد.

در مراحل اولیه یکی از بهترین دستیاران مصنوعی به حساب می آمد اما پس از از دست دادن نسخه موبایلی مایکروسافت در نبرد با اندروید و iOS جایگاه خود را از دست داد. با این حال، در اینجا ما در مورد ویندوز 10 صحبت می کنیم، بنابراین Cortana در حال حاضر یک ابزار قابل دوام است.
امیدواریم با گذشت زمان بهبود یابد. اگر می خواهید کامپیوتر خود را بدون هیچ فرمان صوتی راه اندازی کنید، کورتانا مفید است.
در اینجا نحوه فعال کردن و تنظیم آن برای استفاده بعدی در ویندوز 10 آمده است:
- روی Start کلیک کنید و همه برنامه ها را باز کنید.

- کورتانا را پیدا کنید و آن را باز کنید.

- تیک «استفاده از کورتانا» را بردارید. بسته به اینکه می خواهید دستیار صوتی داده های شما را ردیابی کند (تا شما را بهتر بشناسد) یا خیر، روی «بله» یا «نه متشکرم» ضربه بزنید.

- اکنون که کورتانا را فعال کرده اید، "Windows + S" را فشار دهید یا روی چرخ دنده در سمت چپ کلیک کنید.
- «Hey Cortana» را روشن کنید و میکروفون خود را راهاندازی کنید. میتوانید انتخاب کنید که وقتی شخصی میگوید «Hey Cortana»، «دستیار» پاسخ دهد یا فقط به دستورات صوتی شما پاسخ دهد.

- از تنظیمات خارج شوید و از دستیار دیجیتال خود چیزی بخواهید.

- لیستی از دستورات و وظایف موجود را که کورتانا می تواند انجام دهد در وب جستجو کنید.
ویدئو - نحوه فعال کردن مایکروسافت کورتانا در ویندوز 10
مجموعه برنامه های شخص ثالث
علاوه بر ابزار تشخیص گفتار داخلی و دستیار صوتی کورتانا، برخی از کاربران ممکن است به یک جایگزین شخص ثالث روی بیاورند. از آنجایی که این دسته از نرم افزارها به طور مداوم در حال توسعه هستند، محصولات مختلفی در بازار وجود دارد که با ویندوز 10 سازگار هستند. تنها سوال شما نیازها و خواسته های شماست.
برخی از برنامه ها مانند:
- Typle یک برنامه عالی برای کنترل صدا در رایانه، یک رابط ساده به زبان روسی است.
- Dragon، توسط سازنده Nuance، در دیکته سریع و به طور کلی گفتار به متن تخصص دارد.
- Voice Attack، برای کنترل صوتی گیم پلی است (بله، می توانید سلاح ها را در Call of Duty با یک فرمان صوتی دوباره بارگیری کنید).
- یکی دیگر از ابزارهای خوب VoxCommando است. بیشتر در برنامه های چند رسانه ای مانند Kodi یا iTunes استفاده می شود، اما می تواند هنگام خودکارسازی دستگاه های خانگی نیز مفید باشد.
کنترل صوتی کامپیوتر با استفاده از برنامه Type
- برنامه را دانلود کنید و طبق دستورالعمل های نصب کننده آن را بر روی رایانه خود نصب کنید.


- رابط برنامه ساده و واضح است. در یک تبریک در پنجره ای از برنامه نکاتی برای کاربر وجود دارد. برای شروع، روی دکمه "افزودن" کلیک کنید.

- در پنجره باز شده نام خود را در فیلد وارد کنید سپس دستور را وارد کرده و سپس دکمه ضبط را بزنید و دستور را به صورت صوتی بگویید. روی دکمه Add کلیک کنید.

- روی دکمه Add کلیک کنید.

- مورد مورد نیاز را علامت بزنید. یک برنامه را انتخاب کنید، دکمه قرمز را فشار دهید و فرمان را با صدای بلند بگویید. سپس روی Add کلیک کنید.

- دستور ایجاد شده را مشاهده خواهید کرد، برای بررسی، روی "شروع صحبت" کلیک کنید و این دستور را بگویید. اگر همه چیز به همین صورت کار می کند، بقیه دستورات را اضافه کنید.

Talk Typer را امتحان کنید
این یک برنامه آنلاین است که به شما امکان می دهد متن را دیکته کنید و سپس برخی از گزینه های اساسی را برای انجام کار با آن ارائه می دهد. طرفداران مینیمالیسم قطعا آن را دوست خواهند داشت.


می توانید مطالبی را که می خوانید در کلیپ بورد خود کپی کنید، آن را ایمیل کنید، آن را چاپ کنید، توییت کنید و به زبان دیگری ترجمه کنید. برای ترجمه متن فقط روی دکمه کلیک کنید و زبان مقصد را انتخاب کنید. TalkTyper به طور خودکار یک برگه مرورگر جدید با متنی که در Google Translate جایگذاری شده است باز می کند.
به تازتی توجه کنید
Tazti در دو ویژگی متمایز از سایر برنامه ها متمایز است:
- می توانید از این برنامه برای کنترل رایانه و بازی های خود با دستورات صوتی استفاده کنید. و اگر Tazti تیم مورد نیاز خود را ندارد، می توانید یک (و 299 تیم دیگر) ایجاد کنید.
- این برنامه قادر است برنامه های نصب شده، وب سایت ها، دایرکتوری ها را اجرا کند یا از خط فرمان استفاده کند.
Tazti را همانطور که می خواهید سفارشی کنید. اگر به دستوری نیاز ندارید، آن را ویرایش کنید یا به طور کامل حذف کنید. حتی میتوانید دستورهای «کلیک» و «دوبار کلیک» را اضافه کنید تا نیازی به ماوس نباشد.

با این حال، Tazti یک اشکال بزرگ دارد - عملکرد دیکته متن ندارد، بنابراین قادر به تشخیص صدا نیست. گروه فناوری صدای توسعهدهنده تشخیص میدهد که سایر محصولات در دیکته کردن بسیار بهتر هستند، بنابراین این شرکت تصمیم گرفت تمام تلاش خود را روی ویژگیهای دیگر فرزندانش متمرکز کند.
Tazti بیشتر برای گیمرهایی طراحی شده است که می خواهند از صدای خود برای ارسال شخصیت ها به نبرد استفاده کنند یا کسانی که ترجیح می دهند برنامه ها، پخش کننده های رسانه ای و وب گردی را بدون نیاز به استفاده از صفحه کلید انجام دهند. این واقعیت که شما می توانید قسمت های مهم ویندوز را با Tazti کنترل کنید، آن را به یک حریف شایسته برای برنامه های فوق الذکر تبدیل می کند، حتی اگر دیکته ارائه ندهد.
مهم!این برنامه یک دوره آزمایشی 15 روزه دارد. پس از آن باید 40 دلار پرداخت کنید.
بنابراین، اگر تشخیص گفتار یا کورتانا نیازهای شما را برآورده نمی کند (یا به سادگی نمی توانید از آنها استفاده کنید)، ابزارهای فوق را امتحان کنید.
ویدئو - مروری بر برنامه Type
کدام حرفه ای که رویای کنترل کامپیوتر از روی مبل را فقط با حرکات و دستورات صوتی ندارد؟ به اندازه کافی عجیب، اما در حال حاضر امکان پذیر است. و در آینده ای بسیار نزدیک، هر ثانیه دستان خود را جلوی مانیتور تکان می دهد. این مقاله چندین راه و چشم انداز فوری را مورد بحث قرار می دهد.
کنترل صدا در ویندوز
بیایید با نرم افزار رایگان شروع کنیم که به شما امکان می دهد رایانه خود را با استفاده از گفتار روسی کنترل کنید. می توان او را متقاعد کرد که برنامه ها را باز کند، اقداماتی را انجام دهد و غیره. و دست شما برای چیزهای مهمتر آزاد خواهد بود.
نوع

این برنامه در بین برنامه هایی پیشرو است که به شما امکان می دهد به زبان روسی مادری خود به رایانه فرمان دهید. پس از نصب، باید یک کاربر ایجاد کنید و یک کلمه کلیدی مانند "Ok, Windows" بیابید، اگرچه به ما کلمه "Open" را توصیه می کنیم. از اوست که ما شروع به صحبت می کنیم، یک پیاده سازی آشنا در عینک گوگل وجود دارد.
سپس دستورات را برای کاربر انتخاب می کنیم. شما می توانید فقط راه اندازی برخی از برنامه ها را اضافه کنید، و هنگامی که بر روی آن کلیک کردید، برنامه را خودتان انتخاب کنید و هر آرگومانی را اضافه کنید. شاید اگر چیزی به راه اندازی برنامه اضافه شود، اقداماتی انجام شود. اما به طور کلی، یک کاربر معمولی قادر نخواهد بود کامپیوتر را به طور کامل مدیریت کند، بدون مکث برای شما یا آهنگ بعدی، فقط اجرا کنید و اجرا کنید.
کنترل ژست روی کامپیوتر
از زمان ظهور دوربین PlayStation®Eye و کینکت، مردم خواستار همان ویژگیها در رایانه بودند. بعداً کینکت حتی به توسعه دهندگان نیز فروخته شد، اما چنین محصولی برای کاربر عمومی اعلام نشد. و حتی اخباری وجود دارد که Kinect 2.0 با Xbox One روی رایانه کار نخواهد کرد، اما نسخه ویژه ای از Kinect برای رایانه شخصی وجود خواهد داشت. درست است، بدون نرم افزار مناسب، سود کمی از آن وجود دارد. پس بیایید به سراغ خود نرم افزار برویم.

محبوب ترین و مقرون به صرفه ترین راه برای کنترل حرکات، برنامه Flutter و افزونه کروم مربوطه است. تقریباً هر وب کم با این برنامه کار می کند.
تعداد کمی از ویژگی ها، اما آنها بسیار خوب کار می کنند. می توانیم مکث کنیم و به نشان دادن کف دست ادامه دهیم. آهنگ ها یا ویدیوها را بسته به جایی که انگشت خود را نشان می دهید به چپ یا راست تغییر دهید. این برنامه در PowerPoint، VLC، Winamp، iTunes، YouTube و چندین سرویس دیگر کار می کند که افراد کمی در اینجا از آنها استفاده می کنند.
برای عملکرد صحیح، مطلوب است که از وب کم فاصله داشته باشید، اما نه به طور تصادفی. کنترل دراز کشیدن بسیار بدتر از راست نشستن است. من شخصاً فقط زمانی از یوتیوب استفاده می کنم که دستانم کاملاً راحت کثیف باشد یا زمانی که دراز کشیده ام. هیچ حرکت تصادفی وجود نداشت. اما با این حال، وقتی شما فقط می نشینید و مانند یک احمق تمام دستان خود را جلوی مانیتور تکان می دهید، خطاهایی وجود دارد.
مطمئنا Flutter به زودی پشتیبانی کامل از کروم را دریافت خواهد کرد، زیرا این استارت آپ در اکتبر 2013 توسط گوگل خریداری شد.
حرکت جهشی
بیایید از نرم افزار به دستگاه ها برویم. Leap Motion با ظاهر کوچک و مقدار پتانسیل خود اعتماد به نفس را القا می کند. این مورد، دست های کاربر، به طور دقیق تر، حتی هر انگشت را مشخص می کند. فروشگاه خود با یک دسته از برنامه ها و بازی ها خسته نمی شود. و مهمتر از همه، در حال حاضر در فروش است و حدود 5000 روبل قیمت دارد. برای این نوع جادو زیاد نیست.
اما، در واقع، معایب بسیاری وجود دارد. بحث هایی در مورد Habré و حتی نظر یکی از کاربران وجود داشت. دست ها را باید همیشه با مچ بالا روی دستگاه نگه داشت، به نظر شما آسان است؟ به مدت 5 دقیقه نگه دارید.
در مورد برنامه ها، این نیز یک منفی بزرگ است که همه برنامه های رایگان باگ هستند و خراب می شوند. و بازی ها یک دسته از سفرهای LSD نامفهوم هستند. بله، و مدیریت آن ناخوشایند است، دقت در جهت مخالف بازی می کند و هر حرکت اشتباه دست منجر به عواقب غیر قابل پیش بینی می شود.
و خود درایور Leap Motion تقریباً تمام منابع شما را در رایانه شما می خورد. اما اگر این کار شما را متوقف نکرد، مانند همیشه در دفتر خرید کنید. سایت اینترنتی. حتی به زبان روسی است.
DUO 3D
یک فناوری مشابه از توسعه دهندگان روسی نیز وجود دارد. آنها فقط دو دوربین چشم گرفتند، نرم افزار نوشتند و یک شرکت در کیک استارتر ساختند. متاسفانه یک شکست ما 62000 دلار از 110000 دلار برنامه ریزی شده جمع آوری کردیم. شرم آور است، به خصوص که آنها حتی این پول را دریافت نخواهند کرد، زیرا باید همه چیز جمع شود تا آنها برسند.
در حال حاضر دستگاه ها حتی به صورت رایگان به فروش می رسند، اما ما امیدواریم که چنین تحولاتی از مردم ما به همین سادگی از بین نرود.
Myo
بیا کی اسم میو نشنیده دستبندی که حرکات را نه با استفاده از دوربین، مانند رقبا، بلکه با تشخیص حرکت عضلات تشخیص می دهد. یک ویدیوی زیبا و ویژگی های شگفت انگیز به همه و حتی من رشوه داد. به محض اینکه دستبند برای فروش در دسترس است، برنامه ها و همه ادغام ها مشخص می شوند، بررسی ها ظاهر می شوند، سپس این چیز فوق العاده را خواهم خرید.
اکنون می توان این دستبند را با قیمت 150 دلار پیش خرید کرد، اما می ترسم نسخه خام را دریافت کنم.
کنترل کامپیوتر از طریق وب کم روی لپ تاپ
اکنون سازندگان لپتاپها دوست دارند کنترل حرکتی را آزمایش کنند. PointGrab در این موضوع پیشرفت کرده است و هنر مفهومی آنها کاملاً خوش بینانه است.
محصولات این شرکت توسط ایسر مورد استفاده قرار می گیرد. و لنوو بر اساس این پیشرفت ها، Motion Control 2.0 خود را خواهد ساخت.
و در سپتامبر 2013، اینتل لپتاپهای جدیدی را با کنترل صوتی، کنترل حرکتی، لمسی معرفی کرد و قبل از آن، در تابستان، این شرکت استارتآپ اسرائیلی Omek را خریداری کرد.
بیایید ببینیم از همه اینها چه می شود. اخیراً این احساس ابدی را داشتم که آینده نزدیک است و چند سالی است که همینطور است. شما می توانید مطالب من را با دانش خود تکمیل کنید، شاید وسایل یا روش های دیگری نیز وجود داشته باشد که قابل ذکر باشد؟
مردی به من نزدیک شد و درخواست کرد برنامه ای بنویسم که به شما امکان می دهد ماوس رایانه را با صدای خود کنترل کنید. پس من حتی نمی توانستم تصور کنم که یک فرد تقریباً کاملاً فلج که حتی نمی تواند خودش سرش را بچرخاند، اما فقط می تواند صحبت کند، می تواند فعالیت شدیدی داشته باشد، به خود و دیگران کمک کند تا زندگی فعال داشته باشند، دانش و مهارت های جدید به دست آورند، کار کنند و کسب درآمد کنید، با افراد دیگر در سراسر جهان ارتباط برقرار کنید، در مسابقه پروژه های اجتماعی شرکت کنید.اجازه دهید در اینجا چند پیوند به سایت هایی ارائه دهم که نویسنده و / یا الهام بخش ایدئولوژیک آنها این شخص است - الکساندر ماکارچوک از شهر بوریسوف، بلاروس:
الکساندر برای کار بر روی کامپیوتر از برنامه "جوی استیک صوتی" - توسعه دانشجویان دانشگاه واشنگتن که توسط بنیاد ملی علوم (NSF) تامین می شود، استفاده کرد. به melodi.ee.washington.edu/vj مراجعه کنید
نمی توانستم مقاومت کنم
ضمناً در سایت دانشگاه (http://www.washington.edu/) 90 درصد مطالب در مورد پول است. یافتن چیزی در مورد کار علمی دشوار است. مثلاً در اینجا گزیدههایی از صفحه اول آمده است: «تام، فارغالتحصیل دانشگاه، قارچ میخورد و به زحمت کرایهاش را میداد. اکنون او مدیر ارشد یک شرکت فناوری اطلاعات است و به دانشگاه وام می دهد، "بیگ دیتا به بی خانمان ها کمک می کند"، "شرکت متعهد شده است که 5 میلیون دلار برای ساختمان جدید دانشگاهی بپردازد."
آیا این به تنهایی به چشم من آسیب می زند؟
این برنامه در سال های 2005-2009 ساخته شد و به خوبی روی ویندوز XP کار کرد. در نسخه های جدیدتر ویندوز، برنامه ممکن است یخ بزند، که برای شخصی که نمی تواند از روی صندلی خود بلند شود و آن را دوباره راه اندازی کند غیرقابل قبول است. بنابراین، برنامه باید دوباره انجام شود.
هیچ کد منبعی وجود ندارد، فقط نشریات جداگانه ای وجود دارد که فناوری هایی را که بر اساس آن ها ساخته شده را نشان می دهد (MFCC، MLP - در قسمت دوم در مورد این مطلب بخوانید).
در تصویر و شباهت، برنامه جدیدی نوشته شد (در حدود سه ماه).
در واقع، می توانید ببینید که چگونه کار می کند:
می توانید برنامه را دانلود کنید و/یا کدهای منبع را مشاهده کنید.
برای نصب برنامه نیازی به انجام هیچ عمل خاصی نیست، فقط روی آن کلیک کرده و آن را اجرا کنید. تنها نکته این است که در برخی موارد لازم است که به عنوان مدیر اجرا شود (به عنوان مثال، هنگام کار با صفحه کلید مجازی Comfort Keys Pro):
شاید در اینجا و موارد دیگری که قبلاً انجام دادم تا بتوانم کامپیوتر را بدون دست کنترل کنم قابل ذکر باشد.
اگر توانایی چرخاندن سر خود را دارید، ژیروسکوپ روی سر می تواند جایگزین مناسبی برای eViacam باشد. شما موقعیت یابی سریع و دقیق مکان نما و استقلال نور را دریافت خواهید کرد.
اگر فقط می توانید مردمک چشم ها را حرکت دهید، می توانید از ردیاب نگاه و برنامه برای آن استفاده کنید (ممکن است در صورت استفاده از عینک مشکل باشد).
قسمت دوم. چگونه کار می کند؟
از مطالب منتشر شده در مورد برنامه "جوی استیک صوتی" مشخص شد که به شرح زیر است:- برش جریان صوتی به فریم های 25 میلی ثانیه با همپوشانی 10 میلی ثانیه
- به دست آوردن 13 ضریب مغزی (MFCC) برای هر فریم
- بررسی اینکه یکی از 6 صدای حفظ شده (4 مصوت و 2 صامت) با استفاده از پرسپترون چندلایه (MLP) تلفظ می شود.
- تبدیل صداهای پیدا شده به حرکت/کلیک ماوس
آخرین کار به سادگی با استفاده از تابع SendInput اجرا می شود.
به نظر من کارهای دوم و سوم بیشترین علاقه را دارند. بنابراین.
کار شماره 2. به دست آوردن 13 ضریب مغزی
اگر کسی در این موضوع نباشد - مشکل اصلی تشخیص صدای رایانه این است: مقایسه دو صدا دشوار است، زیرا دو موج صوتی که در طرح کلی متفاوت هستند می توانند از نظر ادراک انسان مشابه به نظر برسند.و در میان کسانی که در تشخیص گفتار دخیل هستند، جستجویی برای "سنگ فیلسوف" وجود دارد - مجموعه ای از ویژگی هایی که به طور واضح موج صوتی را طبقه بندی می کند.
از بین آن دسته از ویژگی هایی که در دسترس عموم است و در کتاب های درسی توضیح داده شده است، پرکاربردترین آن ها ضرایب موسوم به mel-frequency cepstral ضرایب (MFCC) هستند.
تاریخچه آنها به گونه ای است که در ابتدا برای هدف کاملاً متفاوتی در نظر گرفته شده بودند، یعنی سرکوب پژواک در سیگنال (مقاله آموزنده ای در این زمینه توسط آقایان محترم اوپنهایم و شفر نوشته شده است، باشد که شادی در خانه های این مردان نجیب باشد. به A.V. Oppenheim and R.W. Schafer، "از فرکانس تا Quefrency: A History of Cepstrum" مراجعه کنید.
اما نظم و ترتیب انسان به گونه ای است که تمایل دارد از آنچه بهتر می داند استفاده کند. و کسانی که با سیگنالهای گفتاری سروکار داشتند به این فکر افتادند که از یک نمایش فشرده آماده از سیگنال در قالب MFCC استفاده کنند. معلوم شد که به طور کلی کار می کند. (یکی از آشنایان من، متخصص سیستم های تهویه، وقتی از او پرسیدم که چگونه ییلاقی بسازیم، استفاده از کانال های تهویه را پیشنهاد داد. صرفاً به این دلیل که آنها را بهتر از سایر مصالح ساختمانی می شناخت).
آیا MFCC ها طبقه بندی کننده خوبی برای صداها هستند؟ من نمی گویم. همان صدا، که توسط من در میکروفون های مختلف تلفظ می شود، در مناطق مختلف فضای ضرایب MFCC قرار می گیرد و یک طبقه بندی ایده آل آنها را کنار هم می کشد. بنابراین، به ویژه، هنگام تغییر میکروفون، باید برنامه را دوباره آموزش دهید.
این تنها یکی از پیش بینی های فضای 13 بعدی MFCC به 3 بعدی است، اما منظور من را نشان می دهد - نقاط قرمز، بنفش و آبی از میکروفون های مختلف می آیند: (Plantronix، آرایه میکروفون داخلی، Jabra)، اما صدا تلفظ می شود. تنها.
با این حال، از آنجایی که نمی توانم چیز بهتری ارائه دهم، از روش استاندارد نیز استفاده خواهم کرد - محاسبه ضرایب MFCC.
برای اینکه در اجرا اشتباه نشود، در اولین نسخه های برنامه، از کد برنامه معروف CMU Sphinx به عنوان پایه استفاده شد، به طور دقیق تر، پیاده سازی آن در زبان C، به نام pocketsphinx، توسعه یافته در Carnegie. دانشگاه ملون (درود بر هر دو! (ج) Hottabych).
کدهای منبع pocketsphinx باز هستند، اما این بدشانسی است - اگر از آنها استفاده می کنید، باید متنی را در برنامه خود بنویسید (هم در کدهای منبع و هم در ماژول اجرایی) که شامل موارد زیر است:
* این کار تا حدی با بودجه آژانس پروژه های تحقیقاتی دفاع پیشرفته * و بنیاد ملی علوم ایالات متحده * ایالات متحده آمریکا و کنسرسیوم سخنرانی ابوالهول CMU پشتیبانی شد.
به نظر من غیرقابل قبول بود و مجبور شدم کد را دوباره بنویسم. این بر سرعت برنامه تأثیر گذاشت (به هر حال، به هر حال، اگرچه "خوانایی" کد تا حدودی آسیب دید). عمدتاً به دلیل استفاده از کتابخانههای «Intel Performance Primitives» بود، اما او چیزی مانند فیلتر MEL را نیز بهینه کرد. با این وجود، بررسی دادههای آزمایش نشان داد که ضرایب MFCC حاصل کاملاً مشابه ضرایب بهدستآمده با استفاده از ابزار sphinx_fe است.
در برنامه های sphinxbase، محاسبه ضرایب MFCC توسط مراحل زیر انجام می شود:
| گام | تابع پایه اسفینکس | ماهیت عملیات |
|---|---|---|
| 1 | fe_pre_emphasis | بیشتر شمارش قبلی از تعداد فعلی کم می شود (مثلاً 0.97 مقدار آن). یک فیلتر اولیه که فرکانس های پایین را رد می کند. |
| 2 | fe_hamming_window | پنجره همینگ - میرایی را در ابتدا و انتهای قاب معرفی می کند |
| 3 | fe_fft_real | تبدیل فوریه سریع |
| 4 | fe_spec2magnitude | از طیف معمولی، طیف توان را دریافت می کنیم که فاز را از دست می دهد |
| 5 | fe_mel_spec | فرکانس های طیف [مثلا 256 قطعه] را با استفاده از مقیاس MEL و فاکتورهای وزنی به 40 شمع گروه بندی کنید. |
| 6 | fe_mel_cep | لگاریتم را بگیرید و تبدیل DCT2 را به 40 مقدار مرحله قبل اعمال کنید. ما 13 مقدار نتیجه اول را ترک می کنیم. انواع مختلفی از DCT2 (HTK، میراث، کلاسیک) وجود دارد که در ثابتی که ضرایب به دست آمده را با آن تقسیم می کنیم و در یک ثابت خاص برای ضریب صفر تفاوت دارند. شما می توانید هر گزینه ای را انتخاب کنید، این ماهیت را تغییر نمی دهد. |
این مراحل همچنین شامل عملکردهایی هستند که به شما امکان می دهد سیگنال را از نویز و سکوت جدا کنید، مانند fe_track_snr، fe_vad_hangover، اما ما به آنها نیازی نداریم و حواسمان را پرت نمی کنیم.
مراحل زیر برای بدست آوردن ضرایب MFCC انجام شده است:
کار شماره 3. بررسی اینکه یکی از 6 صدای حفظ شده تلفظ می شود
برنامه اصلی Vocal Joystick از یک پرسپترون چندلایه (MLP) برای طبقهبندی استفاده کرد - یک شبکه عصبی بدون زنگها و سوتهای جدید.بیایید ببینیم که استفاده از یک شبکه عصبی در اینجا چقدر موجه است.
به یاد بیاورید که نورون ها در شبکه های عصبی مصنوعی چه می کنند.
اگر نورون دارای N ورودی باشد، نورون فضای N بعدی را به نصف تقسیم می کند. اسلش بک هند با هایپرپلین. در عین حال در یک نیمه از فضا کار می کند (جواب مثبت می دهد) و در نیمه دیگر کار نمی کند.
بیایید به ساده ترین گزینه [تقریبا] نگاه کنیم - یک نورون با دو ورودی. او البته فضای دو بعدی را به نصف تقسیم خواهد کرد.
اجازه دهید مقادیر X1 و X2 ورودی باشند که نورون در ضرایب وزنی W1 و W2 ضرب میکند و عبارت آزاد C را اضافه میکند.
در مجموع، در خروجی نورون (بیایید آن را با Y نشان دهیم) دریافت می کنیم:
Y=X1*W1+X2*W2+C
(بیایید فعلاً از ظرافت های مربوط به توابع سیگموئید بگذریم)
ما در نظر می گیریم که نورون زمانی شلیک می کند که Y>0 باشد. خط مستقیم داده شده توسط معادله 0=X1*W1+X2*W2+C فقط فضا را به قسمتی که Y>0 و قسمتی از Y تقسیم می کند.<0.
بیایید آنچه را که گفته شد با اعداد مشخص نشان دهیم.
اجازه دهید W1=1، W2=1، C=-5.
حالا بیایید ببینیم چگونه می توانیم یک شبکه عصبی را سازماندهی کنیم که در یک منطقه خاص از فضا، به طور نسبی - یک نقطه، کار کند و در همه مکان های دیگر کار نکند.
از شکل مشخص می شود که برای ترسیم یک منطقه در فضای دو بعدی، حداقل به 3 خط، یعنی 3 نورون متصل به آنها نیاز داریم.
ما این سه نورون را با یک لایه دیگر ترکیب می کنیم و یک شبکه عصبی چند لایه (MLP) به دست می آوریم.
و اگر به شبکه عصبی برای کار در دو ناحیه فضا نیاز داشته باشیم، حداقل سه نورون دیگر مورد نیاز خواهد بود (4،5،6 در شکل ها):
و در اینجا شما نمی توانید بدون لایه سوم انجام دهید:
و لایه سوم تقریباً یادگیری عمیق است…
اکنون برای کمک به مثال دیگری می پردازیم. اجازه دهید شبکه عصبی ما روی نقاط قرمز یک پاسخ مثبت و روی نقاط آبی پاسخ منفی بدهد.
اگر از من خواسته شود که قرمز را از آبی با خطوط مستقیم برش دهم، این کار را به شکل زیر انجام می دهم:
اما یک شبکه عصبی به طور پیشینی نمی داند که به چه تعداد (نرون) مستقیم نیاز دارد. این پارامتر باید قبل از آموزش شبکه تنظیم شود. و شخص این کار را بر اساس ... شهود یا آزمون و خطا انجام می دهد.
اگر در لایه اول تعداد بسیار کمی نورون (به عنوان مثال سه) انتخاب کنیم، می توانیم یک برش مانند این را دریافت کنیم که خطاهای زیادی ایجاد می کند (ناحیه اشتباه سایه زده می شود):
اما حتی اگر تعداد نورون ها کافی باشد، در نتیجه آموزش، شبکه ممکن است "همگرا نشود"، یعنی زمانی که میزان خطا زیاد است، به یک حالت پایدار و دور از حد مطلوب برسد. مانند اینجا، میله متقاطع بالایی روی دو کوهان قرار می گیرد و آنها را جایی رها نمی کند. و در زیر آن یک منطقه بزرگ است که خطا ایجاد می کند:
باز هم، امکان چنین مواردی به شرایط اولیه تمرین و ترتیب تمرین، یعنی به عوامل تصادفی بستگی دارد:
- نظرت چیه، اون چرخ اگه بشه به مسکو میرسه یا نه؟
- نظر شما چیست، آیا شبکه عصبی همگرا می شود یا خیر؟
یک لحظه ناخوشایند دیگر در ارتباط با شبکه های عصبی وجود دارد. "فراموشی" آنها.
اگر شروع به تغذیه شبکه فقط با نقاط آبی کنید و از تغذیه نقاط قرمز خودداری کنید، آنگاه می تواند به راحتی تکه ای از ناحیه قرمز را برای خود بگیرد و مرزهای خود را به آنجا حرکت دهد:
اگر شبکههای عصبی دارای ایرادات زیادی هستند و یک فرد میتواند مرزها را بسیار کارآمدتر از یک شبکه عصبی ترسیم کند، پس چرا اصلاً از آنها استفاده کنیم؟
و یک جزئیات کوچک اما بسیار مهم وجود دارد.
من به خوبی می توانم قلب قرمز را از پس زمینه آبی با قطعات خط در فضای دو بعدی جدا کنم.
من به خوبی می توانم مجسمه زهره را با هواپیما از فضای سه بعدی اطراف آن جدا کنم.
اما در فضای چهار بعدی، من نمی توانم کاری انجام دهم، ببخشید. و در 13 بعدی - حتی بیشتر.
اما برای یک شبکه عصبی، بعد فضا مانعی ندارد. در فضاهای کم ابعاد به او خندیدم، اما به محض اینکه از حد معمول فراتر رفتم، او به راحتی مرا کتک زد.
با این وجود، این سوال هنوز باز است - با توجه به مضرات شبکه های عصبی فوق، استفاده از یک شبکه عصبی در این کار خاص چقدر موجه است.
بیایید یک لحظه فراموش کنیم که MFCC های ما در فضای 13 بعدی قرار دارند و تصور کنیم که آنها دو بعدی هستند، یعنی نقاطی در یک هواپیما. در این صورت چگونه می توان یک صدا را از دیگری جدا کرد؟
بگذارید نقاط MFCC صدای 1 دارای انحراف استاندارد R1 باشند، که [تقریبا] به این معنی است که نقاطی که از میانگین فاصله زیادی ندارند، مشخص ترین نقاط، در داخل دایره با شعاع R1 قرار دارند. به همین ترتیب، نقاطی که برای صدای 2 به آن اعتماد داریم، در داخل دایره با شعاع R2 قرار دارند.
توجه، سوال این است: کجا می توان یک خط مستقیم کشید که صدای 1 را از صدای 2 جدا کند؟
پاسخ خود را نشان می دهد: در وسط بین مرزهای دایره ها. آیا اعتراضی وجود دارد؟ هیچ اعتراضی وجود ندارد.
تصحیح:در برنامه، این حاشیه، بخش اتصال مراکز دایره ها را به نسبت R1:R2 تقسیم می کند، بنابراین صحیح تر است.
و در نهایت، فراموش نکنیم که جایی در فضا نقطه ای وجود دارد که نشان دهنده سکوت کامل در فضای MFCC است. نه، آن طور که به نظر می رسد 13 صفر نیست. این نکته ای است که نمی تواند انحراف معیار داشته باشد. و خطوط مستقیمی که با آنها آن را از سه صدای خود قطع می کنیم، می توان مستقیماً در امتداد مرزهای دایره ها ترسیم کرد:
در شکل زیر، هر صدا مربوط به قطعه ای از فضا به رنگ خود است، و همیشه می توانیم بگوییم که این یا آن نقطه از فضا به کدام صدا تعلق دارد (یا به هیچ کدام تعلق ندارد):
خوب، خوب، حالا بیایید به یاد بیاوریم که فضا 13 بعدی است، و چیزی که برای کشیدن روی کاغذ خوب بود، اکنون معلوم می شود چیزی است که در مغز انسان نمی گنجد.
بله، اینطور نیست. خوشبختانه در فضایی با هر بعد، مفاهیمی مانند یک نقطه، یک خط، یک [هیپر] صفحه، یک [فوق] کره باقی مانده است.
همه اقدامات مشابه را در فضای 13 بعدی تکرار می کنیم: پراکندگی را پیدا می کنیم، شعاع کره ها را تعیین می کنیم، مراکز آنها را با یک خط مستقیم به هم وصل می کنیم، آن را با یک صفحه [هیپر] در نقطه ای به همان اندازه از کره زمین برش می دهیم. مرزهای [فوق] کره ها
هیچ شبکه عصبی نمی تواند به درستی یک صدا را از دیگری جدا کند.
اما در اینجا باید رزرو انجام شود. همه اینها در صورتی درست است که اطلاعات مربوط به صدا ابری از نقاط باشد که به طور مساوی در همه جهات از میانگین منحرف می شوند، یعنی به خوبی در ابرکره قرار می گیرند. اگر این ابر یک شکل پیچیده بود، به عنوان مثال، یک سوسیس منحنی 13 بعدی، آنگاه تمام استدلال های بالا درست نبود. و شاید با آموزش صحیح، شبکه عصبی بتواند نقاط قوت خود را در اینجا نشان دهد.
اما من آن را به خطر نمی اندازم. و من برای مثال مجموعهای از توزیعهای عادی (GMM) را اعمال میکنم (که اتفاقاً در CMU Sphinx انجام میشود). وقتی بفهمید کدام الگوریتم خاص منجر به نتیجه شده است، همیشه لذت بخش تر است. نه مانند یک شبکه عصبی: Oracle، بر اساس ساعتهای طولانی تهیه اطلاعات آموزشی، به شما میگوید که تصمیم بگیرید که صدای درخواستی صدای شماره ۳ باشد. (مخصوصاً وقتی میخواهند رانندگی ماشین را به یک شبکه عصبی بسپارند، من را آزار میدهد. پس چگونه، در یک موقعیت غیر استاندارد، بفهمم که چرا ماشین به چپ و راست نمیپیچد؟ نورون متعال دستور داد؟).
اما مجموعههایی از توزیعهای عادی در حال حاضر یک موضوع بزرگ جداگانه است که خارج از محدوده این مقاله است.
امیدوارم که مقاله مفید بوده باشد و/یا باعث شده باشد که پیچیدگی های مغز شما به هم بخورد.
حتی قبل از انتشار رابط کورتانا برای ویندوز 10 که در دست توسعه، آزمایش و رفع اشکال است، کاربران سعی کردند کنترل صوتی یک رایانه را سازماندهی کنند. در مقاله امروز در مورد نحوه اجرای چنین عملکردی در ویندوزی که قبل از 10 منتشر شد صحبت خواهیم کرد.
کورتانا
کورتانا یک دستیار صوتی هوش مصنوعی است که توسط مایکروسافت برای ویندوز 10، تلفن و اندروید با گسترش بیشتر پروژه به XBox و iOS توسعه یافته است. جایگزین رشته جستجوی کلاسیک می شود و اقدامات زیادی را انجام می دهد که در درجه اول مربوط به جستجوی اطلاعات و دستورات سیستم است و آنها را از کاربر در قالب دستورات صوتی دریافت می کند. ادغام عمیق با ویندوز 10، عدم وجود زبان روسی (تاکنون)، جمع آوری تقریباً تمام اطلاعات مربوط به کاربر با ارسال به سرورهای مایکروسافت و عدم وجود نسخه نهایی به اکثر کاربران اجازه نمی دهد تا کنترل کامل صوتی خود را دریافت کنند. کامپیوتر خود
علاوه بر کورتانا، اپلیکیشن های زیادی وجود دارد که به شما اجازه می دهد کامپیوتر خود را از طریق دستورات صوتی کاربر کنترل کنید. بیایید با رایج ترین محصولات برای حل این مشکل در ویندوز 7 و 10 آشنا شویم.
نوع
این برنامه در میان کاربران روسی زبانی که می خواهند با صدا به رایانه فرمان دهند، جایگاه پیشرو را اشغال می کند. این ابزار به راحتی بخش قابل توجهی از عملکردهای کورتانا را در ویندوز 10 جایگزین می کند و در "هفت" قابلیتی را اضافه می کند که اغلب در فیلم هایی نشان داده می شود که در آن افراد رایانه ها را با صدای خود کنترل می کنند.

قبل از شروع کار، ما یک حساب کاربری ایجاد می کنیم و با یک عبارت کلیدی که با شنیدن آن برنامه فعال می شود، می آییم. سپس یک فرمان صوتی برای کنترل رایانه یا انجام یک عمل خاص تنظیم می کنیم و عملیاتی را به آن اختصاص می دهیم (برنامه را راه اندازی کنید، به سایت مشخص شده بروید). در پنجره ویرایش دستورات ایجاد شده، می توان پارامترهایی را که برنامه با آن راه اندازی می شود تنظیم کرد و حالت راه اندازی (تمام صفحه، پنجره ای) را مشخص کرد.
عملکرد ابزار بسیار محدود است و رابط کاربری آن از سبک Metro پیاده سازی شده در ویندوز 10 فاصله زیادی دارد. اجرای کنترل صوتی کامل رایانه شخصی با استفاده از Typle امکان پذیر نخواهد بود: فقط از باز کردن فایل ها، برنامه ها (با آرگومان ها) و پیوندهای از پیش تعریف شده را دنبال کنید. حتی هیچ پشتیبانی برای کنترل پخش (مکث، شروع آهنگ بعدی) وجود ندارد.
بلندگو
- گرفتن اسکرین شات از صفحه نمایش؛
- تغییر طرح صفحه کلید؛
- خاموش کردن ویندوز 7;
- راه اندازی برنامه؛
- باز کردن یک فایل
فرآیند خواندن و شناسایی اطلاعات دریافتی توسط میکروفون پس از فشار دادن کلید مشخص شده شروع می شود (بهتر است برای جلوگیری از مثبت کاذب برنامه، دکمه ای را انتخاب کنید که کمتر از همه استفاده می کنید). پردازش، تشخیص گفتار و اجرای یک فرمان زمان زیادی می برد - 5 ثانیه یا بیشتر از هزینه ای که باید برای ارزانی بپردازید. کلمات کلیدی توسط متن تنظیم می شوند، نه کلمات، بنابراین گفتار شناسایی شده با متن وارد شده مقایسه می شود، که دور از ایده آل است. هیچ کنترل بازیکنی در برنامه وجود ندارد.
گورینیچ
توسعه دهندگان بسته نرم افزاری مدیریت کامپیوتر با ویندوز 7 و 10 اولین تیم داخلی هستند که اپلیکیشنی را برای حل چنین مشکلاتی منتشر کرده اند. وسترن "Dragon Dictate" به عنوان هسته برنامه در نظر گرفته شد، جایی که یک ماژول نرم افزار داخلی برای تشخیص گفتار روسی معرفی شد.