- ترجمه
مقاله در مورد چیه
من شخصاً با یک کد کاری کوچک که می توانم با آن بازی کنم، بهتر یاد می گیرم. در این آموزش الگوریتم پس انتشار را با استفاده از یک شبکه عصبی کوچک پیاده سازی شده در پایتون به عنوان مثال می آموزیم.کد را به من بدهید!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random ((4،1)) - 1 برای j در xrange (60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1) )) syn1 += l1.T.dot(l2_delta) syn0 += XTdot(l1_delta)خیلی مختصر؟ بیایید آن را به بخش های ساده تر تقسیم کنیم.
بخش 1: یک شبکه عصبی اسباب بازی کوچک
یک شبکه عصبی آموزش دیده از طریق پس انتشار سعی می کند از ورودی برای پیش بینی خروجی استفاده کند.فرض کنید باید پیشبینی کنیم که ستون «خروجی» بر اساس دادههای ورودی چگونه خواهد بود. این مشکل را می توان با محاسبه تناظر آماری بین آنها حل کرد. و خواهیم دید که ستون سمت چپ 100% با خروجی همبستگی دارد.
پس انتشار، در ساده ترین حالت، آمارهای مشابهی را برای ایجاد یک مدل محاسبه می کند. بیایید تلاش کنیم.
شبکه عصبی در دو لایه
وارد کردن numpy به عنوان np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x) )) # مجموعه داده ورودی X = np.array([ , , , ]) # داده خروجی y = np.array([]).T # اعداد تصادفی را خاص تر کنید np.random.seed(1) # مقداردهی اولیه وزن ها به میانگین تصادفی 0 syn0 = 2*np.random.random((3,1)) - 1 برای iter در xrange(10000): # انتشار رو به جلو l0 = X l1 = nonlin(np.dot(l0,syn0)) # how ما اشتباه می کنیم؟ l1_error = y - l1 # این را با شیب سیگموئید # بر اساس مقادیر موجود در l1 ضرب کنید l1_delta = l1_error * nonlin(l1,True) # !!! # به روز رسانی وزن syn0 += np.dot(l0.T,l1_delta) # !!! چاپ "خروجی پس از آموزش:" چاپ l1خروجی پس از آموزش: [[ 0.00966449] [ 0.00786506] [ 0.99358898] [ 0.99211957]]
متغیرها و توضیحات آنها
"*" - ضرب بر حسب عنصر - دو بردار هم اندازه مقادیر مربوطه را ضرب می کنند و خروجی یک بردار با همان اندازه است.
"-" - تفریق عنصر به عنصر بردارها
x.dot(y) - اگر x و y بردار باشند، خروجی حاصل ضرب نقطه ای خواهد بود. اگر اینها ماتریس هستند، ضرب ماتریس را بدست می آوریم. اگر ماتریس فقط یکی از آنها باشد، این ضرب یک بردار و یک ماتریس است.
- l1 را بعد از اولین تکرار و بعد از آخرین تکرار مقایسه کنید
- به تابع nonlin نگاه کنید.
- ببینید l1_error چگونه تغییر می کند
- تجزیه خط 36 - مواد اصلی مخفی در اینجا جمع آوری شده است (علامت گذاری شده!!!)
- تجزیه خط 39 - کل شبکه در حال آماده شدن برای این عملیات خاص است (علامت گذاری شده با !!!)
بیایید کد را خط به خط تجزیه کنیم
numpy را به عنوان np وارد کنیدیک کتابخانه جبر خطی numpy را وارد می کند. تنها اعتیاد ما
Def nonlin (x,deriv=False):
غیر خطی بودن ما این تابع خاص یک "سیگموئید" ایجاد می کند. هر عددی را به مقداری از 0 تا 1 نگاشت و اعداد را به احتمالات تبدیل می کند و چندین ویژگی مفید دیگر برای آموزش شبکه های عصبی دارد.
If(deriv==True):
این تابع همچنین می تواند مشتق سیگموئید (deriv=True) را برگرداند. این یکی از خواص مفید آن است. اگر خروجی تابع متغیر out باشد، مشتق خارج از * (1-out) خواهد بود. تاثير گذار.
X = np.array([، ...
راه اندازی آرایه داده های ورودی به عنوان یک ماتریس numpy. هر خط یک نمونه آموزشی است. ستون ها گره های ورودی هستند. ما 3 گره ورودی در شبکه و 4 نمونه آموزشی دریافت می کنیم.
Y = np.array([]).T
خروجی را اولیه می کند. ".T" - تابع انتقال. پس از ترجمه، ماتریس y دارای 4 ردیف با یک ستون است. مانند داده های ورودی، هر ردیف یک مثال آموزشی است و هر ستون (در مورد ما یکی) یک گره خروجی است. به نظر می رسد شبکه 3 ورودی و 1 خروجی دارد.
np.random.seed(1)
به همین دلیل توزیع تصادفی هر بار یکسان خواهد بود. این به ما این امکان را می دهد که پس از ایجاد تغییرات در کد، عملکرد شبکه را راحت تر نظارت کنیم.
Syn0 = 2*np.random.random((3،1)) - 1
ماتریس وزن شبکه syn0 به معنای "سیناپس صفر" است. از آنجایی که ما فقط دو لایه ورودی و خروجی داریم، به یک ماتریس وزن نیاز داریم که آنها را به هم متصل کند. بعد آن (3، 1) است زیرا ما 3 ورودی و 1 خروجی داریم. به عبارت دیگر، l0 دارای اندازه 3 و l1 دارای اندازه 1 است. از آنجایی که ما همه گره های l0 را به همه گره های l1 پیوند می دهیم، به یک ماتریس از بعد (3، 1) نیاز داریم.
توجه داشته باشید که به صورت تصادفی مقداردهی اولیه می شود و میانگین آن صفر است. یک نظریه نسبتاً پیچیده پشت این وجود دارد. در حال حاضر، ما فقط آن را به عنوان یک توصیه در نظر می گیریم. همچنین توجه داشته باشید که شبکه عصبی ما دقیقاً همین ماتریس است. ما "لایه" l0 و l1 داریم، اما آنها مقادیر موقتی بر اساس مجموعه داده هستند. ما آنها را ذخیره نمی کنیم. تمام آموزش ها در syn0 ذخیره می شوند.
برای iter در xrange (10000):
اینجاست که کد آموزش شبکه اصلی شروع می شود. چرخه با کد بارها تکرار می شود و شبکه را برای مجموعه داده بهینه می کند.
اولین لایه، l0، فقط داده است. X شامل 4 مثال آموزشی است. ما همه آنها را به یکباره پردازش می کنیم - به این آموزش گروهی می گویند. در مجموع، ما 4 رشته l0 مختلف داریم، اما می توان آنها را به عنوان یک مثال آموزشی در نظر گرفت - در این مرحله مهم نیست (این امکان وجود داشت که 1000 یا 10000 مورد از آنها را بدون هیچ تغییری در کد بارگذاری کنید).
L1 = nonlin(np.dot(l0,syn0))
این مرحله پیش بینی است. ما به شبکه اجازه می دهیم تا خروجی را بر اساس ورودی پیش بینی کند. سپس خواهیم دید که او چگونه این کار را انجام می دهد تا بتوانیم آن را در جهت بهبود تغییر دهیم.
خط شامل دو مرحله است. اولی ضرب ماتریس l0 و syn0 را انجام می دهد. دومی خروجی را از سیگموئید عبور می دهد. ابعاد آنها به شرح زیر است:
(4×3) نقطه (3×1) = (4×1)
ضرب ماتریس نیاز به مطابقت ابعاد در وسط معادله دارد. ماتریس بهدستآمده دارای همان تعداد سطر اولی و همان تعداد ستون دومی است.
ما 4 مثال آموزشی بارگذاری کردیم و 4 حدس زدیم (ماتریس 4x1). هر خروجی مربوط به حدس شبکه برای ورودی داده شده است.
L1_error = y - l1
از آنجایی که l1 حاوی حدس است، می توانیم تفاوت آنها را با واقعیت با کم کردن l1 از پاسخ صحیح y مقایسه کنیم. l1_error یک بردار از اعداد مثبت و منفی است که مشخص کننده "مس" شبکه است.
و این ماده مخفی است. این خط باید به صورت قسمتی تجزیه شود.
قسمت اول: مشتق
غیرخط (l1, True)
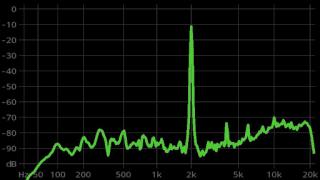
L1 نشان دهنده این سه نقطه است و کد شیب خطوط نشان داده شده در زیر را خروجی می دهد. توجه داشته باشید که در مقادیر بزرگ مانند x=2.0 (نقطه سبز) و مقادیر بسیار کوچک مانند x=-1.0 (بنفش) خطوط شیب کمی دارند. بزرگترین زاویه در نقطه x=0 (آبی) است. این از اهمیت بالایی برخوردار است. همچنین توجه داشته باشید که تمام مشتقات بین 0 و 1 هستند.

بیان کامل: مشتق دارای وزن خطا
L1_delta = l1_error * nonlin(l1, True)
از نظر ریاضی راه های دقیق تری وجود دارد اما در مورد ما این یکی هم مناسب است. l1_error یک ماتریس (4،1) است. nonlin(l1,True) ماتریس (4,1) را برمی گرداند. در اینجا آنها را عنصر به عنصر ضرب می کنیم و در خروجی نیز ماتریس (4,1) l1_delta را بدست می آوریم.
با ضرب مشتقات در خطاها، خطاهای پیش بینی های انجام شده با اطمینان بالا را کاهش می دهیم. اگر شیب خط کوچک بود، شبکه دارای مقدار بسیار بزرگ یا بسیار کوچک است. اگر حدس در شبکه نزدیک به صفر باشد (x=0، y=0.5)، مطمئن نیستید. ما این پیشبینیهای نامطمئن را بهروزرسانی میکنیم و با ضرب کردن آنها در مقادیر نزدیک به صفر، پیشبینیهای با اطمینان بالا را به حال خود رها میکنیم.
Syn0 += np.dot(l0.T، l1_delta)
ما آماده ارتقای شبکه هستیم. بیایید یک مثال آموزشی را در نظر بگیریم. در آن وزن ها را به روز می کنیم. به روز رسانی وزن سمت چپ (9.5)

weight_update = input_value * l1_delta
برای سمت چپ ترین وزن، این 1.0 * l1_delta خواهد بود. احتمالاً این مقدار فقط به میزان 9.5 افزایش می یابد. چرا؟ زیرا پیشبینی از قبل به اندازه کافی مطمئن بود و پیشبینیها عملاً درست بودند. یک خطای کوچک و یک شیب جزئی خط به معنای بروز رسانی بسیار کوچک است.

اما از آنجایی که در حال انجام تمرینات گروهی هستیم، مرحله بالا را برای هر چهار مثال آموزشی تکرار می کنیم. بنابراین بسیار شبیه به تصویر بالا است. پس خط ما چه کار می کند؟ به روز رسانی وزن برای هر وزن، برای هر مثال تمرینی، آنها را خلاصه می کند، و همه وزنه ها را در یک خط به روز می کند.
پس از مشاهده به روز رسانی شبکه، به داده های آموزشی خود بازگردیم. وقتی هر دو ورودی و خروجی 1 باشند، وزن بین آنها را افزایش می دهیم. وقتی ورودی 1 و خروجی 0 است وزن را کم می کنیم.
خروجی ورودی 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
بنابراین، در چهار مثال آموزشی زیر، وزن اولین ورودی نسبت به خروجی دائماً افزایش یا ثابت میماند و دو وزن دیگر بسته به مثالها کم و زیاد میشوند. این اثر به یادگیری شبکه بر اساس همبستگی داده های ورودی و خروجی کمک می کند.
بخش 2: کار دشوارتر است
خروجی ورودی 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0بیایید سعی کنیم داده های خروجی را بر اساس سه ستون ورودی داده پیش بینی کنیم. هیچ یک از ستون های ورودی 100% با خروجی همبستگی ندارند. ستون سوم اصلاً به هیچ چیز مربوط نمی شود، زیرا تماماً شامل مواردی است. با این حال، در اینجا می توانید این طرح را نیز ببینید - اگر یکی از دو ستون اول (اما نه هر دو به طور همزمان) شامل 1 باشد، نتیجه نیز 1 خواهد بود.
این یک طرح غیر خطی است زیرا هیچ تناظر مستقیم یک به یک بین ستون ها وجود ندارد. مطابقت بر اساس ترکیبی از داده های ورودی، ستون های 1 و 2 است.
جالب اینجاست که تشخیص الگو کار بسیار مشابهی است. اگر 100 تصویر با اندازه مساوی از دوچرخه و پیپ دودی دارید، وجود پیکسل های خاص در مکان های خاص ارتباط مستقیمی با وجود دوچرخه یا پیپ در تصویر ندارد. از نظر آماری، رنگ آنها ممکن است تصادفی به نظر برسد. اما برخی از ترکیبات پیکسل ها تصادفی نیستند - آنهایی که تصویر یک دوچرخه (یا لوله) را تشکیل می دهند.


استراتژی
برای ترکیب پیکسل ها در چیزی که می تواند مطابقت یک به یک با خروجی داشته باشد، باید یک لایه دیگر اضافه کنید. لایه اول ورودی را ترکیب می کند، لایه دوم با استفاده از خروجی لایه اول به عنوان ورودی، مطابقت را به خروجی اختصاص می دهد. به جدول توجه کنید.ورودی (l0) وزنهای پنهان (l1) خروجی (l2) 0 0 1 0.1 0.2 0.5 0.2 0 0 1 1 0.2 0.6 0.7 0.1 1 1 0 1 0.3 0.2 0.3 0.9 110.2 0.9 1 0.2 0.2
با تخصیص تصادفی وزن ها، مقادیر پنهانی برای لایه شماره 1 به دست می آوریم. جالب اینجاست که ستون دوم وزن های پنهان همبستگی کمی با خروجی دارد. ایده آل نیست، اما وجود دارد. و این نیز بخش مهمی از فرآیند آموزش شبکه است. آموزش فقط این همبستگی را تقویت می کند. syn1 را به روز می کند تا با خروجی مطابقت داشته باشد و syn0 را برای دریافت بهتر ورودی به روز می کند.
شبکه عصبی در سه لایه
وارد کردن numpy به عنوان np def nonlin(x,deriv=False): if(deriv==True): بازگشت f(x)*(1-f(x)) بازگشت 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # وزن های تصادفی، میانگین 0 syn0 = 2*np.random.random ((3 ,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 برای j در xrange(60000): # از لایه های 0، 1 و 2 به جلو بروید l0 = X l1 = nonlin(np .dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # چقدر در مورد مقدار مورد نظر اشتباه می کنیم؟ l2_error = y - l2 if (j% 10000) == 0: print "Error:" + str(np.mean(np.abs(l2_error))) # به کدام سمت حرکت کنیم؟ # اگر به پیشبینی اطمینان داشتیم، پس نیازی به تغییر آن نداریم. l1_error = l2_delta.dot(syn1.T) # در کدام جهت حرکت کنیم تا به l1 برسیم؟ # اگر به پیش بینی اطمینان داشتیم، دیگر نیازی به تغییر آن نیست l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot( l1_delta)خطا:0.496410031903 خطا:0.00858452565325 خطا:0.00578945986251 خطا:0.00462917677677
متغیرها و توضیحات آنها
X ماتریس مجموعه داده ورودی است. رشته ها - نمونه های آموزشیy ماتریس مجموعه داده های خروجی است. رشته ها - نمونه های آموزشی
l0 اولین لایه شبکه است که توسط داده های ورودی تعریف شده است
l1 - لایه دوم شبکه یا لایه پنهان
l2 لایه نهایی است، این فرضیه ما است. همانطور که تمرین می کنید، باید به پاسخ صحیح نزدیکتر شوید.
syn0 - اولین لایه وزن، Synapse 0، l0 را با l1 ترکیب می کند.
syn1 - دومین لایه وزن، Synapse 1، l1 را با l2 ترکیب می کند.
l2_error - اشتباه شبکه از نظر کمی
l2_delta خطای شبکه است، بسته به قطعیت پیش بینی. تقریباً با خطا یکسان است، به جز پیشبینیهای قوی
l1_error - با وزن کردن l2_delta با وزن های syn1، خطای لایه میانی/مخفی را محاسبه می کنیم.
l1_delta - خطاهای شبکه از l1، مقیاس بندی شده توسط اطمینان پیش بینی. تقریباً مشابه l1_error، به جز پیش بینی های مطمئن
کد باید کاملاً توضیحی باشد - این فقط اجرای قبلی شبکه است که در دو لایه، یکی روی دیگری انباشته شده است. خروجی لایه اول l1 ورودی لایه دوم است. فقط در خط بعدی چیز جدیدی وجود دارد.
L1_error = l2_delta.dot(syn1.T)
از خطاهای وزن شده با اطمینان پیش بینی های l2 برای محاسبه خطای l1 استفاده می کند. شاید بتوان گفت، یک خطای وزن شده توسط مشارکت ها دریافت می کنیم - ما محاسبه می کنیم که چه سهمی در خطاهای l2 توسط مقادیر در گره های l1 ایجاد می شود. این مرحله پس انتشار نامیده می شود. سپس با استفاده از الگوریتم مشابه در شبکه عصبی دو لایه، syn0 را به روز می کنیم.
ما اکنون در حال تجربه یک رونق واقعی در شبکه های عصبی هستیم. آنها برای تشخیص، محلی سازی و پردازش تصویر استفاده می شوند. شبکه های عصبی در حال حاضر قادر به انجام بسیاری از کارهایی هستند که در دسترس انسان نیستند. ما باید خودمان را وارد این تجارت کنیم! یک شبکه نوترونی را در نظر بگیرید که اعداد را در یک تصویر ورودی تشخیص می دهد. همه چیز بسیار ساده است: فقط یک لایه و یک تابع فعال سازی. این به ما اجازه نمی دهد که کاملاً تمام تصاویر آزمایشی را تشخیص دهیم، اما می توانیم اکثریت قریب به اتفاق را مدیریت کنیم. به عنوان داده، ما از مجموعه داده های معروف MNIST در دنیای تشخیص اعداد استفاده خواهیم کرد.
برای کار با آن، پایتون دارای کتابخانه python-mnist است. برای نصب:
Pip install python-mnist
اکنون می توانیم داده ها را بارگذاری کنیم
از mnist وارد کنید MNIST mndata = MNIST("/path_to_mnist_data_folder/") tr_images, tr_labels = mndata.load_training() test_images, test_labels = mndata.load_testing()
باید خودتان آرشیوها را با داده ها بارگیری کنید و مسیر دایرکتوری را با آنها به برنامه مشخص کنید. اکنون متغیرهای tr_images و test_images به ترتیب حاوی تصاویری برای آموزش و تست شبکه هستند. و متغیرهای tr_labels و test_labels برچسب هایی با طبقه بندی صحیح هستند (یعنی اعداد از تصاویر). اندازه تمامی تصاویر 28*28 می باشد. بیایید یک متغیر با اندازه تنظیم کنیم.
img_shape = (28، 28)
بیایید همه داده ها را به آرایه های numpy تبدیل کنیم و آنها را نرمال کنیم (آنها را به اندازه -1 به 1 برسانیم). این امر باعث افزایش دقت محاسبات می شود.
وارد کردن numpy به عنوان np برای i در محدوده (0، len(test_images)): test_images[i] = np.array(test_images[i]) / 255 برای i در محدوده (0، len(tr_images)): tr_images[i] = np.array(tr_images[i]) / 255
توجه داشته باشم که اگرچه مرسوم است که تصاویر را به عنوان یک آرایه دو بعدی نشان دهیم، اما از یک آرایه یک بعدی استفاده خواهیم کرد، اما برای محاسبات آسان تر است. حالا باید بفهمید "شبکه عصبی چیست"! و این فقط یک معادله با ضرایب زیاد است. در ورودی آرایه ای از 28*28=784 عنصر و 784 وزن دیگر برای تعیین هر رقم داریم. در حین کار شبکه عصبی، باید مقادیر ورودی ها را در وزن ضرب کنید. داده های دریافتی را جمع کنید و یک افست اضافه کنید. نتیجه را به تابع فعال سازی ارسال کنید. در مورد ما Relu خواهد بود. این تابع برای همه آرگومان های منفی صفر و برای همه آرگومان های مثبت یک آرگومان است.

بسیاری از توابع فعال سازی بیشتر وجود دارد! اما این ساده ترین شبکه عصبی است! این تابع را با numpy تعریف کنید
Def relu(x): بازگشت np.maximum(x, 0)
حال برای محاسبه تصویر در تصویر، باید نتیجه را برای 10 مجموعه ضرایب محاسبه کنید.
Def nn_calculate(img): resp = list(range(0, 10)) برای i در محدوده(0,10): r = w[:, i] * img r = relu(np.sum(r) + b[ i]) resp[i] = r برگرداندن np.argmax(resp)
برای هر مجموعه، یک نتیجه خروجی دریافت خواهیم کرد. خروجی با بالاترین نتیجه به احتمال زیاد عدد ماست.

در این مورد 7. همین! اما نه ... بالاخره شما باید همین ضرایب را در جایی ببرید. ما باید شبکه عصبی خود را آموزش دهیم. برای این کار از روش پس انتشار استفاده می شود. ماهیت آن این است که خروجی های شبکه را محاسبه کنید، آنها را با موارد صحیح مقایسه کنید و سپس اعداد لازم برای درست بودن نتیجه را از ضرایب کم کنید. باید به خاطر داشت که برای محاسبه این مقادیر، مشتق تابع فعال سازی مورد نیاز است. در مورد ما، برای همه اعداد منفی برابر با صفر و برای همه اعداد مثبت 1 است. ضرایب را به صورت تصادفی تعیین می کنیم.
W = (2*np.random.rand(10, 784) - 1) / 10 b = (2*np.random.rand(10) - 1) / 10 برای n در محدوده (len(tr_images)): img = tr_images[n] cls = tr_labels[n] #انتشار رو به جلو resp = np.zeros(10, dtype=np.float32) برای i در محدوده (0,10): r = w[i] * img r = relu( np.sum(r) + b[i]) resp[i] = r resp_cls = np.argmax(resp) resp = np.zeros(10, dtype=np.float32) resp = 1.0 #back propagation true_resp = np. zeros(10, dtype=np.float32) true_resp = 1.0 error = resp - true_resp delta = error * ((resp >= 0) * np.ones(10)) برای i در محدوده (0,10): w[i ] -= np.dot(img، دلتا[i]) b[i] -= دلتا[i]
در فرآیند یادگیری، ضرایب کمی شبیه به اعداد خواهند بود:
بیایید صحت کار را بررسی کنیم:
Def nn_calculate(img): resp = list(range(0, 10)) برای i در محدوده(0,10): r = w[i] * img r = np.maximum(np.sum(r) + b[ i]، 0) #relu resp[i] = r بازگشت np.argmax(resp) total = len(test_images) valid = 0 invalid = برای i در محدوده(0، total): img = test_images[i] پیش بینی شده = nn_calculate (img) true = test_labels[i] در صورت پیشبینی == true: valid = معتبر + 1 other: invalid.append(("image":img, "predicted":predicted, "true":true)) print("دقت" ()".format(valid/total))
من 88 درصد گرفتم. نه چندان جالب، اما بسیار جالب!
کراسیک کتابخانه محبوب یادگیری عمیق است که سهم بزرگی در تجاری سازی یادگیری عمیق داشته است. استفاده از کتابخانه Keras آسان است و به شما امکان می دهد شبکه های عصبی را تنها با چند خط کد پایتون ایجاد کنید.
در این مقاله یاد خواهید گرفت که چگونه از Keras برای ایجاد یک شبکه عصبی استفاده کنید که رتبه بندی کاربران یک محصول را بر اساس بررسی های آنها پیش بینی می کند و آن را به دو دسته مثبت یا منفی طبقه بندی می کند. این وظیفه نامیده می شود تحلیل احساسات (تحلیل احساسات)و با سایت نقد فیلم IMDb حلش می کنیم. مدلی که می سازیم می تواند برای مشکلات دیگر با تغییرات جزئی نیز اعمال شود.
لطفا توجه داشته باشید که ما وارد جزئیات Keras و یادگیری عمیق نمی شویم. این پست برای ارائه یک طرحواره در کراس و آشنایی شما با اجرای آن است.
- کراس چیست؟
- تحلیل احساسات چیست؟
- مجموعه داده های IMDB
- کاوش داده ها
- آماده سازی داده ها
- ساخت و آموزش مدل
کراس چیست؟
Keras یک کتابخانه منبع باز پایتون است که ایجاد شبکه های عصبی را آسان می کند. این کتابخانه با Microsoft Cognitive Toolkit، Theano و MXNet سازگار است. Tensorflow و Theano رایج ترین فریم ورک های عددی پایتون برای توسعه الگوریتم های یادگیری عمیق هستند، اما استفاده از آنها بسیار دشوار است.
 به محبوبیت چارچوب های یادگیری ماشینی در 7 دسته امتیاز دهید
به محبوبیت چارچوب های یادگیری ماشینی در 7 دسته امتیاز دهید از طرف دیگر Keras یک راه آسان و راحت برای ساخت مدل های یادگیری عمیق ارائه می دهد. خالق آن، François Chollet، آن را طراحی کرد تا فرآیند ساخت شبکه های عصبی را تا حد امکان سریع و آسان کند. او بر توسعه پذیری، مدولار بودن، مینیمالیسم و پشتیبانی از پایتون تمرکز کرد. Keras را می توان با GPU و CPU استفاده کرد. این نرم افزار از Python 2 و Python 3 پشتیبانی می کند. Keras گوگل سهم بزرگی در تجاری سازی یادگیری عمیق داشته است و به این دلیل که شامل پیشرفته ترین الگوریتم های یادگیری عمیق است که قبلا نه تنها در دسترس نبودند بلکه غیر قابل استفاده بودند.
تحلیل احساسات (تحلیل احساسات) چیست؟
با کمک تحلیل احساسات، می توان نگرش (مثلاً خلق و خوی) یک فرد را نسبت به یک متن، تعامل یا رویداد تعیین کرد. بنابراین، تحلیل احساسات متعلق به حوزه پردازش زبان طبیعی است که در آن باید معنای یک متن را رمزگشایی کرد تا احساسات و عواطف از آن استخراج شود.
 مثال مقیاس تحلیل احساسات
مثال مقیاس تحلیل احساسات طیف خلقیات معمولاً به زیر تقسیم می شوند مثبت، منفی و خنثیدسته بندی ها. برای مثال، با استفاده از تجزیه و تحلیل احساسات، می توانید نظرات و نگرش های مشتریان را در مورد یک محصول بر اساس نظرات آنها پیش بینی کنید. بنابراین، تجزیه و تحلیل احساسات به طور گسترده در نظرسنجی ها، نظرسنجی ها، متون و موارد دیگر اعمال می شود.
مجموعه داده های IMDb
 نظرات در IMDb
نظرات در IMDb مجموعه داده های IMDb شامل 50000 نقد کاربر از فیلم ها است که با علامت های مثبت (1) و منفی (0) مشخص شده اند.
- بررسیها از قبل پردازش شدهاند و هر یک توسط دنبالهای از فهرستهای کلمه بهعنوان اعداد صحیح کدگذاری میشوند.
- کلمات موجود در مرورها با فراوانی کلی وقوع آنها در مجموعه داده نمایه می شوند. به عنوان مثال، عدد صحیح "2" دومین کلمه پرکاربرد را رمزگذاری می کند.
- 50000 بررسی به دو مجموعه تقسیم می شوند: 25000 برای آموزش و 25000 برای تست.
مجموعه داده توسط محققان دانشگاه استنفورد ایجاد شد و در مقاله ای در سال 2011 ارائه شد که در آن دقت پیش بینی به دست آمده 88.89٪ بود. این مجموعه داده همچنین به عنوان بخشی از مسابقه انجمن Keggle استفاده شد "کیسه کلمات با کیسه های پاپ کورن ملاقات می کند"در سال 2011.
وابستگی ها را وارد کنید و داده ها را دریافت کنید
بیایید با وارد کردن وابستگی های لازم برای پیش پردازش داده ها و ساخت مدل شروع کنیم.
%matplotlib واردات درون خطی matplotlib واردات matplotlib.pyplot به عنوان plt import numpy به عنوان np از keras.utils import to_categorical از مدل های واردات keras از لایه های واردات keras
بیایید مجموعه داده های IMDb را که قبلاً در Keras تعبیه شده است دانلود کنیم. از آنجایی که نمیخواهیم دادههای آموزشی و آزمایشی 50/50 داشته باشیم، این دادهها را بلافاصله پس از بارگذاری برای تقسیم بعدی ادغام میکنیم. به نسبت 80/20:
از keras.datasets imdb (data_training, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((data_training, testing_data), axis=0(p.intraget_ntargets= ، testing_targets)، axis=0)
کاوش داده ها
بیایید مجموعه داده خود را بررسی کنیم:
Print("Categories:", np.unique(targets)) print("تعداد کلمات منحصر به فرد:"، len(np.unique(np.hstack(data)))) دسته ها: تعداد کلمات منحصر به فرد: 9998 طول = چاپ ("متوسط طول مرور:"، np.mean(طول)) چاپ("انحراف استاندارد:"، دور(np.std(طول))) میانگین طول مرور: 234.75892 انحراف استاندارد: 173.0
مشاهده می شود که تمام داده ها به دو دسته تعلق دارند: 0 یا 1 که نشان دهنده حال و هوای بررسی است. کل مجموعه داده شامل 9998 کلمه منحصر به فرد است، میانگین اندازه بررسی 234 کلمه با انحراف استاندارد 173 است.
یک راه ساده برای یادگیری در نظر بگیرید:
چاپ ("برچسب:"، اهداف) برچسب: 1 چاپ (داده)
در اینجا اولین بررسی از مجموعه داده را مشاهده می کنید که با علامت مثبت (1) مشخص شده است. کد زیر شاخص ها را به کلمات تبدیل می کند تا بتوانیم آنها را بخوانیم. در آن، هر کلمه ناشناخته با "#" جایگزین می شود. این با استفاده از تابع انجام می شود get_word_index().
Index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join() print(decoded) # این فیلم فقط بازیگری درخشان بود مناظر لوکیشن، کارگردانی داستان هر کسی واقعاً با نقشی که بازی می کرد مناسب بود و شما فقط می توانید تصور کنید که آنجا هستید رابرت # بازیگر شگفت انگیزی است و اکنون همان کارگردان # پدر از همان جزیره اسکاتلندی آمده است که من از همان جزیره اسکاتلندی آمده ام، بنابراین من دوست داشتم این واقعیت وجود داشته باشد. ارتباط واقعی با این فیلم، اظهارات شوخ در سراسر فیلم عالی بود، آنقدر عالی بود که من فیلم را به محض اکران برای # خریدم و تماشای آن را به همه توصیه می کنم و فلای ماهیگیری شگفت انگیز بود. در پایان خیلی غمگین بود و می دانید چه می گویند اگر در فیلمی گریه کنید باید خوب بوده باشد و این قطعاً برای دو پسر کوچکی که # نورمن و پل را بازی می کردند نیز همینطور بود. من فکر می کنم از لیست # حذف شد زیرا ستاره هایی که همه آنها را بازی می کنند بسیار خوب هستند wn up نمایه بزرگی برای کل فیلم است، اما این بچه ها شگفت انگیز هستند و باید به خاطر کاری که انجام داده اند ستایش شوند، فکر نمی کنید کل داستان خیلی دوست داشتنی بود زیرا حقیقت داشت و بعد از همه چیزهایی که با آنها به اشتراک گذاشته شد، زندگی یک نفر بود. همه ما
آماده سازی داده ها
زمان آماده سازی داده ها فرا رسیده است. ما باید هر بررسی را برداریم و آن را با صفر پر کنیم تا بردار دقیقاً شامل 10000 عدد باشد. این بدان معناست که هر مرور کوتاهتر از 10000 کلمه با صفر پر میشود. این به این دلیل است که بزرگترین نمای تقریباً یک اندازه است و هر عنصر ورودی شبکه عصبی ما باید اندازه یکسانی داشته باشد. همچنین باید متغیرها را به تایپ تبدیل کنید شناور.
Def vectorize(sequences, dimension = 10000): results = np.zeros((len(دنباله ها)، بعد)) برای i, sequence innumerate(sequences): results = 1 data results results = vectorize(data) targets = np. array(targets).atype("float32")
بیایید مجموعه داده را به مجموعه های آموزشی و آزمایشی تقسیم کنیم. مجموعه آموزشی شامل 40000 بررسی و مجموعه تست شامل 10000 بررسی خواهد بود.
test_x = داده[:10000] test_y = اهداف[:10000] train_x = داده train_y = اهداف
ساخت و آموزش مدل
اکنون می توانید یک شبکه عصبی ساده ایجاد کنید. بیایید با تعریف نوع مدلی که می خواهیم ایجاد کنیم شروع کنیم. دو نوع مدل در Keras موجود است: ترتیبی و با API کاربردی.
سپس باید لایه های ورودی، مخفی و خروجی را اضافه کنید. برای جلوگیری از برازش بیش از حد، از یک استثنا بین آنها استفاده می کنیم ( ترک تحصیل). توجه داشته باشید که همیشه باید از نرخ محرومیت بین 20 تا 50 درصد استفاده کنید. هر لایه یک عملکرد دارد "متراکم"برای اتصال کامل لایه ها به یکدیگر. در لایه های مخفی استفاده خواهیم کرد "relu"، بنابراین تقریباً همیشه به نتایج رضایت بخشی منجر می شود. با خیال راحت با سایر عملکردهای فعال سازی آزمایش کنید. در لایه خروجی، از یک تابع sigmoid استفاده می کنیم که مقادیر را در بازه 0 تا 1 مجدداً عادی می کند. توجه داشته باشید که اندازه عناصر ورودی مجموعه داده را 10000 تنظیم می کنیم زیرا اندازه نماهای ما تا 10000 عدد صحیح است. لایه ورودی عناصر با اندازه 10000 و خروجی با اندازه 50 را می پذیرد.
در نهایت، اجازه دهید Keras یک توضیح مختصر از مدلی که ایجاد کردهایم ارائه دهد.
# ورودی - Layer model.add(layers.Dense(50, activation = "relu", input_shape=(10000,))) # Hidden - Layers model.add(layers.Dropout(0.3, noise_shape=None, seed=None) ) model.add(layers.Dense(50, activation = "relu") model.add(layers.Dropout(0.2, noise_shape=none, seed=none)) model.add(layers.Dense(50, activation = "relu ")) # Output- Layer model.add(layers.Dense(1, activation = "sigmoid"))model.summary() model.summary() _________________________________________________________________ Layer (نوع) Output Shape Param # ======= ================================================== 0 0 ________________________________________________________________ متراکم_3 (متراکم ) (هیچ، 50) 2550 _________________________________________________________________ متراکم_4 (متراکم) (هیچ، 1) 51 =============================== ================================= کل پارامترها: 505201 پارام قابل آموزش: 505201 پارام غیر قابل آموزش: 0
اکنون باید مدل خود را کامپایل کنیم، یعنی در اصل آن را برای آموزش تنظیم کنیم. ما استفاده خواهیم کرد بهینه ساز "آدام".. بهینه ساز الگوریتمی است که وزن ها و سوگیری ها را در طول تمرین تغییر می دهد. مانند توابع از دست دادنما از آنتروپی متقاطع باینری استفاده می کنیم (از آنجایی که ما با طبقه بندی باینری کار می کنیم)، دقت به عنوان یک معیار ارزیابی استفاده می شود.
Model.compile(optimizer = "adam"، loss = "binary_crossentropy"، metrics = ["دقت"])
اکنون می توانیم مدل خود را آموزش دهیم. ما این کار را با اندازه دسته ای 500 و فقط دو دوره انجام خواهیم داد همانطور که متوجه شدم مدل شروع به آموزش مجدد می کنداگر آن را بیشتر آموزش دهید اندازه دسته تعداد عناصری را که در شبکه توزیع می شوند تعیین می کند و دوره یک گذر از تمام عناصر مجموعه داده است. معمولااندازه دسته بزرگتر منجر به یادگیری سریعتر می شود، اما نه همیشه همگرایی سریع. اندازه دسته کوچکتر کندتر حرکت می کند، اما ممکن است سریعتر همگرا شود. انتخاب یک یا آن گزینه قطعاً به نوع مشکل حل شده بستگی دارد و بهتر است هر کدام را امتحان کنید. اگر در این زمینه تازه کار هستید، به شما توصیه می کنم ابتدا استفاده کنید لات سایز 32، که به نوعی استاندارد است.
نتایج = model.fit(train_x، train_y، epochs= 2، batch_size = 500، validation_data = (test_x، test_y)) آموزش روی 40000 نمونه، اعتبارسنجی روی 10000 نمونه دوره 1/2 40000/40000 [===== =======================] - 5 ثانیه 129 us/step - ضرر: 0.4051 - acc: 0.8212 - val_loss: 0.2635 - val_acc: 0.8945 دوره 2/2 400 /40000 [=============================] - 4s 90 us/step - loss: 0.2122 - accc: 0.9190 - val_loss: 0.2598 - val_acc: 0.8950
بیایید عملکرد مدل را ارزیابی کنیم:
چاپ (np.mean(results.history["val_acc"])) 0.894750000536
خوب! مدل ساده ما قبلاً رکورد دقت را در مقاله 2011 شکسته است.در ابتدای پست ذکر شده است. به راحتی می توانید پارامترهای شبکه و تعداد لایه ها را آزمایش کنید.
کد مدل کامل در زیر نشان داده شده است:
وارد کردن numpy بهعنوان np از keras.utils import to_categorical از مدلهای واردات keras از لایههای واردات keras از keras.datasets imdb را وارد میکند (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000data(p. (تعلیم_داده، داده_آزمایی)، محور=0) اهداف = np.concatenate((هدف_های_آموزشی، اهداف_آزمایش)، محور=0) def vectorize(توالی ها، بعد = 10000): نتایج = np.zeros((لن(توالی ها)، بعد) ) برای i، دنباله در enumerate(sequences): results = 1 داده نتایج را برمی گرداند = vectorize(data) targets = np.array(targets).atype("float32") test_x = data[:10000] test_y = اهداف[:10000 ] train_x = داده train_y = مدل هدف = models.Sequential() # ورودی - Layer model.add(layers.Dense(50, activation = "relu", input_shape=(10000,))) # Hidden - Layers model.add( layers.Dropout(0.3، noise_shape=هیچکدام، seed=هیچکدام)) model.add(layers.Dense(50, activation = "relu")) model.add(layers.Dropout(0.2، noise_shape=هیچکدام، seed=هیچکدام) ) مدل. add(layers.Dense(50, activation = "relu")) # Output- Layer model.add(layers.Dense(1, activation = "sigmoid")) model.summary() # کامپایل مدل model.compile(بهینه ساز = "آدام"، ضرر = "تقاطع_دودویی"، متریک = ["دقت"]) نتایج = مدل. fit(train_x, train_y, epochs= 2, batch_size = 500, validation_data = (test_x, test_y)) print("Test- دقت:" np.mean(results.history["val_acc"]))
نتایج
شما آموختید که تجزیه و تحلیل احساسات چیست و چرا Keras یکی از محبوب ترین کتابخانه های یادگیری عمیق است.
ما یک شبکه عصبی ساده با شش لایه ایجاد کرده ایم که می تواند حال و هوای منتقدان فیلم را با دقت 89 درصد محاسبه کند. اکنون می توانید از این مدل برای تجزیه و تحلیل احساسات باینری در منابع دیگر استفاده کنید، اما برای این کار باید اندازه آنها را روی 10000 تنظیم کنید یا پارامترهای لایه ورودی را تغییر دهید.
این مدل (با تغییرات جزئی) می تواند برای سایر مشکلات یادگیری ماشین نیز اعمال شود.
شبکه های عصبی عمدتاً در پایتون ایجاد و آموزش داده می شوند. بنابراین، داشتن یک درک اولیه از نحوه نوشتن برنامه بر روی آن بسیار مهم است. در این مقاله به طور مختصر و واضح در مورد مفاهیم اولیه این زبان صحبت خواهم کرد: متغیرها، توابع، کلاس ها و ماژول ها.
این مطالب برای افرادی است که با زبان های برنامه نویسی آشنایی ندارند.
ابتدا باید پایتون را نصب کنید. سپس باید یک محیط مناسب برای نوشتن برنامه ها در پایتون راه اندازی کنید. این دو مرحله به پورتال اختصاص دارد.
اگر همه چیز نصب و پیکربندی شده باشد، می توانید شروع کنید.
متغیرها
متغیر- یک مفهوم کلیدی در هر زبان برنامه نویسی (و نه تنها در آنها). ساده ترین کار این است که یک متغیر را به عنوان جعبه ای با یک برچسب در نظر بگیرید. این کادر حاوی چیزی است (یک عدد، یک ماتریس، یک شی، ...) که برای ما ارزش دارد.
به عنوان مثال، فرض کنید می خواهیم یک متغیر x ایجاد کنیم که باید مقدار 10 را ذخیره کند. در پایتون، کد ایجاد این متغیر به شکل زیر است:

در سمت چپ ما اعلاممتغیری به نام x. این معادل این است که ما یک برچسب شخصی روی جعبه چسبانده ایم. بعد علامت تساوی و عدد 10 می آید. علامت تساوی در اینجا نقش غیرعادی ایفا می کند. این به این معنی نیست که "x 10 است". برابری در این حالت عدد 10 را در کادر قرار می دهد. درست تر، ما اختصاص دهدمتغیر x عدد 10.
حال در کد زیر می توانیم به این متغیر دسترسی داشته باشیم و اعمال مختلفی را با آن انجام دهیم.
به سادگی می توانید مقدار این متغیر را روی صفحه نمایش دهید:
X=10 چاپ (x)
کتیبه print(x) یک فراخوانی تابع است. ما آنها را بیشتر در نظر خواهیم گرفت. حالا نکته مهم این است که این تابع آنچه را که بین براکت ها قرار دارد را روی کنسول چاپ می کند. بین براکت ها x داریم. قبلاً به x مقدار 10 را اختصاص می دادیم. اگر برنامه بالا را اجرا کنید این دقیقاً 10 است که در کنسول نمایش داده می شود.
با متغیرهایی که اعداد را ذخیره می کنند، می توانید عملیات ساده مختلفی را انجام دهید: جمع، تفریق، ضرب، تقسیم و افزایش به توان.
X = 2 y = 3 # اضافه کردن z = x + y چاپ(z) # 5 # تفاوت z = x - y چاپ(z) # -1 # محصول z = x * y چاپ(z) # 6 # تقسیم z = x / y print(z) # 0.66666... # نمایی z = x ** y print(z) # 8
در کد بالا ابتدا دو متغیر شامل 2 و 3 ایجاد می کنیم. سپس یک متغیر z ایجاد می کنیم که نتیجه عملیات را روی x و y ذخیره می کند و نتایج را در کنسول چاپ می کند. این مثال به وضوح نشان می دهد که یک متغیر می تواند مقدار خود را در طول اجرای برنامه تغییر دهد. بنابراین، متغیر z ما مقدار خود را تا 5 برابر تغییر می دهد.
کارکرد
گاهی اوقات لازم می شود چندین بار اعمال مشابه انجام شود. به عنوان مثال، در پروژه خود اغلب نیاز به نمایش 5 خط متن داریم.
"این متن بسیار مهمی است!"
"این متن قابل خواندن نیست"
"خطا در خط بالایی عمدا انجام شد"
"سلام و خداحافظ"
"پایان"
کد ما به شکل زیر خواهد بود:
X = 10 y = x + 8 - 2 print("این یک متن بسیار مهم است!") print("این متن نباید خوانده شود") print("اشتباهی در خط بالایی عمدا وجود داشت") print( "سلام و خداحافظ") print ("پایان") z = x + y print("این یک متن بسیار مهم است!") print("این متن قابل خواندن نیست") print("اشتباهی در خط بالایی وجود داشت" با هدف") print("سلام و خداحافظ") print ("پایان") test = z print("این یک متن بسیار مهم است!") print("این متن قابل خواندن نیست") print("خطا در خط بالا عمدا ساخته شده است") print("سلام و خداحافظ") چاپ ("پایان")
همه چیز بسیار زائد و ناخوشایند به نظر می رسد. همچنین در خط دوم خطایی وجود دارد. می توان آن را تعمیر کرد، اما باید در سه مکان به طور همزمان رفع شود. و اگر در پروژه ما این پنج خط 1000 بار فراخوانی شود؟ و همه در مکان ها و فایل های مختلف؟
به خصوص برای مواردی که نیاز به اجرای دستورات یکسان است، زبان های برنامه نویسی می توانند توابع ایجاد کنند.
عملکرد- یک بلوک جداگانه از کد که می تواند با نام فراخوانی شود.
یک تابع با استفاده از کلمه کلیدی def تعریف می شود. پس از آن نام تابع و پس از آن براکت ها و دو نقطه وجود دارد. در مرحله بعد، با تورفتگی، باید اقداماتی را که هنگام فراخوانی تابع انجام می شود، فهرست کنید.
Def print_5_lines(): print("این یک متن بسیار مهم است!") print("این متن قابل خواندن نیست") print("اشتباهی در خط بالایی عمدا وجود داشت") print("سلام و خداحافظ") چاپ ("پایان")
اکنون تابع print_5_lines () را تعریف کرده ایم. حال، اگر در پروژه خود یک بار دیگر نیاز به درج پنج خط داشته باشیم، به سادگی تابع خود را فراخوانی می کنیم. به طور خودکار تمام اقدامات را انجام می دهد.
# تعریف تابع def print_5_lines(): print("این یک متن بسیار مهم است!") print("این متن قابل خواندن نیست") print("خطا در خط بالایی عمدا ایجاد شده است") print("سلام" و خداحافظ") print("پایان") # کد پروژه ما x = 10 y = x + 8 - 2 print_5_lines() z = x + y print_5_lines() test = z print_5_lines()
راحت است، اینطور نیست؟ ما به طور جدی خوانایی کد را بهبود بخشیده ایم. علاوه بر این، توابع نیز خوب هستند زیرا اگر می خواهید برخی از اقدامات را تغییر دهید، کافی است خود تابع را تغییر دهید. این تغییر در همه جاهایی که تابع شما فراخوانی می شود کار خواهد کرد. به این معنی که می توانیم خطای خط دوم متن خروجی ("not allow" > "not allow") را در بدنه تابع برطرف کنیم. نوع صحیح به طور خودکار در همه مکان های پروژه ما فراخوانی می شود.

توابع با پارامترها
فقط تکرار چند مرحله البته راحت است. اما این همه ماجرا نیست. گاهی اوقات می خواهیم متغیری را به تابع خود منتقل کنیم. بنابراین، تابع می تواند داده ها را دریافت کرده و از آنها در فرآیند اجرای دستورات استفاده کند.
متغیرهایی که به تابع ارسال می کنیم فراخوانی می شوند استدلال ها.
بیایید یک تابع ساده بنویسیم که دو عدد داده شده را به آن جمع کرده و نتیجه را برمی گرداند.
Def sum(a, b): result = a + b نتیجه را برمی گرداند
خط اول تقریباً شبیه توابع معمولی است. اما بین پرانتزها اکنون دو متغیر وجود دارد. این مولفه هایکارکرد. تابع ما دو پارامتر دارد (یعنی دو متغیر می گیرد).
پارامترها را می توان در داخل یک تابع درست مانند متغیرهای معمولی استفاده کرد. در خط دوم، یک نتیجه متغیر ایجاد می کنیم که برابر با مجموع پارامترهای a و b است. در خط سوم، مقدار متغیر نتیجه را برمی گردانیم.
اکنون، در کدهای بعدی، می توانیم چیزی شبیه به:
جدید = مجموع (2، 3) چاپ (جدید)
تابع sum را فراخوانی می کنیم و دو آرگومان به نوبه خود به آن ارسال می کنیم: 2 و 3. 2 به مقدار متغیر a و 3 تبدیل به مقدار متغیر b می شود. تابع ما یک مقدار را برمی گرداند (مجموع 2 و 3) و از آن برای ایجاد یک متغیر جدید new استفاده می کنیم.
یاد آوردن. در کد بالا، اعداد 2 و 3 آرگومان های تابع sum هستند. و در خود تابع sum متغیرهای a و b پارامتر هستند. به عبارت دیگر، متغیرهایی که هنگام فراخوانی یک تابع به آن ارسال می کنیم، آرگومان نامیده می شوند. اما در داخل تابع به این متغیرهای عبوری پارامتر می گویند. در واقع، این دو نام برای یک چیز هستند، اما شما نباید آنها را اشتباه بگیرید.
بیایید یک مثال دیگر را در نظر بگیریم. بیایید یک تابع مربع (a) بسازیم که یک عدد را بگیرد و آن را مربع کند:
Def Square(a): a * a را برگردانید
تابع ما فقط از یک خط تشکیل شده است. بلافاصله نتیجه حاصل از ضرب پارامتر a در a را برمی گرداند.
فکر می کنم قبلاً حدس زده اید که ما نیز با استفاده از یک تابع، خروجی داده را به کنسول تولید می کنیم. این تابع print() نامیده می شود و آرگومان ارسال شده به آن را به کنسول چاپ می کند: یک عدد، یک رشته، یک متغیر.
آرایه ها
اگر بتوان یک متغیر را بهعنوان جعبهای در نظر گرفت که چیزی (نه لزوماً یک عدد) را در خود جای میدهد، آرایهها را میتوان به عنوان قفسه کتاب در نظر گرفت. آنها شامل چندین متغیر به طور همزمان هستند. در اینجا نمونه ای از یک آرایه از سه عدد و یک رشته آورده شده است:
آرایه =
در اینجا یک مثال است، زمانی که متغیر شامل یک عدد نیست، به یک شی دیگر. در این حالت متغیر ما حاوی یک آرایه است. هر عنصر آرایه شماره گذاری شده است. بیایید سعی کنیم برخی از عناصر آرایه را نمایش دهیم:
آرایه = چاپ (آرایه)
در کنسول شما عدد 89 را خواهید دید. اما چرا 89 و نه 1؟ مسئله این است که در پایتون، مانند بسیاری از زبان های برنامه نویسی دیگر، شماره گذاری آرایه ها از 0 شروع می شود. بنابراین، آرایه به ما می دهد. دومینعنصر آرایه، نه اولین. برای فراخوانی اولین، باید آرایه می نوشت.
اندازه آرایه
گاهی اوقات بدست آوردن تعداد عناصر در یک آرایه بسیار مفید است. برای این کار می توانید از تابع len() استفاده کنید. به طور خودکار تعداد عناصر را شمارش می کند و تعداد آنها را برمی گرداند.
آرایه = چاپ (لن (آرایه))
عدد 4 در کنسول نمایش داده می شود.
شرایط و چرخه ها
به طور پیش فرض، هر برنامه ای به سادگی تمام دستورات را از بالا به پایین در یک ردیف اجرا می کند. اما شرایطی وجود دارد که باید شرایطی را بررسی کنیم و بسته به اینکه درست باشد یا نه، اقدامات مختلفی را انجام دهیم.
علاوه بر این، اغلب لازم است که تقریباً همان توالی دستورات را بارها تکرار کنید.
شرایط در موقعیت اول کمک می کند و چرخه ها در موقعیت دوم کمک می کنند.
شرایط
بسته به اینکه ادعای مورد آزمایش درست یا نادرست باشد، برای انجام دو مجموعه متفاوت از اقدامات، شرایط لازم است.

در پایتون، شرایط را می توان با استفاده از ساختار if: ... else: ... نوشت. فرض کنید مقداری متغیر x = 10 داریم. اگر x کمتر از 10 باشد، میخواهیم x را بر 2 تقسیم کنیم. اگر x بزرگتر یا مساوی 10 باشد، میخواهیم متغیر دیگری ایجاد کنیم که برابر با مجموع x و عدد 100 است. کد به این شکل خواهد بود:
X = 10 if(x< 10): x = x / 2 print(x) else: new = x + 100 print(new)
بعد از ایجاد متغیر x شروع به نوشتن شرط خود می کنیم.
همه چیز با کلمه کلیدی if (از انگلیسی "اگر" ترجمه شده) شروع می شود. در پرانتز، عبارت مورد بررسی را نشان می دهیم. در این مورد، ما بررسی می کنیم که آیا متغیر x ما واقعاً کمتر از 10 است یا خیر. اگر واقعاً کمتر از 10 است، آن را بر 2 تقسیم می کنیم و نتیجه را در کنسول چاپ می کنیم.
سپس کلمه کلیدی else می آید، پس از آن بلوک اقداماتی که اگر عبارت داخل پرانتز بعد از if نادرست باشد، انجام می شود.
اگر بزرگتر یا مساوی 10 باشد، یک متغیر جدید new ایجاد می کنیم که برابر با x + 100 است و همچنین آن را در کنسول چاپ می کنیم.
چرخه ها
از حلقه ها برای تکرار مکرر اعمال استفاده می شود. فرض کنید می خواهیم جدولی از مربع های 10 عدد طبیعی اول را نمایش دهیم. اینجوری میشه انجام داد
Print("Square 1 is " + str(1**2)) print("Square 2 is " + str(2**2)) print("Square 3 is " + str(3**2)) print( "Square 4 is " + str(4**2)) print("Square 5 is " + str(5**2)) print("Square 6 is " + str(6**2)) print("Square 7 is " + str(7**2)) print("Square 8 is " + str(8**2)) print("Square 9 is " + str(9**2)) print("Square 10 is " + str(10**2))
از این واقعیت که رشته ها را اضافه می کنیم تعجب نکنید. "شروع رشته" + "پایان" در پایتون به سادگی به معنای الحاق رشته ها است: "شروع رشته". به طور مشابه، در بالا، رشته "Square x برابر است" را اضافه می کنیم و نتیجه افزایش عدد به توان دوم با استفاده از تابع str (x ** 2) تبدیل می شود.
کد بالا بسیار زائد به نظر می رسد. اما اگر لازم باشد مربع های 100 عدد اول را چاپ کنیم چه؟ ما عذاب میکشیم که عقب نشینی کنیم...
چرخه ها برای همین است. دو نوع حلقه در پایتون وجود دارد: while و for. بیایید به نوبه خود با آنها برخورد کنیم.
حلقه while دستورات لازم را تا زمانی که شرط درست باقی بماند، تکرار می کند.
X = 1 در حالی که x<= 100: print("Квадрат числа " + str(x) + " равен " + str(x**2)) x = x + 1
ابتدا یک متغیر ایجاد می کنیم و عدد 1 را به آن اختصاص می دهیم سپس یک حلقه while ایجاد می کنیم و بررسی می کنیم که آیا x ما کمتر از (یا مساوی) 100 است یا خیر. اگر کمتر از (یا مساوی) باشد، دو عمل انجام می دهیم:
- مربع x را به دست می آوریم
- x را 1 افزایش دهید
پس از دستور دوم، برنامه به حالت باز می گردد. اگر شرط دوباره درست باشد، این دو عمل را دوباره انجام می دهیم. و به همین ترتیب تا زمانی که x برابر 101 شود. سپس شرط false خواهد شد و حلقه دیگر اجرا نمی شود.
حلقه for برای تکرار روی آرایه ها طراحی شده است. بیایید همین مثال را با مربع های صد عدد طبیعی اول بنویسیم، اما از طریق حلقه for.
برای x در محدوده (1101): print("مربع " + str(x) + " برابر است با " + str(x**2))
بیایید خط اول را تحلیل کنیم. برای ایجاد یک حلقه از کلمه کلیدی for استفاده می کنیم. بعد، نشان میدهیم که میخواهیم اقدامات خاصی را برای همه x در محدوده 1 تا 100 تکرار کنیم. تابع range(1101) آرایهای از 100 عدد ایجاد میکند که از 1 شروع میشود و به 100 ختم میشود.
در اینجا مثال دیگری از تکرار روی یک آرایه با استفاده از حلقه for آورده شده است:
برای i in : print(i * 2)
کد بالا 4 رقم خروجی می دهد: 2، 20، 200 و 2000. در اینجا به وضوح می توانید ببینید که چگونه هر عنصر از آرایه را می گیرد و مجموعه ای از اقدامات را انجام می دهد. سپس عنصر بعدی را می گیرد و همان مجموعه اقدامات را تکرار می کند. و به همین ترتیب تا زمانی که عناصر موجود در آرایه تمام شوند.
کلاس ها و اشیاء
در زندگی واقعی، ما نه با متغیرها یا توابع، بلکه با اشیا عمل می کنیم. قلم، ماشین، انسان، گربه، سگ، هواپیما - اشیاء. حالا بیایید شروع کنیم به بررسی جزئیات گربه.
چند گزینه دارد. اینها شامل رنگ کت، رنگ چشم، نام مستعار او است. اما این همه ماجرا نیست. علاوه بر پارامترها، گربه می تواند اقدامات مختلفی را انجام دهد: خرخر، خش خش و خراش.
ما به طور کلی تمام گربه ها را به صورت شماتیک توضیح دادیم. مشابه شرح خواص و اعمالیک شی (مثلاً یک گربه) در زبان پایتون و کلاس نامیده می شود. یک کلاس به سادگی مجموعه ای از متغیرها و توابع است که نوعی شی را توصیف می کند.
درک تفاوت بین یک کلاس و یک شی مهم است. کلاس - طرح A که شی را توصیف می کند. شیء اوست تجسم مادی. کلاس گربه توصیفی از خواص و اعمال آن است. شی گربه خود گربه واقعی است. گربه های واقعی می توانند بسیار متفاوت باشند - بسیاری از اشیاء گربه. اما فقط یک دسته از گربه ها وجود دارد. تصویر زیر نمایش خوبی است:

کلاس ها
برای ایجاد یک کلاس (طرحواره گربه ما)، باید کلمه کلیدی کلاس را بنویسیم و سپس نام این کلاس را مشخص کنیم:
گربه کلاس:
در مرحله بعد، باید اقدامات این کلاس (اقدامات گربه) را فهرست کنیم. همانطور که حدس زده اید، اکشن ها توابعی هستند که در یک کلاس تعریف شده اند. چنین توابعی در یک کلاس متد نامیده می شوند.
روش- یک تابع تعریف شده در یک کلاس.
به صورت شفاهی، ما قبلاً روش های گربه را در بالا شرح داده ایم: خرخر، هیس، خراش. بیایید این کار را در پایتون انجام دهیم.
# کلاس کلاس گربه Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Kshh!") # Scratch def scrabble(self): print("خراش-خراش" !")
ساده است! ما سه تابع منظم را گرفتیم و تعریف کردیم، اما فقط در داخل کلاس.
برای مقابله با پارامتر خود نامفهوم، بیایید یک روش دیگر را به گربه خود اضافه کنیم. این متد هر سه متدی را که قبلا ایجاد شده اند به طور همزمان فراخوانی می کند.
# کلاس کلاس گربه Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Kshh!") # Scratch def scrabble(self): print("خراش-خراش" !") # All together def all_in_one(self): self.purr() self.hiss() self.scrabble()
همانطور که می بینید پارامتر self که برای هر متدی اجباری است به ما امکان دسترسی به متدها و متغیرهای خود کلاس را می دهد! بدون این استدلال ما نمی توانیم چنین اقداماتی را انجام دهیم.
حال بیایید ویژگی های گربه خود را (رنگ مو، رنگ چشم، نام مستعار) تنظیم کنیم. چگونه انجامش بدهیم؟ مطلقاً در هر کلاسی، می توانید تابع __init__() را تعریف کنید. این تابع همیشه زمانی فراخوانی می شود که شی واقعی کلاس خود را ایجاد می کنیم.
در روش __init__() که در بالا برجسته شده است، متغیرهای گربه خود را تنظیم می کنیم. چطوری انجامش میدیم؟ ابتدا 3 آرگومان به این روش پاس می دهیم که مسئولیت رنگ کت، رنگ چشم و نام مستعار را بر عهده دارند. سپس، ما از پارامتر self استفاده می کنیم تا بلافاصله هنگام ایجاد یک شی، گربه خود را با 3 ویژگی توضیح داده شده در بالا تنظیم کنیم.
این خط به چه معناست؟
Self.wool_color = پشمی_رنگ
در سمت چپ، ما یک ویژگی برای گربه خود به نام wool_color ایجاد می کنیم و سپس آن ویژگی را به مقدار موجود در پارامتر wool_color که به تابع __init__() ارسال می کنیم، تنظیم می کنیم. همانطور که می بینید، خط بالا هیچ تفاوتی با ایجاد معمول یک متغیر ندارد. فقط پیشوند self نشان می دهد که این متغیر به کلاس Cat تعلق دارد.
صفت- متغیری که به یک کلاس تعلق دارد.
بنابراین، ما یک کلاس گربه آماده ایجاد کرده ایم. این هم کد او:
# کلاس Cat Cat: # اقداماتی که باید در هنگام ایجاد یک شی Cat def __init__(self, wool_color, eyes_color, name): self.wool_color = پشم_رنگ self.eyes_color = eye_color self.name = name # Purr def purr( self): print("Purrr!") # Scrabble def hiss(self): print("Shh!") # Scrabble def scrabble(self): print("Scratch-scratch!") # All together def all_in_one(self) : self. purr() self.hiss() self.scrabble()
اشیاء
ما یک طرح گربه ایجاد کرده ایم. حالا بیایید طبق این طرح یک شی گربه واقعی بسازیم:
My_cat = گربه ("سیاه"، "سبز"، "زوسیا")
در خط بالا، متغیر my_cat را ایجاد می کنیم و سپس یک شی از کلاس Cat را به آن اختصاص می دهیم. همه اینها به نظر می رسد فراخوانی برای تابع Cat(...) . در واقع اینطور است. با این ورودی، متد __init__() کلاس Cat را فراخوانی می کنیم. تابع __init__() در کلاس ما 4 آرگومان می گیرد: خود شی کلاس self، که نیازی به مشخص شدن ندارد، و همچنین 3 آرگومان مختلف دیگر، که سپس به ویژگی های cat ما تبدیل می شوند.
بنابراین، با کمک خط بالا، یک شی گربه واقعی ایجاد کرده ایم. گربه ما دارای ویژگی های زیر است: موهای سیاه، چشمان سبز و نام مستعار Zosya. بیایید این ویژگی ها را در کنسول چاپ کنیم:
چاپ(گربه_من. رنگ_پشمی) چاپ(رنگ_گربه_من_چشم) چاپ(نام_گربه_من)
یعنی می توان با نوشتن نام شی و نقطه گذاشتن و تعیین نام صفت مورد نظر به صفات یک شی اشاره کرد.
ویژگی های گربه را می توان تغییر داد. به عنوان مثال، بیایید نام گربه خود را تغییر دهیم:
My_cat.name = "نیوشا"
حالا اگر دوباره نام گربه را روی کنسول چاپ کنید به جای زوسیا نیوشا را خواهید دید.
اجازه دهید به شما یادآوری کنم که کلاس گربه ما به آن اجازه می دهد برخی اقدامات را انجام دهد. اگر زوسیا/نیوشا خود را نوازش کنیم، او شروع به خرخر کردن می کند:
My_cat.purr()
با اجرای این دستور، متن "Murrr!" روی کنسول نمایش داده می شود. همانطور که می بینید، دسترسی به متدهای یک شی به اندازه دسترسی به ویژگی های آن آسان است.
ماژول ها
هر فایلی با پسوند py. یک ماژول است. حتی مقاله ای که در آن روی این مقاله کار می کنید. آنها برای چه چیزی مورد نیاز هستند؟ برای آسودگی. بسیاری از مردم فایل هایی با توابع و کلاس های مفید ایجاد می کنند. سایر برنامه نویسان شامل این ماژول های شخص ثالث هستند و می توانند از تمام توابع و کلاس های تعریف شده در آنها استفاده کنند و در نتیجه کار خود را ساده کنند.
به عنوان مثال، برای کار با ماتریس ها نیازی به صرف زمان برای نوشتن توابع خود ندارید. کافی است ماژول numpy را در آن قرار دهید و از توابع و کلاس های آن استفاده کنید.
تا کنون، دیگر برنامه نویسان پایتون بیش از 110000 ماژول مختلف نوشته اند. ماژول numpy که در بالا ذکر شد به شما این امکان را می دهد که سریع و راحت با ماتریس ها و آرایه های چند بعدی کار کنید. ماژول ریاضی روش های زیادی را برای کار با اعداد ارائه می دهد: سینوس، کسینوس، تبدیل درجه به رادیان، و غیره و غیره ...
نصب ماژول
پایتون به همراه مجموعه ای استاندارد از ماژول ها نصب شده است. این مجموعه شامل تعداد بسیار زیادی ماژول است که به شما امکان می دهد با ریاضیات، پرس و جوهای وب، خواندن و نوشتن فایل ها و سایر اقدامات ضروری کار کنید.
اگر می خواهید از ماژولی استفاده کنید که در مجموعه استاندارد گنجانده نشده است، باید آن را نصب کنید. برای نصب ماژول، خط فرمان را باز کنید (Win + R، سپس در قسمت ظاهر شده "cmd" را وارد کنید) و دستور را در آن وارد کنید:
نصب پیپ [module_name]
فرآیند نصب ماژول آغاز خواهد شد. پس از تکمیل، می توانید با خیال راحت از ماژول نصب شده در برنامه خود استفاده کنید.
اتصال و استفاده از ماژول
یک ماژول شخص ثالث بسیار ساده متصل می شود. شما فقط باید یک خط کوتاه کد بنویسید:
وارد کردن [module_name]
به عنوان مثال، برای وارد کردن ماژولی که به شما امکان می دهد با توابع ریاضی کار کنید، باید موارد زیر را بنویسید:
واردات ریاضی
چگونه به یک تابع ماژول دسترسی پیدا کنیم؟ باید نام ماژول را بنویسید، سپس نقطه بگذارید و نام تابع/کلاس را بنویسید. به عنوان مثال، فاکتوریل 10 به صورت زیر یافت می شود:
ریاضی فاکتوریل (10)
یعنی به تابع فاکتوریل(a) که داخل ماژول ریاضی تعریف شده است، رفتیم. این راحت است، زیرا ما نیازی به هدر دادن زمان نداریم و به صورت دستی تابعی ایجاد می کنیم که فاکتوریل یک عدد را محاسبه می کند. می توانید ماژول را متصل کرده و بلافاصله اقدام لازم را انجام دهید.
اصل: ایجاد یک شبکه عصبی در پایتون
نویسنده: جان سرانو
تاریخ انتشار: 26 اردیبهشت 1395
ترجمه: A.Panin
تاریخ انتقال: 15 آذر 1395
شبکههای عصبی برنامههای بسیار پیچیدهای هستند که فقط برای دانشگاهیان و نابغهها قابل درک هستند، که طبق تعریف، توسعهدهندگان عادی نمیتوانند آنها را مدیریت کنند. تو هم اینجور فکر میکنی؟
خب، در واقع اصلا اینطور نیست. پس از ارائه عالی توسط لوئیس مونیر و گرگ رنارد در کالج هولبرتون، متوجه شدم که شبکه های عصبی به اندازه کافی ساده هستند تا هر توسعه دهنده نرم افزار بتواند آن را درک و پیاده سازی کند. البته، پیچیده ترین شبکه ها پروژه های بزرگ مقیاس با معماری ظریف و پیچیده هستند، اما مفاهیم پشت آنها نیز کم و بیش آشکار است. طراحی هر شبکه عصبی از ابتدا می تواند بسیار چالش برانگیز باشد، اما خوشبختانه چندین کتابخانه عالی وجود دارند که می توانند تمام کارهای سطح پایین را برای شما انجام دهند.
در این زمینه، یک نورون یک موجود نسبتا ساده است. چندین مقدار ورودی را می پذیرد و اگر مجموع این مقادیر از حد تعیین شده بیشتر شود، فعال می شود. در این حالت هر مقدار ورودی در وزن آن ضرب می شود. فرآیند یادگیری اساساً فرآیند تنظیم وزن ارزش برای تولید مقادیر خروجی مورد نیاز است. شبکههایی که در این مقاله مورد بحث قرار خواهند گرفت، شبکههای «انتشار رو به جلو» نامیده میشوند، به این معنی که نورونهای موجود در آنها در سطوح مرتب شدهاند که ورودیهایشان از سطح قبلی و خروجیهایشان به سطح بعدی ارسال میشود.

انواع دیگری از شبکه های عصبی مانند شبکه های عصبی تکراری وجود دارد که به روشی متفاوت سازماندهی شده اند، اما این موضوع برای مقاله دیگری است.
نورونی که طبق اصل توضیح داده شده در بالا کار می کند پرسپترون نامیده می شود و بر اساس مدل اصلی نورون های مصنوعی است که امروزه به ندرت استفاده می شود. مشکل پرسپترون ها این است که یک تغییر کوچک در مقادیر ورودی می تواند به دلیل عملکرد مرحله فعال سازی منجر به تغییر زیادی در مقدار خروجی شود. در این حالت، یک کاهش جزئی در مقدار ورودی می تواند منجر به این واقعیت شود که مقدار داخلی از حد تعیین شده تجاوز نمی کند و نورون فعال نمی شود، که منجر به تغییرات مهم تر در وضعیت نورون های متعاقب آن می شود. . خوشبختانه این مشکل با عملکرد نرمافزار فعالسازی که امروزه در اکثر شبکهها استفاده میشود، به راحتی حل میشود.


با این حال، شبکه عصبی ما آنقدر ساده خواهد بود که پرسپترون ها برای ایجاد آن کاملاً مناسب هستند. ما شبکه ای ایجاد خواهیم کرد که عملیات منطقی "AND" را انجام می دهد. این بدان معنی است که ما به دو نورون ورودی و یک نورون خروجی و همچنین چندین نورون در لایه "مخفی" در بین آنها نیاز خواهیم داشت. تصویر زیر معماری این شبکه را نشان می دهد که باید کاملاً گویا باشد.

Monier و Renard از اسکریپت convnet.js برای ایجاد شبکههای نمایشی برای سخنرانی خود استفاده کردند. Convnet.js را می توان برای ایجاد شبکه های عصبی مستقیماً در مرورگر وب خود استفاده کرد و به شما امکان می دهد تقریباً در هر پلتفرمی آنها را کاوش و اصلاح کنید. البته این پیاده سازی جاوا اسکریپت ایرادات قابل توجهی نیز دارد که یکی از آنها سرعت پایین است. خب در این مقاله از کتابخانه FANN (شبکه های عصبی مصنوعی سریع) استفاده خواهیم کرد. در این حالت در سطح زبان برنامه نویسی پایتون از ماژول pyfann استفاده خواهد شد که شامل پیوندهایی برای کتابخانه FANN است. شما باید همین الان بسته نرم افزاری را با این ماژول نصب کنید.
وارد کردن یک ماژول برای کار با کتابخانه FANN به صورت زیر انجام می شود:
>>> از pyfann import libfann
حالا می توانیم شروع کنیم! اولین عملیاتی که باید انجام دهیم ایجاد یک شبکه عصبی خالی است.
>>> neural_net = libfann.neural_network()
شیء ایجاد شده neural_net در حال حاضر حاوی نورون نیست، بنابراین بیایید سعی کنیم آنها را ایجاد کنیم. برای این منظور از تابع libfann.create_standard_array() استفاده خواهیم کرد. تابع ()create_standard_array یک شبکه عصبی ایجاد میکند که در آن تمام نورونها از سطوح همسایه به نورونها متصل هستند، بنابراین میتوان آن را شبکه «کاملا متصل» نامید. به عنوان یک پارامتر، تابع ()create_standard_array آرایه ای با مقادیر عددی مربوط به تعداد نورون ها در هر سطح می گیرد. در مورد ما، این یک آرایه است.
>>> neural_net.create_standard((2، 4، 1))
پس از آن، باید مقدار نرخ یادگیری را تعیین کنیم. این مقدار مربوط به تعداد تغییرات وزن در یک تکرار است. ما نرخ یادگیری نسبتاً بالایی را 0.7 تعیین خواهیم کرد زیرا یک مشکل نسبتاً ساده را با شبکه خود حل خواهیم کرد.
>>> neural_net.set_learning_rate(0.7)
اکنون زمان نصب تابع فعال سازی است که هدف آن در بالا مورد بحث قرار گرفت. ما از حالت فعال سازی SIGMOID_SYMMETRIC_STEPWISE استفاده خواهیم کرد که با تابع تقریب گام به گام مماس هذلولی مطابقت دارد. این تابع دقیق تر و سریعتر از تابع مماس هذلولی معمولی است و برای کار ما عالی است.
>>> neural_net.set_activation_function_output(libfann.SIGMOID_SYMMETRIC_STEPWISE)
در نهایت باید الگوریتم یادگیری شبکه را اجرا کرده و داده های شبکه را در یک فایل ذخیره کنیم. تابع یادگیری شبکه چهار آرگومان می گیرد: نام فایل داده ای که باید روی آن آموزش داده شود، حداکثر تعداد تلاش برای اجرای الگوریتم یادگیری، تعداد عملیات آموزشی قبل از خروجی داده های وضعیت شبکه و میزان خطا.
>>> neural_network.train_on_file("and.data", 10000, 1000, 0.00001) >>> neural_network.save("and.net")
فایل "and.data" باید حاوی داده های زیر باشد:
4 2 1 -1 -1 -1 -1 1 -1 1 -1 -1 1 1 1
خط اول شامل سه مقدار است: تعداد نمونه های موجود در فایل، تعداد مقادیر ورودی و تعداد مقادیر خروجی. در زیر ردیفهای نمونه وجود دارد، که در آن ردیفهای دو ارزشی مقادیر ورودی و ردیفهای تک مقداری مقادیر خروجی هستند.
شما آموزش شبکه را با موفقیت پشت سر گذاشتید و اکنون می خواهید آن را در تولید آزمایش کنید، اینطور نیست؟ اما ابتدا باید داده های شبکه را از فایلی که قبلاً در آن ذخیره شده بود بارگیری کنیم.
>>> neural_net = libfann.neural_net() >>> neural_net.create_from_file("and.net")
پس از آن، به سادگی می توانیم آن را به همان روش فعال کنیم:
>>> print neural_net.run()
خروجی باید [-1.0] یا مشابه باشد، بسته به داده های شبکه تولید شده در طول آموزش شبکه.
تبریک می گویم! شما به تازگی به کامپیوتر آموزش داده اید که عملیات منطقی ساده ای را انجام دهد!