V برتری داشتنراه سریعتر و راحت تری برای رسم رگرسیون خطی وجود دارد (و حتی انواع اصلی رگرسیون های غیرخطی، همانطور که در زیر بحث شده است). این میتواند بصورت زیر انجام شود:
1) ستون های دارای داده را انتخاب کنید ایکسو Y(آنها باید به این ترتیب باشند!)
2) تماس بگیرید جادوگر نمودارو در گروه انتخاب کنید نوعی از – نقطهو بلافاصله فشار دهید آماده;
3) بدون حذف انتخاب از نمودار، مورد ظاهر شده از منوی اصلی را انتخاب کنید نمودار، که در آن باید مورد را انتخاب کنید خط روند را اضافه کنید;
4) در کادر محاوره ای که ظاهر می شود خط رونددر برگه نوعی ازانتخاب کنید خطی;
5) در برگه گزینه هاسوئیچ را می توان فعال کرد نمایش معادله در نمودار، که به شما امکان می دهد معادله رگرسیون خطی (4.4) را مشاهده کنید که در آن ضرایب (4.5) محاسبه می شود.
6) در همان تب می توانید سوئیچ را فعال کنید مقدار اطمینان تقریبی (R ^ 2) را روی نمودار قرار دهید... این کمیت مجذور ضریب همبستگی (4.3) است و نشان می دهد که معادله محاسبه شده چقدر وابستگی تجربی را توصیف می کند. اگر آر 2 نزدیک به وحدت است، سپس معادله رگرسیون نظری وابستگی تجربی را به خوبی توصیف می کند (نظریه به خوبی با آزمایش موافق است) و اگر آر 2 نزدیک به صفر است، پس این معادله برای توصیف وابستگی تجربی مناسب نیست (نظریه با آزمایش موافق نیست).
در نتیجه انجام اقدامات توصیف شده، نموداری با نمودار رگرسیون و معادله آن دریافت خواهید کرد.
§4.3. انواع اصلی رگرسیون غیر خطی
رگرسیون سهموی و چند جمله ای
سهمویوابستگی به کمیت Yروی ارزش NSوابستگی بیان شده توسط یک تابع درجه دوم (پارابولای مرتبه دوم) نامیده می شود:
این معادله نامیده می شود معادله رگرسیون سهموی Yبر NS... گزینه ها آ, ب, بانامیده می شوند ضرایب رگرسیون سهموی... محاسبه ضرایب رگرسیون سهموی همیشه دست و پا گیر است، بنابراین توصیه می شود از رایانه برای محاسبات استفاده کنید.
معادله (4.8) رگرسیون سهموی یک مورد خاص از یک رگرسیون عمومی تر به نام چند جمله ای است. چند جمله ایوابستگی به کمیت Yروی ارزش NSوابستگی بیان شده توسط چند جمله ای نامیده می شود n- مرتبه:
اعداد کجا هستند و من (من=0,1,…, n) نامیده می شوند ضرایب رگرسیون چند جمله ای.
رگرسیون قدرت.
نماییوابستگی به کمیت Yروی ارزش NSوابستگی فرم نامیده می شود:
این معادله نامیده می شود معادله رگرسیون توان Yبر NS... گزینه ها آو بنامیده می شوند ضرایب رگرسیون توان.
ln = ln آ+بلوگاریتم ایکس. (4.11)
این معادله یک خط مستقیم را در یک صفحه با محورهای مختصات لگاریتمی ln توصیف می کند. ایکسو ln. بنابراین، معیار کاربردی بودن رگرسیون توانی این شرط است که نقاط لگاریتم داده های تجربی ln x iو ln مننزدیکترین به خط مستقیم بودند (4.11).
رگرسیون نمایی.
نشان دهنده(یا نمایی) با وابستگی به کمیت Yروی ارزش NSوابستگی فرم نامیده می شود:
(یا ). (4.12)
این معادله نامیده می شود معادله نمایی(یا نمایی) رگرسیون Yبر NS... گزینه ها آ(یا ک) و بنامیده می شوند نمایی(یا نمایی) رگرسیون ها.
اگر لگاریتم دو طرف معادله رگرسیون توان را بگیریم، معادله را بدست می آوریم.
ln = ایکسلوگاریتم آ+ ln ب(یا ln = k x+ ln ب). (4.13)
این معادله وابستگی خطی لگاریتم یک کمیت ln به کمیت دیگر را توصیف می کند. ایکس... بنابراین، ملاک کاربردی بودن رگرسیون توانی این شرط است که داده های تجربی به یک مقدار اشاره کنند. x iو لگاریتم یک کمیت دیگر ln مننزدیکترین به خط مستقیم بودند (4.13).
رگرسیون لگاریتمی
لگاریتمیوابستگی به کمیت Yروی ارزش NSوابستگی فرم نامیده می شود:
=آ+بلوگاریتم ایکس. (4.14)
این معادله نامیده می شود معادله رگرسیون لگاریتمی Yبر NS... گزینه ها آو بنامیده می شوند ضرایب رگرسیون لگاریتمی.
رگرسیون هایپربولیک.
هایپربولیکوابستگی به کمیت Yروی ارزش NSوابستگی فرم نامیده می شود:
این معادله نامیده می شود معادله رگرسیون هذلولی Yبر NS... گزینه ها آو بنامیده می شوند ضرایب رگرسیون هایپربولیکو با روش حداقل مربعات تعیین می شوند. استفاده از این روش به فرمول های زیر منجر می شود:
در فرمول های (4.16-4.17)، جمع بر روی شاخص انجام می شود مناز یک به تعداد مشاهدات n.
متاسفانه در برتری داشتنهیچ تابعی وجود ندارد که ضرایب رگرسیون هذلولی را محاسبه کند. در مواردی که از قبل مشخص نیست که مقادیر اندازه گیری شده با نسبت معکوس مرتبط هستند، توصیه می شود به جای معادله رگرسیون هذلولی به دنبال معادله رگرسیون توان بگردید. برتری داشتنروشی برای یافتن آن وجود دارد. اگر یک وابستگی هذلولی بین مقادیر اندازه گیری شده در نظر گرفته شود، ضرایب رگرسیون آن باید با استفاده از جداول محاسبه کمکی و عملیات جمع با استفاده از فرمول های (4.16-4.17) محاسبه شود.
رگرسیون در اکسل
پردازش داده های آماری را می توان با استفاده از افزونه بسته تحلیلی در آیتم منوی "سرویس" نیز انجام داد. در اکسل 2003، اگر باز کنید سرویس، ما برگه را پیدا نمی کنیم تحلیل داده ها، سپس با کلیک بر روی دکمه سمت چپ ماوس برگه را باز کنید روبناهاو نقطه مقابل بسته تحلیلیبا کلیک بر روی دکمه سمت چپ ماوس، یک علامت تیک بزنید (شکل 17).
برنج. 17. پنجره روبناها
پس از آن در منو سرویسیک برگه ظاهر می شود تحلیل داده ها.
در اکسل 2007 برای نصب بسته تحلیلیباید روی دکمه OFFICE در گوشه سمت چپ بالای برگه کلیک کنید (شکل 18a). در مرحله بعد، روی دکمه کلیک کنید پارامترهای اکسل... در پنجره ای که ظاهر می شود پارامترهای اکسلروی مورد مورد نظر کلیک چپ کنید روبناهاو در سمت راست لیست کشویی مورد را انتخاب کنید بسته تحلیلیبعد، بر روی کلیک کنید خوب.




برنج. 18. نصب و راه اندازی بسته تحلیلیدر اکسل 2007
برای نصب بسته تحلیلی بر روی دکمه کلیک کنید برو،در پایین پنجره باز قرار دارد. پنجره نشان داده شده در شکل 12. یک تیک در مقابل قرار دهید بسته تحلیلیدر برگه داده هایک دکمه ظاهر می شود تحلیل داده ها(شکل 19).

از بین موارد پیشنهادی، او مورد را انتخاب می کند " پسرفت"و با دکمه سمت چپ ماوس روی آن کلیک کنید. سپس روی OK کلیک کنید.

پنجره نشان داده شده در شکل 21

ابزار تحلیل " پسرفت»برای جا دادن نمودار برای مجموعه ای از مشاهدات با استفاده از روش حداقل مربعات استفاده می شود. از رگرسیون برای تجزیه و تحلیل تأثیر مقادیر یک یا چند متغیر توضیحی بر روی یک متغیر وابسته فردی استفاده می شود. به عنوان مثال، عوامل متعددی بر عملکرد ورزشی یک ورزشکار تأثیر می گذارد، از جمله سن، قد و وزن. شما می توانید تاثیر هر یک از این سه عامل را بر عملکرد یک ورزشکار محاسبه کنید و سپس از آن داده ها برای پیش بینی عملکرد ورزشکار دیگر استفاده کنید.
ابزار Regression از تابع استفاده می کند LINEST.
جعبه گفتگوی رگرسیون
برچسب ها اگر سطر اول یا ستون اول محدوده ورودی حاوی سرصفحه باشد، کادر بررسی را انتخاب کنید. اگر عنوانی وجود ندارد، این کادر را پاک کنید. در این صورت سرصفحه های مناسب برای داده های جدول خروجی به صورت خودکار تولید می شوند.
سطح اطمینان کادر را انتخاب کنید تا یک سطح اضافی در جدول کل خروجی لحاظ شود. در قسمت مربوطه، علاوه بر سطح پیشفرض 95 درصد، سطح قابلیت اطمینان برای اعمال را وارد کنید.
ثابت - صفر کادر را انتخاب کنید تا خط رگرسیون از مبدا عبور کند.
فاصله خروجی یک مرجع به سلول سمت چپ بالای محدوده خروجی وارد کنید. حداقل هفت ستون را برای جدول کل خروجی اختصاص دهید که شامل: نتایج ANOVA، ضرایب، خطای استاندارد محاسبه Y، انحرافات استاندارد، تعداد مشاهدات، خطاهای استاندارد برای ضرایب خواهد بود.
کاربرگ جدید این سوئیچ را انتخاب کنید تا یک کاربرگ جدید در کتاب کار باز شود و نتایج تجزیه و تحلیل با شروع سلول A1 وارد شود. در صورت لزوم، یک نام برای برگه جدید در فیلد روبروی موقعیت سوئیچ مربوطه وارد کنید.
کتاب کار جدید روی سوئیچ به این موقعیت کلیک کنید تا یک کتاب کار جدید ایجاد شود که در آن نتایج به یک صفحه جدید اضافه می شود.
باقیمانده ها کادر را انتخاب کنید تا باقیمانده ها در جدول خروجی قرار گیرند.
باقیمانده های استاندارد شده، کادر را انتخاب کنید تا باقیمانده های استاندارد شده در جدول خروجی گنجانده شود.
Plot Residuals برای رسم باقیماندهها برای هر متغیر مستقل، کادر را انتخاب کنید.
فیتینگ نمودار برای رسم نمودار مقادیر پیش بینی شده در مقابل مقادیر مشاهده شده، کادر را انتخاب کنید.
نمودار احتمال عادیبرای رسم نمودار احتمال عادی، کادر را علامت بزنید.
عملکرد LINEST
برای انجام محاسبات، سلولی را که می خواهیم میانگین مقدار را با مکان نما در آن نمایش دهیم انتخاب کرده و کلید = را روی صفحه کلید فشار دهید. سپس در قسمت Name، برای مثال، تابع مورد نظر را مشخص کنید میانگین(شکل 22).

برنج. 22 یافتن توابع در اکسل 2003
اگر در میدان نامنام تابع ظاهر نمی شود، سپس روی مثلث کنار فیلد کلیک چپ کرده و پس از آن پنجره ای با لیستی از توابع ظاهر می شود. اگر این تابع در لیست نیست، روی مورد لیست کلیک چپ کنید توابع دیگر، یک جعبه گفتگو ظاهر خواهد شد استاد توابع، که در آن با استفاده از اسکرول عمودی، عملکرد مورد نظر را انتخاب کرده و با مکان نما انتخاب کرده و بر روی آن کلیک کنید خوب(شکل 23).

برنج. 23. Function Wizard
برای جستجوی یک تابع در اکسل 2007، هر تبی را می توان در منو باز کرد، سپس برای محاسبات، سلولی را که می خواهیم مقدار میانگین را در آن نمایش دهیم، انتخاب کرده و کلید = را روی صفحه کلید فشار دهیم. سپس در قسمت Name تابع را مشخص کنید میانگین... پنجره محاسبه تابع مشابه پنجره اکسل 2003 است.
همچنین می توانید برگه فرمول ها را انتخاب کنید و روی دکمه در منو کلیک چپ کنید " درج تابع(شکل 24)، یک پنجره ظاهر می شود استاد توابعکه نوع آن مشابه اکسل 2003 است. همچنین در منو می توانید بلافاصله دسته ای از توابع (که اخیرا استفاده شده است، مالی، منطقی، متن، تاریخ و زمان، ریاضی، توابع دیگر) را انتخاب کنید که در آن به دنبال توابع خواهیم بود. عملکرد مورد نظر




برنج. 24 انتخاب یک تابع در اکسل 2007
عملکرد LINESTآمار یک سری را با استفاده از حداقل مربعات محاسبه می کند تا خط مستقیمی را که به بهترین شکل با داده های موجود مطابقت دارد محاسبه کند و سپس آرایه ای را برمی گرداند که خط مستقیم حاصل را توصیف می کند. شما همچنین می توانید تابع را ترکیب کنید LINESTبا توابع دیگر برای محاسبه انواع مدل های دیگر که در پارامترهای مجهول خطی هستند (که پارامترهای مجهول آنها خطی هستند)، از جمله سری های چند جمله ای، لگاریتمی، نمایی و توانی. از آنجایی که یک آرایه از مقادیر برگردانده می شود، تابع باید به عنوان یک فرمول آرایه مشخص شود.
معادله یک خط مستقیم به صورت زیر است:
(در صورت وجود چندین محدوده از مقادیر x)،
در جایی که مقدار وابسته y تابعی از مقدار x مستقل است، مقادیر m ضرایب مربوط به هر متغیر x مستقل است و b یک ثابت است. توجه داشته باشید که y، x و m می توانند بردار باشند. عملکرد LINESTآرایه ای را برمی گرداند ![]() . LINESTهمچنین ممکن است آمار رگرسیون اضافی را برگرداند.
. LINESTهمچنین ممکن است آمار رگرسیون اضافی را برگرداند.
LINEST(شناختههای_y، شناختهشدههای x، const، آمار)
Known_y ها مجموعه ای از مقادیر y هستند که قبلاً برای رابطه شناخته شده اند.
اگر Know_y یک ستون داشته باشد، هر ستون درknown_x به عنوان یک متغیر جداگانه تفسیر می شود.
اگر Know_y یک ردیف داشته باشد، هر سطر درknown_x به عنوان یک متغیر جداگانه تفسیر می شود.
Known_x یک مجموعه اختیاری از مقادیر x است که قبلاً برای رابطه شناخته شده است.
Known_x می تواند شامل یک یا چند مجموعه از متغیرها باشد. اگر فقط از یک متغیر استفاده شود، شناخته شده_y و شناخته شده_x می توانند هر شکلی داشته باشند، تا زمانی که ابعاد یکسانی داشته باشند. اگر از بیش از یک متغیر استفاده میشود، شناختهشدهها باید بردار باشند (یعنی یک ردیف ارتفاع یا یک ستون عرض).
اگر array_known_x حذف شود، این آرایه (1; 2; 3; ...) به اندازه آرایه_known_y در نظر گرفته می شود.
Const یک مقدار بولی است که نشان می دهد آیا ثابت b باید 0 باشد یا خیر.
اگر const درست باشد یا حذف شود، ثابت b به روش معمول ارزیابی می شود.
اگر آرگومان "const" FALSE باشد، مقدار b برابر با 0 است و مقادیر m به گونه ای انتخاب می شوند که رابطه برقرار باشد.
Statistics یک مقدار Boolean است که نشان می دهد که آیا می خواهید آمار اضافی را برای رگرسیون برگردانید یا خیر.
اگر آمار درست باشد، LINEST آمار رگرسیون اضافی را برمیگرداند. آرایه برگشتی به این صورت خواهد بود: (mn؛ mn-1؛ ...؛ m1؛ b: sen؛ sen-1؛ ...؛ se1؛ seb: r2؛ sey: F؛ df: ssreg؛ ssresid).
اگر آمار FALSE یا حذف شده باشد، LINEST فقط ضرایب m و ثابت b را برمی گرداند.
آمار رگرسیون اضافی
شکل زیر ترتیب برگشت آمار رگرسیون اضافی را نشان می دهد.

یادداشت:
هر خط مستقیمی را می توان با شیب و تقاطع آن با محور y توصیف کرد:
شیب (m): برای تعیین شیب یک خط مستقیم که معمولا با m نشان داده می شود، باید دو نقطه از خط مستقیم را بگیرید و; شیب خواهد بود ![]() .
.
تقاطع Y (b): تقاطع y یک خط که معمولاً با b نشان داده می شود، مقدار y نقطه ای است که در آن خط محور y را قطع می کند.
معادله خط مستقیم شکل دارد. اگر مقادیر m و b را می دانید، می توانید هر نقطه از خط را با جایگزینی مقادیر y یا x در معادله محاسبه کنید. همچنین می توانید از تابع TREND استفاده کنید.
اگر فقط یک متغیر مستقل x وجود داشته باشد، می توانید شیب و قطع y را مستقیماً با استفاده از فرمول های زیر بدست آورید:
شیب: INDEX (LINEST (known_y's; known_x's); 1)
تقاطع Y: INDEX (LINEST (شناختههای_y، شناخته شدههای_x؛ 2)
دقت تقریب خط LINEST به درجه پراکندگی در داده ها بستگی دارد. هرچه داده ها به یک خط مستقیم نزدیکتر باشند، مدل LINEST دقیق تر است. LINEST از روش حداقل مربعات برای تعیین بهترین تناسب با داده ها استفاده می کند. هنگامی که فقط یک متغیر مستقل x وجود دارد، m و b با استفاده از فرمول های زیر محاسبه می شوند:

که در آن x و y میانگینهای نمونه هستند، برای مثال x = AVERAGE (شناختههای_x) و y = AVERAGE (شناختههای_y).
توابع برازش LINEST و LOGEST می توانند منحنی مستقیم یا نمایی را که داده ها را به بهترین شکل توصیف می کند، محاسبه کنند. با این حال، آنها به این سوال پاسخ نمی دهند که کدام یک از این دو نتیجه برای حل تکلیف مورد نظر مناسب تر است. همچنین میتوانید TREND (sknown_y، شناخته شده_x) را برای یک خط مستقیم، یا GROWTH (known_y، شناخته شده_x) را برای یک منحنی نمایی محاسبه کنید. این توابع، اگر new_x_values را مشخص نکنید، آرایه ای از مقادیر y محاسبه شده را برای مقادیر x واقعی در امتداد یک خط مستقیم یا منحنی برمی گردانند. سپس مقادیر محاسبه شده را می توان با مقادیر واقعی مقایسه کرد. همچنین می توانید نمودارهایی برای مقایسه بصری بسازید.
با تجزیه و تحلیل رگرسیون، مایکروسافت اکسل برای هر نقطه، مجذور تفاوت بین مقدار y پیش بینی شده و مقدار y واقعی را محاسبه می کند. مجموع این مجذور تفاوت ها را مجموع مجذورات باقیمانده (ssresid) می گویند. سپس مایکروسافت اکسل مجموع مجذورات (sstotal) را محاسبه می کند. اگر const = TRUE یا حذف شود، مجموع مجذورات برابر است با مجموع مجذورات تفاوت بین مقادیر واقعی y و مقادیر میانگین y. وقتی const = FALSE، مجموع مجذورات برابر با مجموع مجذورهای مقادیر واقعی y خواهد بود (بدون کسر مقدار میانگین y از مقدار ضریب y). سپس مجموع رگرسیون مربع ها را می توان به صورت زیر محاسبه کرد: ssreg = sstotal - ssresid. هر چه مجموع باقیمانده مربع ها کوچکتر باشد، مقدار ضریب جبر r2 بیشتر است، که نشان می دهد معادله به دست آمده با استفاده از تحلیل رگرسیون چقدر رابطه بین متغیرها را توضیح می دهد. ضریب r2 ssreg / sstotal است.
در برخی موارد، یک یا چند ستون X (اجازه دهید مقادیر Y و X در ستونها باشند) در سایر ستونهای X ارزش اعتباری اضافی ندارند. به عبارت دیگر، حذف یک یا چند ستون X ممکن است به مقادیر Y منجر شود. با همان دقت محاسبه می شود. در این حالت، ستونهای X اضافی از مدل رگرسیون حذف خواهند شد. این پدیده را "هم خطی" می نامند زیرا ستون های X اضافی را می توان به عنوان مجموع چندین ستون غیر زائد نشان داد. LINEST همخطی بودن را بررسی می کند و در صورت یافتن ستون های X اضافی از مدل رگرسیون حذف می کند. ستون های X حذف شده را می توان در خروجی LINEST با ضریب 0 و مقدار se 0 شناسایی کرد. حذف یک یا چند ستون به عنوان اضافی، مقدار df را تغییر می دهد زیرا به تعداد ستون های X که واقعاً برای اهداف پیش بینی استفاده می شوند بستگی دارد. برای اطلاعات بیشتر در مورد محاسبه df، به مثال 4 زیر مراجعه کنید. وقتی df به دلیل حذف ستون های اضافی تغییر می کند، sey و F نیز تغییر می کنند. خطی بودن اغلب دلسرد می شود. با این حال، اگر برخی از ستون های X حاوی 0 یا 1 به عنوان شاخصی باشد که نشان می دهد موضوع آزمایش در یک گروه جداگانه قرار دارد، باید استفاده شود. اگر const = TRUE یا حذف شود، LINEST یک ستون X اضافی را برای شبیه سازی نقطه تقاطع وارد می کند. اگر ستونی با مقادیر 1 برای مردان و 0 برای زنان وجود داشته باشد و همچنین ستونی با مقادیر 1 برای زنان و 0 برای مردان وجود داشته باشد، آخرین ستون حذف می شود زیرا مقادیر آن می تواند باشد. به دست آمده از ستون با "شاخص جنسیت مرد".
محاسبه df برای مواردی که ستون های X به دلیل همخطی بودن از مدل حذف نمی شوند به شرح زیر است: اگر k ستون های شناخته شده_x وجود داشته باشد و مقدار const = TRUE یا مشخص نشده باشد، df = n - k - 1. اگر const = FALSE، سپس df = n - k. در هر دو مورد، حذف ستون های X به دلیل همخطی بودن، مقدار df را 1 افزایش می دهد.
فرمول هایی که آرایه ها را برمی گرداند باید به عنوان فرمول آرایه وارد شوند.
هنگام وارد کردن یک آرایه از ثابتها برای مثالهایknown_x، از یک نقطه ویرگول برای جدا کردن مقادیر روی همان خط و یک دونقطه برای جدا کردن خطوط استفاده کنید. کاراکترهای جداکننده بسته به گزینه های تنظیم شده در پنجره زبان و استانداردها در کنترل پنل متفاوت است.
لازم به ذکر است که مقادیر y پیش بینی شده توسط معادله رگرسیون ممکن است درست نباشد اگر خارج از محدوده مقادیر y باشد که برای تعریف معادله استفاده شده است.
الگوریتم اصلی مورد استفاده در تابع LINEST، با الگوریتم اصلی توابع متفاوت است شیبو بخش... تفاوت بین الگوریتم ها می تواند منجر به نتایج متفاوتی برای داده های نامشخص و هم خطی شود. به عنوان مثال، اگر نقاط داده های شناخته شده_y 0 و نقاط داده های شناخته شده_x ها 1 باشد، آنگاه:
عملکرد LINESTمقداری برابر با 0 برمی گرداند. الگوریتم تابع LINESTبرای برگرداندن مقادیر معتبر برای داده های خطی استفاده می شود که در این صورت حداقل یک پاسخ می تواند پیدا شود.
توابع SLOPE و INTERCEPT خطای # DIV / 0 را برمیگردانند. الگوریتم تابع SLOPE و INTERCEPT برای جستجوی تنها یک پاسخ استفاده می شود و در این مورد ممکن است چندین پاسخ وجود داشته باشد.
علاوه بر محاسبه آمار برای انواع دیگر رگرسیون، LINEST می تواند برای محاسبه محدوده سایر انواع رگرسیون با وارد کردن توابع x و y به عنوان سری x و y برای LINEST استفاده شود. به عنوان مثال، فرمول زیر:
LINEST (مقادیر y، مقادیر x ^ COLUMN ($ A: $ C))
با داشتن یک ستون از مقادیر Y و یک ستون از مقادیر X برای محاسبه تقریبی به یک مکعب (چند جمله ای درجه 3) به شکل زیر عمل می کند:
فرمول را می توان برای محاسبه انواع دیگر رگرسیون تغییر داد، اما در برخی موارد، تنظیماتی در مقادیر خروجی و سایر آمارها مورد نیاز است.
به نظر من به عنوان یک دانشجو، اقتصاد سنجی یکی از کاربردی ترین علومی است که توانستم در دیوارهای دانشگاهم با آن آشنا شوم. با کمک آن، در واقع، می توان مشکلات ماهیت کاربردی را در مقیاس یک شرکت حل کرد. اینکه این راهکارها چقدر موثر خواهند بود، سوال سوم است. نکته پایانی این است که بیشتر دانش به صورت تئوری باقی خواهد ماند، اما اقتصاد سنجی و تحلیل رگرسیون همچنان ارزش مطالعه با توجه ویژه را دارند.
رگرسیون چه چیزی را توضیح می دهد؟
قبل از شروع بررسی عملکردهای MS Excel که امکان حل این مشکلات را فراهم می کند، می خواهم به شما توضیح دهم که اساساً تحلیل رگرسیون به چه چیزی دلالت می کند. با این کار قبولی در آزمون برای شما آسان تر می شود و از همه مهمتر مطالعه موضوع جذاب تر خواهد بود.
امیدواریم با مفهوم تابع از ریاضیات آشنا شده باشید. تابع یک رابطه بین دو متغیر است. وقتی یک متغیر تغییر می کند، برای دیگری اتفاقی می افتد. X را تغییر می دهیم و Y نیز به ترتیب تغییر می کند. توابع قوانین مختلفی را توصیف می کنند. با دانستن تابع، میتوانیم مقادیر دلخواه را جایگزین X کنیم و ببینیم که چگونه Y را تغییر میدهد.
این از اهمیت زیادی برخوردار است، زیرا رگرسیون تلاشی برای توضیح فرآیندهای ظاهراً غیر سیستماتیک و آشفته با استفاده از یک تابع خاص است. بنابراین، برای مثال، می توان رابطه بین نرخ دلار و بیکاری در روسیه را شناسایی کرد.
اگر بتوان این الگو را تشخیص داد، با استفاده از تابعی که در طول محاسبات به دست آوردیم، میتوانیم پیشبینی کنیم که نرخ بیکاری در نرخ تبدیل N-امین دلار در برابر روبل چقدر خواهد بود.
این رابطه را همبستگی می نامند. تجزیه و تحلیل رگرسیون شامل محاسبه یک ضریب همبستگی است که تنگی رابطه بین متغیرهای مورد نظر ما (نرخ تبدیل دلار و تعداد مشاغل) را توضیح می دهد.
این نسبت می تواند مثبت یا منفی باشد. مقادیر آن از 1- تا 1 متغیر است. بر این اساس، می توانیم همبستگی منفی یا مثبت بالایی را مشاهده کنیم. در صورت مثبت بودن افزایش نرخ دلار، ایجاد مشاغل جدید را به دنبال خواهد داشت. اگر منفی باشد یعنی افزایش نرخ ارز کاهش مشاغل را به دنبال دارد.
انواع مختلفی از رگرسیون وجود دارد. می تواند خطی، سهمی، نمایی و غیره باشد. بسته به اینکه کدام رگرسیون به طور خاص با مورد ما مطابقت داشته باشد، مدلی را انتخاب می کنیم که تا حد ممکن به همبستگی ما نزدیک باشد. بیایید این را روی یک مثال از یک مشکل در نظر بگیریم و آن را در MS Excel حل کنیم.
رگرسیون خطی در MS Excel
برای حل مسائل رگرسیون خطی، به عملکرد تجزیه و تحلیل داده ها نیاز دارید. ممکن است برای شما فعال نباشد، بنابراین باید آن را فعال کنید.
- روی دکمه "فایل" کلیک کنید؛
- ما مورد "پارامترها" را انتخاب می کنیم.
- روی تب ماقبل آخر "افزونه ها" در سمت چپ کلیک کنید.

- در زیر کتیبه "Control" و دکمه "Go" را مشاهده خواهیم کرد. ما روی آن فشار می دهیم؛
- ما یک تیک روی "بسته تجزیه و تحلیل" گذاشتیم.
- "ok" را فشار می دهیم.

نمونه کار
عملکرد تجزیه و تحلیل دسته ای فعال می شود. بیایید مشکل زیر را حل کنیم. ما نمونه ای از داده ها را برای چندین سال در مورد تعداد موقعیت های اضطراری در قلمرو شرکت و تعداد کارگران شاغل در اختیار داریم. ما باید رابطه بین این دو متغیر را شناسایی کنیم. یک متغیر توضیحی X وجود دارد - این تعداد کارگران است و یک متغیر توضیح داده شده - Y - تعداد تصادفات است. بیایید داده های اولیه را به دو ستون تقسیم کنیم.
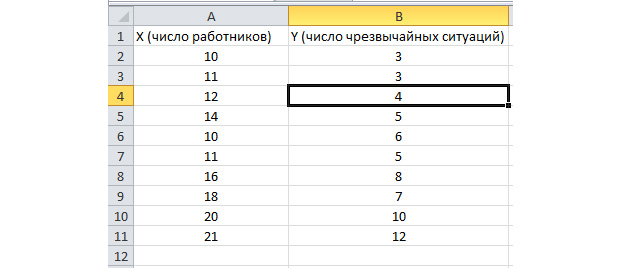
بیایید به تب "داده" برویم و "تحلیل داده ها" را انتخاب کنیم.
در لیستی که ظاهر می شود، "Regression" را انتخاب کنید. در بازه های ورودی Y و X، مقادیر مناسب را انتخاب کنید.
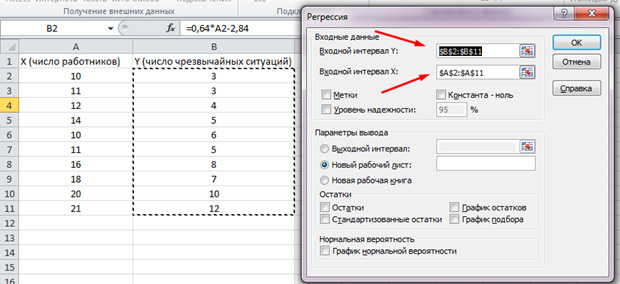
روی "OK" کلیک کنید. تجزیه و تحلیل انجام شده است و نتایج را در یک برگه جدید خواهیم دید.
مهم ترین مقادیر برای ما در شکل زیر مشخص شده است.
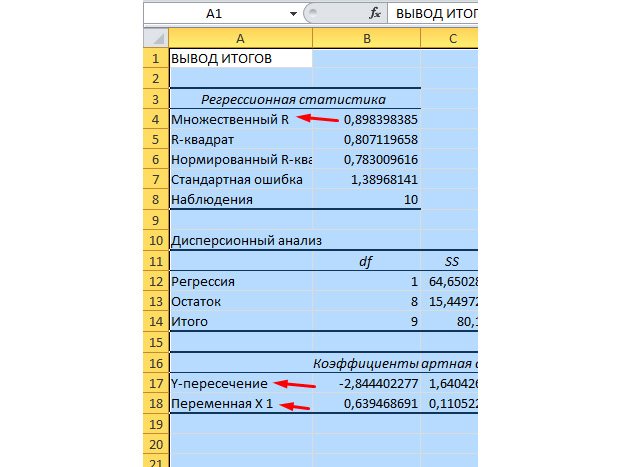
R چندگانه ضریب تعیین است. این یک فرمول محاسبه پیچیده دارد و نشان می دهد که چقدر می توانید به ضریب همبستگی ما اعتماد کنید. بر این اساس، هر چه این مقدار بزرگتر باشد، اعتماد بیشتر، مدل ما به عنوان یک کل موفق تر است.
تقاطع Y و تقاطع X1 ضرایب رگرسیون ما هستند. همانطور که قبلا ذکر شد، رگرسیون یک تابع است و دارای ضرایب خاصی است. بنابراین، تابع ما به این صورت خواهد بود: Y = 0.64 * X-2.84.
چه چیزی به ما می دهد؟ این به ما امکان می دهد پیش بینی کنیم. فرض کنید می خواهیم 25 کارگر را برای یک شرکت استخدام کنیم و باید به طور تقریبی تصور کنیم که تعداد تصادفات چقدر خواهد بود. این مقدار را با تابع خود جایگزین می کنیم و نتیجه Y = 0.64 * 25 - 2.84 را می گیریم. حدود 13 وضعیت اضطراری در کشور ما رخ خواهد داد.
بیایید ببینیم چگونه کار می کند. به تصویر زیر دقت کنید. تابعی که به دست آوردیم با مقادیر واقعی کارمندان درگیر جایگزین می شود. ببینید چقدر ارزش ها به بازی های واقعی نزدیک است.

همچنین می توانید با برجسته کردن گیمرها و ناحیه xs، کلیک کردن بر روی زبانه "درج" و انتخاب نمودار پراکندگی، یک فیلد همبستگی ایجاد کنید.

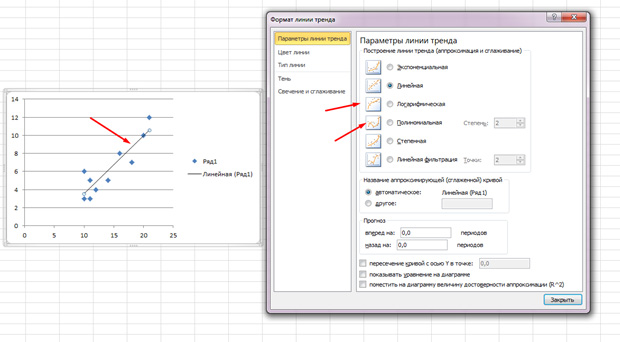
نقاط پراکنده هستند، اما به طور کلی به سمت بالا حرکت می کنند، گویی در یک خط مستقیم در وسط هستند. و همچنین می توانید این خط را با رفتن به برگه "Layout" در MS Excel و انتخاب مورد "Trend Line" اضافه کنید.
روی خط ظاهر شده دابل کلیک کنید و آنچه را که قبلا ذکر شد خواهید دید. بسته به اینکه فیلد همبستگی شما به چه شکل است، می توانید نوع رگرسیون را تغییر دهید.
شاید شما احساس می کنید که نقاط یک سهمی ترسیم می کنند، نه یک خط مستقیم، و برای شما مناسب تر است که نوع دیگری از رگرسیون را انتخاب کنید.
نتیجه
امیدواریم این مقاله به شما درک بهتری از چیستی تحلیل رگرسیون داده باشد و به چه منظور است. همه اینها از اهمیت عملی بالایی برخوردار است.
رگرسیون خطی به ما اجازه می دهد تا خط مستقیمی را که به بهترین وجه با یک سری از جفت های مرتب شده (x، y) مطابقت دارد، توصیف کنیم. معادله یک خط مستقیم که به معادله خطی معروف است در زیر نشان داده شده است:
ŷ مقدار مورد انتظار y برای مقدار معین x است،
x متغیر مستقل است،
a - پاره روی محور y برای یک خط مستقیم،
ب - شیب یک خط مستقیم.
شکل زیر این مفهوم را به صورت گرافیکی نشان می دهد:
تصویر بالا خط توصیف شده توسط معادله ŷ = 2 + 0.5x را نشان می دهد. پاره روی محور y نقطه تقاطع خط با محور y است. در مورد ما a = 2. شیب خط، b، نسبت افزایش خط به طول خط، مقدار 0.5 دارد. شیب مثبت به این معنی است که خط از چپ به راست بالا می رود. اگر b = 0، خط افقی است، به این معنی که هیچ رابطه ای بین متغیرهای وابسته و مستقل وجود ندارد. به عبارت دیگر، تغییر مقدار x تاثیری بر مقدار y ندارد.
Ŷ و y اغلب اشتباه گرفته می شوند. نمودار 6 جفت نقطه مرتب شده و یک خط را مطابق این معادله نشان می دهد

این شکل نقطه مربوط به جفت مرتب شده x = 2 و y = 4 را نشان می دهد. توجه داشته باشید که مقدار مورد انتظار y با توجه به خط در NS= 2 برابر ŷ است. ما می توانیم این را با معادله زیر تأیید کنیم:
ŷ = 2 + 0.5x = 2 +0.5 (2) = 3.
y-value نقطه واقعی است و the-value مقدار y مورد انتظار با استفاده از یک معادله خطی برای یک مقدار x معین است.
مرحله بعدی تعیین معادله خطی است که بیشتر با مجموعه جفت های مرتب شده مطابقت دارد، در مقاله قبلی در مورد این صحبت کردیم، جایی که شکل معادله را با تعیین کردیم.
استفاده از اکسل برای تعریف رگرسیون خطی
برای استفاده از ابزار تحلیل رگرسیون ساخته شده در اکسل، باید افزونه را فعال کنید بسته تحلیلی... با کلیک بر روی برگه می توانید آن را پیدا کنید فایل -> گزینه ها(2007+)، در کادر محاوره ای که ظاهر می شود گزینه هابرتری داشتنبه برگه بروید افزونه هادر زمینه کنترلانتخاب کنید افزونه هابرتری داشتنو کلیک کنید برودر پنجره ظاهر شده یک تیک در مقابل قرار دهید بسته تحلیلی،فشار می دهیم خوب.

در برگه داده هادر یک گروه تحلیل و بررسییک دکمه جدید ظاهر می شود تحلیل داده ها.

برای اینکه نشان دهیم این افزونه چگونه کار میکند، اجازه دهید از دادههایی استفاده کنیم که یک پسر و یک دختر در حمام یک میز را به اشتراک میگذارند. دادههای نمونه وان حمام را در ستونهای A و B صفحه خالی وارد کنید.
به برگه بروید داده ها،در یک گروه تحلیل و بررسیکلیک تحلیل داده ها.در پنجره ای که ظاهر می شود تحلیل داده هاانتخاب کنید پسرفتمطابق شکل و روی OK کلیک کنید.

پارامترهای رگرسیون مورد نیاز را در پنجره تنظیم کنید پسرفت، همانطور که در تصویر نشان داده شده است:

کلیک خوب.شکل زیر نتایج به دست آمده را نشان می دهد:

این نتایج با نتایجی که از طریق محاسبات خود به دست آوردهایم مطابقت دارد.
ساخت یک رگرسیون خطی، تخمین پارامترهای آن و اهمیت آنها را می توان با استفاده از بسته تحلیل اکسل (رگرسیون) بسیار سریعتر انجام داد. تفسیر نتایج به دست آمده در حالت کلی را در نظر بگیرید ( کمتغیرهای توضیحی) مطابق مثال 3.6.
در جدول آمار رگرسیونمقادیر داده شده است:
چندگانه آر - ضریب همبستگی چندگانه؛
آر- مربع- ضریب تعیین آر 2 ;
عادی شد آر - مربع- تنظیم شده آر 2 برای تعداد درجات آزادی تصحیح شد.
خطای استاندارد- خطای استاندارد رگرسیون اس;
مشاهدات -تعداد مشاهدات n.
در جدول ANOVAداده می شود:
1. ستون df - تعداد درجات آزادی برابر است
برای رشته پسرفت df = ک;
برای رشته باقی ماندهdf = n – ک – 1;
برای رشته جمعdf = n– 1.
2. ستون اس اس -مجموع مربعات انحرافات برابر است با
برای رشته پسرفت ;
برای رشته باقی مانده ;
برای رشته جمع .
3. ستون خانمواریانس های تعیین شده توسط فرمول خانم = اس اس/df:
برای رشته پسرفت- واریانس فاکتوریل؛
برای رشته باقی مانده- واریانس باقیمانده
4. ستون اف - ارزش محاسبه شده اف-معیار محاسبه شده با فرمول
اف = خانم(پسرفت)/ خانم(باقی مانده).
5. ستون اهمیت اف - مقدار سطح معنی داری مربوط به محاسبه شده است اف-آمار .
اهمیت اف= FDIST ( F-آمار، df(پسرفت)، df(باقیمانده)).
اگر اهمیت اف < стандартного уровня значимости, то آر 2 از نظر آماری معنادار است.
| ضرایب | خطای استاندارد | آماره t | P-value | 95% پایین | 95% برتر | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| ایکس | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
این جدول نشان می دهد:
1. شانس- مقادیر ضرایب آ, ب.
2. خطای استاندارد- خطاهای استاندارد ضرایب رگرسیون S a, S ب.
3. t-آمار- مقادیر محاسبه شده تی - معیارهای محاسبه شده با فرمول:
t-statistic = ضرایب / خطای استاندارد.
4.آر-ارزش (اهمیت تی) آیا مقدار سطح معناداری مربوط به محاسبه شده است t-آمار.
آر-ارزش = TDIST(تی-آمار، df(باقیمانده)).
اگر آر- معنی< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5... 95% پایین و 95% بالا- مرزهای پایین و بالایی فاصله اطمینان 95% برای ضرایب معادله رگرسیون خطی نظری.
| انصراف باقی مانده است | ||
| مشاهده | y را پیش بینی کرد | باقی می ماند e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
در جدول انصراف باقی مانده استنشان داد:
در ستون مشاهده- شماره مشاهده؛
در ستون پیش بینی شده y - مقادیر محاسبه شده متغیر وابسته؛
در ستون باقی مانده ه - تفاوت بین مقادیر مشاهده شده و محاسبه شده متغیر وابسته.
مثال 3.6.داده ها (واحدهای متعارف) در مورد هزینه های غذا وجود دارد yو درآمد سرانه ایکسبرای نه گروه از خانواده ها:
| ایکس | |||||||||
| y |
با استفاده از نتایج بسته تحلیل اکسل (رگرسیون)، وابستگی هزینه های مواد غذایی را به میزان درآمد سرانه تجزیه و تحلیل می کنیم.
مرسوم است که نتایج تحلیل رگرسیون را به شکل زیر بنویسید:
![]()
که در آن خطاهای استاندارد ضرایب رگرسیون در داخل پرانتز نشان داده شده است.
ضرایب رگرسیون آ = 65,92 و ب= 0.107. جهت ارتباط بین yو ایکسعلامت ضریب رگرسیون را تعیین می کند ب= 0.107، یعنی ارتباط مستقیم و مثبت است. ضریب ب 0.107 = نشان می دهد که با افزایش درآمد سرانه 1 تبدیل. واحدها هزینه های غذا 0.107 تبدیل افزایش می یابد. واحدها
اجازه دهید اهمیت ضرایب مدل حاصل را تخمین بزنیم. اهمیت ضرایب ( الف، ب) توسط بررسی می شود تی-تست:
مقدار P ( آ) = 0,00080 < 0,01 < 0,05
مقدار P ( ب) = 0,00016 < 0,01 < 0,05,
بنابراین، ضرایب ( الف، ب) در سطح 1% و حتی بیشتر از آن در سطح 5% معنی دار هستند. بنابراین، ضرایب رگرسیون معنی دار بوده و مدل برای داده های اصلی مناسب است.
نتایج تخمین رگرسیون نه تنها با مقادیر بدست آمده از ضرایب رگرسیون، بلکه با مقداری از مجموعه آنها (فاصله اطمینان) نیز سازگار است. با احتمال 95 درصد، فواصل اطمینان برای ضرایب (38.16 - 93.68) برای آو (0.0728 - 0.142) برای ب
کیفیت مدل با ضریب تعیین ارزیابی می شود آر 2 .
بزرگی آر 2 = 0.884 به این معنی است که 88.4 درصد از تغییرات (گسترش) در مخارج مواد غذایی را می توان با عامل درآمد سرانه توضیح داد.
اهمیت آر 2 توسط بررسی می شود F-آزمون: اهمیت اف = 0,00016 < 0,01 < 0,05, следовательно, آر 2 در سطح 1% و حتی بیشتر از آن در سطح 5% معنی دار است.
در مورد رگرسیون خطی زوجی، ضریب همبستگی را می توان به صورت تعریف کرد ![]() ... مقدار به دست آمده از ضریب همبستگی نشان می دهد که رابطه بین هزینه های غذایی و درآمد سرانه بسیار نزدیک است.
... مقدار به دست آمده از ضریب همبستگی نشان می دهد که رابطه بین هزینه های غذایی و درآمد سرانه بسیار نزدیک است.