این الگوریتم توسط Joint Photographic Expert Group به طور خاص برای فشرده سازی تصاویر 24 بیتی و مقیاس خاکستری در سال 1991 توسعه داده شد. این الگوریتم تصاویر دو سطحی را به خوبی فشرده نمی کند، اما در مدیریت تصاویر با تن پیوسته که در آن پیکسل های نزدیک تمایل به رنگ های مشابه دارند، به خوبی کار می کند. معمولاً چشم با فشرده شدن 10 یا 20 بار با این روش نمی تواند تفاوتی را متوجه شود.
الگوریتم مبتنی بر DCT است که بر روی ماتریسی از بلوکهای تصویر متمایز 8×8 پیکسل اعمال میشود. DCT این بلوک ها را با توجه به دامنه فرکانس های خاص تجزیه می کند. نتیجه ماتریسی است که در آن بسیاری از ضرایب، به عنوان یک قاعده، نزدیک به صفر هستند، که می تواند به شکل عددی تقریبی نشان داده شود، یعنی. به شکل کوانتیزه بدون افت قابل توجه در کیفیت ترمیم.
بیایید عملکرد الگوریتم را با جزئیات بیشتری در نظر بگیریم. بیایید فرض کنیم که یک تصویر 24 بیتی تمام رنگی در حال فشرده سازی است. در این صورت مراحل کار زیر را بدست می آوریم.
مرحله 1.با استفاده از عبارت زیر تصویر را از فضای RGB به فضای YCbCr تبدیل می کنیم:
بیایید بلافاصله توجه کنیم که تبدیل معکوس به راحتی با ضرب به دست می آید ماتریس معکوسبه یک بردار، که در اصل فضای YUV است:
 .
.
گام 2.ما تصویر اصلی را به ماتریس های 8x8 تقسیم می کنیم. ما از هر کدام سه ماتریس DCT کار می کنیم - 8 بیت به طور جداگانه برای هر جزء. در نسبت های فشرده سازی بالا، بلوک 8x8 به اجزای YCbCr در قالب 4:2:0 تجزیه می شود، یعنی. اجزای Cb و Cr از طریق نقطه در سطرها و ستون ها گرفته می شوند.
مرحله 3.استفاده از DCT بر روی بلوک های تصویر 8x8 پیکسل. به طور رسمی، DCT مستقیم برای یک بلوک 8x8 می تواند به صورت نوشته شود
جایی که  . از آنجایی که DCT "قلب" الگوریتم JPEG است، در عمل مطلوب است که آن را در سریع ترین زمان ممکن محاسبه کنید. یک روش ساده برای سرعت بخشیدن به محاسبات، محاسبه توابع کسینوس از قبل و جدول بندی نتایج است. علاوه بر این، با توجه به متعامد بودن توابع کسینوس با فرکانس های مختلف، فرمول فوق را می توان به صورت نوشتاری نوشت
. از آنجایی که DCT "قلب" الگوریتم JPEG است، در عمل مطلوب است که آن را در سریع ترین زمان ممکن محاسبه کنید. یک روش ساده برای سرعت بخشیدن به محاسبات، محاسبه توابع کسینوس از قبل و جدول بندی نتایج است. علاوه بر این، با توجه به متعامد بودن توابع کسینوس با فرکانس های مختلف، فرمول فوق را می توان به صورت نوشتاری نوشت
 .
.
در اینجا ماتریسی از عناصر 8x8 است که یک فضای 8 بعدی را توصیف می کند تا ستون های یک بلوک را در این فضا نشان دهد. ماتریس یک ماتریس جابجا شده است و همین کار را انجام می دهد، اما برای ردیف های بلوک. نتیجه یک تبدیل قابل تفکیک است که به صورت ماتریسی به صورت نوشته می شود
در اینجا نتیجه DCT است که محاسبه آن به عملیات ضرب و تقریباً به همان اندازه نیاز دارد که به طور قابل توجهی کمتر از محاسبات مستقیم با استفاده از فرمول بالا است. به عنوان مثال، برای تبدیل یک تصویر با ابعاد 512x512 پیکسل به شما نیاز دارید عملیات حسابی. با در نظر گرفتن 3 مولفه روشنایی، مقدار 12,582,912 عملیات حسابی را به دست می آوریم. با استفاده از الگوریتم تبدیل فوریه سریع می توان تعداد ضرب و جمع را کاهش داد. در نتیجه، برای تبدیل یک بلوک 8×8 باید 54 ضرب، 468 جمع و جابجایی بیت انجام دهید.
در نتیجه DCT ماتریسی به دست می آوریم که در آن ضرایب در سمت چپ است گوشه بالابا مولفه فرکانس پایین تصویر و در سمت راست پایین - فرکانس بالا مطابقت دارد.
مرحله 4.کوانتیزاسیون در این مرحله، برخی از اطلاعات کنار گذاشته می شود. در اینجا، هر عدد از ماتریس بر یک عدد خاص از "جدول کوانتیزاسیون" تقسیم می شود و نتیجه به نزدیکترین عدد صحیح گرد می شود:
![]() .
.
علاوه بر این، برای هر ماتریس Y، Cb و Cr، می توانید جداول کوانتیزاسیون خود را تنظیم کنید. استاندارد JPEG حتی امکان استفاده از جداول کوانتیزاسیون خاص خود را نیز فراهم می کند، که با این حال، باید همراه با داده های فشرده به رمزگشا منتقل شود، که باعث افزایش اندازه کلی فایل می شود. واضح است که انتخاب مستقل 64 ضریب برای کاربر دشوار است، بنابراین استاندارد JPEG از دو رویکرد برای ماتریس های کوانتیزاسیون استفاده می کند. اولین مورد این است که استاندارد JPEG شامل دو جدول کوانتیزاسیون توصیه شده است: یکی برای luma و دیگری برای chrominance. این جداول در زیر ارائه شده است. روش دوم سنتز (محاسبه در لحظه) یک جدول کوانتیزاسیون است که به پارامتری که توسط کاربر مشخص شده است بستگی دارد. خود جدول طبق فرمول ساخته شده است


مرحله کوانتیزاسیون جایی است که نسبت تراکم کنترل می شود و در آن بیشترین تلفات رخ می دهد. واضح است که با تعیین جداول کوانتیزاسیون با ضرایب بزرگ، صفرهای بیشتری و در نتیجه نسبت تراکم بالاتری به دست خواهیم آورد.
اثرات خاص الگوریتم نیز با کوانتیزاسیون همراه است. در ارزش های بزرگمرحله کوانتیزاسیون، تلفات می تواند آنقدر زیاد باشد که تصویر به مربع های تک رنگ 8x8 تجزیه شود. به نوبه خود، تلفات در فرکانس های بالا می تواند خود را در به اصطلاح "اثر گیبس" نشان دهد، زمانی که یک "هاله" موج مانند در اطراف خطوط با یک انتقال رنگ تیز تشکیل می شود.
مرحله 5.ماتریس 8x8 را با استفاده از اسکن زیگزاگ به یک بردار 64 عنصری تبدیل می کنیم (شکل 2).

برنج. 2. اسکن زیگزاگ
در نتیجه ضرایب غیر صفر معمولاً در ابتدای بردار نوشته می شوند و زنجیره های صفر در انتها تشکیل می شوند.
مرحله 6.ما بردار را با استفاده از اصلاح شده تبدیل می کنیم الگوریتم RLE، در خروجی آن جفت هایی از نوع (پرش، عدد) دریافت می کنیم، که در آن "پرش" شمارنده صفرهای پرش شده است و "عدد" مقداری است که باید در خانه بعدی قرار داده شود. برای مثال، بردار 1118 3 0 0 0 -2 0 0 0 0 1 ... به جفت (0, 1118) (0,3) (3,-2) (4,1) ... جمع می شود.
لازم به ذکر است که عدد اول مولفه تبدیل شده اساساً برابر با میانگین روشنایی بلوک 8*8 است و ضریب DC نامیده می شود. برای همه بلوک های تصویر یکسان است. این شرایط نشان میدهد که ضرایب DC را میتوان به طور موثر فشرده کرد اگر مقادیر مطلق آنها را نه، بلکه مقادیر نسبی را در قالب تفاوت بین ضریب DC بلوک فعلی و ضریب DC بلوک قبلی به خاطر بسپارید، و ضریب اول را بهعنوان به خاطر بسپارید. این است. در این حالت می توان ترتیب ضرایب DC را مثلاً به این صورت انجام داد (شکل 3). ضرایب باقی مانده که ضرایب AC نامیده می شوند، بدون تغییر باقی می مانند.
مرحله 7جفت های به دست آمده را با استفاده از کدهای هافمن غیر یکنواخت با یک جدول ثابت در هم می پیچیم. علاوه بر این، برای ضرایب DC و AC، کدهای مختلف، یعنی جداول مختلفبا کدهای هافمن

برنج. 3. طرح سفارش ضریب DC

برنج. 4. بلوک دیاگرام الگوریتم JPEG
فرآیند بازیابی تصویر در این الگوریتم کاملاً متقارن است. این روش به شما امکان می دهد تصاویر را 10-15 بار بدون تلفات بصری قابل توجه فشرده سازی کنید.
هنگام توسعه این استاندارد، ما با این واقعیت هدایت شدیم که این الگوریتمباید تصاویر را خیلی سریع فشرده میکرد - بیش از یک دقیقه بر روی تصویر متوسط. این در سال 1991 است! و اجرای سخت افزاری آن باید نسبتاً ساده و ارزان باشد. در این مورد، الگوریتم باید در زمان عملیاتی متقارن باشد. کارایی آخرین نیازانجام داد ظاهر احتمالیدوربین های دیجیتالی که تصاویر 24 بیتی می گیرند. اگر الگوریتم نامتقارن بود، انتظار طولانی مدت برای "شارژ مجدد" دستگاه و فشرده سازی تصویر ناخوشایند خواهد بود.
با اينكه الگوریتم JPEGو استاندارد ISO است، فرمت فایل آن ثابت نشده است. با استفاده از این مزیت، سازندگان فرمت های خود را ایجاد می کنند که با یکدیگر ناسازگار هستند و بنابراین می توانند الگوریتم را تغییر دهند. بنابراین، جداول الگوریتم داخلی توصیه شده توسط ISO با جداول خود جایگزین می شوند. همچنین گزینه های JPEG برای برنامه های خاص وجود دارد.
به راحتی می توان محاسبه کرد که یک تصویر تمام رنگی فشرده نشده با اندازه 2000 * 1000 پیکسل، اندازه ای در حدود 6 مگابایت خواهد داشت. اگر در مورد تصاویر به دست آمده از دوربین های حرفه ای یا اسکنر صحبت کنیم کیفیت بالا، سپس اندازه آنها ممکن است حتی بزرگتر باشد. با وجود رشد سریع ظرفیت دستگاه های ذخیره سازی، الگوریتم های مختلف فشرده سازی تصویر هنوز بسیار مرتبط هستند.
تمام الگوریتم های موجود را می توان به دو کلاس بزرگ تقسیم کرد:
- الگوریتم های فشرده سازی بدون تلفات؛
- الگوریتم های فشرده سازی با اتلاف
الگوریتم های فشرده سازی بدون تلفات
الگوریتم RLE
همه الگوریتم ها سری RLEبر اساس یک ایده بسیار ساده است: گروه های تکرار شونده از عناصر با یک جفت (تعداد تکرار، عنصر تکرار شونده) جایگزین می شوند. بیایید این الگوریتم را با استفاده از مثال دنباله ای از بیت ها در نظر بگیریم. این دنباله گروه های صفر و یک را جایگزین می کند. علاوه بر این، گروه ها اغلب بیش از یک عنصر دارند. سپس دنباله 11111 000000 11111111 00 با مجموعه اعداد 5 6 8 2 زیر مطابقت دارد. این اعداد نشان دهنده تعداد تکرارها هستند (شمارش از یک شروع می شود)، اما این اعداد نیز باید رمزگذاری شوند. ما فرض می کنیم که تعداد تکرارها در محدوده 0 تا 7 قرار دارد (یعنی 3 بیت برای رمزگذاری تعداد تکرارها کافی است). سپس دنباله در نظر گرفته شده در بالا توسط دنباله اعداد 5 6 7 0 1 2 زیر کدگذاری می شود. محاسبه این که برای رمزگذاری دنباله اصلی به 21 بیت و در حالت فشرده آسان است، آسان است. روش RLEدر شکل، این دنباله 18 بیت طول می کشد.اگرچه این الگوریتم بسیار ساده است، اما کارایی آن نسبتا پایین است. علاوه بر این، در برخی موارد، استفاده از این الگوریتم نه به کاهش، بلکه به افزایش طول دنباله منجر می شود. به عنوان مثال، دنباله زیر را 111 0000 11111111 00 در نظر بگیرید. دنباله RL مربوطه به این صورت است: 3 4 7 0 1 2. طول دنباله اصلی 17 بیت است، طول دنباله فشرده شده 18 بیت است.
این الگوریتم برای تصاویر سیاه و سفید بیشترین کارایی را دارد. همچنین اغلب به عنوان یکی از مراحل میانی فشرده سازی الگوریتم های پیچیده تر استفاده می شود.
الگوریتم های دیکشنری
ایده پشت الگوریتمهای فرهنگ لغت این است که زنجیرهای از عناصر دنباله اصلی کدگذاری میشوند. این رمزگذاری از یک دیکشنری ویژه استفاده می کند که بر اساس دنباله اصلی به دست آمده است.یک خانواده کامل از الگوریتم های فرهنگ لغت وجود دارد، اما ما به رایج ترین آنها خواهیم پرداخت الگوریتم LZW، به نام توسعه دهندگان آن Lepel، Ziv و Welch نامگذاری شده است.
فرهنگ لغت در این الگوریتم جدولی است که با اجرای الگوریتم با زنجیره های کدگذاری پر می شود. هنگامی که کد فشرده رمزگشایی می شود، فرهنگ لغت به طور خودکار بازیابی می شود، بنابراین نیازی به انتقال فرهنگ لغت همراه با کد فشرده نیست.
فرهنگ لغت با تمام رشته های تک تن مقداردهی اولیه می شود، یعنی. اولین خطوط فرهنگ لغت نشان دهنده الفبای است که در آن رمزگذاری می کنیم. در طول فشرده سازی، جستجو برای طولانی ترین زنجیره ای که قبلاً در فرهنگ لغت ثبت شده است انجام می شود. هر بار که با زنجیرهای مواجه میشوید که هنوز در فرهنگ لغت نوشته نشده است، در آنجا اضافه میشود و کد فشردهشده مربوط به زنجیرهای که قبلاً در فرهنگ لغت نوشته شده است، خروجی میشود. در تئوری، هیچ محدودیتی در اندازه فرهنگ لغت اعمال نمی شود، اما در عمل محدود کردن این اندازه منطقی است، زیرا با گذشت زمان، زنجیره هایی ظاهر می شوند که دیگر در متن یافت نمی شوند. علاوه بر این، زمانی که اندازه جدول را دو برابر می کنیم، باید یک بیت اضافی را برای ذخیره کدهای فشرده اختصاص دهیم. به منظور جلوگیری از چنین شرایطی معرفی شده است کد ویژه، نمادی از مقداردهی اولیه جدول با تمام زنجیره های تک تنه است.
بیایید به مثالی از الگوریتم فشرده سازی نگاه کنیم. ما خط cuckoocuckoocuckoohood را فشرده می کنیم. فرض کنید دیکشنری دارای 32 موقعیت است، به این معنی که هر کد آن 5 بیت را اشغال می کند. در ابتدا فرهنگ لغت به صورت زیر پر می شود:
این جدول هم در سمت کسی که اطلاعات را فشرده می کند و هم در سمت کسی که آن را از حالت فشرده خارج می کند وجود دارد. اکنون به روند فشرده سازی نگاه خواهیم کرد. 
جدول روند پر کردن فرهنگ لغت را نشان می دهد. به راحتی می توان محاسبه کرد که کد فشرده حاصل 105 بیت طول می کشد، و متن اصلی(با فرض اینکه ما 4 بیت را صرف رمزگذاری یک کاراکتر می کنیم) 116 بیت می گیرد.
در اصل، فرآیند رمزگشایی به رمزگشایی مستقیم کدها خلاصه می شود و مهم است که جدول به همان روشی که در هنگام رمزگذاری مقداردهی اولیه شود. حالا بیایید به الگوریتم رمزگشایی نگاه کنیم. 
رشته اضافه شده به فرهنگ لغت در مرحله i را فقط در i+1 می توانیم به طور کامل تعریف کنیم. بدیهی است که خط i باید به اولین کاراکتر خط i+1 ختم شود. که ما تازه فهمیدیم که چگونه یک دیکشنری را بازیابی کنیم. زمانی که دنبالهای از شکل cScSc کدگذاری میشود، جایی که c یک کاراکتر و S یک رشته است و کلمه cS قبلاً در فرهنگ لغت وجود دارد، جالب توجه است. در نگاه اول ممکن است به نظر برسد که رمزگشا قادر به حل این وضعیت نخواهد بود، اما در واقع تمام خطوط از این نوع باید همیشه با همان کاراکتری که با آن شروع می شوند پایان یابد.
الگوریتم های کدگذاری آماری
الگوریتم های این سری کوتاه ترین کد فشرده شده را به متداول ترین عناصر دنباله ها اختصاص می دهند. آن ها دنباله هایی با طول یکسان با کدهای فشرده با طول های مختلف کدگذاری می شوند. علاوه بر این، هر چه یک دنباله بیشتر اتفاق بیفتد، کد فشرده مربوطه کوتاهتر می شود.الگوریتم هافمن
الگوریتم هافمن به شما امکان می دهد کدهای پیشوندی بسازید. می توانید کدهای پیشوند را به عنوان مسیرهایی در نظر بگیرید درخت دوتایی: یک گذر از یک گره به فرزند سمت چپ آن با 0 در کد مطابقت دارد و به پسر سمت راست آن با 1 مطابقت دارد. کد پیشوندبه شکل درخت دوتاییاجازه دهید الگوریتم ساخت درخت هافمن و به دست آوردن کدهای هافمن را شرح دهیم.
- کاراکترهای الفبای ورودی فهرستی از گره های آزاد را تشکیل می دهند. هر برگ وزنی دارد که برابر فرکانسظاهر نماد
- دو گره درخت آزاد با کوچکترین وزن انتخاب شده است
- والد آنها با وزنی برابر با وزن کل آنها ایجاد می شود
- والد به لیست گره های رایگان اضافه می شود و دو فرزند آن از این لیست حذف می شوند
- یک قوس خروجی از والد به بیت 1 و دیگری به بیت 0 اختصاص داده شده است
- مراحل شروع از دوم تکرار می شود تا زمانی که تنها یک گره آزاد در لیست گره های آزاد باقی بماند. این ریشه درخت در نظر گرفته خواهد شد.
کدگذاری حسابی
الگوریتم های رمزگذاری حسابی رشته هایی از عناصر را در یک کسری رمزگذاری می کنند. در این مورد، توزیع فرکانسی عناصر در نظر گرفته می شود. بر این لحظهالگوریتم های رمزگذاری حسابی توسط پتنت ها محافظت می شوند، بنابراین ما فقط به ایده اصلی نگاه خواهیم کرد.بگذارید الفبای ما از N نماد a1،...،aN و فراوانی وقوع آنها p1،...، pN تشکیل شده باشد. بیایید نیم فاصله را تقسیم کنیم. به طور کلی، این الگوریتم مبتنی بر تبدیل کسینوس گسسته (از این پس به عنوان DCT نامیده می شود) است که در ماتریس تصویر برای به دست آوردن یک ماتریس ضریب جدید اعمال می شود. یک تبدیل معکوس برای به دست آوردن تصویر اصلی اعمال می شود.
DCT تصویر را با توجه به دامنه فرکانس های خاص تجزیه می کند. بنابراین، هنگام تبدیل، ماتریسی به دست می آوریم که در آن بسیاری از ضرایب یا نزدیک یا برابر با صفر هستند. علاوه بر این، به دلیل نقص بینایی انسان، می توان ضرایب را بدون افت قابل توجه کیفیت تصویر، تقریب درشت تری انجام داد.
برای این منظور از کوانتیزاسیون ضریب استفاده می شود. در ساده ترین حالت، این یک شیفت بیتی حسابی به سمت راست است. با این تبدیل، برخی از اطلاعات از بین می رود، اما می توان به درجه فشرده سازی بیشتری دست یافت.
الگوریتم چگونه کار می کند
بنابراین، بیایید به الگوریتم با جزئیات بیشتری نگاه کنیم (شکل 2.1). اجازه دهید یک تصویر 24 بیتی را فشرده کنیم.
مرحله 1.تصویر را از فضای رنگی RGB با اجزای مسئول اجزای قرمز (قرمز)، سبز (سبز) و آبی (آبی) رنگ نقطه تبدیل می کنیم. فضای رنگی YCrCb (گاهی اوقات YUV نامیده می شود).
در آن، Y جزء روشنایی است و Cr، Co اجزای مسئول رنگ (قرمز رنگی و آبی رنگی) هستند. با توجه به این واقعیت که چشم انسان نسبت به روشنایی حساسیت کمتری به رنگ دارد، می توان آرایه هایی را برای اجزای Cr و Co با تلفات زیاد و در نتیجه نسبت تراکم بالا بایگانی کرد.تبدیل مشابهی مدت هاست در تلویزیون استفاده می شود. یک باند فرکانس باریک تری برای سیگنال های مسئول رنگ در آنجا اختصاص داده شده است. یک ترجمه ساده از فضای رنگی RGB به فضای رنگی YCrCb را می توان با استفاده از یک ماتریس انتقال نشان داد:
گام 2.ما تصویر اصلی را به ماتریس های 8x8 تقسیم می کنیم. از هر کدام 3 ماتریس DCT کار می کنیم - 8 بیت به طور جداگانه برای هر جزء. در نسبت تراکم بالاتر، این مرحله می تواند کمی دشوارتر باشد. تصویر بر اساس مولفه Y تقسیم می شود، مانند مورد اول، و برای اجزای Cr و Cb، ماتریس ها از طریق یک ردیف و از طریق یک ستون تایپ می شوند. یعنی از ماتریس اصلی 16x16 فقط یک ماتریس DCT کار به دست می آید. در این صورت، همانطور که به راحتی قابل مشاهده است، ما 3/4 را از دست می دهیم اطلاعات مفیددر مورد اجزای رنگی تصویر و بلافاصله 2 برابر فشرده سازی دریافت کنید. ما می توانیم این کار را با کار در فضای YCrCb انجام دهیم. همانطور که تمرین نشان داده است، این تأثیر قابل توجهی بر روی تصویر RGB ایجاد شده ندارد.
مرحله 3.به شکل ساده شده، DCT برای n=8 می تواند به صورت زیر نمایش داده شود:
nu,v] = ^Hc(i,u)xC(j,v)y rY) Yq= IntegerRound این مرحله جایی است که نسبت تراکم کنترل می شود و بیشترین تلفات رخ می دهد. واضح است که با مشخص کردن MK با ضرایب بزرگ، به صفرهای بیشتر و در نتیجه درجه فشرده سازی بالاتری خواهیم رسید. اثرات خاص الگوریتم نیز با کوانتیزاسیون همراه است. در مقادیر گامای بالا، از دست دادن در فرکانسهای پایین میتواند آنقدر زیاد باشد که تصویر به مربعهای 8x8 تقسیم شود. تلفات در فرکانس های بالا می تواند خود را در به اصطلاح نشان دهد اثر گیبس،هنگامی که نوعی "هاله" در اطراف خطوط با یک انتقال رنگ تیز تشکیل می شود. گام 5. ماتریس 8x8 را با استفاده از اسکن زیگ زاگ به یک بردار 64 عنصری تبدیل می کنیم، یعنی عناصری را با شاخص های (0,0), (0,1), (1,0), (2,0) می گیریم. . بنابراین، در ابتدای بردار، ضرایب ماتریسی مربوط به فرکانس های پایین، و در انتها - به فرکانس های بالا را به دست می آوریم. مرحله 6.ما بردار را با استفاده از الگوریتم کدگذاری گروهی جمع می کنیم. در این صورت جفت هایی از نوع بدست می آوریم<пропустить, число>، که در آن "پرش" تعداد صفرهای حذف شده است و "عدد" مقداری است که باید در سلول بعدی قرار دهید. بنابراین، بردار 42 3000-2 00001 ... به جفت (0.42) (0.3) (3،-2) (4،1) تا می شود. گام 7. جفت های حاصل را با استفاده از کدگذاری هافمن با جدول ثابت جمع می کنیم. فرآیند بازیابی تصویر در این الگوریتم کاملاً متقارن است. این روش به شما امکان می دهد برخی از تصاویر را 10-15 بار بدون تلفات جدی فشرده کنید. جنبه های مثبت مهم الگوریتم عبارتند از: ■ سطح فشرده سازی تنظیم شده است. ■ تصویر رنگی خروجی می تواند 24 بیت در هر نقطه باشد. جنبه های منفی الگوریتم عبارتند از: ■ با افزایش سطح فشرده سازی، تصویر به مربع های جداگانه (8x8) تقسیم می شود. این به دلیل این واقعیت است که تلفات زیادی در فرکانسهای پایین در طول کوانتیزاسیون اتفاق میافتد و بازیابی دادههای اصلی غیرممکن میشود. ■ اثر گیبس ظاهر می شود - هاله ها در امتداد مرزهای انتقال رنگ تیز. همانطور که قبلاً ذکر شد، JPEG نسبتاً اخیراً - در سال 1991 - استاندارد شد. اما حتی در آن زمان نیز الگوریتمهایی وجود داشتند که با افت کیفیت کمتر فشردهتر میشدند. واقعیت این است که اقدامات توسعه دهندگان استاندارد به دلیل قدرت فناوری که در آن زمان وجود داشت محدود شد. یعنی حتی در رایانه شخصی، الگوریتم باید کمتر از یک دقیقه روی تصویر متوسط اجرا می شد و اجرای سخت افزاری آن باید نسبتاً ساده و ارزان باشد. الگوریتم باید متقارن باشد (زمان باز کردن زیپ تقریباً برابر با زمان بایگانی است). برآورده کردن نیاز اخیر امکان ظهور دستگاه هایی مانند دوربین های دیجیتال را فراهم می کند که عکس های 24 بیتی را روی یک فلش کارت 8 تا 256 مگابایتی می گیرند." سپس این کارت در شکاف لپ تاپ شما قرار می گیرد و برنامه مربوطه به شما اجازه می دهد. برای خواندن تصاویر درست نیست نیا،اگر الگوریتم نامتقارن بود، انتظار طولانی مدت برای "شارژ مجدد" دستگاه و فشرده سازی تصویر ناخوشایند خواهد بود. یکی دیگر از ویژگی های نه چندان خوشایند JPEG این است که،که اغلب نوارهای افقی و عمودی روی نمایشگر کاملاً نامرئی هستند و فقط هنگام چاپ به شکل الگوی موآر ظاهر می شوند. زمانی اتفاق میافتد که یک رستر چاپ شیبدار بر روی نوارهای افقی و عمودی تصویر قرار میگیرد. به دلیل این شگفتی ها، JPEG نیست به طور فعال توصیه می شودمورد استفاده در چاپ، تنظیم ضرایب ماتریس کوانتیزاسیون بالا. با این حال، هنگام آرشیو تصاویر در نظر گرفته شده برای مشاهده انسان، در حال حاضر ضروری است. وسیعاستفاده از JPEG برای مدت طولانی محدود بود، شاید تنها به این دلیل که بر روی تصاویر 24 بیتی کار می کند. بنابراین برای مشاهده تصویری با کیفیت قابل قبول بر روی مانیتور معمولی در پالت 256 رنگ، استفاده از الگوریتم های مناسب و به تبع آن زمان معینی نیاز بود. در برنامه های کاربردی با هدف کاربران خواستار، مانند بازی ها، چنین تاخیرهایی غیرقابل قبول است. علاوه بر این، اگر تصاویری دارید، مثلاً با فرمت GIF 8 بیتی، تبدیل شده به JPEG 24 بیتی، و سپس برای مشاهده به GIF برگردید، در طول هر دو تبدیل دو بار کیفیت از دست میرود. با این وجود، افزایش اندازه آرشیو اغلب آنقدر زیاد است (3-20 برابر)، و کاهش کیفیت آنقدر کم است که ذخیره تصاویر در JPEG بسیار مؤثر است. چند کلمه در مورد اصلاحات این الگوریتم باید گفت. اگرچه JPEG یک استاندارد ISO است، فرمت فایل آن ثابت نشده است. با استفاده از این مزیت، سازندگان فرمت های خود را ایجاد می کنند که با یکدیگر ناسازگار هستند و بنابراین می توانند الگوریتم را تغییر دهند. بنابراین، جداول الگوریتم داخلی توصیه شده توسط ISO با جداول خود جایگزین می شوند. علاوه بر این، هنگام تنظیم درجه تلفات، سردرگمی جزئی وجود دارد. به عنوان مثال، در طول آزمایش معلوم می شود که کیفیت "عالی"، "100٪" و "10 امتیاز" تصاویر به طور قابل توجهی متفاوت است. با این حال، به هر حال، کیفیت "100٪" به معنای فشرده سازی بدون تلفات نیست. همچنین گزینه های JPEG برای برنامه های خاص وجود دارد. به عنوان یک استاندارد ISO، JPEG به طور فزاینده ای برای تبادل تصاویر در شبکه های کامپیوتری استفاده می شود. الگوریتم JPEG در فرمتهای Quick Time، PostScript Level 2، Tiff 6.0 پشتیبانی میشود و در حال حاضر جایگاه برجستهای را در سیستمهای چند رسانهای اشغال میکند. ویژگی های الگوریتم JPEG: o ! w ، نسبت تراکم: 2-200 (تنظیم شده توسط کاربر). ,ts, :_,. . کلاس تصویر:تصاویر تمام رنگی 2jj.bit یا iso-| بازتاب در مقیاس خاکستری بدون تغییر رنگ واضح (عکس). تقارن: 1. مشخصات:در برخی موارد الگوریتم ایجاد می کند! "هاله" در اطراف مرزهای افقی و عمودی واضح در یک تصویر (اثر گیبس). علاوه بر این، در یک نسبت تراکم بالا، iso-! تصویر به بلوک های 8x8 پیکسل تقسیم می شود. دانستن الگوریتم JPEG نه تنها برای فشرده سازی تصویر بسیار مفید است. از تئوری از پردازش سیگنال دیجیتال، تجزیه و تحلیل ریاضی، جبر خطی، نظریه اطلاعات، به ویژه، تبدیل فوریه، کدگذاری بدون تلفات و غیره استفاده می کند. بنابراین، دانش به دست آمده می تواند در هر مکانی مفید باشد. در صورت تمایل پیشنهاد می کنم خودتان هم به موازات مقاله همین مراحل را طی کنید. بررسی کنید که استدلال بالا چقدر برای تصاویر مختلف مناسب است، سعی کنید اصلاحات خود را در الگوریتم ایجاد کنید. خیلی جالب است. به عنوان یک ابزار، من می توانم ترکیب فوق العاده Python + NumPy + Matplotlib + PIL (Pillow) را توصیه کنم. تقریباً تمام کارهای من (از جمله گرافیک و انیمیشن) با استفاده از آنها انجام شد. توجه، ترافیک! بسیاری از تصاویر، نمودارها و انیمیشن ها (~ 10 مگابایت). از قضا در مقاله JPEG تنها 2 تصویر با این فرمت از پنجاه تصویر وجود دارد. ما روی گربه های راکون آموزش خواهیم داد. تصویر خاکستری بالا به عنوان نمونه گرفته شده است. هم نواحی همگن و متضاد را به خوبی ترکیب می کند. و اگر یاد بگیریم خاکستری را فشرده کنیم، هیچ مشکلی با رنگ وجود نخواهد داشت. شما می توانید به طور ذهنی به این فکر کنید که چگونه سیگنالی که مقادیر آن به تدریج از مقدار حداکثر در ابتدا به مقدار حداقل در پایان کاهش می یابد، تجزیه می شود. یک تقریب کم و بیش کافی فقط می تواند توسط هارمونیک ها در انتها انجام شود که برای ما چندان عالی نیست. شکل سمت چپ تقریبی از یک سیگنال تک سر است. در سمت راست - متقارن: بنابراین، این ایده به ذهن شما خطور کرد که تحول خود را ایجاد کنید. این را به خاطر بسپار: بلوک های بزرگ نشان داده نمی شوند، زیرا از نظر بصری تقریباً از 32x32 قابل تشخیص نیستند. حالا بیایید به تفاوت مطلق با تصویر اصلی نگاه کنیم (تقویت شده 2 برابر، در غیر این صورت هیچ چیز واقعاً قابل مشاهده نیست): 8x8 نتایج بهتری نسبت به 4x4 می دهد. افزایش بیشتر در اندازه دیگر مزیت واضحی را ایجاد نمی کند. اگرچه من به طور جدی 16x16 را به جای 8x8 در نظر میگیرم: افزایش پیچیدگی تا 33٪ (در مورد پیچیدگی در پاراگراف بعدی بیشتر) یک بهبود کوچک اما همچنان قابل مشاهده برای همان تعداد ضرایب ایجاد میکند. با این حال، انتخاب 8x8 کاملا منطقی به نظر می رسد و ممکن است میانگین طلایی باشد. JPEG در سال 1991 منتشر شد. من فکر می کنم که چنین فشرده سازی برای پردازنده های آن زمان بسیار دشوار بود. دومینبحث و جدل. نکته ای که باید در نظر داشت این است که افزایش اندازه بلوک به محاسبات بیشتری نیاز دارد. بیایید تخمین بزنیم چقدر. پیچیدگی تبدیل، همانطور که قبلاً به خوبی می دانیم: O(N 2)، زیرا هر ضریب از N عبارت تشکیل شده است. اما در عمل از الگوریتم تبدیل فوریه سریع (FFT) کارآمد استفاده می شود. شرح آن از حوصله این مقاله خارج است. پیچیدگی آن: O(N*logN). برای یک بسط دو بعدی باید دو بار N بار از آن استفاده کنید. بنابراین پیچیدگی DCT 2 بعدی O(N 2 logN) است. حالا بیایید پیچیدگی محاسبه یک تصویر را با یک بلوک و چند بلوک کوچک مقایسه کنیم: سومبحث و جدل. اگر یک مرز واضح از رنگ ها در تصویر داشته باشیم، این روی کل بلوک تاثیر می گذارد. شاید بهتر باشد که این بلوک به اندازه کافی کوچک باشد، زیرا در بسیاری از بلوک های همسایه احتمالاً دیگر چنین مرزی وجود نخواهد داشت. با این حال، به دور از مرزها، تضعیف بسیار سریع اتفاق می افتد. علاوه بر این، خود حاشیه بهتر به نظر می رسد. بیایید آن را با استفاده از یک مثال با تعداد زیادی انتقال کنتراست بررسی کنیم، دوباره، تنها با یک چهارم ضرایب: و برای دسر کیفیت 5% را در نظر بگیرید (هنگام کد گذاری در فست استون). به هر حال، حدود 100٪ کیفیت. همانطور که ممکن است حدس بزنید، در این مورد ماتریس کوانتیزاسیون کاملاً از واحدها تشکیل شده است، یعنی هیچ کوانتیزهای رخ نمیدهد. با این حال، به دلیل گرد کردن ضرایب به نزدیکترین عدد صحیح، نمیتوانیم تصویر اصلی را با دقت بازیابی کنیم. به عنوان مثال، راکون دقیقاً 96٪ پیکسل ها را حفظ کرد، اما 4٪ تا 1/256 خاموش بود. البته، چنین "تحریف" را نمی توان از نظر بصری متوجه شد. مثال 0(برای گرم کردن بدن) کلماتی مانند A، B، C... را نشان می دهیم و آنها را نماد می نامیم. علاوه بر این، هر چیزی را می توان زیر نماد پنهان کرد: یک حرف الفبا، یک کلمه یا یک اسب آبی در باغ وحش. نکته اصلی این است که نمادهای یکسان با مفاهیم یکسان مطابقت دارند و نمادهای مختلف با مفاهیم مختلف مطابقت دارند. از آنجایی که وظیفه ما رمزگذاری کارآمد (فشرده سازی) است، ما با بیت ها کار خواهیم کرد، زیرا اینها کوچکترین واحدهای نمایش اطلاعات هستند. بنابراین، بیایید لیست را به صورت ABBAAABA بنویسیم. به جای "کلمه اول" و "کلمه دوم" می توان از بیت های 0 و 1 استفاده کرد سپس ABBAAABA به صورت 01100010 (8 بیت = 1 بایت) کدگذاری می شود. مثال 1 مثال 2 مثال 3 مثال 4 حالا همه چیز مرتب است. ما متوجه شدیم که DCها چگونه ذخیره می شوند: بیایید AC را تماشا کنیم: ما یک هیستوگرام از وابستگی کمیت برای این جفت ها و یک درخت هافمن می سازیم. ویژگی های پیاده سازی در JPEG: ما متوجه شدیم که هر بلوک در فایلی مانند این رمزگذاری و ذخیره می شود: امیدوارم اکنون الگوریتم JPEG را به طور مستقیم درک کرده باشید. با تشکر برای خواندن! UPD برچسب ها: اضافه کردن برچسب الگوریتم تبدیل یک تصویر گرافیکی JPEG شامل چندین مرحله است که به صورت متوالی بر روی تصویر انجام می شود و یکی پس از دیگری انجام می شود: - تبدیل فضای رنگی، - نمونه گیری فرعی، - تبدیل کسینوس گسسته (DCT) - کوانتیزاسیون، - کد نویسی در مرحله تبدیل فضای رنگی، تصویر از فضای رنگی RGB به YCbCr تبدیل می شود (که در آن Y روشنایی است و Cb و Cr اجزای تفاوت رنگ نقطه تصویر هستند): کاربرد فضا YCbCrبه جای معمول RGBبا ویژگی های فیزیولوژیکی بینایی انسان توضیح داده می شود، یعنی این واقعیت که سیستم عصبی انسان به میزان قابل توجهی حساسیت بیشتری به روشنایی دارد. Y) نسبت به اجزای تفاوت رنگ (در این مورد Cbو Cr). تبدیل فضای رنگ معکوس (از YCrCb V RGB) دارای شکل: الگوریتم فشرده سازی JPEG به شما امکان می دهد تصاویر را با اندازه های صفحه رنگی مختلف فشرده کنید. اجازه دهید با نشان دادن x iو y منعرض و ارتفاع منصفحه رنگی ام تصویر اجازه دهید ایکس= حداکثر(x i), Y= حداکثر(y من) برای هر صفحه ضرایبی را تعریف می کنیم سلام= ایکس/ x iو V i= Y/ y من. بزرگترین ارزش برای ایکسو Yطبق الگوریتم JPEG 2 16 است و برای سلامو V i– 2 2 . بنابراین، عرض و ارتفاع صفحات رنگی می تواند از 1 تا 4 برابر کوچکتر از ابعاد بزرگترین هواپیما باشد. برای معمولی RGBدر تصاویر، اندازه همه صفحات رنگی برابر است. نمونه برداری فرعی شامل کاهش اندازه هواپیماها است Crو Cb. رایج ترین کاهش 2 برابر در عرض و 2 برابر در ارتفاع است (شکل 1 را ببینید). برای این Crو Cbصفحات تصویر به بلوک هایی با اندازه 2 در 2 پیکسل تقسیم می شوند و بلوک با یک نمونه از اجزای تفاوت رنگ جایگزین می شود (به جای 4 نمونه موجود، میانگین حسابی آنها برای هر بلوک قرار می گیرد که باعث می شود امکان کاهش اندازه تصویر اصلی تا 2 برابر). شکل 1 - انواع رایج نمونه برداری پایین سپس، به طور جداگانه برای هر جزء فضای رنگی Y, Cbو Cr، تبدیل کسینوس گسسته مستقیم انجام می شود. برای انجام این کار، تصویر به بلوک هایی با اندازه 8 در 8 پیکسل تقسیم می شود و هر بلوک طبق فرمول تبدیل می شود: استفاده از تبدیل کسینوس گسسته به شما امکان می دهد از نمایش فضایی تصویر به طیفی حرکت کنید. تبدیل کسینوس گسسته معکوس به شکل زیر است: پس از این می توانید به کمی سازی اطلاعات دریافتی اقدام کنید. ایده کوانتیزاسیون دور انداختن مقدار معینی از اطلاعات است. مشخص است که چشم انسان نسبت به فرکانسهای بالا (مخصوصاً به فرکانسهای بالای اجزای دارای تفاوت رنگ) حساسیت کمتری دارد؛ بیشتر تصاویر عکاسی حاوی اجزای کمی با فرکانس بالا هستند. علاوه بر این، ظهور فرکانسهای بالا نتیجه فرآیند دیجیتالیسازی است، یعنی. به دلیل ظهور نویز نمونه برداری و کوانتیزاسیون همراه. در این مرحله به اصطلاح جداول کوانتیزاسیون- ماتریس های متشکل از اعداد صحیح مثبت با اندازه 8 در 8، که فرکانس های مربوط به بلوک های تصویر به آنها تقسیم می شود، نتیجه به یک عدد صحیح گرد می شود: فرآیند dequantization از همان جداول کوانتیزاسیون استفاده می کند. کوانتیزاسیون شامل ضرب فرکانس های کوانتیزه شده در عناصر مربوطه جدول کوانتیزه شدن است: بنابراین، با افزایش ضریب کوانتیزاسیون، مقدار اطلاعات دور ریخته شده افزایش می یابد. بیایید با استفاده از یک مثال به این موضوع با جزئیات بیشتری نگاه کنیم. بلوک قبل از کوانتیزه شدن: 3862, –22, –162, –111, –414, 12, 717, 490, 383, 902, 913, 234, –555, 18, –189, 236, 229, 707, –708, 775, 423, –411, –66, –685, 231, 34, –928, 34, –1221, 647, 98, –824, –394, 128, –307, 757, 10, –21, 431, 427, 324, –874, –367, –103, –308, 74, –1017, 1502, 208, –90, 114, –363, 478, 330, 52, 558, 577, 1094, 62, 19, –810, –157, –979, –98 جدول کوانتیزاسیون (کیفیت 90): 24, 16, 16, 24, 40, 64, 80, 96, 16, 16, 24, 32, 40, 96, 96, 88, 24, 24, 24, 40, 64, 88, 112, 88, 24, 24, 32, 48, 80, 136, 128, 96, 32, 32, 56, 88, 112, 176, 168, 120, 40, 56, 88, 104, 128, 168, 184, 144, 80, 104, 128, 136, 168, 192, 192, 160, 112, 144, 152, 160, 176, 160, 168, 160 بلوک پس از کوانتیزاسیون: 161, –1, –10, –5, –10, 0, 9, 5, 24, 56, 38, 7, –14, 0, –2, 3, 10, 29, –30, 19, 7, –5, –1, –8, 10, 1, –29, 1, –15, 5, 1, –9, –12, 4, –5, 9, 0, 0, 3, 4, 8, –16, –4, –1, –2, 0, –6, 10, 3, –1, 1, –3, 3, 2, 0, 3, 5, 8, 0, 0, –5, –1, –6, –1 3864, –16, –160, –120, –400, 0, 720, 480, 384, 896, 912, 224, –560, 0, –192, 264, 240, 696, –720, 760, 448, –440, –112, –704, 240, 24, –928, 48,–1200, 680, 128, –864, –384, 128, –280, 792, 0, 0, 504, 480, 320, –896, –352, –104, –256, 0,–1104, 1440, 240, –104, 128, –408, 504, 384, 0, 480, 560, 1152, 0, 0, –880, –160,–1008, –160 جدول کوانتیزاسیون (کیفیت 45): 144, 96, 88, 144, 216, 352, 456, 544, 104, 104, 128, 168, 232, 512, 536, 488, 128, 112, 144, 216, 352, 504, 616, 496, 128, 152, 192, 256, 456, 776, 712, 552, 160, 192, 328, 496, 600, 968, 912, 680, 216, 312, 488, 568, 720, 920, 1000, 816, 432, 568, 696, 776, 912, 1072, 1064, 896, 640, 816, 840, 872, 992, 888, 912, 880 بلوک پس از کوانتیزاسیون: 27, 0, –2, –1, –2, 0, 2, 1, 4, 9, 7, 1, –2, 0, 0, 0, 2, 6, –5, 4, 1, –1, 0, –1, 2, 0, –5, 0, –3, 1, 0, –1, –2, 1, –1, 2, 0, 0, 0, 1, 2, –3, –1, 0, 0, 0, –1, 2, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, –1, 0, –1, 0 مسدود کردن پس از تبدیل معکوس: 3888, 0, –176, –144, –432, 0, 912, 544, 416, 936, 896, 168, –464, 0, 0, 0, 256, 672, –720, 864, 352, –504, 0, –496, 256, 0, –960, 0,–1368, 776, 0, –552, –320, 192, –328, 992, 0, 0, 0, 680, 432, –936, –488, 0, 0, 0,–1000, 1632, 0, 0, 0, 0, 912, 0, 0, 896, 640, 816, 0, 0, –992, 0, –912, 0 همانطور که مشاهده می شود، در مورد اول تغییر دی سیضریب فشرده سازی 2 و در دومی 26 در حالی که کوانتیزه شده است دی سیضریب در مورد دوم 6 برابر کمتر از مورد اول است. کدگذاری آخرین مرحله فشردهسازی است که در طی آن، بلوکهای تصویر طبق قانون مشخص شده توسط بلوکهای فرم به شکل برداری تبدیل میشوند: 0, 1, 5, 6, 14, 15, 27, 28, 2, 4, 7, 13, 16, 26, 29, 42, 3, 8, 12, 17, 25, 30, 41, 43, 9, 11, 18, 24, 31, 40, 44, 53, 10, 19, 23, 32, 39, 45, 52, 54, 20, 22, 33, 38, 46, 51, 55, 60, 21, 34, 37, 47, 50, 56, 59, 61, 35, 36, 48, 49, 57, 58, 62, 63 که در آن شاخص های برداری اجزای ماتریس مربوطه به عنوان عناصر بلوک نشان داده می شوند. در این حالت، عنصر صفر به عنوان تفاوت با عنصر صفر بلوک قبلی کدگذاری می شود. عناصر صفر نشان می دهد دی سی، آنها شامل جزء ثابت بلوک هستند (همه عناصر AC دیگر معمولاً نشان داده می شوند A.C.). سپس داده های به دست آمده با استفاده از رمزگذاری حسابی یا اصلاح الگوریتم هافمن فشرده می شوند. این مرحله از نظر استگانوگرافی در تصاویر گرافیکی چندان مورد توجه نیست، بنابراین از حوصله ما خارج است.
از عنوان به درستی متوجه شدید که این یک توصیف خیلی معمولی از الگوریتم JPEG نیست (فرمت فایل را به طور مفصل در مقاله "رمزگشایی JPEG برای Dummies" توضیح دادم). اول از همه، روش انتخاب شده برای ارائه مطالب فرض می کند که ما نه تنها در مورد JPEG، بلکه در مورد تبدیل فوریه و کدگذاری هافمن نیز چیزی نمی دانیم. به طور کلی، ما کمی از سخنرانی ها به یاد می آوریم. آنها فقط عکس را گرفتند و شروع کردند به فکر کردن در مورد اینکه چگونه می توان آن را فشرده کرد. بنابراین، من سعی کردم به وضوح فقط ماهیت را بیان کنم، اما در آن خواننده درک نسبتاً عمیق و مهمتر از همه شهودی از الگوریتم ایجاد خواهد کرد. فرمول ها و محاسبات ریاضی - حداقل فقط آنهایی که برای درک آنچه اتفاق می افتد مهم هستند.
الگوریتم فشرده سازی اطلاعات هر چه باشد، اصل آن همیشه یکسان خواهد بود - یافتن و توصیف الگوها. هرچه الگوهای بیشتر، افزونگی بیشتر، اطلاعات کمتری داشته باشد. آرشیوها و کدگذارها معمولاً برای نوع خاصی از اطلاعات "تطبیق" می شوند و می دانند کجا آن را پیدا کنند. در برخی موارد، یک الگو بلافاصله قابل مشاهده است، مانند تصویر یک آسمان آبی. هر ردیف از نمایش دیجیتالی آن را می توان با یک خط مستقیم کاملاً دقیق توصیف کرد.نمایش برداری
ابتدا بیایید بررسی کنیم که دو پیکسل همسایه چقدر به هم وابسته هستند. منطقی است که فرض کنیم به احتمال زیاد آنها بسیار شبیه هستند. بیایید این را برای همه جفت های تصویر بررسی کنیم. بیایید آنها را در صفحه مختصات با نقاط علامت گذاری کنیم تا مقدار نقطه در امتداد محور X مقدار پیکسل اول و در امتداد محور Y - دومین باشد. برای تصویر ما با ابعاد 256 در 256، 256*256/2 پیکسل را دریافت می کنیم: 
به طور قابل پیش بینی، بیشتر نقاط روی یا نزدیک خط y=x قرار دارند (و حتی بیشتر از آن چیزی است که در شکل دیده می شود، زیرا آنها بارها روی یکدیگر همپوشانی دارند و علاوه بر این، نیمه شفاف هستند). اگر چنین است، کار با چرخاندن آنها به اندازه 45 درجه آسان تر خواهد بود. برای انجام این کار، باید آنها را در یک سیستم مختصات متفاوت بیان کنید. 
بردارهای اساسی سیستم جدید بدیهی است: . برای به دست آوردن یک سیستم متعارف (طول بردارهای پایه برابر با یک است) مجبوریم بر ریشه دو تقسیم کنیم. در اینجا نشان داده شده است که یک نقطه معین p = (x, y) در سیستم جدید به عنوان یک نقطه (a 0 , a 1) نشان داده می شود. با دانستن ضرایب جدید، به راحتی می توانیم با چرخاندن ضرایب قبلی، آنها را بدست آوریم. واضح است که مختصات اول (جدید) میانگین است و دومی اختلاف x و y (اما تقسیم بر ریشه 2). تصور کنید که از شما خواسته می شود فقط یکی از مقادیر را بگذارید: یا 0 یا 1 (یعنی دیگری را با صفر برابر کنید). بهتر است 0 را انتخاب کنید، زیرا مقدار 1 به احتمال زیاد حدود صفر خواهد بود. اگر تصویر را فقط از 0 بازیابی کنیم این اتفاق می افتد: 
بزرگنمایی 4 برابر: 
راستش این فشرده سازی خیلی چشمگیر نیست. بهتر است به طور مشابه تصویر را به سه پیکسل تقسیم کنید و آنها را در فضای سه بعدی ارائه دهید. 

این همان نمودار است، اما از دیدگاه های مختلف. خطوط قرمز محورهایی هستند که خودشان را مطرح کردند. آنها با بردارها مطابقت دارند: . به شما یادآوری می کنم که باید بر چند ثابت تقسیم کنید تا طول بردارها برابر با یک شود. بنابراین، با گسترش بر این اساس، 3 مقدار a 0، a 1، a 2 و a 0 مهمتر از 1 است و یک مقدار مهمتر از 2 است. اگر 2 را دور بیندازیم، نمودار در جهت بردار e 2 "مسطح" می شود. این ورق سه بعدی نسبتاً نازک، مسطح خواهد شد. او آنقدرها را از دست نمی دهد، اما ما از شر یک سوم ارزش ها خلاص می شویم. بیایید تصاویر بازسازی شده از سه گانه را با هم مقایسه کنیم: (a 0 , 0 , 0 )، (a 1 , a 2 , 0) و (a 0 , a 1 , a 2). در آخرین نسخه ما چیزی را دور نینداختیم، بنابراین نسخه اصلی را دریافت خواهیم کرد. 
بزرگنمایی 4 برابر: 
نقاشی دوم در حال حاضر خوب است. نواحی تیز کمی صاف شدند، اما در کل تصویر به خوبی حفظ شد. و حالا بیایید به همین ترتیب بر چهار تقسیم کنیم و اساس را در فضای چهار بعدی به صورت بصری تعیین کنیم... اوه، خوب، بله. اما می توانید حدس بزنید که یکی از بردارهای پایه کدام خواهد بود: (1،1،1،1)/2. بنابراین، می توان برای شناسایی فضای چهار بعدی به فضای عمود بر بردار (1،1،1،1) نگاه کرد. اما این بهترین راه نیست.
هدف ما این است که یاد بگیریم چگونه (x 0 , x 1 , ..., x n-1) را به (a 0, a 1, ..., a n-1) تبدیل کنیم تا هر مقدار a i اهمیت کمتری داشته باشد. نسبت به قبلی ها . اگر بتوانیم این کار را انجام دهیم، شاید بتوان آخرین مقادیر دنباله را به کلی دور انداخت. آزمایش های فوق به این امر اشاره می کند که امکان پذیر است. اما شما نمی توانید بدون یک دستگاه ریاضی انجام دهید.
بنابراین، ما باید نقاط را به یک مبنای جدید تبدیل کنیم. اما ابتدا باید یک پایه مناسب پیدا کنید. بیایید به اولین آزمایش جفت شدن برگردیم. بیایید آن را به طور کلی در نظر بگیریم. ما بردارهای پایه را تعریف کرده ایم: 
ما بردار را از طریق آنها بیان کردیم پ:
یا در مختصات: 
برای پیدا کردن 0 و 1 باید پروژه کنید پبر ه 0 و ه 1 به ترتیب. و برای این شما باید محصول اسکالر را پیدا کنید
مشابه:
در مختصات: 
انجام تبدیل به شکل ماتریسی اغلب راحت تر است. 
سپس A = EX و X = E T A. این یک فرم زیبا و راحت است. ماتریس E را ماتریس تبدیل می نامند و متعامد است که بعداً با آن آشنا خواهیم شد. انتقال از بردارها به توابع.
کار با بردارهایی با ابعاد کوچک راحت است. با این حال، ما می خواهیم الگوها را در بلوک های بزرگتر پیدا کنیم، بنابراین به جای بردارهای N-بعدی، راحت تر است که با دنباله هایی که تصویر را نشان می دهند کار کنیم. من چنین دنباله هایی را توابع گسسته می نامم، زیرا استدلال زیر در مورد توابع پیوسته نیز صدق می کند.
در بازگشت به مثال خود، تابع f(i) را تصور کنید که تنها در دو نقطه تعریف شده است: f(0)=x و f(1)=y. به طور مشابه، توابع پایه e 0 (i) و e 1 (i) را بر اساس پایه ها تعریف می کنیم. ه 0 و ه 1 . ما گرفتیم: 
این یک نتیجه گیری بسیار مهم است. حال در عبارت «بسط بردار در بردارهای متعامد» می توان کلمه «بردار» را با «تابع» جایگزین کرد و عبارت کاملاً صحیح «بسط یک تابع در توابع متعامد» را به دست آورد. مهم نیست که چنین تابع کوتاهی داشته باشیم، زیرا همان استدلال برای یک بردار N بعدی کار می کند، که می تواند به عنوان یک تابع گسسته با مقادیر N نمایش داده شود. و کار با توابع واضح تر از بردارهای N بعدی است. برعکس، شما می توانید چنین تابعی را به عنوان یک بردار نشان دهید. علاوه بر این، یک تابع پیوسته معمولی را می توان با یک بردار بیبعدی نشان داد، البته نه در اقلیدسی، بلکه در فضای هیلبرت. اما ما به آنجا نخواهیم رفت؛ ما فقط به عملکردهای گسسته علاقه مند خواهیم بود.
و مشکل ما برای یافتن پایه به مشکل یافتن یک سیستم مناسب از توابع متعارف تبدیل می شود. در استدلال زیر فرض بر این است که ما قبلاً به نحوی مجموعه ای از توابع پایه را تعیین کرده ایم که بر اساس آنها تجزیه می شویم.
فرض کنید تابعی داریم (مثلاً با مقادیر نشان داده می شود) که می خواهیم آن را به عنوان مجموع عملکردهای دیگر نشان دهیم. شما می توانید این فرآیند را به صورت برداری نمایش دهید. برای تجزیه یک تابع، باید آن را یکی یکی بر روی توابع پایه "پروژه" کنید. در مفهوم برداری، محاسبه طرح ریزی، حداقل رویکرد بردار اصلی را از نظر فاصله به بردار دیگر می دهد. با یادآوری اینکه فاصله با استفاده از قضیه فیثاغورث محاسبه می شود، یک نمایش مشابه در قالب توابع بهترین تقریب ریشه میانگین مربع یک تابع را به تابع دیگر می دهد. بنابراین، هر ضریب (k) "نزدیک بودن" تابع را تعیین می کند. به طور رسمی تر، k*e(x) بهترین ریشه تقریب میانگین مربع به f(x) در بین l*e(x) است.
مثال زیر فرآیند تقریب یک تابع را تنها با استفاده از دو نقطه نشان می دهد. در سمت راست یک نمایش برداری است. 
در رابطه با آزمایش ما برای تقسیم به جفت، می توان گفت که این دو نقطه (0 و 1 در امتداد آبسیسا) یک جفت پیکسل همسایه هستند (x,y).
همان چیزی است، اما با انیمیشن: 
اگر 3 امتیاز بگیریم، باید بردارهای سه بعدی را در نظر بگیریم، اما تقریب دقیق تر خواهد بود. و برای یک تابع گسسته با مقادیر N، باید بردارهای N بعدی را در نظر بگیرید.
با داشتن مجموعه ای از ضرایب به دست آمده، می توانید به راحتی تابع اصلی را با جمع کردن توابع پایه گرفته شده با ضرایب مربوطه بدست آورید. تجزیه و تحلیل این ضرایب می تواند اطلاعات مفید زیادی (بسته به مبنا) ارائه دهد. یک مورد خاص از این ملاحظات، اصل بسط سری فوریه است. از این گذشته ، استدلال ما برای هر مبنایی قابل اجرا است و هنگام گسترش به یک سری فوریه ، یک کاملاً خاص گرفته می شود. تبدیل فوریه گسسته (DFT)
در قسمت قبل به این نتیجه رسیدیم که خوب است یک تابع را به اجزای آن تجزیه کنیم. در آغاز قرن نوزدهم، فوریه نیز به این موضوع فکر کرد. درست است، او تصویری از راکون نداشت، بنابراین مجبور شد توزیع گرما را در امتداد حلقه فلزی مطالعه کند. سپس متوجه شد که بیان دما (و تغییر آن) در هر نقطه از حلقه به صورت مجموع سینوسی ها با دوره های مختلف بسیار راحت است. فوریه دریافت (توصیه میکنم مطالعه کنید، جالب است) که هارمونیک دوم 4 برابر سریعتر از اولی کاهش مییابد، و هارمونیکهای مرتبه بالاتر با سرعتی حتی سریعتر تحلیل میروند.»
به طور کلی، به زودی مشخص شد که توابع تناوبی را می توان کاملاً به مجموع سینوسی ها تجزیه کرد. و از آنجایی که در طبیعت اشیاء و فرآیندهای زیادی وجود دارد که توسط توابع دوره ای توصیف شده است، ابزار قدرتمندی برای تجزیه و تحلیل آنها ظاهر شده است.
شاید یکی از بصری ترین فرآیندهای دوره ای صدا باشد. 
اگر در آن لحظه که من از سری فوریه اطلاعی نداشتم مقادیر آخرین تابع را به من می دادند و از من می خواستند آنها را تجزیه و تحلیل کنم، قطعاً گیج می شدم و نمی توانستم چیز ارزشمندی بگویم. خوب، بله، نوعی عملکرد، اما چگونه می توان فهمید که چیزی در آنجا سفارش شده است؟ اما اگر حدس می زدم که آخرین عملکرد را گوش کنم، گوشم لحنی ناب در میان سروصدا می گرفت. اگرچه خیلی خوب نیست، زیرا در طول تولید من به طور خاص چنین پارامترهایی را انتخاب کردم تا در نمودار خلاصه سیگنال به صورت بصری در نویز حل شود. همانطور که متوجه شدم، هنوز دقیقاً مشخص نیست که سمعک چگونه این کار را انجام می دهد. با این حال، اخیراً مشخص شد که صدا را به امواج سینوسی تجزیه نمی کند. شاید روزی بفهمیم که چگونه این اتفاق می افتد و الگوریتم های پیشرفته تری ظاهر شوند. خوب، در حال حاضر ما آن را به روش قدیمی انجام می دهیم.
چرا سعی نمی کنید از سینوسی ها به عنوان پایه استفاده کنید؟ در واقع، ما قبلاً این کار را انجام داده ایم. اجازه دهید تجزیه خود را به 3 بردار پایه به یاد بیاوریم و آنها را در نمودار ارائه کنیم: 
بله، بله، می دانم، به نظر یک تعدیل است، اما با سه بردار انتظار بیشتر از این سخت است. اما اکنون روشن است که چگونه می توان به عنوان مثال 8 بردار پایه را بدست آورد: 
بررسی نه چندان پیچیده نشان می دهد که این بردارها به صورت جفتی عمود هستند، یعنی متعامد. این بدان معنی است که آنها می توانند به عنوان پایه استفاده شوند. تبدیل بر روی چنین مبنایی به طور گسترده ای شناخته شده است و تبدیل کسینوس گسسته (DCT) نامیده می شود. من فکر می کنم از نمودارهای بالا مشخص است که چگونه فرمول تبدیل DCT به دست می آید:
این هنوز همان فرمول است: A = EX با پایه جایگزین. بردارهای پایه DCT مشخص شده (آنها همچنین بردارهای ردیفی ماتریس E هستند) متعامد هستند، اما متعامد نیستند. این را باید در طول تبدیل معکوس به خاطر بسپارم (من در این مورد نمی مانم، اما برای علاقه مندان، DCT معکوس دارای عبارت 0.5*a 0 است، زیرا بردار پایه صفر بزرگتر از بقیه است).
مثال زیر روند تقریب جمع های فرعی را به مقادیر اصلی نشان می دهد. در هر تکرار، مبنای بعدی در ضریب بعدی ضرب می شود و به جمع میانی اضافه می شود (یعنی همان چیزی است که در آزمایش های اولیه روی راکون - یک سوم مقادیر، دو سوم). 
اما، با این وجود، علیرغم برخی استدلال ها در مورد مناسب بودن انتخاب چنین مبنایی، هنوز هیچ استدلال واقعی وجود ندارد. در واقع، بر خلاف صدا، امکان تجزیه یک تصویر به توابع دوره ای بسیار کمتر آشکار است. با این حال، تصویر در واقع می تواند حتی در یک منطقه کوچک بسیار غیرقابل پیش بینی باشد. بنابراین، تصویر به قطعات به اندازه کافی کوچک، اما نه کاملا کوچک، تقسیم می شود تا تجزیه منطقی باشد. در JPEG، تصویر به مربع های 8x8 برش داده می شود. در چنین قطعه ای، عکس ها معمولاً بسیار یکنواخت هستند: پس زمینه به علاوه نوسانات کوچک. چنین مناطقی به زیبایی توسط سینوسی ها نزدیک می شوند.
خوب، بیایید بگوییم که این واقعیت کم و بیش شهودی است. اما احساس بدی در مورد تغییر رنگ ناگهانی وجود دارد، زیرا تغییر آهسته عملکردها ما را نجات نخواهد داد. ما باید توابع مختلف فرکانس بالا را اضافه کنیم که کار خود را انجام می دهند، اما در کنار یک پس زمینه همگن ظاهر می شوند. بیایید یک تصویر 256x256 با دو ناحیه متضاد بگیریم: 
اجازه دهید هر ردیف را با استفاده از DCT تجزیه کنیم، بنابراین 256 ضریب در هر ردیف به دست میآید.
سپس فقط n ضرایب اول را رها می کنیم و بقیه را صفر می کنیم و بنابراین، تصویر به صورت مجموع تنها هارمونیک های اول ارائه می شود: 
عدد در تصویر تعداد شانس باقی مانده است. در تصویر اول فقط مقدار میانگین باقی مانده است. در مورد دوم، قبلاً یک سینوسی با فرکانس پایین اضافه شده است و غیره. به هر حال، به حاشیه توجه کنید - با وجود همه بهترین تقریب ها، 2 نوار به وضوح در کنار مورب قابل مشاهده است، یکی روشن تر، دیگری تیره تر. بخشی از آخرین تصویر 4 بار بزرگ شده است:
و به طور کلی، اگر دور از مرز یک پسزمینه یکنواخت اولیه را ببینیم، پس از نزدیک شدن به آن، دامنه شروع به رشد میکند، در نهایت به یک مقدار حداقل میرسد و سپس ناگهان به حداکثر میرسد. این پدیده به اثر گیبس معروف است. 
ارتفاع این قوزها که در نزدیکی ناپیوستگی های تابع ظاهر می شوند، با افزایش تعداد مجموع توابع کاهش نمی یابد. در یک تبدیل گسسته تنها زمانی ناپدید می شود که تقریباً همه ضرایب حفظ شوند. به طور دقیق تر، نامرئی می شود.
مثال زیر کاملا شبیه به تجزیه مثلث های فوق است، اما در یک راکون واقعی: 
هنگام مطالعه DCT، ممکن است این تصور نادرست ایجاد شود که فقط چند ضرایب اول (فرکانس پایین) همیشه کافی است. این در مورد بسیاری از عکسها صادق است، عکسهایی که معنایشان بهطور چشمگیری تغییر نمیکند. با این حال، در مرز مناطق متضاد، مقادیر به سرعت "پرش" می کنند و حتی آخرین ضرایب نیز بزرگ خواهند بود. بنابراین، وقتی در مورد خاصیت صرفه جویی انرژی DCT می شنوید، این واقعیت را در نظر بگیرید که برای بسیاری از انواع سیگنال هایی که با آنها مواجه می شوند، اعمال می شود، اما نه برای همه. مثلاً به این فکر کنید که یک تابع گسسته که ضرایب انبساط آن به جز تابع آخر برابر با صفر است، چگونه خواهد بود. نکته: به تجزیه به شکل برداری فکر کنید.
با وجود کاستی ها، اساس انتخاب شده یکی از بهترین ها در عکس های واقعی است. کمی بعد مقایسه کوچکی با دیگران خواهیم دید. DCT در مقابل هر چیز دیگری
وقتی موضوع تبدیلهای متعامد را مطالعه کردم، صادقانه بگویم، با این استدلال که همه چیز در اطراف مجموع نوسانات هارمونیک است، خیلی متقاعد نشدم، بنابراین لازم است تصاویر را به سینوسی تجزیه کنیم. یا شاید برخی از توابع مرحله بهتر باشد؟ بنابراین، من به دنبال نتایج تحقیقاتی در مورد بهینه بودن DCT در تصاویر واقعی بودم. این واقعیت که "این DCT است که اغلب در کاربردهای عملی به دلیل خاصیت "تراکم انرژی" یافت می شود" در همه جا نوشته شده است. این ویژگی به این معنی است که حداکثر مقدار اطلاعات در ضرایب اول موجود است. و چرا؟ انجام تحقیق دشوار نیست: ما خود را با مجموعه ای از تصاویر مختلف، پایه های مختلف شناخته شده مسلح می کنیم و شروع به محاسبه انحراف استاندارد از تصویر واقعی برای تعداد متفاوتی از ضرایب می کنیم. من یک مطالعه کوچک در یک مقاله (تصاویر استفاده شده) در مورد این تکنیک پیدا کردم. نمودارهایی از وابستگی انرژی ذخیره شده به تعداد اولین ضرایب انبساط برای پایه های مختلف را نشان می دهد. اگر به نمودارها نگاه کنید، متقاعد شدهاید که DCT مرتباً رتبهی افتخاری را به خود اختصاص میدهد... اوم... مقام سوم. چطور؟ این چه نوع تبدیل KLT است؟ داشتم از DCT تعریف می کردم و بعد... KLT
همه تبدیل ها، به جز KLT، تبدیل هایی با پایه ثابت هستند. و در KLT (تبدیل Karhunen-Loeve) بهینه ترین مبنای برای چندین بردار محاسبه می شود. به گونه ای محاسبه می شود که ضرایب اول کوچکترین میانگین مجذور خطا را در مجموع برای همه بردارها می دهد. ما قبلاً کارهای مشابه را به صورت دستی انجام دادیم و اساس را به صورت بصری تعیین کردیم. در ابتدا ایده خوبی به نظر می رسد. برای مثال میتوانیم تصویر را به بخشهای کوچک تقسیم کنیم و مبنای خود را برای هر کدام محاسبه کنیم. اما نه تنها نگرانی ذخیره این مبنا وجود دارد، بلکه عملیات محاسبه آن نیز کاملاً کار بر است. اما DCT فقط کمی ضرر می کند و علاوه بر این، DCT دارای الگوریتم های تبدیل سریع است. DFT
DFT (تبدیل فوریه گسسته) - تبدیل فوریه گسسته. تحت این نام، نه تنها یک تبدیل خاص، بلکه به کل کلاس تبدیل های گسسته (DCT، DST...) نیز اشاره می شود. بیایید به فرمول DFT نگاه کنیم: 
همانطور که ممکن است حدس بزنید، این یک تبدیل متعامد با نوعی پایه پیچیده است. از آنجایی که چنین شکل پیچیده ای کمی بیشتر از حد معمول رخ می دهد، مطالعه اشتقاق آن منطقی است.
ممکن است به نظر برسد که هر سیگنال هارمونیک خالص (با فرکانس عدد صحیح) با تجزیه DCT تنها یک ضریب غیر صفر مربوط به این هارمونیک را به دست می دهد. این درست نیست، زیرا علاوه بر فرکانس، فاز این سیگنال نیز مهم است. به عنوان مثال، انبساط سینوس به کسینوس (به روشی مشابه در انبساط گسسته) به این صورت خواهد بود:
خیلی برای هارمونیک های خالص. او یک دسته دیگر را تخم ریزی کرد. این انیمیشن ضرایب DCT یک موج سینوسی را در فازهای مختلف نشان می دهد. 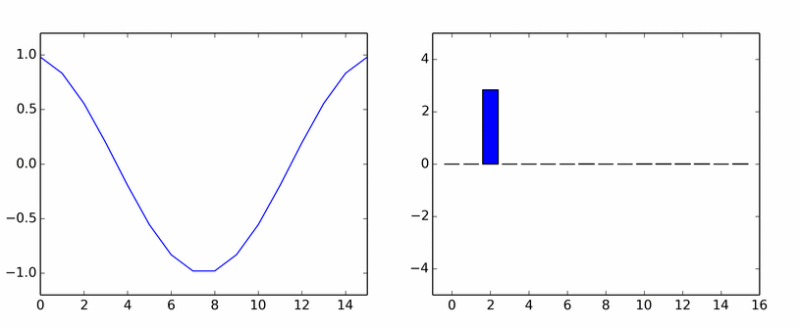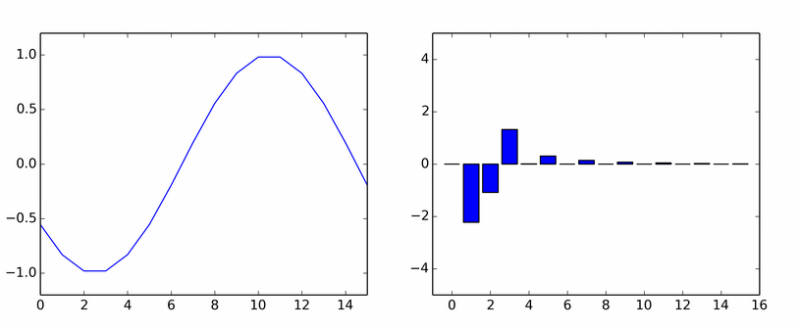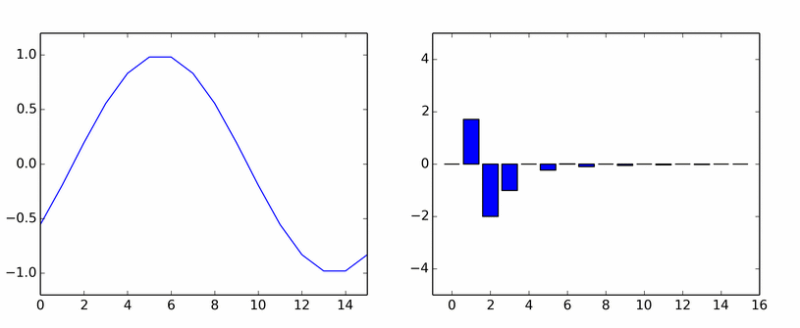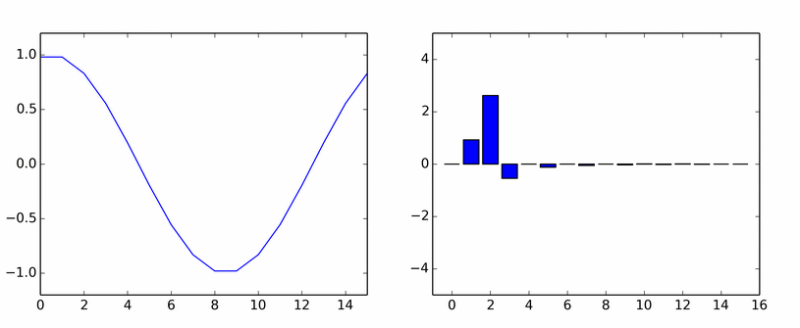
اگر به نظر می رسید که ستون ها حول یک محور می چرخند، به نظر شما نمی رسد.
این بدان معناست که اکنون ما تابع را به مجموع سینوسیها نه تنها با فرکانسهای مختلف، بلکه به آنهایی که در طول یک فاز جابهجا شدهاند نیز گسترش میدهیم. در نظر گرفتن تغییر فاز با استفاده از مثال کسینوس راحت تر خواهد بود:
یک هویت مثلثاتی ساده نتیجه مهمی به دست می دهد: تغییر فاز با مجموع سینوس و کسینوس جایگزین می شود که با ضرایب cos(b) و sin(b) گرفته می شود. این بدان معنی است که توابع را می توان به مجموع سینوس ها و کسینوس ها (بدون هیچ فازی) گسترش داد. این یک شکل مثلثاتی رایج است. با این حال، پیچیده بسیار بیشتر استفاده می شود. برای به دست آوردن آن باید از فرمول اویلر استفاده کنید. به سادگی با جایگزینی فرمول های مشتق برای سینوس و کسینوس، به دست می آوریم: 
حالا برای یک تغییر کوچک. خط زیر عدد مزدوج است.
برابری نهایی را بدست می آوریم:
c یک ضریب مختلط است که قسمت واقعی آن برابر با ضریب کسینوس و قسمت خیالی برابر با ضریب سینوس است. و مجموعه نقاط (cos(b)، sin(b)) یک دایره است. در چنین ضبطی، هر هارمونیک با فرکانس مثبت و منفی وارد انبساط می شود. بنابراین، در فرمول های مختلف تحلیل فوریه، جمع یا ادغام معمولاً از منهای به مثبت بی نهایت اتفاق می افتد. انجام محاسبات در این فرم پیچیده اغلب راحت تر است.
تبدیل سیگنال را به هارمونیک هایی با فرکانس از یک تا N نوسان در ناحیه سیگنال تجزیه می کند. اما نرخ نمونه برداری N در هر ناحیه سیگنال است. و با توجه به قضیه Kotelnikov (معروف به قضیه Nyquist-Shannon)، فرکانس نمونه برداری باید حداقل دو برابر فرکانس سیگنال باشد. اگر اینطور نیست، پس اثر ظاهر شدن یک سیگنال با فرکانس کاذب است: 
خط نقطه چین سیگنال نادرست بازسازی شده را نشان می دهد. شما بارها در زندگی با این پدیده مواجه شده اید. به عنوان مثال، حرکت خنده دار چرخ های ماشین در یک ویدیو، یا افکت moire.
این منجر به این واقعیت می شود که نیمه دوم دامنه های پیچیده N از فرکانس های دیگر تشکیل شده است. این هارمونیک های کاذب نیمه دوم، تصویر آینه ای از اولی هستند و حاوی اطلاعات اضافی نیستند. بنابراین، ما با کسینوس N/2 و سینوس N/2 (که یک پایه متعامد را تشکیل میدهند) باقی میمانیم.
خوب، یک پایه وجود دارد. اجزای آن هارمونیک هایی با تعداد صحیح نوسانات در ناحیه سیگنال هستند، به این معنی که مقادیر شدید هارمونیک ها برابر است. به طور دقیق تر، آنها تقریباً برابر هستند، زیرا آخرین مقدار به طور کامل از لبه گرفته نشده است. علاوه بر این، هر هارمونیک تقریباً آینه ای متقارن نسبت به مرکز خود است. همه این پدیده ها به ویژه در فرکانس های پایین قوی هستند که هنگام رمزگذاری برای ما مهم هستند. این نیز بد است زیرا مرزهای بلوک در تصویر فشرده قابل مشاهده خواهند بود. اجازه دهید مبنای DFT را با N=8 توضیح دهم. 2 ردیف اول مولفه های کسینوس و آخری سینوس هستند: 
با افزایش فرکانس به ظاهر اجزای تکراری توجه کنید. 
همه چیز در مورد اول بسیار بد است.
بنابراین شاید بتوانیم آن را مانند DCT انجام دهیم - فرکانس ها را 2 یا چند بار کاهش دهیم، به طوری که تعداد برخی از نوسانات کسری باشد و مرزها در فازهای مختلف باشند؟ سپس اجزاء غیر متعامد خواهند بود. و هیچ کاری برای انجام آن وجود ندارد.DST
اگر در DCT به جای کسینوس از سینوس استفاده کنیم چه؟ تبدیل سینوسی گسسته (DST) را دریافت خواهیم کرد. اما برای وظیفه ما، همه آنها جالب نیستند، زیرا هر دو دوره کامل و نیمه سینوس ها در مرزها نزدیک به صفر هستند. یعنی تقریباً همان تجزیه نامناسب DFT را خواهیم داشت. بازگشت به DCT
او در مرزها چگونه است؟ خوب. آنتی فاز وجود دارد و صفر وجود ندارد. همه بقیه
تبدیل های غیر فوریه من آن را توصیف نمی کنم.
WHT - ماتریس فقط از اجزای مرحله ای با مقادیر -1 و 1 تشکیل شده است.
هار همچنین یک تبدیل موجک متعامد است.
آنها نسبت به DCT پایین تر هستند، اما محاسبه آنها آسان تر است.
آسان نخواهد بود، درست است؟ با این حال، برای برخی از انواع تصاویر، می توان مبنای بهتری نسبت به DCT انتخاب کرد. تبدیل های دو بعدی
اکنون بیایید سعی کنیم چنین آزمایشی را انجام دهیم. برای مثال، یک قطعه از یک تصویر را در نظر بگیرید. 
نمودار سه بعدی او: 
اجازه دهید از طریق DCT(N=32) از هر خط عبور کنیم: 
حالا میخواهم چشمهایتان را از میان هر ستون ضرایب حاصل، یعنی از بالا به پایین بگذرانید. به یاد داشته باشید که هدف ما این است که تا حد امکان مقادیر کمتری را به جای بگذاریم و آنهایی را که مهم نیستند حذف کنیم. احتمالاً حدس زده اید که مقادیر هر ستون از ضرایب حاصل را می توان دقیقاً به همان روشی که مقادیر تصویر اصلی گسترش داد. هیچ کس ما را در انتخاب یک ماتریس تبدیل متعامد محدود نمی کند، اما ما آن را دوباره با استفاده از DCT(N=8) انجام خواهیم داد: 
ضریب (0.0) خیلی بزرگ است، بنابراین در نمودار 4 برابر کاهش می یابد.
پس چه اتفاقی افتاد؟
گوشه سمت چپ بالا مهم ترین ضرایب گسترش مهم ترین ضرایب است.
گوشه پایین سمت چپ ناچیزترین ضرایب گسترش مهم ترین ضرایب است.
گوشه سمت راست بالا مهم ترین ضرایب انبساط از ناچیزترین ضرایب است.
گوشه پایین سمت راست ناچیزترین ضرایب بسط ناچیزترین ضرایب است.
واضح است که اگر به صورت مورب از سمت چپ بالا به سمت راست پایین حرکت کنید، اهمیت ضرایب کاهش می یابد. کدام مهمتر است: (0، 7) یا (7، 0)؟ اصلا منظورشون چیه؟
ابتدا بر اساس ردیفها: A 0 = (EX T) T = XE T (جابهجایی، زیرا فرمول برای ستونها A=EX است)، سپس توسط ستونها: A=EA 0 = EXE T. اگر با دقت محاسبه کنید، فرمول را دریافت می کنید:
بنابراین، اگر یک بردار به سینوسی تجزیه شود، ماتریس به توابعی به شکل cos(ax)*cos(by) تجزیه می شود. هر بلوک 8x8 در JPEG به صورت مجموع 64 تابع از فرم نشان داده می شود: 
در ویکیپدیا و سایر منابع، چنین توابعی به شکل راحتتری ارائه میشوند: 
بنابراین، ضرایب (0، 7) یا (7، 0) به همان اندازه مفید هستند.
با این حال، در واقع این یک تجزیه یک بعدی معمولی به 64 پایه 64 بعدی است. تمام موارد فوق نه تنها در مورد DCT، بلکه برای هر تجزیه متعامد نیز صدق می کند. بر اساس قیاس، در حالت کلی یک تبدیل متعامد N بعدی به دست می آوریم.
و در اینجا یک تبدیل دوبعدی یک راکون (DCT 256x256) است. مجدداً مقادیر را به صفر برگردانید. اعداد - تعداد ضرایب غیر صفر از همه (مهمترین مقادیر، واقع در ناحیه مثلثی در گوشه سمت چپ بالا، حفظ شد). 
به یاد داشته باشید که ضریب (0, 0) DC نامیده می شود و 63 باقی مانده AC نامیده می شود. انتخاب اندازه بلوک
یکی از دوستان می پرسد چرا JPEG از پارتیشن بندی 8x8 استفاده می کند. از پاسخ رای منفی: DCT با بلوک به گونه ای رفتار می کند که گویی دوره ای است و باید پرش حاصل را در مرزها بازسازی کند. اگر بلوکهای 64x64 را انتخاب کنید، به احتمال زیاد یک پرش بزرگ در مرزها خواهید داشت، و برای بازسازی آن با دقت رضایتبخش به قطعات زیادی با فرکانس بالا نیاز خواهید داشت.
مانند، DCT فقط روی توابع دوره ای به خوبی کار می کند، و اگر بزرگ شوید، احتمالاً یک پرش غول پیکر در مرزهای بلوک خواهید داشت و برای پوشش دادن آن به اجزای فرکانس زیاد زیادی نیاز دارید. این درست نیست! این توضیح بسیار شبیه به DFT است، اما نه به DCT، زیرا این جهش ها را با اجزای اول کاملاً پوشش می دهد.
در همان صفحه پاسخی از پرسشهای متداول MPEG، با استدلالهای اصلی علیه بلوکهای بزرگ وجود دارد:
پیشنهاد می کنم خودتان در این مورد تحقیق کنید. بیا شروع کنیم با اولین.
محور افقی سهم اولین ضرایب غیر صفر را نشان می دهد. عمودی - انحراف استاندارد پیکسل ها از اصلی. حداکثر انحراف ممکن به عنوان یک در نظر گرفته می شود. البته یک عکس به وضوح برای یک حکم کافی نیست. علاوه بر این، من کاملاً درست عمل نمی کنم، فقط به صفر بازنشانی می کنم. در یک JPEG واقعی، بسته به ماتریس کوانتیزاسیون، فقط مقادیر کوچکی از اجزای فرکانس بالا صفر می شوند. بنابراین، آزمایشها و نتیجهگیریهای زیر برای آشکارسازی اصول و الگوها در نظر گرفته شده است.
می توانید تقسیم را به بلوک های مختلف با 25 درصد ضرایب سمت چپ (از چپ به راست و سپس از راست به چپ) مقایسه کنید: 

این بدان معنی است که برای مثال، محاسبه برای یک پارتیشن 64x64 دو برابر پیچیده تر از یک پارتیشن 8x8 است. 
اگرچه اعوجاج بلوکهای 16×16 بیشتر از 8×8 است، اما حروف صافتر است. بنابراین، تنها دو استدلال اول مرا متقاعد کرد. اما من به نوعی بخش 16x16 را بیشتر دوست دارم.کوانتیزاسیون
در این مرحله ما یک دسته ماتریس 8x8 با ضرایب تبدیل کسینوس داریم. وقت آن است که از شر ضرایب ناچیز خلاص شویم. راه حل ظریف تری از تنظیم مجدد ضرایب آخر به صفر وجود دارد، همانطور که در بالا انجام دادیم. ما از این روش راضی نیستیم، زیرا مقادیر غیر صفر با دقت بیش از حد ذخیره می شوند و در بین کسانی که بدشانس بودند، مقادیر بسیار مهمی وجود دارد. راه حل استفاده از ماتریس کوانتیزاسیون است. ضرر و زیان دقیقاً در این مرحله رخ می دهد. هر ضریب فوریه بر عدد مربوطه در ماتریس کوانتیزاسیون تقسیم می شود. بیایید به یک مثال نگاه کنیم. بیایید اولین بلوک را از راکون خود بگیریم و کوانتیزاسیون را انجام دهیم. مشخصات JPEG یک ماتریس استاندارد را ارائه می دهد: 
ماتریس استاندارد با کیفیت 50% در FastStone و IrfanView مطابقت دارد. این جدول از نظر تعادل بین کیفیت و نسبت تراکم انتخاب شده است. من فکر می کنم که مقدار ضریب DC از همسایگانش بزرگتر است به دلیل اینکه DCT نرمال نیست و مقدار اول بزرگتر از آنچه باید باشد. ضرایب فرکانس بالا به دلیل اهمیت کمتر، به شدت درشت می شوند. من فکر می کنم که اکنون به ندرت از چنین ماتریس هایی استفاده می شود، زیرا بدتر شدن کیفیت به وضوح قابل توجه است. هیچ کس استفاده از جدول شما را ممنوع نمی کند (با مقادیر 1 تا 255)
در طول رمزگشایی، فرآیند معکوس رخ می دهد - ضرایب کوانتیزه شده ترم به ترم در مقادیر ماتریس کوانتیزاسیون ضرب می شوند. اما از آنجایی که مقادیر را گرد کردیم، نمیتوانیم ضرایب فوریه اصلی را به دقت بازیابی کنیم. هرچه عدد کوانتیزاسیون بزرگتر باشد، خطا بزرگتر است. بنابراین، ضریب بازسازی شده تنها نزدیکترین مضرب است.
مثالی دیگر: 

وقتی این بلوک را بازیابی می کنیم، فقط مقدار متوسط به اضافه گرادیان عمودی (به دلیل مقدار حفظ شده 1-) را دریافت می کنیم. اما فقط دو مقدار برای آن ذخیره می شود: 7 و -1. وضعیت با بلوک های دیگر بهتر نیست، در اینجا تصویر بازیابی شده است: 
یا می توانید به ماتریس های کوانتیزاسیون دوربین های مختلف نگاه کنید.کد نویسی
قبل از حرکت، باید از مثالهای سادهتری استفاده کنیم تا بفهمیم چگونه میتوانیم مقادیر حاصل را فشرده کنیم.
چنین شرایطی را تصور کنید که دوستتان یک تکه کاغذ با لیستی را در خانه شما فراموش کرده و اکنون از شما می خواهد که آن را از طریق تلفن دیکته کنید (هیچ روش ارتباطی دیگری وجود ندارد).
فهرست:
چگونه کار خود را آسان تر می کنید؟ شما تمایل خاصی به دیکته کردن همه این کلمات ندارید. اما تنها دو مورد از آنها وجود دارد و آنها تکرار می شوند. بنابراین، شما به سادگی دو کلمه اول را دیکته می کنید و موافقت می کنید که از این به بعد کلمه اول را "d9rg3" و کلمه دوم را "wfr43gt" صدا کنید. سپس برای دیکته کردن کافی است: 1، 2، 2، 1، 1، 1، 2، 1. 
ABC را رمزگذاری کنید.
غیرممکن است که 3 کاراکتر مختلف (A، B، C) را با 2 مقدار بیت ممکن (0 و 1) مرتبط کنید. و اگر چنین است، می توانید از 2 بیت برای هر نماد استفاده کنید. مثلا:
دنباله بیت های مرتبط با یک نماد، کد نامیده می شود. ABC به این صورت رمزگذاری می شود: 000110. 
AAAAAABC را رمزگذاری کنید.
استفاده از 2 بیت در هر کاراکتر A کمی بیهوده به نظر می رسد. اگر این را امتحان کنید چه می شود:
دنباله کدگذاری شده: 000000100.
بدیهی است که این گزینه مناسب نیست، زیرا مشخص نیست که چگونه دو بیت اول این دنباله را رمزگشایی کنیم: به صورت AA یا C؟ استفاده از هر گونه جداکننده بین کدها بسیار بیهوده است، ما به این فکر خواهیم کرد که چگونه این مانع را به روش دیگری دور بزنیم. بنابراین، شکست به این دلیل است که کد C با کد A شروع می شود. اما ما مصمم هستیم که A را با یک بیت رمزگذاری کنیم، حتی اگر B و C هر کدام دو بیت داشته باشند. بر اساس این خواسته، به A کد 0 می دهیم. سپس کدهای B و C نمی توانند با 0 شروع شوند، اما می توانند با 1 شروع شوند: 
دنباله به این صورت رمزگذاری شده است: 0000001011. سعی کنید به صورت ذهنی آن را رمزگشایی کنید. شما فقط می توانید این کار را یک راه انجام دهید.
ما دو مورد نیاز کدنویسی را ایجاد کرده ایم:
بدیهی است که ترتیب شخصیت ها مهم نیست، ما فقط به دفعات وقوع آنها علاقه داریم. بنابراین هر نماد با عددی به نام وزن همراه است. وزن یک نماد می تواند یک مقدار نسبی باشد، که نسبت وقوع آن را منعکس می کند، یا یک مقدار مطلق، برابر با تعداد کاراکترها. نکته اصلی این است که وزن ها متناسب با وقوع نمادها هستند.
بیایید حالت کلی را برای 4 نماد با هر وزن در نظر بگیریم.
بدون از دست دادن کلیت، اجازه دهید pa ≥ pb ≥ pc ≥ pd را قرار دهیم. تنها دو گزینه وجود دارد که اساساً در طول کد متفاوت هستند: 
کدام یک ارجحیت دارد؟ برای انجام این کار، باید طول پیام های کدگذاری شده را محاسبه کنید:
W1 = 2*pa + 2*pb + 2*pc + 2*pd
W2 = pa + 2 * pb + 3 * pc + 3 * pd
اگر W1 کمتر از W2 باشد (W1-W2<0), то лучше использовать первый вариант:
W1-W2 = pa - (pc+pd)< 0 =>pa< pc+pd.
اگر C و D با هم بیشتر از بقیه رخ دهند، آنگاه راس مشترک آنها کوتاهترین کد یک بیتی را دریافت می کند. در غیر این صورت، یک بیت به کاراکتر A می رود. این بدان معنی است که اتحاد کاراکترها مانند یک کاراکتر مستقل رفتار می کند و وزنی برابر با مجموع کاراکترهای ورودی دارد.
به طور کلی، اگر p وزن یک کاراکتر باشد که با کسری از وقوع آن نشان داده شده است (از 0 تا 1)، بهترین طول کد s=-log 2 p است.
بیایید این را در یک مورد ساده در نظر بگیریم (به راحتی می توان آن را به عنوان یک درخت نشان داد). بنابراین، باید 2 s کاراکتر با وزن های مساوی (1/2 ثانیه) رمزگذاری کنیم. به دلیل برابری وزن ها، طول کدها یکسان خواهد بود. هر شخصیت به بیت های s نیاز دارد. به این معنی که اگر وزن یک نماد 1/2 ثانیه باشد، طول آن s است. اگر وزن را با p جایگزین کنیم، طول کد s=-log 2 p را دریافت می کنیم. این به این معنی است که اگر یک کاراکتر دو بار بیشتر از دیگری رخ دهد، طول کد آن یک بیت بیشتر خواهد بود. با این حال، این نتیجه گیری آسان است اگر به یاد داشته باشید که اضافه کردن یک بیت به شما امکان می دهد تعداد گزینه های ممکن را دو برابر کنید.
و یک مشاهده دیگر - دو نماد با کمترین وزن همیشه بیشترین طول کد را دارند اما برابر هستند. علاوه بر این، بیت های آنها، به جز مورد آخر، یکسان است. اگر این درست نبود، حداقل یک کد را میتوان 1 بیت کوتاه کرد بدون اینکه پیشوند شکسته شود. این بدان معنی است که دو نماد با کمترین وزن در درخت کد دارای یک والد مشترک در سطح بالاتر هستند. می توانید این را در مثال C و D در بالا مشاهده کنید.
بیایید سعی کنیم با توجه به نتایج به دست آمده در مثال قبل، مثال زیر را حل کنیم.
مراحل تکرار می شود تا زمانی که فقط یک گروه باقی بماند. در هر گروه، یک کاراکتر (یا زیرگروه) به بیت 0 و دیگری کاراکتر بیت 1 اختصاص می یابد.
این الگوریتم کدگذاری هافمن نام دارد.
تصویر نمونه ای با 5 کاراکتر را نشان می دهد (A: 8، B: 6، C: 5، D: 4، E: 3). در سمت راست وزن نماد (یا گروه) است. 
ضرایب را رمزگذاری می کنیم
بیا برگردیم. اکنون بلوک های زیادی با 64 ضریب در هر کدام داریم که باید به نحوی ذخیره شوند. ساده ترین راه حل استفاده از تعداد ثابتی از بیت ها در هر ضریب است - بدیهی است ناموفق. بیایید یک هیستوگرام از تمام مقادیر به دست آمده بسازیم (یعنی وابستگی تعداد ضرایب به مقدار آنها): 
لطفا توجه داشته باشید - مقیاس لگاریتمی است! آیا می توانید دلیل پیدایش خوشه ای از مقادیر بیش از 200 را توضیح دهید؟ اینها ضرایب DC هستند. از آنجایی که آنها بسیار متفاوت از سایرین هستند، جای تعجب نیست که آنها به طور جداگانه کدگذاری شوند. اینجا فقط DC است: 
توجه داشته باشید که شکل نمودار یادآور نمودارهای اولین آزمایشهای جفتسازی و سهگانه کردن پیکسل است.
به طور کلی، مقادیر ضریب DC می تواند از 0 تا 2047 متفاوت باشد (به طور دقیق تر از 1024- تا 1023، زیرا JPEG 128 را از تمام مقادیر اصلی کم می کند، که مربوط به تفریق 1024 از DC است) و به طور نسبتاً مساوی با پیک های کوچک توزیع می شود. بنابراین کدنویسی هافمن در اینجا کمک زیادی نخواهد کرد. و تصور کنید درخت کدنویسی چقدر بزرگ خواهد بود! و در حین رمزگشایی باید به دنبال معانی در آن بگردید. خیلی گرونه بیشتر فکر می کنیم.
ضریب DC مقدار متوسط یک بلوک 8x8 است. بیایید یک انتقال گرادیان را تصور کنیم (البته ایده آل نیست)، که اغلب در عکس ها یافت می شود. مقادیر DC خود متفاوت خواهند بود، اما نشان دهنده یک پیشرفت حسابی هستند. این بدان معنی است که تفاوت آنها کم و بیش ثابت خواهد بود. بیایید یک هیستوگرام از تفاوت ها بسازیم: 
این بهتر است، زیرا مقادیر به طور کلی حول صفر متمرکز می شوند (اما الگوریتم هافمن دوباره درخت بسیار بزرگی را نشان می دهد). مقادیر کوچک (در مقدار مطلق) رایج هستند، مقادیر بزرگ نادر هستند. و از آنجایی که مقادیر کوچک چند بیت را اشغال می کنند (اگر صفرهای ابتدایی حذف شوند)، یکی از قوانین فشرده سازی به خوبی رعایت می شود: نمادهایی با وزن های بزرگ به کدهای کوتاه اختصاص داده می شوند (و بالعکس). ما در حال حاضر به دلیل عدم رعایت قانون دیگر محدود شده ایم: عدم امکان رمزگشایی بدون ابهام. به طور کلی، این مشکل را می توان به روش های زیر حل کرد: با کد جداکننده اذیت شوید، طول کد را مشخص کنید، از کدهای پیشوند استفاده کنید (از قبل آنها را می شناسید - این مورد زمانی است که هیچ کدی با کد دیگری شروع نمی شود). بیایید با گزینه دوم ساده برویم، یعنی هر ضریب (به طور دقیق تر، تفاوت بین همسایگان) به این صورت نوشته می شود: (طول) (مقدار)، با توجه به این علامت: 
یعنی مقادیر مثبت مستقیماً با نمایش دودویی آنها رمزگذاری می شوند و مقادیر منفی به همین ترتیب رمزگذاری می شوند، اما با 0 جایگزینی 1 پیشرو می شود. از آنجایی که 12 مقدار ممکن وجود دارد، می توان از 4 بیت برای ذخیره طول استفاده کرد. اما اینجاست که بهتر است از کدنویسی هافمن استفاده کنید. 
بیشترین مقادیر با طول های 4 و 6 وجود دارد، بنابراین آنها کوتاه ترین کدها (00 و 01) را دریافت کردند.
ممکن است این سوال پیش بیاید: چرا در مثال، مقدار 9 دارای کد 1111110 است و نه 1111111؟ پس از همه، شما می توانید با خیال راحت "9" را به یک سطح بالاتر، در کنار "0" افزایش دهید؟ واقعیت این است که در JPEG نمی توانید از کدی استفاده کنید که فقط از یک کد تشکیل شده باشد - چنین کدی رزرو شده است.
یک ویژگی دیگر وجود دارد. کدهای به دست آمده توسط الگوریتم هافمن توصیف شده ممکن است در بیت با کدهای JPEG مطابقت نداشته باشند، اگرچه طول آنها یکسان خواهد بود. با استفاده از الگوریتم هافمن، طول کدها به دست می آید و خود کدها تولید می شوند (الگوریتم ساده است - با کدهای کوتاه شروع کنید و آنها را یکی یکی به درخت تا جایی که ممکن است به سمت چپ اضافه کنید، با حفظ ویژگی پیشوندی. ). به عنوان مثال، برای درخت بالای لیست ذخیره می شود: 0،2،3،1،1،1،1،1. و، البته، لیستی از مقادیر ذخیره می شود: 4،6،3،5،7،2،8،1،0،9. در طول رمزگشایی، کدها به همین ترتیب تولید می شوند.
[کد هافمن برای طول اختلاف DC (به بیت)]
که در آن اختلاف DC = جریان DC - DC قبلی
از آنجایی که نمودار بسیار شبیه به نمودار تفاوت های DC است، اصل یکسان است: [کد هافمن برای طول AC (به بیت)]. اما واقعا نه! از آنجایی که مقیاس روی نمودار لگاریتمی است، فوراً قابل توجه نیست که تقریباً 10 برابر مقادیر صفر بیشتر از مقادیر 2 وجود دارد که بیشترین فراوانی بعدی است. این قابل درک است - همه از کوانتیزاسیون جان سالم به در نبردند. بیایید به ماتریس مقادیر بدست آمده در مرحله کوانتیزاسیون (با استفاده از ماتریس کوانتیزاسیون FastStone، 90%) برگردیم. 
از آنجایی که گروه های زیادی از صفرهای متوالی وجود دارد، یک ایده مطرح می شود - فقط تعداد صفرهای گروه را یادداشت کنید. این الگوریتم فشرده سازی RLE (Run-length encoding) نامیده می شود. باقی مانده است که مسیر دور زدن "متوالی" را دریابیم - چه کسی پشت چه کسی است؟ نوشتن از چپ به راست و از بالا به پایین خیلی مؤثر نیست، زیرا ضرایب غیر صفر در گوشه بالا سمت چپ متمرکز شده اند و هر چه به سمت راست پایین نزدیکتر باشد، صفرهای بیشتری می شود. 
بنابراین JPEG از ترتیبی به نام "Zig-zag" استفاده می کند که در شکل سمت چپ نشان داده شده است. این روش گروه های صفر را به خوبی متمایز می کند. در تصویر سمت راست یک روش بای پس جایگزین وجود دارد که مربوط به JPEG نیست، اما با یک نام کنجکاو (اثبات) است. می توان آن را در MPEG برای فشرده سازی ویدئویی درهم استفاده کرد. انتخاب الگوریتم پیمایش بر کیفیت تصویر تأثیر نمیگذارد، اما ممکن است تعداد گروههای کدگذاری شده صفر را افزایش دهد که در نهایت ممکن است بر اندازه فایل تأثیر بگذارد.
بیایید ورودی خود را اصلاح کنیم. برای هر ضریب AC غیر صفر:
[تعداد صفرها قبل از AC][کد هافمن برای طول AC (به بیت)]
من فکر می کنم شما می توانید بلافاصله بگویید که تعداد صفرها نیز کاملاً توسط هافمن رمزگذاری شده است! این یک پاسخ بسیار نزدیک و خوب است. اما می توان آن را کمی بهینه کرد. تصور کنید که مقداری ضریب AC داریم که قبل از آن 7 صفر وجود دارد (البته اگر به ترتیب زیگزاگ نوشته شده باشد). این صفرها روح مقادیری هستند که از کوانتیزاسیون دوام نیاوردند. به احتمال زیاد ضریب ما هم خیلی خراب شده و کوچک شده یعنی طولش کمه. این بدان معنی است که تعداد صفرهای جلوی AC و طول AC کمیت های وابسته هستند. بنابراین آن را به این صورت می نویسیم:
[کد هافمن برای (تعداد صفرها قبل از AC، طول AC (به بیت)]
الگوریتم رمزگذاری ثابت باقی می ماند: آن جفت ها (تعداد صفرهای قبل از AC، طول AC) که مکرراً رخ می دهند، کدهای کوتاه دریافت می کنند و بالعکس. 
"خط الراس کوهستانی" طولانی فرض ما را تایید می کند.
چنین جفتی 1 بایت اشغال می کند: 4 بیت برای تعداد صفرها و 4 بیت برای طول AC. 4 بیت مقادیری از 0 تا 15 هستند. برای طول AC این بیش از حد کافی است، اما آیا می توان بیش از 15 صفر داشته باشد؟ سپس از جفت های بیشتری استفاده می شود. به عنوان مثال، برای 20 صفر: (15، 0) (5، AC). یعنی صفر شانزدهم به صورت ضریب غیر صفر کد گذاری می شود. از آنجایی که همیشه صفرهای زیادی در انتهای بلوک وجود دارد، جفت (0,0) بعد از آخرین ضریب غیر صفر استفاده می شود. اگر در هنگام رمزگشایی با آن مواجه شد، مقادیر باقی مانده 0 است.
[کد هافمن برای طول اختلاف DC]
[کد هافمن برای (تعداد صفرهای قبل از AC 1، طول AC 1]
…
[کد هافمن برای (تعداد صفرهای قبل از AC n، طول AC n]
جایی که AC i ضرایب AC غیر صفر هستند.تصویر رنگی
نحوه ارائه یک تصویر رنگی به انتخاب شده بستگی دارد مدل رنگ. یک راه حل ساده این است که از RGB استفاده کنید و هر کانال رنگی تصویر را به طور جداگانه رمزگذاری کنید. سپس رمزگذاری با رمزگذاری یک تصویر خاکستری تفاوتی نخواهد داشت، فقط 3 برابر بیشتر کار می کند. اما فشرده سازی تصویر را می توان افزایش داد اگر به یاد داشته باشیم که چشم نسبت به رنگ ها به تغییرات روشنایی حساس تر است. این بدان معنی است که رنگ را می توان با تلفات بیشتر از روشنایی ذخیره کرد. RGB کانال روشنایی جداگانه ندارد. بستگی به مجموع مقادیر هر کانال دارد. بنابراین، مکعب RGB (این نمایشی از تمام مقادیر ممکن است) به سادگی روی مورب "قرار می گیرد" - هر چه بالاتر، روشن تر باشد. اما آنها در اینجا متوقف نمی شوند - مکعب کمی از طرفین فشرده می شود و بیشتر شبیه یک موازی شکل می شود ، اما این فقط برای در نظر گرفتن ویژگی های چشم است. به عنوان مثال به رنگ سبز حساس تر از آبی است. اینگونه بود که مدل YCbCr ظاهر شد. 
(تصویر از Intel.com)
Y جزء روشنایی، Cb و Cr اجزای تفاوت رنگ آبی و قرمز هستند. بنابراین، اگر بخواهند تصویر را بیشتر فشرده کنند، RGB به YCbCr تبدیل میشود و کانالهای Cb و Cr نازک میشوند. یعنی آنها به بلوک های کوچک تقسیم می شوند، به عنوان مثال 2x2، 4x2، 1x2، و تمام مقادیر یک بلوک به طور متوسط است. یا به عبارت دیگر اندازه تصویر را برای این کانال 2 یا 4 برابر به صورت عمودی و/یا افقی کاهش می دهند. 
هر بلوک 8x8 کدگذاری می شود (DCT + Huffman) و دنباله های کدگذاری شده به ترتیب زیر نوشته می شوند:
عجیب است که مشخصات JPEG انتخاب مدل را محدود نمی کند، یعنی پیاده سازی رمزگذار می تواند تصویر را به هر طریقی به اجزای رنگی (کانال) تقسیم کند و هر کدام به طور جداگانه ذخیره شوند. من از استفاده از Grayscale (1 کانال)، YCbCr (3)، RGB (3)، YCbCrK (4)، CMYK (4) آگاه هستم. سه مورد اول تقریبا توسط همه پشتیبانی می شود، اما در مورد آخرین 4 کانال مشکلاتی وجود دارد. FastStone، GIMP به درستی از آنها پشتیبانی می کنند، و برنامه های استاندارد ویندوز، paint.net به درستی همه اطلاعات را استخراج می کنند، اما سپس کانال 4 سیاه را بیرون می اندازند، بنابراین (آنتل گفت آنها را دور نمی اندازند، نظرات او را بخوانید) آنها یک فندک نشان می دهند. تصویر در سمت چپ یک YCbCr JPEG کلاسیک، در سمت راست یک CMYK JPEG است: 

اگر رنگ آنها متفاوت است، یا فقط یک تصویر قابل مشاهده است، به احتمال زیاد شما IE (هر نسخه ای) دارید (UPD. در نظرات می گویند "یا سافاری"). می توانید مقاله را در مرورگرهای مختلف باز کنید. و یه چیز دیگه
به طور خلاصه در مورد ویژگی های اضافی. حالت پیشرو
اجازه دهید جداول حاصل از ضرایب DCT را به مجموع جداول (تقریباً مانند این (DC, -19, -22, 2, 1) = (DC, 0, 0, 0, 0) + (0, -20) تجزیه کنیم. ، -20، 0، 0) + (0، 1، -2، 2، 1)). ابتدا تمام عبارت های اول را رمزگذاری می کنیم (همانطور که قبلاً یاد گرفتیم: هافمن و پیمایش زیگزاگ)، سپس دومی و غیره. این ترفند زمانی مفید است که اینترنت کند است، زیرا ابتدا فقط ضرایب DC بارگذاری می شوند که برای استفاده از آنها استفاده می شود. یک تصویر خشن با "پیکسل" 8x8 بسازید. سپس ضرایب AC را گرد کرد تا شکل را اصلاح کند. سپس اصلاحات تقریبی آنها، سپس اصلاحات دقیق تر. و غیره. ضرایب گرد هستند، زیرا در مراحل اولیه بارگذاری دقت آنچنان مهم نیست، اما گرد کردن تأثیر مثبتی بر طول کدها دارد، زیرا هر مرحله از جدول هافمن خود استفاده می کند. حالت بدون ضرر
فشرده سازی بدون اتلاف بدون DCT از پیش بینی نقطه چهارم بر اساس سه نقطه همسایه استفاده شده است. خطاهای پیش بینی کد هافمن هستند. به نظر من کمی بیشتر از هرگز استفاده می شود. حالت سلسله مراتبی
چندین لایه با وضوح های مختلف از تصویر ایجاد می شود. اولین لایه درشت طبق معمول کدگذاری میشود و سپس تنها تفاوت (تصفیه تصویر) بین لایهها (تظاهر به موجک هار) است. DCT یا Lossless برای رمزگذاری استفاده می شود. به نظر من کمی کمتر از هرگز استفاده می شود. کدگذاری حسابی
الگوریتم هافمن کدهای بهینه را بر اساس وزن کاراکترها تولید می کند، اما این فقط برای نگاشت کاراکتر به کد ثابت صادق است. حسابی چنین صحافی سفت و سختی ندارد، که امکان استفاده از کدهایی را که گویی با تعداد کسری از بیت ها وجود دارد، می دهد. ادعا می کند که حجم فایل را به طور متوسط 10٪ در مقایسه با هافمن کاهش می دهد. به دلیل مشکلات ثبت اختراع گسترده نیست، توسط همه پشتیبانی نمی شود.
vanwin پیشنهاد کرد نرم افزار مورد استفاده را نشان دهد. من خوشحالم که اعلام کنم همه چیز در دسترس و رایگان است:




 .
.