Federal Agency for Education
State educational institution of higher professional education
"CHELYABINSK STATE UNIVERSITY"
Course work
Database Application Development
Domain analysis
Description of the subject area and functions of the tasks to be solved
In the course work, in accordance with the assignment, the activities of the sales department of the "Russian Food" enterprise are automated.
The subject of automation is some of the job functions of the sales department. The sales department has a plan for the release of finished products drawn up for three months. In accordance with this plan, the workshops produce products, but the actual production output depends on many factors and may differ from the planned one. The sales department also receives shop invoices, which reflect the actual production and delivery of products to certain warehouses.
The task of the sales department is to analyze the implementation of the plan for the delivery of products to warehouses. To do this, you need to select the planned and actual data for a certain period for a certain warehouse and analyze the deviation of the fact from the plan.
The enterprise has 3 workshops where the products are manufactured. The range of products is shown in the table.
Table 1.
Shop No. Shop name Product name Minimum production unit Price per unit milk 3.5% box 50 pieces 650,00 rub. 1 milk milk 4.0% carton 50 pieces 700,00 rub. cream box 50 pieces1 200,00 rub. boiled sausagepackaging 50 pieces2 500,00 rub. 2 sausage smoked sausagespackaging 50 pieces3 400,00 rub. sausages pack of 50 pieces1 200,00 rub. canned pike-perch box of 50 cans 670,00 rub. 3 fish caviar black box 50 cans 5 400,00 rub. red box caviar 50 cans 5 370,00 rub. Products released by workshops are delivered to warehouses Table 2. Warehouse number Warehouse name 1 Warehouse number 12 Warehouse number 23 Warehouse number 3 List of input (primary) documents. The following are used as primary documents for solving this problem: production plan for workshops list of shop invoices Workshop number Workshop invoice number Submission date workshop invoice specification Workshop number Workshop invoice number Product code Quantity Subject area limitation. When developing a course project, the following restrictions are allowed: the finished product is assigned to one finished product warehouse and can be produced by several workshops. the finished product has only one unit of measure. one workshop can produce several types of products. several items of finished products can be stored in one warehouse. the production of finished products by the workshop is planned monthly. the same item can be scheduled for release in different months. A shop invoice for the delivery of finished products to the warehouse may contain several product names, its number is unique only for one shop. Formulation of the problem Organizational and economic essence of the complex of tasks. One of the main problems at the enterprise is the discrepancy between the planned quantity of production, which is formed in accordance with the requests of buyers and the actual amount of products shipped by workshops to warehouses. To solve this problem, it is necessary to timely (promptly) receive information about the availability, shortage or surplus of products in warehouses in relation to the plan. Surplus stays in the warehouse, their shelf life may be exceeded, and illiquid assets are created. Description of the output information The output information will be presented in the form of a reporting form. Analysis of the implementation of the plan for the delivery of products to the warehouse _________________ Month Product name Unit of measure Quantity Surplus Plan Fact To obtain this form, the data of primary documents are used: product list; list of warehouses; list of workshops; a plan for the production of products by workshops; list of shop invoices; Description of the input information. Input information is divided into conditionally constant (reference books), retaining its values for a long period of time, and constantly changing, that is, operational accounting information. Conditionally permanent information includes: list of manufactured products; list of manufacturing workshops; list of warehouses; reference units of measurement. Operational accounting information includes: a plan for the production of products by workshops; list of shop invoices; specification of the shop invoice. Let's present the primary documents with the details in Table 3: No. of p / p Document name Details 1 List of manufactured products 1. Product code 2. Product name. 3. Unit code. 4.Price. 5. Warehouse number 3 List of warehouses 1. Warehouse code. 2.Name of the warehouse. 2 List of workshops 1. Code of the workshop. 2.Name of the workshop. 4 Reference units of measurement 1. Code of the unit of measurement. 2. The name of the unit of measurement. 5 The plan of the production of products by the shops 1. The number of the shop. 2. Month of release. 3.Product code. 4.Quantity 6 List of shop invoices 1. Shop number. 2.Number of the shop invoice. 3. Date of delivery. 7 Specification of the shop invoice. 1. Number of the shop. 2.Number of the shop invoice. 3.Product code. 4.Quantity. Database design Allocation of information objects One of the most difficult stages in the database design process is the development of tables, since the results that the database should produce (reports, output forms, etc.) do not always give a complete picture of the structure of the table. Information in the table should not be duplicated. There should be no repetitions between tables. When certain information is stored in only one table, then it will only have to be changed in one place. This makes the work more efficient, and also eliminates the possibility of information mismatch in different tables. Each table should contain information on only one topic. Information on each topic is much easier to process if it is contained in tables independent of each other. Each table contains information on a different topic, and each field in the table contains separate information on the topic of the table To implement data connections from different tables, each table must contain a field or a set of fields that will set an individual value for each record in the table. Such a field or set of fields is called a primary key. After distributing the data across the tables and defining the key fields, you need to define the relationships between the tables. Table 4 Information objects Information obektSootvetstvuyuschy dokumentRekvizityKlyuchIzdeliyaSpisok produced izdeliyKod izdeliyaDa Name izdeliyaKod unit izmereniyaTsena number skladaTsehaSpisok tsehovNomer tsehaDa Name tsehaSkladySpisok skladovNomer skladDaNaimenovanie skladaEdinitsa izmereniyaSpravochnik unit izmereniyaKod units Unit izmereniyaDa Name izmereniyaPlan vypuskaPlan release products tsehamiNomer tsehaDaNomer mesyatsaDa code izdeliyaDa KolichestvoTsehovye nakladnyeSpisok shop nakladnyhNomer tsehaDa number guild nakladnoyDa Date sdachiSpetsifikatsii Specification guild nakladnoyNomer tsehaDaNomer shop invoiceYes Product codeYes QuantityMonthFor "Release plan" object Month numberYesMonth name Information-logical modeling and determination of links between information objects An information-logical model is a data model that displays a subject area in the form of a set of information objects and structural links between them. Our information-logical model will look like this: Fig. 1. Infological model As a result of the development of the database, 8 information objects were obtained. Let's define the type of connection in each pair of these inf. objects. Unit of measurement - Product The link type is 1-to-many, since several items can be measured by one unit of measure, but each item is currently measured by one unit of measure. The connection between these objects is according to the Unit code attribute. Warehouses - Product The link type is 1-to-many, since several items of finished products can be stored in one warehouse. Communication - by attribute Warehouse number. Products - Release Plan The relationship type is 1-to-many, as one item can be scheduled for release in different months, but each planned quantity refers to only one item in a given month. Communication by requisite Product code. Month - Release Plan The link type is 1-to-many, each month a production plan is drawn up. Communication by requisite Number of the month. Workshop - Release plan Communication type 1 - to many, one workshop is scheduled to be released in different months. Communication by requisite Shop number. Workshops - Workshop invoices Workshop - Specifications The type of connection is 1-to-many, one shop issues many invoices. Communication by requisite Shop number. Workshop invoices - Specifications The link type is 1-to-many, one shop invoice can contain several BOMs. Communication by requisites - Shop invoice number and shop number. Product - Specifications Link type 1 - to many, one product is issued more than once, but this issued quantity refers to only one product. Communication by requisite Product code. Logical database structure The logical structure of a relational database is an adequate reflection of the obtained information-logical model of the subject area. No additional transformations are required for the canonical model. Each data model information object is mapped to a corresponding relational table. The structure of a relational table is determined by the attributes of the corresponding information object, where each column (field) corresponds to one of the attributes. Key attributes form a unique key for a relational table. For each column in the table, the type, data size, and other properties are specified. The topology of the data schema design practically coincides with the topology of the information - logical model. As part of this course work, the logical structure of the database will look like (Fig. 2.): Fig. 2. Logical database structure Database implementation in Microsoft Access environment To implement the designed database, we will use one of the most popular database management systems for the Windows Microsoft Access operating system. This DBMS is included in the widespread integrated package of Microsoft Office and is fully compatible with the programs of this package. A big advantage of MS Access is the availability of information systems development tools for users of various qualifications: from beginners to professionals. MS Access DBMS is focused on working with the following objects: Tables are the main element of any relational database, they are designed to define and store data; Queries serve as sources for building other queries, forms, and reports. Queries allow you to modify and analyze data. The most common type of query, a select query, is a set of rules used to select data from one or more related tables. The results of the query execution are presented in the form of a virtual table. Forms are an object primarily designed to enter data, display it on the screen, or control the operation of an application. It is possible to use forms in order to fulfill the user's requirements for the presentation of data from queries or tables, the forms can also be printed. Reports are a means of organizing the output of data for printing. With the help of the report, it is possible to display the necessary information in the required form. You can preview the report before printing. Data sources for reports are tables and queries; Macros - an object that is a structured description of one or more actions that should be performed by MS Access in response to a specific event. Modules are objects that contain programs written in the Visual Basic for Applications (VBA) language. As part of the task, there is no need to create macros and modules in the designed database. All MS Access objects are located in one file on disk. MS Access has a multi-window interface, but it can only process one database at a time. To create a new database, you need to start MS Access, select the "New Database" mode, enter the name of the database and select its location on disk. The tables of the designed database are information objects, the fields of the tables are the details of information objects. To fill in the input information, it will be necessary to design a user interface - forms: form "Products" - for editing the table "Products"; "Release plan" form - for correcting the plan for the number of manufactured products; the "Workshop waybills" form connecting the "Workshop waybills" table and the table "Workshop waybills specifications" dependent on the "Workshop waybills". To implement the report "Analysis of the implementation of the plan for the delivery of products to the warehouse", it will be enough to execute one request for the selection of the month (table "month"), product name (table "Products"), units of measurement (table "Unit of measurement"), quantities according to the plan ( “Production plan” table), actual quantities (“Specifications” table), with the addition of a “surplus” column with a deduction formula. Creating tables and data schema application database sales There are several modes for creating tables (table mode, designer, table wizard, import tables, link to tables from other databases). The most versatile way to create a table is by using design mode. To create a table in this mode, you must define the table fields. Each field is characterized by a name, data type, and properties. The field name must not contain special characters. Microsoft Access can use the following data types: Text - serves to store alphanumeric information. The field length must not exceed 255 characters; MEMO field - intended for storing alphanumeric information up to 65535 characters long; Numeric - used for numeric data involved in calculations; Date / time - date and (or) time in the range from 100 to 9999; Monetary - used for monetary values and numerical data used in mathematical calculations, carried out with an accuracy of 15 digits in the whole and up to 4 digits in the fractional part; Counter - serves to generate unique sequentially increasing or random numbers that are automatically entered into the field when each new record is added to the table. The values of fields of the Counter type cannot be changed; Boolean - intended for boolean values (Yes / No, True / False). The logical field length is 1 bit; OLE object field - any object in binary format (Word document, Excel table, picture, sound recording) linked or embedded in an MS Access table. The size of such a field must not exceed 1 GB; Lookup Wizard - Creates a field that prompts you to select values from a list, or from a combo box containing a set of constant values or values from another table. Selecting this option from a list box in a cell launches the lookup wizard, which determines the type of the field. Field properties are set at the bottom of the table design window on the General tab. The list of properties is different for each data type. Let's consider some of them: Field size - limits the field length to the specified number of characters; Format - specifies the format for dates and numbers; Number of decimal places - for monetary and numeric fields, sets the number of decimal places; Input mask - for text and date fields, defines the template according to which data will be entered into the field; Indexed field - allows you to create an index that will serve to speed up the search and sorting of the table by this field. An index is an internal service table consisting of two columns: the value of the indexed field and the table number. You can set the following properties for indexes: a) "Yes (matches are allowed)" - an index is created that includes matching field values, b) "Yes (no matches are allowed)" - an index is created based on the unique value of the field, c) "No "- no index is created A table in MS Access usually contains a primary key. To create a key, you need to select a field in the constructor and assign it a key through the context menu. Field Data Type Field Size Primary Key Unit Code Numeric Long Integer Yes Unit Name Text 50 "Products" table Field Data Type Field Size Primary Key Item Code Numeric Long Integer Yes Item Name Text100 Unit Code Numeric Long Integer Price Currency-Warehouse Number Numeric Byte Warehouses table Field Data Type Field Size Primary Key Warehouse Number Numeric Byte Yes Warehouse Name Text 20 Month table Field Data Type Field Size Primary Key Month Number Numeric Integer Yes (no matches allowed) Month Name Text 20 Workshop table Field Data Type Field Size Primary Key Shop Number Numeric Byte Yes Shop Name Text 30 Release Plan table FieldData TypeField SizePrimary KeyShop NumberNumericByteYesMonthNumberNumericIntegerYesProduct CodeNumeric Long IntegerYesNumberNumericReal (16) Workshop invoices table Field Data Type Field Size Primary Key Shop Number Numeric Byte Yes Shop Invoice Number NumericLong Integer Yes Delivery DateDate \ Time- Table "Specifications" Field Data Type Field Size Primary Key Shop Number Numeric ByteYes Shop Invoice Number NumericLong IntegerYes Item CodeNumeric Long IntegerYesNumberNumericValid (16) Let's create a data schema in Microsoft Access: Fig. 3. Data schema Creating a user interface Forms are the primary means of creating a user interface that provides the most convenient way to present, view, edit data, and control the progress of an application. The main functions of forms are data input, information output and editing, application progress control, message output, information printing. There are the following types of forms: Normal - displays one record of the data source; Multi-page - designed to work with a data source that has a large number of fields; Ribbon - shows several records of the data source, convenient for a small number of fields; Popup - displayed in the foreground of the screen and allows you to work with other forms; Exclusive - does not allow switching to other forms until it is closed; A slave is a good way to represent data on the "many" side of a one-to-many relationship, is embedded in the master form and always depends on it. Structurally, the form consists of three sections - heading, notes and data areas. The sections of the form contain controls. Any control can be placed on a form using the Toolbox, which is displayed in the form's designer. The most commonly used elements: (inscription) - serves to create permanent inscriptions in the form; (field) - an element that shows the value from the data source; (combo box) - designed to create drop-down lists in the form; (button) - designed to create command buttons in the form that perform certain actions; (checkbox) - an element that allows you to enable or disable the value of a parameter; (subform) - serves to embed a subform into the main one. It is more convenient to create a form using a wizard. The first step is to select the data source and fields for the form. At the second step, you should specify the appearance of the projected form. The third step is to choose the style of the form (background image for the form, format of fonts and colors). At the last step, enter the name of the form, under which it will be stored in the database. The form created with the help of the wizard needs to be finalized in design mode. Add the necessary labels, buttons, subforms. As part of the course work, the following forms were created: Rice. 4. Products. Fig. 5. Release plan. The form "shop invoices" contains the subform "Specifications" Fig. 6. Workshop invoices. Report implementation Before generating a report, you need to create a query. Queries are an essential tool in any database management system. The purpose of requests is in the description of request types. Queries can be created both in the Query Wizard mode (then you have to select the type of query), and in the Query Designer. There are four types of queries in Microsoft Access: simple select queries display data from one or more tables in a table; adding a parameter (selection condition) is allowed; Cross-reference queries collect data from one or more tables in a spreadsheet-like format and are used to analyze the data; adding a parameter (selection condition) is allowed; Change requests are used to create new tables from query results and to make changes (add, delete) to the data of existing tables; adding a parameter (selection condition) is allowed; a query to find records that do not match any record in the subordinate table. With the help of queries in the query wizard mode (by selecting the final report of the query), it is possible to perform a calculation (sum, average, minimum, maximum) using the selected data. To implement the report "Analysis of the implementation of the plan for the delivery of products to warehouse No. ___", it will be enough to execute one request for a selection of the month (table "month"), product name (table "Products"), units of measure (table "Unit of measurement"), quantities by plan ("Release Plan" table), actual quantities ("Specifications" table), with the addition of a "surplus" column with a subtraction formula, as well as with a selection of the warehouse number ("warehouses" table) with a selection condition without displaying this warehouse in the resulting table. For this report, a query was created using the constructor: Fig. 8. The result of the query. According to the different quantity of goods from the specification, it can be seen that canned pike perch was handed over to the warehouse both in July and in September twice. Report generation Reports are the best way to present information from a database as a hard copy. They provide powerful options for grouping and calculating subtotals and subtotals for large datasets. The reports can be used to generate beautifully designed invoices, purchase orders, mailing labels, presentation materials, and other documents you may need to run your business successfully. The report contains the following areas: title - displayed only once at the beginning of the report; header and footer - repeated on each sheet of the report, used to display permanent or periodic information (report date, page numbers, etc.); headings and notes for groups - displayed when grouping is performed in the report at the beginning and at the end of each group, respectively. Up to ten levels of grouping can be created in the report; data area - is used to enter informative report lines; report note - designed to display summary information on the report as a whole, printed once at the end of the report. It is more convenient to create a report, like a form, using a wizard. After creating a report, you can change its structure in design mode (correct and format the column headings of the report, add or remove fields, etc.). As a result of the report execution, its printed form was obtained. Analysis of the implementation of the plan for the delivery of products to warehouse No. 1, 2, 3 - Fig. 10-12. The field “shop invoice number” was added to show that the product could be handed over to the warehouse twice a month under two different invoices. Fig. 9. Report designer Fig. 10. Analysis of the implementation of the plan for the delivery of products to warehouse No. 1 Fig. 11. Analysis of the implementation of the plan for the delivery of products to warehouse No. 2 Fig. 12. Analysis of the implementation of the plan for the delivery of products to warehouse No. 3 Bibliography Tarasov V.L. Working with databases in the Access environment, Tutorial / Nizhny State University, Nizhny Novgorod, 2005. Shekhtman V.E. Databases, SQL Textbook on the disciplines "Databases", "Databases and expert systems", "Modern SQL programming technology". / - NPI KemSU, Novokuznetsk, 2006. Andreev V.A., Tupikina E.N., Database management systems (Microsoft Access), guidelines / FESAEU, Vladivostok, 2003. Veiskas D., Effective work with ACCESS, study guide / SPb, 1996. Khomonenko A.F., Tsygankov V.M., Maltsev M.G. Databases, Textbook for Universities / Ed. prof. A.D. Khomonenko. - SPb .: KORONA print, 2002.
- Tutorial
- Recovery Mode
Hello everyone! My name is Oleg and I am an amateur programmer for Android. Amateur because at the moment I am making money by programming in a completely different direction. And this is a hobby to which I devote my free time. Unfortunately, I have no familiar Android programmers and I draw all my basic knowledge either from books or from the Internet. In all those books and articles on the Internet that I read, very little space is allocated to creating a database for the application, and in fact the whole description boils down to creating a class that is a heir SQLiteOpenHelper and the subsequent injection of SQL code into Java code. Apart from the fact that we get poorly readable code (and if more than 10 tables appear in our application, then remembering all these relationships between tables is still hell), then, in principle, you can live, of course, but somehow you absolutely don't want to.
I forgot to say the most important thing, we can say that this is my test of the pen here. And so we went.
On the eternal question: why?
Why in books and articles devoted to programming for Android do not describe tools for designing database architecture and any patterns for working with databases at the stage of their creation, I honestly do not know. It would seem to add just a couple of pages to a book or write a separate article (as I am doing now) as easy as shelling pears - but no. In this article, I will briefly go through the tools that I use in my work and in more detail on the code that is responsible for the initial creation of the database, which, from my point of view, looks more readable and convenient.
If our application has more than 5 tables, then it would be nice to use some tool for visual design of the database architecture. Since this is a hobby for me, I use an absolutely free tool called Oracle SQL Developer Data Modeler (you can download it).
This program allows you to visually draw tables, and build relationships with them. Many design mistakes in database architecture can be avoided with this design approach (I’m already telling you this as a professional database programmer). It looks like this:

Having designed the architecture itself, we proceed to the more tedious part, which consists in creating sql code for creating tables. To help in this matter, I already use a tool called SQLiteStudio (which in turn can be downloaded here).

This tool is analogous to such well-known products as SQL Naviagator, Toad etc. But as the name suggests, it is tailored for working with SQLite. It allows you to visually create a database and get the DDL code of the tables being created. By the way, it also allows you to create Views, which you can also use in your application if you want. I don’t know how correct is the approach of using views in Android programs, but in one of my applications I used them.

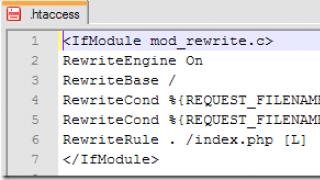
As a matter of fact, I no longer use any third-party tools, and then the magic begins with Android Studio. As I already wrote above, if we start to inject SQL code into Java code, then the output will be poorly readable and, therefore, poorly extensible code. Therefore, I transfer all SQL statements to external files that are in the directory assets... In Android Studio, it looks something like this:

About db and data directories
Inside the directory assets i created two directories db_01 and data_01... The numbers in the names of the directories correspond to the version number of my database with which I work. In the directory db I store the SQL scripts for creating tables themselves. And in the directory data the data necessary for the initial filling of the tables is stored.
Now let's take a look at the code inside my DBHelper which I use in my projects. First the class variables and the constructor (no surprises here):
Private static final String TAG = "RoadMap4.DBHelper"; String mDb = "db_"; String mData = "data_"; Context mContext; int mVersion; public DBHelper (Context context, String name, int version) (super (context, name, null, version); mContext = context; mVersion = version;)
Now the method onCreate and here it becomes more interesting:
@Override public void onCreate (SQLiteDatabase db) (ArrayList
Logically, it is divided into two loops, in the first loop I get a list of SQL statements for creating a database and then execute them, in the second loop I already fill the tables created earlier with initial data. And so, step one:
Private ArrayList
Everything is quite simple here, we just read the contents of the files, and concatenate the contents of each file into an array element. Please note that I am sorting the list of files, since tables can have foreign keys, which means that tables must be created in a specific order. I use numbering in the name of the files, and with the help of it I do the sorting.
Private class QueryFilesComparator implements Comparator
With filling in the tables, everything is more fun. My tables are filled not only with hard-coded values, but also with values from resources and UUID keys (I hope someday come to the network version of my program so that my users can work with shared data). The structure of the initial data files looks like this:

Despite the fact that my files have the sql extension, there is no sql code inside, but this thing:
Prioritys
pri_id: UUID: UUID
pri_name: string: normal
pri_color: color: colorGreen
pri_default: int: 1
prioritys
pri_id: UUID: UUID
pri_object: string: object_task
pri_name: string: hold
pri_color: color: colorBlue
pri_default: int: 0
prioritys
pri_id: UUID: UUID
pri_object: string: object_task
pri_name: string: important
pri_color: color: colorRed
pri_default: int: 0
prioritys
pri_id: UUID: UUID
pri_name: string: normal
pri_color: color: colorGreen
pri_default: int: 1
prioritys
pri_id: UUID: UUID
pri_object: string: object_project
pri_name: string: hold
pri_color: color: colorBlue
pri_default: int: 0
prioritys
pri_id: UUID: UUID
pri_object: string: object_project
pri_name: string: important
pri_color: color: colorRed
pri_default: int: 0
The file structure is like this: I make a function call split (":") in relation to a line and if I get that its size is 1, then this is the name of the table where the data should be written. Otherwise, it is the data itself. The first field is the name of the field in the table. The second field is the type by which I determine what I need to write in this very field. If it's a UUID, it means I need to generate a unique UUID value. If string means I need to pull out the string value from the resources. If it is color, then again, you need to extract the color code from the resources. If int or text, then I just convert the given value to int or String without any gestures. The code itself looks like this:
Private ArrayList
30.04.2009 Alexey Kovyazin
Relational databases have penetrated almost all information systems, and, it would seem, have become the most established area of IT, where little can be invented, but the reality is far from ideal.
Relational databases are used today in almost all applications, from embedded in mobile and special devices, Web-based applications, and ending with enterprise management systems. The penetration of databases into all kinds of applications is increasing, and developers are getting more and more user-friendly tools and approaches. One might get the impression that the developers of database applications are the most "well-off" layer of programmers who have tools for all occasions, but this is far from the case. Embarcadero Technologies, by acquiring Borland's CodeGear development tools division in 2008, combined professional application development and design tools, development and database management tools to address both application and database issues.
Chaotic database design
In the modern software development industry, it is a common belief that it is impossible to define product requirements before starting a project, and therefore development must be adapted to their constant change. As a result, iterative processes have emerged to accommodate changing requirements, and refactoring of source code has become an integral part of software development. What happens to databases during iterative development? Changing requirements forces you to adjust the database schema, and most often this happens in an opaque manner, without analyzing the overall picture and dependencies. Tables, fields, foreign keys and constraints are created and changed chaotically, no one monitors referential integrity, and no one can say for sure how the database at iteration N differs from its state at iteration N-1.
In fact, the development of databases today is carried out by the "patch" method, as in the days of the domination of the "waterfall" process - at the beginning of the project, a certain model of the database is "drawn" based on the partial requirements known at the moment, then a physical database is generated, and then about the model is forgotten by making changes directly to the database. The disadvantages of this approach are obvious: the exchange of knowledge and understanding the big picture are difficult, and changes are opaque, they can generate contradictions in the logic and schema of the database, which will remain undisclosed until the moment the software system is put into operation, which leads to very large losses. Modern database application developers need tools that are geared towards iterative database development.
The first and most important condition for such adaptability is the presence of full-fledged opportunities reverse engineering(reverse engineering, creation of a database model based on the analysis of its physical scheme) and direct engineering(forward engineering; creation and modification of the physical database schema based on the model). In practice, this means that using a design tool, you can analyze the schema of an existing database, create a database model based on it, change the model and immediately apply changes that should really correctly and consistently change the database schema, and not spoil or confuse it.
The iterative approach also pushes us to create submodels associated with a particular iteration. Highlighting any entities and their attributes into a submodel helps to separate areas of responsibility both between different developers and between different iterations, while ensuring the overall integrity of the model. Naturally, you also need the ability to compare the two models, and not in the form of SQL scripts, but at the entity and attribute level, in order to see and fully understand the changes made during iteration and their impact on the entire model.
Application developers rarely work alone, so they need collaboration tools, but if that's okay on the application development side, database collaboration is usually not supported at the tooling level in any way. Collaboration necessarily implies a version control system: all versions of the models and the physical database schema must be stored in a single repository, providing the ability to rollback and compare schemas from the very beginning of the development process.
Database development is no less important than application development, therefore, the strategic direction of development is to provide the database development process with version control and requirements management, as well as explicitly linking the stages of modeling and modifying databases to iterations and changing requirements of a software project. To solve the above problems and support the modern iterative process of database development, Embarcadero offers ER / Studio - a design, analysis, reverse and forward engineering tool that allows you to control model versions based on its own repository. The Change Manager tool can be used to control metadata changes in physical databases.
Disaggregated code
The most famous problem that greatly slows down the process of developing database applications is the need to use different tools to debug application code and SQL code in the database.
Let's take a look at a simple example. Suppose you are developing an application in Delphi that calls a stored procedure in an Oracle DBMS. Using Delphi tools, the application developer can step by step in debug mode until the moment of calling the SQL query, see the parameters passed to the stored procedure and the result that the procedure will return. But what happens inside the procedure when it is executed on the database server? It is impossible to determine this from the development environment of our application - for this you need to download an application for SQL development, which has the ability to debug stored procedures, and also shows plans for SQL queries, statistics of their execution, allows you to view and change the database schema. However, you cannot pass parameters from the application development environment to the SQL development environment, and you have to copy them manually, switching from one window to another. It is also not possible to see the detailed results of executing SQL code in the Application Builder, such as query plan, execution statistics, and so on. The advent of cross-language debugging technology has solved these problems.
The first Embarcadero product that supports cross-language debugging is RapidSQL Developer (formerly PowerSQL), the visual part of which is based on Eclipse technology and therefore allows you to integrate into any development environment based on it (including, of course, JBuilder) and dynamically cross -language debugging. Now, when the stored procedure is executed on the server, the developer automatically switches to a full-fledged SQL debugging environment within the framework of the same tool, capable of debugging both ordinary SQL queries and stored procedures. The developer can see the actual input parameters of queries and stored procedures, getting the opportunity to step-by-step debugging of the SQL code. Integrating RapidSQL Developer into Eclipse-compatible development tools is the first step in integrating application and database development, and the next step is to provide similar capabilities for Delphi, C ++ Builder, and other application development tools from Embarcadero.
Multi-platform database applications
A particular challenge for developers is the development of database applications that need to work with multiple DBMSs. For example, banks and insurance companies usually have several large offices and many small branches. Most of the business processes related to the entry of operational information and day-to-day workflow are the same at the head office and in the branches, but the scales are different. The natural desire to save on the cost of industrial DBMS licenses for use in branches leads to the idea that it would be good to choose another DBMS without changing the application.
Experienced database developers understand well the essence of the problems arising here: the difference in data types and SQL dialects, the absence of migration and replication mechanisms between different DBMSs, the complexity of migration verification make writing and operating applications for different DBMSs a nightmare. From the side of application development tools, they are trying to solve this problem by creating data access libraries (dbExpress in Delphi and C ++ Builder, ADO and ADO.Net from Microsoft), built on uniform architectural principles and access methods, as well as by using numerous object-relational "Wrappers" (Object Relation Mapping, ORM) over the relational logic and the structure of the database, generating source code for working with data based on the analysis of the database schema and using the mechanism of "adapters" to implement the protocol of a specific DBMS. Among the most popular ORMs are Hibernate for Java and ActiveRecord in RubyOnRails, which provide an object-oriented interface to the data stored in the DBMS. For Delphi there is a similar project tiOPF, for C # - NHibernate.
Of course, the use of such universal libraries and sets of components can significantly reduce the number of routine operations in the process of multi-platform database development. However, this is not enough when it comes to applications using more complex databases, in which the logic inherent in stored procedures and triggers is actively used - for its implementation, debugging and testing, separate tools are required, sometimes completely different for different DBMSs. For the development of cross-platform database applications, Embarcadero offers the RapidSQL tool.
All Embarcadero database products support multiple platforms and are based on Thunderbolt's schema analysis and database statistics engine. Each supported DBMS and each specific version of the DBMS have corresponding branches of code in the Thunderbolt core, which allows you to map the database schema to the internal representation in this core as accurately as possible and, most importantly, to carry out correct conversions between the representation and real databases. It is thanks to the Thunderbolt core that RapidSQL allows you to develop high-quality SQL code for all supported platforms (Oracle, MS SQL, Sybase and various variants of IBM DB2), and ER / Studio can perform accurate reverse and forward engineering of database schemas.
If you are developing an application for two or more platforms or migrating an existing application from one platform to another, RapidSQL will provide all the necessary tools for migrating schema, users and permissions between different DBMS. Of course, RapidSQL does not automatically convert PL / SQL procedures to T-SQL - this still requires a programmer - however, the tool provides a single window for multi-platform development, unified editors for schema objects, users and their rights, and SQL debugging on all supported platforms. ... According to RapidSQL users, this saves up to 70% of the time spent migrating between different DBMSs.
Changes to data and diagrams
Migration from one DBMS to another is impossible without its verification. Who and how can guarantee that the data transferred from one DBMS to another is really identical? Different client libraries, different data types and different encodings make the process of comparing data a non-trivial task.
In the real world, the work does not end with the deployment of the application and the database - there is maintenance, new versions of the application executable files and patches to the database appear. How can you get guarantees that all the necessary updates have been applied to the database and that the entire software package will work correctly?
Embarcadero has developed the Change Manager tool for comparing data, schemas and database configurations. The comparison takes place within the framework of one or several DBMS, with automatic checking of the correspondence between data types and the formation of SQL-scripts of differences, which can be immediately applied to bring the databases into an identical state. The metadata comparison module provides comparison of database schemas both between live databases and between database and SQL script and generates a script for metadata differences. This functionality can be used not only to check databases for compliance with the benchmark, but also to organize a regular database update process, as well as to check for unauthorized changes, say, in remote branches of a large organization. The situation is similar with configuration files - Change Manager compares configuration files and allows you to ensure that the configuration of deployed applications meets the requirements for this software.
Database Application Performance
How often do we see applications that work fine on small test volumes of data, but become unacceptably slow on real volumes. Miscalculations in requirements, inadequate testing in the early stages, rush to deliver a project are all familiar reasons for poor application development. In this case, software development theorists propose to engage in self-improvement and fundamentally improve the quality of programs, however, all practitioners know that rewriting a project is sometimes impossible, either economically or, in some cases, politically, and the task of optimizing performance must be solved in any way.
The main cause of performance problems in database applications lies in unoptimized SQL queries and stored procedures. Modern database optimizers are powerful enough, however, they also have certain limits of their capabilities, and in order to achieve good performance, you need to correctly compose SQL queries, create (or drop) additional indexes, in certain cases denormalize the database, transfer some of the logic to triggers and stored procedures.
During development, query optimization can be performed using RapidSQL, which includes a SQL Profiler module that can analyze plans and generate hints to improve the performance of SQL queries. But what if the problem occurs during production and is not localized in a specific SQL query? If performance drops at a certain time of the day, or, even more annoyingly, the problem occurs on a remote copy of the system, while everything is fine on the main server? This is where DBOptimizer, a database profiling tool for Oracle, Microsoft SQL Server, Sybase, and IBM DB2, is designed.
When the profiling mode is started, DBOptimizer collects information about the database and the runtime, including information about the CPU load and other parameters of the operating system, writing it to the profiling session. The result is a list of queries executed at any given time interval, sorted by consumed resources. For each problematic request, you can see its plan, execution statistics, and other details. Moreover, DBOptimizer also shows hints and recommendations for improving the query in relation to specific DBMS.
Toolbox
All of the tools mentioned, while solving problems, are used at different stages in the database development lifecycle. It is rather inconvenient and costly to keep a dozen applications for all occasions that may or may not be needed during the design, development, migration, optimization and operation of databases.
Released in February 2009, the versatile Emdacadero All-Access toolkit includes the essential tools for all stages of database application development, from ER / Studio to DBOptimizer, from Delphi and C ++ Builder to DBArtisan. The best way to describe All-Access is the comparison with the toolbox that every zealous owner has at home. Perhaps not all tools are used every day, but an adjustable wrench should always be at hand in case of a leak.
All-Access does not impose other roles on programmers or database architects, but provides a universal set of tools suitable for all roles in the database application development process, from architect to tester; offers all members of the development team tools for all stages of database development, as well as a set of highly specialized tools for optimizing databases (DBOptimizer) and applications (JOptimizer) to "expand" bottlenecks. The package supports multiple DBMS, which provides cost savings.
The technical differences between object-oriented and relational database technologies have resulted in cultural differences that still separate the data management community from the development community. What to do next with this?
Delphi is a development environment that uses the Delphi programming language (starting from version 7, the language in the environment is called Delphi, earlier - Object Pascal), developed by Borland and originally implemented in its Borland Delphi package, from which it received its current name in 2003 ... Object Pascal, in fact, is the inheritor of the Pascal language with object-oriented extensions.
Delphi is the ultimate tool for building database applications. Optimal, because supports visual development technology, which can significantly reduce development time while maintaining good quality and reliability of the software product. Delphi in the structure of the language allows you to avoid hidden errors.
Features of the Delphi 7 family:
* A rapid application development environment that integrates modeling tools for the development and deployment of e-commerce applications and Web services.
* Support for programming languages for Win32 (Delphi and C / C ++) and for .NET (Delphi and C #) in a single development environment, which makes it easier to maintain and create new Win32 applications and more easily master .NET technologies;
* The ability for both developers of traditional Windows applications and developers using Java to develop .NET applications without abandoning the tools used, while maintaining skills and with similar programming concepts;
* The new system of code templates and other innovations in the development environment qualitatively improve the work with source codes and increase development productivity;
Microsoft SQL Server 2000 is a complete database and data analytics offering for rapidly building scalable e-commerce solutions, business applications and data warehouses.
It can significantly reduce the time to market for these solutions while providing scalability to meet the most demanding requirements.
The Delphi package is a continuation of Borland's line of Pascal compilers. As a language, Pascal is very simple, and strong data type checking facilitates early error detection and allows you to quickly create reliable and efficient programs.
Database application development is one of the most requested features of the Delphi programming environment. Delphi's database power and flexibility is based on a low-level core, the Borland Database Engine (BDE). Its interface with applications is called the Integrated Database Application Programming Interface (IDAPI). BDE allows access to data using both the traditional record-oriented (navigation) approach and the set-oriented approach used in SQL database servers.
The object library contains a set of visual components that greatly simplify the development of applications for DBMS with client-server architecture. Objects encapsulate the lower layer, the Borland Database Engine.
There are special sets of components responsible for accessing data and components that display data. Data access components allow making connections to the database, making selections, copying data, etc.
Data visualization components allow you to display data in the form of tables, fields, lists. The displayed data can be in text, graphic, or any format.
The tables are stored in the database. Some DBMSs store the database as several separate files that are tables (basically all local DBMSs), while others consist of a single file that contains all tables and indexes (InterBase).
Database objects in Delphi are SQL-based and incorporate the full power of the Borland Database Engine. Delphi also includes Borland SQL Link, so access to Oracle, Sybase, Informix and InterBase DBMS is highly efficient. In addition, Delphi includes a local Interbase server so that you can develop offline extensible applications to any external SQL server.
Scalability in practice - the same application can be used for both local and more serious client / server options.
Although Delphi does not have its own database table format, it nevertheless provides powerful support for a large number of different DBMSs - both local (for example, dBase or Paradox) and industrial (for example, Sybase or InterBase).