Topics: database design stages, database design based on an object-relationship model.
Before creating a database, the developer must determine what tables the database should consist of, what data should be placed in each table, how to link the tables. These issues are addressed at the database design stage.
As a result of the design, the logical structure of the database should be determined, that is, the composition of relational tables, their structure and inter-table relationships.
Before creating a database, you must have a description of the selected subject area, which should cover real objects and processes, identify all the necessary sources of information to meet the expected user requests and determine the needs for data processing.
On the basis of such a description, at the database design stage, the composition and structure of the data of the subject area are determined, which should be in the database and ensure the fulfillment of the necessary queries and user tasks. The data structure of the subject area can be displayed by an information-logical model. Based on this model, a relational database is easily created.
The stages of designing and creating a database are determined by the following sequence:
Building information logical model subject area data;
Defining the logical structure of a relational database;
Designing database tables;
Creating a data schema;
Entering data into tables (creating records);
Development of necessary forms, requests, macros, modules, reports;
User interface development.
In the process of developing a data model, it is necessary to identify information objects that meet the requirements of data normalization and determine the relationships between them. This model allows you to create relational database data without duplication, which ensures a single entry of data during initial loading and adjustments, as well as data integrity when changes are made.
When developing a data model, two approaches can be used. In the first approach first, the main tasks are determined, for the solution of which the base is built, the needs of the tasks in data are identified, and the composition and structure of information objects are determined accordingly. With the second approach typical objects of the subject area are immediately installed. The most rational combination of both approaches. This is due to the fact that on initial stage, as a rule, there is no exhaustive information about all tasks. The use of such a technology is all the more justified because the flexible means of creating relational databases allow at any stage of development to make changes to the database and modify its structure without prejudice to the previously entered data.
The process of selecting information objects of the subject area that meet the requirements of normalization can be carried out on the basis of an intuitive or formal approach. Theoretical basis formal approach were developed and fully described in monographs on the organization of databases by the famous American scientist J. Martin.
With an intuitive approach, information objects corresponding to real objects can be easily identified. However, the resulting information-logical model, as a rule, requires further transformations, in particular, the transformation of multi-valued relationships between objects. With this approach, significant errors are possible if there is not enough experience. Subsequent verification of the fulfillment of the normalization requirements usually shows the need to refine the information objects.
Consider the formal rules that can be used to highlight information objects:
Based on the description of the subject area, identify documents and their attributes to be stored in the database;
Define functional dependencies between attributes;
Select all dependent attributes and indicate for each of its key attributes, i.e. those on which it depends;
Group attributes equally dependent on key attributes. The resulting groups of dependent attributes along with their key attributes form information objects.
When defining the logical structure of a relational database based on the model, each information object is adequately represented by a relational table, and the relationships between tables correspond to the relationships between information objects.
During the creation process, the database tables corresponding to the information objects built data model. Further, a data schema can be created, in which the existing logical relationships between tables are fixed. These links correspond to the links of information objects. The data schema can be set to maintain the integrity of the database if the data model was designed in accordance with the requirements of normalization. Data integrity means that relationships between records are established and correctly maintained in the database. different tables when loading, adding and deleting records in related tables, as well as when changing the values of key fields.
After the formation of the data schema, the input of consistent data from the documents of the subject area is carried out.
On the basis of the created database, the necessary queries, forms, macros, modules, reports are formed that perform the required processing of the database data and their presentation.
Using the built-in database tools and tools, a user interface is created that allows you to manage the processes of entering, storing, processing, updating and presenting database information.
Designing a database based on an object-relationship type model
There are a number of methods for creating information-logical models. One of the most popular modeling techniques today is using ERD (Entity-Relationship Diagrams). In Russian literature, these diagrams are called "object - relation" or "essence - connection". The ERD model was proposed by Peter Ping Shen Chen in 1976. To date, several of its varieties have been developed, but all of them are based on graphic diagrams proposed by Chen. Charts are constructed from a small number components. Due to the clarity of presentation, they are widely used in CASE-tools (Computer Aided Software Engineering).
Consider the terminology and notation used.
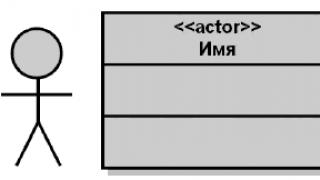
Entity- a real or imaginary object that is essential for the subject area under consideration, information about which is to be stored.
Each entity must have a unique identifier. Each instance of an entity must be uniquely identifiable and distinct from all other instances. of this type(entities).
Each entity must have some properties:
Have a unique name; moreover, the same interpretation (entity definition) must always be applied to this name. Conversely, the same interpretation cannot apply to different names, unless they are aliases;
Have one or more attributes that either belong to the entity or are inherited by it through a relationship;
Have one or more attributes that uniquely identify each entity instance.
An entity can be independent or dependent. A sign of a dependent entity is the presence of attributes inherited through a relationship (Fig. 1.).
Each entity can have any number of relationships with other model entities.
Relationship- a named association between two entities that is significant for the subject area under consideration. One of the entities participating in the relationship is independent, called the parent entity, the other is dependent, called the child or descendant entity. As a rule, each instance of the parent entity is associated with an arbitrary (including zero) number of instances of the child entity. Each child entity instance is associated with exactly one instance of the parent entity. Thus, an instance of a child entity can only exist if the parent entity exists.
The connection is given a name expressed by the grammatical turnover of the verb and placed near the line of connection.

The name of each relationship between two given entities must be unique, but relationship names in the model need not be unique. Each link has a definition. A relationship definition is formed by combining the name of the parent entity, the name of the relationship, the expression of the degree of relationship, and the name of the child entity.
For example, the relationship of a seller to a contract can be defined as follows:
The Seller may be rewarded for one or more Contracts;
The contract must be initiated by exactly one Seller.
In the diagram, the relationship is represented by a segment (polyline). Line ends with special designations(Figure 2) indicate the degree of association. In addition, the nature of the line - dashed or solid, indicates the obligation of communication.
Attribute- any characteristic of an entity that is significant for the subject area under consideration. It is intended to qualify, identify, classify, quantify, or express the state of an entity. An attribute represents a type of characteristics (properties) associated with a set of real or abstract objects (people, places, events, states, ideas, pairs of objects, etc.) (Fig. 3).
Attribute instance is a specific characteristic of a particular instance of an entity. An attribute instance is defined by a characteristic type (for example, "Color") and its value (for example, "lilac"), called the attribute value. In the ER model, attributes are associated with specific entities. Each entity instance must have one specific value for each of its attributes.
 |
The attribute can be either compulsory, or optional. Mandatory means that the attribute cannot have null values. An attribute can either be descriptive (i.e., a normal entity descriptor) or be part of a unique identifier (primary key).
Unique identificator is an attribute or a set of attributes and/or relationships that uniquely characterizes each instance of a given entity type. In the case of full identification, an instance of this entity type is fully identified by its own key attributes, otherwise attributes of another entity, the parent, also participate in the identification.
The nature of the identification is displayed in the diagram on the communication line (Fig. 4).

Each attribute is identified by a unique name, expressed by a noun phrase that describes the characteristic that the attribute represents. Attributes are displayed as a list of names within an associated entity block, with each attribute occupying a separate line. Attributes that define the primary key are placed at the top of the list and are marked with a "#" sign.
Each entity must have at least one possible key. A possible entity key is one or more attributes whose values uniquely identify each entity instance. With the existence of several possible keys one of them is designated as the primary key, and the rest as alternate keys.
Currently, based on Chen's approach, the IDEF1X methodology has been created, which is designed taking into account such requirements as ease of study and the possibility of automation. IDEFlX diagrams are used by a number of common CASE tools (eg ERwin, Design/IDEF).
 An entity in the IDEF1X methodology is called identifier-independent, or simply independent, if each entity instance can be uniquely identified without defining its relationship to other entities. An entity is called dependent on identifiers or simply dependent if the unique identification of an entity instance depends on its relation to another entity (Fig. 5).
An entity in the IDEF1X methodology is called identifier-independent, or simply independent, if each entity instance can be uniquely identified without defining its relationship to other entities. An entity is called dependent on identifiers or simply dependent if the unique identification of an entity instance depends on its relation to another entity (Fig. 5).
Each entity is assigned a unique name and number, separated by a slash "/" and placed above the block.
If an instance of a descendant entity is uniquely determined by its relationship with the parent entity, then the relationship is called identifying, otherwise it is called non-identifying.
An identifying relationship between a parent entity and a child entity is shown as a solid line. On fig. 5: No. 2 - dependent entity, Relationship 1 - identifying relationship. A child entity in an identifying relationship is an identity-dependent entity. The parent entity in an identifying relationship can be either independent or dependent on the identifier (this is determined by its relationships with other entities).
The dashed line depicts a non-identifying relationship. On fig. 5: #4 is an independent entity, Relationship 2 is a non-identifying relationship. A child entity in a non-identifying relationship will be identifier-independent unless it is also a child entity in an identifying relationship.
A relationship can be further defined by specifying a degree or cardinality (the number of child entity instances that can exist for each parent entity instance).
In IDEF1X, the following cardinalities can be expressed:
Each parent entity instance can have zero, one, or more child entity instances associated with it;
Each parent entity instance must have at least one child entity instance associated with it;
Each parent entity instance must have no more than one child entity instance associated with it;
Each parent entity instance is associated with some fixed number of child entity instances.

The link power is denoted as shown in Fig. 6 (default power — N).
 |
![]()
Attributes are displayed as a list of names inside an entity block. Attributes that define the primary key are placed at the top of the list and are separated from other attributes by a horizontal bar (Fig. 7).
The result is an information-logical model, which is used by a number of common CASE-tools, such as ERwin, Design / IDEF. In turn, CASE-technologies have high potential in the development of databases and information systems namely, increasing labor productivity, improving the quality of software products, supporting a unified and consistent work style.
Entities can also have Foreign Keys. With an identifying relationship, they are used as part or the whole of the primary key, with a non-identifying relationship, they serve as non-key attributes. In the attribute list, the foreign key is marked with the letters FK in parentheses.
The essence of database design (DB), as well as any other design process, is to create a description of a new system that did not previously exist in this form, which, when implemented, is capable of supposedly functioning under appropriate conditions. It follows from this that the stages of database design should consistently and logically reflect the essence of this process.
Content of database design and stages
The design idea is based on some formulated social need. This need has an environment for its occurrence and a target audience of consumers who will use the result of the design. Therefore, the database design process begins by examining a given need from the point of view of the customers and the functional environment of its intended location. That is, the first stage is the collection of information and the definition of a model of the subject area of the system, as well as a look at it from the point of view of the target audience. In general, to determine the requirements for the system, the scope of actions is determined, as well as the boundaries of the database applications.
Further, the designer, who already has certain ideas about what he needs to create, clarifies the tasks supposedly solved by the application, forms a list of them (especially if the design development has a large and complex database), clarifies the sequence of solving problems and analyzes the data. This process is also a step project work, but usually in the design structure these steps are absorbed by the step conceptual design- the stage of selecting objects, attributes, links.
The creation of a conceptual (information model) involves the preliminary formation of the conceptual requirements of users, including requirements for applications that may not be immediately implemented, but the consideration of which will improve the functionality of the system in the future. Dealing with representations of object-abstractions of a set (without specifying the methods of physical storage) and their relationships, the conceptual model corresponds to the content of the domain model. Therefore, in the literature, the first stage of database design is called infological design.
Next, a separate stage (or addition to the previous one) is followed by the stage of formation of requirements for the operating environment, where the requirements for computing resources that can ensure the functioning of the system are evaluated. Accordingly, the larger the volume of the database being designed, the higher the user activity and the intensity of calls, the higher the requirements for resources: for the computer configuration, for the type and version operating system. For example, the multi-user mode of the future database requires network connection using an operating system that is appropriate for multitasking.
The next step the designer must choose a database management system (DBMS), as well as tools programmatic. After that, the conceptual model must be transferred to a data model compatible with the selected control system. But often this is associated with the introduction of amendments and changes to the conceptual model, since not always the relationships of objects to each other, reflected by the conceptual model, can be implemented using the means of this DBMS.
This circumstance determines the emergence of the next stage - the emergence of a specific DBMS provided with funds. conceptual model. This step corresponds to the stage of logical design (creation of a logical model).
Finally, final stage database design becomes physical design - the stage of linking the logical structure and the physical storage environment.
Thus, the main stages of design in a detailed form are represented by the stages:
- infological design,
- formation of requirements for the operating environment
- choice of control system and software tools DB,
- logical design,
- physical design
The key ones will be discussed in more detail below. 
infological design
Identification of entities is the semantic basis of infological design. An entity here is such an object (abstract or concrete), information about which will be accumulated in the system. In the infological model of the subject area, in user-friendly terms that do not depend on the specific implementation of the database, the structure and dynamic properties of the subject area are described. But the terms are taken on a typical scale. That is, the description is expressed not through individual objects of the subject area and their relationships, but through:
- description of object types,
- the integrity constraints associated with the described type,
- processes leading to the evolution of the subject area - its transition to another state.
An infological model can be created using several methods and approaches:
- The functional approach is based on the tasks set. It is called functional because it is used if the functions and tasks of persons who, with the help of the designed database, will serve their information needs, are known.
- The subject approach focuses on information about the information that will be contained in the database, despite the fact that the structure of queries may not be determined. In this case, in the research of the subject area, they are guided by its most adequate display in the database in the context of the full range of supposed information requests.
- An integrated approach based on the "entity-relationship" method combines the advantages of the two previous ones. The method is reduced to dividing the entire subject area into local parts, which are modeled separately, and then re-combined into a single area.
Since the use of the entity-relationship method is a combined design method at this stage, it becomes a priority more often than others.
Local representations with methodical separation should, if possible, include information that would be enough to solve a separate problem or to provide requests for some group of potential users. Each of these areas contains about 6-7 entities and corresponds to any separate external application.
The dependence of entities is reflected in their division into strong (base, parent) and weak (child). A strong entity (for example, a reader in a library) can exist in the database on its own, while a weak entity (for example, this reader's subscription) is "attached" to a strong one and does not exist separately.
It is necessary to separate the concepts of “entity instance” (an object characterized by specific property values) and the concept of “entity type” - an object that is characterized by a common name and a list of properties.
For each individual entity, attributes (a set of properties) are selected, which, depending on the criterion, can be:
- identifying (with unique value for entities of that type, making them potential keys) or descriptive;
- single-valued or multi-valued (with the appropriate number of values for an entity instance);
- basic (independent of other attributes) or derivatives (calculated based on the values of other attributes);
- simple (indivisible one-component) or composite (combined from several components).
After that, the specification of the attribute, the specification of the links in the local representation (divided into optional and mandatory), and the union of local representations are performed. With up to 4-5 local regions, they can be combined in one step. In the case of an increase in the number, the binary merging of areas occurs in several stages.
During this and other intermediate stages, the iterative nature of the design is reflected, which is expressed here in the fact that in order to eliminate contradictions, it is necessary to return to the stage of modeling local representations for clarification and change (for example, to change the same names of semantically different objects or to agree on integrity attributes on the same attributes in different applications).
Choice of control system and database software
 The choice of database management system depends practical implementation information system. The most significant criteria in the selection process are the parameters:
The choice of database management system depends practical implementation information system. The most significant criteria in the selection process are the parameters:
- type of data model and its compliance with the needs of the subject area,
- margin of opportunity in case of expansion of the information system,
- performance characteristics of the selected system,
- operational reliability and convenience of the DBMS,
- tooling geared towards data administration personnel,
- the cost of the DBMS itself and additional software.
Mistakes in the choice of DBMS will almost certainly provoke the need to adjust the conceptual and logical models later.
Logical database design
The logical structure of the database must correspond to the logical model of the subject area and take into account the relationship of the data model with the supported DBMS. Therefore, the stage begins with the choice of a data model, where it is important to take into account its simplicity and clarity.
Preferably, the natural data structure matches the model that represents it. So, for example, if the data is presented in the form hierarchical structure, then it is better to choose a hierarchical model. However, in practice, such a choice is more often determined by the database management system, and not by the data model. Therefore, the conceptual model is actually translated into a data model that is compatible with the selected database management system.
Here, too, the nature of design is reflected, which allows for the possibility (or need) to return to the conceptual model to change it if the relationships between objects (or attributes of objects) reflected there cannot be implemented using the means of the selected DBMS.
Upon completion of the stage, database schemas of both levels of architecture (conceptual and external) should be generated, created in the data definition language supported by the selected DBMS.
 Database schemas are generated using one of two divergent approaches:
Database schemas are generated using one of two divergent approaches:
- or using a bottom-up approach when working with lower levels determining attributes grouped into relationships representing objects based on existing relationships between attributes;
- or with the help of the reverse, top-down approach, applied with a significant (up to hundreds and thousands) increase in the number of attributes.
The second approach involves the definition of a number of high-level entities and their relationships, followed by detailing up to right level, which reflects, for example, a model created on the basis of the "entity-relationship" method. In practice, however, both approaches are usually combined.
Physical database design
At the next stage of the physical design of the database, the logical structure is displayed in the form of a database storage structure, that is, it is linked to such a physical storage medium where the data will be placed as efficiently as possible. Here, the data schema is described in detail, indicating all types, fields, sizes, and restrictions. In addition to developing indexes and tables, basic queries are defined.
The construction of a physical model is associated with the solution of contradictory problems in many respects:
- data storage space minimization problems,
- objectives to achieve integrity, security and maximum performance.
The second task conflicts with the first because, for example:
- for the efficient functioning of transactions, you need to reserve disk space for temporary objects,
- to increase the search speed, you need to create indexes, the number of which is determined by the number of all possible combinations of fields involved in the search,
- for data recovery will be created backups database and keep a log of all changes.
All this increases the size of the database, so the designer is looking for a reasonable balance in which tasks are optimally solved by competently placing data in memory space, but not at the expense of database protection, which includes both protection from unauthorized access and protection from failures.
To complete the creation of a physical model, its operational characteristics are evaluated (search speed, efficiency of query execution and resource consumption, correctness of operations). Sometimes this stage, like the stages of database implementation, testing and optimization, as well as maintenance and operation, is taken out of the scope of the direct database design.
Lecture
Database design.
Models of the multilevel architecture of database systems. Design Automation Tools
1. Models of the multilevel architecture of database systems
In the field of design and development of database systems, various modeling tools are used, and even within the framework of one specific system, a whole complex of models for different purposes is needed.
Published in 1975, the ANSI/X3/SPARC report recorded not only the widespread acceptance of the concepts of a layered architecture of database systems, but also the need for an explicit allocation of a special conceptual presentation layer of the database, common to all its applications and independent of them. In addition to this level, two more levels were envisaged: an internal level, which should provide support for the view of the stored database, and an external one, which supports views of the database "from the point of view" of applications. At each architectural level, it was supposed to use one or another data model. In addition, there can be several such models at the external (application, user) level. The models, as well as the schemas specified on their basis, are called external, conceptual, and internal, respectively.
As is obvious, the ultimate goal of design is to build a specific database that, to one degree or another, embodies the designer's idea of the subject area and tasks solved by users using the created database. Considering the database as concrete implementation of the model, we essentially establish the order of the process by separating the stage of determining the principles (which base must be) from the stage of implementation of these principles when implementing a database in a specific DBMS environment, OS and programming languages. And, as practice shows, there are always discrepancies between database implementations and the principles of their construction. Differences are the result of various reasons, but most often it is an explicit or implicit rejection of some fundamental restrictions imposed, for example, by a data model or basic (embedded) processing algorithms, in favor of a particular solution, which, in the opinion of the designer, will be more efficient, for example , to understand or process data.
The importance of separating the design at the abstract level from the physical implementation is that when we declare principles, we constructively limit the scope. First, the dimension and complexity of the problem must be reduced to such a level that the implementation becomes possible in given specific conditions - the resources of the environment, the professionalism of the designer, the readiness of the user, etc. Second, since a database is, by definition, designed to multifunctional use various users, and at the same time - to serve requests, unforeseen when designing, such an explicit declaration of principles will allow not to mislead the user and not to create applications for solving problems that, due to their fundamental difference from those considered during design, will cause inefficient data processing. Thirdly, design is a process of kind of harmonization of the points of view of two main subjects: the user and the database designer. The user is characterized by the requirements of a high degree of generality and breadth of representation (and not cumbersome detailed descriptions), allowing him to obtain enough information without spending significant time or intellectual resources. For an administrator who designs and optimizes a database system, a high degree of detail and formalization is required to ensure the validity of technical solutions, as well as the possibility of design automation.
7.2. Typology of models
The main differences between any methods of information representation are the way in which the semantics of the subject area is fixed. But, it should be especially noted that for all levels and for any method of representing the subject area (but for us it is important that in the context of creating and using machine databases) the basis of the display (i.e., the actual formation of the representation) is coding concepts and relationships between concepts. A multi-level system of information representation models is illustrated slides 2, 3, 4 (Typology of models) .
The key stage in the development of any information system is the implementation of system analysis: the formalization of the subject area and the presentation of the system as a set of components. System analysis allows, on the one hand, to better understand “what needs to be done” and “who needs to be done” (analyst, developer, manager, user), and on the other hand, to track changes in the considered model over time and update the project.
Decomposition, as the basis of system analysis, can be functional (building function hierarchies) or object.
However, in most systems, such as databases, data types are more static than how they are handled. Therefore, such methods of system analysis as data array diagrams (Data Flow Diagram) have been intensively developed. The development of relational databases, in turn, stimulated the development of methods for building data models, and in particular, ER-diagrams (Entity Relationship Diagram ). But both functional decomposition and data diagrams give only some cut of the studied subject area, but do not allow to get an idea of the system as a whole.
The display methods used at the stage of building datalogical models, reflecting the way of identifying elements and relationships, but, most importantly, in the context of their future representation in a one-dimensional memory space, also differ. computer. Models are subdivided into factographic - focused on the presentation of well-structured information, and documentary - representing the most common way of reflecting semi-structured information. If in the first case they talk about relational, hierarchical or network data models, then in the second - about semantic networks and documentary models. Although, the division into factual and documentary in this group of models is rather arbitrary. A document as a sequence of fields can be represented, among other things, by a relational model. And in this case, the choice of a specialized solution is most often determined by the requirement of overall efficiency.
When designing information systems, the properties of objects (their characteristics) are set by attributes. It is the attribute values that make it possible to distinguish both different objects (types of objects) in the subject area, and their different instances among objects of the same type. The representation of attributes is most conveniently modeled by set-theoretic relations. A relation is visually represented as a table, where each row is a tuple of the relation, and each column (domain) represents a set of attribute values. The list of relation attribute names forms the relation schema, and the set of relation schemas used to represent the database, in turn, forms the database schema.
Representing database schemas as relationship schemas simplifies database design process. This explains the creation of systems in which database design is carried out in terms of relay rational data model, and work with the database is supported by the DBMSone of the types described in this manual.
The data model should, one way or another, provide a basis for describing data and manipulating data, as well as providing tools for analyzing and synthesizing data structures. Any model for built more or less neatly from the point of view of mathematics, she herself creates objects for research and begins to live as would be in parallel with practice.
The relational model is givennyh as the basis of the display directly uses the concept of relation. It is closest to the so-called conceptual model of the object environment and often underlies the latter.
In contrast to graph-theoretic models, in the relational model, the connections between relations are implemented implicitly, for which they are used relationship keys. For example, a relationship of a hierarchical type is implemented by the mechanism of primary / foreign keys, when a set of attributes must be present in a subordinate relationship that links this relationship with the main one. Such a set of attributes will be called the primary key in the main relation, and the secondary key in the subordinate relation.
Progress in the development of programming languages, associated primarily with data typing and the emergence of object-oriented languages, has made it possible to approach the analysis of complex systems from the point of view of hierarchical representations - classes of objects with encapsulation, inheritance and polymorphism properties, whose schemes display not only data and their relationships, but also methods of data processing.
In this sense, the object-oriented approach is a hybrid method and allows you to get a more natural formalization of the system as a whole. As a result, this allows to reduce the existing barrier between analysts and developers (designers and programmers), increase system reliability and simplify maintenance, in particular, integration with other systems.
7.3. Design stages and modeling objects
Database design is an ordered, formalized process of creating systems of interconnected descriptions, those. such domain models that connect (fix) the data stored in the database with the domain objects described by this data. The applied purpose of such descriptions is that the user, who has practically no idea about the organization of data in the database (the physical location of data in memory and the mechanisms for their search), by making a request to the database, would have a practical opportunity to obtain adequate information about the state of the object of the subject area. (Slide 5 - Stages and objects)
Design begins with an analysis of the subject area and the identification of functional and other requirements for the system being designed. This process will be discussed in more detail below, but here we note that the design is usually performed by a person (group of people) - a system analyst (and in practice more often a database administrator), which can be either a dedicated employee or a future database user, quite well familiar with machine data processing.
Combining individual views of the contents of the database, obtained as a result of user surveys, and your views on the data that may be required to solve practical tasks, the system analyst first creates a generalized informal description of the database being created. This description, made using natural language, mathematical expressions, tables, graphs, and other means understandable to all people working on database design, is called infological model.
Such a human-oriented model is almost completely independent of the physical parameters of the data storage medium, which can be both human and computer memory. Therefore, the infological model does not change until some changes in the real world (that part of it that is related to the subject area) require changes in the model of the corresponding fragment of the description so that this model continues to adequately reflect the subject area.
The remaining models are machine-oriented. With their help, the DBMS allows programs and users to access stored data only by their names, without worrying about physical location this data.
Since data is accessed using a specific DBMS, the models must be represented in the data description language of this DBMS. Such a description, created according to the infological data model, is called datalogical model data.
To locate and search for data on external storage devices, the DBMS uses physical model data.
The presented three-level architecture (infological, datalogical and physical layers) allows you to ensure the independence of the stored data from the programs using them. Stored data can be rewritten to other media or their physical structure can be reorganized, including adding fields for new applications, but this will only entail a change in the physical and possibly datalogical data model. The main thing is that such changes in the physical and datalogical models will not be noticed by the users of the system (they will be "transparent" to them). In addition, data independence provides the ability to create new applications to solve new problems without destroying existing ones.
Quote quoted ( slide 6) still relevant, although the book was published more than 20 years ago. Indeed, design tools are constantly evolving, but the tasks that the user intends to automate using database systems have become much more complicated, and for the effective use of formalization and automation tools, it is necessary to understand the nature of the model system.
From the point of view of modeling objects, it is necessary to distinguish between domain models and database models. These models are interconnected, since they are images of the same original - a certain set of objects of the real world, information about which we intend to store and process using the database being designed. The nature of interrelations (and, accordingly, differences) is also manifested in the process of designing a database system. The domain model is rather associated with the informal level of semantic modeling, and the database model is associated with the formalized level of the system (and in particular, the DBMS).
The variety of models is also associated with the difference in the modeling paradigms used, which essentially determine the way representation relationships of objects at the level data structures. From this point of view, there are relational, network, hierarchical, object, object-relational, documentary and other types of models. Accordingly, the database schemas described by their means also differ.
7.4. Database Design Approaches
There are two main approaches to database design: descending and ascending (slide 7)
At ascending approach, work starts from the verythe lower level of attributes (i.e., properties of entities and relationships), which, based onanalysis of the links existing between them are grouped into relations,defining types of entities and relationships between them. Next will be discussed in detailthe process of normalization of relations, which is a variant of ascendingcommon approach when designing databases. Normalization provides creating a norm lyzed relationships based on functional dependencies between selected attributes.
The bottom-up approach is most suitable for designsimple databases with relatively little large quantity attributes. However, the use of this approach becomes much more complicated when designing databases with a large number of attributes, among which everything exists.existing functional dependencies is difficult. Because theconceptual and logical data models for complex databases can contain hundreds to thousands of attributes, it is important to choose an approach thatwould help simplify the design phase. Moreover, in the early stages formulating data requirements can be difficultbut install all attributes The to be included in the data model.
A more appropriate strategy for designing complex databases isusage descending an approach that predetermines the priority of the development of the conceptual model of the ObA. This model contains several high-level entities and relationships that are refined (detailed and expanded) until all objects, their attributes and relationships between them, reflecting the specifics of the tasks of a particular ObD, are identified.
The bottom-up approach is often, for example, in the case of complex ObD, a very inconvenient process for the designer himself. Moreover, here it appears limitations of the relational model, in particular: (slide 8)
- the relational model does not provide sufficient means to capture the meaning of the data, i.e. the semantics of the subject area is not fixed directly in relations;
- for many applications it is difficult to model the subject area based on flat tables;
- although the entire design process takes place on the basis of dependency accounting, the relational model does not have the means of representing (reflecting the semantics) of these dependencies;
- despite the fact that the design process begins with the selection of some essential objects of the subject area (“entities”) for the application and the identification of relationships between these entities, the relational data model does not offer any apparatus for distinguishing between entities and relationships.
In addition to these design approaches,other approaches, such as the “general to specific” or “mixeddesign strategy. An approach " From general to specific» resembles nishoapproach, but differs from it in that a set of fundamentals is first identifiedentities with subsequent expansion of the range of entities under consideration, relationships and attributes that interact with the originally definedentities. AT mixed strategy ascending and descending are used firstwalking approaches to create different parts models, after whichfragments are assembled into a single whole.
Running a little ahead, we note the relationship between two well-known methods for modeling the infological level - ER -diagrams and the normalization method, which are often perceived as alternative. In fact, normalization using well-formalized methods provides the decomposition of the original relations (variables) of high dimension to the largest possible set of relations, but of lower dimension. These methods do not depend on the features of the subject area, but as a result, they do not allow to determine the initial relation and, accordingly, the semantics of the processed data. For this more convenient use techniques like ER -diagrams - they are characterized by top-down design technology approaches, and which give an idea “as a whole”, but that is why (due to comparative simplicity) they do not allow for a full-fledged base design. That is, we can say that the normalization method and ER -diagrams are essentially complementary.
7.5. Infological models (system analysis) of the subject area
The databases themselves are of relative value. Databases are always the most important, but only one of components of some information system. And it should be noted that any IS intended, for example, for the operational management of an enterprise or archival storage and retrieval of documents is not only programs, data and communications, but also people (customers, users, analysts, developers), organizational structures, and also goals, incentives for the operation of the enterprise or individual people. And all these components must be understandable to both the designer and the user, and, moreover, they must be connected in a consistent way into one system.
The main idea of the process of such coordination is that it must begin with an analysis of the most important characteristics of the subject area, considering the most important substantive aspects. And to carry it out not "mentally" and not "in words", but on explicit descriptions (models) of objects in the subject area, allowing you to see all the essential relationships. But it should be noted that attempts to use the usual notations of formal models (structural, object, or any other) at this stage lead to a lower (more detailed and at the same time limited) level of representation of the subject area than is necessary for a general understanding.
AT general case There are two approaches to determining the composition and structure of the subject area. (Slide 9 Functional - object approaches)
Functionalthe approach assumes that the design begins with an analysis of the tasks and, accordingly, the functions that ensure the implementation of information needs.
At object(subject) approach, the information needs of users (tasks) are not rigidly fixed, and the focus is on identifying essential objects - objects and relationships, information about which can be used in applied tasks user.
The conditionality of such a division is quite obvious, therefore, in practice, compromise options are used, which, as the system develops, expand both the composition of objects and the range of applied tasks.
The purpose of the system analysis of the subject area as a design stage is select a subject area how a system of objects and their relationships, while defining functional and informational requirements for their subsequent presentation in the form of a system of interrelated data.
The main result of the system analysis stage is the determination paradigms information (infological) model: the requirements for the means of representing the system are determined based on the analysis of the level of structured information and the nature of the perception of its semantics by the user (exact / approximate, clear / indefinite).
For example, the choice attributive form of presentation objects of the subject area will lead, respectively, to the choice of the paradigm factual databases, a verbal- the need for choice documentary databases. In the following presentation, we will consider the process and design tools only for the case of factual databases using the relational model.
The result - the conceptual schema of the database (in terms of the semantic model) is then converted to a relational schema.
7.6. Datalogical models
The task of the next stage of designing a database system is to select an appropriate DBMS and map into its environment (data structures) the specifications of the infological model of the subject area. In other words, the domain model of the system being developed must be represented in terms of the conceptual level data model of the selected specific DBMS. This stage is called the logical (or datalogical) design of the database, and its result is a conceptual database schema, including the definition of all information elements (units) and relationships, including the definition of types, characteristics and names.
Although data logical design does not operate physical records, but logical concepts associated with the structure of the database, however, the features of data presentation, rules and languages for aggregating and manipulating data have a decisive influence. Not all types of relationships, such as many-to-many relationships, can be directly mapped to a logical model.
In addition, there may be many options for mapping the domain infological model to the database datalogical model. Here, the influence of the following two significant factors related to the practice of database development should be taken into account.
First, domain relationships can be displayed in two ways, both declaratively - in logic diagram, and procedural - working out connections through program modules that process (link) the corresponding stored data.
Secondly, the nature of information processing may be a significant factor. For example, frequent access to collaborative data obviously implies their joint storage, and data (especially large dimensions) that are accessed infrequently should be stored separately from frequently used ones.
7.7. Physical Models
The physical design phase of a database generally includes:
- choice of database organization method;
- development of the specification of the internal schema by means of the data model of its internal level;
- description of the mapping of the conceptual schema to the internal one.
It is important to note that, unlike early DBMSs, many modern systems do not provide the developer with any choice at this stage. In reality, the issues of designing a physical model include the choice of a data layout scheme (separation by files or type RAID -array) and specifying the number and type of indexes (for example, clustered or non-clustered in the case MS SQL Server).
The way the database is stored is determined by the DBMS engines automatically “by default” based on the specifications of the conceptual database schema, and the internal schema is not explicitly used in such systems.
It should also be noted that external database schemas are usually constructed at the application development stage.
7.8. Design Automation Tools
Formalized knowledge about the subject area in the general case can be represented as text descriptions: sets of job descriptions, business rules, etc. However, the textual way of representing the domain model is not efficient. More informative and useful in the development of databases and information systems are descriptions of the subject area, made using specialized graphic notations that implement methods for representing knowledge about the subject area. The most famous today are the methods of structural analysis SADT (Structured Analysis and Design Technique) ) and the notation based on it IDEF 0, dataset diagrams, object-oriented analysis technique UML (Unified Modeling Language) ), etc. Any of these models describes, on the one hand, the processes occurring in the subject area, and, on the other hand, the data used by these processes.
Most complete system models, on which the methods of functional, informational and behavioral modeling of ObD are based, is presented in the family of standards IDEF (Integrated DEFinition )(slide 10).
Conceptual design methodology, based on a visual graphic technique, has provided developers of information systems with strict formalized methods for describing IS and technical solutions. These models are essentially a system of agreements that provide mutual understanding between the business analyst representing the realities of the subject area and the programmer (or software tool) creating a data model to reflect the state of this SbA. If the conventions are exactly implemented in software products based on this methodology, then such an automated system that can "read" the models developed by the analyst will allow you to control the syntax of the model and, as a result, generate a data schema.
Following the conceptual design methodology, specialized software and technological tools of a special class appeared - CASE-tools that implement the technology for creating and maintaining IS.
CASE technology is an IS design methodology, as well as a set of tools that allow you to visually model the subject area, analyze this model at all stages of IS development and maintenance, and develop applications in accordance with the information needs of users.
CASE-tools in accordance with their functional orientation to certain processes life cycle IS can be divided into the following groups(slide 11 - SASE).
The applied formal languages for representing the subject area do not allow describing all relationships that the designer considers important. On the other hand, many projects (and, in particular, those under consideration examples ) are perceived as fairly simple, and design solutions seem obvious. In addition, an experienced programmer can always offer some empirical and perhaps valid effective method for the targeted presentation and processing of the necessary information. However, this means the rejection of a single formalism, which, with an increase in the amount of data and connections, greatly complicates the problems of database management and, in particular, the user's understanding of the organization and access methods.
It would be more correct to speak of informality associated with the impossibility of reasonable unambiguous selection (from really existing) objects of the means used for modeling.
Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Hosted at http://www.allbest.ru/
ATineating
interface program user system
Hundreds of millions of people work in the world today personal computers. Scientists, economists, politicians believe that by the beginning of the third millennium:
The number of computers in the world will equal the number of inhabitants of developed countries.
most of these computers will be included in the world's information networks.
all the information accumulated by mankind by the beginning of the third millennium will be converted into a computer (binary) form, and all information will be prepared with the help (or with the participation) of computers; all information will be stored indefinitely in computer networks;
a full-fledged member of the society of the third millennium will have to interact daily with local, regional or global networks using computers.
With such computerization of almost all branches of human life, the question arises of creating programs that allow creating such databases. Therefore, this program was developed, which allows you to create a database that stores information about the progress of schoolchildren.
1. Database and ways to represent it
A database (DB) is information presented in the form of two-dimensional tables. The database contains many rows, each of which corresponds to an object. For each object, certain independent positions are used, which are called fields. Imagine such a database containing rows and columns ( simplest case). Each line, also called a record, corresponds to certain object. Each column contains the values of the corresponding object data.
A database may not consist of one table, but of two, three or more. Additional information about the object can be stored in additional tables.
One of the powerful features of the database is that information can be sorted according to the criteria that the user specifies. In Pascal, the database is provided as a list of terms of the form: base_predicate_name (record_fields). The database names are described in the section. Database records are accessed using the base predicate. pascal provides quite a lot of tools for working with such databases: loading, writing, adding, etc.
A database is an organized structure for storing information. Modern databases store not only data, but also information.
This statement is easy to explain if, for example, we consider the database of a large bank. She has everything necessary information about clients, their addresses, credit history, current account status, financial transactions etc. A fairly large number of bank employees have access to this database, but among them there is hardly a person who has access to the entire database and is able to make arbitrary changes to it on his own. In addition to data, the database contains methods and tools that allow each of the employees to operate only with the data that are within his competence. As a result of the interaction of the data contained in the database with the methods available to specific employees, information is formed that they consume and on the basis of which they enter and edit data within their own competence. Closely related to the concept of a database is the concept database management systems. This is a set of software tools designed to create the structure of a new database, fill it with content, edit content and visualize information. Under information visualization database refers to the selection of displayed data in accordance with a given criterion, their ordering, design and subsequent issuance to output devices or transmission via communication channels. There are many database management systems in the world. Although they may work differently with different objects and provide the user with various functions and tools, most DBMSs are based on a single, well-established set of basic concepts. This gives us the opportunity to consider one system and generalize its concepts, techniques and methods to the entire DBMS class. As such a training object, we will choose the Pascal 7.0 DBMS included in the Pascal 7.0 package.
2. Database field properties
Database fields do not just define the structure of the database - they also define the group properties of the data written to the cells belonging to each of the fields. The main properties of database table fields are listed below using Pascal 7.0 DBMS as an example.
Field name - determines how the data of this field should be accessed during automatic operations with the database (by default, field names are used as table column headings).
Field type - defines the type of data that can be contained in this field.
Field size - determines the maximum length (in characters) of data that can be placed in this field.
Field format - determines how data is formatted in the cells belonging to the field.
Input mask - defines the form in which data is entered in the field (data entry automation tool).
Caption - defines the heading of the table column for given field(If the label is not specified, then the Field Name property is used as the column heading).
The default value is the value that is automatically entered into the field cells (data entry automation tool).
A value condition is a constraint used to validate data entry (an input automation tool that is typically used for data that has a numeric, currency, or date type).
Error message - a text message that is displayed automatically when you try to enter erroneous data in the field.
Mandatory field - a property that determines the mandatory filling of this field when filling the database.
Empty strings - a property that allows the input of empty string data (it differs from the Required field property in that it does not apply to all data types, but only to some, for example, text).
Indexed field - if the field has this property, all operations related to searching or sorting records by the value stored in this field are significantly accelerated. In addition, for indexed fields, you can make it so that the value in the records will be checked against this field for duplicates, which automatically eliminates data duplication.
Since different fields can contain data different type, then the properties of the fields may differ depending on the data type. So, for example, the list of field properties above applies primarily to fields of the text type.
Fields of other types may or may not have these properties, but may add their own to them. For example, for data representing real numbers, an important property is the number of decimal places. On the other hand, for fields used to store pictures, sound recordings, video clips, and other OLE objects, most of the above properties are meaningless.
3 . Tsewhether and tasks
The objectives of this program were:
· Write a program that would allow you to process, sort and modify information about the parking lot.
Also, when creating this program, the following tasks were set:
· This program should have a simple and convenient user interface.
· This program should have low resource consumption.
4. Development of the system menu
The system menu or the main menu should provide convenient user interaction with the program. The menu should include items for saving, viewing, entering new data, etc. The user only needs to press the `enter' button. There are six items on the menu of this program:
1 - File creation
2 - Adding an entry
3 - Record correction
4 - View record from file
5 - Deleting an entry
6 - Exit
1 - Create a new file - Created new file with a user-specified program name
2 - Viewing the contents of the file - the previously created entries are displayed on the screen one by one in the form:
Owner's last name:
Host name:
machine brand:
machine model:
body type:
number of the car:
region:
year of issue:
color:
3 - Add entry - Create new record and file by adding it to the end of the record.
4 - Search by room number - Allows you to find data about a vacationer by the number of the ward in which the vacationer is registered.
5 - Exit the program - exit the program
Conclusion
The work done allows any user to easily create large amounts of information, process them, sort, make selections according to certain criteria.
The use of such a program in modern world greatly facilitates human activity.
Hosted on Allbest.ru
Similar Documents
Determination of the necessary program modules, the structure of the database file. Description of program development, debugging and testing. Development of the Organizer.exe application, menu and user manual. Algorithm for processing events of the main menu (schedule).
term paper, added 02/11/2014
Features of designing a C++ program for processing data from database tables. The main functions of the program, the creation of a conceptual database model and class diagrams, the development of a user interface and database queries.
term paper, added 06/08/2012
The choice of the composition of hardware and software for system development. Description of input and output data. Selecting a database model. Development of a subsystem for filling the database, generating reports. User interface development, system testing.
term paper, added 12/04/2014
Stages of creating and developing a database. Building a domain model. Development of datalogical and physical models data, ways of processing data about employees of the organization. Designing user applications. Creating a button form.
term paper, added 02/14/2011
Schema of the conceptual data model. Development of relational database structure and user interface. Features of the main stages of database design. Ways to implement queries and reports. The specifics of the user manual.
term paper, added 12/18/2010
The process of developing a database for storing and processing information. Keys, indexes, triggers, stored procedures. Development of user interface and database. Basic tools for developing client and server parts.
thesis, added 05/18/2013
Stages of database design, definition of goals and content of tables. Adding data and creating other database objects. Datalogical model: structuring, normalization, data schemas. The order, principles of creating a user interface.
term paper, added 03/26/2013
User interface development technology in Delphi environment. Creation of tables, menus, forms for entering and editing data. Principles of menu organization as a user interface element. Implementation of sorting, filtering, calculations in the table.
term paper, added 11/13/2012
Basic rules for designing a user interface. Creation of a database using the developed models. Module coding software system for the purpose of prototyping. The primary window when the program starts. Information loss protection.
laboratory work, added 06/13/2014
Description of the subject area of development. Features of storing information about cars and owners. Description of the database structure. Main tables: cars, owners, types of work, spare parts, orders, services. Instructions for the programmer and user.
Translation of a series of 15 articles on database design.
The information is intended for beginners.
Helped me. Perhaps it will help someone else fill in the gaps.
Database Design Guide.
1. Introduction.
If you're going to build your own databases, it's a good idea to stick to database design rules, as this will ensure the long-term integrity and ease of maintenance of your data. This guide will tell you what databases are and how to design a database that obeys relational database design rules.Databases are programs that allow you to store and retrieve large volumes of data. related information. The databases are made up of tables, which contain information. When you create a database, you need to think about what tables you need to create and what connections exist between the information in the tables. In other words, you need to think about project your database. good project database, as mentioned earlier, will ensure data integrity and ease of maintenance.A database is created to store information in it and retrieve this information when needed. This means that we must be able to place, insert ( INSERT) information to the database and we want to be able to fetch information from the database ( SELECT).
The database query language was invented for this purpose and was called Structured Query Language or SQL. The operations of inserting data (INSERT) and their selection (SELECT) are parts of this very language. Below is an example of a data fetch query and its result.
SQL is a big story and is beyond the scope of this tutorial. This article is strictly focused on the presentation database design process. Later, in a separate tutorial, I will cover the basics of SQL.
relational model.
In this tutorial, I will show you how to create a relational data model. A relational model is a model that describes how to organize data in tables and how to define relationships between those tables.
The rules of the relational model dictate how information should be organized in tables and how tables are related to each other. Ultimately, the result can be provided in the form of a database diagram or, more precisely, an entity-relationship diagram, as in the figure (Example taken from MySQL Workbench).
Examples.
I used a number of applications as examples in the guide.RDBMS.
The RDBMS I used to create the example tables is MySQL. MySQL is the most popular RDBMS and is free.
Database administration tool.
After MySQL installations you only get a command line interface to interact with MySQL. Personally, I prefer a GUI for managing my databases. I use SQLyog a lot. it free utility With GUI. The table images in this manual are taken from there.
Visual modeling.
There is a great free MySQL application workbench. It allows you to design your database graphically. The illustrations of the diagrams in the manual are made in this program.
Design independent of RDBMS.
It is important to know that although this tutorial provides examples for MySQL, database design is independent of RDBMS. This means that the information applies to relational databases in general, not just MySQL. You can apply knowledge from this guide to any relational database like Mysql, Postgresql, Microsoft Access, Microsoft SQL or Oracle.In the next part, I will briefly talk about the evolution of databases. You will learn where databases and the relational data model come from.
2. History.
In the 70s and 80s, when computer scientists still wore brown tuxedos and big, square-rimmed glasses, data was stored structurelessly in files that were a text document with data separated by (usually) commas or tabs.
This is what information technology professionals looked like in the 70s. (Bottom left is Bill Gates).
Text files are still used today to store small amounts of simple information. Comma-Separated Values (CSV) - comma-separated values are very popular and widely supported today by various software and operating systems. Microsoft Excel is one of the examples of programs that can work with CSV files. Data stored in such a file can be read by a computer program.

The above is an example of what such a file might look like. Reading program given file, must be notified that the data is comma delimited. If the program wants to select and display the category in which the lesson is located "Database Design Tutorial", then it should read line by line until the words are found "Database Design Tutorial" and then she will need to read the next word after the comma in order to output the category Software.
Database tables.
Reading a file line by line is not very efficient. In a relational database, data is stored in tables. The table below contains the same data as the file. Each line or “entry” contains one lesson. Each column contains some property of the lesson. AT this case this is the title (title) and its category (category).
A computer program could search the table's tutorial_id column for a specific tutorial_id to quickly find its corresponding title and category. This is much faster than searching through a file line by line, like a program would do in a text file.
Modern relational databases are designed to allow data to be retrieved from specific rows, columns, and multiple tables, all at once, very quickly.
History of the relational model.
The relational database model was invented in the 70s by Ted Codd, a British scientist. He wanted to overcome his shortcomings network model databases and hierarchical model. And he was very successful at it. The relational database model is now universally accepted and is considered a powerful model for efficiently organizing data.A wide variety of database management systems are available today, from small desktop applications to rich server systems with highly optimized search methods. Here are some of the most known systems relational database management (RDBMS):
- Oracle– used primarily for professional, large applications.
- Microsoft SQL server
– RDBMS Microsoft. Available only for the Windows operating system.
- MySQL is a very popular open-source RDBMS source code. Widely used by both professionals and beginners. What else is needed?! It's free.
- IBM- has a number of RDBMS, the most famous is DB2.
- Microsoft Access– RDBMS, which is used in the office and at home. In fact, it is more than just a database. MS Access allows you to create databases with a user interface.
In the next part, I will talk about some of the characteristics of relational databases.
3. Characteristics of relational databases.
Relational databases are designed for quick save and obtaining large amounts of information. The following are some of the characteristics of relational databases and the relational data model.Use of keys.
Each row of data in a table is identified by a unique "key" called the primary key. Often, the primary key is an auto-incrementing (auto-incrementing) number (1,2,3,4, etc.). Data in different tables can be linked together using keys. The primary key values of one table can be added to the rows (records) of another table, thereby linking those records together.Using Structured Query Language (SQL), data from different tables that are linked by a key can be selected in one go. For example, you can create a query that will select all orders from the orders table (orders) that belong to the user with id (id) 3 (Mike) from the users table (users). We will talk about keys further in the following parts.

The id column in this table is the primary key. Each entry has a unique primary key, often a number. The usergroup column is a foreign key. Judging by its name, it apparently refers to a table that contains user groups.
No data redundancy.
In a database design that follows the rules of the relational data model, each piece of information, such as a username, is stored in only one place. This eliminates the need to work with data in multiple locations. Data duplication is called data redundancy and should be avoided in good project Database.Input restriction.
Using a relational database, you can determine what kind of data is allowed to be stored in a column. You can create a field that contains integers, decimals, small text snippets, large text snippets, dates, and so on.
When you create a database table you provide a data type for each column. For example, varchar is a data type for small chunks of text with a maximum of 255 characters, while int is numbers.
In addition to data types, RDBMS allows you to further restrict the data that can be entered. For example, limit the length or force the uniqueness of the value of records in this column. The last restriction is often used for fields that contain user registration names (logins), or addresses. Email.
These restrictions give you control over the integrity of your data and prevent situations like the following:
Entering an address (text) in the field where you expect to see a number
- entering the index of the region with the length of this very index in a hundred characters
- creating users with the same name
- creating users with the same email address
- input of weight (number) in the field of birthday (date)
Maintaining data integrity.
By customizing field properties, linking tables together, and setting constraints, you can increase the reliability of your data.Assignment of rights.
Most RDBMSs offer a permissions setting that allows you to assign certain rights certain users. Some actions that can be allowed or denied to the user: SELECT (selection), INSERT (insertion), DELETE (deletion), ALTER (change), CREATE (creation), etc. These are operations that can be performed using Structured Query Language (SQL).Structured Query Language (SQL).
Structured Query Language (SQL) is used to perform certain operations on the database, such as storing data, retrieving data, changing data. SQL is relatively easy to understand and allows, incl. and nested selections, such as selecting related data from multiple tables using SQL statement JOIN. As mentioned earlier, SQL will not be discussed in this tutorial. I will focus on database design.How you design your database will have a direct bearing on the queries you will need to execute to retrieve data from the database. This is another reason why you need to think about what your base should be. With a well-designed database, your queries can be cleaner and easier.

Portability.
The relational data model is standard. By following the rules of the relational data model, you can be sure that your data can be transferred to another RDBMS with relative ease.As stated earlier, database design is a matter of identifying data, linking them together, and placing the results of a decision this issue on paper (or in a computer program). Designing a database independent of the RDBMS you intend to use to create it.
In the next part, we'll take a closer look at primary keys.