If you have a question "How to compose a semantic core", then before making a decision, you must first figure out what you have contacted.
Semantic core of the site is a list of phrases that users enter in search engines. Accordingly, the pages being promoted should respond to user requests. Of course, you can't shove a bunch of different types of key phrases on the same page. One main search term = one page.
It is important that the keywords correspond to the topic of the site, do not have grammatical errors, have a reasonable frequency, and also correspond in a number of other characteristics.
The semantic core is usually stored in an Excel spreadsheet. This table can be stored / created anywhere - on a USB flash drive, in Google Docs, on Yandex.Disk, or somewhere else.
Here is an illustrative example of the simplest design:
Features of the selection of the semantic core of the site
To begin with, you should understand (at least approximately) which phrases your audience uses when working with a search engine. This will be quite enough for working with tools for the selection of key phrases.
What keys are used by the audience
Keys- these are exactly the very phrases that users enter into search engines to obtain this or that information. For example, if a person wants to buy a refrigerator, he writes so - "buy a refrigerator", well, or "buy a refrigerator inexpensively", "buy a samsung refrigerator", etc., depending on preferences.
Now let's deal with the signs by which you can classify keys.
Sign 1 - popularity... Here, the keys can be conditionally divided into high-frequency, mid-frequency and low-frequency.
Low-frequency queries (sometimes referred to as LF) have a frequency of up to 100 impressions per month, medium-frequency (MF) - up to 1000, and high-frequency (HF) - from 1000.
However, these figures are purely arbitrary, because there are many exceptions to this rule. For example, the subject of cryptocurrency. Here it is much more correct to consider low-frequency queries with a frequency of up to 10,000 impressions per month, medium-frequency ones - from 10 to 100 thousand, and high-frequency ones - everything else. As of today, the keyword "cryptocurrency" has a frequency of more than 1.5 million impressions per month, and "bitcoin" has gone off scale for 3 million.
And despite the fact that "cryptocurrency" and "bitcoin", at first glance, are very tasty search queries, it is much more correct (at least at the initial stages) to focus on low-frequency queries. Firstly, because these are more accurate queries, which means that it will be easier to prepare relevant content. Secondly, there are ALWAYS tens to hundreds of times more low-frequency requests than high-frequency and medium-frequency requests (and in 99.5% of cases - also taken together). Third, the "low-frequency core" is much easier and faster to expand than the other two. BUT ... This does not mean that MF and HF should be ignored.
Feature 2 - user needs... Here it can be conditionally divided into 3 groups:
- transactional - imply some kind of action (contain the words "buy", "download", "order", "delivery", etc.)
- informational - just a search for certain information (“what will happen if”, “which is better”, “how to do it right”, “how to do it”, “description”, “characteristics”, etc.)
- others. This is a special category because it is not clear what exactly the user wants. Let's take the query "cake" as an example. "Cake" what? Buy? To order? Bake the recipe? View photos? Unclear.
Now about the application of the second feature.
Firstly, it is better not to "mix" these queries. For example, we have 3 search queries - "buy dell 5565 amd a10 laptop 8 gb hd", "dell 5565 amd a10 laptop 8 gb hd review" and "dell 5565 amd a10 8 gb hd laptop". The keys are almost completely identical. However, it is the differences that play a decisive role. In the first case, we have a "transactional" request, according to which it is necessary to promote exactly the product card. In the second - "informational", and in the third - "other". And if a separate page is needed for the information key, then it is logical to ask the question - what to do with the third key? It's very simple - to view the TOP-10 of Yandex and Google for a given request. If there are a lot of trade offers, then the request is still commercial, and if not, it means informational.
Secondly, transactional queries can be conditionally subdivided into "commercial" and "non-commercial". In commercial inquiries, you will have to compete with the "heavyweights". For example, for the request "buy samsung galaxy" you will have to compete with Euroset, Svyaznoy, for the request "buy an ariston oven" - with M.Video and Eldorado. And what to do? It is very simple to “swing” at requests that have a much lower frequency. For example, today the request “buy samsung galaxy” has a frequency of about 200,000 impressions per month, while “buy samsung galaxy a8” (and this is a very specific model of the line) has a frequency of 3600 impressions per month. The difference in frequency is enormous, but on the second request (precisely due to the fact that a very specific model is implied), you can get much more traffic than on the first.
Anatomy of search terms
The key phrase can be broken down into 3 parts - body, specifier, tail.
For clarity, let's take the previously considered "other" query - "cake". It is not clear what the user wants. it consists only of a body and has no specifier and no tail. However, it is high-frequency, which means it has fierce competition in search results. However, when visiting the site, 99.9% will say “no, this is not what I was looking for” and just leave, which is a negative behavioral factor.
Add the "buy" qualifier and get a transactional (and as a bonus - also a commercial) request "buy a cake". The word "buy" reflects the intent of the user.
Let's change the specifier to “photo” and get a request “cake photo”, which is no longer transactional, because the user is just looking for photos of cakes and is not going to buy anything.
Those. it is with the help of the qualifier that we determine what kind of request it is - transactional, informational or other.
We sorted out the sale of cakes. Now add the phrase “for a wedding” to the query “buy a cake”, which will be the “tail” of the query. It is the “tails” that make the requests more specific, more detailed, but at the same time do not cancel the user's intentions. In this case, since the cake is a wedding, then the cakes with the inscription "happy birthday" are swept aside immediately, because they don't fit by definition.
Those. if we take requests:
- buy a cake for the birth of a child
- buy a cake for a wedding
- buy a cake for an anniversary
then we will see that the user's goal is the same - "to buy a cake", and "for a baby's birth", "for a wedding" and "for an anniversary" reflect the need in more detail.
Now that you know the anatomy of search queries, you can derive a certain formula for selecting a semantic core. First, you define some basic terms that are directly related to your activity, and then collect the most appropriate specifiers and tails (we will tell you a little later).
Semantic core clustering
Clustering refers to the distribution of previously collected requests across pages (even if the pages have not yet been created). This process is often referred to as "Semantic Core Grouping".
And here many make the same mistake - you need to separate requests according to meaning, and not according to the number of available pages on the site or in the section. Pages can always be created if necessary.
Now let's figure out which keys to distribute where. Let's do this using the example of a structure that already has several sections and groups:
- Home page. For it, only the most important, competitive and high-frequency queries are selected, which are the basis for promoting the site as a whole. ("Beauty salon in St. Petersburg").
- Categories of services / goods. It is quite logical to place requests here that do not contain any special specifics. In the case of the "beauty salon in St. Petersburg" it is quite logical to create several categories according to the keys "make-up artist services", "men's room", "women's room", etc.
- Services / goods. More specific queries should already appear here - "wedding hairstyles", "manicure", "evening hairstyles", "coloring", etc. To some extent, these are “categories within a category”.
- Blog. Information requests are fine here. There are much more of them than transactional ones, so there should be more pages that will be relevant to them.
- News. The keys that are most suitable for creating short news notes are highlighted here.

How Query Clustering Works
There are 2 main methods of clustering - manual and automatic.
Manual clustering has 2 main disadvantages: long, time consuming. However, the whole process is controlled by you personally, which means you can achieve a very high quality. For manual clustering, Excel, Google Sheets or Yandex.Disk will be enough. The main thing is to be able to filter and sort data by certain parameters.
Many people use the Keyword Assistant service for clustering. In fact, this is manual clustering with automation elements.

Now let's consider the pros and cons of automatic grouping, fortunately, there are many services (both free and paid) and there is plenty to choose from.
For example, a free clustering service from the SEOintellect team is worthy of attention. It is suitable for working with small semantic cores.
For "serious" volumes (several thousand keys) it already makes sense to use paid services (for example, Topvisor, SerpStat and Rush Analytics). They work as follows: You upload key queries, and the output is a ready-made Excel file. The three services mentioned above work approximately according to the same scheme - they are grouped by meaning, analyzing the intersection of phrases, and also, for each request, they scan the TOP-30 search results in order to find out on how many URLs the requested phrase is found. Based on the above, distribution into groups occurs. All this happens “in the background”.

Semantic core programs
There are many free and paid tools to collect relevant search queries, there are plenty to choose from.
Let's start with the free ones.
Service wordstat.yandex.ru. This is a free service. For convenience, it is recommended to install the Wordstat Assistant plugin in your browser. That is why we will be considering these 2 instruments in pairs.
How it works?
Very simple.
For example, we will put together a small core for travel packages to Antalya. As "basic" we will have the 2nd request - "tours to antalya" (in this case, the number of "basic" requests is not important).
Now go to the address https://wordstat.yandex.ru/, log in, insert the first "basic" request and get a list of keys. Then, using the plus signs, add the appropriate keys to the list. Please note that if the key phrase is colored blue and is marked with a plus on the left, then it can be added to the list. If the phrase is “discolored” and marked with a minus, then it has already been added to the list, and clicking on the minus will remove it from the list. By the way, the list of keys on the left and the pros and cons - these are the very features of the Wordstat Assistant plugin, without which working in Yandex.Wordstat does not make sense at all.

It is also worth noting that the list will be saved exactly until it is personally corrected or cleared by you. Those. if you enter "samsung TVs" into the line, the list of Yandex.Wordstat keys will be updated, but the previously collected keys will remain in the plug-in list.

According to this scheme, we run through Wordstat all the previously prepared "basic" keys, collect everything we need, and then, by clicking on one of these two buttons, copy the previously collected list to the clipboard. Please note that the button with two leaves copies the list without frequencies, and with two leaves and the number 42 - with frequencies.

The list copied to the clipboard can then be pasted into an Excel spreadsheet.
Also, during the collection process, you can view the statistics of impressions by region. To do this, Yandex.Wordstat has such a switch.

Well, as a bonus, you can look at the history of the request - find out when the frequency increased and when it decreased.

This feature can be useful in determining the seasonality of the request, as well as to identify the fall / rise in popularity.
Another interesting feature is the statistics of impressions for the specified phrase and its forms. To do this, you need to enclose the query in quotation marks.

Well, if you add an exclamation mark in front of each word, then the statistics will display the number of impressions by key, excluding word forms.

The minus operator is equally useful. It removes key phrases that contain the specified word (or several words).
There is one more tricky operator - the vertical separator. It is necessary in order to combine several lists of keys at once into one (we are talking about the same type of keys). For example, let's take two keys: "tours to antalya" and "tours to antalya". In the Yandex.Wordstat line, write them in the following way and get 2 lists of these keys, combined into one, at the output:

As you can see, we have a bunch of keys, where there are "tours", but no "vouchers" and vice versa.
Another important feature is the frequency binding to the region. The region can be selected here.

Using Wordstat to collect the semantic core is suitable if you collect mini-kernels for some individual pages, or do not plan large kernels (up to 1000 keys).
SlovoEB and Key Collector
We are not kidding, the program is called just that. In a nutshell, the program allows you to do exactly the same thing, but in automatic mode.
This program was developed by the LegatoSoft team - the same team that developed the Key Collector, we will also talk about it. In fact, Slovoyob is a heavily trimmed (but free) version of Kay Collector, but it does quite well for collecting small semantic kernels.
Especially for Slovoyob (or Kay Collector), it makes sense to create a separate account on Yandex (if they get banned, it's not a pity).
It is necessary to make one-time small adjustments.

A login-password pair must be entered separated by a colon and without spaces. Those. if your login [email protected] and the password is 15101510ioioio, then the pair will look like this: my_login: 15101510ioioio
Please note that there is no need to register @ yandex.ru in the login.
This setting is a one-time event.

Let's clarify a couple of points right away:
- how many projects to create for each site - it's up to you
- the program will not work without creating a project.
Now let's deal with the functionality.
To collect keys from Yandex.Wordstat, on the Data Collection tab, click on the button “Batch collection of words from the left column of Yandex.Wordstat”, insert a list of previously prepared key phrases, click “Start collection” and wait for it to end. There is only one downside to this collection method - after the end of parsing, you have to manually delete unnecessary keys.

As a result, we get a table with keywords and base frequency of impressions collected from Wordstat.

But you and I remember that you can also use quotes and an exclamation mark, right? This is what we will do. Moreover, this functionality is implemented in the Sloob.

We start collecting frequencies in quotes and watch how the data will gradually appear in the table.

The only drawback is that data collection is performed through the Yandex.Wordstat service, which means that even collecting frequencies for 100 keys will take a lot of time. However, this problem is solved in Key Collector.
And one more function that I would like to talk about is the collection of search suggestions. To do this, copy the list of previously parsed keys to the clipboard, press the button for collecting search hints, insert the list, select the search engines from which the collection of search hints will be carried out, press "Start collecting" and wait for it to end.
As a result, we get an expanded list of key phrases.

Now let's move on to the "elder brother" of Slovoyob - Key Collector.
Key Collector is paid, but has much wider functionality. So if you are professionally engaged in website promotion or marketing - Key Collector is just a must-have, for Wordyob will not be enough. In short, Kay Collector is able to perform:
- Parse keys from Wordstat *.
- Parse search suggestions *.
- Cutting off search phrases by stop words *.
- Sort requests by frequency *.
- Revealing duplicate requests.
- Definition of seasonal requests.
- Collection of statistics from Liveinternet.ru, Metrika, Google Analytics, Google AdWords, Direct, Vkontakte and others.
- Determination of relevant pages for a particular query.
(the * marks the functional available in Slovoeb)

The process of collecting keywords from Wordstat and collecting search suggestions is absolutely identical to what is implemented in Wordstat. However, the collection of frequencies is implemented in two ways - through Wordstat (as in Slovoyob) and through Direct. Through Direct, the collection of frequencies is accelerated several times.
This is done as follows: click on the D button (short for "Direct", put a check mark on filling the columns of Wordstat statistics, check the boxes (if necessary) about which frequency we want to get (base, in quotes, or in quotes and with exclamation marks ", click" Get data "and wait for the end of the collection.

Collecting data through Yandex.Direct takes much less time than through Wordstat. However, there is one drawback here - statistics may not be collected for all keys (for example, if the key phrase is too long). However, this disadvantage is compensated by collecting data from Wordstat.
Google Keyword Planner
This tool is extremely useful for collecting a core tailored to the needs of users of the Google search engine.
Using Google Keyword Planner, you can find new queries for queries (no matter how strange it may sound), and even sites / topics. Well, as a bonus, you can even predict traffic and combine new search queries.
For available requests, statistics can be obtained by selecting the appropriate option on the main page of the service. If necessary, you can select the region and negative keywords. The result will be output in CSV format.

How to find out the semantic core of a competitor's site
Competitors can also be friends for us, because you can borrow ideas for the selection of keywords from them. For almost every page, you can get a list of keywords for which it is optimized, and manually.
The first way is to examine the page content, the Title, Description, H1 and KeyWords meta tags. You can do everything manually.
The second way is to use Advego or Istio services. This is quite enough for the analysis of specific pages.

If you need to make a comprehensive analysis of the semantic core of the site, then it makes sense to use more powerful tools:
- SEMrush
- Searchmetrics
- SpyWords
- Google Trends
- Wordtracker
- WordStream
- Ubersuggest
- Topvisor

However, the above tools are more suitable for those who are professionally promoting several sites at the same time. Even a manual method will be quite enough "for myself" (in extreme cases - Advego).
Errors in compiling the semantic core
The most common mistake is a very small semantic core
Of course, if this is some highly specialized niche (for example, manual production of elite musical instruments), then there will be few keys in any scenario (one hundred, one and a half or two).
The larger the semantic core (but without "garbage"), the better. In some niches, the semantic core may consist of several ... MILLION keys.
The second mistake is synonymizing. More precisely - his absence
Remember the example of Antalya. Indeed, in this context, "tours" and "vouchers" are one and the same, but these 2 lists of keys can be radically different. Stripper may well be searched for wire stripper or wire stripper.

At the bottom of the search results, Google and Yandex have the following block:
It is there that you can often spy on synonyms.
Compilation of the semantic core solely from RF queries
Remember that at the beginning of the post we talked about low-frequency queries, and the question "why is this a mistake?" you will never have. Low-frequency requests will bring the bulk of the traffic.
"Garbage", i.e. inappropriate requests
It is necessary to remove from the assembled kernel all queries that do not suit you. If you have a cell phone store, then for you the request "sale of cell phones" will be targeted, and "repair of cell phones" - junk. In the case of a service center for the repair of cell phones, everything is exactly the opposite: “cell phone repair” is targeted, and “sale of cell phones” is trash. The third option - if you have a cell phone store to which the service center is "attached", then both requests will be targeted.
Once again, there should be no garbage in the kernel.
Lack of grouping requests
It is strictly necessary to split the kernel into groups.
First, it will allow you to create a competent site structure.
Secondly, there will be no “key conflicts”. For example, let's take a page that is promoted for the queries “buy self-leveling floor” and “buy acer laptop”. The search engine can be confused. As a result, both keys will fail. But for the queries “buy hp 15-006 laptop” and “hp 15-006 price laptop” it already makes sense to promote one page. Moreover, not only "makes sense", but will be the only correct decision.
Thirdly, clustering will allow you to estimate how many pages still need to be created in order for the core to be fully covered (and most importantly - is it necessary?).
Errors in separating commercial and information requests
The main mistake is that requests that do not contain the words “buy”, “order”, “delivery”, etc. may also turn out to be commercial.
For example, the query "". How to determine if this is a commercial or informational request? It's very simple - we look at the search results.
Google tells us that this is a commercial request, because in our search results, the first 3 positions are occupied by documents with the word “buy”, and although “reviews” are in the fourth position, take a look at the address - this is a fairly well-known online store.

But with Yandex, everything turned out to be not so simple, tk. in the TOP-5 we have 3 pages with reviews / reviews and 2 pages with trade offers.

Nevertheless, this request is still classified as a commercial one, since there are commercial offers both there and there.
However, there is also a tool for mass verification of keys for "commerce" - Semparser.
Picked up "empty" requests
Frequencies must be collected both base and in quotes. If the frequency in quotes is zero, it is better to delete the query, since it's a dummy. It often happens that the base frequency exceeds several thousand impressions per month, and the frequency in quotes is zero. And immediately a concrete example - the key "cream for the skin is inexpensive." The base frequency is 1032 impressions. Looks delicious, right?

But all the taste is lost if you break through the same phrase in quotes:

Not all users print correctly. Because of them, "crooked" key queries get into the database. It makes no sense to include them in the semantic core, since search engines still redirect the user to the "corrected" query.

And it's exactly the same with Yandex.
So, we delete "crooked" requests (even if they are high-frequency) without regret.
An example of the semantic core of the site
Now let's move from theory to practice. After collecting and clustering, the semantic core should look something like this:

Outcome
What do we need to compose a semantic core?
- at least a little bit of thinking of a businessman (or at least a marketer)
- at least a little optimizer skills.
- it is important to pay special attention to the structure of the site
- think about what queries users can search for the information they need
- on the basis of "estimates" collect a list of the most suitable queries (Yandex.Wordstat + Wordstat Assistant, Slovoyob, Key Collector, Google Keyword Planner), frequency, taking into account word forms (without quotes), as well as without taking into account (in quotes), remove "garbage ".
- the collected keys must be grouped, i.e. distribute across the pages of the site (even if these pages have not yet been created).
No time? Contact us, we will do everything for you!
The semantic core is a pretty hackneyed topic, isn't it? Today we'll fix that together by putting together the semantics in this tutorial!
Don't believe me? - see for yourself - it's enough just to drive the phrase into the semantic core of the site into Yandex or Google. I think today I will correct this annoying mistake.
But in fact, what is she for you - perfect semantics? You might think that this is a stupid question, but in fact it is not even stupid at all, it's just that most webmasters and site owners firmly believe that they can compose semantic cores and that any schoolchild can cope with all this. and they themselves are trying to teach others ... But in reality, everything is much more complicated. Once I was asked - what should I do first? - the site itself and the content, or sem core, and asked a man who does not consider himself a newbie in SEO. This question made me understand the complexity and ambiguity of this problem.
The semantic core - the basis of the foundations - is the very first step that stands before and launching any advertising campaign on the Internet. Along with this, the semantics of the site is the most dreary process that will take a lot of time, but it will pay off with interest in any case.
Well ... Let's create his together!
A small preface
To create the semantic field of the site, we need one and only program - Key collector... Using the Collector as an example, I will analyze an example of collecting a small seme group. In addition to the paid program, there are free analogs like SlovoEb and others.
Semantics is collected in several basic stages, among which should be highlighted:
- brainstorming - analysis of basic phrases and preparation of parsing
- parsing - an extension of basic semantics based on Wordstat and other sources
- dropout - dropout after parsing
- analysis - analysis of frequency, seasonality, competition and other important indicators
- revision - grouping, separation of commercial and informational phrases of the core
The most important stages of the collection will be discussed below!
VIDEO - compiling a semantic core for competitors
Brainstorming Semantic Core - Straining Your Brains
At this stage it is necessary make a selection in your mind the semantic core of the site and come up with as many phrases as possible for our topic. So, we launch the key collector and select parsing Wordstat as shown in the screenshot:

A small window opens in front of us, where it is necessary to enter a maximum of phrases on our topic. As I already said, in this article we will create an example set of phrases for this blog so phrases can be as follows:
- seo blog
- SEO blog
- blog about SEO
- blog about seo
- promotion
- promotion the project
- promotion
- promotion
- blog promotion
- blog promotion
- promotion of blogs
- blog promotion
- promotion by articles
- article promotion
- miralinks
- work in sape
- buying links
- buying links
- optimization
- page optimization
- internal optimization
- self-promotion
- how to promote a resource
- how to promote your site
- how to promote the site yourself
- how to promote a website yourself
- self-promotion
- free promotion
- free promotion
- search engine optimization
- how to promote a site in Yandex
- how to promote a site in Yandex
- promotion under Yandex
- Google promotion
- Google promotion
- indexing
- acceleration of indexing
- donor selection for the site
- screening donors
- promotion by guards
- use of guards
- blog promotion
- Yandex algorithm
- update tic
- search base update
- Yandex update
- links forever
- eternal links
- link rent
- rented link
- links with monthly payment
- compilation of the semantic core
- promotion secrets
- promotion secrets
- seo secrets
- optimization secrets
I think that's enough, and so a list with half a page;) In general, the idea is that at the first stage you need to analyze your industry as much as possible and choose as many phrases as possible that reflect the topic of the site. Although, if you missed anything at this stage - do not despair - missing phrases will surely come up at the next stages, you just have to do a lot of extra work, but that's okay. We take our list and copy it to the key collector. Next, click on the button - Parse from Yandex.Wordstat:

Parsing can take quite a long time, so be patient. The semantic core usually takes 3-5 days and the first day will take you to prepare the basic semantic core and parsing.
I wrote detailed instructions on how to work with a resource, how to choose keywords. And you can find out about website promotion for low frequency requests.
In addition, I will say that instead of brainstorming, we can use the ready-made semantics of competitors using one of the specialized services, for example, SpyWords. In the interface of this service, we simply enter the keyword we need and see the main competitors who are present for this phrase in the TOP. Moreover, the semantics of the site of any competitor can be completely unloaded using this service.

Further, we can select any of them and pull out its requests, which will remain to be weeded out from garbage and used as basic semantics for further parsing. Or we can do it even easier and use it.
Cleaning up semantics
As soon as the parsing of the wordstat stops completely - it's time to weed out the semantic core... This stage is very important, so treat it with due attention.
So, my parsing ended, but the phrases turned out Lots of, and therefore, sifting out words can take away extra time from us. Therefore, before proceeding to the definition of frequency, you should perform the primary cleaning of words. We will do this in several stages:
1. Filter out queries with very low frequencies
To do this, we cash in on the symbol for sorting by frequency, and we begin to clean up all requests with frequencies below 30:

I think that you can easily cope with this item.
2. Let's remove inappropriate queries
There are requests that have sufficient frequency and low competition, but they do not fit our theme at all... Such keys must be removed before checking the exact occurrences of the key. verification can be very time-consuming. We will manually delete such keys. So, for my blog, the following turned out to be superfluous:
search engine optimization courses selling a promoted site
Semantic core analysis
At this stage, we need to determine the exact frequencies of our keys, for which you need to click on the magnifying glass symbol, as shown in the image:

The process is quite long, so you can go and make yourself some tea)
When the check is successful, you need to continue cleaning our kernel.
I suggest you delete all keys with a frequency of less than 10 requests. Also, for my blog, I will delete all requests with values above 1,000, since I do not plan to advance on such requests yet.
Semantic core export and grouping
Do not think that this stage will be the last. Not at all! Now we need to transfer the resulting group to Exel for maximum clarity. Further, we will sort by pages and then we will see many shortcomings, and we will fix them.
It is not difficult to export the semantics of the site to Excel. To do this, you just need to click on the corresponding symbol, as shown in the image:
After inserting into Exel, we will see the following picture:
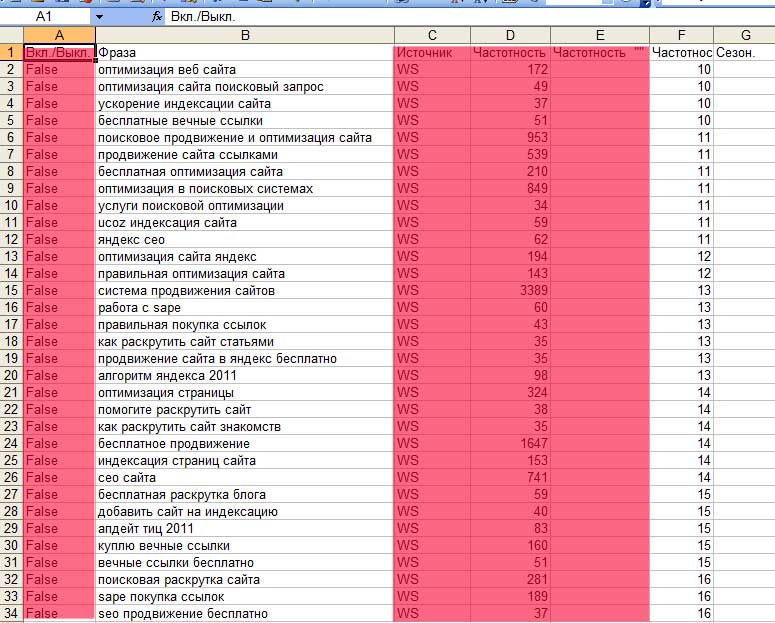
Columns marked in red must be deleted. Then we create another table in Exel, which will contain the final semantic core.
The new table will have 3 columns: Urlpages, key phrase and his frequency... As the URL, select either an existing page or a page that will be created in the perspective. First, let's select the keys for the home page of my blog:

After all the manipulations, we see the following picture. And several conclusions immediately suggest themselves:
- frequent queries like these should have a much larger tail from less frequent phrases than we see
- seo news
- a new key has surfaced, which we did not take into account earlier - SEO articles... This key needs to be parsed
As I said, not a single key can hide from us. The next step for us is to brainstorm these three phrases. After brainstorming, repeat all the steps starting from the very first point for these keys. You may find all this too long and tedious, but it is so - compiling the semantic core is a very responsible and painstaking work. On the other hand, a well-designed this field will greatly help in website promotion and can greatly save your budget.
After all the operations done, we were able to get new keys for the main page of this blog:
- best seo blog
- seo news
- seo articles
And some others. I think that the technique is clear to you.
After all these manipulations, we will see which pages of our project need to be changed (), and which new pages need to be added. Most of the keys we found (with a frequency of up to 100, and sometimes much higher) can be easily promoted alone.
Final elimination
In principle, the semantic core is almost ready, but there is another rather important point that will help us significantly improve our sem group. For this we need Seopult.
* In fact, here you can use any of the similar services that allow you to find out the competition for keywords, for example, Mutagen!
So, we create another table in Exel and copy only the names of the keys (middle column) there. In order not to waste a lot of time, I will only copy the keys for the main page of my blog:
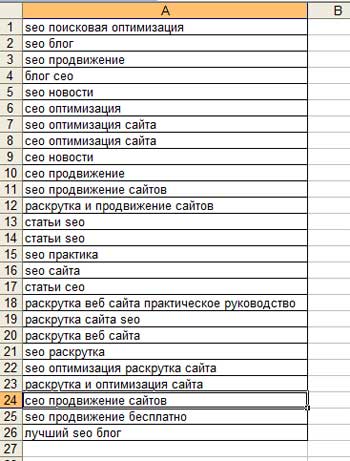

Then we check the cost of getting one click on our keywords:

The cost of the transition for some phrases exceeded 5 rubles. Such phrases must be excluded from our core.

Perhaps your preferences will turn out to be somewhat different, then you can exclude less expensive phrases, or vice versa. In my case, I deleted 7 phrases.
Helpful information!
on compiling a semantic core, with an emphasis on screening out the most low-competitive keywords.
If you have your own online store - read for a description of how the semantic core can be used.
Semantic core clustering
I am sure that you have heard this word in relation to search engine promotion before. Let's figure out what kind of animal it is and why is it needed when promoting a website.
The classic search engine promotion model looks like this:
- Selection and analysis of search queries
- Grouping requests by site pages (creating landing pages)
- Preparing seo texts for landing pages based on a group of requests for these pages
To facilitate and improve the second stage in the list above, clustering serves. In essence, clustering is a programmatic method that serves to simplify this stage when working with large semantics, but everything is not as simple as it might seem at first glance.
To better understand the theory of clustering, you should take a short excursion into the history of SEO:
Just a few years ago, when the term clustering did not look out of every corner, SEO specialists, in the overwhelming majority of cases, grouped semantics by hand. But when the huge semantics were grouped into 1000, 10,000 and even 100,000 queries, this procedure turned into a real hard labor for an ordinary person. And then the method of grouping by semantics began to be used everywhere (and today many people use this approach). The method of grouping by semantics implies combining queries that have semantic affinity into one group. As an example, the queries “buy a washing machine” and “buy a washing machine up to 10,000” were combined into one group. And everything would be fine, but this method contains a number of critical problems and for their understanding it is necessary to introduce a new term into our narrative, namely - “ request intent”.
The easiest way to describe this term can be as a user's need, his desire. The intent is nothing more than the desire of the user entering the search query.
The basis for grouping semantics is to collect queries that have the same intent, or as close as possible, into one group, and here 2 interesting features pop up at once, namely:
- The same intent can have several queries that do not have any semantic proximity, for example - "car maintenance" and "sign up for a maintenance"
- Queries that have an absolute semantic similarity can contain radically different intents, for example, a textbook situation - “mobile phone” and “mobile phones”. In one case, the user wants to buy a phone, and in the other to watch a movie
So, the grouping of semantics by semantic match does not take into account the intents of the requests in any way. And groups composed in this way will not allow you to write a text that will fall into the TOP. At the time of manual grouping, to eliminate this misunderstanding, the guys with the profession of "assistant SEO specialist" analyzed the results by hand.
The essence of clustering is comparing the generated results of a search engine in search of patterns. From this definition, you should immediately make a note for yourself that clustering itself is not the ultimate truth, because the generated issue may not fully disclose the intent (the Yandex database may simply not have a site that correctly combined requests into a group).
The clustering mechanics are simple and look like this:
- The system one by one enters all the queries submitted to it in the search results and remembers the results from the TOP
- After entering queries one by one and saving the results, the system looks for intersections in the output. If the same site with the same document (site page) is in the TOP for several queries at once, then these queries can theoretically be combined into one group
- A parameter such as the strength of the grouping becomes relevant, which tells the system exactly how many intersections must be in order for queries to be added to one group. For example, a grouping strength of 2 means that there must be at least two intersections in the results for 2 different queries. To put it even simpler - at least two pages of two different sites must be present simultaneously in the TOP for one and the other request. See example below.
- When grouping large semantics, the logic of connections between requests becomes relevant, on the basis of which 3 basic types of clustering are distinguished: soft, middle and hard. We will talk about the types of clustering in the following entries of this diary.
The semantic core (SJ) is a set of keywords, queries, search phrases for which you need to promote your site so that targeted visitors from search engines come to it. Compilation of the semantic core is the second step after setting up your site on the hosting. How much quality traffic will be on your site depends on a well-designed CL.
The need to compile a semantic core consists of several points.
Firstly, it makes it possible to develop a more effective strategy for search engine promotion, since the webmaster, who will form the semantic core for his project, will have a clear idea of what methods of search engine promotion he will need to apply to his site, decide on the cost of search engine promotion, which strongly depends on the level of competition of key phrases in the search results.
Secondly, the semantic core makes it possible to fill the resource with better quality content, that is, content that will be well optimized for key queries. For example, if you want to create a site about stretch ceilings, then the semantic core of requests should be selected "starting from" this keyword.
In addition, the compilation of the semantic core implies the determination of the frequency of use of keywords by users of search engines, which makes it possible to determine the search engine in which it is necessary to pay more attention to the promotion of a particular query.
It is also necessary to note some rules for compiling the semantic core, which must be observed in order to be able to compose a high-quality and effective SY.
So, in the composition of the semantic core, it is necessary to include all possible key queries by which the site can be promoted, except for those queries that cannot bring at least a small amount of traffic to the resource. Therefore, the semantic core should include high-frequency keywords (HF), medium (MF) and low-frequency (LF) queries.
Conventionally, these requests can be broken down as follows: LF - up to 1,000 requests per month, MF - from 1,000 to 10,000 requests per month, HF - more than 10,000 requests per month. It is also necessary to take into account the fact that in different topics these numbers can differ significantly (in some especially narrow topics, the maximum frequency of requests does not exceed 100 requests per month).
Low-frequency queries simply need to be included in the structure of the semantic core, because any young resource has the opportunity to advance in search engines, first of all, through them (and without any external website promotion - they wrote an article for a low-frequency query, the search engine indexed it, and your the site may be in the TOP in a few weeks).
It is also necessary to observe the rule of structuring the semantic core, which is that all keywords of the site must be combined into groups not only in terms of their frequency, but also the degree of similarity. This will make it possible to better optimize the content, for example, to optimize some texts for several queries.
It is also advisable to include such types of queries as synonymous queries, slang queries, abbreviations, and so on in the structure of the semantic core of many sites.
Here is a good example of how you can increase website traffic by writing optimized articles that include midrange and a large number of low-frequency queries:
1. A site for men. Although it is very rarely updated (for all the time, a little more than 25 articles were published), thanks to well-chosen queries, it is gaining more and more traffic. There was no purchase of links to the site at all!

At the moment, the growth in attendance has stopped, since only 3 articles were published.
2. Site for women. At first, non-optimized articles were published on it. In the summer, a semantic core was compiled, which consisted of queries with very low competition (I will describe how to collect such queries below). For these requests, relevant articles were written and several links were acquired on thematic resources. You can see the results of such a promotion below: 
3. Medical site. A medical niche with more or less adequate competition was chosen and more than 200 articles were published for tasty requests with good bids (on the Internet, the term “bid” denotes the cost of one user click on an advertisement link). I started buying links in February, when the site was 1.5 months old. So far, most of the traffic comes from Google, Yandex has not yet taken into account purchased links.

As you can see, the selection of the semantic core plays an important role in website promotion. Even with a small or no budget, you can create a traffic site that will bring you profit.
Selection of search queries
You can select queries for the semantic core in the following ways:
With the help of free services of statistics of search queries Google, Yandex or Rambler
With the help of special software or online service (free or paid).
After analyzing the sites of competitors.
Selection of search queries using the statistics services of search queries Google, Yandex or Rambler
I want to warn you right away that these services show not entirely accurate information about the number of search queries per month.
For example, if you look at 4 pages of search results for the query "plastic windows", then the statistics service will show you that this query was searched not 1, but 4 times, since not only the first page of search results is counted as an impression, but also all subsequent ones, which viewed by the user. Therefore, in practice, the real numbers will be slightly lower than those shown by various services.
To determine the exact number of clicks, the best thing, of course, would be to look at the traffic statistics of competitors who are in the TOP-10 (liveinternet or mail.ru, if it is open). Thus, it will be possible to understand how much traffic the request you are interested in will bring.
You can also roughly calculate how many visitors a given request will bring you, depending on the position that the site will occupy in the search results. Here's how the CTR (click-through rate) of your site will change at various positions in the TOP:

For example, let's consider the query "! Renovate! Apartments", the region "Moscow and region":

In this case, if your site occupies the 5th position in the search results, this request will bring you about 75 visitors per month (6%), 4th place (8%) - 100 pp / month, 3rd place (11%) - 135 villages / month, 2nd place (18%) - 223 villages / month. and 1st position (28%) - 350 visitors per month.
CTR can also be influenced by a bright snippet, thereby increasing traffic for a given request. You can read how to improve the snippet and what it is.
Google search statistics
Previously, I used the statistics of Google search queries more often, since I first of all promoted myself under this search engine. Then it was enough to optimize the article, buy as many different PR links to it as possible (it is very important that these links are natural and the links are followed by visitors) and voila - you are in the TOP!
Now in Google the situation is such that it is not much easier to promote in it than in Yandex. Therefore, you have to pay much more attention to both the writing and design (!) Of articles, and the purchase of links for the site.
I would also like to draw your attention to the following fact:
Yandex is the most popular in Russia (Yandex - 57.7%, Google - 30.6%, Mail.ru - 8.9%, Rambler -1.5%, Nigma / Ask.com - 0.4%), so if you are promoting in this country, you are in the first place turn it is worth focusing on Yandex.
In Ukraine, the situation looks different: Google - 70-80%, Yandex - 20-25%. Therefore, Ukrainian webmasters should focus on promotion in Google.
To use Google search statistics, go to
Let's look at an example of keyword research for a culinary website.
First of all, you need to enter the main query, on the basis of which keyword options for the future semantic core of the site will be selected. I entered the query "how to cook".
The next step is to choose the type of match. There are 3 types of match in total: broad, phrasal, and exact. I advise you to choose the exact one, as for this option the most accurate information on request will be shown. And now I will explain why.
Broad match means that impressions statistics will be shown for all words that are in this query. For example, for the query "plastic windows", it will be shown for all words that include the word "plastic" and the word "windows" (plastic, window, buy windows, buy blinds for windows, pvc windows prices). In short, there will be a lot of "rubbish".
Phrasal matching means that the statistics for words will be shown in the exact order in which they are listed. Along with the specified phrase of words, other words may be present in the request. For the query "plastic windows" the words "inexpensive plastic windows", "plastic windows Moscow", "how much are plastic windows", etc. will be taken into account.

We are most interested in the metric "Number of requests per month (target regions)" and "Estimated CPC" (if we are going to place Adsense ads on the site pages).
Yandex search query statistics
I use search query statistics almost every day, as it is presented in a more convenient form than its Google counterpart.
The only drawback of Wordstat is that you will not find matching types in it, you will not save the selected queries to your computer, you will not be able to find out the cost per click, etc.
To get more accurate results, you need to use special operators, with which you can refine the queries we are interested in. You will find a list of operators on this one.
If you just enter the query "how to cook" in Wordstat, we get the following statistics:

This is the same as if we chose broad match in Adwords.
If you enter the same query, but in quotes, we will get more accurate statistics (analogous to phrase matching in Adwords):

Well, to get statistics only for a given request, you need to use the "!" Operator: "! How! To cook"

To get even more accurate results, you need to specify the region for which the site is being promoted:

Also in the top panel of Wordstat there are tools with which you can view statistics for a given query by region, by month and by week. By the way, with the help of the latter, it is very convenient to analyze the statistics of seasonal requests.
For example, by analyzing the query "how to cook", you can find out that it is most popular in the months of December (this is not surprising - everyone is preparing for the New Year):

Rambler search statistics
I want to warn you right away that the statistics of queries from Rambler every year more and more lose their relevance (first of all, this is due to the low popularity of this search engine). So you probably won't even have to work with it.


You do not need to enter any operators in Adstat - it immediately displays the frequency of the request in the case in which it was entered. It also has separate statistics for the frequency of requests for the first page of search results and for all search results pages, including the first.
Selection of search queries using special software or online services
Rookee can not only promote your queries, but it can also help you create the semantic core of your site.
With the help of Rookee, you can easily select a semantic core for your site, you can approximately predict the number of visits for selected queries and the cost of their promotion to the top.
Selection of queries using the free Slovoyob program
If you are going to compose the SY (semantic core) at a more professional level, or you need statistics of queries on Google.Adwords, Rambler.Adstat, Vkontakte social network, various link aggregators, etc., I advise you to immediately purchase Kay Collector.
If you want to compose a large semantic core, but at the same time do not want to spend money on buying paid programs, the best option in this case would be the Slovoyob program (read information about the program here). She is the "younger brother" of Kay Collector and allows you to collect SY based on the statistics of queries on Yandex.Wordstat.
Installing the SlovoEB program.
Download the archive with the software.
Make sure the archive is unlocked. To do this, in the file properties (in the context menu, select the "Properties" item), click the "Unblock" / "Unblock" button, if there is one.
Unzip the contents of the archive.
Run the executable file Slovoeb.exe
We create a new project:

Select the required region (the button Regions Yandex.Wordstat):

We save the changes.
Click on the button "Left column Yandex.Wordstat"
If necessary, set "Stop words" (words that should not be included in our semantic core). Stop the words can be such words: "free" (if you sell something on your site), "forum", "Wikipedia" (if you have your own information site, which does not have a forum), "porn", "sex" (well, everything is clear here), etc.
Now you need to set an initial list of words, on the basis of which the CJ will be compiled. Let's make the core for a company that is engaged in the installation of stretch ceilings (in Moscow).
When choosing any semantic core, first of all, you need to make a classification of the analyzed topic.
In our case, stretch ceilings can be classified according to the following criteria (I make such convenient mind maps in the MindJet MindManager program):

Useful advice: for some reason, many webmasters forget to include the names of small settlements in the semantic core.
In our case, it would be possible to include the names of the districts of Moscow and cities of the Moscow region that are of interest to us in the SY. Even if there are very few requests per month for these keywords ("Golitsyno stretch ceilings", "Aprelevka stretch ceilings", etc.), you still need to write at least one small article for them, the title of which would include the required key. You won't even have to promote such articles, because more often than not, there will be very low competition for these requests.
10-20 such articles, and your site will consistently have several additional orders from these cities.
Press the button "Yandex.Wordstat left column" and enter the required queries:

Click on the "Parse" button. As a result, we get the following list of requests:

We filter out all unnecessary requests that do not fit the topic of the site (for example, "do-it-yourself stretch ceilings" - although this request will bring some traffic, it will not bring us customers who will order the installation of ceilings). We select these requests and delete them so as not to waste time analyzing them in the future.
Now we need to clarify the frequency for each of the keys. Click on the button "Collect frequencies"! "":

Now we have the following information: the request, its general and exact frequency.
Now, based on the frequencies obtained, you need to once again review all requests and delete unnecessary ones.
Unnecessary queries are queries that have:
The exact frequency ("!") Is very low (in my chosen topic, in principle, you need to value every visitor, so I will filter out requests with a monthly frequency of less than 10). If it was not a construction topic, but, say, some general topic, then you can safely filter out requests with a frequency below 50-100 per month.
The ratio of general and precise frequency exceeds very high. For example, the query "buy stretch ceilings" (1335/5) can be deleted immediately, because it is a "dummy query".
Requests with very high competition also need to be removed, it will be difficult to advance on them (especially if you have a young site and a small budget for promotion). Such a request, in our case, is "stretch ceilings". In addition, most often, those queries that consist of 3.4 or more words are more effective - they bring more targeted visitors.
In addition to Slovoyob, there is another excellent program for convenient automatic collection, analysis and processing of Yandex.Direct keyword display statistics.
News Searches
In this case, the SJ is not created in the same way as for a regular content project. For a news site, first of all, you need to select the headings under which the news will be published:

After that, you need to select requests for each of the sections. News requests are expected and not expected.
For the first type of requests, the informational reason is predictable. Most often, you can even pinpoint the date when there will be a surge in the popularity of a particular request. It can be any holiday (New Year, May 9, March 8, February 23, Independence Day, Constitution Day, church holidays), an event (music events, concerts, film premieres, sports competitions, presidential elections).
Prepare such requests in advance and determine the approximate volume of traffic in this case using
Also, do not forget to look at the statistics of traffic to your site (if you have already reviewed some event in your time) and competitors' sites (if their statistics are open).
The second type of queries is less predictable. These include breaking news: cataclysms, disasters, some events in the families of famous people (birth / wedding / death), the release of an unannounced software product, etc. In this case, you just need to be one of the first to publish this news.
To do this, it is not enough just to monitor news in Google and Yandex - in this case, your site will simply be one of those who simply reprinted this event. A more effective method that allows you to hit a big jackpot is to follow foreign sites. By publishing this news one of the first on the Runet, you, in addition to tons of traffic that will put the servers on your hosting, will receive a huge number of backlinks to your site.
Cinema-related queries can also be categorized into the first type (expected queries). Indeed, in this case, the date of the premiere of the film is known in advance, the script of the film and its actors are approximately known. Therefore, you need to prepare in advance the page on which the film will appear, add its trailer there for a while. You can also publish on the site news about the film, its actors. This tactic will help you to take TOP positions in search engines in advance and will bring visitors to the site even before its premiere.
Do you want to find out what queries are currently in trend or predict the relevance of your topic in the future? Then use the services that provide information on trends. It allows you to perform many analysis operations: comparing search trends for several queries, analyzing geographic regions of a query, viewing the hottest trends at the moment, viewing relevant relevant queries, exporting results to CSV format, the ability to subscribe to an RSS feed for hot trends, etc. ...
How to speed up the collection of the semantic core?
I think that everyone who came across the collection of the semantic core had the thought: “How long and tedious is the parsing, tired of sorting and grouping thousands of these requests!”. This is fine. It happens to me sometimes too. Especially when you have to parse and iterate over the CL, which consists of several tens of thousands of requests.
Before starting parsing, I strongly advise you to split all requests into groups. For example, if your site is "Building a House", break it down into foundations, walls, windows, doors, roofs, wiring, heating, etc. a small group and are linked by a certain narrow theme. If you just parse everything in one pile, you will end up with an unrealistically huge list, which will take more than one day to process. And so, processing the entire list of CYs in small steps, you will not only work through all the requests in a better quality, but you will also be able to simultaneously order articles from copywriters for the keys already collected.
The process of collecting the semantic core for me almost always begins with automatic parsing of requests (for this I use the Kay Collector). You can also collect manually, but if we work with a large number of requests, I see no reason to waste my precious time on this routine work.
If you work with other programs, then most likely the function of working with proxy servers will be available in them. This allows you to speed up the parsing process and protect your IP from the search engine ban. Honestly, it's not very pleasant when you need to urgently fulfill an order, and your IP is banned for a day due to frequent calls to the Google / Yandex statistics service. This is where paid proxy servers come to the rescue.
Personally, at the moment I do not use them for one simple reason - they are constantly banned, it is not so easy to find high-quality working proxies, and I have no desire to pay money for them once again. Therefore, I found an alternative way of collecting SN, which accelerated this process several times.
Otherwise, you will have to look for other sites for analysis.
In most cases, sites close these statistics, so you can use the entry point statistics.
As a result, we will have statistics of the most visited pages of the site. We switch to them, write out the main queries for which it was optimized, and already on their basis we collect the SY.
By the way, if the site has statistics "By search phrases", you can make your work easier and collect requests using the Key Collector (you just need to enter the site address and click on the "Get data" button):

The second way to analyze a competitor's site is by analyzing their site.
Some resources have such a "Most Popular Articles" widget (or something like that). Sometimes the most popular articles are selected based on the number of comments, sometimes based on the number of views.

In any case, having a list of the most popular articles in front of your eyes, you can figure out what requests this or that article was written for.
The third way is to use tools. In general, it was created to analyze the trust of sites, but, to be honest, he considers trust to be very bad. But what he knows how to do well is to analyze the requests of competitors' websites.
Enter the address of any site (even with closed statistics!) And click the trust check button. At the very bottom of the page, site visibility statistics by keywords will be displayed:
Site visibility in search engines (by keywords)

The only drawback is that these queries cannot be exported, you have to copy everything manually.
The fourth way is to use services and.

With its help, you can determine all the queries for which the site takes positions in the TOP-100 in both search engines. It is possible to export positions and requests to xls format, but I could not open this file on any of the computers.

Well, the last way to find out the keywords of competitors is with the help
Let's analyze the query "log house" as an example. In the "Competitor Analysis" tab, enter this request (if you want to analyze a specific site, you just need to enter its url in this field).
As a result, we get information about the frequency of the request, the number of advertisers in each of the search engines (and if there are advertisers, then there is money in this niche) and the average cost of a click in Google and Yandex:

You can also view all ads in Yandex.Direct and Google Adwords:


And this is how the TOP of each of the PS looks like. You can click on any of the domains and see all the requests for which it is in the TOP and all its contextual ads:

There is another way to analyze competitors' requests, which few people know about - with the help of a Ukrainian service.
I would call it the "Ukrainian version of Spywords", since they are very similar in functionality. The only difference is that the database contains key phrases that Ukrainian users are looking for. So if you work in a UA-net, this service will be very useful to you!
Analysis of competition requests
So, the requests are collected. Now you need to analyze the competition for each of them in order to understand how difficult it will be to promote this or that keyword.
Personally, when I create a new site, first of all I try to write articles for requests for which there is low competition. This will allow for a short time and with minimal investment to bring the site to a pretty good traffic. At least in such topics as construction, medicine, you can reach an attendance of 500-1000 visitors in 2.5 months. I am generally silent about the women's theme.
Let's see how you can analyze the competition in a manual and automatic way.
Manual way of analyzing competition
Enter the desired keyword in the search and look at T0P-10 (and if necessary, T0P-20) sites that are in the search results.
The most basic parameters to look at are:
The number of main pages in the TOP (if you are promoting the internal page of the site, and in the TOP the competitors mostly have main pages, then, most likely, you will not be able to overtake them);
The number of direct keyword drives in the Title of the page.
For such queries as “website promotion”, “how to lose weight”, “how to build a house”, there is unrealistically high competition (there are many main pages in the TOP with a direct entry of the keyword into Title), so you should not advance on them. But if you move on to the query "how to build a house from foam blocks with your own hands with a basement", then you will have a better chance of getting into the TOP. Therefore, I once again focus my attention on the fact that you need to advance on requests that consist of 3 or more words.
Also, if you are analyzing the results in Yandex, you can pay attention to the TCI of sites (the higher, the harder it will be to overtake them, because a high TCI most often indicates a large link mass of the site), are they in Yandex Catalog (sites from Yandex Catalog have more trust), its age (age-old sites are loved by search engines more).
If you are analyzing the TOP sites in Google, pay attention to the same parameters that I wrote about above, only in this case instead of Yandex Catalog there will be a DMOZ catalog, and instead of the TCI indicator there will be a PR indicator (if in the TOP pages of sites have a PR from 3 to 10, it won't be easy to overtake them).
I advise you to analyze sites using a plugin. It shows all the information about a competitor's site:

Automatic way of analyzing competition requests
If there are a lot of requests, then you can use programs that will do all the work for you hundreds of times faster. In this case, you can use Slovoeb or Kay Collector.
Previously, when analyzing competitors, I used the indicator "KEI" (a measure of competition). This function is available in Key Collector and Slovoyob.
In Slovoyob, the KEI indicator simply shows the total number of sites in the search results for a particular query.
In this regard, Kay Collector has an advantage, since it has the ability to independently set the formula for calculating the KEI parameter. To do this, go to Program Settings - KEI:

In the field "Formula for calculating KEI 1" insert:
(KEI_YandexMainPagesCount * KEI_YandexMainPagesCount * KEI_YandexMainPagesCount) + (KEI_YandexTitlesCount * KEI_YandexTitlesCount * KEI_YandexTitlesCount)
In the field "Formula for calculating KEI 2" insert:
(KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount) + (KEI_GoogleTitlesCount * KEI_GoogleTitlesCount * KEI_GoogleTitlesCount)
This formula takes into account the number of main pages in the SERP for a given keyword and the number of pages in the TOP-10 in which this keyword is included in the page title. Thus, you can get more or less objective data on competition for each request.
In this case, the smaller the request KEI, the better. The best keywords will have a KEI = 0 (if they, of course, have at least some traffic).
Click on the data collection buttons for Yandex and Google:

Then click on this button:

In the column KEI 1 and KEI 2, data on KEI queries for Yandex and Google will appear
respectively. Let's sort the requests in ascending order of the KEI 1 column:

As you can see, among the selected queries there are those, the promotion of which should not pose any particular problems. In less competitive topics, in order to bring such a query to the TOP-10, you just need to write a good optimized article. And you will not need to buy external links to promote it!
As I said above, I have used the KEI indicator before. Now, to assess the competition, I just need to get the number of main pages in the TOP and the number of occurrences of the keyword in the Title of the page. Key Collector has a similar function:


After that, I sort requests by the column "Number of main pages in Yandex PS" and make sure that for this parameter there are no more than 2 main pages in the TOP and as few entries as possible in the titles. After I have compiled a CY for all these queries, I decrease the filter parameters. Thus, the first articles on the site will be published for NK requests, and the last - for SK and VK requests.
After all the most interesting queries have been collected and grouped (I will talk about the grouping below), click on the "Export data" button and save them to a file. I usually include the following parameters in the export file: frequency by Yandex with "!" in a given region, the number of main pages of sites and the number of occurrences of the keyword in the headings.
Tip: The Kay Collector sometimes does not quite correctly show the number of occurrences of requests in the headers. Therefore, it is advisable to additionally enter these queries in Yandex and look at the results manually.
You can also evaluate the competitiveness of search queries using the free
Grouping requests
After all the requests have been selected, the time comes for the rather boring and monotonous work of grouping requests. You need to select similar queries that can be combined into one small group and promoted within one page.
For example, if you have such requests in the received list: “how to learn to do push-ups”, “how to learn to do push-ups at home”, “learn to do push-ups for a girl”. Such queries can be combined into one group and write one large optimized article for it.
To speed up the grouping process, parsing keywords in parts (for example, if you have a site about fitness, then during parsing, break the YA into groups that will include requests related to the neck, arms, back, chest, abs, legs, etc. etc.). This will greatly facilitate your work!
If the received groups will contain a small number of requests, then you can stop there. And when you still end up with a list of several dozen or even hundreds of requests, then you can try the following methods.
Working with stop words
In Key Collector it is possible to specify stop words that can be used to mark unwanted keywords in the resulting query table. Such queries are usually removed from the semantic core.
In addition to removing unwanted queries, this function can be used to search for all the necessary word forms for a given key.
We indicate the required key:

All word forms of the specified key are highlighted in the table with queries:

We transfer them to a new tab and already there we manually work with all requests.
Filtering for the "Phrase" field
You can find all word forms of a given keyword using the filtering settings for the "Phrase" field.
Let's try to find all queries that include the word "bars":

As a result, we get:

Group Analysis Tool
This is the most convenient tool for grouping phrases and further manually filtering them.
Go to the "Data" - "Group Analysis" tab:

And this is what is displayed if you open any of these groups:

By marking any group of phrases in this window, you simultaneously mark or uncheck a phrase in the main table with all queries.
In any case, you cannot do without manual work. But, thanks to Kay Collector, part of the work (and not a small one!) Has already been done, and this, at least a little, but facilitates the process of compiling the site's SYS.
After you manually process all the requests, you should get something like the following:

How to find a low-competitive profitable niche?
First of all, you must decide for yourself how you will earn on your website. Many novice webmasters make the same stupid mistake - they first create websites on a topic that they like (for example, after buying an iPhone or iPad, everyone immediately runs to make another “apple-themed” website), and then they begin to understand that competition in this niche is very high and it will be almost unrealistic for their govnositik to break through to the first places. Or they create a culinary website because they like to cook, and then they realize with horror that they don't know how to monetize that kind of traffic.
Before creating any site, immediately decide how you will monetize the project. If you have an entertainment theme, then teaser ads are most likely suitable for you. For commercial niches (in which something is sold) contextual and banner ads are perfect.
Just want to dissuade you from creating sites of general topics. Sites on which it is written "everything about everything" is now not so easy to promote, because the TOPs have long been occupied by well-known trust portals. It will be more profitable to make a narrow-topic site that will surpass all competitors in a short time and gain a foothold in the TOP for a long time. I am telling you this from personal experience.
My narrow-topic medical site, already 4 months after its creation, takes the first places in Google and Yandex, overtaking the largest medical general-topic portals.
To promote narrow-topic sites EASIER and FASTER!
Let's move on to choosing a commercial niche for a site where we will earn on contextual advertising. At this stage, you need to adhere to 3 criteria:

When assessing the competition in a certain niche, I use the search for the Moscow region, in which the competition is usually higher. To do this, specify in the region settings in your Yandex account "Moscow":
The exceptions are cases when the site is made for a specific region - then you need to look at competitors in this particular region.
The main signs of low competition in search results are as follows:
Lack of full-fledged answers to the request (irrelevant issue).
In the TOP there are no more than 2-3 main pages (they are also called "muzzles"). A large number of "faces" means that the entire site is purposefully promoted for this request. In this case, it will be much more difficult to promote the internal page of your site.
Inaccurate phrases in the snippet indicate that the required information is simply not available on the competitors' sites, or that their pages are not optimized for this request at all.
A small number of large thematic portals. If, for many requests from your future SN, there are many large portals and narrow-topic sites in the TOP, you need to understand that the niche has already been formed, and the competition there is very high.
More than 10,000 requests per month in terms of base frequency. This criterion means that you should not "narrow down" the topic of the site too much. The niche should have a sufficient amount of traffic that can be earned in the context. Therefore, the main query in the selected topic should have at least 10,000 queries per month for the wordstat (without quotes and taking into account the region!). Otherwise, you will need to expand the topic a little.
You can also roughly estimate the amount of traffic in a niche using statistics on traffic to sites that occupy the first positions in the TOP. If this statistics is closed for them, then use
Most seasoned MFA-Schnicks are looking for niches for their sites not in this way, but using the service or Micro Niche Finder program.
The latter, by the way, shows the SOC parameter (0-100 - the request will go to the TOP only on internal optimization, 100-2000 - average competition). You can easily select requests with SOC less than 300.
On the screen below, you can see not only the frequency of requests, but also the average cost of a click, the position of the site by requests:

There is also a useful trick like "Potential Advertising Buyers":

You can also just enter the query you are interested in and analyze it and similar queries:

As you can see, the whole picture is in front of you, you just have to check the competition for each of the requests and choose the most interesting of them.

Estimating the cost of bids for YAN sites
Now let's look at how to analyze the cost of bids for YAN sites.
We pass on to enter the queries we are interested in:

As a result, we get:

Attention! We look at the rate of guaranteed impressions! The real approximate cost of a click will be 4 times less than that shown by the service.
It turns out that if you display a page about sinusitis treatment in the TOP and visitors click on the advertisement, then the cost of 1 click on the YAN advertisement will be 12 rubles (1.55 / 4 = $ 0.39).
If you select the region "Moscow and the region" then the bids will be even higher.
That is why it is so important to take first places in the TOP in this particular region.
Please note that when analyzing requests, you do not need to take into account commercial requests (for example, "buy a table"). For content projects, you need to analyze and promote information requests ("how to make a table with your own hands", "how to choose a table for the office", "where to buy a table", etc.).
Where to look for niche search queries?
1. Start brainstorming, write down all your interests.
2. Write down what inspires you in life (it could be some kind of dream, or a relationship, lifestyle, etc.).
3. Look around and write down all the things that surround you (write down literally everything in a notebook: pen, light bulb, wallpaper, sofa, armchair, pictures).
4. What is your occupation? Do you work in a factory for a machine or as an ENT doctor in a hospital? Write down all the things you use at work in a notebook.
5. What are you good at? Write this down as well.
6. Look through advertisements in newspapers, magazines, advertisements on websites, spam in the mail. Perhaps they offer something interesting that you could make a website about.
Find there sites with a traffic of 1000-3000 people per day. Look at the topics of these sites and write down the most frequent requests that bring them traffic. Perhaps there is something interesting there.
I will give you a selection of one narrow topic niche.
So, I was interested in such a disease as "heel spur". This is a very narrow micronishe, for which you can make a small site of 30 pages. Ideally, I advise you to look for broader niches, for which you could make a site of 100 or more pages.
Open and check the frequency of this request (we will not specify anything in the region settings!):

Fine! The frequency of the main request is more than 10,000. There is traffic in this niche.
Now I want to check the competition for the requests for which the site will be promoted ("heel spur treatment", "heel spur treatment", "heel spur how to treat")
I switch to Yandex, specify the "Moscow" region in the settings, and this is what I get:

In the TOP there are many internal pages of general thematic medical sites, which will not be difficult for us to overtake (though this will happen, not earlier than in 3-4 months) and there is a muzzle of 1 site, which is sharpened for the treatment of heel spurs.
The wnopa site is a 10-page govnosite (which, however, has PR = 3) with a traffic of 500 visitors. A similar site can also be overtaken if you make a better site and promote the home page for this request.
Having analyzed the TOP for each of the queries in this way, we can come to the conclusion that this micronish is not yet busy.
Now the last stage is left - checking bids.
We go to and enter our requests there (you do not need to select the region, since our site will be visited by Russian-speaking people from all over the world)
Now I find the arithmetic average of all guaranteed impressions metrics. That makes $ 0.812. We divide this indicator by 4, it turns out on average $ 0.2 (6 rubles) per 1 click. For medical topics, this is, in principle, a normal indicator, but if you wish, you can find topics with the best bids.
Should you choose a similar niche for your website? It's up to you to decide. I would look for broader niches that have more traffic and better cost per click.
If you really want to find a good topic, I strongly suggest you take the next step!
Make a plate with the following columns (I indicated the data approximately):

You must write at least 25 requests per day in this way! Spend from 2 to 5 days looking for a niche and, in the end, you will have a lot to choose from!
Choosing a niche is one of the most important steps in creating a website, and if you treat it negligently, you can assume that in the future you will simply waste your time and money.
How to write the right optimized article
When I write an article optimized for any request, I first of all think about making it useful and interesting for site visitors. Plus, I try to arrange the text so that it is pleasant to read. In my understanding, ideally designed text should contain:
1. Bright effective headline. It is the title that first attracts the user when he views the search results page. Please note that the title must be fully relevant to what is written in the text!
2. Absence of "water" in the text. I think that few people like it when what could be written in 2 words is set out on several sheets of text.
3. Simplify paragraphs and sentences. To make the text easier to read, be sure to break large sentences into short ones that fit on one line. Simplify complex turns. It is not for nothing that in all newspapers and magazines the text is published in small sentences in columns. Thus, the reader will perceive the text better, and his eyes will not get tired so quickly.
The paragraphs in the text should also be small. Best of all, text will be perceived in which there is an alternation of small and medium paragraphs. A paragraph that is 4-5 lines long would be ideal.
4. Use subheadings in the text (h2, h3, h4). A person needs 2 seconds to "scan" an open page and decide whether to read it or not. During this time, he scans the page with his eyes and highlights the most important elements for himself that help him understand what the text is about. Subheadings are exactly the tool with which you can catch the attention of the visitor.
To make the text structured, easier to read, use one subheading for every 2-3 paragraphs.
Please note that these tags must be used in order (h2 to h4). For example:
You don't need to do this:
<И3>Subtitle<И3>
<И3>Subtitle<И3>
<И2>Subtitle<И2>
And this is how you can:
<И2>Subtitle<И2>
<И3>Subtitle<И3>
<И4>Subtitle<И4>
You can also do the following:
<И2>How to pump up the press<И2>
<И3>How to build abs at home<И3> <И3>How to pump up the press on the horizontal bar<И3> <И2>How to build biceps<И2> <И3>How to build biceps without exercise machines<И3>
In the texts, keywords should be used to a minimum (no more than 2-3 times, depending on the size of the article). The text should be as natural as possible!
Forget about bold and italicized keywords. This is a clear sign of over-optimization and Yandex doesn't like it very much. In this way, highlight only important sentences, thoughts, ideas (at the same time, try not to get keywords in them).
5. Use in all your texts bulleted and numbered lists, quotes (do not confuse with quotes and aphorisms of famous people! We write only important thoughts, ideas, advice in them), pictures (with filled in the alt, title and signature attributes). Insert interesting thematic videos into articles, this has a very good effect on the duration of visitors' stay on the site.
6. If the article is very long, then it makes sense to use the content and anchor links to navigate through the text.
After you have made all the necessary changes in the text, go over it with your eyes again. Isn't it hard to read it? Maybe some suggestions need to be done even less? Or do you need to change the font to a more readable one?
Only after you are satisfied with all the changes in the text, you can fill in the title, description and keywords and send it for publication.
Title requirements
Title - This is the title in the snippet that appears in the search results. The title in the title and the title in the article (the one that is highlighted by the tag
) must be different from each other and at the same time, they must contain the main keyword (or several keys).Description requirements
The description should be bright and interesting. In it, you need to briefly convey the meaning of the article and do not forget to mention the necessary keywords.
Requirements for Keywords
Enter the promoted keywords here separated by a space. No more than 10 pieces.
So how do I write optimized articles.
First of all, I choose the queries that I will use in the article. For example, I will take the basic query "how to learn to do push-ups." We drive it into wordstat.yandex.ru

Wordstat has displayed 14 queries. I will try to use most of them in the article whenever possible (it is enough to mention each keyword once). Keywords can and should be declined, rearranged, replaced with synonyms, made as diverse as possible. Search engines that understand Russian (especially Yandex) perfectly recognize synonyms and take them into account when ranking.
I try to determine the article size by the average size of articles from the TOP.
For example, if there are 7 sites in the TOP-10 in the search results, the text size of which is mainly 4,000-7,000 characters, and 3 sites in which this indicator is very low (or high), the last 3 I simply do not take into Attention.
Here is an approximate html-structure of an article, optimized for the query "how to learn to push up":
……………………………
How a girl can learn to do push-ups 100 or more times in 2 months
……………………………
What should be the right nutrition?
……………………………
Daily regime
……………………………
……………………………
Training program
Some SEOs advise to write the primary key in the first paragraph without fail. In principle, this is a powerful method, but if you have 100 articles on your site, each of which contains a promoted query in the first paragraph, it can backfire.
In any case, I advise you not to get hung up on one specific scheme, experiment, experiment and experiment again. And remember, if you want to make a site that search robots love, make it so that real people love it!
How to increase website traffic using simple linking manipulation?
I think that each of you has seen many different linking schemes on the sites, and I am more than sure that you did not attach much importance to these schemes. But in vain. Let's take a look at the first linking scheme that is found on most sites. On it, however, there are still not enough links from internal pages to the main page, but this is not so important. It is important that in this case, the most important on the site will be the category pages (which most often are not promoted and closed from indexing in robots.txt!) And the main page of the site. Post pages in this case have the least weight:

Now let's think logically: SEOs who promote content projects promote which pages in the first place? That's right - pages with records (in our case, these are pages of the 3rd level). So why, when promoting the site with external factors (links), we so often forget about no less important - internal factors (correct linking)?
Now let's take a look at a scheme in which internal pages will have more weight:

This can be achieved simply by properly adjusting the flow of weight from the top-level pages to the bottom, third-level pages. Also, do not forget that internal pages will be additionally pumped by external links on other sites.
How do you set up this weight transfer? Very simple - with nofollow noindex tags.
Let's take a look at a site where you need to pump internal pages:
On the main page (1 level): all internal links are open for indexing, external links are closed via nofollow noindex, the link to the sitemap is open.
On pages with headings (2nd level): links to pages with posts (3rd level) and to a sitemap are open for indexing, all other links (to the main, headings, tags, external) are closed via nofollow noindex.
On pages with posts (3rd level): links to pages of the same, 3rd level and to the site map are open, all other links (to the main, headings, tags, external) are closed via nofollow noindex.
After such a linking was done, the sitemap received the most weight, which evenly distributed it to all internal pages. The inner pages, in turn, have improved significantly in weight. The main page and the rubric page got the least weight, which is exactly what I wanted to achieve.
I will check the weight of the pages using the program. It helps to visually see the distribution of static weight on the site, focus it on the pages being promoted, and thereby raise your site in the search engine results, significantly saving the budget on external links.
Now, let's move on to the fun part - the results of such an experiment.
Women's site. The changes to the weight distribution on the site were made in January of this year. A similar experiment brought +1000 to the attendance:

The site is under the Google filter, so the traffic went up only in Yandex:

Do not pay attention to the drop in traffic in May, this is seasonality (May
holidays).
2. Second site for women, changes were also made in January:


This site, however, is constantly updated and links are purchased to it.
TK for copywriters for writing articles
Article title: how can greens be useful?
Uniqueness: not less than 95% by Etxt
Article size: 4,000-6,000 characters without spaces
Keywords:
what are the benefits of greens - the main key
healthy greens
useful properties of greens
benefits of greenery
Requirements for the article:
The main keyword (listed first in the list) does not have to be in the first paragraph, it just has to appear in the first half of the text !!!
FORBIDDEN: to group keywords in parts of the text, it is necessary to distribute keywords throughout the text.
Key words should be highlighted in bold (this is necessary to make it easier for you to check the order)
Keywords must be entered harmoniously (therefore, you need to use not only direct occurrences of keys, but you can also declare them, swap words, use synonyms, etc.)
Use subheadings in your text. Try not to use direct occurrences of keywords in your subheadings. Make subheadings as varied as possible for each article!
Use no more than 2-3 direct occurrences of the main query in the text!
If in an article you need to use the keywords "how greens are useful" and "how greens are useful for humans," then by writing the second keyword, you will automatically use the first one. That is, there is no special need to write a key 2 times, if one already contains an entry for another key.
Quick navigation on this page:
Like almost all other webmasters, I compose the semantic core with the KeyCollector program - this is by far the best program for composing the semantic core. How to use it is a topic for a separate article, although the Internet is full of information on this matter - I recommend, for example, a manual from Dmitry Sidash (sidash.ru).
Since the question has been raised about an example of compiling a kernel, I give an example.
Key List
Suppose we have a site dedicated to British cats. I type in the phrase "British cat" into the "List of phrases" and click on the "Parse" button.
I get a long list of phrases, which will begin with the following phrases (the phrase and particulars are given):
British cats 75553 British cats photo 12421 British Fold cat 7273 British cats cattery 5545 British cats 4763 British Shorthair 3571 British cat colors 3474 British cats price 2461 British blue cat 2302 British fold cat photo 2224 British cats mating 1888 British cats character 1394 cat 1179 british cats buy 1179 longhair british cat 1083 british cat pregnancy 974 british chinchilla cat 969 british cats photo 953 british cat cattery moscow 886 british cat color photo 882 british cats grooming 855 british shorthair cat photo 840 scottish and british cats 763 names of british cats 762 cat british blue photo 723 photo of british blue cat 723 british cat black 699 how to feed british cats 678
The list itself is much longer, I just gave its beginning.
Key grouping
Based on this list, on my site there will be articles about the varieties of cats (fold, blue, shorthaired, longhaired), there will be an article about the pregnancy of these animals, about what to feed them, about the names, and so on according to the list.
For each article, one main such request is taken (= topic of the article). However, the article is not limited to just one request - it also adds other relevant queries, as well as different variations and word forms of the main query, which can be found in the Key Collector below in the list.
For example, with the word "lop-eared" there are the following keys:
British fold 7273 british fold cat photo 2224 british fold cat price 513 cat breed british fold 418 british blue fold cat 224 scottish fold and british cats 190 british fold cats photo 169 british fold cat photo price 160 british fold british fold buy cat photo 129 british fold cats character 112 british fold cat grooming 112 mating british fold cats 98 british shorthair fold cat 83 color british fold cats 79
So that there is no overspam (and overspam may be due to the combination of using too many keys in the text, in the header, in, etc.), I would not take all of them with the inclusion of the main request, but separate words from them make sense use in the article (photo, buy, character, care, etc.) so that the article is better ranked by a large number of low-frequency queries.
Thus, a group of keywords will be formed under the article about lop-eared cats, which we will use in the article. Groups of keywords for other articles will be formed in the same way - this is the answer to the question of how to create the semantic core of the site.
Frequency and competition
There is also an important point related to the exact frequency and competition - they must be collected in the Key Collector. To do this, select all requests by ticking and on the tab "Frequencies Yandex.Wordstat" click the button "Collect frequencies"! " - the exact particularity of each phrase will be shown (that is, with exactly the same word order and in this case), this is a much more accurate indicator than the overall frequency.
To check the competition in the same Key Collector, you need to click the button "Get data for Yandex PS" (or for Google), then click "Calculate KEI from available data". As a result, the program will collect how many main pages for a given request are in the TOP-10 (the more, the more difficult it is to get there) and how many pages in the TOP-10 contain such a title (similarly, the more, the more difficult it is to break into the top).
Then we need to act on the basis of our strategy. If we want to create a comprehensive cat site, then exact frequency and competition are not so important to us. If we only need to publish a few articles, then we take the queries that have the highest frequency and at the same time the lowest competition, and on their basis we write articles.
In addition to the site, it is important to know how to properly apply it with maximum benefit for internal and external site optimization.
Already a lot of articles have been written on the topic of how to make a semantic core, therefore, within the framework of this article, I want to draw your attention to some features and details that will help you use the semantic core correctly, and thereby help promote an online store or website ... But first, I will briefly give my definition of the semantic core of the site.
What is the semantic core of the site?
The semantic core of the site is a list, set, array, set of keywords and phrases that are requested by users (your potential visitors) in search engine browsers to find the information of interest.
Why does a webmaster need to compose a semantic core?
Based on the definition of the semantic core, there are a lot of obvious answers to this question.
It is important for online store owners to know how potential buyers are trying to find the product or service that the online store owner wants to sell or provide. The position of the online store in the search results directly depends on this understanding. The more the content of the online store corresponds to consumer search queries, the closer the online store is to the TOP of the search results. This means that the conversion of visitors to buyers will be higher and better.
For bloggers who are actively involved in monetizing their blogs (moneymaking), it is also important to be in the TOP of search results on topics relevant to the content of the blog. An increase in search traffic brings more profit from impressions and clicks from contextual advertising on the site, impressions and clicks on advertising blocks of affiliate programs and an increase in profits for other types of earnings.
The more original and useful content on the site, the closer the site is to the TOP. Life exists primarily on the first page of search engine results. Therefore, the knowledge of how to make the semantic core is necessary for the SEO of any site, online store.
Sometimes webmasters and online store owners wonder where to get high-quality and relevant content? The answer comes from the question - you need to create content in accordance with the key requests of users. The more search engines consider the content of your site to be relevant (suitable) keywords of users - the better for you. By the way, this gives rise to the answer to the question - where to get the variety of content topics? It's simple - by analyzing the search queries of users, you can find out what they are interested in and in what form. Thus, having made the semantic core of the site, you can write a series of articles and / or descriptions for the products of the online store, optimizing each page for a specific keyword (search query).
For example, I decided to optimize this article for the key query "how to make a semantic core", because the competition for this query is lower than for the query "how to create a semantic core" or "how to make a semantic core". Thus, it is much easier for me to get to the TOP of search engine results for this query using absolutely free methods of promotion.
How to make a semantic core, where to start?
There are a number of popular online services for compiling the semantic core.
The most popular service, in my opinion, is Yandex keyword statistics - http://wordstat.yandex.ru/
With the help of this service, you can collect the vast majority of search queries in various word forms and combinations for any topic. For example, in the left column we see statistics on the number of requests not only for the keyword "semantic core", but also statistics for various combinations of this keyword in different conjugations and with dilution and additional words. In the left column, we see the statistics of the search phrases that were searched along with the keyword "semantic core". This information can be valuable, at least as a source of topics for creating new content that is relevant to your site. I also want to mention one feature of this service - you can specify the region. Thanks to this option, you can more accurately find out the number and nature of the search queries you need in the required region.

Another service for compiling the semantic core is the statistics of rambler's search queries - http://adstat.rambler.ru/

In my subjective opinion, this service can be used when there is a battle for attracting every single user to your site. Here you can clarify some low-frequency and long tail queries, the users' turnover for them is approximately from 1 to 5-10 per month, i.e. very little. Immediately I will make a reservation that in the future we will consider the topic of classification of keywords and the features of each group from the point of view of their application. Therefore, personally, I very rarely use these statistics, as a rule in those cases when I am engaged in a highly specialized site.
To form the semantic core of the site, you can also use the hints that appear when you enter a search query in the search engine browser.


And one more option for residents of Ukraine to replenish the list of keywords for the semantic core of the site is to view site statistics at - http://top.bigmir.net/

Having chosen the desired topic of the section, we are looking for open statistics of the most visited and suitable site for the topic

As you can see, the statistics of interest may not always be open, as a rule, webmasters hide it. However, as an additional source of keywords it can work too.
By the way, a wonderful article by Globator (Mikhail Shakin) - http://shakin.ru/seo/keyword-suggestion.html You can also read about how to make a semantic core for English-language projects.
What to do next with the list of keywords?
First of all, to make a semantic core, I recommend to structure the list of keywords - to break it down into conditional groups: high-frequency (HF), mid-frequency (MF) and low-frequency (LF) keywords. It is important that these groups include keywords that are very similar in morphology and subject matter. It is most convenient to do this in the form of a table. I do it something like this:

The top row of the table is high frequency (HF) search queries (written in red). I put them at the head of the thematic columns, in each cell of which I sorted mid-frequency (MF) and low-frequency (LF) search queries as uniformly as possible by topic. Those. for each HF request, I linked the most suitable groups of MF and LF requests. Each cell of MF and LF queries is a future article that I am writing and optimizing strictly for a set of keywords in a cell. Ideally, one article should correspond to one keyword (search query), but this is a very routine and time-consuming job, because there can be thousands of such keywords! Therefore, if there are a lot of them, you need to select the most significant for yourself, and weed out the rest. Also, you can optimize the future article for 2 - 4 MF and LF keywords.
For online stores, MF and LF, search queries are usually product names. Therefore, there are no special difficulties in the internal optimization of each page of the online store, it's just a long process. The more goods are in the online store, the longer it takes.
In green, I highlighted those cells for which I already have articles ready, thus. I will not get confused in the future with the list of ready-made articles.
I will talk about how to optimize and write articles for the site in one of the future articles.
So, having made such a table, you can have a very clear idea of how you can make the semantic core of the site.
As a result of this article, I want to say that here we to some extent touched on the detailing of the issue of promoting an online store. Surely, after reading some of my articles about the promotion of an online store, you got the idea that the compilation of the semantic core of the site and internal optimization are interrelated and interdependent activities. I hope I was able to argue the importance and priority of the question - how to make a semantic core site.


