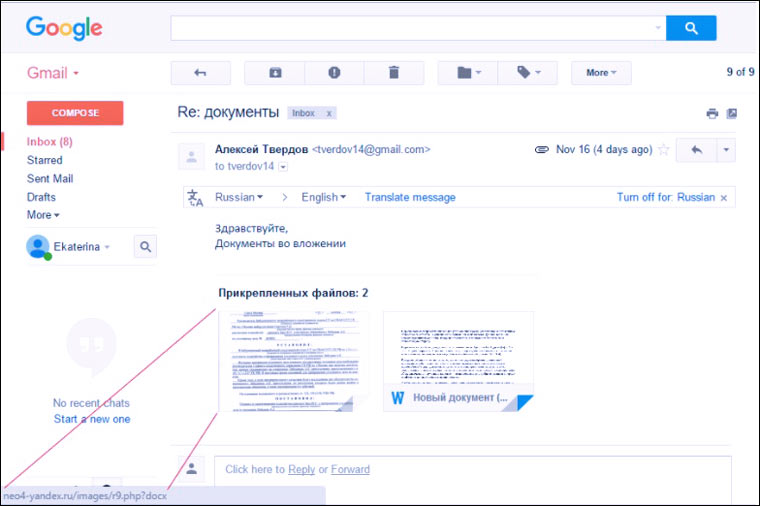
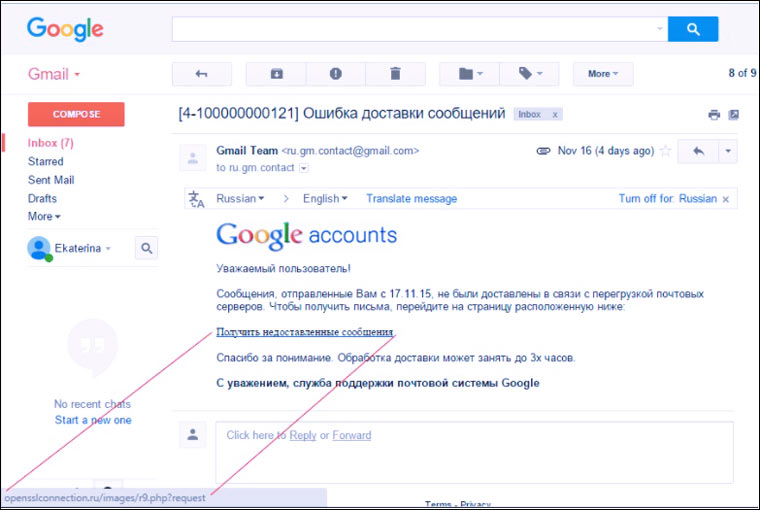
: всегда хотел это понять, но значимость его была настолько мала, что всегда находился повод этого не делать:)
А вы задавались вопросом: URL — что это ?
Всегда с таким сталкиваюсь, но до сих пор не желал понять в чем различие между терминами URI, URL, URN, а тут вдруг постик (к сожалению, он уже канул в Лету), решил - и сам почитаю, и другим поведаю, хотя, как сказано выше, от этого ничего не изменится, но люблю я иногда побуквоедствовать, так-что читайте толковый переводец:
Вы когда-нибудь обращали внимание на адресную строку в Вашем браузере? Что это? URI, URL или URN? Многие из нас не делают различий между URI, URL, URN, а кое-кто даже и не слышал терминов URI и URN, все просто пользуются термином URL. Давайте вместе попытаемся разобраться в этом.
Расшифровка аббревиатур
URI - Uniform Resource Identifier (унифицированный идентификатор
ресурса)
URL - Uniform Resource Locator (унифицированный определитель местонахождения
ресурса)
URN - Unifrorm Resource Name (унифицированное имя
ресурса)
Внимание, здесь в мелочах кроется истина, но пока ничего не понятно, какая-то каша. Едем дальше.
Определение
URI: Обозначает имя и адрес ресурса в сети. Как правило, делится на URL и URN, поэтому URL и URN это составляющие URI.
URL: Адрес некоторого ресурса в веб. URL определяет местонахождение ресурса и способ обращения к нему.
URN: Имя некоторого ресурса в веб. Смысл URN в том, что он определяет только название конкретного предмета, который может находится во множестве конкретных мест.
Нет ничего лучше, чем конкретный пример
URI = http://сайт/2009/09/uri-url-urn.html
URL = http://сайт
URN = /2009/09/uri-url-urn.html
Подведем итоги
URI это концепция абстрактного идентификатора, тогда как URL и URN конкретная реализация - адреса и имени.
Надеюсь всем всё понятно. Будьте грамотны!
Восприятие каждого из нас индивидуально, поэтому — спорьте и читайте обсуждения в комментариях к статье, там много чего интересного.
Споры по этому вопросу - как правильно писать URL, со слешем на конце или без? - были и будут. Аргументация встречается разнообразная, и часто противоречива. А расплату за неверную запись универсального локатора ресурса (URL) воображают двух видов. Со стороны поисковиков - это якобы штрафные санкции за дубли страниц. С точки зрения производительности - якобы лишний редирект на страницу верной записи, автоматически генерируемый сервером.
Однако, разбирая технические спецификации стандартов Интернета, в частности документ " RFC 1738 - Uniform Resource Locators (URL)", приходится признать, что оба варианта записи адреса веб-ресурса формально правильные, и санкция за использование того или иного варианта - не более чем бзик поисковой системы или байки псевдо-SEO-шников.
С позиции лаконичности, более правильным представляется вариант без слеша на конце вне зависимости от того, адресует ли ваша ссылка "файл" на сервере или "папку", косвенное доказательство чему будет продемонстрировано ниже. Но и нет ни одного утверждения в документе, что иной вариант неверный или ссылается совсем на другой ресурс.
Загружать вас многостраничным переводом упомянутого RFC не стану, так как, во-первых, целью вопроса были слеши на конце URL, и во-вторых, публикация адресована простым пользователям движков, в том числе и , которым вся детализация не интересна, они ждут кратких разъяснений и доказательств по существу. Соответственно, я буду цитировать выдержки из сего документа в качестве доказательной базы и пояснять. Кому и это не интересно, может сразу смотреть вывод в конце статьи.
Общий синтаксис URL
Первым делом привлеку внимание к выдержке из параграфа 2. General URL Syntax (общий синтаксис URL). В каждом случае буду приводить фрагмент текста на языке оригинала и следом перевод на русский язык.
URLs are used to `locate" resources, by providing an abstract identification of the resource location. URLы используются для "нахождения" ресурсов, предоставляя абстрактное обозначение местоположения ресурса.
То есть сам URL - это чистая абстракция. Что он может показаться нам внешне похожим на имя файла или папки, вовсе не означает физическое указание на именно такой-то файл, а не какой-нибудь другой в файловом пространстве сервера. Ниже в документе об этом будет заявлено прямо.
Заметка Вообще в отношении http-ссылок в принципе неверно говорить, что например
- http://domain.com/path/subpath/filename.txt - якобы указывает на файл
- http://domain.com/path/subpath/ - якобы указывает на папку
- http://domain.com/path - якобы неверно указывает на папку
Мы просто привыкли так говорить, потому что удобно ассоциировать ссылки с файлами на сайте. В действительности все эти ссылки указывают на некие ресурсы, никоим образом не обозначая тип ресурса. Что же скрывается за каждым ресурсом, то есть какой именно реальный файл или папка и какой тип контента будет отдан по такой ссылке, то уже определено конфигурацией сервера.
Важно уяснить, что в ссылках нет такого понятия как "файл", "папка", "подпапка", "текст", "картинка", "html", "скрипт", "таблица стилей" и так далее. Никакой слеш на конце или его отсутствие не значит ровным счётом ничего до тех пор, пока ссылка не пройдёт трансформацию внутри сервера, и уже он сам решит, куда же на самом деле указывает ссылка и какой контент какого типа скрывается за ней. Только это решение относится к внутренней архитектуре сервера.
Иерархические схемы
Далее выдержка из параграфа 2.3 Hierarchical schemes and relative links (иерархические схемы и относительные ссылки).
Some URL schemes (such as the ftp, http, and file schemes) contain names that can be considered hierarchical; the components of the hierarchy are separated by "/". Некоторые схемы URL (такие как ftp, http и file) содержат имена, которые можно считать иерархическими; элементы иерархии разделены символом "/".
То есть утверждается, что в отдельных схемах адресов содержимое локатора ресурса не воспрещено подразумевать иерархическим, причём пока не оговаривалось, что иерархия эквивалентна какой-либо форме, скажем файловой.
Общий синтаксис сетевой схемы
Далее выдержка из параграфа 3.1. Common Internet Scheme Syntax (общий синтаксис сетевой схемы).
//
Заметка Это, кстати, ответ на вопрос, производный от рассматриваемого нами. Нередко и по такому вопросу спорят: как правильно давать ссылку на домен (хост) - без слеша в конце или со слешем?
Как правильно http://domain.com/ или http://domain.com ?
И так и так правильно. Просто первый слеш после имени хоста предназначен для отделения имени пути от имени хоста. Тот же параграф документа сообщает об этом так:
Url-path The rest of the locator consists of data specific to the scheme, and is known as the "url-path". It supplies the details of how the specified resource can be accessed. Note that the "/" between the host (or port) and the url-path is NOT part of the url-path. Остальная часть локатора состоит из данных, характерных для схемы, и известна как "url-path" (путь URL). Она сообщает подробности, как можно получить доступ к указанному ресурсу. Обратите внимание, что символ "/" между хостом (или портом) и путём URL - это не часть url-path.
Ни словом не обязали вас ставить этот замыкающий символ или не ставить, когда url-path равен пустой строке (как сказали бы многие из нас, когда URL ссылается в корень сайта). Никто не имеет права применить к вам штрафные санкции "за два дубля главной страницы", ибо согласно спецификации, в обоих случаях вы ссылаете URL на один и тот же ресурс.
Продолжим ещё одной выдержкой из того же параграфа.
The url-path syntax depends on the scheme being used, as does the manner in which it is interpreted. Синтаксис url-path зависит от используемой схемы, как и способ, которым он интерпретируется.
Это лишнее подтверждение, что у каждой схемы локатора своё понятие "иерархии" и способ её интерпретации.
Иерархия
For some file systems, the "/" used to denote the hierarchical structure of the URL corresponds to the delimiter used to construct a file name hierarchy, and thus, the filename will look similar to the URL path. This does NOT mean that the URL is a Unix filename. Символ "/" использован для обозначения иерархической структуры URL соответственно разделителю, используемому в конструировании иерархии файловых имён, и таким образом в некоторых файловых системах имя файла выглядит подобным пути URL. Но это не означает, что URL - это Unix-подобное имя файла.Несмотря на то, что этот параграф относится к схеме ftp, тем не менее его утверждения распространимы и на другие схемы (http, gopher, prospero и так далее). Лишь в схеме file символ слеша логично обозначает то же, что и в именах файлов, например file://server_or_device/path/subpath/filename.txt .
Http
An HTTP URL takes the form:
http://
Заметка Здесь также утверждается, что можно указывать ссылку без оконечного слеша. В данном случае речь шла о ситуации, когда путь ссылки пустой - указывает на корень хоста.
Формальная запись
И наконец выдержка из параграфа 5. BNF for specific URL schemes (формальная запись для конкретных схем URL).
Здесь в квадратных скобках указаны опциональные части. Звёздочка перед скобкой обозначает 0 или более повторов такого фрагмента, как указан в скобках. Вертикальную черту следует понимать как ИЛИ.
Hostport = host [ ":" port ] ... ... httpurl = "http://" hostport [ "/" hpath [ "?" search ]] hpath = hsegment *[ "/" hsegment ] hsegment = *[ uchar | ";" | ":" | "@" | "&" | "=" ] search = *[ uchar | ";" | ":" | "@" | "&" | "=" ] ... ... lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" hialpha = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "I" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | "Q" | "R" | "S" | "T" | "U" | "V" | "W" | "X" | "Y" | "Z" alpha = lowalpha | hialpha digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" safe = "$" | "-" | "_" | "." | "+" extra = "!" | "*" | """ | "(" | ")" | "," hex = digit | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" escape = "%" hex hex unreserved = alpha | digit | safe | extra uchar = unreserved | escape
Обратите внимание, как точно по правилам формируется элемент hpath - путь ссылки. Элементы hsegment пути - сегменты - разделяются слешем. Словно намекая на важную идею, что слеш делит путь на иерархические части и всегда находится внутри. В принципе не исключается, что последний элемент hsegment может являться пустой строкой (это следует из его определения), и тогда на конце URL невольно появляется закрывающий слеш.
Вывод
Деление пути на сегменты с помощью символа слеша подразумевает наличие непустых имён этих сегментов. Соответственно, ссылка со слешем на конце видится нелогичной (хотя и не воспрещена) в том смысле, что она вроде бы указывает на некий последний сегмент пути, но притом никак не называет этот сегмент. Точно так как нелогична (но тоже не воспрещена) ссылка http://domain.com/level1////levelX , не называющая промежуточные сегменты пути, если путь рассматривать не как набор параметров, а как иерархическую структуру.
Просторечным языком смысловое наполнение двух ссылок можно пояснить так:
- - адресует в дефолтную начальную точку второго уровня иерархии
- - адресует в неопределённую точку внутри второго уровня иерархии, то есть как бы на сервер возлагают задачу, что "мы обращаемся ко второму уровню иерархии, а ты сам определи, какую точку считаешь в этом уровне дефолтной начальной".
Из всего сказанного выше следует , что аналогично тому, как ссылки
- http://domain.com
- http://domain.com/
адресуют посетителя в корень сайта, так и например ссылки
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
адресуют посетителя во второй уровень иерархии ресурса. А то что некий сервер может интерпретировать слеш на конце по-своему и начать внутренне редиректить на дефолтную начальную точку уровня - скажем на файл index.html , это уже частный случай конкретной конфигурации. Точно так как и в реализации системы человеко-понятных URL все записи редиректов с помощью серверного модуля mod_rewrite определяют своё (присущее конкретному движку) понятие иерархического строения URL, в котором элементы пути могут приравниваться к параметрам запроса и вовсе не иметь общего с файловой структурой сайта (классический пример: http://domain.com/ru/path , элемент ru - это параметр текущего языка, а не папка на сайте).
Особо подчеркну, что это внутренние знания сервера, обусловленные его конфигурацией, а также установленным на сайте движком. Внешний сервис, скажем тот же поисковик, домыслов делать не может и понятия не имеет, отличаются ли и чем ссылки со слешем и без, если только сервер сайта специально не настроили так, чтобы по таким ссылкам выдавать разный контент.
К сведению
На уровне реализации вопрос слешей на концах не имеет принципиального значения, чему множество подтверждений среди именитых порталов. На одних все ссылки завершают слешем, на других - без слеша. Главное чтобы контент по ссылкам не оказывался разным, и ещё для Яндекса нужно прописать 301-й редирект с тех ссылок, которыми вы не пользуетесь (скажем оканчивающихся слешем), на те, которыми пользуетесь. Дело в том, что по неподтверждённым утверждениям службы поддержки Яндекса, этот поисковик якобы может ошибаться и не "склеивать" (запоминать в своих знаниях) или с некоторым запозданием склеивать слеш-без-слешевые адреса в один.

Вот пример реализации такого редиректа с помощью корневого файла .htaccess :
# если входной url оканчивается слеш(ем, ами), # задаём 301-й редирект на страницу без слеша RewriteCond %{REQUEST_URI} ^/.+/$ RewriteRule ^(.*?)/+$ http://%{HTTP_HOST}/$1
Гуглу (опять же по сведениям , не подтверждённым экспериментом) эти редиректы не важны, так как он будто бы умеет склеивать такие адреса правильно и без редиректов.
Помните Есть немало людей, считающих себя SEO-специалистами. Но не каждый из них таким является. Более того, темой SEO часто спекулируют без должных знаний и оснований, просто в расчёте на то, что и вы неосведомлены в этой области, поэтому легко поверите в любую "лапшу". Когда вам говорят, что какая-то ваша страница "вылетела из индекса", воспользуйтесь очень хорошей рекомендацией Яндекса: Узнавать об ошибках индексирования , если таковые возникают, можно в сервисе Яндекс.Вебмастер. В этом сервисе всегда можно увидеть список ваших страниц, находящихся в поиске и список страниц, по какой-то причине исключённых из поиска . Похожий сервис есть и у Гугла. Доверяйте этим знаниям, а не мнению псевдо-специалистов, которые где-то что-то краем уха слышали, и на том основании рекомендуют вам делать так, как им кажется единственно правильным.
Вот Очень интересная публикация Малоизвестные факты SEO , вышедшая в апреле 2017 года. Там представлено большое исследование со множеством скриншотов, которое начиналось с целью проверить справедливость нескольких популярных суждений в области поискового продвижения и на понятных примерах донести результаты до обычного владельца сайта. То же исследование попутно демонстрирует молодому читателю ряд очевидных, обыденных, и скорее даже неприметных, но всё же удивительных особенностей органической выдачи в поисках Google и Yandex.
Вот Хотя следующая ссылка почти не касается SEO, всё же станет привлекательной для seo-мастеров, находящихся сейчас в поиске дополнительных заказов. Под ссылкой размещено коммерческое предложение, ребята нашли любопытный способ использования сайта. Частному бизнесу предлагают создание рекламного щита онлайн на основе какой-то специальной темы, под управлением которой сайт, а точнее его первый экран выглядит словно бы баннерная растяжка на билбордах наружной рекламы. На смартфоне повернул экран, растяжка стала вертикальной и занимает всю площадь экрана, повернул назад, стала горизонтальной и снова на весь экран. А под первым экраном есть текстовый придаток, куда пользователи обычно не скролят, но поисковик хорошо видит этот текст. Так вот самые шустрые буратины регионального бизнеса покупают себе эти недорогие онлайн билборды в качестве выгодной альтернативы контекстной рекламе и контекстно-медийной сети Яндекса и Гугла. А чтобы по-максимуму тусоваться в местном поисковом индексе, на продвижение своего щита готовы стегнуть денег сразу на кучу seo-текстов, что пахнет некислой суммой. Судя по слухам, заказы на 30 килорублей проскакивают, и так как ребята аутсорсят их партнёрам сеошникам, тут можно навести мосты партнёрства и получать хороший приработок.
Заблудиться можно не только в лесу, но и в онлайне. И тому виной может стать неверный путь или адрес, ведущий к ресурсу. Вы не знаете, что такое URL адрес? Тогда прежде, чем пускаться в дальнейшее путешествие по виртуальному пространству, давайте разберемся с системой электронных адресов.
Что такое URL
URL является общепринятым стандартом записи адреса и указания на расположение ресурса в интернете. С английского его название (Uniform Resource Locator ) переводится как единый указатель ресурсов. Можно встретить более раннюю расшифровку аббревиатуры URL — Universal Resource Locator (универсальный локатор ресурсов ). Но оба значения скорее дополняют понятие URL , чем перечат друг другу.
Основной формат записи структуры URL адреса выглядит так:
://:@:/?#
— чаще всего имеется в виду протокол.
логин
– логин пользователя, используемый для авторизации на ресурсе.
пароль
– пароль пользователя для авторизации.
хост
– доменное имя хоста.
порт
– порт хоста, используемый во время подключения.
URL
– путь, по которому находится запрашиваемый ресурс на сервере.
параметры и якорь
– значение переменных и идентификатор на определенном ресурсе.
Передача значения переменных в строке запроса возможна лишь с помощью метода GET .
Рассмотрим формат URL
адреса страницы запрашиваемого ресурса на практических примерах. На клиентской стороне URL отображается в адресной строке браузера:
Чаще всего встречаются такие варианты:
- http:// ru.wikipedia.org/wiki/Заглавная_страница – для передачи запроса используется http (протокол передачи гипертекста );
- https://ru.wikipedia.org/wiki/Заглавная_страница — в качестве способа передачи используется https . Является защищенной формой протокола http , использующего шифрование (SSL или TLS );
- fttp://wikipedia.org/wiki/file.txt – протокол передачи файлов fttp ;
- http://mail.ru/script.php?num=10&type=new&v=text – передача значений переменных в строке запроса с помощью метода GET .
Любой формат URL адреса представляет собой, прежде всего, символьную строку. В ее состав могут входить:
2; Латинские буквы.
2; Арабские цифры (0-9).
2; Зарезервированные символы («+», «=», «!» и другие).
2; Специальные символы – на них остановимся более подробно.
Использование специальных символов в URL
Конечно, таких уж слишком «специальных» символов в URL не используют. Но несколько есть:
- ? – служит для отделения в строке запроса блока с передаваемыми параметрами;
- & — отделяет передаваемые параметры друг от друга;
- = — отделяет в параметре переменную от ее значения;
- : — служит для отделения протокола от остальной части URL;
- # — символ используется в локальной части адреса. Позволяет обратиться к определенной части запрашиваемой страницы;
- @ — указывается в регистрационных данных пользователя и при передаче данных с помощью протокола mailto.
Но все это лишь теория. Поэтому перед тем, как узнать остальное, рассмотрим небольшой практический пример.
Наглядный пример
Возьмем для наглядности вот такую простую форму регистрации:
Вот ее код: