IN Excel Postoji još brži i pogodniji način za crtanje linearne regresije (pa čak i glavne vrste nelinearnih regresija, kao što je objašnjeno u nastavku). To se može uraditi na sljedeći način:
1) odaberite kolone sa podacima X I Y(trebalo bi da budu tim redom!);
2) poziv Čarobnjak za karte i izaberite u grupi Tip – Tacka i odmah pritisnite Spreman;
3) bez poništavanja izbora dijagrama, izaberite stavku glavnog menija koja se pojavi Dijagram, u kojem trebate odabrati stavku Dodajte liniju trenda;
4) u dijaloškom okviru koji se pojavi Linija trenda u kartici Tip izabrati Linearno;
5) u kartici Opcije možete aktivirati prekidač Pokažite jednačinu na dijagramu, što će vam omogućiti da vidite jednačinu linearne regresije (4.4), u kojoj će se izračunati koeficijenti (4.5).
6) U istoj kartici možete aktivirati prekidač Postavite vrijednost pouzdanosti aproksimacije (R^2) na dijagram. Ova vrijednost je kvadrat koeficijenta korelacije (4.3) i pokazuje koliko dobro izračunata jednačina opisuje eksperimentalnu ovisnost. Ako R 2 je blizu jedinice, tada teorijska regresijska jednadžba dobro opisuje eksperimentalnu ovisnost (teorija se dobro slaže s eksperimentom), a ako R 2 je blizu nule, onda ova jednadžba nije prikladna za opisivanje eksperimentalne ovisnosti (teorija se ne slaže s eksperimentom).
Kao rezultat izvođenja opisanih radnji, dobit ćete dijagram sa grafom regresije i njegovom jednadžbom.
§4.3. Glavne vrste nelinearne regresije
Parabolična i polinomska regresija.
Parabolic zavisnost vrednosti Y od veličine X naziva se zavisnost izražena kvadratnom funkcijom (parabola 2. reda):
Ova jednačina se zove jednadžba paraboličke regresije Y on X. Opcije A, b, With su pozvani koeficijenti paraboličke regresije. Izračunavanje koeficijenata paraboličke regresije je uvijek glomazno, pa se preporučuje korištenje računara za proračune.
Jednačina (4.8) paraboličke regresije je poseban slučaj općenitije regresije koja se naziva polinom. Polinom zavisnost vrednosti Y od veličine X naziva se zavisnost izražena polinomom n-ti red:
gdje su brojevi i ja (i=0,1,…, n) su pozvani koeficijenti polinomske regresije.
Regresija snage.
Snaga zavisnost vrednosti Y od veličine X naziva se zavisnost oblika:
Ova jednačina se zove jednadžba regresije snage Y on X. Opcije A I b su pozvani koeficijenti regresije snage.
ln =ln a+b· ln x. (4.11)
Ova jednadžba opisuje pravu liniju na ravni sa logaritamskim koordinatnim osa ln x i ln. Stoga je kriterij primjenjivosti regresije stepena zahtjev da tačke logaritama empirijskih podataka ln x i i ln y i bili najbliži pravoj liniji (4.11).
Eksponencijalna regresija.
Indikativno(ili eksponencijalna) zavisnost vrijednosti Y od veličine X naziva se zavisnost oblika:
(ili ). (4.12)
Ova jednačina se zove eksponencijalna jednačina(ili eksponencijalna) regresija Y on X. Opcije A(ili k) I b su pozvani eksponencijalni koeficijenti(ili eksponencijalna) regresija.
Ako uzmemo logaritam obje strane jednadžbe regresije moći, dobićemo jednačinu
ln = x ln a+ln b(ili ln = k x+ln b). (4.13)
Ova jednadžba opisuje linearnu ovisnost logaritma jedne veličine ln od druge veličine x. Stoga je kriterij primjenjivosti regresije snage zahtjev da empirijski podaci ukazuju na istu vrijednost x i i logaritmi druge veličine ln y i bili najbliži pravoj liniji (4.13).
Logaritamska regresija.
Logaritamski zavisnost vrednosti Y od veličine X naziva se zavisnost oblika:
=a+b· ln x. (4.14)
Ova jednačina se zove jednadžba logaritamske regresije Y on X. Opcije A I b su pozvani koeficijenti logaritamske regresije.
Hiperbolička regresija.
Hyperbolic zavisnost vrednosti Y od veličine X naziva se zavisnost oblika:
Ova jednačina se zove jednadžba hiperboličke regresije Y on X. Opcije A I b su pozvani koeficijenti hiperboličke regresije a određuju se metodom najmanjih kvadrata. Primjena ove metode dovodi do formula:
U formulama (4.16-4.17) sumiranje se vrši preko indeksa i od jednog do broja zapažanja n.
Nažalost, in Excel ne postoje funkcije koje izračunavaju koeficijente hiperboličke regresije. U slučajevima kada nije poznato da su izmjerene veličine povezane inverznom proporcionalnošću, preporučuje se tražiti jednadžbu regresije snage umjesto jednačine hiperboličke regresije, tako da u Excel postoji procedura za pronalaženje. Ako se pretpostavi hiperbolička zavisnost između izmjerenih veličina, tada će se njeni regresijski koeficijenti morati izračunati korištenjem pomoćnih proračunskih tablica i operacijama sumiranja pomoću formula (4.16-4.17).
Regresija u Excelu
Statistička obrada podataka može se izvršiti i pomoću dodatka Paket analiza u podstavci menija „Usluga“. U Excel 2003, ako otvorite SERVIS, ne možemo pronaći karticu ANALIZA PODATAKA, zatim kliknite lijevu tipku miša da otvorite karticu NADGRADNJE i suprotno od tačke PAKET ANALIZE Kliknite levim tasterom miša da stavite kvačicu (slika 17).
Rice. 17. Prozor NADGRADNJE
Nakon toga u meniju SERVIS pojavljuje se kartica ANALIZA PODATAKA.
U programu Excel 2007 za instalaciju PAKET ANALIZE potrebno je da kliknete na dugme OFFICE u gornjem levom uglu lista (slika 18a). Zatim kliknite na dugme EXCEL SETTINGS. U prozoru koji se pojavi EXCEL SETTINGS kliknite levim tasterom miša na stavku NADGRADNJE i na desnoj strani padajuće liste izaberite stavku PAKET ANALIZE. Zatim kliknite na uredu.




Rice. 18. Instalacija PAKET ANALIZE u Excel 2007
Da biste instalirali paket za analizu, kliknite na dugme IDE, nalazi se na dnu otvorenog prozora. Pojavit će se prozor kao što je prikazano na sl. 12. Stavite kvačicu ispred PAKET ANALIZE. U kartici PODACI pojaviće se dugme ANALIZA PODATAKA(Sl. 19).

Od predloženih stavki odaberite stavku “ REGRESIJA" i kliknite na njega lijevim dugmetom miša. Zatim kliknite na OK.

Pojavit će se prozor kao što je prikazano na sl. 21

Alat za analizu" REGRESIJA» se koristi za uklapanje grafa u skup opažanja koristeći metodu najmanjih kvadrata. Regresija se koristi za analizu učinka na jednu zavisnu varijablu vrijednosti jedne ili više nezavisnih varijabli. Na primjer, nekoliko faktora utiče na sportske performanse sportiste, uključujući godine, visinu i težinu. Moguće je izračunati stepen do kojeg svaki od ova tri faktora utiče na performanse jednog sportiste, a zatim koristiti te podatke za predviđanje učinka drugog sportiste.
Alat Regresija koristi funkciju LINEST.
REGRESSION Dijaloški okvir
Oznake Označite potvrdni okvir ako prvi red ili prva kolona raspona unosa sadrži naslove. Poništite ovo polje za potvrdu ako nema zaglavlja. U tom slučaju će se automatski kreirati odgovarajuća zaglavlja za podatke izlazne tablice.
Nivo pouzdanosti Označite polje za potvrdu da biste uključili dodatni nivo u tabelu sažetka izlaza. U odgovarajuće polje unesite nivo pouzdanosti koji želite da primenite, pored podrazumevanog nivoa od 95%.
Konstanta - nula Potvrdite izbor u polju za potvrdu kako biste prisilili liniju regresije da prođe kroz ishodište.
Izlazni opseg Unesite referencu na gornju lijevu ćeliju izlaznog raspona. Navedite najmanje sedam kolona za izlaznu zbirnu tabelu, koja će uključivati: rezultate ANOVA, koeficijente, standardnu grešku izračunavanja Y, standardne devijacije, broj zapažanja, standardne greške za koeficijente.
Novi radni list Odaberite ovu opciju da otvorite novi radni list u radnoj knjizi i zalijepite rezultate analize, počevši od ćelije A1. Ako je potrebno, unesite naziv za novi list u polje koje se nalazi nasuprot odgovarajućeg radio dugmeta.
Nova radna sveska Izaberite ovu opciju da biste kreirali novu radnu svesku sa rezultatima dodatim novom radnom listu.
Ostaci Označite potvrdni okvir da biste uključili ostatke u izlaznu tablicu.
Standardizirani reziduali Označite potvrdni okvir da biste uključili standardizirane ostatke u izlaznu tablicu.
Residual Plot Označite potvrdni okvir za iscrtavanje reziduala za svaku nezavisnu varijablu.
Fit Plot Označite polje za potvrdu da biste nacrtali predviđene u odnosu na posmatrane vrijednosti.
Grafikon normalne vjerovatnoće Označite potvrdni okvir da nacrtate normalan graf vjerovatnoće.
Funkcija LINEST
Da biste izvršili proračune, odaberite kursorom ćeliju u kojoj želimo da prikažemo prosječnu vrijednost i pritisnite tipku = na tastaturi. Zatim u polju Ime naznačite željenu funkciju, na primjer PROSJEČNO(Sl. 22).

Rice. 22 Pronalaženje funkcija u programu Excel 2003
Ako je na terenu NAME naziv funkcije se ne pojavljuje, a zatim lijevom tipkom miša kliknite na trokut pored polja, nakon čega će se pojaviti prozor sa listom funkcija. Ako ova funkcija nije na popisu, kliknite lijevom tipkom miša na stavku liste DRUGE FUNKCIJE, pojavit će se okvir za dijalog FUNCTION MASTER, u kojem pomoću vertikalnog pomicanja odaberite željenu funkciju, označite je kursorom i kliknite na uredu(Sl. 23).

Rice. 23. Čarobnjak za funkcije
Za traženje funkcije u programu Excel 2007, bilo koja kartica se može otvoriti u izborniku; zatim za izračune odaberite kursorom ćeliju u kojoj želimo da prikažemo prosječnu vrijednost i pritisnite tipku = na tastaturi. Zatim, u polju Ime navedite funkciju PROSJEČNO. Prozor za izračunavanje funkcije sličan je onom prikazanom u programu Excel 2003.
Također možete odabrati karticu Formule i kliknuti lijevom tipkom miša na dugme u meniju “ INSERT FUNCTION(Sl. 24), pojaviće se prozor FUNCTION MASTER, čiji je izgled sličan Excelu 2003. Također u meniju možete odmah odabrati kategoriju funkcija (nedavno korištene, finansijske, logičke, tekstualne, datum i vrijeme, matematičke, druge funkcije) u kojima ćemo tražiti željene funkcije. funkcija.




Rice. 24 Odabir funkcije u programu Excel 2007
Funkcija LINEST izračunava statistiku za seriju koristeći metodu najmanjih kvadrata da izračuna pravu liniju koja najbolje aproksimira dostupne podatke, a zatim vraća niz koji opisuje rezultirajuću ravnu liniju. Također možete kombinirati funkciju LINEST sa drugim funkcijama za izračunavanje drugih vrsta modela koji su linearni u nepoznatim parametrima (čiji su nepoznati parametri linearni), uključujući polinomske, logaritamske, eksponencijalne i nizove stepena. Budući da se vraća niz vrijednosti, funkcija mora biti navedena kao formula niza.
Jednačina za pravu liniju je:
(u slučaju nekoliko raspona x vrijednosti),
gdje je zavisna vrijednost y funkcija nezavisne vrijednosti x, m vrijednosti su koeficijenti koji odgovaraju svakoj nezavisnoj varijabli x, a b je konstanta. Imajte na umu da y, x i m mogu biti vektori. Funkcija LINEST vraća niz ![]() . LINEST može također vratiti dodatnu statistiku regresije.
. LINEST može također vratiti dodatnu statistiku regresije.
LINEST(poznate_vrijednosti_y; poznate_vrijednosti_x; konst; statistika)
Poznate_y_vrijednosti - skup y vrijednosti koje su već poznate za relaciju.
Ako niz known_y_values ima jedan stupac, tada se svaki stupac u nizu known_x_values tretira kao zasebna varijabla.
Ako niz known_y_values ima jedan red, tada se svaki red u nizu known_x_values tretira kao zasebna varijabla.
Poznate_x-vrijednosti su izborni skup x-vrijednosti koje su već poznate za odnos.
Niz poznatih_x_values može sadržavati jedan ili više skupova varijabli. Ako se koristi samo jedna varijabla, tada nizovi known_y_values i known_x_values mogu imati bilo koji oblik - sve dok imaju istu dimenziju. Ako se koristi više od jedne varijable, tada poznate_y_vrijednosti moraju biti vektor (tj. interval visok jedan red ili širok jedan stupac).
Ako se array_known_x_values izostavi, tada se pretpostavlja da je niz (1;2;3;...) iste veličine kao niz_poznate_vrijednosti_y.
Const je logička vrijednost koja određuje da li konstanta b mora biti jednaka 0.
Ako je argument "const" TRUE ili izostavljen, tada se konstanta b procjenjuje kao i obično.
Ako je argument “const” FALSE, tada se vrijednost b postavlja na 0, a vrijednosti m se biraju na takav način da je relacija zadovoljena.
Statistics - Boolean vrijednost koja pokazuje da li treba vratiti dodatnu statistiku regresije.
Ako je statistika TRUE, LINEST vraća dodatnu statistiku regresije. Vraćeni niz će izgledati ovako: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Ako je statistika FALSE ili je izostavljena, LINEST vraća samo koeficijente m i konstantu b.
Dodatna statistika regresije.
Slika ispod pokazuje redoslijed po kojem se vraćaju dodatne statistike regresije.

napomene:
Bilo koja prava linija može se opisati svojim nagibom i presjekom s y-osom:
Nagib (m): Za određivanje nagiba prave, obično označene sa m, uzimate dvije točke na pravoj i ; nagib će biti jednak ![]() .
.
Y-presjek (b): y-presjek prave, koji se obično označava sa b, je y-vrijednost za tačku u kojoj linija seče y-osu.
Jednačina prave linije ima oblik . Ako su poznate vrijednosti m i b, tada se bilo koja točka na pravoj može izračunati zamjenom vrijednosti y ili x u jednadžbu. Također možete koristiti funkciju TREND.
Ako postoji samo jedna nezavisna varijabla x, možete dobiti nagib i y-presjek direktno koristeći sljedeće formule:
Nagib: INDEX(LINEST(poznate_y_vrijednosti; poznate_x_vrijednosti); 1)
Y-presjek: INDEX(LINEST(poznate_y_vrijednosti; poznate_x_vrijednosti); 2)
Preciznost aproksimacije pomoću prave linije izračunate funkcijom LINEST zavisi od stepena rasipanja podataka. Što su podaci bliži pravoj liniji, to je tačniji model koji koristi funkcija LINEST. Funkcija LINEST koristi najmanje kvadrate kako bi odredila najbolje uklapanje u podatke. Kada postoji samo jedna nezavisna varijabla x, m i b se izračunavaju pomoću sljedećih formula:

gdje su x i y uzorci, na primjer x = PROSJEK (poznati_x) i y = PROSJEK (poznati_y).
Funkcije uklapanja LINEST i LGRFPRIBL mogu izračunati pravu liniju ili eksponencijalnu krivu koja najbolje odgovara podacima. Međutim, oni ne daju odgovor na pitanje koji je od dva rezultata pogodniji za rješavanje problema. Također možete procijeniti funkciju TREND(poznati_y; poznati_x) funkciju za pravu liniju ili funkciju GROW(poznati_y; poznati_x) funkciju za eksponencijalnu krivu. Ove funkcije, osim ako nisu specificirane new_x-vrijednosti, vraćaju niz izračunatih y-vrijednosti za stvarne x-vrijednosti duž linije ili krive. Zatim možete uporediti izračunate vrijednosti sa stvarnim vrijednostima. Takođe možete kreirati grafikone za vizuelno poređenje.
Prilikom izvođenja regresione analize, Microsoft Excel izračunava, za svaku tačku, kvadrat razlike između predviđene vrijednosti y i stvarne vrijednosti y. Zbir ovih kvadrata razlika naziva se rezidualni zbir kvadrata (ssresid). Microsoft Excel zatim izračunava ukupan zbir kvadrata (sstotal). Ako const = TRUE ili vrijednost ovog argumenta nije navedena, ukupan zbroj kvadrata će biti jednak zbroju kvadrata razlika između stvarnih vrijednosti y i prosječnih y vrijednosti. Kada je const = FALSE, ukupan zbir kvadrata će biti jednak zbiru kvadrata realnih y vrijednosti (bez oduzimanja prosječne vrijednosti y od djelimične y vrijednosti). Regresijski zbir kvadrata se tada može izračunati na sljedeći način: ssreg = sstotal - ssresid. Što je manji rezidualni zbir kvadrata, to je veća vrijednost koeficijenta determinacije r2, što pokazuje koliko dobro jednačina dobijena regresionom analizom objašnjava odnose između varijabli. Koeficijent r2 je jednak ssreg/sstotal.
U nekim slučajevima, jedan ili više X stupaca (neka Y i X vrijednosti budu u kolonama) nemaju dodatnu predikativnu vrijednost u drugim X stupcima. Drugim riječima, uklanjanje jednog ili više X stupaca može rezultirati Y vrijednostima izračunatim sa istu preciznost. U ovom slučaju, redundantni X stupci će biti isključeni iz regresijskog modela. Ovaj fenomen se naziva "kolinearnost" jer se redundantni stupci X mogu predstaviti kao zbir nekoliko neredundantnih kolona. Funkcija LINEST provjerava kolinearnost i uklanja sve redundantne X stupce iz regresijskog modela ako ih otkrije. Uklonjeni X stupci mogu se identificirati u LINEST izlazu faktorom 0 i se vrijednošću 0. Uklanjanje jednog ili više stupaca kao suvišnih mijenja vrijednost df jer ovisi o broju X stupaca koji se stvarno koriste u svrhe predviđanja. Za više informacija o izračunavanju df, pogledajte primjer 4 u nastavku. Kada se df promijeni zbog uklanjanja suvišnih kolona, mijenjaju se i vrijednosti sey i F. Ne preporučuje se često korištenje kolinearnosti. Međutim, treba ga koristiti ako neki X stupci sadrže 0 ili 1 kao indikator koji pokazuje da li subjekt eksperimenta pripada posebnoj grupi. Ako const = TRUE ili vrijednost za ovaj argument nije navedena, LINEST umeće dodatni X stupac za modeliranje točke presjeka. Ako postoji kolona sa vrijednostima 1 za muškarce i 0 za žene, a postoji kolona sa vrijednostima 1 za žene i 0 za muškarce, onda se posljednja kolona uklanja jer se njene vrijednosti mogu dobiti iz kolone "muški indikator".
Izračunavanje df za slučajeve kada X stupaca nije uklonjeno iz modela zbog kolinearnosti se dešava na sljedeći način: ako postoji k poznatih_x kolona i vrijednost const = TRUE ili nije navedena, onda je df = n – k – 1. Ako je const = NETAČNO, tada je df = n - k. U oba slučaja, uklanjanje X stupaca zbog kolinearnosti povećava df vrijednost za 1.
Formule koje vraćaju nizove moraju se unijeti kao formule niza.
Prilikom unosa niza konstanti kao argumenta, na primjer, poznate_x_vrijednosti, trebali biste koristiti tačku i zarez da odvojite vrijednosti u istom redu i dvotočku za razdvajanje redaka. Znakovi za razdvajanje mogu se razlikovati u zavisnosti od postavki u prozoru Jezik i postavke na kontrolnoj tabli.
Treba napomenuti da y vrijednosti predviđene jednadžbom regresije možda neće biti tačne ako su izvan raspona y vrijednosti koje su korištene za definiranje jednadžbe.
Osnovni algoritam koji se koristi u funkciji LINEST, razlikuje se od algoritma glavne funkcije INCLINE I LINIJSKI SEGMENT. Razlika između algoritama može dovesti do različitih rezultata s nesigurnim i kolinearnim podacima. Na primjer, ako su argumentirane podatkovne točke poznate_y_values 0, a argumentirane podatkovne točke poznate_x_values 1, tada:
Funkcija LINEST vraća vrijednost jednaku 0. Algoritam funkcije LINEST koristi se za vraćanje odgovarajućih vrijednosti za kolinearne podatke i u ovom slučaju se može pronaći barem jedan odgovor.
Funkcije SLOPE i LINE vraćaju grešku #DIV/0!. Algoritam funkcija SLOPE i INTERCEPT se koristi za pronalaženje samo jednog odgovora, ali u ovom slučaju može biti nekoliko.
Pored izračunavanja statistike za druge vrste regresije, LINEST se može koristiti za izračunavanje raspona za druge vrste regresije unosom funkcija varijabli x i y kao niza varijabli x i y za LINEST. Na primjer, sljedeća formula:
LINEST(y_vrijednosti, x_vrijednosti^COLUMN($A:$C))
radi tako što ima jednu kolonu Y vrijednosti i jednu kolonu X vrijednosti za izračunavanje aproksimacije kocke (polinom 3. stepena) sljedećeg oblika:
Formula se može modificirati kako bi se izračunale druge vrste regresije, ali u nekim slučajevima će možda biti potrebno prilagoditi izlazne vrijednosti i druge statistike.
Po mom mišljenju, kao studentu, ekonometrija je jedna od najprimijenjenijih nauka sa kojom sam se mogao upoznati u zidovima svog univerziteta. Uz njegovu pomoć, zaista je moguće riješiti primijenjene probleme na razini poduzeća. Koliko će te odluke biti efikasne je treće pitanje. Suština je da će većina znanja ostati teorija, ali ekonometrija i regresijska analiza su i dalje vrijedni proučavanja s posebnom pažnjom.
Šta regresija objašnjava?
Pre nego što počnemo da razmatramo funkcije MS Excel-a koje nam omogućavaju da rešimo ove probleme, želeo bih da vam detaljno objasnim šta regresiona analiza, u suštini, uključuje. To će vam olakšati polaganje ispita, a što je najvažnije, biće zanimljivije učiti predmet.
Nadamo se da ste upoznati s konceptom funkcije iz matematike. Funkcija je odnos između dvije varijable. Kada se jedna varijabla promijeni, nešto se događa drugoj. Mijenjamo X, i Y se mijenja u skladu s tim. Funkcije opisuju različite zakone. Poznavajući funkciju, možemo zamijeniti proizvoljne vrijednosti X i vidjeti kako se Y mijenja.
Ovo je od velike važnosti jer je regresija pokušaj da se na prvi pogled objasne nesistematski i haotični procesi pomoću određene funkcije. Na primjer, moguće je identificirati odnos između kursa dolara i nezaposlenosti u Rusiji.
Ako se ovaj obrazac može otkriti, onda ćemo pomoću funkcije koju smo dobili tokom proračuna moći napraviti prognozu kolika će biti stopa nezaposlenosti pri N-om kursu dolara u odnosu na rublju.
Ovaj odnos će se zvati korelacija. Regresiona analiza uključuje izračunavanje koeficijenta korelacije koji će objasniti blisku vezu između varijabli koje razmatramo (kurs dolara i broj poslova).
Ovaj koeficijent može biti pozitivan ili negativan. Njegove vrijednosti se kreću od -1 do 1. Shodno tome, možemo uočiti visoku negativnu ili pozitivnu korelaciju. Ako bude pozitivan, onda će porast kursa dolara biti praćen otvaranjem novih radnih mesta. Ako je negativan, to znači da će povećanje kursa biti praćeno smanjenjem broja radnih mjesta.
Postoji nekoliko vrsta regresije. Može biti linearna, parabolična, moćna, eksponencijalna, itd. Odabiremo model ovisno o tome koja će regresija odgovarati konkretno našem slučaju, koji će model biti što bliži našoj korelaciji. Pogledajmo ovo koristeći primjer problema i riješimo ga u MS Excel-u.
Linearna regresija u MS Excel-u
Da biste riješili probleme linearne regresije, trebat će vam funkcija analize podataka. Možda vam nije omogućeno, pa ga morate aktivirati.
- Kliknite na dugme „Datoteka“;
- Odaberite stavku "Opcije";
- Kliknite na pretposljednju karticu “Dodaci” na lijevoj strani;

- Ispod ćemo vidjeti natpis “Upravljanje” i dugme “Idi”. Kliknite na njega;
- Označite okvir za “Paket analize”;
- Kliknite na “ok”.

Primer zadatka
Aktivirana je funkcija analize serije. Hajde da rešimo sledeći problem. Imamo uzorak podataka za više godina o broju vanrednih situacija na teritoriji preduzeća i broju zaposlenih radnika. Moramo identificirati odnos između ove dvije varijable. Postoji varijabla za objašnjenje X - ovo je broj radnika i varijabla za objašnjenje - Y - ovo je broj hitnih incidenata. Podijelimo izvorne podatke u dvije kolone.
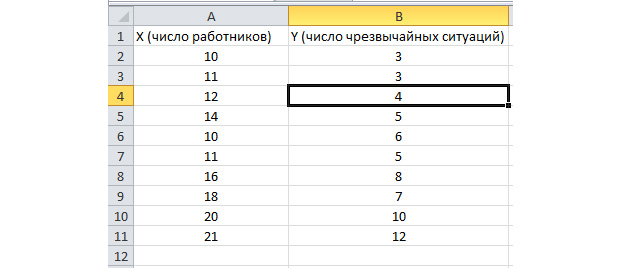
Idemo na karticu "podaci" i odaberite "Analiza podataka"
Na listi koja se pojavi odaberite "Regresija". Odabiremo odgovarajuće vrijednosti u ulaznim intervalima Y i X.
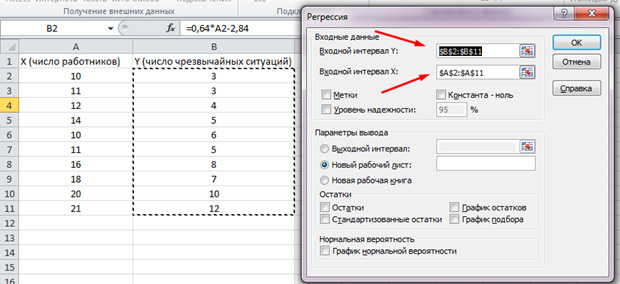
Kliknite na “OK”. Analiza je završena, a rezultate ćemo vidjeti u novom listu.
Najznačajnije vrijednosti za nas označene su na donjoj slici.
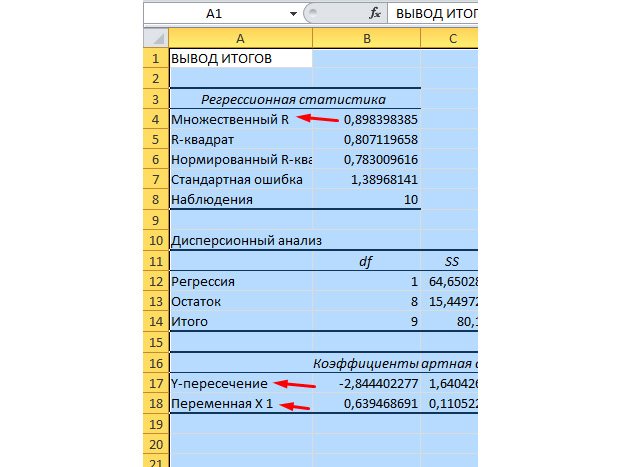
Višestruki R je koeficijent determinacije. Ima složenu formulu za izračunavanje i pokazuje koliko možete vjerovati našem koeficijentu korelacije. Shodno tome, što je ova vrijednost veća, to je više povjerenja, uspješniji je naš model u cjelini.
Y-presjek i X1-presjek su naši koeficijenti regresije. Kao što je već spomenuto, regresija je funkcija i ima određene koeficijente. Dakle, naša funkcija će izgledati ovako: Y = 0,64*X-2,84.
Šta nam ovo daje? Ovo nam daje priliku da napravimo prognozu. Recimo da želimo da zaposlimo 25 radnika za preduzeće i trebamo otprilike da zamislimo koliki će biti broj hitnih incidenata. Ovu vrijednost zamjenjujemo u našu funkciju i dobivamo rezultat Y = 0,64 * 25 – 2,84. Imaćemo otprilike 13 hitnih slučajeva.
Hajde da vidimo kako to radi. Pogledajte sliku ispod. Funkcija koju smo dobili sadrži stvarne vrijednosti za uključene zaposlenike. Pogledajte koliko su vrijednosti bliske stvarnim igračima.

Također možete izgraditi polje korelacije odabirom područja Y i X, klikom na karticu "insert" i odabirom dijagrama raspršenja.

Tačke su raštrkane, ali se uglavnom kreću prema gore, kao da je u sredini prava linija. A ovu liniju možete dodati i tako što ćete otići na karticu "Izgled" u MS Excelu i odabrati "Linija trenda"
Dvaput kliknite na liniju koja se pojavi i vidjet ćete ono što je ranije spomenuto. Možete promijeniti tip regresije ovisno o tome kako izgleda vaše polje korelacije.
Možda ćete osjetiti da tačke crtaju parabolu, a ne ravnu liniju i da bi bilo bolje da odaberete drugu vrstu regresije.
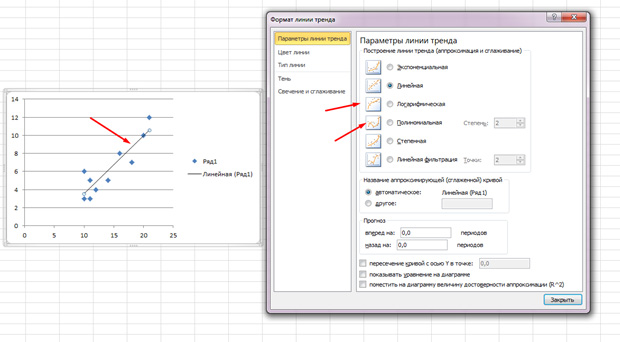
Zaključak
Nadamo se da vam je ovaj članak dao bolje razumijevanje šta je regresiona analiza i zašto je potrebna. Sve ovo je od velike praktične važnosti.
Metoda linearne regresije nam omogućava da opišemo pravu liniju koja najbolje odgovara nizu uređenih parova (x, y). Jednačina za pravu liniju, poznata kao linearna jednačina, data je u nastavku:
ŷ je očekivana vrijednost y za datu vrijednost x,
x je nezavisna varijabla,
a je segment na y-osi za pravu liniju,
b je nagib prave linije.
Slika ispod grafički ilustruje ovaj koncept:
Na slici iznad prikazana je linija opisana jednadžbom ŷ =2+0,5x. Y-presjek je tačka u kojoj prava siječe y-osu; u našem slučaju, a = 2. Nagib prave, b, odnos uspona prave i dužine prave, ima vrijednost 0,5. Pozitivan nagib znači da se linija diže s lijeva na desno. Ako je b = 0, linija je horizontalna, što znači da nema veze između zavisnih i nezavisnih varijabli. Drugim riječima, promjena vrijednosti x ne utiče na vrijednost y.
ŷ i y se često brkaju. Na grafikonu je prikazano 6 uređenih parova tačaka i prava, prema datoj jednačini

Ova slika prikazuje tačku koja odgovara uređenom paru x = 2 i y = 4. Imajte na umu da je očekivana vrijednost y prema liniji na X= 2 je ŷ. To možemo potvrditi sljedećom jednačinom:
ŷ = 2 + 0,5h =2 +0,5(2) =3.
Vrijednost y predstavlja stvarnu tačku, a vrijednost ŷ je očekivana vrijednost y pomoću linearne jednačine za datu vrijednost x.
Sljedeći korak je određivanje linearne jednadžbe koja najbolje odgovara skupu uređenih parova, o tome smo govorili u prethodnom članku, gdje smo odredili tip jednadžbe pomoću .
Korištenje Excela za definiranje linearne regresije
Da biste koristili alat za regresijsku analizu ugrađen u Excel, morate aktivirati dodatak Paket analiza. Možete ga pronaći klikom na karticu Datoteka -> Opcije(2007+), u dijaloškom okviru koji se pojavi OpcijeExcel idite na karticu Dodaci. Na terenu Kontrola izabrati DodaciExcel i kliknite Idi. U prozoru koji se pojavi označite polje pored Paket analiza, kliknite UREDU.

U kartici Podaci u grupi Analiza pojaviće se novo dugme Analiza podataka.

Da bismo demonstrirali rad dodatka, koristit ćemo podatke gdje momak i djevojka dijele sto u kupatilu. Unesite podatke iz našeg primjera kade u kolone A i B praznog lista.
Idite na karticu podaci, u grupi Analiza kliknite Analiza podataka. U prozoru koji se pojavi Analiza podataka izaberite Regresija kao što je prikazano na slici i kliknite na OK.

Postavite potrebne parametre regresije u prozoru Regresija, kao što je prikazano na slici:

Kliknite UREDU. Na slici ispod prikazani su dobijeni rezultati:

Ovi rezultati su u skladu s onima koje smo dobili radeći vlastite proračune u .
Konstrukcija linearne regresije, evaluacija njenih parametara i njihovog značaja može se izvršiti mnogo brže kada se koristi Excel paket za analizu (Regression). Razmotrimo interpretaciju rezultata dobijenih u opštem slučaju ( k objašnjavajuće varijable) prema primjeru 3.6.
U tabeli regresijska statistika date su sljedeće vrijednosti:
Višestruko R – koeficijent višestruke korelacije;
R- kvadrat- koeficijent odlučnosti R 2 ;
Normalizovano R - kvadrat– prilagođeno R 2 prilagođen broju stupnjeva slobode;
Standardna greška– standardna greška regresije S;
Zapažanja – broj zapažanja n.
U tabeli Analiza varijanse daju se:
1. Kolona df - broj stepeni slobode jednak
za niz Regresija df = k;
za niz Ostatakdf = n – k – 1;
za niz Ukupnodf = n– 1.
2. Kolona SS – zbir kvadrata odstupanja jednak
za niz Regresija ;
za niz Ostatak ;
za niz Ukupno .
3. Kolona GOSPOĐA varijanse određene formulom GOSPOĐA = SS/df:
za niz Regresija– faktor disperzije;
za niz Ostatak– rezidualna varijansa.
4. Kolona F – izračunata vrijednost F-kriterijum izračunat pomoću formule
F = GOSPOĐA(regresija)/ GOSPOĐA(ostatak).
5. Kolona Značaj F – vrijednost nivoa značajnosti koja odgovara izračunatoj F-statistika .
Značaj F= FDIST( F- statistika, df(regresija), df(ostatak)).
Ako značaj F < стандартного уровня значимости, то R 2 je statistički značajno.
| Odds | Standardna greška | t-statistika | P-vrijednost | donjih 95% | Top 95% | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Ova tabela prikazuje:
1. Odds– vrijednosti koeficijenata a, b.
2. Standardna greška– standardne greške koeficijenata regresije S a, Sb.
3. t- statistika– izračunate vrijednosti t -kriterijumi izračunati po formuli:
t-statistic = Koeficijenti/Standardna greška.
4.R-vrijednost (značaj t) je vrijednost nivoa značajnosti koja odgovara izračunatoj t- statistika.
R-vrijednost = STUDIDIST(t-statistika, df(ostatak)).
Ako R-značenje< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. Donjih 95% i gornjih 95%– donja i gornja granica 95% intervala povjerenja za koeficijente teorijske jednačine linearne regresije.
| POVLAČENJE OSTALOGA | ||
| Opservacija | Predviđeno y | Ostaci e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
U tabeli POVLAČENJE OSTALOGA naznačeno:
u koloni Opservacija– broj posmatranja;
u koloni Predviđeno y – izračunate vrijednosti zavisne varijable;
u koloni Ostaci e – razlika između posmatrane i izračunate vrednosti zavisne varijable.
Primjer 3.6. Postoje podaci (konvencionalne jedinice) o troškovima hrane y i dohodak po glavi stanovnika x za devet grupa porodica:
| x | |||||||||
| y |
Koristeći rezultate Excel paketa analize (Regresija), analiziraćemo zavisnost troškova hrane od prihoda po glavi stanovnika.
Rezultati regresione analize se obično pišu u obliku:
![]()
gdje su standardne greške koeficijenata regresije naznačene u zagradama.
Regresijski koeficijenti A = 65,92 i b= 0,107. Smjer komunikacije između y I x određuje predznak koeficijenta regresije b= 0,107, tj. veza je direktna i pozitivna. Koeficijent b= 0,107 pokazuje da uz povećanje dohotka po glavi stanovnika za 1 konv. jedinice troškovi hrane rastu za 0,107 konvencionalnih jedinica. jedinice
Procijenimo značajnost koeficijenata rezultirajućeg modela. Značaj koeficijenata ( a, b) provjerava t-test:
P-vrijednost ( a) = 0,00080 < 0,01 < 0,05
P-vrijednost ( b) = 0,00016 < 0,01 < 0,05,
dakle, koeficijenti ( a, b) su značajni na nivou od 1%, a još više na nivou značajnosti od 5%. Dakle, koeficijenti regresije su značajni i model je adekvatan originalnim podacima.
Rezultati procjene regresije su kompatibilni ne samo s dobivenim vrijednostima koeficijenata regresije, već i sa određenim skupom njih (interval pouzdanosti). Sa vjerovatnoćom od 95%, intervali povjerenja za koeficijente su (38,16 – 93,68) za a i (0,0728 – 0,142) za b.
Kvaliteta modela se ocjenjuje koeficijentom determinacije R 2 .
Magnituda R 2 = 0,884 znači da faktor dohotka po glavi stanovnika može objasniti 88,4% varijacije (raspršenosti) u troškovima hrane.
Značaj R 2 provjerava F- test: značaj F = 0,00016 < 0,01 < 0,05, следовательно, R 2 je značajan na nivou od 1%, a još više na nivou značajnosti od 5%.
U slučaju parne linearne regresije, koeficijent korelacije se može definirati kao ![]() . Dobijena vrijednost koeficijenta korelacije ukazuje da je veza između troškova hrane i prihoda po glavi stanovnika veoma bliska.
. Dobijena vrijednost koeficijenta korelacije ukazuje da je veza između troškova hrane i prihoda po glavi stanovnika veoma bliska.