Algoritam je razvijen od strane Joint Photographic Expert Group posebno za kompresiju 24-bitnih i sivih slika 1991. godine. Ovaj algoritam ne komprimira slike na dva nivoa baš dobro, ali dobro radi u rukovanju slikama kontinualnih tonova u kojima bliski pikseli obično imaju slične boje. Obično oko ne može primijetiti nikakvu razliku kada se komprimira ovom metodom 10 ili 20 puta.
Algoritam se zasniva na DCT primenjenom na matricu disjunktnih blokova slike od 8x8 piksela. DCT dekomponuje ove blokove prema amplitudama određenih frekvencija. Rezultat je matrica u kojoj su mnogi koeficijenti, po pravilu, blizu nule, što se može prikazati u grubom numeričkom obliku, tj. u kvantizovanom obliku bez značajnog gubitka u kvalitetu rekonstrukcije.
Razmotrimo rad algoritma detaljnije. Pretpostavimo da se komprimuje 24-bitna slika u punoj boji. U ovom slučaju dobijamo sledeće faze rada.
Korak 1. Konvertujemo sliku iz RGB prostora u YCbCr prostor koristeći sljedeći izraz:
Odmah primijetimo da se inverzna transformacija lako dobija množenjem inverzna matrica u vektor, koji je u suštini YUV prostor:
 .
.
Korak 2. Originalnu sliku podijelimo na matrice 8x8. Formiramo tri radne DCT matrice od svake - 8 bita posebno za svaku komponentu. Pri visokim omjerima kompresije, blok 8x8 se dekomponuje na YCbCr komponente u formatu 4:2:0, tj. komponente za Cb i Cr su uzete kroz tačku u redovima i kolonama.
Korak 3. Primjena DCT-a na blokove slike 8x8 piksela. Formalno, direktni DCT za blok 8x8 se može napisati kao
Gdje  . Pošto je DCT „srce“ JPEG algoritma, poželjno je u praksi da se izračuna što je brže moguće. Jednostavan pristup ubrzavanju izračunavanja je da se unaprijed izračunaju kosinusne funkcije i da se rezultati tabele. Štoviše, s obzirom na ortogonalnost kosinusnih funkcija s različite frekvencije, gornja formula se može napisati kao
. Pošto je DCT „srce“ JPEG algoritma, poželjno je u praksi da se izračuna što je brže moguće. Jednostavan pristup ubrzavanju izračunavanja je da se unaprijed izračunaju kosinusne funkcije i da se rezultati tabele. Štoviše, s obzirom na ortogonalnost kosinusnih funkcija s različite frekvencije, gornja formula se može napisati kao
 .
.
Ovdje je matrica od 8x8 elemenata, koja opisuje 8-dimenzionalni prostor, za predstavljanje stupaca bloka u ovom prostoru. Matrica je transponirana matrica i radi istu stvar, ali za blok redove. Rezultat je odvojiva transformacija, koja se u matričnom obliku zapisuje kao
Evo rezultata DCT-a, za čije izračunavanje su potrebne operacije množenja i skoro isto toliko sabiranja, što je znatno manje od direktnih proračuna korištenjem gornje formule. Na primjer, trebat će vam za konverziju slike veličine 512x512 piksela aritmetičke operacije. Uzimajući u obzir 3 komponente svjetline, dobijamo vrijednost od 12.582.912 aritmetičkih operacija. Broj množenja i sabiranja može se dodatno smanjiti korištenjem algoritma brze Fourierove transformacije. Kao rezultat toga, za transformaciju jednog bloka 8x8 morat ćete napraviti 54 množenja, 468 sabiranja i pomaka bitova.
Kao rezultat DCT-a dobijamo matricu u kojoj su koeficijenti lijevo gornji ugao odgovaraju niskofrekventnoj komponenti slike, au donjem desnom - visokofrekventnoj.
Korak 4. Kvantizacija. U ovom koraku neke informacije se odbacuju. Ovdje se svaki broj iz matrice dijeli posebnim brojem iz "tablice kvantizacije", a rezultat se zaokružuje na najbliži cijeli broj:
![]() .
.
Štaviše, za svaku matricu Y, Cb i Cr, možete postaviti vlastite tablice kvantizacije. JPEG standard čak dozvoljava upotrebu sopstvenih tabela kvantizacije, koje će, međutim, morati da se prenesu u dekoder zajedno sa kompresovanim podacima, što će povećati ukupnu veličinu datoteke. Jasno je da je korisniku teško samostalno odabrati 64 koeficijenta, pa JPEG standard koristi dva pristupa za matrice kvantizacije. Prvi je da JPEG standard uključuje dvije preporučene tabele kvantizacije: jednu za lumu i jednu za hrominaciju. Ove tabele su predstavljene u nastavku. Drugi pristup je da se sintetizira (izračunavanje u hodu) tablice kvantizacije koja ovisi o jednom parametru koji je odredio korisnik. Sama tabela je izgrađena prema formuli


Faza kvantizacije je gdje se kontrolira omjer kompresije i gdje se javljaju najveći gubici. Jasno je da ćemo specificiranjem tablica kvantizacije sa velikim koeficijentima dobiti više nula, a samim tim i veći omjer kompresije.
Specifični efekti algoritma su takođe povezani sa kvantizacijom. At velike vrijednosti korak kvantizacije, gubici mogu biti toliki da se slika razbije na monohromatske kvadrate 8x8. Zauzvrat, gubici na visokim frekvencijama mogu se manifestirati u takozvanom "Gibbsovom efektu", kada se oko kontura s oštrim prijelazom boja formira talasast "halo".
Korak 5. Konvertujemo matricu 8x8 u vektor od 64 elementa koristeći cik-cak skeniranje (slika 2).

Rice. 2. Cik-cak skeniranje
Kao rezultat toga, koeficijenti različiti od nule će, po pravilu, biti zapisani na početku vektora, a lanci nula će se formirati na kraju.
Korak 6. Transformišemo vektor koristeći modifikovani RLE algoritam, na čijem izlazu dobijamo parove tipa (skip, broj), pri čemu je “skip” brojač preskočenih nula, a “number” je vrijednost koja se mora staviti u sljedeću ćeliju. Na primjer, vektor 1118 3 0 0 0 -2 0 0 0 0 1 ... bit će skupljen u parove (0, 1118) (0,3) (3,-2) (4,1) ... .
Treba napomenuti da je prvi broj pretvorene komponente u suštini jednak prosječnoj svjetlini bloka 8x8 i naziva se DC koeficijent. Isto za sve blokove slika. Ova okolnost sugerira da se DC koeficijenti mogu efikasno komprimirati ako zapamtite ne njihove apsolutne vrijednosti, već relativne u obliku razlike između DC koeficijenta trenutnog bloka i DC koeficijenta prethodnog bloka, i zapamtite prvi koeficijent kao TO JE. U ovom slučaju, poredak DC koeficijenata može se izvršiti, na primjer, ovako (slika 3). Preostali koeficijenti, koji se nazivaju AC koeficijenti, ostaju nepromijenjeni.
Korak 7 Konvolviramo rezultirajuće parove koristeći neuniformne Huffmanove kodove sa fiksnom tablicom. Štaviše, za DC i AC koeficijente, različite šifre, tj. različiti stolovi sa Huffman kodovima.

Rice. 3. Šema uređenja koeficijenta DC

Rice. 4. Blok dijagram JPEG algoritma
Proces obnavljanja slike u ovom algoritmu je potpuno simetričan. Metoda vam omogućava da komprimirate slike 10-15 puta bez vidljivih gubitaka vida.
Prilikom izrade ovog standarda vodili smo se činjenicom da ovaj algoritam morao da komprimuje slike prilično brzo - ne više od jedne minute na prosečnoj slici. Ovo je 1991! A njegova hardverska implementacija bi trebala biti relativno jednostavna i jeftina. U ovom slučaju, algoritam je morao biti simetričan u vremenu rada. Performanse najnoviji zahtjev učinio mogući izgled digitalni fotoaparati koji snimaju 24-bitne slike. Da je algoritam asimetričan, bilo bi neugodno dugo čekati da se uređaj "napuni" i komprimira sliku.
Iako JPEG algoritam i ISO je standard, njegov format datoteke nije fiksiran. Koristeći ovo, proizvođači kreiraju vlastite formate koji su međusobno nekompatibilni, te stoga mogu promijeniti algoritam. Stoga su interne tabele algoritama koje preporučuje ISO zamijenjene njihovim vlastitim. Postoje i JPEG opcije za određene aplikacije.
Lako je izračunati da će nekomprimirana slika u punoj boji veličine 2000 * 1000 piksela imati veličinu od oko 6 megabajta. Ako govorimo o slikama dobivenim profesionalnim fotoaparatima ili skenerima visoka rezolucija, tada njihova veličina može biti i veća. Unatoč brzom rastu kapaciteta uređaja za pohranu, različiti algoritmi kompresije slike i dalje su vrlo relevantni.
Svi postojeći algoritmi mogu se podijeliti u dvije velike klase:
- Algoritmi kompresije bez gubitaka;
- Algoritmi kompresije sa gubitkom.
Algoritmi kompresije bez gubitaka
RLE algoritam
Svi algoritmi RLE serija zasnivaju se na vrlo jednostavnoj ideji: ponavljajuće grupe elemenata zamjenjuju se parom (broj ponavljanja, element koji se ponavlja). Razmotrimo ovaj algoritam koristeći primjer niza bitova. Ovaj niz će izmjenjivati grupe nula i jedinica. Štaviše, grupe će često imati više od jednog elementa. Tada će niz 11111 000000 11111111 00 odgovarati sljedećem skupu brojeva 5 6 8 2. Ovi brojevi označavaju broj ponavljanja (brojanje počinje od jedinica), ali ovi brojevi također moraju biti kodirani. Pretpostavit ćemo da se broj ponavljanja nalazi u rasponu od 0 do 7 (to jest, 3 bita su nam dovoljna da kodiramo broj ponavljanja). Tada se gore razmatrana sekvenca kodira sljedećim nizom brojeva 5 6 7 0 1 2. Lako je izračunati da je za kodiranje originalne sekvence potreban 21 bit, a u komprimiranom RLE metoda U obliku, ovaj niz traje 18 bita.Iako je ovaj algoritam vrlo jednostavan, njegova efikasnost je relativno niska. Štoviše, u nekim slučajevima korištenje ovog algoritma ne dovodi do smanjenja, već do povećanja dužine niza. Na primjer, razmotrite sljedeću sekvencu 111 0000 11111111 00. Odgovarajuća RL sekvenca izgleda ovako: 3 4 7 0 1 2. Dužina originalne sekvence je 17 bita, dužina komprimirane sekvence je 18 bita.
Ovaj algoritam je najefikasniji za crno-bijele slike. Takođe se često koristi kao jedna od međufaza kompresije složenijih algoritama.
Algoritmi rječnika
Ideja iza algoritama rječnika je da se lanci elemenata originalnog niza kodiraju. Ovo kodiranje koristi poseban rečnik, koji se dobija na osnovu originalnog niza.Postoji čitava porodica algoritama rječnika, ali ćemo pogledati najčešće LZW algoritam, nazvan po svojim programerima Lepel, Ziv i Welch.
Rječnik u ovom algoritmu je tabela koja se puni lancima kodiranja dok algoritam radi. Kada se komprimirani kod dekodira, rječnik se automatski vraća, tako da nema potrebe za prijenosom rječnika zajedno sa komprimiranim kodom.
Rječnik se inicijalizira sa svim singleton stringovima, tj. prvi redovi rječnika predstavljaju abecedu kojom kodiramo. Tokom kompresije, traži se najduži lanac koji je već zabilježen u rječniku. Svaki put kada se naiđe na lanac koji još nije upisan u rječnik, on se dodaje tamo i izlazi komprimirani kod koji odgovara lancu koji je već napisan u rječniku. U teoriji se ne nameću ograničenja na veličinu rječnika, ali u praksi ima smisla ograničiti ovu veličinu, jer s vremenom počinju da se pojavljuju lanci koji se više ne nalaze u tekstu. Osim toga, kada udvostručimo veličinu tablice, moramo dodijeliti dodatni bit za pohranjivanje komprimiranih kodova. Kako bi se spriječile ovakve situacije, uvodi se poseban kod, simbolizirajući inicijalizaciju tablice sa svim singleton lancima.
Pogledajmo primjer algoritma kompresije. Komprimovaćemo liniju cuckoocuckoocuckoohood. Pretpostavimo da će rječnik sadržavati 32 pozicije, što znači da će svaki njegov kod zauzimati 5 bita. U početku se rječnik popunjava na sljedeći način:
Ova tabela postoji i na strani onoga ko kompresuje informaciju i na strani onoga ko je dekomprimuje. Sada ćemo pogledati proces kompresije. 
U tabeli je prikazan proces popunjavanja rječnika. Lako je izračunati da rezultirajući komprimirani kod zauzima 105 bita, i originalni tekst(pod pretpostavkom da potrošimo 4 bita na kodiranje jednog znaka) uzima 116 bita.
U suštini, proces dekodiranja se svodi na direktno dekodiranje kodova, a važno je da se tabela inicijalizuje na isti način kao i tokom kodiranja. Pogledajmo sada algoritam dekodiranja. 
Mi možemo u potpunosti definirati string dodan u rječnik u i-tom koraku samo na i+1. Očigledno, i-ti red mora završiti prvim znakom i+1 reda. To. Upravo smo shvatili kako vratiti rječnik. Zanimljiva je situacija kada je kodiran niz oblika cScSc, gdje je c jedan znak, a S niz, a riječ cS se već nalazi u rječniku. Na prvi pogled može izgledati da dekoder neće moći riješiti ovu situaciju, ali zapravo svi redovi ovog tipa uvijek moraju završavati istim znakom kojim počinju.
Statistički algoritmi kodiranja
Algoritmi u ovoj seriji dodeljuju najkraći komprimovani kod najčešćim elementima sekvenci. One. sekvence iste dužine kodirane su komprimiranim kodovima različitih dužina. Štaviše, što se sekvenca češće javlja, kraći je odgovarajući komprimovani kod.Huffmanov algoritam
Hafmanov algoritam vam omogućava da konstruišete prefiksne kodove. Možete razmišljati o prefiksnim kodovima kao o putanjama do binarno stablo: prijelaz od čvora do njegovog lijevog djeteta odgovara 0 u kodu, a desnog sina odgovara 1. Ako označimo listove stabla znakovima koje treba kodirati, dobićemo reprezentaciju prefiks kod u obliku binarnog stabla.Hajde da opišemo algoritam za konstruisanje Hafmanovog stabla i dobijanje Hafmanovih kodova.
- Znakovi ulazne abecede formiraju listu slobodnih čvorova. Svaki list ima težinu koju jednaka frekvenciji izgled simbola
- Odabrana su dva slobodna čvora stabla sa najmanjim težinama
- Njihov roditelj je kreiran sa težinom jednakom njihovoj ukupnoj težini
- Roditelj se dodaje na listu slobodnih čvorova, a njegova dva podređena se uklanjaju sa ove liste
- Jednom luku koji izlazi iz nadređenog je dodeljen bit 1, drugom - bit 0
- Koraci koji počinju od drugog se ponavljaju sve dok samo jedan slobodni čvor ne ostane na listi slobodnih čvorova. Ovo će se smatrati korijenom drveta.
Aritmetičko kodiranje
Algoritmi aritmetičkog kodiranja kodiraju nizove elemenata u razlomak. U ovom slučaju se uzima u obzir frekvencijska raspodjela elemenata. On ovog trenutka Algoritmi aritmetičkog kodiranja zaštićeni su patentima, pa ćemo se osvrnuti samo na osnovnu ideju.Neka se naša abeceda sastoji od N simbola a1,...,aN i njihove frekvencije pojavljivanja p1,...,pN, redom. Podijelimo poluinterval. Općenito, algoritam se zasniva na diskretnoj kosinusnoj transformaciji (u daljem tekstu DCT) primijenjenoj na matricu slike da bi se dobila nova matrica koeficijenata. Za dobivanje originalne slike primjenjuje se inverzna transformacija.
DCT dekomponuje sliku prema amplitudama određenih frekvencija. Dakle, prilikom transformacije dobijamo matricu u kojoj su mnogi koeficijenti ili blizu ili jednaki nuli. Osim toga, zbog nesavršenosti ljudskog vida, moguće je grublje aproksimirati koeficijente bez primjetnog gubitka kvaliteta slike.
U tu svrhu koristi se kvantizacija koeficijenta. U najjednostavnijem slučaju, ovo je aritmetički pomak udesno. Ovom konverzijom neke informacije se gube, ali se može postići veći stepen kompresije.
Kako algoritam radi
Dakle, pogledajmo algoritam detaljnije (slika 2.1). Hajde da komprimujemo 24-bitnu sliku.
Korak 1. Konvertujemo sliku iz RGB prostora boja, sa komponentama odgovornim za crvene (Red), zelene (Green) i plave (Blue) komponente boje tačke, u prostor boja YCrCb (ponekad se naziva YUV).
U njemu je Y komponenta svjetline, a Cr, Co komponente odgovorne za boju (hromatska crvena i hromatska plava). Zbog činjenice da je ljudsko oko manje osjetljivo na boju nego na svjetlinu, postaje moguće arhivirati nizove za Cr i Co komponente s velikim gubicima i, shodno tome, visokim omjerima kompresije Slična konverzija se dugo koristi. Tamo je dodijeljen uži frekvencijski pojas za signale odgovorne za boju. Pojednostavljeni prijevod iz RGB prostora boja u YCrCb prostor boja može se predstaviti korištenjem prijelazne matrice:
Korak 2. Originalnu sliku podijelimo na matrice 8x8. Formiramo 3 radne DCT matrice od svake - 8 bitova posebno za svaku komponentu. Pri većim omjerima kompresije, ovaj korak može biti malo teži. Slika je podijeljena Y komponentom, kao u prvom slučaju, a za Cr i Cb komponente matrice se kucaju kroz red i kroz kolonu. Odnosno, iz originalne 16x16 matrice dobija se samo jedna radna DCT matrica. U ovom slučaju, kao što je lako vidjeti, gubimo 3/4 korisne informacije o komponentama u boji slike i odmah dobiti 2 puta kompresiju. To možemo učiniti radeći u YCrCb prostoru. Kao što je praksa pokazala, ovo nema značajan uticaj na rezultujuću RGB sliku.
Korak 3. U pojednostavljenom obliku, DCT za n=8 se može predstaviti na sljedeći način:
nu,v] = ^Hc(i,u)xC(j,v)y rY) Yq= IntegerRound Ovaj korak je gdje se kontrolira omjer kompresije i gdje se javljaju najveći gubici. Jasno je da ćemo specificiranjem MK sa velikim koeficijentima dobiti više nula, a samim tim i veći omjer kompresije. Specifični efekti algoritma su takođe povezani sa kvantizacijom. Pri visokim gama vrijednostima, gubitak na niskim frekvencijama može biti toliki da se slika razbije na kvadrate 8x8. Gubici na visokim frekvencijama mogu se manifestovati u tzv Gibbsov efekat, kada se oko kontura s oštrim prijelazom boja formira neka vrsta „oreola“. Korak 5. Konvertujemo matricu 8x8 u vektor od 64 elementa koristeći cik-cak skeniranje, tj. uzimamo elemente sa indeksima (0,0), (0,1), (1,0), (2,0). . Dakle, na početku vektora dobijamo matrične koeficijente koji odgovaraju niskim frekvencijama, a na kraju - visokim. Korak 6. Sažimamo vektor koristeći algoritam grupnog kodiranja. U ovom slučaju dobijamo parove tipa<пропустить, число>, gdje je "skip" broj preskočenih nula, a "number" je vrijednost koju treba staviti u sljedeću ćeliju. Tako će vektor 42 3000-2 00001 ... biti presavijen u parove (0,42) (0,3) (3,-2) (4,1).... Korak 7. Dobivene parove skupljamo koristeći Huffman kodiranje s fiksnom tablicom. Proces obnavljanja slike u ovom algoritmu je potpuno simetričan. Metoda vam omogućava da komprimirate neke slike 10-15 puta bez ozbiljnih gubitaka. Značajni pozitivni aspekti algoritma su: ■ postavljen je nivo kompresije; ■ Izlazna slika u boji može biti 24 bita po tački. Negativni aspekti algoritma su: ■ Kako se nivo kompresije povećava, slika se raspada na pojedinačne kvadrate (8x8). To je zbog činjenice da se veliki gubici javljaju na niskim frekvencijama tokom kvantizacije i postaje nemoguće vratiti originalne podatke. ■ Pojavljuje se Gibbsov efekat - oreoli duž granica oštrih prelaza boja. Kao što je već pomenuto, JPEG je standardizovan relativno nedavno - 1991. Ali čak i tada su postojali algoritmi koji su se jače kompresovali sa manjim gubitkom kvaliteta. Činjenica je da su akcije standardnih programera bile ograničene snagom tehnologije koja je postojala u to vrijeme. To jest, čak i na PC-u, algoritam je morao raditi manje od jednog minuta na prosječnoj slici, a njegova hardverska implementacija je morala biti relativno jednostavna i jeftina. Algoritam je morao biti simetričan (vrijeme raspakiranja je približno jednako vremenu arhiviranja). Ispunjavanje posljednjeg zahtjeva omogućilo je pojavu uređaja poput digitalnih fotoaparata koji snimaju 24-bitne fotografije na fleš kartici od 8-256 MB." Zatim se ova kartica ubacuje u slot na vašem laptopu i odgovarajući program vam omogućava da čitam slike Nya, da je algoritam asimetričan, bilo bi neugodno dugo čekati da se uređaj "napuni" i komprimira sliku. Još jedno ne baš prijatno svojstvo JPEG-a je to, da su često horizontalne i vertikalne pruge na displeju potpuno nevidljive i mogu se pojaviti samo pri štampanju u obliku moiré uzorka. Javlja se kada se nagnuti raster za štampanje preloži na horizontalne i vertikalne pruge slike. Zbog ovih iznenađenja, JPEG nije aktivno se preporučuje koristi se u štampi, postavljajući visoke koeficijente matrice kvantizacije. Međutim, kada se arhiviraju slike namijenjene ljudskom gledanju, ono je trenutno neizostavno. Široko Upotreba JPEG-a dugo je bila ograničena, možda, samo činjenicom da radi na 24-bitnim slikama. Stoga je za gledanje slike prihvatljivog kvaliteta na običnom monitoru u paleti od 256 boja bila potrebna upotreba odgovarajućih algoritama i, shodno tome, određeno vrijeme. U aplikacijama koje su namijenjene zahtjevnim korisnicima, kao što su igre, takva kašnjenja su neprihvatljiva. Osim toga, ako imate slike, recimo, u 8-bitnom GIF formatu, konvertovane u 24-bitni JPEG, a zatim nazad u GIF za gledanje, gubitak kvaliteta će se dogoditi dva puta tokom obje konverzije. Ipak, povećanje u veličini arhive je često tako veliko (3-20 puta), a gubitak u kvalitetu je tako mali da je skladištenje slika u JPEG formatu veoma efikasno. Treba reći nekoliko riječi o modifikacijama ovog algoritma. Iako je JPEG ISO standard, njegov format datoteke nije fiksiran. Koristeći ovo, proizvođači kreiraju vlastite formate koji su međusobno nekompatibilni i stoga mogu promijeniti algoritam. Stoga su interne tabele algoritama koje preporučuje ISO zamijenjene njihovim vlastitim. Osim toga, postoji mala zabuna prilikom postavljanja stepena gubitka. Na primjer, tokom testiranja se ispostavilo da “odličan” kvalitet, “100%” i “10 bodova” daju značajno različite slike. Međutim, usput, "100%" kvaliteta ne znači kompresiju bez gubitaka. Postoje i JPEG opcije za određene aplikacije. Kao ISO standard, JPEG se sve više koristi za razmjenu slika na računarskim mrežama. JPEG algoritam je podržan u formatima Quick Time, PostScript Level 2, Tiff 6.0 i trenutno zauzima istaknuto mjesto u multimedijalnim sistemima. Karakteristike JPEG algoritma: o ! w. ,. Omjer kompresije: 2-200 (podešava korisnik). ,ts, :_,. . Klasa slike: slike u punoj boji 2jj.bit ili iso-| refleksije u sivim tonovima bez oštrih prelaza boja (fotografije). simetrija: 1. karakteristike: u nekim slučajevima algoritam kreira! "halo" oko oštrih horizontalnih i vertikalnih granica na slici (Gibbsov efekat). Osim toga, pri visokom omjeru kompresije, iso-! Slika je razbijena na blokove 8x8 piksela. Poznavanje JPEG algoritma je veoma korisno ne samo za kompresiju slike. Koristi teoriju iz digitalne obrade signala, matematičke analize, linearne algebre, teorije informacija, posebno Fourierove transformacije, kodiranja bez gubitaka, itd. Stoga stečeno znanje može biti korisno svuda. Ako želite, predlažem da sami prođete kroz iste korake paralelno sa člankom. Provjerite koliko je gornje obrazloženje prikladno za različite slike, pokušajte napraviti vlastite izmjene u algoritmu. Veoma je zanimljivo. Kao alat, mogu preporučiti divnu kombinaciju Python + NumPy + Matplotlib + PIL(Pillow). Gotovo sav moj rad (uključujući grafiku i animaciju) radio sam pomoću njih. Pažnja, saobraćaj! Mnogo ilustracija, grafikona i animacija (~ 10Mb). Ironično, u članku o JPEG-u postoje samo 2 slike ovog formata od pedeset. Treniraćemo na rakunskim mačkama. Siva slika iznad je uzeta kao primjer. Dobro kombinuje i homogena i kontrastna područja. A ako naučimo komprimirati sivu, onda neće biti problema s bojom. Možete mentalno razmišljati o tome kako bi se signal čije vrijednosti postepeno smanjuju od maksimalne vrijednosti na početku do minimalne vrijednosti na kraju mogao razložiti. Manje ili više adekvatnu aproksimaciju mogli bi napraviti samo harmonici pred kraj, što za nas nije baš sjajno. Slika na lijevoj strani je aproksimacija jednostranog signala. Desno - simetrično: Dakle, došla vam je ideja da osmislite vlastitu transformaciju. Zapamtite ovo: Veliki blokovi nisu prikazani, jer se vizualno gotovo ne razlikuju od 32x32. Sada pogledajmo apsolutnu razliku u odnosu na originalnu sliku (pojačana 2 puta, inače ništa nije vidljivo): 8x8 daje bolje rezultate od 4x4. Dalje povećanje veličine više ne pruža jasno vidljivu prednost. Iako bih ozbiljno razmotrio 16x16 umjesto 8x8: povećanje složenosti za 33% (više o složenosti u sljedećem paragrafu) daje malo, ali još uvijek vidljivo poboljšanje za isti broj koeficijenata. Međutim, izbor 8x8 izgleda sasvim razuman i može biti zlatna sredina. JPEG je objavljen 1991. Mislim da je takva kompresija bila veoma teška za procesore tog vremena. Sekunda argument. Jedna stvar koju treba imati na umu je da će povećanje veličine bloka zahtijevati više proračuna. Procijenimo koliko. Složenost konverzije, kao što već dobro znamo: O(N 2), budući da se svaki koeficijent sastoji od N članova. Ali u praksi se koristi efikasan algoritam brze Fourierove transformacije (FFT). Njegov opis je izvan okvira ovog članka. Njegova složenost: O(N*logN). Za dvodimenzionalno proširenje morate ga koristiti dva puta N puta. Dakle, složenost 2D DCT je O(N 2 logN). Sada uporedimo složenost izračunavanja slike s jednim blokom i nekoliko malih: Treće argument. Ako imamo oštru granicu boja na slici, to će utjecati na cijeli blok. Možda bi bilo bolje da ovaj blok bude dovoljno mali, jer u mnogim susjednim blokovima takve granice vjerovatno više neće biti. Međutim, daleko od granica, slabljenje se događa prilično brzo. Osim toga, sama granica će izgledati bolje. Provjerimo to na primjeru s velikim brojem kontrastnih prijelaza, opet sa samo četvrtinom koeficijenata: A za desert, uzmite u obzir kvalitet od 5% (kada kodirate u Fast Stone). Inače, oko 100% kvaliteta. Kao što možete pretpostaviti, u ovom slučaju matrica kvantizacije se u potpunosti sastoji od jedinica, odnosno ne dolazi do kvantizacije. Međutim, zbog zaokruživanja koeficijenata na najbliži cijeli broj, ne možemo precizno vratiti originalnu sliku. Na primjer, rakun je zadržao 96% piksela tačno, ali je 4% bilo manje za 1/256. Naravno, takva "izobličenja" se ne mogu uočiti vizuelno. Primjer 0(za zagrevanje) Riječi ćemo označiti kao A, B, C... i nazvati ih simbolima. Štaviše, pod simbolom se može sakriti bilo šta: slovo abecede, riječ ili nilski konj u zoološkom vrtu. Glavna stvar je da identični simboli odgovaraju identičnim konceptima, a različiti odgovaraju različitim. Pošto je naš zadatak efikasno kodiranje (kompresija), radićemo sa bitovima, jer su to najmanje jedinice za predstavljanje informacija. Stoga, napišimo listu kao ABBAAABA. Umjesto "prve riječi" i "druge riječi" mogu se koristiti bitovi 0 i 1. Tada se ABBAAABA kodira kao 01100010 (8 bitova = 1 bajt). Primjer 1 Primjer 2 Primjer 3 Primjer 4 Sada je sve u redu. Shvatili smo kako se DC pohranjuju: Pogledajmo AC: Za ove parove i Hafmanovo stablo gradimo histogram količinske zavisnosti. Karakteristike implementacije u JPEG: Saznali smo da je svaki blok kodiran i pohranjen u datoteci poput ove: Nadam se da sada intuitivno razumete JPEG algoritam. Hvala na čitanju! UPD Oznake: Dodaj oznake Algoritam za pretvaranje JPEG grafičke slike sastoji se od nekoliko faza koje se na slici izvode uzastopno, jedna za drugom: – konverzije prostora boja, – poduzorkovanje, – diskretna kosinusna transformacija (DCT), – kvantizacija, – kodiranje. U fazi konverzije prostora boja, slika se pretvara iz RGB prostora boja u YCbCr (gdje je Y svjetlina, a Cb i Cr komponente razlike u boji tačke slike): Primjena prostora YCbCr umjesto uobičajenog RGB objašnjava se fiziološkim karakteristikama ljudskog vida, odnosno činjenicom da ljudski nervni sistem ima znatno veću osjetljivost na sjaj ( Y) nego na komponente koje se razlikuju u boji (u ovom slučaju Cb I Cr). Inverzna konverzija prostora boja (od YCrCb V RGB) ima oblik: Algoritam kompresije JPEG vam omogućava da komprimirate slike s različitim veličinama ravni boja. Označimo sa x i I y iširina i visina i ravan boje slike. Neka X= max(x i), Y= max(y i), definišemo za svaku ravan koeficijente H i= X/ x i I V i= Y/ y i. Najveća vrijednost za X I Y prema JPEG algoritmu je 2 16, a za H i I V i– 2 2 . Dakle, širina i visina ravni boja mogu biti od 1 do 4 puta manje od dimenzija najveće ravni. Za obične RGB slike, veličine svih ravni boja su jednake. Poduzorkovanje se sastoji od smanjenja veličine ravni Cr I Cb. Najčešće smanjenje je 2 puta u širinu i 2 puta u visinu (vidi sliku 1). Za ovo Cr I Cb Ravni slike su podijeljene na blokove veličine 2 x 2 piksela, a blok je zamijenjen jednim uzorkom komponenti razlike u boji (umjesto postojeća 4 uzorka stavlja se njihova aritmetička sredina za svaki blok, što čini moguće je smanjiti veličinu originalne slike za 2 puta). Slika 1 – Uobičajeni tipovi smanjenja uzorkovanja Zatim, posebno za svaku komponentu prostora boja Y, Cb I Cr, izvodi se direktna diskretna kosinusna transformacija. Da biste to učinili, slika je podijeljena na blokove veličine 8 x 8 piksela i svaki blok se transformira prema formuli: Upotreba diskretne kosinusne transformacije omogućava vam prelazak sa prostornog prikaza slike na spektralni. Inverzna diskretna kosinusna transformacija ima oblik: Nakon toga možete nastaviti sa kvantizacijom primljenih informacija. Ideja kvantizacije je odbacivanje određene količine informacija. Poznato je da je ljudsko oko manje osjetljivo na visoke frekvencije (naročito na visoke frekvencije komponenti s razlikom u boji) većina fotografskih slika sadrži malo visokofrekventnih komponenti. Osim toga, pojava visokih frekvencija je posljedica procesa digitalizacije, tj. zbog pojave pratećeg šuma uzorkovanja i kvantizacije. U ovoj fazi tzv tabele kvantizacije- matrice koje se sastoje od pozitivnih cijelih brojeva veličine 8 puta 8, na koje su podijeljene odgovarajuće frekvencije blokova slike, rezultat se zaokružuje na cijeli broj: Proces dekvantizacije koristi iste tabele kao i kvantizacija. Dekvantizacija se sastoji od množenja kvantizovanih frekvencija sa odgovarajućim elementima tabele kvantizacije: Dakle, kako se faktor kvantizacije povećava, količina odbačenih informacija raste. Pogledajmo ovo detaljnije koristeći primjer. Blokiraj prije kvantizacije: 3862, –22, –162, –111, –414, 12, 717, 490, 383, 902, 913, 234, –555, 18, –189, 236, 229, 707, –708, 775, 423, –411, –66, –685, 231, 34, –928, 34, –1221, 647, 98, –824, –394, 128, –307, 757, 10, –21, 431, 427, 324, –874, –367, –103, –308, 74, –1017, 1502, 208, –90, 114, –363, 478, 330, 52, 558, 577, 1094, 62, 19, –810, –157, –979, –98 Tablica kvantizacije (kvalitet 90): 24, 16, 16, 24, 40, 64, 80, 96, 16, 16, 24, 32, 40, 96, 96, 88, 24, 24, 24, 40, 64, 88, 112, 88, 24, 24, 32, 48, 80, 136, 128, 96, 32, 32, 56, 88, 112, 176, 168, 120, 40, 56, 88, 104, 128, 168, 184, 144, 80, 104, 128, 136, 168, 192, 192, 160, 112, 144, 152, 160, 176, 160, 168, 160 Blok nakon kvantizacije: 161, –1, –10, –5, –10, 0, 9, 5, 24, 56, 38, 7, –14, 0, –2, 3, 10, 29, –30, 19, 7, –5, –1, –8, 10, 1, –29, 1, –15, 5, 1, –9, –12, 4, –5, 9, 0, 0, 3, 4, 8, –16, –4, –1, –2, 0, –6, 10, 3, –1, 1, –3, 3, 2, 0, 3, 5, 8, 0, 0, –5, –1, –6, –1 3864, –16, –160, –120, –400, 0, 720, 480, 384, 896, 912, 224, –560, 0, –192, 264, 240, 696, –720, 760, 448, –440, –112, –704, 240, 24, –928, 48,–1200, 680, 128, –864, –384, 128, –280, 792, 0, 0, 504, 480, 320, –896, –352, –104, –256, 0,–1104, 1440, 240, –104, 128, –408, 504, 384, 0, 480, 560, 1152, 0, 0, –880, –160,–1008, –160 Tablica kvantizacije (kvalitet 45): 144, 96, 88, 144, 216, 352, 456, 544, 104, 104, 128, 168, 232, 512, 536, 488, 128, 112, 144, 216, 352, 504, 616, 496, 128, 152, 192, 256, 456, 776, 712, 552, 160, 192, 328, 496, 600, 968, 912, 680, 216, 312, 488, 568, 720, 920, 1000, 816, 432, 568, 696, 776, 912, 1072, 1064, 896, 640, 816, 840, 872, 992, 888, 912, 880 Blok nakon kvantizacije: 27, 0, –2, –1, –2, 0, 2, 1, 4, 9, 7, 1, –2, 0, 0, 0, 2, 6, –5, 4, 1, –1, 0, –1, 2, 0, –5, 0, –3, 1, 0, –1, –2, 1, –1, 2, 0, 0, 0, 1, 2, –3, –1, 0, 0, 0, –1, 2, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, –1, 0, –1, 0 Blokiraj nakon obrnute konverzije: 3888, 0, –176, –144, –432, 0, 912, 544, 416, 936, 896, 168, –464, 0, 0, 0, 256, 672, –720, 864, 352, –504, 0, –496, 256, 0, –960, 0,–1368, 776, 0, –552, –320, 192, –328, 992, 0, 0, 0, 680, 432, –936, –488, 0, 0, 0,–1000, 1632, 0, 0, 0, 0, 912, 0, 0, 896, 640, 816, 0, 0, –992, 0, –912, 0 Kao što se može vidjeti, u prvom slučaju promjena DC koeficijent kao rezultat kompresije je 2, au drugom 26, dok je kvantizovan DC koeficijent u drugom slučaju je 6 puta manji nego u prvom. Kodiranje je konačna faza kompresije tokom nje, blokovi slike se pretvaraju u vektorsku formu prema pravilu određenom blokovima forme: 0, 1, 5, 6, 14, 15, 27, 28, 2, 4, 7, 13, 16, 26, 29, 42, 3, 8, 12, 17, 25, 30, 41, 43, 9, 11, 18, 24, 31, 40, 44, 53, 10, 19, 23, 32, 39, 45, 52, 54, 20, 22, 33, 38, 46, 51, 55, 60, 21, 34, 37, 47, 50, 56, 59, 61, 35, 36, 48, 49, 57, 58, 62, 63 gdje su vektorski indeksi odgovarajućih komponenti matrice označeni kao blok elementi. U ovom slučaju, nulti element je kodiran kao razlika sa nultim elementom prethodnog bloka. Nulti elementi označavaju DC, sadrže konstantnu komponentu bloka (svi ostali AC elementi se obično označavaju A.C.). Rezultirajući podaci se zatim komprimiraju korištenjem aritmetičkog kodiranja ili modifikacije Huffmanovog algoritma. Ova faza nije od velikog interesa sa stanovišta steganografije u grafičkim slikama, pa je izvan okvira našeg razmatranja.
Dobro ste shvatili iz naslova da ovo nije sasvim običan opis JPEG algoritma (format fajla sam opisao detaljno u članku “JPEG dekodiranje za lutke”). Prije svega, odabrana metoda prezentacije materijala pretpostavlja da ne znamo ništa ne samo o JPEG-u, već ni o Fourier-ovoj transformaciji i Huffman-ovom kodiranju. Generalno, malo toga pamtimo sa predavanja. Samo su uzeli sliku i počeli razmišljati o tome kako se može komprimirati. Stoga sam pokušao jasno izraziti samo suštinu, ali u kojoj će čitatelj razviti prilično duboko i, što je najvažnije, intuitivno razumijevanje algoritma. Formule i matematičke kalkulacije - u najmanju ruku samo one koje su važne za razumijevanje onoga što se dešava.
Bez obzira na algoritam kompresije informacija, njegov princip će uvijek biti isti - pronalaženje i opisivanje obrazaca. Što više obrazaca, to je više redundantnosti, manje informacija. Arhivari i koderi su obično „skrojeni“ za određenu vrstu informacija i znaju gdje ih pronaći. U nekim slučajevima, uzorak je odmah vidljiv, kao što je slika plavog neba. Svaki red njegove digitalne reprezentacije može se prilično precizno opisati ravnom linijom.Vektorska reprezentacija
Prvo, hajde da proverimo koliko su zavisna dva susedna piksela. Logično je pretpostaviti da će najvjerovatnije biti vrlo slični. Provjerimo ovo za sve parove slika. Označimo ih na koordinatnoj ravni tačkama tako da vrijednost tačke duž ose X bude vrijednost prvog piksela, a duž ose Y - drugog. Za našu sliku dimenzija 256 x 256 dobijamo 256*256/2 piksela: 
Očekivano, većina tačaka se nalazi na ili blizu linije y=x (a ima ih čak i više nego što se može videti na slici, pošto se mnogo puta preklapaju i, osim toga, prozirne su). Ako je tako, bilo bi lakše raditi ako ih rotirate za 45°. Da biste to učinili, morate ih izraziti u drugom koordinatnom sistemu. 
Osnovni vektori novog sistema su očigledno: . Primorani smo da podijelimo korijenom od dva da bismo dobili ortonormirani sistem (dužine baznih vektora su jednake jedan). Ovdje je pokazano da će određena tačka p = (x, y) u novom sistemu biti predstavljena kao tačka (a 0 , a 1). Poznavajući nove koeficijente, lako možemo dobiti stare okrećući ih. Očigledno je prva (nova) koordinata prosjek, a druga razlika x i y (ali podijeljena korijenom 2). Zamislite da se od vas traži da ostavite samo jednu od vrijednosti: ili 0 ili 1 (to jest, izjednačite drugu s nulom). Bolje je odabrati 0, jer će vrijednost 1 najvjerovatnije biti oko nule. Evo šta se dešava ako vratimo sliku samo iz 0: 
4x uvećanje: 
Iskreno, ova kompresija nije baš impresivna. Bolje je slično podijeliti sliku na trojke piksela i predstaviti ih u trodimenzionalnom prostoru. 

Ovo je isti grafikon, ali iz različitih uglova. Crvene linije su sjekire koje su se sugerirale. Oni odgovaraju vektorima: . Da vas podsjetim da morate podijeliti sa nekim konstantama tako da dužine vektora postanu jednake jedan. Dakle, proširivanjem na ovoj osnovi, dobijamo 3 vrijednosti a 0, a 1, a 2, a 0 je važnije od 1, a 1 je važnije od 2. Ako izbacimo 2, tada će se graf "spljoštiti" u smjeru vektora e 2. Ovaj već prilično tanak trodimenzionalni list postat će ravan. Neće toliko izgubiti, ali ćemo se osloboditi trećine vrijednosti. Uporedimo slike rekonstruisane iz trojki: (a 0, 0, 0), (a 1, a 2, 0) i (a 0, a 1, a 2). U prošloj verziji nismo ništa bacili, pa ćemo dobiti original. 
4x uvećanje: 
Drugi crtež je već dobar. Oštre oblasti su malo izglađene, ali je slika u celini veoma dobro očuvana. A sada, podijelimo na četiri na isti način i vizualno odredimo osnovu u četverodimenzionalnom prostoru... O, pa, da. Ali možete pogoditi koji će biti jedan od osnovnih vektora: (1,1,1,1)/2. Stoga, možemo pogledati projekciju četverodimenzionalnog prostora na prostor okomit na vektor (1,1,1,1) da bismo identificirali druge. Ali ovo nije najbolji način.
Naš cilj je naučiti kako transformirati (x 0 , x 1 , ..., x n-1) u (a 0 , a 1 , ..., a n-1) tako da svaka vrijednost a i bude manje važna od prethodnih. Ako to možemo učiniti, onda se možda posljednje vrijednosti niza mogu potpuno odbaciti. Gore navedeni eksperimenti nagovještavaju da je to moguće. Ali ne možete bez matematičkog aparata.
Dakle, moramo transformisati tačke na novu osnovu. Ali prvo morate pronaći odgovarajuću osnovu. Vratimo se prvom eksperimentu uparivanja. Razmotrimo to općenito. Definirali smo osnovne vektore: 
Kroz njih smo izrazili vektor str:
ili u koordinatama: 
Da biste pronašli 0 i 1 morate projektirati str on e 0 i e 1 respektivno. A za ovo morate pronaći skalarni proizvod
slično:
U koordinatama: 
Često je zgodnije izvršiti transformaciju u matričnom obliku. 
Tada je A = EX i X = E T A. Ovo je lijep i zgodan oblik. Matrica E se zove transformaciona matrica i ortogonalna je, sa njom ćemo se susresti kasnije. Prijelaz sa vektora na funkcije.
Pogodno je raditi s vektorima malih dimenzija. Međutim, želimo da pronađemo obrasce u većim blokovima, pa je umjesto N-dimenzionalnih vektora pogodnije raditi sa sekvencama koje predstavljaju sliku. Takve sekvence ću nazvati diskretnim funkcijama, budući da se sljedeće razmišljanje primjenjuje i na kontinuirane funkcije.
Da se vratimo na naš primjer, zamislimo funkciju f(i), koja je definirana u samo dvije točke: f(0)=x i f(1)=y. Slično, definiramo osnovne funkcije e 0 (i) i e 1 (i) na osnovu baza e 0 i e 1 . Dobijamo: 
Ovo je veoma važan zaključak. Sada u frazi „proširenje vektora u ortonormiranim vektorima“ možemo zamijeniti riječ „vektor“ sa „funkcija“ i dobiti potpuno ispravan izraz „proširenje funkcije u ortonormalne funkcije“. Nema veze što smo dobili tako kratku funkciju, jer isto razmišljanje radi i za N-dimenzionalni vektor, koji se može predstaviti kao diskretna funkcija sa N vrijednosti. A rad sa funkcijama je jasniji nego sa N-dimenzionalnim vektorima. Suprotno tome, takvu funkciju možete predstaviti kao vektor. Štaviše, obična kontinuirana funkcija može biti predstavljena beskonačno-dimenzionalnim vektorom, iako ne u Euklidskom, već u Hilbertovom prostoru. Ali nećemo ići tamo; zanimaju nas samo diskretne funkcije.
A naš problem nalaženja baze pretvara se u problem nalaženja odgovarajućeg sistema ortonormiranih funkcija. U nastavku razmišljanja pretpostavlja se da smo već nekako odredili skup osnovnih funkcija prema kojima ćemo dekomponirati.
Recimo da imamo neku funkciju (predstavljenu, na primjer, vrijednostima) koju želimo predstaviti kao zbir drugih. Ovaj proces možete predstaviti u vektorskom obliku. Da biste dekomponirali funkciju, trebate je "projecirati" na osnovne funkcije jednu po jednu. U vektorskom smislu, izračunavanje projekcije daje minimalni pristup originalnog vektora drugom u smislu udaljenosti. Imajući u vidu da se udaljenost izračunava pomoću Pitagorine teoreme, sličan prikaz u obliku funkcija daje najbolju aproksimaciju srednjeg kvadrata funkcije drugoj. Dakle, svaki koeficijent (k) određuje “zatvorenost” funkcije. Formalnije, k*e(x) je najbolja aproksimacija srednjeg kvadrata za f(x) među l*e(x).
Sljedeći primjer pokazuje proces aproksimacije funkcije koristeći samo dvije točke. Desno je vektorski prikaz. 
U odnosu na naš eksperiment podjele u parove, možemo reći da su ove dvije tačke (0 i 1 duž apscise) par susjednih piksela (x, y).
Ista stvar, ali sa animacijom: 
Ako uzmemo 3 točke, onda moramo uzeti u obzir trodimenzionalne vektore, ali će aproksimacija biti preciznija. A za diskretnu funkciju sa N vrijednostima, morate uzeti u obzir N-dimenzionalne vektore.
Imajući skup dobijenih koeficijenata, možete lako dobiti originalnu funkciju zbrajanjem osnovnih funkcija uzetih s odgovarajućim koeficijentima. Analiza ovih koeficijenata može pružiti mnogo korisnih informacija (u zavisnosti od osnove). Poseban slučaj ovih razmatranja je princip ekspanzije Fourierovog reda. Na kraju krajeva, naše razmišljanje je primjenjivo na bilo koju osnovu, a kada se proširi u Fourierov niz, uzima se potpuno specifična. Diskretne Fourierove transformacije (DFT)
U prethodnom dijelu smo došli do zaključka da bi bilo lijepo funkciju razložiti na njene komponente. Početkom 19. veka o tome je razmišljao i Fourier. Istina, nije imao sliku rakuna, pa je morao proučiti raspodjelu topline duž metalnog prstena. Tada je otkrio da je vrlo zgodno izraziti temperaturu (i njenu promjenu) u svakoj tački prstena kao zbir sinusoida sa različitim periodima. “Fourier je otkrio (preporučujem da pročitate, zanimljivo je) da drugi harmonik opada 4 puta brže od prvog, a harmonici višeg reda raspadaju još bržom brzinom.”
Općenito, ubrzo se pokazalo da se periodične funkcije mogu savršeno razložiti u zbir sinusoida. A budući da u prirodi postoji mnogo objekata i procesa opisanih periodičnim funkcijama, pojavio se moćan alat za njihovu analizu.
Možda je jedan od najvizuelnijih periodičnih procesa zvuk. 
Da su mi dali vrijednosti posljednje funkcije u onom trenutku kada nisam znao za Fourierove redove i zamolili me da ih analiziram, onda bih se definitivno zbunio i ne bih mogao reći ništa vrijedno. Pa da, nekakva funkcija, ali kako shvatiti da je tu nešto naručeno? Ali da sam pogodio da slušam posljednju funkciju, moje uho bi među bukom uhvatilo čist ton. Iako ne baš dobro, jer sam tokom generacije posebno odabrao takve parametre kako bi se na sumarnom grafikonu signal vizualno otopio u šumu. Koliko sam shvatio, još uvijek nije jasno kako to radi slušni aparat. Međutim, nedavno je postalo jasno da on ne razlaže zvuk na sinusne talase. Možda ćemo jednog dana shvatiti kako se to događa i pojavit će se napredniji algoritmi. Pa, za sada to radimo na starinski način.
Zašto ne biste pokušali koristiti sinusoide kao osnovu? U stvari, mi smo to već uradili. Prisjetimo se naše dekompozicije na 3 bazna vektora i predstavimo ih na grafu: 
Da, da, znam da izgleda kao prilagodba, ali s tri vektora teško je očekivati više. Ali sada je jasno kako dobiti, na primjer, 8 baznih vektora: 
Ne baš komplikovana provjera pokazuje da su ovi vektori u parovima okomiti, odnosno ortogonalni. To znači da se mogu koristiti kao osnova. Transformacija na takvoj osnovi je široko poznata i naziva se diskretna kosinusna transformacija (DCT). Mislim da je iz gornjih grafikona jasno kako se dobija formula DCT transformacije:
Ovo je i dalje ista formula: A = EX sa zamijenjenom osnovom. Bazni vektori specificiranog DCT-a (oni su također vektori reda matrice E) su ortogonalni, ali ne i ortonormalni. Ovo treba imati na umu tokom inverzne transformacije (neću se zadržavati na ovome, ali za one koji su zainteresovani, inverzni DCT ima termin 0,5*a 0, pošto je vektor nulte baze veći od ostalih).
Sljedeći primjer pokazuje proces aproksimacije međuzbroja originalnim vrijednostima. Na svakoj iteraciji, sljedeća osnova se množi sa sljedećim koeficijentom i dodaje srednjem zbroju (to jest, isto kao u ranim eksperimentima na rakunu - trećina vrijednosti, dvije trećine). 
Ali, ipak, uprkos nekim argumentima o preporučljivosti odabira takve osnove, pravih argumenata još nema. Zaista, za razliku od zvuka, izvodljivost dekompozicije slike na periodične funkcije je mnogo manje očigledna. Međutim, slika zaista može biti previše nepredvidljiva čak i na maloj površini. Dakle, slika je podijeljena na komadiće dovoljno male, ali ne baš sićušne, da bi dekompozicija imala smisla. U JPEG-u, slika je “isječena” na kvadrate 8x8. Unutar takvog komada, fotografije su obično vrlo ujednačene: pozadina plus male fluktuacije. Takvim područjima se lijepo približavaju sinusoidi.
Pa, recimo da je ova činjenica manje-više intuitivna. Ali postoji loš osjećaj o naglim prijelazima boja, jer nas polagana promjena funkcija neće spasiti. Moramo dodati razne visokofrekventne funkcije koje rade svoj posao, ali se pojavljuju postrance na homogenoj pozadini. Uzmimo sliku 256x256 sa dva kontrastna područja: 
Proširimo svaki red koristeći DCT, tako da dobijemo 256 koeficijenata po redu.
Tada ostavljamo samo prvih n koeficijenata, a ostale postavljamo na nulu, pa će slika biti predstavljena kao zbir samo prvih harmonika: 
Broj na slici je broj preostalih kvota. Na prvoj slici ostaje samo prosječna vrijednost. Na drugom je već dodana jedna niskofrekventna sinusoida itd. Usput, obratite pažnju na ivicu - uprkos svim najboljim aproksimacijama, 2 pruge su jasno vidljive pored dijagonale, jedna svjetlija, druga tamnija. Dio posljednje slike uvećan 4 puta:
I općenito, ako daleko od granice vidimo početnu jednoliku pozadinu, onda kada joj se približimo, amplituda počinje rasti, konačno dostiže minimalnu vrijednost, a zatim odjednom postaje maksimalna. Ovaj fenomen je poznat kao Gibbsov efekat. 
Visina ovih grba, koje se pojavljuju u blizini diskontinuiteta funkcije, neće se smanjivati kako se broj sabiraka funkcija povećava. U diskretnoj transformaciji nestaje tek kada su sačuvani gotovo svi koeficijenti. Tačnije, postaje nevidljiv.
Sljedeći primjer je potpuno sličan gornjoj dekompoziciji trokuta, ali na pravom rakunu: 
Prilikom proučavanja DCT-a može se steći pogrešan utisak da je uvijek dovoljno samo prvih nekoliko (niskofrekventnih) koeficijenata. To vrijedi za mnoge fotografije, one čija se značenja ne mijenjaju dramatično. Međutim, na granici kontrastnih područja, vrijednosti će brzo "skočiti", pa će čak i posljednji koeficijenti biti veliki. Stoga, kada čujete za svojstvo očuvanja energije DCT-a, uzmite u obzir činjenicu da se ono primjenjuje na mnoge vrste signala na koje se nailazi, ali ne na sve. Na primjer, razmislite o tome kako bi izgledala diskretna funkcija čiji su koeficijenti proširenja jednaki nuli, osim posljednje. Savjet: Zamislite dekompoziciju u vektorskom obliku.
Unatoč nedostacima, odabrana osnova je jedna od najboljih na pravim fotografijama. Videćemo malo poređenje sa ostalima malo kasnije. DCT naspram svega ostalog
Kada sam proučavao pitanje ortogonalnih transformacija, da budem iskren, nisam se baš uvjerio u argumente da je sve okolo zbir harmonijskih oscilacija, pa je potrebno slike razložiti na sinusoide. Ili bi možda neke funkcije koraka bile bolje? Stoga sam tražio rezultate istraživanja o optimalnosti DCT-a na stvarnim slikama. Svugdje je zapisano da se „u praktičnim primjenama najčešće nalazi DCT zbog svojstva „energetskog zbijanja“. Ovo svojstvo znači da je maksimalna količina informacija sadržana u prvim koeficijentima. I zašto? Nije teško provesti istraživanje: naoružamo se gomilom različitih slika, različitih poznatih baza i počinjemo računati standardnu devijaciju od stvarne slike za različit broj koeficijenata. Pronašao sam malu studiju u članku (korišćene slike) o ovoj tehnici. Prikazuje grafove zavisnosti pohranjene energije od broja prvih koeficijenata ekspanzije za različite baze. Ako ste pogledali grafikone, bili ste uvjereni da DCT konstantno zauzima počasno... hm... 3. mjesto. Kako to? Kakva je ovo KLT konverzija? Hvalio sam DCT, a onda... KLT
Sve transformacije, osim KLT, su transformacije sa konstantnom osnovom. A u KLT-u (Karhunen-Loeve transformacija) izračunava se najoptimalnija osnova za nekoliko vektora. Izračunava se na način da prvi koeficijenti daju najmanju srednju kvadratnu grešku ukupno za sve vektore. Prethodno smo obavljali sličan rad ručno, vizualno određujući osnovu. U početku se čini kao zdrava ideja. Mogli bismo, na primjer, podijeliti sliku na male dijelove i izračunati vlastitu osnovu za svaki. Ali ne samo da postoji briga o čuvanju ove osnove, već je i operacija njenog izračunavanja prilično radno intenzivna. Ali DCT gubi samo malo, a osim toga, DCT ima brze algoritme konverzije. DFT
DFT (Discrete Fourier Transform) - diskretna Fourierova transformacija. Pod ovim imenom se ponekad spominje ne samo određena transformacija, već i čitava klasa diskretnih transformacija (DCT, DST...). Pogledajmo DFT formulu: 
Kao što možete pretpostaviti, ovo je ortogonalna transformacija sa nekom vrstom složene osnove. Budući da se takav složeni oblik javlja malo češće nego inače, ima smisla proučiti njegovo izvođenje.
Može se činiti da će svaki čisti harmonijski signal (sa cjelobrojnom frekvencijom) sa DCT dekompozicijom dati samo jedan koeficijent različit od nule koji odgovara ovom harmoniku. To nije tačno, jer je osim frekvencije važna i faza ovog signala. Na primjer, proširenje sinusa u kosinuse (na sličan način u diskretnoj ekspanziji) će biti ovako:
Toliko o čistim harmonicima. Izrodila je gomilu drugih. Animacija prikazuje DCT koeficijente sinusnog vala u različitim fazama. 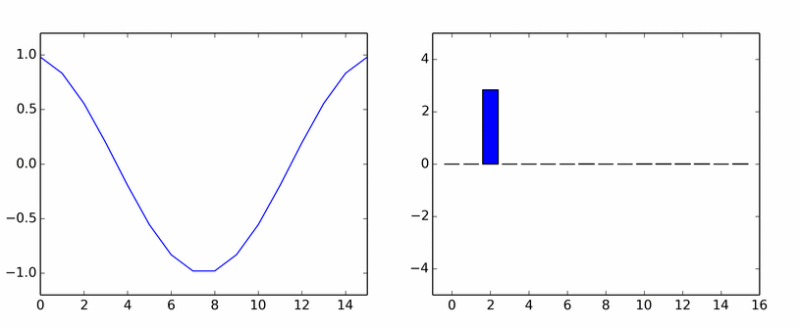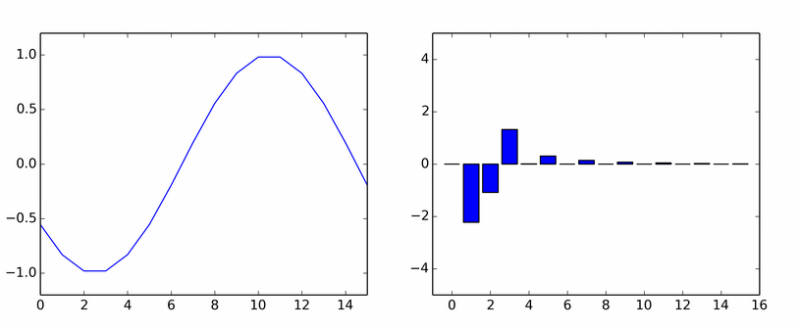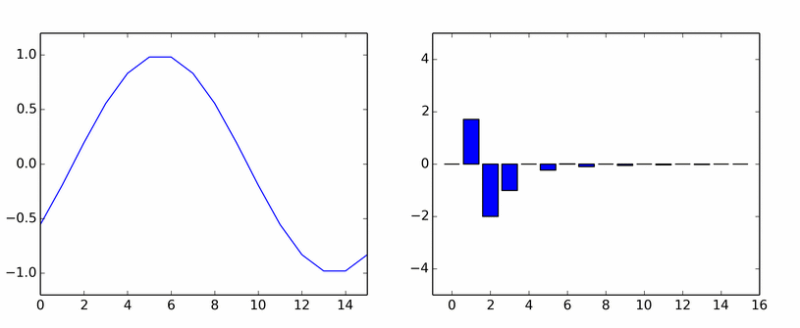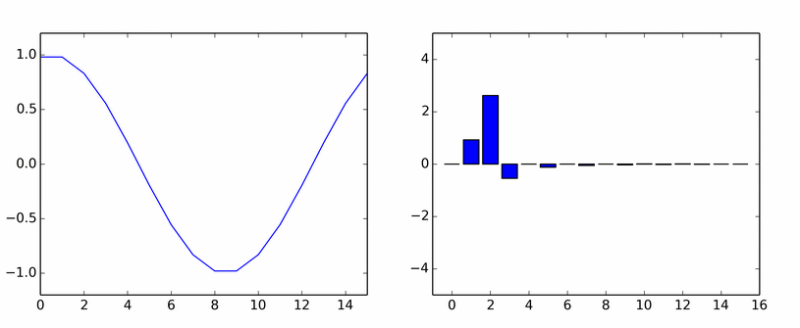
Ako vam se činilo da se stupovi okreću oko ose, onda vam se nije činilo.
To znači da ćemo sada proširiti funkciju na zbir sinusoida ne samo različitih frekvencija, već i onih pomaknutih duž neke faze. Bit će prikladnije razmotriti fazni pomak na primjeru kosinusa:
Jednostavan trigonometrijski identitet daje važan rezultat: fazni pomak je zamijenjen sumom sinusa i kosinusa, uzetim sa koeficijentima cos(b) i sin(b). To znači da se funkcije mogu proširiti na zbir sinusa i kosinusa (bez ikakvih faza). Ovo je uobičajena trigonometrijska forma. Međutim, kompleks se koristi mnogo češće. Da biste je dobili potrebno je koristiti Eulerovu formulu. Jednostavnom zamjenom derivativnih formula za sinus i kosinus, dobivamo: 
Sada za malu promjenu. Donja crta je konjugirani broj.
Dobijamo konačnu jednakost:
c je kompleksni koeficijent čiji je stvarni dio jednak koeficijentu kosinusa, a imaginarni dio je jednak koeficijentu sinusa. A skup tačaka (cos(b), sin(b)) je krug. U takvom snimku svaki harmonik ulazi u ekspanziju i sa pozitivnom i sa negativnom frekvencijom. Stoga se u različitim formulama Fourierove analize obično zbraja ili integracija odvija od minus do plus beskonačnosti. Često je prikladnije izvršiti proračune u ovom složenom obliku.
Transformacija razlaže signal u harmonike sa frekvencijama od jedne do N oscilacija u području signala. Ali stopa uzorkovanja je N po području signala. A prema Kotelnikovoj teoremi (poznatoj kao Nyquist-Shannon teorem), frekvencija uzorkovanja mora biti najmanje dvostruko veća od frekvencije signala. Ako to nije slučaj, onda je učinak pojava signala s lažnom frekvencijom: 
Isprekidana linija prikazuje pogrešno rekonstruirani signal. Često ste se susreli sa ovim fenomenom u životu. Na primjer, smiješno kretanje kotača automobila u videu ili moire efekat.
Ovo dovodi do činjenice da se čini da se druga polovina amplituda N kompleksa sastoji od drugih frekvencija. Ovi lažni harmonici druge polovine su zrcalna slika prve i ne nose dodatne informacije. Dakle, ostaje nam N/2 kosinusa i N/2 sinusa (koji formiraju ortogonalnu osnovu).
U redu, postoji osnova. Njegove komponente su harmonici sa cijelim brojem oscilacija u području signala, što znači da su ekstremne vrijednosti harmonika jednake. Tačnije, oni su skoro jednaki, jer posljednja vrijednost nije uzeta u potpunosti sa ruba. Štaviše, svaki harmonik je gotovo zrcalno simetričan u odnosu na njegov centar. Sve ove pojave su posebno jake na niskim frekvencijama, koje su nam važne pri kodiranju. Ovo je također loše jer će granice bloka biti vidljive na komprimiranoj slici. Dozvolite mi da ilustrujem DFT osnovu sa N=8. Prva 2 reda su kosinusne komponente, a zadnja su sinusne: 
Obratite pažnju na pojavu duplih komponenti kako se frekvencija povećava. 
Sa prvim su stvari izuzetno loše.
Pa možda možemo to učiniti kao u DCT-u - smanjiti frekvencije za 2 ili drugi broj puta, tako da broj nekih oscilacija bude razlomačan, a granice u različitim fazama? Tada će komponente biti neortogonalne. I tu se ništa ne može učiniti.DST
Šta ako koristimo sinuse umjesto kosinusa u DCT? Dobićemo diskretnu sinusnu transformaciju (DST). Ali za naš zadatak, svi su oni nezanimljivi, jer su i cijeli i poluperiod sinusa blizu nule na granicama. To jest, dobićemo približno istu neprikladnu dekompoziciju kao DFT. Vraćanje na DCT
Kako mu ide na granici? U redu. Ima antifaza i nema nula. Sve ostalo
Ne-Furierove transformacije. Neću to opisivati.
WHT - matrica se sastoji samo od komponenti koraka sa vrijednostima -1 i 1.
Haar je također ortogonalna wavelet transformacija.
Oni su inferiorni u odnosu na DCT, ali ih je lakše izračunati.
Neće biti lako, zar ne? Međutim, za neke vrste slika moguće je odabrati bolju osnovu od DCT-a. 2D transformacije
Pokušajmo sada provesti takav eksperiment. Uzmimo, na primjer, dio slike. 
Njegov 3D grafikon: 
Idemo kroz DCT(N=32) kroz svaki red: 
Sada želim da prođete očima kroz svaki stupac dobijenih koeficijenata, odnosno od vrha do dna. Zapamtite da nam je cilj ostaviti što manje vrijednosti, eliminirajući one koje nisu značajne. Vjerovatno ste pogodili da se vrijednosti svake kolone rezultirajućih koeficijenata mogu proširiti na potpuno isti način kao i vrijednosti originalne slike. Niko nas ne ograničava u odabiru matrice ortogonalne transformacije, ali ćemo to ponoviti koristeći DCT(N=8): 
Pokazalo se da je koeficijent (0,0) prevelik, pa je na grafikonu smanjen za 4 puta.
Šta se desilo?
U gornjem lijevom uglu su najznačajniji koeficijenti proširenja najznačajnijih koeficijenata.
U donjem lijevom uglu su najbeznačajniji koeficijenti ekspanzije najznačajnijih koeficijenata.
U gornjem desnom uglu su najznačajniji koeficijenti ekspanzije od najbeznačajnijih koeficijenata.
U donjem desnom uglu su najbeznačajniji koeficijenti proširenja najbeznačajnijih koeficijenata.
Jasno je da se značajnost koeficijenata smanjuje ako se krećete dijagonalno od gornjeg lijevog ka donjem desnom. Šta je važnije: (0, 7) ili (7, 0)? Šta oni uopće znače?
Prvo, po redovima: A 0 = (EX T) T = XE T (transponirano, pošto je formula A=EX za kolone), zatim po kolonama: A=EA 0 = EXE T . Ako pažljivo izračunate, dobit ćete formulu:
Dakle, ako se vektor razloži na sinusoide, tada se matrica razlaže na funkcije oblika cos(ax)*cos(by). Svaki blok 8x8 u JPEG-u predstavljen je kao zbir 64 funkcije oblika: 
Na Wikipediji i drugim izvorima takve su funkcije predstavljene u prikladnijem obliku: 
Stoga su koeficijenti (0, 7) ili (7, 0) podjednako korisni.
Međutim, u stvari ovo je obična jednodimenzionalna dekompozicija na 64 64-dimenzionalne baze. Sve gore navedeno se ne odnosi samo na DCT, već i na bilo koju ortogonalnu dekompoziciju. Postupajući po analogiji, u opštem slučaju dobijamo N-dimenzionalnu ortogonalnu transformaciju.
A evo i 2D transformacije rakuna (DCT 256x256). Opet sa vrijednostima resetiranim na nulu. Brojevi - broj nenuliranih koeficijenata od svih (zadržane su najznačajnije vrijednosti koje se nalaze u trouglastom području u gornjem lijevom uglu). 
Zapamtite da se koeficijent (0, 0) naziva DC, a preostalih 63 naziva se AC. Odabir veličine bloka
Prijatelj pita zašto JPEG koristi 8x8 particije. Iz odgovora koji je odbijen: DCT tretira blok kao da je periodičan i mora rekonstruisati rezultujući skok na granicama. Ako uzmete blokove 64x64, najvjerovatnije ćete imati ogroman skok na granicama i trebat će vam puno visokofrekventnih komponenti da to rekonstruišete na zadovoljavajuću preciznost
Kao, DCT dobro radi samo na periodičnim funkcijama, a ako krenete na veliko, vjerovatno ćete dobiti ogroman skok na granicama bloka i trebat će vam puno visokofrekventnih komponenti da to pokrijete. Ovo nije istina! Ovo objašnjenje je vrlo slično DFT-u, ali ne i DCT-u, jer savršeno pokriva takve skokove s prvim komponentama.
Na istoj stranici je odgovor iz MPEG FAQ, sa glavnim argumentima protiv velikih blokova:
Predlažem da ovo sami istražite. Počnimo sa prvo.
Horizontalna os prikazuje udio prvih nenuliranih koeficijenata. Vertikalno - standardna devijacija piksela od originala. Maksimalno moguće odstupanje se uzima kao jedan. Naravno, jedna slika očigledno nije dovoljna za presudu. Osim toga, ne ponašam se sasvim ispravno, jednostavno resetujem na nulu. U stvarnom JPEG-u, ovisno o matrici kvantizacije, samo male vrijednosti visokofrekventnih komponenti se nule. Stoga, sljedeći eksperimenti i zaključci imaju za cilj da iznesu principe i obrasce.
Možete uporediti podjelu na različite blokove sa 25 posto koeficijenata lijevo (s lijeva na desno, zatim s desna na lijevo): 

To znači da je, na primjer, proračun za particiju 64x64 dvostruko složeniji od particije 8x8. 
Iako se distorzija blokova 16x16 proteže dalje od one kod 8x8, slova su glatkija. Dakle, samo prva dva argumenta su me uvjerila. Ali nekako mi se više sviđa divizija 16x16.Kvantizacija
U ovom trenutku imamo gomilu 8x8 matrica sa kosinusnim koeficijentima transformacije. Vrijeme je da se riješite beznačajnih koeficijenata. Postoji elegantnije rešenje od jednostavnog resetovanja poslednjih koeficijenata na nulu, kao što smo uradili gore. Nismo zadovoljni ovom metodom, jer se nenulte vrijednosti pohranjuju s pretjeranom preciznošću, a među onima koji nisu imali sreće moglo bi biti i prilično važnih. Rješenje je korištenje matrice za kvantizaciju. Gubici nastaju upravo u ovoj fazi. Svaki Fourier koeficijent je podijeljen sa odgovarajućim brojem u matrici kvantizacije. Pogledajmo primjer. Uzmimo prvi blok od našeg rakuna i izvršimo kvantizaciju. JPEG specifikacija pruža standardnu matricu: 
Standardna matrica odgovara 50% kvaliteta u FastStone i IrfanView. Ova tabela je odabrana u smislu ravnoteže između kvaliteta i omjera kompresije. Mislim da je vrijednost za DC koeficijent veća od njegovih susjeda zbog činjenice da DCT nije normaliziran i prva vrijednost je veća nego što bi trebala biti. Visokofrekventni koeficijenti su jače grublji zbog manje važnosti. Mislim da se takve matrice sada rijetko koriste, jer je pogoršanje kvaliteta jasno vidljivo. Niko ne zabranjuje korišćenje vaše tabele (sa vrednostima od 1 do 255)
Tokom dekodiranja dolazi do obrnutog procesa - kvantizirani koeficijenti se množe pojam po član vrijednostima matrice kvantizacije. Ali pošto smo zaokružili vrijednosti, nećemo moći precizno vratiti originalne Fourierove koeficijente. Što je veći broj kvantizacije, veća je greška. Dakle, rekonstruisani koeficijent je samo najbliži višekratnik.
Drugi primjer: 

Kada vratimo ovaj blok, dobićemo samo prosječnu vrijednost plus vertikalni gradijent (zbog očuvane vrijednosti -1). Ali za njega se pohranjuju samo dvije vrijednosti: 7 i -1. Ništa bolja situacija nije ni sa ostalim blokovima, evo restaurirane slike: 
Ili možete pogledati matrice kvantizacije raznih kamera.Kodiranje
Prije nego što krenemo dalje, moramo koristiti jednostavnije primjere da bismo razumjeli kako možemo komprimirati rezultirajuće vrijednosti.
Zamislite takvu situaciju da vam je prijatelj kod kuće zaboravio komad papira sa spiskom i sada traži da ga diktirate telefonom (drugih načina komunikacije nema).
Lista:
Kako biste olakšali svoj zadatak? Nemate posebnu želju da bolno diktirate sve ove riječi. Ali postoje samo dva i ponavljaju se. Stoga jednostavno nekako diktirate prve dvije riječi i slažete se da ćete od sada prvu riječ zvati “d9rg3”, a drugu “wfr43gt”. Tada će biti dovoljno da izdiktirate: 1, 2, 2, 1, 1, 1, 2, 1. 
Kodiranje ABC.
Ne postoji način da se 3 različita znaka (A, B, C) mogu povezati sa 2 moguće vrijednosti bita (0 i 1). A ako je tako, onda možete koristiti 2 bita po simbolu. Na primjer:
Niz bitova povezanih sa simbolom će se zvati kod. ABC će biti kodiran ovako: 000110. 
Kodirajte AAAAAABC.
Korišćenje 2 bita po karakteru A izgleda malo rasipnički. Šta ako probate ovo:
Kodirana sekvenca: 000000100.
Očigledno, ova opcija nije prikladna, jer nije jasno kako dekodirati prva dva bita ove sekvence: kao AA ili kao C? Vrlo je rasipno koristiti bilo kakav separator između kodova, razmislit ćemo o tome kako zaobići ovu prepreku na drugačiji način. Dakle, greška je zbog činjenice da kod C počinje kodom A. Ali mi smo odlučni da kodiramo A sa jednim bitom, čak i ako B i C imaju po dva. Na osnovu ove želje, A dajemo kod 0. Tada kodovi B i C ne mogu početi sa 0. Ali mogu početi sa 1: 
Slijed je kodiran ovako: 0000001011. Pokušajte ga mentalno dekodirati. Ovo možete učiniti samo na jedan način.
Razvili smo dva zahtjeva za kodiranje:
Očigledno, redosled likova nije bitan, zanima nas samo učestalost njihovog pojavljivanja. Stoga je svaki simbol povezan s brojem koji se naziva težina. Težina simbola može biti ili relativna vrijednost, koja odražava proporciju njegovog pojavljivanja, ili apsolutna vrijednost, jednaka broju znakova. Glavna stvar je da su težine proporcionalne pojavljivanju simbola.
Razmotrimo opći slučaj za 4 simbola s bilo kojom težinom.
Bez gubitka opštosti, stavljamo pa ≥ pb ≥ pc ≥ pd. Postoje samo dvije opcije koje se fundamentalno razlikuju po dužini koda: 
Koji je poželjniji? Da biste to učinili, morate izračunati rezultirajuće dužine kodiranih poruka:
W1 = 2*pa + 2*pb + 2*pc + 2*pd
W2 = pa + 2*pb + 3*pc + 3*pd
Ako je W1 manji od W2 (W1-W2<0), то лучше использовать первый вариант:
W1-W2 = pa - (pc+pd)< 0 =>pa< pc+pd.
Ako se C i D zajedno javljaju češće od ostalih, tada njihov zajednički vrh prima najkraći jednobitni kod. U suprotnom, jedan bit ide znaku A. To znači da se unija karaktera ponaša kao nezavisni karakter i ima težinu jednaku zbroju ulaznih znakova.
Općenito, ako je p težina karaktera predstavljena dijelom njegovog pojavljivanja (od 0 do 1), onda je najbolja dužina koda s=-log 2 p.
Razmotrimo ovo u jednostavnom slučaju (može se lako predstaviti kao stablo). Dakle, trebamo kodirati 2 s karaktera sa jednakim težinama (1/2 s). Zbog jednakosti težina, dužine kodova će biti iste. Svaki znak će zahtijevati s bitova. To znači da ako je težina simbola 1/2 s, onda je njegova dužina s. Ako zamenimo težinu sa p, dobićemo dužinu koda s=-log 2 p. To znači da ako se jedan znak pojavljuje dva puta češće od drugog, tada će dužina njegovog koda biti za jedan bit duža. Međutim, ovaj zaključak je lako izvući ako se sjetite da vam dodavanje jednog bita omogućava udvostručenje broja mogućih opcija.
I još jedno zapažanje - dva simbola s najmanjom težinom uvijek imaju najveću, ali jednaku dužinu koda. Štaviše, njihovi bitovi, osim posljednjeg, su isti. Ako to nije tačno, onda bi se barem jedan kod mogao skratiti za 1 bit bez razbijanja prefiksa. To znači da dva simbola sa najmanjom težinom u kodnom stablu imaju zajedničkog roditelja na višem nivou. Ovo možete vidjeti u primjerima C i D iznad.
Pokušajmo riješiti sljedeći primjer, na osnovu zaključaka dobijenih u prethodnom primjeru.
Koraci se ponavljaju dok ne ostane samo jedna grupa. Unutar svake grupe, jednom karakteru (ili podgrupi) je dodijeljen bit 0, a drugom karakterni bit 1.
Ovaj algoritam se zove Huffmanovo kodiranje.
Ilustracija prikazuje primjer sa 5 znakova (A: 8, B: 6, C: 5, D: 4, E: 3). Desno je težina simbola (ili grupe). 
Kodiramo koeficijente
Hajdemo nazad. Sada imamo mnogo blokova sa 64 koeficijenta u svakom, koje treba nekako sačuvati. Najjednostavnije rješenje je korištenje fiksnog broja bitova po koeficijentu - očito neuspješno. Napravimo histogram svih dobijenih vrijednosti (tj. ovisnost broja koeficijenata o njihovoj vrijednosti): 
Imajte na umu - skala je logaritamska! Možete li objasniti razlog za pojavu klastera vrijednosti koje prelaze 200? Ovo su DC koeficijenti. Budući da se jako razlikuju od ostalih, ne čudi što su kodirani zasebno. Evo samo DC: 
Imajte na umu da oblik grafa podsjeća na grafove iz najranijih eksperimenata uparivanja i utrostručenja piksela.
Općenito, vrijednosti DC koeficijenta mogu varirati od 0 do 2047 (tačnije od -1024 do 1023, budući da JPEG oduzima 128 od svih originalnih vrijednosti, što odgovara oduzimanju 1024 od DC) i raspoređuje se prilično ravnomjerno s malim vrhovima. Dakle, Huffmanovo kodiranje ovdje neće puno pomoći. I zamislite koliko će veliko stablo kodiranja biti! I tokom dekodiranja morat ćete tražiti značenje u njemu. Veoma je skupo. Razmišljamo dalje.
DC koeficijent je prosječna vrijednost bloka 8x8. Zamislimo gradijentni prijelaz (iako nije idealan), koji se često nalazi na fotografijama. Same vrijednosti DC bit će različite, ali će predstavljati aritmetičku progresiju. To znači da će njihova razlika biti manje-više konstantna. Napravimo histogram razlika: 
Ovo je bolje, jer su vrijednosti uglavnom koncentrisane oko nule (ali Huffmanov algoritam će opet dati preveliko stablo). Male vrijednosti (u apsolutnoj vrijednosti) su uobičajene, velike vrijednosti su rijetke. A budući da male vrijednosti zauzimaju nekoliko bitova (ako se uklone vodeće nule), dobro se poštuje jedno od pravila kompresije: simbolima s velikim težinama dodjeljuju se kratki kodovi (i obrnuto). Trenutno smo ograničeni nepoštovanjem još jednog pravila: nemogućnosti nedvosmislenog dekodiranja. Općenito, ovaj problem se može riješiti na sljedeće načine: zamarati se kodom za razdvajanje, naznačiti dužinu koda, koristiti prefiksne kodove (već ih znate - to je slučaj kada nijedan kod ne počinje drugim). Idemo sa jednostavnom drugom opcijom, tj. svaki koeficijent (tačnije, razlika između susjednih) biće napisan ovako: (dužina)(vrijednost), prema ovom znaku: 
To jest, pozitivne vrijednosti su direktno kodirane njihovim binarnim prikazom, a negativne vrijednosti su kodirane na isti način, ali s vodećim 1 zamijenjenim 0. Ostaje odlučiti kako kodirati dužine. Pošto postoji 12 mogućih vrijednosti, 4 bita se mogu koristiti za pohranjivanje dužine. Ali ovdje je bolje koristiti Huffmanovo kodiranje. 
Najviše je vrijednosti sa dužinama 4 i 6, tako da su dobili najkraće kodove (00 i 01).
Može se postaviti pitanje: zašto, u primjeru, vrijednost 9 ima šifru 1111110, a ne 1111111? Na kraju krajeva, možete bezbedno podići "9" na viši nivo, pored "0"? Činjenica je da u JPEG-u ne možete koristiti kod koji se sastoji samo od jedan - takav je kod rezerviran.
Postoji još jedna karakteristika. Kodovi dobijeni opisanim Huffman algoritmom možda se neće poklopiti u bitovima sa kodovima u JPEG formatu, iako će njihove dužine biti iste. Koristeći Huffman algoritam, dobiju se dužine kodova, a sami kodovi se generiraju (algoritam je jednostavan - počnite s kratkim kodovima i dodajte ih jedan po jedan u stablo što je više moguće lijevo, čuvajući svojstvo prefiksa ). Na primjer, za stablo iznad liste je pohranjeno: 0,2,3,1,1,1,1,1. I, naravno, pohranjuje se lista vrijednosti: 4,6,3,5,7,2,8,1,0,9. Tokom dekodiranja, kodovi se generišu na isti način.
[Huffmanov kod za dužinu DC razlike (u bitovima)]
gdje je DC diff = DC struja - DC prethodni
Pošto je graf vrlo sličan grafu za DC razlike, princip je isti: [Huffmanov kod za AC dužinu (u bitovima)]. Ali ne baš! Budući da je skala na grafikonu logaritamska, nije odmah uočljivo da ima otprilike 10 puta više nultih vrijednosti od vrijednosti 2, sljedeće po učestalosti. To je razumljivo – nisu svi preživjeli kvantizaciju. Vratimo se na matricu vrijednosti dobijenih tokom faze kvantizacije (koristeći FastStone matricu kvantizacije, 90%). 
Pošto postoji mnogo grupa uzastopnih nula, nameće se ideja - da se zapiše samo broj nula u grupi. Ovaj algoritam kompresije se zove RLE (Run-length encoding). Ostaje da se otkrije smjer obilaznice "uzastopnih" - ko je iza koga? Pisanje s lijeva na desno i odozgo prema dolje nije vrlo efikasno, jer su koeficijenti različiti od nule koncentrisani blizu gornjeg lijevog ugla, a što je bliže donjem desnom, to je više nula. 
Stoga JPEG koristi redoslijed nazvan "cik-cak", koji je prikazan na lijevoj slici. Ova metoda dobro razlikuje grupe nula. Na desnoj slici je alternativna metoda zaobilaženja, koja nije vezana za JPEG, ali sa zanimljivim nazivom (dokaz). Može se koristiti u MPEG-u za prepletenu video kompresiju. Izbor algoritma prelaska ne utiče na kvalitet slike, ali može povećati broj kodiranih grupa nula, što na kraju može uticati na veličinu datoteke.
Izmijenimo naš unos. Za svaki AC koeficijent koji nije nula:
[Broj nula prije AC][Huffman kod za AC dužinu (u bitovima)]
Mislim da možete odmah reći da je broj nula također savršeno kodiran od strane Huffmana! Ovo je vrlo blizak i dobar odgovor. Ali može se malo optimizirati. Zamislite da imamo neki koeficijent AC, prije kojeg je bilo 7 nula (naravno, ako je napisano cik-cak redoslijedom). Ove nule su duh vrijednosti koji nije preživio kvantizaciju. Najvjerovatnije je i naš koeficijent bio jako oštećen i postao je mali, što znači da je njegova dužina kratka. To znači da su broj nula ispred AC i dužina AC zavisne veličine. Stoga to pišemo ovako:
[Huffmanov kod za (Broj nula prije AC, dužina AC (u bitovima)]
Algoritam kodiranja ostaje isti: oni parovi (broj nula prije AC, dužina AC) koji se pojavljuju često će dobiti kratke kodove i obrnuto. 
Dugačak "planinski greben" potvrđuje našu pretpostavku.
Takav par zauzima 1 bajt: 4 bita za broj nula i 4 bita za dužinu AC. 4 bita su vrijednosti od 0 do 15. Za dužinu AC ovo je više nego dovoljno, ali može li biti više od 15 nula? Tada se koristi više parova. Na primjer, za 20 nula: (15, 0)(5, AC). To jest, 16. nula je kodirana kao koeficijent koji nije nula. Pošto uvijek ima puno nula blizu kraja bloka, par (0,0) se koristi nakon posljednjeg koeficijenta različitog od nule. Ako se naiđe tokom dekodiranja, preostale vrijednosti su 0.
[Huffmanov kod za dužinu DC razlike]
[Huffmanov kod za (broj nula prije AC 1, dužina AC 1]
…
[Huffmanov kod za (broj nula prije AC n, dužina AC n]
Gdje su AC i koeficijenti AC različiti od nule.Slika u boji
Kako je slika u boji predstavljena zavisi od odabranog model u boji. Jednostavno rješenje je korištenje RGB-a i kodiranje svakog kanala boje slike zasebno. Tada se kodiranje neće razlikovati od kodiranja sive slike, samo 3 puta više posla. Ali kompresija slike se može povećati ako se sjetimo da je oko osjetljivije na promjene svjetline od boja. To znači da se boja može pohraniti s većim gubicima od svjetline. RGB nema poseban kanal za osvetljenje. Zavisi od zbira vrijednosti svakog kanala. Stoga se RGB kocka (ovo je prikaz svih mogućih vrijednosti) jednostavno "smjesti" na dijagonalu - što je veća, to je svjetlija. Ali oni se tu ne zaustavljaju - kocka je malo pritisnuta sa strane, i ispada više kao paralelepiped, ali to je samo da se uzmu u obzir karakteristike oka. Na primjer, osjetljiviji je na zelenu nego na plavu. Tako se pojavio model YCbCr. 
(Slika sa Intel.com)
Y je komponenta osvjetljenja, Cb i Cr su komponente razlike u plavoj i crvenoj boji. Stoga, ako žele više komprimirati sliku, onda se RGB pretvara u YCbCr, a Cb i Cr kanali se razrjeđuju. Odnosno, podijeljeni su na male blokove, na primjer 2x2, 4x2, 1x2, a sve vrijednosti jednog bloka su prosječne. Ili, drugim riječima, smanjuju veličinu slike za ovaj kanal za 2 ili 4 puta vertikalno i/ili horizontalno. 
Svaki 8x8 blok je kodiran (DCT + Huffman), a kodirane sekvence su napisane ovim redoslijedom:
Zanimljivo je da JPEG specifikacija ne ograničava izbor modela, odnosno implementacija enkodera može proizvoljno podijeliti sliku na komponente boje (kanale) i svaka će se posebno čuvati. Svjestan sam upotrebe sivih tonova (1 kanal), YCbCr (3), RGB (3), YCbCrK (4), CMYK (4). Prva tri podržavaju skoro svi, ali postoje problemi sa zadnjim 4-kanalnim. FastStone, GIMP ih podržava korektno, a standardni Windows programi, paint.net korektno izdvajaju sve informacije, ali onda izbacuju 4. crni kanal, pa (Antelle je rekao da ga ne bacaju, pročitajte njegove komentare) pokazuju upaljač slika. Sa lijeve strane je klasični YCbCr JPEG, sa desne strane je CMYK JPEG: 

Ako se razlikuju po boji, ili je vidljiva samo jedna slika, onda najvjerovatnije imate IE (bilo koju verziju) (UPD. u komentarima kažu “ili Safari”). Možete pokušati otvoriti članak u različitim pretraživačima. I još nešto
Ukratko o dodatnim funkcijama. Progresivni način rada
Razložimo rezultirajuće tablice DCT koeficijenata u zbir tabela (približno ovako (DC, -19, -22, 2, 1) = (DC, 0, 0, 0, 0) + (0, -20 , -20, 0, 0) + (0, 1, -2, 2, 1)). Prvo kodiramo sve prve pojmove (kao što smo već naučili: Huffman i cik-cak prelazak), zatim drugi, itd. Ovaj trik je koristan kada je internet spor, jer se prvo učitavaju samo DC koeficijenti koji se koriste za konstruisati grubu sliku sa 8x8 “piksela”. Zatim se zaokružuju AC koeficijenti da se precizira broj. Zatim grube korekcije, pa one preciznije. I tako dalje. Koeficijenti su zaokruženi, jer u ranim fazama učitavanja točnost nije toliko važna, ali zaokruživanje ima pozitivan učinak na dužinu kodova, jer svaka faza koristi svoju Huffmanovu tablicu. Način rada bez gubitaka
Kompresija bez gubitaka. Nema DCT. Koristi se predviđanje 4. tačke na osnovu tri susedne tačke. Greške predviđanja su Huffman kodirane. Po mom mišljenju, koristi se malo češće nego nikad. Hijerarhijski način rada
Iz slike se kreira nekoliko slojeva različitih rezolucija. Prvi grubi sloj se kodira kao i obično, a zatim samo razlika (pročišćavanje slike) između slojeva (pretvara se da je Haar talas). DCT ili Lossless se koristi za kodiranje. Po mom mišljenju, koristi se malo rjeđe nego nikad. Aritmetičko kodiranje
Huffmanov algoritam proizvodi optimalne kodove na osnovu težine znakova, ali to vrijedi samo za fiksno mapiranje karaktera u kod. Aritmetika nema tako kruto vezivanje, što omogućava korištenje kodova kao da su s razlomkom broja bitova. Tvrdi da smanjuje veličinu datoteke u prosjeku za 10% u odnosu na Huffman. Nije široko rasprostranjeno zbog problema sa patentima, ne podržavaju ga svi.
vanwin je predložio navođenje softvera koji se koristi. Sa zadovoljstvom mogu objaviti da je sve dostupno i besplatno:




 .
.